 ISSN
ISSN 



-
随着物联网和移动应用的发展,基于位置信息的应用服务越来越多。在各种移动应用中,大量的个人位置信息和活动信息被收集,如共享单车的轨迹信息、用户的签到信息。这些信息反映了用户的移动模式和活动意图,可以用于提供各种各样的服务,如交通规划、智能推荐和智能城市规划等。这为研究人员提供了一个挖掘人类移动模式的新机会,衍生了很多新研究,如下一个兴趣点(point of interest, POI)推荐[1]、基于位置的信息推送[2]及在线社交推荐[3]等。在众多的研究中,轨迹用户链接(trajectory-user linking, TUL)[4]问题旨在研究如何将轨迹链接到生成该轨迹的用户,可以更好地掌握各种基于位置的移动应用中用户的移动模式和规律。基于位置的社交网络(location-based social networks, LBSNs),如Foursquare和Yelp等网站收集了很多用户的签到位置信息,出于隐私考虑,第三方服务提供商会对用户身份进行匿名处理,因此用户轨迹数据或用户签到数据一般不包含对应的真实用户。将这些轨迹与相应的用户关联起来,可以挖掘出用户的访问意图和活动规律,用于POI推荐和用户旅行路线推荐等。此外,TUL还可以识别出可疑的访问和移动模式,预防违法犯罪活动。
近些年来,与人类移动相关的数据呈爆炸式增长[5]。由于轨迹数据的稀疏性和带标记轨迹的数量不足,解决TUL问题存在一定的挑战。传统的工作通常是通过马尔可夫链等序列学习模型来建模人类的移动规律,进而将轨迹和用户相链接。这些模型捕获的是用户签到点之间的短期依赖关系。受现有深度学习技术的启发,一些研究人员采用循环神经网络(recurrent neural networks, RNN)建模用户轨迹,其表现优于浅层机器学习方法。文献[4]正式定义了TUL问题,并提出了基于POI嵌入和循环神经网络的轨迹用户链接模型TULER。TULVAE[6]通过轨迹分布的变分推断扩展了TULER,利用半监督学习方式学习人类移动规律。TGAN[7]和STULIG[8]是两种深度生成模型,通过数据增强增加轨迹数据量,并分别使用对抗学习和分级自编码器对用户轨迹进行分类。而最近关于用户签到点预测的方法,如DeepMove[9]、CATHI[10]和VaNext[11],也可以用于解决TUL问题。它们利用RNN的变体,如长短时记忆网络(long short term memory network, LSTM)[12]和门控循环单元(gatedrecurrent unit, GRU)[13]学习轨迹中的序列变换规律,在捕获用户个性化移动模式方面表现良好。
尽管上述研究在用户移动模式学习和分类方面取得了很好的成果,但它们仍存在一定的局限性。首先,签到点之间的空间位置关系尚未得到充分挖掘。现有方法只依靠轨迹数据来获取签到点嵌入,忽略了签到点之间的地理位置信息。因此,仅从轨迹序列数据中不足以学习到有代表性的签到点嵌入。其次,大多数POI被访问的频率非常低,导致基于位置的社交网络中的签到数据往往过于稀疏,使得模型忽略了数据中隐含的访问偏好和移动模式。另外,以往的工作主要使用生成模型来丰富轨迹数据,这通常需要非常高的计算成本。如,TULVAE和TGAN分别利用变分自编码器(variational auto-encoder, VAE)[14]和生成对抗网络(generative adversarial networks, GAN)[15]来推断潜在的轨迹分布,这对于训练和计算效率而言是一个挑战。这些生成模型的效率问题限制了它们在大规模移动数据上的应用。
为了解决上述挑战和当前模型存在的不足,本文提出了一种新的基于图神经网络的轨迹用户链接模型GTUL。GTUL不再只依赖用户的访问序列,而是利用签到点构建签到图,收集轨迹中的空间信息和时间信息,然后使用图神经网络(graph neural network, GNN)[16]学习签到图中的签到点的表示,再结合循环神经网络建模用户的移动模式,最后使用全连接网络对轨迹进行用户分类,实现轨迹与用户的正确链接。签到图可以综合所有的历史轨迹信息,提取出原始轨迹数据的访问偏好和复杂移动规律。与现有的轨迹数据增强算法相比,该方法更具通用性、可扩展性和有效性。
-
一个移动用户的轨迹数据由大量的签到点数据组成。每一个签到点都包含了用户访问一个POI的空间信息和时间信息。本文将用户
