 ISSN
ISSN 


-
随着社会的飞速发展,我国私家车的数量也逐年增加。同时,汽车登记数量和机动车驾驶人数量的上升,使交通拥堵现象愈发明显。智慧交通系统旨在借助先进的信息与通信技术提供高效快捷的出行服务,其中,路径规划作为智慧交通系统的核心技术之一,它的研究进展直接影响着智慧交通系统的部署。
目前,路径规划算法主要分为静态路径规划和动态路径规划。在静态路径规划中,路段的权值不会随着时间发生变化,典型的算法如Dijkstra算法[1]、A*算法[2]、蚁群算法[3]等等。Xu等使用双向搜索策略来改进传统A*算法来加快搜索的效率[4]。Lee等人利用遗传算法改进蚁群算法中的影响信息素的参数,提高了算法的收敛性能和最优解寻找能力[5]。但是路网具有动态性,前一时刻的还畅通无阻的路段,有可能在车辆到达时变得拥堵,而固定的路段权值很难适应动态的路网,难以避开拥堵。相对于静态路径规划,动态路径规划算法考虑了时变的路段权值,在行进过程中不断获取实时路况,重新计算路段的权值并更新修正路线,以此避开拥堵,如典型D*算法。Ramkumar研究了基于车载自组织网络VANET的动态路径规划,降低了车辆的行驶成本和提高了避开拥堵的能力[6],Noguchi利用人工势场法结合强化学习的方式来在动态环境中得到安全的路径[7]。虽然动态路径规划算法通过周期性重规划的措施可以在一定程度上避开拥堵,但只考虑当前时刻的路况,没有从全局角度出发考虑路径在未来时刻的潜力,很难得到全局最优的路径[8]。
本文通过分析大量历史交通流数据的时空相关性预测未来时刻的交通流参数,再通过熵权法和模糊综合判定得出拥堵状态分级,之后综合考虑当前时刻和未来时刻拥堵状况规划出更加合理的路径。
-
交通流预测通过分析历史交通流中的流动趋势,对未来时刻的交通流给出预测结果,可以看做是一类序列预测问题。然而,交通流序列呈现出一种复杂和动态的时空相关性[1],对于路网中的每一个节点,在同一时刻,邻居节点会对它影响,这是空间相关性。此外,每一个节点也可能受到过去时刻自己的影响,这是时间相关性。
在空间相关性建模方面,目前的主流方案是ChebNet图卷积[2],卷积核
$\Theta $ 和图信号$ x $ 在时域上的卷积结果如式(1)所示。$$ \Theta {*}_{g}x={\sum }_{k=0}^{K-1}{\theta }_{k}{T}_{k}\left(\bar{L}\right)x$$ (1) 其中
$ {\theta }_{k} $ 是切比雪夫多项式系数,K是卷积核的感受野半径,$ L=D-A $ 是图的拉普拉斯矩阵,由邻接矩阵$ A $ 和度矩阵$ D $ 计算得来。$ \bar{L}=2L/{\lambda }_{max}-{I}_{n} $ 是归一化的拉普拉斯矩阵,$ {\lambda }_{max} $ 是拉普拉斯矩阵的最大特征值。$ {T}_{k}\left(\bar{L}\right) $ 是第$ k $ 阶的切比雪夫多项式,其中$ {T}_{0}\left(\bar{L}\right)={I}_{n} $ ,$ {T}_{1}\left(\bar{L}\right)=\bar{L} $ ,之后的结果通过式(2)进行推导。$$ {T}_{k}\left(\bar{L}\right)=2\bar{L}{T}_{k-1}\left(\bar{L}\right)-{T}_{k-2}\left(\bar{L}\right) $$ (2) 式(2)中,由于
