 ISSN
ISSN 

























-
时间序列有序分类(time series ordinal classification, TSOC)是时间序列数据挖掘领域的一项重要任务。该任务旨在训练一个分类器,实现对类别标签有序的时间序列数据的自动分类。与传统时间序列分类[1]任务不同,TSOC采用错分代价来衡量算法有效性。如在医疗辅助诊断系统中,将危重型病症错分成轻型病症的代价远高于将其错分成重型病症的代价。除了医疗辅助诊断外,本任务在金融投资、气象预测等领域都有重要应用。但目前关于该任务的研究非常少,尚处于起步阶段[2]。
基于Shapelet的时间序列分类近年来受到学界广泛关注[3-5]。Shapelet是指时间序列中具有良好分类能力的子序列,最早由文献[6]提出,它采用Brute-Force算法搜索子序列,并用信息增益(information gain, IG)对其分类能力进行评价,最后利用计算得到的Shapelet构造决策树。由Shapelet构造的决策树具有非常好的可解释性。随后,文献[7]提出了ST(shapelet transformation)方法。该方法获得Top-K个最优Shapelet,然后将原始时间序列转换到新的特征空间并采用传统方法训练分类器,使算法的分类能力大幅提升。但是,上述两类算法都采用暴力方法搜索Shapelet,计算效率低。为解决该问题,文献[8]提出了基于三角不等式的剪枝策略,以及提前计算距离的方法;文献[9]用符号聚合近似(symbolic aggregate approximation, SAX)表示时间序列,采用随机投射技术,计算最优Shapelet集合;文献[10]提出了基于随机采样的Shapelet抽取算法;文献[11]提出了基于随机采样的随机Shapelet森林算法gRSF;文献[12]在上述工作基础上进一步改进,提出了压缩随机Shapelet森林算法CRSF。CRSF采用SAX表示时间序列,通过随机采样构建一个高质量的Shapelet池,然后从池中随机选择Shapelet生成决策树节点,提升了算法性能。近年来,基于Shapelet构建深度学习模型也受到学界广泛关注[13-14],但考虑到深度神经网络可解释性不足,本文不再详细介绍。
文献[15]提出了基于Shapelet的时间序列有序分类算法。该工作主要提出了两项面向TSOC的Shapelet评价指标,Spearman相关系数和Pearson相关系数。与IG不同,这两项评价指标通过计算Shapelet与时间序列的欧式距离和标签距离之间的相关系数来评价Shapelet。实验结果表明,评价指标与IG相比有效地降低了算法的错分代价。但是,该方法中提出的Shapelet评价指标都需要计算Shapelet到时间序列的距离,计算效率较低。
本文提出一种基于覆盖集中度和覆盖优势度的Shapelet评价指标CD-Cover(concentration and dominance of coverage),以及一种面向时间序列有序分类的Shapelet抽取算法。该算法采用SAX表示时间序列,通过随机采样Shapelet,使用CD-Cover指标评价Shapelet,抽取最终的Shapelet结果集。然后,通过ST方法将时间序列数据集转换到新的特征空间并训练有序分类器。最后,在UCR和UEA时间序列分类资源库[16]挑选适合TSOC任务的11个数据集上,采用CCR(correct classification rate)和Weighted-κ两个指标对所提算法进行了实验验证。
-
通常,时间序列是按照固定时间间隔采集得到的数值型数据序列,可以表示为
$ X = \left\langle {{x_1},{x_2}, \cdots ,{x_m}} \right\rangle $ ,$ {x_i} \in \mathbb{R} $ ,m为时间序列的长度。进一步,将二元组$T = \left\langle {X,c} \right\rangle $ 称为时间序列样本,c是时间序列样本的类别标签(简称标签)。$ D = \{ {T_1},{T_2}, \cdots ,{T_n}\} $ 为一个时间序列数据集,其中,n称为时间序列数据集的大小。$ Y = \{ {c_1},{c_2}, \cdots ,{c_Q}\} $ 表示时间序列数据集D中所有样本标签的集合,Q是标签数。在TSOC问题中,要求$ Q \geqslant 3 $ ,且标签之间存在全序关系$ {c_1} \prec {c_2} \prec \cdots \prec {c_Q} $ 。时间序列数据通常都是高维实数,不仅需要大量存储空间,而且计算代价也很高。文献[17]提出一种时间序列的SAX表示方法,将数值型时间序列转换为符号型时间序列,可以达到数据降维、降低噪声、节省存储和简化计算等目的。SAX表示方法的转换过程如下。
给定时间序列
$ X = \left\langle {{x_1},{x_2}, \cdots ,{x_m}} \right\rangle $ 、动态窗口长度ω和字母表Σ,将$ X $ 平均分成$t = \left\lceil {m/\omega } \right\rceil $ 段,得到$ \overline X = \left\langle {{{\overline x }_1},{{\overline x }_2}, \cdots ,{{\overline x }_t}} \right\rangle $ ,其中$ {\overline x _i} $ 为:$$ {\overline x _i} = \frac{1}{\omega }\sum\limits_{j = 1}^\omega {{x_{(i - 1) \cdot \omega + j}}} \qquad i = 1,2, \cdots ,t $$ (1) 进一步,基于映射函数
$\varphi $ ,将$ {\overline x _i} $ 映射到字母表空间,记为$ {\widehat x_i} = \varphi ({\overline x _i}) $ ,$ {\widehat x_i} \in \Sigma $ 。采用SAX表示后的时间序列记为$ \widehat{X}=\langle {\widehat{x}}_{1},{\widehat{x}}_{2},\cdots ,{\widehat{x}}_{t}\rangle $ ,时间序列样本为$ \widehat T = \langle \widehat X,c\rangle $ ,时间序列数据集为$ \widehat{D}=\langle {\widehat{T}}_{1},{\widehat{T}}_{2},\cdots ,{\widehat{T}}_{n}\rangle $ 。传统的Shapelet是指时间序列的任意子序列,本文的候选Shapelet是基于SAX表示的时间序列,下面给出其定义。
定 义 1(候选Shapelet) 给定SAX表示的时间序列
$ \widehat X = \left\langle {{{\widehat x}_1},{{\widehat x}_2}, \cdots ,{{\widehat x}_t}} \right\rangle $ ,称该时间序列的任意子序列$s_b^l$ 为一个候选Shapelet,其中b和l分别表示候选Shapelet在时间序列中的开始位置和长度,且$1 \leqslant b \leqslant t + 1 - l$ ,$0 < l \leqslant t$ 。为表述方便,将
$s_b^l$ 统一表示为s。如果没有特别说明,本文中时间序列、时间序列样本、时间序列数据集和Shapelet,均采用SAX表示。基于Shapelet的时间序列分类,核心是找出最具代表性的候选Shapelet集合,称为Shapelet抽取。
问题描述:给定SAX表示的时间序列数据集
$ \widehat D $ ,Shapelet抽取就是从$ \widehat D $ 中找出最优候选Shapelet集合S,使评价函数$ \varPsi ( \cdot ) $ 取得最大值,为:$$ J(\widehat D) = \mathop {\arg \max }\limits_S \varPsi (\widehat D,S) $$ (2) 文献[6]最早采用IG对Shapelet的分类能力进行评价。IG也是当前研究和实践中最常用的Shapelet评价指标。文献[7]提出了Kruskal-Wallis、F-statistic和Mood's median 这3种指标,并通过实验证明了其有效性。但上述指标没有考虑错分代价,在TSOC任务中表现不佳。文献[15]提出了Spearman相关系数和Pearson相关系数两项指标,充分考虑了类别有序这一特征。但是,两项指标都需要计算Shapelet到时间序列之间的距离,计算成本较高。
-
本文设计的面向时间序列有序分类算法框架如图1所示。首先,采用SAX方法将数值型时间序列数据集转化为符号型时间序列数据集。然后,采用随机采样+布隆过滤+Shapelet评价的策略,实现对Shapelet的抽取。其中,随机采样+布隆过滤旨在提升算法效率以及进行预剪枝。该策略在文献[18]中已被验证有效。本文提出一种新的面向SAX表示时间序列有序分类的Shapelet评价指标CD-Cover。图1中


图 1 面向时间序列有序分类算法框架
-
为提升Shapelet评估效率,本节介绍一种适用于时间序列有序分类的Shapelet评价指标CD-Cover。首先,给出覆盖、覆盖集中度和覆盖优势度的定义。
定 义 2 (覆盖) 给定一个SAX表示的时间序列数据集
$\widehat D = \{ {\widehat T_1},{\widehat T_2}, \cdots ,{\widehat T_n}\} $ 和一个Shapelet$ s $ ,$ \widehat D $ 的标签数为$ Q $ ,称$\varPhi \left( s \right) = \left\langle {{\lambda _1},{\lambda _2}, \cdots ,{\lambda _Q}} \right\rangle$ 为$ s $ 在$ \widehat D $ 上的覆盖。其中,$ {\lambda _i} $ 为包含$ s $ 的$ {c_i} $ 类时间序列样本数。定 义 3(覆盖集中度) 给定Shapelet
$ s $ 在时间序列数据集$ \widehat D $ 上的覆盖$\varPhi \left( s \right) = \left\langle {{\lambda _1},{\lambda _2}, \cdots ,{\lambda _Q}} \right\rangle$ ,$ Q $ 为$ \widehat D $ 的标签数。则$ s $ 在$ \widehat D $ 上的覆盖集中度${\rm{con}}\left( s \right)$ 定义为:$$\begin{split} &\qquad{\rm{con}}\left( s \right) = 1 - \frac{{{\rm{Var}}(\varPhi (s))}}{{{\rm{Va}}{{\rm{r}}_{\max }}}} \\&{\rm{Var}}\left( {\varPhi \left( s \right)} \right) =\sum\limits_{i = 1}^Q {{p_i}} {\left( {i - \sum\limits_{i = j}^Q {{p_j}}j} \right)^2}\\&\qquad\quad {p_i} = {{{\lambda _i}} \mathord{\left/ {\vphantom {{{\lambda _i}} {\sum\limits_{j = 1}^Q {{\lambda _j}} }}} \right. } {\sum\limits_{j = 1}^Q {{\lambda _j}} }} \end{split} $$ (3) 式中,
