 ISSN
ISSN 







-
骨组织是人体重要的组织之一,属于独特的多孔结构[1]。在骨组织工程领域,三维骨多孔结构的数字建模是诸多研究的基础技术[2]。当前,对于具有仿生特征的三维骨多孔结构数字模型,大多还是利用骨切片图像(以下称:切片图像)进行三维重构得到的。
文献[3-8]提出两点相关函数法[3]、分形蒙特卡洛法[4]、多点统计法[5]、基于深度学习的方法[6-8]等切片图像训练方法,同时基于切片图像(包括重构生成的图像)建模得到满意的三维骨多孔结构数字模型。由于成像设备精度、存储设备容量等原因,切片图像在获取过程中会出现数据丢失、图像受损或图像尺寸异常等问题,导致只能得到具有局部特征信息的图像[9]。另外,虽然计算机断层扫描技术[10]和扫描电子显微镜[11]等成像技术取得了进步,但在实际情况下,获取大区域、完整的切片图像还是比较困难的[12]。本文把受损的切片图像以及小尺寸切片图像称为局部骨切片图像(以下称:局部切片图像),即只包含局部骨多孔特征的切片图像。由于局部切片图像中的数据是不完整的,所以其无法在统计意义和实际意义上表达三维结构的主要特征。因此,为了得到准确的三维骨多孔结构数字模型,对局部切片图像进行修复并重构,得到完整且相似的图像是很关键的。
近年来,研究人员对局部切片图像的修复重构进行了深入研究,其中主要有以下3种方法:逐像素法[13]、逐区块法[14]和基于深度学习的方法。逐像素法是基于fast marching method (FMM)的修复算法,逐区块法则是基于exemplar-based inpainting的算法,这两种方法都是通过统计单张局部图像的像素特征来推测全局信息,其重构修复得到的完整图像与真实切片图像不具有很好的相似性。而基于深度学习的方法可以利用局部图像的局部特征,生成与真实切片图像特征相似的完整图像,有着更好的重构效果,如文献[7]应用了条件生成对抗网络实现了对多种局部多孔图像的重构,并运用统计相关函数证明了生成图像的合理性。
本文在条件生成对抗网络(pix2pix)[15]的基础上,对生成器进行改进,加入嵌套残差密集块(residual-in-residual dense block, RRDB)[16],同时,在判别器中加入极化自注意力模块(polarized self-attention, PSA)[17],提出改进条件生成对抗网络(RRDB-PSA-pix2pix)对局部切片图像进行完整重构,并通过性能相似性与优异性分析,验证了重构生成的图像与真实骨多孔图像的相似程度。
-
条件生成对抗网络(conditional generative adversarial networks, cGAN)是生成对抗网络[18](generative adversarial network, GAN)的扩展。
cGAN主要由两部分构成:一个是生成器(generator network),用来生成数据;另一个是判别器(discriminator network),用来分辨原始数据和生成数据的真伪。生成器和判别器相互训练对抗,从而使生成的数据越来越接近真实数据。另外,由于cGAN的生成器输入的是随机噪声和约束条件,因此,判别器需要加上约束条件一起辨别。
-
pix2pix是cGAN的变体之一,它可以进行图像对图像的风格变换,由于该网络有强大的变现能力,使其在图像修复中得到了广泛应用。pix2pix的生成器是跳跃连接形成的U型结构,维度从高到低又从低到高,且左右两边对应维度通道相拼接。跳跃连接可以有效保留输入数据的潜在信息,因此,对于局部切片图像的局部特征信息,可以得到很好的保留和传递,这有利于局部切片图像的完整重构。
为了更好地获得图像中的细节,网络需要搭建到一定的深度才能重构出优质的图像。然而,一味地增加网络的深度会造成深度模型退化,这样的网络是很难训练的。本文在pix2pix网络的生成器上加入嵌套残差密集块RRDB来减弱网络模型的退化,RRDB的残差块里有残差组合的密集块,因此其拥有残差块[22]和密集块[23]各自的优势。
另外,极化自注意力(PSA)模块是能耗尽通道注意力和空间注意力表现能力的自注意力模块,将其应用到网络中,可以帮助提高网络的辨别能力,因此,本文把PSA模块加入到pix2pix网络的判别器中。
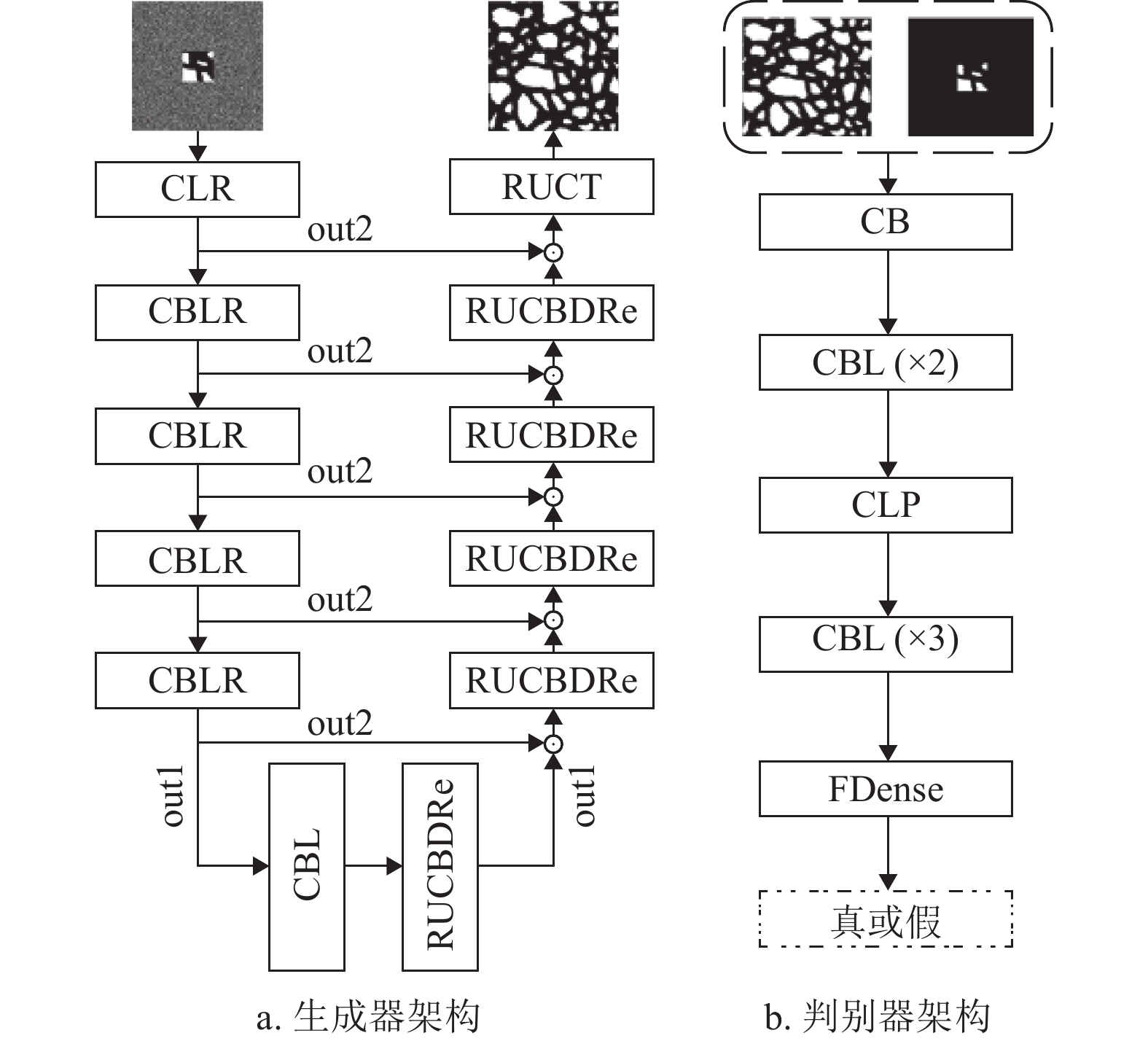
最后,将网络中的各个模块进行搭建和调试,得到了改进条件生成对抗网络(RRDB-PSA-pix2pix)。图1为该网络的生成器和判别器的架构,其中一个方块代表一个网络块,块中传递顺序从左往右,一个字母表示一个网络层,如C为卷积层,L为LeakyReLU激活函数层,R为RRDB模块层,B为批归一化层,U为上采样层,D为Dropout层,Re为ReLU激活函数层,T为Tanh激活函数层,P为PSA注意力层,F为Flatten层。
