 ISSN
ISSN 



-
在一些网络中,节点之间的连接关系根据不同的涵义可以分成两类:正关系和负关系。其中,正关系表示积极的涵义,如喜欢、信任、合作、支持等;而负关系表示消极的涵义,如讨厌、不信任、对立、否决等[1]。若将相关网络中的正关系标注为正号,负关系标注负号,就形成了一个符号网络。目前,符号网络存在于很多的领域,如社交网络用户之间存在朋友与敌人关系、生物领域细胞间存在促进与抑制作用、国际关系中国家之间存在合作与敌对关系、游戏网络中玩家存在协作与竞争关系等。对符号网络进行分析和研究也越来越成为社会网络研究中不可忽视的部分[2]。
在针对符号网络结构的研究中,一个重要的问题就是如何合理有效地对符号网络的结构信息进行表示。传统的网络结构表示主要采用高维稀疏矩阵的形式,但高维稀疏矩阵往往需要更多的时间和空间成本。随着人工智能和机器学习的突飞猛进,越来越多的研究领域都融入了深度学习等相关技术,而传统的网络结构表示方法都无法直接应用这些算法,为此,研究人员开始转向探索网络节点的低维向量表示的方法,即网络表示学习(network representation learning)或网络嵌入(network embedding)。网络表示学习是衔接网络中原始数据和网络应用任务的桥梁,旨在将网络中的节点表示为低维稠密向量,并且能够最大程度地保留原网络中的结构信息和特性。
虽然,网络表示学习的研究已经取得了一系列的成果,但现有的方法大都仅适用于无符号网络,将其应用于符号网络会导致网络中符号涵义等关键信息丢失,难以获得质量较高的节点表示学习。如在朋友敌人网络中,互为敌人关系的节点可能会在嵌入空间被放得很近,这十分不合理。为此,需要研究针对符号网络的表示学习方法。
本文基于结构平衡理论和高阶互信息原理来对符号网络的拓扑结构进行研究,旨在建立结合机器学习与传统网络理论的相似度指标,提出一种新的符号网络表示学习方法SNSH (signed network representation learning algorithm based on structural balance theory and high-order mutual information),并用于解决无向符号网络中的链路符号预测问题。
-
网络表示学习旨在用低维、稠密、实值的向量表示网络中的节点。一般来说,通过网络表示学习得到的节点嵌入需要体现节点的各项特征,并能在各种下游任务取得良好的性能。
网络表示学习已被广泛应用于节点分类[3-4]、链路预测[5]、聚类[6-8]、可视化[9]、节点排序[10-11]、社区分析[12]、图形生成[13]、异常检测[14]等任务,并取得了良好的效果。节点分类的目的是根据其他节点和网络的拓扑结构来确定节点的标签;链接预测是指预测未来可能出现的缺失或链接;聚类用于寻找相似节点并将它们分组;可视化可用于洞察网络结构[15]。在符号网络中,主要的下游任务是链路符号预测[16],即预测节点之间边的符号类型。
网络表示学习的方法大致可以分为矩阵分解、随机游走、深度学习和其他4个类别。如基于矩阵分解的Laplacian Eigenmaps[17]、HOPE[18]等,基于随机游走的DeepWalk[19]、node2vec[20]等,基于深度学习的SDNE[21]、DNGR[22]、GCN[23]等,还有混杂的LINE[24]等。
对于符号网络表示学习,SiNE[25]通过多层神经网络来优化基于结构平衡理论指导的目标函数,对符号网络的表示进行了学习。Signet[26]修改了word2vec[27]模型的采样方式,通过随机游走构造高阶结构平衡环来拟合远距离邻居节点对节点符号的影响。SGCN[28]将GCN推广到符号网络中,并基于平衡理论设计了一种新的信息聚合器。SNEA[29]利用自注意机制来提高符号网络表示学习的效果。SDGNN[30]引入了一种新的逐层有向符号网络GNN模型。但这些方法都并未考虑高阶互信息对节点嵌入的影响。
本文提出的基于高阶互信息的符号网络表示学习算法,通过将符号网络中的关系反转,生成网络的负符号嵌入、负特征属性向量、负局部概括等负信息。该项工作通过负信息强化网络的正信息,以此捕获网络中高阶互信息所隐含的信息量。
-
本文涉及的符号网络的定义如下:将符号网络用无向图表示,记为
$G = \left( {V,E,S} \right)$ 。其中V代表社交网络中节点的集合,E代表网络中节点之间关系的边集合,$S = \left\{ {1, - 1} \right\}$ 代表边的符号关系。对于$\forall e\left( {i,j} \right) \in E$ ,则$s\left( {i,j} \right)$ 表示节点${v_i}$ 与节点${v_j}$ 之间的关系符号,$s\left( {i,j} \right) = 1$ 代表“+”,表示节点之间具有信任、合作、友好、支持等积极关系;$s\left( {i,j} \right) = - 1$ 代表“−”,表示节点之间具有不信任、敌对、讨厌、否决等消极关系。 -
结构平衡理论是无向符号网络研究的理论基础,为无向符号网络的结构分析提供了依据。根据该理论,在无向符号网络中,由k(k≥3)条边组成的闭合环是结构平衡的当且仅当该环上所有边的符号之积为正。文献[31]研究表明,真实符号网络中结构平衡环的数量远大于不平衡环的数量,且随着网络结构的演变,不平衡的结构会朝着平衡的结构转换。此外,文献[32]用大量实证分析表明,结构平衡理论能更好地捕获并分析无向符号网络中节点间的相互作用模式以及结构平衡性。
结构平衡理论[33]最初仅在个体层面上提出,接着由文献[34]在群体层面的图论形成中加以推广,而后又由文献[35]发展为可聚类图的概念。最近,结构平衡理论被扩展为符号网络中的一种结构,它应确保节点的“朋友”比“敌人”更近[36],即节点的位置应该离“朋友”(或具有正链接的节点)比“敌人”(或具有负链接的节点)更近。这种节点之间的结构描述如图1所示。图中,对节点1来说,它的“朋友”节点2在特征空间上的距离应当相对于它的“敌人”节点3来说会更近些。

图 1 结构平衡理论示意图
-
互信息可以度量两个随机变量之间的相互依赖性。给定两个随机变量X和Y,它们的互信息为:
$$ \begin{split} &{I\left( {X;Y} \right) = H\left( X \right) + H\left( Y \right) - H\left( {X,Y} \right)}= \\ &\qquad\qquad { H\left( X \right) - H\left( {X{\text{|}}Y} \right)} \end{split} $$ (1) 式中,
$H\left( X \right)$ 和$H\left( {X{\text{|}}Y} \right)$ 分别表示熵和条件熵;$H\left( {X,Y} \right)$ 表示X和Y的联合分布。为了测量多个随机变量之间的相互依赖性,在信息论中引入高阶/多元互信息的概念[37]。高阶互信息是互信息在随机变量数目增多时的推广,给定N个随机变量,高阶互信息的定义与互信息的定义类似,具体为:
$$ {I\left( {{X_1},{X_2}, \cdots ,{X_N}} \right) = \sum \limits_{n = 1}^N {{\left( { - 1} \right)}^{n + 1}} \sum \limits_{{i_1} < \cdots < {i_n}} H ( {{X_{{i_1}}},{X_{{i_2}}}, \cdots ,{X_{{i_n}}}} )} $$ (2) 式中,
$H ( {{X_{{i_1}}},{X_{{i_2}}}, \cdots ,{X_{{i_n}}}} )$ 表示${X_{{i_1}}}, {X_{{i_2}}},\cdots ,{X_{{i_n}}}$ 的联合熵,且$\displaystyle\sum_{{i_1} < \cdots < {i_n}} H ( {{X_{{i_1}}},{X_{{i_2}}}, \cdots ,{X_{{i_n}}}} )$ 为$\left\{ {{i_1},{i_2}, \cdots ,{i_n}} \right\} \in \left[ {1, 2,\cdots ,N} \right]$ 中所有随机变量组合的和。高阶互信息不仅能捕捉所有随机变量对之间的互信息,还能衡量随机变量间的协同作用。
-
深度图互信息( deep graph infomax, DGI )[38]是一种自监督或无监督的机器学习方法,其主要思想是最大化网络
$G:I\left( {h,s} \right)$ 的概括向量s和节点嵌入$ {{\boldsymbol{h}}_i} $ 之间的互信息。DGI使用负采样来最大化
$I\left( {h,s} \right)$ ,首先它通过函数$G = \tilde C\left( G \right)$ 生成一个补图$\tilde G$ ,然后使用同一个编码器来分别获得正图的节点嵌入和补图的节点嵌入,本文考虑到符号网络的特殊性,通过转换链接的符号正负来生成负网络。即对于负网络$\tilde G$ ,${\tilde s_{ij}} = - {s_{ij}}$ ,其余属性与图G保持一致。正网络G通过聚合网络中所有节点的方式得到整图的特征表示,即概括向量,对于给定的概括向量s,DGI使用一个鉴别器D来区分正网络嵌入
$ {{\boldsymbol{h}}_i} $ 和负网络嵌入$ {{\tilde{\boldsymbol h}}_i} $ 。给定节点嵌入
$ {{\boldsymbol{h}}_i} $ 、概括向量s和负节点嵌入$ {{\tilde{\boldsymbol h}}_i} $ ,可以通过下面的目标函数来最大化$ {{\boldsymbol{h}}_i} $ 和s之间的互信息:$$ {I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}}} \right) = \mathop {{\text{sup}}}\limits_{{{{\varTheta}} }} \mathbb{E}\left[ {\log D\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}}} \right)} \right] + \mathbb{E}\left[ {\log ( {1 - D( {{{{\tilde{\boldsymbol h}}}_i},{\boldsymbol{s}}} )} )} \right]} $$ (3) 式中,D是一个用来区分负节点嵌入和真实节点嵌入的鉴别器;
${{\varTheta }}$ 表示参数空间;$\mathbb{E}$ 表示期望。 -
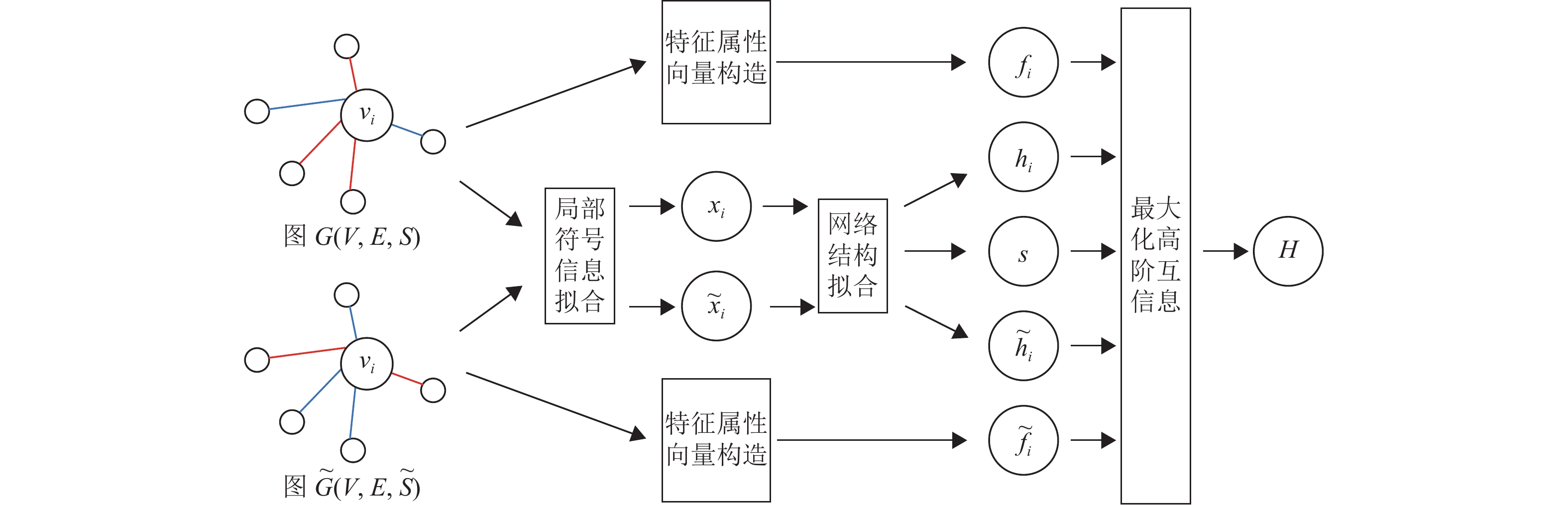
本文提出的基于结构平衡理论和高阶互信息的符号网络表示学习算法SNSH,通过改进的上下文词向量模型得到节点的局部符号嵌入,又通过一个单层的图卷积神经网络(graph convolutional network, GCN)得到网络的局部嵌入矩阵和全局概括向量,同时使用节点的出/入度等有价值特征作为其特征属性向量。本文通过最大化这三者间的高阶互信息,挖掘符号网络中隐含的内部信息、外部信息与联合信息。
本算法由局部符号信息拟合、网络结构拟合、特征属性向量构造和最大化高阶互信息4个部分组成,其基本框架如图2所示。
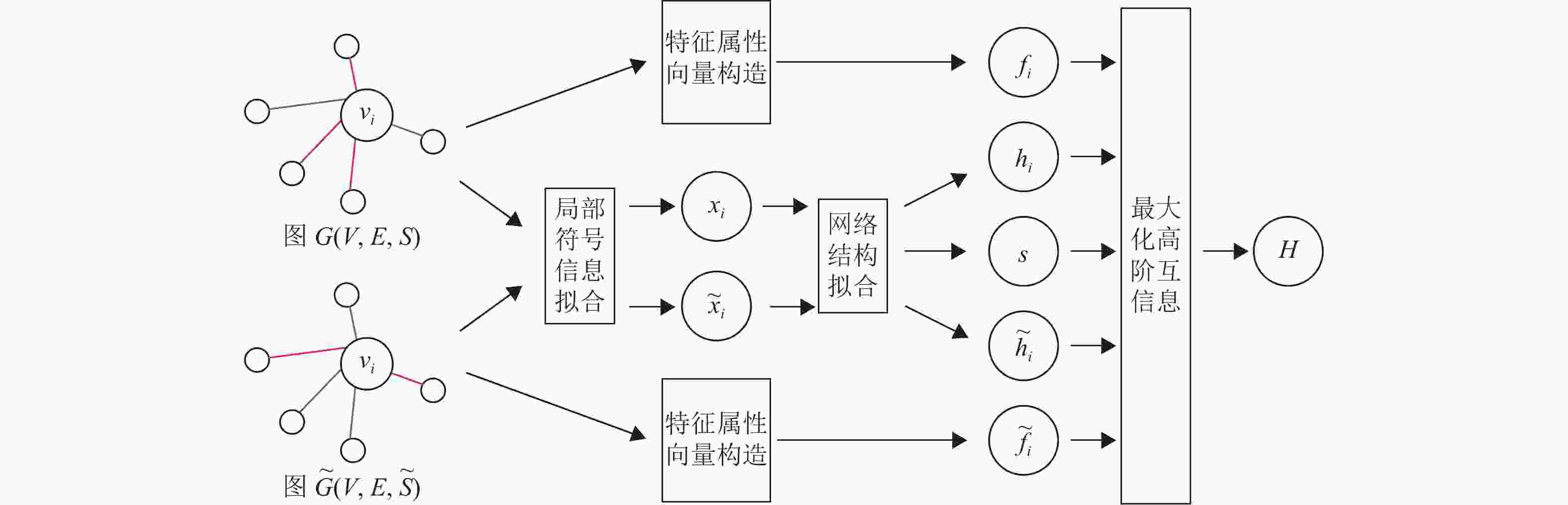
图 2 算法整体框架图
1) 局部符号信息拟合
局部符号信息拟合用于得到符号网络中节点的局部符号信息。该模块改进了传统上下文的节点嵌入模式,首先根据节点的直接邻居构造正负关系邻居集,接着基于结构平衡理论,使用新的负采样方式优化节点嵌入,从而捕捉节点对与直接邻居间的符号信息。
2) 网络结构拟合
网络结构拟合用于进行全局网络结构传播拟合。该模块使用能体现网络符号信息特征的嵌入作为输入,经过单层GCN的聚合,得到体现网络局部特征的嵌入矩阵H与体现网络全局特征的概括向量s。
3) 特征属性向量构造
特征属性向量构造用于得到综合考虑节点内在特征的特征属性向量。在该模块中对每个节点计算其度数、正邻居节点数、负邻居节点数以及体现节点建立正向链接趋势的指标,并将其构成节点特征属性向量。这些指标在传统符号链路预测方式中被证明能够有效体现节点特征。
4) 最大化高阶互信息
