 ISSN
ISSN 













-
现实生活中的复杂系统(如交通运输系统、生物系统)可以很自然地用图表示,其中节点表示系统中的各个要素,边表示要素之间的关系[1]。复杂网络的研究逐渐从宏观层面深入微观层面[2]。节点作为系统中最小的元素,不同节点在系统中的地位是不同的。重要节点是指相比于网络中其他节点,能更大程度地影响网络功能的一些特殊节点。这种节点数量不多,但是其影响力却可以快速波及网络中大部分节点,如社交网络中权威账号的舆论引导,交通网路中重要路口堵塞导致交通系统瘫痪等。节点重要性排序[1]和相对重要节点的挖掘[3-4]对现实生活有着重要的指导意义。在网络分析中,节点的重要性通常用中心性[5]来度量,其主要目的是为基础网络的每个节点分配一个实值,用于度量该节点对其他节点的影响力。目前已有不少成熟的节点中心性计算方法,主要分为两类[3]:1) 基于网络结构特征的指标和方法;2) 基于随机游走的指标和方法。
基于结构特征的指标和方法主要根据其他节点与已知节点之间的网络结构特征设计相对重要指标。这些方法通过捕捉节点之间的局部连边信息或路径信息,衡量节点的重要性。度中心性(degree)是最简单的中心性度量方法,主要利用网络节点的连边信息刻画节点的重要性。度中心性认为一个节点邻居数目越多,该节点影响力就越大。但若节点在网络中属于核心位置,即使它本身度很小,也有较高的影响力。基于此,文献[6]提出了基于K-壳分解(K-shell decomposition)的K-shell中心性,该中心性将外围的节点层层剥去,使处于内层的节点拥有较高的影响力。还有一些基于路径的中心性计算方法,如节点的接近中心性(closeness)[7]考虑将节点与其他节点的测地距离之和的倒数作为节点重要性。而介数中心性(betweenness)[8]认为经过一个节点的最短路径越多,这个节点就越重要。受到介数中心性启发,流介数中心性(flow betweenness)[9]、连通介数中心性(communicability betweenness)[10]、随机游走介数中心性(random walk betweenness)[11]和路由介数中心性(routing betweenness)[12]相继被提出。除此以外,H-index[13]作为评价学者学术成就的权威方法,也能很自然地延伸到复杂网络的重要节点挖掘任务中。
上述方法能够很好地捕捉节点周围的局部结构信息。除此之外,很多学者采用基于路径和随机游走的方法,利用整个图的拓扑信息挖掘图中的重要节点。在不考虑时间开销的前提下,从初始节点出发将信息传播出去,当随机游走趋于稳定时,信息保留越多的节点越重要。特征向量中心性(eigenvector)传播时不仅考虑节点的邻居数目,也同时考虑每个邻居节点的重要性。另外,学者们还提出了HITs[14]、LeaderRank[15]、PageRank[16]、Vote Rank[17]等其他全局游走的方法。总体而言,这些基于全局游走的方法计算成本较高,不能有效地应用于超大规模网络。文献[18]考虑四阶邻居,提出了局部中心性方法LocalRank,在时间复杂度和准确率之间找到了一个较好的平衡点。
虽然复杂网络中检测节点重要性的方法很多,但它们都试图找到能反映节点重要性的某种因素。但节点重要性之所以不同,是因为不同节点周围的结构是异质的[19]。因此,本文利用机器学习方法挖掘节点结构特征与节点重要性之间的关系。首先基于二步可达子图的节点信息,采用特征工程中的特征提取、特征重构方法,提出能描述节点周围信息的特征集合。再利用简单的线性回归模型(linear regression model)[20],学习节点局部结构与节点重要性之间的关系。在13个真实网络中,将训练所得模型与度中心性、介数中心性[8]、K-shell[6]、H-index[13]和DynamicRank[21]中心性进行了比较。实验结果表明,本方法能更准确、更有效地识别出复杂网络中对信息传播影响较大的重要节点。
-
重要节点挖掘是网络攻击和信息传播及控制等领域中的核心问题之一。网络中的少数节点具有非常高的影响力。而造成网络中节点重要性差异的根本原因是节点周围的结构差异[19]。闭塞的局部结构会阻碍节点影响力的传播,而好的局部结构会促进信息在网络中传播。
本文研究主要针对无向无权图
$G(V,E)$ ,其中$V = \{ {v_1},{v_2},\cdots,{v_n}\} $ 是节点集合,$E = \{ {e_1},{e_2},\cdots,{e_m}\} $ 是边集合,n和m分别是节点数量和边数量。为了提取和重构节点邻居信息得到节点的局部结构特征,首先拓展两个邻居的定义。定义1 二阶邻居
若网络中节点u的一阶邻居定义为
${\varGamma _1}(u)$ ,那么节点u的二阶邻居可定义为:$${\varGamma _2}(u) = \{ v|v \in {\varGamma _1}(x),x \in {\varGamma _1}(u),v \ne u\} $$ 定义2 二阶外联邻居
二阶外联邻居属于二阶邻居的子集,区别在于二阶外联邻居是二阶邻居与一阶邻居的差集,定义如下:
