 ISSN
ISSN 
















-
人脸表情生成技术是人工智能研究领域的热点之一,由于不同人种之间脸部轮廓和不同年龄段人群皮肤纹理存在差异等问题,给生成真实感的人脸表情任务带来很大的挑战。面部角度、光线、复杂的背景环境都会给生成效果带来影响。
传统的表情生成方法有多种,表情渐变技术使用几何或参数插值方式在同一个人两幅不同表情之间进行控制面部表情[1-2],插值的帧间形变函数根据表情任务的复杂度确定,线性插值由于简单而被广泛使用。然而,在实际应用中,通常会存在不同人之间表情转换的需求,表情映射法可实现任意人物不同表情的合成,一般的表情映射需要两个人物的中性表情,获取同一个人的中性表情和目标表情的特征差值作用到特定的中性人脸表情上[3],该方法仅解决了新表情的生成,忽略了表情转化引起皮肤的纹理变化,使生成的图像缺少真实感。二维网格法综合考虑了这两个方面,头部的几何信息抽象出由三角形组成的网格结构,并用参数化模型表示,改变表情肌肉群对应的三角顶点位置参数合成新的表情。同时,为了完成皮肤细节的变化,对改变后的图像像素进行重新分配[4]。
随着计算机硬件条件的提高,使用大规模参数运算的深度学习变为流行,2014年文献[5-6]提出了生成对抗网络(generative adversarial networks, GAN),使生成对抗网络在深度学习领域掀起了热潮,图像域间的转换、脸部外观改变等高质量图像的生成技术出现。与只考虑特定外观修饰的面部属性编辑相比,面部表情编辑是一项更具挑战性的任务,因为它通常涉及较大的几何变化,需要同时修改多个面部成分。
目前生成离散的面部表情模型居多,这些网络基本可完成面部属性变化的任务[7-9]。IcGAN利用两个Encoder网络分别对输入图像提取头部基本特征向量和属性特征[10],将头部属性特征向量对应位置的特征值进行0-1转换,使其转换为目标向量。再与基本特征向量串联输入到生成网络IcGAN。在生成离散表情领域里,StarGAN是最成功的框架,可生成多属性的高清人脸图像。该网络把表情作为其中一个目标属性域,使用单个生成器学习多领域图像之间映射关系[11]。由于StarGAN在属性标签的基础上完成图像生成,生成的目标表情受数据集表情标签限制,在数据集注释粒度定义的离散属性中改变面部一个特定的部分,在表情方面只能渲染离散的情绪类别。
在实际的应用中,希望模型可合成任意表情,然而表情幅度可控的高质量图像生成研究较少[12-14],ExprGAN是第一个基于GAN模型且将允许连续地控制表情强度,该模型能够分离地学习身份特征和表情表示,但每种表情仅允许5个固定强度变化[15]。G2-GAN使用面部几何(基准点)作为可控制条件来指导具有特定表情的面部纹理合成,一对生成性对抗性子网络被联合训练做相反的任务:表情移除和表情合成。成对的网络在无表情人脸和表情人脸之间之间形成一个映射循环,能很好地捕捉表情变化引起的面部纹理的变化,合成不同强度的表情[16]。GANimation算法能够在一个连续的区域内生成具有解剖学意义的更广泛的表情,无需预先计算输入图像中面部标志点的位置[17],通过编码脸部肌肉运动单元AU(action unit),调节脸部某些区域肌肉运动强度,从而实现复杂的面部表情合成。但是,该模型容易在表情密集区域产生伪影和模糊,提取的特征还原不到位,表情操控能力相对较弱,存在生成图像达不到目标表情要求的问题。
为了解决这些问题,对GANimation生成器的网络结构进行改进,在生成器的Decoder中加入一层上采样,保持数据维度一致,且在生成器的Encoder和Decoder特征层之间以长跳跃连接的方式引入4个多尺度特征融合模块(multi dimension feature fusion, MFF),每个模块融合来自当前层的编码特征和添加在下一层融合模块的融合特征,提高图像质量和表情编辑性能。
-
近年来,生成对抗网络已经在面部表情合成任务中取得了重大的进展,改进后的网络使用符合人类解剖学的面部动作编码系统(facial action coding system for human anatomy, FACS),以肌肉动作单元AU向量来描述面部表情[18]。如图1的表情,由以下AU激活产生:眉毛内侧向上拉起(AU1)、眉毛外侧向上拉起(AU2)、上眼睑提升(AU5)、嘴角向下拉肌肉(AU25)、AU26(下颌下垂)[19]。AU输入到网络模型,通过控制其强度值实现连续面部表情的生成。

图 1 表情对应的脸部肌肉区域
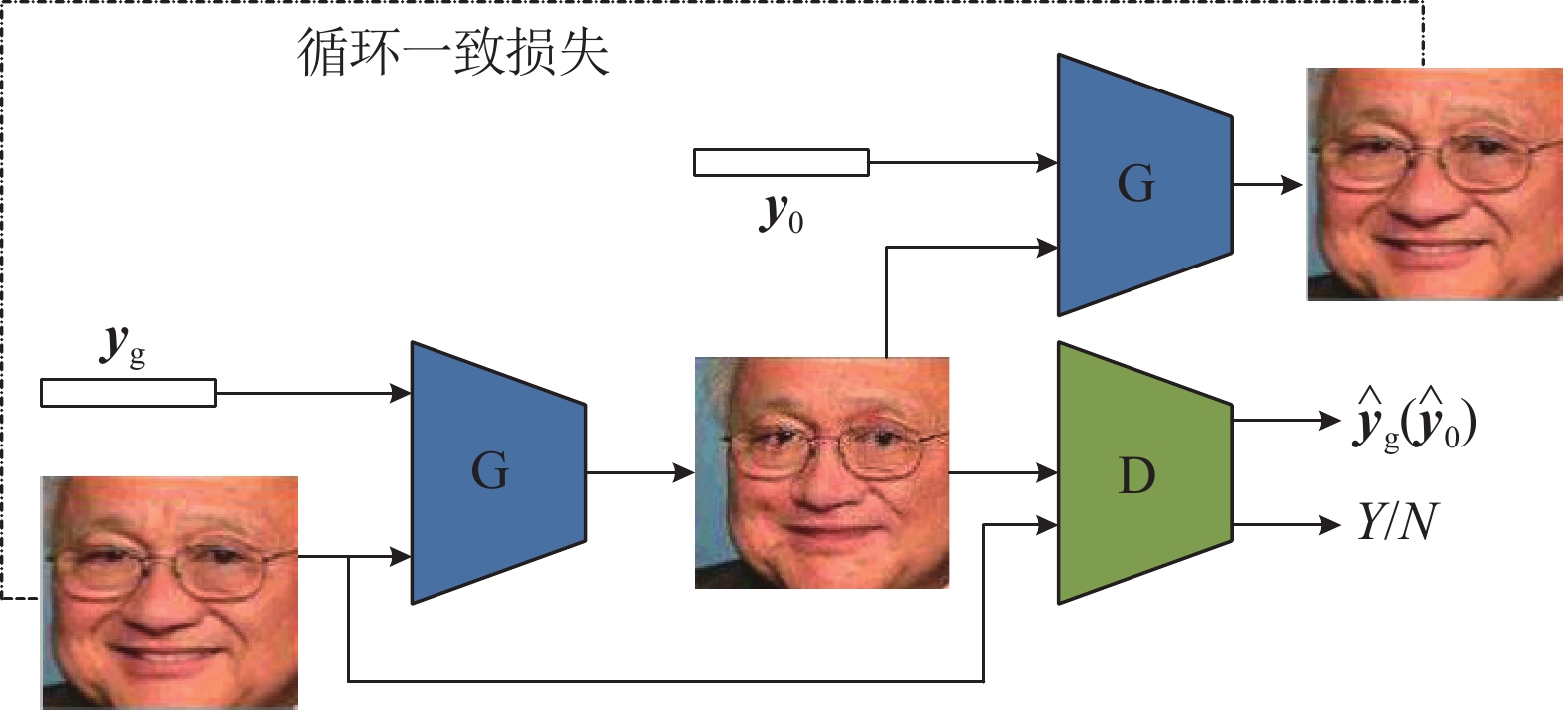
改进后的连续表情生成网络模型结构由生成器G和判别器D组成,如图2所示。2个G网络分别提取目标表情AU向量
