 ISSN
ISSN 



-
随着基于位置的社交网络(LBSNs)的发展,用户能够在签到位置发布评论分享自己的感受。理解用户活动的语义对分析用户行为起着重要的作用[1-2]。如,一位用户发布一条评论“愿你在天堂安好!”。如果这条评论附加一个医院的位置语义,将有利于更好地理解用户的悲伤体验。同时,位置语义对城市生活中一些基于位置的服务如位置检索和位置推荐有所帮助[3-4]。如,当用户到达一个新城市时,用户将搜索目的地附近的酒店或餐馆等语义信息。智能手机中的应用程序,如城市旅行中的导航,都依赖于位置语义[5-6]。位置语义对于跨越网络和现实环境之间的鸿沟起着重要的作用。然而,据统计,至少有30%的位置在LBSNs中缺乏语义标签[7]。另一方面,尽管地图服务提供商的业务增长迅速,但位置语义标签查询服务的成本却很高。谷歌提供语义搜索服务,每1000个地点收费超过千元。
位置语义研究一直是轨迹数据挖掘研究中的热点,位置语义推断也得到了许多研究者的广泛关注。一般的研究思路为通过手工提取用户签到活动中的时空模式,或通过手工定义位置的时空特征,利用分类器推断位置语义。如文献[7]提取特定位置的显式模式(explicit patterns, EP)和相似位置之间的隐式关联(implicit relatedness, IR)。基于EP和IR特征,训练支持向量机分类器推断位置语义。文献[8]提出一种新的位置特征,称为相似用户模式(similar user pattern, SUP),同时考虑个人用户活动的规律性,以及不同用户之间的相似性。提取SUP后,利用SUP度量位置间的相似性,训练分类器学习每个未标注语义的位置的语义标签。文献[9]提出一种基于图表征学习的位置语义推断算法,称为预测位置嵌入(predictive place embedded, PPE)。PPE首先构造用户−标签二部图,通过用户−标签二部图获得用户向量表征。优化每个位置作为其签到用户向量的质心嵌入表征的方式,将用户相似度转换为位置相似度,获取位置语义标签。
现有位置语义推理算法目标是提取签到活动中所隐含的位置时空特征或用户签到时空模式,并将语义推理转化为分类问题。但度量位置间的相似度或提取长效稳定的用户签到模式是一项困难的任务。为了克服这种局限性,本文提出一种基于图卷积神经网络的位置语义推理框架(semantic inferences with graph convolutional networks, SI-GCN)。SI-GCN通过无监督的方式提取位置的时空特征,利用图卷积神经网络(graph convolutional networks, GCN[10])推断位置的语义类别标签。具体来说,SI-GCN通过node2vec[11-12]和变分自编码器(variational autoencoder, VAE[13])自动提取位置时空特征。然后,SI-GCN利用图卷积网络来捕获用户−位置访问二部图中的高阶访问关系,同时利用自注意力机制来学习用户−位置访问二部图中相邻节点的不同贡献。实验结果表明,相较于传统的位置语义推断算法,SI-GCN取得了更好的位置语义推断结果。
-
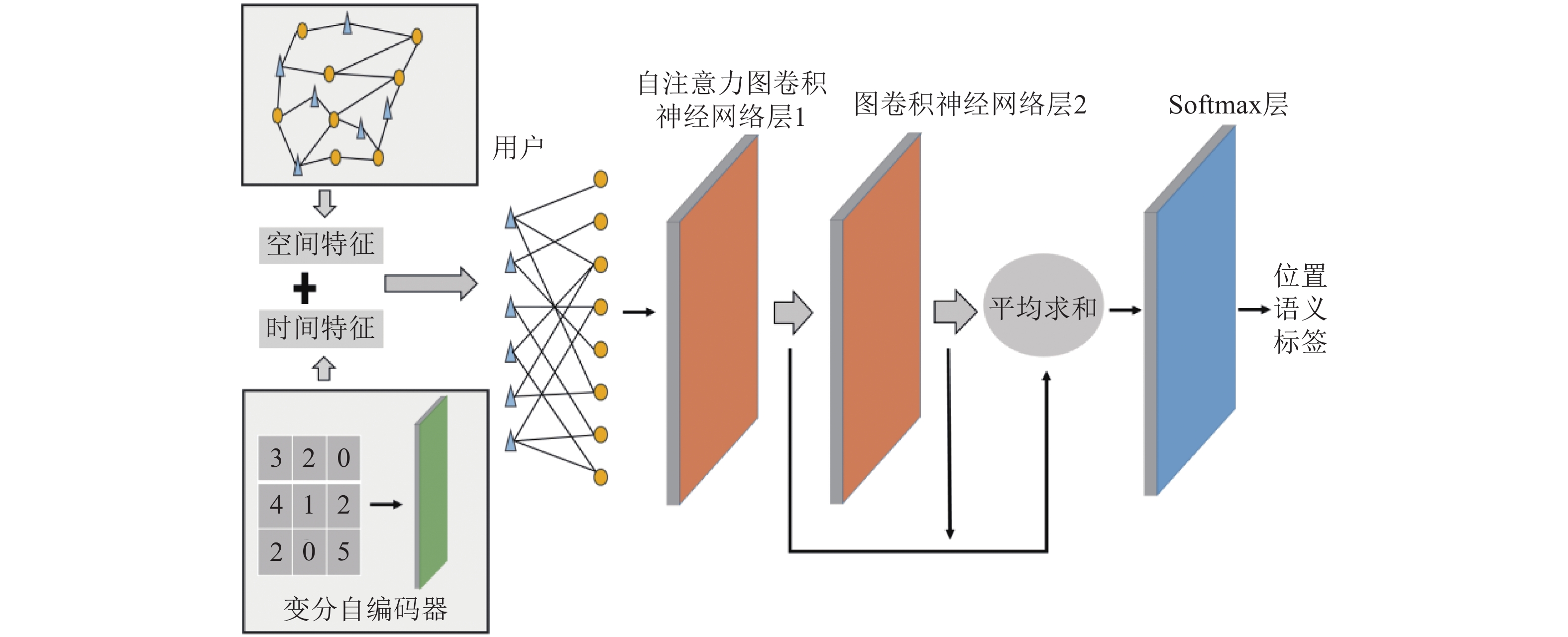
图1为SI-GCN的整体框架,从左至右分别是时空特征提取、用户−位置访问二部图构建、利用两层GCN进行语义推理。
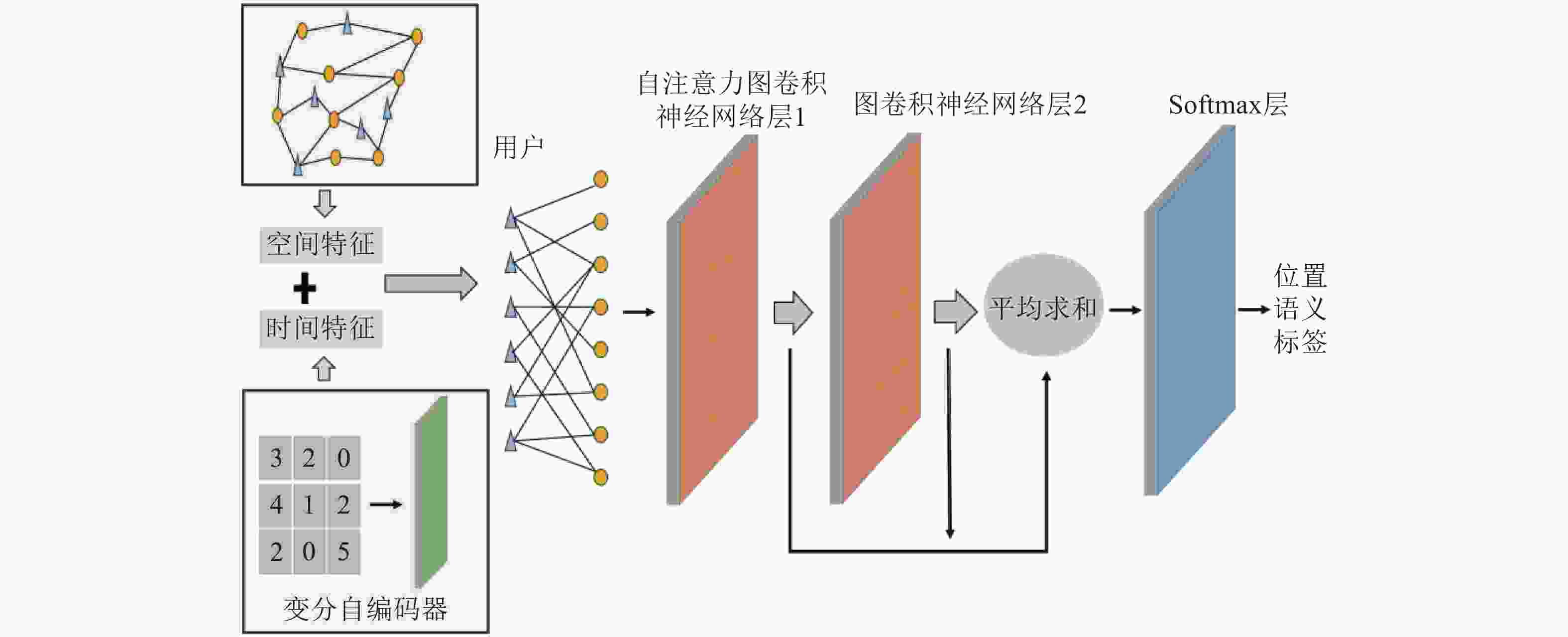
图 1 SI-GCN框架图
-
