 ISSN
ISSN 


 下载:
下载:
-
“虚实结合”的虚拟试验系统往往采用分布式的子系统部署[1]。实际工作过程中,子系统之间通讯的高效和稳定是整个虚拟试验系统的关键。发布/订阅模型是属于分布式环境中应用程序之间通信模型的一种,能够适应动态多变的分布式系统的需求[2]。此模型让分布式系统中各程序发生交互时使用其特有的发布/订阅的方式。从订阅语言的角度来看,可以将发布/订阅系统分为基于主题的和基于内容两类[3]。在内容发布/订阅系统中,约束条件通过事件内容来体现,以增强订阅的灵活性。当用户发布一个事件时,需要系统将每个约束条件与对应的事件进行匹配。但由于系统中每个订阅都需要较大数目的约束条件,所以事件匹配效率也需要有所提高[4]。目前主流的基于内容的发布订阅匹配算法中,对于匹配过程的精简算法主要有两种方法:以匹配网络等数据结构为代表的剪枝法和以索引列表为代表的精确定位法[5]。这两种方法在特定情形下表现都不稳定,无法满足变化多端的应用环境需求。
目前主要的匹配算法都可以归为两个类别:基于索引的和基于树的[6]。这些算法可进一步按照是否基于关键字进行分类,基于关键字代表选择一组谓词作为表达式的表示符。索引方法的主要目的是通过对所有分离的谓词构建逆序的索引顺序,以尽量减少谓词的评估数量[7]。基于树的匹配方法的主要目的则是通过树形结构对订阅条件建立索引,从而提高匹配效率。而针对这些匹配算法在匹配过程中进行的优化方式主要有以下两个特性。
1)利用订阅间存在的覆盖关系形成偏序树结构,当遇到不匹配的订阅时,可知其覆盖的所有订阅都不符合匹配规则,从而对其进行剪枝操作,以达到减少订阅规模的目的。如Siena[6]系统中的偏序树匹配算法,这种方法对订阅之间的关系要求较高,如果订阅之间存在大量的覆盖关系,则效果较好;如果订阅间很少存在覆盖关系或几乎不存在覆盖关系,例如存在大量事件属性,则会退化为暴力匹配的方式,严重影响匹配性能。还有一种对偏序树结构进行剪枝的方式是对特定属性部分剪枝,这种方式将订阅组织为匹配网络,保留匹配过程中的所有信息,能够充分利用谓词间的相关性,匹配时利用过往匹配信息进行大量的迅速的剪枝,匹配效率较高,但结构较复杂,难以支持动态订阅变更[8]。文献[5]提到了一种基于树的匹配算法,在原本树的结构上添加了一条额外的出边,该边可以检测出与该节点谓词测试结果无关的订阅,并且使用该方法后匹配事件的复杂度与订阅数线性相关。但是由于其取消和添加订阅的处理方式是以改变量为主,因此当用户更新订阅时得不到及时的反馈。
2)将订阅的属性分离,利用哈希算法迅速定位属性位置,再利用区间树、有序表等方式较快地查找到匹配属性。这样做可以大量减少无关属性的检测,并且由于属性的分离特性,对原订阅的结构无要求,当事件属性数目增加时,匹配速度由于属性的查找是哈希的原因,反而会提高。但订阅属性的分离也破坏了订阅之间的关系信息,从而无法利用订阅之间的覆盖关系来进行匹配优化,并且由于订阅和属性之间失去关联,会造成大量的无意义匹配[9]。在谓词索引方面,对于等值谓词,可以使用哈希表的存储方式达到高效率的查找,对于区间谓词,可以考虑使用区间树或有序表的方式加以存储[10]。而对谓词进行索引的相关算法的主要代表有计数算法:对所有谓词进行测试,建立一个映射表,该表包含的两个元素分别是谓词和订阅,开始进行匹配时,将表中的该订阅所对应的谓词数与该订阅原本含有的谓词数进行比较,相等即可得出事件与订阅相匹配。汉森算法通过测试淘汰一部分订阅,接着从剩下的这些订阅中测试,这样可以让效率进一步提高。CEEM算法[5]以构建谓词表对谓词族进行划分,其索引的构建方式采用的是排序或哈希表,能够以更高的效率对谓词进行匹配;并且可以依靠谓词之间所具有的关联性进一步提高匹配速度。这类算法虽然能够支持动态订阅,但只考虑了谓词间的关联关系,不能高效地完成事件匹配[11]。
还有一些算法欲将这两个特性相结合,如BE-Tree和PRBT-Tree[12]。BE-Tree用属性来进行聚类集合,用值进行分类集合,通过划分小集团的方法来提高匹配效率,当属性维度较高且订阅之间相关性较小时表现较好[13]。PRBT-Tree利用谓词的区间性质建立同时存在覆盖和偏序关系的树结构,但由于仍然无法避免属性分离的限制,最终只是单属性查找时的剪枝而不是大粒度的整体剪枝[14]。由于订阅覆盖和属性分离在本质上是矛盾的,因此,这些方法最终沦落为在分离的属性上进行覆盖检测的方式。