$ {T}_{0}\left(\bar{L}\right)={I}_{n} $ ,$ {T}_{0}\left(\bar{L}\right)x $ 使得图中每个节点都提取了自己的信息。$ {T}_{1}\left(\bar{L}\right) $ 中的所有非零元素都是1阶邻居和当前节点本身,如果将本身作为0阶邻居节点,那么$ {T}_{1}\left(\bar{L}\right)x $ 使得图中每个节点都提取了0阶到1阶邻居的信息。以此类推,$ {T}_{k}\left(\bar{L}\right)x $ 使得每个节点都提取了0阶到k阶邻居的信息。最终这些信息通过切比雪夫多项式系数$ {\theta }_{k} $ 进行加权求和,这些系数决定哪一阶的邻居提供更多的信息。而同一阶邻居对当前节点的不同影响程度由邻接矩阵$ A $ 进行区分。在时间相关性建模方面,目前主流的方案主要有循环卷积神经网络RNN[11]和卷积神经网络CNN[4]。CNN模型一般空间维度的卷积核大小为1,步长为1,使得只在时间维度聚集信息。时间维度的卷积核大小为
$ {K}_{t} $ ,步长为1,使得每一个节点都聚集了当前时刻以及$ {K}_{t}-1 $ 个邻近历史时刻的信息。路阻函数表述了路段的通行时间与路段上采集到的交通流参数之间的关系,BPR路阻函数如式(3)所示[13]:
$$t={t}^{0}\frac{2}{1\pm \sqrt{1-Q/C}}$$ (3) 其中,
$ t $ 是通行时间,$ {t}^{0} $ 是自由行驶时的通行时间。$ C $ 是路段通行能力,是流量$ Q $ 能够达到的理论最大值,如式(4)所示:$$ C={Q}_{max}=\frac{{V}_{f}{K}_{j}}{4} $$ (4) 其中
$ {K}_{j} $ 是阻塞时的交通密度,$ {V}_{f} $ 是自由行驶时的通行速度。 -
本文的拥堵预测模型主要包括交通流预测和拥堵状态判定两个阶段。交通流预测模型对路网中的时空相关性进行建模,然后对未来时刻的交通流参数进行预测。拥堵状态判定模块在给定交通流参数的情况下,对拥堵状态进行分级判定。
-
在ChebNet模型中,同一阶邻居节点对当前节点的不同影响程度由邻接矩阵区分,邻接矩阵的构建,主要有基于连接和基于距离这两种方式。基于连接的邻接矩阵只表达了连接关系,没有对同一阶的邻居节点做区分。基于距离的邻接矩阵单一使用距离作为区分标准,不够全面。
针对上述问题,本文采用三维权重矩阵
$ W\in {R}^{K\times N\times N} $ 进行优化,其中第一个维度是切比雪夫多项式的阶数,后面两个维度为路网节点数量,并按照式(5)进行初始化。$${w}_{ij}^{k}=\left\{ {\begin{array}{*{20}{c}} 1&{{T}_{k}\left(\bar{L}\right)}_{ij}!=0\\ 0&\mathrm{否}\mathrm{则} \end{array}} \right.$$ (5) 使用权重矩阵后的图卷积式如(6)所示。
$$ \Theta {*}_{g}x={\sum }_{k=0}^{K-1}{\theta }_{k}{(w}^{k}{\odot T}_{k}\left(\bar{L}\right))x $$ (6) 通过可训练参数
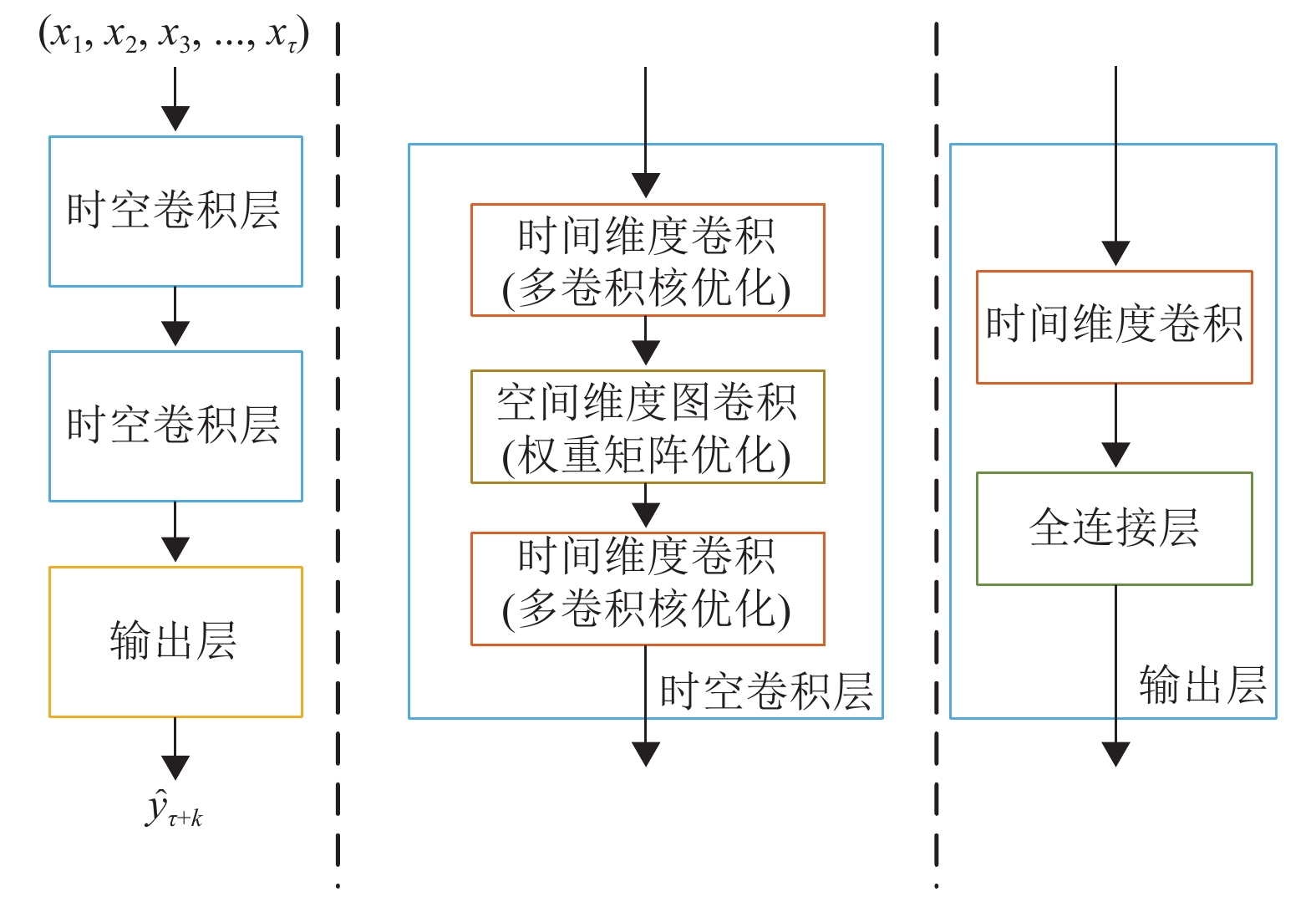
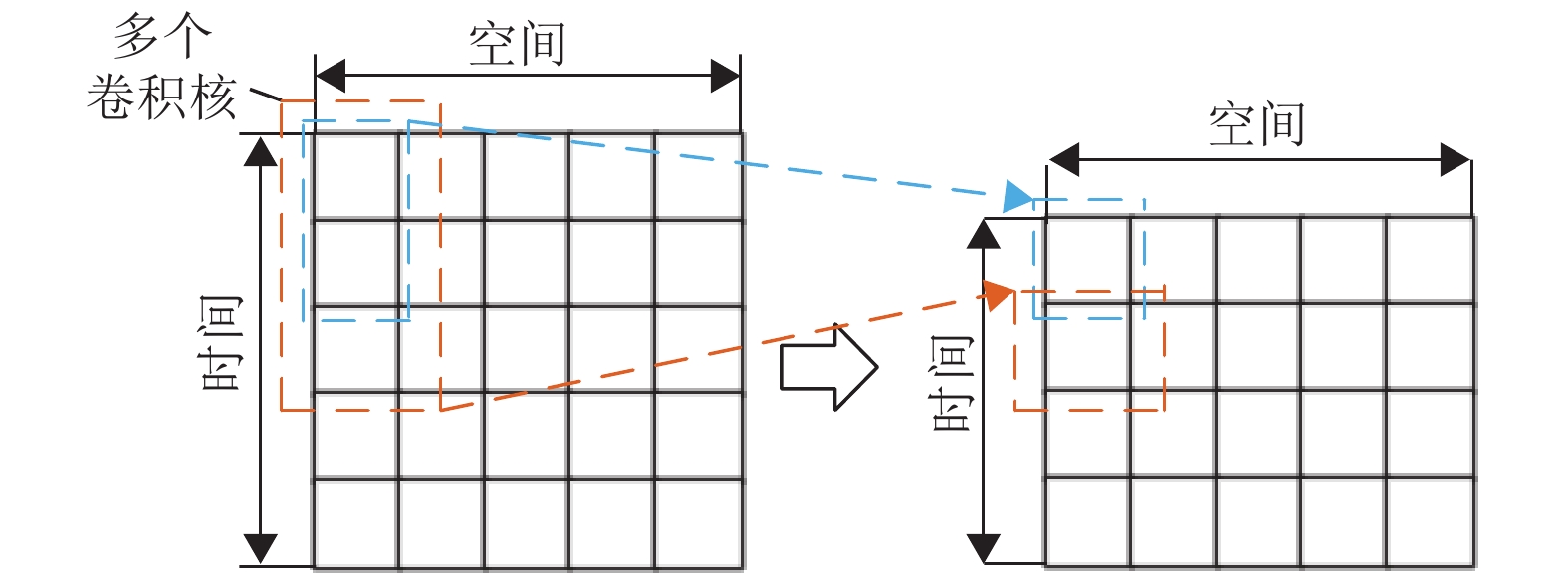
$ {w}^{k} $ ,可以自适应的调整同一阶邻居的影响程度。时间相关性提取方面,本文改进了传统的CNN模型,如图1所示。其中横轴代表空间信息,表示当前路网中所有节点在同一时刻采集到的交通参数。纵轴代表时间信息,从上往下是路网中每个节点严格按照时间顺序采集到的交通参数序列。在空间维度,卷积核的长度为1,相当于在卷积的过程中只聚集时间维度的信息,并且空间维度的卷积步长也为1,从而对路网中的所有节点都提取时间相关性。在时间维度,使用不同大小的卷积核进行卷积。使用多个卷积核进行卷积后,时间轴上越靠后的时刻能聚集到更多的信息,从而尽可能的提高信息利用率,增加卷积的感受野,提高时间相关性的提取能力。