位置的时空特征是位置社交网络中位置语义研究的关键问题。SI-GCN利用无监督学习的方式提取位置的空间结构信息和时间信息,其基本思想为在城市规划中,具有相同的功能位置(即相同的语义类别)在城市中具有近似的空间结构。因此,提取空间特征主要目标是保留位置在地理空间中的结构特征。由于用户与地理位置不同,用户没有直接的经纬度,SI-GCN首先计算出用户访问频率最高的3个地理位置的平均经纬度作为用户的地理坐标,为了构建地理空间网络
${N_{{\rm{sp}}}}$ ,SI-GCN将用户的坐标$({u_{{\rm{lon}}}},{u_{{\rm{lat}}}})$ 映射到城市中,利用用户坐标和位置坐标,建立城市地理空间网络${N_{{\rm{sp}}}}$ 。具体如下:计算城市中节点之间的距离,如果距离小于$\delta $ ,则将两个节点连接为边,反之亦然。在完成地理空间网络
${N_{{\rm{sp}}}}$ 的构建后,使用node2vec算法以无监督的方式学习用户和位置的空间特征${f_{{\rm{sp}}}}$ 。空间特征学习希望通过最大化一个节点与相邻节点同时出现的概率的方式保留位置的空间结构信息,即最大化$\Pr ({\cal N}(v)|{f_{{\rm{sp}}}}(v))$ 。定义$V$ 是${N_{{\rm{sp}}}}$ 中的节点集合,$v$ 是$V$ 的一个节点$v \in V$ ,${\cal N}(v)$ 是$v$ 的邻居。空间特征提取的目标函数表示为:$${{\cal L}_{{\rm{sp}}}} = \mathop {\max }\limits_{{f_{{\rm{sp}}}}} \sum\limits_{v \in V} {\log \Pr ({\cal N}(v)|{f_{{\rm{sp}}}}(v))} $$ (1) 提取时间特征的目标是学习用户或位置签到活动时间模式的特征向量。本研究中,时间模式定义为一个7×24的时间矩阵来计算用户或位置访问频次。如,如果用户A在周一上午9:00−10:00访问位置B,则用户的时间矩阵的对应元素增加1。位置的访问时间矩阵计算方法与用户方法一致。
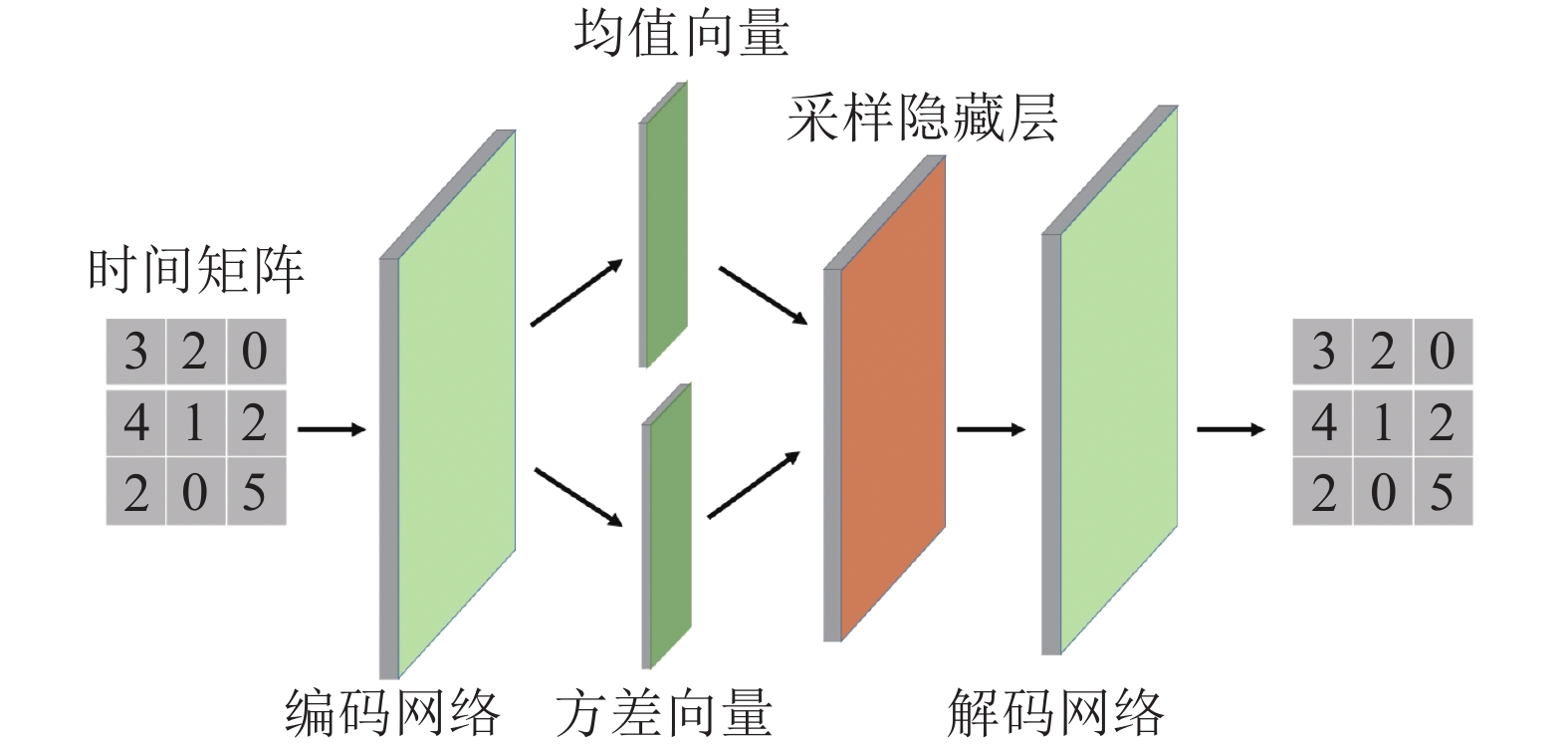
图2为利用变分自编码器提取时间特征的过程,利用变分自编码器无监督学习时间矩阵的特征向量。
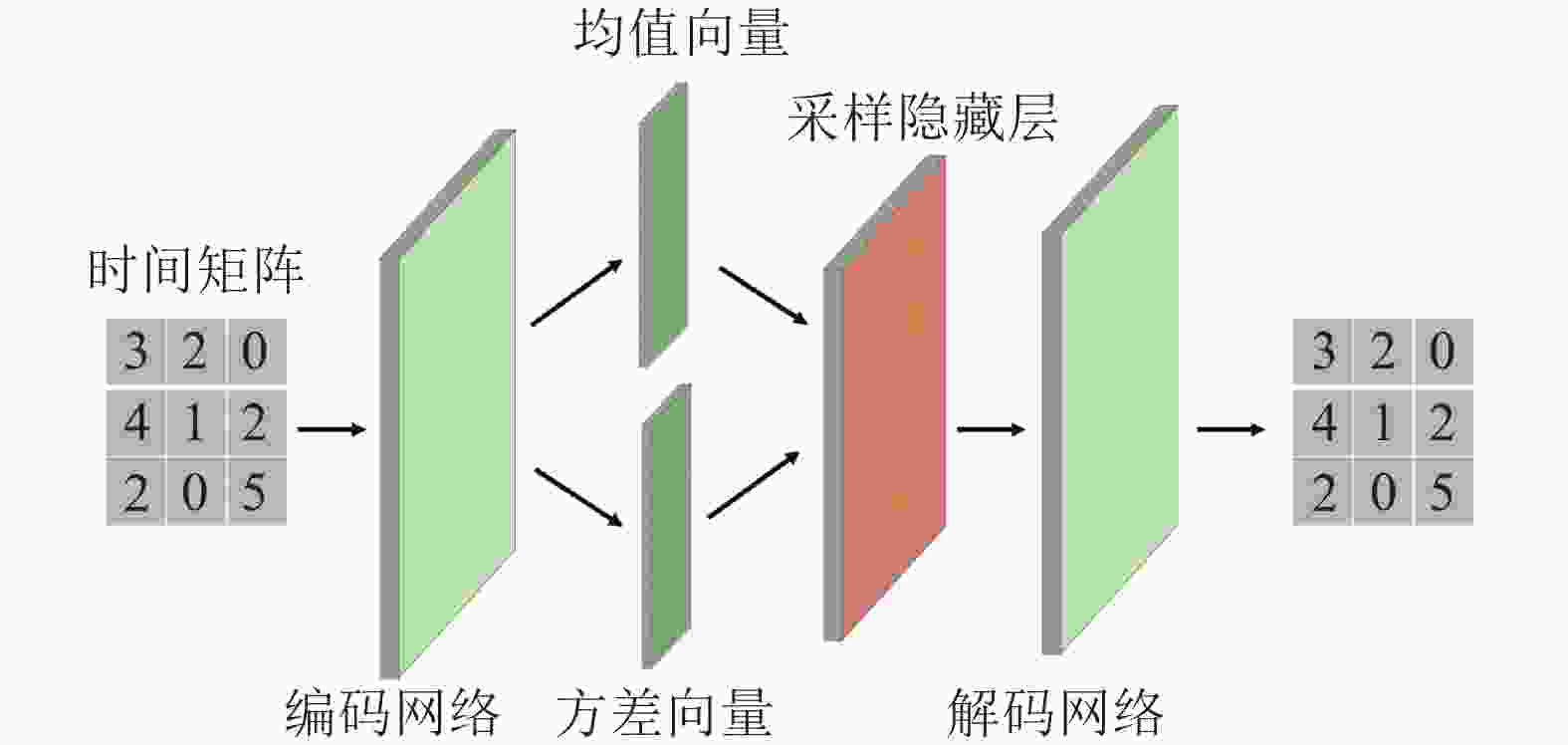
图 2 变分自编码器提取时间特征的图示
具体如下:时间矩阵作为编码器层的输入向量进行编码;重参数化层是获取编码网络输出向量的均值向量和方差向量;隐层向量是由重参数化层采样恢复的时间矩阵的隐向量表征;最后,解码器层通过隐向量重构时间矩阵。VAE的损失函数表示为:
$${{\cal L}_{{\rm{te}}}} = - 0.5 (1 + {\lg {{\sigma ^2}}} - {\mu ^2} - {\sigma ^2}) + \frac{1}{V}\sum\limits_{i = 1}^V {\sqrt {{{({{{x}}_i} - \widetilde {{{{x}}_i}})}^2}} } $$ (2) 式中,第一部分是通过Kullback-Leibler散度最小化均值向量和方差向量与正态分布之间的距离;第二部分是输入和输出之间的重构损失;
$\mu $ 为重参数化层的均值向量;$\sigma $ 为重参数化层的方差向量;${{{x}}_i}$ 为输入时间矩阵;$\widetilde {{{{x}}_i}}$ 为解码网络输出时间矩阵。完成网络学习后,提取VAE的采样隐藏层输出的隐向量,得到时间特征${f_{{\rm{te}}}}$ 。将用户、位置的空间特征和时间特征直接连接起来,作为用户、位置的时空特征${f_{{\rm{st}}}} = [{f_{{\rm{sp}}}}||{f_{{\rm{te}}}}]$ 。 -