综上所述,考虑到订阅匹配时的不同特性,如果能够将具备不同特性的订阅有效地分离开,分别使用不同的适合其特性的匹配方法,便可以大大地提高匹配效率。本文在对已有事件匹配算法进行分析的基础上,提出了一种基于匹配特性融合的内容网络匹配算法(hybrid matching algorithm for content-based delivery,HMACD),提供了高效的匹配性能,并通过实验和性能分析验证了该匹配算法的优越性。
-
定义1 事件,谓词,订阅。事件E作为实体交互单元出现在发布/订阅系统中,包含了属性a的序列
$[{a_1},\;{a_2},\;\cdots ,{a_n}]$ 。一个属性值v的记录$[{v_1},{v_2}, \cdots ,{v_n}]$ 叫做事件实例e。基于典型的条件变量$P:: ={\rm{ acv}}$ ,订阅谓词可以描述为$P:: = {\rm{acv}}$ 的形式,即关于事件属性的一系列限制。由基本的谓词可以构成不同的订阅(条件)$\varPhi :: = \varPhi \wedge P|\varPhi \vee P|P$ 。定义2 偏序关系。如果订阅间存在覆盖关系,则称它们之间的关联为偏序关系,偏序关系可以用偏序树来存储。
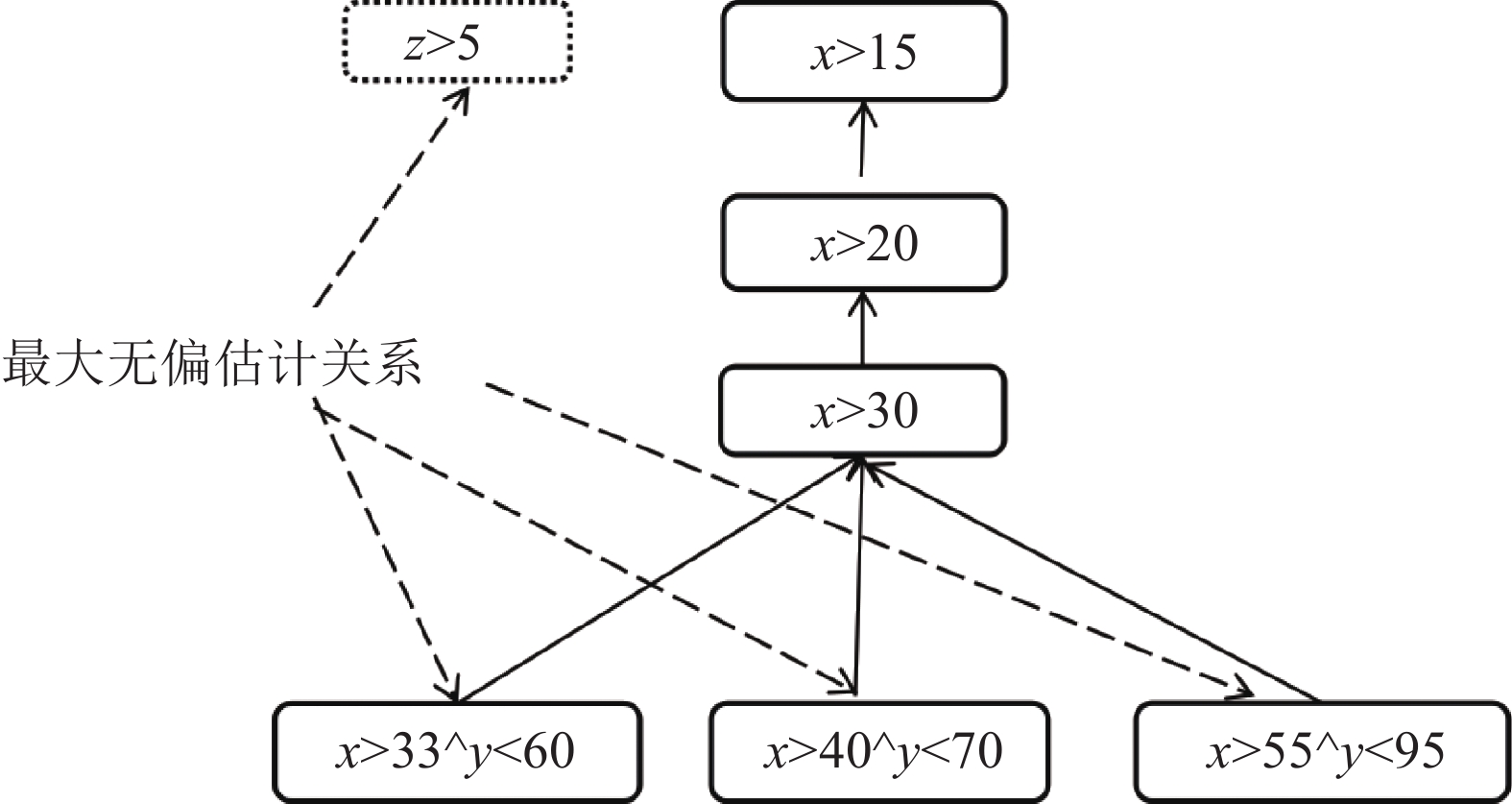
定义3 无偏关系。如果订阅间不存在覆盖关系,则称它们之间的关联为无偏关系。图1虚框和虚线之间的订阅关系为无偏关系。

图 1 无偏关系及最大无偏关系示意图
定义4 最大无偏关系订阅列表。在所有订阅中,满足无偏关系的所有订阅组成了最大无偏关系订阅列表。图1中,虚线连接的4个订阅组成了一个最大无偏关系订阅列表。
-
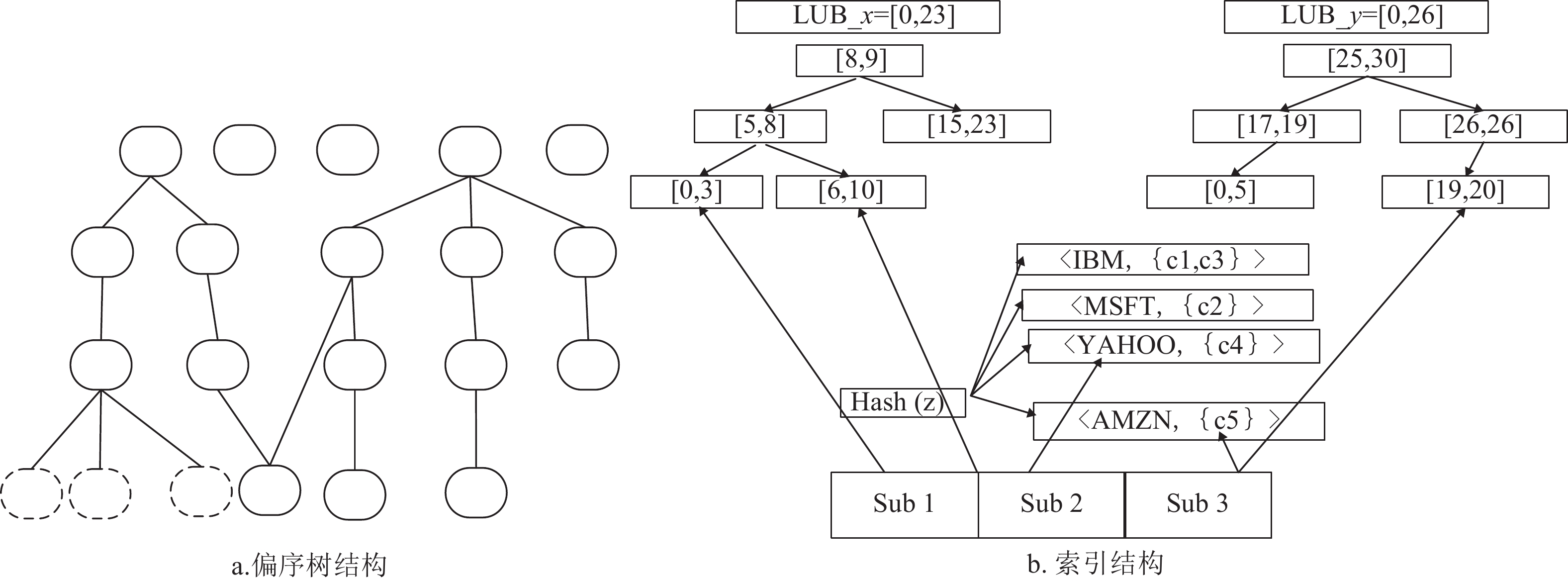
算法的数据结构主要分为两部分:树形结构部分和索引结构部分[15]。对于树形结构部分,采用Siena中的基于poset的偏序树结构,这是因为其高效的剪枝策略避免了许多不必要的匹配过程。对于索引结构部分,采用相比较其他算法而言效率出色的区间树索引和哈希表结合的结构。区间树是一种元素为区间的操作树,每个节点的关键值与每个区间的左端点相对应[16]。这样的结构可以让其元素在无论是查找或插入的情况下都可以将时间复杂度保持在O(lgn)内,而哈希表的定位复杂度为O(1)。
数据结构的关键是决定何时将偏序树中“溢出”的订阅加入到索引结构中[17]。通过分析偏序树中的结构,得出两种结论:1)过多的游离根节点可以加入区间树结构;2)具有过多兄弟节点的叶子节点可以加入区间树结构。下面是算法中主要的数据结构。
偏序树(poset-tree):将订阅项组织成偏序森林,偏序关系为上覆盖下,即如果订阅条件满足下层的条件,那么它一定也满足所有上层的条件;如果上层条件不满足,那么其所有后继一定不满足事件条件,无需继续遍历[18],越往下条件越严格。这种整体的偏序结构在事件匹配时平均效率较高,无需遍历所有订阅,可以在匹配的过程中淘汰相当一部分的订阅条件。但如果给出的订阅之间不存在覆盖关系或者覆盖关系较少,则这种偏序森林的结构会退化为单一节点的结构,匹配效率也会退化为和暴力匹配相当的水平。
在实际应用过程中,无偏关系通常存在于偏序树中同父的叶子节点之间,本文规定当无偏订阅的数量达到一定限度时,将其存入区间树索引结构中去。
区间树索引(interval tree-index):将订阅进行各个属性的分离,按属性及操作符建立更加细粒度的索引结构。索引结构采用具备多级索引的区间树和哈希列表相结合的方式[19]。以属性名称建立第一级索引,对于等值谓词加入相应属性的值为键值的哈希列表中,对于区间谓词,加入相应属性的区间树中。
混合结构:将两种结构结合起来,对于到来的订阅,首先将其加入到偏序树结构中,如果新加入的订阅满足最大无偏关系,则加入到索引订阅列表中,如图2所示。