${\rm{Var}}(\varPhi (s))$ 为$\varPhi (s)$ 的方差;${\rm{Va}}{{\rm{r}}_{\max }}$ 为方差上界。根据方差性质可知,当覆盖取值平均分布在值域两端时取得最大值,因此覆盖集中度的方差上界${\rm{Va}}{{\rm{r}}_{\max }} = {{{{\left( {1 - Q} \right)}^2}} \mathord{\left/ {\vphantom {{{{\left( {1 - Q} \right)}^2}} 4}} \right. } 4}$ 。从上述定义容易看出,${\rm{con}}(s)$ 取值范围为[0,1],值越大,表明覆盖的方差越小,覆盖越集中。特殊情况下,如果$ s $ 仅覆盖一类时间序列,则方差为0,${\rm{con}}(s)$ 值为1;如果$ s $ 仅覆盖类别标签最小和类别标签最大的时间序列,且覆盖比率相同,则方差达到上界,${\rm{con}}(s)$ 值为0。定 义 4(覆盖优势度) 给定Shapelet
$ s $ 在时间序列数据集$ \widehat D $ 上的覆盖$\varPhi \left( s \right) = \left\langle {\lambda _1},{\lambda _2}, \cdots , {\lambda _Q} \right\rangle$ ,且$ \widehat D $ 中$ Q $ 类样本数分别为$ {n_1},{n_2}, \cdots ,{n_Q} $ ,称$\varPi \left( s \right) = \left\langle {\kappa _1},{\kappa _2}, \cdots , {\kappa _Q} \right\rangle$ 为Shapelet$ s $ 在数据集$ \widehat D $ 上的覆盖率,其中$ {{{\kappa _i} = {\lambda _i}} \mathord{\left/ {\vphantom {{{\kappa _i} = {\lambda _i}} {{n_i}}}} \right. } {{n_i}}} $ 为类别$ {c_i} $ 的覆盖率。令$\varPi '\left( s \right) = \left\langle {\kappa {'_1},\kappa {'_2}, \cdots ,\kappa {'_Q}} \right\rangle$ 为$\varPi \left( s \right)$ 降序排列的结果,则$ s $ 在$ \widehat D $ 上的覆盖优势度为${\rm{dom}}\left( s \right) = \kappa {'_1} - \kappa {'_2}$ 。换言之,覆盖优势度为类别最高覆盖率与次高覆盖率之差。覆盖优势度
${\rm{dom}}(s)$ 的取值范围是[0,1],值越大,表明覆盖的优势越明显。如果Shapelet s仅覆盖一个类别的时间序列,则覆盖优势度为该类类别的覆盖率。定 义 5(CD-Cover) 给定Shapelet
$ s $ 和时间序列数据集$ \widehat D $ ,$ s $ 在$ \widehat D $ 上的覆盖集中度和覆盖优势度分别为${\rm{con}}\left( s \right)$ 和${\rm{dom}}\left( s \right)$ ,则$ s $ 的CD-Cover评价值为:$$ \sigma \left( s \right) = \alpha {\rm{con}}\left( s \right) + \left( {1 - \alpha } \right) {\rm{dom}}\left( s \right)\qquad 0 < \alpha < 1 $$ (4) 式中,
$ \alpha $ 是权重因子,用来调节覆盖集中度和覆盖优势度的权重,默认两者权重相同,即$ \alpha $ 取0.5。如果覆盖集中度越高,则${\rm{con}}(s)$ 值越大;如果覆盖优势度越大,则${\rm{dom}}(s)$ 越大,并且,$ \sigma (s) $ 取值范围为[0,1]。因此,如果CD-Cover值越大,表明其分类能力越强。下面,通过4个算例来展示CD-Cover指标的计算过程及其有效性。
算例1 时间序列数据集
$ \widehat D $ 标签$ Y = \left\langle {1,2,3,4} \right\rangle $ ,即$ Q = 4 $ ,且每类时间序列样本数分别为$ \left\langle {5,5,2,2} \right\rangle $ 。如果给定一个Shapelet$ {s_1} $ ,且$ {s_1} $ 在数据集$ \widehat D $ 上的覆盖$\varPhi \left( {{s_1}} \right) = \left\langle {4,1,0,0} \right\rangle$ 。则计算可得,${\rm{Var}}\left( {\varPhi \left( {{s_1}} \right)} \right) = 0.17$ ,而${\rm{Va}}{{\rm{r}}_{\max }} = {(1 - 4)^2}/4 = 2.25$ ,所以,$ {s_1} $ 的覆盖集中度${\rm{con}}\left( s \right) = 1 - 0.17/2.25 = 0.924$ 。根据定义4,覆盖率为$\varPi \left( {{s_1}} \right) = \left\langle {4/5,1/5,0/2,0/2} \right\rangle$ ,因此,类别1覆盖率最高为0.8,类别2覆盖率次高为0.2。所以,覆盖优势度${\rm{dom}}\left( {{s_1}} \right) = 0.8 - 0.2 = 0.6$ 。根据式(4),计算$ {s_1} $ 的CD-Cover为$ \sigma \left( {{s_1}} \right) = 0.5 \times 0.924 + \left( {1 - 0.5} \right) \times 0.6 = 0.762 $ 。算例2 算例1相同的时间序列数据集
$ \widehat D $ 中,如果给定Shapelet$ {s_2} $ ,在$ \widehat D $ 上的覆盖$\varPhi \left( {{s_2}} \right) = \left\langle {2,0,0,1} \right\rangle$ ,则${\rm{Var}}\left( {\varPhi \left( {{s_2}} \right)} \right) = 1.25$ ,${\rm{con}}\left( {{s_2}} \right) = 1 - 1.25/2.25 = 0.444$ ;$ {s_2} $ 在$ \widehat D $ 上的覆盖率$\varPi \left( {{s_2}} \right) = \left\langle {2/5,0/5,0/2,1/2} \right\rangle$ ,覆盖优势度为${\rm{dom}}\left( {{s_2}} \right) = 0.5 - 0.4 = 0.1$ 。因此,$ {s_2} $ 的CD-Cover为$ \sigma ({s_2}) = 0.5 \times 0.444 + (1 - 0.5) \times 0.1 = 0.272 $ 。算例3 算例1相同的时间序列数据集
$ \widehat D $ 中,如果给定Shapelet$ {s_3} $ ,在$ \widehat D $ 上的覆盖$\varPhi \left( {{s_3}} \right) = \left\langle {1,1,0,0} \right\rangle$ ,则${\rm{Var}} \left( {\varPhi \left( {{s_3}} \right)} \right) = 0.125$ ,${\rm{con}} \left( {{s_3}} \right) = 1 - 0.125/2.25 = 0.944$ ;$ {s_3} $ 在$ \widehat D $ 上的覆盖率$\varPi \left( {{s_3}} \right) = \left\langle {1/5,1/5,0/2,0/2} \right\rangle$ ,覆盖优势度为${\rm{dom}}\left( {{s_3}} \right) = 0.2 - 0.2 = 0$ 。因此,$ {s_3} $ 的CD-Cover值为$ \sigma ({s_3}) = 0.5 \times 0.944 + (1 - 0.5) \times 0 = 0.472 $ 。算例4 算例1相同的时间序列数据集
$ \widehat D $ 中,如果给定Shapelet$ {s_4} $ ,在$ \widehat D $ 上的覆盖$\varPhi \left( {{s_4}} \right) = \left\langle {1,0,0,2} \right\rangle$ ,则${\rm{Var}}\left( {\varPhi \left( {{s_4}} \right)} \right) = 1.25$ ,${\rm{con}}\left( {{s_4}} \right) = 1 - 1.25/2.25 = 0.444$ ;$ {s_4} $ 在$ \widehat D $ 上的覆盖率$\varPi \left( {{s_4}} \right) = \left\langle {1/5,0/5,0/2,2/2} \right\rangle$ ,覆盖优势度为${\rm{dom}}\left( {{s_4}} \right) = 1 - 0.2 = 0.8$ 。因此,$ {s_4} $ 的CD-Cover值为$ \sigma ({s_4}) = 0.5 \times 0.444 + (1 - 0.5) \times 0.8 = 0.622 $ 。通过以上算例可以发现,CD-Cover的目标是找出最优的Shapelet。这些Shapelet覆盖的时间序列集中在某个类别附近,且对该类时间序列有很高的覆盖比例。如果Shapelet覆盖且只覆盖一个类别的所有时间序列,其CD-Cover值为1。
-
基于随机采样的面向时间序列有序分类的Shapelet抽取算法核心步骤算法如下。
输入
$ D $ : 原始时间序列训练集;$ \alpha $ : 权重因子;$ \varepsilon $ : CD-Cover阈值;$ \omega $ : SAX窗口大小,$ \varSigma $ : SAX字符集大小;$ \tau $ : Shapelet评价时间限制;N: Shapelet数目输出
$ S $ : 抽取得到的最佳Shapelet集合1.