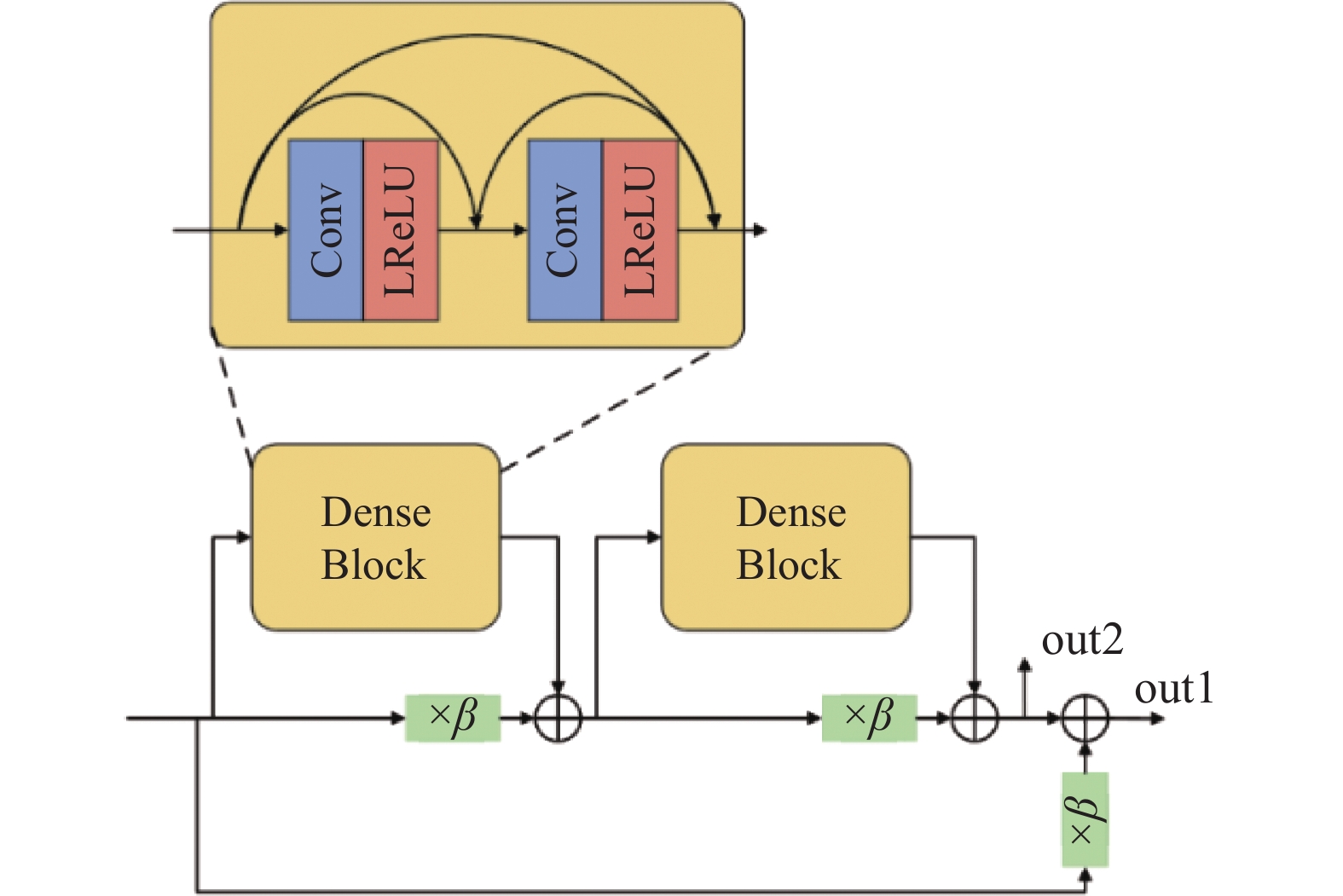
如图1a所示,生成器的左半边(编码作用)的主线输出为out1,跳跃连接上输出的是out2。生成器的右半边(解码作用)整合局部图像信息和左半边传递过来的out2信息,其RRDB不输出out2,只输出out1。另外,RRDB中的残差尺度参数在密集模块的支线上,这会阻碍密集模块数据的传递,并使局部切片图像中的噪声信息传递到下层,进而影响生成图像的质量。因此,本文将RRDB架构进行了改进,即将残差尺度参数放置在“短路连接”上,这样局部切片图像的信息可以得到保留,并且密集模块可以学习局部切片图像中剩余的细节。同时,考虑到资源分配的问题,改进后的架构使用2个密集残差和2层密集模块。如图2所示,改进的RRDB架构有两个输出,分别为out1和out2,out1比out2包含更多的局部图像信息。
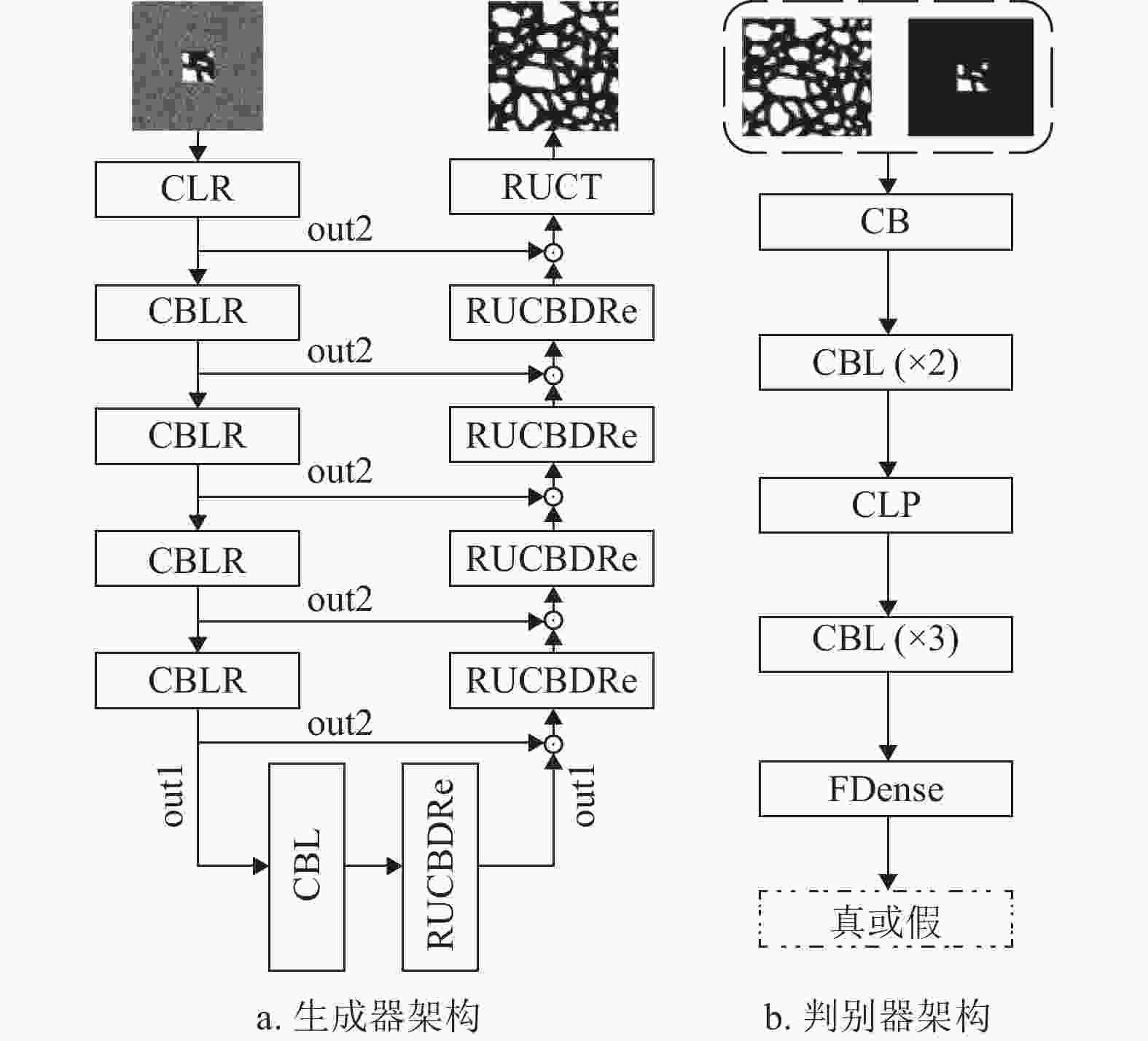
图 1 RRDB-PSA-pix2pix网络架构
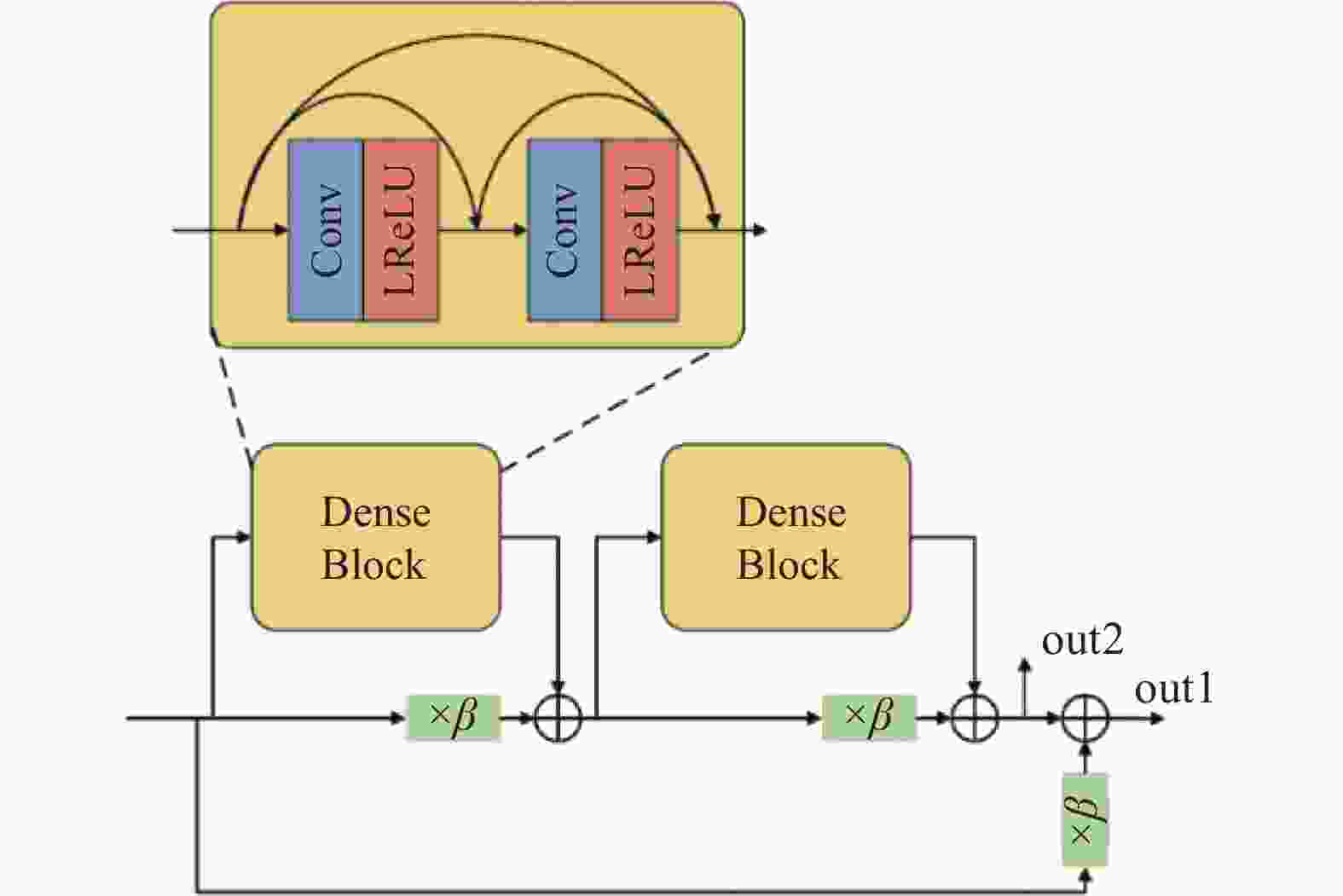
图 2 本文改进的RRDB架构
对于条件生成对抗网络,判别器损失采用Wasserstein距离[24]和梯度惩罚[25]进行目标优化,同时需要加上其条件概率,可以表示为:
$$ \begin{split} &{L_D} = {E_{x \sim {P_{{\rm{data}}}}(x)}}[D(x|y)] - {E_{z \sim {P_z}(z)}}[D(G(z)|y)] +\\ &\qquad\quad \lambda {E_{x \sim {P_{{\rm{penalty}}}}}}{\left( {\left\| {{\nabla _x}D(x)} \right\| - 1} \right)^2} \end{split} $$ (1) 同时,为了让生成器生成更高质量的图像,在生成器损失中加入感知损失,计算过程表示为:
$$ {L_{{\rm{perceptual}}}} = {E_{x \sim {P_{{\rm{data}}}}(x),z \sim {P_z}(z)}}{\left\| {\varPhi (G(z)) - \varPhi (x)} \right\|_1} $$ (2) 式中,
$ \varPhi(G(x)) $ 表示利用VGG19网络[26]从生成图像中提取的特征映射(不通过最后激活层);$ \varPhi(x) $ 表示从真实图像中提取的特征。孔隙率是多孔结构最重要的结构参数。为了得到与真实图像孔隙率相似的生成图像,将生成图像孔隙率和真实图像孔隙率的曼哈顿距离作为孔隙率损失,如下所示:
$${L_{{\rm{porosity}}}} = {E_{x \sim {P_{{\rm{data}}}}(x),z \sim {P_z}(z)}}[{\left\| {{x_{{\rm{porosity}}}} - G{{\left( z \right)}_{{\rm{porosity}}}}} \right\|_1}] $$ (3) 孔隙率如式(4)所示:
$$ \varphi_{ {{\rm{porosity}} }}=\frac{A_{ {{\rm{void}} }}}{A_{ {{\rm{void}} }}+A_{ {{\rm{solid}} }}} $$ (4) 式中,
$ \varphi_{ {{\rm{porosity}} }} $ 为孔隙率;$ A_{ {{\rm{void}} }} $ 为孔隙(即空相)的面积;$ A_{ {{\rm{void}} }}+A_{ {{\rm{solid}} }} $ 为总面积。另外,为了更准确地描述生成图像和真实图像的相似情况,本文在生成器损失中加入L1损失。根据式(1)~式(3),可以得到网络的生成器损失表达:
$$ \begin{split} &{L_G} = {\lambda _{{\rm{perceptual}}}}{L_{{\rm{perceptual}}}} + {\lambda _{{L_1}}}{L_1} + {\lambda _{{\rm{porosity}}}}{L_{{\rm{porosity}}}}-\\ &\qquad\quad {\lambda _G}{E_{z \sim {P_z}\left( z \right)}}[D\left( {G\left( z \right)} \right)|y] \end{split} $$ (5) 式中,