图 2 混合事件匹配算法数据结构
匹配桶:用于索引结构匹配时存储暂时符合若干条件的订阅。匹配是根据到来事件的值逐条进行的,有些订阅达到了部分条件,但还没有完全达到可以发送的条件,便暂时存储到匹配桶中,防止匹配信息的丢失[20]。匹配桶是set的结构,即只允许加入不同的订阅,当执行加入匹配桶中已存在的订阅时,该执行失败。
接口列表和订阅列表:所有加入谓词表的订阅都会被存储登记在订阅列表中,其记录内容为该订阅谓词集合中的第一个谓词的指针,这样做的目的是可以方便访问所有位于谓词表中的谓词。接口是指事件的传送方向。一个连接的订阅信息仅对应一个接口,每个连接可以有多个订阅,通过订阅列表和接口列表将所有的订阅组织在一起[21]。接口列表和订阅列表都是针对索引结构的,对于偏序树结构而言,订阅信息和接口信息都存储在节点中。
-
当接收到新的订阅后,需要将该订阅加入到相应的数据结构中。算法的关键是决定在何种情况下将订阅加入哪个集合,判别方法首先将订阅加入树结构的偏序集中,如果新加入的节点满足最大无偏关系,则将其移入索引结构中的索引订阅列表中[13]。
订阅过程:
1)将订阅s加入到树形结构poset-trees中;
2)如果s在poset-trees中是单独的根节点并且超出了独立根节点的上限个数,则将其移入到index-tables中;
3)如果s在poset-trees中是叶节点并且超出了当前同前驱叶节点的上限个数,则将其移入到index-tables中。
当需要取消某订阅时,需要分别在两种结构中查找该订阅。在索引集中,可以直接查找订阅集合;在树结构偏序集中需要遍历整个树结构,查找到该订阅执行删除操作。
取消订阅过程:
1)在索引结构的订阅列表中查找要取消的订阅,找到之后,将其所链接的所有属性节点在相应的哈希表或区间树中删除,如果是在区间树中删除的话则需重新调整区间树。最后在订阅列表中删除该订阅。如果没有找到,则进行步骤2);
2) 在poset-trees中从根节点开始遍历各个节点,直到找到包含要取消的订阅节点为止。找到之后,如果要取消的节点是该节点所包含的唯一节点,则直接删除该订阅;如果不是,则需要删除该节点并将该节点的所有前驱、后继节点相连。
-
当事件到来时,由于满足该事件的订阅在两种集合中都存在,因此需要分别遍历偏序集和索引结构这两个集合来找到匹配事件的所有订阅。
匹配过程:
1)在树形结构内进行匹配。首先创建匹配候选集Sa和匹配成功集Sm,将所有偏序树的根节点加入匹配候选集中;接着依次对匹配候选集中的所有根节点进行遍历,判断其每一个根节点是否与当前事件匹配;如果匹配,则将该根节点的后继节点加入到匹配候选集中,同时,将该节点加入到匹配成功集中,然后继续进行匹配;如果匹配不成功,则将其从匹配候选集移除,直到该集合为空时,遍历结束,返回最终存有与该事件相匹配的所有订阅的匹配成功集Sm。
2)在索引结构中进行匹配。分解事件的谓词,创建存有匹配当前事件的所有订阅集合result,以及匹配桶bucket,先在哈希列表中找到对应该谓词属性的列表,接着在该列表中找到该谓词的值的条目,将该条目对应的所有订阅加入到匹配桶中;然后在区间森林中找到对应该谓词属性的区间树,在该区间树中定位到该值对应的节点,将该节点上的条目所对应的所有订阅加入到匹配桶中。当处理完一个属性的谓词后,需要对匹配桶中的所有订阅执行匹配属性加一的操作。然后检查匹配中的内容,如果匹配桶中存在达到匹配要求的操作,便将该节点对应的订阅加入到result集合中,并在匹配桶中移除该订阅。然后检查事件的下一个属性,执行同样的操作。当该事件的所有谓词处理完成时,清空匹配桶,以备下一次事件到来时使用。此时的result集合中已经包含了所有匹配当前事件的订阅,作为最终算法输出结果返回,以进行下一步的转发动作。
算法1 在偏序集中匹配
match in poset(event e)
let Sm = empty
let Sa = roots
for each node n in Sa
if cover(e,n.fliter)
Sm.add(n)
Sa.remove(n)
Sa.add(n.successors)
