 ISSN
ISSN 




-
工程中的不确定性广泛存在,如振动、冲击、加速度、噪声及载荷等,这些因素对结构的性能和可靠性产生重要影响[1]。结构可靠性理论和方法为处理工程中各种不确定性问题提供有效解决途径。
蒙特卡洛仿真(monte carlo simulation, MCS)方法具有较高的精度和鲁棒性,其可靠性分析结果常常作为衡量其他方法优劣的标准,广泛应用于结构可靠性分析领域[2]。但对于小概率问题,MCS方法需要大量样本来保证精度,尤其性能函数是隐式时,需通过数值仿真,如有限元分析(finite element analysis, FEA)[3-4]求解输入变量的输出响应,导致可靠性分析耗费大量时间,效率低下。为了提高可靠性分析的效率,一阶、二阶可靠性分析方法(first-/second-order reliability methods, FORM/SORM)[5]被广泛采用。FORM、SORM在可靠性设计点(most probable point, MPP)对性能函数分别进行一阶、二阶泰勒展开。然而,由于忽略展开式中的高阶项,对于非线性程度较高的性能函数,FORM、SORM的精度较低,很难得到准确的可靠性指标。为了更好地平衡精度和效率,近年来,代理模型技术在结构可靠性领域广泛发展。常见的代理模型有:响应面法(response surface method, RSM)[6-7]、神经网络(neural networks, NN)[8-9]、支持向量机(support vector machine, SVM)[10-11]、克里金插值(Kriging)[12-18]等。
Kriging模型因具有准确的插值特性和提供估计值的不确定性方差,而被广泛应用于结构可靠性领域。文献[19]提出一种学习方程—U方程,为Kriging在结构可靠性领域广泛发展奠定了坚实的基础;文献[17]提出一种基于子集模拟(subset simulation, SS)的可靠性分析方法,为解决小概率失效问题提供了一种可行的途径;文献[18]考虑变量权重并保证所选样本点之间保持一定的距离且分布在极限状态方程周围;文献[20]引入了K-Means聚类算法考虑变量之间的相关性问题;文献[21]连接极限状态方程两侧异号的特定样本点,再在此直线上随机产生n个样本点,寻找最佳候选样本点。虽然以上方法都在一定程度上提升了可靠性分析的效率,但很少关注代理模型更新过程中的抽样区域问题;鉴于此,本文通过
$3\sigma $ 准则、欧式距离确定代理模型更新过程中的抽样区域,避免因对失效概率贡献较小的区域持续抽样而造成计算资源的浪费,提高了可靠性分析的效率。另外,通过改变抽样区域带宽,该方法也可用于解决结构可靠性分析中的小失效概率问题。 -
