 ISSN
ISSN 




-
图像修复是为了补全图像的破损区域或信息缺失区域,进而得到理想的视觉效果。目前修复损坏的图像方法可以大致分为3种:1)基于偏微分方程的修复方法;2)基于图像样本块的纹理合成算法;3)基于神经网络的图像修复算法。其中,基于偏微分方程方法仅适用于小区域图像修复,如附加文字、噪声、划痕去除等,目前已基本成熟。传统基于样本块的纹理合成算法只能从破损图像中提取有用信息,信息来源有限,无法修复复杂的结构和纹理信息。而基于深度学习的图像修复算法虽然可以获得更多的有用信息,但训练时间长,纹理合成效果往往不够理想。
为解决上述问题,本文提出一种破损图像的相似度计算方法,通过在数据库中寻找相似图像来为图像修复提供更多的有用信息。使用基于图像配准的方法实现破损图像与其相似图像的粗略对齐。最后,通过改进最佳匹配块搜索方法和匹配准则来提高纹理合成效果。仿真实验结果证明了本算法的有效性。
-
文献[1]提出了基于图像样本块的经典纹理合成修复算法,利用图像待修复区域周围的纹理结构信息,计算优先权和相似度,从中提取特征对破损区域进行修复,可以获得比较理想的图像修复效果。在此基础上,研究者提出了许多改进算法,例如:文献[2]重新定义了优先级计算函数,可自适应确定样本块大小;文献[3]生成了5个具有不同初始化的图像,通过适当混合可产生更好的修复结果;文献[4]使用图像结构张量来检测图像的基本结构,并重新制定优先级函数;文献[5]提出了一种改进的补丁距离,可以改善纹理补丁的比较,并解决了初始化和金字塔等级数选择的关键问题;文献[6]通过添加梯度信息,利用样本块的结构、对比度和亮度来确定最优样本块大小。
此外,文献[7]通过优化离散马尔可夫随机场,保证结构和纹理信息的正确传播,同时提出了优先级置信度传播(p-BP);文献[8]提出首先在输入图像的粗糙版本上执行修复,然后使用分层的超分辨率算法来恢复丢失区域的详细信息;文献[9]根据图像的上下文将图像分为可变大小的块,可以限制候选块的搜索范围。
近年来,卷积神经网络(convolutional neural networks, CNN)[10]和生成对抗性网络(generative adversarial networks, GAN)[11]技术的快速发展,为图像修复领域提供了新的方法和方向。文献[12]首次提出用编码器-解码器结构结合卷积神经网络和GAN进行图像修复;文献[13]将图像修复描述为一个图像生成问题,基于上下文编码器,使用一个经过对抗性损失训练的卷积神经网络进行处理;文献[14]采用一种全卷积神经网络,利用全局鉴别器和局部鉴别器进行预测,并提出了一种上下文注意力机制;文献[15]提出采用门控卷积和频谱归一化鉴别器,以及一个基于补丁的GAN损失函数进行修复;文献[16]利用级联生成对抗网络来修复人脸图像,可以获得更高质量的修复效果。
在目前大区域图像修复算法中,基于样本块的纹理合成算法,以及基于MRF的置信度传播算法,都是从图像已知区域中获取相关信息,不能实现复杂场景结构及相关纹理的自动修复,效果不佳。而基于深度学习的修复方法,能有效地利用图像的语义信息,可从图像库中获得更加丰富的图像信息,有效提高修复质量。但当图像缺失区域较大,图像内容比较丰富时,容易出现如图像模糊、纹理失真、边界伪影等问题。