图 1 提取时间相关性的CNN模型
本文采取的交通流预测模型如图2所示,使用时空图卷积层提取时空相关性。时空图卷积层由上述的一个图卷积和两个时间维度卷积堆叠而成。模型最后的输出通过时间维度卷积和全连接层转为为未来时刻的交通流参数。

图 2 交通流预测模型
-
拥堵状态评估主要分为单参数评估和多参数评估。单参数评估只使用到了一种交通流参数,根据输入参数的取值得到所在的区间,即为最终的拥堵状态判定结果。由于路网的复杂性,单参数不能够完全反映路网的通行状况,所以本文选取了多参数判定方案,通过熵权法为影响因子更高的参数赋予更高的权重,最后利用模糊综合法判定,综合考虑多参数后确定最终分级。具体步骤如下:
(a)假设样本长度为
$ k $ ,每个样本有$ n $ 种交通流参数,$ {d}_{il} $ 代表第$ i $ 个样本的第$ l $ 种交通流参数。(b)将样本归一化并计算第
$ i $ 个样本的第$ l $ 种参数占该种参数的比重$ {p}_{il} $ ,通过比重$ {p}_{il} $ 计算出第$ l $ 种参数的熵值$ {e}_{l} $ 和差异系数$ {g}_{l}=1-{e}_{l} $ ,如式(7)所示。$$ {e}_{l}=-\frac{1}{\mathrm{ln}\left(k\right){\displaystyle\sum }_{i=1}^{k}{p}_{il}\mathrm{ln}\left({p}_{il}\right)} $$ (7) (c)通过差异系数确定第
$ l $ 种参数的权值,某种交通流参数的差异系数越大,说明参数对拥堵状态的影响更大,如式(8)所示。$${w}_{l}=\frac{{g}_{l}}{{\displaystyle\sum }_{l=1}^{n}{g}_{l}} $$ (8) 确定好权重后,通过模糊综合判定进行拥堵分级。模糊综合判定的核心思想是不绝对的肯定与否定,而是利用隶属度来描述一个元素的归属问题,隶属度越接近1,那认为该元素归的归属度更高。具体步骤如下:
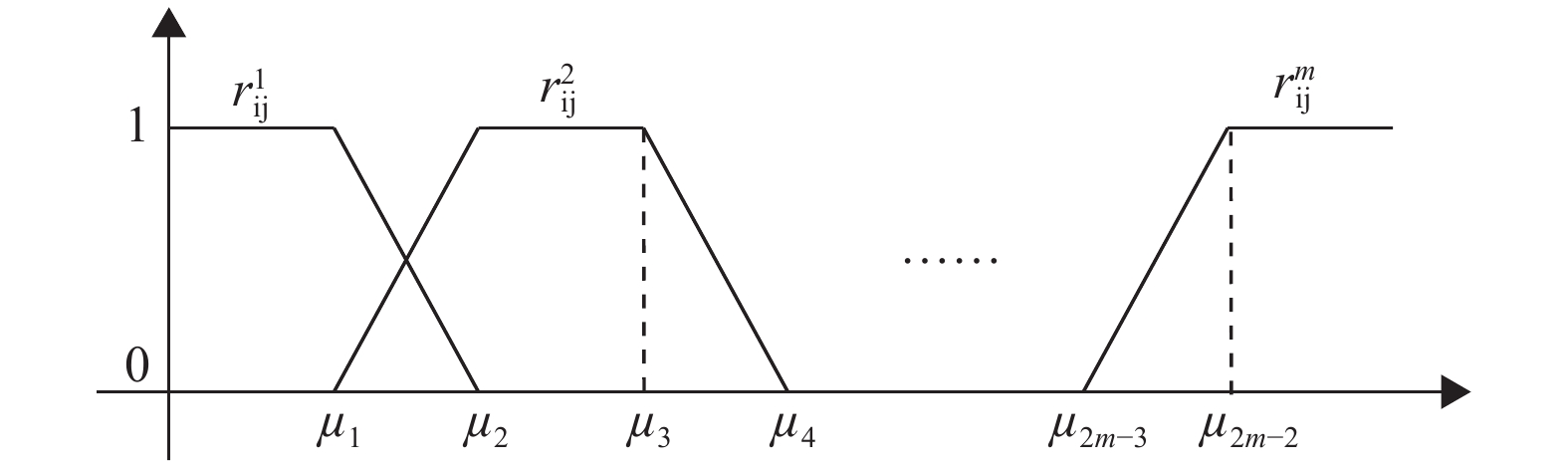
(a)确定每一种交通参数分级区间以及拥堵状态分级。假设有
$ m $ 种拥堵分级,$ \mathrm{{\rm H}}=\{{\mu }_{1},\cdots,{\mu }_{2m-2}\} $ 是对应的临界值。(b)计算参数
$ {d}_{il} $ 对应每一种拥堵分级的隶属度$ {r}_{il}^{m} $ ,采用梯形隶属度函数下的计算方式如图3所示。
图 3 隶属度函数
(c)综合考虑每一种参数,得到第
$ i $ 个样本的评价矩阵$ {P}_{i} $ ,如式(9)所示。$$ {P}_{i}=\left[{w}_{1},\cdots ,{w}_{n}\right]\left[\begin{array}{ccc}{r}_{i1}^{1}& \cdots & {r}_{i1}^{m}\\ \cdots & \cdots & \cdots \\ {r}_{in}^{1}& \cdots & {r}_{in}^{m}\end{array}\right]=\left[{p}_{1},\cdots ,{p}_{m}\right] $$ (9) 最终的拥堵分级为
$ \mathrm{m}\mathrm{a}\mathrm{x}({p}_{1},\cdots ,{p}_{m}) $ 所在的下标。 -
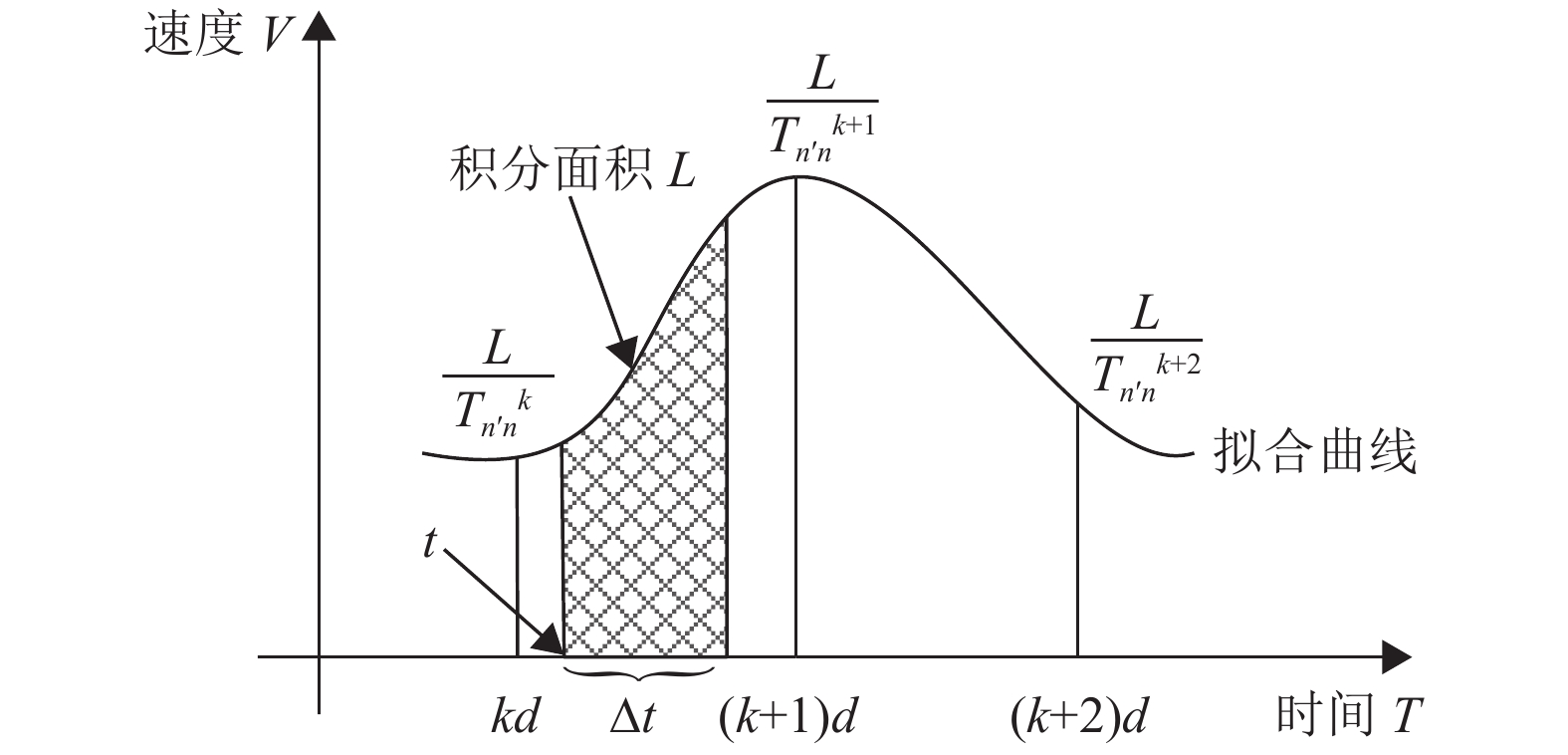
