 ISSN
ISSN 



-
时间触发光纤通道(time trigger fiber channel, TTFC)具有全局时钟和预定义的传输时间表[1],通过解决一部分光纤通道(fiber channel, FC)网络数据交换的冲突问题,改善了重要业务的传输确定性和实时性,提升了航电任务系统的整体性能,成为了航电网络通信的发展方向。
TTFC网络支持时间触发(time trigger, TT)和事件触发(events trigger, ET)多种优先级业务。TT业务具有最高优先级,通过离线通信调度保证其准确性,TT业务可在定义的延迟和抖动范围内在TTFC交换网络上无冲突地精确传送[2]。ET业务按优先级从高到底可划分为流量控制(rate-constrained, RC)和尽力而为(best-effort, BE)两种不同的优先级业务[3]。TTFC交换机是TTFC网络的关键组件,TTFC交换机在传统FC交换机基础上增加了时钟触发TT业务的数据交换。传统FC交换机的实现由于受硬件的交换加速能力限制,大多采用无阻塞的交叉开关矩阵(crossbar)式直通交换结构[4],并根据信元缓存位置的不同分为输入和输出两种排队方式。而输入队列会出现线头(head of line, HOL)堵塞现象,通常采用虚拟输出队列(virtual output queue, VOQ)的方法来解决HOL问题[5]。
为提升交换转发效率,降低转发延迟,减少交换调度开销,FC交换机采用针对多优先级的变长调度算法来实现交换调度。OSP (orthogonal subspace projection)、p-iDRR (prioritized iDRR)等算法虽支持多优先级,但算法设计时采用固定长度的信元,其应用变长信元交换时会引入额外开销。RRM算法在输出端指针同步时会增加性能的损耗等,这些问题在vp-RRM算法中已得到了很好地解决。
在TTFC网络中,由于TT业务的加入,占用了交换端口的部分流量,同时TT业务对各端口流量的占用不同,导致在进行ET业务数据交换时,端口流量也不均匀。目前对于TTFC网络的研究,大多从网络模型仿真的角度对网络的实现算法进行分析,暂没有文献结合TTFC网络特点,对ET业务的交换调度效率进行深入分析[6]。vp-RRM 算法基于端口序号进行轮询调度,每个队列的输出是无差别的,但流量的非均匀分布会导致个别队列等待时间较长,吞吐性能变差[7]。因此,本文在加权轮询调度算法的基础上,提出了基于流量自适应的多优先级变长轮询调度算法(traffic adaptive variable-length priority round robinmatching, tavp-RRM),该算法针对非均匀流量状态下的交换调度算法进行改进,使流量大的端口得到更多的调度机会,以此提升网络的吞吐效率。
-