$\widehat D \leftarrow {\rm{convert}}\_to\_{\rm{SAX}}\left( {D,\omega ,\Sigma } \right)$ ;2.
$S \leftarrow \emptyset $ ;3.
${\rm{BF}} \leftarrow {\rm{initialize}}\_{\rm{bloom}}\_{\rm{filter}}()$ ;4. while not
${\rm{timeout}}(\tau )$ do5.
$\widehat T \leftarrow {\rm{random}}\_{\rm{sampling}}\_{\rm{time}}\_{\rm{series}}\left( {\widehat D} \right)$ ;6.
$s \leftarrow {\rm{random}}\_{\rm{sampling}}\_{\rm{shapelet}}\left( {\widehat T} \right)$ ;7. if
${\rm{exist} }\_{\rm{in} }\_{\rm{bloom} }\_{\rm{filter} }\left( {{\rm{BF}},s} \right)$ then8. continue;
9.
${\rm{BF}} \leftarrow {\rm{update}}\_{\rm{bloom}}\_{\rm{filter}}\left( {{\rm{BF}},s} \right);$ 10.
${\rm{cd}}\_{\rm{cover}} \leftarrow {\rm{CD}}\_{\rm{Cover}}(s,\widehat D,\alpha )$ ;11. if
${\rm{cd}}\_{\rm{cover}} > \varepsilon$ then12.
$S \leftarrow S \cup s$ ;13. if
$|S| > 2*N$ then14.
$S \leftarrow {\rm{remove}}\_{\rm{worst}}(S)$ ;15.
$\varepsilon \leftarrow {\rm{update}}\_{\rm{threshold}}(S)$ ;16.
$S \leftarrow {\rm{remove}}\_{\rm{similar}}\_{\rm{and}}\_{\rm{select}}\_{\rm{top}}\left( {S,N} \right)$ ;17. return S;
算法第1行:根据参数
$ \omega $ 和$\varSigma$ 将原始时间序列训练集D转换为SAX表示的时间序列训练集$\widehat D$ 。算法第2、3行:初始化Shapelet结果集合
$ S $ 和布隆过滤器BF。本算法采用布隆过滤器检索当前候选Shapelet是否已经出现并评价,如果此前已经出现则不再进行评价,提升算法效率[18]。算法第4行:进入循环,当计时器超过限定时间,结束Shapelet抽取。
算法第5、6行:随机从
$\widehat D$ 中选择一条时间序列,然后从该时间序列中随机抽取一个候选Shapelet。算法第7、8行:通过布隆过滤器判断Shapelet
$s$ 是否已经出现;如果已出现,则跳过CD-Cover值计算,重新进行Shapelet采样。算法第9、10行:更新布隆过滤器,并计算候选Shapelet
$s$ 的CD-Cover值。算法第11、12行:判断当前候选Shapelet
$s$ 的CD-Cover值是否大于给定阈值$ \varepsilon $ ,只有评估值大于$ \varepsilon $ ,才将其加入$ S $ ,保证抽取高质量Shapelet。算法第13、14、15行:判断抽取得到的Shapelet集合大小是否大于预设数目
$ N $ 的两倍,如果满足条件,则从$ S $ 中移除CD-Cover值最小的候选Shapelet,同时将阈值$ \varepsilon $ 更新为$ S $ 中Shapelet的最小CD-Cover值。保留预设数$ N $ 两倍数量的候选Shapelet是后续还要从中移除自相似的Shapelet。算法第16行:首先从
$ S $ 中移除自相似的Shapelet。自相似Shapelet指的是两个候选Shapelet取自同一条时间序列,且存在重叠部分。大量自相似的Shapelet会造成特征空间冗余,降低算法分类效果。移除自相似Shapelet的算法在文献 [12,19]中均有介绍。最后,返回剩余候选Shapelet中CD-Cover值最高的$ N $ 个Shapelet。 -
如果时间序列数据集D的大小为n,所包含的时间序列长度均为m,SAX窗口大小为
$ \omega $ 。则经过转换,采用SAX表示的时间序列数据集$\widehat D$ 中包含n条字符形时间序列,每条长度均为$ t = \left\lceil {{m \mathord{\left/ {\vphantom {m \omega }} \right. } \omega }} \right\rceil $ 。在上述算法中,将原始时间序列转换为SAX表示时间序列的时间复杂度为