$$ {{\tilde \varGamma }_2}(u) = {\varGamma _2}(u){\rm{ - }}{\varGamma _1}(u)= \{ v|v \in {\varGamma _2}(u) \wedge v \notin {\varGamma _1}(u)\} $$ 从局部角度考虑,节点的度以及节点邻居的度最能反映节点的局部结构特征。除此以外,现有的中心性算法中,H-index和K-shell也是能较好反映节点重要程度的中心性指标。然而这些中心性指标对节点周围复杂多样的局部结构还是很难刻画。
度中心性可以广泛地概括简单图中重要节点的规律,一般来说,节点的邻居越多,影响力越大。现实网络中节点的局部结构非常复杂,单独用某一种复杂网络指标无法准确地刻画节点周围的结构信息。如图1a~1d中,节点A、B、C、D具有不同的局部结构,相应的中心节点的影响力也有差异,使用传统的中心性方法无法准确区分这4个节点的真实重要性。如采用度中心计算时,A、B、C、D属于同一类型节点(
${d_A} = {d_B} = {d_C} = {d_D} = 2$ )。而H-index无法判断节点A、C、D(${h_A} = {h_C} = {h_D} = 2$ )。另外K-shell中心性也无法判断A、B和C、D (${k_A} = $ $ {k_B} = 1,\;{k_C} = {k_D} = 2$ )。可以看出,传统方法在节点重要性分析中还属于粗粒度方法,对于不同的微观局部结构有时很难区分。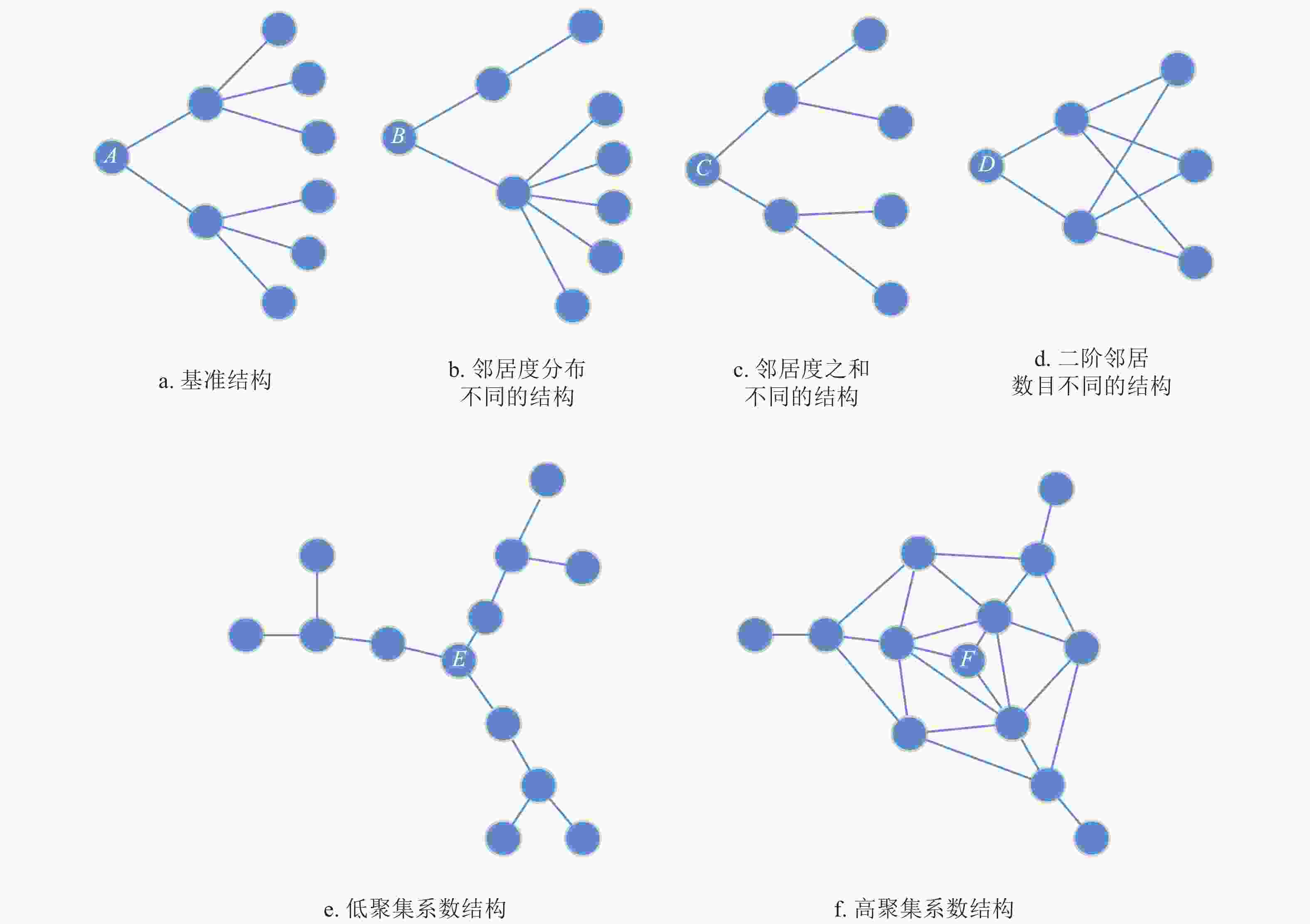
图 1 复杂网络中节点的局部结构示例
-
由于传统的基于中心性的方法不能很好地刻画节点的局部结构,特别是对于二阶邻居结构信息的刻画过于粗糙。因此本文主要以节点的邻居信息为基础,提取和重组能刻画节点局部结构的特征。
-
从一阶邻居开始,一般而言,度越大,信息越有可能传播出去,因此,节点的度是刻画信息传播能力的一个重要特征。除此以外,一阶邻居度的分布一定程度上反映了节点二阶邻居的结构信息。如图1中,虽然节点A、B、C、D的度都为2,但是它们的一阶邻居度分布相差却很大。特别地,A的一阶邻居度分布为[4,4],而B的分布是[2,6]。显然,A的一阶邻居度的分布更加均衡,而B的邻居度分配不均衡。由于这两个一阶邻居度的分布对应的局部结构不同,导致节点的影响力也不同。在低感染率下,邻居度分布越均匀,信息往外传播能力越强。若度分布极度不均衡,在图1b中,若度为6的节点没有被感染,B节点的传播能力会大打折扣。
为了描述邻居度的分布均衡性,本文引入国际通用的,用以衡量一个国家或地区居民收入差距的常用指标:基尼系数(Gini coefficient),基尼系数最大为1,最小等于0。系数越大说明该分布越不均匀,系数越接近0表明收入分配越是趋向平等。对给定的序列
$x = [{x_1},{x_2},\cdots,{x_n}]$ ,该序列数据平均值为$\,\mu $ ,可采用下式直接计算序列的基尼系数:$$ {\rm{Gini}}(x) = \frac{{\displaystyle\sum\limits_{i = 1}^n {\displaystyle\sum\limits_{j = 1}^n {\left| {{x_i} - {x_j}} \right|} } }}{{2{n^2}\mu }}$$ (1) 如图1所示,B的一阶邻居度的差距很大,而A的一阶邻居相对平衡。给定节点u,其一阶邻居为
${\varGamma _1}(u)$ ,一阶邻居度的集合为${D_1}(u) = \{ {d_v}|v \in {\varGamma _1}(u)\} $ 。为了刻画节点u的一阶邻居度分布的平衡度,定义节点u的一阶邻居度的基尼系数:$$ {\rm{Gini}}({D_1}(u)) = \frac{{\displaystyle\sum\limits_{{v_i} \in {\varGamma _1}(u)}^{} {\displaystyle\sum\limits_{{v_j} \in {\varGamma _1}(u)}^{} {\left| {{d_{{v_i}}} - {d_{{v_j}}}} \right|} } }}{{2n \displaystyle\sum\limits_{v \in {\varGamma _1}(u)}^{} {{d_v}} }}$$ (2) 然而,只有基尼系数还不能完全反映节点一阶邻居局部结构。如图1中A和C,一阶邻居的基尼系数都为0且中心节点的度都为2,仅靠这两个特征还不能很好区分相同度节点重要性的差异,有时小度节点甚至比大度节点具有更高的传播影响力。为了体现这种差异性,引入特征2区分这种情况,特征2为一阶邻居度之和,定义如下:
$$ {\rm{SUM}}({D_1}(u)) = \displaystyle\sum\limits_{{d_i} \in {D_1}(u)} {{d_i}} $$ (3) -
有时仅用一阶邻居的特征还不能很好地刻画节点周围的局部特征,如图1中的节点A和D,