tavp-RRM算法可基于端口流量队列的长度自适应调整其请求优先级,使负载量大的端口优先进行数据交换,从而提升TTFC网络的吞吐率。其优点包括:支持非定长信元、非固定时隙、支持单播和广播队列、采用流水线工作和使用VOQ等。
-
算法原理如下:
1) 为了提升TTFC网络的有序性,广播和组播业务均规划为TT业务,ET业务仅处理单播业务,因此在本文中,不讨论该算法对组播和广播业务的适用性。
2) 支持多优先级调度。TTFC网络的ET业务按优先级分为RC和BE两种业务。如图1所示,业务信元传输至TTFC交换机后,将依据其优先级存入各个VOQ中。VOQ向输出端口发起请求时,VOQ的优先级会根据其队列长度及等待时间进行调整。优先级从高到低依次为P3、P2、P1、P0,RC业务的起始优先级为P2,可提升的优先级为P3,BE业务的起始优先级为P0,可提升的优先级为P1。
3) 输出端口同时收到多个输入端口的请求时,对优先级最高的输入端口先进行授权。
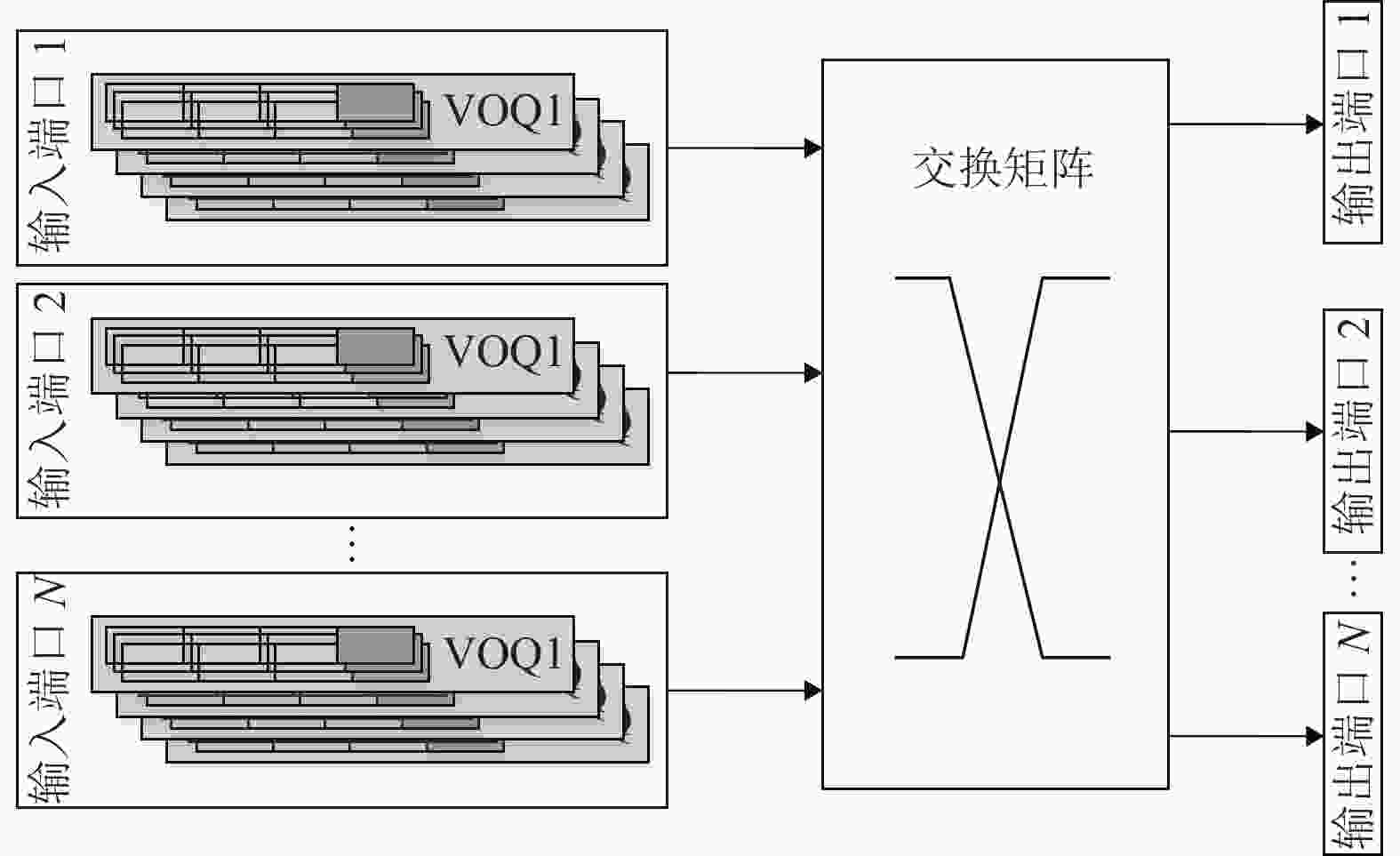
图 1 VOQ架构示意图
tavp-RRM 调度算法在研发阶段即注重硬件的可实现性,经过多次迭代,完成输入、输出端口的最优匹配[8]。通过在每个输入、输出端口设置多个仲裁器,通过循环优先级仲裁来依次匹配所有有效的输入和输出,以保证每一次迭代的独立性。
-
tavp-RRM 算法的执行过程与 RRM 类似,分为“请求−授权−接受”,步骤如下:
1) 请求
输入端口接收到信元后,会向信元的输出端口发起包含当前数据优先级的请求,请求的优先级由3种因素决定,分别为ET业务的优先级、当前VOQ的队列长度及当前VOQ的等待时间。图2给出了ET业务VOQ队列优先级的确定流程。
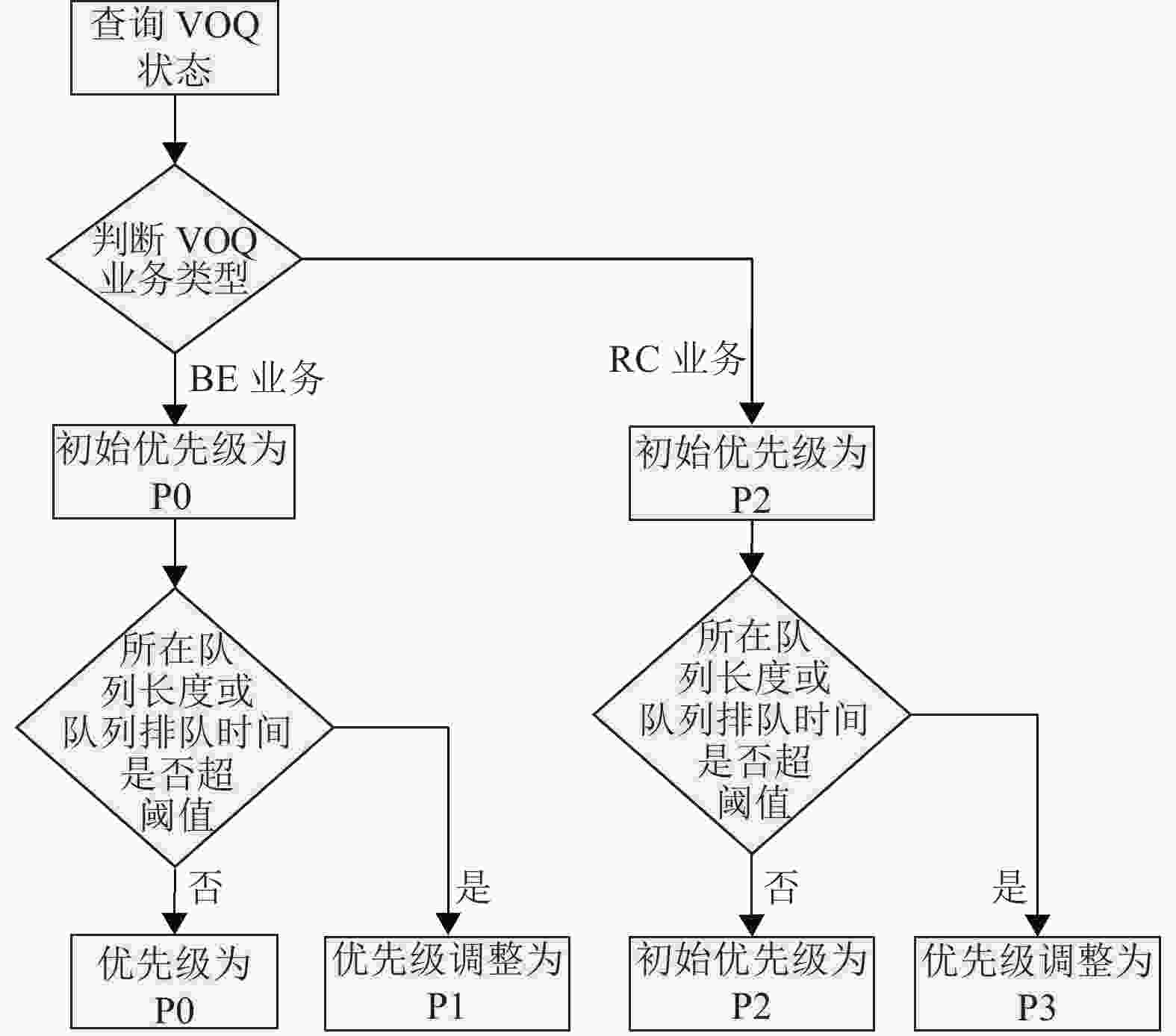
图 2 ET业务VOQ队列优先级的确定流程
基于以下原则来确定阈值:
① 队列长度的阈值点距离队列满不小于2个FC最长帧的空间,防止阈值生效太晚,从而导致对外部输入端产生流控;
② 队列长度的阈值点应大于队列半满的位置,避免阈值被频繁触发;
③ 队列排队时间阈值应小于系统可接收的最大延迟。
本文在仿真及实验验证过程中,以队列深度的3/4作为队列长度阈值,以100 µs作为队列排队时间阈值。
2) 授权
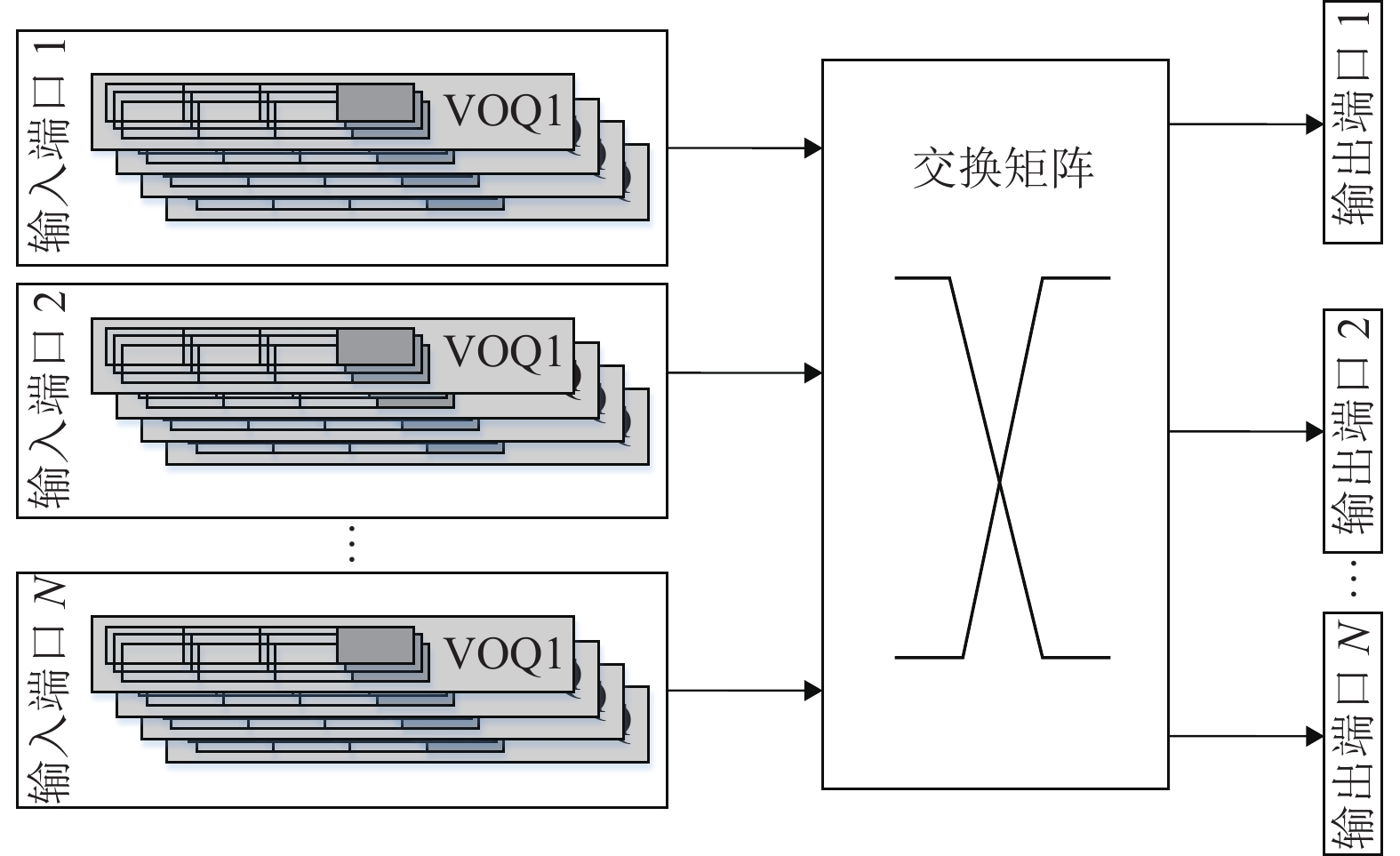
每个输出端口处设有1个调度器,调度器通过轮询调度算法来匹配多个端口的请求,在均匀业务状态下具有良好的公平性。由于输入端的业务数据按照业务类型(RC或BE)分配队列缓存,因此每个输出端口对不同类型的业务通过轮询指针r0和r1分别维护其调度状态。r1对应RC业务,优先级为P2或P3;r0对应BE业务,优先级为P0或P1。调度器进行调度时,先过滤出当前最高优先级的请求,在根据r0或r1的当前位置按顺序开始轮询查找,对找到的第一个请求进行授权,并通过r0或r1更新到当前授权位置的下一个位置处。