${{{{\boldsymbol{y}}}}_{{\rm{g}}}}$ 的操纵特征以合成目标表情图像和使用原表情AU向量${{{{\boldsymbol{y}}}}_0}$ 对生成表情进行还原重构。判别器D判别图像的真伪以及回归目标表情向量${{\hat {{{{\boldsymbol{y}}}}}} _{{\rm{g}}}}$ 和${{\hat {{{\boldsymbol{y}}}}} _0}$ 。该算法采用无监督的学习方式,即不需要同一个人不同表情的图像对比,也不需要目标图像的已知。
图 2 改进后连续表情生成模型结构
-
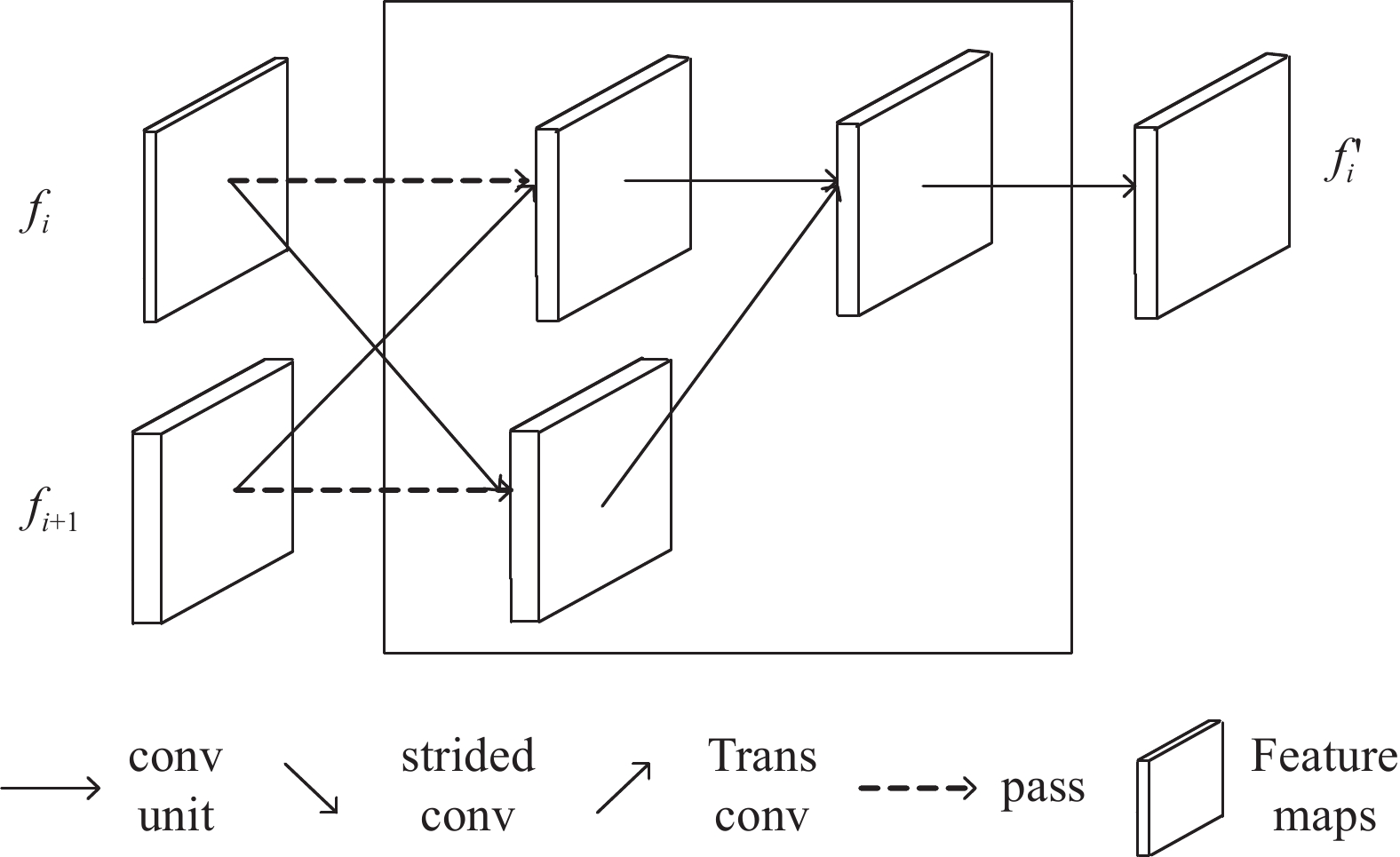
生成器的Encoder部分通过下采样获得表情动作单元操纵的高级抽象,但是下采样不可逆地降低空间分辨率和特征图的细节,这些细节无法通过反卷积完全恢复,导致生成的面部缺失模糊,表情强度不够。为了提高编辑结果的图像质量,本文构建了多尺度特征融合模块MFF[20],在生成器的编码与解码网络之间以跳跃连接的形式引入,用在不同的空间分辨率下增强图像的修改特征。图3给出了一个多尺度特征融合模块MFF的输入输出,当前层的编码特征是指所加MFF模块对应位置的编码特征,输出在不同空间大小下学习的融合特征。

图 3 多尺度特征融合模块的输入输出
图4给出了多尺度特征融合模块MFF的内部结构。在不失一般性的前提下,以第
$i$ 层的MFF模块为例,${f_i}$ 和${f_{i + 1}}$ 分别表示来自编码器第$i$ 层的图像编码特征和第$i$ +1层的MFF模块输出的融合特征,两个输入并行计算,输出融合后的特征为$ {f'_i}$ 。该模块内部操作有上采样(trans conv)、下采样(strided conv)和卷积单元(conv unit),其中,下采样层和上采样层卷积核大小都为4×4,其余卷积层核大小为5×5。应用卷积单元和上下采样获取不同空间大小的特征,下采样特征与来自第$i$ +1层的MFF模块的高级特征连接,以多尺度的方式协作学习和转换图像特征。 -
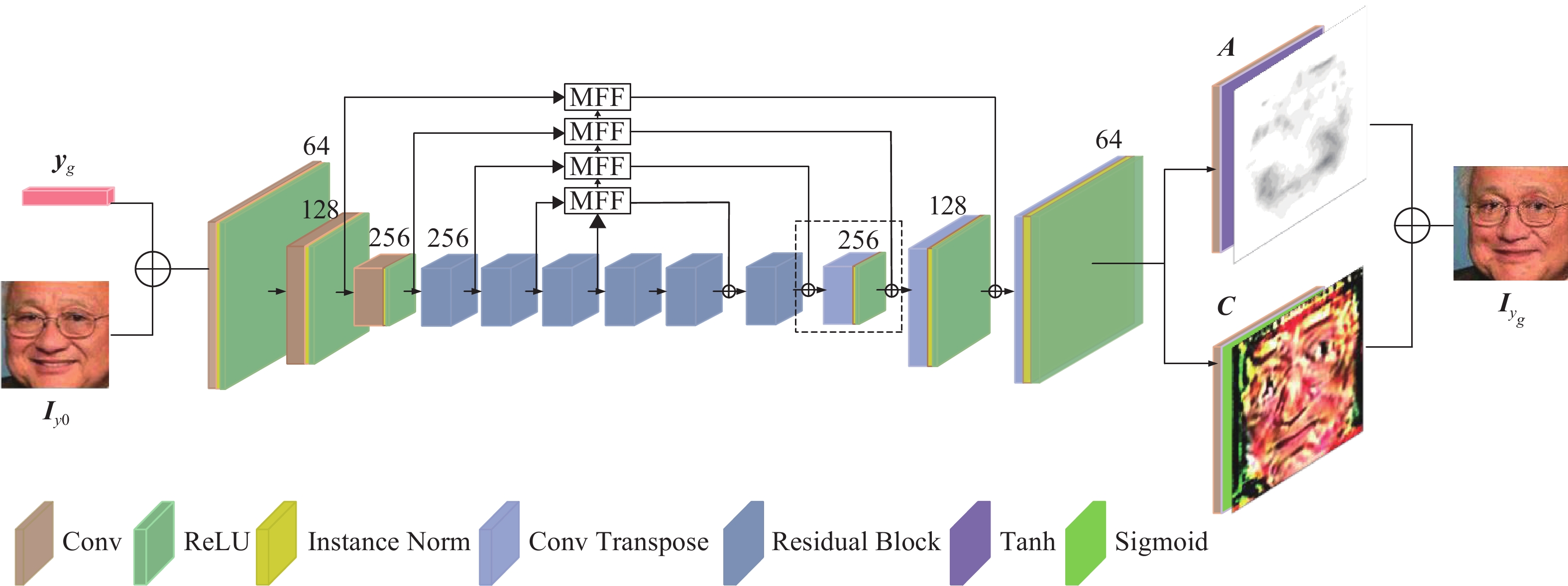
生成器的特征层通道数在结构上保持对称,图片编码和解码的信息内容保持一致。改进后的生成网络通过包含上下采样的生成器生成目标表情图像,下采样在解码时对重要图像特征进行选择,可以增加对输入图像一些小扰动的鲁棒性,比如图像平移、旋转等,降低过拟合的风险,减少运算量和增加感受的大小,上采样把抽象的特征还原解码到原图的尺寸。当在原网络添加MFF模块时,第一个残差模块的卷积编码特征与下一阶段的融合特征通过MFF模块在输出通道为64的逆卷积进行还原,在生成网络Decoder中增加一层输出通道为256的逆卷积(inverse convolution),其卷积核大小为3×3,
${\rm{stride}}$ =1,${\rm{padding}}$ =1。详细的添加位置如图4中用虚线框标出,其中,残差模块包含:2次Conv2d,2次InstanceNorm,1次ReLU函数激活,这样也使得其特征层通道数在结构上保持对称,图片编码和解码的信息内容保持一致。
图 4 多尺度特征融合模块MFF
-
在生成器Encoder-Decoder的结构中,加入4个多尺度特征融合模块MFF。作为跳跃单元,每个模块融合了来自高分辨率和低分辨率的特征。其生成器总结构如图5所示,图中的数字64、128、256等表示的是输出特征层的维度。在生成器中嵌入了注意力机制,输出的注意力掩码特征为:

图 5 生成器网络结构
$${\boldsymbol{A}} = {G_A}({{\boldsymbol{I}}_{{{y}}{}_0}}|{{\boldsymbol{y}}_g}) \in {\left[ {0,1} \right]^{H \times W}}$$ (1) 注意力掩码A定义了每个像素的强度,指定扩展源图像的每个像素对最终渲染图像的影响,其中较暗区域显示了图像中与每个目标AU相关的区域,较亮的区域从原始图像中保留下来。颜色掩码特征定义为:
$${\boldsymbol{C}} = {G_c}({{\boldsymbol{I}}_{{y_0}}}|{{\boldsymbol{y}}_g}) \in {{\bf{R}}^{H \times W \times 3}}$$ (2) 注意力掩码A和颜色掩码特征C并行操作,二者的网络结构在最后一层的操作存在差异,具体为颜色掩膜采用卷积操作和Tanh函数的激活,卷积核大小
$k$ =3×3,步长${\rm{stride}}$ =1,填充${\rm{pad}}$ =1,输出维度${{o}}$ =3,注意力掩膜使用Sigmoid激活函数,在卷积方面的区别是输出维度是1。利用A和C合成新表情图像${I{\boldsymbol{}}_{{y_g}}}$ :$${{\boldsymbol{I}}_{{y_g}}} = G({{\boldsymbol{I}}_{{y_0}}}|{{\boldsymbol{y}}_g}) = (1 - {\boldsymbol{A}}) \cdot {\boldsymbol{C}} + {\boldsymbol{A}} \cdot {{\boldsymbol{I}}_{{y_o}}}$$ (3) -