$ {\rm{Gini}}({D_1}(A)) = {\rm{Gini}}({D_1}(D)) = 0$ 且$ {\rm{SUM}}({D_1}(A)){\rm{ = }}$ $ {\rm{SUM}} $ $ ({D_1}(D)) = 0$ ,仅从这两个角度还是无法区别A、D两种局部结构。针对上述情况,本文将二阶邻居数目作为特征,记为$ {\rm{Len}}({\varGamma _2}(u))$ ,其中$ {\rm{Len}} $ $ ({\varGamma _2}(A)) = 6$ ,$ {\rm{Len}}({\varGamma _2}(D)) = 3$ 。在对一阶邻居的规模和分布进行分析后,将基尼系数和规模作为二阶邻居的特征。但与一阶邻居不同的是,一阶邻居与二阶邻居会出现重叠邻居的情况。如图1f中的F节点,其周围很多一阶邻居之间存在连接。在获取二阶邻居时,很多一阶邻居还会被判定为二阶邻居。重叠的邻居越多,节点聚集系数越大,节点的影响力在局部区域内能充分地传播,但这种结构会导致信息很难再往外传播[22]。如图1所示,在邻居节点数目一致的情况下,E节点往外传播的能力大于F节点。因此中心节点的二阶外联邻居
${\tilde \varGamma _2}(u)$ 度的分布和规模反映了信息从中心节点向外传播的能力。基于此,本文提取二阶外联邻居度的基尼系数和SUM值作为节点的局部结构特征。至此,本文从局部结构的规模和平衡性两个角度,针对一阶、二阶邻居,提取了共8个特征,具体计算方法和描述总结在表1中。除上述特征外,还有其他类型的特征对排序结果也有影响,如邻居度的最大值、平均值、方差等。这些特征都会对节点重要性判断带来影响,本文仅作为一种算法思路,通过重构二阶邻居内的度信息,得到刻画节点邻居结构最主要的8个特征用于节点重要性排序。
表 1 节点局部结构特征度量
序号 名称 计算公式 1 自身度 dv 2 一阶邻居的度之和 $\displaystyle\sum\limits_{v \in {\varGamma _1}(u)} {{d_v}} $ 3 一阶邻居度的基尼系数 $\frac{ {\displaystyle\sum\limits_{ {v_i} \in {\varGamma _1}(u)}^{} {\displaystyle\sum\limits_{ {v_j} \in {\varGamma _1}(u)}^{} {\left| { {d_{ {v_i} } } - {d_{ {v_j} } } } \right|} } } }{ {2n \displaystyle\sum\limits_{v \in {\varGamma _1}(u)}^{} { {d_v} } } }$ 4 二阶邻居总数 ${\rm{Len}}({\varGamma _2}(u))$ 5 二阶邻居度之和 $\displaystyle\sum\limits_{v \in {\varGamma _2}(u)} {{d_v}} $ 6 二阶邻居度的基尼系数 $\frac{ {\displaystyle\sum\limits_{ {v_i} \in {\varGamma _2}(u)}^{} {\displaystyle\sum\limits_{ {v_j} \in {\varGamma _2}(u)}^{} {\left| { {d_{ {v_i} } } - {d_{ {v_j} } } } \right|} } } }{ {2n \displaystyle\sum\limits_{v \in {\varGamma _2}(u)}^{} { {d_v} } } }$ 7 二阶外联邻居度之和 $\displaystyle\sum\limits_{v \in {{\tilde \varGamma }_2}(u)} {{d_v}} $ 8 二阶外联邻居度的基尼系数 $\frac{ {\displaystyle\sum\limits_{ {v_i} \in { {\tilde \varGamma }_2}(u)}^{} {\displaystyle\sum\limits_{ {v_j} \in { {\tilde \varGamma }_2}(u)}^{} {\left| { {d_{ {v_i} } } - {d_{ {v_j} } } } \right|} } } }{ {2n \displaystyle\sum\limits_{v \in { {\tilde \varGamma }_2}(u)}^{} { {d_v} } } }$ -
节点的重要性与节点周围的局部结构有着紧密的关系。本文根据表1列出的特征,采用线性回归(linear regression)模型对节点局部特征与节点重要性关系进行建模。定义一个线性回归函数
$f:x \to s$ ,将节点的结构特征映射为节点的相对重要性,具体可表示为:$${f_w}({\boldsymbol{x}}) = {\boldsymbol{w}}^{\rm{T}} \cdot {\boldsymbol{x}} + b$$ (4) 式中,w为特征向量的权重向量;
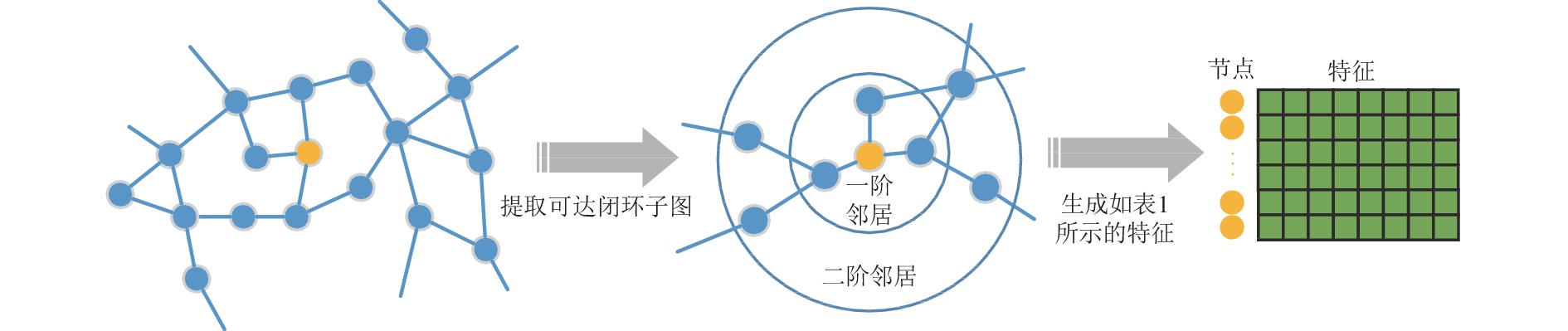
${\boldsymbol{x}}$ 是特征向量;b是误差项。节点的数字化结构特征提取过程如图2所示,首先提取出节点v的二步可达闭环子图。接着,根据表1,计算得到8个描述节点局部结构信息的特征,组成特征向量
${ {\boldsymbol{x}}_v} = [x_v^1,x_v^2,\cdots,x_v^8]$ 。为了将提取出的特征用于不同网络的训练和预测,对每一维度的特征进行线性归一化处理,从而得到节点v归一化后的特征向量${ {\boldsymbol{x}}_v} = [{{x_v^1}/ {x_{\max }^1}},{{x_v^2} / {x_{\max }^2}},\cdots,{{x_v^8} / {x_{\max }^8}}]$ 。