在路径规划中,计算路段的通行时间是非常重要的环节,是影响车辆在路网中行驶的重要因素。在基于拥堵预测的场景下,拥堵预测模型能够提供未来时刻的交通流参数以及拥堵状态,通过路阻函数可以将路段上采集到的交通流量转化为路段的通行时间。路段通行时间如图4所示。

图 4 路段通行时间
$ \mathrm{其}\mathrm{中}d $ 是预测的时间间隔,$ L $ 是该路段的长度,$ t $ 是进入路段的时刻。通过拥堵预测模型和分段路阻函数能够得到未来每个时刻的瞬时通行时间$ {T}_{ij}^{k} $ 和平均通行速度$ L/{T}_{ij}^{k} $ ,之后利用拟合补全拥堵预测未提供的细节,采用积分的方式将离散的信息组合成连续的形式。再从$ t $ 时刻开始积分,则路段在未来时刻的通过时间为积分面积$ L $ 的多边形在时间轴上的投影。上述路段通行时间的计算方法可以量化拥堵时长带来的影响,从而发现更有潜力的路段。并且能够及时规避拥堵,比如某些路段在进入时刻还是畅通状态,但在驶离阶段发生拥堵,那么这些影响会表现在路段的通行时间上,使得最短路径算法不再选择该路段,达到避开拥堵的目的。
计算完路段的通行时间后,路网中的每条路段都有了权重,之后可以通过路径规划算法搜索路径。
算法1 拥堵预测下的路径规划算法
1: 输入起点
$ {n}_{s} $ , 终点$ {n}_{g} $ , 开始时刻$ t $ 2: 通行时间矩阵
$ T=cal\_travelT\left(t\right) $ 3: 初始化
$ Q=\varnothing $ ,$ rhs\left({n}_{s}\right)=0 $ 4: for
$ n\in N:g\left(n\right)=\infty ,rhs\left(n\right)=\infty $ 5:
$ Q.add({n}_{s},key({n}_{s}\left)\right) $ 6: while
$ Q.minKey < key\left({n}_{g}\right)\left|\right|rhs\left({n}_{g}\right)\ne g\left({n}_{g}\right) $ 7:
$ n=Q.minNode\left(\right) $ 8: if
$ g\left(n\right) > rhs\left(n\right): $ 9:
$ g\left(n\right)=rhs\left(\right) $ 10: for
$ q\in Out\left(n\right):updateNode(q,g\left(q\right),T) $ 11: else:
12:
$ g\left(n\right)=\infty $ 13: for
$ q \in Out\left(n\right) \cup \left\{n\right\} : updateNode(q,g\left(q\right),T) $ 14: function
$ updateNode(n,g\left(n\right),T) $ 15: if
$ n\ne {n}_{g}: $ 16:
$ rhs\left(n\right) = {\mathrm{m}\mathrm{i}\mathrm{n}}_{n{\text{`}}\in In\left(n\right)}(g\left(n{\text{`}}\right) + cost(n{\text{`}},n,g\left(n\right)\left)\right) $ 17: if
$ n\in Q:Q.remove\left(n\right) $ 18: if