Kriging模型(高斯过程回归)是起源于地质统计学的一种插值方法,不仅可以估计样本点响应的均值,还可以表征估计结果不确定程度,目前在可靠性领域已得到广泛的应用。Kriging模型通常分为线性回归部分和随机过程部分,其数学模型可表示为[22]:
$$G({{x}}) = f({{x}}) \beta + z({{x}})$$ (1) 式中,
$f({{x}})$ 为变量x的一个多项式函数,本文$f({{x}})$ 取值1;β是回归系数;$z({{x}})$ 是一随机过程,服从正态分布$z({{x}})\sim N(0,{\sigma ^2})$ ,其协方差方程为:$${\rm{Cov}}\left[ {z({{{x}}_i}),z({{{x}}_j})} \right] = {\sigma ^2}{R_\theta }({{{x}}_i},{{{x}}_j})$$ (2) 式中,
${R_\theta }({{{x}}_i},{{{x}}_j})$ 是${{{x}}_i}\text{,}{{{x}}_j}$ 之间的相关函数,本文选择鲁棒性更强的高斯方程,表示如下:$$\begin{split} &{R_\theta }({{{x}}_i},{{{x}}_j}) = \exp \left( { - \sum\limits_{d = 1}^n {{\theta _d}{{(x_i^d - x_j^d)}^2}} } \right) = \\ &\qquad\quad{ \prod\limits_{d = 1}^n {\exp \left( { - {\theta _d}{{(x_i^d - x_j^d)}^2}} \right)} } \end{split} $$ (3) 根据设计空间样本
${{x}}$ 及其响应$G({{x}})$ ,可得回归系数以及随机过程方差的估计值[23]:$$\hat \beta = {\left( {{{\bf{1}}^{\rm{T}}}{{R}}_\theta ^{ - {{1}}}{{{{{\textit{1}}}}}}} \right)^{ - 1}}{{\bf{1}}^{\rm{T}}}{{R}}_\theta ^{ - 1}{{Y}}$$ (4) $${\hat \sigma ^2} = \frac{1}{m}{\left( {{{Y}} - \hat \beta {\bf{1}}} \right)^{\rm{T}}}{{R}}_\theta ^{ - 1}\left( {{{Y }}- \hat \beta {\bf{1}}} \right)$$ (5) 式中,1是元素均为1的m×1向量;Y为样本响应。求得Kriging模型后,通过式(6)和式(7)估计样本x的响应