3) 接受
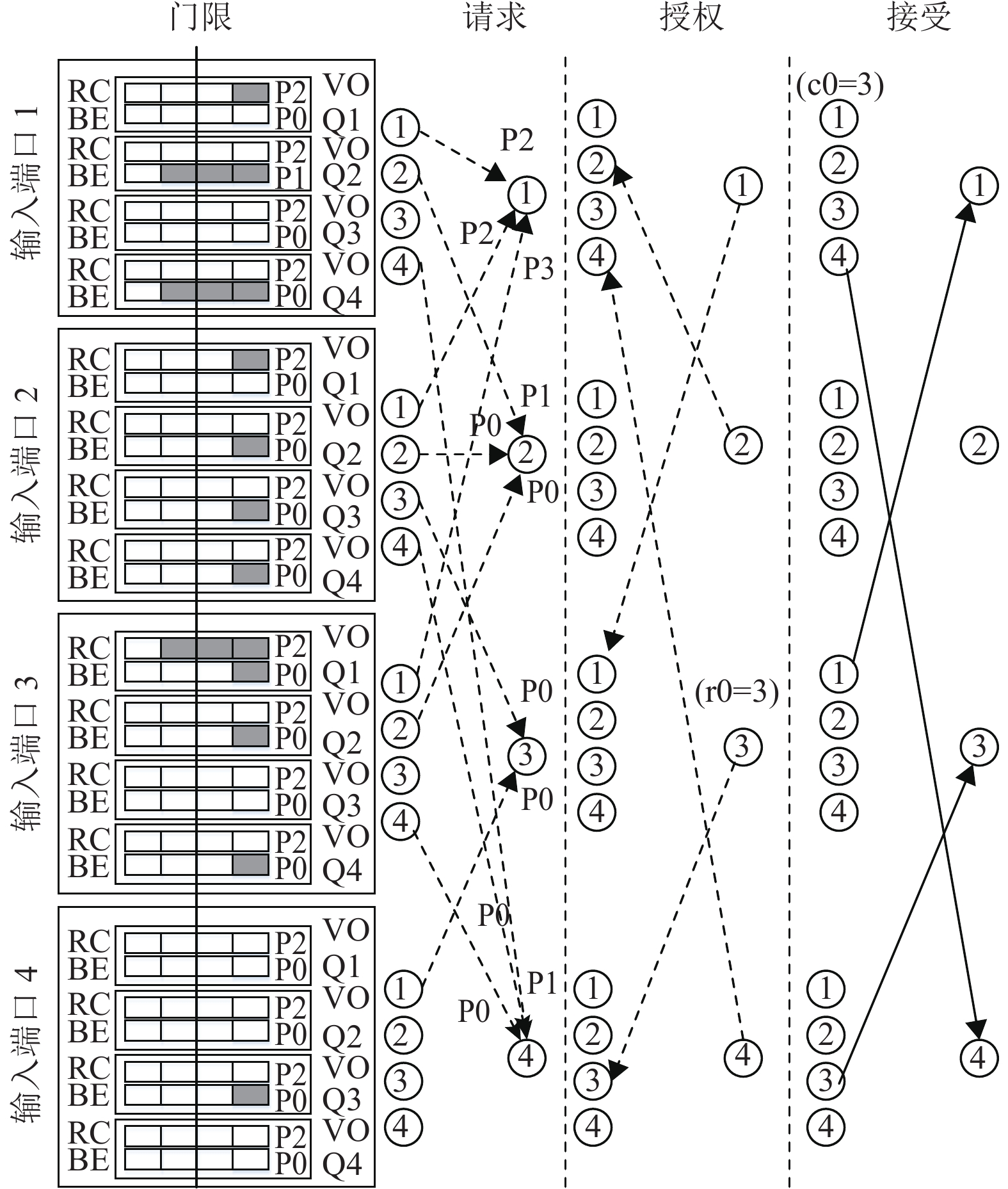
输入端口会同时向多个输出端口发起调度请求,当输入端口同时接收到多个端口的授权时,同一时刻只能接受一个授权。因此,输入端口需要对接收到的授权进行仲裁来选择最终接受方。输入端口的接受仲裁对不同类型的业务通过轮询指针c0和c1分别维护其仲裁状态。c1对应RC业务,优先级为P2或P3;c0对应BE业务,优先级为P0或P1。仲裁器进行仲裁时,先过滤出当前最高优先级的请求,在根据c0或c1的当前位置按顺序开始轮询查找,对找到的第一个授权进行接受,并通过c0或c1更新到当前授权位置的下一个位置处。图3为一个4×4端口的调度过程,在请求授权阶段,输出端口 1 在优先级 P2、P3之间选择高优先级P3对应的输入端口3;输出端口2在3路BE业务中选择输入端口,输入端口1由于其队列长度大于门限值,请求将优先级调整为为P1,因此选择高优先级P1对应的输入端口1;输出端口3在两个相同优先级 P0端口间选择,此时输出端口3对应BE业务的r0=3,按照轮询机制,最终选择输入端口4进行授权;输出端口4在优先级 P1、P0间选择高优先级P1对应的输入端口1。
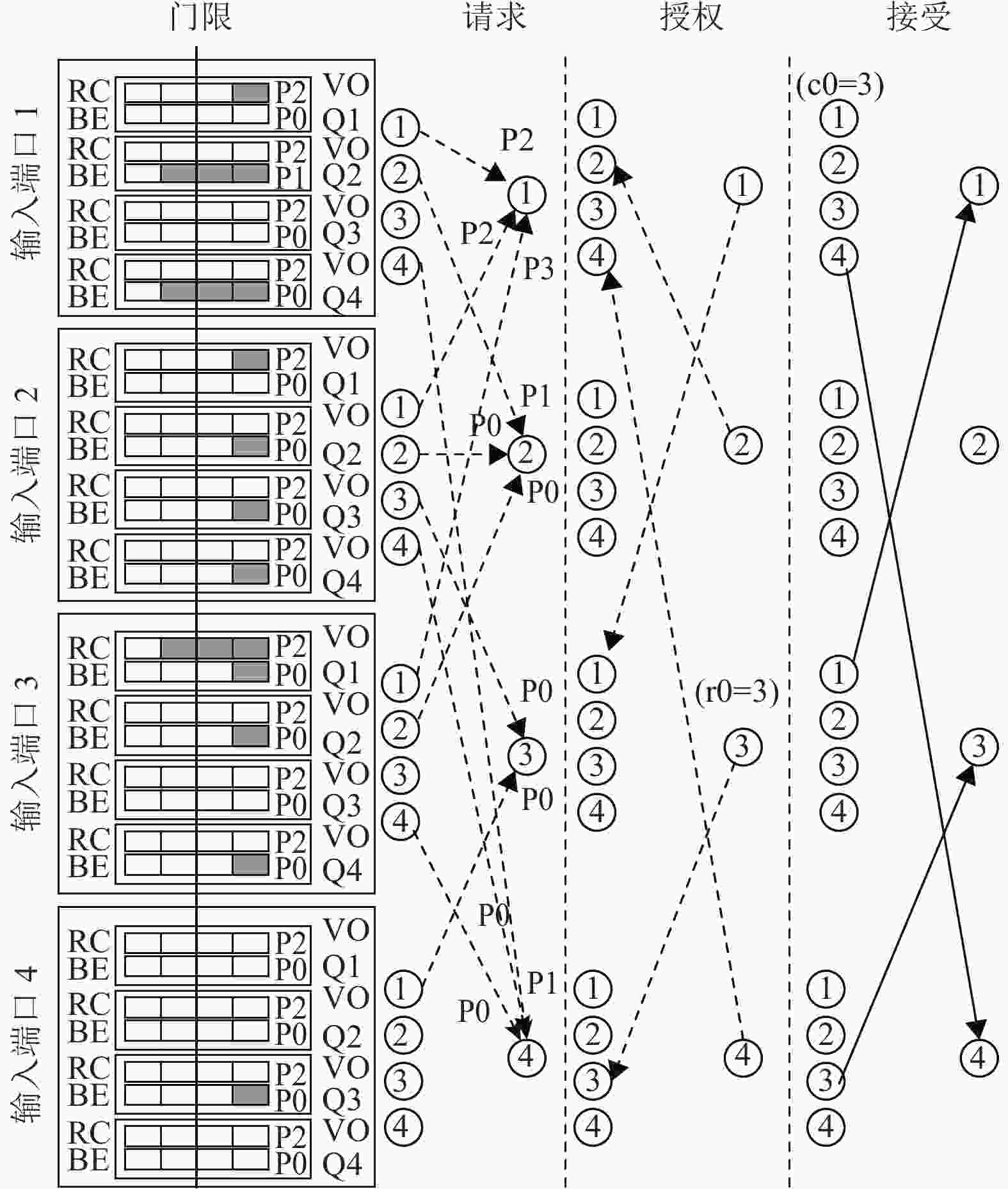
图 3 4×4端口的调度过程
接受阶段,输入端口1同时收到输出端口2和输出端口4的授权,由于两个授权的优先级相同均为P1,按照轮询机制从当前BE的指针c0=3启动轮询。输入端口1优先查询到输出端口4的授权,因此选择输出端口4的授权进行接受。输入端口3和4由于仅接收了1个授权,直接接受即可。
-
使用计算机仿真可以大幅降低crossbar调度算法性能分析的难度,本节将通过计算机仿真来分析tavp-RRM算法的吞吐量。吞吐量是指输出端口的平均利用率,即在一个时隙内平均发送的信元数量。在分析吞吐量性能时,本文将vp-RRM算法作为比较的对象,vp-RRM算法和tavp-RRM的差异在于对优先级的管理不同,下面选取均匀业务流和非均匀业务流对两种算法的吞吐量性能进行对比。
1) 均匀业务流
输入端负载均相同,即
$ {\gamma _i} = \gamma $ ,所有业务流在VOQ中均匀分布。均匀业务流模型下,tavp-RRM和vp-RRM的吞吐量均为相同的恒定值:$$ {\gamma }_{i,j}=\gamma \frac{1}{N}\begin{array}{cc}& 0\leqslant i\text{,}j\leqslant N-1\end{array} $$ (1) 2) 非均匀业务流
采用如下两种非均匀业务流模型来研究tavp-RRM算法的吞吐量。