$i$ 的轨迹表示为${T^i}$ ,${T^i}$ 由签到点$l$ 的集合来表示,即${T^i} = \left\{ {l_1^i,l_2^i, \cdots ,l_K^i} \right\} $ $ \in \mathcal{T}$ ,$l_k^i$ 表示用户$i$ 在时间${t_k}$ 访问的位置点,包含了它的经纬度信息;$\mathcal{T}$ 表示所有轨迹的集合。一个缺少了标签(即生成轨迹的用户)的轨迹被称为一个未链接的轨迹。给定一个未链接轨迹的集合$\mathcal{T}' = \left\{ {{{T'_1}},{{T'_2}}, \cdots ,{{T'_M}}} \right\}$ 和生成这些轨迹的用户集合$\mathcal{U} = \left\{ {{u_1},{u_2}, \cdots ,{u_N}} \right\}(M \gg N)$ ,轨迹用户链接问题的目标是学习一个多分类模型实现未链接轨迹和用户的正确匹配。 -
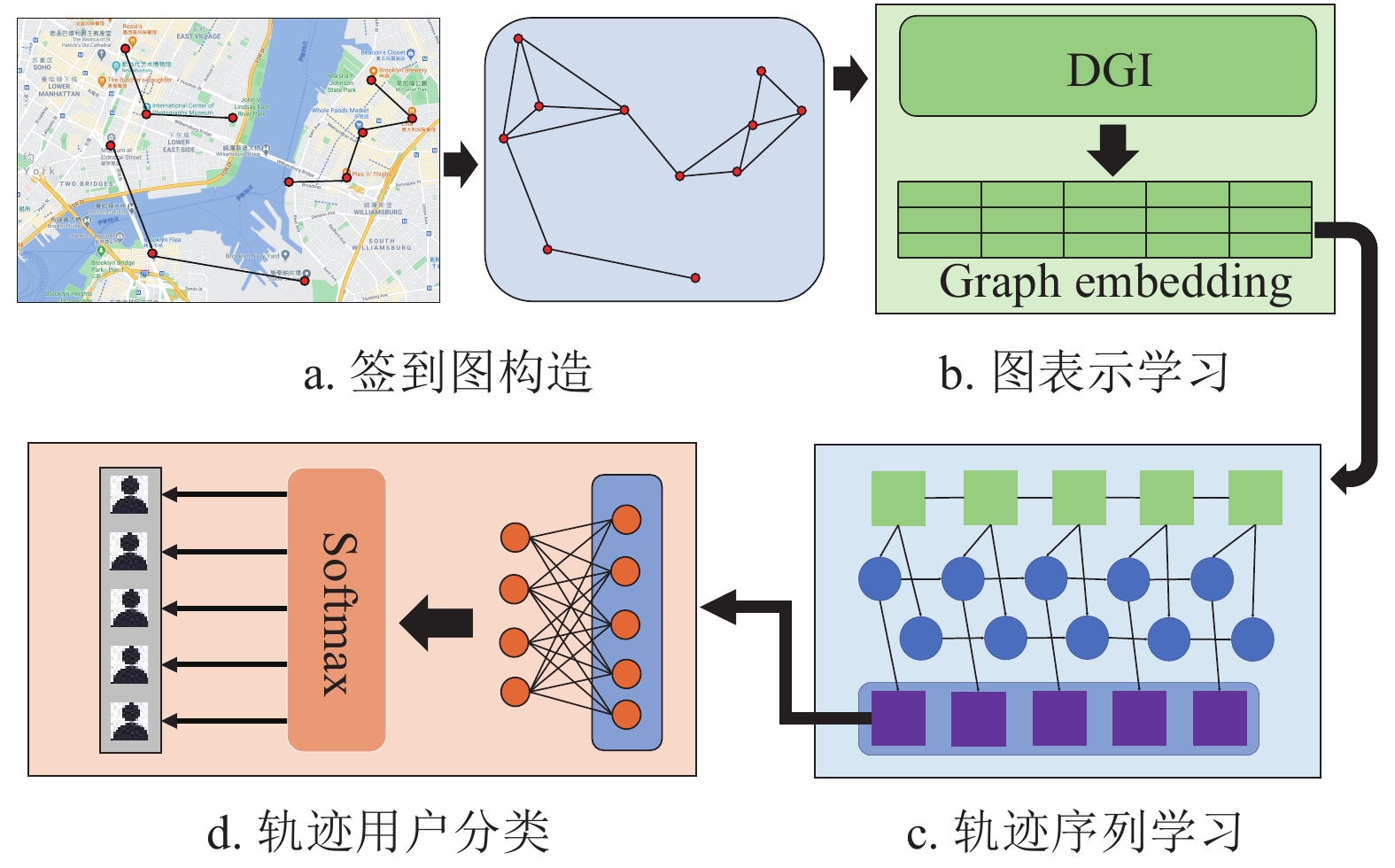
本文模型分为4个模块,模型总体框架如图1所示。首先,对原始轨迹数据进行分割处理,并基于分割后的轨迹数据构建用户签到图(如图1a所示);其次,利用GNN学习签到图中的节点嵌入(如图1b所示);然后,利用RNN构建轨迹序列的向量表示(如图1c所示);最后使用全连接网络得到最终的分类结果(如图1d所示)。

图 1 基于图神经网络的用户轨迹分类模型架构
-
根据文献[4,9]的研究,用户轨迹包含的签到数量因人而异,轨迹的时间跨度也极不规则。因此,需要对用户轨迹进行分割,划分成多个子轨迹。文献[4,10]发现用户的签到点存在很强的周期性,因此本文将每个用户的历史轨迹按固定的时间间隔(如6 h)划分为若干个子轨迹。
构建方法如图2所示,首先分别构建两个图来表示签到点的地理特征(图2c)和用户的访问偏好(图2d),并将这两个图合并形成最终的签到图(图2e)。

图 2 签到图构建方法
正如文献[4,9]中所观察到的,移动应用用户通常更喜欢访问距离自己更近的位置。因此,连接距离相近的签到点构造无向图
${G_S} = < V,{E_S} > $ ,称为空间图(spatial graph),其中每个节点${v_i} \in V$ 表示一个真实的签到点,${E_S}$ 表示边的集合。如果签到点之间的地理距离小于某一个阈值$\varepsilon $ ,那么它们之间将有边相连。除了地理特征,还构建了有向访问图(visiting graph),即
${G_V} = < V,{E_V} > $ 来收集用户的访问意图和序列移动模式,其中${E_V}$ 表示所有的访问轨迹。一条边${e_{ij}} \in {E_V}$ 表示从地点$i$ 到地点$j$ 的一个用户访问行为。如用户${u_i}$ 的一个子轨迹为${T^i} = \left\{ {l_1^i,l_2^i,l_3^i} \right\}$ ,则在${E_V}$ 中添加$e_{12}^i$ 和$e_{23}^i$ 。因此,${G_V}$ 保存了所有用户的历史访问偏好信息。为了整合地理特征和序列信息,将上述
${G_S}$ 和${G_V}$ 合并形成最终的无向签到图$\mathcal{G}$ 。具体来说,$\mathcal{G}$ 是通过将属于${G_V}$ 的边添加到${G_S}$ 中来形成的。为简单起见,根据LBSN轨迹中的地理可互换的属性省略了${G_V}$ 中的方向,即如果存在从位置$i$ 到位置$j$ 的移动转移,那么从$j$ 到$i$ 的访问模式对于另一个用户来说是合理的。因此,签到图保存了空间图的地理信息,同时保存了访问图中的用户访问偏好和签到模式信息。此外,签到图的节点特征由签到点的地理信息和POI分类信息组成。 -
图表示学习的目标是学习一种编码映射函数,将图节点映射为低维密集的向量,以保持图的结构和属性特征。GNN是神经网络在图结构数据上的一个延伸,现在已经成为学习图表示的强大模型。在本文任务中,基于深度图互信息最大化(deep graph infomax, DGI)[17]算法实现GNN模块,来学习签到图中的节点嵌入表示。DGI是一种无监督的图神经网络模型,通过最大化近邻表示(patch representation)与对应的高阶图摘要(high-level summaries of graphs)之间的互信息(mutual information)来学习一个对比任务。DGI能够学习到包含图全局结构信息的节点嵌入向量,用于分类、预测等下游任务。
