 ISSN
ISSN 


-
强化学习(reinforcement learning, RL)是机器学习的一个重要子领域,已被广泛应用于解决智能体如何在环境中采取行动以最大化其累积奖励的问题[1]。其中,深度强化学习(deep reinforcement learning, DRL)通过利用深度神经网络(deep neural networks, DNN)卓越的函数近似能力,已经在许多方面取得了显著成果[2],如围棋游戏[3-4]、雅达利游戏[5-7]、机器人控制[8]等。作为深度强化学习的重要算法之一,深度Q值网络(deep Q-network, DQN)[6]通过结合卷积神经网络(convolution neural network, CNN)[9]和Q学习算法(Q-learning)[10],在一些雅达利游戏上已经能达到人类玩家的水平。然而,现有深度强化学习仍然存在许多问题,如样本效率低、探索−利用困境、面对复杂任务环境的维数灾难等,这些问题将严重限制深度强化学习的应用范围。
最近,量子计算在加速经典机器学习算法方面显示出强大的能力[11-14],同时也已被用以解决强化学习问题[15-21]。一种量子强化学习的实现方案是利用量子纠缠和量子叠加态等资源以提升经典强化学习算法的学习效率[15-16]。还有一些量子强化学习算法主要研究量子智能体在量子环境下的交互学习模式以及如何基于量子交互框架实现学习效率的平方或者指数加速[17-19]。除此之外,随着含噪中等规模量子(noisy intermediate-scale quantum, NISQ)计算机的发展,变分量子线路(variational quantum circuit, VQC)作为一种适用于NISQ设备的可优化量子线路模块,已被广泛应用于量子神经网络的设计,进而被用于构建量子深度强化学习算法[20-21]。与经典强化学习算法相比,这种基于VQC的量子深度强化学习算法在减少参数数量方面展现出一定优势。然而,现有的量子深度强化学习方法仍然存在样本效率低下的问题,即它们的训练过程需要大量的量子智能体与经典环境进行交互,这会导致执行量子电路的调用次数迅速增加。
最近,基于情景记忆的传统强化学习方法由于可以快速锁定先前好的策略来加速强化学习训练而引起广泛关注。受这些研究工作的启发,本文提出了一种量子情景记忆深度Q网络(quantum episode memory deep Q-network, QEMDQN)模型以提高样本效率。该模型通过使用情景记忆监督量子智能体的训练,学习更优策略,使用情景记忆存储高奖励的历史经验信息,使用情景记忆中的高奖励的历史信息以指导量子智能体训练,显著地降低了学习最优策略所需的算法迭代次数。此外,在训练过程中,该模型可以随时从情景记忆中提取高奖励的历史信息,并将这些信息整合到量子神经网络中从而更有效地利用样本。在5种实验环境中与几种量子深度强化学习方法进行对比,本文方法获得了更好的性能和更低的算法运行时间。
-
强化学习(RL)指智能体从与环境的交互中不断学习以解决问题的方法[22-23],常被描述为一个马尔可夫决策过程(Markov decision process, MDP)。马尔可夫决策过程常常由一个五元组
$ \left( {S,A,R,T,\gamma } \right) $ 表示:其中$ S $ 表示状态的集合,$ A $ 表示动作的集合,$ R:S \times A \to \mathbb{R} $ 表示奖励函数,$ T:S \times A \times S \to \left[ {0,1} \right] $ 表示状态转移矩阵,$ \gamma \in \left[ {0,1} \right] $ 表示衰减因子。马尔可夫决策过程的目标是学习一个最优策略${\pi}\left( s \right)$ :$$ {\pi}\left( s \right) = \arg \mathop {\max }\limits_a {Q^*}\left( {s,a} \right) $$ (1) 式中,
$$ {Q^*}\left( {s,a} \right) = {\rm{E}}\left[ {r\left( {{s_t},{a_t}} \right) + \gamma T\left( {{s_t},{a_t},{s_{t + 1}}} \right)\mathop {\max }\limits_{{a_{t + 1}}} {Q^*}\left( {{s_{t + 1}},{a_{t + 1}}} \right)} \right] $$ (2) 深度强化学习(DRL)融合了强化学习和深度学习(DL),使用RL定义问题和优化目标,使用DL解决策略和价值函数的建模问题,然后使用误差反向传播算法优化目标函数[24]。一个代表性的深度强化方法深度Q网络(DQN)成功地利用深度卷积神经网络来逼近状态−动作值函数
