 ISSN
ISSN 



-
国家级(或权威)报刊的头版新闻通常报道与国家政治、经济政策相关的重要信息。正确评价国家级报刊的新闻重要性对理解国家政策变化具有重要意义。如《人民日报》是中国共产党的机关报刊,也是中共中央向外界表达其观点的宣传工具。《人民日报》的头版新闻(第01版要闻)在不同时期对我国政治、经济政策有着指导作用,甚至起到了改变中国发展历史的作用[1]。《人民日报》除了为外界提供中国共产党的政策及观点等直接信息外,其社论亦反映了中共中央对事件的处理意见,被外界作为分析我国政治、经济政策变化的重要渠道之一[2]。
在自然界中存在的大量复杂系统都可以通过不同的复杂网络加以描述[3]。一个典型的复杂网络是由许多节点与节点之间的连边组成,其中节点用来代表真实系统中不同的实体,而连边则用来表示实体间的关系[4]。如大脑神经系统可以看作大量神经细胞(或功能单元)通过神经纤维相互连接形成的神经网络[5];电力系统可以看作不同的变压设备通过电缆相互连接形成的电力网络[6];社会系统可以看作不同的人通过交互关系连接形成的社交网络[7]。类似地,新闻媒体(如《人民日报》)也可以通过其新闻(文章)的内容相似度形成新闻网络[8]。
在复杂网络研究领域,节点重要性可以用于识别社交网络中意见领袖[9]、科研人员的学术影响力[10]及新闻关键词提取[11]等等。网络节点中心性是对节点核心地位的定量刻画,以反映该节点在网络中的重要性[12-13]。本文通过对H指数和PageRank排序算法的深入分析,提出改进的PageRank排序算法—H-PageRank。H-PageRank排序算法保留了H指数局部邻域内对大度节点的依赖,同时结合了PageRank算法随机游走的全局性,是一种兼顾局部和全局中心性的节点排序算法。
本文以《人民日报》为例,抽取发表在1946−2008年期间的新闻,利用新闻内容相似性,基于表示学习构建新闻网络。在此基础上,基于H-PageRank排序算法对新闻网络进行节点重要性度量。以是否成为头版新闻作为新闻重要性评价准则,相比其他的网络节点中心性指标,H-PageRank中心性能够更正确地评价新闻重要性,验证H-PageRank排序算法的有效性。
-
H-PageRank排序算法是通过引入H指数,对PageRank排序算法的改进。本章将重点阐述H-PagerRank排序算法的改进。
-
文献[14]提出了PageRank排序算法,该算法针对新闻网络
$ G=(V,E) $ 中任意节点$ {v}_{i} $ ,其初始${\rm{PR}}$ 值的计算为:$$ {\rm{PR}}\left( {{v_i}} \right) = \mathop \sum \limits_{{v_j} \in V \;{\rm{and}} \;{v_j} \ne {v_i}} \frac{{{\rm{PR}}( {{v_j}} )}}{{D( {{v_j}} )}} $$ (1) 式中,
$D({v}_{j})$ 表示节点${v_j}$ 的度。考虑到${\rm{PR}}$ 值的结果不应该为0,所以文献[14]将式(1)改写为:$$ {\rm{PR}}\left( {{v_i}} \right) = d \mathop \sum \limits_{{v_j} \in V \;{\rm{and}} \;{v_j} \ne {v_i}} \frac{{{\rm{PR}}( {{v_j}})}}{{D( {{v_j}} )}} + \frac{{1 - d}}{{{N_G}}} $$ (2) 式中,
$ d $ 为阻尼系数(通常取$ d=0.85 $ );$ {N}_{G}=\left|V\right| $ 表示$ G $ 的节点数量。经过迭代计算,节点${v_i}$ 的${\rm{PR}}$ 值会趋向于收敛状态。PageRank排序算法有一些显著的缺陷,首先在巨大网络中随机游走本就是一件极其复杂的过程,容易导致在实际计算过程中需要计算网络大小为几十万阶乃至上亿阶的矩阵的乘法,而超大矩阵的乘法在时间和空间上都难以负担[15]。在实际应用中,PageRank排序算法是基于连接分析的,易受到直接连接的重要性较小的节点影响,不能对网络降噪之后再进行处理,导致它计算出来的搜索结果存在误差[16]。
为了解决上述问题,本文引入H指数,使用支持H指数贡献矩阵(support H-index contribution matrix, SHCM)改进PageRank排序算法。
-
H指数是一个混合量化指标[17]。文献[18-19]将H指数引入节点中心性度量。它们认为一个节点
${v_i}$ 的H指数如果是${{H}}\left( {{v_i}} \right)$ ,说明这个节点有${{H}}\left( {{v_i}} \right)$ 个邻居,且它们的度都不小于${{H}}\left( {{v_i}} \right)$ 。文献[18]理论证明H指数是一个很好的度量节点中心性的指标,可以简单、直观地反应网络结构特征和节点重要性。另外,对于节点
$ {v}_{i} $ 的H指数,${{H}}\left( {{v_i}} \right)$ 虽然反映了该节点在当前网络中的重要性,但是受网络规模影响,不便于进行网络间对比。为此,本文通过利用网络规模归一化H指数,定义节点的H中心性(HC):$$ {C_H}\left( {{v_i}} \right) = \frac{{{{H}}\left( {{v_i}} \right)}}{{{N_G} - 1}} $$ (3) -
受到文献[18]启发,一个节点的H指数一般要远小于其节点的度,所以针对一个点的H指数,往往只与该节点的邻域中的少数大度节点有关。因此,本文定义SHCM的元素
${B_{ij}}$ 满足:$$ {B_{ij}} = \left\{\begin{split} & {{A_{ij}}{\rm{}}}\qquad\quad{ \;{\rm{}}D( {{v_j}} ) > H\left( {{v_i}} \right)}\\ & 0\qquad\quad\;\;\;\, \text{其他}\end{split} \right. $$ (4) 式中,