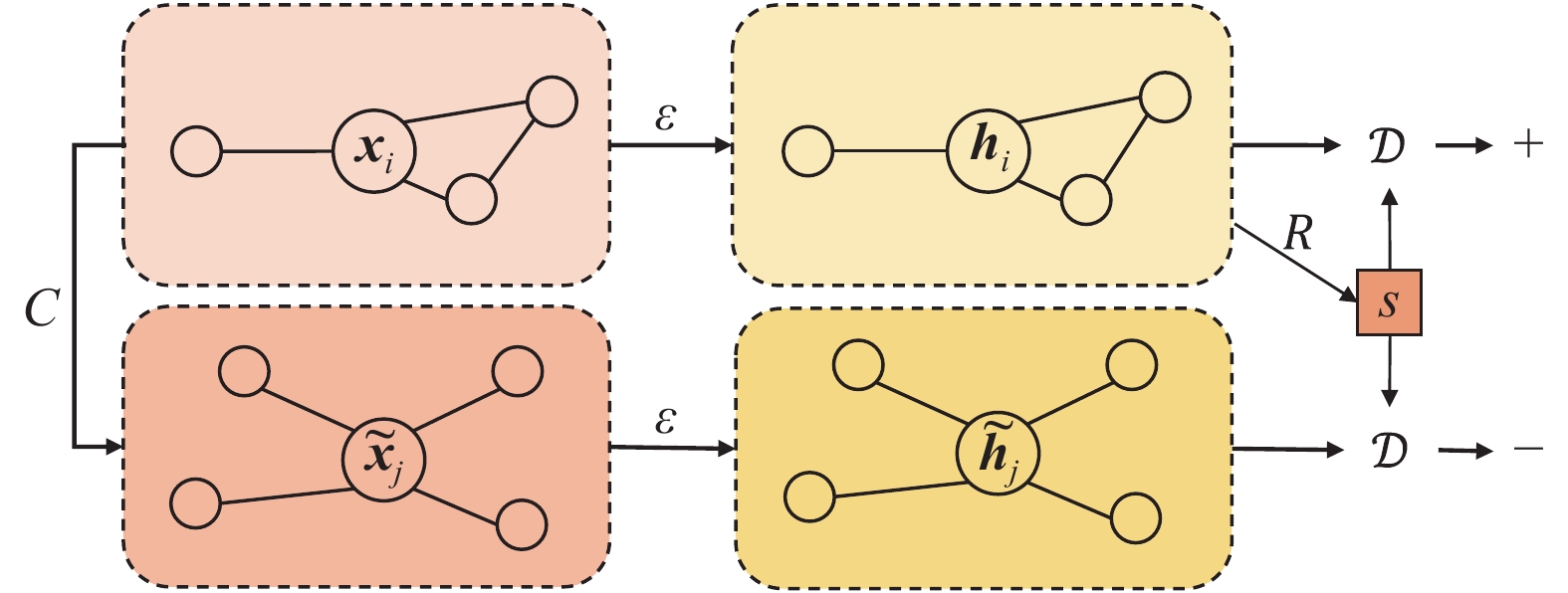
在签到图
$\mathcal{G} = (V,E,\boldsymbol{X},\boldsymbol{A})$ 中,V代表签到点的集合,E代表边的集合,X代表签到点特征的集合,A代表邻接矩阵,由V和E得出。如图3所示,基于DGI通过5个步骤实现签到图的节点嵌入学习。
图 3 图神经网络表示学习
1)利用签到图,通过扰动函数(corruption function)构建负例节点,即不改变邻接矩阵,对特征矩阵进行行变换,改变节点的特征向量:
$\left( {\boldsymbol{\widetilde X},\boldsymbol{\widetilde A}} \right) \sim $ $ {C} \left( {\boldsymbol{X},\boldsymbol{A}} \right)$ ,$C $ 表示扰动函数。2)使用图卷积网络(graph convolutional nueral network, GCN)[18]学习正例节点的邻近节点表示:
$\boldsymbol{H} = \varepsilon \left( {\boldsymbol{X},\boldsymbol{A}} \right)$ ,$\varepsilon $ 表示由图卷积网络构成的编码器。3)使用GCN学习负例节点的邻近节点表示:
$\boldsymbol{\widetilde H} = \varepsilon \left( {\boldsymbol{\widetilde X},\boldsymbol{\widetilde A}} \right)$ 。4)利用正例节点的节点表示获得包含图全局信息的高阶图摘要,生成摘要向量
${\boldsymbol{s}} = {R} \left( \boldsymbol{H} \right)$ ,R表示获得高阶图摘要的输出函数。5)最大化签到点的邻近节点表示(局部特征)与摘要向量(全局特征)之间的互信息,作为整个GNN模块的优化目标。由于互信息计算困难,利用Infomax准则[19],将互信息计算等价转化为关于联合分布和边缘分布乘积间的JS散度计算(Jensen-Shannon divergence),即最大化互信息等价于最大化JS散度:
$$\mathcal{L} = \frac{1}{{N + M}}\left( \begin{split} &\displaystyle\sum\limits_{{i} = 1}^N {{\mathbb{E}_{\left( {{\boldsymbol{X}},{\boldsymbol{A}}} \right)}}} \left[ {{\rm{log}}\mathcal{D}\left( {{{\boldsymbol{h}}_i},{\boldsymbol{s}}} \right)} \right] + \\ &\displaystyle\sum\limits_{{j} = 1}^M {{\mathbb{E}_{\left( {\widetilde {\boldsymbol{X}},\widetilde {\boldsymbol{A}}} \right)}}} \left[ {{\rm{log}}\left( {1 - \mathcal{D}\left( {{{\tilde {\boldsymbol{h}}}_j},{\boldsymbol{s}}} \right)} \right)} \right] \\ \end{split} \right)$$ (1) 式中,N表示正例的数量;M表示负例的数量;
$\mathcal{D}$ 表示判别器,用于计算节点表示与摘要向量之间的互信息。如果该节点表示包含在摘要向量中,得到的分数更高。利用GNN模块学习到签到图的所有节点嵌入表示H,按照分割后的轨迹序列组成轨迹签到点嵌入表示向量z,就可以进行后续的分类任务。
-
该模块中的分类器是一个基于RNN的神经网络,包含一个双向LSTM和一个单层全连接网络。LSTM可以有效捕获轨迹中高阶复杂的序列信息,其结构包含一个存储单元和3个门结构:输入门
