 ISSN
ISSN 




-
社交机器人是一种具有虚拟人格化形象的算法智能体,它们渗透于社交网络之中,通过大量连接社交网络用户并发送特定信息,在一定程度上影响着公众舆论。其中,部分社交机器人利用了其对于舆论的影响力,在社交网络中实施谣言传播、虚假消息散布等恶意行为,威胁着社交网络的安全与稳定。基于此,针对社交机器人的检测技术成了近年来的研究热点。
然而,为逃避检测,另有一部分社交机器人通过升级换代,具有了逼真的网络身份(头像、用户名等详细的个人资料)、发送带有情感色彩博文的能力、相当数量的粉丝及关注者等一系列更为“类人”的网络形象特征。本文将上述经过升级的社交机器人命名为“类人”社交机器人。基于其“类人”的属性,从海量的网络用户群体中识别出“类人”社交机器人的难度更大,正因如此,能够使用相应的技术手段对它们进行有效、准确的检测就显得更加重要。
与普通的社交机器人检测任务相同,“类人”社交机器人检测,旨在使用分类模型对“类人”社交机器人用户和人类用户进行二分类。然而,现实中能够直接从社交网络中识别并获取到的“类人”社交机器人用户的数量远少于正常人类用户的数量,在此情况下训练得到的检测模型将存在严重的过拟合问题。为了获得性能更为优越的检测模型,就要求在训练模型之前首先进行训练数据集的扩充。由于“类人”社交机器人已经混迹在真实人类用户之中且难以被“识破”,那么便可以学习人类用户的社交行为数据,并生成相似数据,以达到扩充其检测训练集的目的。
为实现数据扩充,文献[1]提出使用数字DNA编码社交机器人用户的行为寿命,并使用遗传算法对当前的机器人用户进行迭代优化,由此生成符合实验要求的数据。虽然该方法具有一定的作用,但是需要事先对采集到的每个数据样本进行建模,工作量大、且实现效率低。
不同于文献[1],文献[2-3]分别提出使用生成式对抗网络(generative adversarial networks, GAN)和改进的条件对抗网络(conditional generative adversarial networks, CGAN)来扩充社交机器人数据集。文中二者均取得了良好的扩充效果,且提出的方法相较于文献[1]均更易于操作、实现效率更高。但是文献[2-3]均未考虑到GAN的固有缺点(如生成器模式崩溃问题等)对于数据扩充结果可能产生的影响,更没有提出相应的解决办法。
为缓解GAN[4]生成器的模式崩溃问题,文献[5]提出了进化生成式对抗网络(evolutionary generative adversarial networks, E-GAN)。训练中,E-GAN借用种群进化的思想训练生成器、使用多目标函数评价各生成器的性能并保留最优个体,以此保证了生成的数据同时具有较高的“真实性”与多样性,从而缓解了模式崩溃问题。但是E-GAN的设计并非完美。首先,由单个全连接网络或卷积网络构成的生成器,难以从输入的随机噪声中充分挖掘出与训练数据相关的隐藏特征,导致生成数据的“真实性”与多样性程度差强人意。其次,E-GAN生成器损失函数的优化目标存在自相矛盾的现象,导致训练过程中模型收敛速度慢、生成器梯度不稳定;训练结束后,生成数据的质量优劣不一。
为优化E-GAN的训练效果,文献[6]提出修改E-GAN生成器的损失函数及判别器结构,以避免梯度消失的发生;文献[7]提出改变判别器的输出形式及生成器的损失函数,从而提高生成数据的多样性;文献[8]提出使用帕累托优势度(Pareto dominance)函数作为评估生成器性能的多目标评估函数;文献[9]在E-GAN的 “突变”步骤后引入“交叉”步骤,以进一步提高生成数据的多样性。文献[6-9]的实验结果较之原始E-GAN均有一定的提高,但是均未解决制约模型性能提高的本质问题。
基于此,本文提出了一种基于改进的海林格距离的变分进化生成式对抗网络(Hellinger distance based variational evolutionary generative adversarial network, HVE-GAN)模型,以提高E-GAN性能、实现“类人”社交机器人检测数据集的有效扩充。
-
E-GAN的结构如图1所示,若无特殊说明,则文中D特指判别器(discriminator),D特指解码器(decoder)。父代生成器
$ {G_\theta } $ 通过变异产生子代生成器,子代生成器分别生成数据,通过评估函数对于各子代生成器的性能进行评估,性能最优的子代生成器将被保留作为下一次变异的父代;此时被挑选出来的生成器与判别器进行对抗训练,且根据对抗结果进行优化。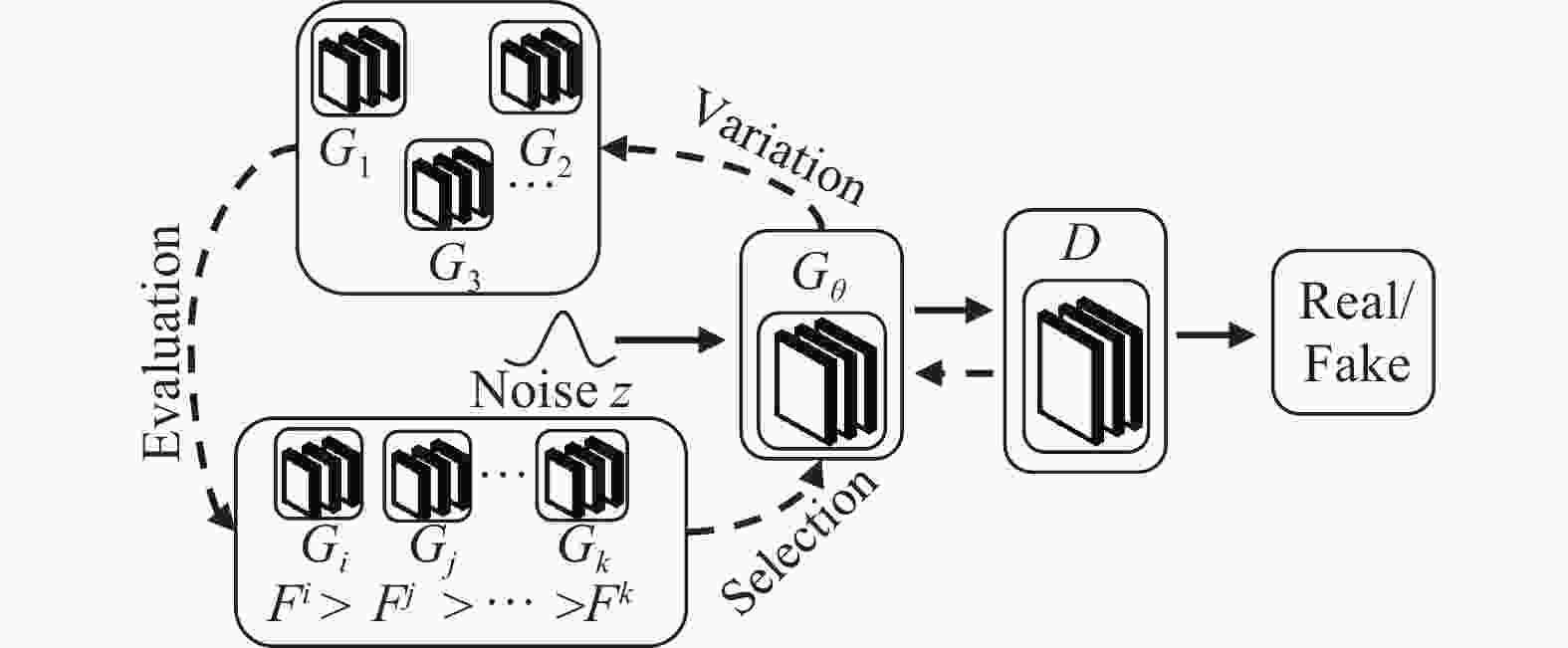
图 1 E-GAN模型结构图
由图1可知,E-GAN模型在训练过程中借用了进化算法的思想,其每个训练步骤由3个阶段组成:
1)变异(variation):给定一个父代生成器个体