$ y $ 是约束条件;L1损失表示真实图像数据分布$ x $ 与生成器生成图像分布$ G(x) $ 的L1范数,可写为:$$ L_{1}=E_{x \sim P_{{{\rm{data}}}}(x), z \sim P_{z}(z)}\left[\|x-G(z)\|_{1}\right] $$ (6) -
利用工业级CT扫描机(型号:Y.CT modular, 3.5 mA, 200 kV)对生物骨(猪肋骨)进行扫描,得到40张切片图像。对切片图像进行二值化处理和形态处理,得到更高质量的图像。然后对处理过的切片图像进行裁剪,每张切片图像可裁剪出4~5张骨多孔图像。考虑到图像质量和计算成本,本文对裁剪后的骨多孔图像进行缩放,缩放至512×512大小,则得到190张图像,如图3所示。实际上,190张图像作为深度学习的数据集是远远不够的,本文通过对骨多孔图像进行旋转和翻转来实现增强数据的目的,最终得到1140张图像作为数据集。
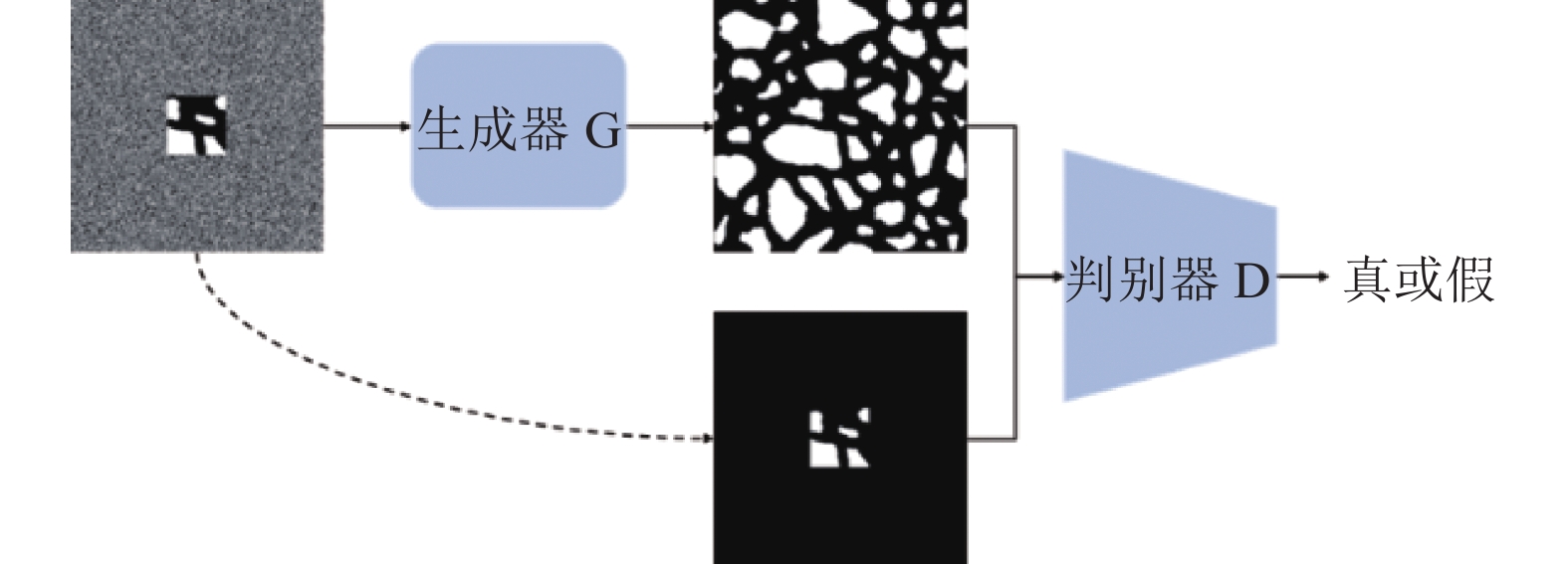
将上述获得的骨多孔图像与掩膜矩阵相乘得到局部切片图像,如下所示:
$$ f(x,y) \odot ({\bf{1}} - {\boldsymbol{M}}) = f(x',y') $$ (7) 式中,
$ f(x, y) $ 为骨多孔图像;$ f\left(x^{\prime}, y^{\prime}\right) $ 为局部切片图像;掩膜矩阵$ {\boldsymbol{M}} $ 中缺失区域信息为1,背景区域为0,如图4所示。
图 3 数据集获取过程
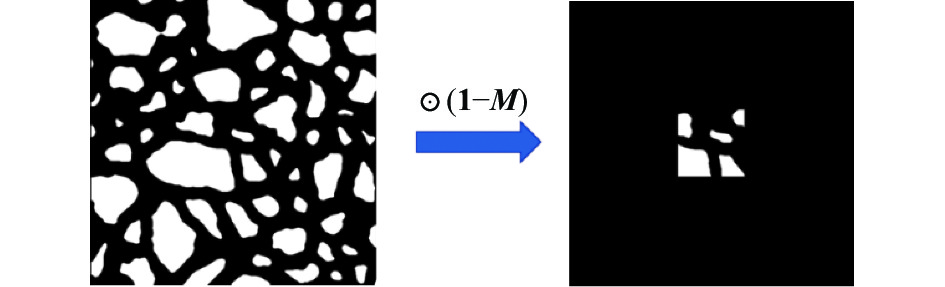
图 4 局部骨切片图像的生成
-
本文采用在掩膜矩阵的背景图像上加随机噪声作为网络生成器的输入,如图5所示。

图 5 生成器输入形式
将局部切片图像设置为网络的约束条件,同时,对局部切片图像进行重构,需要构建局部切片图像与重构生成图像之间的关系,否则当生成器生成出与输入不对应但又清晰的图像时,判别器仍然会给高分,影响重构结果。将不带噪声的局部切片图像与重构生成图像拼接在一起,输入到判别器中进行判断,如图6所示。
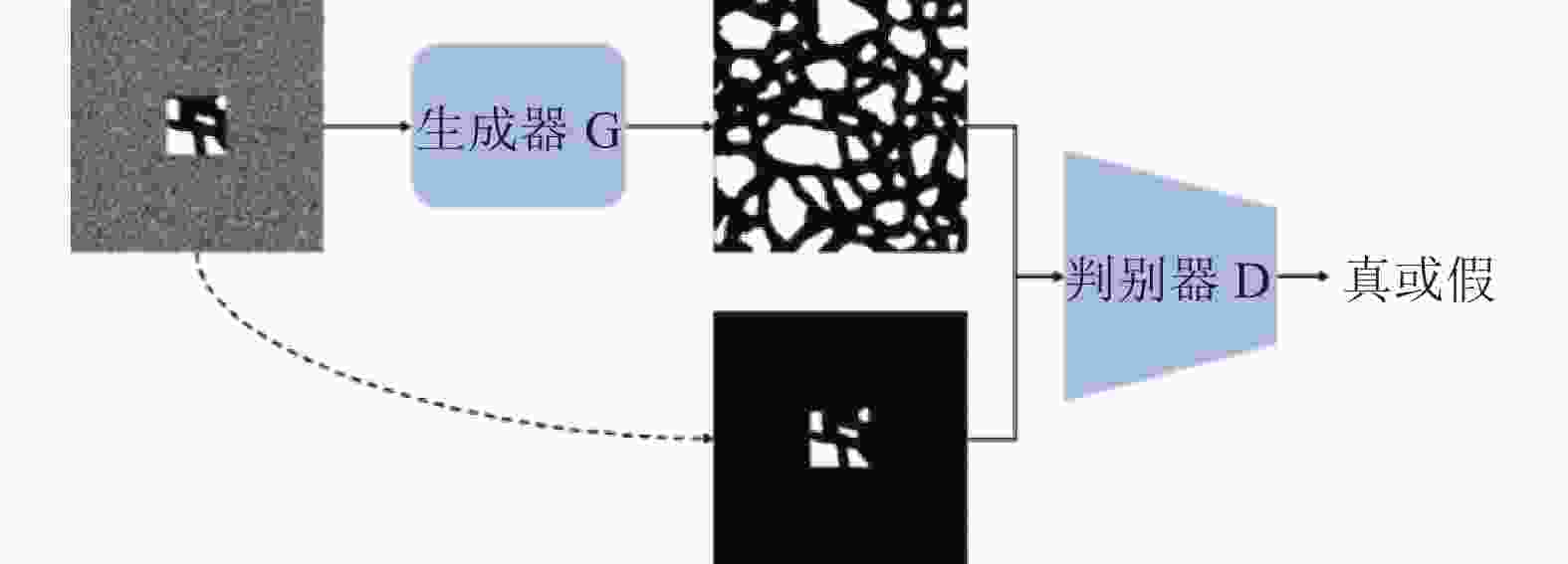
图 6 判别器输入形式
-
本文提出的网络模型在搭载单张RTX 2070super GPU及Intel-i5 10600KF主机的前提下,使用pytorch框架进行训练和推理,训练过程采用如下超参数。
对于LeakyReLU激活函数,参数
$ a $ 设置为0.2,式(5)中$ \lambda_{G} $ 设为0.1,$ \lambda_{\text {perceptual }} $ 设为1,$ \lambda_{L_{1}} $ 设为0.02,$ \lambda_{\text {porosity }} $ 取0.3;对于所有模型,均使用Adam优化器($ \beta_{1}=0 $ ,$ \beta_{2}=0.9 $ )进行训练;使用双时间尺度更新规则,即判别器的学习速率设为0.0004,生成器的学习速率设为0.0001;式(1)中判别器梯度惩罚的参数$ {\lambda} $ 设为10。骨多孔图像数据集被按照3:1比例划分为训练集和测试集。将训练集中的图像数据进行处理,得到局部切片图像数据集。为了完整地描述骨多孔结构的特征,本文以闵可夫斯基泛函(minkowski functionals, MF)[27]作为测试集测试网络的判据。对于二维骨切片图像,它们的
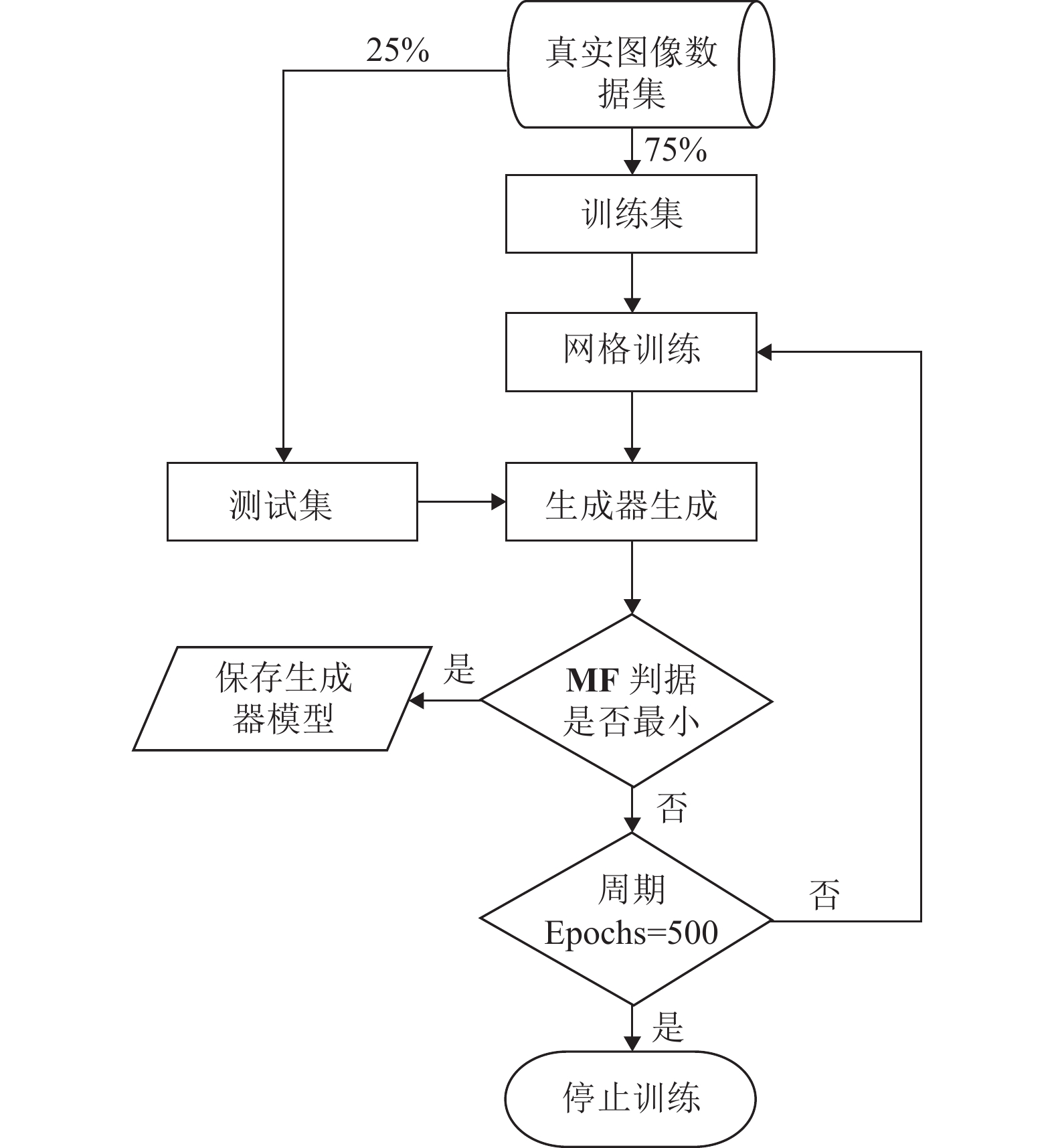
${\bf{MF}}$ 由总表面积$ S $ 、总周长$ C $ 和2D欧拉示性数组成,表示为${\bf{MF}} = [S,C,\chi ]$ 。同时,设置测试集$ {\boldsymbol{T}}=\left\{t_{1}, t_{2}, \cdots, t_{N}\right\} $ ,生成图像$G({\boldsymbol{T}}) = \left\{ G({t_1}), G({t_2}), \cdots, G({t_N}) \right\}$ ,判据$ \varDelta_{{\bf{MF}}} $ 可以表示为式(8),其值越小说明网络越好:$$ \varDelta_{{\bf{MF}}}=\frac{1}{N} \sum_{i=1}^{N} \lg \left\|{\bf{MF}}\left(t_{i}\right)-{\bf{MF}}\left(G\left(t_{i}\right)\right)\right\|_{2}^{2} $$ (8) 网络训练的周期为500轮,每一轮训练后的生成器模型对测试集图像进行重构,用闵可夫斯基泛函判据来确定最好的模型,整个训练过程如图7所示。