$ {A}_{ij} $ 为$G$ 的邻接矩阵的元素;$ {v}_{i} $ 为目标节点,$ {v}_{j} $ 为${v_i}$ 的邻居节点${v_j} \in {{N}}\left( {{v_i}} \right)$ ;$D({v}_{j})$ 为邻域中节点$ {v}_{j} $ 的度;${{H}}\left( {{v_i}} \right)$ 为目标节点$ {v}_{i} $ 的H指数。SHCM描述对$ G $ 过滤操作后的新闻网络$ {G}_{{\rm{SHCM}}}=({V}_{{\rm{SHCM}}},{E}_{{\rm{SHCM}}}) $ 。对于$G$ 中的节点${v_i}$ 来说,它在$ {G}_{{\rm{SHCM}}} $ 中只保留其邻域$N\left( {{v_i}} \right)$ 中节点度最大的$N\left( {{v_i}} \right)$ 个节点。通过这种方式,不再考虑$ G $ 中那些节点度相对较小的节点,从而较大程度地简化了$G$ 的邻接矩阵,保证H-PageRank排序算法的高效计算。H-PageRank排序算法的详细流程如下。对于
${G_{{\rm{SHCM}}}}$ 中任意节点${v_i}$ ,定义其${\rm{HPR}}$ 值为:$$ {\rm{HPR}}({{v_i}}) = d \mathop \sum \limits_{{v_j} \in {N_{{\rm{SHCM}}}}( {{v_i}} } \frac{{{\rm{HPR}}( {{v_j}})}}{{{D_{{\rm{SHCM}}}}( {{v_j}} )}} + \frac{{1 - d}}{{{N_{{\rm{SHCM}}}}}} $$ (5) 式中,
$d$ 为阻尼系数;$ {N}_{{\rm{SHCM}}}= $ $ \left|{V}_{{\rm{SHCM}}}\right| $ 为$ {G}_{{\rm{SHCM}}} $ 中节点数量(等同于新闻网络$G$ 的节点数量);$ {N}_{{\rm{SHCM}}}\left({v}_{i}\right) $ 为${G_{{\rm{SHCM}}}}$ 中节点${v_i}$ 的邻域;${D_{{\rm{SHCM}}}}( {{v_j}} )$ 为${G_{{\rm{SHCM}}}}$ 中节点${v_j}$ 的度。${G_{{\rm{SHCM}}}}$ 中所有节点的${\rm{HPR}}$ 值可以形成一个特征向量${\bf{HR}}$ :$$ {\bf{HR}} = \left( {\begin{aligned} &{{\rm{HPR}}\left( {{v_1}} \right)}\\ &{{\rm{HPR}}\left( {{v_2}} \right)}\\ &\;\;\;\;\;\;{\vdots}\\ &{{\rm{HPR}}\left( {{v_i}} \right)}\\ &\;\;\;\;\;\;{\vdots}\\ &{{\rm{HPR}}\left( {{v_n}} \right)} \end{aligned}} \right) $$ (6) 同时,特征向量
${\bf{HR}}$ 也是式(7)中方程组的稳定解,$$ \begin{split} & {\bf{HR}} = d\left( {\begin{array}{*{20}{c}} {l({v_1},{v_1})}&{l({v_1},{v_2})}&{\cdots}&{l({v_1},{v_n})}\\ {l({v_2},{v_1})}&{l({v_2},{v_2})}&{\cdots}&{l({v_2},{v_n})}\\ {\vdots}&{\vdots}&&{\vdots}&\\ {l({v_n},{v_1})}&{l({v_n},{v_1})}&{\cdots}&{l({v_n},{v_1})} \end{array}} \right) \times\\ & \qquad\qquad\qquad{\bf{HR}} + \left( {\begin{array}{*{20}{c}} {\dfrac{{1 - d}}{{{N_{{\rm{SHCM}}}}}}}\\ {\dfrac{{1 - d}}{{{N_{{\rm{SHCM}}}}}}}\\ \vdots \\ {\dfrac{{1 - d}}{{{N_{{\rm{SHCM}}}}}}} \end{array}} \right) \end{split} $$ (7) 式中,邻接函数
$l( {{v_i},{v_j}} )$ 代表在${G_{{\rm{SHCM}}}}$ 中节点${v_j}$ 在${v_i}$ 邻域${N_{{\rm{SHCM}}}}\left( {{v_i}} \right)$ 中的节点总数中的比重。如果${v_i}$ 和${v_j}$ 不相邻,则$l({v}_{i},{v}_{j})=0$ 。一般情况,对于任意节点$ {v}_{i} $ ,其满足:$$ \mathop \sum \limits_j^N l( {{v_i},{v_j}} ) = 1 $$ (8) 由于矩阵
$ {{\mathit{\boldsymbol{L}}}}=\left\{{l\left({v}_{i},{v}_{j}\right)}_{i,j}\right\} $ 的特征值很大,式(7)只需几次迭代后,即可在极高置信度得到计特征向量${\bf{HR}}$ ,其元素值(即是${\rm{HPR}}$ 值)度量节点重要性。 -
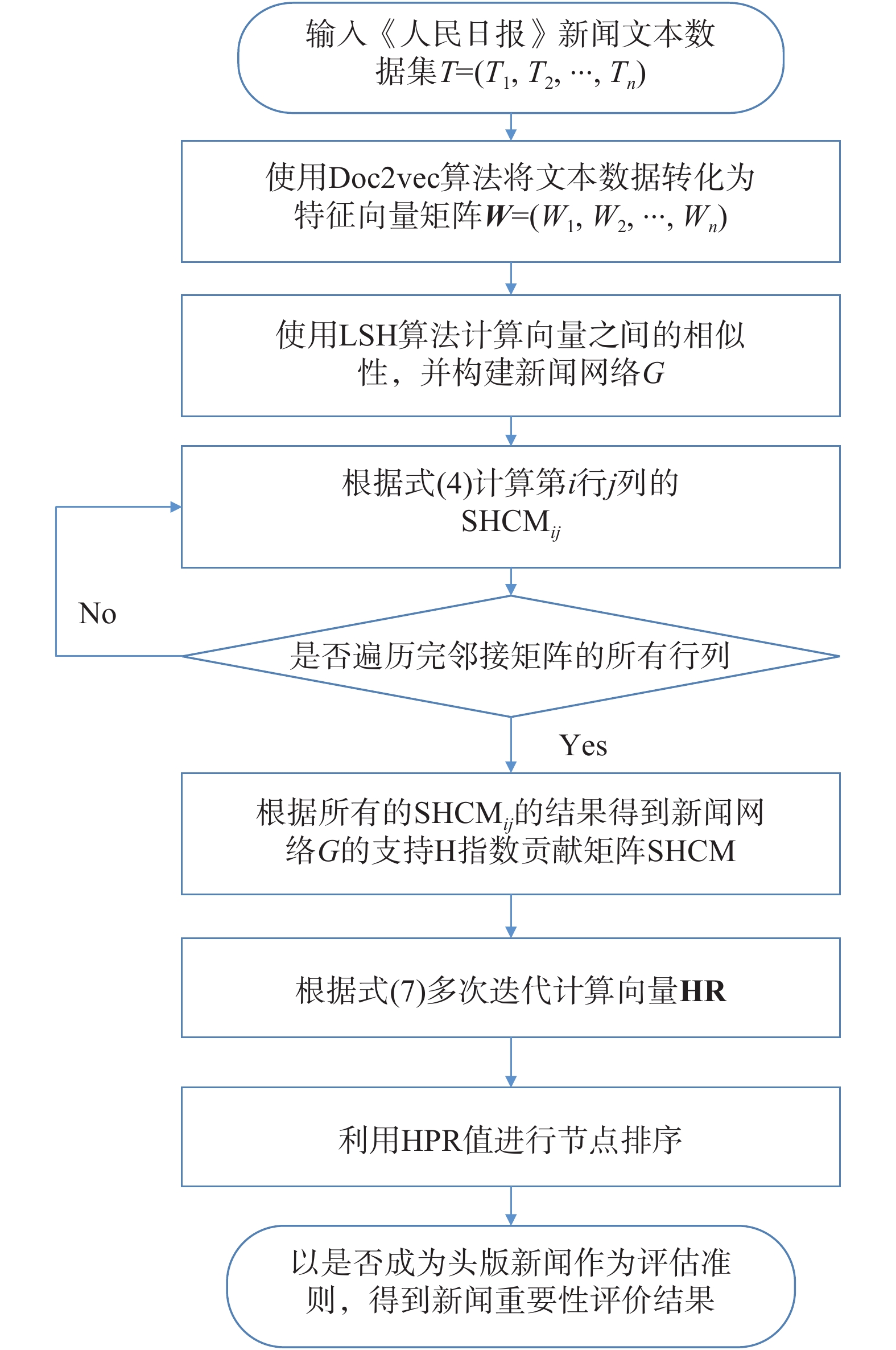
在新闻重要性评价方法设计过程中,本文首先通过自然语言处理方法得到每条新闻的表示向量,利用每条新闻的表示向量计算它们的相似度性时。该过程面临高时间复杂度。本文采用局部敏感哈希算法实现新闻之间的相似性计算,进而得到刻画新闻网络的相似性矩阵。在此基础上,基于H-PageRank中心性对新闻网络中的节点进行排序,以是否成为头版新闻作为新闻重要性评价准则,通过全局排序与局部排序度量的实验结果验证Top-N评价方法。图1给出新闻重要性评价方法的具体工作流程。

图 1 新闻重要性评价方法工作流程图
-
词嵌入(word embedding)是一种将文本中的词转换成向量的方法[20]。本文将《人民日报》的所有新闻作为文本语料,采用Doc2Vec算法[21]将新闻进行向量表示。Doc2Vec算法同时训练词向量表示和新闻向量表示。设新闻