$ {Q_\theta } = Q\left( {{s_t},{a_t};\theta } \right) $ ,其中$ \theta $ 是策略网络的参数,$ \left( {s,a} \right) $ 表示一对状态−行动。深度Q网络的目标损失函数定义如下:$$ L\left( \theta \right) = {\rm{E}}\left[ {{{\left( {{r_t} + \gamma \mathop {\max }\limits_{a'} Q\left( {{s_{t + 1}},a';{\theta ^ - }} \right) - Q\left( {{s_t},{a_t};\theta } \right)} \right)}^2}} \right] $$ (3) 式中,
$ {\theta ^ - } $ 是目标网络的参数。 -
情景记忆来源于人类记忆的心理生物学和认知研究[25-26],并遵循基于实例的决策理论[27]。大量研究工作将情景记忆应用于强化学习以提高其样本效率[28-31]。如文献[28]提出一种上下文控制方法,通过使用情景记忆来存储经验使得智能体可以模拟先前具有高奖励值的状态动作序列。文献[29]提出一种神经情景控制(neural episodic control, NEC)方法,该方法使用可微分的神经字典来记录那些缓慢变化的状态−动作对和快速更新的状态函数值,并通过状态函数上下文的查找值来修正策略。文献[30]使用情景记忆来构建用于状态值函数估计的上下文强化学习。文献[31]在目标函数中添加正则化项,将情景记忆的信息提炼成参数模型,显著提升了DQN的性能。
-
变分量子电路(VQC)是由若干含参的单量子比特旋转门和双量子比特控制门组合而成的量子线路,其参数可通过经典计算机对特定目标函数求解梯度进行优化。通过在一个含参量子线路中添加更多的量子门,可增强量子电路的表达能力。原则上,近似任意的酉变换需要指数多的单比特门和多比特门,然而根据现有的NISQ设备的要求,通常在变分量子线路中使用相对于量子比特数是多项式增加的量子门来求解特定问题。如变分量子电路可被用来构建变分量子本征求解器,从而可利用量子计算机来近似一些物理汉密尔顿量的基态能量。已有结果显示,利用量子线路构建的变分量子本征求解器具有一定削弱量子线路噪声的能力[32-33]。此外,变分量子线路可用来模拟量子多体系统,或构造量子神经网络。基于量子变分线路的量子神经网络相较于传统的经典神经网络可能存在需要更少参数等方面的优势。其他的一些研究表明,变分量子电路可以在经典计算机上近似求解传统算法难以处理的函数,甚至可以对量子多体物理进行模拟[34-35]。在某些情况下,变分量子电路可以用比传统神经网络更少的参数来模拟复杂环境[36-37] 。
-
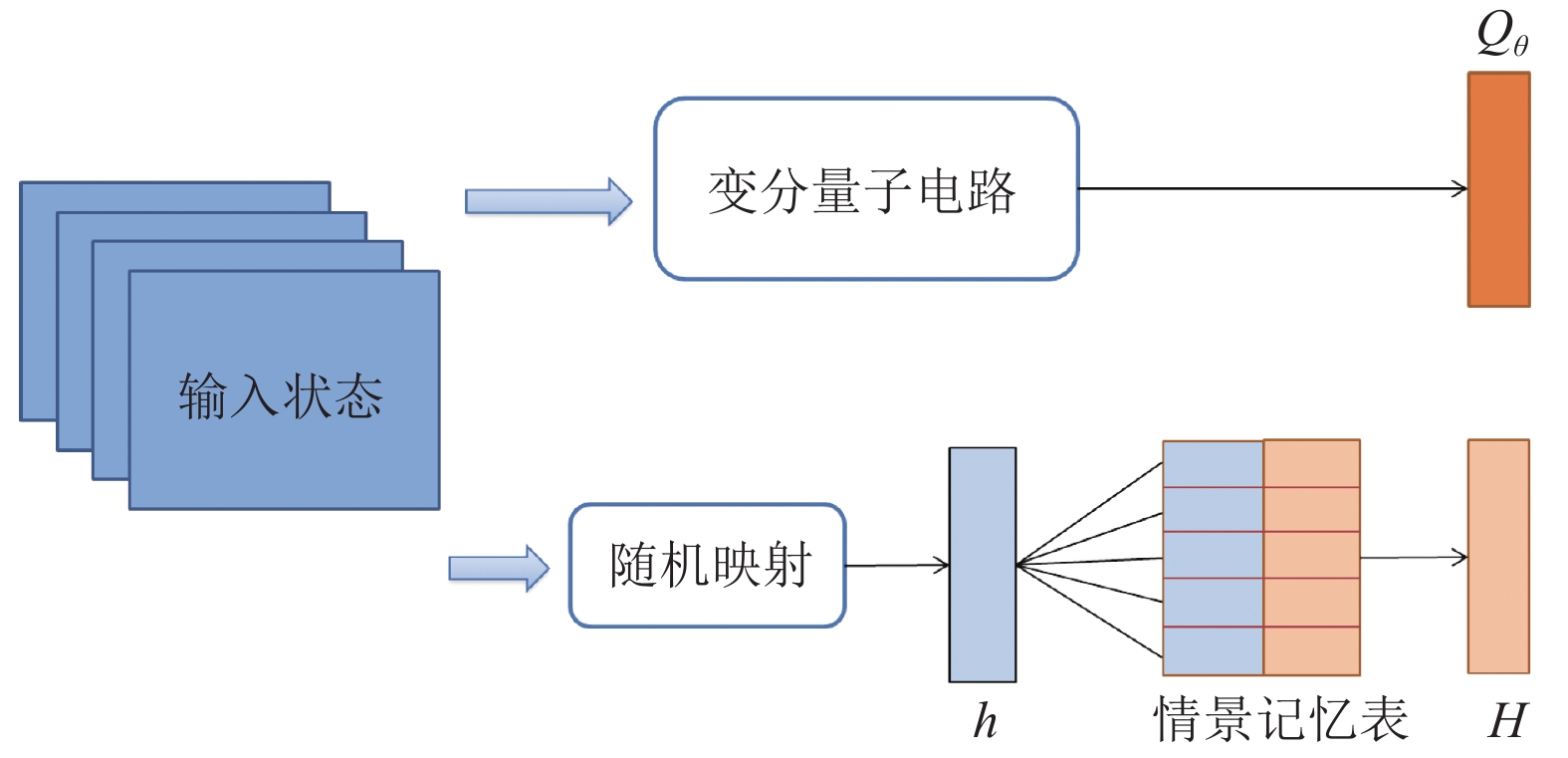
本节提出了量子情景记忆深度Q网络 (QEMDQN)方法,该方法使用情景记忆来加速量子智能体的训练,如图1所示。
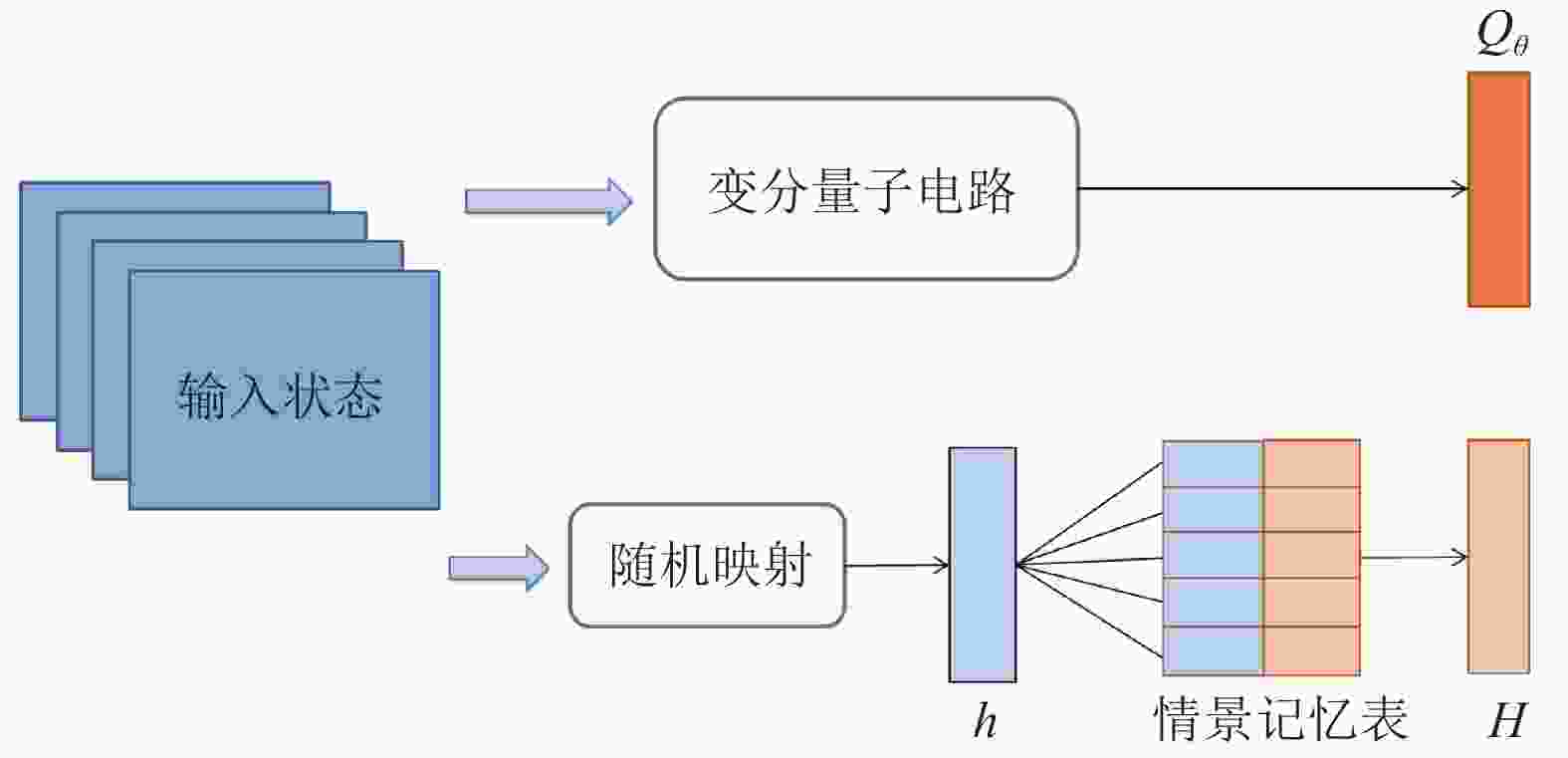
图 1 QEMDQN算法的框架结构
具体地,受大脑中纹状体和海马体之间竞争与合作作用的启发[25-26],该方法采用两个变分量子电路来逼近量子智能体的
$ Q $ 函数,从而分别为量子智能体构造了一个由$ U $ 表示的推断目标和一个由$ H $ 表示的情景记忆目标。该方法构造了一个新的目标损失函数:$$ L = {\left( {{Q_\theta } - U} \right)^2} + \tau {\left( {{Q_\theta } - H} \right)^2} $$ (4) 式中,
$ U = {r_t} + \gamma \mathop {\max }\limits_{a'} Q\left( {{s_{t + 1}},a';{\theta ^ - }} \right) $ 是目标网络值函数;$ \tau $ 表示$ U $ 和$ H $ 的相对权重系数;情景记忆目标$ H $ 被定义为最佳的历史奖励,其数学表达形式为:$$ H\left( {{s_t},{a_t}} \right) = \mathop {\max }\limits_i {R_i}\left( {{s_t},{a_t}} \right),{\text{ }}i \in \left\{ {1,2, \cdots ,E} \right\} $$ (5) 式中,
$ E $ 表示智能体更新策略所使用的回合的数目。情景记忆表的更新方式如下所示:$$ H\left( {{s_t},{a_t}} \right) = \left\{ {\begin{array}{*{20}{l}} {R\left( {{s_t},{a_t}} \right)\;\;\;\;{\text{ if}}\left( {{s_t},{a_t}} \right) \notin H} \\ {\max \left\{ {H\left( {{s_t},{a_t}} \right),R\left( {{s_t},{a_t}} \right)} \right\}\;\;\;\;{\text{ else}}} \end{array}} \right. $$ (6) 目标函数可被重新表述为下列形式:
