 ISSN
ISSN 



-
人脸作为人类的内在属性,具有唯一性和确定性,因此人脸识别被视为一种非侵入性的生物特征[1]正迅速成为身份识别和监控领域的主要工具之一。得益于互联网搜索技术的进步,2D人脸数据集可以方便地通过网络搜索技术获取,因此数据规模通常是百万级的。在海量数据的支持下,基于卷积神经网络(convolutional neural networks, CNN)的人脸识别算法在2D人脸识别上发挥了巨大的潜力。如FaceNet[2]使用200万人脸数据来训练CNN,在LFW[3]测试基准上达到99.63%的准确率,超过了人类的水平。由于2D人脸数据规模足够大,当前的2D人脸识别的研究[2, 4-7]主要集中在设计更合理的损失函数,让不同身份间的人脸特征更加分离,相同身份间的人脸特征聚集更紧凑。尽管性能得到了较大提升,但2D人脸仅包含图像的纹理信息,仍不可避免地受到光照、姿态、表情等因素的干扰[8]。
3D人脸除了包含基本的纹理信息,也包含人脸的深度信息,本质上可以不受光照变化的约束,能够克服2D人脸识别的不足。因此,关于3D人脸的识别越来越受到研究者的重视[9-13]。3D人脸的数据采集不能像2D人脸数据[14-16]一样通过网络搜索收集,只能通过特定的三维相机获取,经济及时间代价高,导致3D数据量非常有限。当前主要的高质量3D数据集ND-2006[17]只包含888个人的13 450个模型,Bosphorus[18]只包含105个人的4 666个模型。这与2D人脸数据集中的MS-Celeb-1M[19]10万个人的1 000万张人脸图片,Casia-WebFace[20]1万个人的47万张人脸图片相差甚远。由于数据规模小且质量较高,高质量3D人脸识别难度相对低质量人脸数据较低,3D高质量人脸识别方法[21]在多个测试标准上如FRGCv2[22]、Bosphorus[18]和BU-3DFE[23]上已经接近满分。但是,高质量3D人脸数据采集时间成本高、采集流程复杂、设备昂贵且需要对象配合,一定程度上限制了3D人脸识别技术的发展。
相对于高精度扫描仪,低精度设备(如Microsoft Kinect,Intel RealSense等)价格低廉、使用方便,具备更广阔的应用场景。与高质量3D人脸相比,低质量人脸图像表面有大量的毛刺、孔洞,识别难度更高,通常这类数据更多使用在姿态估计[24]和行为识别[25]等领域。虽在人脸识别[11, 16-18, 26]上也存在一些尝试,但所涉及的数据规模有限,实用性不足。在大规模低质量3D人脸数据集Lock3dFace[27]上当前最高的识别准确率Led3D[28]只有54.28%。
基于以上分析,研究基于消费级相机采集的低质量3D人脸数据应用价值强,是3D人脸识别未来的发展趋势。针对这类数据,本文提出了SAD和IR Loss两种新方法,基于低质量的3D人脸的几何信息实现3D人脸识别。SAD和IR Loss可以作为两个独立的模块嵌入到CNN网络训练过程中。在推理阶段,这两个模块都不会参与运算,不会影响网络的运行效率。与当前Lock3DFace[27]数据集准确率最高的测试模型Led3D相比,在不清理任何测试数据的情况下,本文方法准确率达54.83%,而在遮挡和姿态子集,本文方法的准确率分别有17.46%和7.54%的提升。
-
本节从高质量和低质量两方面简要介绍3D人脸识别方法、人脸识别损失函数及CNN中的Dropout方案的相关工作。
1) 高质量3D人脸识别。近年来,随着传感器技术的进步和高质量3D人脸模型数据库的推广,3D人脸识别技术得到了较大的发展。与2D人脸识别领域相比,基于3D人脸的深度学习方法的探索并不广泛,这主要是因为缺乏大规模公共3D数据库。基于深度学习的人脸识别技术对数据规模极度依赖,因此需要对人脸数据进行增强。文献[10]整合现有基准,通过生成表达式和姿势以及随机裁剪增加样本,生成10 K增强深度人脸,使用这些数据在2D人脸预训练模型VGG-Face[29]网络上微调,在Bosphorus[18]测试基准上取得当时最高的精度98.1%。文献[21]通过添加私有数据集和合成虚拟ID进一步增强数据,并从零开始训练深度模型,在多个3D人脸测试标准[17-18]上都较高。高质量深度人脸因为缺乏大规模的统一测试数据集,测试结果基本接近满分。