最大化高阶互信息用于最大化符号网络节点的高阶互信息,涵盖节点嵌入与概括向量之间的外部信息量、节点嵌入与特征属性向量之间的内部信息量,以及节点嵌入与概括向量和特征属性向量两者间的联合信息量,更有利于全面地捕捉符号网络隐含的特征信息。
-
1) 模型构建
使用P维向量
$ {{\boldsymbol{x}}_i} \in {\mathbb{R}^P} $ 作为节点${v_i} \in V$ 的局部符号向量表示,不同节点${v_i}$ 与${v_j}$ 之间的相似度$P( {{v_i},{v_j}} )$ 为:$$ {P( {{v_i},{v_j}} ) = \sigma ( {{\boldsymbol{x}}_j^{\rm{T}} \cdot {{\boldsymbol{x}}_i}} )} $$ (4) 式中,
${\sigma }$ 是sigmoid函数。基于结构平衡理论,最大化正关系节点间的相似度,并最小化负关系节点间的相似度,目标函数构造为:
$$ {L = \sum \limits_{{e_{ij}} \in E} {s_{ij}}\sigma ( {{\boldsymbol{x}}_j^{\rm{T}} \cdot {{\boldsymbol{x}}_i}} ) = \sum \limits_{{e_{ij}} \in E} {s_{ij}}P( {{v_i},{v_j}} )} $$ (5) 式中,
${s_{ij}} \in \left\{ {1, - 1} \right\}$ 。通过最大化式(5),就可以得到节点
${v_i}$ 的局部符号特征的k维向量表示${{\boldsymbol{x}}_i}$ 。2) 节点对采样
给定节点
${v_i}$ ,分别构造正邻居集${\eta }_i^ +$ 与负邻居集${\eta}_i^ -$ ,其中,${\eta}_i^ +$ 为节点${v_i}$ 的所有正关系邻居,${\eta}_i^ -$ 为节点${v_i}$ 的所有负关系邻居。在这里,SNSH拓展了传统的负采样策略,依据边的类型,在相应集合中选取负采样节点,以使其适用于符号网络。如对于
${s_{ij}} = 1$ 的正关系节点对,该方法从节点${v_i}$ 与${v_j}$ 的负邻居集${\eta}_i^ -$ 及${\eta}_j^ -$ 进行采样,来最大化节点${v_i}$ 与${v_j}$ 之间相对于其负邻居集中节点的相似度。同理,对于${s_{ij}} = - 1$ 的负关系节点对,从节点${v_i}$ 与${v_j}$ 的正邻居集${\eta}_i^ +$ 及${\eta}_j^ +$ 进行采样,来最小化节点${v_i}$ 与${v_j}$ 之间相对于其正邻居集中节点的相似度。因此,基于条件独立假设和特征空间的对称性假设,可以为每个节点构造目标函数:$$ \begin{split} &{L}_{i}={{\displaystyle \sum_{{v}_{j}\in {\text{η}}^+} }}\mathrm{log}\left[\sigma ({s}_{ij}({{\boldsymbol{x}}}_{j}^{{\rm{T}}}\cdot {{\boldsymbol{x}}}_{i}))\right]+ \\ &\;\; {{\displaystyle \sum_{{v}_{u}\in {\text{η}}^-} }}\mathrm{log}\left[\sigma ({s}_{iu}({{\boldsymbol{x}}}_{u}^{{\rm{T}}}\cdot {{\boldsymbol{x}}}_{i}))\right] \end{split} $$ (6) 式中,
${s_{ij}} = 1$ ;${s_{iu}} = - 1$ ;${\sigma }$ 是sigmoid函数。3) 模型优化
为了方便计算,改进了传统的负采样方式,每次仅优化一对节点及确定数目的负样本。同时采用定义虚拟节点的方法,解决了部分节点不存在负样本的问题。
本模块采用了创新的负采样方式,基于词向量模型及结构平衡理论,对符号网络中的正负关系进行了拟合,最终得到了可以体现符号网络特性分布的p维节点嵌入矩阵X,供后面使用。
-
在该部分使用一个节点嵌入编码器
$\varepsilon = {\mathbb{R}^{N \times P}} \times {\mathbb{R}^{P \times d}} \to {\mathbb{R}^{N \times d}}$ 来进行网络结构拟合。模型的输入是节点的局部符号信息拟合向量${{\boldsymbol{x}}_i} \in {{\boldsymbol{X}}^P}$ ,目标是生成d维节点嵌入矩阵H(用${{\boldsymbol{h}}_i}$ 来表示矩阵H的第i行向量)以及概括向量s。该编码器是一个单层的GCN:$$ {{\boldsymbol{H}} = \varepsilon \left( {{\boldsymbol{X}},{\boldsymbol{A}}{\text{|}}{\boldsymbol{W}}} \right) = {\sigma }( {{{\hat D}^{ - \tfrac{1}{2}}}{\hat{\boldsymbol A}}{{\hat D}^{ - \tfrac{1}{2}}}{\boldsymbol{XW}}} )} $$ (7) 式中,A是邻接矩阵;D是度矩阵;
${\hat{\boldsymbol A}} = {\boldsymbol{A}} + {{\omega }_1}{\boldsymbol{I}}_n^ + + {{\omega }_2}{\boldsymbol{I}}_n^ -$ ;${{\hat{\boldsymbol D}}_{ii}} = \displaystyle\mathop \sum \nolimits_j {{\hat{\boldsymbol A}}_{ij}}$ ;${\boldsymbol{W}} \in {\mathbb{R}^{P \times d}}$ ;$ \sigma $ 是sigmoid函数。使用拟合符号结构后的节点嵌入作为GCN的输入,而非重新定义GCN的传播模式,并引入