$ {G_\theta } $ ,使其在不同的损失函数的指导下变异并产生新的子代${G_{{\theta _1}}},{G_{{\theta _2}}},\cdots,{G_{{\theta _k}}}$ ;2)评价(evaluation):对于每一个子代生成器,它们的性能将在当前的“自然环境”(即与判别器的对抗训练)下,由评价函数给出;
3)选择(selection):E-GAN将根据子代生成器的评估值进行“自然选择”,即优秀的子代生成器被保留到下一代,作为下一次训练过程中进行变异的父本。
变分自编码器[10](variational autoencoder, VAE)是以自编码器(autoencoder, AE)[11]结构为基础的深度生成模型。但是AE的解码器不具有数据生成能力,而VAE通过引入“重参数化”过程,使其解码器具有了数据生成能力。
-
为了进一步提高E-GAN生成数据的“真实性”与多样性,本文将E-GAN的生成器由变分自编码器取代,形成变分进化生成式对抗网络(variational evolutionary generative adversarial networks, VE-GAN)。
VE-GAN的模型结构如图2所示。修改后的生成器中,编码器E负责接收人类用户数据,并将其编码至包含人类用户数据隐藏特征的低维数据空间
$\tilde z $ ,解码器D负责从$\tilde z $ 中采样,并将采样数据在不同的损失函数的指导下解码为与人类用户数据相似的“类人”社交机器人数据。
图 2 VE-GAN模型结构图
对生成器的结构进行修改后,模型的损失函数也要相应地发生变化。借鉴文献[12],则此时编码器E的损失函数为:
$$ {L_{{\rm{VE - GAN}}}}({\rm{E}}) = {L_{{\rm{E - GAN}}}}({\rm{KL}}) + {L_{{\rm{E - GAN}}}}(D) $$ (1) 其中,
$$\begin{split}& \;\;\;{{L_{{\rm{E - GAN}}}}({\rm{KL}}) = {\rm{KL}}(Q(\tilde Z|X)||P(Z)) }\\ &{ {L_{{\rm{E - GAN}}}}(D) = - {E_{P(\tilde Z|X)}}(\log P(X|\tilde Z)) } \end{split}$$ (2) 式中,
$ X $ 为真实数据;先验分布$ Z\sim N(0,1) $ ,$ \tilde Z $ 为重参数化后的隐空间数据;$ Q(\tilde Z|X) $ 与$ P(Z) $ 分别为$ \tilde Z $ 与$ Z $ 采样分布情况的表示。对于单个生成器G而言,其损失函数为:
$$ {L_{{\rm{VE - GAN}}}}(G) = {L_{{\rm{E - GAN}}}}(D) + {L_{{\rm{E - GAN}}}}(G\_{\rm{fake}}) $$ (3) 式中,
${L_{{\rm{E - GAN}}}}(G\_{\rm{fake}})$ 为用于指导当前生成器变异的损失函数。判别器D的损失函数为:$$ \begin{split}& {L_{{\rm{VE - GAN}}}}(D) = {E_{x\sim P(X)}}\log (D(x)) + \hfill \\ &\;\frac{1}{2} ({E_{\tilde x\sim P(X|\tilde Z)}}\log (1 - D(G(\tilde x))) + \hfill \\ &\;\;\;\;\;\;\;\;{E_{z\sim P(z)}}\log (1 - D(G(z)))) \hfill \end{split} $$ (4) 则模型整体的损失函数为:
$$ {L_{{\rm{VE - GAN}}}} = {L_{{\rm{VE - GAN}}}}(E) + {L_{{\rm{VE - GAN}}}}(G) + {L_{{\rm{VE - GAN}}}}(D) $$ (5) 将E-GAN的单个网络结构的生成器修改为VAE结构,修改后:1)模型使用编码得到的隐空间数据而非随机噪声进行数据生成,隐空间数据中含有丰富的训练数据隐藏特征信息,有助于模型在信息加持下,生成“真实性”和多样性程度与训练数据更为相似的用户数据;2)生成器训练过程中,VAE的损失函数能够迫使解码器输出与训练数据更为相似的数据,不断提升解码器利用隐空间数据拟合训练数据的能力。以上两点共同作用,使得生成数据的“真实性”和多样性程度得到了提高。
-
用于指导E-GAN生成器变异的损失函数之一为Heuristic损失函数,其定义为:
$$ M_G^{{\rm{Heuristic}}} = - \frac{1}{2}{E_{z\sim {p_z}}}[\log (D(G(z)))] $$ (6) 推理可知,最小化式(6)相当于最小化