Return Sm
算法2 在索引结构中匹配
Match in index(event e)
result = empty
bucket = empty
for each attribute a in e
if a exist in Hassh table or in interval tree
add all a subscriptions in Hash table/interval tree into bucket
all subscriptions in bucket’s count++
for each subscription s in bucket
if s.count== s.value
add s into result
remove s from bucket
Return result
-
订阅
$\varPhi $ 与事件e的匹配过程不仅与事件参数相关,还跟时间t相关,看作$\varPhi \left( {e,t} \right)$ 。假设某订阅进程Pi的订阅为${\varPhi _i}$ ,Pi的订阅只在t0时刻变更,在${\varPhi _i}$ 上发生的事件匹配是确定的。即:$\forall e,\forall t \geqslant {t_0}\,,{\varPhi _i}\left( {e,t} \right)$ 成立,或$\forall t \geqslant {t_0}\neg {\varPhi _i}\left( {e,t} \right)$ 成立。活性定义为:若
${\varPhi _i}\left( {e,{t_0}} \right)$ 在时间t0后发布的事件e被进程Pi匹配。订阅的活性指订阅更新的延迟对订阅匹配的影响。订阅过程中,订阅变更初始时刻位为t0,订阅变更结束时刻为tf。通常tf−t0不做限制,只通过减小其差值的方式提高系统活性。该混合事件匹配算法降低了订阅变更的时间,即减小tf−t0的值,使事件过滤更加精细,进而提高系统活性。在具有混合结构的事件匹配复杂度方面,假设订阅数为S,属性数目为A。在索引结构中的属性索引表中查找属性的复杂度为O(1),哈希查找的复杂度为O(1),区间树查找的复杂度为O(logM),事件e所含属性数目为j,其中M为区间树中包含的所有节点数目,M的最大值为S,因此在索引结构中查找单个属性的复杂度为O(logS)。最坏的情况下需要查找所有属性,所以综合复杂度为O(AlogS);在Poset结构中,由于偏序结构的存在,只需遍历根节点和部分后继节点即可。最坏的情况下,即事件不会匹配任何订阅时,需要遍历所有节点,此时的复杂度为O(AS)。但是这种情况很少会发生,一方面是因为很少会出现无意义的事件,另一方面是由于有着最大无偏的设定,过多的游离节点已经被加入到索引结构中。这里的偏序结构规模是有限的,因此可以认为复杂度为常数。因此,综合来看,总的复杂度为O(logS)。
-
为了对比混合匹配算法、基于索引的匹配算法和基于树结构的匹配算法的效率差异,本文选取了以Poset为基础的Siena匹配方法以及基于索引的counting算法进行对比。实验环境方面选取1台路由服务器和9台主机,其中服务器用于运行各匹配算法,3台主机用于发布,6台主机用于订阅。以某武器系统的对抗试验在HLA仿真系统中测试为例,定义其订阅实体和发布实体分别为战术雷达和战斗机。并采用以下数据产生规则。
数据类型(value type):int float bool string
属性名称(value name):数据属性的名称,首先随机生成若干长度为5的字符串,属性名在其中随机选取。
操作符(operator):对于int float而言,支持 >, <, =, ≤, ≥这5种操作符。对于bool string而言,支持=操作符。具体实验数据如表1所示。
-
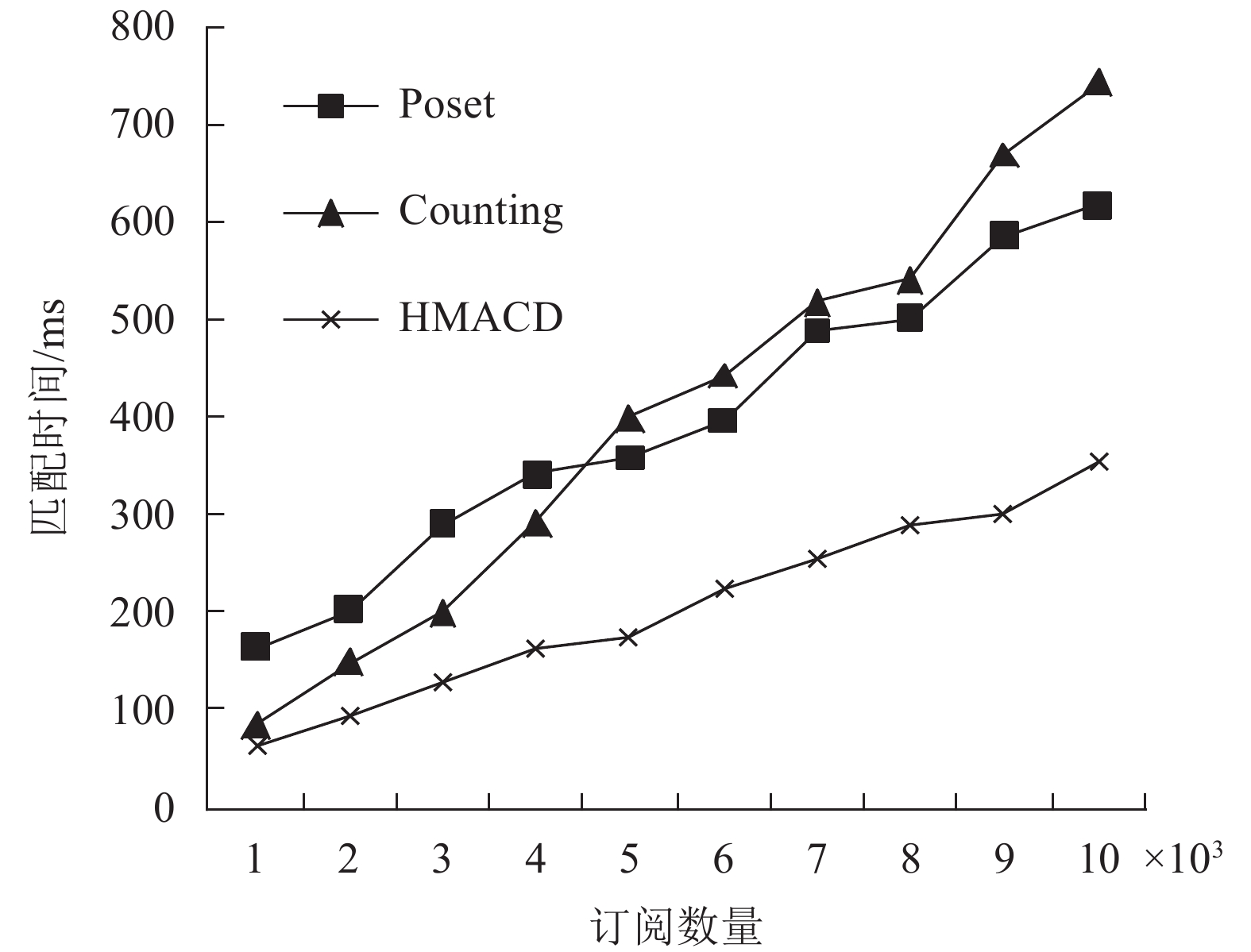
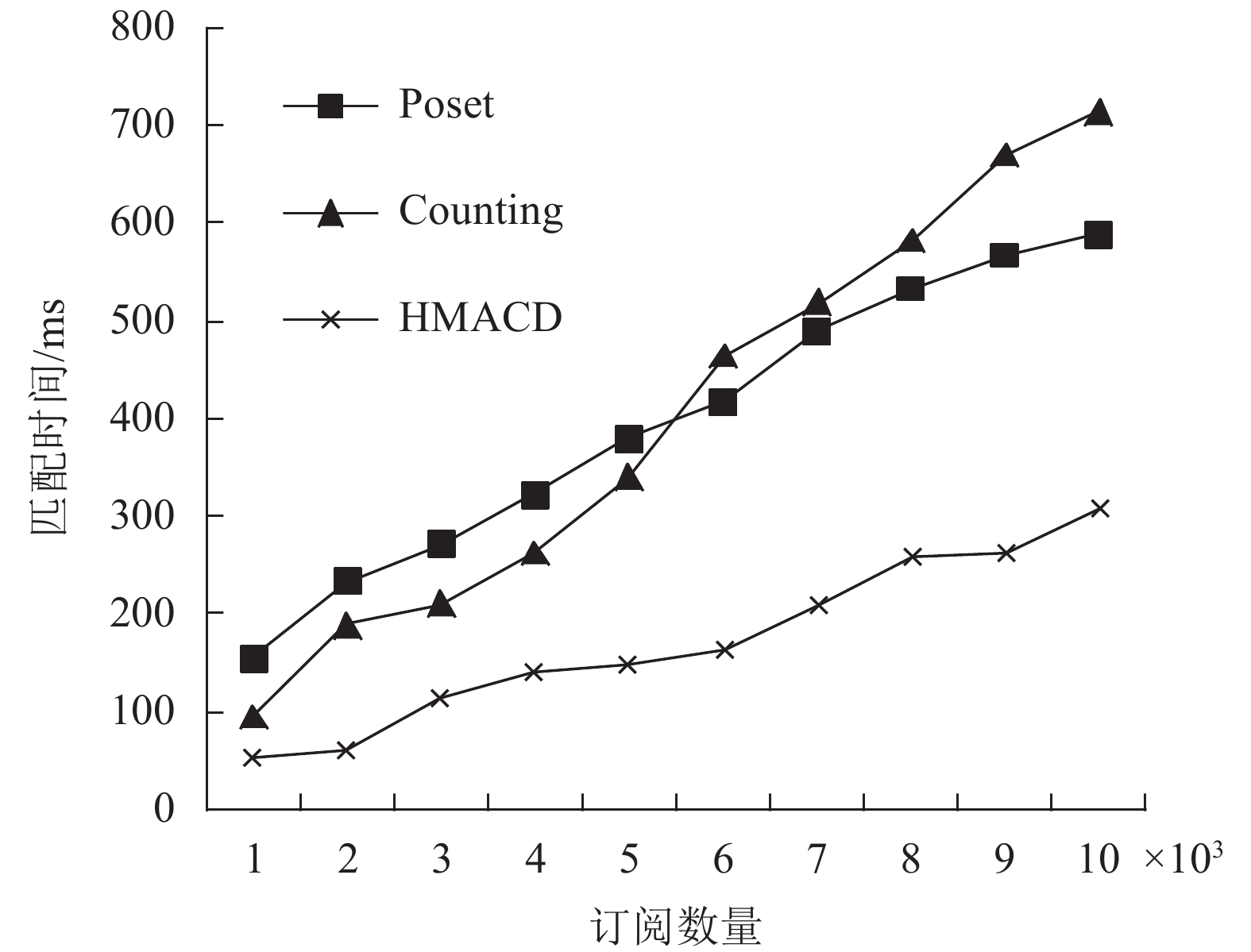
实验中,根据表1中的两组参数,设置实验样本数为50000,取样间隔设置为5000,记录下每次取样后订阅插入以及匹配200个事件的时间损耗。