${\omega _1},{\omega _2} \in R$ 来控制自连接的权重。较小的${{\omega }_1}$ 或${{\omega }_2}$ 表明,节点本身在生成其嵌入中起着更重要的作用,这也意味着降低了其邻居节点的重要性。对于正关系和负关系给予不同的权重,以拟合它们在传播中对邻居的不同影响。编码器产生的
${{\boldsymbol{h}}_i}$ 嵌入了以节点${v_i}$ 为中心的网络的区域特征,而不仅仅是节点本身。为了得到网络级别的概括向量s,使用函数${\mathbb{R}^{N \times d}} \to {\mathbb{R}^d}$ ,通过聚合节点特征的方式来得到整图的特征表示,函数定义为:$$ {{\boldsymbol{s}} = {\text{Readout}}\left( {{\boldsymbol{H}}} \right) = {\sigma }\left( {\frac{1}{n} \sum \limits_{i = 1}^n {{\boldsymbol{h}}_i}} \right)} $$ (8) -
传统方法使用节点的入度、出度、地位、建立正向边趋势等属性对边符号进行预测[39],实验表明,这些节点的特征属性对节点的特征学习是有意义的,但它们往往在符号网络表示学习方法中被忽略。对节点
${v_i} \in V$ ,其特征属性向量${{\boldsymbol{f}}_i} \in {\boldsymbol{F}}$ 表示为:$$ {{{\boldsymbol{f}}_i} = ( {{\rm{ne}}_i^ + /{\rm{d}}{{\rm{e}}_i},{\rm{ne}}_i^ - /{\rm{d}}{{\rm{e}}_i},{\rm{p}}{{\rm{r}}_i}} )} $$ (9) 式中,
${\rm{d}}{{\rm{e}}_i}$ 代表节点${v_i}$ 的度;${\rm{ne}}_i^ + $ ,${\rm{ne}}_i^ - $ 分别表示节点${v_i}$ 的正关系邻居数以及负关系邻居数;${\rm{p}}{{\rm{r}}_i}$ 表示节点${v_i}$ 建立正向边的趋势,其计算方法为:$$ {{\rm{p}}{{\rm{r}}_i} = \frac{{{\rm{ne}}_i^ + - {\rm{ne}}_i^ - }}{{{\rm{ne}}_i^ + + {\rm{ne}}_i^ - }}} $$ (10) -
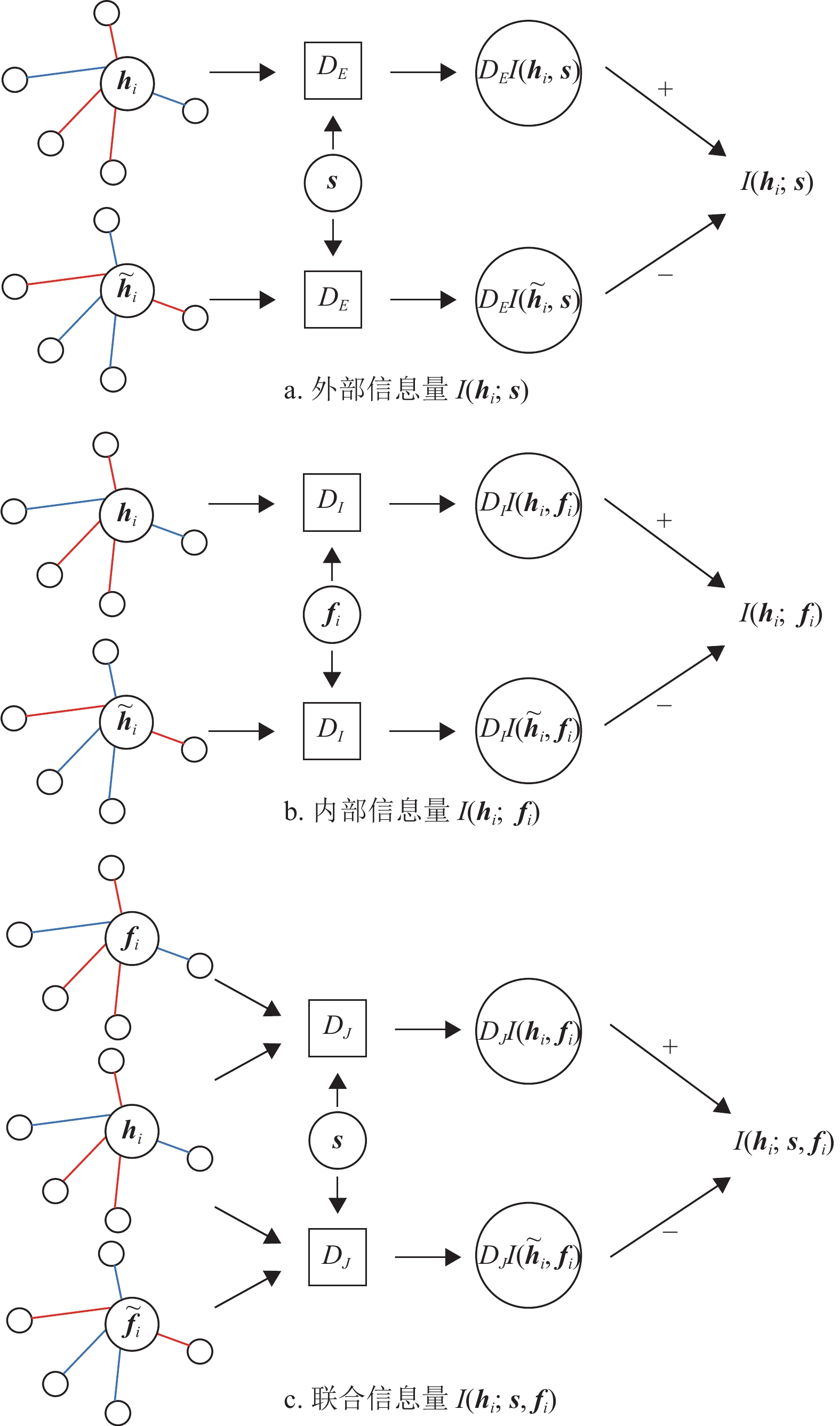
对于符号网络中的节点,使用最大化高阶互信息来综合考量3类变量,分别是节点嵌入
${{\boldsymbol{h}}_i}$ 、网络的概括向量s和节点的特征向量${{\boldsymbol{f}}_i}$ 。根据高阶互信息的定义,当N=3,有:
$$ \begin{split} &\qquad\quad I\left( {{X_1};{X_2};{X_3}} \right)= \\ & H\left( {{X_1}} \right) + H\left( {{X_2}} \right) + H\left( {{X_3}} \right)- \\ & H\left( {{X_1},{X_2}} \right) - H\left( {{X_1},{X_3}} \right)- \\ & H\left( {{X_2},{X_3}} \right) + H\left( {{X_1},{X_2},{X_3}} \right) \end{split}$$ (11) 该式可进一步化为:
$$ \begin{split} &\qquad\qquad I\left({X}_{1};{X}_{2};{X}_{3}\right)=\\ &\quad H\left({X}_{1}\right)+H\left({X}_{2}\right)-H\left({X}_{1},{X}_{2}\right)+\\ &\quad H\left({X}_{1}\right)+H\left({X}_{3}\right)-H\left({X}_{1},{X}_{3}\right)-\\ &H\left({X}_{1}\right)-H\left({X}_{2},{X}_{3}\right)+H\left({X}_{1},{X}_{2},{X}_{3}\right)=\\ &I\left({X}_{1};{X}_{2}\right)+I\left({X}_{1};{X}_{3}\right)-I\left({X}_{1};{X}_{2},{X}_{3}\right) \end{split} $$ (12) 式中,
$I\left( {{X_1};{X_2},{X_3}} \right)$ 表示变量${X_1}$ 同变量${X_2}$ ,${X_3}$ 的联合分布之间的互信息。通过使用${{\boldsymbol{h}}_i}$ ,s和${{\boldsymbol{f}}_i}$ 替代${X_1}$ ,${X_2}$ ,${X_3}$ ,可以得到式子:$$ {I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}};{{\boldsymbol{f}}_i}} \right) = I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}}} \right) + I\left( {{{\boldsymbol{h}}_i};{{\boldsymbol{f}}_i}} \right) - I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}},{{\boldsymbol{f}}_i}} \right)} $$ (13) 式中,
$I\left( {{{\boldsymbol{h}}_i},s} \right)$ 捕获外部信息量,即节点局部嵌入h与全局嵌入之间s的依赖;$I\left( {{{\boldsymbol{h}}_i},{{\boldsymbol{f}}_i}} \right)$ 捕获内部信息量,即节点局部嵌入h与节点本身特征属性向量f之间的依赖;$I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}},{{\boldsymbol{f}}_i}} \right)$ 捕获联合信息量,即外部和内部信息量之间的交互。即通过外部信息量、内部信息量和联合信息量三者,可以衡量网络的高阶互信息,这3个信息量的嵌入过程如图3所示。在高阶互信息最大化模块,将依次进行目标函数的构造。
