 ISSN
ISSN 


 下载:
下载:


-
模糊集指边界不明确的集合。1965年,Zadeh教授首次提出模糊集的概念,他提出用模糊数学来解决模糊问题[1]。模糊数学在实践中运用数学方法来研究和处理大量的不确定问题。近年来,机器学习领域[2]发展迅速,其中人工神经网络算法[3]得到了广泛的研究和应用。神经网络算法可以模拟人脑神经元对某些事物做出判断的功能。只要用训练数据集对神经网络模型进行训练,对模型参数进行更新和优化,模型就有可能对输入数据做出正确的判断。然而,随着大数据的发展,现实生活中出现了很多模糊数据。传统的神经网络不能很好地处理一些模糊问题,模型输出精度不高。因此,一些研究人员将模糊数学与神经网络相结合。提出了BP模糊神经网络[4]、基于自适应网络的模糊推理系统(a fuzzy inference system based on adaptive network, ANFIS)[5]和B-spline模糊神经网络。这些神经网络吸收了模糊逻辑和神经网络的优点,在处理非线性和模糊问题方面具有一定的优势。
机器学习算法通常需要对大数据进行处理,这使得它们的执行时间很长,这是传统计算机无法企及的。近年来,量子计算领域发展迅速,研究人员利用量子叠加态、量子纠缠和量子测量的特点设计了一些量子算法。如Shor大数分解算法、Grover搜索算法、HHL算法[6]等。因此,使用量子计算来解决机器学习算法[7-8]的高时间复杂度问题是一个很好的选择。研究人员在经典机器学习算法的基础上设计了一些量子机器学习算法,如量子支持向量机[9]、量子主成分分析[10]和量子神经网络[11-14]。与经典算法相比,这些算法具有指数加速的优势。结合模糊神经网络在处理模糊问题上的优势和量子神经网络在计算速度上的优势,便可以设计出量子模糊神经网络[15-16]。
ANFIS将模糊规则强度与样本特征以乘法相结合作为输出,这样能使系统计算速度加快,但却限制了输出的准确度。本文将ANFIS与QBP相结合,提出了基于自适应网络的量子模糊推理系统(ANQFIS),其将样本特征通过一层QBP处理后,再将模糊规则强度转化为角度作为量子门的参数,对QBP的输出的量子比特做量子门旋转操作,最后以量子态的测量概率作为输出。量子计算的速度优势和神经网络的高准确度使得ANQFIS在拥有高计算速度的同时又具有更高的输出准确率。
-
一个量子比特可以是
$\left| 0 \right\rangle $ 、$\left| 1 \right\rangle $ 或是$\left| 0 \right\rangle $ 与$\left| 1 \right\rangle $ 的叠加态,一个叠加态的量子比特可以表示为:$$ \left| \varphi \right\rangle = \alpha \left| 0 \right\rangle + \beta \left| 1 \right\rangle $$ (1) 式中,
$\alpha $ 和$\beta $ 是复数,表示振幅,且满足$ {\left| \alpha \right|^2} + {\left| \beta \right|^2} = 1 $ ,即在$Z$ 基测量下,$\left| \varphi \right\rangle $ 被测量得到$\left| 0 \right\rangle $ 的概率为$ {\left| \alpha \right|^2} $ ,被测量得到$\left| 1 \right\rangle $ 的概率为$ {\left| \beta \right|^2} $ 。对量子比特的操作变换通常使用量子门来实现,量子比特
$\left| \varphi \right\rangle $ 写成向量的形式为$\left( {\cos {\theta _0}\;\;\sin {\theta _0}} \right)^{\rm{T}}$ ,其中$\cos {\theta _0} = \alpha $ ,$\sin {\theta _0} = \beta $ 。而一个量子门可以被写成矩阵的形式,本文用到的量子门定义为:$$ R(\theta ) = \left( {\begin{array}{*{20}{c}} {\cos \theta }&{ - \sin \theta } \\ {\sin \theta }&{\cos \theta } \end{array}} \right) $$ (2) 将此量子门作用到
$\left| \varphi \right\rangle $ 上则可以看作是对$\left| \varphi \right\rangle $ 做了一个旋转操作:$$ R(\theta )\left| \varphi \right\rangle {\text{ = }}\left( {\begin{array}{*{20}{c}} {\cos ({\theta _0} + \theta )} \\ {\sin ({\theta _0} + \theta )} \end{array}} \right) $$ (3) -
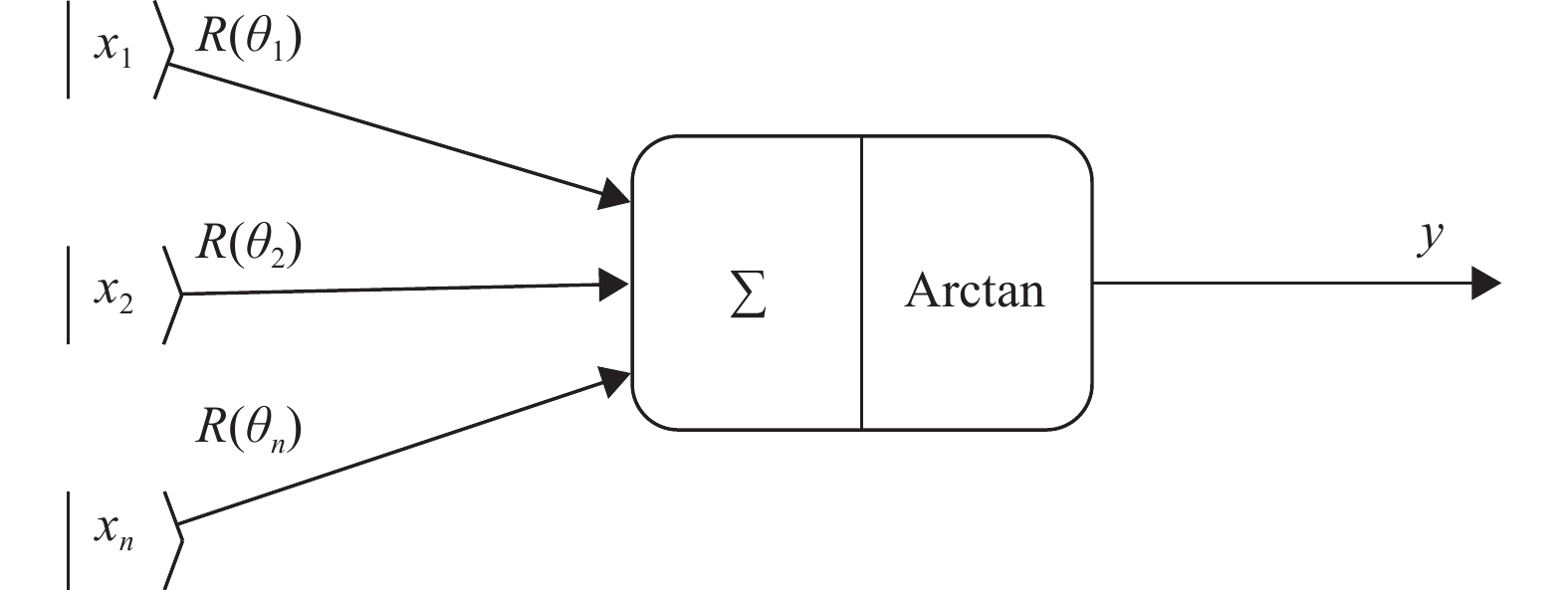
本文使用的是文献[11]提出的一种量子神经元结构的简化版本,如图1所示。
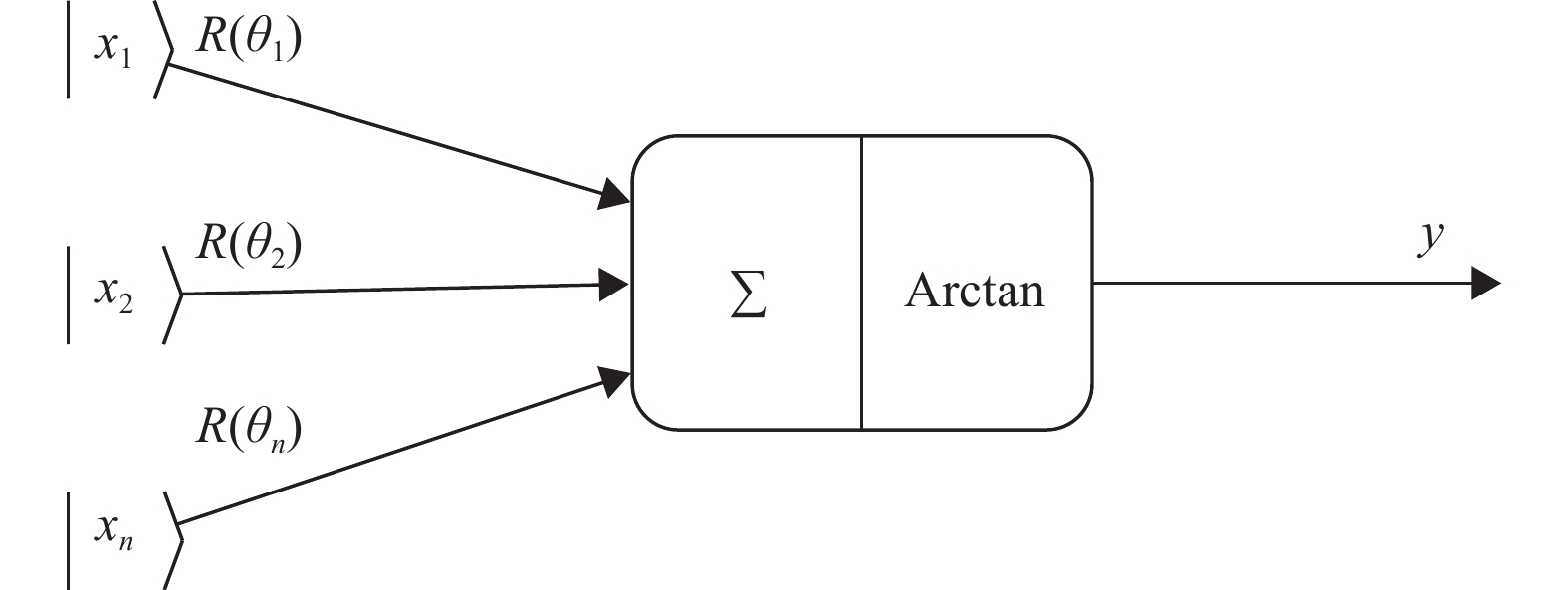
图 1 量子神经元结构
正如经典神经网络中的神经元一样,此量子神经元有n个输入和1个输出,假设图1中的量子比特