$i$ 对应的one-hot编码向量为${p_i}$ ,新闻中词$ t $ 对应的one-hot编码向量为$ {w}_{t} $ 。可以构建词$ t $ 在文本$ i $ 的和向量${{\mathit{\boldsymbol{h}}}}({w_t}|{p_i})$ 为如下形式:$$ {{\mathit{\boldsymbol{h}}}}\left( {{w_t}{\rm{|}}{p_i}} \right) = \mathop \sum \limits_{i = - \frac{T}{2}}^{\frac{T}{2}} {w_{t + i}} + {p_i} $$ (9) 式中,
$T$ 为Doc2Vec算法考虑的上下文词数。进一步,将
${{\mathit{\boldsymbol{h}}}}({w_t}|{p_i})$ 代入Doc2Vec算法的神经网络模型中,可得到如下输出:$$ y = {\rm{Softmax}}\left( {{{\mathit{\boldsymbol{h}}}}\left( {{w_t}{\rm{|}}{p_i}} \right) \times W} \right) + b $$ (10) 式中,
${{W}}$ 为Doc2Vec算法的神经网络模型中的隐层;b为偏置。利用上述输出函数构建如下损失函数:
$$ {\rm{Loss}} = \sum D\left( {y,{w_t}} \right) $$ (11) 式中,
$D$ 为向量间距离函数,本文采用二阶欧氏距离。通过优化式(11),得到一个${{{\mathit{\boldsymbol{W}}}}}_{{\rm{best}}}$ 矩阵和${{{\mathit{\boldsymbol{b}}}}_{{\rm{best}}}}$ 偏置。以新闻$i$ 对应的one-hot向量${{{\mathit{\boldsymbol{p}}}}_i}$ 作为输入,可以得到其低维向量表征${{{\mathit{\boldsymbol{R}}}}_i}$ 为如下形式:$$ {{{\mathit{\boldsymbol{R}}}}_i} = {{{\mathit{\boldsymbol{p}}}}_i} \times {{{\mathit{\boldsymbol{W}}}}_{{\rm{best}}}} $$ (12) -
Doc2Vec算法所得的新闻的表示向量,其维度仍然较高,同时本文实际探讨的新闻规模也是较大的,所以在遍历计算新闻之间的相似性具有较高的时间复杂度。为了解决该问题,本文基于局部敏感哈希(local sensitive Hash, LSH)的近似最近邻查找方法(简称LSH算法)来计算新闻之间相似性[22]。
LSH算法将
$ n $ 个准备计算相互之间相似性的新闻向量${{{\mathit{\boldsymbol{R}}}}}_{i}$ ($i = 1,2, \cdots ,n$ )分别与同一个稳定分布的正态分布的数列$ \alpha $ 做向量点乘,得到的$ n $ 个一维的点值,对于向量${{{\mathit{\boldsymbol{R}}}}}_{i}$ 映射到其对应的一维点值的过程:$$ {{{\mathit{\boldsymbol{h}}}}_{{\mathit{\boldsymbol{\alpha}}}} }\left( {{{{\mathit{\boldsymbol{R}}}}_i}} \right) = \alpha {\rm{\cdot}}{{{\mathit{\boldsymbol{R}}}}_i} $$ (13) 它利用一维点值的差异来近似高维空间的距离。在实际计算中,LSH算法把原始向量分成
$ K $ 段,对每一段子向量进行一维点乘,且添加一个随机的噪音$\varepsilon $ ,以提高算法稳定性。如对于向量${{{\mathit{\boldsymbol{R}}}}}_{i}$ 的第$k$ 段子向量${{{\mathit{\boldsymbol{r}}}}_{i,k}}$ 的哈希值表示为:$$ {{{\mathit{\boldsymbol{h}}}}_{\alpha ,\varepsilon }}\left( {{{{\mathit{\boldsymbol{r}}}}_{i,k}}} \right) = \alpha {\rm{\cdot}}{r_{i,k}} + \varepsilon $$ (14) 因此,任意一个向量都有
$K$ 个哈希值。LSH算法假设,对任意一对向量${{{\mathit{\boldsymbol{R}}}}}_{i}$ 和${{{\mathit{\boldsymbol{R}}}}_j}$ ,如果存在任意一段子向量对的哈希值相同,即${{{\mathit{\boldsymbol{h}}}}_{\alpha ,\varepsilon }}( {{{{\mathit{\boldsymbol{r}}}}_{i,k}}}) = {{{\mathit{\boldsymbol{h}}}}_{\alpha ,\varepsilon }}( {{{{\mathit{\boldsymbol{r}}}}_{j,k}}} )$ $\left( {k = 1,2, \cdots ,K} \right)$ ,则该对向量相似,标记为$ {s}_{i,j}=1 $ ,否则$ {s}_{i,j}=0 $ [22]。 -
通过Doc2vec算法和LSH算法,可以高效地获取与节点
$ {v}_{i} $ 相似的节点集合,从而快速构建新闻网络。在此基础上,本文基于H-PageRank中心性(HPR)对新闻网络中节点进行排序。通过节点排序序列,构建Top-N评价方法(${{N}}$ 是截取节点排序序列的列表长度)[23]。以是否成为头版新闻作为新闻重要性评价准则,本文通过调节${{N}}$ 实现全局排序和局部排序的度量(详见3.1节实验设计),设计基于H-PageRank中心性的Top-N评价方法。本文将H-PageRank中心性与其他的中心性指标,如PageRank中心性(PR)、LeaderRank中心性(LR)[24]、度中心性(DC)[25]、H中心性、接近中心性(CC)[26]及特征向量中心性(EC)[27]进行对比研究,进一步验证了H-PageRank排序算法与基于网络节点中心性的Top-N评价方法的有效性。 -
在处理数据的过程中,本文考虑到不同领导核心执政时期《人民日报》的新闻风格与新闻版面差异性,将原始数据按照执政时间划分为4个时代,形成对应的4个子数据集,每一个子数据集的时间划分和新闻数量等描述如表1所示。