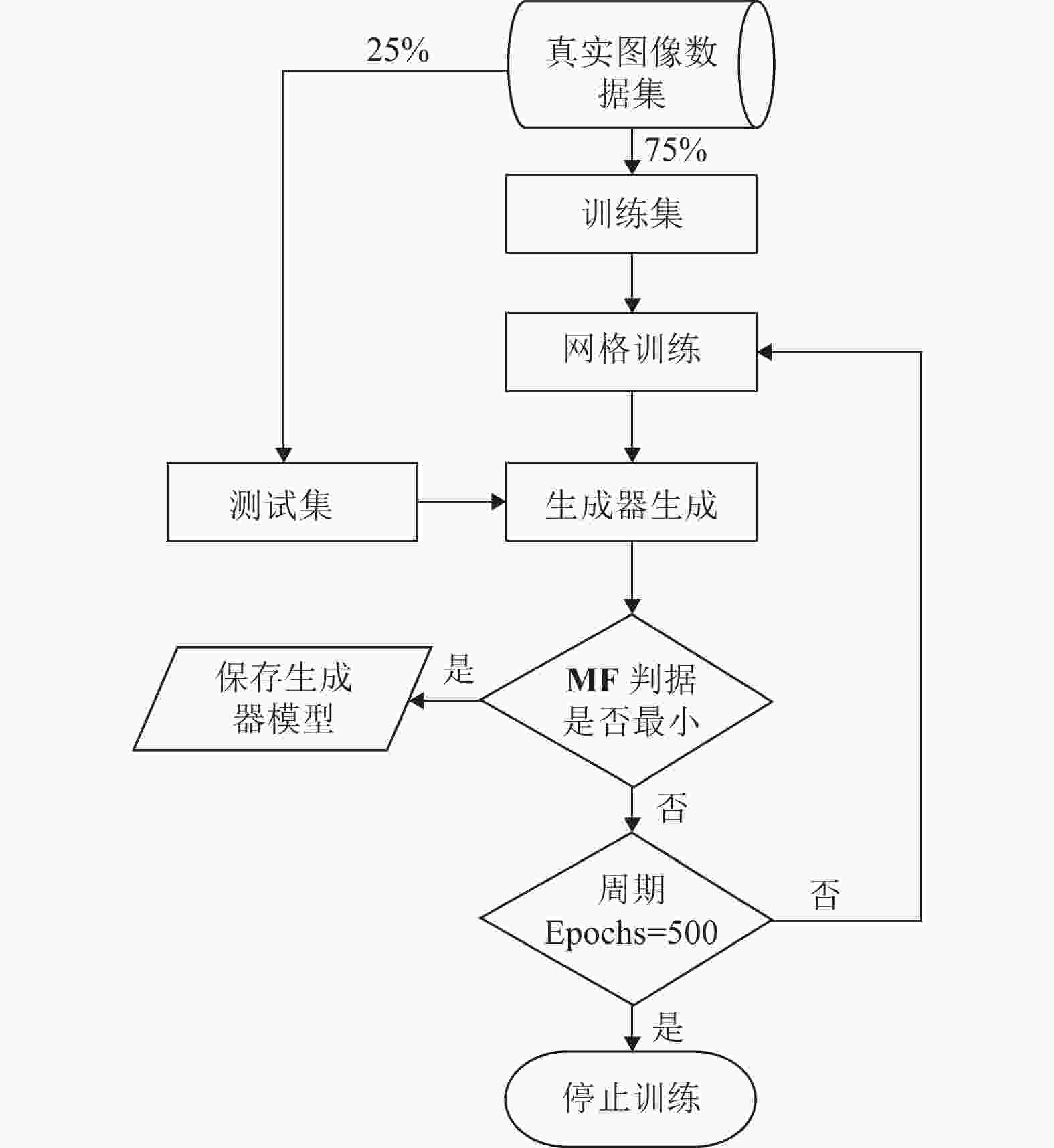
图 7 RRDB-PSA-pix2pix网络训练过程
-
近年来,文献[7-8]提出U-NetGAN网络和Dense-W-pix2pix网络对多孔结构图像进行重构。本文分别对U-NetGAN网络和Dense-W-pix2pix网络进行修改使其能够训练本文数据集,并使用MF判据,将二者与本文提出的RRDB-PSA-pix2pix网络进行对比。骨多孔图像(图8a)与掩膜矩阵相乘得到了如图8b所示的局部骨切片图像。3种网络分别对局部骨切片图像进行重构,得到了图8c~8e所示的生成图像。

图 8 3种网络的生成图像比较
如图8所示,U-NetGAN网络生成的图像质量最差,图中噪声多,孔隙边缘轮廓不清晰,出现伪影,且生成的图像轮廓与真实图像相同。而另外两种网络生成的图像表现较好。同时,由表1可以看出, RRDB-PSA-pix2pix网络
$ \varDelta_{{\bf{MF}}} $ 判据值比Dense-W-pix2pix网络更小,由此可知,本文提出的RRDB-PSA-pix2pix网络重构出的图像质量最好。表 1 3种网络MF判据比较
网络 $\varDelta_{{\bf{MF}}}$ U-NetGAN 7.491 Dense-W-pix2pix 7.092 RRDB-PSA-pix2pix 6.946 -
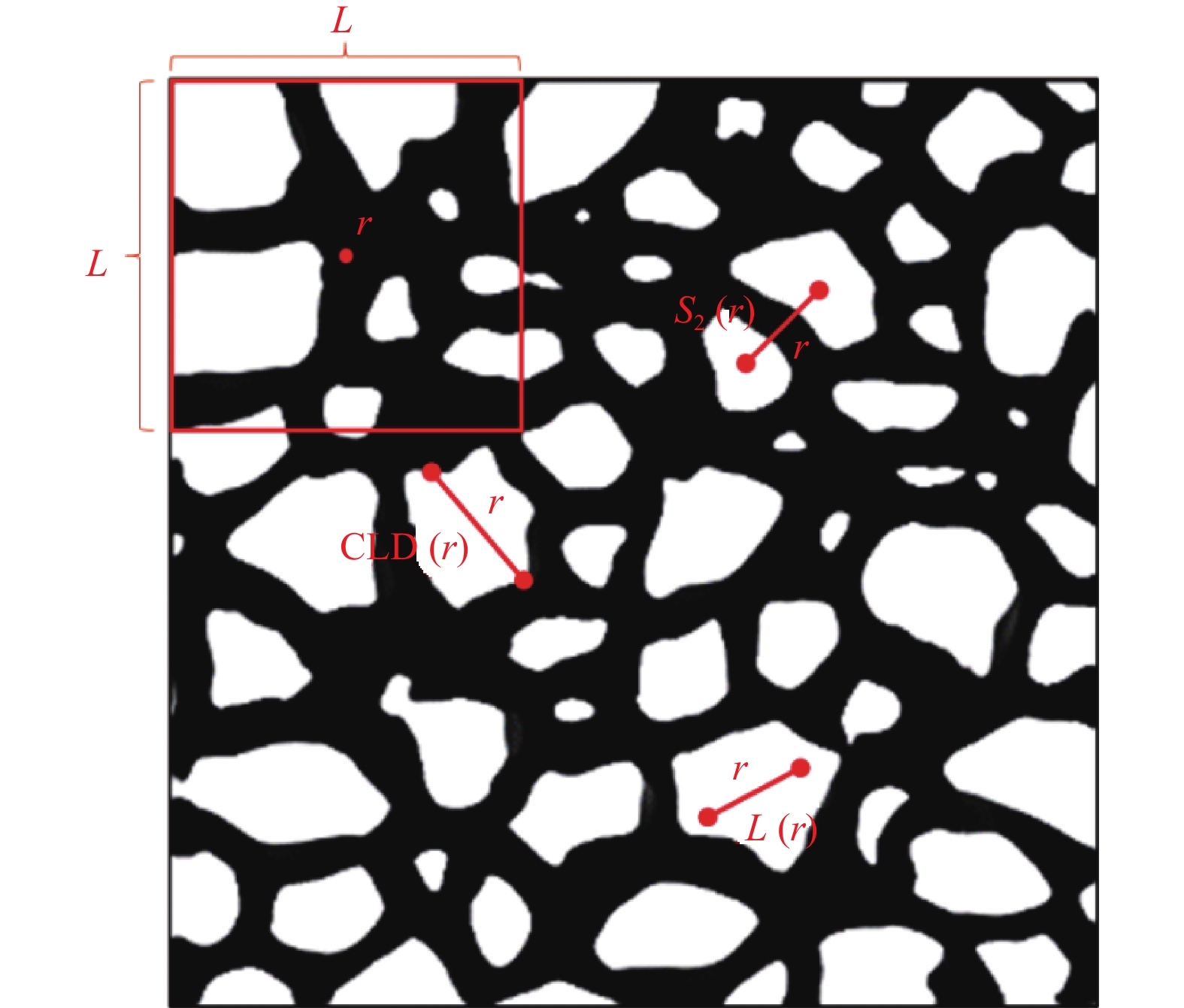
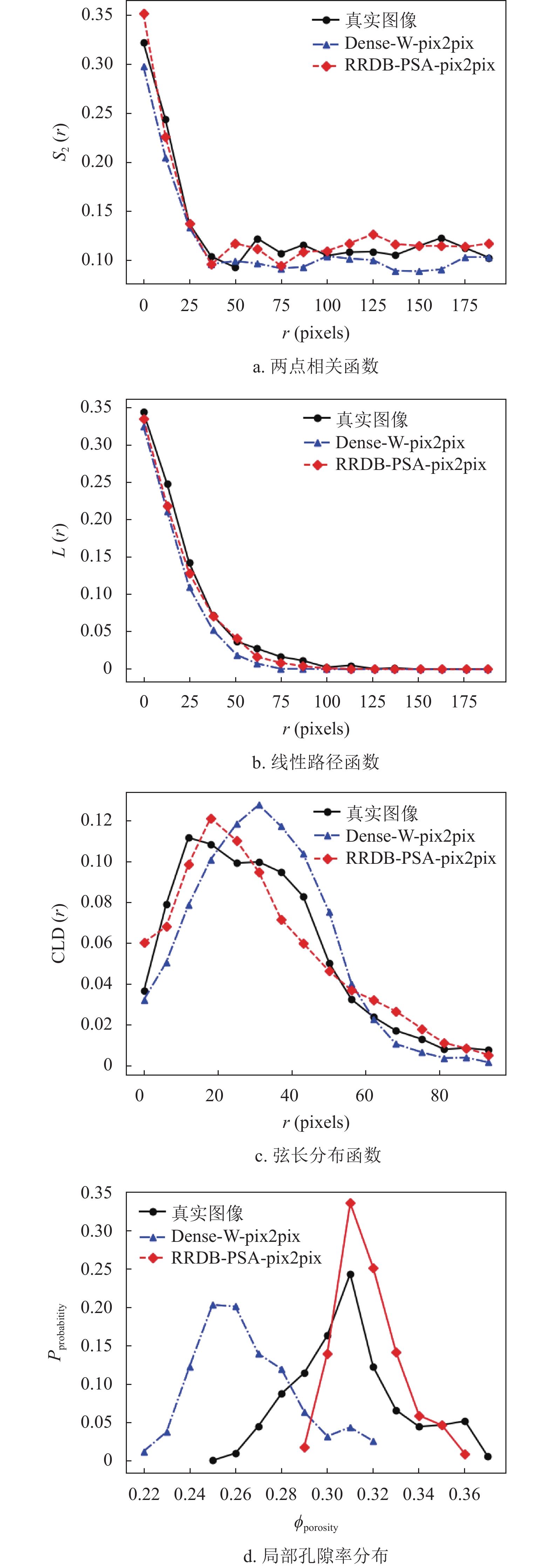
本文通过3种形态学函数分析和局部孔隙率分布研究[28],评价了RRDB-PSA-pix2pix网络重构生成的图像与真实图像的相似程度。这3种形态学函数分别为两点相关函数[29]、线性路径函数[30]和弦长分布函数[31]。两点统计函数
${S_2}(r)$ 用来表示空间中两点的关系。线性路径函数$L(r)$ 统计给定长度为$ r $ 的线段完全位于同一相的概率,包含了多孔结构的连通性信息。弦长分布函数${\rm{CLD}}(r)$ 计算位于同一相位相同弦长的概率,可以较为准确地捕获多孔图像内部的空间信息,用来描述孔洞大小、形状和空间排布等特征。局部孔隙率分布通常用于表征数字化模型中不同长度下的孔隙率和连通性的波动。与孔隙率不同,局部孔隙率$\phi (r,L)$ 是在位于$ r $ 为中心且长度为$ L $ 的二维测量单元$K(r,L)$ 内测得。图9为3种形态学函数和局部孔隙率分布的定义示意图。
图 9 3种形态学函数和局部孔隙率分布的定义示意图
本文以Dense-W-pix2pix网络重构生成的图像作为对比,来评价分析RRDB-PSA-pix2pix网络生成的图像与真实图像的相似程度。图10为两种网络生成图像的形态学函数和局部孔隙率分布统计图,其中局部孔隙率分布中的测量单元取大小为320×320。
图中的统计分布均进行了两组独立样本的Kolmogorov-Smirnov检验(K-S检验),且p值皆大于0.05。由图10可以看出, RRDB-PSA-pix2pix网络生成的图像分布曲线更接近于真实图像的分布曲线,因此可以得出,本文提出的网络能够重构出高质量的完整骨多孔切片图像,并且其两相位置分布关系和连通性更符合真实情况。
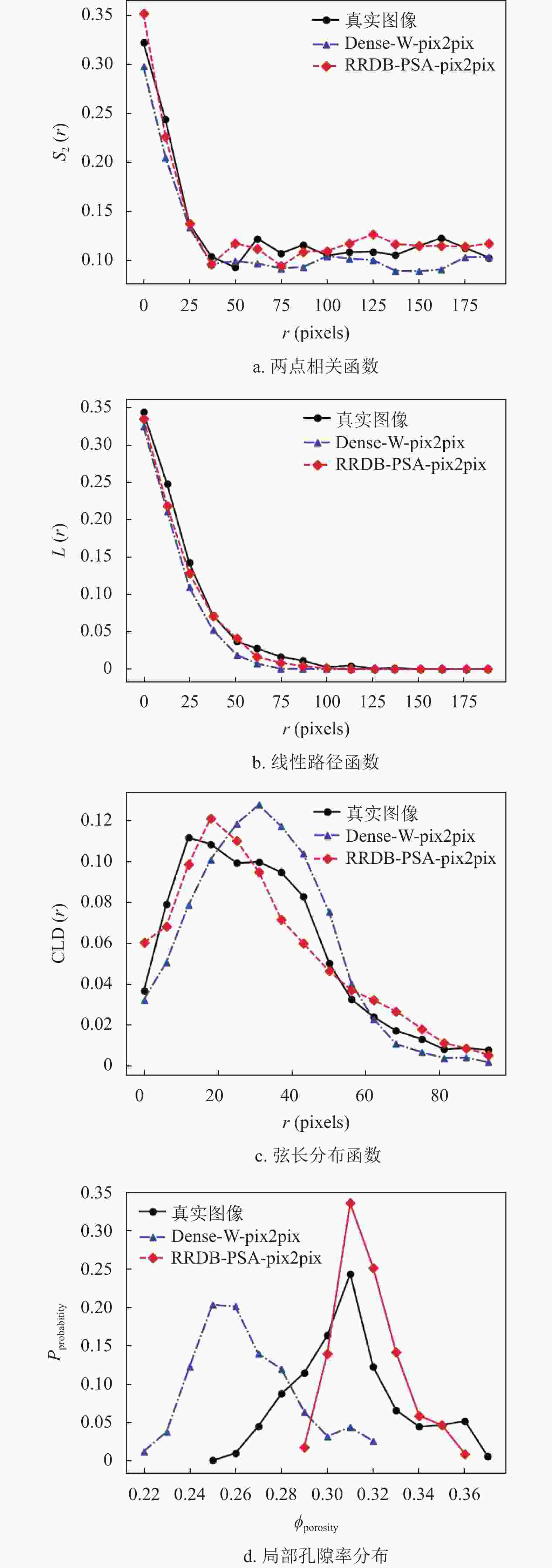
图 10 形态学函数与局部孔隙率分布统计图
-
孔隙率是骨多孔结构最重要的结构参数之一,孔隙率的不同,直接影响着骨多孔结构的质量、渗透性能、机械性能以及相关生物性能,实际上,除孔隙率外,还有一些参数可用来评价骨多孔结构,但是,不同参数的评价方法,所采用的网络算法与数学模型也各不相同,因此,考虑到篇幅问题,本文重点考虑通过孔隙率来评价骨多孔结构。
1) 本文在pix2pix基础上,对生成器进行改进,加入嵌套残差密集块(RRDB),在判别器中加入PSA模块,提出对局部骨切片图像进行完整修复重构的RRDB-PSA-pix2pix网络。
2) 研究并分析了闵可夫斯基泛函对骨多孔结构唯一性的表征,建立了闵可夫斯基泛函判据,为快速筛选网络提供了方法。