$\left| {{x_j}} \right\rangle = {\left( {\cos {\theta _j}\;\;\sin {\theta _j}} \right)^{\rm{T}}}$ ,且$R(\theta )$ 的定义如(3)所示,那么输入n个量子比特$ \left| {{x_1}} \right\rangle \cdots \left| {{x_n}} \right\rangle $ 后,获得一个新的量子比特${\left( {\cos \theta '\;\;\sin \theta '} \right)^{\rm{T}}}$ 作为量子神经元的输出,其中:$$ \theta ' = \arctan \left( {\frac{{\displaystyle\sum\limits_{j = 1}^n {\sin \left( {{t_j} + {\theta _j}} \right)} }}{{\displaystyle\sum\limits_{j = 1}^n {\cos \left( {{t_j} + {\theta _j}} \right)} }}} \right) $$ (4) -
对于一个普通集合,一个元素可能属于它或不属于它。而对于模糊集合,元素就不能说属于还是不属于此模糊集合,而是用隶属度来衡量此元素属于它的程度大小。隶属度由隶属度函数来计算得到。如果存在一个模糊集A,A(x)为此模糊集的隶属度函数,它的值域为[0,1],如果A(x)越接近1,则表明x属于模糊集合A的程度越大,越接近0则程度越小。模糊集A可以表示为:
$$ A = \left\{ {\left( {x,A(x)} \right)\left| {A(x) \in \left[ {0,1} \right]} \right.} \right\} $$ (5) 模糊if-then规则或模糊条件语句,是一种以 if A then B 为形式的表达式,其中A和B都是语言标签(小、大等),拥有自己的隶属度函数。下面简要介绍ANFIS的模型结构。
在ANFIS中,所考虑的模糊推理系统假设有两个输入和一个输出,分别是
${x_1}$ 、${x_2}$ 和$R$ ,假设规则库中包含有两个Takagi和Sugeno提出的if-then规则:$$ \begin{gathered} {\rm{Rule}}{\text{ }}1 :{\text{If }}{x_1}{\text{ is }}{A_1}{\text{ and }}{x_2}{\text{ is }}{B_1}{\text{, then }}{f_1} = {p_1}{x_1} + {q_1}{x_2} + {r_1} \\ {\rm{Rule}}{\text{ 2}} :{\text{If }}{x_1}{\text{ is }}{A_2}{\text{ and }}{x_2}{\text{ is }}{B_2}{\text{, then }}{f_2} = {p_2}{x_1} + {q_2}{x_2} + {r_2} \\ \end{gathered} $$ (6) 式中,
$ {p_i} $ ,$ {q_i} $ ,$ {r_i} $ 是待训练更新的参数,被称作后件参数。并且$ {A_i} $ ,$ {B_i} $ 的隶属度函数采用的是高斯隶属度函数,假设模糊集$ {A_i} $ 的高斯隶属度函数可以表示为:$$ {\mu _{{A_i}}}(x) = \exp \left[ { - \frac{1}{2}{{( {\frac{{x - {c_i}}}{{{\sigma _i}}}} )}^2}} \right] $$ (7) 式中,
$ {c_i} $ 和$ {\sigma _i} $ 是待训练更新的参数,被称作前件参数。之后根据语言标签的个数,计算出每个节点的输出:$$ {w_i} = {\mu _{{A_i}}}(x) {\mu _{{B_i}}}(y)\;\;{\text{ }}i = 1,2\cdots $$ (8) 式中,
$ {w_i} $ 是模糊规则的强度。之后计算出第$ i $ 个模糊规则强度占所有模糊规则强度之和的比例:$$ {\bar w_i} = \frac{{{w_i}}}{{\displaystyle\sum\limits_i {{w_i}} }}\;\;{\text{ }}i = 1,2\cdots $$ (9) 式中,
$ {\bar w_i} $ 被称作归一化强度。最后,根据式(7)的规则,计算得到最后的输出:$$ {R_i} = {\bar w_i}{f_i}\;\;{\text{ }}i = 1,2\cdots $$ (10) $$ R = \sum\limits_i^{} {{R_i}} $$ (11) -
因为一个多输入多输出的系统总是可以由多个多输入单输出的系统组成,所以本文提出的ANQFIS模型结构具有n个输入和1个输出。模型可以看做由两部分组成,一个是量子部分,另一个是模糊部分。量子部分由量子BP神经网络启发而来,模糊部分由ANFIS启发而来。模型结构如图2所示。
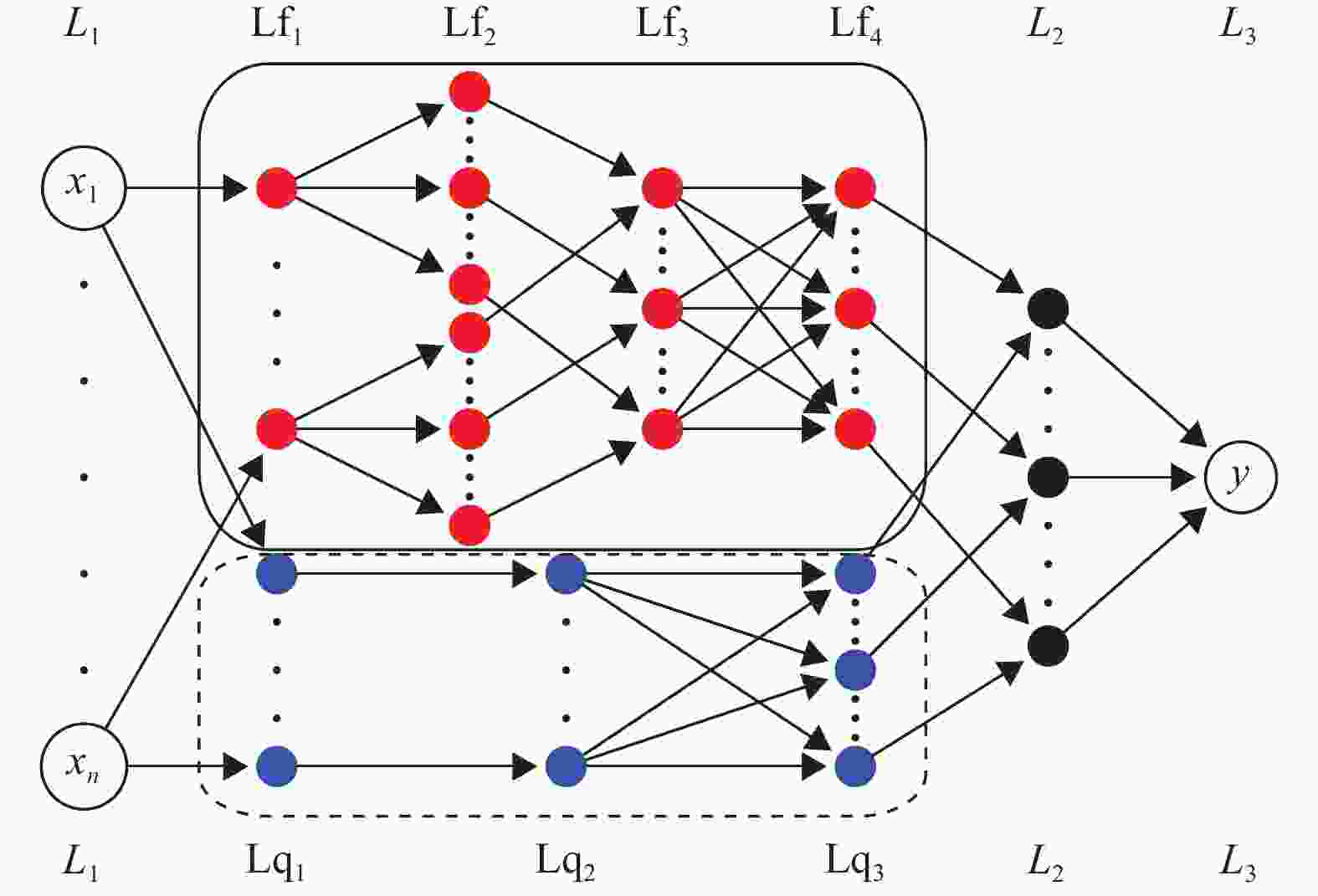
图 2 ANQFIS结构图
模型的实线框部分为模糊部分,虚线框部分为量子部分。整个模型的第
$i$ 层表示为${{{L}}_i}$ ,模糊部分的第$i$ 层表示为${{L}}{{\text{f}}_i}$ ,量子部分的第$i$ 层表示为${{L}}{{\text{q}}_i}$ 。对于${{{L}}_i}$ ,${{L}}{{\text{f}}_i}$ ,${{L}}{{\text{q}}_i}$ ,它们的第$j$ 个节点的输入分别表示为$\mu _{{{{L}}_i}}^j$ ,$\mu _{{{L}}{{\text{f}}_i}}^j$ ,$\mu _{{{L}}{{\text{q}}_i}}^j$ ,第$j$ 个节点的输出分别表示为$o_{{{{L}}_i}}^j$ ,$o_{{{L}}{{\text{f}}_i}}^j$ ,$o_{{{L}}{{\text{q}}_i}}^j$ 。如果节点有多个输入或输出,则第$j$ 个节点的第$k$ 个输入分别表示为$\mu _{{{{L}}_i}}^{jk}$ ,$\mu _{{{L}}{{\text{f}}_i}}^{jk}$ ,$\mu _{{{L}}{{\text{q}}_i}}^{jk}$ ,第$j$ 个节点的第$k$ 个输出分别表示为$o_{{{{L}}_i}}^{jk}$ ,$o_{{{L}}{{\text{f}}_i}}^{jk}$ ,$o_{{{L}}{{\text{q}}_i}}^{jk}$ 。