2) 低质量3D人脸识别。对于低质量数据的3D人脸识别,研究比较有限。最先采用传统的特征提取方式,如ICP、PCA、LBP和HOG,并出现一些效果较好的方法[9, 11, 13, 30]。但这些方法使用的数据库在主题或图像数量方面很小,所涉及的变化和数量也很少。文献[31]使用孪生神经网络进行RGB和深度图像的训练,用于面部验证任务。文献[32]在文献[11]的基础上,采用了一种称为基于学习的重建方法,使用自动编码器从RGB和深度图像中获取映射函数,并使用映射函数中重构的图像进行识别。文献[33]使用交叉质量数据验证,低质量3D人脸识别难度更大。文献[32]使用深度学习技术解决了特征融合问题,将RGB和深度两种模式提供的共同和互补信息有效融合。这些方法除了使用几何信息,还使用了RGB信息,但并不能完全克服2D人脸识别中光照、姿态等造成的影响,而本文只使用了几何信息。
3) 人脸识别中的损失函数。损失函数是深度学习的关键部分,是人脸识别方向的研究热点,在大规模数据上充分提取到训练数据的信息至关重要。人脸识别中的损失函数的主要目的是增大不同身份人脸特征向量的类间距离以及缩小相同身份人脸特征向量的类内距离,使用这一思路惩罚网络,使相同身份人脸的特征向量聚集在一起。早期的损失函数主要是基于欧式距离的损失,如triplet loss[2],它主要构建不同的正负样本对,利用欧氏距离来度量特征之间的相似性。后来在这些方法的基础上衍生出center loss[34]和range loss[35],通过最小化类与类中心之间的欧式距离来训练整个模型。但是基于欧式空间的约束不足以实现最优泛化,所以在之后的工作中,研究者改进Softmax损失函数来增大人脸特征向量类间距离的同时减小类内距离,如L-Softmax[36],Am-Softmax[37]。在最近的研究中增加margin的人脸识别损失能够增加模型学习的难度,所以将角度约束集成到Softmax损失函数中,SphereFace[4]、CosFace[5]、ArcFace[6]都应用了这种思想。本文方法首次将2D人脸识别中的聚类中心的思想运用到3D人脸识别,并根据低质量3D数据存在噪声信息的特点,提出新的类间正则化损失函数。与ArcFace[6]相比,本文方法除使用margin来降低人脸特征向量与类中心的相似度外,还对不同类别的类中心进行显示约束,让欧氏距离最近的不同类别的类中心相似度变低,避免了类中心相似度越高,不同身份人脸相似度越高的问题。
4) Dropout[38]是一种用于缓解神经网络过拟合的正则化技术。具体来说,在训练阶段,对神经网络全连接层的每个隐藏节点随机置零,丢弃部分信息。这样网络在学习的过程中鲁棒性更高,达到良好的正则化效果。与全连接层不同的是,Dropout不能在卷积特征图上使用,因为空间相邻像素在卷积特征图上具有很强的相关性,它们共享冗余的上下文信息。因此,传统的基于像素的Dropout不能完全抛弃卷积特征图信息。为了在卷积层上应用Dropout,文献[39]提出了MaxDrop,即在特征图上通过通道或空间的方式去除最大激活的像素,这种方法能删除强激活的神经元,但也存在一定的局限性,因为卷积操作会共享周围的神经元信息,从而降低丢弃后的效果。文献[40]提出了Spatial Dropout,即随机丢弃特征图的部分通道,而不是丢弃每个像素。这种基于通道的丢失,可以解决像素丢失的问题。本文方法与Spatial Dropout的不同之处在于,本文只去除强激活区域,而不是整个通道区域。并且本文的方法只在最后一层的卷积层使用,不存在被共享特征的上下文信息。
-
3D人脸主要是由空间中一系列的点组成,将所有的点按照x, y, z坐标放置在对应的坐标系下得到的一个点集合。由于构成人脸点云数据规模较大,为了易于数据对齐并充分利用点云的几何及拓扑信息,本文首先对3D点云数据进行预处理,然后生成深度几何图像用于后续识别。本节主要描述点云数据的处理过程,包括鼻尖校准、人脸标准化、数据增强和几何人脸表示。数据处理流程如图1所示。

图 1 人脸点云数据处理流程
-
鼻尖通常被作为3D人脸的原点,鼻尖位置深度值不准确会干扰三维人脸的表示。虽然现有数据集(如Lock3DFace[27])提供了鼻尖位置的x和y轴坐标,但在低质量3D人脸上存在大量的毛刺和孔洞,通常会导致位置不准确。本文以给定的xy轴坐标为中心,周围选择10×10的网格,以其中值作为鼻尖位置的深度值,如图1a所示。需要注意的是,对于原始数据集中未提供鼻尖位置的少量样本,本文使用手动标注的方式设定鼻尖位置。
-