判别器用来评估生成图像的逼真度和期望表情完成度的网络,分为
${D_I}$ 和${D_y}$ 并行训练,${D_I}$ 集成了PatchGan网络的组件,将输入图像映射到一个特征矩阵${{\boldsymbol{Y}}_I} \in {{\bf{R}}^{H/{2^6} \times W/{2^6}}}$ ,${{\boldsymbol{Y}}_I}[i,j]$ 被用于计算真实图像斑块的分布与生成图像的重叠斑块i、j之间的EMD,判断生成图片${I_{{y_f}}}$ 的真实性。此外,${D_y}$ 回归估计生成图像的表情向量AU编码值$\hat {{{\boldsymbol{y}}_{\rm{g}}}} = (\hat {{y_1}} ,\hat {{y_2}}, \cdots, $ $ \hat {{y_N}} )^{\rm{T}}$ ,向量长度为N,表示脸部N个区域,每个值的范围从0~5表示运动强度,与${{\boldsymbol{y}}_{{\rm{g}}}}$ 比较评估条件表情的完成度。两个判别器公共部分为1个对输入图像的卷积操作和6个卷积核大小、$k$ =4、${\rm{stride}}$ =2、${\rm{padding}}$ =1的连续下采样层。为了减少模型的参数数量,${D_I}$ 和${D_y}$ 共享前5层的权重。 -
为了让生成图的分布趋近于训练图像的分布,使用对抗损失
${L_I}$ ,包括两部分,其中第一部分定义如下:$$ {L}_{a}=-{{\rm{E}}}_{{I}_{{y}_{{\rm{o}}}}\sim{P}_{{\rm{o}}}}[{D}_{I}(G({I}_{{y}_{{\rm{o}}}}|{y}_{g}))]+{{\rm{E}}}_{{I}_{{y}_{{\rm{o}}}}\sim{P}_{{\rm{o}}}}[{D}_{I}({I}_{{y}_{{\rm{o}}}})]$$ (4) 式中,
${P_{\rm{o}}}$ 为输入图像的数据分布,最大化生成图像通过判别器${D_I}$ 得到的结果,最小化原始图像通过判别器${D_I}$ 的结果,另外,为解决训练过程中梯度消失或爆炸问题,在此基础上给判别器增加一个梯度惩罚项:$${L_b} = {\lambda _{gp}}{{\rm{E}}_{\tilde I \sim {P_{\tilde I}}}}[{(||{\nabla _{\tilde I}}{D_I}(\tilde I)|{|_2} - 1)^2}]$$ (5) 式中,
${P_{\tilde I}}$ 是随机插值分布;${\lambda _{gp}}$ 是惩罚系数。${L_I}$ 总损失为:$${L_I} = {L_a} + {L_b}$$ (6) 由于模型数据没有注意力掩码的参考数值,掩码A的强度值极易趋于过饱和状态。因此,对注意力掩码引入全差分损失
$L({\boldsymbol{A}})$ :$$L({\boldsymbol{A}}) = {\lambda _{{\rm{TV}}}}\left[ {\mathop \sum \limits_{i,j}^{H,W} \left[ {{{\left( {{A_{i + 1,j}} - {A_{ij}}} \right)}^2} + {{\left( {{A_{i,j + 1}} - {A_{i,j}}} \right)}^2}} \right]} \right] + {\rm{E}}\left[ {\left\| A \right\|} \right]$$ (7) 式中,
${\lambda _{{\rm{TV}}}}$ 是掩码平滑的惩罚系数;${A_{i,j}}$ 代表${\boldsymbol{A}}$ 的第[i, j]项;注意力掩码特征${\boldsymbol{A}}$ 如式(1)。为了避免同一个人在不同表情下成对图像的训练需求,使用包含两个生成网络的双向对抗性架构,完成对生成图像的重构任务,利用循环一致损失
${L_{{\rm{dit}}}}$ :$$ {L_{{\rm{dit}}}}={{\rm{E}}_{{I_{y0}}\sim {P_0}}}[||G(G({{\boldsymbol{I}}_{{y_0}}}|{{\boldsymbol{y}}_g})|{{\boldsymbol{y}}_0}) - {{\boldsymbol{I}}_{{y_0}}})|{|_1}] $$ (9) 该损失与输入图像直接比较,保证生成的人脸和原始图像对应同一个人。