一个n维数据$ x = ({x_1},{x_2},\cdots,{x_n}) $ 被输入该模型后,分别经过量子部分和模糊部分处理,最后相结合得到输出$y$ 。模型各个部分每一层的输入和输出描述如下。${{{L}}_1}$ (输入层):n维数据$ x = ({x_1},{x_2},\cdots,{x_n}) $ 被输入到ANQFIS模型。${{{\rm{L}}}}{{\text{f}}_1}$ (模糊部分−输入层):n维数据$ x = ({x_1},{x_2},\cdots, {x_n}) $ 被输入到模糊部分,这一层中第$j$ 个节点的第$k$ 个输出为:$$ o_{{{{L}}_1}}^{jk} = {x_j} $$ (12) ${\text{L}}{{\text{f}}_2}$ (模糊部分−模糊化层):设规则库有$ r $ 个规则,则易得该层有$ nr $ 个节点。结合式(13)从图2中可以得知这一层中每一个节点的输入。每一个节点都定义了一个高斯隶属度函数,第$j$ 个节点的输出为:$$ o_{{{\text{L}}_2}}^j:{g_j} = \exp \left[ {\left. { - \frac{1}{2}{{\left( {\left. {\frac{{\mu _{{\text{L}}{{\text{f}}_2}}^j - {c_j}}}{{{\sigma _j}}}} \right)} \right.}^2}} \right]} \right. $$ (13) 式中,
$ {c_j} $ 和$ {\sigma _j} $ 是待训练参数,$ j = 1,2,{\text{ }}\cdots,nr $ 。${{{\rm{L}}}}{{\text{f}}_3}$ (模糊部分−模糊规则层):在这一层中,每一个节点可以看作是一个模糊规则,规则库有$ r $ 个规则,故该层有$ r $ 个节点。根据模糊规则,该层的第$j$ 个节点取${\text{L}}{{\text{f}}_2}$ 中的$ {g_j} $ ,$ {g_{j{\text{ + }}r}} $ , ···,$ {g_{j{\text{ + }}nr}} $ 作为其输入$ \mu _{{\text{L}}{{\text{f}}_3}}^{j1} $ ,$ \mu _{{\text{L}}{{\text{f}}_3}}^{j2} $ , ···,$ \mu _{{\text{L}}{{\text{f}}_3}}^{jr} $ ,将这些输入相乘获得输出。第$ j $ 个节点的输出就是其规则强度:$$ o_{{\text{L}}{{\text{f}}_3}}^j:{w_j} = \prod\limits_{k = 1}^n {\mu _{{\text{L}}{{\text{f}}_3}}^{jk}} $$ (14) 式中,
$ j = 1,2,{\text{ }}\cdots,r $ 。${{{\rm{L}}}}{{\text{f}}_4}$ (模糊部分−归一化层):在这一层中,第$ j $ 个节点的输出为${\text{L}}{{\text{f}}_3}$ 中第$ j $ 个模糊规则强度占所有模糊规则强度之和的比例,再转换为角度:$$ o_{{\text{L}}{{\text{f}}_{_4}}}^j:{\bar w_j} = 2{\text{π}} \frac{{{w_j}}}{{\displaystyle\sum\limits_{i = 1}^r {{w_i}} }} $$ (15) ${{{\rm{L}}}}{{\text{q}}_1}$ (量子部分−角度化层):在这一层中,n维数据$ x = ({x_1},{x_2},\cdots,{x_n}) $ 被输入到量子部分,$ {x_1},{x_2},\cdots, {x_n} $ 被转化为$ {t_1},{t_2},\cdots,{t_n} $ ,第$ j $ 个节点的输出为:$$ o_{{\text{L}}{{\text{q}}_1}}^j:{t_j} = \frac{{2{\text{π}} }}{{\left[ {1 + \exp ( - {x_j})} \right]}} $$ (16) ${{{\rm{L}}}}{{\text{q}}_2}$ (量子部分−量子化层):在这一层中,根据$ {t_1},{t_2},\cdots,{t_n} $ 制备相应的量子比特$ \left| {{x_1}} \right\rangle ,\left| {{x_2}} \right\rangle ,\cdots,\left| {{x_n}} \right\rangle $ ,并将其输出给下一层的每一个节点。该层第$ j $ 个节点的第$k$ 个输出为:$$ o_{{\text{L}}{{\text{q}}_2}}^{jk}:\left| {{x_j}} \right\rangle = \cos {t_j}\left| 0 \right\rangle + \sin {t_j}\left| 1 \right\rangle $$ (17) ${{{\rm{L}}}}{{\text{q}}_3}$ (量子部分−量子神经元层):在这一层中有$ r $ 个节点。第$ j $ 个节点的第$k$ 个输入为:$$ \mu _{{\text{L}}{{\text{q}}_3}}^{jk}{\text{ = }}\left| {{x_j}} \right\rangle = \cos {t_j}\left| 0 \right\rangle + \sin {t_j}\left| 1 \right\rangle $$ (18) 式中,