在3D人脸数据集中,除包含人脸信息外还包含大量的背景信息。在确定鼻尖位置之后,本文首先以2D深度图的鼻尖xy轴坐标为中心,在原始2D深度图上裁剪出160×160像素的区域作为人脸区域,然后把裁剪后的人脸区域映射到3D坐标系中,得到3D的人脸区域,整体移动人脸,将鼻尖移动到坐标(0, 0, 100)。最后把3D人脸中深度值大于400的点视为背景去掉,得到标准化的三维人脸,如图1b所示。
-
由于训练数据有限,本文需要对现有的数据进行扩充,数据增强通过旋转三维坐标轴实现。将原始3D人脸点云图绕y轴从−75°旋转到75°,每间隔15°保存3D人脸,绕x轴从−30°旋转到30°每间隔15°保存3D人脸,每张深度图共生成14张额外人脸,如图1c所示。
-
本文使用归一化曲面法向量作为最终的人脸表示,计算过程使用文献[41]中的方法,将人脸的x, y, z轴法线贴图图像(normal map image, NMI)NMIx、NMIy、NMIz的结果作为人脸的3个通道堆叠,如图1d所示。需要注意的是,本文没有对3D人脸的姿态进行校正,这主要是因为在大姿态时,校正后的正面人脸信息丢失严重,无法满足识别要求。为了追求处理效率,本文方法仅使用了最原始的深度信息,不做任何的滤波和填充处理。
-
低质量3D人脸表面具有大量的孔洞和毛刺,给识别造成一定的难度,这主要是因为CNN在学习的过程中会把部分噪声当作人脸特征,导致识别效果较差。为了解决这一问题,本文提出了基于空间注意力机制的Dropout方案,在高层语义特征上进行随机遮挡,避免网络只把噪声信息当作人脸特征。同时,为了避免遮挡后不同身份间的人脸特征相似度过高,本文提出了一个新的类间正则化损失函数,以增加不同身份人脸特征聚类中心之间的相似度。
-
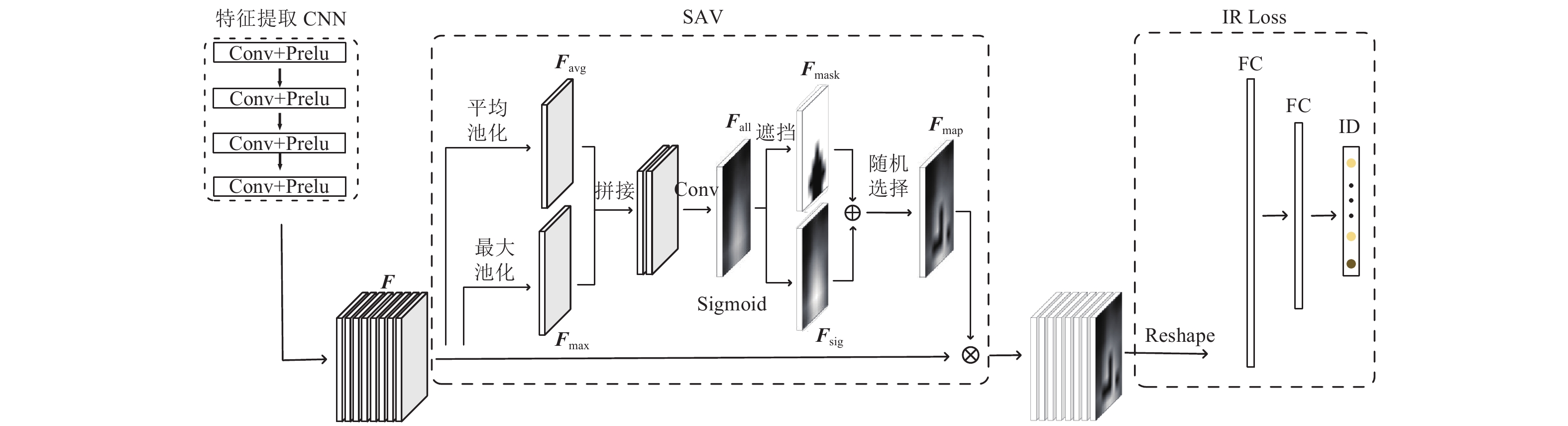
空间注意力Dropout(spatial attention-based dropout, SAD)使用空间注意力机制的方式定位特征图中的重点区域进行随机遮挡。对于特征图
$ {{F}}\in R^{H\times W\times C}$ 通过全局通道平均池化得到2D特征,$ {{F}}_{\rm{avg}}\in {{R}}^{H\times W}$ 代表全局的特征信息,其中H表示特征F的高,W表示宽,C表示通道数。同时,为了得到F中的最具有区分性的信息,使用全局通道最大池化得到2D特征,$ {{F}}_{\rm{max}}\in R^{H\times W}$ 代表F中最具有分辨能力的特征。对Favg和Fmax按照式(1)进行特征融合,融合后的特征通道数为1,得到融合全局特征信息和最具有分辨能力特征信息的特征图$ {{F}}_{\rm{all}}\in R^{H\times W}$ :$$ {{F}}_{\rm{all}}={\rm{Conv}}({{F}}_{\rm{avg}}\odot {{F}}_{\rm{max}}) $$ (1) 式中,
$ \odot $ 表示按照通道拼接;Conv()表示卷积计算,使用3×3的卷积核。对于特征图Fall找到其中最大的前k个数中的最小值作为阈值t,按照式(2)进行归一化:$$ {{{F}}_{{\rm{mask}}}} = \left\{ {\begin{aligned} & {0}\quad\;{F_{\rm{{all}}}(x) \geqslant t}\\ & {1}\quad\;{F_{\rm{{all}}}(x) < t} \end{aligned}} \right. $$ (2) 得到遮挡特征图
$ {{F}}_{\rm{mask}}\in R^{H\times W}$ 。使用Fmask对F中最具有分辨能力的特征进行遮挡,让网络学习到更多的权重更小的隐藏特征。为了避免长期遮挡到最具分辨性的特征导致特征退化不再具有区分性,本文使用sigmoid激活函数对Fall按照式(3)进行激活操作:
$$ {{F}}_{\rm{sig}}=\frac{1}{1+{\rm{e}}^{-{m{F}}_{\rm{all}}(x)}} $$ (3) 得到特征图
$ {{F}}_{\rm{sig}}\in {{R}}^{H\times W}$ ,在Fsig中Fall更大的值对应更大的权重,这与Fmask是相反的。本文以0.5的概率对Fmask和Fsig的对应神经元位置随机选择得到最终的遮挡$ {{F}}_{\rm{map}}\in {{R}}^{H\times W}$ ,避免每次都丢失最具有分辨能力的特征。对输入特征F的每一个通道按照式(4)计算最终的dropout特征:$$ {{{F}}_{{\rm{out}}}} = {{F}} \otimes {{{F}}_{{\rm{map}}}} $$ (4) 式中,