表 1 各个时代的子数据集属性信息
时间划分 数据子集 新闻数量/条 头版新闻数量/条 头版新闻占比/% 非头版新闻数量/条 非头版新闻占比/% 1946.05.01−1977.07.15 Stage1 445 749 77 021 17.28 368 728 82.72 1977.07.16−1987.06.24 Stage2 237 351 30 542 12.87 206 809 87.13 1987.06.25−2002.11.14 Stage3 476 690 48 142 10.10 428 548 89.90 2002.11.15−2008.12.31 Stage4 207 400 15 697 7.57 191 703 92.43 为了验证H-PageRank排序算法与基于网络节点中心性的新闻重要性评价方法,本文引入4个准确性评价指标:AUC指标用于全局排序(
$N$ 等于新闻网络规模)条件下度量Top-N评价方法;正确率(precision)、召回率(recall)和F1指标(F1-score)用于局部排序(N显著小于新闻网络规模)条件下度量Top-N评价方法。AUC指标可以通过排序算法产生的全局排序列表中头版新闻的平均排序分(rank score)近似估算[27]。正确率定义排序列表中头版新闻与所有新闻的比例;召回率(recall)定义排序列表中头版新闻与数据集中所有头版新闻的比例;F1指标(F1-score)定义准确率召回率的调和结果[28]。 -
本文将《人民日报》的新闻划分为4个时代,对每一个时代构建其新闻网络(对应4个数据子集),在此基础上利用头版新闻作为新闻重要性评价准则,验证基于多种网络节点中心性的Top-N评价方法。因此,本文对实验结果的论述主要分为两部分:1) 新闻网络实证研究;2) 基于Top-N评价方法的新闻重要性评价研究。
-
通过上述LSH算法,可以高效地计算得到新闻(二元)相似性矩阵。值得注意的是,LSH算法过滤了相似性较低的新闻,使得新闻相似性矩阵中存在值全为0的行或列。这些值全为0的行或列对应新闻网络中的孤立节点。本小节对形成的新闻网络进行实证研究。表2给出了去除掉孤立节点后,4个新闻网络的拓扑结构特征。它的基本统计参量包括节点数、边数、连通分支数、最大连通分支(包括相对于新闻网络节点的比例)、平均度、聚类系数和同配系数。实验结果表明:1) 新闻网络存在较多的孤立节点(即是新闻网络节点数远小于新闻数)与较多的连通分支,但是最大连通分支相对于新网络节点的比例较大;2) 新闻网络具有较高的平均度、高聚集特性和和同配特性。
表 2 各个时代的新闻网络拓扑属性
网络 节点数/个 边数/条 连通分
支数最大连通
分支平均度 聚类
系数同配
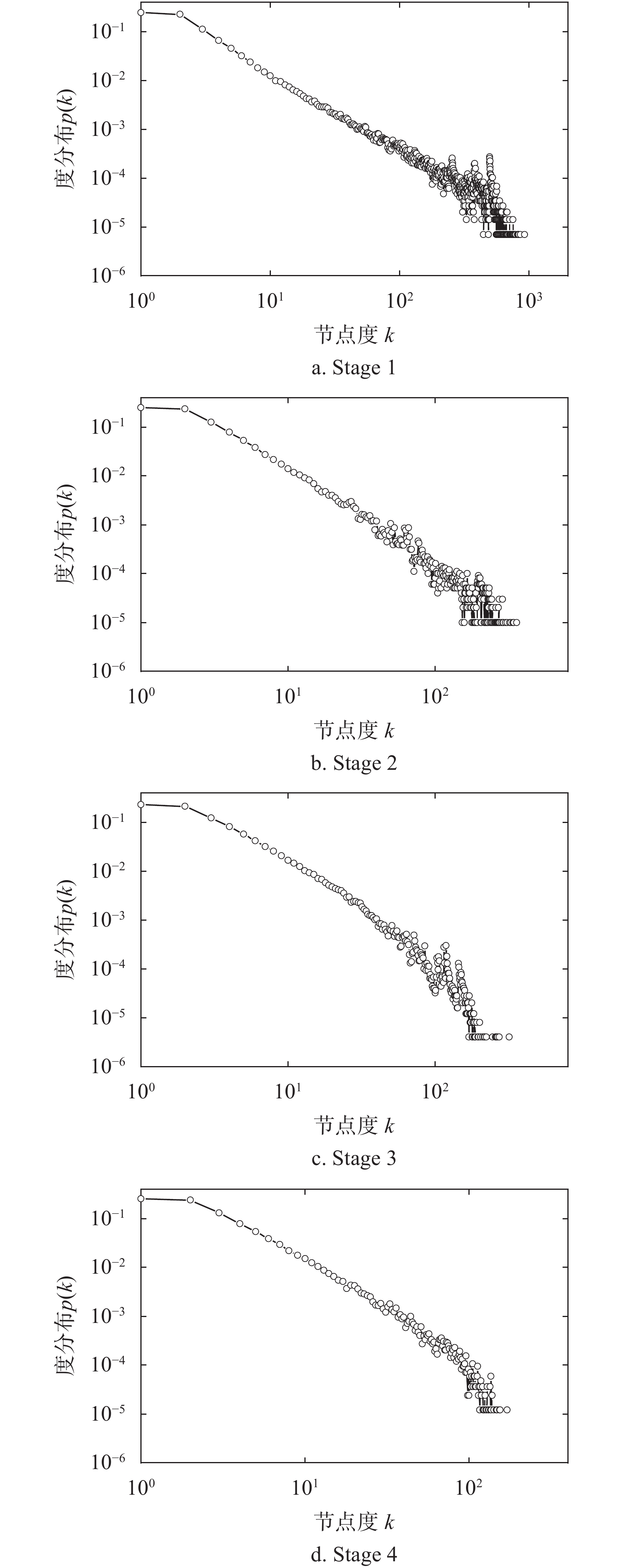
系数Stage1 136311 1436869 15259 86 430 (63.4%) 21.08 0.40 0.72 Stage2 86099 247532 12115 48 664 (56.5%) 5.75 0.39 0.82 Stage3 215671 662558 23060 153 080 (71.0%) 6.14 0.41 0.84 Stage4 69989 172406 10719 39 584 (56.6%) 4.93 0.39 0.72 同时,通过实证分析新闻网络,从时代1~时代4表示头版新闻的节点数与新闻网络节点数之比依次是18.98%、12.11%、10.73%、8.76%,以及分析4个新闻网络的度分布
${{p}}\left( {{k}} \right)$ 。如图2所示,4个新闻网络的度分布都具有出无标度特性(即是近似幂律分布),表现出复杂网络的一般特性。
图 2 新闻网络度分布
-
基于新闻网络的邻接矩阵,分别计算网络中各节点的H-PageRank中心性、PageRank中心性、LeaderRank中心性、度中心、H中心性、接近中心性及特征向量中心性,形成基于不同网络节点中心性的节点排序序列。在此基础上,利用不同排序列表长度条件下的Top-N评价方法,对比分析H-PageRank排序算法与基于其他的网络节点中心性的新闻重要性评价的有效性。
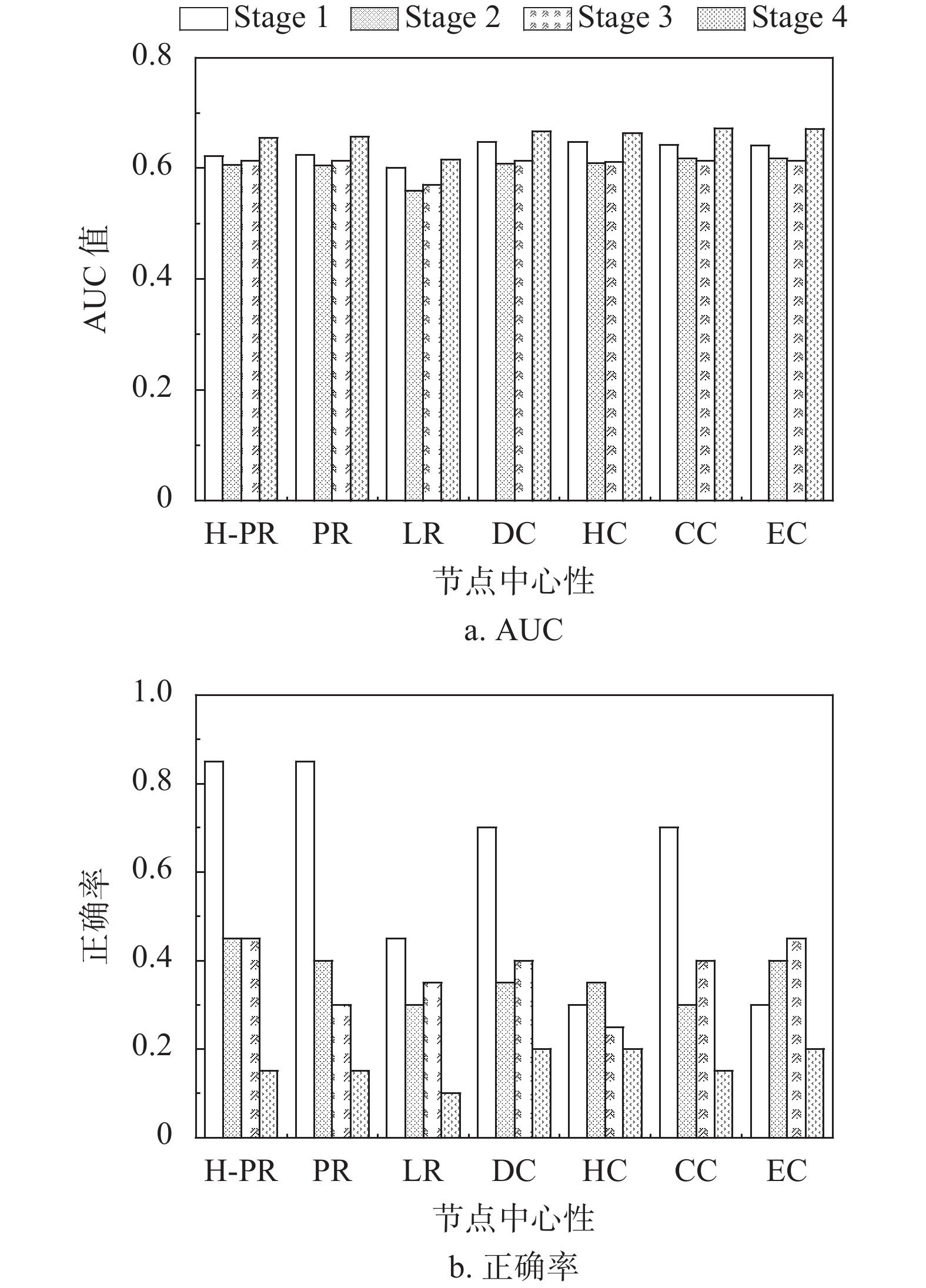
首先,针对每一个新闻网络,本文基于7种网络节点中心性对其节点进行全局排序,通过全局排序列表条件下Top-N评价方法计算头版新闻的平均排序分估算出对应的AUC值。图3a给出不同网络节点中心性计算得到的AUC值。对于每一个新闻网络,7种网络节点中心性给出非常相近的AUC值,表明它们对新闻网络全局排序的相近性,但是AUC值都显著高于随机排序理论值0.5,表明它们对新闻网络进行全局排序的有效性。值得注意的是,对于每一个新闻网络,基于HPR和HR的AUC值对阻尼系数
$ d $ 都有很高的鲁棒性,因此本文选取最优AUC值对应的阻尼系数,$ d=0.9 $ 。
进一步,为了能够区分7种网络节点中心性对新闻重要性评价的影响力,本文通过局部排序条件下Top-N (N=20)评价方法,计算头版新闻的(预测)正确率(图3b)、召回率(图3c)和F1指标(图3d)。对比分析实验结果,可以发现基于H-PageRank中心性Top-20评价方法在3个正确性评价指标上表现出较好的性能(除了时代4的新闻网络)。具体而言,H-PageRank中心性对应的评价指标平均值相比于PageRank中心性、Leaderrank中心性、度中心性、H中心性、接近中心性及特征向量中心性,从正确率角度分别提高18.8%、58.5%、12.9%、70.3%、25.0%及45.8%;从召回率角度分别提高18.6%、58.7%、12.9%、70.2%、24.9%及45.8%;从F1指标角度分别提高18.7%、58.6%、12.9%、70.3%、25.1%及45.8%。这些实验结果表明基于H-PageRank中心性的新闻重要性评价更优,验证了H-PageRank排序算法的有效性。
通过图3实验结果的对比分析,可以得出3个正确性指标给出H-PageRank中心性相比于其他网络节点中心性的相似结果,所以本文从正确率角度对比分析不同局部排序列表长度条对基于7种网络节点中心性的Top-N评价方法的影响。图4给出不同局部排序列表长度对Top-N评价方法的实验结果,虚线对应的理论基准(即是头版新闻占比)。依据不同时代的新闻网络。