$$ \mathop {\min }\limits_\theta \sum\limits_{\left( {{s_i},{a_i},{r_i},{s_{i + 1}} \in D} \right)} \begin{array}{l} [{\left( {{Q_\theta }\left( {{s_i},{a_i}} \right) - U\left( {{s_i},{a_i}} \right)} \right)^2} + \tau \left( {{Q_\theta }\left( {{s_i},{a_i}} \right) - } \right.\\ {\left. {H\left( {{s_i},{a_i}} \right)} \right)^2}] \end{array} $$ (7) 式中,
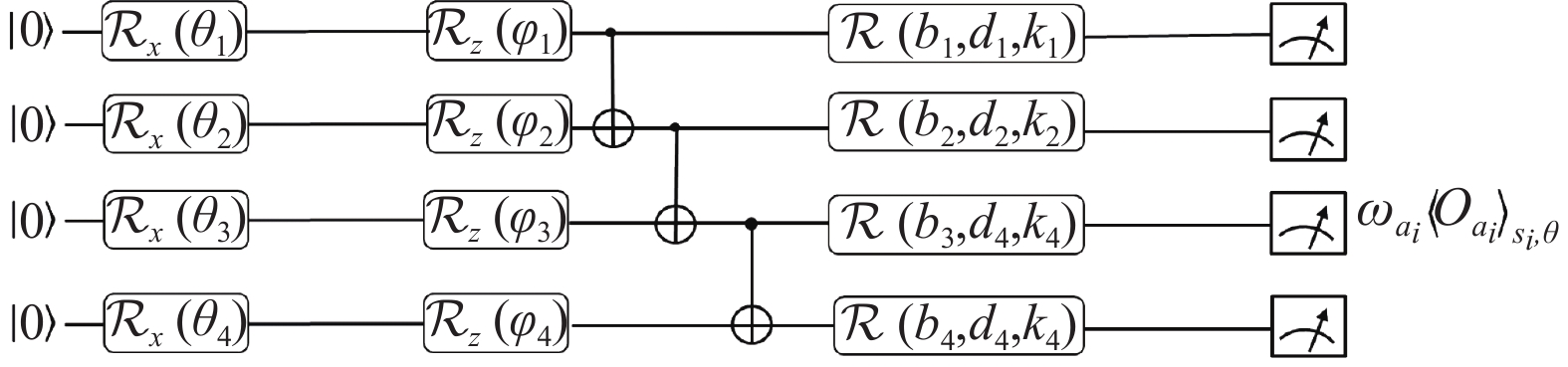
$ D $ 表示经验回放池使用的批次数量。在算法实现过程中,文献[20]提出变分量子电路来近似估计量子智能体的
$ Q $ 函数,如图2所示。其中,$ {\mathcal{R}_\sigma }\left( \theta \right) $ ,$\sigma \in \left\{X, Y, Z\right\}$ ,分别表示绕X, Y, Z轴旋转的单比特旋转门,同时,$ \mathcal{R}\left( {{b_i},{d_i},{k_i}} \right) = $ $ {\mathcal{R}_x}\left( {{b_i}} \right){\mathcal{R}_y}\left( {{d_i}} \right){\mathcal{R}_z}\left( {{k_i}} \right) $ 。除单比特旋转门外,该线路利用CNOT门使得量子系统产生纠缠。最后该方法测量可观测量$ {O_{{a_i}}} $ 的期望值,并将其视为量子智能体所生成的$ Q $ 函数,即:$$ Q\left( {{s_i},{a_i};\theta } \right) = {\left\langle {{O_{{a_i}}}} \right\rangle _{{s_i},\theta }} $$ (8) 式中,
$ {\omega _{{a_i}}} $ 是用于输出处的一个可观察的权重参数。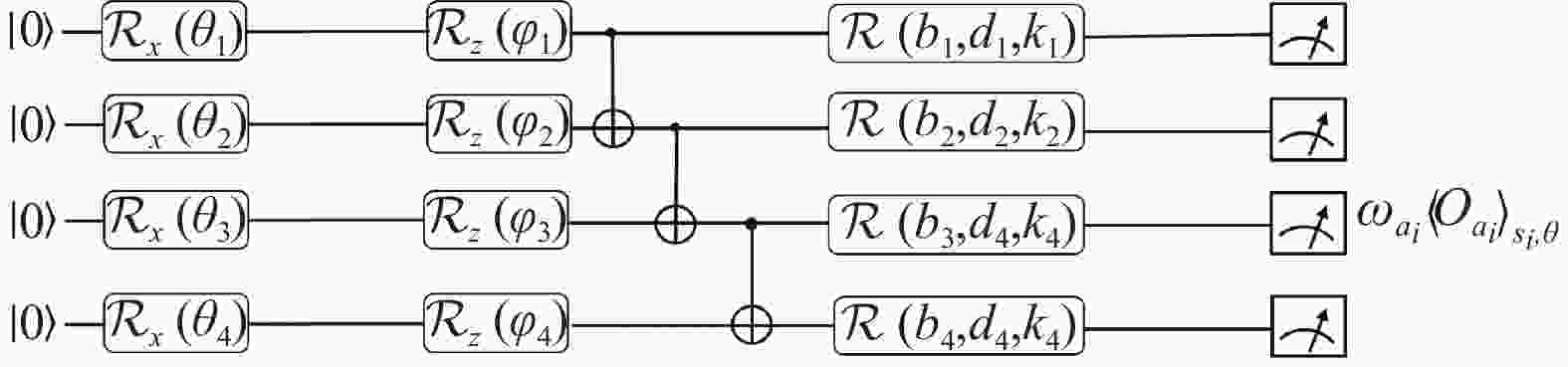
图 2 QEMDQN算法使用的变分量子电路结构
此外,本文使用计算基础编码方法将经典状态编码为量子比特的状态[38]。对于一般的
$ n $ -量子比特状态,其数学表达式为$\left| \psi \right\rangle = \displaystyle\sum\limits_{{i} = 1}^{{2^{n - 1}}} {{\alpha _i}} \left| i \right\rangle$ ,其中$ {\alpha _i} \in \mathbb{C} $ 表示第$ i $ 个基底上的振幅,并满足$ {\left\| \alpha \right\|^2}{\text{ = }}1 $ 。特别地,该方法利用$ n $ 个量子比特构成的希尔伯特空间的计算基底来编码量子智能体的当前状态。以量子智能体在当前时刻观察到的状态为11为例。该方法首先将状态的十进制数11转换为二进制数1011,然后使用单量子门将其编码为量子态$ \left| {1011} \right\rangle $ 。本文方法使用情景记忆中的最佳历史回报来学习策略,使得智能体在当前环境的状态与情景记忆中的某状态相似时快速地获得期望的动作,从而显著地加快收敛速度。在训练过程中,本文方法可以随时从情景记忆中提取高奖励的历史信息,并将这些信息整合到量子神经网络中。通过这种方式,可以更有效地利用样本。算法的伪代码如下所示。
算法 量子情景记忆深度Q网络算法
初始化经验回放池
$ D $ 、量子状态行动值函数$ Q $ 以及情景记忆$ H $ for 情景记忆数目
$ e = 1,2, \cdots ,E $ do初始化状态
$ {s_1} $ 并将其编码为量子态for
$t = 0,1, \cdots ,T$ do从变分量子电路的输出中获得动作
$ {a_t} $ 执行动作
$ {a_t} $ 来获得奖励$ {r_t} $ 和状态$ {s_{t + 1}} $ 将元组
$ \left( {{s_t},{a_t},{r_t},{s_{t + 1}}} \right) $ 存储到经验回放池$ D $ 将三元组
$ \left( {{s_t},{a_t},{r_t}} \right) $ 存储到情景记忆$ H $ 从经验回放池
$ D $ 中采样一个批次的元组$\left( {{s_i},{a_i},{r_i},{s_{i + 1}}} \right)$ 设定推断目标