图 2 节点局部特征生成示例
而为了获取节点真实的重要性,目前主要采用基于传播动力学的SIR模型进行仿真得到。具体地,在每个时间步,每个已感染节点与其邻居进行接触,每个易感邻居以概率
$\beta $ 被感染,然后,每个已感染节点以概率$\lambda $ 恢复,为简单起见,本文将$\lambda $ 设置为1。为了量化目标节点v的传播影响,以v作为唯一感染的种子开始向外传播,当不再有任何已感节点时,传播过程结束。此时,恢复的节点数记为${R_v}$ ,假设节点v的三步可达子图的节点规模为$R_{\max }^v$ 。此时,选取${{{R_v}} / {R_{\max }^v}}$ 用于衡量节点v的重要性。如果感染概率
$\beta $ 很小,受到感染的节点数量也很少,信息几乎传播不出去。当$\beta $ 值很高时,几乎感染网络中所有节点,因此过大或过小的$\beta $ ,通过仿真得到的节点重要性没有太大差异,对节点重要性评估没有实质性意义。本文根据非均匀平均场理论[23-25],使用真实网络的平均度信息计算SIR模型中的传染阈值[26]$\,{\beta _c} \approx {{\langle k \rangle } / {( {\langle {{k^2}}\rangle - \langle k \rangle } )}}$ ,用此阈值作为感染概率进行仿真获得节点的真实重要性。为了消除波动的影响,本文进行1 000次独立仿真,取平均值sv作为节点v的真实重要性。至此,在获得了节点v的归一化结构特征
${ {\boldsymbol{x}}_v}$ 和真实重要性sv后,采用线性回归模型,选取均方误差(mean squared error, MSE)建立目标函数以学习节点局部结构特征与真实重要性之间的关系:$$\min J = s - f( {\boldsymbol{x}})$$ (5) 为了获得模型最优的回归系数,本文采用Adam优化器[27]优化目标函数。
-
本文用LastFM[28]作为训练网络对节点重要性挖掘模型进行训练学习。LastFM是一个2020年3月从公共API收集的社交网络,节点代表亚洲的用户账号,边代表它们之间相互关注的关系,其节点规模为7 624,边数量为27 806,最大度为216。首先从LastFM网络中提取节点的特征向量;同时,以LastFM网络中每个节点为初始感染节点,进行1 000次独立的SIR传播仿真,将1 000次的平均sv作为每个节点的标签;最后,将标签和特征向量作为训练集输入线性回归模型,训练得到节点重要性度量模型,用于预测其他网络中每个节点的重要性。
-
本文用13个不同类型的真实网络对本文提出的方法进行测试,并和度中心性、介数中心性、K-shell中心性、H-index中心性和DynamicRank中心性进行对比。
-
为了评估各方法是否能准确发现网络中的重要节点,采用Kendall Tau系数[29]评估节点重要性预测排序与真实排序的相关性。给定两个有序序列,每个序列关联图中|V|个节点的重要程度,
$X = ({x_1}, $ $ {x_2},\cdots,{x_{|V|}}\} $ ,$Y = ({y_1},{y_2},\cdots,{y_{|V|}}\} $ 。从图中选取两个节点$i,j$ , 若${x_i} > {x_j}$ 且${y_i} > {y_j}$ ,或者${x_i} < {x_j}$ 且${y_i} < {y_j}$ ,这两个节点是和谐的。而如果${x_i} > {x_j}$ 且${y_i} < {y_j}$ ,或者${x_i} < {x_j}$ 且${y_i} > {y_j}$ ,那么两个节点是不和谐的。除此以外,若${x_i} = {x_j}$ 或${y_i}{\rm{ = }}{y_j}$ ,这两个节点不属于任何一种。对网络中$\dfrac{1}{2}\left| V \right|(\left| V \right| - 1)$ 节点对进行比较,可得到两个序列的Kendall Tau系数:$$\tau {\rm{ = }}\frac{{2({n_ + } - {n_ - })}}{{\left| V \right|(\left| V \right| - 1)}}$$ (6) 式中,
${n_ + }$ 是和谐节点对的数目;${n_{\rm{ - }}}$ 是不和谐节点对的数目。这个系数值在[−1,1]的范围内。若X和Y不相关,那么$\tau $ 趋近于0。相反Kendall Tau系数越大,说明两个序列相关性强,排序结果越一致。 -
表 2 13个真实网络的基本特征数据