$[{\rm{KL}} $ $ ({p_g}||{p_{{\rm{real}}}}) - 2{\rm{JS}}({p_g}||{p_{{\rm{real}}}})]$ ,这便意味着生成器要在减小$ {p}_{g} $ 和${p}_{{\rm{real}}}$ 之间的KL散度的同时增大其JS散度,显然该目标是自相矛盾的。在实践中,该目标也会严重影响生成器梯度的稳定性。因此需要对该损失函数进行替换。本文使用改进的海林格距离(Hellinger distance)替换Heuristic损失函数,将其作为生成器的损失函数之一。海林格距离是f散度的一种,被用来度量两个概率分布之间的距离。在可度量空间上,海林格距离被定义为:
$$ M_G^{{\rm{Hellinger}}} = \sqrt {\sum\limits_{x \in X} {{{(\sqrt {P(x)} - \sqrt {Q(x)} )}^2}} } $$ (7) 式中,
$ P(x) $ 和$ Q(x) $ 分别为在给定连续空间$ X $ 中,$ x \in X $ 的两个连续性分布。由于海林格距离具有对于不平衡数据集不敏感的优秀特征,被广泛应用于采样方法中。基于上述考虑,可将海林格距离应用于本模型,作为指导生成器变异的损失函数。同时,为了避免在具体的训练过程中,由于生成器生成的数据量较大,导致原始的海林格距离的值也较大,从而给梯度带来较大的影响,本文将原始的海林格距离进行了缩放改进,使其更加适用于当前模型的特点。
改进的海林格距离为:
$$ {M^{{\rm{Hellinger}}}} = \sqrt {\frac{1}{n}\sum\limits_{z \sim p(z)} {{{(\sqrt {D(G(z))} - 1)}^2}} } $$ (8) 式(8)可理解为:生成器试图缩小其生成数据的实际概率分布值与目标概率分布值1之间的海林格距离。式中,n为生成器生成数据的数量。式(8)仅对原始公式进行了缩放处理,既不会影响公式的性能,又能很好地将函数值控制在较小的范围内,从而也稳定了梯度。
在更为鲁棒的损失函数(改进的海林格距离)的指导下,彻底解决了在训练过程中,由不合理的损失函数优化目标导致的生成器梯度不稳定问题,从而使生成数据的质量也得到了保证。本文将进行了上述生成器结构与损失函数改进的模型称为基于海林格距离的变分进化生成式对抗网络(HVE-GAN),并使用该模型完成“类人”社交机器人检测数据集的扩充任务。
-
利用本文提出的HVE-GAN进行“类人”社交机器人数据生成的算法步骤如下。
算法:“类人”社交机器人数据生成
输入:人类用户的数据X
输出:“类人”社交机器人数据X′
1) 初始化一个VAE结构的生成器
$ {G_0} $ ,并令其编码器$ {\text{En}}{{\text{c}}_0} $ 为初代编码器,解码器为初代解码器,初始化一个判别器D;2) 将X输入给
$ {\text{En}}{{\text{c}}_0} $ ,并将其编码得到的包含人类用户隐藏特征的隐空间数据$ {\tilde z_0} $ 输入给$ {\text{De}}{{\text{c}}_0} $ ,令其解码得到“类人”社交机器人数据$ {\tilde x_0} = {\text{Dec}}({\tilde z_0}) $ ;3) 将
$ {\tilde x_0} $ 输入D,并根据D的反馈在不同的损失函数的指导下进行$ {G_0} $ 中$ {\text{En}}{{\text{c}}_0} $ 和$ {\text{De}}{{\text{c}}_0} $ 的变异,生成子代编码器种群$\{ {\text{En}}{{\text{c}}_1},{\text{En}}{{\text{c}}_2}, \cdots ,{\text{En}}{{\text{c}}_n}\} $ 与子代解码器种群$ \{ {\text{De}}{{\text{c}}_1},{\text{De}}{{\text{c}}_2}, \cdots ,{\text{De}}{{\text{c}}_n}\} $ ;4) 利用评估函数
$ F = {F_q} + \gamma {F_d} $ ,$ \gamma > 0 $ 评估$ {G_0} $ 的性能,并给出相应的评估分数,其中,$ \gamma $ 为一个可学习的超参数,$ {F_q} $ 为适应度分数,$ {F_d} $ 为多样性分数;5) 优化判别器D,以提高判别器性能,从而更好地促进生成器的进化;
6) 将X输入给子代生成器的编码器种群