为了分析签到活动和位置语义之间的关系,SI-GCN构建一个用户−位置访问二部图,记作
${N_c}$ 。如图1所示,二部图的一侧是用户$u$ ,另一侧是位置$l$ 。如果用户${u_i}$ 访问过位置${l_i}$ ,则${e_{ij}} = 1$ ,反之亦然:$${e_{ij}} = \left\{ {\begin{array}{*{20}{c}} 1&{{u_i}\begin{array}{*{20}{c}} {{\rm{visited}}}&{{l_j}} \end{array}} \\ 0&{{u_i}\begin{array}{*{20}{c}} {{\rm{not}}}\;{{\rm{visited}}} \end{array}{l_j}} \end{array}} \right.$$ (3) SI-GCN的目的是利用GCN结合位置时空特征和用户−位置访问二部图来学习位置在语义空间中的表征。如图1的右侧所示,SI-GCN通过两层图卷积层来完成这项工作。在
${N_c}$ 中,将用户和位置视为同一类别节点。定义${N_c}$ 中的节点集合为$V$ ,${{X}} = \left\{ { {{{{x}}_1}} , {{{{x}}_2}} ,\cdots, {{{{x}}_v}} , {{{{x}}_i}} \in {\mathbb{R}^F}} \right\}$ 是节点的F维时空特征向量集合,${{A}}$ 是用户−位置访问二部图${N_c}$ 的邻接矩阵,${{D}}$ 是${N_c}$ 的度矩阵。为了区分来自邻居节点的不同贡献,引入文献[14]提出的自注意力机制:$${e_{ij}} = {{a}}({{{W}}_1} {{{{x}}_i}} ,{W_1} {{{{x}}_j}} )$$ (4) 式中,
${e_{ij}}$ 表示节点j对节点i的重要性;${{{W}}_1} \in {\mathbb{R}^{{F^\prime } \times F}}$ 是权重矩阵;${{a}}$ 是权值矩阵${\mathbb{R}^{F'}} \times {\mathbb{R}^F} \to \mathbb{R}$ 的变换。为避免过多信息的干扰,SI-GCN仅关注邻居节点,表示为$j \in {N_{ei}}$ 。同时,使用softmax函数进行正则化,得到节点i对节点j的注意力系数为${\alpha _{ij}}$ :$${\alpha _{ij}} = {\rm{softmax(}}{{\rm{e}}_{ij}}{\rm{) = }}\frac{{\exp ({{\rm{e}}_{ij}})}}{{\displaystyle\sum\limits_{k \in {N_{ei}}} {\exp ({{\rm{e}}_{ik}})} }}$$ (5) SI-GCN采用文献[14]中提出的具有LeakyRelu激活函数的前馈神经层
$a$ :$${\alpha _{ij}} = \frac{{\exp ({\rm{LeakyRelu(}}{{ {{a}} }^{\rm{T}}}{\rm{[}}{W_1} {{{{x}}_i}} ||{W_1} {{{{x}}_j}} {\rm{])}})}}{{\displaystyle\sum\limits_{k \in {N_{ei}}} {\exp ({\rm{LeakyRelu(}}{{ {{a}} }^{\rm{T}}}{\rm{[}}{W_1} {{{{x}}_i}} ||{W_1} {{{{x}}_k}} {\rm{])}})} }}$$ (6) 式中,||表示连接操作。完成邻居节点注意力系数计算后,利用非线性激活函数