-
传统的纹理合成算法信息来源有限,无法实现复杂纹理和结构图像的自动修复。而深度学习方法则存在训练时间长,纹理合成效果不佳,结果容易模糊等缺点。为解决上述问题,本文提出了一种基于相似图像配准的图像修复算法。
-
为了获取破损图像的相似图像,为图像修复提供更多的有效信息,本文提出了一种基于卷积特征向量的破损图像相似度计算方法。
首先采用迁移学习的方法,利用VGG-16模型[17]对所选数据集进行分类训练,提取图像的特征信息。为了保证网络训练的稳定性,防止梯度消失,同时加快学习速度,增强网络的非线性表达能力,训练采用ReLU激活函数,输入特征图为
$m \times n \times C1$ ,其中,$m \times n$ 为输入特征数目,$C1$ 为输入通道数目,卷积层的输出特征图尺寸为:$$M1 = \left[ {\frac{{m - a + {\rm pad} \times 2}}{{\rm str}} + 1} \right] \times \left[ {\frac{{n - a + {\rm pad} \times 2}}{{\rm str}} + 1} \right] \times F1$$ (1) 式中,卷积采用小尺度卷积核;
$a$ 表示卷积核尺度;${\rm pad}$ 为填充;${\rm str}$ 为步长;$F1$ 为输出通道数目。卷积层之后连接池化层,用于压缩数据和参数的量,同时保留了网络学习到的主要特征,并防止过拟合。池化层大小设为
$G H$ ,该层输入特征图大小为$p w C2$ ,输出通道数为$F2$ ,其输出特征图尺寸为:$$M2 = \left[ {\frac{{p - G + {\rm pad} \times 2}}{{\rm str}} + 1} \right] \times \left[ {\frac{{w - H + {\rm pad} \times 2}}{{\rm str}} + 1} \right] \times F2$$ (2) 经卷积层输出后,每个神经元的特征向量为:
$${{{\mathit{\boldsymbol{y}}}}_{\rm conv}} = f\left( {\sum\limits_{j = 0}^{J = 1} {\sum\limits_{i = 0}^{I = 1} {{{\mathit{\boldsymbol{x}}}_{m + i,n + j}}{\omega _{ij}} + b} } } \right)\;\;{0 \leqslant m \leqslant M,0 \leqslant n \leqslant N}$$ (3) 式中,
$f$ 为激活函数;$j$ ,$i$ 为卷积核的长、宽;${\mathit{\boldsymbol{x}}}$ 为输入的二维向量;$M,N$ 分别是二维向量的长、宽;$\omega $ 代表卷积核;$b$ 为输出的偏置项;${{{\mathit{\boldsymbol{y}}}}_{{\rm{conv}}}}$ 为输出的卷积结果。然后,利用训练后的网络提取图像的特征参数,计算相似度。具体过程如图1所示,利用卷积网络提取数据集中每张图像和破损图像最后一层卷积层的特征向量,利用提取到的特征向量来计算破损图像和数据集中图像的相似度,进而找到与破损图像最为相似的图像。为了便于计算,对图像的特征向量进行归一化处理:

