 ISSN
ISSN 

























































-
模拟电路作为军事、国防、航空等领域的重要支柱[1],其准确且高效的故障诊断已成为电路测试领域中的研究热点[2],并且开发高效且精确的诊断策略成为了模拟电路故障诊断领域的迫切需求[3-6]。然而由于模拟电路复杂的故障现象,及多重并发故障导致了模拟电路的故障状态是无限的,故障特征可以是连续的,同时模拟电路的输入-输出关系往往呈非线性映射关系,且电路中还存在非线性元件,使得实际应用中很难建立电路响应的精确数学模型。同时受各类因素影响,模拟电路非故障元件的实际参数值会在标称值上下随机波动,加之元件的非线性表征误差、测试误差等,使得传统的模拟电路故障诊断方法如故障字典法、参数识别法[7-8]等在实际生产生活中难以发挥重要作用。随着故障诊断技术的深入研究,小波变换等信号处理方法在非线性系统故障特征提取与诊断中得到广泛应用[9-11],但信号处理方法在特征提取的过程中容易忽略本质特征,导致非线性模拟电路故障诊断的效率和准确率过低[12-14]。
为解决上述问题,支持向量机(Support Vector Machine, SVM)[15]、极限学习机(Extreme Learning Machine, ELM)[18]等数据驱动的人工智能方法广泛进入研究领域,为模拟电路故障诊断提供了可行的技术支持。 文献[15]提出了一种基于控制系统脉冲响应特性的常规时域特征向量,根据最小二乘支持向量机(Least Squares Support Vector Machine, LSSVM)实验表明:利用改进后的向量可以提高LSSVM分类性能。文献[16]利用马氏距离(Mahalanobis distance, MD)的粒子群算法(particle swarm optimization, PSO)对分类器进行优化,合理选择特征向量从而提高分类精度。文献[17]提出了一种基于双链量子遗传算法(Double Chains Quantum Genetic Algorithm, DCQGA)的诊断模型,实验表明DCQGA-SVM的总体最佳适应度和分类精度都有所提高。