$ \otimes $ 表示对F中每一个通道都乘以Fmap,具体流程如图2中的SAD部分所示。在推理阶段,SAD直接返回特征图,不再进行随机遮挡。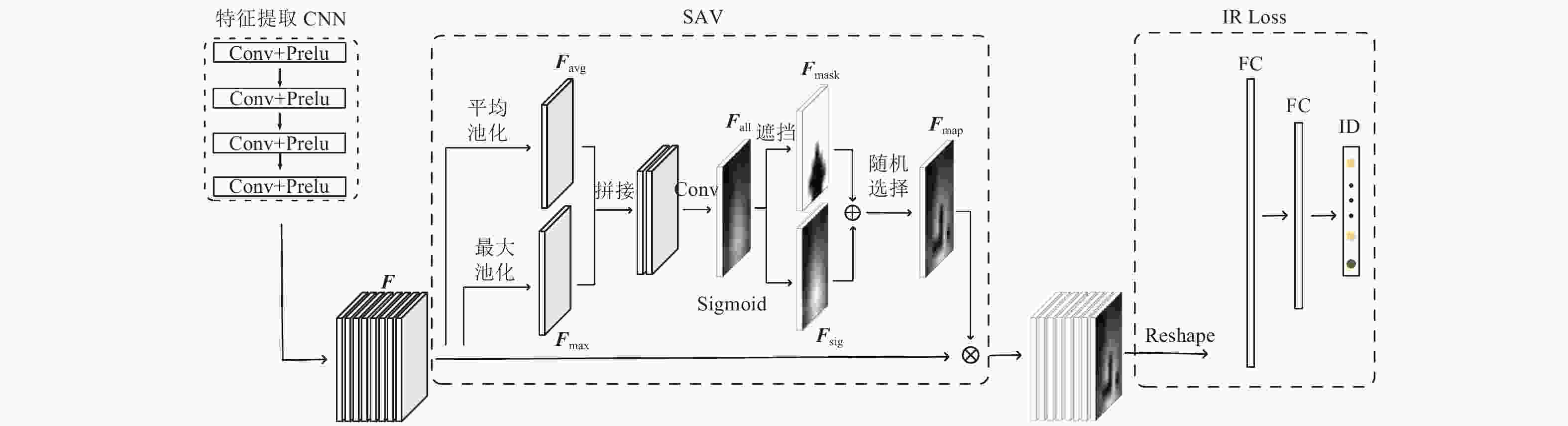
图 2 本文方法整体流程图
本文使用Grad-Cam[42]可视化了原始ResNet-20[43]网络和加入SAD后的ResNet-20网络,最后一层卷积层的结果如图3所示。其中,图3a为原始ResNet-20网络的结果,在不加入SAD时,网络提取到的人脸特征比较单一和集中,由于低质量3D数据的噪声来源具有不确定性,容易把噪声特征识别成人脸特征。图3b为加入SAD后的ResNet-20网络的结果,ResNet-20网络加入SAD后,模型提取到了更分散的人脸特征,更利于抑制低质量3D人脸噪声信息的干扰。
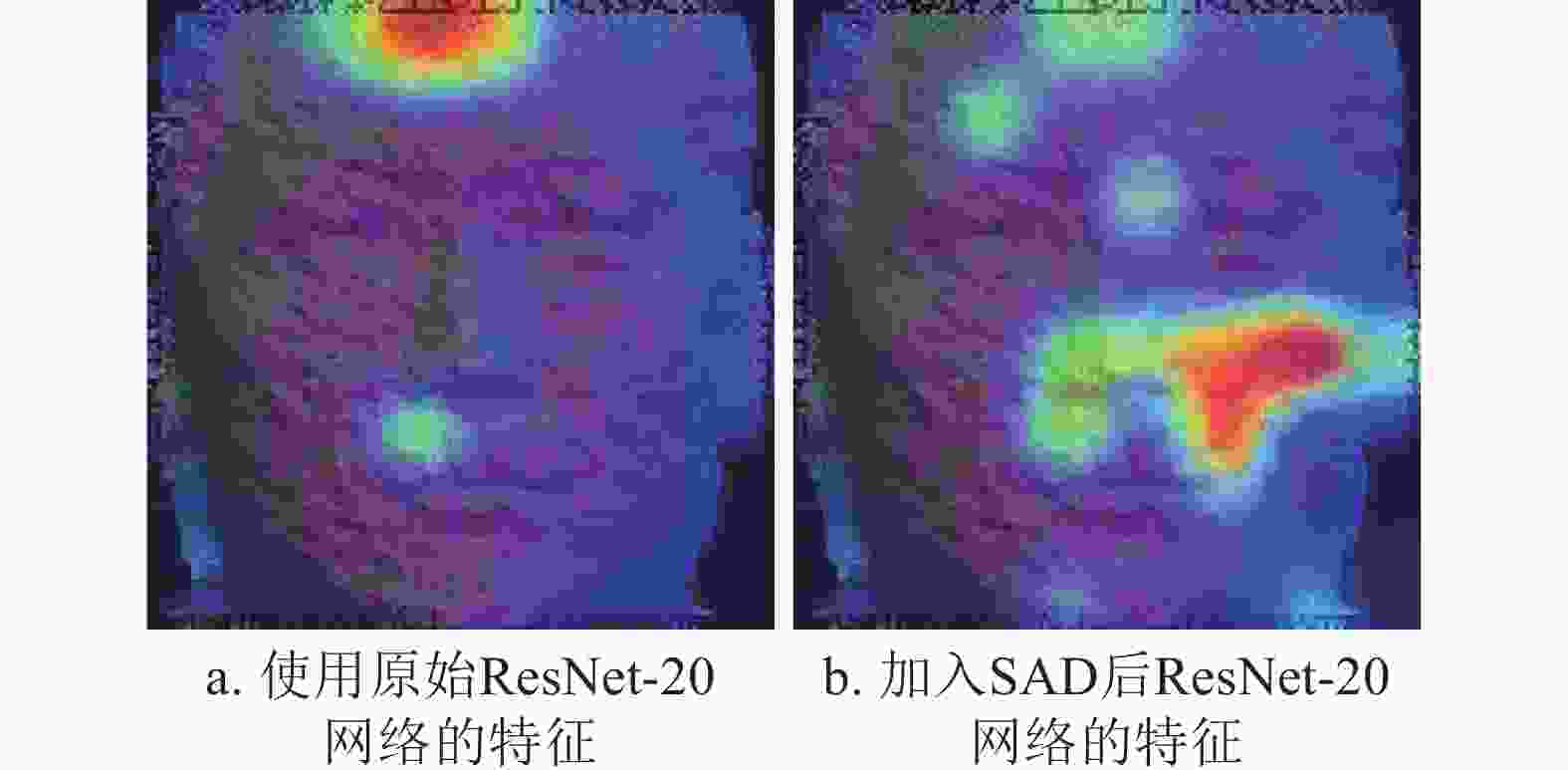
图 3 不同模型最后一层的卷积层的可视化
-
经过SAD遮挡后的特征包含部分值为0的神经元,为了避免在池化过程中遮挡信息丢失,本文没有使用常规的池化方法,而是直接将特征图reshape成一维特征向量,并通过两个全连接层对人脸特征进行降维。其中,第一层全连接层主要是把reshape后的人脸特征向量降维到固定512维,表示当前的人脸特征,用来计算人脸之间的相似度。第二层全连接层把人脸特征向量降维到训练集中人脸的类别数N,用来预测每个人脸的ID。特征图在被遮挡后,得到的特征向量会存在部分0值的神经元,导致不同身份人脸的特征向量之间的距离过近,为了解决这一问题,本文提出了新的类间正则化损失函数(inter-class regularization loss, IR Loss)。
当前基于深度学习的3D人脸识别方法[9-13]主要设计更合理的网络结构,本文方法除考虑网络鲁棒性外,还在损失函数上针对低质量3D人脸数据重新设计,对人脸特征向量的相似度做更严格的约束。类间正则化损失函数以2D人脸识别中基于margin的损失函数ArcFace[6]为基础,进一步对每个类别的聚类中心进行约束,让不同类别的聚类中心更分散。IR Loss的实现如下:
$$ {L}_{{\rm{IR}}}={L}_{m}+\lambda {L}_{i} $$ (5) 式中,Lm表示基于margin的损失函数;λ表示平衡因子,在本文的实验中设置为1;Li表示本文提出的类间正则化约束。其中Lm为:
$$ {L}_{m}=\frac{1}{C}{\displaystyle \sum _{i=1}^{C}-{\rm{log}}\left(\frac{{\rm{e}}^{s{\rm{cos}}(\theta +m)}}{{\rm{e}}^{s{\rm{cos}}(\theta +m)}+{\rm{e}}^{s{\rm{cos}}\theta }}\right)} $$ (6) 式中,C表示批量数据中样本的个数;m、s为超参数;
$ {\rm{cos}}\theta $ 表示样本特征与类别中心的余弦距离,具体为:$$ {\rm{cos}}{\theta }_{{i,j}}=\frac{{{X}}_{{i}}}{\left|\right|{{X}}_{{i}}\left|\right|}\frac{{{W}}_{{j}}}{\left|\right|{{W}}_{{j}}\left|\right|} $$ (7) 式中,Xi和Wj分别
表示标签i对应特征向量和第j类的类中心向量;||Xi||和||Wj||分别表示向量Xi和类中心向量Wj的模长。式(5)中Li为: $$ {L}_i=\frac{C}{{\displaystyle \sum _{i=1}^{C}\min\left(\frac{{{W}}_{{i}}}{\left|\right|{{W}}_{{i}}\left|\right|}-\frac{{{W}}_{{j}}}{\left|\right|{{W}}_{{j}}\left|\right|}\right)}} $$ (8) 式中,
$ \min()$ 表示取最小值,这一部分主要约束不同类别间的类中心相似度更低。在数值上,聚类中心矩阵
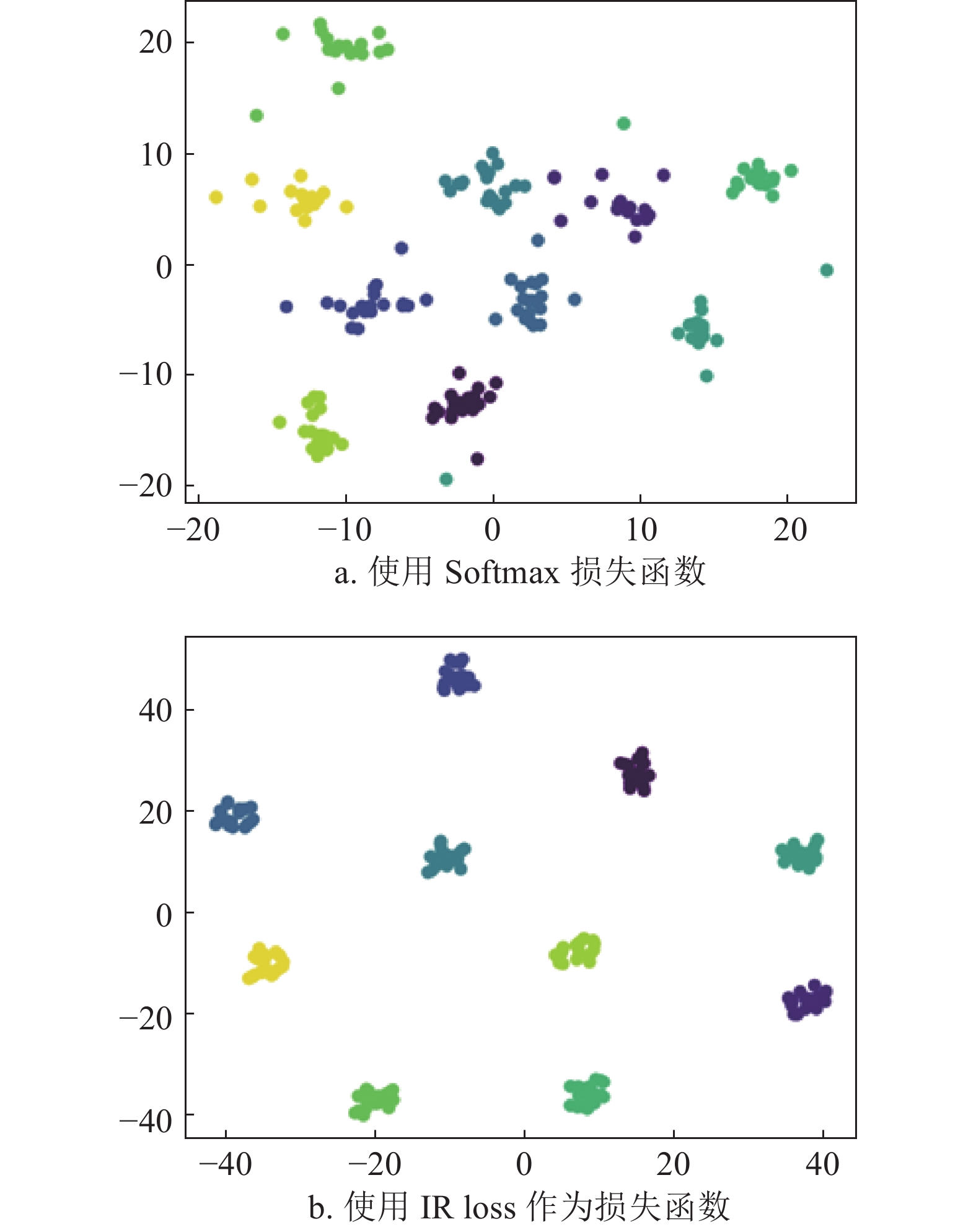