网络 n m $\left\langle k \right\rangle $ ${k_{\max }}$ $\left\langle c \right\rangle $ Router 5 022 6 258 2.490 106 0.010 0 Grid 4 941 6 594 2.669 17 0.103 0 CM 27 519 116 181 3.030 202 0.630 0 Stelzl 1 702 3155 3.700 95 0.006 0 Vidal 3 023 6 149 4.100 129 0.065 8 Sex 16 730 39 044 4.700 305 0 NS 379 914 4.820 34 0.370 0 Figeys 2 239 6 432 5.700 314 0.039 9 Email 1 133 5 451 9.620 71 0.110 0 Hamster 2 426 16 631 13.700 273 0.537 6 Jazz 198 2 742 27.690 91 0.520 0 Polblog 1 224 19 025 31.08 467 0.226 0 USAir 1 574 28 236 35.880 596 0.380 0 本文采用的13个真实网络中,包括了规模较小的网络(如Jazz),也有规模较大的网络(如Cond-Mat, CM),其平均度的范围为2~35。其中,1) Jazz是爵士乐手之间的协作网络,每条边表示两个乐手在一个乐队中一起演奏;2) NetScience(NS)是发表关于复杂网络主题论文的科学家之间的合作者网络;3) Email是Rovirai Virgili大学成员之间的电子邮件交换网络;4) Sex是研究男女性伙伴的网络;5) Polblog是2004年美国大选中博客之间的超链接形成的网络;6) USAir是2010年美国机场之间的航空网络;7) Router是由Rocketfuel项目收集的互联网路由器拓扑网络;8) Cond-Mat(CM)是1995年−1999年arXiv出版物的科学家合作网络;9) Grid是美国西部的某电力网络;10) Figeys、Stelzl和Vidal是3个蛋白质−蛋白质相互作用网络;11) Hamster是一个包含网站用户之间的友谊和家庭关系的网络。以上数据集可从网站(
http://konect.cc/networks/ )获得,这13个真实网络的详细特征如表2所示,其中,n是节点数目,m是边数目,$\left\langle k \right\rangle $ 表示所有节点的平均度,${k_{\max }}$ 代表节点的最大度,所有节点的平均聚集系数为$\left\langle c \right\rangle $ 。 -
为了检测模型预测的准确性,本文首先对测试网络中每个节点作1 000次SIR传播仿真,将1 000次的平均
$ s_v$ 作为测试网络节点的真实影响力。再根据节点影响力的预测值和真实值的Kendall Tau系数评价模型的预测效果。本文方法和其他基准方法的对比结果如表3所示。从表3可以看出,本文提出的方法在大部分网络中表现非常好,13个网络中有10个网络都好于对比方法,尤其在NS网络中,相比于表现第二好的DynamicRank中心性方法,相关系数提升了0.2456。在平均度比较高(平均度大于20)的网络中,由于训练集中缺少类似的大度点的局部结构,无法学习到大度节点的重要性,极大影响了模型的判断,如在Polblog网络中,最大度为467,远高于训练网络的最大度216。另一方面,平均度反映网络中常见的局部结构。如训练网络LastFM的平均度为7.294,虽然也存在度为20的局部结构,但这种结构在训练网络中并不常见,转换得到的训练集会极不平衡。模型对度为20的局部结构无法充分学习,因此模型在度大于20的网络表现也就较差。
表 3 不同方法与SIR模型仿真结果的Kendall Tau相关性系数
网络 H-index 介数中心性 K-shell 度中心性 DynamicRank中心性 本文方法 Router 0.453 1 0.207 9 0.454 0 0.4342 0.6411 0.8377 Grid 0.422 0 0.390 0 0.326 0 0.4406 0.575 0 0.7827 CM 0.592 6 0.304 8 0.577 4 0.5617 0.6023 0.7969 Stelzl 0.530 2 0.440 0 0.523 1 0.4969 0.7029 0.8917 Vidal 0.587 8 0.491 1 0.588 3 0.5553 0.7302 0.9062 Sex 0.526 1 0.444 4 0.534 6 0.4963 0.7399 0.8704 NS 0.515 0 0.181 0 0.502 0 0.5408 0.632 0 0.8776 Figeys 0.670 0 0.585 0 0.668 0 0.6528 0.7931 0.8287 Email 0.802 5 0.682 5 0.769 5 0.7924 0.8254 0.9252 Hamster 0.734 0 0.579 0 0.717 0 0.7425 0.7785 0.8582 Jazz 0.893 0 0.502 0 0.759 0 0.8841 0.893 0 0.5814 Polblog 0.930 7 0.713 5 0.911 2 0.9269 0.944 0 0.7543 USAir 0.808 1 0.5419 0.801 4 0.7857 0.8287 0.6197 为了验证本文学习模型的鲁棒性,本文在不同感染概率下对模型效果进行了分析。设置