模型1 :输入端负载均相同,即
$ {\gamma _i} = \gamma $ ,业务流在VOQ中的分布方式为:$$ {\gamma _{i,j}} = \left\{ {\begin{array}{*{20}{c}} {\gamma \delta }&{j = i}\\ {\gamma \left( {1 - \delta } \right)}&{j = \left( {i + 1} \right)\,\boldsymbolod \,N} \end{array}} \right.\;\;0 \leqslant i,j \leqslant N - 1 $$ (2) 式中,
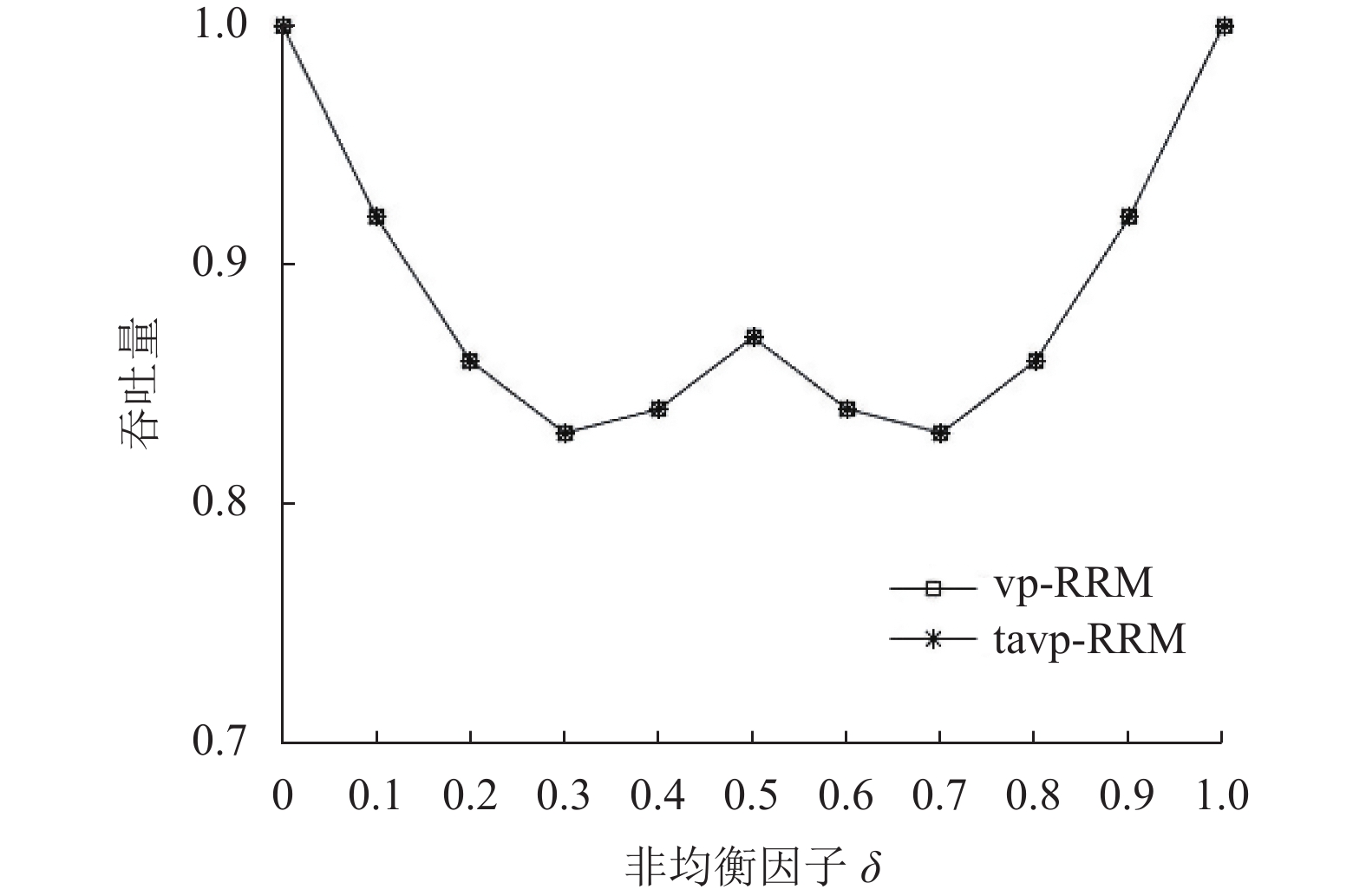
${\gamma _{i,j}}$ 表示从输入端i到输出端j的负载;$ \delta $ 为非均衡(unbalanced)因子$(0\leqslant \delta \leqslant 1)$ 。业务流模型1的算法吞吐量对比如图4所示,根据式(2)可推算得知,1个输出端口同时只转发两个输入端口的数据,在交换调度时竞争较少,转发效率本来较高,基于端口流量队列的长度自适应调整其请求优先级的功能(traffic adaptive, TA)作用不明显,vp-RRM和tavp-RRM仿真结果基本一致。
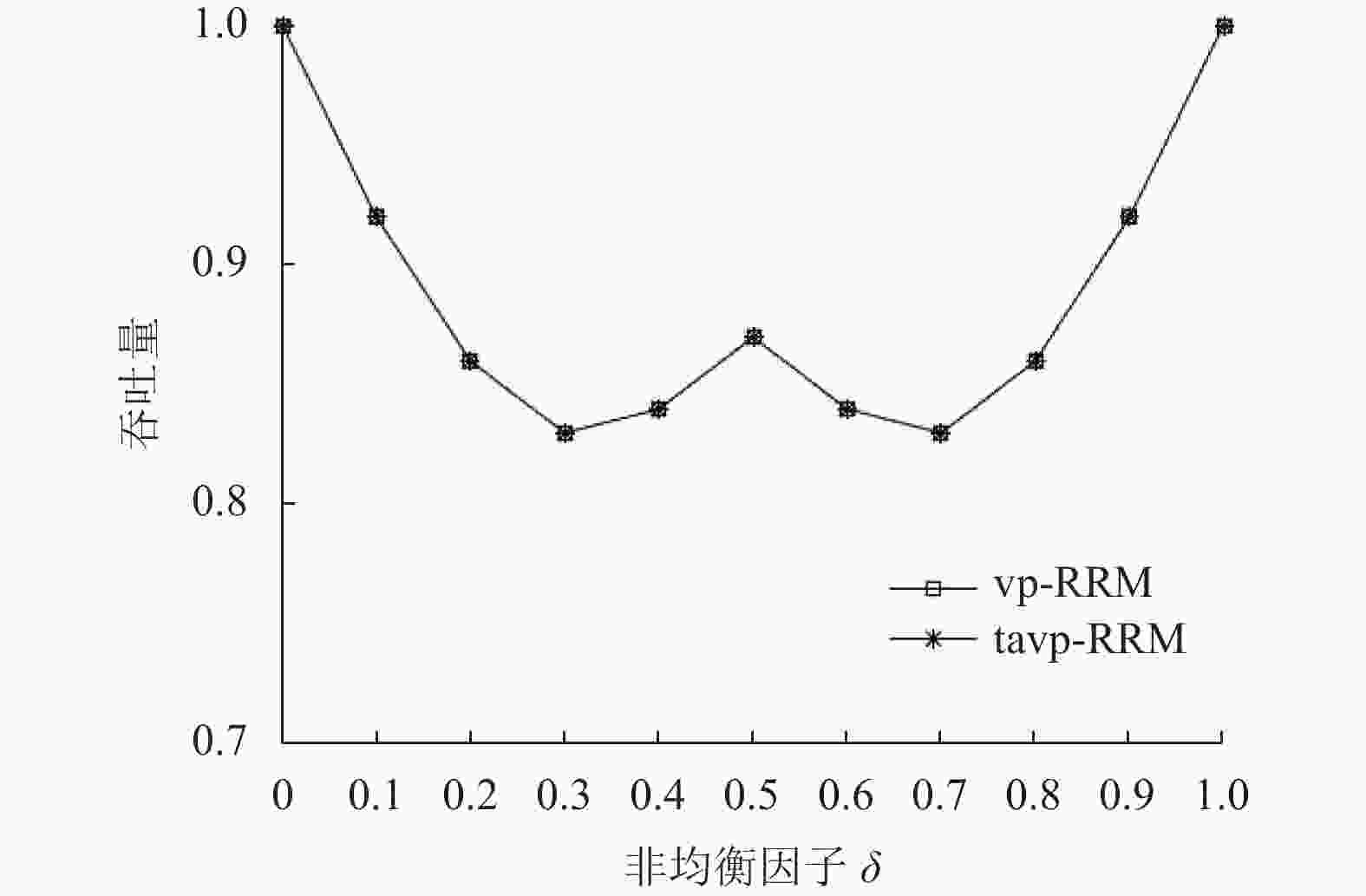
图 4 业务流模型1的算法吞吐量对比
模型2:输入端负载均相同,即
$ {\gamma _i} = \gamma $ ,业务流在VOQ中的分布方式为[9]:$$ {\gamma _{i,j}} = \left\{ {\begin{array}{*{20}{c}} {\gamma \left( {w + \dfrac{{1 + w}}{N}} \right)}&{j = i}\\ {\gamma \dfrac{{1 - w}}{N}}&{j \ne i} \end{array}} \right.\;\;0 \leqslant i,j \leqslant N - 1 $$ (3) 式中,
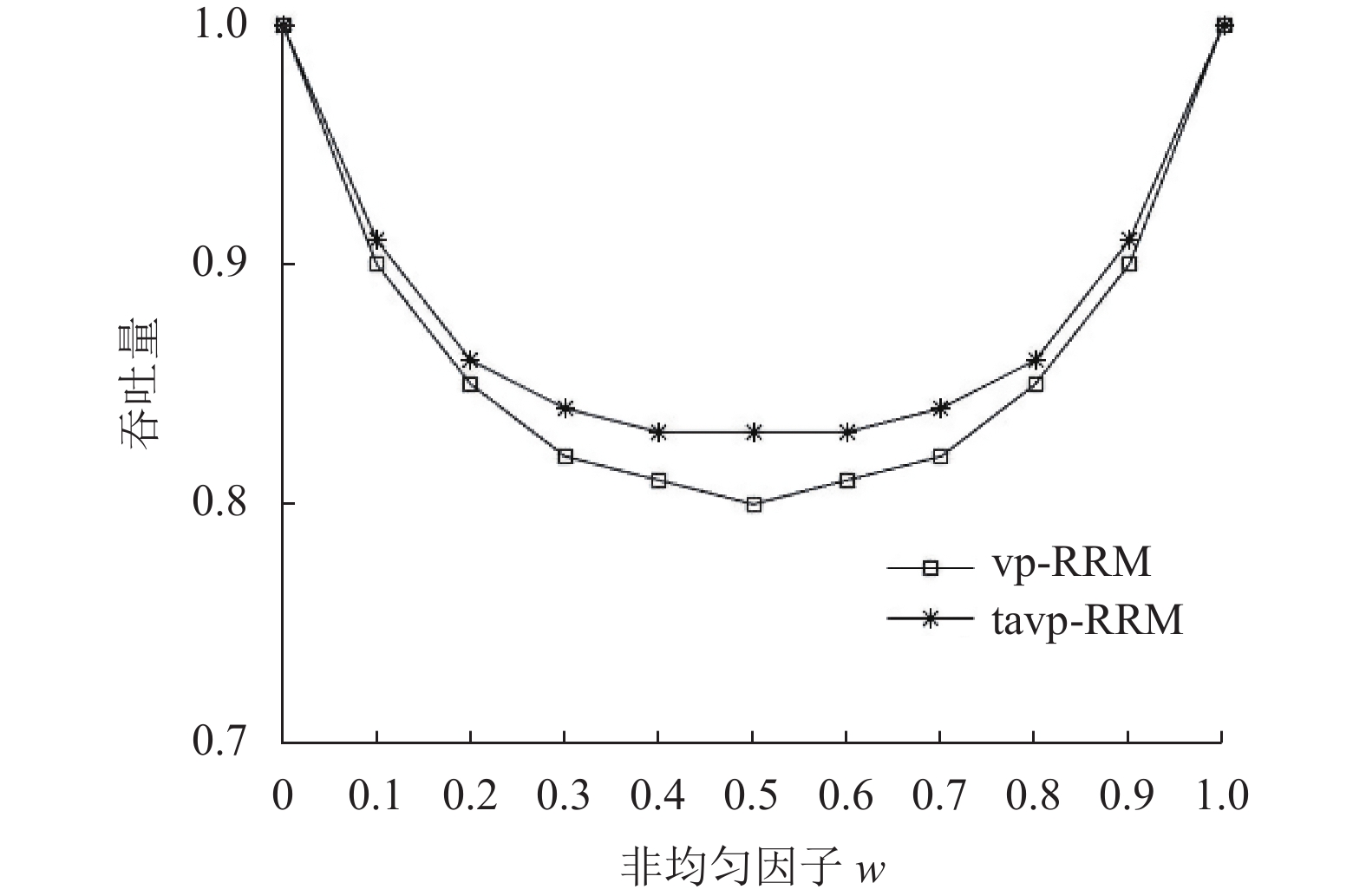
$ w $ 为非均匀(nonuniform)因子$ (0\leqslant w\leqslant 1) $ ,当$ w = 0 $ 时,该业务流就是均匀业务流。业务流模型2的算法吞吐量对比如图5所示。图5展示了在16×16的crossbar中tavp-RRM和vp-RRM算法的吞吐量。从图中可以看到,当w=0时,业务流为均匀业务流,tavp-RRM算法的吞吐量与vp-RRM算法一致;当w=1时,业务流集中到同一个端口,达到满额负荷,tavp-RRM算法的吞吐量与vp-RRM算法相同。其他状态下tavp-RRM算法的吞吐量性能始终优于vp-RRM,且w在0.5附近时,性能差异达到最大。图5的仿真结果说明tavp-RRM算法相对于vp-RRM算法,在多个输入端口向同一个输出端口发生转发竞争,且流量不均匀时,具有更高的交换调度效率。