文献[18]提出了一种基于极限学习机的自动编码器进行故障诊断,可有效提高诊断准确率。文献[19]将圆模型和极限学习机进行结合,提出了一种线性模拟电路的故障诊断方法,实验表明该方法加速和简化了故障诊断的过程,为故障诊断领域提供了一种新方法。文献[20]指出ELM与SVM相比具有较少的优化约束拥有更好的泛化性能。 然而,SVM、神经网络等分类算法的输出仅仅是故障样本对应的故障类别标签,无法输出其他诊断信息,如故障样本属于各故障类别的概率。在高维特征样本的分类器设计中,故障特征的维数约简与分类器建模是分离进行,存在约简后输入到分类器的特征与该分类器可能不是最佳匹配的问题,难以表征被测信号与装备健康状况之间复杂的映射关系,且面临维数灾难等问题。因此文献[21]指出,利用浅层学习模型无法全面彻底的揭示故障根源和信号特征之间复杂的内在关系。
近年来,卷积神经网络(Convolutional Neural Network, CNN)[22]和深度置信网络(Deep Belief Network, DBN)[23]等深度学习以其强大的学习能力和特征提取能力在故障诊断领域中广泛应[24-25]。文献[26]针对于局部信号较弱的情况,先对信号进行变分模态分解(Variational Mode Decomposition, VMD)和奇异值分解(Singular-Value Decomposition, SVD)构造奇异值向量矩阵,然后输入到卷积神经网络可以对故障精准分类。文献[27]构造了由错位层、卷积层、子采样层和全连接层组成的错位时间序列卷积神经网络(Dislocated time series convolutional neural network,DTS-CNN)。实验表明DTS-CNN更适用于工业信号的故障诊断。文献[28]利用DBN网络自适应提取信号的特征并自动分类,可以灵活高效的对模拟电路的故障进行诊断,为不同的诊断问题提供新的解决思路。