 ISSN
ISSN 










-
信号识别是智能接收机的首要任务,是无线通信系统中不可或缺的一部分。它在民用和军用应用中有着广泛的应用,如认知无线电、动态频谱访问和信号检测 [1-4]。
近年来,由于特征提取已成为信号识别中的一项关键技术,因此它是信号识别的主流研究方向。许多手工特征是根据统计特征和星座图设计的。在文献[5]中,分析了信号参数在时域、频域和空间域的分布信息,提取了功率谱和信噪比(SNR)等特征信息,这些特征信息被用作分类的依据。文献[6]提出了一种基于星座图的识别算法,使用减法聚类算法找到星座图的中心点,然后利用中心点与星座图的映射关系找到调制类型。
与传统的手工特征提取方法相比,深度学习可以从包含多种类型的接收信号中提取更多的判别特征[7-11]。 文献[7]首次在调制分类领域引入了深度学习模型,从而开启了调制分类领域的新纪元。 文献[8]提出了一种用于深度学习的调制和分类数据增强,它从对数据本身的处理来提高分类精度,或者在较小的训练集下获得相同的分类效果。文献[9]将深度神经网络应用于无线电调制识别任务,得出无线电调制识别不受网络深度限制的结论。文献[10]提出了一种识别发射器的方法,该方法使用卷积神经网络仅使用接收到的原始IQ数据作为输入来估计每个发射器的同相正交不平衡参数。文献[11]提出了一种基于端到端卷积神经网络(CNN)的调制样式识别(CNN-AMC)算法,该算法自动提取长比特率观测序列的特征和估计的SNR。
尽管基于监督学习的信号识别已经取得了不错的结果,但它的成功归功于于大规模标注良好的数据集。在现实中,信号识别任务数据标记成本高昂。为了应对这一挑战,半监督学习(SSL)[12]引起了研究人员的关注,文献[13]的结果表明 SSL具有实现与监督学习相同的性能的潜力。受SSL的启发,SSL已成为处理标记数据太少的主要工具,研究人员将半监督学习方法与信号识别相结合。例如,文献[14]提出了一种名为 SSRCNN 的半监督方法,它充分利用未标记的数据来辅助深度学习模型的训练。在文献[15]中,提出了具有特征匹配的半监督SSACG-FM。文献[16]指出了具有稀疏表示的聚合自动编码器结构ConvAE,但由于自编码器结构上的缺陷,会导致信息的丢失,因此其性能上限较低。此外上述半监督方法均未考虑如何降低噪声的影响。
因此本文提出了一种用于缓解噪声影响的半监督信号识别框架(SSCNN),本文选用了特征学习性能更为优良的深度残差网络(Resnet)作为编码器,以获得特征向量;使用梯度逆转层(GRL)[17]来改善噪声对性能的影响;精心设计了新的损失函数来优化网络,能够有效提升性能。
-
系统模型的框架如图1所示,其中
$ {L_{ \times \times }} $ 为损失函数,$ {\theta _ \times } $ 为各部分的训练参数。该模型由三部分组成:特征提取器、标签分类器(黄色)和鉴别器(橙色)。 特征提取器由 Resnet 组成,它具有出色的特征提取性能,可以轻松避免网络过深带来的诸多问题。 鉴别器由一个梯度反转层和三个全连接层组成,该层用于在反向传播时使判别损失变为负值。 标签分类器由多层全连接层构成。
图 1 SSCNN 模型架构
-
卷积神经网络(CNNs)是深度学习的关键技术。 CNNs可以提取特征信息,特征的层次会随着网络深度的加深而增加。因此,网络层的深度是影响网络性能的关键因素。通常,更高层次的特征更具区分性。为了在本文的工作中获得更好的性能,有必要提取更具有判别性的高层次的特征。然而,网络深度是导致梯度消失、梯度爆炸和退化问题的原因,梯度消失导致网络无法从训练数据中获取更新,梯度爆炸导致网络不稳定,网络退化是增加网络层数反而会导致准确率降低的现象。因此太深的网络会成为影响网络性能的障碍。