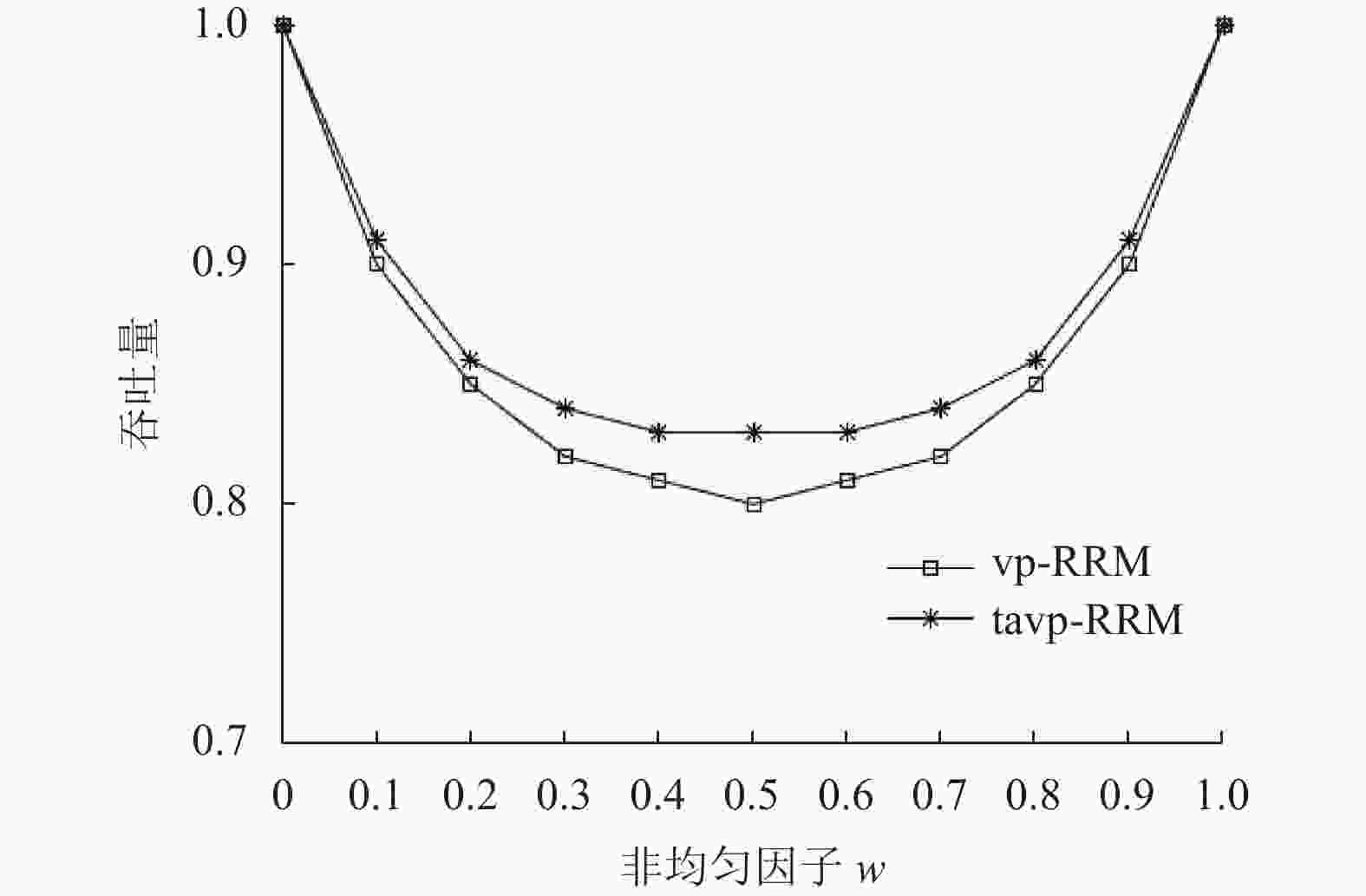
图 5 业务流模型2的算法吞吐量对比
-
本文采用复旦微电子公司的JFM7K325TFPGA设计了4×4端口,速率为2.125 Gb/s的TTFC交换机。为了进行算法对比测试,TA功能支持通过软件配置进行使能或关闭。
通过对交换机的TT业务转发进行规划,使交换机各端口的TT业务占用不同的带宽。TT业务在端口1至端口4的输入带宽占用分别为9%、12%、15%和18%,输出带宽在非输入端口均匀分布。
使用JSDU公司的XgigLoadTester测试仪对TTFC交换机进行ET业务的吞吐量测试,由于测试仪不支持TT业务注入,为了在测试中模拟TT业务引入的非均匀性,TTFC交换机采用如下设计:初始化TTFC交换机各端口的TT调度配置,并在TT业务的转发时隙,强制TT转发路径处于忙状态,时隙内不进行ET业务的转发[10]。
具体测试说明如下:
1)各端口激励数据均采用帧长为1024 B的ET帧;
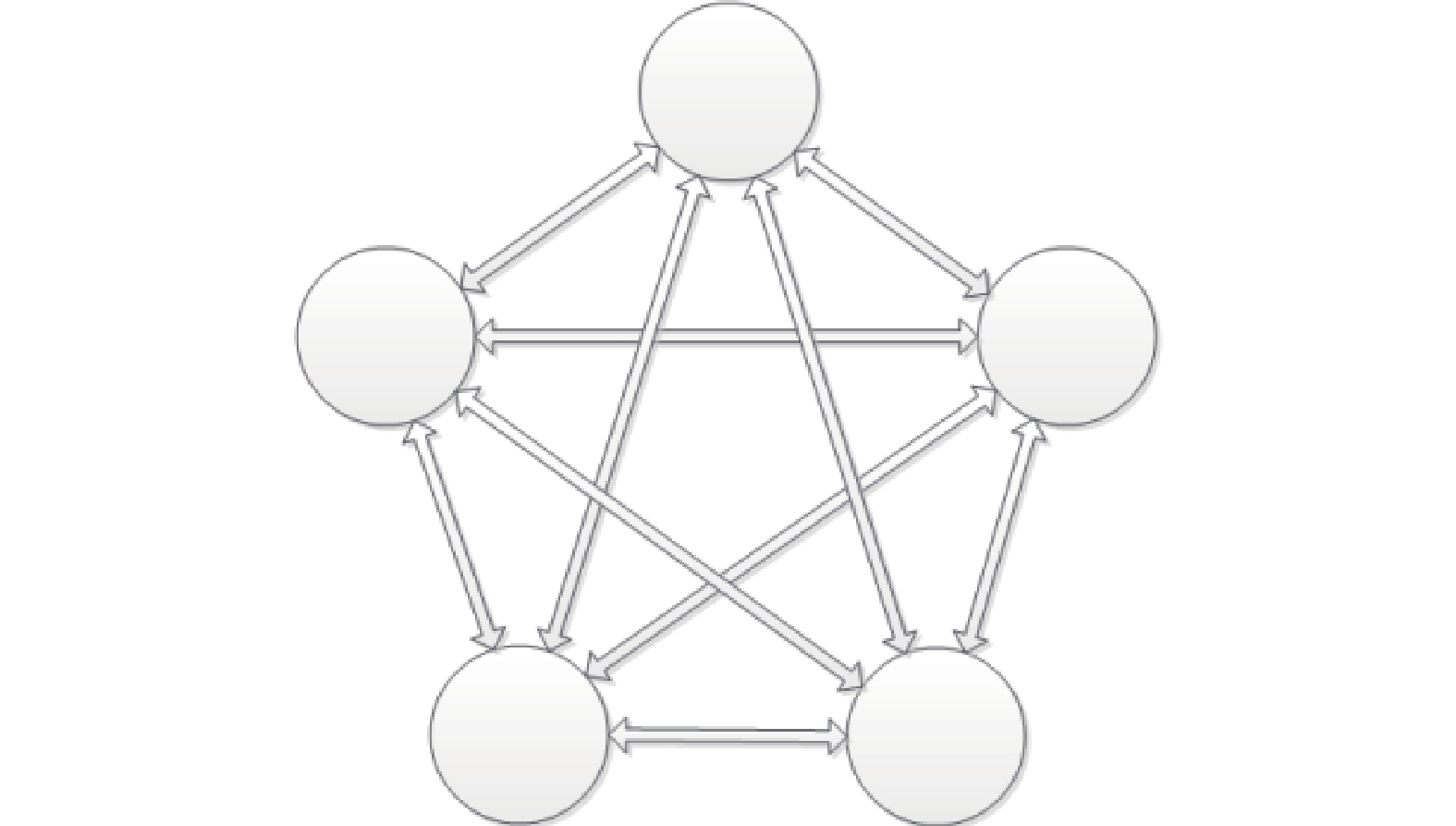
2)测试拓扑采用图6所示的不带自环的全网络拓扑模型。受测试仪功能限制,VOQ分布采用均匀分布,通过TT业务的影响引入非均匀因素;
3)各端口测试激励初始为100%负载;
4)分别在TA功能使能和关闭的状态下进行测试。
各端口在未开启TA功能和开启TA功能后的对比如表1所示。tavp-RRM算法的实测吞吐量性能优于vp-RRM,吞吐量提升在5%以上,表明TA功能对于非均匀流量环境下的吞吐量有改善作用。
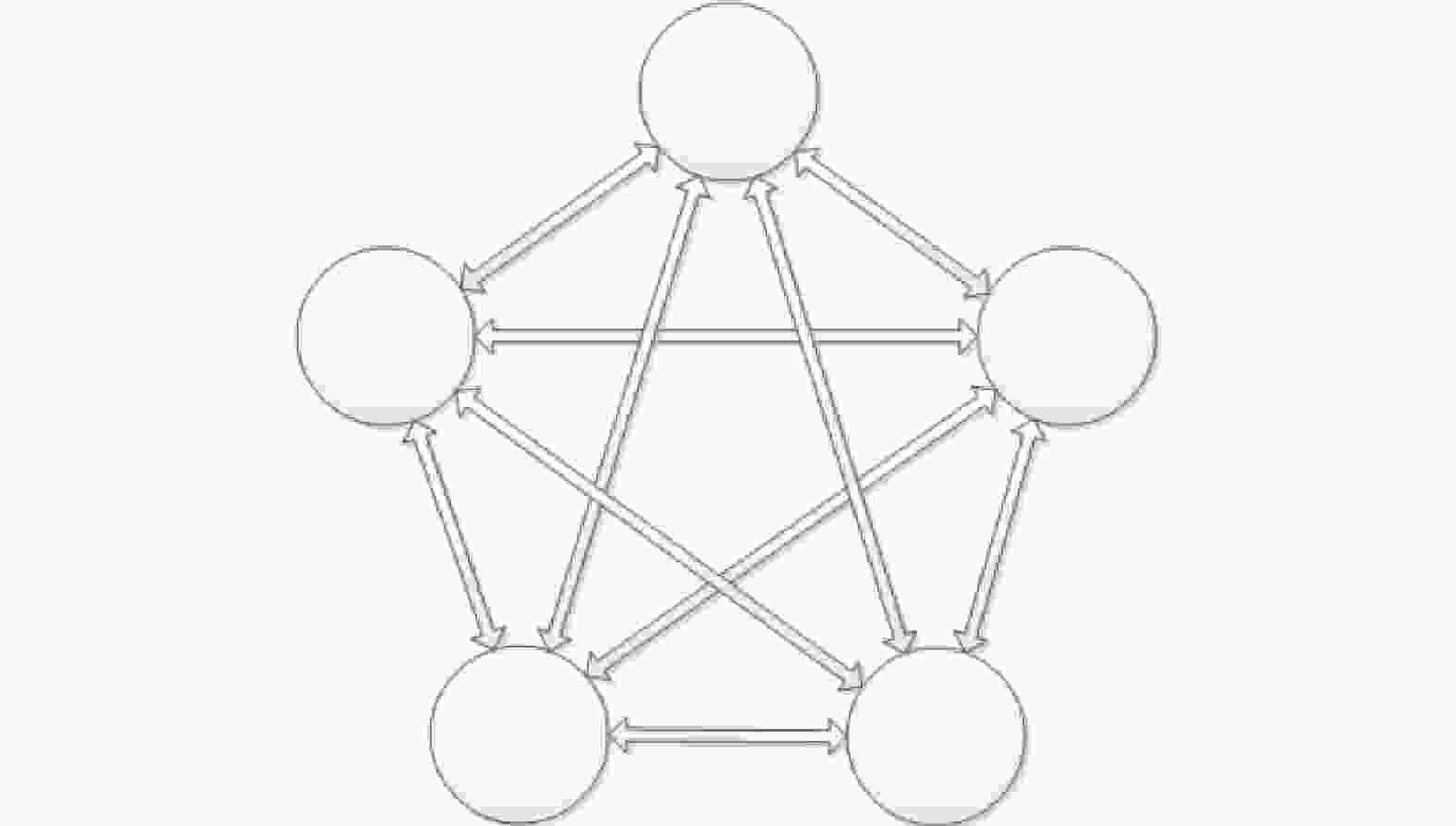
图 6 测试拓扑模型
表 1 实测结果对比
端口
序号端口吞吐量(未开启
TA功能) / MB·s−1端口吞吐量(开启
TA功能)/ MB·s−11 291.426 312.749 2 281.818 302.439 3 272.211 292.129 4 262.603 281.818 -
本文根据TTFC网络中ET业务流量不均匀的特点,提出一种多优先级交换调度方案,基于端口流量队列长度进行优先级的自适应调整,使带宽资源紧张的VOQ得到更多的授权机会,从而改善TTFC网络的吞吐量性能,提高交换调度效率,更加适用于TTFC网络的事件触发业务的交换调度。
A Switching Scheduling Algorithm Based on Time Triggered Fibre Channel Network