$O(nm)$ (第1行),移除自相似算法的时间复杂度依赖于候选Shapelet的数量,该数量远小于时间序列数据集的大小n与长度m的乘积$ n m $ 。因此,第1行和第16行的时间复杂度合计为$O(n m)$ 。本文采用的随机采样框架设置了Shapelet评价时间限制,通常应采用单位时间内的吞吐量来分析算法性能。但是,反过来,也可以通过分析抽取单个候选Shapelet的时间复杂度来评价算法性能。Shapelet抽取算法的主要时间开销为CD-Cover值计算,需要判断候选Shapelet是否存在于某条时间序列中。本文采用KMP算法,其最坏时间复杂度为
$O(t)$ 。在n条时间序列中进行字符串匹配,其最坏时间复杂度为$O(tn)$ 。该时间复杂度明显低于文献[15]提出的Spearman相关系数和Pearson相关系数的时间复杂度。换言之,在相同时间约束内,本文提出的算法抽取和评价的Shapelet数量要远多于文献[15]提出的算法。 -
为了验证所提Shapelet抽取算法的有效性,在公开数据集上进行实验,训练生成有序分类器,并采用不同指标来评价这些分类器的分类能力。
-
实验硬件配置为Intel Xeon Gold 5215 CPU(2.5 GHz主频,8核)和64 GB内存。操作系统为Windows Server 2016。实验工具采用Python3.6.8、时间序列挖掘工具包sktime 0.9.0和有序分类开源框架ORCA(ordinal regression and classification algorithm)[20]。ORCA的运行环境为MATLAB 2018b。
从时间序列分类资源库UCR和UEA[16],根据以下条件筛选出11个实验数据集:1)类别标签之间有明确的全序关系;2)类别数不小于3;3)时间序列长度相等。数据集的基本信息如表1所示。
表 1 实验数据集
编号 数据集 训练
样本测试
样本标签数 序列
长度1 AbnormalHeartbeat 302 304 5 3053 2 Beef 30 30 5 470 3 ChlorineConcentration 467 3840 3 166 4 Colposcopy 99 101 6 180 5 DistalPhalanxOutlineAgeGroup 400 139 3 80 6 DistalPhalanxTW 400 139 6 80 7 EthanolLevel 504 500 4 1751 8 MiddlePhalanxOutlineAgeGroup 400 154 3 80 9 MiddlePhalanxTW 399 154 6 80 10 ProximalPhalanxOutlineAgeGroup 400 205 3 80 11 ProximalPhalanxTW 400 205 6 80 -
传统ST方法将抽取的Shapelet用于训练标准分类器,如支持向量机、随机森林等。但标准分类器没有考虑类别标签有序的问题。实验采用了3种有序分类研究中常用的分类器SVC1V1[21]、SVOREX [22] 和SVORIM [22]来验证本文所提Shapelet抽取算法。其中,SVC1V1是标量分类器,SVOREX和SVORIM是有序分类器,这些分类器的实现均来自ORCA开源框架[20]。
实验采用CCR和Weighted-κ作为分类器分类能力的评价指标。前者是最常用的分类评价指标,但没有考虑类别标签有序的特征;后者是目前研究验证的、更适用于评价有序分类能力的指标[23]。CCR和Weighted-κ分别由式(5)和式(6)计算所得。
$$ {\rm{CCR}} = \frac{1}{n}\sum\limits_{i = 1}^n {\delta ({c_i},\widehat {{c_i}})} $$ (5) 式中,n是时间序列测试集大小;
${c_i}$ 和$\widehat {{c_i}}$ 分别表示测试集中时间序列样本$ {T_i} $ 的实际标签和分类器预测标签;$\delta ({c_i},\widehat {{c_i}})$ 是Kronecker函数,当且仅当${c_i}$ 和$\widehat {{c_i}}$ 相同时,函数值为1,否则函数值为0。CCR取值范围为[0,1],值越大,表明分类器性能越好。$$ {\rm{Weighted}} - \kappa = 1 - \dfrac{{\displaystyle\sum\limits_{i = 1}^Q {\displaystyle\sum\limits_{j = 1}^Q {{\theta _{i,j}}{M_{i,j}}} } }}{{\displaystyle\sum\limits_{i = 1}^Q {\displaystyle\sum\limits_{j = 1}^Q {{\theta _{i,j}}{e_{i,j}}} } }} $$ (6) 式中,Q表示时间序列数据集的标签数;
$ {\theta _{i,j}} $ 表示将$ {c_i} $ 类时间序列预测为$ {c_j} $ 类的权重(错分代价),通常采用线性权重或二次权重,本文采用线性权重,即$ {\theta _{i,j}} = \left| {O({c_i}) - O({c_j})} \right| $ ,其中$ O(c) $ 表示类别标签c的序号,所有序号是连续整数,如果类别标签本身是连续整数,则可简化为$ {\theta _{i,j}} = \left| {{c_i} - {c_j}} \right| $ ;$ {M_{i,j}} $ 表示分类器将$ {c_i} $ 类时间序列预测为$ {c_j} $ 类的样本数;$ {e_{i,j}} $ 表示期望的预测结果,计算式为:$$ {e_{i,j}} = \dfrac{1}{n}\displaystyle\sum\limits_{k = 1}^Q {{M_{i,k}} } \displaystyle\sum\limits_{k = 1}^Q {{M_{k,j}}} $$ (7) Weighted-κ取值范围为[−1,1],值越大,表明分类器的分类效果越好。