图 3 外部、内部和联合信息量示意图
-
通过最大化局部互信息来捕获整个网络的高阶信息量。根据式(13),最大化高阶互信息等同于最大化3种局部互信息:
$$ \begin{split} &\qquad\qquad\qquad \max I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}};{{\boldsymbol{f}}_i}} \right)= \\ &\quad \max \left( {I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}}} \right) + I\left( {{{\boldsymbol{h}}_i};{{\boldsymbol{f}}_i}} \right) - I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}},{{\boldsymbol{f}}_i}} \right)} \right) = \\ & \max I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}}} \right) + \max I\left( {{{\boldsymbol{h}}_i};{{\boldsymbol{f}}_i}} \right) - \min I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}},{{\boldsymbol{f}}_i}} \right)\approx \\ & \max I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}}} \right) + \max I\left( {{{\boldsymbol{h}}_i};{{\boldsymbol{f}}_i}} \right) + \max I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}},{{\boldsymbol{f}}_i}} \right) \\ \end{split} $$ (14) 接下来,给定节点嵌入矩阵H、概括向量s及其特征属性向量矩阵F,最大化式(13)中的3种信息量来对参数进行优化,最终目标函数为下:
$$ {L = {\lambda _E}I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}}} \right) + {\lambda _I}I\left( {{{\boldsymbol{h}}_i};{{\boldsymbol{f}}_i}} \right) + {\lambda _J}I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}},{{\boldsymbol{f}}_i}} \right)} $$ (15) 式中,
$ {\lambda _E} $ ,${\lambda _I}$ 和${\lambda _J}$ 是训练参数。分别计算3种信息量的交叉熵,外部信息量
$I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}}} \right)$ 对应的交叉熵${L_E}$ 为:$$ {L_E} = \mathbb{E}\left[ {\log {D_E}\left( {{{\boldsymbol{h}}_i},{\boldsymbol{s}}} \right)} \right] + \mathbb{E}\left[ {\log ( {1 - {D_E}( {{{\tilde {\boldsymbol{h}}}_i},{\boldsymbol{s}}} )} )} \right] $$ (16) 内部信息量
$I\left( {{{\boldsymbol{h}}_i};{{\boldsymbol{f}}_i}} \right)$ 对应的交叉熵${L_I}$ 为:$$ {L_I} = \mathbb{E}\left[ {\log {D_I}\left( {{{\boldsymbol{h}}_i},{{\boldsymbol{f}}_i}} \right)} \right] + \mathbb{E}\left[ {\log ( {1 - {D_I}( {{{\tilde {\boldsymbol{h}}}_i},{{\boldsymbol{f}}_i}} )} )} \right]$$ (17) 联合信息量
$I\left( {{{\boldsymbol{h}}_i};{\boldsymbol{s}},{{\boldsymbol{f}}_i}} \right)$ 对应的交叉熵${L_J}$ 为:$$ {L_J} = \mathbb{E}\left[ {\log {D_J}\left( {{{\boldsymbol{h}}_i},{\boldsymbol{s}},{{\boldsymbol{f}}_i}} \right)} \right] + \mathbb{E}\left[ {\log ( {1 - {D_J}( {{{\boldsymbol{h}}_i},{\boldsymbol{s}},{{\tilde {\boldsymbol{f}}}_i}} )} )} \right] $$ (18) 式中,
${{\boldsymbol{h}}_i}$ 和${\tilde {\boldsymbol{h}}_i}$ 分别是图G的正节点嵌入和负节点嵌入。为了生成负节点嵌入
${\tilde {\boldsymbol{h}}_j}$ ,通过转换正负关系,并按行打乱来破坏原始矩阵以生成图$\tilde G$ 。具体来说,令${\tilde s_{ij}} = - {s_{ij}}$ ,并将图$\tilde G$ 作为输入,重复使用3.1节和3.2节中的模型,以得到负嵌入节点特征矩阵$\tilde {\boldsymbol{H}}$ 。同时,对于联合信息量,去除了在外部和内部信息量中所捕获的信息,因此仅对属性向量取反。