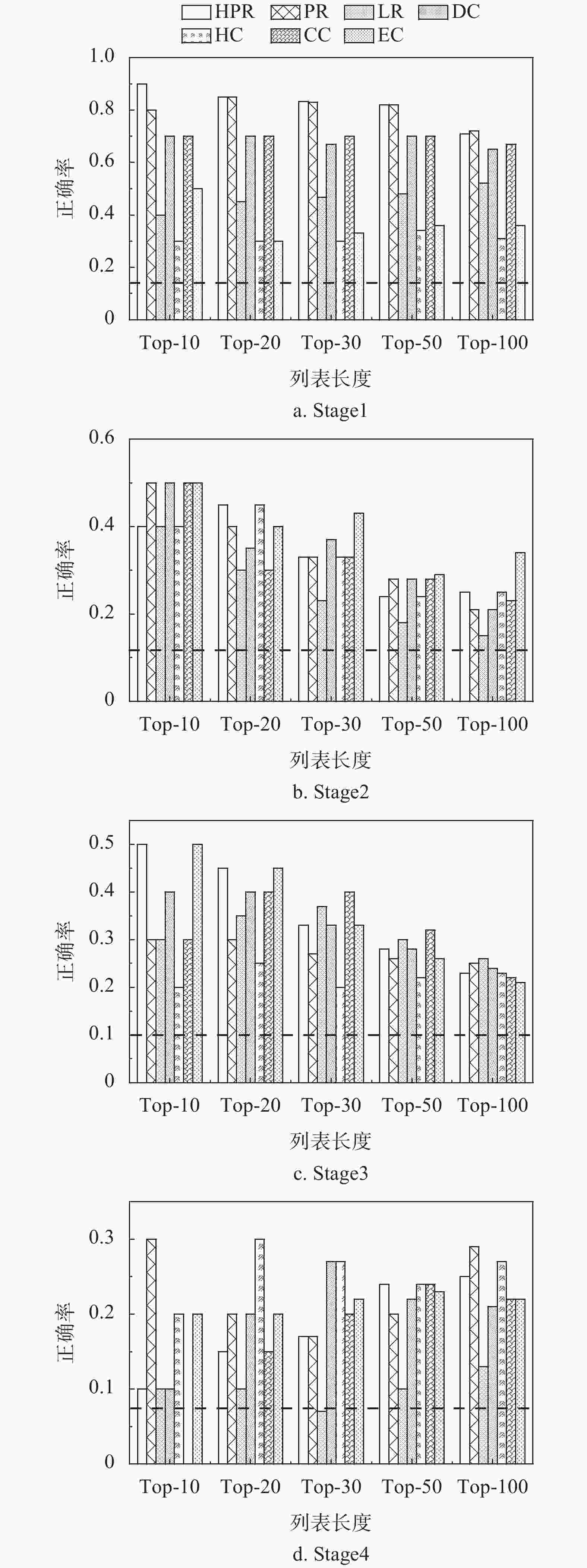
图 4 不同局部排序列表长度条件下基于7种中心性的Top-N评价方法的性能对比分析
时代1的新闻网络如图4a所示。H-PageRank中心性和PageRank中心性对Top-N评价方法影响最大,基于这两类中心性的正确率要显著高于其他4类中心性。特别是,基于H-PageRank中心性的Top-N评价方法,其正确率受局部排序列表长度影响较小,且相比于理论基准有极大的提高,比如Top-10评价方法的正确率可达4.5倍。
时代2的新闻网络如图4b所示。基于特征向量中心性的Top-N评价方法,在不同局部排序列表长度条件下的平均正确率最高,且相比于理论基准有极大的提高,如Top-10评价方法的正确率可达3.9倍。
时代3的新闻网络如图4c所示。与时代1的实验结果相类似,H-PageRank中心性和Page-Rank中心性显著优于其他4类中心性。但是,局部排序列表长度对基于H-PageRank中心性和Page-Rank中心性的Top-N评价方法影响较明显。同时,对于基于H-PageRank中心性和Page-Rank中心性的Top-N评价方法,其Top-10评价方法的正确率相比于理论基准可达5倍。
时代4的新闻网络如图4d所示。基于H中心性的Top-N评价方法,在不同局部列表长度条件下的平均正确率最高,且相比于理论基准有显著的提高,如Top-10评价方法的正确率可达4倍。
值得注意的是,如果局部排序列表长度过小,样本数目过少会使实验结果有较大的误差,反之,如果推荐列表长度继续加大,基于不同网络节点中心性的实验结果的差异变小,且会逐渐趋向于理论基准。但是,对于有限的局部排序列表长度条件下,基于7种网络节点中心性的Top-N评价方法的正确率都优于理论基准。特别是,当选取的局部排序列表长度N=20时,在4个时代的新闻网络上,基于H-PageRank中心性的评价方法的最优正确率相比于理论基准,分别提高391.9%、249.7%、345.5%和98.2%。综上所述,实验结果表明基于7种网络节点中心性的Top-N评价方法对于有限的局部排序列表长度的鲁棒性。
-
本文以《人民日报》为例,从复杂网络视角研究新闻网络,利用新闻网络节点中心性,构建Top-N评价方法。在此基础上,以是否成为头版新闻作为新闻重要性评价准则,比较不同网络节点中心性指标的表现。在横向比较各类中心性排序算法对评价新闻重要性的影响时,尽管7种网络节点中心性指标在全局排序条件下表现出相近的AUC值,但是Top-20评价方法的平均正确率、平均召回率及平均
$ {F}_{1} $ 值都表明H-PageRank排序算法要明显优于其他6种中心性排序算法。基于此,本文认为提出的H-PageRank算法是有效且高效的。
Research on Importance Evaluation of News Based on Nodal Centralities of Complex Network
-
摘要: 评价权威报刊的新闻重要性对于正确理解国家政策变化具有重要意义。该文以《人民日报》为例,抽取发表在1946−2008年期间的新闻,利用其内容相似性构建新闻网络。从复杂网络视角,一篇新闻与其他新闻的相似性越高,其在新闻网络中连接越紧密,具有较大的节点中心性。鉴于此,该文将H指数引入PageRank排序算法,提出H-PageRank排序算法,利用其计算H-PageRank中心性,评价新闻重要性。在实验过程中,考虑到不同领导核心执政时期《人民日报》的新闻风格与新闻版面的差异性将新闻划分为4个时代,基于表示学习分别形成对应的新闻网络。研究结果表明:1) 4个新闻网络的拓扑结构都表现出高聚类性与同配性,且具有近似幂律的度分布,表现出复杂网络一般特性;2) 基于多种网络节点中心性指标,对每个新闻网络中的节点进行全局排序,并以是否成为头版新闻为重要性的评价准则计算得到相近的AUC值,然后基于局部排序的Top-N评价方法计算得到正确率、召回率和F1指标,综合以上指标的实验结果表明,H-PageRank中心性显著优于其他算法的中心性,验证H-PageRank排序算法的有效性;3) 针对每个新闻网络,基于网络节点中心性的Top-N评价方法不同排序列表长度条件,其计算得到的正确率显著高于理论基准,表明评价方法的鲁棒性。
-
关键词:
- H-PageRank排序算法 /
- 新闻重要性评价 /
- 新闻网络 /
- 节点中心性 /
- 表示学习
Abstract: It is of great significance to correctly evaluate the importance of news in national newspapers and magazines for better understanding the changes of national policies. In this paper, we take People’s Daily as an example, extract news published in 1946−2008, and construct news network by using their content-based similarities. In the view of complex network, news has higher similarities with others, making it be closely connected and larger nodal centrality in news network. In respect to this, we propose an H-PageRank ranking algorithm by introducing the H-index to improve the PageRank ranking algorithm. In the experiment, all news in People’s Daily is divided into four stages according to their styles and editions in different governing