网络中引入了目标表情约束向量。为了保证生成网络回归标签的信息正确性,对约束条件施加损失
${L_y}$ ,${L_y}$ 分为由生成网络生成的假图片回归的AU值编码和由判别网络在真实图片中回归的AU值编码两个部分,表示如下:$${{\rm{E}}_{{I_{{y_0}}\sim {P_0}}}}[\left\| {{D_y}(G({{\boldsymbol{I}}_{{y_0}}}|{{\boldsymbol{y}}_g})){\rm{ - }}{{\boldsymbol{y}}_g}} \right\|_2^2] + {{\rm{E}}_{{{{{I}}}_{{{\boldsymbol{y}}_0}}}\sim {P_0}}}[\left\| {{D_y}({I_{{y_0}}}) - {{\boldsymbol{y}}_0})} \right\|_2^2]$$ (10) 为了生成目标图像,线性组合上面的损失来建立总损失函数
$L$ :$$ \begin{split} & L={L}_{I}(G,{D}_{I},{{\boldsymbol{I}}}_{{y}_{r}},{{\boldsymbol{y}}}_{g})+{\lambda }_{y}{L}_{y}(G,{D}_{y},{{\boldsymbol{I}}}_{{y}_{r}},{{\boldsymbol{y}}}_{r},{{\boldsymbol{y}}}_{g}) +\\ & \qquad{\lambda }_{A}({L}_{A}(G,{{\boldsymbol{I}}}_{{y}_{g}},{{\boldsymbol{y}}}_{r})+{L}_{A}(G,{{\boldsymbol{I}}}_{{y}_{r}},{{\boldsymbol{y}}}_{g})) +\\ & \qquad\qquad{\lambda }_{{\rm{idt}}}{L}_{{\rm{idt}}}(G,{{\boldsymbol{I}}}_{y_r},{{\boldsymbol{y}}}_{r},{{\boldsymbol{y}}}_{g})\end{split}$$ (11) 式中,
${\lambda _y}$ 、${\lambda _A}$ 、${\lambda _{{\rm{idt}}}}$ 为调节总损失的权重系数。 -
本文所提算法使用的实验数据是预处理后的CelebA数据集[21],根据图片已有的脸部器官landmark坐标,使用几何归一化方法剪裁脸部图片,进行人脸对齐,统一
${\rm{resize}}$ 调整为128×128。再使用符合FACS编码标准的开源面部行为分析工具OpenFace[22],识别标注肌肉表情运动单元AU,与表情相关的AU共有17个,自制的数据集需要满足AU标签分布均匀,保证复杂表情的生成精度,经过各AU统计、特定图片筛选、AU填充和剔除操作,整理出158 374张图片。按照训练集与测试集9∶1的比例随机划分,143 000张图片用于训练,15 374张用于测试。图6展示了图像各AU的分布情况。各AU的占比大致均在6%左右,分布较为均匀。有些AU数量较少,但都大于4%,属于合理范围。
图 6 数据集各AU占比
-
该模型通过Adam[23]优化器对模型进行训练,根据改进后的网络特点和研究者的经验设置训练参数,如表1所示。判别器网络每执行5个训练步骤,生成器执行一次优化步骤。依据GANimation原网络损失各权重系数的制定,本文对网络目标总损失函数的权重分别设置为:
${\lambda _{{\rm{gp}}}}$ =10,${\lambda _{\rm{A}}}$ =0.1,${\lambda _{{\rm{TV}}}}$ =0.000 1,${\lambda _y}$ =4 000,${\lambda _{{\rm{idt}}}}$ =10。表 1 训练参数
衰减率
$(\beta 1)$衰减率
$(\beta 2)$训练
$({\rm{epoch} })$学习率 20~30 $({\rm{epochs} } )$
学习率${\rm{batchsize}}$ 0.5 0.999 30 1×10−4 线性衰减到1×10−5 25 -
实验中利用以上参数对改进后的算法进行训练,并与原网络进行对比,图7展示了训练过程中判别器对真实图和生成图表情向量的损失优化过程。在训练期间,真实图通过判别器提取表情向量与自身的真实向量做差比较,得到损失值
${\rm{d\_cond}}$ ,从图7a可以得出,改进之后判别器对损失曲线的趋势没有较大的影响,但比具有原网络的生成器收敛速度快,在经过迭代运算后,训练集${\rm{Loss}}$ 值下降到了0.145左右。${\rm{g\_cond }}$ 是使用同一判别器提取生成图的表情向量与输入目标表情向量做差比较,验证表情生成的准确性,由图7b所示,${\rm{Loss}}$ 值下降到了1.0左右,网络达到了很好的生成效果,MFF机制带来了明确的改进。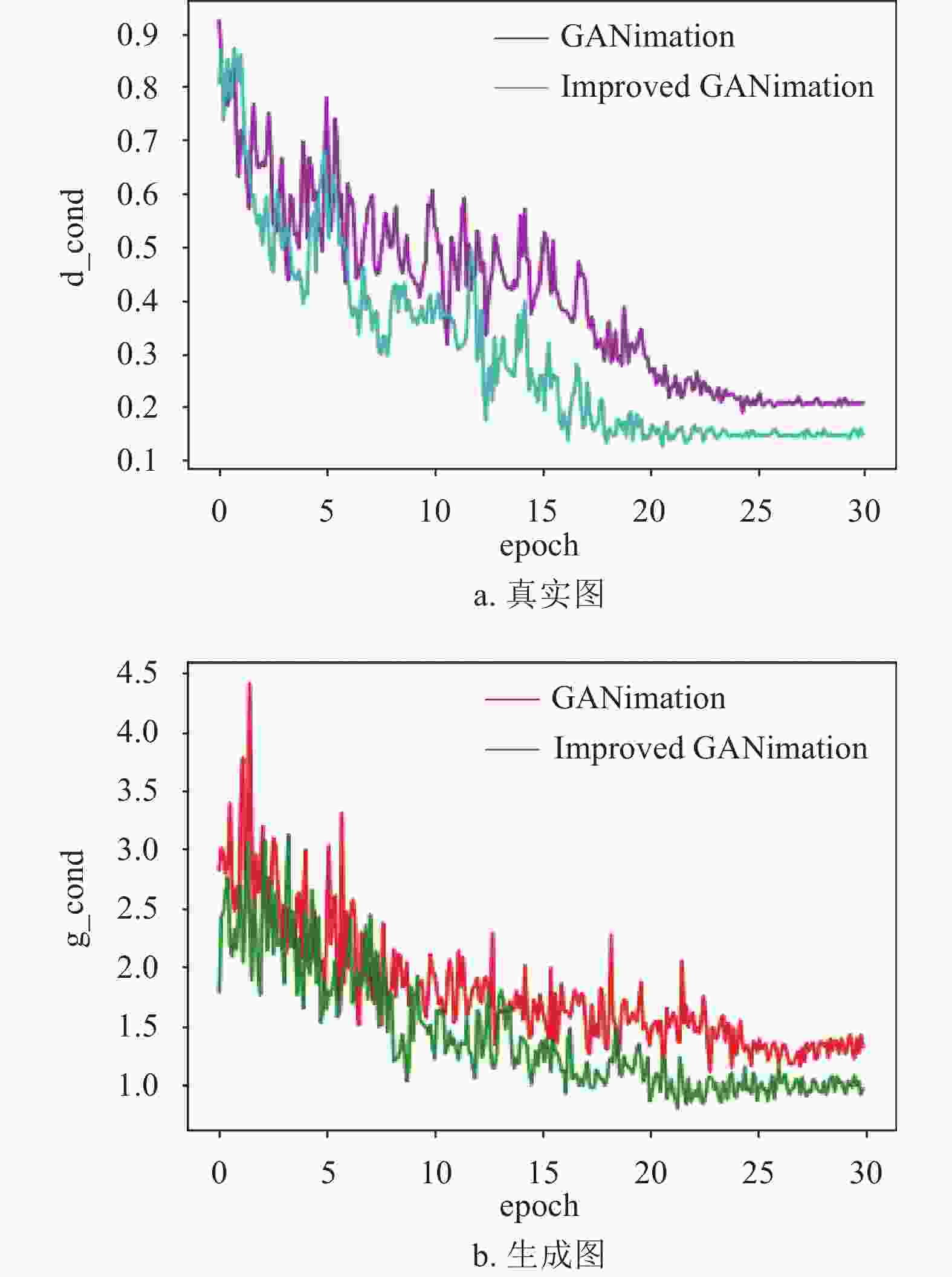