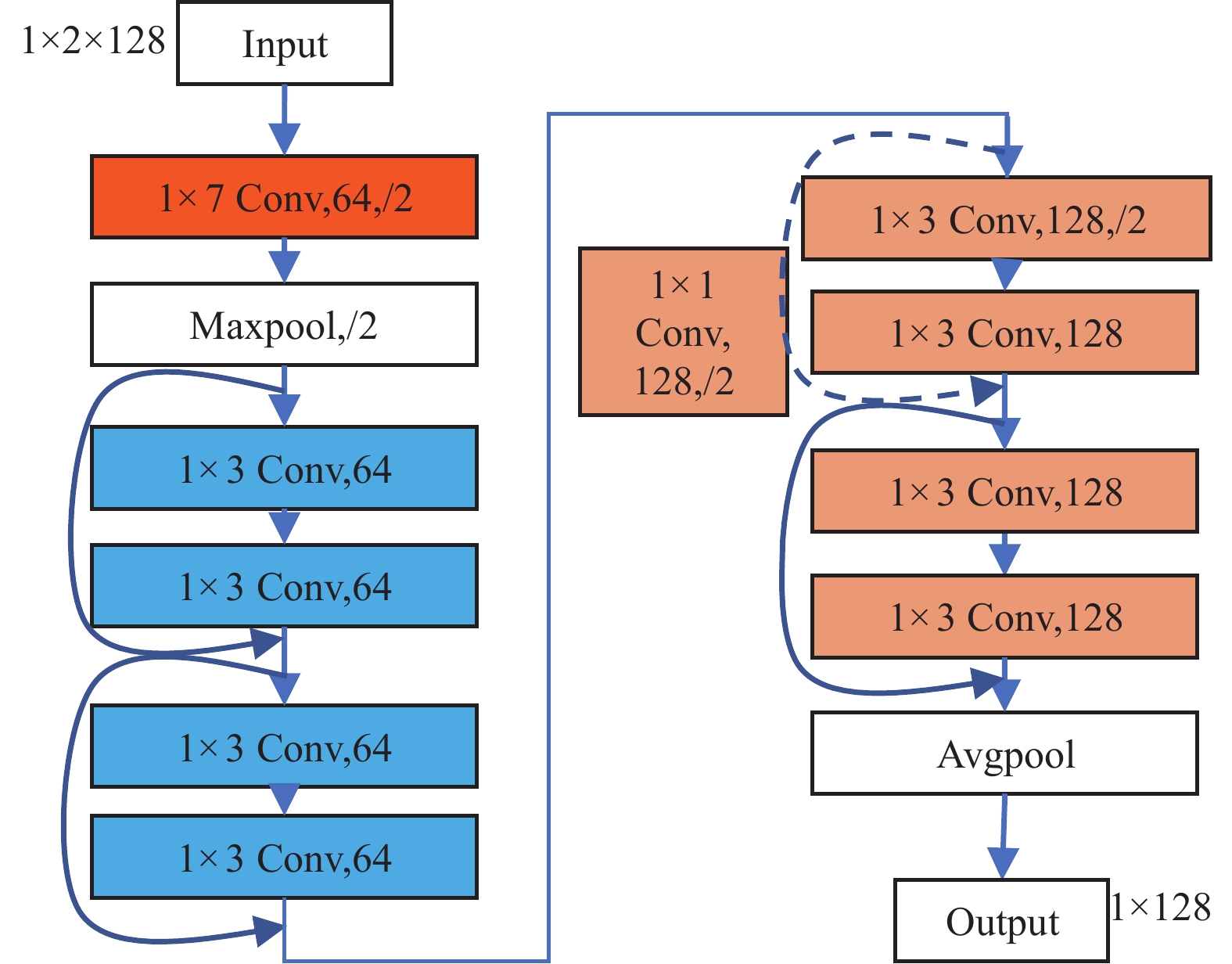
Resnet可以在一定程度上解决这个问题。 Resnet的主要原理是保留前一个网络层的输出,让输入数据直接传递到后一个网络层。所以下一层的神经网络不需要学习整个输出,只需要学习前一个网络输出的残差。通过这种方式保护了信息的完整性,简化了训练的难度,特征提取器的网络结构如下图2所示。

图 2 特征提取器的网络结构
特征提取器提取标记样本、未标记样本和噪声样本的特征,Resnet的输入大小为
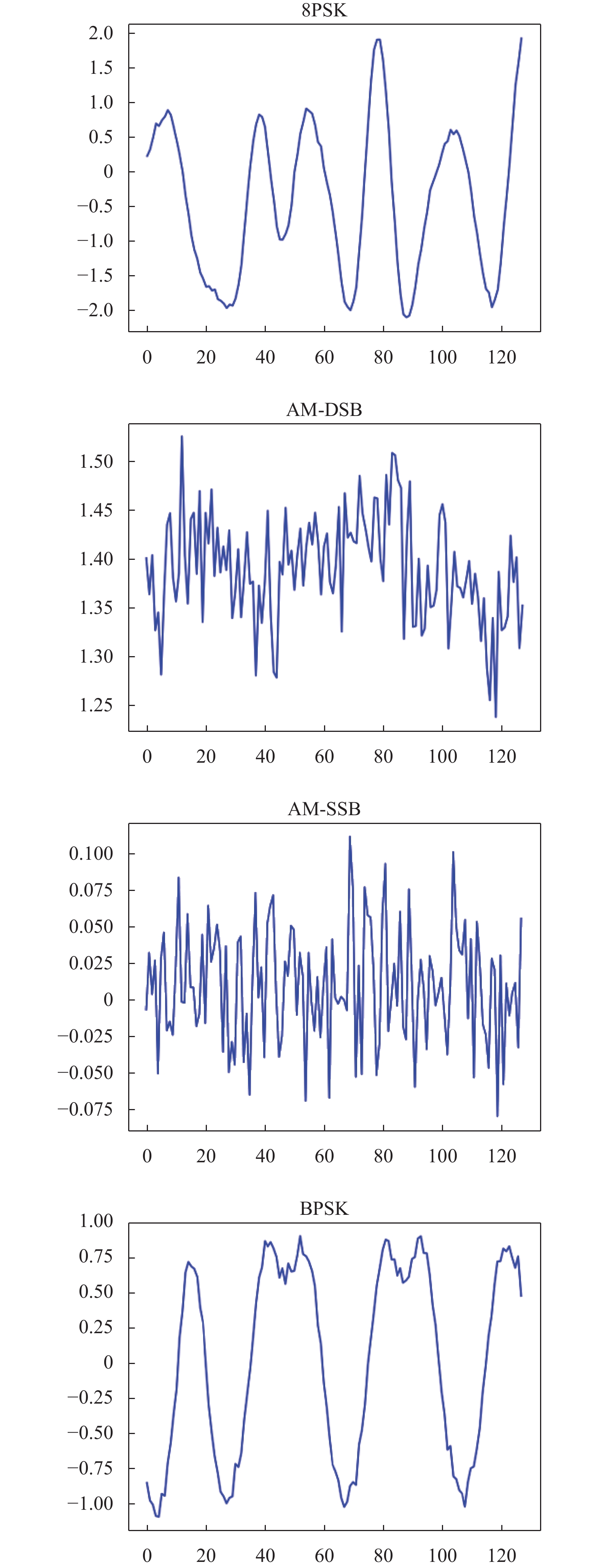
$ 1 \times 2 \times 128 $ ,输出大小为$ 1 \times 128 $ ,输入信号的部分波形图如下图所示,不同调制样式的信号波形图不尽相同。
图 3 输入信号原始波形
完成特征提取后输出特征的T-sne空间分布图,如下图所示。
特征提取器学习到的特征,其本质上是对输入样本的一种高维描述,本文中输入特征提取器的各类样本均为同相正交(I/Q)数据,它使用I路和Q路来描述信号样本,而本文中的特征提取器输出的特征则是一个128维的向量,希望使用这一高维特征向量来拟合输入样本。因此本文中特征提取器的输入样本是
$ 1 \times 2 \times 128 $ 的IQ波形,输出128维的特征向量。 -
本文中从特征判断样本调制类型的任务是在标签分类器中完成的,它由全连接层组成,其结构参数如下表所示,其中dim即是指调制样式的类别数,不同数据集中的类别数有所不同。在训练阶段,利用标签和损失函数训练标签分类器和特征提取器,在测试阶段由它获得预测调制样式类型。
具体的,其输入为特征提取器学习到的样本特征向量,输出为样本预测类别向量。从表中可以看出标签分类器的最后一层为softmax函数层,通过此层后就可得到在不同类别的分类概率,其中概率最大位置的索引即是样本的预测类别。
表 1 标签分类器网络结构
层名 输入维度 输出维度 Fc1 128 64 标签
分类器批归一化 Fc2 64 dim softmax -
鉴别器是模型的主要创新点之一,它由梯度逆转层和两个全连接层组成。 它的输入是未标记样本的特征和对应的未标记带噪声样本的特征,输出是对是否带噪声的判别。其网络结构如下表2所示。
表 2 鉴别器网络结构
层名 输入维度 输出维度 梯度逆转层 128 128 鉴别器 Fc3 128 64 批归一化 Fc4 64 2 softmax GRL在梯度回传时完成梯度反转,GRL是一种用于模拟对抗的结构。 GRL 的数学表达式如(1)和(2)所示。在前向传播中,梯度反转层的输入和输出是相同的。在反向传播中,将负系数与原始梯度的乘积作为反向传播梯度,完成梯度反转。
$$ R(x) = x $$ (1) $$ \frac{{d(R(x))}}{{dx}} = - \lambda {\boldsymbol{I}} $$ (2) 式中,
$ {\boldsymbol{I}} $ 是一个单位矩阵,GRL使网络在反向传播过程中自动反转梯度方向,在前向传播过程中实现单位转换。因此,在反向传播的过程中,损失函数的梯度在传播回特征提取器的参数之前会自动反转,从而达到类似于生成对抗网络(GAN)的对抗过程。同时,由于参数的同时更新,避免了GAN的两阶段训练过程。GRL 是一种通用方法。在本文中,通过人为的加噪获得未标记噪声样本,因此未标记噪声样本和未标记样本是否加噪的标签是可以得到,使用有标签的训练方式后,鉴别器很容易将它们分开。然而,在梯度回传的时候,GRL可以反转梯度,减少未标记噪声样本和未标记样本通过特征提取器产生的特征向量之间的差异,使得鉴别器无法区分二者之间的差异。最终,它提高了特征提取器对噪声的适应能力。
-