图 1 相似图像搜索过程示意图
$${\mathit{\boldsymbol{W}}} = [{{\mathit{\boldsymbol{W}}}_{\rm{1}}},{{\mathit{\boldsymbol{W}}}_{\rm{2}}},\cdots,{{\mathit{\boldsymbol{W}}}_{h \times w}}]{\rm{ }},{\rm{ }}{{\mathit{\boldsymbol{W}}}_i} = \frac{{{{\mathit{\boldsymbol{W}}}_i}}}{{\sqrt {\displaystyle\sum\limits_{i = 1}^{h \times w} {{{\mathit{\boldsymbol{W}}}_i}^{\rm{2}}} } }}$$ (4) 式中,
${\mathit{\boldsymbol{W}}}$ 为特征矩阵;$h \times w$ 为每幅特征图大小。基于式(5)计算两个向量的余弦相似度:
$${\mathit{\boldsymbol{A}}}{\mathit{\boldsymbol{B}}} {\rm{ = }}\left\| {\mathit{\boldsymbol{A}}} \right\|\left\| {\mathit{\boldsymbol{B}}} \right\|\cos \theta $$ (5) 式中,
${\mathit{\boldsymbol{A}}}$ 、${\mathit{\boldsymbol{B}}}$ 为两个向量;$\theta $ 为两向量之间夹角。针对破损图像中部分区域信息缺失的问题,引入一个权重值,仅利用破损区域的周围信息来计算其相似度
$M$ :$$M = \frac{{\displaystyle\sum\limits_{i = 1}^n {V\left( {{A_i} \times {q_i}} \right) \times V({B_i})} }}{{\sqrt {\displaystyle\sum\limits_{i = 1}^n {{{[V\left( {{A_i} \times {q_i}} \right)]}^2}} } \times \sqrt {\displaystyle\sum\limits_{i = 1}^n {{{[V\left( {{B_i}} \right)]}^2}} } }}$$ (6) 式中,
${A_i}$ 和${B_i}$ 分别代表破损图像和相似图像;$V$ 代表图像经过卷积网络并归一化;${q_i}$ 为对应像素的权重值,在破损区域和信息区域分别取值为0和1。相似度M越大,代表破损图像与数据集中候选图像相似程度越高。采用最大相似度准则,在数据库中选取与破损图像特征向量相似度最大的候选图像,作为其相似图像B,即:
$$B = {\rm Arg}\max (M)$$ (7) -