图 7 通过判别器的表情向量损失
-
该算法使用PSNR(peak signal-to-noise ratio)[24]和FID(frechet inception distance)[25]指标分别评估表情生成的准确度和生成的图像质量。PSNR是在计算同一身份的合成表情和对应表情之间的均方误差相对于255^2的对数值,FID分数是对预训练模型InceptionV3提取真实人脸与合成人脸的特征层面进行距离评价。如表2所示。改进后的GANimation在celebA数据集上测量
${\rm{PSNR}}$ 和${{\rm{FID}}}$ ,生成质量分别比最新方法提高了1.28和2.52。表 2 与最先进的算法定量比较
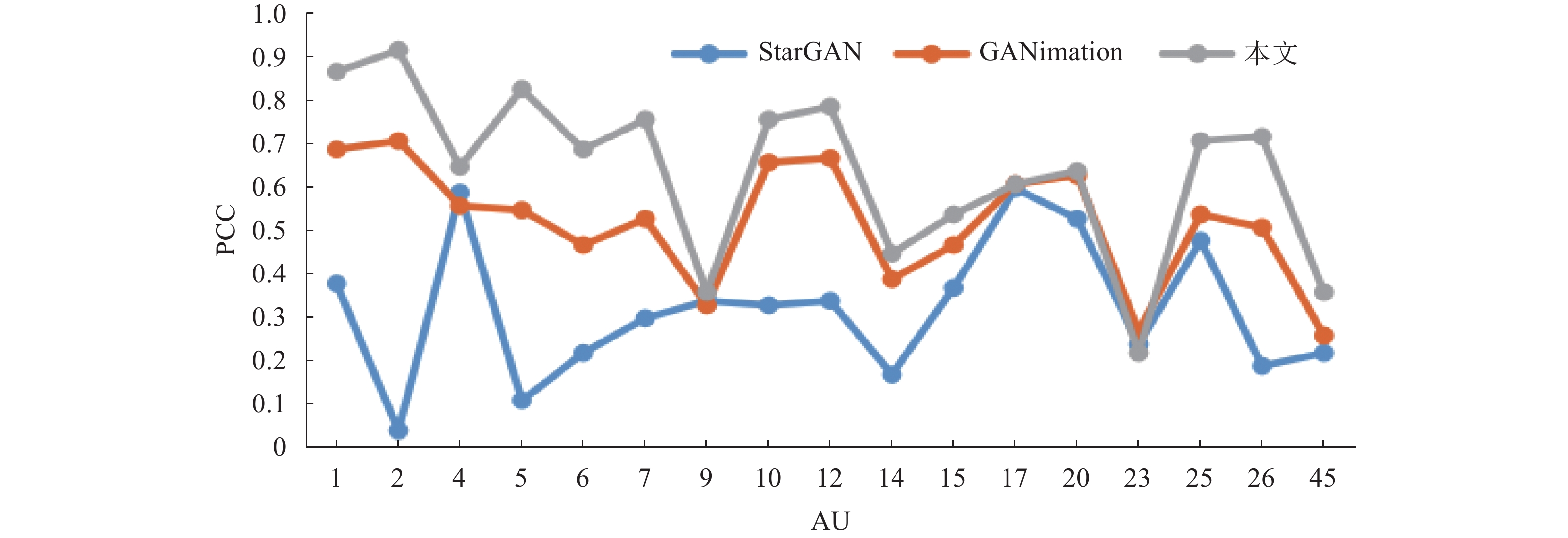
算法 ${\rm{PSNR}} \uparrow$ ${\rm{FID}} \downarrow$ StarGAN 20.15 61.29 GANimation 22.89 46.43 本文 24.17 43.91 为了进一步定量评估表情变化的准确性,使用皮尔逊相关系数(PCC)计算目标图像和生成图像各个AU对应点的相似度,生成图像的AU强度也使用OpenFace预测。从测试集中随机抽取含当前要评估某AU的图片200张作为目标表情图像,其标记的AU用作网络的目标标签,在剩余的测试集中再抽取3张作为输入的原图像,每张图片都要生成200张的目标的表情。图8显示了17个AU强度之间的PCC,取值范围为0~1,改进后的网络与GANimation和StarGAN进行比较,StarGAN仅在AU4生成的准确度高于GANimation,改进的网络有87.5%占比的AU生成准确度高于GANimation。

图 8 表情AU强度的
${\rm{ PCC}}$ -
改进后的网络是在上面描述的公开可用的面部表情数据集上进行评估。表情编辑对比如图9所示,其中每列对应一个表情编辑任务,对GANimation以及改进后的网络进行比较。GANimation方法容易模糊眼睛、鼻子和嘴巴周围区域,产生的伪影不同程度地破坏了面部图像。而从改进网络的生成效果来看,除解决掉了这些问题,其生成的图像表情更锐利和清晰。更好的合成主要归功于包含了多尺度特征融合模块,更好地保留与身份相关的特征和细节。

图 9 表情编辑对比
-
图10展示了原网络和改进后网络注意力掩码的生成结果,注意力被设计用来引导网络关注表情相关区域的转换,反应模型对表情向量的操纵能力。从实验结果看,原码的注意力掩码缺失严重,大部分出现在嘴和眼睛的附近,注意力表示的是面部像素的强度,颜色深的区域表示面部动作部位,因此,动作部位像素值不准确或缺少导致面部表情控制能力减弱。图10第一行,原网络注意力掩码大部分缺失,且没有明显的明暗区分,眉间纹理无变化。第二、三行原码生成的表情没有变化。

图 10 表情向量控制能力对比
-
为了更好地体现编辑连续表情的好处,在不同表情之间的AUs进行插值,并在图11中给出结果。第一列是输入的原始表情图像
${{\boldsymbol{I}}_{{y_0}}}$ ,最右一列是目标表情${{\boldsymbol{I}}_{{y_g}}}$ ,其余的列是通过对原始表情和目标表情之间进行线性插值来合成图片。线性插值器根据$\alpha {{\boldsymbol{I}}_{{y_g}}} + (1 - \alpha ){{\boldsymbol{I}}_{{y_r}}}$ ($\alpha \in 0{\rm{\sim }}1$ )计算生成器的结果,显示了平滑和跨帧一致的转换,验证了该模型在动作单元空间的连续性和处理大间隙表情转换的鲁棒性,证明了该模型的泛化性能。
图 11 表情插值效果图
-
本文提出了对GANimation方法的改进,将多尺度融合机制纳入基于Encoder-Decoder的任意面部表情编辑体系结构中。特征融合模块在很大程度上提高了模型性能,特别是对于动作单元的保持、质量重建和身份保持。作为一种简单有竞争力的方法,与改进前的GANimation方法相比,在视觉质量和操纵能力都取得了更好的实验结果。
Facial Expression Editing Technology with Fused Feature Coding
-