-
实验中,本文提出的Shapelet抽取算法的参数设置如表2所示。其中CD-Cover计算公式中的权重因子
$ \alpha $ 设置为0.5,换言之,设定覆盖集中度和覆盖优势度有同等的重要性;Shapelet抽取过程中根据候选Shapelet的CD-Cover值是否大于初始阈值$ \varepsilon $ 决定是否对其保留,$ \varepsilon $ 设置为0.5。此外,SAX的参数$ \omega $ 和$\varSigma$ 分别设置为1和10。这样设置有两个理由:1)文献[12]通过实验证明该设置在大部分数据集上能取得较好的分类结果;2)本文主要是利用SAX的符号表示能力,即将数值型时间序列转换为符号型时间序列,并不特别关注其对数据的维度约减能力。此外,训练有序分类器的时候,3种支持向量分类器的惩罚参数和核函数参数都设置为相同的搜索范围$ \{ {10^{ - 3}},{10^{ - 2}}, \cdots ,{10^2},{10^3}\} $ ,并采用5折交叉验证,搜索最优参数组合。时间约束$ \tau $ 设定为300 s。表 2 实验参数设置
序号 参数 取值 1 $ \alpha $ 0.5 2 $ \varepsilon $ 0.5 3 $ \omega $ 1 4 $ \Sigma $ 10 5 $\tau/s$ 300 -
本节首先验证所提CD-Cover指标的有效性。实验将根据IG、Spearman相关系数、Pearson相关系数和CD-Cover 4种评价指标抽取的Shapelet,分别用来训练3.1.2节中的3种分类器,然后比较4种指标在实验数据集上的有序分类效果。由于算法具有随机性,为保证结果的公平性,CCR和Weighted-κ结果都取50次实验的平均值。
1)CCR
采用3种分类器SVC1VC、SVOREX和SVORIM在11个数据集上进行实验,得到的CCR结果如表3所示,表中IG、
$ \rho $ 、$ \gamma $ 和$ \sigma $ 分别代表IG、Spearman相关系数、Pearson相关系数和CD-Cover指标。对每个数据集而言,同一分类器不同指标的CCR最高值用粗体标注。表格最后的“胜出”,表示采用当前分类器的4种Shapelet评价指标中,各指标在11个数据集上取得CCR最优分类结果的数据集个数。如采用SVC1V1分类器结合IG评价指标,分别在第2、第6和第9个数据集上取得3次最优分类结果。“排名”表示采用当前分类器的4种Shapelet评价指标中,各指标在11个数据集上取得的CCR值的平均排名。例如,采用SVORIM分类器结合Pearson相关系数,在11个数据集上的平均排名为2.55。CD-Cover指标在3种分类器上“胜出”的数据集都是6个(超过数据集的半数),且在3种分类器上的平均排名都最高,分别为1.77、1.91和1.86。2)Weighted-κ
表4给出了采用3种分类器结合4种Shapelet评价指标在11个数据集上获得的Weighted-κ结果。由表4可知,在11个数据集上,CD-Cover指标在3种分类器上分别取得了6次、6次和7次最优的表现。同时,CD-Cover指标在3种分类器上都取得了最高的平均排名,分别为1.77、1.64和1.50。
表 3 不同Shapelet评价指标的CCR值
数据集 SVC1V1 SVOREX SVORIM IG $ \rho $ $ \gamma $ $ \sigma $ IG $ \rho $ $ \gamma $ $ \sigma $ IG $ \rho $ $ \gamma $ $ \sigma $ 1 0.589 0.622 0.592 0.638 0.586 0.589 0.576 0.592 0.592 0.586 0.586 0.592 2 0.667 0.600 0.533 0.633 0.367 0.533 0.500 0.533 0.467 0.533 0.367 0.567 3 0.568 0.611 0.655 0.708 0.533 0.570 0.655 0.670 0.533 0.572 0.655 0.670 4 0.218 0.307 0.327 0.337 0.248 0.218 0.297 0.238 0.238 0.218 0.307 0.248 5 0.727 0.741 0.755 0.733 0.755 0.748 0.755 0.748 0.747 0.755 0.755 0.747 6 0.669 0.633 0.633 0.656 0.684 0.691 0.656 0.668 0.676 0.684 0.676 0.662 7 0.350 0.258 0.258 0.564 0.252 0.258 0.252 0.550 0.248 0.248 0.262 0.556 8 0.623 0.636 0.623 0.630 0.617 0.630 0.623 0.623 0.623 0.630 