由于视角、偏差、尺度、光照等因素的影响,相似图像与参考图像之间往往存在较大程度的扭曲和偏移。为了能更有效地利用相似图像的相关信息,基于仿射不变性原理,对两幅图像的形变差异进行纠正。首先,对两幅图像进行局部特征向量的检测和匹配,采用完全仿射不变配准(affine-Scale invariant feature transform, ASIFT)算法[18]实现两幅图像的特征配准。然后,采用最优化的随机采样一致性(optimized RANSAC, ORSA)算法[19]实现误匹配点的自动筛选,以减少误匹配,提高配准精度。最后,利用单应性变换实现两幅图像的粗对齐。经过单应性变换之后,相似参考图像与破损图像的视角基本一致,取得了比较理想的校正效果。上述操作有助于初步定位最优匹配块的搜索范围,避免全局搜索,可有效减少算法的时间消耗。
-
校正图像与破损区域的结构和纹理信息基本一致,实现了图像的粗对齐,但校正后的图像与破损区域仍有一定的偏差,直接利用校正图像进行信息填充,容易出现被修复区域的纹理和结构信息与边界不一致的情况。受纹理合成算法基本思想的启发,本文将校正图像作为附加源区域,以增加辅助信息源,提高结构和纹理合成效果。
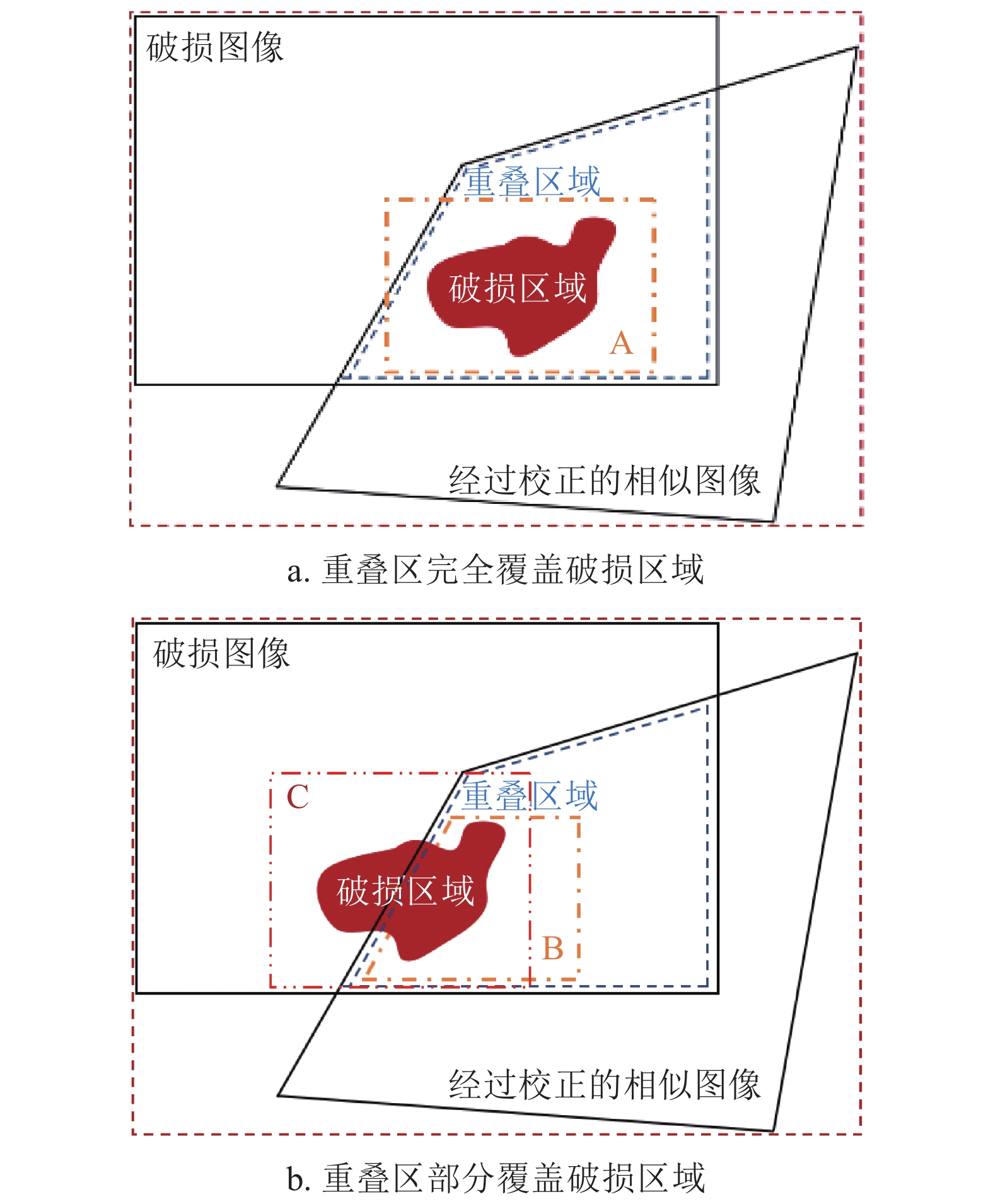
研究表明,对于破损区域,最可靠的信息来源于两个方面:1)校正图像中与破损区域的重叠部分;2)破损区域图像本身边界处的信息。破损图像与校正后的相似图像之间的位置关系通常有两种情况:1)校正图像完全覆盖破损区域,如图2a所示;2)校正图像部分覆盖破损区域,如图2b所示。
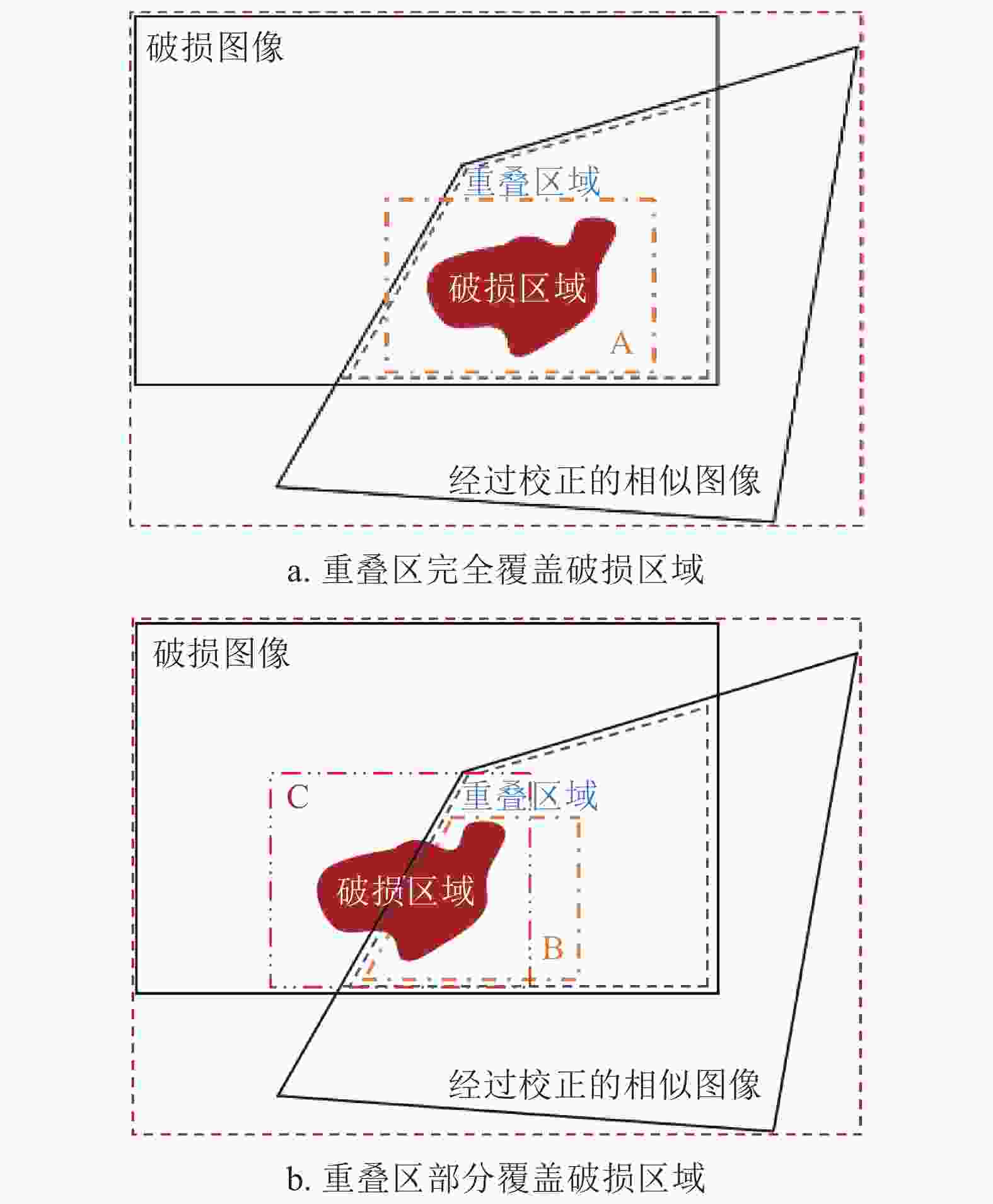
图 2 匹配块搜索范围示意图
针对第一种情况,将最佳匹配块的搜索范围限定为:1) 校正后相似图像中与破损区域重叠的部分以及重叠部分边界周围的区域;2) 原图像中破损区域边界周围的区域,如图2a中A框内部区域。
针对第二种情况,将修复优先权和搜索范围设定为:1)首先对被校正的相似图像覆盖的破损区域进行修复,如图2b中B框的内部区域,其最佳匹配块搜索范围与第一种情况相同;2)对于在相似图像中没有对应的重叠部分的破损区域,设定原始图像破损区域周围的已知区域和步骤1)中已经修复的部分区域为其最佳匹配块的搜索范围,如图2b中C框的内部区域。
传统纹理合成算法通常采用最小均方准则来获取最佳匹配块,而本文中最佳匹配块与原图像块分属两幅不同图像,在颜色、亮度等方面存在较大差异。因此,在传统算法[1]的基础上,引入结构相似度(structural similarity, SSIM),对匹配准则函数加以改进,以提高匹配精度。结构相似度函数定义如下:
$${\rm SSIM}\left( {x,y} \right) = \frac{{( {2{\mu _x}{\mu _y} + {M_1}} )( {2{\sigma _{xy}} + {M_2}} )}}{{( {\mu _x^2 + \mu _y^2 + {M_1}} )( {\sigma _x^2 + \sigma _{\rm{y}}^2 + {M_2}} )}}$$ (8) 式中,