$\hat G({{x}})$ 和方差$\hat \sigma _{\hat G}^2$ ,其中$\mu ({{x}}) = {{\bf{1}}^{\rm{T}}}{{R}}_\theta ^{ - 1}{{r}}({{x}}) - {\bf{1}}$ [23]:$$\hat G({{x}}) = \hat \beta + {{r}}{({{x}})^{\rm{T}}}{{R}}_\theta ^{ - 1}\left( {{{Y}} - \hat \beta {\bf{1}}} \right)$$ (6) $${{r}}({{{x}}_{\rm{0}}}) = {\left[ {{R_\theta }({{{x}}_{\rm{0}}},{{{x}}_1}),{R_\theta }({{{x}}_{\rm{0}}},{{{x}}_2}),\cdots,{R_\theta }({{{x}}_{\rm{0}}},{{{x}}_m})} \right]^{\rm{T}}}$$ (7) $$ \begin{split} & \hat \sigma _{\hat G}^2({{x}}) = {{\hat \sigma }^2}[1 - {{r}}{({{x}})^{\rm{T}}}{{R}}_\theta ^{ - 1}r({{x}}) + \\ & \quad\; {\mu {{({{x}})}^{{{\rm{T}}}}}{{({\bf{1}}{{R}}_\theta ^{ - 1}{\bf{1}})}^{ - 1}}\mu ({{x}})]} \end{split} $$ (8) -
构建高效的代理模型,样本点的选取策略是关键。设计空间不同区域的样本点对失效概率的贡献不一样,因此在代理模型构建过程中,若在贡献较小的区域过多的选取样本点,或贡献较大的区域过少的选取样本点,都会影响代理模型的构建效率和精度;再者,依据传统的AK-MCS方法选取样本点,同样避免不了对失效概率贡献较小的区域过多的选取样本点。基于代理模型的结构可靠性分析中,为了提高所构建模型的建模效率和精度,需构建特定的抽样区域,该区域的样本点相对其他区域样本点对失效概率有较大的贡献。因此,所选样本点应分布在极限状态方程附近;再构建抽样特定区域,通过选取该区域内的样本点对代理模型进行更新。分析如下。
1)通过AK-MCS中U[19]方程,即
$U = |\hat G({{x}})|/ {\sigma _{\hat G}}({{x}})$ ,可确定样本空间中3类样本点,如图1所示。若选中的样本点落在对失效概率贡献较小的区域,代理模型不能进行有效的更新,反而增加了对性能函数的无效调用,降低了可靠性分析的效率。因此,避开样本空间对失效概率贡献较小的区域尤为重要。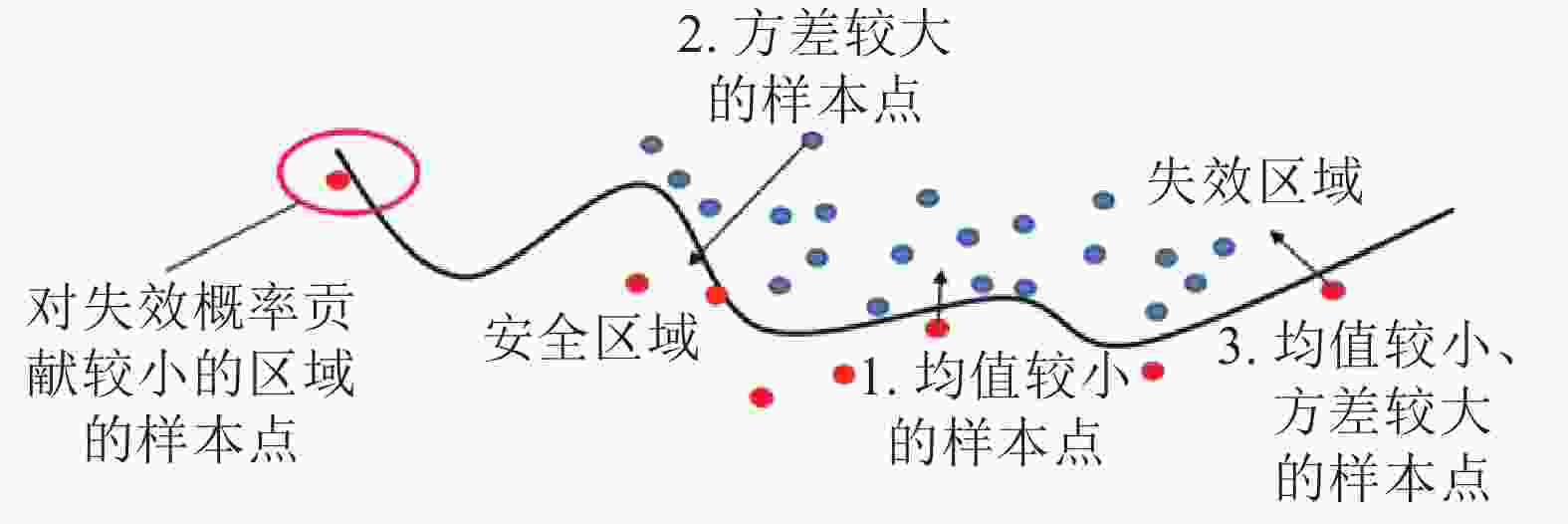
图 1 U方程选取的3类样本点
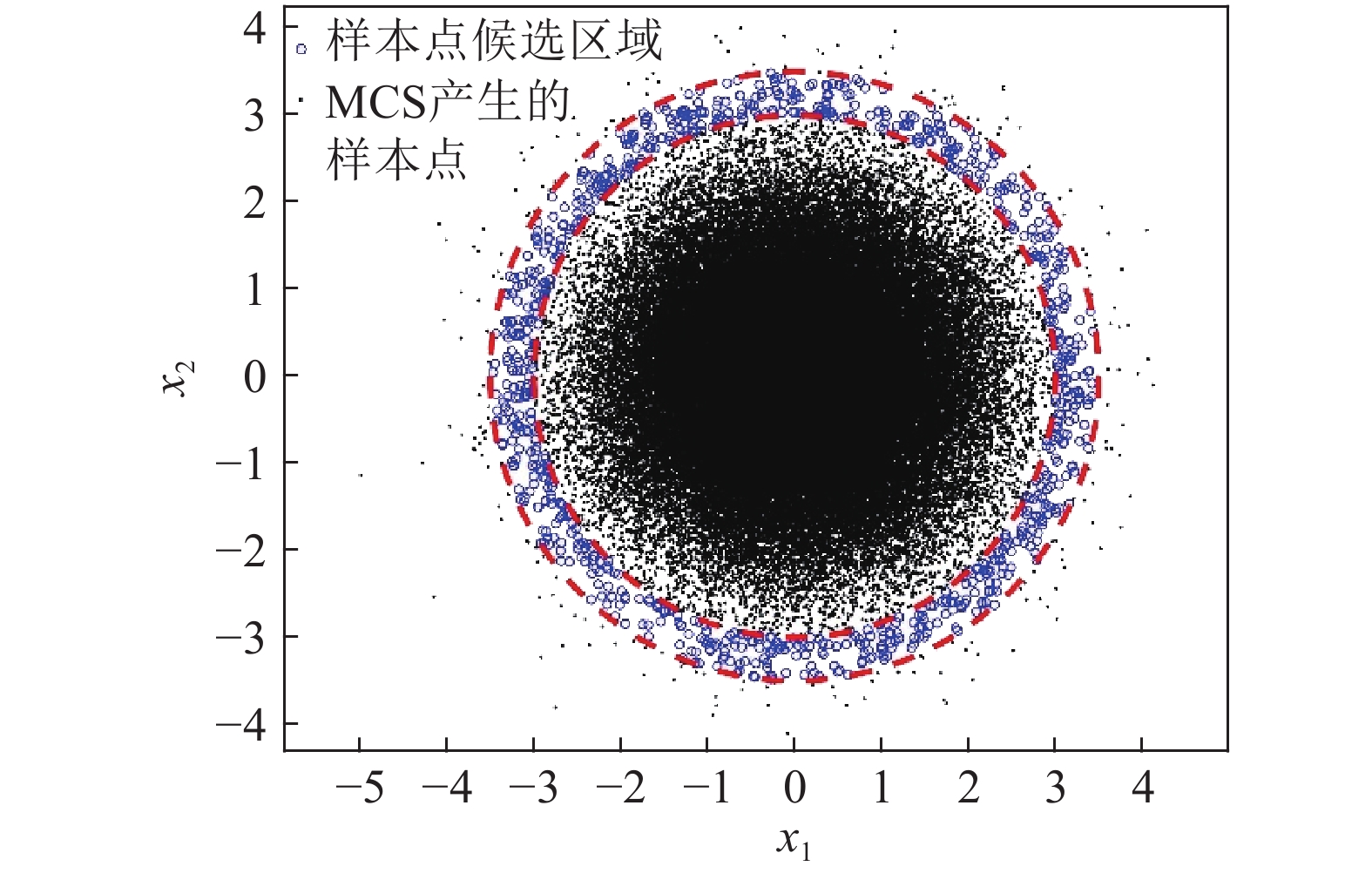