0.623 0.623 9 0.597 0.591 0.597 0.578 0.584 0.565 0.597 0.584 0.597 0.526 0.552 0.587 10 0.844 0.859 0.863 0.863 0.844 0.863 0.849 0.868 0.859 0.859 0.859 0.868 11 0.785 0.756 0.785 0.810 0.766 0.771 0.771 0.776 0.766 0.771 0.771 0.776 胜出 3 1 3 6 1 3 3 6 2 3 2 6 排名 2.86 2.82 2.55 1.77 3.09 2.41 2.50 1.91 2.86 2.64 2.55 1.86 表 4 不同Shapelet评价指标的Weighted-κ值
数据集 SVC1V1 SVOREX SVORIM IG $ \rho $ $ \gamma $ $ \sigma $ IG $ \rho $ $ \gamma $ $ \sigma $ IG $ \rho $ $ \gamma $ $ \sigma $ 1 0.129 0.177 0.156 0.132 0.079 0.099 0.115 0.109 0.073 0.039 0.044 0.122 2 0.655 0.534 0.478 0.504 0.429 0.268 0.340 0.562 0.396 0.363 0.409 0.552 3 0.151 0.398 0.489 0.575 0.000 0.378 0.378 0.528 0.000 0.378 0.378 0.548 4 0.063 0.009 0.156 0.174 0.000 0.000 0.000 0.026 0.008 0.000 0.000 0.054 5 0.587 0.637 0.622 0.612 0.615 0.580 0.573 0.641 0.615 0.591 0.573 0.612 6 0.783 0.775 0.808 0.810 0.829 0.780 0.837 0.821 0.813 0.777 0.831 0.830 7 0.238 0.020 0.042 0.541 0.000 0.006 0.149 0.548 0.000 0.064 0.096 0.546 8 0.254 0.228 0.260 0.255 0.244 0.254 0.264 0.246 0.252 0.252 0.213 0.250 9 0.688 0.735 0.691 0.722 0.676 0.698 0.715 0.708 0.679 0.707 0.715 0.710 10 0.751 0.771 0.746 0.789 0.742 0.771 0.780 0.778 0.742 0.771 0.780 0.785 11 0.875 0.867 0.884 0.884 0.856 0.858 0.869 0.880 0.856 0.858 0.876 0.876 胜出 1 3 2 6 0 0 5 6 2 1 3 7 排名 3.09 2.73 2.41 1.77 3.36 3.05 1.95 1.64 2.95 3.14 2.41 1.50 -
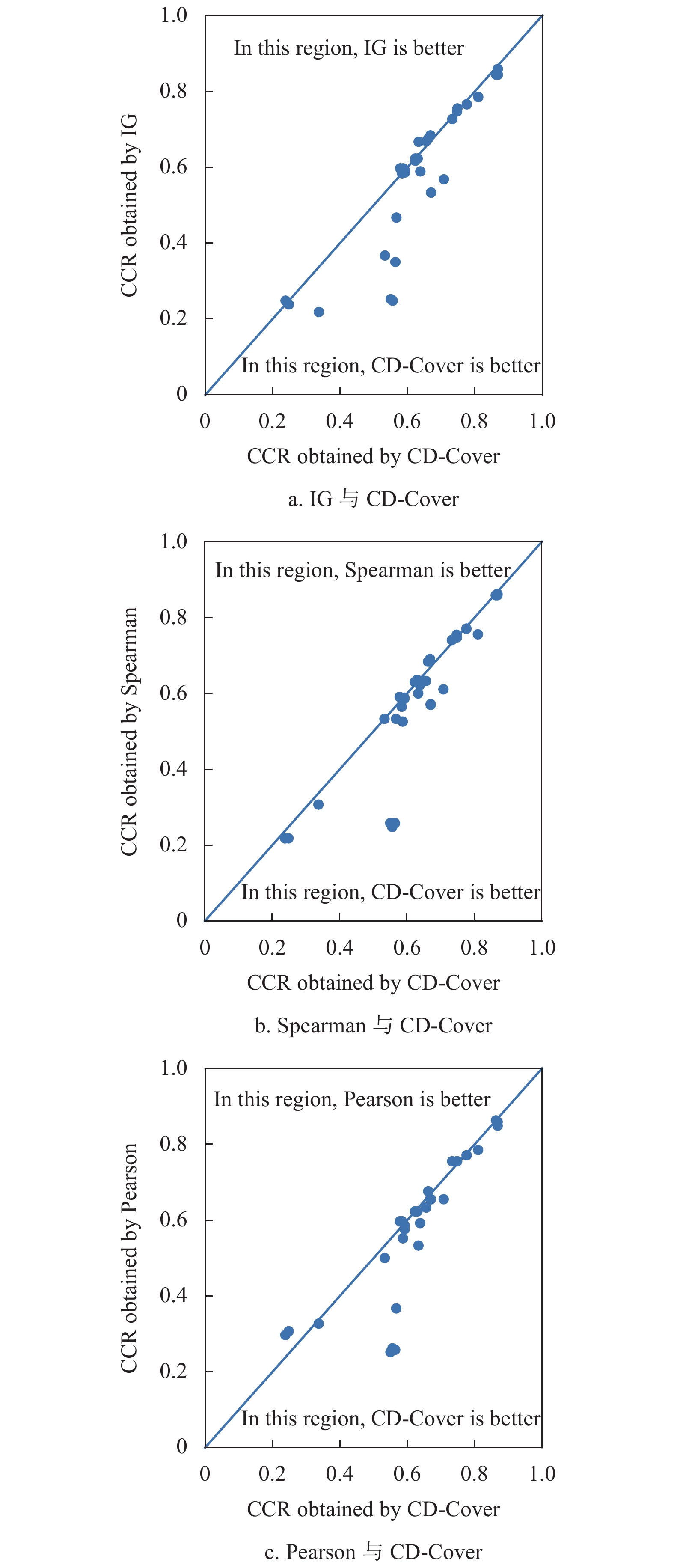
为了更清晰地对实验结果进行分析,将3.2节的实验数据绘制为散点图,如图2所示。3个散点图分别代表CD-Cover与IG、Spearman相关系数和Pearson相关系数在3种算法、11个数据集上“一对一”比较的结果,每个散点图中散点数目合计33个。图2的横坐标和纵坐标分别表示采用CD-Cover指标与对比指标得到的CCR值。散点如果正好处于对角线上,表明采用两种指标得到的CCR值相同;如果散点处于对角线右下方,表明采用CD-Cover指标得到的CCR值更优;如果散点处于对角线左上方,表明采用对比指标得到的CCR值更优。从图2可以发现,大多数散点处于对角线右下方,或者在对角线附近;明显处于对角线左上方的散点数目较少。
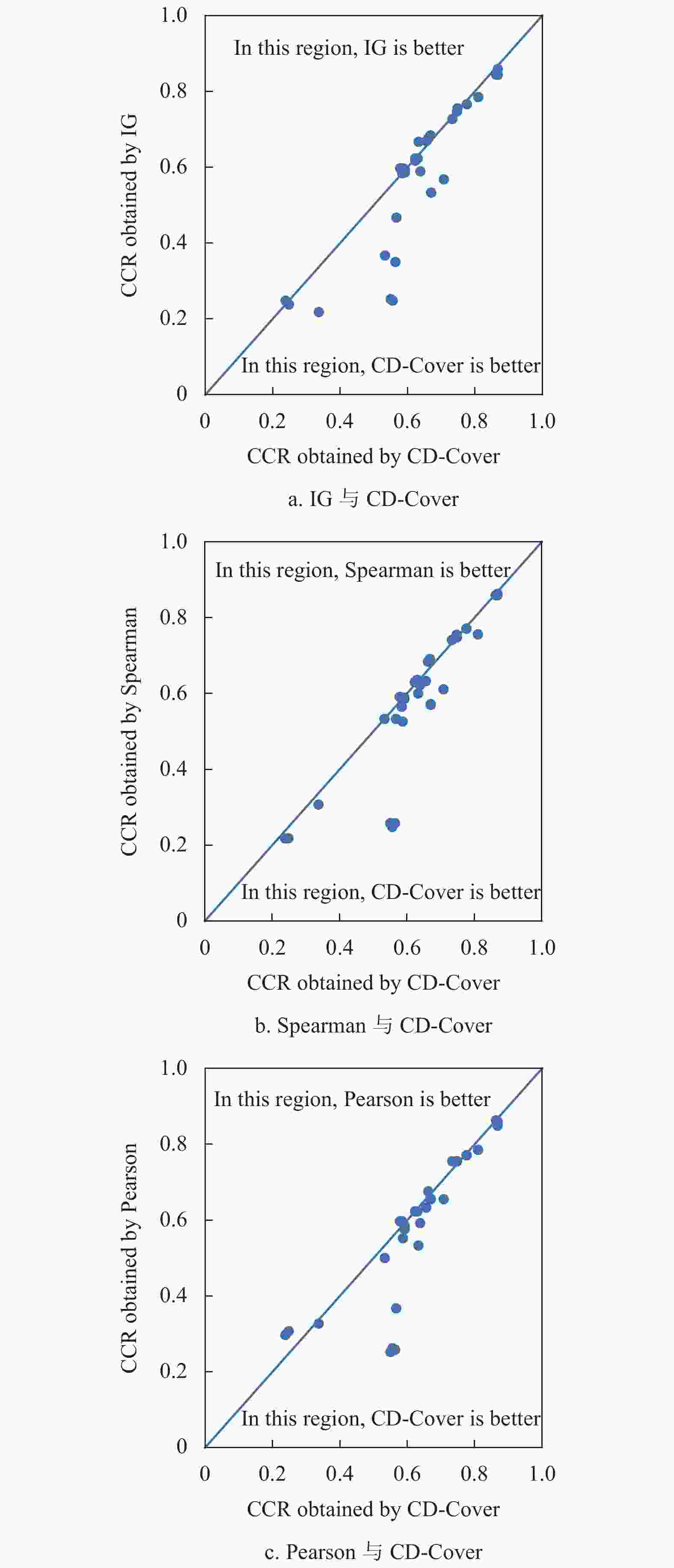
图 2 CD-Cover与3个指标的CCR值比较
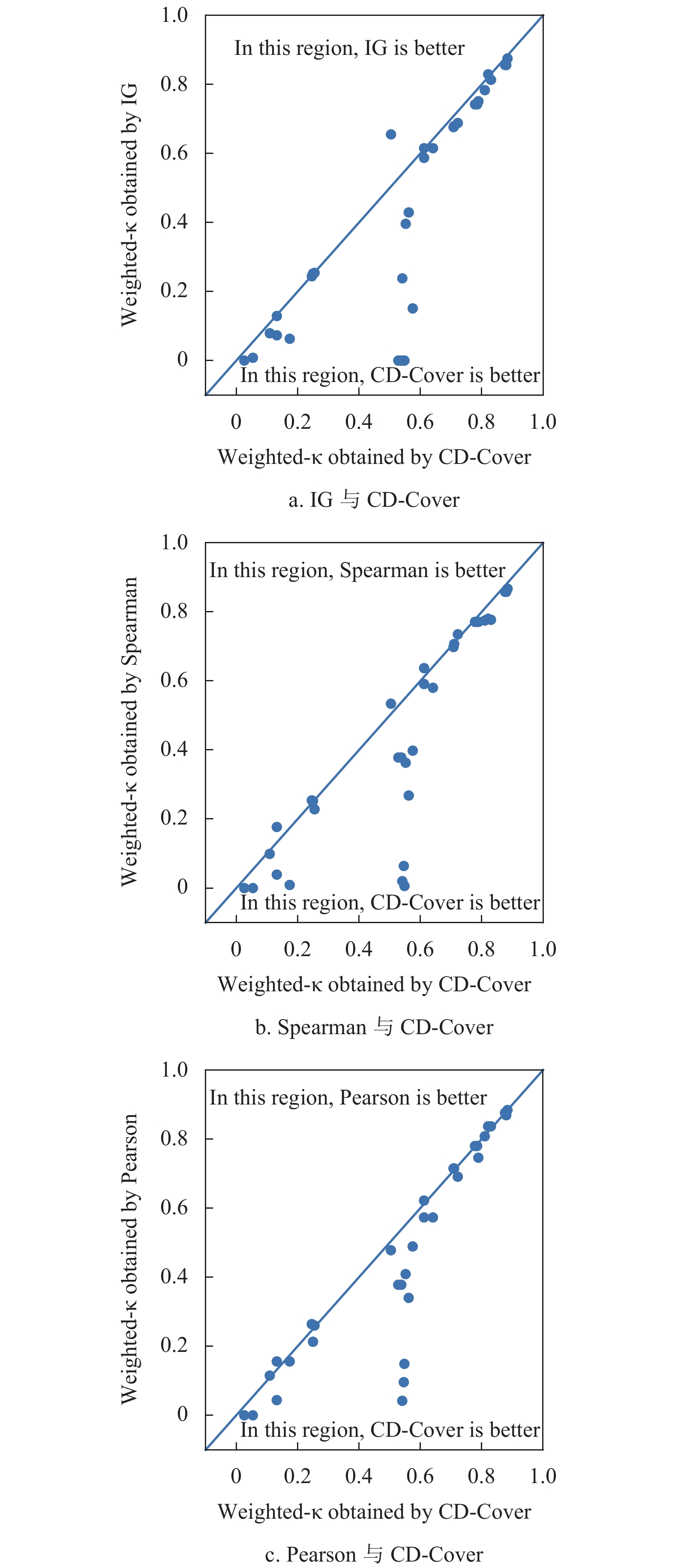
图3为采用CD-Cover指标与采用3个对比指标得到的Weighted-κ值对比结果。图3的横坐标和纵坐标分别表示采用CD-Cover指标与对比指标得到的Weighted-κ值。可以发现,图3的大多数散点都处于对角线右下方区域,且相对图2而言,偏离对角线更明显。图2和图3表明,与采用的3种对比指标相比,CD-Cover指标无论是CCR还是Weighted-κ,都能得到更好的结果。
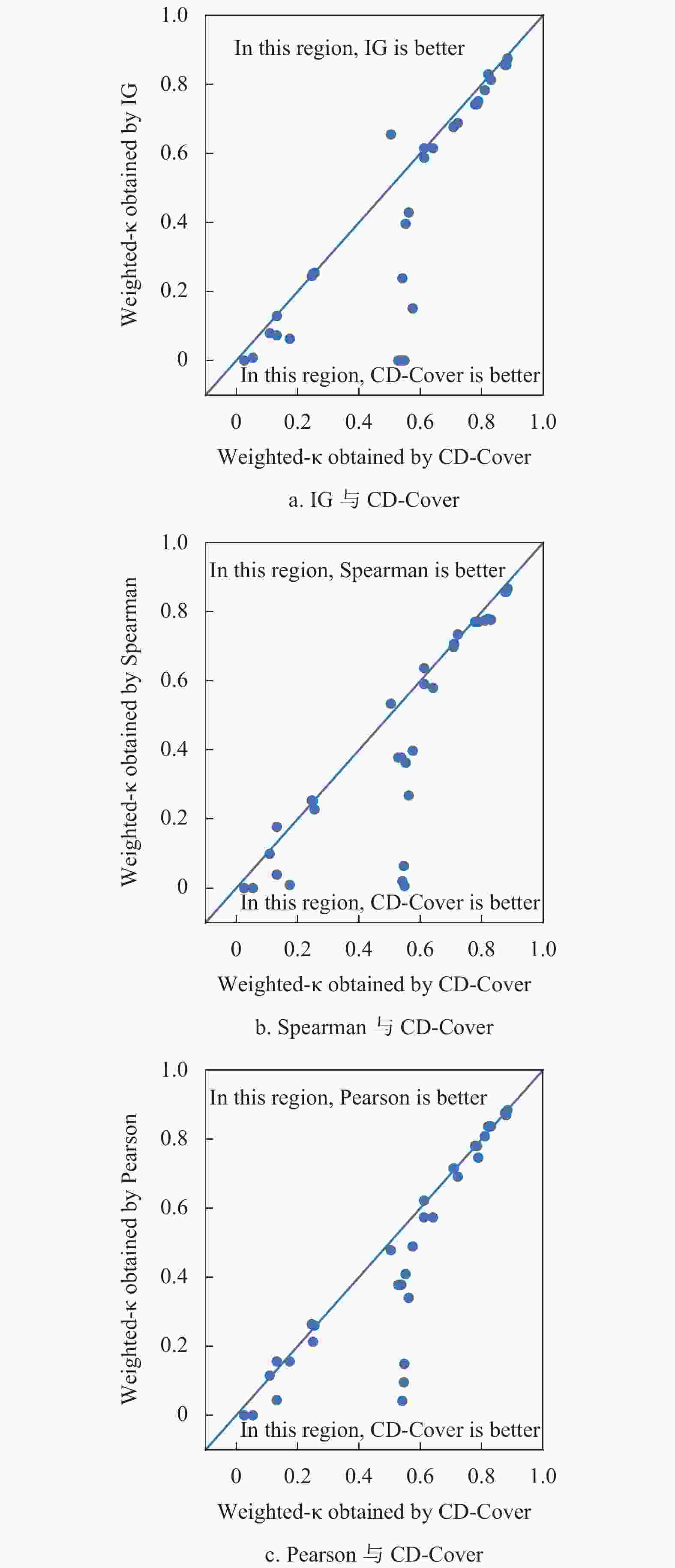
图 3 CD-Cover与3个指标的Weighted-κ值比较
-
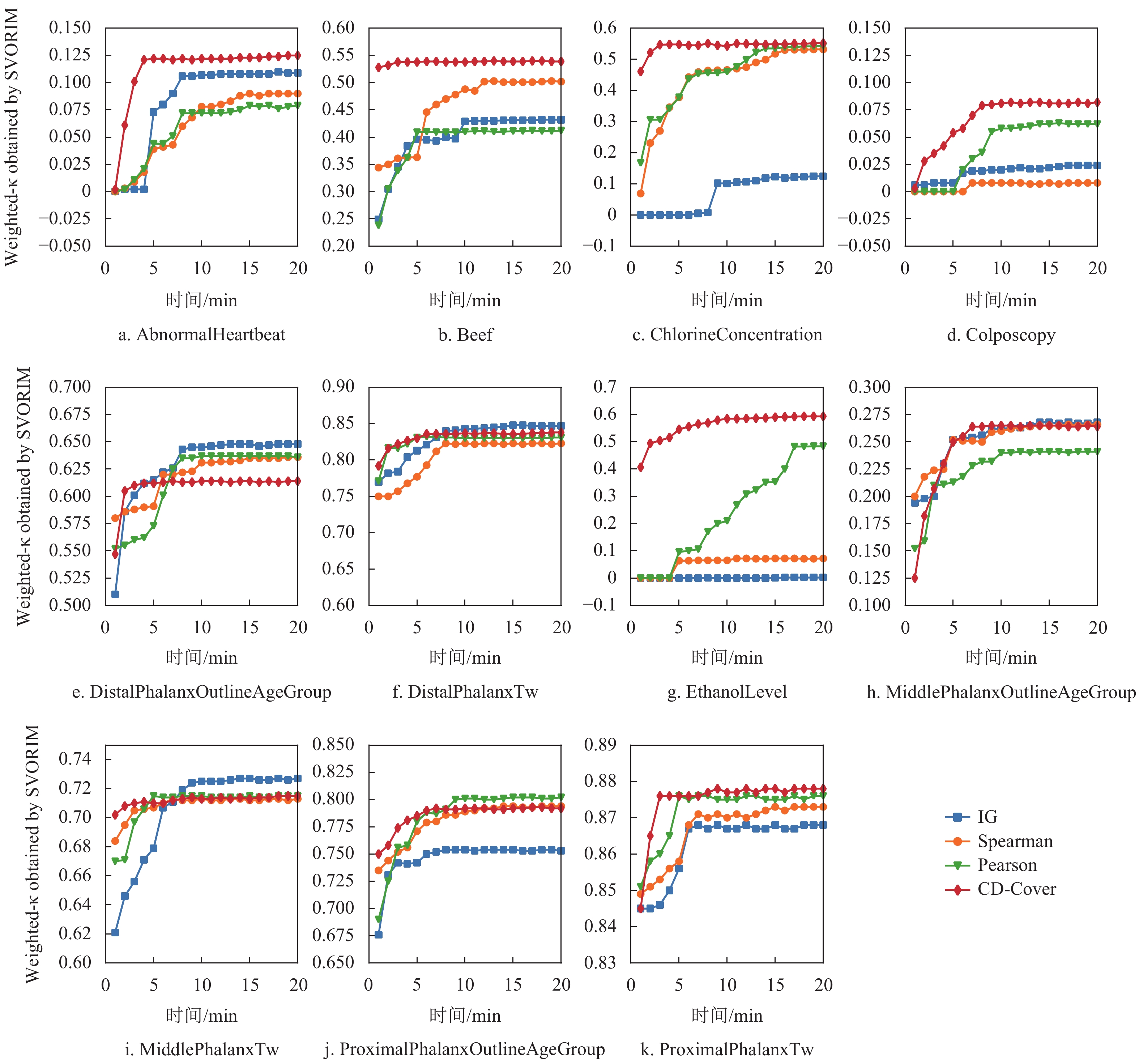
参与比较的仍然是3.3节的4种评价指标。区别在于,IG、Spearman和Pearson相关系数不需要将原始时间序列进行SAX表示。有序分类器只选择SVORIM分类器,分类器的评价指标选择Weighted-κ。基于不同Shapelet评价指标的Shapelet抽取算法均持续运行20 min,并记录下每分钟的Weighted-κ值。为保证稳定性,实验结果为50次实验的均值,结果如图4所示。