$x$ ,$y$ 代表进行匹配的两幅图像;${\mu _x}$ ,${\mu _y}$ 为两幅图像的平均灰度;${M_1}$ ,${M_2}$ 为固定常数;${\sigma _x}$ ,${\sigma _y}$ 为图像的标准差;${\sigma _{xy}}$ 为图像的协方差。根据文献[20]选取${M_1}$ =6.50,${M_2}$ =58.52。改进后的匹配准则定义为:$${d_{\rm ss}}( {{\psi _{\hat p}},{\psi _q}} ) = d( {{\psi _{\hat p}},{\psi _q}} ) \times {\left[ {{\rm SSIM}( {{\psi _{\hat p}},{\psi _q}} )} \right]^2}$$ (9) 式中,
$p$ 为优先权最大的像素点;${\psi _{\hat p}}$ 表示以$p$ 为中心点的图像块;${\psi _{\hat p}}$ 为优先修复的目标图像块;${\psi _q}$ 表示待匹配块;$d( {{\psi _{\hat p}},{\psi _q}} )$ 表示目标图像块${\psi _{\hat p}}$ 中与待匹配块${\psi _q}$ 中对应位置像素点的方差和(sum of squared difference, SSD)。${\rm SSIM}( {{\psi _{\hat p}},{\psi _q}} )$ 取值在0~1范围内,相匹配的图像块越相似,其值越偏向1,对${d_{{\rm{ss}}}}( {{\psi _{\hat p}},{\psi _q}} )$ 的影响越小。根据以下匹配准则得到最优匹配块${\psi _{\widehat q}}$ :$${\psi _{\widehat q}} = \arg \mathop {\min }\limits_{{\psi _q} \in \phi } {d_{{\rm{ss}}}}({\psi _{\hat p}},{\psi _q})$$ (10) 式中,
$\phi $ 为待搜索区域。 -
算法采用python平台实现,计算机配置如下:CPU处理器为Core i9-9900k;主频为3.60 GHz;内存为64.00 GB。选取“hertford”“triomphe”两幅破损图像,这两幅图像具有比较复杂的纹理和结构信息。在国际标准数据集Oxford Building Dataset和Paris Dataset中搜索其相似图像,结果如图3所示。从图中可以看出,本算法能够准确地获取破损图像的相似图像,且校正效果良好。基于相似图像及改进的匹配准则,破损区域的结构、纹理和图像内容都得到了合理的修复,修复效果理想。为便于观察,对红色矩形框区域做了放大处理。
为了验证本算法的有效性,任意选取8幅图像,人工标记破损区域,从6个国际标准数据集:FGVC aircraft、Oxford Building Dataset、Paris Dataset、Standford-cars、PairsStreet Dataset和Places2中寻找其相似图像,分别采用不同经典算法和本文算法进行图像修复,实验对比结果如图4所示。其中,Kumar[3]算法是纹理合成的最新改进算法,contextual attention (CA)算法[14]是使用注意力机制的神经网络改进算法,gated convolution (GC)算法[15]是使用门控卷积和生成对抗网络的最新神经网络算法。考虑到相似图像与破损图像往往具有不同的光照条件,本文结果作了适当的增强处理,以消除光照的影响。