3) 利用3种形态学函数与局部孔隙率分布对本文提出的RRDB-PSA-pix2pix网络进行分析评价。研究表明,该网络重构生成的骨切片图像中的多孔结构特征,更加接近于真实图像,并且生成的图像质量更高。
4) 本文所提出的网络框架可以很容易地扩展到其他应用,如2D-to-3D或3D-to-3D的重构。理论上,它可以将任意数量的任何类型的对象函数以及任何用户定义的条件数据合并到重构中。当通知某一区域存在特定结构时,这在实践中可能特别有用。此外,它还可以通过与其他方法相结合来降低计算成本。
Reconstruction of Partial Slice Bone Images Based on Improved Network Model
-
摘要: 基于骨切片图像的三维骨多孔结构数字建模是骨组织工程的技术基础,也是生物医学工程领域的研究热点,骨切片图像的质量决定了骨多孔结构数字模型的准确程度。然而,骨切片图像在获取过程中会出现数据丢失、图像受损或图像尺寸过小等问题,导致只能得到局部的切片图像。为了解决这个问题,提出对局部骨切片图像进行完整重构修复的改进条件生成对抗网络,即在条件生成对抗网络基础上,对生成器进行改进,加入嵌套残差密集块,同时,在判别器中加入极化自注意力模块,并对重构的图像进行形态学函数分析和局部孔隙率分布研究来评价生成图像与真实骨多孔图像的相似程度。结果表明该网络能准确、稳定地重构出多样化的完整骨多孔切片图像。
-
关键词:
- 骨切片图像 /
- 重构图像评价 /
- 改进条件生成对抗网络 /
- 局部切片图像重构
Abstract: Digital modeling of 3D bone porous structure based on bone slice images is the technical basis of bone tissue engineering and a research hotspot in the field of biomedical engineering. The quality of bone slice image determines the accuracy of the digital model of bone porous structure. However, problems such as data loss, image damage or too small image size may occur in the process of acquiring bone section images, resulting in only partial slice images, and thus such incomplete image information seriously affects the accuracy of 3D porous bone structure modeling. In order to solve this problem, an improved conditional generative adversarial network for complete reconstruction and repair of partial bone slice images was proposed, that is, on the basis of conditional generative adversarial network, the nested residual dense block is added to the generator, and the polarized self-attention module is added to the discriminator. Morphological function analysis and partial porosity distribution study were performed to evaluate the similarity between the reconstructed images and the real bone porous images. The results show that the network can accurately and stably reconstruct complete bone porous slice images. -
表 1 3种网络MF判据比较
网络 $\varDelta_{{\bf{MF}}}$ U-NetGAN 7.491 Dense-W-pix2pix 7.092 RRDB-PSA-pix2pix 6.946  下载: 导出CSV