图4的每个子图4a~图4k分别对应单个数据集的实验结果。所有子图的横坐标均表示Shapelet抽取算法的执行时间(min),纵坐标表示基于不同评价指标抽取的Shapelet训练的SVORIM分类器,在测试数据集上获得的Weighted-κ值。分析图4可以发现:1)在不同执行时间内,基于CD-Cover指标抽取Shapelet训练分类器的结果,整体上优于其他3种评价指标;2)基于CD-Cover指标抽取Shapelet,在较短时间内就能获得高质量的抽取结果(Colposcopy数据集为8 min,其余数据集均为2~5 min)。根据上述实验结果可知,本文所提的CD-Cover评价指标在计算效率上明显优于其他3个评价指标,因为给定相同时间限制,基于CD-Cover指标的方法能够评估更多的Shapelet。

图 4 不同评价指标计算效率对比
-
针对当前基于Shapelet的时间序列有序分类研究中,采用Spearman相关系数和Pearson相关系数进行Shapelet抽取时计算效率较低的问题,本文提出了一种基于SAX表示时间序列的Shapelet评价指标CD-Cover,以及一种基于随机采样的Shapelet抽取算法。在11个时间序列数据集上进行了实验。实验结果证明了CD-Cover评价指标以及所提Shapelet抽取算法的有效性,且展示了其在计算效率上的优越性。下一步将继续研究时间序列长度不相等的情况,并将算法扩展至多元时间序列,并结合实际应用对时间序列有序分类问题进行深入研究。
Shapelet Extraction Algorithm for Time Series Ordinal Classification
-
摘要: 当前面向时间序列有序分类的Shapelet抽取算法,首先计算Shapelet与时间序列之间的欧式距离及其类别标签之间的距离,然后根据两种距离的皮尔逊相关系数或斯皮尔曼相关系数来对Shapelet进行评价,效率较低。针对该问题,提出一种基于SAX表示时间序列的Shapelet评价指标CD-Cover,该指标同时考虑Shapelet对时间序列数据集的覆盖集中度和覆盖优势度。其次,提出一种基于随机采样的Shapelet抽取算法,该算法采用布隆过滤器对候选Shapelet进行预剪枝,采用移除自相似策略对抽取结果进行后剪枝。在11个时间序列公开数据集上的实验结果表明,相比现有方法,该算法抽取的Shapelet具有更好的有序分类能力,且算法的计算效率也更高。Abstract: The current Shapelet extraction algorithm for time series ordinal classification, which suffers from low efficiency, needs to figure out the Pearson's correlation coefficient or the Spearman's correlation coefficient between the Euclidean distances and the label distances from time series to Shapelets to evaluate the Shapelets. To handle this problem, this paper first proposes a Shapelet measure CD-Cover (concentration and dominance of coverage) based on the SAX (symbolic aggregate approximation)-represented time series. The measure takes into account both the concentration and the dominance of coverage of a Shapelet on the time series dataset. Secondly, this paper also proposes a Shapelet extraction algorithm based on random sampling. The algorithm uses the Bloom filter to pre-prune Shapelet candidates and employs a strategy of removing self-similar Shapelets to post-prune the extracting results. Experimental results on 11 time series public datasets show that the Shapelet extracted by the proposed algorithm has better ability for ordinal classification than the existing methods, and meanwhile, the computing efficiency of the proposed algorithm is superior to that of the existing methods.