${D_E}$ ,${D_I}$ ,${D_J}$ 分别是3种表示对分数的鉴别器,本文参考HDMI,应用了一个简单的双线性评分函数:$$ {{D_E}\left( {{{\boldsymbol{h}}_i},{\boldsymbol{s}}} \right) = {\text{σ}}( {{\boldsymbol{h}}_i^{\rm{T}}{{\boldsymbol{M}}_E}{\boldsymbol{s}}} )} $$ (19) $$ {{D_I}\left( {{{\boldsymbol{h}}_i},{{\boldsymbol{f}}_i}} \right) = {\text{σ}}( {{\boldsymbol{h}}_i^{\rm{T}}{{\boldsymbol{M}}_I}{{\boldsymbol{f}}_i}} )} $$ (20) $$ {z{{\boldsymbol{f}}_i} = {\text{σ}}( {{{\boldsymbol{W}}_f}{{\boldsymbol{f}}_i}} )} $$ (21) $$ {{z_{\boldsymbol{s}}} = {\text{σ}}\left( {{{\boldsymbol{W}}_s}{\boldsymbol{s}}} \right)} $$ (22) $$ {z = {\text{σ}}\left( {{{\boldsymbol{W}}_z}\left[ {z{{\boldsymbol{f}}_i};{z_{\boldsymbol{s}}}} \right]} \right)} $$ (23) $$ {{D_J} = {\text{σ}}( {{\boldsymbol{h}}_i^{\rm{T}}{{\boldsymbol{M}}_J}z} )} $$ (24) 式中,
${{\boldsymbol{M}}_E} \in {\mathbb{R}^{d \times d}}$ ;${{\boldsymbol{M}}_I} \in {\mathbb{R}^{d \times {d_F}}}$ ;${{\boldsymbol{W}}_f} \in {\mathbb{R}^{d \times {d_F}}}$ ;${{\boldsymbol{W}}_s} \in {\mathbb{R}^{d \times d}}$ ;${{\boldsymbol{W}}_z} \in {\mathbb{R}^{d \times 2d}}$ 和${{\boldsymbol{M}}_J} \in {\mathbb{R}^{d \times d}}$ 是可训练的参数矩阵。在该部分,经过训练,得到最终的高阶互信息节点嵌入
${{\boldsymbol{h}}_i} \in {{\boldsymbol{H}}^{N \times d}}$ 。 -
为了研究符号网络中的学习表示,选取了4个真实的符号网络数据集进行实验,即Bitcoin-Alpha,Bitcoin-OTC[40-41],Slashdot[42]和New Guinea,表1列出了相关数据集的统计信息。
表 1 实验数据集统计信息
数据集 节点数 边数 正边率/% 负边率/% Bitcoin-Alpha 3784 14145 89.9 10.0 Bitcoin-OTC 5901 24291 85.4 14.5 Slashdot 82144 549202 77.4 22.5 New Guinea 16 58 50 50 Bitcoin-Alpha和Bitcoin-OTC数据集都来自支持比特币消费的开放市场,由于比特币账户的匿名机制,网站出于安全考虑建立了在线信任网络,用户可以选择对他人信任或不信任。Slashdot是一个技术新闻网站,用户之间可以创建双向的好友或敌人关系,代表他们对彼此之间的态度。New Guinea是一个拥有16个节点的数据集,表示新几内亚中部高地16个部落之间的关系。
以上4个数据集,都是符号网络研究领域的经典数据集,比较具有代表性。对于这些数据集中的网络,本文忽略其中的链接方向,统一将其视为无向网络进行研究。
-
链路符号预测问题,即给定符号网络中存在的一组链接,将其排除在训练集之外的同时,希望能预测出它们在节点对之间的符号正负性。
为此,训练了一个二分类器,该分类器根据一对节点的输入特征集来预测其对应的符号 (本文使用逻辑回归模型)。本文将两个节点的最终嵌入向量直接相连来作为模型的输入,并利用训练数据中边的标签对模型进行训练。鉴于数据集中正链接数远多于负链接数,同时使用F1与AUC两种指标来评估算法的效果,更高的F1及AUC都意味着更好的性能。对于每个数据集,随机选择50%的数据作为测试集,其余50%作为训练集。
-
为了验证本文提出算法的有效性,选择了DeepWalk[19]、LINE[24]、SNEA[29]、SGCN[28]、SDGNN[30]这5个算法,来与SNSH算法在链路符号预测任务上进行对比实验。在评估SNSH算法的性能时,将局部符号信息嵌入和高阶互信息嵌入拼接以作为线性模型的输入特征,另外,测试了仅考虑其中一种额外信息量时模型的效果,分别为SNSH-E、SNSH-I、SNSH-J,其实验结果如表2和表3所示。在该部分,选取Bitcoin-Alpha、Bitcoin-OTC和Slashdot这3个数据集,用以进行实验效果的分析对比。
表 2 F1衡量的链路符号预测任务算法效果对比
策略 数据集 Bitcoin-Alpha Bitcoin-OTC Slashdot DeepWalk 0.907 0.862 0.837 LINE 0.901 0.831 0.812 SNEA 0.927 0.924 0.868 SGCN 0.965 0.963 0.936 SDGNN 0.949 0.935 0.861 SNSH-E 0.967 0.968 0.922 SNSH-I 0.968 0.969 0.939 SNSH-J 0.965 0.953 0.950 SNSH 0.980 0.976 0.981 表 3 AUC衡量的链路符号预测任务算法效果对比