$\{ {\text{En}}{{\text{c}}_1}, $ $ {\text{En}}{{\text{c}}_2}, \cdots ,{\text{En}}{{\text{c}}_n}\} $ 中的各编码器个体$ {\text{En}}{{\text{c}}_i} $ ,n为子代生成器的数量,$i \in \{ 1,2,\cdots,n\}$ ;经过单独的编码及重参数化后,分别得到数据集的不同隐空间变量数据集$ \tilde z = \{ {\tilde z_1},{\tilde z_2}, \cdots ,{\tilde z_n}\} $ ,将$ \stackrel{~}{z} $ 中的各数据集$ {\tilde z_i} $ 分别输入给子代生成器的解码器种群$ \{ {\text{De}}{{\text{c}}_1},{\text{De}}{{\text{c}}_2}, \cdots ,{\text{De}}{{\text{c}}_n}\} $ 中相应的解码器个体$ {\text{De}}{{\text{c}}_i} $ ,各解码器分别解码出“类人”社交机器人数据集$ \tilde x = \{ {\tilde x_1},{\tilde x_2}, \cdots ,{\tilde x_n}\} $ ,$ {\tilde x_i} = {\text{Dec}}({\tilde z_i}) $ ;7) 将由不同子代生成器生成的
$ {\tilde x_i} $ 分别输入D中,由判别器来评估各候选子代生成器$ {G_i} $ 生成的数据集的真实性;8) 由F给出该生成数据集的候选子代生成器
$ {G_i} $ 的评估分数,若任意$ {G_i} $ 的评估函数值均低于$ {G_0} $ 的值,则继续选择$ {G_0} $ 作为本次训练中变异的父本生成器,否则根据他们的评估函数值排名选出最优模型代替$ {G_0} $ 作为本次的变异父本;9) 本次变异父本
$ {G_0} $ 在不同的损失函数的指导下进行变异,得到子代生成器及其相应的编码器、解码器种群;10) 优化判别器D;
11) 若未完成预设次数的训练,则返回步骤6),进入下一次训练;若完成预设次数的训练后停止训练,并进入步骤12);
12) 取得HVE-GAN当前的解码器模型,对其输入
$ z\sim N(0,1) $ ,获得所需“类人”社交机器人的数据$ {X}^{'} $ 。在上述算法中,步骤1)~步骤5)为利用HVE-GAN的初始生成器生成“类人”社交机器人数据阶段;步骤6)~步骤11)为子代生成器的数据生成阶段;步骤11)为循环条件,步骤12)为最终的检测数据集生成阶段。
其中,步骤4)提到的评估函数
$ F $ 的适应度分数为:$$ {F_q} = {E_z}[D(G(z))] $$ (9) 即
$ {F}_{q} $ 为判别器对于待评估数据给出的真实性度量。多样性分数为:$$ \begin{split}& {F_d} = - \log ||{\nabla _D} - {E_x}[\log D(x)] - \hfill \\ &\;\;\;\;\;\;\;\;\;{E_z}[\log (1 - D(G(z)))] \hfill || \end{split} $$ (10) 即
$ {F}_{d} $ 为判别器D的优化函数时,通过D的梯度值的高低反映出待评估数据分布的集中程度。梯度值越小,则数据分布越分散,其多样性程度越高。 -
为了验证HVE-GAN模型性能的优越性,及其生成的“类人”社交机器人数据的“真实性”与多样性,选取文献[3]提出的社交机器人数据集扩充模型,以及E-GAN作为基线模型,与本文提出的VE-GAN、HVE-GAN一同进行数据生成,并进行对比实验;为了验证损失函数改进的有效性,进行E-GAN、VE-GAN及HVE-GAN在训练过程中生成器损失函数的变化情况对比实验。
-
本文所提出的HVE-GAN模型是基于E-GAN模型(http://github.com:WANG-Chaoyue/EvolutionaryGAN.git)做出的进一步改进。模型搭建于Theano框架下。HVE-GAN的生成器中,编码器为有一个隐藏层的全连接层结构,隐藏层的激活函数为LeakyRelu,输出层的激活函数为Sigmoid;解码器为有3个隐藏层的全连接层结构,隐藏层的激活函数为LeakyRelu,输出层为一层线性连接层,没有激活函数;判别器同样为有3个隐藏层的全连接层结构,其隐藏层的激活函数为LeakyRelu,而输出层的激活函数为Sigmoid。E-GAN的生成器与判别器结构与VE-GAN无异,只是减少了编码器结构。
模型训练时,上述模型的编码器、解码器或生成器、判别器均使用了Adam优化算法,生成器与判别器的学习率均为0.0001,编码器的学习率为0.0002。训练时的batch size大小设为64,训练次数设为10000。同样,除了编码器的超参数被去掉外,E-GAN与HVE-GAN的超参数设置均一致。
本文基于代码(https://github.com/eriklindernoren/PyTorch-GAN.git)对文献[2]中提出的GAN的社交机器人生成模型进行了复现。GAN搭建于PyTorch框架之下,生成器与判别器均采用了具有3个隐藏层的全连接层结构,隐藏层的激活函数均为LeakyRelu。其中,GAN判别器输出层的激活函数为Sigmoid。训练时,GAN的其他超参数的设置也与E-GAN完全相同,不再赘述。