$ U = {r_i} + \gamma \mathop {\max }\limits_{a'} Q\left( {{s_{i + 1}},a';{\theta ^ - }} \right) $ 从情景记忆中搜索记忆目标
$ H\left( {{s_i},{a_i}} \right) $ 根据目标函数更新参数
$ \theta $ 更新情景记忆
$ H $ end for
end for
-
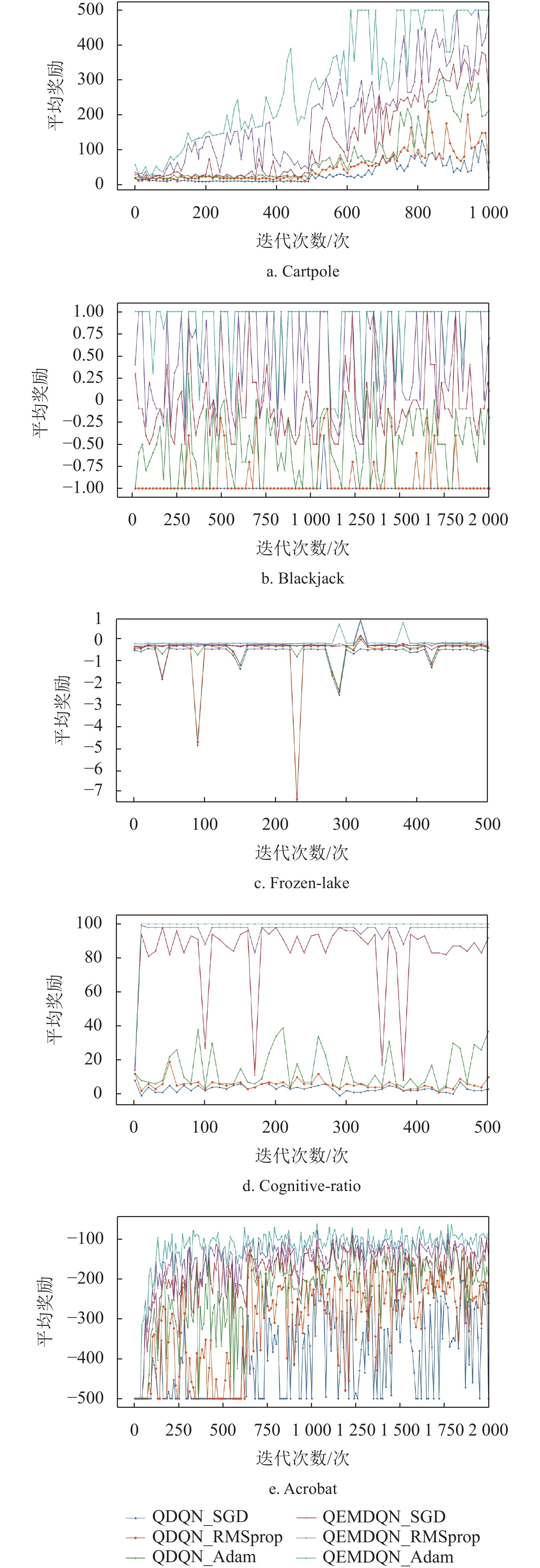
本文在Frozen-lake、Cognitive-ratio、Cartpole、Blackjack和Acrobat实验环境[39-40]上进行了对比实验。实验所采用的服务器配置为:Intel i9 9900K处理器、64 GB内存、GPU为GeForce RTX 2080Ti、Ubuntu 16.04 64位操作系统,代码基于Python 3.7编写。此外,使用Pytorch机器学习库来实现线性代数运算的计算加速模拟[41]。同时,本文分别使用深度强化学习中广泛使用的SGD、RMSprop和Adam优化方法来训练量子智能体[42-44],其主要参数设置为
$ \eta = 0.01 $ ,$ \alpha = 0.99 $ ,${\rm{momentum}} = 0.9$ ,$ \tau = $ $ {10^{ - 8}} $ 。在几个实验环境中,经验回放的批次大小统一设置为5,$ \varepsilon $ -贪心策略的选择方法为:$$ \varepsilon \leftarrow \frac{\varepsilon }{{\dfrac{E}{{100}} + 1}} $$ 图3和表1分别展示了不同量子深度强化学习算法的期望累积回报和运行时间实验对比结果。可以发现,虽然不同的优化算法对实验结果有一定的影响,但在使用相同的优化算法的前提下,本文方法依然比原来的量子深度强化学习方法获得了更高的平均得分和更低的算法运行时间。如图3所示,在采用不同的优化算法的情况下,通过结合情景记忆,本文方法(分别由红色、紫色和青色曲线表示)在不同的实验环境上经过几十个回合之后就获得了比原始的量子深度强化学习方法(分别由蓝色、黄色和绿色曲线表示)高许多的平均得分(得分越高表示学习到的策略越好),并且保持这个优势到整个算法迭代结束。这是因为本文方法在那些可以遇到重复的状态的实验环境上表现得很好,说明情景记忆的引入可提升算法的性能。此外,由图3可知,本文方法吸收了情景记忆的快速收敛特性,同时保持了量子神经网络的良好泛化性,使其在后期训练中保持了优越的学习能力。
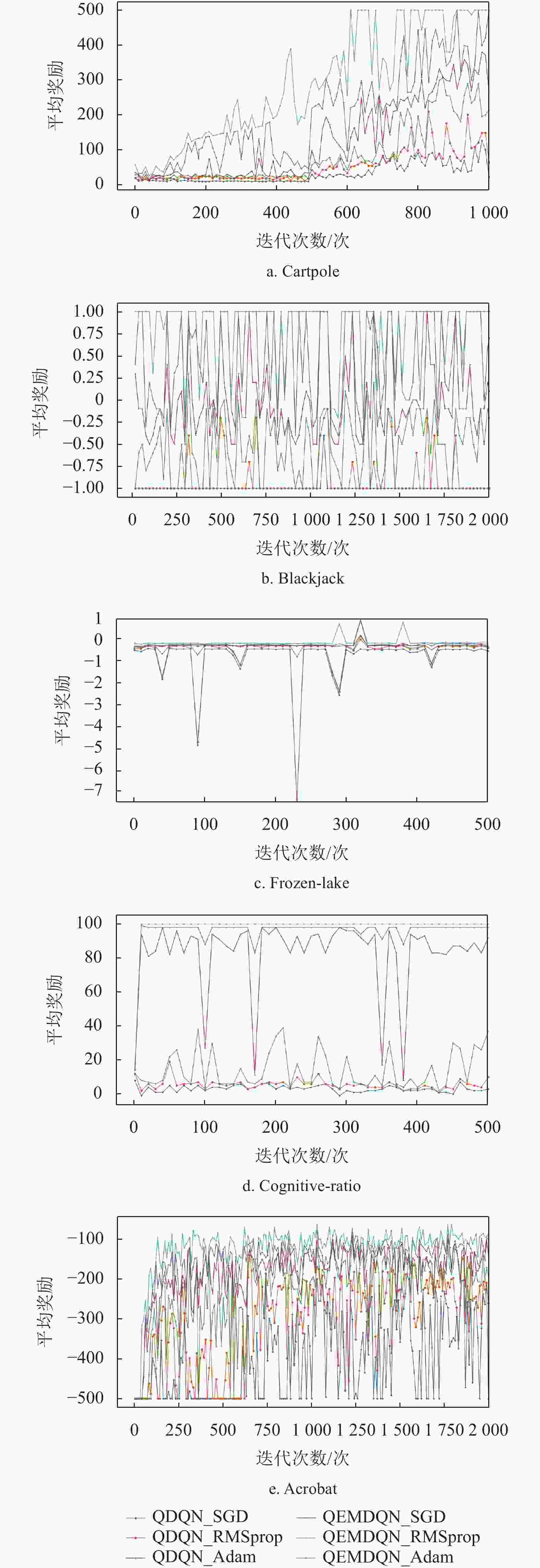
图 3 不同的量子深度强化学习算法在几个雅达利游戏环境中的实验对比结果
表 1 不同量子深度强化学习的运行时间对比
s 方法 Frozen-lake Cognitive-ratio Cartpole Acrobat Blackjack QEMDQN_SGD 7131.23 1352.67 4988.04 8706.83 10.72 QEMDQN_RMSprop 6199.15 889.98 4822.28 8655.77 10.44 QEMDQN_Adam 4308.87 676.43 4463.86 5142.92 8.13 QDQN_SGD 8706.83 3142.92 6903.91 11007.89 22.44 QDQN_RMSprop 8545.32 2880.15 5886.79 9917.65 17.41 QDQN_Adam 7846.82 2133.37 5571.79 8706.83 14.5 -
本文提出了一种基于情景记忆的量子深度强化学习方法,通过使用情景记忆来加速量子智能体的训练过程。该方法将历史上出现的拥有高奖励值的经验记录到情景记忆中,并使用它们提供额外的监督信息来指导量子智能体的训练。通过这种方式,当量子智能体在当前状态与情景记忆中的某个状态相似时,可以快速获得想要的动作,从而显著地加快收敛速度。本文针对5种典型的雅达利游戏做了数值模拟,结果显示,本文方法可以获得更高的期望累积回报和更低的算法运行时间。
Quantum Deep Reinforcement Learning Based on Episodic Memory
-
摘要: 作为量子机器学习的一个新兴子领域,量子深度强化学习旨在利用量子神经网络构建一个量子智能体,使其通过与环境进行不断交互习得一个最优策略,以达到期望累积回报最大化。然而,现有量子深度强化学习方法在训练过程中需要与经典环境进行大量交互,从而导致大量多次调用量子线路。为此,该文提出了一种基于情景记忆的量子深度强化学习模型,称为量子情景记忆深度Q网络,该模型利用情景记忆来加速量子智能体的训练过程。具体来说,该模型将历史上出现的拥有高奖励值的经验记录到情景记忆中,使得在当前环境的状态与情景记忆中的某状态相似时,量子智能体可以根据该历史状态快速地获得想要的动作,从而减少了算法优化的迭代次数。