times, which is respectively used to construct news networks based on representation learning. The experimental results show that 1) the topologies of four news networks all have a general properties of complex network, including the high clustering coefficients, positive assortativity coefficients and approximately power-law degree distributions; 2) each news network presnets a mostly similar AUC calculated by the global rank score of the front-page news according to diverse nodal centralities, however the precision, recall and F1-score calculated by the Top-N evaluating model according to the H-PageRank centrality are optimal, which validate the efficiency of local ranking news according to the H-PageRank centrality; 3) the precision of each news network is significantly superior to the theoretical baselines even when the ranking list is restricted into different length, which suggests the roubustness of evaluating model. -
表 1 各个时代的子数据集属性信息
时间划分 数据子集 新闻数量/条 头版新闻数量/条 头版新闻占比/% 非头版新闻数量/条 非头版新闻占比/% 1946.05.01−1977.07.15 Stage1 445 749 77 021 17.28 368 728 82.72 1977.07.16−1987.06.24 Stage2 237 351 30 542 12.87 206 809 87.13 1987.06.25−2002.11.14 Stage3 476 690 48 142 10.10 428 548 89.90 2002.11.15−2008.12.31 Stage4 207 400 15 697 7.57 191 703 92.43  下载: 导出CSV
下载: 导出CSV
表 2 各个时代的新闻网络拓扑属性
网络 节点数/个 边数/条 连通分
支数最大连通
分支平均度 聚类
系数同配
系数Stage1 136311 1436869 15259 86 430 (63.4%) 21.08 0.40 0.72 Stage2 86099 247532 12115 48 664 (56.5%) 5.75 0.39 0.82 Stage3 215671 662558 23060 153 080 (71.0%) 6.14 0.41 0.84 Stage4 69989 172406 10719 39 584 (56.6%) 4.93 0.39 0.72
下载: 导出CSV
-
[1] 汪晓东, 张炜, 钱一彬. 风雨兼程, 与党和人民同行——写在人民日报创刊七十周年之际[J]. 新闻战线, 2018(11): 2-7. WANG Xiao-dong, ZHANG Wei, QIAN Yi-bin. Go hand in hand with the party and the people——Written on the occasion of the 70th anniversary of the People's Daily[J]. News Front, 2018(11): 2-7. [2] ZHONG Wei-feng, CHAN J T. Reading China: Predicting policy change with machine learning[M]. [S.l.]: American Enterprise Institute, 2018. [3] 周涛, 柏文洁, 汪秉宏, 等. 复杂网络研究综述[J]. 物理, 2005, 34(1): 31-36. doi: 10.3321/j.issn:0379-4148.2005.01.007 ZHOU Tao, BAI Wen-jie, WANG Bing-hong, et al. A brief review of complex networks[J]. Physics, 2005, 34(1): 31-36. doi: 10.3321/j.issn:0379-4148.2005.01.007 [4] 周涛, 张子柯, 陈关荣, 等. 复杂网络研究的机遇与挑战[J]. 电子科技大学学报, 2014, 43(1): 1-5. doi: 10.3969/j.issn.1001-0548.2014.01.001 ZHOU Tao, ZHANG Zi-ke, CHEN Guan-rong, et al. The opportunities and chanllenges of complex netowrks research[J]. Journal of University of Electronic Science and Technology of China, 2014, 43(1): 1-5. doi: 10.3969/j.issn.1001-0548.2014.01.001 [5] WANG R, LIN P, LIU M, et al. Hierarchical connectome modes and critical state jointly maximize human brain