-
摘要: 提出了一种基于时间触发的光纤通道网络数据交换调度算法,在基于端口序号进行轮询调度(vp-RRM)算法的基础上增加了流量自适应机制。该算法对光纤通道网络中的传输数据按TT、RC、BE等业务类型分队列缓存,将队列长度与交换调度的优先级建立关联,可明显改善非均匀业务流的交换调度效率。经仿真及实验验证,该算法吞吐量性能在非均匀业务流下较vp-RRM明显提升,更加适用于TTFC网络的事件触发业务的交换调度。Abstract: In this paper, a data exchange scheduling algorithm based on time trigger fibre channel network is proposed. Based on variable-length priority round Robin matching (vp-RRM), a traffic adaptive mechanism is added. The algorithm queues and caches the transmission data in the fibre channel network according to the service types such as time trigger (TT), rate-constrained (RC) and best-effort (BE), and correlates the queue length with the priority of switching scheduling, which can significantly improve the switching scheduling efficiency of non-uniform service flow. Through simulation and experimental verification, the throughput performance of the algorithm is significantly improved compared with VP-RRM under non-uniform traffic flow, and it is more suitable for the exchange scheduling of event triggered services in time trigger fiber channel (TTFC) network.
-
Key words:
- data exchange /
- fiber-channel /
- scheduling algorithm /
- time trigger
-
表 1 实测结果对比
端口
序号端口吞吐量(未开启