SSCNN的损失函数分为三部分:中心损失、分类损失和鉴别损失。 中心损失作用于特征提取网络的特征,致力于优化特征提取网络。 分类损失作用于分类结果,致力于优化分类网络和特征提取网络。 判别损失作用于判别结果,优化特征提取网络和判别网络。
-
为了优化特征提取器习得的特征向量,使它们在同类之间保持良好的一致性、细化特征使其更加的紧密。本文利用中心损失和标签样本来实现这一目标。
记标记样本数量为
$ {N_l} $ ,特征提取网络输入的第$ i \in \left\{ {1,\cdots,{N_l}} \right\} $ 个标记样本为$ {l_i} $ ,输出的特征为$ {f_i} $ ,则中心损失$ {L_{ct}} $ 的计算公式如下:$$ {L_{ct}} = \frac{1}{2}\sum\limits_{i = 1}^{{N_l}} {\left\| {{f_i} - {c_j}} \right\|_2^2} $$ (3) 式中,
$ {c_j} $ 是类别的语义中心,随类别$ j $ 对应特征的变化而变化,$ K $ 是样本类别数, 表示$ {\Vert \cdot \Vert }_{2} $ 向量2范数。语义中心是对每个类的语义特征向量取平均值得到的,当迭代训练时,某一类的语义特征向量发生变化,语义中心也应该得到更新,理想状态下应考虑整个训练集,但是实际中受限于硬件的能力,只能对每个batch的语义中心向量进行更新和校正。因此本文语义中心的更新方法如下所示:
$$ {c_j} \leftarrow {c_j} - \alpha {\Delta _{{c_j}}} $$ (4) 式中,
$ \alpha $ 是学习率;$ {\Delta _{{c_j}}} $ 是批次语义中心变更量,在批次中有$ j $ 类样本的情况下,$ {\Delta _{{c_j}}} $ 的计算方法如下:$$ {\Delta _{{c_j}}} = \frac{{\displaystyle\sum\nolimits_{i = 1}^{{N_l}} {\delta ({y_i} = j)({c_j} - {f_i})} }}{{\displaystyle\sum\nolimits_{i = 1}^{{N_l}} {\delta ({y_i} = j)} }} $$ (5) 当
$ {y_i} = j $ 时$ \delta ({y_i} = j) $ 为1,否则为0。值得一提的是,中心损失只优化特征提取器。
-
虽然在中心损失中已经利用了标签样本,但是它并未直接作用于预测结果,它只是优化特征向量的一种方式,为了利用特征向量获得优异的分类结果以及高效的利用标签信号样本,本文利用标签样本设计了分类函数。
本文以交叉熵损失为基础构建分类损失函数,从而优化特征提取器和标签分类器。
记标记样本
$ {l_i} $ 的分类向量为$ F({l_i}) $ ,对应的样本类别为$ {y_i} $ ,那么$ {l_i} $ 的交叉熵损失为:$$ {L_{{l_i}}} = - \sum\limits_{j = 1}^K {y_i^j\log (F{{({l_i})}^j})} $$ (6) 式中,
$ {\cdot}^{j} $ 代表向量·的第j位元素。从而所有标记样本的交叉熵损失$ {L_l} $ 为:$$ {L_l} = - \frac{1}{{{N_l}}}\sum\limits_{j = 1}^{{N_l}} {{L_{{l_i}}}} $$ (7) 相对于标记样本,未标记样本没有确定的样本类别,无法直接计算交叉熵损失,因此需要给未标记样本一个伪标签作为它的样本类别。本文假设分类器的分类结果正确,即未标记样本对应的分类向量的最大值代表的类别为伪标签,那么的交叉熵损失为:
$$ {L_{{u_i}}} = - \sum\limits_{j = 1}^K {p_i^j\log (F{{({u_i})}^j})} $$ (8) 所有未标记样本的交叉熵损失为:
$$ {L_u} = \frac{1}{{{N_u}}}\sum\limits_{i = 1}^{{N_u}} {{L_{{u_i}}}} $$ (9) 其中为未标记样本的数量。所有样本的交叉熵损失为:
$$ {L_{ce}} = {L_l} + {\lambda _1}{L_u} $$ (10) 其中
$ {\lambda _1} $ 是未标记样本交叉熵损失的权重系数。由于在模型训练初期,分类器的分类准确度比较低,未知样本伪标签有较大概率是错误的,因此需要给未标记样本交叉熵损失较低的权重。随着模型训练轮次的增加,分类器能够取得较高的分类准确度,此时未标记样本的伪标签的准确率较高,因此可以给未标记样本交叉熵损失较高的权重。 -
为了提高模型对噪声的适应能力,本文设计了鉴别器和鉴别损失。通过鉴别器的去噪操作,降低SSCNN对噪声的敏感性。
鉴别网络输入未标记样本特征和与之对应的加噪样本特征,输出鉴别类别。对于未标记样本,设定鉴别标签为0,相对的,对加噪的未标记样本,设定鉴别标签为1。同样的鉴别器也使用交叉熵损失,因此鉴别损失:
$$ {L_D} = \frac{1}{{{N_u}}}\sum\limits_{i = 1}^{{N_u}} {({L_f} + {L_n})} $$ (11) $$ {L_f} = - \frac{1}{2}\sum\limits_{i = 1}^2 {d_{{f_i}}^j\log (D{{({f_i})}^j})} $$ (12) $$ {L_n} = - \frac{1}{2}\sum\limits_{i = 1}^2 {d_{{n_i}}^j\log (D{{({n_i})}^j})} $$ (13) 由于梯度逆转层的存在,鉴别损失在鉴别网络中的两个全连接层中反向传播时为正数,因此会降低鉴别器鉴别错误的概率;而在经过梯度逆转层后,鉴别损失变为负数,会增加特征提取网络生成更小差异的未标记样本特征和加噪样本特征的能力,从而增加网络稳定性和在低信噪比下的分类准确率。
综上所述,本模型总体损失函数
$ L $ 由中心损失$ {L_{ct}} $ 、分类损失$ {L_{ce}} $ 和鉴别损失$ {L_D} $ 这3部分加权组成:$$ L = {L_{ct}} + {\lambda _{ct}}{L_{ct}} + {\lambda _D}{L_D} $$ (14) 其中
$ {\lambda _{ct}} $ 和$ {\lambda _D} $ 为平衡三种损失的超参数。 -
本文使用公开数据集RML2016.10A、 RML2016.10B和RML2016.10C,它们包括11种调制类型信号:八相移键控(8PSK)、双边带调幅(AM-DSB)、单边带调幅(AM-SSB)、二进制相移键控(BPSK)、连续相位频移键控(CPFSK)、高斯频移键(GFSK)、四阶脉冲幅度调制(PAM4)、l6正交幅度调制(QAM16)、64 正交幅度调制(QAM64)、正交相移键控(QPSK)和宽带调频(WBFM)。数据集包含从−20 dB到18 dB(步长为2 dB)的20种信噪比(SNR)的信号。数据集是由GNU Radio生成的,其数据格式为2×128,表示信号的同相和正交数据。数据集中每个调制样式的样本在相同信噪比下数量相同,在不同信噪比下,数量从206到1247不等。
实验选择了7个信噪比,从低到高依次为:−12、−8、−4、0、4、8、12 dB。在各种信噪比条件下独立进行实验,每种调制样式信号样本按照训练集80%、测试集20%的比例进行划分,在训练集中随机选择40个样本作为标记样本,其余样本均作为未标记样本,因此总共有440个标记样本。实验初始学习率为0.001,并随着训练轮次的增加逐渐减小。标记样本和未标记样本的批处理大小均为64。