$g(i)$ 、输出门$g(o)$ 和遗忘门$g(f)$ 。LSTM在第t时刻的输入为t时刻签到点嵌入表示${{\boldsymbol{z}}_t}$ :$${g_t}(i){\rm{ }} = \sigma ({{\boldsymbol{W}}_i}{{\boldsymbol{z}}_t} + {{\boldsymbol{U}}_i}{{\boldsymbol{m}}_{t - 1}} + {{\boldsymbol{V}}_i}{{\boldsymbol{c}}_{t - 1}} + {b_i})$$ (2) $${g_t}(o){\rm{ }} = \sigma ({{\boldsymbol{W}}_o}{{\boldsymbol{z}}_t} + {{\boldsymbol{U}}_o}{{\boldsymbol{m}}_{t - 1}} + {{\boldsymbol{V}}_o}{{\boldsymbol{c}}_{t - 1}} + {b_o})$$ (3) $${g_t}(f){\rm{ }} = \sigma ({{\boldsymbol{W}}_f}{{\boldsymbol{z}}_t} + {{\boldsymbol{U}}_f}{{\boldsymbol{m}}_{t - 1}} + {{\boldsymbol{V}}_f}{{\boldsymbol{c}}_{t - 1}} + {b_f})$$ (4) 式中,
${\boldsymbol{W}}$ ,${\boldsymbol{U}}$ ,${\boldsymbol{V}}$ ,$b$ 均为可学习的参数;$\sigma $ 表示sigmoid激活函数;${{\boldsymbol{c}}_t}$ 表示当前单元的状态,它通过以下方式获得门的组合:$$\begin{split} {{\boldsymbol{c}}_t}= {g_t}(f) \odot {{\boldsymbol{c}}_{t - 1}} +{g_t}(i) \odot \tanh ({{\boldsymbol{W}}_c}{{\boldsymbol{x}}_t} + {{\boldsymbol{U}}_c}{{\boldsymbol{m}}_{t - 1}} + {b_c}) \\ \end{split} $$ (5) 式中,“
$ \odot $ ”表示矩阵对应元素相乘,最终的候选状态${{\boldsymbol{m}}_t}$ 为:$${{\boldsymbol{m}}_t} = {g_t}(o) \odot \tanh ({{\boldsymbol{c}}_t})$$ (6) 为了增强RNN的记忆能力,使用由前向LSTM与后向LSTM组合而成的BiLSTM,以利用来自正反两个方向的上下文信息。在第t步时,可以得到轨迹嵌入
${{\boldsymbol{q}}_t}$ :$${{\boldsymbol{q}}_t} = [{{\boldsymbol{m}}_t} \oplus {\boldsymbol{m}}'_t]$$ (7) 式中,mt和
${\boldsymbol{m}}'_t$ 是BiLSTM的两个输出。轨迹向量q用最后时刻的${{\boldsymbol{q}}_t}$ 来表示。分类器还包含了一层的全连接网络,用于输出轨迹对应用户(标签)的概率分布。将轨迹向量q输入至全连接网络中,最后利用softmax函数映射成C维的向量,得到分类输出。其中C表示用户数量,softmax函数为归一化指数函数:
$$y = \operatorname{softmax} ({{\boldsymbol{W}}_{fc}}{\boldsymbol{q}} + {b_{fc}})$$ (8) 式中,
$y$ 为该轨迹属于每个用户的概率。在模型训练中,将模型输出的概率分布和真实分布(one-hot向量)之间的交叉熵作为模型的损失函数并进行训练。本文模型GTUL的预测算法如下。输入:新的用户轨迹
${T_h}$ 输出:预测生成该轨迹可能性top-K的用户
对轨迹
${T_h}$ 按时间间隔进行分割初始化轨迹
${T_h}$ 的签到点嵌入表示向量zfor l in
${T_h}$ 将签到点l输入GNN模块中,GNN模块计算出签到点l的embedding
将签到点l的embedding添加到轨迹
${T_h}$ 的签到点嵌入表示向量z中end for
for t = 1:T
将签到点嵌入表示zt输入BiLSTM,得到两个方向的输出向量mt和
${\boldsymbol{m}}'_t$ 轨迹嵌入
${{\boldsymbol{q}}_t} = [{{\boldsymbol{m}}_t} \oplus {\boldsymbol{m}}'_t]$ ;轨迹嵌入q =
${{\boldsymbol{q}}_{\rm{T}}}$ 将轨迹嵌入q输入全连接网络中,计算轨迹属于每个用户的概率,取top-K用户输出