TA功能) / MB·s−1端口吞吐量(开启
TA功能)/ MB·s−11 291.426 312.749 2 281.818 302.439 3 272.211 292.129 4 262.603 281.818  下载: 导出CSV
下载: 导出CSV
-
[1] KIRNER R, PUSCHNER P. A quantitative analysis of interfaces to time-triggered communication buses[J]. IEEE/ACM Transactions on Networking, 2021, 29(4): 1786-1797. doi: 10.1109/TNET.2021.3073460 [2] FINZI A, ZHAO L X. Impact of AS6802 synchronization protocol on time-triggered and rate-constrained traffic[C]//32nd Euromicro Conference on Real-Time Systems (ECRTS 2020). Dagstuhl: [s.n.], 2020, 165: 17: 1-17, 22. [3] SAE Technical Standard. SAE AS6802[S]. SAE Aerospace Standard. 2011(11): 1-108 [4] 彭来献, 田畅, 郑少仁. 高速交换网络的建模与仿真[J]. 系统仿真学报, 2003, 15(10): 1474-1476. doi: 10.3969/j.issn.1004-731X.2003.10.034 PENG L X, TIAN C, ZHENG S R. Modeling and simulation for high-speed switching fabrics[J]. Journal of System Simulation, 2003, 15(10): 1474-1476. doi: 10.3969/j.issn.1004-731X.2003.10.034 [5] LIU Y L, ZHANG H, JIANG N. Design and performance analysis of fibre channel network switch based on link aggregation optimization port circuit[J]. Journal of Nanoelectronics and Optoelectronics, 2020, 15(9): 1137-1145, 1149. [6] MA X F, HAMDULLA A. Hybrid scheduling technology of time-triggered ethernet switches: A review[J]. Journal of Physics: Conference Series, 2020, 1673(1): 012024. doi: 10.1088/1742-6596/1673/1/012024 [7] 张建东, 吴勇, 史国庆, 等. 