$ g\left(n\right)\ne rhs\left(n\right):Q.add(n,key(n\left)\right) $ 19: end function
如算法1所示,
$ out\left(n\right) $ 表示经过节点$ n $ 一跳能到达的节点,$ in\left(n\right) $ 表示一跳能到达$ n $ 的节点,$ g\left(n\right) $ 表示上一轮迭代中到达节点$ n $ 的最短时间。$ rhs\left(n\right) $ 表示当前迭代中到达节点$ n $ 的最短时间,计算方式如第16行所示,其中$ cost(n{\text{`}},n,g(n\left)\right) $ 是路段$ (n{\text{`}},n) $ 通行时间。如果$ g\left(n\right)\ne rhs\left(n\right) $ 表示当前迭代中$ g\left(n\right) $ 未同步到最优;如果$ g\left(n\right)=rhs\left(n\right) $ ,节点$ n $ 已经同步到最优。除此之外,启发因子$ key $ 如式(10)所示。$$ key\left(n\right)=\mathrm{min}\left(g\left(n\right),rhs\left(n\right)\right)+h\left(n,{n}_{g}\right) $$ (10) 式中
$ h\left(n,{n}_{g}\right) $ 是当前节点到终点的预估代价。在算法的初始化阶段,通过拥堵预测模型和分段路阻函数计算路网的瞬时通行时间矩阵,并设置起点的
$ rhs\left({n}_{s}\right) $ 为0,其余节点的$ g\left(n\right) $ 和$ rhs\left(n\right) $ 都为∞,并将起点加入优先队列,如第1到5行所示。之后从起点开始搜索迭代。每次迭代从优先队列取出
$ key $ 值最小的节点,如果$ g\left(n\right) > rhs\left(n\right) $ ,说明上游节点找到了更优的路径,此时需要同步节点$ n $ ,并采用广度优先搜索策略,并将影响向下游节点传播。如果$ g\left(n\right) < rhs\left(n\right) $ ,则当前节点信息有误,更新当前节点和其下游节点。搜索迭代过程一致持续到发现终点完成同步并且其
$ key $ 是优先队列中的最小值。当迭代结束后,通过判断$ g\left({n}_{g}\right) $ 是否为∞可得是否找到路径,并且从终点不断回溯上游节点$ n{\text{`}} $ 中$ g\left(n{\text{`}}\right)+cost(n{\text{`}},n) $ 最小的节点即可得到最优路径。 -
本文使用的地图数据来源于开放街道图OpenStreetMap,下载江苏省无锡市巡塘镇的部分地图,对原始地图进行清洗。之后使用交通仿真软件SUMO产生交通流并添加检测点,获取仿真期间路网上的交通流量、通行速度、交通密度等交通流参数。在交通流预测阶段,使用平均绝对误差MAE、平均绝对百分比误差MAPE、均方根误差RMSE作为准确度指标。在拥堵预测阶段,将拥堵状态划分为畅通、基本畅通、轻度拥堵、重度拥堵4个分级。仿真参数设置如表1所示,其中地图面积为在OSM官网中选取地图所对应的真实地图面积,选取路网中的主干路及其支路作为检查点。每轮实验进行10轮迭代,每次迭代投入20辆测试车辆,在所有的测试车辆到达终点后,统计各项指标的平均值。
表 1 仿真参数