$ j = 1,2,{\text{ }}\cdots,n $ ,$ k = 1,2,{\text{ }}\cdots,r $ 。该层中的节点实现神经网络中神经元的功能,节点的每一个$ \mu _{{\text{L}}{{\text{q}}_3}}^{jk} $ 都对应着一个以随机值为初值的角度$ {\theta _{jk}} $ ,它们会在模型学习时被训练更新。对于第$ k $ 个节点(注意此处用$ k $ 而不是用$ j $ 作为节点下标),使用式(2)中提到的量子门和$ {\theta _{jk}} $ 对其输入的所有量子比特进行旋转,并根据式(4)得到新的量子比特$ \left| {{a_k}} \right\rangle $ ,并将其作为该节点的输出:$$ {\varphi _k} = \arctan \left( {\frac{{\displaystyle\sum\limits_{j = 1}^n {\sin ({t_j} + {\theta _{jk}})} }}{{\displaystyle\sum\limits_{j = 1}^n {\cos ({t_j} + {\theta _{jk}})} }}} \right) $$ (19) $$ o_{{\text{L}}{{\text{q}}_3}}^k:\left| {{a_k}} \right\rangle = \cos {\varphi _k}\left| 0 \right\rangle + \sin {\varphi _k}\left| 1 \right\rangle $$ (20) 式中,
$ k = 1,2,{\text{ }}\cdots,r $ 。${{{L}}_2}$ (量子模糊层):在这一层中,第$ j $ 个节点接受${\text{L}}{{\text{f}}_4}$ 和$ {\text{L}}{{\text{q}}_3} $ 的输出作为其两个输入:$$ \mu _{{{\text{L}}_2}}^{j1} = o_{{\text{L}}{{\text{f}}_3}}^j = {\bar w_j} $$ (21) $$ \mu _{{{\text{L}}_2}}^{j2} = o_{{\text{L}}{{\text{q}}_3}}^j = \left| {{a_j}} \right\rangle = \cos {\varphi _j}\left| 0 \right\rangle + \sin {\varphi _j}\left| 1 \right\rangle $$ (22) 式中,
$ j = 1,2,{\text{ }}\cdots,r $ 。再将$ {\bar w_j} $ 作为角度使用式(2)中提到的量子门作用到$ \left| {{a_j}} \right\rangle $ 上,得到新的量子比特$ \left| {{b_j}} \right\rangle $ ,并将其作为输出:$$ o_{{{\text{L}}_2}}^j:\left| {{b_j}} \right\rangle = \cos {\psi _j}\left| 0 \right\rangle + \sin {\psi _j}\left| 1 \right\rangle $$ (23) 式中,
$ {\psi _j} $ =$ {\varphi _j} $ +$ {\bar w_j} $ ,$ j = 1,2,{\text{ }}\cdots,r $ 。总之,这一层按照模糊部分输出的角度值来对量子部分输出的量子比特进行旋转,得到新的量子比特。${{{L}}_3}$ (输出层):这一层是整个模型的输出层。将上一层输出的所有量子比特按照式(4)的方式融合得到新的量子比特$ \left| y \right\rangle $ :$$ \gamma = \arctan \left( {\frac{{\displaystyle\sum\limits_{j = 1}^r {\sin {\psi _j}} }}{{\displaystyle\sum\limits_{j = 1}^r {\cos {\psi _j}} }}} \right) $$ (24) $$ \left| y \right\rangle = \cos \gamma \left| 0 \right\rangle + \sin \gamma \left| 1 \right\rangle $$ (25) 最后,取对
$ \left| y \right\rangle $ 测量得到$ \left| 1 \right\rangle $ 的概率作为整个模型的输出:$$ y = {\sin ^2}\gamma $$ (26) -
在ANQFIS模型中,有一些参数需要在模型训练学习中被更新优化,它们分别是
$ {\text{L}}{{\text{q}}_3} $ 中的$ {\theta _{jk}} $ ($ j = 1,2,{\text{ }}\cdots,n $ ,$ k = 1,2,{\text{ }}\cdots,r $ )以及${{{\rm{L}}}}{{\text{f}}_2}$ 中的$ {c_j} $ ,$ {\sigma _j} $ ($ j = 1,2,{\text{ }}\cdots, nr $ )。模型的损失函数定义为:$$ L = \frac{1}{2}{\left( {y - \hat y} \right)^2} $$ (27) 式中,