functional diversity[J]. Physical Review Letters, 2019, 123(3): 038301. doi: 10.1103/PhysRevLett.123.038301 [6] AKSOY S G, PURVINE E, COTLLA-SANCHEZ E, et al. A generative graph model for electrical infrastructure networks[J]. Journal of Complex Networks, 2019, 7(1): 128-162. doi: 10.1093/comnet/cny016 [7] SCOTT J. Social network analysis[J]. Sociology, 1988, 22(1): 109-127. doi: 10.1177/0038038588022001007 [8] BOVET A, MAKSE H A, Influence of fake news in Twitter during the 2016 US presidential election[J]. Nature Communication, 2020, 36(12): DOI: http://doi.org/10.1038/s41467-020-20274-1. [9] 顾亦然, 朱梓嫣. 基于LeaderRank和节点相似度的复杂网络重要节点排序算法[J]. 电子科技大学学报, 2017, 46(2): 441-448. doi: 10.3969/j.issn.1001-0548.2017.02.020 GU Yi-ran, ZHU Zi-yan. Node ranking in complex networks based on LeaderRank and modes similarity[J]. Journal of University of Electronic Science and Technology of China, 2017, 46(2): 441-448. doi: 10.3969/j.issn.1001-0548.2017.02.020 [10] 胡小军, 郭强, 杨凯, 等. 基于相对熵的多属性作者学术影响力排名研究[J]. 电子科技大学学报, 2018, 47(2): 279-285. doi: 10.3969/j.issn.1001-0548.2018.02.019 HU Xiao-jun, GUO Qiang, YANG Kai, et al. Multi-attribute researcher academic influence ranking based on relative entropy[J]. Journal of University of Electronic Science and Technology of China, 2018, 47(2): 279-285. doi: 10.3969/j.issn.1001-0548.2018.02.019 [11] 顾亦然, 许梦馨. 基于PageRank的新闻关键词提取算法[J]. 电子科技大学学报, 2017, 46(5): 777-783. doi: 10.3969/j.issn.1001-0548.2017.05.021 GU Yi-ran, XU Meng-xin. Keyword extraction from news articles based on PageRank algorithm[J]. Journal of University of Electronic Science and Technology of China, 2017, 46(5): 777-783. doi: 10.3969/j.issn.1001-0548.2017.05.021 [12] LÜ L, CHEN D, REN X L, et al. Vital nodes identification in complex networks[J]. Physics Reports, 2016, 650: 1-64. doi: 10.1016/j.physrep.2016.06.007 [13] 朱军芳, 陈端兵, 周涛, 等. 网络科学中相对重要节点挖掘方法综述[J]. 电子科技大学学报, 2019, 48(4): 595-603. doi: 10.3969/j.issn.1001-0548.2019.04.018 ZHU Jun-fang, CHEN Duan-bing, ZHOU Tao, et al. A survey on mining relatively important nodes in network science[J]. Journal of University of Electronic Science and Technology of China, 2019, 48(4): 595-603. doi: 10.3969/j.issn.1001-0548.2019.04.018 [14] PAGE L, BRIN S, MOTWANI R, et al. The pagerank citation ranking: Bringing order to the web[R]. [S.l.]: Stanford InfoLab, 1999. [15] KIM S J, LEE S H. An improved computation of the pagerank algorithm[C]//European Conference on Information Retrieval. [S.l.]: Springer, 2002: 73-85. [16] 宋聚平, 王永成, 尹中航, 等. 对网页PageRank算法的改进[J]. 