策略 数据集 Bitcoin-Alpha Bitcoin-OTC Slashdot DeepWalk 0.740 0.809 0.746 LINE 0.695 0.793 0.733 SNEA 0.816 0.818 0.799 SGCN 0.871 0.893 0.826 SDGNN 0.899 0.912 0.865 SNSH-E 0.881 0.862 0.819 SNSH-I 0.910 0.887 0.805 SNSH-J 0.857 0.839 0.831 SNSH 0.921 0.916 0.871 F1分数是用来衡量二分类模型精确度的常用指标,是模型精准率和召回率的调和平均,由于真实符号网络中绝大部分都是正向边,因此所有算法得到的F1分数都较高,但本文算法还是在所有数据集上取得了最好的效果。
在AUC指标上,SNSH同样获得了最好的性能。同时可以看到,针对3个中大型符号网络数据集,SNSH算法的实验结果稳定,F1指标分别为0.980、0.976、0.981,AUC指标分别为0.921、0.916、0.871,显示了算法良好的稳健性。
实验表明,本文方法在所有指标与数据集上取得了最佳的效果。并且,仅考虑单一信息量的SNSH模型也取得了超过现有算法的效果。这证明本文选取的信息量,能够有效提取到真实网络中的额外信息。SNSH算法能高效地拟合真实符号网络中的信息,从而得到有效的向量表示。
-
为了衡量算法对网络真实结构的拟合效果,接下来进行验证分析SNSH学习的嵌入空间是否遵循结构平衡理论的原理。
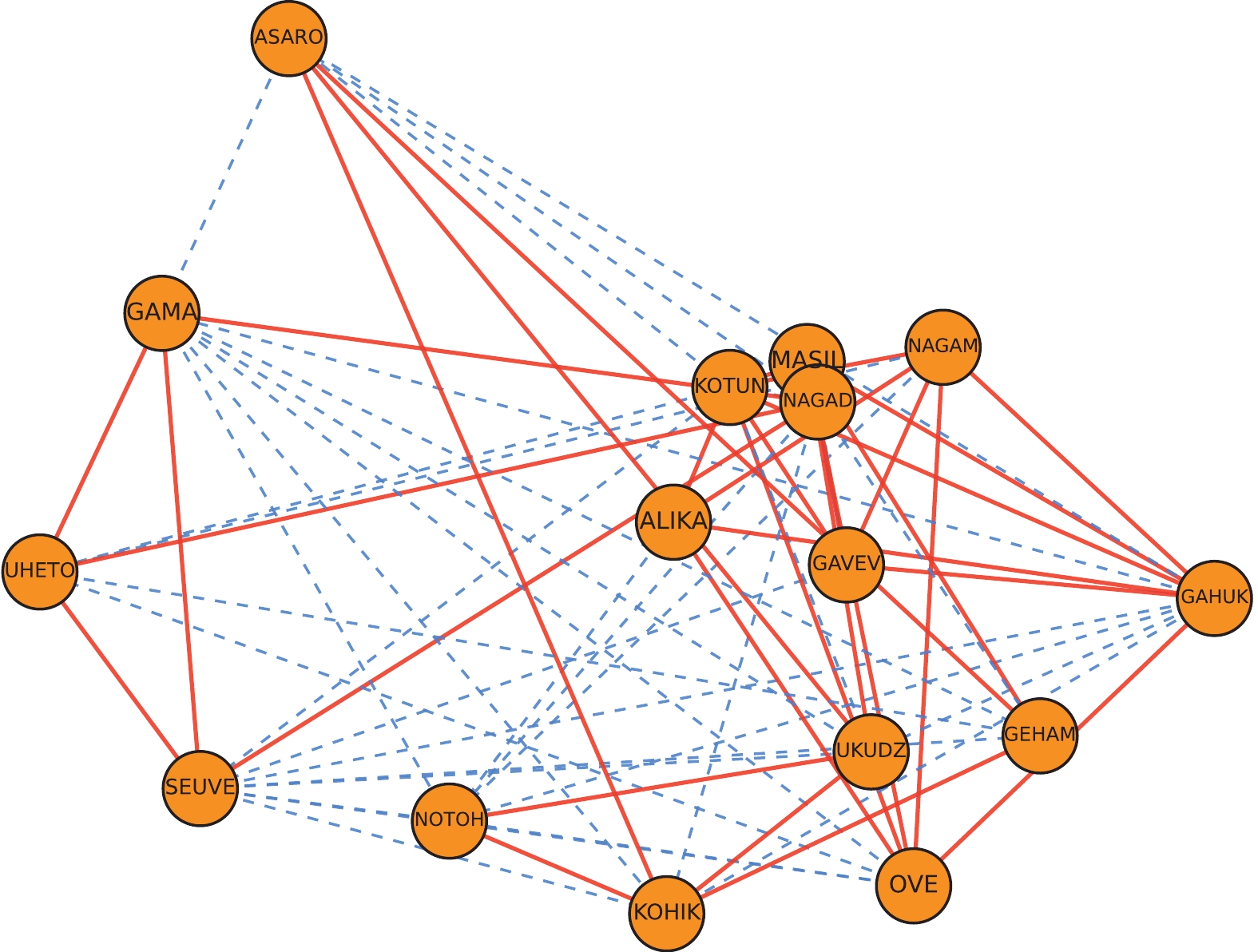
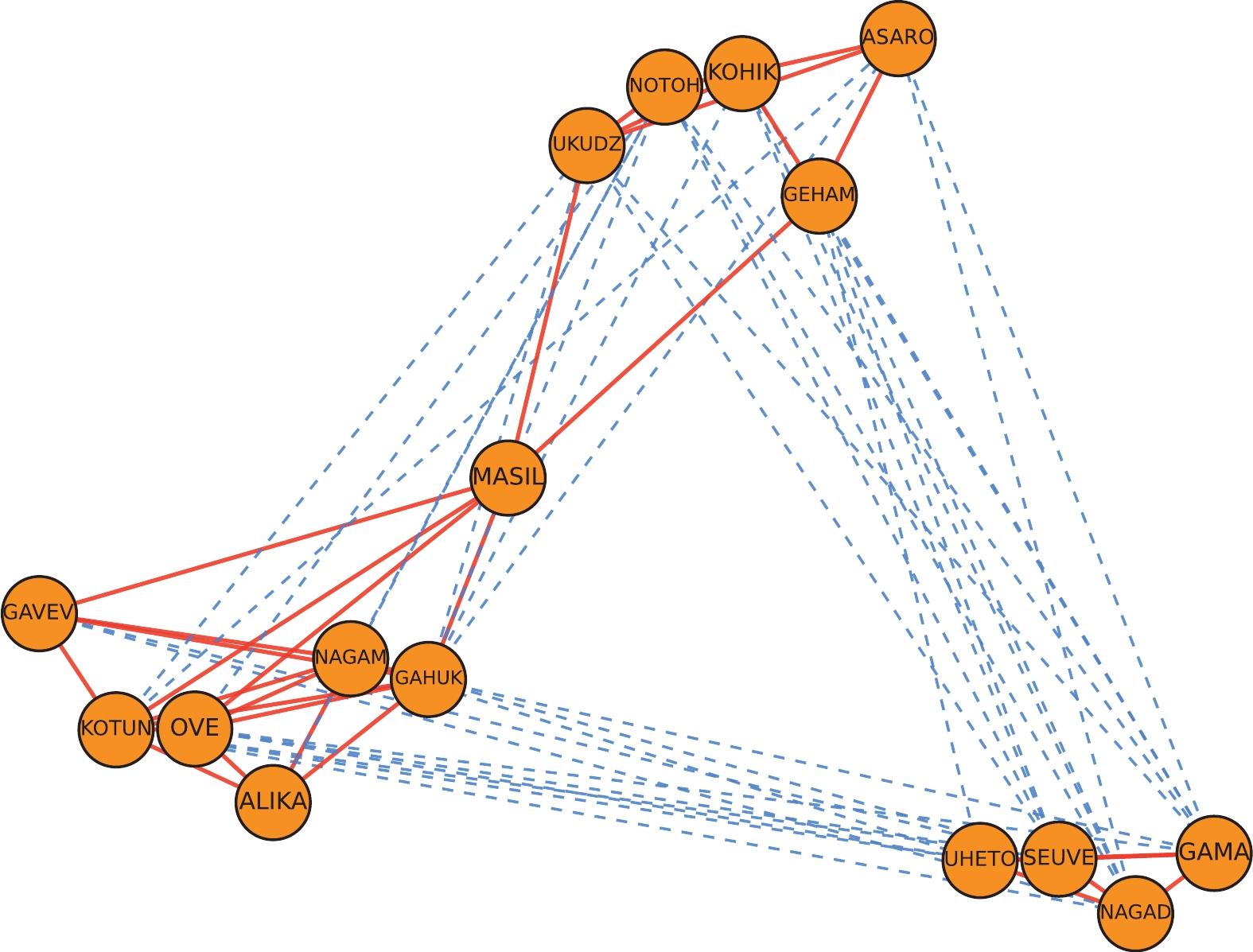
分别使用LINE、SGCN与SNSH算法对New Guinea网络的拓扑结构进行嵌入来进行效果分析。具体来说,分别将网络作为算法的输入,经过训练得到了数据集在网络嵌入后的二维表示,其绘制结果分别如图4、图5、图6所示。
在示意图中,网络中的正边用加粗表示,负边用虚线表示。在由LINE算法得到的图4中,节点分布杂乱无序,不符合符号网络的特征。相对而言,从考虑了符号网络特性的SGCN算法与SNSH算法得到的图5和图6可以看出,代表正关系的线条普遍较短,代表负关系的线条普遍较长。这表明具有正边关系的节点在二维空间上是接近的,而具有负边关系的节点在二维空间上是疏远的,更符合符号社会网络的特征,且能与社会结构平衡理论的观点相印证,即节点的“朋友”比节点的“敌人”更近。
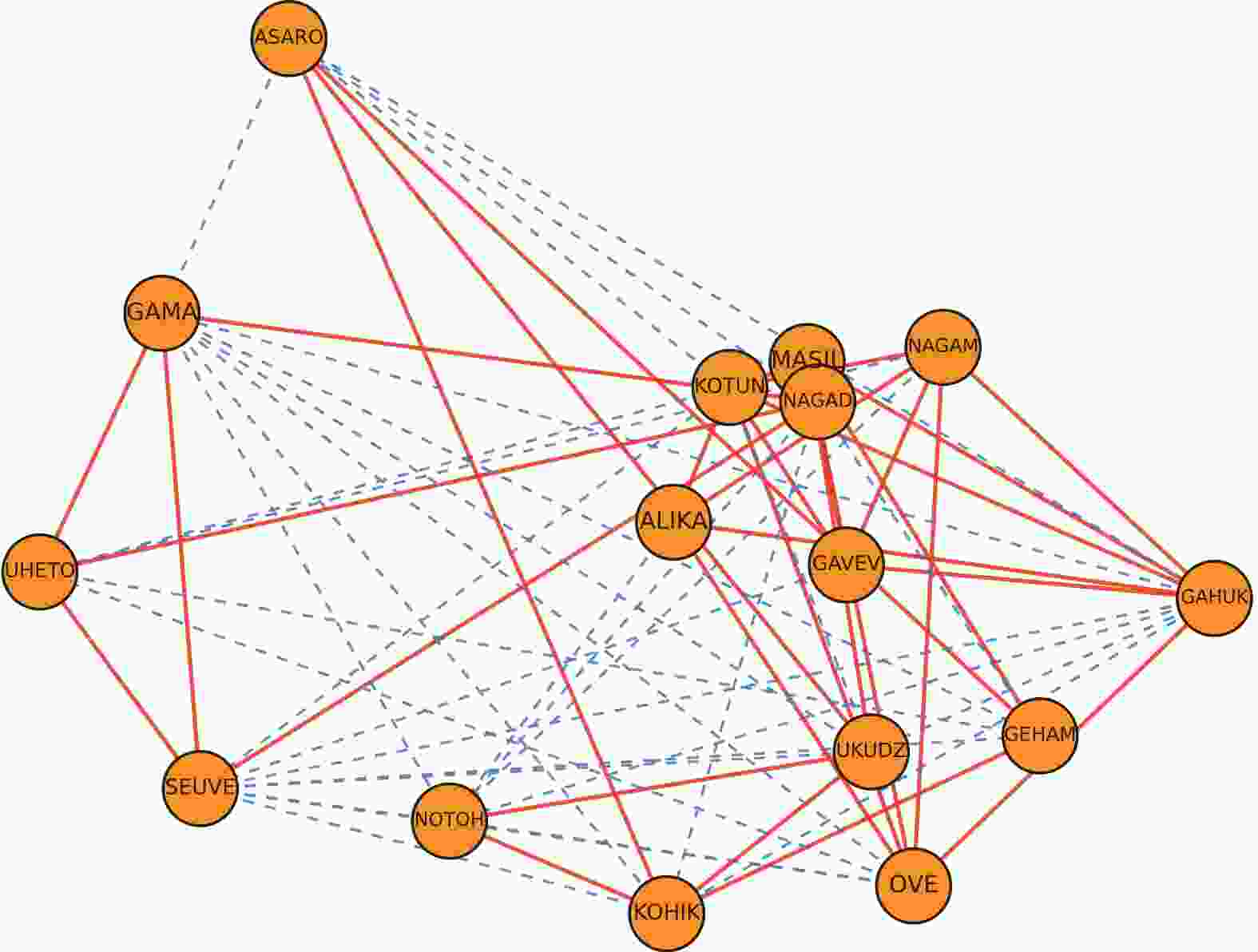
图 4 LINE二维嵌入效果示意图

图 5 SGCN二维嵌入效果示意图
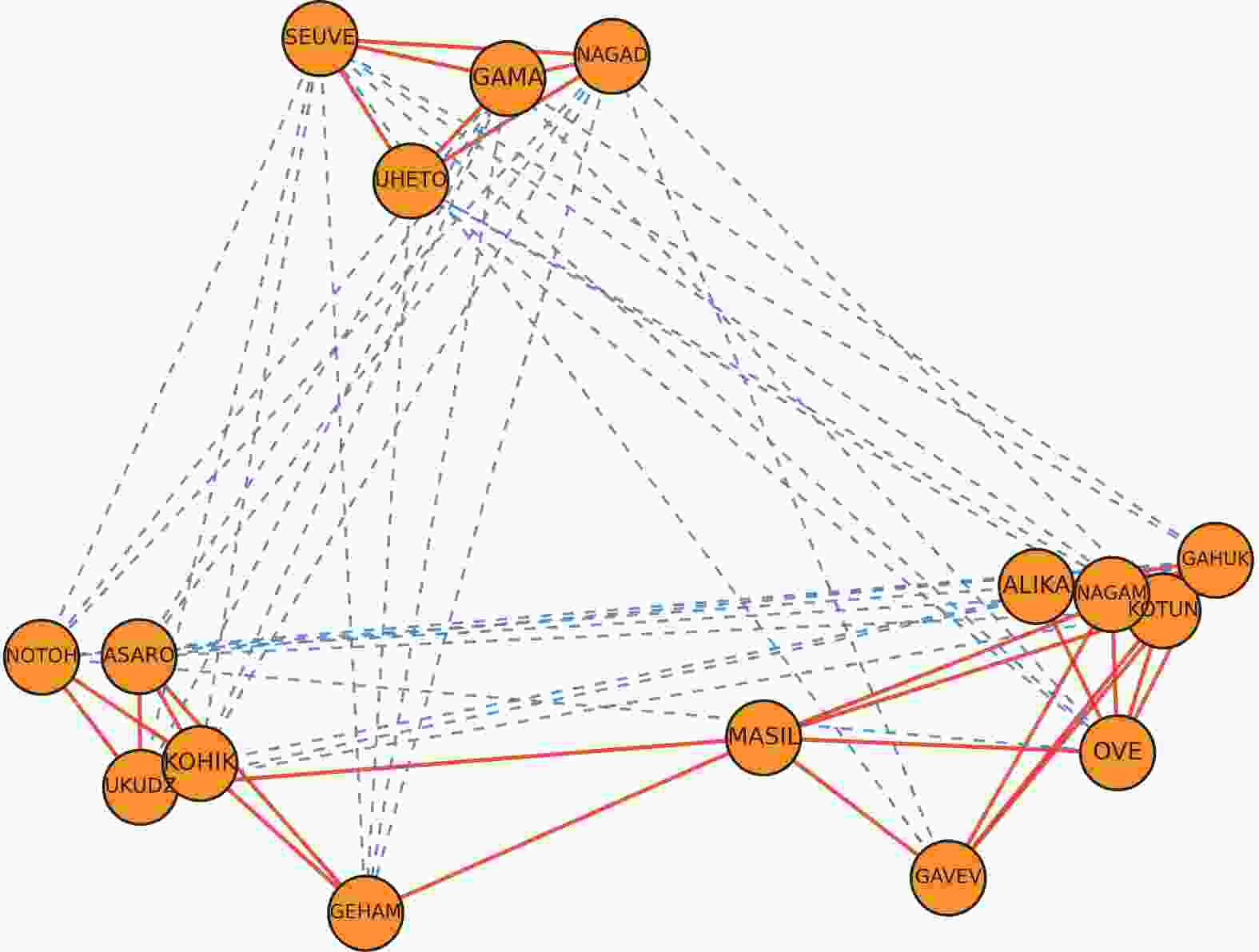
图 6 SNSH二维嵌入效果示意图
在图5和图6的对比中,由SNSH算法得到的图6拥有更清晰合理的网络节点布局,在部分节点上优于SGCN。可以说,SNSH算法更好地拟合了数据集的真实结构,这体现了算法的合理性与解释性。因此,SNSH所学习到的嵌入是符合结构平衡理论和符号网络真实情况的。本文使用的实验数据、相关源代码和算法的描述等内容详见链接:
https://github.com/amoius/SNSH 。 -
针对现有网络表示学习领域中符号嵌入方法的缺失与嵌入深度的局限性,本文提出了一种基于结构平衡理论与高阶互信息的符号网络表示学习方法SNSH,来对符号网络中的隐藏信息进行更深层的挖掘。在不影响甚至提高准确率的情况下,对符号网络的内部、外部及联合信息进行了捕捉,从而得到符合符号网络特性的节点嵌入。在3个真实数据集上进行了链路符号预测性能的对比实验,并在New Guinea数据集上进行了可视化实验,验证了本文所提模型具有较高的有效性与合理性。未来计划将算法拓展到复合符号网络表示学习等问题的研究中。
Signed Network Representation Learning Algorithm Based on Structural Balance Theory and High-Order Mutual Information
-
摘要: 提出了一种基于结构平衡理论和高阶互信息的符号网络表示算法SNSH,通过反转符号网络中的正负关系生成负图,来挖掘符号网络中隐含的高阶互信息。该方法旨在通过加强的社会平衡理论来模拟符号网络的局部隐含特征,并通过节点局部嵌入、网络全局结构和节点特征属性三者之间的高阶互信息,得到更全面的符合符号网络特性的节点嵌入。Abstract: In this paper, a symbolic network representation learning framework signed network representation learning algorithm based on structural balance theory and high-order mutual information (SNSH) is proposed. By reversing the positive and negative relationships in symbolic networks to generate negative graphs, the hidden high-order mutual information in symbolic networks is mined. This method aims to simulate the local implicit features of symbolic networks through the strengthened social balance theory, and obtain a more comprehensive node embedding that conforms to the characteristics of symbolic networks through the high-order mutual information among the local embedding of nodes, the global structure of the network and the characteristic attributes of nodes.