$ y $ 是模型的真实输出;$ \hat y $ 是标签(0或1)。为了能够正确的表示节点,令$ J = j\% r $ ,便可得到这些参数对损失函数的梯度为:$$ {\nabla _{{\theta _{jk}}}}{\text{ = }}\frac{{\partial L}}{{\partial {\theta _{jk}}}} = \frac{{\partial L}}{{\partial y}}\frac{{\partial y}}{{\partial \gamma }}\frac{{\partial \gamma }}{{\partial{\psi _k}}}\frac{{\partial {\psi _k}}}{{\partial {\varphi _k}}}\frac{{\partial {\varphi _k}}}{{\partial {\theta _{jk}}}} $$ (28) $$ {\nabla _{{c_j}}} = \frac{{\partial L}}{{\partial {c_j}}} = \frac{{\partial L}}{{\partial y}}\frac{{\partial y}}{{\partial \gamma }}\frac{{\partial \gamma }}{{\partial {\psi _J}}}\frac{{\partial {\psi _J}}}{{\partial {{\bar w}_j}}}\frac{{\partial {{\bar w}_J}}}{{\partial {w_J}}}\frac{{\partial {w_J}}}{{\partial {g_j}}}\frac{{\partial {g_j}}}{{\partial {c_j}}} $$ (29) $$ {\nabla _{{\sigma _j}}} = \frac{{\partial L}}{{\partial {\sigma _j}}} = \frac{{\partial L}}{{\partial y}}\frac{{\partial y}}{{\partial \gamma }}\frac{{\partial \gamma }}{{\partial {\psi _J}}}\frac{{\partial {\psi _J}}}{{\partial {{\bar w}_J}}}\frac{{\partial {{\bar w}_J}}}{{\partial {w_J}}}\frac{{\partial {w_J}}}{{\partial {g_j}}}\frac{{\partial {g_j}}}{{\partial {\sigma _j}}} $$ (30) 定义变量:
$$ {\nabla _0}{\text{ = 2}}\left( {y - \hat y} \right)\sin \gamma \cos \gamma $$ (31) $$ {\nabla _{{\theta _{jk}}1}} = \frac{{\cos {\psi _k}{\rm{T}}{{\rm{c}}_0} + \sin {\psi _k}{\rm{T}}{{\rm{s}}_0}}}{{{\rm{T}}{{\rm{s}}_0}^2 + {\rm{T}}{{\rm{c}}_0}^2}} $$ (32) 式中,
${\rm{T}}{{\rm{s}}_0} = \displaystyle\sum\limits_{i = 1}^r {\sin {\psi _i}}$ ,${\rm{T}}{{\rm{c}}_0} = \displaystyle\sum\limits_{i = 1}^r {\cos {\psi _i}}$ $$ {\nabla _{{\theta _{jk}}2}} = \frac{{\cos ({t_j} + {\theta _{jk}}){\rm{T}}{{\rm{c}}_1} + \sin ({t_j} + {\theta _{jk}})\sin {\psi _k}{\rm{T}}{{\rm{s}}_1}}}{{({\rm{T}}{{\rm{s}}_1}^2 + {\rm{T}}{{\rm{c}}_1}^2)}} $$ (33) 式中,
${\rm{T}}{{\rm{s}}_1} = \displaystyle\sum\limits_{i = 1}^n {\sin ({t_i} + {\theta _{ik}})}$ ,${\rm{T}}{{\rm{c}}_1} = \displaystyle\sum\limits_{i = 1}^n {\cos ({t_i} + {\theta _{ik}})}$ 。$$ {\nabla _1} = \frac{{\cos {\psi _J}{\rm{T}}{{\rm{c}}_0} + \sin {\psi _J}{\rm{T}}{{\rm{s}}_0}}}{{{\rm{T}}{{\rm{s}}_0}^2 + {\rm{T}}{{\rm{c}}_0}^2}} $$ (34) $$ {\nabla _2} = 2{\text{π}} \frac{{{\rm{Tw}} - {w_J}}}{{{\rm{T}}{{\rm{w}}^2}}} $$ (35) 式中,
${\rm{Tw}} = \displaystyle\sum\limits_{i = 1}^r {{w_i}}$ 。$$ {\nabla _3} = \dfrac{{\displaystyle\prod\limits_{i = 0}^{i = n - 1} {{g}_{_{J =ir}} }}}{{{g_j}}} $$ (36) $$ {\nabla _{{c_j}1}} = \exp \left[ {\left. { - \frac{1}{2}{{\left( {\left. {\frac{{\mu _{{\text{L}}{{\text{f}}_2}}^j - {c_j}}}{{{\sigma _j}}}} \right)} \right.}^2}} \right]} \right.\frac{{\mu _{{\text{L}}{{\text{f}}_2}}^j - {c_j}}}{{{\sigma _j}^2}} $$ (37) $$ {\nabla _{{o_j}1}} = - \exp \left[ {\left. { - \frac{1}{2}{{\left( {\left. {\frac{{\mu _{{\text{L}}{{\text{f}}_2}}^j - {c_j}}}{{{\sigma _j}}}} \right)} \right.}^2}} \right]} \right.\frac{{{{\left( {\mu _{{\text{L}}{{\text{f}}_2}}^j - {c_j}} \right)}^2}}}{{{\sigma _j}^3}} $$ (38) 那么根据链式求导法则可得这些参数的梯度的准确值:
$$ {\nabla _{{\theta _{jk}}}}{\text{ = }}{\nabla _0}{\nabla _{{\theta _{jk}}1}}{\nabla _{{\theta _{jk}}2}} $$ (39) $$ {\nabla _{{c_j}}}{\text{ = }}{\nabla _0}{\nabla _1}{\nabla _2}{\nabla _3}{\nabla _{{c_j}1}} $$ (40) $$ {\nabla _{{o_j}}}{\text{ = }}{\nabla _0}{\nabla _1}{\nabla _2}{\nabla _3}{\nabla _{{o_j}1}} $$ (41) 在模型训练时,只需要按照下面的方式更新这些参数,即可优化模型:
$$ {\theta _{jk}}(t + 1) = {\theta _{jk}}(t) - \eta {\nabla _{{\theta _{jk}}}} $$ (42) $$ {c_j}(t + 1) = {c_j}(t) - \eta {\nabla _{{c_j}}} $$ (43) $$ {\sigma _j}(t + 1) = {\sigma _j}(t) - \eta {\nabla _{{\sigma _j}}} $$ (44) 式中, t是指当前训练轮数,t+1则是下一个训练轮数;
$ \eta $ 是学习率,其决定了模型训练的每一步的步长,在模型训练一开始时被定义为一个固定值。 -
由于ANQFS执行时需要大量的量子比特对高维数据进行编码,而目前网络量子云平台所提供的量子设备是难以实现的,因此本文采用Pennylane[16]仿真框架构建了ANQFIS模型来验证其学习算法的正确性,并且对ANQFIS、ANFIS和QBP的输出准确率和鲁棒性进行了分析和比较。由于仿真模型是使用经典计算机来模拟量子计算机,并不能体现出真实量子设备的速度优越性,所以本文没有在实验中对比模型之间的时间消耗。
下面分别使用低维数据集和高维数据集来训练和验证模型,让其实现二分类功能。对于低维数据集,选择IRIS鸢尾花卉数据集(4维)中的所有0类和1类数据作为训练集与验证集,学习率
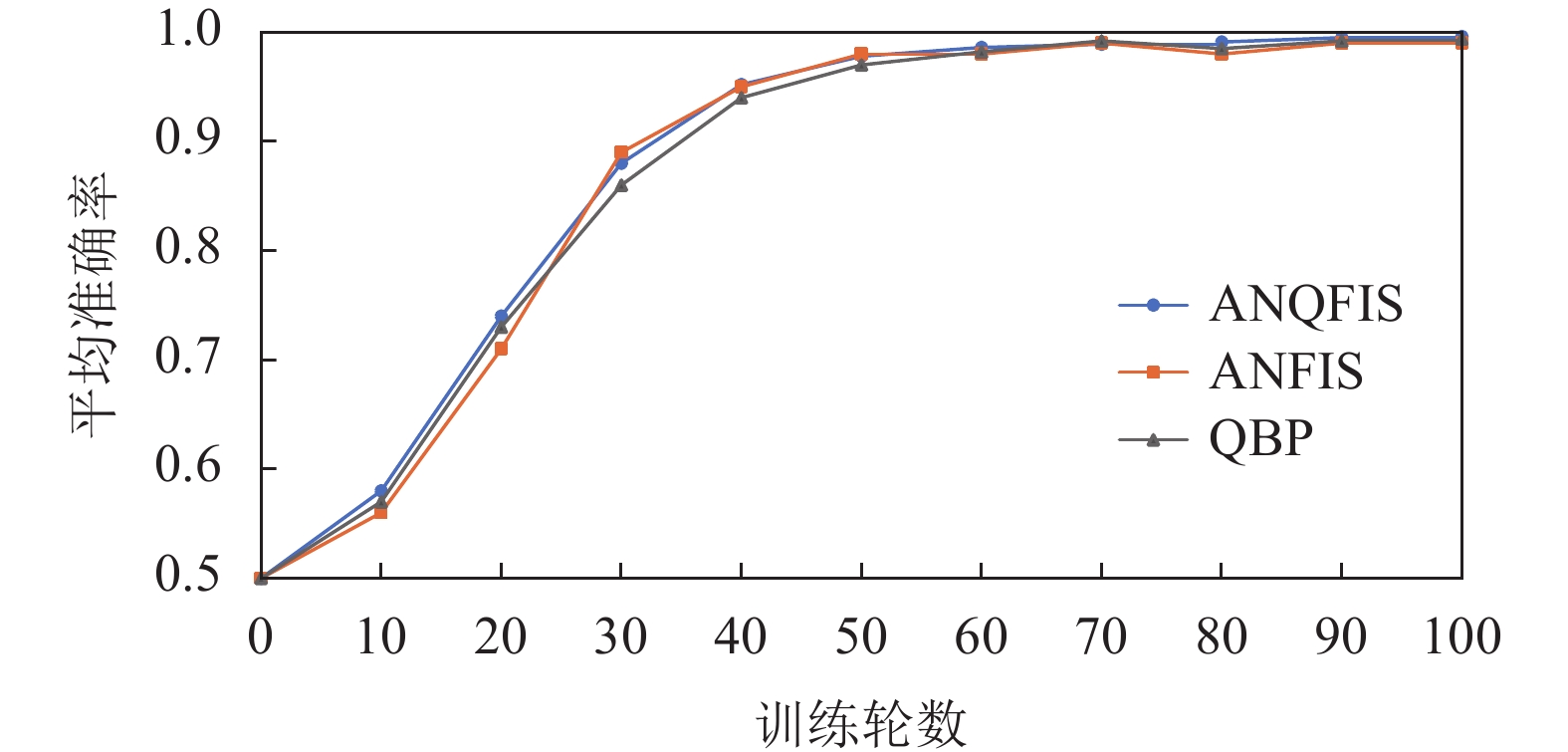
$ \eta $ 选择0.1。对ANQFIS、ANFIS、QBP模型设置同样的学习率进行训练,每次训练100轮,一共分别训练50次。每一次训练中,每当训练10轮之后,使用验证集来测试模型的准确率并记录结果。图3是通过对50次训练结果求平均值,从而得到模型的平均准确率与训练轮数之间的关系图。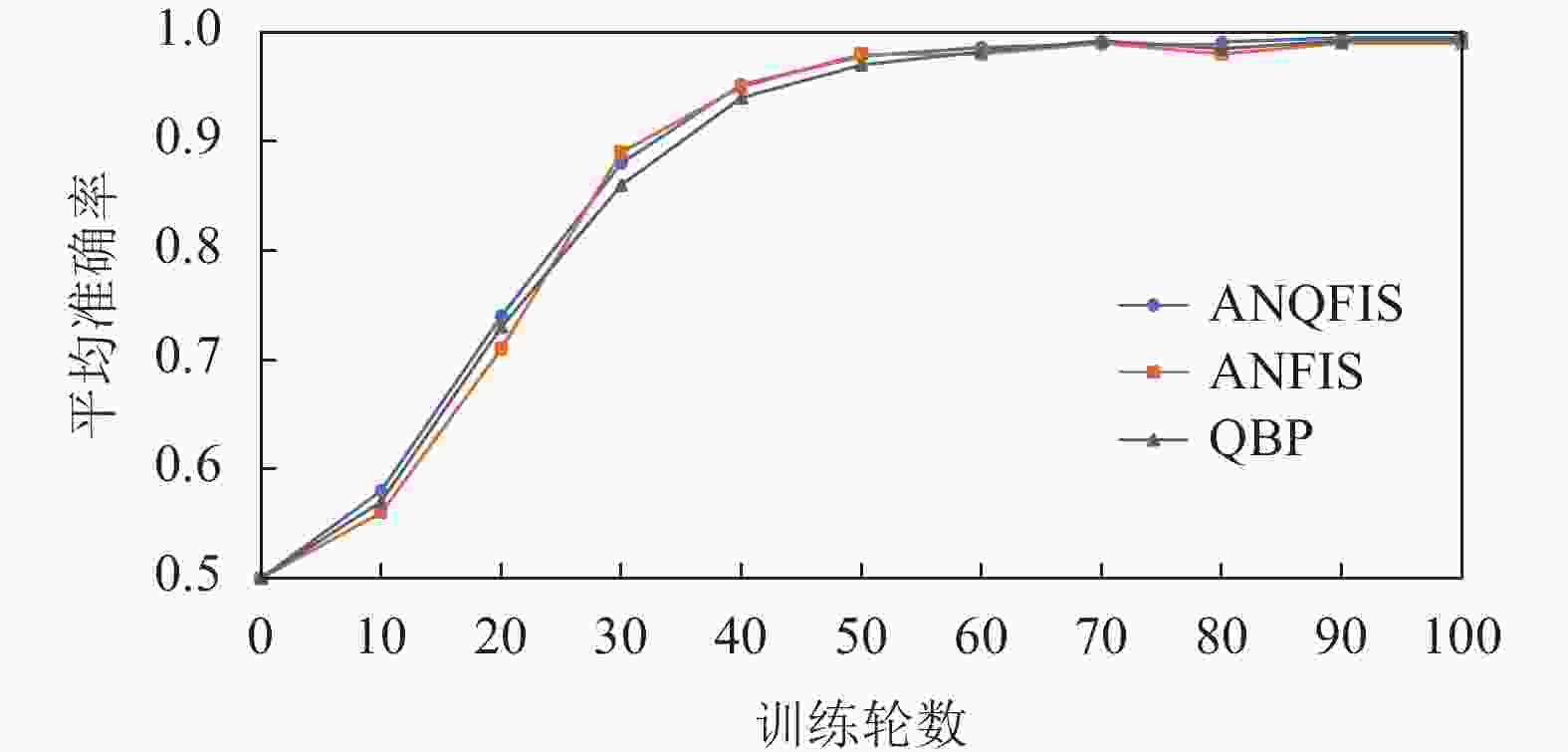
图 3 使用IRIS鸢尾花卉数据集时平均准确率与训练轮数的关系图
根据图3可以看出,在使用低维数据集作为训练集和验证集时,ANQFIS在准确率上并没有更优异的表现。下面采用高维数据集进行实验,选择MNIST手写数字数据集(784维)中的所有标签为0和1的数据作为高维数据集,对ANQFIS、ANFIS、QBP模型设置同样的学习率
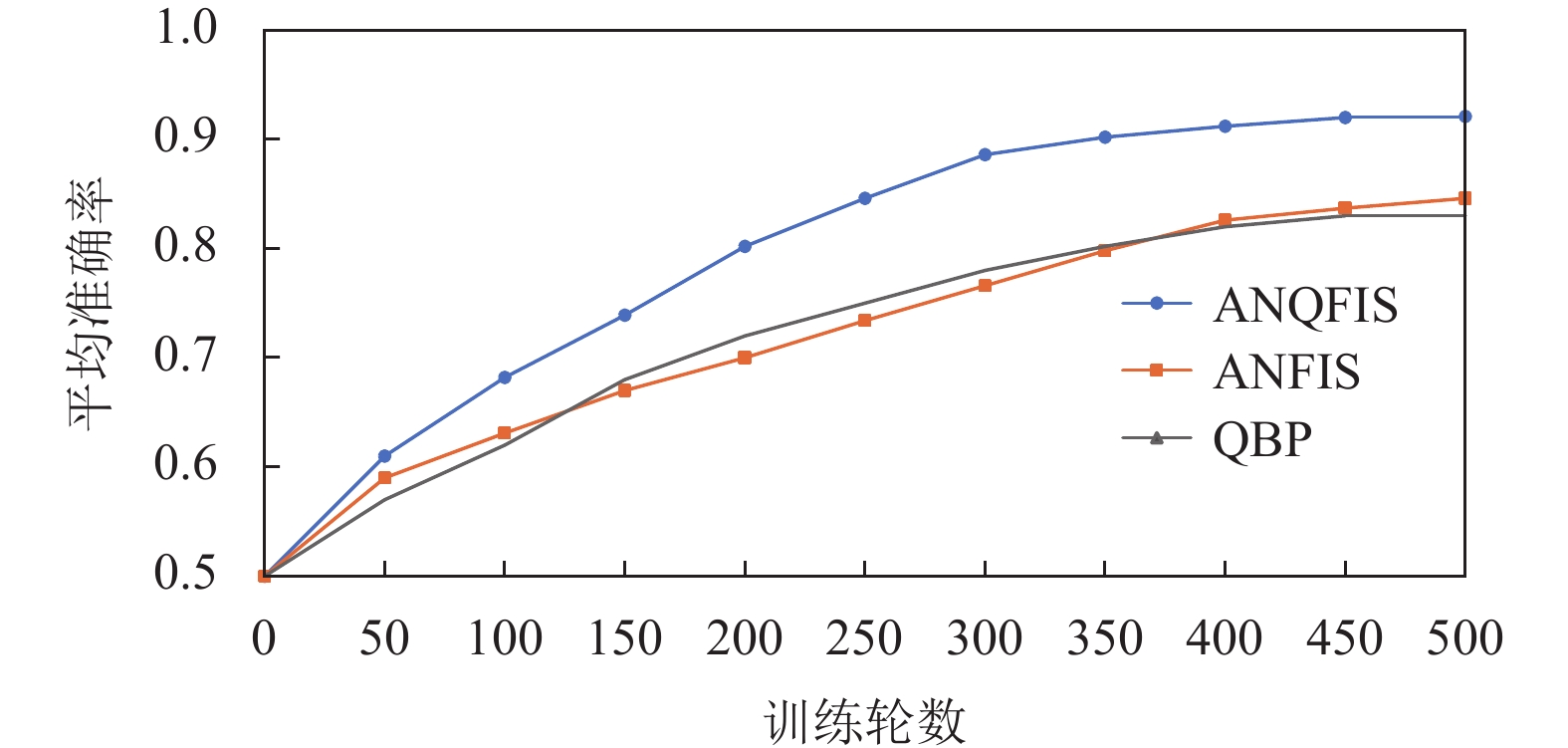
$ \eta {\text{ = }}0.1 $ 进行训练,每次训练500轮,一共分别训练50次。在一次训练中,每当训练50轮之后,使用验证集来测试模型准确率并记录结果。图4为通过对50次训练的结果求平均值,从而得到模型平均准确率与训练轮数之间的关系图。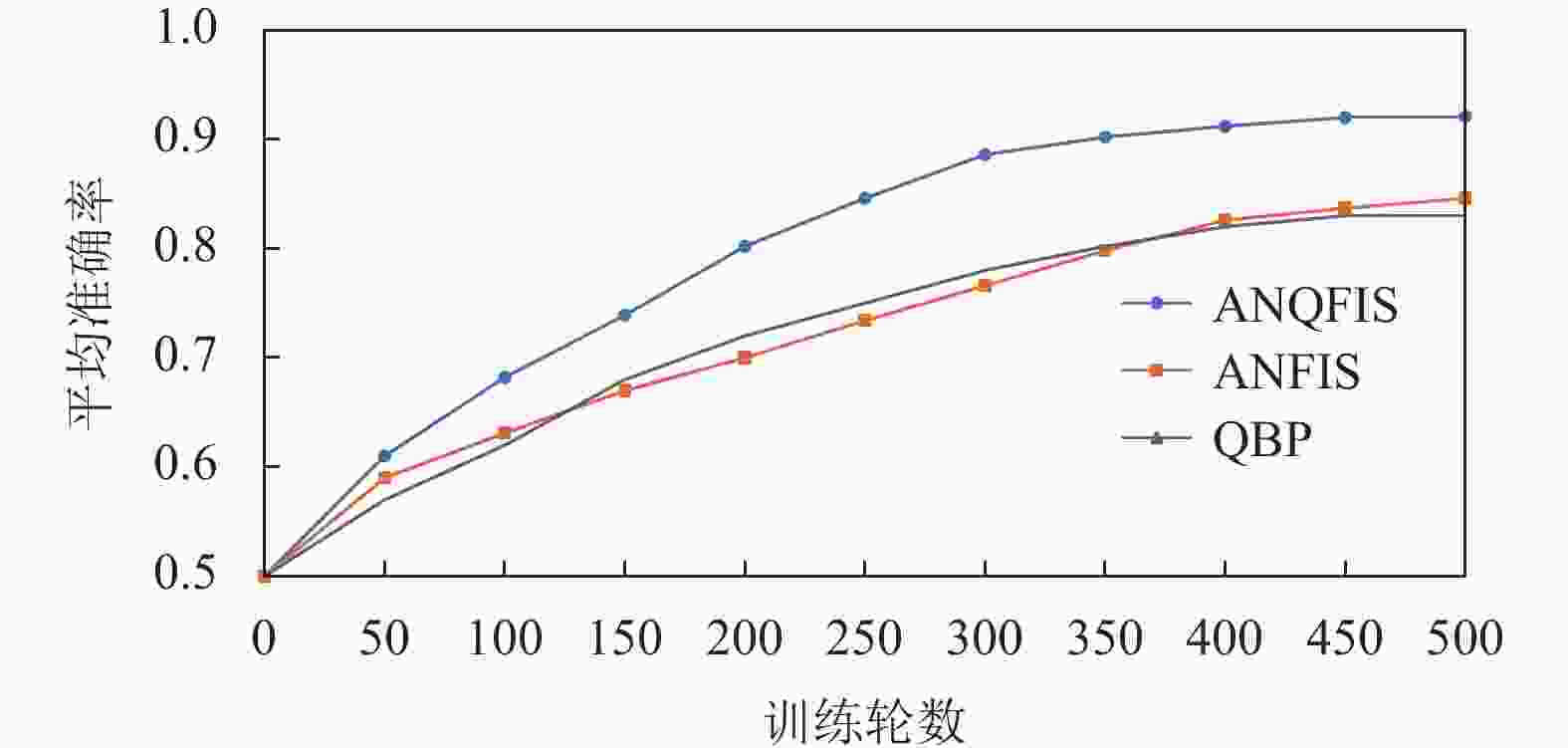
图 4 使用MNIST数据集时平均准确率与训练轮数的关系图
根据图4可以看出,在使用高维数据集作为训练集和验证集时,500轮之后,ANFIS和QBP的准确率基本稳定在85%左右,而ANQFIS的准确率稳定在92%左右,这说明ANQFIS在准确率上明显优于ANFIS和QBP。
为了测试ANQFIS模型的鲁棒性,使用FGSM攻击算法[17]分别对经过MNIST数据集500轮训练后的3种模型生成对抗样本来测试。FGSM算法首先求出模型损失函数相对于模型输入x的梯度
$ {\nabla _{{\boldsymbol{x}}}} $ ,对其取符号,再定义一个扰动系数δ,便可得到一个扰动值,最后将此扰动添加到合法样本上,便可得到对抗样本$ {{\boldsymbol{x}}}' $ :$$ {{\boldsymbol{x}}}' = {{\boldsymbol{x}}} + \delta {\rm{sign}}{\nabla _{{\boldsymbol{x}}}} $$ (45) 通过调整扰动系数δ,便可以调整对抗样本的对抗性强弱。在MNIST数据集中选取一个标签为0的数据,如图5a所示,且ANQFIS、ANFIS、QBP都能对其准确分类。再设置δ=0,使其每次增加0.1,并生成相应的对抗样本,然后输入3个模型,直到模型对其错误分类,此时δ的值称之为该模型对该样本的“扰动系数阈值”,此时的对抗样本称为“阈值样本”。ANQFIS、ANFIS、QBP的阈值样本分别如图5b、5c、5d所示。

图 5 阈值样本对比图
图5a为合法样本,图5b为ANQFIS的阈值样本,扰动系数阈值为2.61,图5c为ANFIS的阈值样本,扰动系数阈值为1.89,图5d为QBP的阈值样本,扰动系数阈值为1.75。可看出,仅对这一个样本而言,ANQFIS的扰动系数阈值更高,ANQFIS具有更高的鲁棒性。