2)蒙特卡洛抽样的样本分布情况如图2所示(如变量服从高斯分布),对于结构可靠性分析中的小概率失效问题,设计空间的最优样本点往往存在于蒙特卡洛抽样样本分布的边缘部分,如图3中红色虚线之间的蓝色样本点;假设有1×106个样本服从标准正态分布,且失效概率的数量级为10−3,由
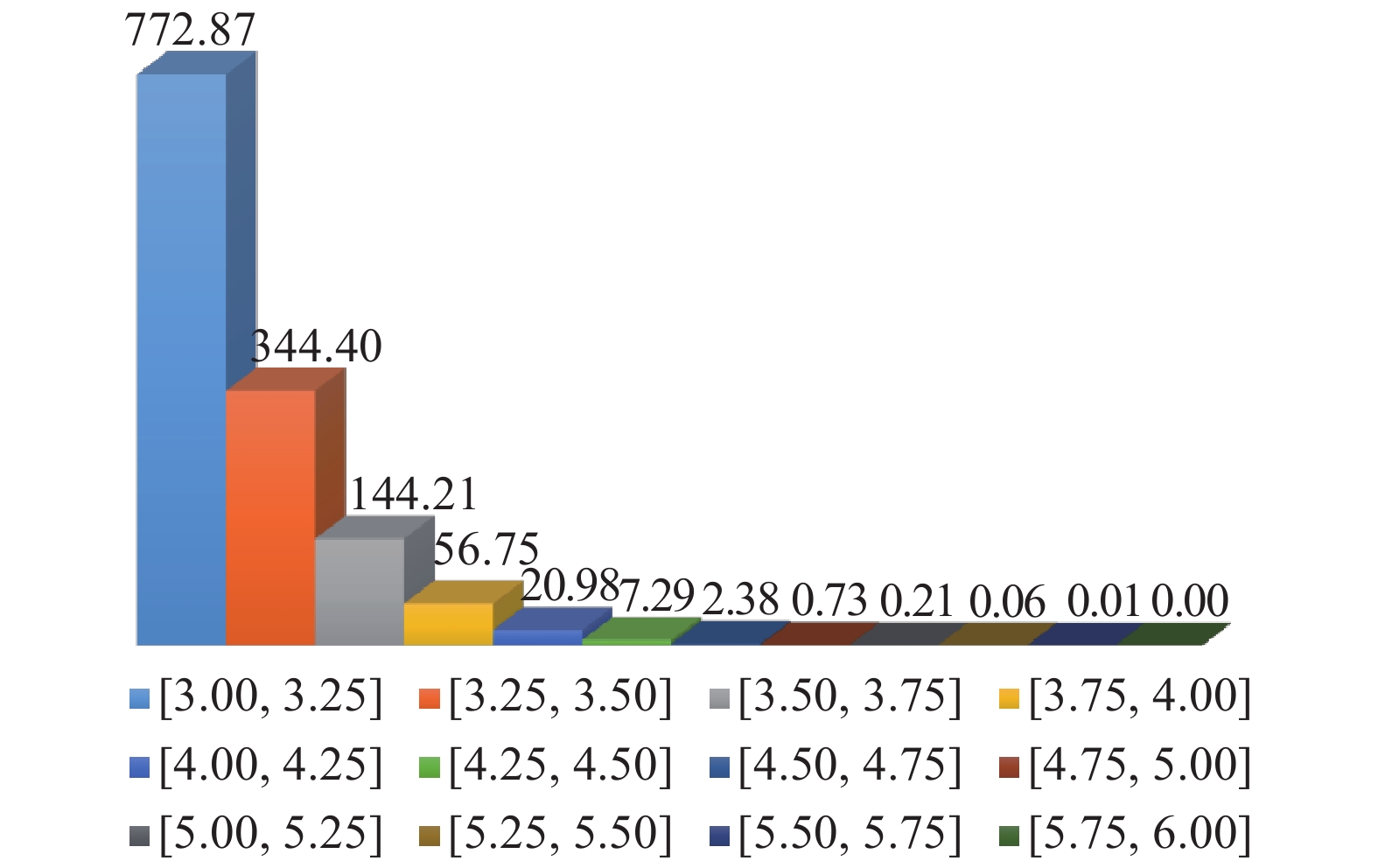
$3\sigma $ 准则可得,分布在各个区间的样本量数目如图4所示,并且随着区间远离原点,区间内的样本数量急剧减少。如图4所示,即使区间$[4, + \infty )$ 内的31.67个样本全部落在失效域内,对失效概率的贡献仅仅为10−5数量级;况且,对于结构可靠性中小概率失效问题,区间$[4, + \infty )$ 内的样本仅有少量分布于可靠性问题的失效区域。因此,此区域的样本点最终对失效概率的贡献估计仅为10−6数量级,甚至更小,可忽略不计。另外,如图3所示,外圈红色虚线外侧的样本点对模型更新后的准确率影响较小;同理,内圈红色虚线内侧的样本点对模型更新后的准确率影响同样较小。因此,为了避免代理模型更新过程中对失效概率贡献较小的区域过多抽样或对失效概率贡献较大的区域过少抽样,图3红色虚线区域样本点即为最佳样本点的目标区域(样本服从标准正态分布)。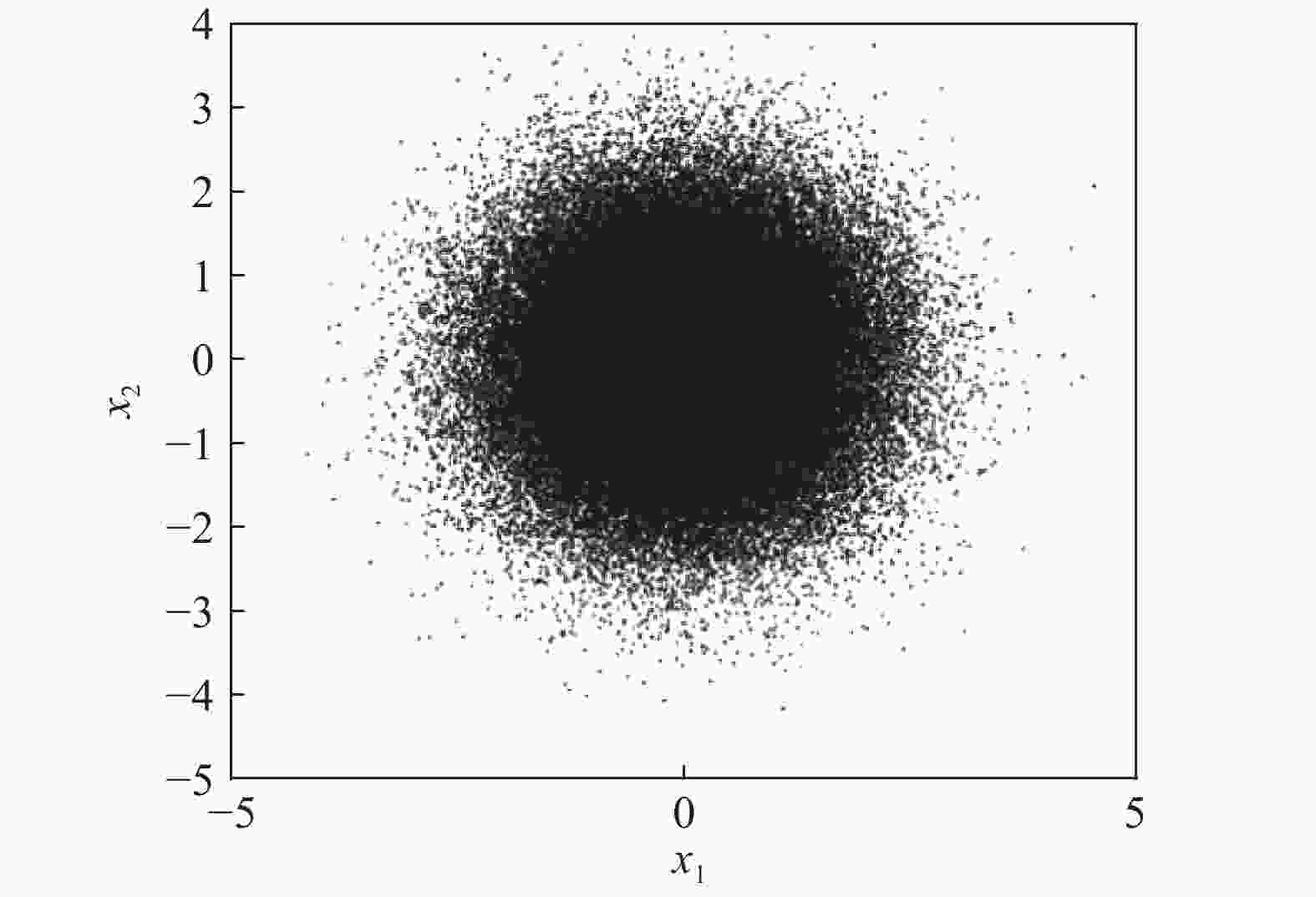
图 2 蒙特卡洛产生的候选样本点
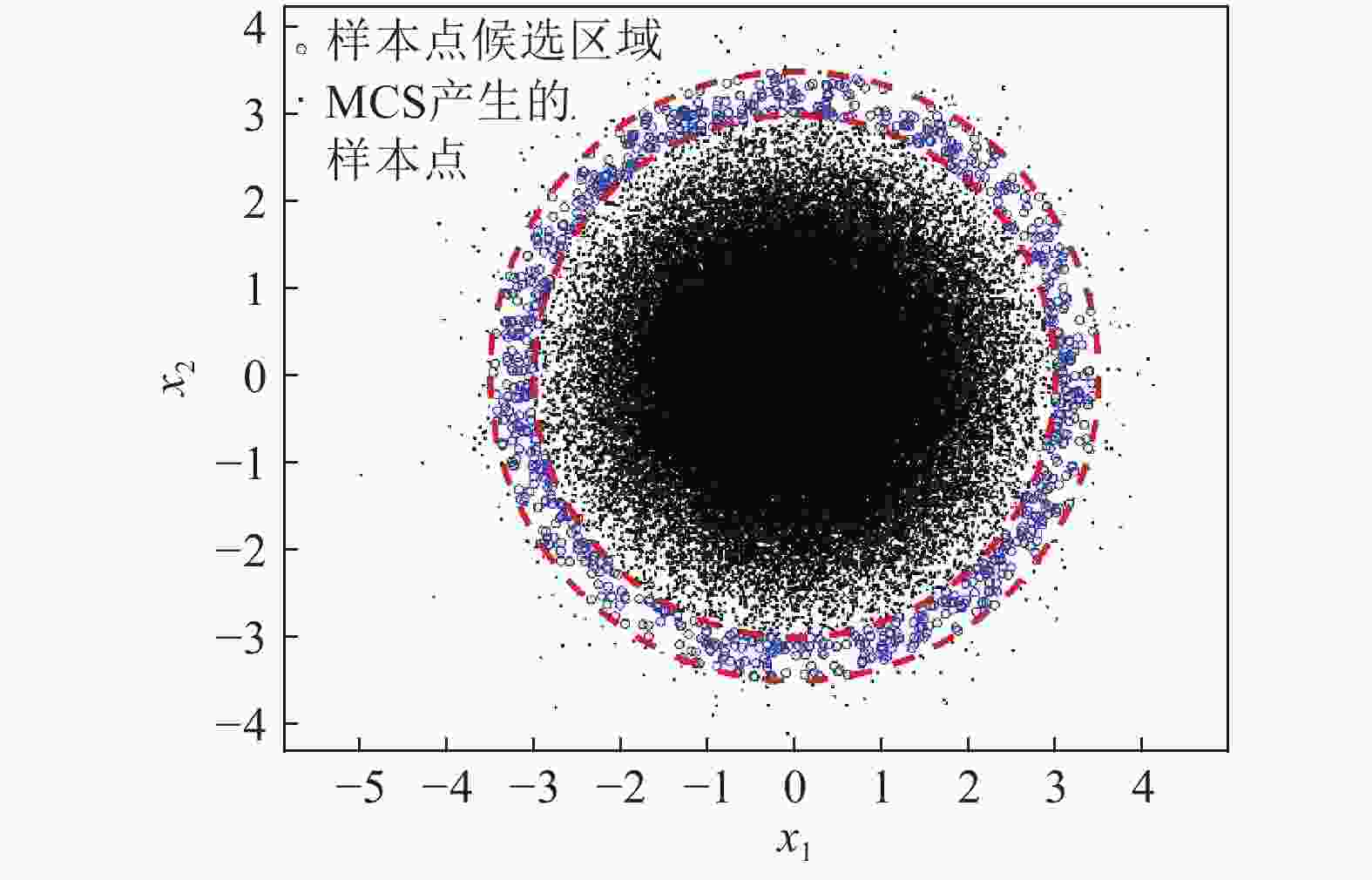
图 3 所提方法抽样策略的抽样区域
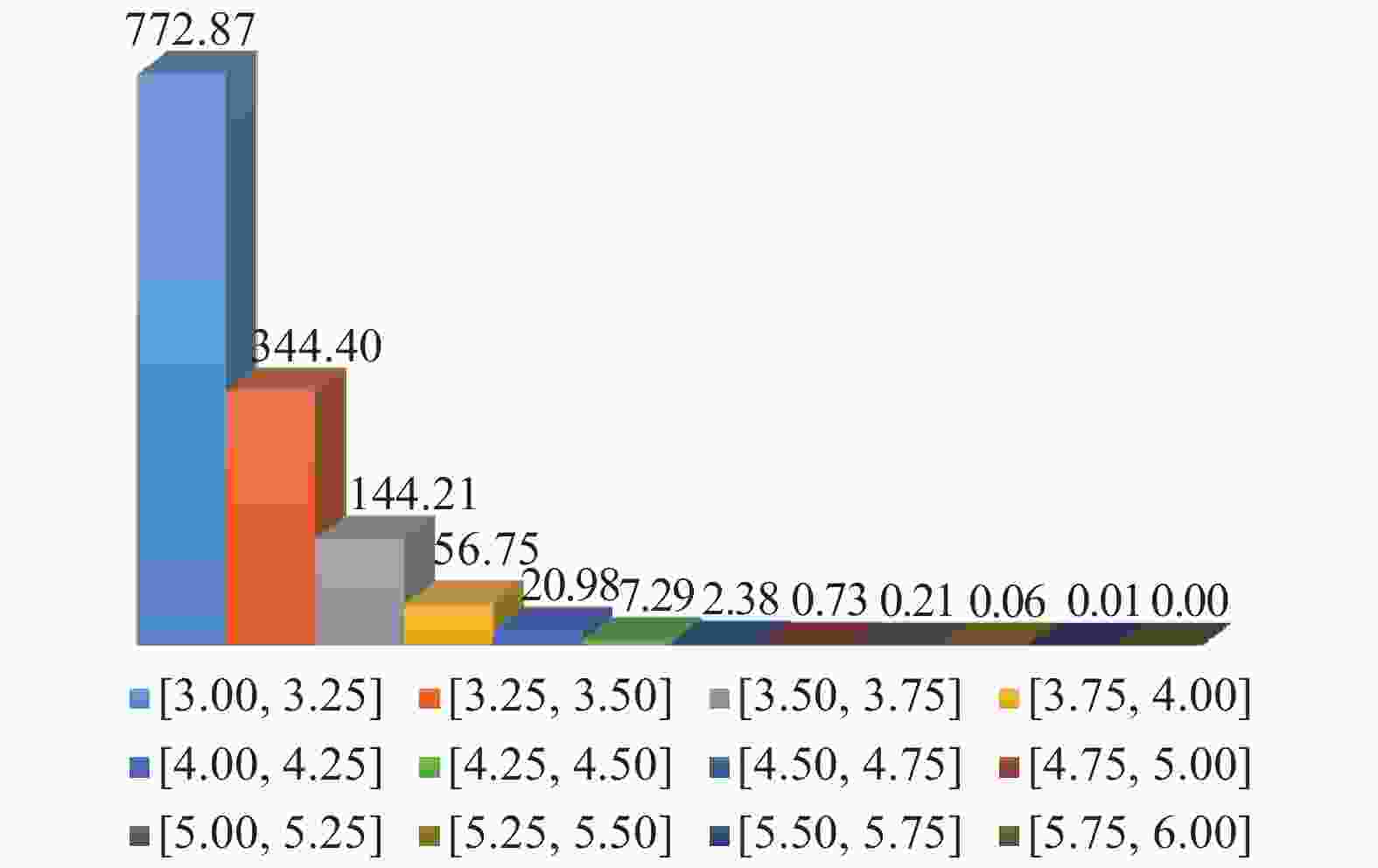
图 4 标准正态分布各区间内样本点数量
为了确定此区域的大小,引入欧式方程。
$n$ 维空间任意两点${{{x}}_i}\text{,}{{{x}}_j}$ 的欧式距离可表示为:$$d_E^{ij} = \sqrt {\sum\limits_{k = 1}^n {{{({{x}}_i^k - {{x}}_j^k)}^2}} } $$ (9) 通过欧式距离来确定目标区域,这里欧式距离的两端是指样本点到设计空间坐标原点的距离,即:
$${r_1} \leqslant d_E^{ij} \leqslant {r_2}$$ (10) 式中,r1、r2分别为目标抽样区域样本点到设计空间坐标原点的欧式距离。基于经典AK-MCS方法,目标区域样本点的选取即为一个优化问题,表示为:
$$\left\{ {\begin{aligned} &{\min U({{x}})} \\ &{{\rm{s}}{\rm{.t}}{\rm{. }}\;{r_1}{\rm{ }} \leqslant d_E^{ij} \leqslant {r_2}} \end{aligned}} \right.$$ (11) 通过以上优化方法在目标区域选取最佳样本点,代理模型不断迭代更新,直至满足收敛条件,见参考文献[19]。最终求得失效概率,完整的可靠性分析步骤如下。