$\;\beta = c{\beta _c}$ ,选取不同c值用于分析选取不同传染概率对重要节点挖掘的影响。如图3所示,在不同感染概率β=βc、1.5βc、2βc、2.5βc下,本文利用特征工程的方法提出的特征能够很好地描述节点在网络中的重要性。在不同的感染概率下,本文方法依旧能在低平均度的网络中取得最好的效果。图3的结果表明,虽然基于特征工程的方法在训练时依赖于感染概率,但训练得到的重要性评估模型对感染概率并不敏感,适用于对不同感染概率下,节点重要性的挖掘。
进一步,为了验证这8个特征的有效性,本文在不同网络上选取不同特征组合进行实验分析。
1) 在Figeys网络中去除特征1后,算法排序结果和实际仿真排序结果的Kendall Tau相关性系数从0.83下降到0.77。
2) 在NS网络中去除特征1后,Kendall Tau相关性系数从0.879下降至0.872,若去除特征2,Kendall Tau相关性系数下降更为明显,降至0.861。
3) 若在Grid网络中去除特征2,Kendall Tau相关性系数从0.775下降至0.728。若再进一步去除特征7,Kendall Tau相关性系数大幅降低至0.688。
4) 在Stelzl网络中,若同时去除特征3和7时,Kendall Tau相关性系数从0.89大幅下降至0.79。
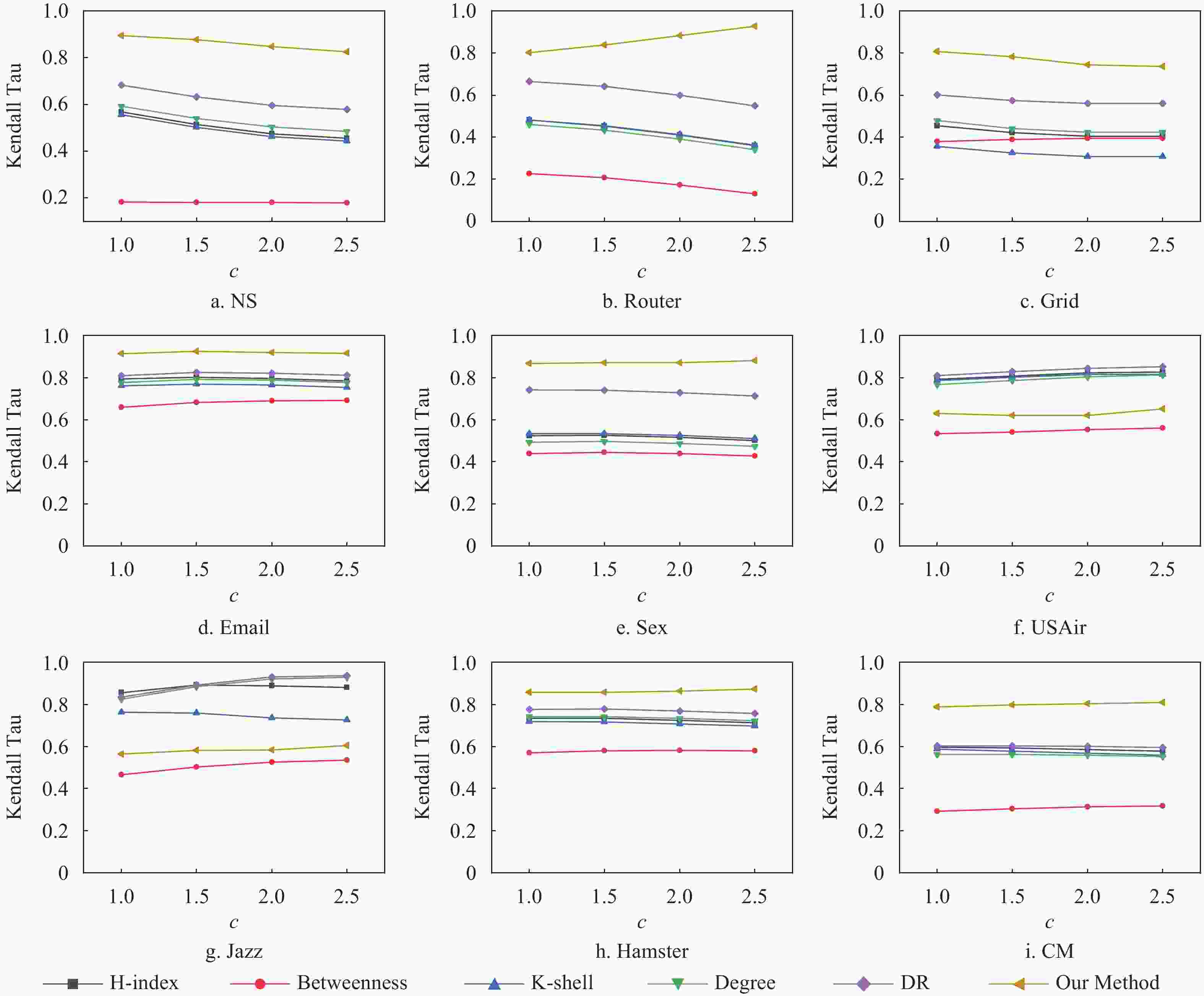
图 3 本文方法与其他基准方法在各网络中不同感染概率下的Kendall Tau相关性系数对比
从上面的分析可以看出,8个特征在不同网络的重要节点排序上相互补充和促进,去掉某个或某组特征,对节点重要性研判将带来直接影响。而完整的8个特征,模型更稳定,也能更准确地判断网络中节点的重要性。
同时,根据信息传播理论,节点对三阶邻居以外的影响已经很小,更高阶的邻居信息趋于同质化[30]。为了验证更高阶邻居对模型的影响,根据特征4-8,拓展三阶邻居的特征9-13(三阶邻居的度之和、三阶邻居数目、三阶邻居度的基尼系数、三阶外联邻居度之和、三阶外联邻居度的基尼系数)。选取email作为测试网络,发现8个特征训练所得模型的排序结果与仿真结果的Kendall Tau相关性系数为0.925,而13个特征的相关系数为0.927,提升并不明显。实验表明,选取二阶邻居以内的信息已足够。
-
本文利用特征工程方法对节点的邻居信息进行提取和重构,提取更能反映节点局部结构的特征向量。根据节点的局部结构特征信息,建立了用于挖掘网络中重要节点的机器学习模型。用13个实际网络对本文所提方法的有效性进行了测试,并和典型的基准方法进行了对比。实验结果表明,本文提出的机器学习模型能有效地挖掘网络中的重要节点,13个网络中有10个网络的效果显著地优于已有方法。由于本文方法一定程度上依赖于训练网络的局部结构,对于训练数据中出现较少的局部结构,由于训练不充分,在测试时表现出的效果整体欠佳。在未来的研究中,一方面是构建更加丰富多样的训练集,另一方面,需提取更为丰富的局部特征,提升模型的预测能力。近年来,随着深度学习的发展,尤其是图神经网络的研究深入,如何利用图神经网络训练泛化性能更好的复杂网络局部结构特征的表达模型[31],从而提高重要节点识别的准确率也是一个重要的研究方向。
Identifying Critical Nodes Based on Feature Engineering
-
摘要: 复杂网络中重要节点的挖掘对分析和治理现实复杂系统有着重要的指导意义。设计能反映节点重要性的有效计算方法,是高效准确挖掘重要节点的关键。该文基于节点的邻居信息,采用特征工程中的特征提取、特征重构等方法提取能有效反映节点局部结构的特征向量。利用局部特征向量,通过回归模型建立节点局部结构和重要性的关系模型。在13个真实网络上的实验结果表明,相比于已有的重要节点挖掘基准方法,该方法具有更优的性能。Abstract: To mine important nodes in complex networks is very important for analyzing and governing real complex systems. Designing a good indicator that reflects the importance of nodes is a key issue on efficiently and accurately mining critical nodes. On the bases of the neighbor information of nodes, the features that can effectively reflect the local structure of nodes are extracted through feature extraction and reconstruction. The relational model between local structure and real importance of nodes is established by utilizing regression model based on the extracted features. The experimental results on 13 real networks show that the proposed method outperforms the benchmark methods of critical nodes identification.