图 3 本文算法的修复效果

图 4 不同算法修复效果对比
从图4中可以看出,由于信息来源有限,Kumar算法只能修复部分结构信息,并且存在明显的结构混乱、断层,以及纹理传播错误等情况;CA算法在修复中存在明显的模糊现象,纹理修复效果不理想,且在结构上存在断裂、轻微扭曲现象;GC算法能够较好地修复出主体结构,但在边界部分存在扭曲变形,修复痕迹明显;而本文算法对所有图像均取得了比较理想的修复效果,结果更加真实可信。
为了分析图像破损区域大小对最终修复程度的影响,分别选取3种破损区域大小:1) 100×100以内;2) 100×100~200×200;3) 200×200~300×300。对图像进行修复,并计算修复图像的PSNR值,结果如表1所示。从表中可以看出,图像破损区域越大,可参考的信息越少,出现误差的概率越大,图像修复质量逐渐降低。
表 1 不同破损区域大小算法性能对比
破损区域大小 100×100以内 100×100~200×200 200×200~300×300 PSNR/dB 18.64 17.37 15.52 此外,为了对不同算法性能进行量化评估,从6个国际标准数据库中随机选取200幅图像,分别利用经典算法和本文算法进行修复。几种算法的PSNR、平均训练时间和运行时间对比结果如表2所示,其中第二行给出了本文算法相比于其他算法的PSNR值提升率。从表中可以看出,本文方法相比于经典算法,PSNR值分别提升了13.7%、11.4%及8.1%,修复准确度最高。同时可以看出,Kumar算法时间消耗过大;CA算法和GC算法修复时间最短,但网络训练时间过长;与之相比,本文算法虽然修复时间略长,但训练时间缩短。
表 2 不同算法性能对比
性能 Kumar CA GC 本文 PSNR/dB 15.44 15.76 16.23 17.55 PSNR提升率/% 13.7 11.4 8.1 − 训练时间/s − 75600 50400 21600 运算时间/s 952.7 5.2 4.3 64.1 -
本文提出了一种基于相似图像配准的图像修复算法,通过寻找破损图像的相似图像来扩大信息来源,进而实现复杂图像的自动修复。实验结果表明,与传统深度学习方法相比,本算法训练时间减少,且修复准确度高,对于具有复杂结构和纹理的图像,仍然能够获得理想的修复效果。
Image Inpainting Approach Using Similar Image Registration
-
摘要: 传统基于纹理合成的图像修复算法只能从破损图像中提取有用信息,不能修复复杂结构;基于深度学习的修复算法训练时间长,纹理合成效果不理想。为解决上述问题,该文提出了一种基于相似图像配准的图像修复算法。首先提出一种破损图像的相似度计算方法,利用图像的深度学习特征,在数据库中寻找与之最为相近的图像,为修复过程提供更多的有效信息;然后对破损图像和相似图像进行配准,利用单应性变换实现图像空间位置的自动粗纠正;最后使用改进的最佳匹配块搜索方法和匹配准则来改善纹理合成效果,实现图像的最终修复。仿真实验结果表明,该方法可以获得较多的有用信息,产生良好的纹理合成效果,克服了传统算法和深度学习方法的缺点,即使对于具有复杂纹理信息和结构的破损图像,也能够得到良好的修复效果。Abstract: The traditional texture synthesis image inpainting approaches can only extract useful information from the damaged image, but cannot deal with the complex structures. In the meanwhile, the deep-learning-based ones usually have long training time and unsatisfactory texture synthesis effects. To solve the problems, this paper proposes an image inpainting approach based on similar image registration. First, a similarity calculation method of damaged image is proposed by using the deep learning features of images, thus the most similar image of the damaged ones in dataset can be found to provide more useful information for the image inpainting process. Second, this paper matches the damaged image with its similar ones and use the homography transform to realize the automatic rough correction of image space position. At last, the texture synthesis effects are improved by using the improved optimal patch searching method and the relative matching criteria, then the image inpainting is performed. Simulation results demonstrate that the approach can obtain more useful information, yield perfect texture synthesis effect, and overcome the shortcomings of the traditional deep-learning-based and texture synthesis approaches. Besides that, the proposed approach can also obtain ideal inpainting effects even for the damaged images with complex textural information and structures.