参数 取值 切比雪夫阶数 3 时间卷积最小卷积核大小 3 历史数据长度 1h 地图面积 8.2平方公里 路网道路数量 2224条 检测点数量 552个 表2~4给出了不同预测模型下交通流量、交通密度、平均通行速度的预测结果。可以看出,LSTM模型预测效果好于传统SVR模型,而本模型和STGCN模型则优于LSTM和SVR模型。这是因为LSTM和SVR只提取时间相关性,而本模型和STGCN还考虑了路网拓扑方面的空间相关性。
表 2 交通流量预测结果(单位:vec/h)
模型 MAE MAPE(%) RMSE 本模型 23.68 9.19 31.36 STGCN 24.85 9.62 32.52 LSTM 28.35 12.55 35.46 SVR 29.48 12.69 37.76 表 3 交通密度预测结果(单位:%)
模型 MAE MAPE(%) RMSE 本模型 1.23 9.21 0.0222 STGCN 1.26 9.7 0.0253 LSTM 1.32 11.5 0.0254 SVR 1.37 11.16 0.0263 表 4 平均通行速度(单位:km/h)
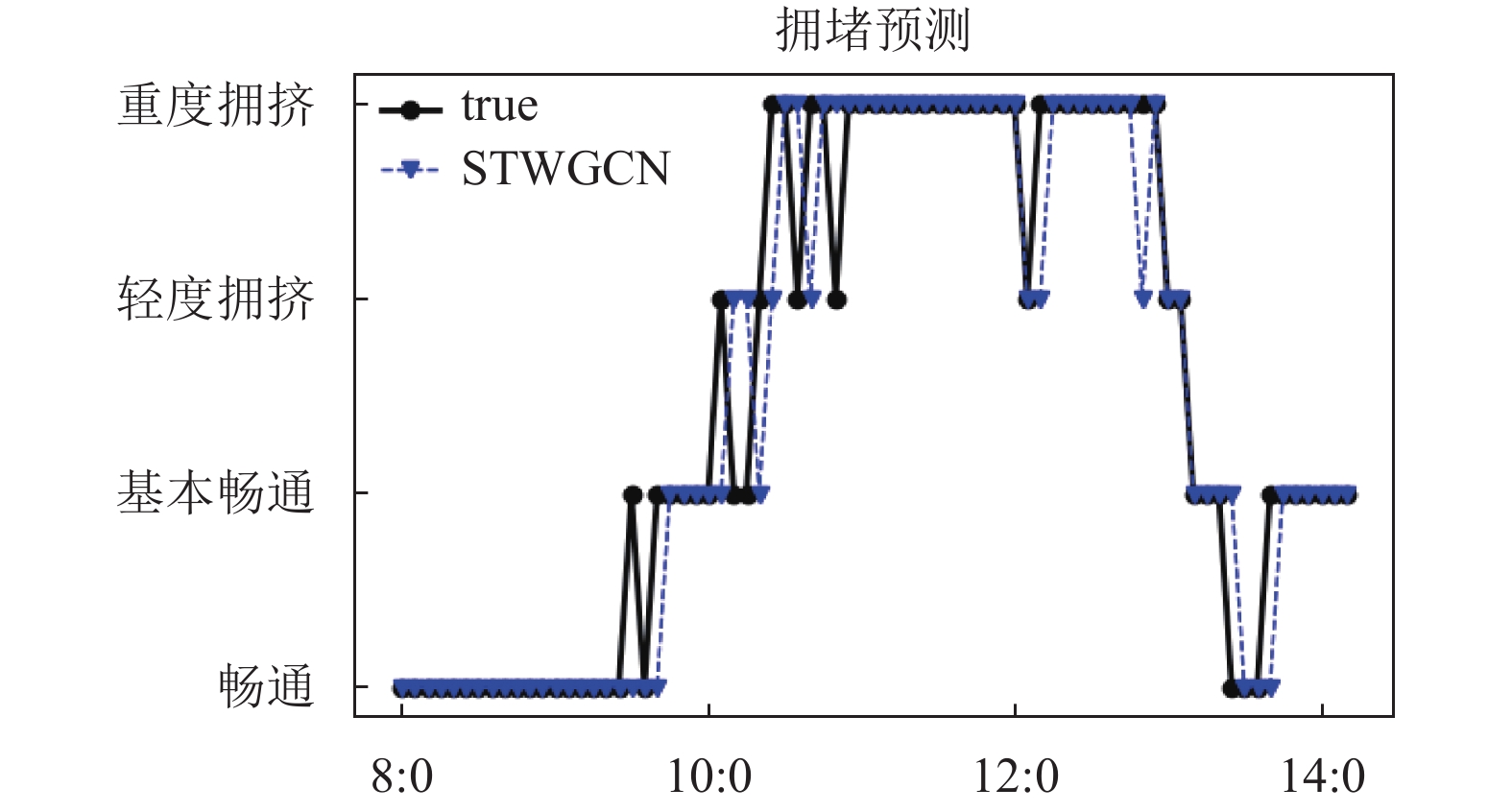
模型 MAE MAPE(%) RMSE 本模型 1.59 2.96 2.57 STGCN 1.64 3.09 2.68 LSTM 1.97 3.81 3.79 SVR 2.01 3.91 3.46 图5给出了本文模型在高峰时期的拥堵预测细节图。可以看到拥堵预测的结果和实际状况较为吻合,包括9点至10点半期间畅通到重度拥堵的转变,以及1点至1点半期间重度拥堵到畅通的过渡,都能被本模型大致捕捉到。在8点至2点15的75个采样点中,畅通状态的预测错误次数为5次,基本畅通状态的预测错误次数为5次,轻度拥堵状态的预测错误次数为4次,总计高峰时期的预测准确度为81.33%。

图 5 拥堵预测细节
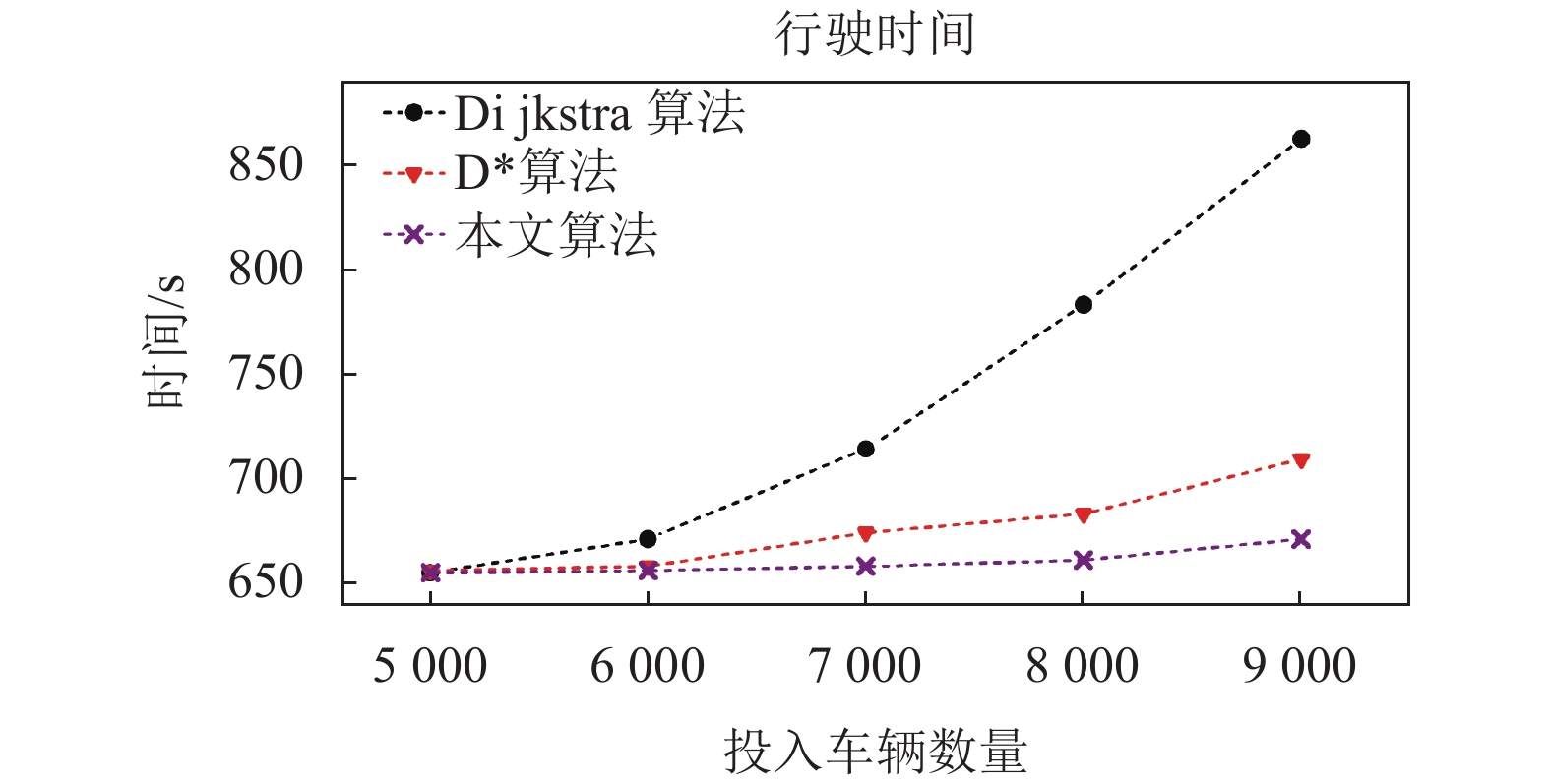
图6给出了不同数量车辆情况下不同算法的行驶时间对比。可以发现,随着投入车辆的增加,Dijkstra算法的劣势逐渐显现,因为在当前时刻的最优路径并不一定是未来时刻的合理路径,导致后续的行驶过程中遇上拥堵从而影响了行驶时间。D*算法在每个交叉路口重新规划路径,从而避开了拥堵,提高了行驶效率。而本文的算法因为结合了当前时刻和未来时刻的路况,其长期收益更大。在投入900辆车时,本文算法相对于Dijkstra算法在行驶时间上减少了22.13%,相对于D*算法减少了5.35%。

图 6 行驶时间
表5给出了预期行驶时间与实际行驶时间对比。可以看到Dijkstra算法采用当前时刻路况计算路段通行时间,因此预期行驶时间与实际行驶时间的差值会随着路况的复杂变化而急剧增大。D*算法会不断重规划进行修正,所以差值相对Dijkstra算法较小但波动性强。本文算法考虑了未来时刻路况并且完整的利用了路况的变化趋势,因此差值能稳定的维持在一个较小的范围。
表 5 实际与预期行驶时间对比(单位:时间(s))
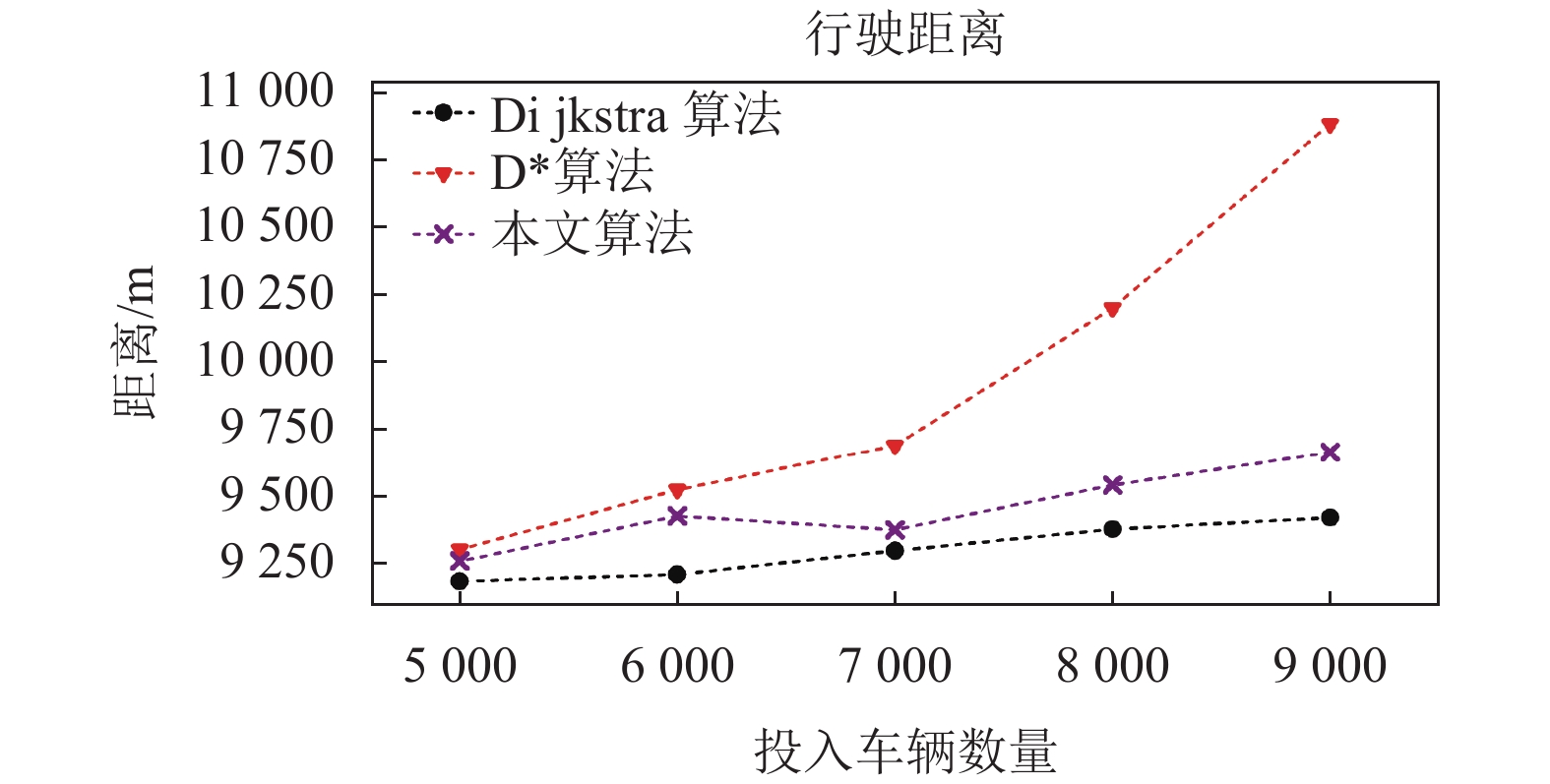
车辆数 5000 6000 7000 8000 9000 Dijkstra 实际 656 672 715 784 863 预期 588 591 583 596 605 D* 实际 657 659 675 684 710 预期 586 588 647 605 657 本文 实际 656 657 659 662 672 预期 621 629 621 630 645 图7给出了不同算法的行驶距离对比图。可以明显看到,D*算法行驶距离最长,这是因为频繁的重新规划带来了绕行。Dijkstra算法的行驶距离最短,但是最容易遇上拥堵。本文的算法能在行驶时间比D*少的情况下也有更短的行驶距离,在投入数量为9000辆车时,行驶距离比D*算法减少了11.72%。

图 7 行驶距离
-