$ {{W}}\in R^{512\times N}$ 表示第二层全连接中的参数,维度j为矩阵W中的列序号。训练过程使相同身份的人脸图片与矩阵W中对应的列相似度越高,损失函数的值越小。本文通过约束类中心矩阵W中每一列的相似度,使其越低,以达到不同身份人脸特征相似度越低的目的。在图4中,本文从Lock3DFace数据集中随机抽取10类数据,每类包含20个人脸数据。使用t-SNE将人脸特征向量降维到2维,实现人脸特征可视化。其中图4a表示ResNet-20[43]网络使用Softmax损失函数的结果。图4b表示ResNet-20网络使用IR Loss的结果。结果表明,在使用相同的ResNet-20网络结构下,IR Loss相对于Softmax损失函数得到的同类特征更紧凑,不同类别间人脸特征更加分散,进一步验证了本文方法的有效性。
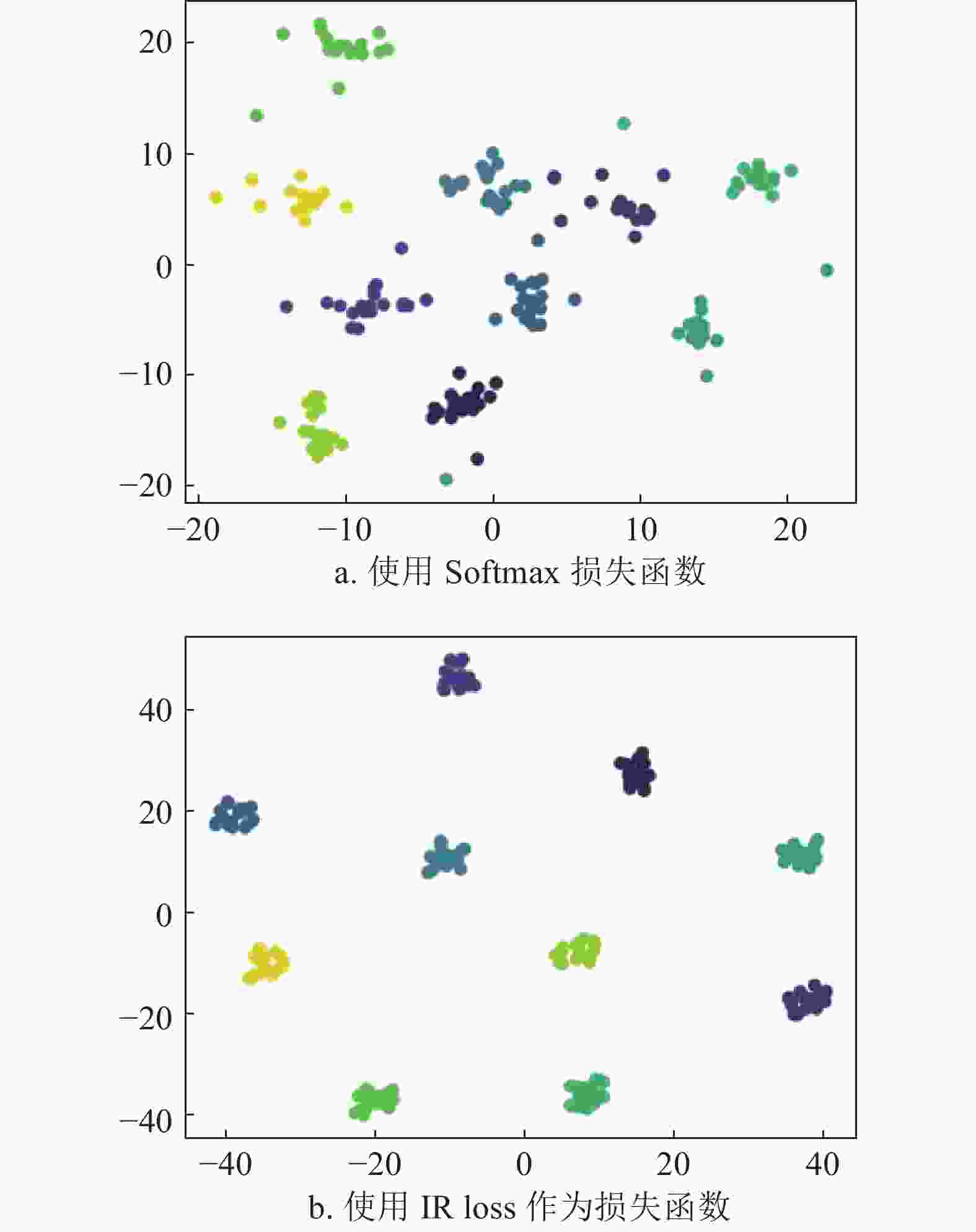
图 4 使用不同损失函数的特征可视化
-
Lock3DFace[27]是目前规模最大的低质量3D人脸公开数据集,由KinectV2收集。它包括5 671个视频序列509个个体,每个视频序列包含59帧图片。包括表情的变化、遮挡、姿态和时间4个子集,是目前最具挑战性的3D人脸识别数据集之一。
CurtinFaces[44]是一个低分辨率的3D人脸数据集。微软Kinect传感器共捕捉52人的5 000多张RGB-D图像。变化包括姿势、照明、面部表情和装饰性的太阳镜遮挡等子集。CurtinFaces中的人脸模型由于姿态变化大且质量不高,使得人脸识别任务具有极大的挑战性。
Bosphorus[18]包含105个人的4 666张3D脸。由结构光3D系统采集,呈现了表情、遮挡和姿态的变化。
FRGCv2[22]由466个人的4 007个3D面部模型组成,数据集由高精度激光3D扫描仪采集,每个人的表情都不同。
-
1) 闭集测试。实验部分选择当前Lock3DFace数据集准确率最高的Led3D[28]的方法作为基准,主要在Lock3DFace数据集上进行了实验。为了实现更公平的对比,本文采用与文献[28]相同的设置。具体来说,选择509个人的中性表情的第一个视频前6帧作为训练集,并按照2.3节中的方法进行增强,剩余视频作为测试集,并分别划分为4个子集(表情、遮挡、姿态、时间)。在测试阶段,对所有视频的每一帧的标签进行预测,选择所有数据帧中出现次数最多的结果作为该视频的真实预测标签,需要注意的是由于视频中每帧人脸图片的相似度极高,本文只选择了每个视频的前6帧数据。
2) 开集测试。文献[28]还提出了另一种测试设置,随机在509个个体中选择340类的全部视频数据的6帧用于训练,剩余的169类作为测试数据。训练集中的每个人的第一个中性表情的前6帧用于数据增强,其余数据使用原始数据。用于测试的169个个体的每个视频分别提取6帧,中性表情的第1帧作为gallery,剩余帧作为probe,包含5个子集(标准、表情、遮挡、姿态和时间)。通过计算probe集中每个样本与gallery集中特征向量的余弦距离,来统计测试结果。
3) CurtinFaces协议。为了探索在新的场景中本文方法的有效性,本文也在CurtinFaces[44]数据集上进行了实验。与文献[44]中的测试方法一致,使用每个人中性表情的16张图片作为训练集,并按照2.3节中的方法进行增强。每个人的剩余数据作为测试集,分为3个子集(姿态、光照和遮挡)。选择每人一张中性表情作为gallery,剩余数据作为probe。
所有的训练和测试数据都按照第2节中的方法预处理,本文的方法只使用3D人脸的几何信息。
-
本文的特征提取网络统一使用ResNet-20[43],所有的训练数据都被调整到128×128。权重衰减设置为0.0005,初始学习率为0.1,衰减周期为10,衰减乘数因子为0.1。模型先在FRGCv2和Bosphorus两个高质量数据集进行预训练,然后在对应的训练数据集上进行微调。所有的CNN使用相同的SGD优化器进行训练,Batch Size为64,遮挡比例k设置为0.6。实验的硬件平台为:Intel(R) Xeon(R) CPU E3-1231 v3 @ 3.40 GHz(NVIDIA TiTan Xp)12 GB;软件环境为:Windows 10,Pytorch1.1.0。
-
为了评估IR Loss中超参数s和m对结果的影响,本文选择了4组参数在ResNet-20[43]网络上分别训练4个模型,遵循4.1节中的开集测试协议,具体参数值如表1所示。结果表明,在m=0.5和s=64时,识别准确率最高。s和m为正相关,s越大,对应的m更大。
表 1 不同超参数设置对结果的影响