表 1 实验的参数设置
参数 实验1 实验2 属性数/个 13 15 订阅中的谓词族数/个 1~6 3~8 等值谓词比例/% 10 20 两组实验结果如图3和图4所示。可以看出,在事件匹配的效率比较方面,随着订阅数量不断增加,其匹配时间也随之线性增长,这在3种算法中都得到了体现。但是由于HMACD算法订阅中不同的匹配特性采取了不同的匹配策略,其斜率远远小于另外两种算法,即在订阅数量一致时,与另外两种匹配算法相比,HMACD算法的匹配效率更加出色。以两图中订阅数量为10000时的匹配时间为例,HMACD算法的匹配时间耗时仅为基于Poset的Siena算法和Couting算法的54%和45%。并且在事件匹配总体效果方面,通常情况下,随着订阅数目的增加,Poset的偏序关系越发明显,匹配效果也会变好,而Counting算法随着订阅数目的增加,单个属性谓词的查找效率会降低,因而匹配效果越来越差。HMACD算法综合了两种算法的优点,匹配效果始终维持在一个相对不错的水准。

图 3 实验1匹配时间

图 4 实验2匹配时间
可见,相对于其他算法,HMACD算法在保持不错的匹配效果的情况下有效的提高了事件匹配的效率。
-
随着算法交易和分布虚拟环境等新应用的不断涌现,对系统底层的事件匹配算法提出更加高效的处理要求。本文融合了偏序结构和索引结构的不同匹配特性,提出了一种混合的事件匹配算法。算法将具备不同特性的订阅组织分别组织到不同的数据结构中,并采用不同的匹配方法,充分利用了不同订阅的特点,提升了匹配效率。实验表明,与同类算法相比,该算法的匹配效率更高,能够满足相关应用需求。下一步工作准备从路由算法、订阅表达方式方面进行研究,以提高系统性能为主,从而能够广泛适用于更多的应用需求。
Event Matching Algorithm Based on Joint Characteristics for Content-Based Publish/Subscribe System in Virtual Experiment
-
摘要: 在应用广泛的基于Map的内容发布/订阅系统中,系统会让订阅中的每个约束条件与对应事件进行匹配,但由于系统中每个订阅都有着较大数目的约束条件,从而需要较高的事件匹配效率。在分析匹配网络中的覆盖剪枝和具有精确定位特性的谓词索引基础上,该文提出一种基于匹配特性融合的内容网络匹配算法。给出了算法的数据结构、订阅处理流程及匹配处理流程。理论分析及典型实验对比表明,相比于单纯的覆盖算法及索引算法,该算法可以提供更高效的匹配。Abstract: In the widely-used map-based content publishing/subscription systems (CPS), the system always match each constraint in the subscription with the corresponding event. However, the large number of constraints in each subscription of the system call for higher efficiency of event matching. Based on the coverage pruning and predicate index with precise location properties in the matching network algorithm, this paper proposes a matching algorithm based on matching feature fusion. The data structure, subscription processing flow and matching processing flow of the algorithm are given. Theoretical analysis and typical experimental comparisons show that the algorithm can provide more efficient matching compared with the simple coverage algorithm and indexing algorithm.