-
由于“类人”社交机器人检测技术的原理为基于用户的社交行为特征向量进行二分类,则扩充检测数据集即为扩充“类人”社交机器人的社交行为特征向量,因此需要提取人类用户的社交行为特征,构造出每一位用户的特征向量用作实验的训练数据。为此,本文借鉴文献[13-14],提取了具有较高信息熵且普适的情感、非情感两类特征。
1) 情感特征提取。情感特征特指用户所发布的微博文本(以下简称博文)中所蕴含的语义情感特征。本实验借鉴文献[14],使用基于Attention机制的BiLSTM模型进行用户博文情感特征提取。博文情感特征定义为:
$$ \begin{split}& {{\rm{Mean}}} \_{\rm{of}}\_{\rm{affective}}\_{\rm{values}} = \hfill \\ &\;\;\;\;\;\frac{1}{K}\sum\limits_{i = 1}^K {{\rm{affective\_value}}{{\text{s}}_i}} \hfill \end{split} $$ (11) 式中,K为该用户发布的所有博文的数量;
$ {\rm{affective\_value}}{{\text{s}}_i} $ 表示该用户发布的第i条博文的情感分数。Mean_of_affective_values的取值范围为[0,1],越靠近0或者1,则该用户所发布的博文中所蕴含的情感越强烈鲜明,该用户是真实人类用户的概率越大;若该值越靠近0.5,表明该用户发布的微博文本中蕴含的情感越微弱,或具有正向情感倾向和负向情感倾向的微博分布越均匀,则该用户是社交机器人用户的可能性越大。2) 非情感特征提取。本文提取的非情感特征共3类:用户发微博的时序特征、微博用户账号特征、用户微博传播特征,如表1~表3所示。对于表中提到的Pic、Name、Verified、Location 4个特征,分别用“1”或“0”替代“是”或“否”的值,其他非情感特征的提取方法参见文献[13-14],此处不再赘述。
表 1 用户发微博的时序特征
特征名 含义 发布博文时间间隔均值
Interval_avg用户发布博文的时间间隔均值 发布博文时间间隔方差
Interval_variance用户发布博文的时间间隔方差 发布博文时间间隔最小值
Interval_variance_min用户发布博文的最小时间间隔 发布博文时间间隔最大值
Interval_variance_max用户发布博文的最大时间间隔 发布博文时间间隔突发性参数
Interval_paroxysmal_parameter用户发布博文的行为突发性程度 发布博文时间间隔信息熵
Interval_information_entropy用户发布博文的时间规律性程度 表 2 微博用户账号特征
特征名 含义 粉丝数 FollowerCount 用户被其他用户关注的数量 博文总数 TotalCount 用户发布的微博总数 关注数 FriendCount 用户关注其他用户的数量 是否默认头像 Pic 用户是否使用默认头像 是否默认用户名 Name 用户是否使用默认用户名 是否认证 Verified 用户是否为微博平台的认证用户 表 3 用户微博传播特征
特征名 含义 微博平均被转发数
ReforwardCount_Avg用户发布的所有微博被转发数量的均值 微博平均被点赞数
RefavouritedCount_Avg用户发布的所有微博被点赞数量的均值 经过上述两个步骤的特征提取,最终构造出的人类用户特征向量,即可作为HVE-GAN的“学习对象”。
模型训练完成后,即可利用训练好的生成器生成实验所需的数据。但由于训练时间较短,生成的数据虽然与真实数据的差异性较小,仍然难以完全符合实验需求的精度,因此需要人为对数据进行预处理,处理方法如下:
1)将负数全部重置为0;
2) FriendCount与FollowerCount的特征数据仅保留整数部分;
3)对Pic、Name、Verified、Location的特征数据,筛选出大于等于0.6,小于等于1.5的数值,将其更新为1,小于0.6的值将其更新为0;去掉这4列值中不为0或1的特征向量数据;
4)去掉Mean_of_affective_values >1的特征向量数据。
经过上述处理后的数据最终用于本文的实验。
-
实验一:生成数据“真实性”对比实验。
为了验证HVE-GAN模型性能的优越性,及HVE-GAN生成的“类人”社交机器人特征向量数据是否可以“以假乱真”,本实验利用各模型分别生成250个“类人”社交机器人用户数据集,分别与同一批的250个人类用户数据集混合,并使用分类器对各混合数据集进行分类,根据分类情况评价各模型的性能及生成数据的“真实性”程度。实验中选取AdaBoost、支持向量机(support vector machines, SVM)、逻辑回归(logistic regression)分类器,对上述经过混合数据集中的数据进行分类。并使用精确度(precision)、准确度(accuracy)、召回率(recall)、F1值4个指标对于分类结果进行评价。上述分类器对各个模型生成的“类人”社交机器人特征向量数据的分类评价情况如表4所示。