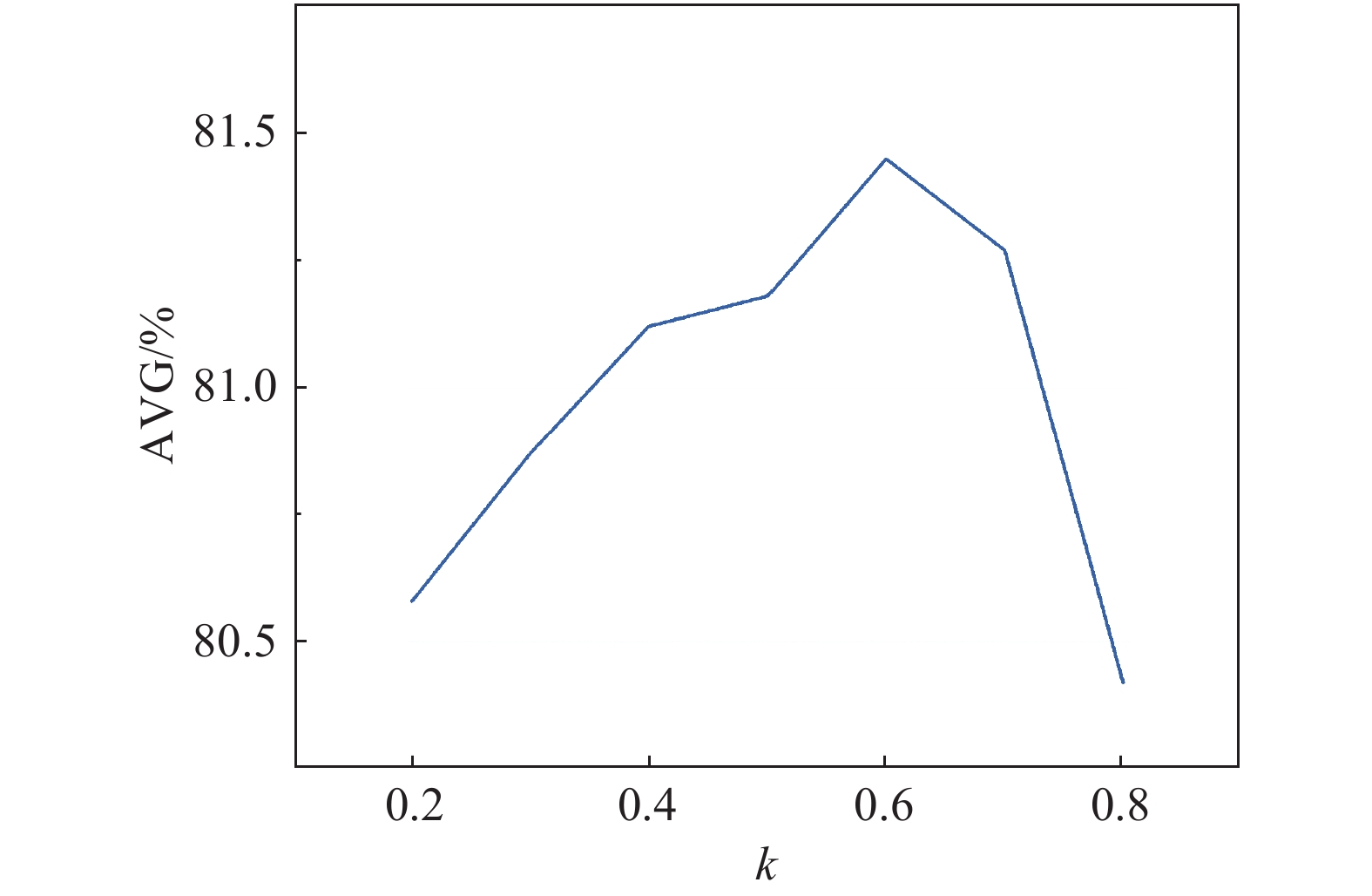
% s m 测试子集 正面 表情 姿态 遮挡 时间 平均 64 0.5 98.77 95.52 54.95 85.09 41.52 80.18 64 0.3 98.79 96.78 53.18 84.59 39.53 79.76 64 0.1 98.79 96.23 53.80 83.06 39.31 79.61 32 0.5 98.67 95.58 49.79 82.95 36.34 78.45 32 0.3 98.95 95.45 50.94 82.79 41.10 79.86 32 0.1 97.78 94.65 44.43 78.34 33.23 76.50 对于SAD,本文也设置了不同的k值,来探索不同遮挡比例对结果的影响。实验结果如图5所示,遮挡比例k=0.6时网络的识别准确率最高,并且所有的遮挡比例的结果均优于表1中不添加SAD的结果。遮挡比例应该设置到合适的范围,太大或太小都会降低SAD模块的性能。
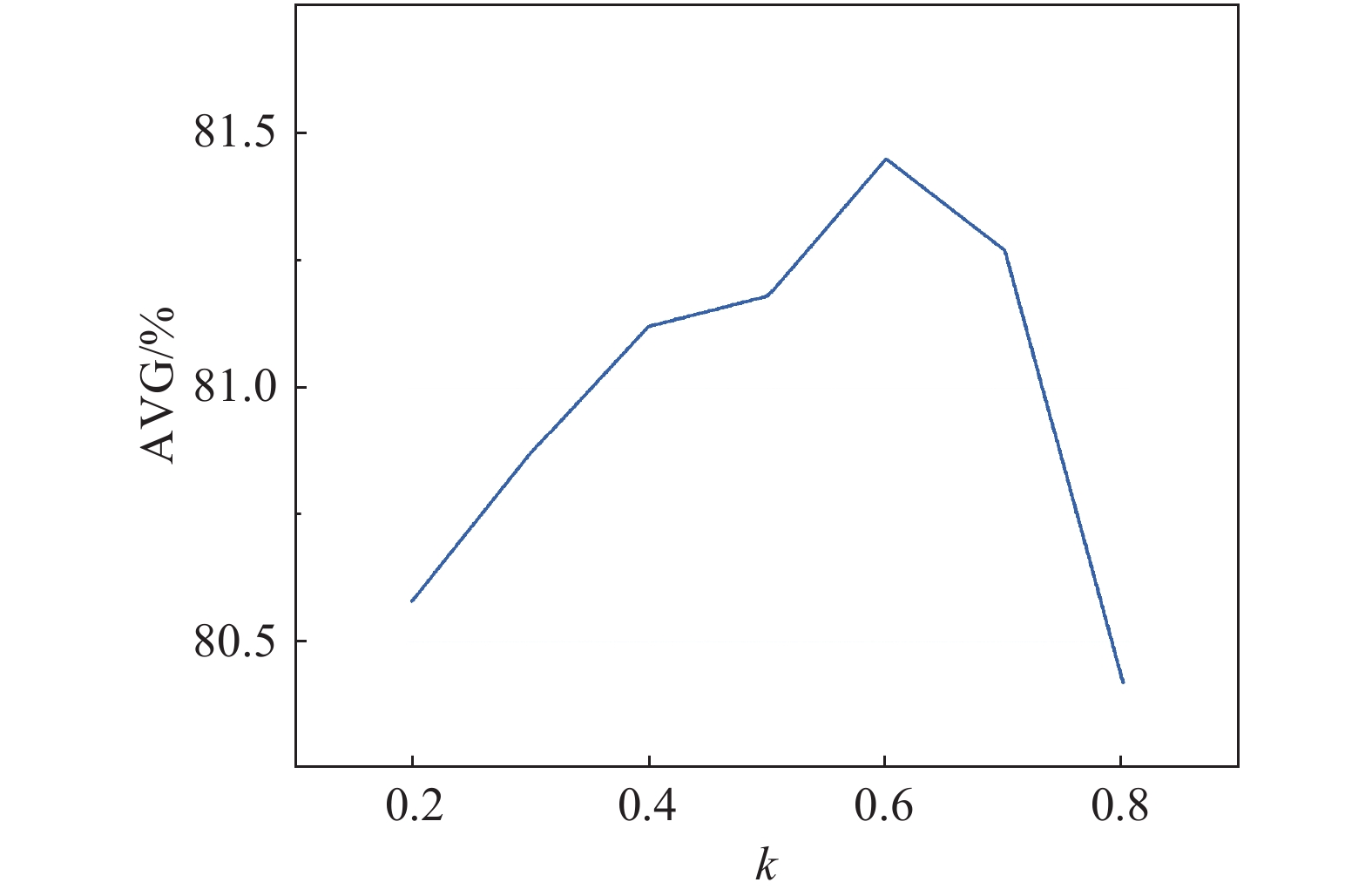
图 5 遮挡比例k与平均识别率曲线
-
为了评估SAD和IR Loss模块的贡献。本文遵循4.1节中的开集测试协议,训练4个网络:1) 原始的ResNet-20[43]网络结构,使用Softmax损失函数;2) 使用IR Loss作为损失函数的ResNet-20网络;3) 在最后一层卷积层之后插入SAD的ResNet-20网络;4) 具有IR Loss和SAD模块的ResNet-20网络。表2显示了4种方法的结果,与基准网络ResNet-20相比,可以看到SAD和IR Loss提高了性能。一方面,SAD能够遮挡部分噪声信息,在正面识别结果上取得更高的识别率。另一方面,IR Loss证明了约束不同类别间的类中心距离可以有效提高识别率。在最终结果中,结合SAD和IR Loss的模型能取得最佳性能,且结合之后提升效果最明显。
表 2 不同模块的识别准确率比较
% 方法 SAD IR Loss 测试子集 正面 表情 姿态 遮挡 时间 平均 1 94.53 92.18 33.65 67.00 23.09 70.62 2 √ 95.78 92.00 35.26 71.66 26.41 72.47 3 √ 95.15 93.04 47.14 76.81 33.13 74.14 4 √ √ 99.03 95.98 52.19 82.13 40.68 79.89 -
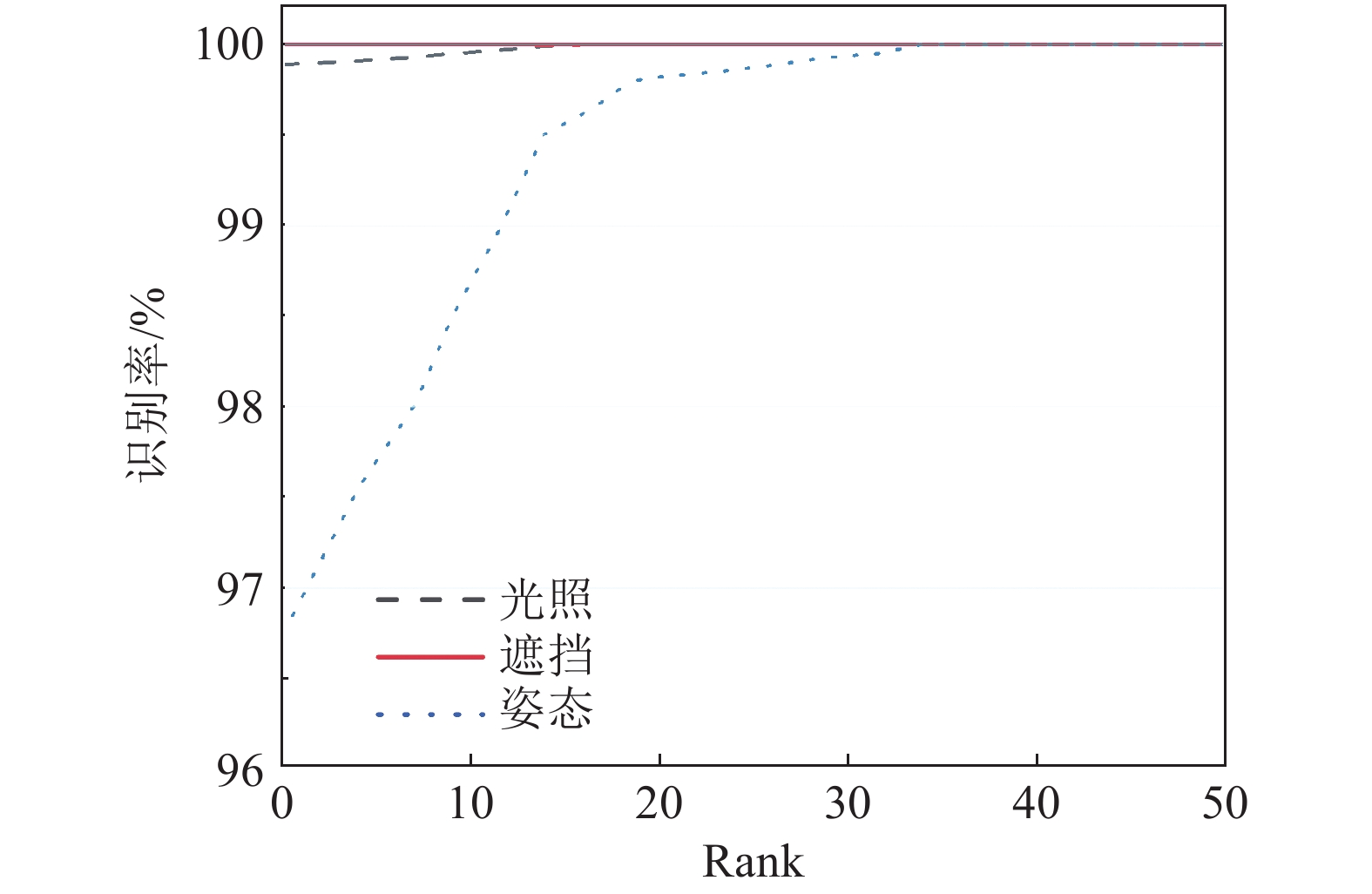
为了评估在其他数据集上本文方法的性能,本文在另外一个大规模的低质量3D人脸数据集上验证,并与基准方法[44]和Led3D[28]比较。测试协议使用文献[44]中的方法,实验结果如表3所示。结果表明,本文方法在不同的数据集上具有很好的鲁棒性,获得了最高的准确率,本文方法的CMC曲线如图6所示。其中文献[44]中的方法结合了RGB信息,Led3D和本文的方法只使用了几何信息。相对于Led3D,本文的方法的识别结果在光照、姿态、遮挡方面都有较大提升,这主要是因为Led3D对数据预处理要求较高,需要对低质量数据进行填充、滤波、裁剪等一系列复杂预处理。本文方法能够从最原始的低质量人脸数据中,提取鲁棒的特征。
表 3 CurtinFaces数据集的识别率比较
% 模型 测试子集 光照 姿态 遮挡 平均 文献[35] 96.30 98.40 90.40 96.95 Led3D 86.53 75.04 82.69 80.45 本文 99.87 96.74 100.00 98.30 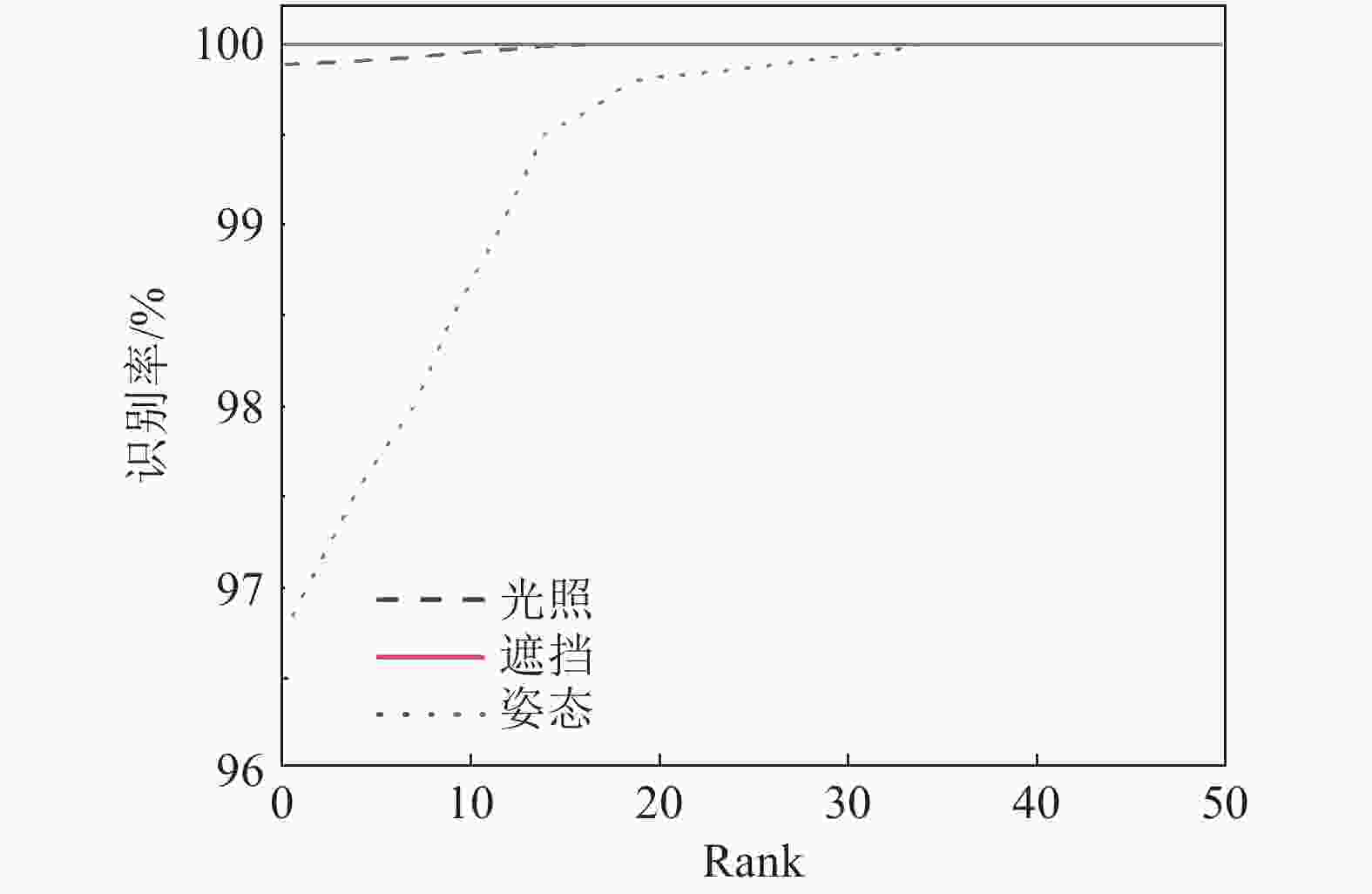
图 6 本文方法在CurtinFaces数据集上的CMC曲线
-
将本文方法与多个不同的网络结构[29, 42, 45-46]对比,以验证方法的有效性,结果如表4所示。本文方法在多个子集上取得了最好的结果,并超过了更深的ResNet-34网络,在遮挡和姿态两个子集中取得了较大提升。特别地,为了与Led3D[28]的测试协议保持一致,本文使用4.1节中的闭集测试协议。为了避免复现结果与原文有差异,表4中非本文方法的结果均从文献[28]中摘录,本文统计结果包含所有的原始数据,没有剔除任何数据。测试子集的样本数量分别为:“表情”1287个、“遮挡”1005个、“姿态”1014个、“时间”1352个。
表 4 Lock3DFace数据集测试结果