下载: 导出CSV
-
[1] 陈华伟, 伍权. 骨支架多孔结构建模综述[J]. 现代制造工程, 2019(6): 147-153. doi: 10.16731/j.cnki.1671-3133.2019.06.026 CHEN H W, WU Q. Review of porous structure modeling for bone scaffold[J]. Modern Manufacturing Engineering, 2019(6): 147-153. doi: 10.16731/j.cnki.1671-3133.2019.06.026 [2] ADLER P M, THOVERT J F. Real porous media: Local geometry and macroscopic properties[J]. Applied Physics Reviews, 1998, 51(9): 537-585. [3] JIAO Y, STILLINGER F H, TORQUATO S. Modeling heterogeneous materials via two-point correlation functions: Basic principles[J]. Physical Review E, 2007, 76(3): 031110. doi: 10.1103/PhysRevE.76.031110 [4] 王敏, 申玉清, 陈震宇, 等. 随机多孔介质的蒙特卡罗重构与渗流特性模拟[J]. 计算物理, 2021, 38(5): 623-630. doi: 10.19596/j.cnki.1001-246x.8315 WANG M, SHEN Y Q, CHEN Z Y, et al. Reconstruction and seepage simulation of random porous media with Monte Carlo method[J]. Chinese Journal of Computational Physics, 2021, 38(5): 623-630. doi: 10.19596/j.cnki.1001-246x.8315 [5] 张挺, 卢德唐, 李道伦. 基于二维图像和多点统计方法的多孔介质三维重构研究[J]. 中国科学技术大学学报, 2010, 40(3): 271-277. doi: 10.3969/j.issn.0253-2778.2010.03.011 ZHANG T, LU D T, LI D L. A method of reconstruction of porous media using a two-dimensional image and multiple-point statistics[J]. Journal of University of Science and Technology of China, 2010, 40(3): 271-277. doi: 10.3969/j.issn.0253-2778.2010.03.011 [6] 苏俊铜. 基于深度学习的多孔铜泡沫CT图像生成的系统与设计[D]. 绵阳: 西南科技大学, 2021. SU J T. System and design of CT image generation of porous copper foam based on deep learning[D]. Mianyang: Southwest University of Science and Technolog, 2021. [7] FENG J, HE X, TENG Q, et al. Reconstruction of porous media from extremely limited information using conditional generative adversarial networks[J]. Physical Review E, 2019, 100: 33308. [8] 陈龙. 基于生成对抗网络的多孔介质重构[D]. 