在5个经典的雅达利游戏上的数值模拟表明,该文提出的方法可以显著地减少训练量子智能体的迭代次数,进而可以获得比其他量子深度强化学习方法更高的分数。Abstract: As an emerging subfield of quantum machine learning, quantum deep reinforcement learning (QDRL) utilizes quantum neural networks (QNNs) to construct a quantum agent and trains QNNs through multiple interactions with an environment to maximize the expected cumulative return. However, existing QDRL methods require the quantum agent to interact with a classical environment many times, requiring a huge number of executions of the QNN circuit. To address this problem, this work proposes a QDRL model, a quantum episodic memory deep Q-network, which utilizes episodic memory to accelerate the training process. Specifically, the proposed model stores experiences with high rewards in history into the episodic memory, which then helps the quantum agent to obtain the desired action with significantly fewer iterations when the environment state is similar to one of those stored in the episodic memory. Numerical simulations on five typical Atari games show that the proposed method can significantly reduce the number of training iterations and can achieve a higher score compared to other conventional QDRL methods.
-
表 1 不同量子深度强化学习的运行时间对比
s 方法 Frozen-lake Cognitive-ratio Cartpole Acrobat Blackjack QEMDQN_SGD 7131.23 1352.67 4988.04 8706.83 10.72 QEMDQN_RMSprop 6199.15 889.98 4822.28 8655.77 10.44 QEMDQN_Adam 4308.87 676.43 4463.86 5142.92 8.13 QDQN_SGD 8706.83 3142.92 6903.91 11007.89 22.44 QDQN_RMSprop 8545.32 2880.15 5886.79 9917.65 17.41 QDQN_Adam 7846.82 2133.37 5571.79 8706.83 14.5  下载: 导出CSV
下载: 导出CSV
-
[1] YANN L, YOSHUA B, GEOFFREY H. Deep learning[J]. Nature, 2015, 521(7553): 436-444. doi: 10.1038/nature14539 [2] LAN G, YOSHUA B, ARON C. Deep Learning[M]. Cambridge: MIT Press, 2016. [3] DAVID S, HUANG A, MADDISON C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489. doi: 10.1038/nature16961 [4] DAVID S, JULIAN S, KAREN S, et al. Mastering the game of go without human knowledge[J]. Nature, 2017, 550(7676): 354-359. doi: 10.1038/nature24270 [5] RICHARD, ANDRE G. Reinforcement learning: An introduction[M]. Cambridge: MIT Press, 2018. [6] VOLODYMY M, KORAY