% 模型 测试子集 表情 遮挡 姿态 时间 平均 VGG-16 79.63 36.95 21.70 12.84 42.80 ResNet-34 62.83 20.32 22.56 5.07 32.23 Inception-V2 80.48 32.17 33.23 12.54 44.77 MobileNet-V2 85.38 32.77 28.30 10.60 44.92 Led3D[32] 86.94 48.01 37.63 26.12 54.28 本文 87.02 65.47 45.17 23.52 54.83 -
数据质量差、包含大量噪声是提取低质量3D人脸特征的难点。为了解决这些问题,本文提出了一个新的Dropout方法SAD和损失函数IR Loss。作为两个独立的模块,很容易嵌入到其他网络中,而不产生任何计算复杂性。可以有效地协同提取3D人脸特征,为模型特征表示提供了有力的工具。广泛的实验已经在两个最具有挑战性的低分辨率3D人脸数据集中给出,结果显示本文的方法优于其他先进的3D人脸识别方法。
但是本方法也存在一定的局限性,主要是在SAD和IR Loss单独使用时,相对于组合使用,对识别准确率提升不明显,需要结合使用。并且IR Loss存在两个超参数,其数值的设置只能根据经验给出,没有具体量化的计算公式。本文方法的本质是降低训练数据上的不确定性噪声信息对特征提取的干扰,在细粒度识别、行人重识别、分类等领域也可能发挥作用,在未来的工作中还需要进一步探索。
本文的研究工作得到了北京航空航天大学的支持,感谢其提供Lock3DFace[30]数据集。此外,本文代码将在https://github.com/SWJTU-3DVision进行共享。
3D Face Recognition for Low Quality Data
-
摘要: 该文提出了面向低质量数据的3D人脸识别方法。该方法针对快速采集设备的低质量3D人脸数据提出了空间注意力机制的Dropout(SAD)、类间正则化损失函数(IR Loss),有效提升了不完整3D人脸数据的识别精度。SAD通过空间注意力机制对特征图中权重大的部分随机Dropout,让网络学习到更多的隐藏特征;IR Loss通过约束不同身份人脸间的聚类中心的距离分离,使网络学习到的不同身份人的人脸特征相似度更低。实验表明,在当前最大规模的低质量数据集(Lock3DFace)上,该方法优于当前的基准方法,且提出的SAD和IR Loss表现出了强大的适用性和鲁棒性。Abstract: For the low-quality 3D face data collected by the fast collection device, we propose a face recognition method which consists of Spatial Attention-based Dropout (SAD) and Inter-class Regularization Loss function (IR Loss). This method effectively improves the recognition accuracy of incomplete 3D face data. SAD allows the network to learn more hidden features by randomly dropping out the important parts of the feature map based on the spatial attention mechanism. And IR Loss makes the feature similarity between faces with different identities lower by restricting the distance separation of the class centers between them. Experiments show that the method proposed in this paper is superior to the current benchmark methods on a largest low-precision dataset (Lock3DFace), and the SAD and IR Loss we proposed show strong applicability and robustness.