摘要: 为解决当前连续面部表情生成模型易在表情密集区域产生伪影、表情控制能力较弱等问题,该文对GANimation模型进行了研究改进,提高对表情肌肉运动单元AU控制的准确度。在生成器的编码和解码特征层之间引入多尺度特征融合(MFF)模块,以长跳跃连接的方式将得到的融合特征用于图像解码。在生成器的解码部分中加入一层逆卷积,便于MFF模块添加,更加高效合理。在自制的数据集上与原网络进行对比实验,表情合成的准确度和生成的图像质量分别提高了1.28和2.52,验证了该算法在生成图像没有模糊和伪影存在的情况下,面部表情编辑能力得到加强。
-
关键词:
- 连续面部表情生成 /
- 逆卷积 /
- GANimation改进 /
- 多尺度特征融合
Abstract: In order to solve the problems that the current continuous facial expression generation model is easy to produce artifacts in the expression-intensive areas and the expression control ability is weak, the GANimation model is improved for increasing the accuracy of the AU control of the expression muscle motor unit. A multi dimension feature fusion (MFF) module is introduced between the encoding and decoding feature layers of the generator, and the obtained fusion features are used for image decoding in a long-hop connection. A layer of inverse convolution is added to the decoding part of the generator to facilitate the addition of the MFF module to be more efficient and reasonable. Comparing experiments with the original network on the self-made data set, the accuracy of expression synthesis and the quality of the generated images of the improved model have been increased by 1.28 and 2.52 respectively, which verifies that the improved algorithm has better performance in facial expression editing when the image is not blurred and artifacts exist. -
表 1 训练参数
衰减率 $(\beta 1)$ 衰减率 $(\beta 2)$ 训练 $({\rm{epoch} })$ 学习率 20~30 $({\rm{epochs} } )$
学习率${\rm{batchsize}}$ 0.5 0.999 30 1×10−4 线性衰减到1×10−5 25  下载: 导出CSV
下载: 导出CSV
表 2 与最先进的算法定量比较
算法 ${\rm{PSNR}} \uparrow$ ${\rm{FID}} \downarrow$ StarGAN 20.15 61.29 GANimation 22.89 46.43 本文 24.17 43.91
下载: 导出CSV
-
[1] ZHANG Y, BADLER N I. Synthesis of 3D faces using region-based morphing under intuitive control[J]. Computer Animation & Virtual Worlds, 2006, 17(3-4): 421-432. [2] FU T, FOROOSH H. Expression morphing from distant viewpoints[C]//2004 International Conference on Image Processing. [S.l.]: IEEE, 2004: 3519-3522. [3] LITWINOWICZ P, WILLIAMS L. Animating images with drawings[C]//Proceedings of the 21st Annual Conference on Computer Graphics and Interactive Techniques. [S.l.]: ACM, 1994: 409-412. [4] GAO W. Synthesis of facial behavior for virtual human[J]. Chinese Journal of Computers, 1998, 21: 694-703. [5] 陈俊周, 王娟, 龚勋. 