$ {\lambda _{ct}} $ =0.002,$ {\lambda _D} $ =2。$ {\lambda _1} $ 在训练轮次小于100时为0,大于等于100时为1。训练最大轮次设置为500。比较对象是完全的有监督的分类、部分有监督方法和半监督信号识别分类方法SSRCNN、经典半监督方法SSACG-FM、ConvAE。此外,还比较了不同数据集、样本容量、信噪比和损失函数的影响。准确率作为该方法的评价指标,它表示为正确分类的样本数与总样本数的比值。
-
在7种信噪比下,4种方法的准确率显示在表1中,其中Supervised为完全使用标签训练,Supervised-base为SSCNN去除无标签部分,仅使用部分有标签,SSRCNN为目前取得最优效果的半监督信号识别方法之一。
从表3中可以看出,SSCNN的分类性能明显优于SSRCNN。在信噪比大于0 dB时,SSCNN的准确率比SSRCNN至少高出4%,在12 dB时,能够达到97.37%,远高于SSRCNN。其一是因为ResNet独特的残差模块结构能够够好地学习信号的深度特征用于分类,其二是由于GRL对于特征提取网络的参数优化作用。实验结果表明SSCNN能够有效地学习未标记样本的特征。当信噪比为−12 dB时,SSCNN的准确率小于25%。这是因为当噪声的相对功率过大时,即使采用完全监督的Supervised方法,其也很难从信号中提取有用的特征。
表 3 不同信噪比下的分类精度。
SNRs(dB) Supervised Supervised-base SSCNN SSRCNN 12 98.35% 96.61% 97.37% 93.80% 8 94.44% 90.91% 92.52% 86.79% 4 93.26% 90.08% 92.06% 85.58% 0 92.74% 87.23% 89.50% 81.23% −4 80.72% 66.31% 70.63% 46.48% −8 54.55% 37.56% 41.40% 35.22% −12 33.35% 20.03% 24.84% 18.52% 与此同时在低信噪比的情况下, SSCNN的识别精度相对于SSRCNN,SSCNN改善了在低信噪比下的性能,特别是在0 dB和−4 dB时,SSCNN的识别性能表现得到了极大的提升。这是因为相较于KL散度,使用梯度逆转层避免了由于KL散度的非对称特性带来的特征漂移问题,GRL对于提升特征提取网络对于噪声的敏感性更加的可靠。除此之外,由于Supervised-base中并未使用无标签样本,所以Supervised-base未利用鉴别器优化特征提取网络。相较于Supervised-base,SSCNN在每个信噪比上均取得更加优异的识别效果。同时SSCNN在低信噪比时依旧保证了稳定的识别优势,这是因为在鉴别器的帮助下,特征提取网络学到了更加优秀信号识别特征,这充分证明了SSCNN中鉴别器利用无标签数据优化网络参数的有效性,表明了在强干扰对抗环境下SSCNN依旧具有保持识别优越的识别性能的能力。
SNR为12 dB的混淆矩阵如图4所示。SNR为12 dB时,除8PSK外,其他10种调制方案的分类精度均在90%以上,BPSK、AM-SSB、CPFSK、GFSK和PAM4的分类精度大于等于99%,证明了 SSCNN 方法的有效性。由于标注样本的数量有限,SSCNN容易在相似度高的调制类型信号中出现误分类。从图中可以看出,当8PSK调制的信号被误分类为QPSK时,QPSK调制的信号也被误分类为8PSK,此现象同样存在于AM-DSB和WBFM之间。

图 4 SNR=12dB时的混淆矩阵