1) 通过MCS产生N个样本点,本文随机选择12个样本点,作为设计空间(design of experiment, DoE)的初始样本点;
2) 更新DoE中的样本点,通过DoE中的样本点构建更新Kriging模型,用此模型预测步骤1) 中N个样本点的均值和方差;
3) 通过欧氏距离确定环形抽样区域Z;
4) 计算环形抽样区域Z中的U值,并确定环形抽样区域Z中的最小U值及对应的样本点x;
5) 判断步骤4)得到的U值是否满足收敛条件
$U \geqslant 2$ 。若不满足,返回步骤2);否则,进行下一步;6) 通过步骤2)构建的最终Kriging代理模型计算失效概率。
-
为了验证本文可靠性分析方法具有较高的精度和效率,给出一个包含4个分支的串联系统。该系统包含两个随机变量
${{{x}}_1}\text{、}{{{x}}_2}$ ,均服从标准正态分布,即$ {{X}}\sim N(0,1)$ 。本文中蒙特卡洛抽样(106)仿真得到的结果视为精确解,用于比较分析,蒙特卡洛计算失效概率的变异系数(coefficient of variation, CoV)为$1.48 {\rm{\% }}$ 。系统的性能函数[19]如下:
$$G({{{x}}_1},{{{x}}_2}) = \min \left\{ {\begin{aligned} & {3 + 0.1{{({{{x}}_1} - {{{x}}_2})}^2} - \frac{{{{{x}}_1} + {{{x}}_2}}}{{\sqrt 2 }}}, \\ & {3 + 0.1{{({{{x}}_1} - {{{x}}_2})}^2} + \frac{{{{{x}}_1} + {{{x}}_2}}}{{\sqrt 2 }}}, \\ &{({{{x}}_1} - {{{x}}_2}) + \frac{k}{{\sqrt 2 }}} ,\\ & {({{{x}}_2} - {{{x}}_1}) + \frac{k}{{\sqrt 2 }}} \end{aligned}} \right\}$$ (12) 式中,
$k = 6$ 。本例中,为了与经典算法AK-MCS进行比较,样本量均为7×105,DoE初始样本量均设定为12个,环形区域设定为:
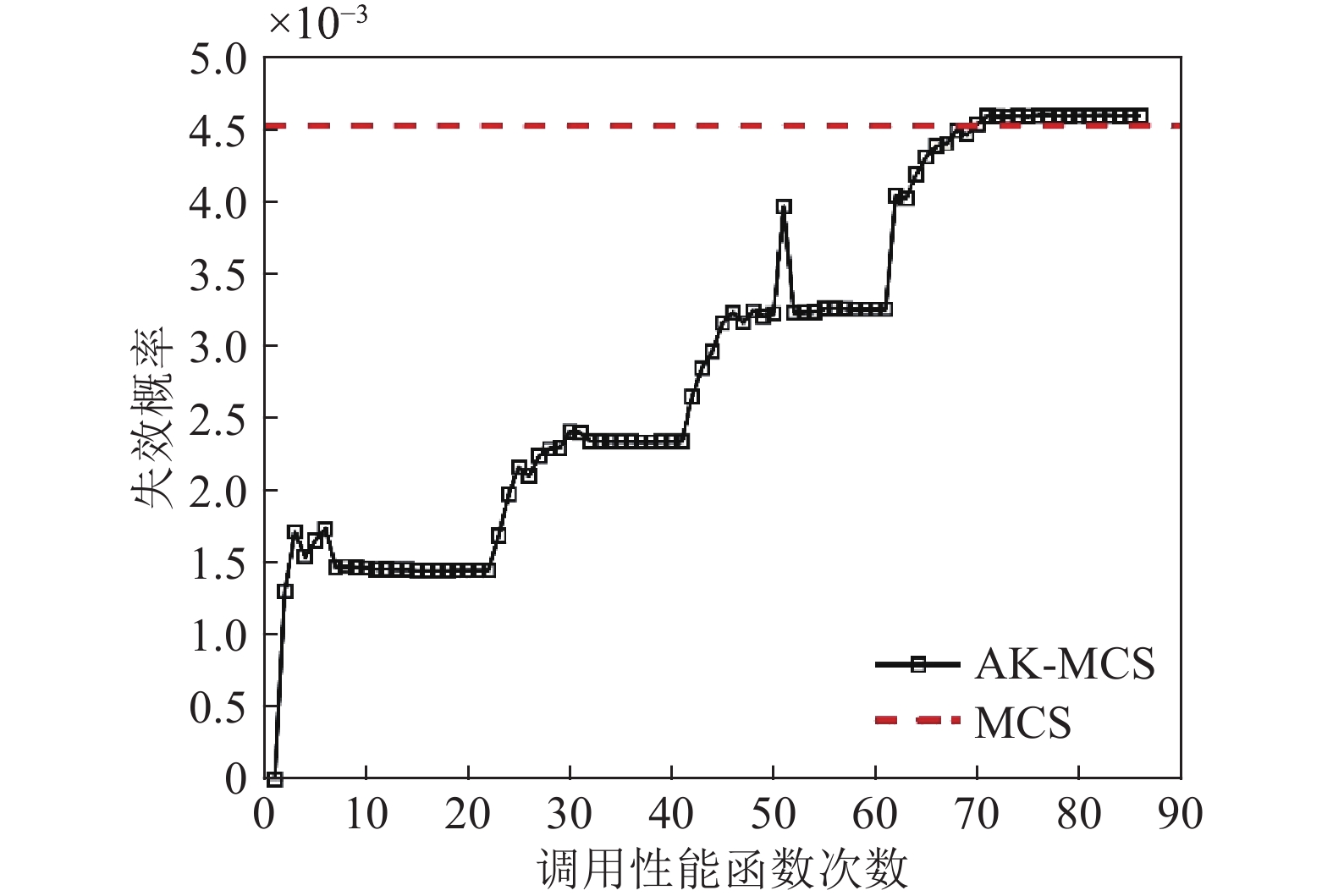