$\varphi $ ,每个节点的输出为:$${h_{1i}} = \varphi \left(\sum\limits_{k \in {N_{ei}}} {{\alpha _{ij}}{{{W}}_1}} {{{{x}}_k}} \right)$$ (7) 先前的研究表明叠加图卷积层能够探索图中节点的高阶信息。因此,SI-GCN引入两层GCN来挖掘签到活动中的高阶信息。第一层探索节点的邻居节点的影响,如在
${N_c}$ 中两个朋友共同访问的位置或用户访问的两个位置。第二层旨在获取${N_c}$ 中的二阶信息,例如多个好友共同访问同一个位置。引入两层GCN能够更好的捕获用户签到活动中的高阶信息。在用户−位置访问二部图${N_c}$ 中,邻接矩阵为A,根据GCN的传播公式,SI-GCN第一层的输出为:$${h_2} = {\rm{Relu}}(\widehat {{A}}{h_1}{{{W}}_{\rm{2}}})$$ (8) 式中,
${h_1}$ 是自注意力层的输出;$\widehat {{A}} = {\widetilde {{D}}^{ - \frac{1}{2}}}\widetilde {{A}}{\widetilde {{D}}^{ - \frac{1}{2}}}$ ,$\widetilde {{A}} = {{A}} + {{I}}$ ,${{I}}$ 是单位矩阵,$\widetilde {{D}}$ 是$\widetilde {{A}}$ 的度矩阵($\widetilde {{D}} = \displaystyle\sum\limits_j {{{\widetilde {{A}}}_{ij}}} $ )。同时,为了充分利用两层图卷积层,SI-GCN计算两层图卷积层的平均结果作为softmax层的输入,GCN输出:$$z = {\rm{softmax}}(0.5(\varphi (\widehat {{A}}\varphi (\widehat {{A}}{h_1}{{{W}}_{2}}){{{W}}_{3}}) + \widehat {{A}}{h_1}{{{W}}_{2}}))$$ (9) 式中,
${{{W}}_{2}}$ 、${{{W}}_{3}}$ 是网络参数。由于用户没有语义标签,对于用户的语义标签,将用户访问次数最多的位置的语义标签视为用户的语义标签。最终,SI-GCN的损失函数为:$${\cal L} = - \sum\limits_{m \in {Y_m}} {\sum\limits_{c = 1}^C {{Y_{mc}}\ln ( - {z_{mc}})} } $$ (10) 式中,
$C$ 是语义类别集合;${Y_m}$ 是训练集中具有真实语义类别标签的节点集合;${Y_{mc}}$ 是${Y_m}$ 中有真实语义类别的节点集合;${z_{mc}}$ 是SI-GCN预测的语义类别。SI-GCN采用ADAM算法学习网络参数。最后,SI-GCN的完整过程总结如下:1)对位置签到数据集中的每一个用户,检索用户访问频率最高的3个访问位置作为用户在地理空间中的坐标(
${u_{{\rm{lon}}}}$ ,${u_{{\rm{lat}}}}$ ):${u_{{\rm{lon}}}} = \dfrac{1}{3}(l_{{\rm{lon}}}^1 + l_{{\rm{lon}}}^2 + l_{{\rm{lon}}}^3)$ ,${u_{{\rm{lat}}}} = \dfrac{1}{3}(l_{{\rm{lat}}}^1 + l_{{\rm{lat}}}^2 + l_{{\rm{lat}}}^3)$ ;2)计算每个用户与地理位置之间以及地理位置之间的距离:
${\rm{dist}}(i,j) = \sqrt {{{({x_i} - {x_j})}^2} + {{({y_i} - {y_j})}^2}} $ ,如果距离小于$\delta $ ,则将两个节点连接为边,由此构造城市地理网络空间${N_{{\rm{sp}}}}$ ,通过 node2vec 算法计算节点的${f_{{\rm{sp}}}}$ ;3)对签到数据集中的每一个用户,计算每个用户和位置的时间矩阵,采用VAE算法计算时间特征
${f_{{\rm{te}}}}$ ;4)由空间特征
${f_{{\rm{sp}}}}$ 和时间特征${f_{{\rm{te}}}}$ 组成时空特征:${f_{{\rm{st}}}} = [{f_{{\rm{sp}}}}||{f_{{\rm{te}}}}]$ ;5)由式(3)构造用户−地理位置访问二部图
${N_c}$ 。利用两层GCN模型推断位置语义,利用 ADAM 优化方法训练网络参数,推断地理位置语义标签结果。 -
为了全面评估SI-GCN的性能,实验利用来自Foursquare的两个真实的签到数据集进行实验,验证SI-GCN的语义推断性能。同时,将SI-GCN与3种基准算法进行比较,分别是SAP[7]、SUP[8]和PPE[9]。SI-GCN是在PyTorch框架下实现的,所有的实验都是在一台4核(3.5 GHz CPU) 32 GB内存的服务器上进行的,使用双NVIDIA GPU (8 GB显存)。
-
实验采用FourSquare收集的纽约市(NYC)和东京市(Tokyo)的签到数据,时间从2012年4月12日−2013年2月16日[6]。每个签到记录包括用户ID、位置ID、位置类别ID、位置语义类别、纬度、经度、与UTC标准时间的偏差和UTC标准时间。
由于部分位置签到记录过少,无法有效提取位置的时间特征。因此,在数据预处理中,删除签到记录少于10条的位置。表1列出纽约市和东京市的签到数据集的统计信息。实验采取两种语义标签策略评估SI-GCN的语义推断性能:1)将FourSquare数据集的语义标签分为9大类,包括餐馆、酒店、景点、交通枢纽、商店、教育、娱乐、宗教、公司等类别;2)从原有的FourSquare数据集中选出两个新的子数据集,其中仅包含按签到次数排名前20位的位置语义类别。为了评估SI-GCN的综合性能,实验从准确性(Acc)、微观F1值(microF1)和宏观F1值(macroF1)3个评价指标对SI-GCN的性能进行评价。为了评价SI-GCN的性能,实验中设置不同比例的测试数据:20%、30%、40%、50%。SI-GCN的语义性能如表2所示。
表 1 实验所用数据集统计信息
数据集 用户数 位置数 语义类别 签到数 NYC 1083 5135 321 147938 Tokyo 2293 7873 292 447570 表 2 SI-GCN在NYC和Tokyo两个数据集的实验结果
数据集 语义类别测试数据比例 10 20 20% 30% 40% 50% 20% 30% 40% 50% NYC Acc 0.709 0.684 0.613 0.504 0.551 0.476 0.439 0.388 microF1 0.587 0.545 0.490 0.424 0.519 0.454 0.411 0.345 macrof1 0.534 0.452 0.419 0.372 0.477 0.399 0.374 0.295 Tokyo Acc 0.719 0.670 0.623 0.573 0.643 0.563 0.504 0.418 microF1 0.591 0.533 0.479 0.419 0.511 0.483 0.414 0.365 macrof1 0.505 0.482 0.409 0.368 0.469 0.417 0.344 0.222 -