由表4可知,利用AdaBoost分类器对于各模型生成的数据的分类情况相同;使用Logistic Regression分类器对于上述模型生成的数据进行分类时,HVE-GAN的评价指标值均明显低于其他模型;使用SVM分类器进行分类时,HVE-GAN在Precision与Accuracy指标值上仅略高于VE-GAN,但低于基线模型。且使用Logistic Regression与SVM分类时,VE-GAN的分类评价情况也明显优于基线模型。
表 4 各模型生成数据分类情况
评价指标 被测模型 分类器 AdaBoost SVM Logistic Regression Precision HVE-GAN 0.4754 0.4746 0.4033 VE-GAN 0.4754 0.4664 0.4639 E-GAN 0.4754 0.6049 0.7079 GAN 0.4754 0.5212 0.5471 Accuracy HVE-GAN 0.4747 0.4421 0.354 VE-GAN 0.4747 0.4421 0.4551 E-GAN 0.4747 0.4421 0.7977 GAN 0.4747 0.4421 0.602 Recall HVE-GAN 1.0000 1.0000 0.7432 VE-GAN 1.0000 1.0000 0.9247 E-GAN 1.0000 1.0000 0.9795 GAN 1.0000 1.0000 0.9555 F1 HVE-GAN 0.6445 0.6437 0.5229 VE-GAN 0.6445 0.6362 0.6178 E-GAN 0.6445 0.7538 0.8218 GAN 0.6445 0.6852 0.6958 由此可得,HVE-GAN生成的数据质量优于基线模型,即其性能优于基线模型。且由VE-GAN的表现可知,模型性能的提升主要依赖于生成器模型结构的改进,由此证明了模型结构改进的有效性。由表4还可以看出,虽然HVE-GAN分类结果的Recall值较高,但是Precision与Accuracy均低于0.5(即分类器能够正确分类的概率低于0.5),说明分类器虽然能识别出人类用户的特征向量数据,但是难以区分生成的“类人”社交机器人的数据。由此可知,HVE-GAN生成的数据具有较高的“真实性”。
实验二:生成数据多样性对比实验。
本实验旨在通过使用各模型一同生成“类人”社交机器人特征向量数据,并进行对原始数据覆盖图像的对比,验证HVE-GAN在生成数据多样性方面的优越性及模型结构改进的有效性。
为了突出体现各模型生成的数据的多样性差异,本实验利用熵权法计算出人类用户特征向量中各特征的权重,选择权重排名前三的特征来表示该用户,并基于上述特征进行数据覆盖图像的绘制。权重较大,表明该特征对于用户身份识别的影响较大,从而可以代表该用户。
根据熵权法计算结果,本实验分别进行了粉丝数,发布博文时间间隔方差(以下简称时间间隔方差)和关注数特征的生成数据的覆盖对比。若某个模型生成的“类人”社交机器人特征向量数据可以较高程度地覆盖人类用户数据,则可以证明该模型生成的数据多样性程度高。
如图3所示,HVE-GAN除了在时间间隔方差特征覆盖对比实验中表现略逊于E-GAN外,其生成的数据覆盖程度相比其他模型均有明显的优势。该情况一方面证明了E-GAN本身即具有强大的生成能力,另一方面也证明了HVE-GAN生成的数据的多样性程度显然更胜一筹,也可证明HVE-GAN模型的性能优于基线模型。

图 3 特征覆盖对比
VE-GAN的覆盖能力虽然不如HVE-GAN,但它们之间的差距并不大,由此也可以证明模型结构的修改是提高生成数据的多样性程度的决定因素。又由图3可知,HVE-GAN生成的数据虽然与基线模型相比其多样性程度有了明显的提高,但是与原始训练数据相比还有较大的差距。这是由于为了提高本次实验效率,对模型进行的训练时间较短、训练不够充分导致的。
实验三:损失函数修改有效性验证实验。
用于指导E-GAN变异的损失函数共有3种,除了Heuristic损失函数外,还有Minimax与Least Square两种损失函数,其定义分别为:
$$M_G^{{\rm{minimax}}} = \frac{1}{2}{E_{z\sim {p_z}}}[\log (1 - D(G(z)))] $$ (12) $$ M_G^{{\rm{least - square}}} = {E_{z\sim {p_z}}}[{(D(G(z)) - 1)^2}] $$ (13) 经推导,Minimax损失函数的优化目标相当于最小化生成数据的实际分布概率与目标分布概率之间的JS散度;Least Square损失函数的优化目标为缩小生成数据的实际分布概率与目标分布概率之间的均方误差。上述两个函数的优化目标均为缩小生成数据的实际分布概率与目标分布概率之间的距离,与本文的损失函数设计目标是完全一致的。
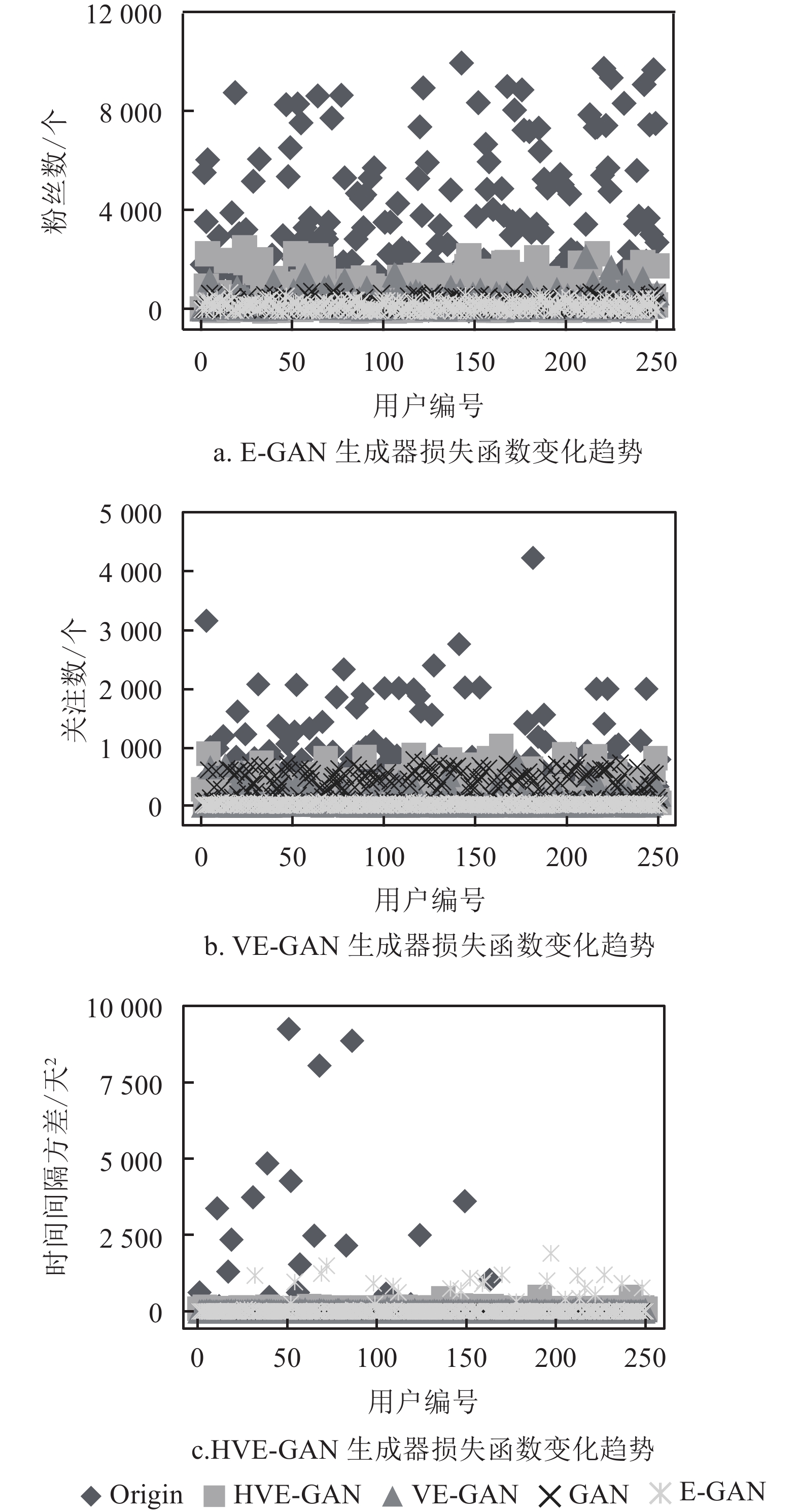
E-GAN生成器损失函数的变化情况如图4a所示,可见,Heuristic损失函数在E-GAN训练过程中震荡严重,由此可以推导出,在该损失函数指导下进行训练的生成器模型梯度十分不稳定,导致训练出的生成器生成数据的质量参差不齐。
VE-GAN生成器的损失函数变化趋势如图4b所示,由图可知训练中VE-GAN生成器的Heuristic损失函数震荡幅度依然较大。可见,即使进行了模型结构的改进,Heuristic损失函数依然影响着生成器的性能。
如图4c所示,进行了损失函数的更换的HVE-GAN,训练中生成器的损失函数均呈平稳下降的趋势,模型的收敛速度得到了显著提升。由此可知,HVE-GAN生成器的性能及生成数据的质量得到了持续稳定的提高。可见本文提出的损失函数的改进是必要和有效的。
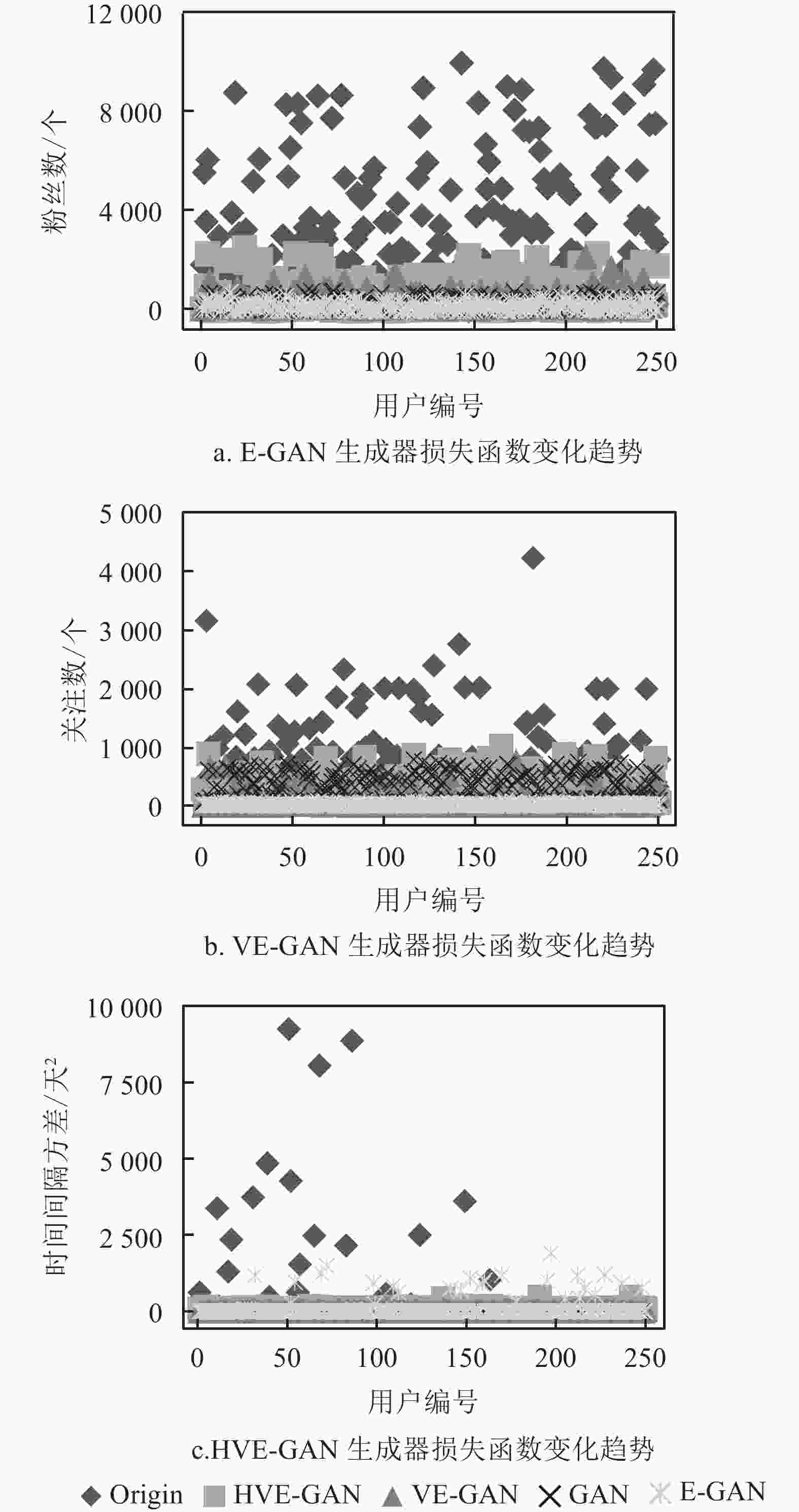
图 4 各生成模型生成器损失函数变化趋势
-
针对“类人”社交机器人检测所需的训练数据不足的问题,本文提出了一种数据集扩充模型HVE-GAN,模型将生成器修改为VAE结构,提高了生成的“类人”社交机器人数据的“真实性”与多样性;将Heuristic损失函数修改为改进的海林格距离,稳定了生成器的梯度,提高了模型收敛速度,保证了生成数据的质量。对比实验结果也充分表明,本文提出的HVE-GAN模型,在生成数据“真实性”和多样性方面优于基线模型;在训练过程中其损失函数的变化趋势更加平稳,从而证明了HVE-GAN性能的优越性及模型结构修改的有效性。
Research on Expansion Method of Detection Dataset for “Human-like” Socialbots
-
摘要: 该文提出了基于海林格距离的变分进化生成式对抗网络(HVE-GAN),实现“类人”社交机器人检测数据集的扩充。HVE-GAN将进化生成式对抗网络(E-GAN)的生成器修改为变分自编码器(VAE)结构,提高了生成数据的“真实性”及多样性程度;将E-GAN生成器Heuristic损失函数更改为改进的海林格距离,在训练过程中加快了模型收敛速度、稳定了生成器的梯度,避免了不稳定的训练过程影响生成数据质量。实验结果表明,利用HVE-GAN模型生成的“类人”社交机器人数据的“真实性”与多样性程度均明显优于基线模型。Abstract: A Hellinger distance based variational evolutionary generative adversarial networks (HVE-GAN) is proposed to expand the detection dataset of “human-like” Socialbots. HVE-GAN modifies the generator of evolutionary generative adversarial networks (E-GAN) to a variational autoencoder (VAE) structure to improve the “authenticity” and diversity of the generated data, and changes the Heuristic loss function of the E-GAN generator to an improved Hellinger distance to speed up the model convergence during the training process, stabilize the gradient of the generator, and further avoid unstable training processes that affect the quality of the generated data. Comparative experimental results show that the “authenticity” and diversity of the “human-like” social robot data generated by the HVE-GAN model proposed in this paper are significantly better than the baseline models.