基于级联生成对抗网络的人脸图像修复[J]. 电子科技大学学报, 2019, 48(6): 910-917. CHEN J Z, WANG J, GONG X. Face image inpainting using cascaded generative adversarial networks[J]. Journal of University of Electronic Science and Technology of China, 2019, 48(6): 910-917. [6] 何磊, 李玉霞, 彭博, 等. 基于生成对抗网络的无人机图像道路提取[J]. 电子科技大学学报, 2019, 48(4): 580-585. doi: 10.3969/j.issn.1001-0548.2019.04.016 HE L, LI Y X, PENG B, et al. Road extraction with UAV images based on generative adversarial networks[J]. Journal of University of Electronic Science and Technology of China, 2019, 48(4): 580-585. doi: 10.3969/j.issn.1001-0548.2019.04.016 [7] ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision. [S.l.]: IEEE, 2017: 2223-2232. [8] HE Z, ZUO W, KAN M, et al. AttGAN: Facial attribute editing by only changing what you want[J]. IEEE Transactions on Image Processing, 2019(99): 1. [9] CHEN Y C, SHEN X, LIN Z, et al. Semantic component decomposition for face attribute manipulation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. [S.l.]: IEEE, 2019: 9859-9867. [10] PERARNAU G, van de WEIJER J, RADUCANU B, et al. Invertible conditional gans for image editing[EB/OL]. [2020-02-23]. https://arxiv.org/pdf/1611.06355v1. [11] CHOI Y, CHOI M, KIM M, et al. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. San Diego: IEEE, 2018: 8789-8797. [12] LIN T Y, DOLLAR P, GIRSHICK R B, et al. Feature pyramid networks for object detection[C]//Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 936-944. [13] SHEN Y, GU J, TANG X, et al. Interpreting the latent space of gans for semantic face editing[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. San Diego: IEEE, 2020: 9243-9252. [14] WU R, ZHANG G, LU S, et al. Cascade ef-gan: Progressive facial expression editing with local focuses[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. San Diego: IEEE, 2020: 5021-5030. [15] CHEN L C, PAPANDREOU C, KOKKINOS I, et al. Deep