西安: 长安大学, 2020. CHEN L. Reconstruction of porous media based on generative adversarial network[D]. Xian: Chang'an University, 2020. [9] SOKAT K Y, DOLINSKAYA I S, SMILOWITZ K, et al. Incomplete information imputation in limited data environments with application to disaster response[J]. European Journal of Operational Research, 2018, 269(2): 466-485. doi: 10.1016/j.ejor.2018.02.016 [10] WANG Y, ARNS J Y, RAHMAN S S, et al. Three-dimensional porous structure reconstruction based on structural local similarity via sparse representation on micro-computed-tomography images[J]. Physical Review E, 2018, 98(4): 043310. doi: 10.1103/PhysRevE.98.043310 [11] TAHMASEBI P, JAVADPOUR F, SAHIMI M. Three-dimensional stochastic characterization of shale SEM images[J]. Transport in Porous Media, 2015, 110(3): 521-531. doi: 10.1007/s11242-015-0570-1 [12] WILDENSCHILD D, SHEPPARD P. X-Ray imaging and analysis techniques for quantifying pore scale structure and processes in subsurface porous medium systems[J]. Advances in Water Resources, 2013, 51: 217-246. [13] TELEA A. An image inpainting technique based on the fast marching method[J]. Journal of Graphics Tools, 2004, 9(1): 23-34. doi: 10.1080/10867651.2004.10487596 [14] XIANG S, DENG H, ZHU L, et al. Exemplar-based depth inpainting with arbitrary-shape patches and cross-modal matching[J]. Signal Processing: Image Communication, 2019, 71: 56-65. [15] KIM H, LEE D. Image denoising with conditional generative adversarial networks (CGAN) in low dose chest images[J]. Nuclear Instruments and Methods in Physics Research, Section A. Accelerators, Spectrometers, Detectors and Associated Equipment, 2020, 954: 161914. [16] WANG X, YU K, WU S, et al. ESRGAN: Enhanced super-resolution generative adversarial networks[EB/OL]. (2018-09-01). https://arxiv.org/abs/1809.00219. [17] LIU H J, LIU F Q, FAN X Y, et al. Polarized self-attention: Towards high-quality pixel-wise regression[EB/OL]. (2021-07-02). https://arxiv.org/abs/2107.00782. [18] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]//International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 2672-2680. [19] MEHDI M, SIMON