上海交通大学学报, 2003, 37(3): 397-400. doi: 10.3321/j.issn:1006-2467.2003.03.024 SONG Ju-ping, WANG Yong-cheng, YIN Zhong-hang, et al. Improved PageRank alorihtm for ordering web pages[J]. Journl of Shanghai Jiaotong University, 2003, 37(3): 397-400. doi: 10.3321/j.issn:1006-2467.2003.03.024 [17] HIRSCH J E. An index to quantify an individual ’s scientific research output[J]. Proceedings of the National academy of Sciences USA, 2005, 102(46): 16569-16572. doi: 10.1073/pnas.0507655102 [18] LÜ L, ZHOU T, ZHANG Q M, et al. The H-index of a network node and its relation to degree and coreness[J]. Nature Communications, 2016, 7: 10168. doi: 10.1038/ncomms10168 [19] 范天龙, 吕琳瑗. H-指数及其衍生指标的本质探讨[J]. 电子科技大学学报, 2019, 48(1): 142-149. doi: 10.3969/j.issn.1001-0548.2019.01.021 FANG Tian-long, LÜ Lin-yuan. The study of the essense of H-index and its derivative indices[J]. Journal of University of Electronic Science and Technology of China, 2019, 48(1): 142-149. doi: 10.3969/j.issn.1001-0548.2019.01.021 [20] LEVY O, GOLDBERG Y. Neural word embedding as implicit matrix factorization[C]//Proceedings of the 27th International Conference on Neural Information Processing Systems. [S.1.]: ACM, 2014: 2177-2185. [21] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]//Proceedings of the 26th International Conference on Neural Information Processing Systems. [S.1.]: ACM, 2013: 3111-3119. [22] DATAR M, IMMORLICA N, INDYK P, et al. Locality-sensitive hashing scheme based on p-stable distributions[C]//Proceedings of the Twentieth Annual Symposium on Computational Geometry. [S.l.]: ACM, 2004: 253-262. [23] 陈玲娇, 蔡世民, 张千明, 等. 基于信任关系的资源分配推荐算法改进研究[J]. 电子科技大学学报, 2019, 48(3): 449-455. doi: 10.3969/j.issn.1001-0548.2019.03.022 CHEN Ling-jiao, CAI Shi-min, ZHANG Qian-ming, et al. Improved research on resource-allocation recommendation algorithm based on trust relationship[J]. Journal of University of Electronic Science and Technology of China, 2019, 48(3): 449-455. doi: 10.3969/j.issn.1001-0548.2019.03.022 [24] LÜ L, ZHANG Y C, YEUNG C H, et al. Leaders in social networks: The delicious case[J]. PLoS ONE, 2011, 6(6): e21202. [25] MACKENZIE K D. Structural centrality in communications networks[J]. Psychometrika, 1966, 31(1): 17-25. doi: 10.1007/BF02289453 [26] BAVELAS A. Communication patterns in task-oriented groups[J]. The Journal of The Acoustical Society of America, 1950, 22(6): 725-730. doi: 10.1121/1.1906679 [27] ZAKI M J, MEIRA J W, MEIRA W. Data mining and analysis: fundamental concepts and algorithms[M]. Cambridge: Cambridge University Press, 2014. [28] ZHOU T, REN J, MEDO M, et al. Bipartite network projection and personal recommendation[J]. Physical Review E, 2007, 76: 046115. -

 点击查看大图
点击查看大图
图(4) / 表(2)
计量
- 文章访问数: 5169
- HTML全文浏览量: 1395
- PDF下载量: 70
- 被引次数: 0




























































































