-
Key words:
- complex network /
- local structure /
- critical nodes /
- feature engineering
-
表 1 节点局部结构特征度量
序号 名称 计算公式 1 自身度 dv 2 一阶邻居的度之和 $\displaystyle\sum\limits_{v \in {\varGamma _1}(u)} {{d_v}} $ 3 一阶邻居度的基尼系数 $\frac{ {\displaystyle\sum\limits_{ {v_i} \in {\varGamma _1}(u)}^{} {\displaystyle\sum\limits_{ {v_j} \in {\varGamma _1}(u)}^{} {\left| { {d_{ {v_i} } } - {d_{ {v_j} } } } \right|} } } }{ {2n \displaystyle\sum\limits_{v \in {\varGamma _1}(u)}^{} { {d_v} } } }$ 4 二阶邻居总数 ${\rm{Len}}({\varGamma _2}(u))$ 5 二阶邻居度之和 $\displaystyle\sum\limits_{v \in {\varGamma _2}(u)} {{d_v}} $ 6 二阶邻居度的基尼系数 $\frac{ {\displaystyle\sum\limits_{ {v_i} \in {\varGamma _2}(u)}^{} {\displaystyle\sum\limits_{ {v_j} \in {\varGamma _2}(u)}^{} {\left| { {d_{ {v_i} } } - {d_{ {v_j} } } } \right|} } } }{ {2n \displaystyle\sum\limits_{v \in {\varGamma _2}(u)}^{} { {d_v} } } }$ 7 二阶外联邻居度之和 $\displaystyle\sum\limits_{v \in {{\tilde \varGamma }_2}(u)} {{d_v}} $ 8 二阶外联邻居度的基尼系数 $\frac{ {\displaystyle\sum\limits_{ {v_i} \in { {\tilde \varGamma }_2}(u)}^{} {\displaystyle\sum\limits_{ {v_j} \in { {\tilde \varGamma }_2}(u)}^{} {\left| { {d_{ {v_i} } } - {d_{ {v_j} } } } \right|} } } }{ {2n \displaystyle\sum\limits_{v \in { {\tilde \varGamma }_2}(u)}^{} { {d_v} } } }$  下载: 导出CSV
下载: 导出CSV
表 2 13个真实网络的基本特征数据
网络 n m $\left\langle k \right\rangle $ ${k_{\max }}$ $\left\langle c \right\rangle $ Router 5 022 6 258 2.490 106 0.010 0 Grid 4 941 6 594 2.669 17 0.103 0 CM 27 519 116 181 3.030 202 0.630 0 Stelzl 1 702 3155 3.700 95 0.006 0 Vidal 3 023 6 149 4.100 129 0.065 8 Sex 16 730 39 044 4.700 305 0 NS 379 914 4.820 34 0.370 0 Figeys 2 239 6 432 5.700 314 0.039 9 Email 1 133 5 451 9.620 71 0.110 0 Hamster 2 426 16 631 13.700 273 0.537 6 Jazz 198 2 742 27.690 91 0.520 0 Polblog 1 224 19 025 31.08 467 0.226 0 USAir 1 574 28 236 35.880 596 0.380 0
下载: 导出CSV
表 3 不同方法与SIR模型仿真结果的Kendall Tau相关性系数
网络 H-index 介数中心性 K-shell 度中心性 DynamicRank中心性 本文方法 Router 0.453 1 0.207 9 0.454 0 0.4342 0.6411 0.8377 Grid 0.422 0 0.390 0 0.326 0 0.4406 0.575 0 0.7827 CM 0.592 6 0.304 8 0.577 4 0.5617 0.6023 0.7969 Stelzl 0.530 2 0.440 0 0.523 1 0.4969 0.7029 0.8917 Vidal 0.587 8 0.491 1 0.588 3 0.5553 0.7302 0.9062 Sex 0.526 1 0.444 4 0.534 6 0.4963 0.7399 0.8704 NS 0.515 0 0.181 0 0.502 0 0.5408 0.632 0 0.8776 Figeys 0.670 0 0.585 0 0.668 0 0.6528 0.7931 0.8287 Email 0.802 5 0.682 5 0.769 5 0.7924 0.8254 0.9252 Hamster 0.734 0 0.579 0 0.717 0 0.7425 0.7785 0.8582 Jazz 0.893 0 0.502 0 0.759 0 0.8841 0.893 0 0.5814 Polblog 0.930 7 0.713 5 0.911 2 0.9269 0.944 0 0.7543 USAir 0.808 1 0.5419 0.801 4 0.7857 0.8287 0.6197
下载: 导出CSV
-
[1] 任晓龙, 吕琳媛. 网络重要节点排序方法综述[J]. 科学通报, 2014, 59(13): 1175-1197. REN X L, LYU L Y. Review of ranking nodes in complex networks[J]. Science Bulletin, 2014, 59(13): 1175-1197. [2] 吕琳媛. 复杂网络链路预测[J]. 电子科技大学学报, 2010, 39(5): 651-661. doi: 10.3969/j.issn.1001-0548.2010.05.002 LYU L Y. Link prediction in complex networks[J]. Journal of University of Electronic Science and Technology of China, 2010, 39(5): 651-661. doi: 10.3969/j.issn.1001-0548.2010.05.002 [3] 朱军芳, 陈端兵, 周涛, 等. 网络科学中相对重要节点挖掘方法综述[J]. 电子科技大学学报, 2019, 48(4): 595-603. doi: 10.3969/j.issn.1001-0548.2019.04.018 ZHU J F, CHEN D B, ZHOU T, et al. A survey on mining relatively important nodes in network science[J]. Journal of University of Electronic Science and Technology of China, 2019, 48(4): 595-603. doi: 10.3969/j.issn.1001-0548.2019.04.018 [4] 赫南, 李德毅, 淦文燕, 等. 复杂网络中重要性节点发掘综述[J]. 计算机科学, 2007, 34(12): 1-5. doi: 10.3969/j.issn.1002-137X.2007.12.001 HE N, LI D Y, GAN W Y, et al. Mining vital nodes in complex networks[J]. Computer Science, 2007, 34(12): 1-5. doi: 10.3969/j.issn.1002-137X.2007.12.001 [5] LYU L Y, CHEN D, REN X L, et al. Vital nodes identification in complex networks[J]. Physics Reports, 2016, 650: 1-63. doi: 10.1016/j.physrep.2016.06.007 [6] KITSAK M, GALLOS L K, HAVLIN S, et al. Identification of influential spreaders in complex networks[J]. Nature Physics, 2010, 6: 888-893. doi: 10.1038/nphys1746 [7] FREEMAN L C. Centrality in social networks conceptual clarification[J]. Social Networks, 1978, 1(3): 215-239. doi: 10.1016/0378-8733(78)90021-7 [8] FREEMAN