本文利用权重矩阵和多卷积核提高交通流预测的准确度,并采用熵权法和模糊综合判定进行拥堵分级输出,在此基础上计算未来时刻路段的通行时间并进行路径规划。仿真表明该种方式能更准确的计算路段通行时间,从而降低路径规划算法的实际行驶时间和行驶距离,为智慧交通提供一种可行的路径规划方案。
Research on route planning based on congestion prediction
-
摘要: 随着城市出行车辆数的急剧增加,城市交通路网拥堵日益严重,因此研究路网通行效率最大化、个人通行时间和路径最优化具有重要意义。目前智慧交通大多采用周期性监测拥堵并重新规划路径的方法,这类方法得到的最优路径往往导致下次重规划的绕行,不利于全局的最优化。本文提出一种基于拥堵预测的路径规划算法,通过分析大量历史交通流数据的时空相关性预测未来时刻的交通流参数,再通过熵权法和模糊综合判定得出拥堵状态分级,之后综合考虑当前时刻和未来时刻拥堵状况从而规划出更加合理的路径。仿真结果表明,与基于重规划的动态路径规划算法相比,本算法在行驶时间上减少5.35%,在行驶距离上减少11.72%。Abstract: With the rapid increase of vehicles, the road network has become increasingly congested. It is of great significance to study the maximization of road network traffic efficiency, personal traffic time and path optimization. The existing methods periodically monitor congestion and replan paths. The previous path obtained by this kind of algorithm often leads to the detour of the next replanning, which is not conducive to the global optimization. This paper proposes a path planning algorithm based on congestion prediction. By analyzing the temporal and spatial correlation in a large number of historical traffic flow data, the traffic flow parameters at the future time are predicted, and then the congestion state classification is obtained through entropy weight method and fuzzy comprehensive judgment. Then a more reasonable path is planned by comprehensively considering the current and future congestion conditions. The simulation results show that compared with the dynamic path planning algorithm, this algorithm reduces the travel time by 5.35% and the travel distance by 11.72%.