End for
-
Gowalla[20]是一个基于LBSN网站的数据集,该数据集收集了2009年2月−2010年10月期间1万多个用户的轨迹,包括详细的时间戳和每次签到点的地理坐标。Foursquare[21]包括从Foursquare网站收集的2012年4月−2013年2月期间大约10个月的签到数据。签到数据包含了签到点的地理位置坐标、签到时间和签到点的类别属性,以及签到用户的个人应用ID。
-
本文的实验模型都基于PyTorch深度学习框架来实现,使用了一块GTX1070 GPU来加速计算。实验数据集设置遵循文献[4,6]中的设置。实验从Gowalla中随机选择了201个用户及其生成的轨迹,从Foursquare中随机选择了300个用户和相应轨迹进行评估。具体的数据集设置如表1所示。
表 1 实验中使用的数据集统计
数据集 用户数量 签到点个数 训练集/测试集 Gowalla 201 10958 9920/10048 Foursquare 300 6146 13281/13129 在实验中,需要分开训练GNN模型和多分类器模型。其中,GNN模块的具体参数设置如表2所示,多分类器模块在训练中使用Adam优化器(adaptive moment estimation),多分类器学习率设置为0.0016,批处理块大小为16,全局迭代了50次。
表 2 GNN模块参数设置
参数 值 优化器 Adam 学习率 0.001 最大长度 32 迭代次数 400 输出维度 128 -
本文使用ACC@K、macro-P、macro-R和macro-F1作为评价指标来评价TUL任务的性能。ACC@K表示用户轨迹分类的准确性,如果生成轨迹T的用户u(T)位于预测的top-K用户集UK(T)内,则认为是正确的。可表示为:
$$ {\rm{ACC}}@K = \frac{{\left| {\left\{ {T \in \varGamma:{u^*}(T) \in {U_K}(T)} \right\}} \right|}}{{|\varGamma|}} $$ (9) 式中,ACC@K表示轨迹正确分类到生成该轨迹的用户的比率。macro-F1是所有类的macro-P和macro-R的调和平均值。三者的计算方式为:
$$ {\rm{macro}}\text{-}P = \frac{1}{n}\sum\limits_{i = 1}^n {\frac{{{\rm{T}}{{\rm{P}}_{(i)}}}}{{{\rm{T}}{{\rm{P}}_{(i)}} + {\rm{F}}{{\rm{P}}_{(i)}}}}} $$ (10) $$ {\rm{macro}}\text{-}R = \frac{1}{n}\sum\limits_{i = 1}^n {\frac{{{\rm{T}}{{\rm{P}}_{(i)}}}}{{{\rm{T}}{{\rm{P}}_{(i)}} + {\rm{F}}{{\rm{N}}_{(i)}}}}} n $$ (11) $$ {\rm{macro}}\text{-}F1 = 2*\frac{{{\rm{macro}} \text{-} P*{\rm{macro}} \text{-} R}}{{{\rm{macro}} \text{-} P + {\rm{macro}} \text{-} R}} $$ (12) 式中,i表示在第i个用户标签上的评价指标;R为召回率(recall);P为精准率(precision);TP为正类用户标签被模型预测为正类的样本数量;FN为正类用户标签被模型预测为负类的样本数量;FP为负类用户标签被模型预测为正类的样本数量。
-
将GTUL与TUL相关模型进行比较:
1) TULER[4]是第一个TUL解决方案,它使用各种RNN模型对用户移动规律进行建模。
2) HTULER[6]是一个分层的TUL模型,由3个变体组成,包括HTULER-LSTM、HTULER-Bi和HTULER-GRU。
3) TULVAE[6]以半监督学习方式学习轨迹分布和用户移动规律,该算法利用VAE来学习RNN中隐藏状态的随机隐变量的层次语义信息。
4) TGAN[7]是一种轨迹增强方法,利用条件对抗网络来学习基本轨迹分布并生成综合轨迹。原始轨迹数据将与增广数据一起进行训练,以解决数据的稀疏性问题。
5) STULIG[8]是最新的TUL模型,它使用分层隐因子扩展了TULVAE。利用合成轨迹丰富了训练数据,同时通过联合训练提高了TUL的性能。