-
表 1 用户发微博的时序特征
特征名 含义 发布博文时间间隔均值
Interval_avg用户发布博文的时间间隔均值 发布博文时间间隔方差
Interval_variance用户发布博文的时间间隔方差 发布博文时间间隔最小值
Interval_variance_min用户发布博文的最小时间间隔 发布博文时间间隔最大值
Interval_variance_max用户发布博文的最大时间间隔 发布博文时间间隔突发性参数
Interval_paroxysmal_parameter用户发布博文的行为突发性程度 发布博文时间间隔信息熵
Interval_information_entropy用户发布博文的时间规律性程度  下载: 导出CSV
下载: 导出CSV
表 2 微博用户账号特征
特征名 含义 粉丝数 FollowerCount 用户被其他用户关注的数量 博文总数 TotalCount 用户发布的微博总数 关注数 FriendCount 用户关注其他用户的数量 是否默认头像 Pic 用户是否使用默认头像 是否默认用户名 Name 用户是否使用默认用户名 是否认证 Verified 用户是否为微博平台的认证用户
下载: 导出CSV
表 3 用户微博传播特征
特征名 含义 微博平均被转发数
ReforwardCount_Avg用户发布的所有微博被转发数量的均值 微博平均被点赞数
RefavouritedCount_Avg用户发布的所有微博被点赞数量的均值
下载: 导出CSV
表 4 各模型生成数据分类情况
评价指标 被测模型 分类器 AdaBoost SVM Logistic Regression Precision HVE-GAN 0.4754 0.4746 0.4033 VE-GAN 0.4754 0.4664 0.4639 E-GAN 0.4754 0.6049 0.7079 GAN 0.4754 0.5212 0.5471 Accuracy HVE-GAN 0.4747 0.4421 0.354 VE-GAN 0.4747 0.4421 0.4551 E-GAN 0.4747 0.4421 0.7977 GAN 0.4747 0.4421 0.602 Recall HVE-GAN 1.0000 1.0000 0.7432 VE-GAN 1.0000 1.0000 0.9247 E-GAN 1.0000 1.0000 0.9795 GAN 1.0000 1.0000 0.9555 F1 HVE-GAN 0.6445 0.6437 0.5229 VE-GAN 0.6445 0.6362 0.6178 E-GAN 0.6445 0.7538 0.8218 GAN 0.6445 0.6852 0.6958
下载: 导出CSV
-
[1] CRESCI S, PETROCCHI M, SPOGNARDI A, et al. Better safe than sorry: An adversarial approach to improve social bot detection[C]//Proceedings of the 10th ACM Conference on Web Science. [S.l.]: ACM, 2019: 47-56. [2] WU B, LIU L, DAI Z, et al. Detecting malicious social robots with generative adversarial networks[J]. KSII Trans. Internet Inf Syst, 2019, 13(11): 5515-5594. [3] WU B, LIU L, YANG Y, et al. Using improved conditional generative adversarial networks to detect social bots on Twitter[J]. IEEE Access, 2020, 8: 36664-36680. doi: 10.1109/ACCESS.2020.2975630 [4] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Advances in Neural Information Processing Sytems, 2014, 3: 2672-2680. [5] WANG C, XU C, YAO X, et al. Evolutionary generative adversarial networks[J]. IEEE Transcations on Evolutionary Computation, 2018, 23(6): 921-934. [6] WU Z, HE C, YANG L, et al. Attentive evolutionary generative adversarial network[J]. Applied Itelligence, 2020(6): 1-15. [7] MU J, ZHOU Y, CAO S, et al. Enhanced evoltionary generative adversarial networks[C]//2020 39th Chinese Control Conference (CCC). [S.l.]: IEEE, 2020: DOI: 10.23919/CCC50068.2020.9188912. [8] BAIOLETTI M, COELLO C A C, DI BARI G, et al. Multi-objective evolutionary GAN[C]//GECCO '20: Genetic and Evolutionary Computation Conference. LiUe: [s.n.], 2020: 1824-1831. [9] LI J, ZHANG J, GONG X, et al. Evolutionary generative adversarial networks with crossover based knowledge distillation[EB/OL]. [2021-01-20]. https://arxiv.org/abs/2101.11186v1. [10] KINGMA D P, WELLING M. Auto-encoding variational bayes[EB/OL]. [2021-02-20]. https://arxiv.org/pdf/1312.6114v1.pdf. [11] HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507. doi: 10.1126/science.1127647 [12] 武广. 生成对抗网络中隐空间分布学习及其应用研究[D]. 合肥: 合肥工业大学, 2020. WU G. Latent space distribution learning in generative adversarial networks and application [D]. Hefei: Hefei University of Technology, 2020. [13] 四川大学. 一种基于深度神经网络的微博社交机器人检测方法: CN202010509757.9[P]. 2020-07-17. Sichuan University. A deep neural network based detection method for microblog social robot: CN202010509757.9[P]. 2020-07-17. [14] 刘蓉. 基于深度神经网络的恶意社交机器人检测技术研究[D]. 南京: 南京师范大学, 2019. LIU R. Research on detection methods for malicious social bot based on deep neural network[D]. Nanjing: Nanjing Normal University, 2019. -

 点击查看大图
点击查看大图

图(4) / 表(4)
计量
- 文章访问数: 3856
- HTML全文浏览量: 1279
- PDF下载量: 43
- 被引次数: 0













































