-
表 1 实验数据集统计信息
数据集 节点数 边数 正边率/% 负边率/% Bitcoin-Alpha 3784 14145 89.9 10.0 Bitcoin-OTC 5901 24291 85.4 14.5 Slashdot 82144 549202 77.4 22.5 New Guinea 16 58 50 50  下载: 导出CSV
下载: 导出CSV
表 2 F1衡量的链路符号预测任务算法效果对比
策略 数据集 Bitcoin-Alpha Bitcoin-OTC Slashdot DeepWalk 0.907 0.862 0.837 LINE 0.901 0.831 0.812 SNEA 0.927 0.924 0.868 SGCN 0.965 0.963 0.936 SDGNN 0.949 0.935 0.861 SNSH-E 0.967 0.968 0.922 SNSH-I 0.968 0.969 0.939 SNSH-J 0.965 0.953 0.950 SNSH 0.980 0.976 0.981
下载: 导出CSV
表 3 AUC衡量的链路符号预测任务算法效果对比
策略 数据集 Bitcoin-Alpha Bitcoin-OTC Slashdot DeepWalk 0.740 0.809 0.746 LINE 0.695 0.793 0.733 SNEA 0.816 0.818 0.799 SGCN 0.871 0.893 0.826 SDGNN 0.899 0.912 0.865 SNSH-E 0.881 0.862 0.819 SNSH-I 0.910 0.887 0.805 SNSH-J 0.857 0.839 0.831 SNSH 0.921 0.916 0.871
下载: 导出CSV
-
[1] SONG D, MEYER D A, TAO D. Efficient latent link recommendation in signed networks[C]//Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Sydney: ACM, 2015: 1105-1114. [2] CHENG S Q, SHEN H W, ZHANG G Q, et al. Survey of signed network research[J]. Journal of Software, 2014, 25: 1-15. [3] XIAO S, WANG S, DAI Y, et al. Graph neural networks in node classification: Survey and evaluation[J]. Machine Vision and Applications, 2021, 33(1): 4. [4] MADHAWA K, MURATA T. Active learning for node classification: An evaluation[J]. Entropy, 2020, 22(10): 1164. doi: 10.3390/e22101164 [5] ZHOU T. Progresses and challenges in link prediction[J]. iScience, 2021, 24(11): 103217. doi: 10.1016/j.isci.2021.103217 [6] CHEN M S, LIN J Q, LI X L, et al. Representation learning in multi-view clustering: A literature review[J]. Data Science and Engineering, 2022, 7(3): 225-241. doi: 10.1007/s41019-022-00190-8 [7] TSITSULIN A, PALOWITCH J, PEROZZI B, et al. Graph clustering with graph neural networks[J]. Journal of Machine Learning Research, 2023, 24(127): 1-21. [8] BO D, WANG X, SHI C, et al. Structural deep clustering network[C]//Proceedings of The Web Conference 2020. Taipei, China: ACM, 2020: 1400-1410. [9] QIN X, LUO Y, TANG N, et al. Making data visualization more efficient and effective: A survey[J]. The VLDB Journal, 2020, 29(1): 93-117. doi: 10.1007/s00778-019-00588-3 [10] WU S, YIN H, CAO H, et al. Node ranking strategy in virtual network embedding: An overview[J]. China Communications, 2021, 18(6): 114-136. doi: 10.23919/JCC.2021.06.010 [11] CHEN S Z, GUO C C, LAI J H. Deep ranking for person re-identification via joint representation learning[J]. IEEE Transactions on Image Processing, 2016, 25(5): 2353-2367. doi: 10.1109/TIP.2016.2545929 [12] SOURAVLAS S, SIFALERAS A, TSINTOGIANNI M, et al. A classification of community detection methods in social networks: A survey[J]. International Journal of General Systems, 2021, 50(1): 63-91. doi: 10.1080/03081079.2020.1863394 [13] SIMONOVSKY M, KOMODAKIS N. Graphvae: Towards generation of small graphs using variational autoencoders[C]//International Conference on Artificial Neural Networks. Cham: Springer International Publishing, 2018: 412-422. [14] ZHAO Y, HRYNIEWICKI M K. XGBOD: Improving supervised outlier detection with unsupervised representation learning[C]//2018 International Joint Conference on Neural Networks (IJCNN). Piscataway: IEEE Computer Society, 2018: 1-8. [15] GOYAL P, FERRARA E. Graph embedding techniques, applications, and performance: A survey[J]. Knowledge-Based Systems, 2018, 151: 78-94. doi: 10.1016/j.knosys.2018.03.022 [16] LESKOVEC J, HUTTENLOCHER D, KLEINBERG J. Predicting positive and negative links in online social networks[C]//Proceedings of the 19th International Conference on World Wide Web. Raleigh: ACM, 2010: 641-650. [17] BELKIN M, NIYOGI P. Laplacian eigenmaps and spectral techniques for embedding and clustering[J]. Advances in Neural Information Processing Systems, 2001, 14(6): 585-591. [18] OU M, CUI P, PEI J, et al. Asymmetric transitivity preserving graph embedding[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 1105-1114. [19] PEROZZI B, AL-RFOU R, SKIENA S. Deepwalk: Online learning of social representations[C]//Proceedings of the 20th ACM SIGKDD International Conference On Knowledge Discovery And Data Mining. New York: ACM, 2014: 701-710. [20] GROVER A, LESKOVEC J. node2vec: Scalable feature learning for networks[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data mining. New York: ACM, 2016: 855-864. [21] WANG D, CUI P, ZHU W. Structural deep network embedding[C]//Proceedings of the 22nd ACM SIGKDD International Conference On Knowledge Discovery and Data Mining. San Francisco: ACM, 2016: 1225-1234. [22] CAO S, LU W, XU Q. Deep neural networks for learning graph representations[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Phoenix: AAAI Press, 2016, 30(1): 1145-1152. [23] WELLING M, KIPF T N. Semi-Supervised classification with graph convolutional networks[C]//International Conference on Learning Representations (ICLR 2017). Vancouver: ICLR, 2017: 1-14. [24] TANG J, QU M, WANG M, et al. Line: Large-Scale information network embedding[C]//Proceedings of the 24th International Conference On World Wide Web. Florence: International World Wide Web Conferences Steering Committee, 2015: 1067-1077. [25] WANG S, TANG J, AGGARWAL C, et al. Signed network embedding in social media[C]//Proceedings of the 2017 SIAM International Conference on Data Mining (SDM). Houston: Society for Industrial and Applied Mathematics, 2017: 327-335. [26] ISLAM M R, ADITYA P B, RAMAKRISHNAN N. Signet: Scalable embeddings for signed networks[C]//Pacific-Asia Conference on Knowledge Discovery and Data Mining. Cham: Springer International Publishing, 2018: 157-169. [27] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013-09-07). https://doi.org/10.48550/arXiv.1301.3781. [28] DERR T, MA Y, TANG J. Signed graph convolutional networks[C]//2018 IEEE International Conference on Data Mining (ICDM). Singapore: IEEE, 2018: 929-934. [29] LI Y, TIAN Y, ZHANG J, et al. Learning signed network embedding via graph attention[C]//Proceedings of the AAAI Conference on Artificial Intelligence. New York: AAAI Press, 2020, 34(4): 4772-4779. [30] HUANG J, SHEN H, HOU L, et al. SDGNN: Learning node representation for signed directed networks[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Menlo Park: AAAI Press, 2021, 35(1): 196-203. [31] GUO S S, WANG J S, XIE W, et al. Improved grasshopper algorithm based on gravity search operator and pigeon colony landmark operator[J]. IEEE Access, 2020, 8: 22203-22224. doi: 10.1109/ACCESS.2020.2967399 [32] CHEN X, YE Y, DONG C, et al. Grasshopper optimization algorithm combining Gaussian and chaos theory for optimization design[C]//2019 3rd International Conference on Electronic Information Technology and Computer Engineering (EITCE). [S.l.]: IEEE, 2019: 1484-1488. [33] HEIDER, FRITZ. Attitudes and cognitive organization[J]. The Journal of Psychology Interdisciplinary and Applied, 1946, 21(1): 107-112. doi: 10.1080/00223980.1946.9917275 [34] CARTWRIGHT D, HARARY F. Structural balance: A generalization of Heider's theory[J]. Psychological Review, 1956, 63(5): 277-293. doi: 10.1037/h0046049 [35] DAVIS J A. Clustering and structural balance in graphs[J]. Human Relations, 1967, 20(2): 181-187. doi: 10.1177/001872676702000206 [36] CYGAN M, PILIPCZUK M, PILIPCZUK M, et al. Sitting closer to friends than enemies, revisited[C]//International Symposium on Mathematical Foundations of Computer Science. Bratislava: Springer-Verlag, 2012: 296-307. [37] MCGILL W. Multivariate information transmission[J]. Transactions of the IRE Professional Group on Information Theory, 1954, 4(4): 93-111. doi: 10.1109/TIT.1954.1057469 [38] VELICKOVIC P, FEDUS W, HAMILTON W L, et al. Deep graph infomax[C]//International Conference on Learning Representations (ICLR 2019). Vancouver: ICLR, 2019: 1-17. [39] 卢志刚, 叶美丽. 基于节点地位和相似性的社交网络边符号预测[J]. 计算机应用研究, 2020, 37(2): 411-415. LU Z G, YE M L. Social network edge sign prediction based on node status and similarity[J]. Application Research of Computers, 2020, 37(2): 411-415. [40] KUMAR S, SPEZZANO F, SUBRAHMANIAN V, et al. Edge weight prediction in weighted signed networks[C]// 2016 IEEE 16th International Conference on Data Mining (ICDM). Barcelona: IEEE, 2016: 221-230. [41] KUMAR S, HOOI B, MAKHIJA D, et al. Rev2: Fraudulent user prediction in rating platforms[C]// Proceedings of the 11th ACM International Conference on Web Search and Data Mining. Marina Del Rey: ACM, 2018: 333-341. [42] LESKOVEC J, HUTTENLOCHER D, KLEINBERG J. Signed networks in social media[C]//Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. Atlanta: ACM, 2010: 1361-1370. -

 点击查看大图
点击查看大图

图(6) / 表(3)
计量
- 文章访问数: 4442
- HTML全文浏览量: 1147
- PDF下载量: 48
- 被引次数: 0




















































































































