为了使结果更有说服力,从MNIST数据集中分别选取了100个标签为0的数据和100个标签为1的数据,并且再引入一个FGM攻击算法[18-19]。此算法生成对抗样本的方式是:
$$ {{\boldsymbol{x}}}' = {{\boldsymbol{x}}} + \delta { }{\nabla _{{\boldsymbol{x}}}} $$ (46) 在这两种攻击算法下,分别计算出这3个模型对这200个样本的扰动系数阈值。由于对于不同的样本而言,扰动系数阈值往往不在同一个数量级,因此将扰动系数阈值进行归一化处理,3个模型在两种攻击算法下对这200个合法样本的平均归一化扰动系数阈值如表1所示。
表 1 平均归一化扰动系数阈值
模型 FGSM攻击算法 FGM攻击算法 ANQFIS 0.418 0.395 ANFIS 0.301 0.311 QBP 0.281 0.294 根据表1可以看出,ANQFIS在鲁棒性上也明显优于ANFIS和QBP。
-
本文将ANFIS与QBP相结合,提出了一种基于自适应网络的量子模糊推理系统ANQFIS。经过仿真实验得出,该模型对于高维数据集在准确率方面明显优于ANFIS和QBP和鲁棒性。
Adaptive Network-Based Quantum Fuzzy Inference System
-
摘要: 基于ANFIS与量子BP神经网络(QBP)提出了一种基于自适应网络的量子模糊推理系统(ANQFIS)。不同于ANFIS,ANQFIS以量子门旋转的方式将模糊规则强度与QBP相结合,最后以量子态的测量概率作为输出,QBP的加入使得模型的输出准确率更高,且凭借量子计算的速度优越性提升了模型的计算速度。根据梯度下降法,给出了该系统中参数的学习算法。在仿真实验中,分别使用低维数据和高维数据作为数据集来训练模型,使用攻击算法生成对抗样本进行测试,结果表明ANQFIS在输出准确率、鲁棒性方面优于ANFIS与QBP。Abstract: In this paper, a quantum fuzzy inference system based on adaptive network (ANQFIS) is proposed based on ANFIS and quantum BP (QBP) neural network. Different from ANFIS, ANQFIS combines the strength of fuzzy rules with QBP in the way of quantum gate rotation, and finally takes the measurement probability of quantum states as the output. The addition of QBP makes the output accuracy of the model higher, and the calculation speed of the model is improved by virtue of the speed advantage of quantum computing. According to the gradient descent method, the parameters learning algorithm of the system is given. In the simulation experiment, low-dimensional data and high-dimensional data are used as data sets to train the model, and attack algorithms are used to generate adversarial examples for testing. The results show that ANQFIS is superior to ANFIS and QBP in output accuracy and robustness.
-
[1] ZADEH L A. Fuzzy sets[J]. Information and Control, 1965, 8(3): 338-353. doi: 10.1016/S0019-9958(65)90241-X [2] JORDAN M I, MITCHELL T M. Machine learning: Trends, perspectives, and prospects[J]. Science, 2015, 349(6245): 255-260. doi: 10.1126/science.aaa8415 [3] SCHMIDHUBER J. Deep learning in neural networks: An overview[J]. Neural Networks, 2015, 61: 85-117. doi: 10.1016/j.neunet.2014.09.003 [4] LEE H M, LU B H. Fuzzy BP: A neural network model with fuzzy inference[C]//Proceedings of 1994 IEEE International Conference on Neural Networks. Orlando: IEEE, 1994: 1583-1588. [5] JANG R J S. ANFIS: Adaptive-Network-Based fuzzy inference system[J]. IEEE Transactions on Systems Man & Cybernetics, 1993, 37(4): 446-461. [6] HARROW A W, HASSIDIM A, LLOYD S. Quantum algorithm for linear systems