lab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848. doi: 10.1109/TPAMI.2017.2699184 [16] CHEN L C, ZHU Y, PAPANDREOU C, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//European Conference on Computer Vision. Munich: ECCV, 2018: 833-851. [17] PUMAROLA A, AGUDO A, MARTINEZ A M, et al. Ganimation: Anatomically-aware facial animation from a single image[C]//Proceedings of the European Conference on Computer Vision. Munich: ECCV, 2018: 818-833. [18] EKMAN P, FRIESEN W. Facial action coding system: A technique for the measurement of facial movement[M]. Palo Alto: Consulting Psychologists Press, 1978. [19] DU S, TAO Y, MARTINEZ A M. Compound facial expressions of emotion[J]. Proceedings of the National Academy of Sciences, 2014, 111(15): E1454-E1462. doi: 10.1073/pnas.1322355111 [20] LING J, XUE H, SONG L, et al. Toward Fine-grained facial expression manipulation[C]//European Conference on Computer Vision. Berlin: Springer, 2020: 37-53. [21] LIU Z, LUO P, WANG X, et al. Deep learning face attributes in the wild[C]//Proceedings of the IEEE International Conference on Computer Vision. San Diego: IEEE, 2015: 3730-3738. [22] BALTRUSAITIS T, ZADEH A, LIM Y C, et al. Openface 2.0: Facial behavior analysis toolkit[C]//2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018). [S. l. ]: IEEE, 2018: 59-66. [23] CHEN L C, YANG Y, WANG J, et al. Attention to scale: Scale-aware semantic image segmentation[C]//Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 3640-3649. [24] HUYNH-THU Q, GHANBARI M. Scope of validity of PSNR in image/video quality assessment[J]. Electronics Letters, 2008, 44(13): 800-801. doi: 10.1049/el:20080522 [25] HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. Gans trained by a two time-scale update rule converge to a local nash equilibrium[C]//3lst Conference on Neural Information Processing Systems. Long Beach, CA:[s.n.], 2017: 6626-6637. -

 点击查看大图
点击查看大图

图(11) / 表(2)
计量
- 文章访问数: 4597
- HTML全文浏览量: 1599
- PDF下载量: 104
- 被引次数: 0














































