当信噪比为12 dB时,每种调制类型的标记样本数分别增加到50、60、70和80,因此标记样本总数分别为550、660、770和880。SSCNN调制类型分类精度的变化如表4所示。在本表中,模型的分类精度随着标记样本数量的增加而逐渐提高。这是因为更多的标记样本可以提供更明确的信息来帮助模型学习特征。此外,它还可以减少由于未标注样本的错误标注误差和分类丢失而导致的特征提取网络的负优化。
表 4 不同标记样本数量下的正确率
标签样本数量 正确率/% 440 97.37 550 97.72 660 97.71 770 97.88 880 98.01 -
当模型的损失函数在SNR = 12 dB变化时,调制信号样本的分类精度如表5所示。从中可以看出,分类损失
$ {L_{ce}} $ 在3个损失函数中的作用最大。在仅$ {L_{ce}} $ 的情况下,模型的分类准确率可以达到 94.02%。相比之下,在没有$ {L_{ce}} $ 的情况下,即在中心损失$ {L_{ct}} $ 和鉴别损失$ {L_D} $ 的共同作用下,模型的分类准确率仅为14.53%。这是因为分类损失直接作用于标签分类器的分类结果,而中心损失和鉴别损失只是优化特征向量的方式,它们不能够直接得到分类结果,预测结果是通过标签分类器得到的,在训练中如果没有分类损失,只依靠鉴别损失和中心损失训练,则标签分类器的网络参数不会得到训练并且是随机的,即便再优秀的特征向量也难以获得准确的预测类别。表 5 不同损失函数下的SSCNN性能
类型 正确率/% SSCNN 97.37 $ {L_{ct}} $和$ {L_D} $ 14.53 $ {L_{ce}} $和$ {L_{ct}} $ 94.54 $ {L_{ce}} $ 94.02 $ {L_{ce}} $和$ {L_D} $ 95.22 其次,
$ {L_D} $ 和$ {L_{ce}} $ 组合的分类准确率比仅$ {L_{ce}} $ 高约1.2%,这证实了鉴别器对特征向量的优化作用,即便是在信噪比较高的条件下仍然能获得更好的识别性能。$ {L_{ct}} $ 和$ {L_{ce}} $ 组合的分类准确率比仅$ {L_{ce}} $ 高约0.5%,这是由于对于相同类别的信号样本,中心损失能够优化了特征提取器,使得从同类样本中提取的特征差异很小,不同类样本的差异性很大,从而降低了分类错误的可能性。性能提升不高,则是受限于计算机性能,批次过小,语义中心计算不够准确导致的。总之,3个损失函数都从不同方面提高了模型的准确率。
-
本文研究了 SSCNN 与其他在信号识别领域广泛使用的半监督方法之间的性能差异,并将比较扩展到另外两个更大的数据集 RML2016.10A 和 RML2016.10B。
除SSRCNN以外,本文选择了文献[15]和文献[16]中提出半监督的方法SSACG-FM和ConvAE。此外,本文还对两个较大的公共数据集 RML2016.10A和RML2016.10B进行了相关对比实验,这两个数据集与 RML2016.10C相似,但信号样本更多。在实验设置方面,选择SNR=12 dB,其他条件与使用 RML2016.10C数据集的实验一致。
实验结果如表6所示。可以看出,SSCNN 的准确率优于 SSACG-FM、ConvAE 和 SSRCNN。这说明SSCNN的结构和损失函数更加合理有效。然而,与 RML2016.10C 相比,SSCNN 在其他两个数据集中的性能有所下降,这可能是由于从 RML2016.10A 和 RML2016.10B 中提取信号样本特征的困难。
表 6 不同半监督信号识别方法的比较
方法 2016.10A 2016.10B 2016.10C SSCNN 72.81% 67.45% 97.37% SSRCNN 69.31% 65.66% 93.80% SSACGAN 47.81% 41.63% 80.50% ConvAE 42.42% 36.63% 79.08% -