of equations[J]. Physical Review Letters, 2009, 103(15): 150502. doi: 10.1103/PhysRevLett.103.150502 [7] DAS S S, DENG D L, DUAN L M. Machine learning meets quantum physics[J]. Physics Today, 2019, 72(3): 48-54. doi: 10.1063/PT.3.4164 [8] BIAMONTE J, WITTEK P, PANCOTTI N, et al. Quantum machine learning[J]. Nature, 2017, 549(7671): 195-202. doi: 10.1038/nature23474 [9] REBENTROST P, MOHSENI M, LLOYD S. Quantum support vector machine for big data classification[J]. Physical Review Letters, 2014, 113(13): 130503. doi: 10.1103/PhysRevLett.113.130503 [10] CONG I, DUAN L. Quantum discriminant analysis for dimensionality reduction and classification[J]. New Journal of Physics, 2016, 18(7): 073011. doi: 10.1088/1367-2630/18/7/073011 [11] LI P C, LI S Y. Learning algorithm and application of quantum BP neural networks based on universal quantum gates[J]. Journal of Systems Engineering and Electronics, 2008, 19(1): 167-174. doi: 10.1016/S1004-4132(08)60063-8 [12] BENEDETTI M, LLOYD E, SACK S, et al. Parameterized quantum circuits as machine learning models[J]. Quantum Science and Technology, 2019, 4(4): 019601. [13] CONG I, CHOI S, LUKIN M D. Quantum convolutional neural networks[J]. Nature Physics, 2019, 15(12): 1273-1278. doi: 10.1038/s41567-019-0648-8 [14] DALLAIRE-DEMERS P L, KILLORAN N. Quantum generative adversarial networks[J]. Physical Review A, 2018, 98(1): 012324. doi: 10.1103/PhysRevA.98.012324 [15] CHEN C H, LIN C J, LIN C T. An efficient quantum neuro-fuzzy classifier based on fuzzy entropy and compensatory operation[J]. Soft Computing, 2008, 12(6): 567-583. doi: 10.1007/s00500-007-0229-0 [16] MIAO F Y, XIONG Y, CHEN H H, et al. A fuzzy quantum neural network and its application in pattern recognition[J]. Chinese Journal of Electronics, 2005, 14(3): 524-528. [17] VILLE B. A open-source software framework for quantum machine learning[EB/OL]. [2021-10-11]. https://github.com/PennyLaneAI/pennylane. [18] GOODFELLOW I, SHLENS J, SZEGEDY C, et al. Explaining and harnessing adversarial examples[EB/OL]. [2021-10-15]. https://arxiv.org/abs/1412.6572v1. [19] MIYATO T, DAI A M, GOODFELLOW I. Adversarial training methods for semi-supervised text classification[EB/OL]. [2021-12-11]. https://arxiv.org/abs/1605.07725v2. -

 点击查看大图
点击查看大图
图(5) / 表(1)
计量
- 文章访问数: 3797
- HTML全文浏览量: 1020
- PDF下载量: 69
- 被引次数: 0











































































































































































