O. Conditional generative adversarial nets[EB/OL]. (2014-11-06). https://arxiv.org/abs/1411.1784. [20] ANTIPOV G, BACCOUCHE M, DUGELAY J L. Face aging with conditional generative adversarial networks[C]//2017 IEEE International Conference on Image Processing (ICIP). Washington, DC: IEEE, 2017: 2089-2093. [21] ZHANG H, XU T, LI H, et al. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision. Washington, DC: IEEE, 2017: 5907-5915. [22] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE, 2016: 770-778. [23] HUANG G, LIU Z, VAN DER M L, et al. Densely connected convolutional networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE, 2017: 4700-4708. [24] ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein GAN[EB/OL]. (2017-12-06). https://arxiv.org/abs/1701.07875. [25] WANG G, HU X. Low-dose CT denoising using a progressive wasserstein generative adversarial network[J]. Computers in Biology and Medicine, 2021, 135: 104625. [26] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10). https://arxiv.org/abs/1409.1556. [27] ARMSTRONG R, MCCLURE J, ROBINS V, et al. Porous media characterization using minkowski functionals: Theories, applications and future directions[J]. Transport in Porous Media. 2019, 130(1): 305-335. [28] HILFER R. Local-porosity theory for flow in porous media[J]. Physical Review B, 1992, 45(13): 7115-7121. doi: 10.1103/PhysRevB.45.7115 [29] YEONG C, TORQUATO S. Reconstructing random media[J]. Physical Review E, 1998, 57(1): 495. doi: 10.1103/PhysRevE.57.495 [30] LU B, TORQUATO S. Lineal-path function for random heterogeneous materials[J]. Physical Review A, 1992, 45(2): 922-929. doi: 10.1103/PhysRevA.45.922 [31] KAINOURGIAKIS M, KIKKINIDES E, GALANI A, et al. Digitally reconstructed porous media: Transport and sorption properties[J]. Transport in Porous Media, 2005, 58(1): 43-62. -

 点击查看大图
点击查看大图
图(10) / 表(1)
计量
- 文章访问数: 3818
- HTML全文浏览量: 1135
- PDF下载量: 83
- 被引次数: 0











