$3 \leqslant r \leqslant 3.5$ 。为了减少因初始训练样本点不同对结果的影响,本文方法和AK-MCS均进行12次计算,所得结果为平均值。MCS计算结果作为本文的参考标准。本文方法与MCS、AK-MCS方法的效率与精度的比较如表1所示。从表1可知,本文方法调用性能函数的次数为73.9次,AK-MCS调用性能函数的次数为102.9次,效率提升明显。另外,本文方法的相对误差为1.93×10−2,而AK-MCS的相对误差为1.68×10−2。但是本文方法在整个可靠性分析过程用时224.4 s,AK-MCS用时416.2 s,所用时间减少了46.1%,效率高于AK-MCS。表 1 几种方法的精度与效率对比
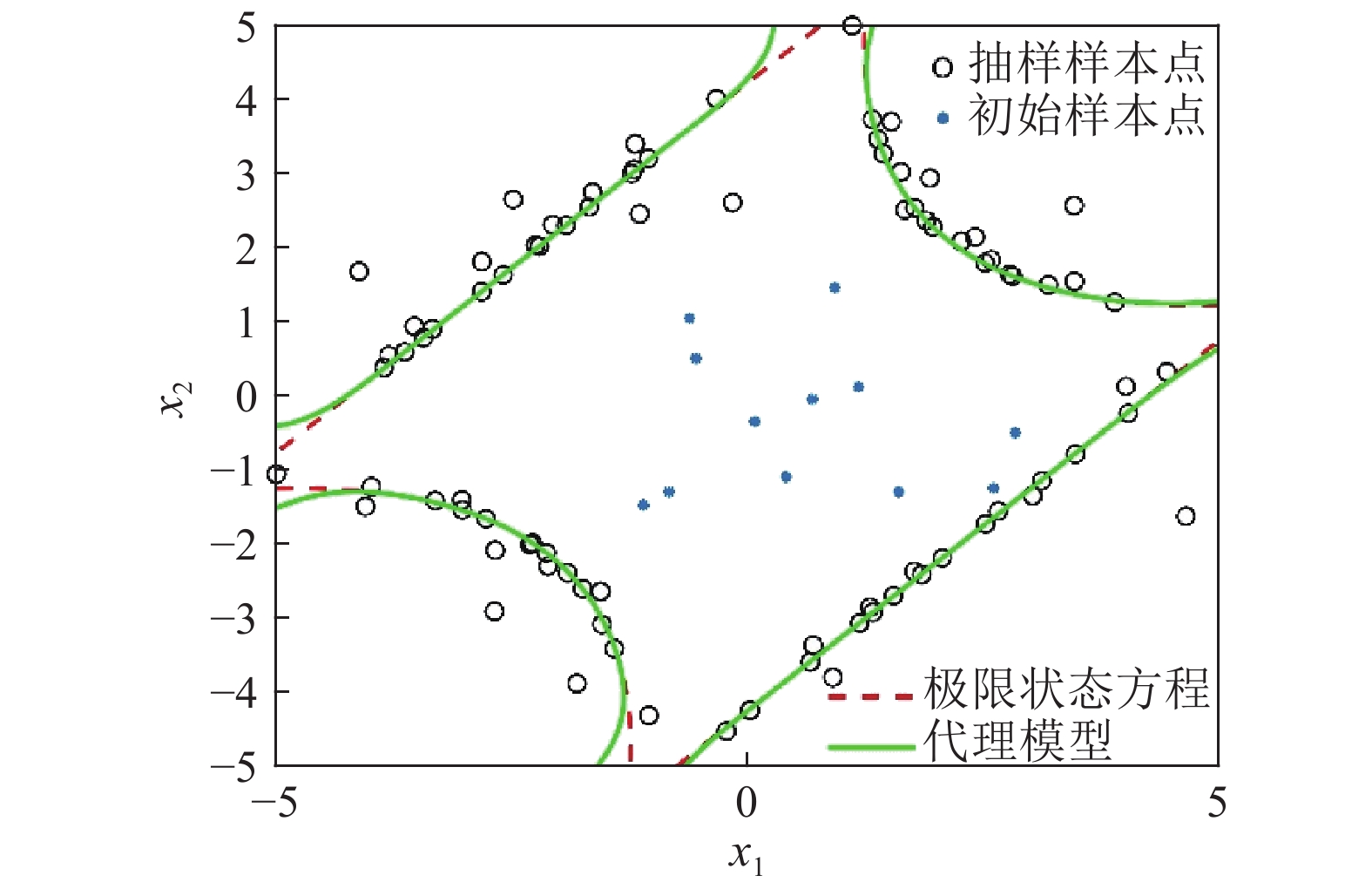
方法 函数调用/次 失效概率 时间/s 相对误差 MCS 1×106 4.52×10−3 (1.48%) − − AK-MCS 12+90.9 4.46×10−3 416.2 1.68×10−2 本文方法 12+61.9 4.44×10−3 224.4 1.93×10−2 为了说明建模过程中样本点的选取、收敛情况,选取了其中一次计算结果。图5、图6分别为本文方法在构建代理模型过程中迭代抽样示意图,以及样本量与失效概率的关系变化情况。从图5中可以看出,本文方法在更新代理模型的过程中避开了对失效概率贡献较小的区域抽样,从而实现抽样集中在对失效概率贡献大的区域。代理模型与极限状态方程能较好的拟合。
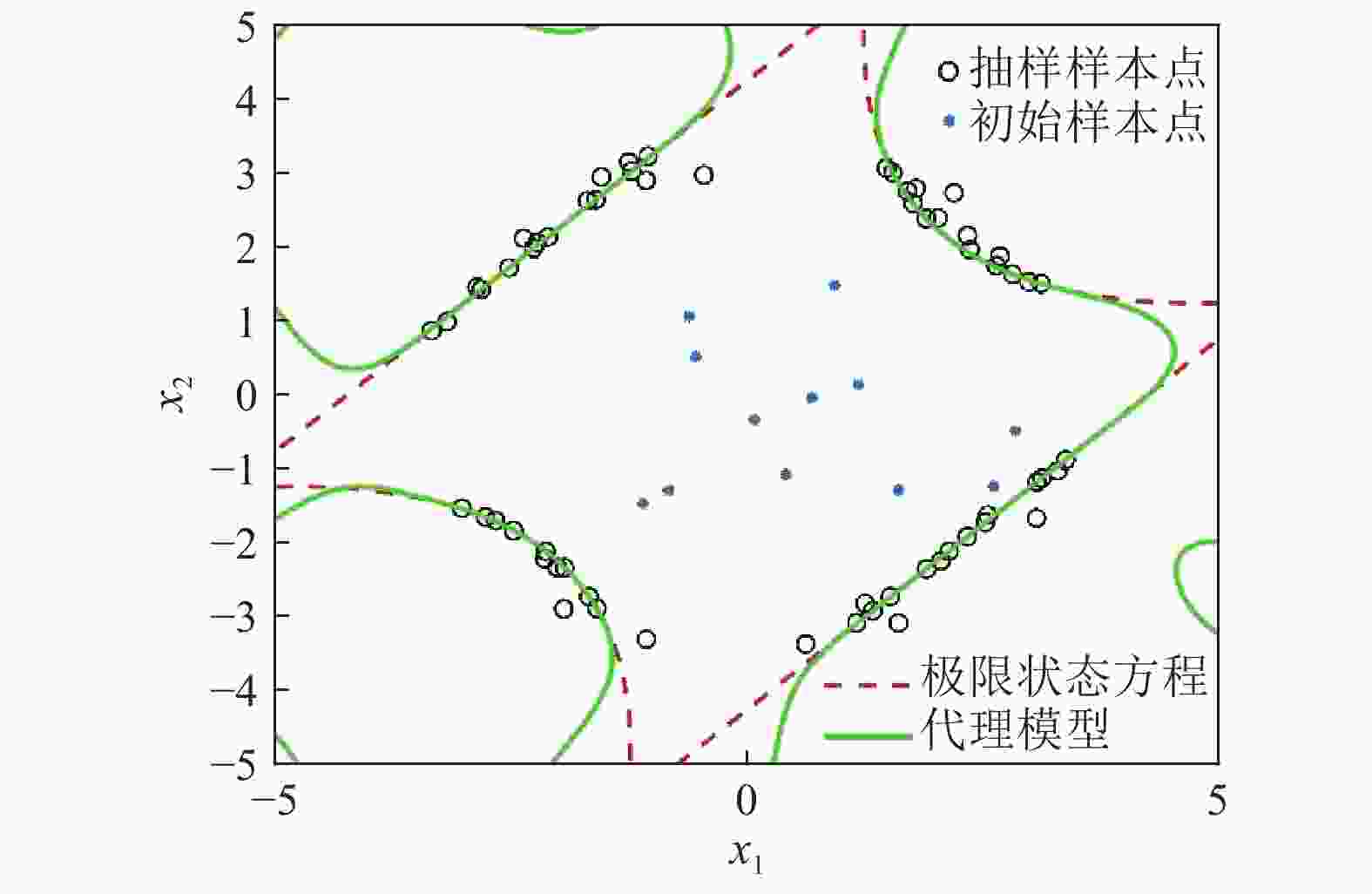
图 5 本文方法抽样示意图
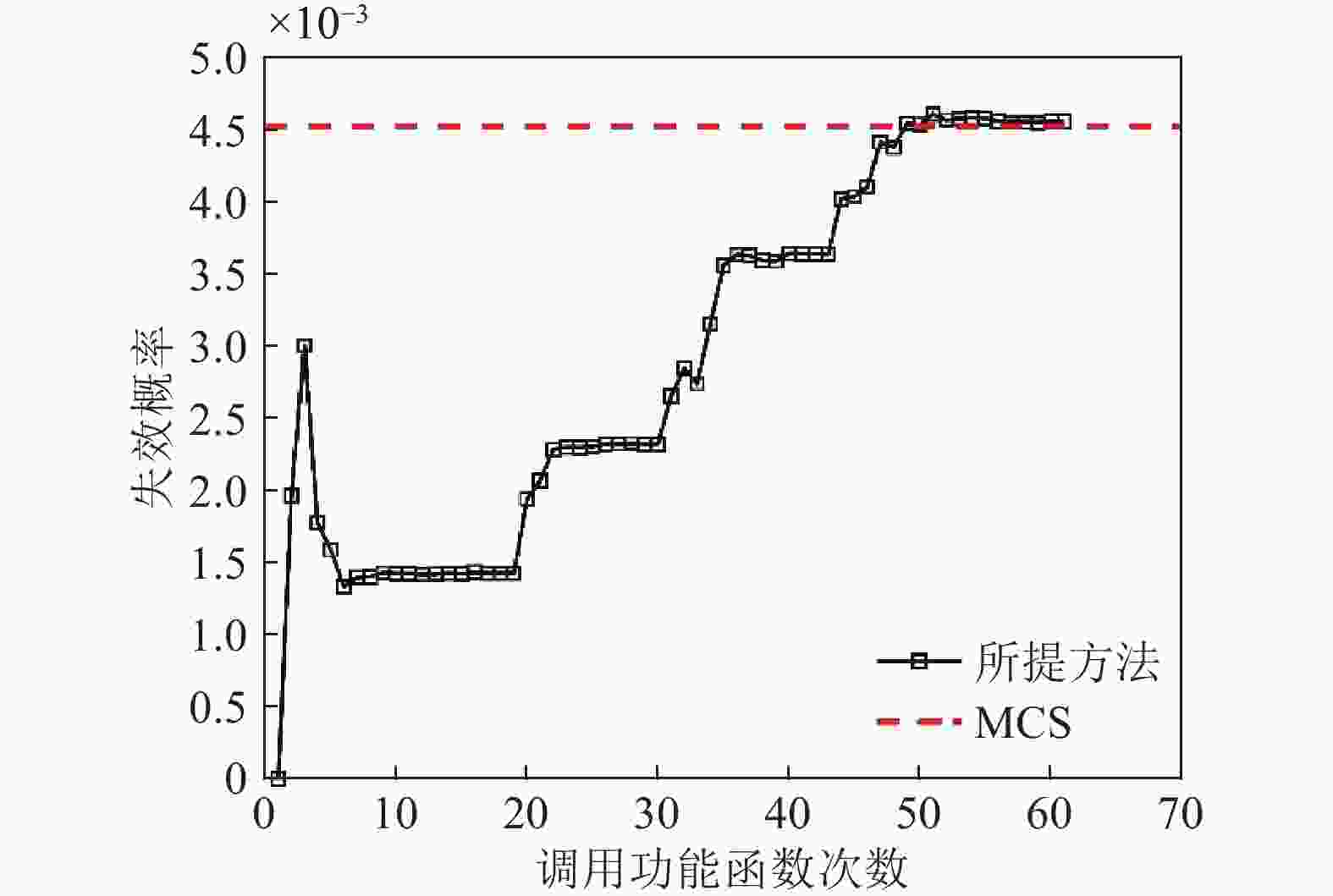
图 6 本文方法样本量与对应的失效概率
图7、图8分别给出了经典AK-MCS方法在构建代理模型过程中迭代抽样示意图,以及样本量与失效概率的关系变化情况。从图5、图7中不难发现,在选取相同初始点的情况下,图5抽样的样本点数量明显少于图7,效率提升明显。另外,从图6、图8可知,本文方法与AK-MCS方法均能得到精度较高的结果,但调用性能函数的次数明显少于AK-MCS方法。
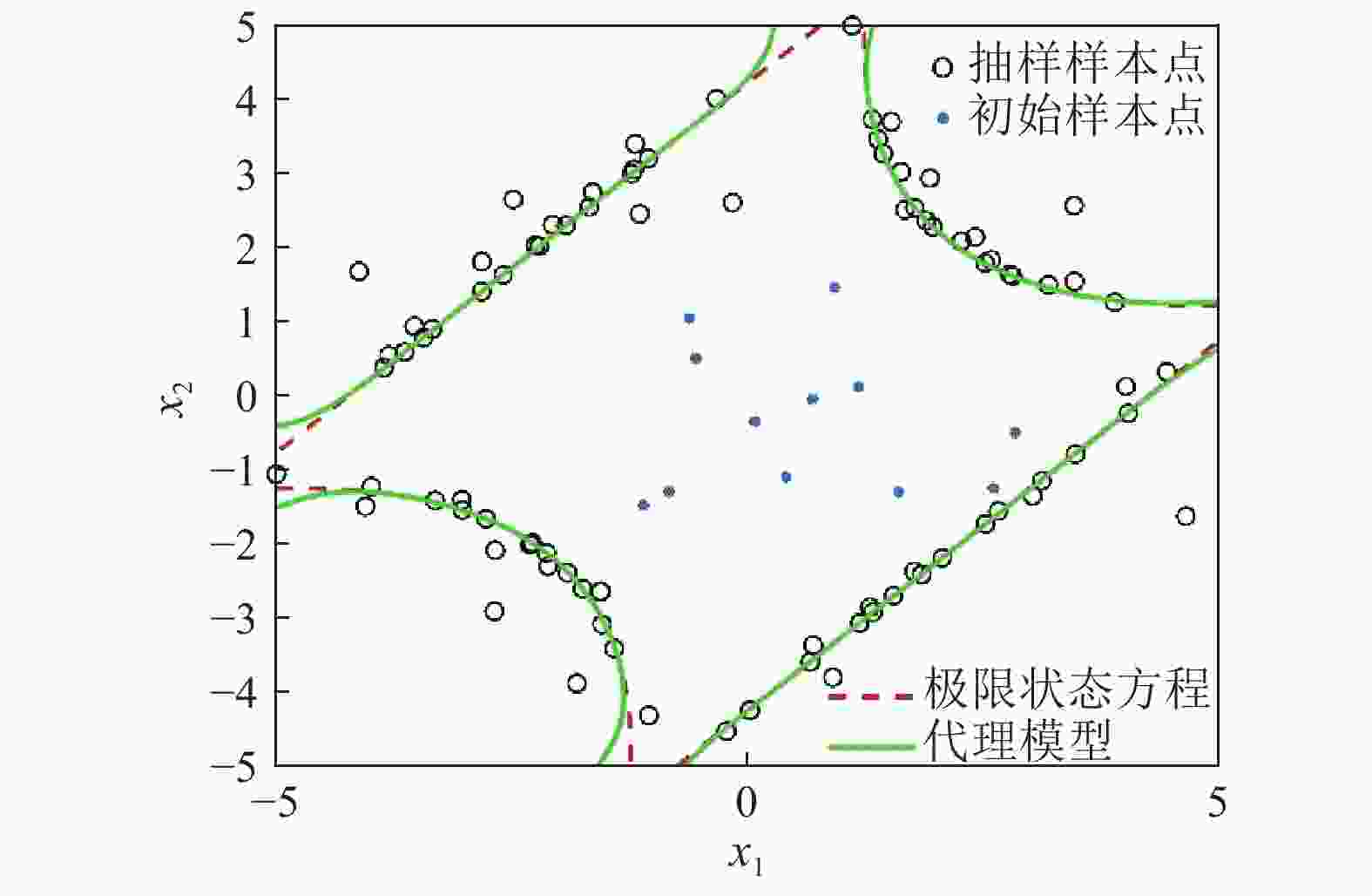
图 7 AK-MCS抽样示意图
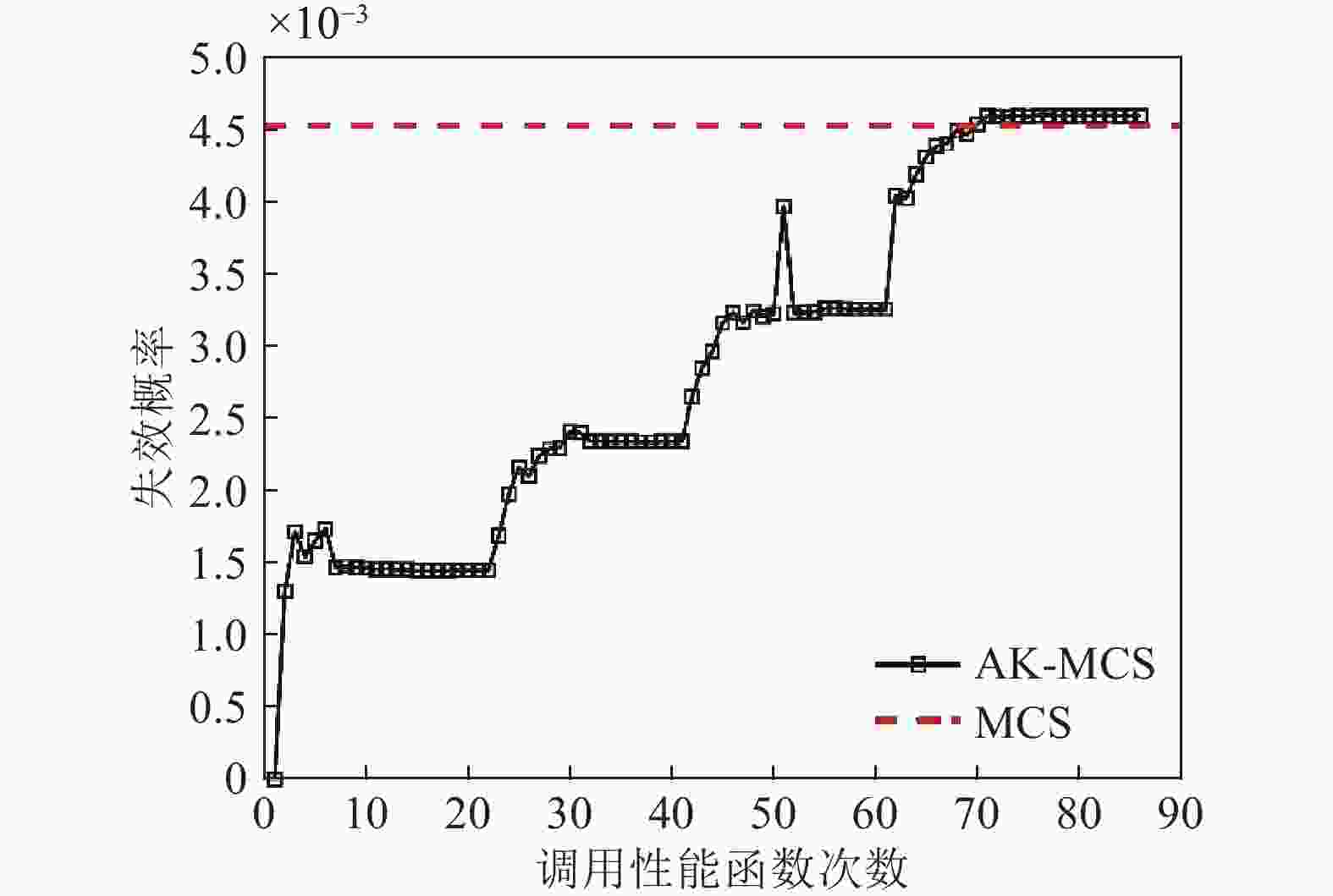
图 8 AK-MCS样本量与对应的失效概率
-
本文基于欧氏距离环形抽样,对基于Kriging代理模型的结构可靠性分析方法进行了研究,并用数值算例验证了该方法的合理性,结果如下:
1) 工程中涉及到的性能函数往往是隐式的,需要通过FEA计算响应值。然而,FEA非常耗时,因此,基于代理模型的高效结构可靠性分析方法可提升可靠性分析的效率;
2) 本文方法中的环形抽样区域通过欧氏距离进行确定,使代理模型在更新过程中避免了对失效概率贡献小的区域进行重复抽样,提升了可靠性分析的效率;
3) 本文方法具有较高的精度和效率,可应用于结构可靠性及可靠性灵敏度分析。同时,可通过改变环形抽样区域的大小来提升方法的鲁棒性和计算效率。
Structural Reliability Analysis Using Circular Sampling Surrogate Models
-
摘要: 该文提出一种基于高效代理模型—Kriging模型的可靠性分析方法,通过欧式距离构造抽样区域,用于确定代理模型更新过程中样本点的选取范围,保证代理模型在更新过程中只对失效概率贡献大的区域选取样本点。算例分析表明该方法具有较高的精度和效率,不仅适用于性能函数为隐式的结构可靠性分析,而且通过改变环形抽样区域的带宽,同样适用于结构可靠性分析中的小概率失效问题,为结构可靠性分析提供了新途径。Abstract: The performance functions of components or systems are often implicit in engineering. A new reliability analysis method based on efficient surrogate model, Kriging model, is proposed. The sampling area is determined by the Euclidean distance and used to determine the area of sampling in the update process of the surrogate model. The proposed method can sample just in the area which have more contribution to the calculation of the failure probability in the update process of the surrogate model. The numerical example shows that the proposed method is accurate and efficient, and can be used in the structural reliability analysis with implicit performance functions. Also, the proposed method can be applied to structural reliability problem with small failure probability by changing the width of the circular sampling area. The proposed method provides a new way to the structural reliability analysis.