本文提出了一种用于信号识别的半监督学习方法SSCNN,解决了大量标签数据难以获得以及改善了噪声影响模型性能的问题。SSCNN能够有效利用无标签数据信息,通过多个公共数据集上与各种半监督方法进行交叉对比实验结果表明,在SNR=12 dB时,准确率可达到97.37%,这证明了该方法的优越性。由GRL组成的鉴别网络通过降低由加噪样本和样本所生成的特征向量之间的差异,改善了噪声对识别性能的影响,有效提高了低信噪比下的识别精度。
A semi-supervised signal modulation mode recognition algorithm based on deep learning
-
摘要: 得益于深度学习的发展,使用神经网络来提升信号识别性能取得了很大进步。然而,大多数现有的基于深度学习的信号识别方法都是有监督的,这需要大量标记良好的数据进行训练,但是信号标注成本相当昂贵。这鼓励使用半监督方法充分利用未标记数据来辅助深度模型的训练,但是现有的半监督信号识别方法未考虑噪声的影响,因此本文提出了一种基于深度残差网络(Resnet)的半监督信号识别方法,并利用梯度逆转层改善了噪声对性能的影响。本文在开源数据集RML2016.10A、RML2016.10B和RML2016.10C上的实验结果表明,所提出的半监督方法可以借助少量标签数据信息和未标记数据有效的训练深度模型,并且缓解了噪声对性能的影响。Abstract: Benefiting from the development of deep learning, the neural networks improve signal recognition performance has achieved great progress. However, most of the existing deep learning-based signal recognition methods are supervised, which requires a large amount of well-labeled data for training, but the cost of signal labeling is quite expensive. This encourages the semi-supervised methods to make full use of unlabeled data to assist the training of deep models, but existing semi-supervised signal recognition methods do not consider noise influence. Therefore, a semi-supervised signal recognition method is proposed based on deep residual network (Resnet) by using gradient reversal layers to improve noise effect on performance. Experimental results on open source datasets RML2016.10A, RML2016.10B and RML2016.10C show that the proposed semi-supervised method effectively extracts discriminative features from unlabeled data by using a small amount of labeled data information, which alleviates noise influence.