表2为SI-GCN在纽约市和东京市两个签到数据集的实验结果。从表2中得到以下观察结果:1)更多的数据有利于SI-GCN取得更好的实验结果,能够从更多的训练数据中更好地捕捉到用户签到活动的时空特征与用户−位置访问二部图的拓扑结构之间的关系,从而获得更好的性能;2)数据分布不均衡对模型性能有负面影响。如纽约和东京的餐馆标签分别为30.8%和27.1%,SI-GCN准确率较高,但microF1和macroF1值较低;3) 10个大类别的语义推断的性能优于前20个类别的性能,原因是更多的语义标签导致模型性能的下降;4) SI-GCN在纽约集的结果优于东京数据集。分析数据集发现:纽约市的每个用户有4.74个访问过的位置,而东京的每个用户只有3.43个访问位置。尽管东京的用户有更高的访问频率(纽约市每名用户有136.6条签到记录,东京每名用户有195.2条签到记录),但SI-GCN仍能够从更多访问位置中捕获用户的偏好。
实验对比仅采用空间特征的SI-GCN-S和仅采用时间特征SI-GCN-T验证空间、时间特征对模型性能的影响。表3为两种模型变体在东京市数据集的实验结果。从准确率评价指标分析,空间特征或时间特征对模型的影响基本相同。从microF1和macroF1结果分析,尤其是当训练数据较少时,SI-GCN-T在两个数据集上的结果均显著低于SI-GCN-S,说明缺失空间特征对模型性能影响比时间特征大。
表 3 SI-GCN模型变体在Tokyo签到数据集的结果
参数 SI-GCN-S SI-GCN-T 20% 30% 40% 20% 30% 40% Acc 0.527 0.464 0.435 0.497 0.420 0.383 microF1 0.417 0.378 0.290 0.425 0.324 0.294 macrof1 0.381 0.317 0.267 0.352 0.257 0.174 图3为SI-GCN与3种基准模型SUP、PPE、SAP在纽约市签到数据集的对比实验结果。从中能够得出以下观察结果:1) SI-GCN优于其他3种基准算法;2) PPE的性能优于SUP和SAP,SUP的性能接近SAP。具体分析如下:首先,SI-GCN利用node2vec和VAE学习空间结构特征和时间特征,而不是手工提取时空模式。其次,SI-GCN采用图卷积神经网络和自注意力机制,在签到活动中能够有效区分来自用户−位置访问二部图中邻居节点的不同贡献和高阶信息。因此,本文所提出的SI-GCN比基准算法具有更好的位置语义推理性能。

图 3 SI-GCN与3种基准算法在NYC数据集对比结果
-
本文提出一种基于图卷积神经网络的位置语义推断模型。与现有的方法不同,SI-GCN避免手工提取签到活动中时空特征的局限。同时,SI-GCN引入图卷积神经网络获取签到活动中的高阶信息。此外,为了区分用户−位置访问二部图中不同邻居节点的影响,引入自注意力机制计算邻居节点的影响力大小。SI-GCN在两个签到数据集上的实验结果表明,SI-GCN优于现有方法。
Location Semantics Inference with Graph Convolutional Networks
-