-
Key words:
- feature evaluation /
- ordinal classification /
- Shapelet /
- time series
-
表 1 实验数据集
编号 数据集 训练
样本测试
样本标签数 序列
长度1 AbnormalHeartbeat 302 304 5 3053 2 Beef 30 30 5 470 3 ChlorineConcentration 467 3840 3 166 4 Colposcopy 99 101 6 180 5 DistalPhalanxOutlineAgeGroup 400 139 3 80 6 DistalPhalanxTW 400 139 6 80 7 EthanolLevel 504 500 4 1751 8 MiddlePhalanxOutlineAgeGroup 400 154 3 80 9 MiddlePhalanxTW 399 154 6 80 10 ProximalPhalanxOutlineAgeGroup 400 205 3 80 11 ProximalPhalanxTW 400 205 6 80  下载: 导出CSV
下载: 导出CSV
表 3 不同Shapelet评价指标的CCR值
数据集 SVC1V1 SVOREX SVORIM IG $ \rho $ $ \gamma $ $ \sigma $ IG $ \rho $ $ \gamma $ $ \sigma $ IG $ \rho $ $ \gamma $ $ \sigma $ 1 0.589 0.622 0.592 0.638 0.586 0.589 0.576 0.592 0.592 0.586 0.586 0.592 2 0.667 0.600 0.533 0.633 0.367 0.533 0.500 0.533 0.467 0.533 0.367 0.567 3 0.568 0.611 0.655 0.708 0.533 0.570 0.655 0.670 0.533 0.572 0.655 0.670 4 0.218 0.307 0.327 0.337 0.248 0.218 0.297 0.238 0.238 0.218 0.307 0.248 5 0.727 0.741 0.755 0.733 0.755 0.748 0.755 0.748 0.747 0.755 0.755 0.747 6 0.669 0.633 0.633 0.656 0.684 0.691 0.656 0.668 0.676 0.684 0.676 0.662 7 0.350 0.258 0.258 0.564 0.252 0.258 0.252 0.550 0.248 0.248 0.262 0.556 8 0.623 0.636 0.623 0.630 0.617 0.630 0.623 0.623 0.623 0.630 0.623 0.623 9 0.597 0.591 0.597 0.578 0.584 0.565 0.597 0.584 0.597 0.526 0.552 0.587 10 0.844 0.859 0.863 0.863 0.844 0.863 0.849 0.868 0.859 0.859 0.859 0.868 11 0.785 0.756 0.785 0.810 0.766 0.771 0.771 0.776 0.766 0.771 0.771 0.776 胜出 3 1 3 6 1 3 3 6 2 3 2 6 排名 2.86 2.82 2.55 1.77 3.09 2.41 2.50 1.91 2.86 2.64 2.55 1.86
下载: 导出CSV
表 4 不同Shapelet评价指标的Weighted-κ值
数据集 SVC1V1 SVOREX SVORIM IG $ \rho $ $ \gamma $ $ \sigma $ IG $ \rho $ $ \gamma $ $ \sigma $ IG $ \rho $ $ \gamma $ $ \sigma $ 1 0.129 0.177 0.156 0.132 0.079 0.099 0.115 0.109 0.073 0.039 0.044 0.122 2 0.655 0.534 0.478 0.504 0.429 0.268 0.340 0.562 0.396 0.363 0.409 0.552 3 0.151 0.398 0.489 0.575 0.000 0.378 0.378 0.528 0.000 0.378 0.378 0.548 4 0.063 0.009 0.156 0.174 0.000 0.000 0.000 0.026 0.008 0.000 0.000 0.054 5 0.587 0.637 0.622 0.612 0.615 0.580 0.573 0.641 0.615 0.591 0.573 0.612 6 0.783 0.775 0.808 0.810 0.829 0.780 0.837 0.821 0.813 0.777 0.831 0.830 7 0.238 0.020 0.042 0.541 0.000 0.006 0.149 0.548 0.000 0.064 0.096 0.546 8 0.254 0.228 0.260 0.255 0.244 0.254 0.264 0.246 0.252 0.252 0.213 0.250 9 0.688 0.735 0.691 0.722 0.676 0.698 0.715 0.708 0.679 0.707 0.715 0.710 10 0.751 0.771 0.746 0.789 0.742 0.771 0.780 0.778 0.742 0.771 0.780 0.785 11 0.875 0.867 0.884 0.884 0.856 0.858 0.869 0.880 0.856 0.858 0.876 0.876 胜出 1 3 2 6 0 0 5 6 2 1 3 7 排名 3.09 2.73 2.41 1.77 3.36 3.05 1.95 1.64 2.95 3.14 2.41 1.50
下载: 导出CSV
-
[1] 李海林, 贾瑞颖, 谭观音. 基于K-Shape的时间序列模糊分类方法[J]. 电子科技大学学报, 2021, 50(6): 899-906. LI H L, JIA R Y, TAN G Y. Fuzzy classification for time series data based on K-shape[J]. Chinese Journal of University of Electronic Science and Technology of China, 2021, 50(6): 899-906. [2] GUIJO-RUBIO D, GUTIÉRREZ P A, BAGNALL A J, et al. Time series ordinal classification via shapelets[C]//Proceedings of the 2020 International Joint Conference on Neural Networks. Glasgow: IEEE, 2020: 1-8. [3] 王子一, 商琳. 基于子段距离计算的时间序列分类方法[J]. 小型微型计算机系统, 2018, 39(7): 1386-1389. WANG Z Y, SHANG L. New method of time series classification based on sub-sequence distance computation[J]. Chinese Journal of Chinese Computer Systems, 2018, 39(7): 1386-1389. [4] 闫汶和, 李桂玲. 基于shapelet的时间序列分类研究[J]. 计算机科学, 2019, 46(1): 29-35. doi: 10.11896/j.issn.1002-137X.2019.01.005 YAN W H, LI G L. Research on time series classification based on shapelet[J]. Chinese Journal of Computer Science, 2019, 46(1): 29-35. doi: 10.11896/j.issn.1002-137X.2019.01.005 [5] 赵超, 王腾江, 刘士军, 等. 融合选择提取与子类聚类的快速Shapelet发现算法[J]. 软件学报, 2020, 31(3): 763-777. doi: 10.13328/j.cnki.jos.005912 ZHAO C, WANG T J, LIU S J, et al. Fast shapelet discovery algorithm combining selective extraction and subclass clustering[J]. Chinese Journal of Software, 2020, 31(3): 763-777. doi: 10.13328/j.cnki.jos.005912 [6] YE L, KEOGH E. Time series shapelets: A new primitive for data mining[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Paris: ACM, 2009: 947-956. [7] HILLS J, LINES J, BARANAUSKAS E, et al. Classification of time series by shapelet transformation[J]. Data Mining and Knowledge Discovery, 2014, 28(4): 851-881. doi: 10.1007/s10618-013-0322-1 [8] MUEEN A, KEOGH E, YOUNG N. Logical-Shapelets: An expressive primitive for time series classification[C]// Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Diego: ACM, 2011: 1154-1162. [9] KEOGH E, RAKTHANMANON T. Fast Shapelets: A scalable algorithm for discovering time series shapelets[C]// Proceedings of the 13th SIAM International Conference on Data Mining. Austin: SIAM, 2013: 668-676. [10] WISTUBA M, GRABOCKA J, SCHMIDT-THIEME L. Ultra-Fast shapelets for time series classification[EB/OL]. [2022-07-21]. https://arxiv.org/pdf/1503.05018v1.pdf. [11] KARLSSON I, PAPAPETROU P, BOSTRÖM H. Generalized random shapelet forests[J]. Data Mining and Knowledge Discovery, 2016, 30(5): 1053-1085. doi: 10.1007/s10618-016-0473-y [12] YANG J, JING S Y, HUANG G Y. Accurate and fast time series classification based on compressed random Shapelet Forest[J]. Applied Intelligence, 2022, DOI: 10.1007/s10489-022-03852-2. [13] LI G Z, CHOI B, XU J L, et al. ShapeNet: A shape-let-neural network approach for multivariate time series classification[C]//Proceedings of the 35th AAAI Confer-ence on Artificial Intelligence. Virtual Event: AAAI, 2021: 8375-8383. [14] MA Q L, ZHUANG W Q, LI S, et al. Adversarial dynamic shapelet networks[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York: AAAI Press, 2020: 5069-5076. [15] GUIJO-RUBIO D, GUTIÉRREZ P A, BAGNALL A J, et al. Ordinal versus nominal time Series classification[C]//Proceedings of the Advanced Analytics and Learning on Temporal Data-5th ECML PKDD. Ghent: Springer, 2020: 19-29. [16] BAGNALL A, LINES J, VICKERS W, et al. The UEA & UCR time series classification repository[EB/OL]. [2022-07-31]. http://www.timeseriesclassification.com. [17] LIN J, KEOGH E, LONARDI S, et al. A symbolic representation of time series, with implications for streaming algorithms[C]//Proceedings of the 8th ACM SIGMOD workshop on Research issues in data mining and knowledge discovery. San Diego: ACM, 2003: 2-11. [18] LI G Z, CHOI B, XU J L, et al. Efficient shapelet discovery for time series classification[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(3): 1149-1163. doi: 10.1109/TKDE.2020.2995870 [19] YAN W H, Li G L, WU Z D, et al. Extracting diverse-shapelets for early classification on time series[J]. World Wide Web, 2020, 23(6): 3055-3081. doi: 10.1007/s11280-020-00820-z [20] GUTIÉRREZ P A, PÉREZ-ORTIZ M, SÁNCHEZ-MONEDERO J, et al. Ordinal regression methods: Survey and experimental study[J]. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(1): 127-146. doi: 10.1109/TKDE.2015.2457911 [21] HSU C W, LIN C J. A comparison of methods for multiclass support vector machines[J]. IEEE Transactions on Neural Networks, 2002, 13(2): 415-425. doi: 10.1109/72.991427 [22] CHU W, KEERTHI S S. Support vector ordinal regression[J]. Neural Computation, 2007, 19(3): 792-815. doi: 10.1162/neco.2007.19.3.792 [23] SAKAI T. Evaluating evaluation measures for ordinal classification and ordinal quantification[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics. Virtual Event: Association for Computational Linguistics, 2021: 2759-2769. -

 点击查看大图
点击查看大图

图(4) / 表(4)
计量
- 文章访问数: 4071
- HTML全文浏览量: 1065
- PDF下载量: 43
- 被引次数: 0
























































































































































































