K, DAVID S, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533. doi: 10.1038/nature14236 [7] MATTEO H, JOSEPH M, HASSELT V, et al. Rainbow: Combining improvements in deep reinforcement learning[C]//Proceedings of the 32nd AAAI Conference on Artificial Intelligence. New Orleans, Louisiana: AAAI Press, 2018: 3215-3222. [8] MARCIN A, BOWEN B, MACIEK C, et al. Learning dexterous in-hand manipulation[J]. The International Journal of Robotics Research, 2020, 39(1): 3-20. doi: 10.1177/0278364919887447 [9] LAN G, YOSHUA B. Convolutional networks for images, speech, and time-series[M]. Cambridge: MIT Press, 1995. [10] CHRIS W, PETER D. Q-learning[J]. Machine learning, 1992, 8(3-4): 279-292. doi: 10.1007/BF00992698 [11] LIU, Y, SRINIVASAN A, KRISTAN T. A rigorous and robust quantum speed-up in supervised machine learning[J]. Nature Physics, 2021, 17(9): 1013-1017. doi: 10.1038/s41567-021-01287-z [12] CAI X, WU D, SU Z, et al. Entanglement-based machine learning on a quantum computer[J]. Physical Review Letters, 2015, 114(11): 110504. doi: 10.1103/PhysRevLett.114.110504 [13] JACOB B, PETER W, NICOLA P, et al. Quantum machine learning[J]. Nature, 2017, 549(7671): 195-202. doi: 10.1038/nature23474 [14] SETH L, CHRISTIAN W. Quantum generative adversarial learning[J]. Physical Review Letters, 2018, 121(4): 040502. doi: 10.1103/PhysRevLett.121.040502 [15] LOCKWOOD O, SI M. Reinforcement learning with quantum variational circuits[C]//Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment. New York: AAAI Press, 2020: 245-251. [16] WANG Z, ASHIDA Y. Deep reinforcement learning control of quantum cartpoles[J]. Physical Review Letters, 2020, 125(10): 100401. doi: 10.1103/PhysRevLett.125.100401 [17] BRIEGEL H, CUEVAS G. Projective simulation for artificial intelligence[J]. Scientific Reports, 2012, 2(1): 1-16. [18] PAPARO D, DUNJK V, MAKMAL A, et al. Quantum speedup for active learning agents[J]. Physical Review X, 2014, 4(3): 031002. doi: 10.1103/PhysRevX.4.031002 [19] DUNJK V, JACOB M, BRIEGEL, H, et al. Quantum-enhanced machine learning[J]. Physical Review Letters, 2016, 117(13): 130501. doi: 10.1103/PhysRevLett.117.130501 [20] JERB S, GYURIK C, MARSHALL S, et al. Parametrized quantum policies for reinforcement learning[EB/OL]. (2021-03-09). https://arxiv.org/abs/2103.05577.. [21] DONG D, MA H, XING X, et al. Learning-based quantum robust control: Algorithm, applications, and experiments[J]. IEEE Transactions on Cybernetics, 2019, 50(8): 3581-3593. [22] MICHAEL L. Reinforcement learning improves behaviour from evaluative feedback[J]. Nature, 2015, 521(7553): 445-451. doi: 10.1038/nature14540 [23] MARTIN L. Markov decision processes: Discrete stochastic dynamic programming[M]. New Jersey: John Wiley & Sons, 2014. [24] ARULKUMARAN K, DEISENROTH M, BRUNDAGE M, et al. Deep reinforcement learning: A brief survey[J]. IEEE Signal Processing Magazine, 2017, 34(5): 26-38. [25] ROBERT S, JERRY R. Configural association theory: The role of the hippocampal formation in learning, memory, and amnesia[J]. Psychobiology, 1989, 17(2): 129-144. doi: 10.3758/BF03337828 [26] MATTHEW B, SAM R, WANG J, et al. Reinforcement learning, fast and slow[J]. Trends in Cognitive Sciences, 2019, 23(5): 408-422. doi: 10.1016/j.tics.2019.02.006 [27] JENNIFER T, PERNILLE H. The generalized quantum episodic memory model[J]. Cognitive Science, 2017, 41(8): 2089-2125. doi: 10.1111/cogs.12460 [28] MATE L, DAYAN P. Hippocampal contributions to control: The third way[C]//Proceedings of the 21st Annual Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2007, 20: 889-896. [29] ALEXANDER P, BENIGNO U, SRINIVASAN S, et al. Neural episodic control[C]//Proceedings of the 34th International Conference on Machine Learning. New York: ACM, 2017: 2827-2836. [30] SAMUEL G, NATHANIEL D. Reinforcement learning and episodic memory in humans and animals: An integrative framework[J]. Annual Review of Psychology, 2017, 68: 101-128. doi: 10.1146/annurev-psych-122414-033625 [31] LIN Z, ZHAO T, YANG G, et al. Episodic memory deep Q-networks[C]//Proceedings of the 27th International Joint Conference on Artificial Intelligence. New York: AAAI Press, 2018: 2433-2439. [32] LOV G. Quantum computers can search arbitrarily large databases by a single query[J]. Physical Review Letters, 