光纤通道交换网络WRR实时调度算法分析[J]. 航空学报, 2012, 33(2): 306-314. ZHANG J D, WU Y, SHI G Q, et al. Analysis of fibre channel switching network WRR real-time scheduling algorithm[J]. Acta Aeronautica et Astronautica Sinica, 2012, 33(2): 306-314. [8] 孙雪, 曹素芝, 许辉. FC交换机中多优先级变长CROSSBAR调度策略[J]. 光通信技术, 2018, 10(15): 15-19. SUN X, CAO S Z, XU H. Multi-priority variable-length CROSSBAR scheduling strategy in FC switch[J]. Optical Communication Technology, 2018, 10(15): 15-19. [9] 彭来献, 田畅, 赵文栋. 一种具有O(logN)信息复杂度的高速crossbar调度算法[J]. 电子学报, 2016, 11: 2024-2029. PENG L X, TIAN C, ZHAO W D. A new scheduling algorithm with O(logN) control messages complexity for high-speed crossbars[J]. Acta Electronica Sinica, 2016, 11: 2024-2029. [10] 谢军, 涂晓东, 孟中楼. 多用途光纤通道交换机的设计与实现[J]. 计算机研究与发展, 2011, 48: 335-339. XIE J, TU X D, MENG Z L. Design and implementation of multi-purposefibre channel switch[J]. Journal of Computer Research And Development, 2011, 48: 335-339. -

 点击查看大图
点击查看大图
图(6) / 表(1)
计量
- 文章访问数: 4006
- HTML全文浏览量: 1411
- PDF下载量: 27
- 被引次数: 0