-
Key words:
- deep learning /
- feature matching /
- image inpainting /
- similar image /
- texture synthesis
-
表 2 不同算法性能对比
性能 Kumar CA GC 本文 PSNR/dB 15.44 15.76 16.23 17.55 PSNR提升率/% 13.7 11.4 8.1 − 训练时间/s − 75600 50400 21600 运算时间/s 952.7 5.2 4.3 64.1  下载: 导出CSV
下载: 导出CSV
-
[1] CRIMINISI A, PEREZ P, TOYAMA K. Region filling and object removal by exemplar-based image inpainting[J]. IEEE Transactions on Image Processing, 2004, 13(9): 1200-1212. doi: 10.1109/TIP.2004.833105 [2] LI K, WEI Y, YANG Z, et al. Image inpainting algorithm based on TV model and evolutionary algorithm[J]. Soft Computing: A Fusion of Foundations, Methodologies and Applications, 2016, 20(3): 885-893. [3] KUMAR V, MUKHERJEE J, MANDAL S D. Image inpainting through metric labeling via guided patch mixing[J]. Transactions on Image Processing, 2016, 25(11): 5212-5226. doi: 10.1109/TIP.2016.2605919 [4] SIADATI S Z, YAGHMAEE F, MAHDAVI P. A new exemplar-based image inpainting algorithm using image structure tensors[C]//Iranian Conference on Electrical Engineering (ICEE). Shiraz, Iran: IEEE, 2016: 995-1001. [5] NEWSON A, ALMANSA A, GOUSSEAU Y. Non-local patch-based image inpainting[J]. Image Processing on Line, 2017, 7: 373-385. doi: 10.5201/ipol.2017.189 [6] 何凯, 牛俊慧, 沈成南, 等. 基于SSIM的自适应样本块图像修复算法[J]. 天津大学学报(自然科学与工程技术版), 2018, 51(7): 763-767. HE Kai, NIU Jun-hui, SHEN Cheng-nan, et al. Image inpainting algorithm with adaptive patch using SSIM[J]. Journal of Tianjin University: Science and Technology, 2018, 51(7): 763-767. [7] KOMODAKIS N, TZIRITAS G. Image completion using efficient belief propagation via priority scheduling and dynamic pruning[J]. IEEE Transactions on Image Processing, 2007, 16(11): 2649-2661. doi: 10.1109/TIP.2007.906269 [8] MEUR L, EBDELLI M, GUILLEMOT C. Hierarchical super resolution-based inpainting[J]. IEEE Transactions on Image Processing, 2013, 22(10): 3779-3790. doi: 10.1109/TIP.2013.2261308 [9] RUZIC T, PIZURICA A. Context-aware patch-based image inpainting using Markov random field modeling[J]. IEEE Transactions on Image Processing, 2015, 24(1): 444-456. doi: 10.1109/TIP.2014.2372479 [10] ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks[C]//Proceedings of the 13th European Conference on Computer Vision. Zurich, Switzerland: Springer, 2014: 818-833. [11] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[J]. Advances in Neural Information Processing Systems, 2014(4): 2672-2680. [12] PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context encoders: Feature learning by inpainting[C]// IEEE Conference on Computer Vision and Pattern Recognition. Lasvegas, USA: IEEE, 2016: 2536-2544. [13] IIZUKA S, SIMO-SERRA E, ISHIKAWA H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics, 2017, 36(4): 1-14. [14] YU J, LIN Z, YANG J, et al. Generative image inpainting with contextual attention[C]//IEEE Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018: 5505-5514. [15] YU J, LIN Z, YANG J, et al. Free-form image inpainting with gated convolution[C]//Proceedings of the IEEE International Conference on Computer Vision. California, USA: IEEE, 2019: 4471-4480. [16] 陈俊周, 王娟, 龚勋. 基于级联生成对抗网络的人脸图像修复[J]. 电子科技大学学报, 2019, 48(6): 910-917. CHEN Jun-zhou, WANG Juan, GONG Xun. Face image inpainting using cascaded generative adversarial networks[J]. Journal of University of Electronic Science and Technology of China, 2019, 48(6): 910-917. [17] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [C]//International Conference on Learning Representations. San Diego, USA: ICLR, 2015:1-14. [18] MOREL J M, YU G. ASIFT: A new framework for fully affine invariant image comparison[J]. Journal on Imaging Sciences, 2009, 2(2): 438-469. doi: 10.1137/080732730 [19] MOISAN L, MOULON P, MONASSE P. Automatic homographic registration of a pair of images, with a contrario elimination of outliers[J]. Image Processing on Line, 2012, 2: 56-73. doi: 10.5201/ipol.2012.mmm-oh [20] ZHOU W, BOVIK A C, SHEIKH H R, et al. Image quality assessment: From error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612. doi: 10.1109/TIP.2003.819861 -

 点击查看大图
点击查看大图

图(4) / 表(2)
计量
- 文章访问数: 5018
- HTML全文浏览量: 1600
- PDF下载量: 86
- 被引次数: 0





























