文献[29]提出高斯-伯努利深度置信网络(Gauss-Bernoulli Deep Confidence Network, GB-DBN)可以更有效地捕捉原始输出信号中的高阶语义特征,使诊断结果更加精确。文献[30]对模拟电路中的间歇性故障,提出了一种基于总体平均经验模式分解(Ensemble Empirical Mode Decomposition, EEMD)和DBN的模拟电路间歇性故障诊断方法。实验结果表明,该方法在诊断方面的高效性要优于传统DBN。文献[31]利用小波包变换(Wavelet Packet Transform, WPT)与分层诊断网络(Hierarchical Diagnosis Network, HDN)相结合的模型,其中HDN由两层DBN组成分别用来提取和特征和进行故障诊断。文献[32]利用混沌粒子群优化算法优化受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)中的学习率,进一步提升特征提取的性能。文献[33]利用多个两层稀疏自动编码器(Sparse Autoencoder, SAE)神经网络中对时域特征和频域特征进行融合,最后,利用DBN进行进一步分类。实验结果表明,该方法可以提取有效故障特征并准确分类。这些文献为本文在研究过程中提供了参考。
尽管DBN在多个领域展现了广泛的应用前景,然而由于其正向训练阶段所需的时间较长,这使得DBN在应对信息爆炸式增长的大数据时代中显得不太适用。针对该问题,利用参数更新方向的异同动态选择学习率,加速模型收敛并提高模型的稳定性;其次,传统DBN利用BP算法反向精调权重,然而BP算法存在容易陷入局部最小的问题,因此DBN的性能也会受此影响。为了获得一种具有强鲁棒性且同时能够避开局部极小点的DBN模型,利用IMODA算法进行精调权重,并验证其收敛性及稳定性。最后利用二级四运放双二阶复杂电路进行仿真实验,验证本文诊断模型的优越性。综上所述,本文主要贡献概括如下:
1) 根据传统DBN在无监督学习部分采用固定学习率