摘要: 挖掘位置社交网络(LBSNs)中的签到数据背后所蕴藏的信息是城市计算、智慧城市的重要研究方向,其中一个关键的任务是推断位置语义。位置语义因其在位置检索、位置推荐、数据预处理等领域的广泛应用而受到越来越多的关注。现有的推断方法倾向于手工提取位置的时空特征或用户签到活动的时空模式训练分类器进而推断位置语义。然而,提取有价值的时空模式或时空特征是一项困难的任务。该文提出一种新的基于图卷积神经网络的位置语义推理模型(SI-GCN)。SI-GCN利用node2vec和变分自编码器来学习位置的空间和时间特征。构建用户−位置访问二部图,利用图卷积神经网络来捕获用户签到活动中的高阶信息。此外,SI-GCN引入自注意力机制区分用户−位置访问二部图中不同邻居节点的贡献。SI-GCN在两个真实签到数据集上的实验表明,SI-GCN比现有3种算法具有更好的推断性能。Abstract: Data mining on check-in data inlocation based social networks (LBSNs) is an important research direction of urban computing and smart city, and a critical task is to infer location semantic. The study of location semantics has attracted increasing attention in diverse fields due to its wide applications such as location retrieval, location recommendation, data preprocessing and so on. Established inference approaches tend to manually discover the spatiotemporal pattern of unique location as features for training classifiers. However, extracting valuable spatiotemporal patterns or features is a non-trivial task. In this paper, we propose a novel location semantic inference with graph convolutional networks (SI-GCN). We introduce node2vec and variational autoencoder to learn spatial and temporal features of location, respectively. Furthermore, we leverage graph convolutional networks to capture high order relations in user’s check-in activity with building a user-location bipartite network. And leveraging self-attention mechanism is allowed to distinguish contributions of the different nodes. Extensive experiments on several real-world check-in data sets show that our proposed framework outperforms than three state-of-art algorithms.