-
[1] EUGSTER P T, FELBER P A, GUERRAOUI R, et al. The many faces of publish/subscribe[J]. ACM Computing Surveys, 2003, 35(2): 114-131. doi: 10.1145/857076.857078 [2] CAPPS M, MCGREGOR D, BRUTZMAN D, et al. Npsnet-v: A new beginning for dynamically extensible virtual environments[J]. IEEE Computer Graphics and Applications, 2003, 20(5): 12-15. [3] ASHAYER G, LEUNG H K Y, JACOBSEN H A. Predicate matching and subscription matching in publish/subscribe systems[C]//The 22nd International Conference on Distributed Computing Systems Workshops. Vienna: [s. n.], 2002: 22-27. [4] AGUILERA M K, STROM R E, STURMAN D C. Matching events in a content-based subscription system[C]//The 18th ACM Symposium on Principles of Distributed Computing. Atlanta: [s. n.], 1999: 3-7. [5] 陈继明, 鞠时光, 潘金贵, 等. 基于内容的快速事件匹配算法[J]. 通信学报, 2011, 32(6): 78-85. doi: 10.3969/j.issn.1000-436X.2011.06.011 CHEN J M, JU S G, PAN J G, et al. Content-based effective event matching algorithm[J]. Journal of Communications, 2011, 32(6): 78-85. doi: 10.3969/j.issn.1000-436X.2011.06.011 [6] CARZANIGA A, ROSENBLUM D S, WOLF A L. Design and evaluation of a wide-area event notification service[J]. ACM Transaction on Computer Systems, 2001, 19(3): 332-383. doi: 10.1145/380749.380767 [7] RAN Z, ZHENG D, LAI Y, et al. Applying stack bidirectional LSTM model to intrusion detection[J]. CMC-Computers, Materials & Continua, 2020, 65(1): 309-320. [8] 郝玫, 马建峰. 基于特征观点对语义匹配的产品评论可信度研究[J]. 现代情报, 2019, 39(6): 102-110. doi: 10.3969/j.issn.1008-0821.2019.06.011 HAO M, MA J F. Research on product reviews credibility based on semantic matching of feature opinion pairs[J]. Journal of Modern Information, 2019, 39(6): 102-110. doi: 10.3969/j.issn.1008-0821.2019.06.011 [9] 秦婕. 