-
表3展示了GTUL与其他基准算法在两个真实数据集上的性能比较。结果表明,GTUL模型在各种指标中均取得了最好的性能,并且在用户轨迹辨别的直接指标上有了明显的提升,说明GTUL可以有效提取历史轨迹信息,建模用户的移动规律。
表 3 模型分类性能实验结果
% 模型 Gowalla Foursquare ACC@1 ACC@5 macro-P macro-R macro-F1 ACC@1 ACC@5 macro-P macro-R macro-F1 TULER 41.24 56.88 31.70 28.60 30.07 51.22 59.11 47.19 44.23 45.66 HTULER 43.40 60.25 34.43 33.63 34.02 52.78 60.37 48.97 45.97 47.43 TULVAE 45.40 62.39 36.13 34.71 35.41 54.28 61.96 50.06 48.42 49.22 TGAN 46.30 63.19 36.06 34.99 35.52 55.67 62.67 52.56 50.22 51.36 STULIG 46.84 63.03 36.84 35.55 36.18 57.28 63.99 55.06 51.87 53.42 GTUL 49.01 64.12 41.86 36.37 38.92 59.21 68.09 58.39 53.98 56.10 除了模型的优越性之外,本文还有以下发现。首先,像TULER和HTULER这样的确定性分类模型表现整体不佳。这些模型使用简单的RNN模型来建模用户轨迹,极大地依赖历史轨迹的数量和质量,所以它们不足以从稀疏的训练数据中捕捉复杂的用户移动模式。这一结果表明,在LBSNs中,用户轨迹分类并不是一项简单的任务,因为对于大多数用户来说,许多必要的用户移动模式因为签到行为过少而无法发掘。由此可见,提高解决TUL问题的效果还需要借助更多的数据处理技术,发掘更多的时空信息,以解决稀疏训练数据带来的问题。
另一方面,与传统的基于RNN的模型相比,TULVAE、TGAN和STULIG有效提高了TUL的性能。这些方法依靠深度生成模型,利用合成轨迹来增强训练数据。TULVAE使用具有随机隐变量的生成架构来学习用户的移动规律。TGAN使用从分布中采样生成的轨迹来增强训练数据,并且通过对抗学习的方式对模型进行训练。STULIG则利用合成轨迹增强训练数据,并使用分层隐因子扩展生成架构。这些模型均取得了一定的效果,但它们都依赖于深层生成技术来推断潜在的移动分布和估计潜在因素,通常计算效率低。更重要的是,由于数据稀疏性问题,生成模型可能引入关于数据分布的额外偏差。相比上述方法,本文提出的解决方案更简洁,并省去了后验分布推理的开销。GTUL算法基于用户历史轨迹构建签到图,使用图神经网络学习签到点的向量表示,使签到点的表示包含更多的位置信息和时间信息,成功提高了轨迹用户辨别的准确度。
-
GTUL的另一主要优点是训练效率高。为了证明这一点,本文对比了所有方法的训练时间,并将结果展示在表4中。在所有方法中,TULVAE,TGAN和STULIG等生成模型为了生成新的合成轨迹需要花费大量计算开销进行数据基础分布的估算,无法迅速收敛。在这些生成模型中,基于VAE的模型更为昂贵。它们在推理期间计算每个时期每个轨迹的发生概率,其时间复杂度随着用户数量的增加而显著增加。用户越多,每个时期的迭代就越多,会产生巨大的计算成本。与这些方法相比,本文提出的GTUL模型结构简单清晰,不需要进行潜在因素推断。GTUL构建了信息丰富的签到图,利用GNN模块进行自监督对比学习,可以高效无监督地学习到包含地理位置信息和用户访问偏好信息的签到点嵌入表示。因此GTUL省去了生成模型的轨迹合成过程,在提取有用信息的同时极大地减少了计算成本,训练时间大大缩短。
表 4 训练时间对比
h 模型 Gowalla Foursquare TULVAE 18.6 14.2 TGAN 12.4 10.1 STULIG 8.3 5.3 HTULER 2.6 1.7 TULER 1.8 1.2 GTUL 0.6 0.4 -
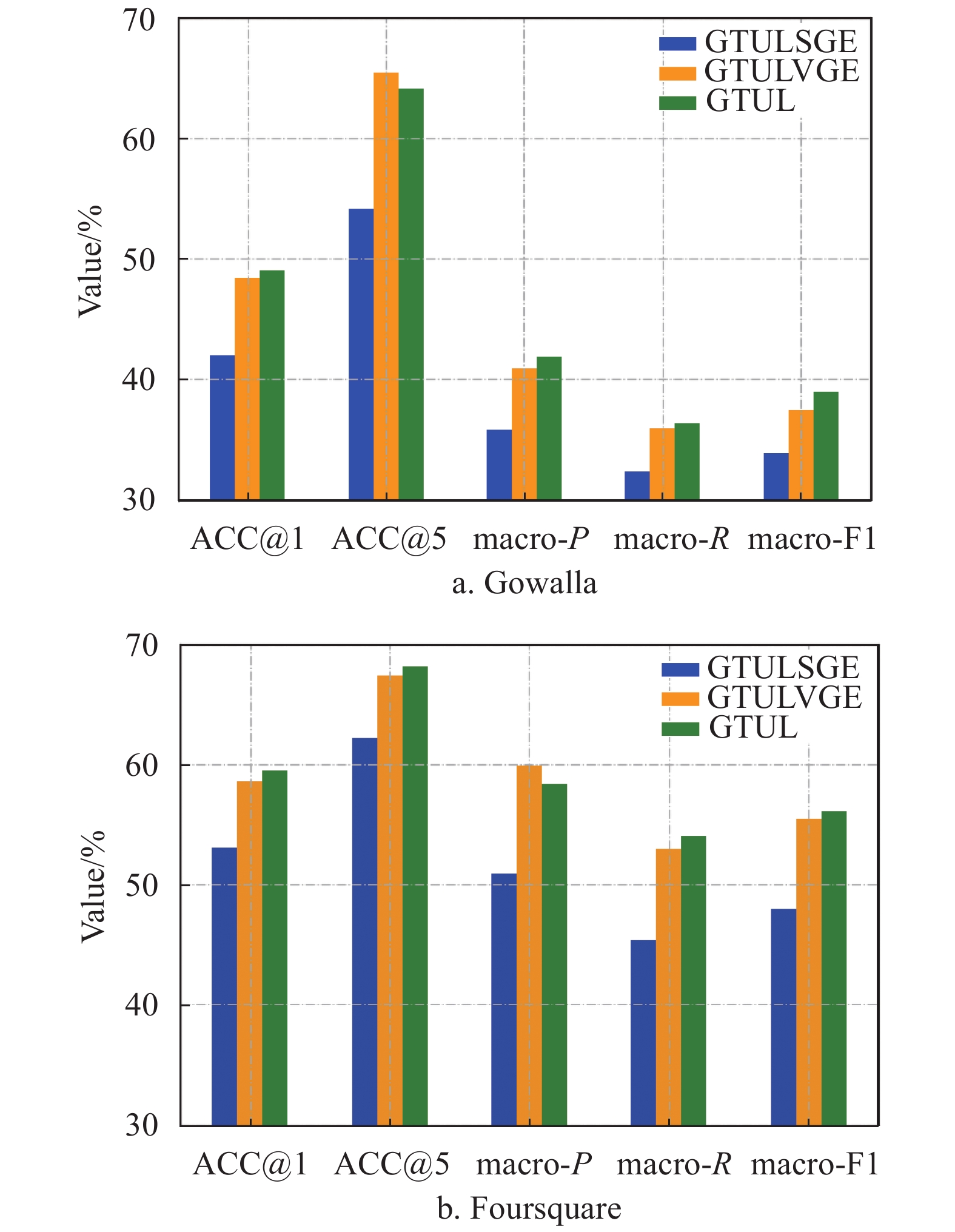
为了探究签到图包含的时空信息的有效性,增强本文方法的可解释性,本文设计了一个模块对比实验。具体而言,分别只利用空间图和访问图学习签到点的嵌入表示,替换GTUL中原有的签到图节点嵌入,得到两个新的方法分别表示为GTULSGE和GTULVGE。将GTUL、GTULSGE和GTULVGE一起对比,得到的结果如图4所示,其中value表示各项评价指标的具体数值。