1997, 79(23): 4709-4712. doi: 10.1103/PhysRevLett.79.4709 [33] ABHINAV K, ANTONIO M, KRISTAN T, et al. Hardware-Efficient variational quantum eigensolver for small molecules and quantum magnets[J]. Nature, 2017, 549(7671): 242-246. doi: 10.1038/nature23879 [34] JARROD M, JONATHAN R, BABBUSH R, et al. The theory of variational hybrid quantum-classical algorithms[J]. New Journal of Physics, 2016, 18(2): 023023. doi: 10.1088/1367-2630/18/2/023023 [35] KOSUKE M, MAKOTO N, KITAGAWA M, et al. Quantum circuit learning[J]. Physical Review A, 2018, 98(3): 032309. doi: 10.1103/PhysRevA.98.032309 [36] FRANK A, KUNAL A, BABBUSH R, et al. Quantum supremacy using a programmable superconducting processor[J]. Nature, 2019, 574(7779): 505-510. doi: 10.1038/s41586-019-1666-5 [37] MARIA S, VILLE B, GOGOLIN C, et al. Evaluating analytic gradients on quantum hardware[J]. Physical Review A, 2019, 99(3): 032331. doi: 10.1103/PhysRevA.99.032331 [38] MARIA S, PETRUCCIONE F. Information encoding[M]. Berlin: Springer, 2018. [39] PRAFULLA D, CHRISTOPHER H, KLIMOV O, et al. Openai baselines[EB/OL]. [2021-12-13]. https://github.com/openai/baselines. [40] PIOTR G, ANATOLIJ Z. Ns-3 meets openAI gym: The playground for machine learning in networking research[C]//Proceedings of the 22nd International ACM Conference on Modeling. New York: ACM, 2019: 113-120. [41] SERGEY Z, ADAM L, LIN T, et al. A multipath network for object detection[C]//Proceedings of the British Machine Vision Conference. New York: BMVA Press, 2016: 1-12. [42] TIJMEN T, GEOFFREY H. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude[J]. COURSERA: Neural Networks for Machine Learning, 2012, 4(2): 26-31. [43] DIEDRIK P. KINGMA, JIMMY B. Adam: A method for stochastic optimization[C]//International Conference on Learning Representations. San Diego, CA: [s.n.], 2015: arXiv:1412.6980. [44] SEBASTIAN RUDER. An overview of gradient descent optimization algorithms[EB/OL]. [2016-09-15]. https://arxiv.org/abs/1609.04747. -

 点击查看大图
点击查看大图
图(3) / 表(1)
计量
- 文章访问数: 4217
- HTML全文浏览量: 1238
- PDF下载量: 39
- 被引次数: 0







































