-
Key words:
- circular sampling /
- Euclidean distance /
- failure probability /
- structural reliability /
- surrogate model
-
表 1 几种方法的精度与效率对比
方法 函数调用/次 失效概率 时间/s 相对误差 MCS 1×106 4.52×10−3 (1.48%) − − AK-MCS 12+90.9 4.46×10−3 416.2 1.68×10−2 本文方法 12+61.9 4.44×10−3 224.4 1.93×10−2  下载: 导出CSV
下载: 导出CSV
-
[1] 吕震宙, 李璐袆, 宋述芳, 等. 不确定性结构系统的重要性分析理论与求解方法[M]. 北京: 科学出版社, 2015. LÜ Zhen-zhou, LI Lu-hui, SONG Shu-fang, et al. Important analysis theory and solution method of uncertain structural system[M]. Beijing: Science Press, 2015. [2] JING Zhao, CHEN Jian-qiao, LI Xu. RBF-GA: An adaptive radial basis function metamodeling with genetic algorithm for structural reliability analysis[J]. Reliability Engineering & System Safety, 2019, 189: 42-57. [3] LI Dian-qing, XIAO Te, CAO Zi-jun, et al. Efficient and consistent reliability analysis of soil slope stability using both limit equilibrium analysis and finite element analysis[J]. Applied Mathematical Modelling, 2016, 40(9-10): 5216-5229. doi: 10.1016/j.apm.2015.11.044 [4] GAO Wei, WU Di, GAO Kang, et al. Structural reliability analysis with imprecise random and interval fields[J]. Applied Mathematical Modelling, 2018, 55: 49-67. doi: 10.1016/j.apm.2017.10.029 [5] BONSTROM H, COROTIS R B. Building portfolio seismic loss assessment using the first-order reliability method[J]. Structural Safety, 2015, 52: 113-120. doi: 10.1016/j.strusafe.2014.09.005 [6] ZHAO Wei, FAN Feng, WANG Wei. Non-linear partial least squares response surface method for structural reliability analysis[J]. Reliability Engineering & System Safety, 2017, 161: 69-77. [7] BAI Y C, HAN X, JIANG C, et al. A response-surface-based structural reliability analysis method by using non-probability convex model[J]. Applied Mathematical Modelling, 2014, 38(15-16): 3834-3847. doi: 10.1016/j.apm.2013.11.053 [8] CHOJACZYK A A, TEIXEIRA A P, NEVES L C, et al. Review and application of artificial neural networks models in reliability analysis of steel structures[J]. Structural Safety, 2015, 52: 78-89. doi: 10.1016/j.strusafe.2014.09.002 [9] MORFIDIS K, KOSTINAKIS K. Approaches to the rapid seismic damage prediction of r/c buildings using artificial neural networks[J]. Engineering Structures, 2018, 165: 120-141. doi: 10.1016/j.engstruct.2018.03.028 [10] KANG Fei, XU Qing, LI Jun-jie. Slope reliability analysis using surrogate models via new support vector machines with swarm intelligence[J]. Applied Mathematical Modelling, 2016, 40(11-12): 6105-6120. doi: 10.1016/j.apm.2016.01.050 [11] MOHAMMAD A H, FARHAD P. Support vector machine based reliability analysis of concrete dams[J]. Soil Dynamics and Earthquake Engineering, 2018, 104: 276-295. doi: 10.1016/j.soildyn.2017.09.016 [12] WANG Ze-yu, SHAFIEEZADEH A. REAK: Reliability analysis through Error rate-based adaptive Kriging[J]. Reliability Engineering & System Safety, 2019, 182: 33-45. [13] NICOLAS L, BEAUREPAIRE P, CÉCILE M, et al. AK-MCSi: A Kriging-based method to deal with small failure probabilities and time-consuming models[J]. Structural Safety, 2018, 73: 1-11. doi: 10.1016/j.strusafe.2018.01.002 [14] HAERI A, FADAEE M J. Efficient reliability analysis of laminated composites using advanced Kriging surrogate model[J]. Composite Structures, 2016, 149: 26-32. doi: 10.1016/j.compstruct.2016.04.013 [15] XUE Guo-feng, DAI Hong-zhe, ZHANG Hao, et al. A new unbiased metamodel method for efficient reliability analysis[J]. Structural Safety, 2017, 67: 1-10. doi: 10.1016/j.strusafe.2017.03.005 [16] XIAO Ning-cong, ZUO Ming-Jian, ZHOU Cheng-ning. A new adaptive sequential sampling method to construct surrogate models for efficient reliability analysis[J]. Reliability Engineering & System Safety, 2018, 169: 330-338. [17] HUANG Xiao-xu, CHEN Jian-qiao, ZHU Hong-ping. Assessing small failure probabilities by AK–SS: An active learning method combining Kriging and subset simulation[J]. Structural Safety, 2016, 59: 86-95. doi: 10.1016/j.strusafe.2015.12.003 [18] 肖宁聪, 袁凯, 王永山. 基于序列代理模型的结构可靠性分析方法[J]. 电子科技大学学报, 2019, 48(1): 156-160. doi: 10.3969/j.issn.1001-0548.2019.01.023 XIAO Ning-cong, YUAN Kai, WANG Yong-shan. Structural reliability analysis using sequential surrogate models[J]. Journal of University of Electronic Science and Technology of China, 2019, 48(1): 156-160. doi: 10.3969/j.issn.1001-0548.2019.01.023 [19] ECHARD B, GAYTON N, LEMAIRE M. AK-MCS: An active learning reliability method combining Kriging and Monte Carlo simulation[J]. Structural Safety, 2011, 33(2): 145-154. doi: 10.1016/j.strusafe.2011.01.002 [20] FENGKUN C, MICHEL G. Implementation of machine learning techniques into the subset simulation method[J]. Structural Safety, 2019, 79: 12-25. doi: 10.1016/j.strusafe.2019.02.002 [21] ZHENG Peng-juan, WANG Chien-ming, ZONG Zhou-hong. A new active learning method based on the learning function U of the AK-MCS reliability analysis method[J]. Engineering Structures, 2017, 148: 185-194. doi: 10.1016/j.engstruct.2017.06.038 [22] SACKS J, SCHILLER S B, WELCH W J. Design for computer experiment[J]. Technometrics, 1989, 31(1): 41-47. doi: 10.1080/00401706.1989.10488474 [23] JONES D R, SCHONLAU M, WELCH W J. Efficient global optimization of expensive black-box functions[J]. J Global Optimiz, 1998, 13(4): 455-492. doi: 10.1023/A:1008306431147 -

 点击查看大图
点击查看大图

图(8) / 表(1)
计量
- 文章访问数: 4795
- HTML全文浏览量: 1364
- PDF下载量: 40
- 被引次数: 0




