图 4 空间图和访问图对TUL性能的影响
根据图4可知,GTUL的性能优于GTULSGE和GTULVGE,说明空间信息和访问意图都对解决TUL问题有重要作用,基于GNN的签到点嵌入表示成功获取了这些关键信息。此外,GTULSGE的性能明显低于GTUL和GTULVGE,说明只利用地理位置信息,不考虑用户访问习惯,不足以学习到有代表性的签到点嵌入表示。
-
本文提出了一种新的基于图神经网络的用户轨迹分类模型。该模型实现一种通过轨迹数据生成签到图的通用构造方法,对与用户签到位置和时间移动意图相关的时空特征进行建模;利用图神经网络获取高阶时空信息,发掘所构造的签到图中隐含的签到之间的转换模式。在真实移动应用的用户轨迹数据上的实验结果表明,本文模型能够有效解决轨迹数据的稀疏问题和提高用户移动模式的学习效率,高效区分不同用户的轨迹,提高了TUL任务的性能。未来的研究工作将考虑利用轨迹上下文 POI 属性来提高模型的效率。另一种可能的扩展是引入额外的信息,如考虑用户的交通方式、天气或节假日等信息以提高模型的综合预测能力。
Trajectory-User Classification with Graph Neural Network
-
摘要: 针对现有轨迹用户链接(TUL)算法对轨迹信息提取不充分、计算成本过高等问题,该文提出了一种新的基于图神经网络(GNN)的TUL算法。首先,利用轨迹中的签到点构建签到图;其次,在签到图的基础上使用图神经网络学习签到图中的节点嵌入,保存签到点的位置信息和用户的访问偏好信息;最后,利用循环神经网络(RNN)构建轨迹序列的向量表示,并使用全连接网络对轨迹进行用户分类,实现轨迹与用户链接。实验结果表明,相比于传统的用户轨迹分类算法,该方法能更有效地挖掘用户轨迹的潜在移动规律,显著提高了两个数据集上的链接准确性和学习效率。Abstract: To address the insufficient data issue and the high computational cost of existing algorithms, we present a new TUL model based on graph neural network (GNN). More specifically, the check-in graph is constructed using the check-in points in trajectories, based on which we use a graph neural network to learn the check-in embeddings in the graph, which could preserve users' check-in preference and spatio-temporal visiting patterns in a graph representation learning manner. Subsequently, the check-in representations in the trajectory are fed into a recurrent neural network, followed by a fully connected network, to learn the sequential dependencies of visits while distinguishing different users' trajectories. Experimental evaluations conducted on benchmark datasets show that our method can better capture the underlying moving patterns of users' trajectories more effectively compared with the previous TUL algorithms. Furthermore, the user linking accuracy and learning efficiency are significantly improved compared with the existing methods.