-
Key words:
- 3D face recognition /
- loss function /
- low-quality 3D face /
- spatial attention
-
表 1 不同超参数设置对结果的影响
% s m 测试子集 正面 表情 姿态 遮挡 时间 平均 64 0.5 98.77 95.52 54.95 85.09 41.52 80.18 64 0.3 98.79 96.78 53.18 84.59 39.53 79.76 64 0.1 98.79 96.23 53.80 83.06 39.31 79.61 32 0.5 98.67 95.58 49.79 82.95 36.34 78.45 32 0.3 98.95 95.45 50.94 82.79 41.10 79.86 32 0.1 97.78 94.65 44.43 78.34 33.23 76.50  下载: 导出CSV
下载: 导出CSV
表 2 不同模块的识别准确率比较
% 方法 SAD IR Loss 测试子集 正面 表情 姿态 遮挡 时间 平均 1 94.53 92.18 33.65 67.00 23.09 70.62 2 √ 95.78 92.00 35.26 71.66 26.41 72.47 3 √ 95.15 93.04 47.14 76.81 33.13 74.14 4 √ √ 99.03 95.98 52.19 82.13 40.68 79.89
下载: 导出CSV
-
[1] BOWYER K W, CHANG K, FLYNN P. A survey of approaches and challenges in 3D and multi-modal 3D + 2D face recognition[J]. Computer Vision and Image Understanding, 2006, 101(1): 1-15. [2] SCHROFF F, KALENICHENKO D, PHILBIN J. Facenet: A unified embedding for face recognition and clustering[C]//The IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 815-823. [3] HUANG G B, RAMESH M, BERG T, et al. Labeled faces in the wild: A database for studying face recognition in unconstrained environments[R]. Amherst: University of Massachusetts, 2007. [4] LIU Wei-yang, WEN Yan-dong, YU Zhi-ding, et al. SphereFace: Deep hypersphere embedding for face recognition[C]//The IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 212-220. [5] WANG H, WANG Y, ZHOU Z, et al. Cosface: Large margin cosine loss for deep face recognition[C]//The IEEE Conference on Computer Vision and Pattern Recognition. Utah: IEEE, 2018: 5265-5274. [6] DENG J, GUO J, XUE N, et al. Arcface: Additive angular margin loss for deep face recognition[C]//The IEEE Conference on Computer Vision and Pattern Recognition. California: IEEE, 2019: 4690-4699. [7] SUN Yi-fan, CHENG Chang-mao, ZHANG Yu-han et al. Circle loss: A unified perspective of pair similarity optimization[C]//The IEEE Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2020: 6398-6407. [8] MASI I, WU Y, HASSNER T, et al. Deep face recognition: A survey[C]//2018 31st SIBGRAPI Conference on Graphics, Patterns and Images. Parana: IEEE, 2018: 471-478. [9] BERRETTI S, BIMBO A D, PAL A. Superfaces: A super resolution model for 3d faces[C]//The European Conference on Computer Vision. Florence: Springer, 2012: 73-82. [10] GILANI S Z, MIANN A, EASTWOOD P. Deep dense and accurate 3D face correspondence for generating population specific deformable models[J]. Pattern Recognition, 2017, 69(1): 238-250. [11] GOSWAMI G, BHARADWAJ S, VATSA M, et al. On RGB-D face recognition using Kinect[C]//IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems. Arlington: IEEE, 2013: 1-6. [12] 赵青, 余元辉. 基于分层特征化网络的三维人脸识别[J]. 计算机应用, 2020, 40(9): 2514-2518. ZHAO Qing, YU Yuan-hui. 3D face recognition based on hierarchical feature network[J]. Computer Applications, 2020, 40(9): 2514-2518. [13] MIN R, KOSE N, DUGELAY J L. A Kinect database for face recognition[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2014, 44(11): 1534-1548. [14] SHLIZERMAN K, SEITZ S M, MILLER D, et al. The megaface benchmark: 1 million faces for recognition at scale[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 4873-4882. [15] AARON N, IRA K S. Level playing field for million scale face recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hawaii: IEEE, 2017: 7044-7053. [16] PARKHI M, VEDALDI A, ZISSERMAN A, et al. Deep face recognition[C]//British Machine Vision Association. Swansea, UK: ORA, 2015: 1-12. [17] FALTEMIER T C, BOWYER K W, FLYNN P J. Using a multi-instance enrollment representation to improve 3D face recognition[C]//IEEE International Conference on Biometrics: Theory, Applications, and Systems. Crystal City, VA: IEEE, 2007: 1-6. [18] DRAN S A, ALYUZ N, DIBEKLIO H G, et al. Bosphorus database for 3D face analysis[C]//The First European Workshop on Biometrics and Identity Management. Denmark: Springer, 2008: 47-56. [19] GUO Y, ZHANG L, HU Y, et al. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition[C]//The European Conference on Computer Vision. Amsterdam: Springer, 2016: 87-102. [20] YI D, LEI Z, LIAO S, et al. Learning face representation from scratch[EB/OL]. (2014-11-28). https://arxiv.org/abs/1411.7923. [21] GILANI S Z, MIAN A. Learning from millions of 3D scans for large-scale 3D face recognition[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City: IEEE, 2018: 1896-1905. [22] PHILIPS P J, FLYNN P, SCRUGGS T, et al. Overview of the face recognition grand challenge[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, CA, USA: IEEE, 2005: 947-954. [23] YIN L, WEI X. A 3D facial expression database for facial behavior research[C]//The 7th International Conference on Automatic Face and Gesture Recognition. Southampton: IEEE, 2006: 211-216. [24] WU D, ZHU F, SHAO L. One shot learning gesture recognition from RGB-D images[C]//2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. Providence: IEEE, 2012: 7-12. [25] HUYNH T, MIN R, DUGELAY J L. An efficient lbp-based descriptor for facial depth images applied to gender recognition using RGB-D face data[C]//Asian Conference on Computer Vision. [S.l.]: Springer, 2012: 133-145. [26] ZHANG Hao, HAN Hu, CUI Ji-yun, et al. RGB-D face recognition via deep complementary and common feature learning[C]//IEEE International Conference on Automatic Face & Gesture Recognition. Xi'an: IEEE, 2018: 8-15. [27] ZHANG J, HUANG D, WANG Y, et al. Lock3DFace: A large-scale database of low-cost kinect 3D faces[C]//2016 International Conference on Biometrics. Halmstad: IEEE, 2016: 1-8. [28] MU Guo-dong, HUANG Di, HU Guo-sheng, et al. Led3D: A lightweight and efficient deep approach to recognizing low-quality 3D faces[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. California: IEEE, 2019: 5773-5782. [29] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-4-10). https://arxiv.org/abs/1409.1556. [30] HU Zheng-guo, GUI Peng-hui, FENG Zi-qing, et al. Boosting depth-based face recognition from a quality perspective[J]. Sensors, 2019, 19(19): 4124. doi: 10.3390/s19194124 [31] BORGHI G, PINI S, GRAZIOLI F, et al. Face verification from depth using privileged information[C]//British Machine Vision Conference. Newcastle: ORA, 2018: 303-316. [32] CHOWDHURY A, GHOSH S, SINGH R, et al. RGB-D face recognition via learning-based reconstruction[C] //IEEE 8th International Conference on Biometrics Theory, Applications and Systems. Niagara Falls: IEEE, 2016: 1-7. [33] HU Zheng-guo, ZHAO Qi-jun, LIU Feng. Revisiting depth-based face recognition from a quality perspective [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. California: IEEE, 2019: 2354-2362. [34] WEN Yan-dong, ZHANG Kai-peng, LI Zhi-feng et al. A discriminative feature learning approach for deep face recognition[C]//European Conference on Computer Vision. Amsterdam: Springer, 2016: 499-515. [35] ZHANG Xiao, FANG Zhi-yuan, WEN Yan-dong, et al. Range loss for deep face recognition with long-tailed training data[C]//The IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 5409-5418. [36] LIU Wei-yang, WEN Yan-dong, YU Zhi-ding, et al. Large-margin softmax loss for convolutional neural networks[C]//The 33rd International Conference on Machine Learning. New York: IEEE, 2016: 507-516. [37] WANG Feng, LIU Wei-yang, LIU Hai-jun, et al. Additive margin softmax for face verification[J]. IEEE Signal Processing Letters, 2018, 25(7): 926-930. [38] SRIVASTAVA N, HINTON G K, ILYASUTSKEVER A, et al. Dropout: A simple way to prevent neural networks from overfitting[J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958. [39] PARK S, KWAK N. Analysis on the dropout effect in convolutional neural networks[C]//Asian Conference on Computer Vision. Taiwan, China: Springer, 2016: 189-204. [40] TOMPSON J, GOROSHIN R, JAIN A, et al. Efficient object localization using convolutional networks[C]//The IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 648-656. [41] YANG X, HUANG D, WANG Y, et al. Automatic 3D facial expression recognition using geometric scattering representation[C]//2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition. Ljubljana: IEEE, 2015: 1-6. [42] SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 618-626. [43] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778. [44] LI B Y, MIAN A S, LIU W, et al. Using kinect for face recognition under varying poses, expressions, illumination and disguise[C]//2013 IEEE Workshop on Applications of Computer Vision. Tampa, FL: IEEE, 2013: 186-192. [45] IOFFE S, SZEGEDY C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[EB/OL]. (2015-2-11). https://arxiv.org/abs/1502.03167. [46] SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4510-4520. -

 点击查看大图
点击查看大图

图(6) / 表(4)
计量
- 文章访问数: 5810
- HTML全文浏览量: 1684
- PDF下载量: 120
- 被引次数: 0




