-
Key words:
- Modulation /
- Semi-supervised learning /
- Convolutional neural network /
- Signal recognition
-
表 3 不同信噪比下的分类精度。
SNRs(dB) Supervised Supervised-base SSCNN SSRCNN 12 98.35% 96.61% 97.37% 93.80% 8 94.44% 90.91% 92.52% 86.79% 4 93.26% 90.08% 92.06% 85.58% 0 92.74% 87.23% 89.50% 81.23% −4 80.72% 66.31% 70.63% 46.48% −8 54.55% 37.56% 41.40% 35.22% −12 33.35% 20.03% 24.84% 18.52%  下载: 导出CSV
下载: 导出CSV
表 5 不同损失函数下的SSCNN性能
类型 正确率/% SSCNN 97.37 $ {L_{ct}} $ 和$ {L_D} $ 14.53 $ {L_{ce}} $ 和$ {L_{ct}} $ 94.54 $ {L_{ce}} $ 94.02 $ {L_{ce}} $ 和$ {L_D} $ 95.22
下载: 导出CSV
表 6 不同半监督信号识别方法的比较
方法 2016.10A 2016.10B 2016.10C SSCNN 72.81% 67.45% 97.37% SSRCNN 69.31% 65.66% 93.80% SSACGAN 47.81% 41.63% 80.50% ConvAE 42.42% 36.63% 79.08%
下载: 导出CSV
-
[1] SUN X, SU S, ZUO Z, et al. Modulation classification using compressed sensing and decision tree-support vector machine in cognitive radio system[J]. Sensors (Basel), 2020, 20(5): E1438. doi: 10.3390/s20051438 [2] XIONG Wei, ZHANG Lin, MCNEIL M, et al, Symme-try: Exploiting mimo self-similarity for under-determined modulation recognition[J]. IEEE Transactions on Mobile Computing, 2021, 21(11): 4111-4124. [3] SHANMUGHAM B, REVATHI PONMOZHI B, SEKAR V. Index modulation and hierarchical signal detection approach for MIMO OFDMA[J]. Materials Today: Proceedings, 2021, 47: 181-184. doi: 10.1016/j.matpr.2021.04.068 [4] FLOWERS B, BUEHRER R M, HEADLEY W C. Evaluating adversarial evasion attacks in the context of wireless communications[J]. IEEE Transactions on Information Forensics and Security, 2020, 15: 1102-1113. doi: 10.1109/TIFS.2019.2934069 [5] SHEN W G, GAO Q X. Automatic digital modulation recognition based on locality preserved projection[C]//Proceedings of the International Conference on Wireless Communication and Sensor Network. New York: IEEE, 2014: 348-352. [6] WANG L, LI Y B. Constellation based signal modulation recognition for MQAM[C]//Proceedings of the IEEE 9th International Conference on Communication Software and Networks. New York: IEEE, 2017: 826-829. [7] O’SHEA T J, CORGAN J, CLANCY T C. Convolutional radio modulation recognition networks[M]//Engineering Applications of Neural Networks. Cham: Springer International Publishing, 2016: 213-226. [8] HUANG L, PAN W J, ZHANG Y, et al. Data augmentation for deep learning-based radio modulation classification[J]. IEEE Access, 2020, 8: 1498-1506. doi: 10.1109/ACCESS.2019.2960775 [9] WEST N E, O’SHEA T. Deep architectures for modulation recognition[C]//Proceedings of the IEEE International Symposium on Dynamic Spectrum Access Networks. New York: IEEE, 2017: 1-6. [10] WONG L J, HEADLEY W C, MICHAELS A J. Specific emitter identification using convolutional neural network-based IQ imbalance estimators[J]. IEEE Access, 2019, 7: 33544-33555. doi: 10.1109/ACCESS.2019.2903444 [11] MENG F, CHEN P, WU L N, et al. Automatic modulation classification: A deep learning enabled approach[J]. IEEE Transactions on Vehicular Technology, 2018, 67(11): 10760-10772. doi: 10.1109/TVT.2018.2868698 [12] ADAMS N. Semi-supervised learning[J]. Journal of the Royal Statistical Society Series A:Statistics in Society, 2009, 172(2): 530. [13] KING M, D P, REZENDE D J, et al, Semi-supervised learning with deep generative models, Advances in Neural Information Processing Systems, 2014, 27: 3581–3589. [14] DONG Y H, JIANG X H, CHENG L, et al. SSRCNN: A semi-supervised learning framework for signal recognition[J]. IEEE Transactions on Cognitive Communications and Networking, 2021, 7(3): 780-789. doi: 10.1109/TCCN.2021.3067916 [15] TU Y, LIN Y, WANG J, et al. Semi-Supervised Learning with Generative Adversarial Networks on Digital Signal Modulation Classification[J]. Computers, Materials & Continua, 2018(5): 243-254. [16] O’SHEA T J, WEST N, VONDAL M, et al. Semi-supervised radio signal identification[C]//Proceedings of the 2017 19th International Conference on Advanced Communication Technology (ICACT). New York: IEEE, 2017: 33-38. [17] GANIN Y, LEMPITSKY V. Unsupervised domain adaptation by backpropagation[EB/OL]. [2022-03-21]. http://www.arxiv.org/pdf/1409.7495.pdf. -

 点击查看大图
点击查看大图

图(4) / 表(6)
计量
- 文章访问数: 188
- HTML全文浏览量: 69
- PDF下载量: 3
- 被引次数: 0






























