-
Key words:
- deep learning /
- graph neural network /
- recurrent neural network /
- trajectory-user linking
-
表 3 模型分类性能实验结果
% 模型 Gowalla Foursquare ACC@1 ACC@5 macro-P macro-R macro-F1 ACC@1 ACC@5 macro-P macro-R macro-F1 TULER 41.24 56.88 31.70 28.60 30.07 51.22 59.11 47.19 44.23 45.66 HTULER 43.40 60.25 34.43 33.63 34.02 52.78 60.37 48.97 45.97 47.43 TULVAE 45.40 62.39 36.13 34.71 35.41 54.28 61.96 50.06 48.42 49.22 TGAN 46.30 63.19 36.06 34.99 35.52 55.67 62.67 52.56 50.22 51.36 STULIG 46.84 63.03 36.84 35.55 36.18 57.28 63.99 55.06 51.87 53.42 GTUL 49.01 64.12 41.86 36.37 38.92 59.21 68.09 58.39 53.98 56.10  下载: 导出CSV
下载: 导出CSV
表 4 训练时间对比
h 模型 Gowalla Foursquare TULVAE 18.6 14.2 TGAN 12.4 10.1 STULIG 8.3 5.3 HTULER 2.6 1.7 TULER 1.8 1.2 GTUL 0.6 0.4
下载: 导出CSV
-
[1] LIU Q, WU S, WANG L, et al, Predicting the next location: A recurrent model with spatial and temporal contexts[C]//AAAI Conference on Artificial Intelligence. Phoenix: AAAI, 2016: 194-200. [2] ZHONG T, LIU F, ZHOU F, et al. Motion based inference of social circles via self-attention and contextualized embedding[J]. IEEE Access, 2019, 7: 61934-61948. doi: 10.1109/ACCESS.2019.2915535 [3] GAO Q, TRAJCEVSKI G, ZHOU F, et al. Trajectory-based social circle inference[C]//Proceedings of the 26th ACM Sigspatial International Conference on Advances in Geographic Information Systems. Seattle: ACM, 2018: 369-378. [4] GAO Q, ZHOU F, ZHANG K P, et al. Identifying human mobility via trajectory embeddings[C]//Proceedings of IJCAI. Melbourne: IJCAI, 2017: 1689-1695. [5] 高强, 张凤荔, 王瑞锦, 等. 轨迹大数据: 数据处理关键技术研究综述[J]. 软件学报, 2017, 28(4): 959-992. GAO Q, ZHANG F L, WANG R J, et al. Trajectory big data: A review of key technologies in data processing[J]. Journal of Software, 2017, 28(4): 959-992. [6] ZHOU F, GAO Q, TRAJCEVSKI G, et al, Trajectory-user linking via variational autoencoder[C]//Proceedings of IJCAI. Stockholm: IJCAI, 2018: 3212-3218. [7] ZHOU F, YIN R Y, TRAJCEVSKI G, et al. Improving human mobility identification with trajectory augmentation[J]. Geoinformatica, 2019, DOI: 10.1007/s10707-019-00378-7. [8] ZHOU F, LIU X, ZHANG K P, et al. Toward discriminating and synthesizing motion traces using deep probabilistic generative models[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, DOI: 10.1109/TNNLS.2020.3005325. [9] FENG J, LI Y, ZHANG C, et al. DeepMove: Predicting human mobility with attentional recurrent networks[C]//The World Wide Web Conference. Lyon: ACM, 2019: 1459-1468. [10] ZHOU F, YUE X L, TRAJCEVSKI G, et al. Context-aware variational trajectory encoding and human mobility inference[C]//The World Wide Web Conference. San Francisco: ACM, 2019: 3469-3475. [11] GAO Q, ZHOU F, TRAJCEVSKI G, et al. Predicting human mobility via variational attention[C]//The World Wide Web Conference. San Francisco: ACM, 2019: 2750-2756. [12] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. doi: 10.1162/neco.1997.9.8.1735 [13] CHUNG J, GULCEHRE C, CHO K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling[EB/OL]. [2020-11-5]. https://arxiv.org/pdf/1412.3555.pdf. [14] KINGMA D P, WELLING M. Auto-encoding variational bayes[EB/OL]. [2020-11-7]. https://arxiv.org/pdf/1312.6114.pdf. [15] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al, Generative adversarial nets[C]//Advances in Neural Information Processing Systems. Montreal: MIT, 2014: 2672-2680. [16] SCARSELLI F, GORI M, TSOI A C, et al. The graph neural network model[J]. IEEE Transactions on Neural Networks, 2009, 20(1): 61-80. doi: 10.1109/TNN.2008.2005605 [17] VELICKOVIC P, FEDUS W, HAMILTON W L et al. Deep graph infomax[EB/OL]. [2020-11-10]. https://arxiv.org/pdf/1809.10341.pdf. [18] KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. [2020-11-8]. https://arxiv.org/pdf/1609.02907.pdf. [19] HJELM R D, FEDOROV A, LAVOIE-MARCHILDON S, et al. Learning deep representations by mutual information estimation and maximization[EB/OL]. [2020-11-10]. https://arxiv.org/pdf/1808.06670.pdf. [20] CHO E, MYERS S A, LESKOVEC J. Friendship and mobility: User movement in location-based social networks[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego: ACM, 2011: 1082-1090. [21] YANG D Q, ZHANG D Q, ZHENG V W, et al. Modeling user activity preference by leveraging user spatial temporal characteristics in LBSNs[J]. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2014, DOI: 10.1109/TSMC.2014.2327053. -

 点击查看大图
点击查看大图
图(4) / 表(4)
计量
- 文章访问数: 5032
- HTML全文浏览量: 1793
- PDF下载量: 91
- 被引次数: 0



















































