信息分发系统中基于多维度内容的事件匹配技术研究[D]. 北京: 北京邮电大学, 2019. QIN J. Research on event matching based on multidumensional content in information distribution system[D]. Beijing: Beijing University of Posts and Telecommunications, 2019. [10] 张澧枫, 殷铭, 袁平. 一种改进的多维度并行匹配发布与订阅算法[J]. 现代计算机, 2020, 61(4): 11-15. doi: 10.3969/j.issn.1007-1423.2020.04.003 ZHANG L F, YIN M, YUAN P. An improved multi-dimensional parallel matching publish and subscribe algorithm[J]. Modern Computer, 2020, 61(4): 11-15. doi: 10.3969/j.issn.1007-1423.2020.04.003 [11] 汪锦岭, 金蓓弘, 李京, 等. 基于本体的发布/订阅系统的数据模型和匹配算法[J]. 软件学报, 2005, 25(9): 18-26. WANG J L, JIN B H, LI J, et al. Data model and matching algorithm in an ontology-based publish/subscribe system[J]. Journal of Software, 2005, 25(9): 18-26. [12] 薛涛, 冯博琴, 李波, 等. 基于内容的发布订阅系统中快速匹配算法的研究[J]. 小型微型计算机系统, 2006, 27(3): 529-533. doi: 10.3969/j.issn.1000-1220.2006.03.031 XUE T, FENG B Q, LI B, et al. Efficient matching for content-based publish-subscribe systems[J]. Journal of Chinese Computer Systems, 2006, 27(3): 529-533. doi: 10.3969/j.issn.1000-1220.2006.03.031 [13] 吴雯君, 沈卓炜, 曹玖新. 基于频繁项集挖掘的发布/订阅 分布式系统运行模式识别[J]. 网络空间安全, 2020, 11(8): 9-12. WU W J, SHEN Z W, CAO J X. Running modes recognition of publish/subscribe distributed system based on frequent itemsets mining[J]. Information Security and Technology, 2020, 11(8): 9-12. [14] 黄思猛, 程良伦, 王涛. 基于双数组trie树的多模式复杂事件检测方法[J]. 计算机工程与应用, 2019, 25(4): 91-95. doi: 10.3778/j.issn.1002-8331.1711-0415 HUANG S M, CHENG L L, WANG T. Multi-pattern complex event detection method based on double-array trie-tree[J]. Computer Engineering and Applications, 2019, 25(4): 91-95. doi: 10.3778/j.issn.1002-8331.1711-0415 [15] 罗韶杰, 张立臣. 