L C. A set of measures of centrality based on betweenness[J]. Sociometry, 1977, 40(1): 35-41. doi: 10.2307/3033543 [9] FREEMAN L C, BORGATTI S P, WHITE D R. Centrality in valued graphs: A measure of betweenness based on network flow[J]. Social Networks, 1991, 13(2): 141-154. doi: 10.1016/0378-8733(91)90017-N [10] ESTRADA E, HIGHAM D J, HATANO N. Communicability betweenness in complex networks[J]. Physica A, 2009, 388(5): 764-774. doi: 10.1016/j.physa.2008.11.011 [11] NEWMAN M. A measure of betweenness centrality based on random walks[J]. Social Networks, 2005, 27(1): 39-54. doi: 10.1016/j.socnet.2004.11.009 [12] DOLEV S, ELOVICI Y, PUZIS R. Routing betweenness centrality[J]. Journal of the ACM, 2010, 57(4): 1-27. [13] LYU L Y, ZHOU T, ZHANG Q M, et al. The H-index of a network node and its relation to degree and coreness[J]. Nature Communications, 2016, 7(1): 10168. doi: 10.1038/ncomms10168 [14] KLEINBERG J M. Authoritative sources in a hyperlinked environment[J]. Journal of the ACM, 1999, 46(5): 604-632. doi: 10.1145/324133.324140 [15] LYU L Y, ZHANG Y C, YEUNG C H, et al. Leaders in social networks, the delicious case[J]. PLoS ONE, 2011, 6: e21202. doi: 10.1371/journal.pone.0021202 [16] BRIN S, PAGE L. The Anatomy of a Large-scale hypertextual web search engine[J]. Computer Networks and ISDN Systems, 1998, 30: 107-117. doi: 10.1016/S0169-7552(98)00110-X [17] ZHANG J X, CHEN D B, DONG Q, et al. Identifying a set of influential spreaders in complex networks[J]. Scientific Reports, 2016, 6(1): 27823. doi: 10.1038/srep27823 [18] CHEN D, LYU L Y, SHANG M S, et al. Identifying influential nodes in complex networks[J]. Physica A, 2012, 391: 1777-1787. doi: 10.1016/j.physa.2011.09.017 [19] MOREENO Y, PASTOR-SATORRAS R, VESPIGNANI A. Epidemic outbreaks in complex heterogeneous networks[J]. The European Physical Journal B, 2002, 26(4): 521-529. [20] COHEN J, COHEN P, WEST S G, et al. Applied multiple regression/correlation analysis for the behavioral sciences[M]. London: Routledge, 2013. [21] CHEN D B, SUN H L, TANG Q, et al. Identifying influential spreaders in complex networks by propagation probability dynamics[J]. Chaos, 2019, 29(3): 033120. doi: 10.1063/1.5055069 [22] CHEN D B, GAO H, LYU L Y, et al. Identifying influential nodes in large-scale directed networks: The role of clustering[J]. PLoS ONE, 2013, 8(10): e77455. doi: 10.1371/journal.pone.0077455 [23] NEWMAN M. Spread of epidemic disease on networks[J]. Physical Review E, 2002, 66(1): 016128. doi: 10.1103/PhysRevE.66.016128 [24] CASTELLANO C, PASTOR-SATORRAS R. Thresholds for epidemic spreading in networks[J]. Physical Review Letters, 2010, 105(21): 218701. doi: 10.1103/PhysRevLett.105.218701 [25] COHEN R, EREZ K, BEN-AVRAHAM D, et al. Resilience of the internet to random breakdowns[J]. Physical Review Letters, 2000, 85(21): 4626-4628. doi: 10.1103/PhysRevLett.85.4626 [26] SHU P, WANG W, TANG M, et al. Numerical identification of epidemic thresholds for susceptible-infected-recovered model on finite-size networks[J]. Chaos, 2015, 25(6): 063104. doi: 10.1063/1.4922153 [27] KINGMA D, BA J. Adam: A method for stochastic optimization[EB/OL]. (2014-12-22). https://arxiv.org/abs/1412.6980. [28] ROZEMBERCZKI B, SARKAR R. Characteristic functions on graphs: Birds of a feather, from statistical descriptors to parametric models[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. [S.l.]: ACM, 2020: 1325-1334. [29] KNIGHT W R. A computer method for calculating Kendall’s Tau with ungrouped data[J]. Journal of the American Statistical Association, 1966, 61(314): 436-439. doi: 10.1080/01621459.1966.10480879 [30] CHRISTAKIS N A, FOWLER J H. Social contagion theory: Examining dynamic social networks and human behavior[J]. Statistics in Medicine, 2013, 32(4): 556-577. doi: 10.1002/sim.5408 [31] YU E Y, WANG Y P, FU Y, et al. Identifying critical nodes in complex networks via graph convolutional networks[J]. Knowledge-Based Systems, 2020, 198: 105893. doi: 10.1016/j.knosys.2020.105893 -

 点击查看大图
点击查看大图
图(3) / 表(3)
计量
- 文章访问数: 4430
- HTML全文浏览量: 1347
- PDF下载量: 66
- 被引次数: 0



































