-
Key words:
- data mining /
- GCN /
- LBSNs /
- self-attention mechanism /
- semantics inference
-
表 2 SI-GCN在NYC和Tokyo两个数据集的实验结果
数据集 语义类别测试数据比例 10 20 20% 30% 40% 50% 20% 30% 40% 50% NYC Acc 0.709 0.684 0.613 0.504 0.551 0.476 0.439 0.388 microF1 0.587 0.545 0.490 0.424 0.519 0.454 0.411 0.345 macrof1 0.534 0.452 0.419 0.372 0.477 0.399 0.374 0.295 Tokyo Acc 0.719 0.670 0.623 0.573 0.643 0.563 0.504 0.418 microF1 0.591 0.533 0.479 0.419 0.511 0.483 0.414 0.365 macrof1 0.505 0.482 0.409 0.368 0.469 0.417 0.344 0.222  下载: 导出CSV
下载: 导出CSV
表 3 SI-GCN模型变体在Tokyo签到数据集的结果
参数 SI-GCN-S SI-GCN-T 20% 30% 40% 20% 30% 40% Acc 0.527 0.464 0.435 0.497 0.420 0.383 microF1 0.417 0.378 0.290 0.425 0.324 0.294 macrof1 0.381 0.317 0.267 0.352 0.257 0.174
下载: 导出CSV
-
[1] ZHENG Y. Trajectory data mining: an overview[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2015, 6(3), DOI: 10.1145/2743025 [2] RODRIGUES F, MARKOU I, PEREIRA F C. Combining time-series and textual data for taxi demand prediction in event areas: A deep learning approach[J]. Information Fusion, 2019, 49: 120-129. doi: 10.1016/j.inffus.2018.07.007 [3] ZHENG Y. Methodologies for cross-domain data fusion: An overview[J]. IEEE Transactions on Big Data, 2015, 1(1): 16-34. doi: 10.1109/TBDATA.2015.2465959 [4] ZHENG Y, CAPRA L, WOLFSON O, et al. Urban computing: Concepts, methodologies, and applications[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2014, 5(3): 1-55. [5] PARENT C, SPACCAPIETRA S, RENSO C, et al. Semantic trajectories modeling and analysis[J]. ACM Computing Surveys (CSUR), 2013, 45(4): 1-32. [6] YANG D, ZHANG D, ZHENG V W, et al. Modeling user activity preference by leveraging user spatial temporal characteristics in LBSNs[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2014, 45(1): 129-142. [7] YE M, SHOU D, LEE W C, et al. On the semantic annotation of places in location-based social networks[C] //Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego, USA: ACM, 2011: 520-528. [8] LI Y, ZHAO X, ZHANG Z, et al. Annotating semantic tags of locations in location-based social networks[J]. GeoInformatica, 2020, 24(1): 133-152. doi: 10.1007/s10707-019-00367-w [9] WANG Y, QIN Z, PANG J, et al. Semantic annotation for places in LBSN through graph embedding [C]//Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. New York, USA: ACM, 2017: 2343-2346. [10] KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. [2018-10-15]. https://arxiv.org/abs/1609.02907. [11] GROVER A, LESKOVEC J. Node2vec: Scalable feature learning for networks[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, USA: ACM, 2016: 855-864. [12] ZHANG D, YIN J, ZHU X, et al. Network representation learning: A survey[J]. IEEE Transactions on Big Data, 2018, 6(1): 3-28. doi: 10.1089/big.2017.0083 [13] XU W, SUN H, DENG C, et al. Variational autoencoder for semi-supervised text classification[C]//Proceedings of the 31st AAAI Conference on Artificial Intelligence. San Francisco, USA: [s.n.], 2017: 3358-3364. [14] VELIČKOVIĆ P, CUCURULL G, CASANOVA A, et al. Graph attention networks[EB/OL]. [2018-10-20]. https://arxiv.org/abs/1710.10903. -

 点击查看大图
点击查看大图
图(3) / 表(3)
计量
- 文章访问数: 6079
- HTML全文浏览量: 1824
- PDF下载量: 63
- 被引次数: 0


















































