信息物理融合系统体系结构研究[J]. 计算机应用与软件, 2019, 22(2): 8-12. LUO S J, ZHANG L C. Architecture of cyber-physical system[J]. Computer Applications and Software, 2019, 22(2): 8-12. [16] 李娜, 陈福, 朱建明, 等. MQTT数据交换协议的分析与优化[J]. 网络空间安全, 2020, 10(9): 1-4. doi: 10.3969/j.issn.1674-9456.2020.09.001 LI N, CHEN F, ZHU J M, et al. Analysis and optimization of MQTT data exchange protocol[J]. Information Security and Technology, 2020, 10(9): 1-4. doi: 10.3969/j.issn.1674-9456.2020.09.001 [17] 张根涛. 基于匹配树的发布订阅中快速匹配算法研究[D]. 开封: 河南大学, 2018. ZHANG G T. Research on fast matching algorithm based on matching tree's publishing subscription[D]. Kaifeng: Henan University, 2018. [18] 丁建立, 罗云生, 王家亮, 等. 基于 B+ 树的发布/订阅并行匹配算法[J]. 计算机工程与设计, 2018, 39(1): 66-71. DING J L, LUO Y S, WANG J L, et al. Parallel matching algorithm based on B+ tree in publish/subscribe system[J]. Computer Engineering and Design, 2018, 39(1): 66-71. [19] CAO G. An event matching algorithm of attribute value domain division for content-based publish/subscribe system[C]//2018 IEEE 4th International Conference on Big Data Security on Cloud (Big Data Security), IEEE International Conference on High Performance and Smart Computing, (HPSC) and IEEE International Conference on Intelligent Data and Security (IDS). [S. l.]: IEEE, 2018: 177-182. [20] ALHAKBANI N, HASSAN M M, YKHLEF M, et al. An efficient event matching system for semantic smart data in the internet of things (IoT) environment[J]. Future Generation Computer Systems, 2019, 95(2): 163-174. [21] CHEN L, SHANG S. Approximate spatio-temporal top-k publish/subscribe[J]. World Wide Web, 2019, 22(5): 2153-2175. doi: 10.1007/s11280-018-0564-3 -

 点击查看大图
点击查看大图
图(4) / 表(1)
计量
- 文章访问数: 4070
- HTML全文浏览量: 1298
- PDF下载量: 19
- 被引次数: 0