-
Key words:
- smart transportation /
- congestion prediction /
- route planning
-
表 2 交通流量预测结果(单位:vec/h)
模型 MAE MAPE(%) RMSE 本模型 23.68 9.19 31.36 STGCN 24.85 9.62 32.52 LSTM 28.35 12.55 35.46 SVR 29.48 12.69 37.76  下载: 导出CSV
下载: 导出CSV
表 3 交通密度预测结果(单位:%)
模型 MAE MAPE(%) RMSE 本模型 1.23 9.21 0.0222 STGCN 1.26 9.7 0.0253 LSTM 1.32 11.5 0.0254 SVR 1.37 11.16 0.0263
下载: 导出CSV
表 4 平均通行速度(单位:km/h)
模型 MAE MAPE(%) RMSE 本模型 1.59 2.96 2.57 STGCN 1.64 3.09 2.68 LSTM 1.97 3.81 3.79 SVR 2.01 3.91 3.46
下载: 导出CSV
表 5 实际与预期行驶时间对比(单位:时间(s))
车辆数 5000 6000 7000 8000 9000 Dijkstra 实际 656 672 715 784 863 预期 588 591 583 596 605 D* 实际 657 659 675 684 710 预期 586 588 647 605 657 本文 实际 656 657 659 662 672 预期 621 629 621 630 645
下载: 导出CSV
-
[1] Zhu Z, Li L, Wu W, et al. Application of improved Dijkstra algorithm in intelligent ship path planning[C]. Chinese Control and Decision Conference, Kunming, 2021: 4926-4931 [2] Candra A, Budiman M A, Hartanto K. Dijkstra's and AStar in finding the shortest path: a tutorial[C]. International Conference on Data Science, Artificial Intelligence and Business Analytics, Medan, 2020: 28-32 [3] Jangra R, Kait R. Analysis and comparison among ant system ant colony system and Max-Min ant system with different parameters setting[C]. International Conference on Computational Intelligence & Communication Technology, Ghaziabad, 2017: 1-4 [4] Xu Z, Liu X, Chen Q. Application of improved Astar algorithm in global path planning of unmanned vehicles[C]. Chinese Automation Congress, Hangzhou, 2019: 2075-2080 [5] Lee M, Yu K. Dynamic path planning based on an improved ant colony optimization with genetic algorithm[C]. IEEE Asia-Pacific Conference on Antennas and Propagation, Auckland, 2018: 1-2 [6] Ramkumar P, Uma R, Usha S, et al. Real time path planning using intelligent transportation system for hybrid VANET[C]. International Conference on Power Energy Control and Transmission Systems, Chennai, 2020: 1-7 [7] Noguchi y, Maki T. Path planning method based on artificial potential field and reinforcement learning for intervention AUVs[C]. IEEE Underwater Technology, Kaohsiung, 2019: 1-6 [8] Li J. A Traffic prediction enabled double rewarded value iteration network for route planning[J]. IEEE Transactions on Vehicular Technology, 2019, 68(5): 4170-4181 doi: 10.1109/TVT.2019.2893173 [9] Shi X, Chen Z, Wang H. Convolutional LSTM network: A machine learning approach for precipitation nowcasting[C]. Annual Conference on Neural Information Processing Systems, Montreal, 2015: 802-810 [10] Hammond D K, Vandergheynst P, Gribonval R. Wavelets on graphs via spectral graph theory[J]. Applied and Computational Harmonic Analysis, 2011, 30(2): 129-150 doi: 10.1016/j.acha.2010.04.005 [11] Madan R, Mangipudi P S. Predicting computer network traffic: a time series forecasting approach using DWT ARIMA and RNN[C]. Eleventh International Conference on Contemporary Computing, Noida, 2018: 1-5 [12] Yu B, Yin H, Zhu Z. Spatio-temporal graph convolutional networks: a deep learning framework for traffic forecasting[C]. International Joint Conference on Artificial Intelligence. Stockholm, 2018: 3634-3640 [13] 周继彪, 王露, 孟现勇. 道路路阻函数模型及适用性研究[J]. 交通信息与安全, 2013, 31(2): 14-17 doi: 10.3963/j.issn.1674-4861.2013.02.004 -

 点击查看大图
点击查看大图
图(7) / 表(5)
计量
- 文章访问数: 305
- HTML全文浏览量: 81
- PDF下载量: 2
- 被引次数: 0

















































































