$ \eta $ 的方式进行参数更新,从而可能加大收敛困难现象的发生。因此,依据连续两次迭代后的参数更新方向是否相同设计了自适应CD算法。2) 考虑到传统DBN在有监督学习部分中采用的BP算法存在易陷入局部最优等问题。因此,采用IMODA算法取代传统的BP算法,提高模型的分类效果。另外,对于IMODA算法的稳定性和收敛性采用7个多目标数学基准问题进行验证。
3) 基于Matlab\Simulink平台搭建了二级四运放双二阶低通滤波器,根据仿真数据对IMODA-ADBN中关于无监督学习和有监督学习这两部分中的对比试验表明对DBN的改进设计具有合理性和有效性。关于IMODA-ADBN模型的仿真实验验证表明IMODA-ADBN模型的精度、可靠性和泛化性能方面具有较高水平。除此之外,关于IMODA-ADBN的噪声实验也论证了上述结果。
-
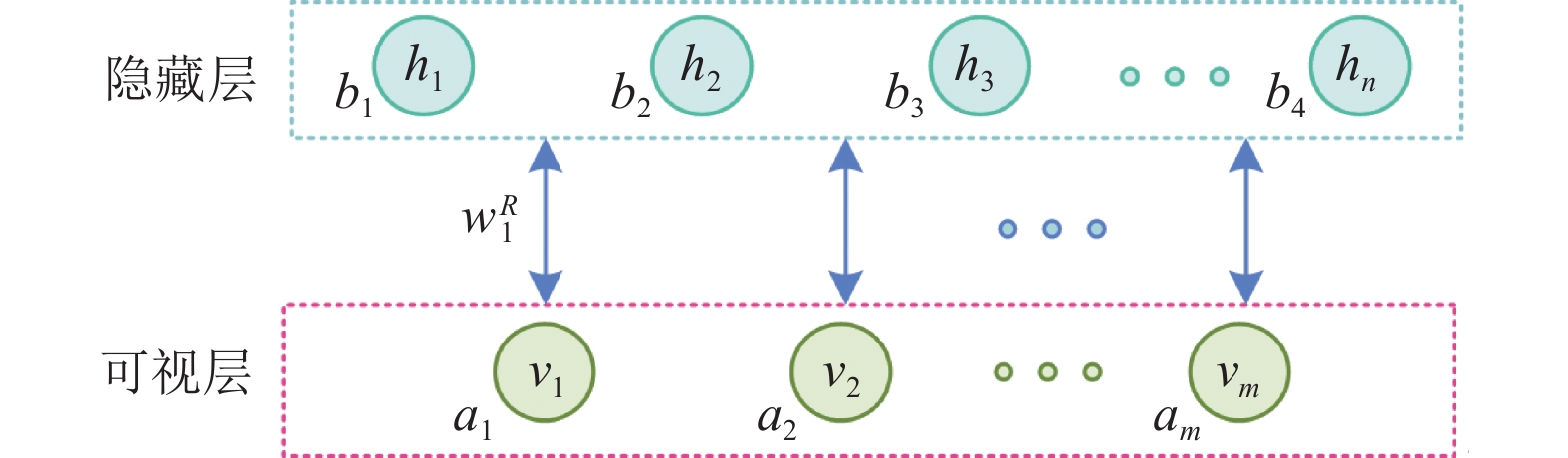
2006年Hinton提出DBN,它是由多个受限玻尔兹曼机堆叠组成的概率生成模型[23]。 RBM作为两层网络,由可视层和隐藏层双向连接,并且同一层网络的神经元相互独立。可视层主要的作用是训练数据的输入,而隐藏层则用于提取特征。RBM的结构图如图1所示。其中,w表示连接权重;b为隐藏层的偏倚系数;a为可视层的偏倚系数。
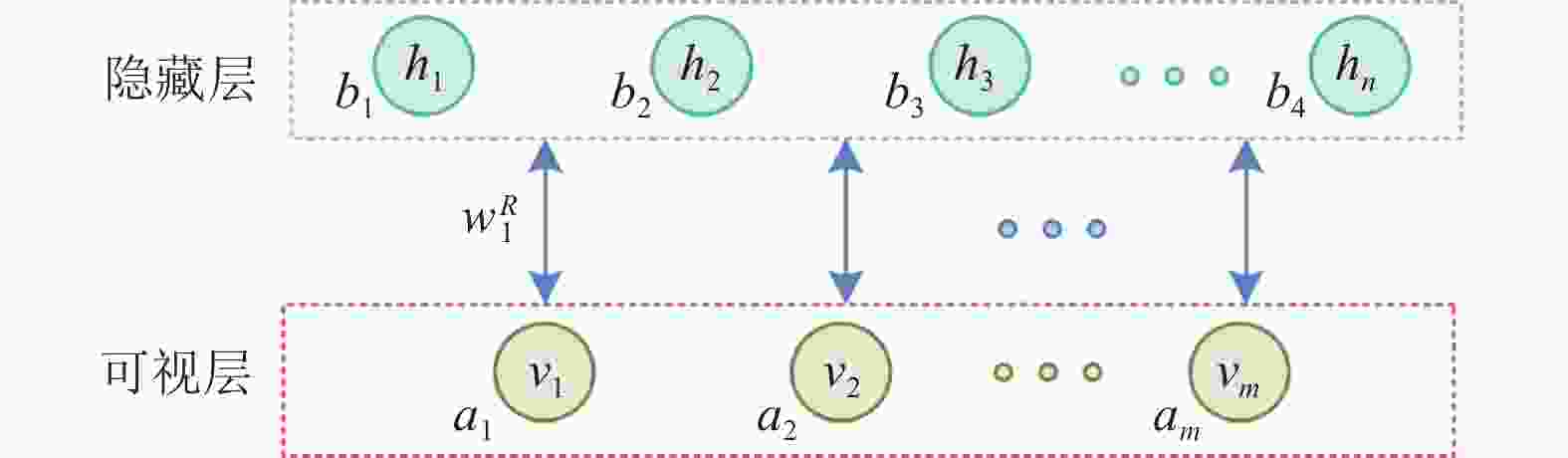
图 1 RBM结构图
DBN特征提取的过程分为两个阶段:分别是预训练阶段和微调阶段。在预训练阶段中,先将所有的RBM进行逐层无监督预训练,从而形成一个无监督学习的特征模型。接下来再用有监督算法进行反向训练,将所有的RBM初始连接权重进行微调,从而减少训练产生的误差,有利于DBN提取输入数据的本质特征,结构如图2所示。
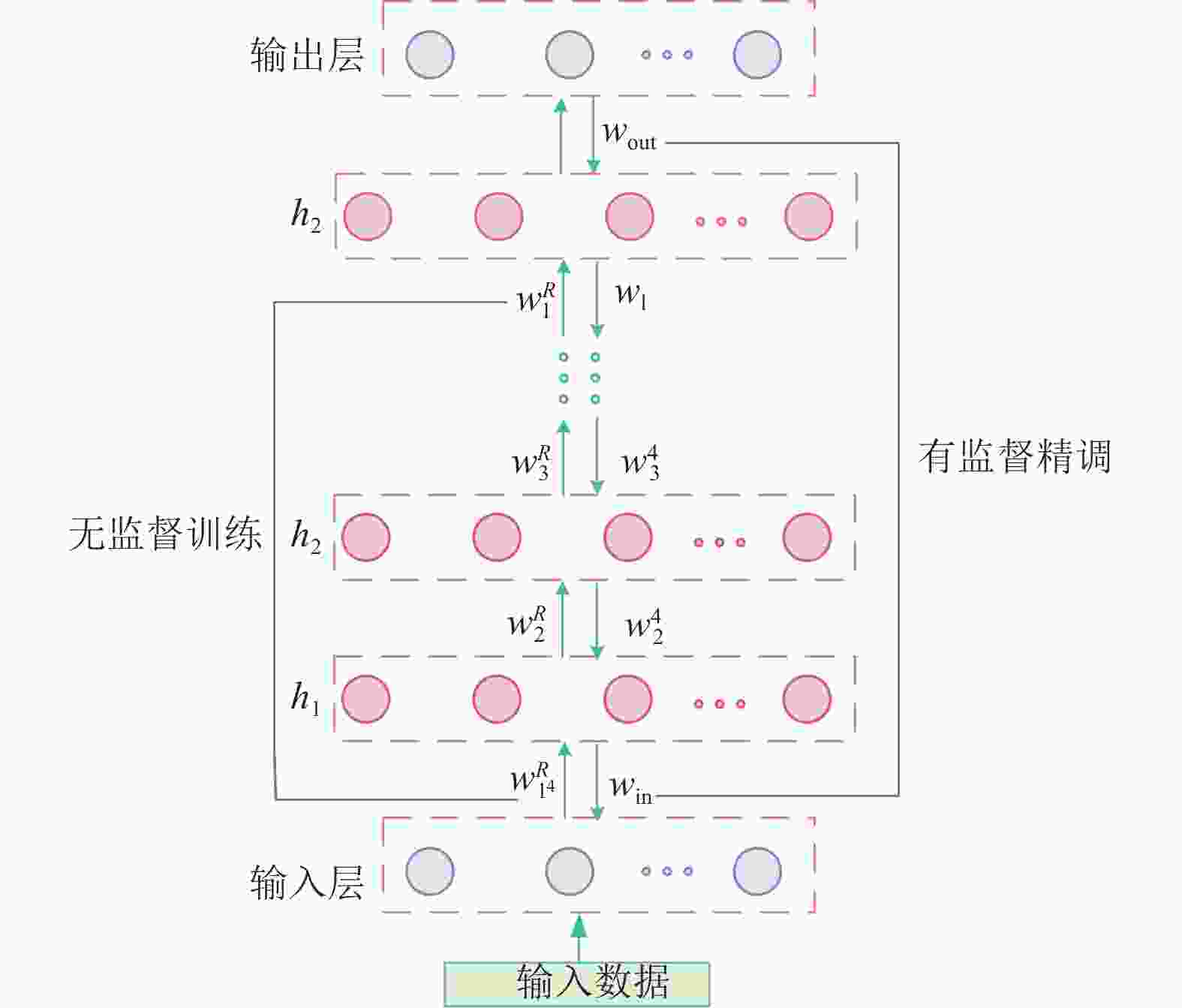
图 2 DBN结构图
-
为了确定网络的初始权值,Hinton采用无监督训练方法学习参数。1个RBM中包括一个可视层和1个隐藏层,分别用v和h来表示。
给定模型参数
$ \theta=\left\{w^R, a, b\right\} $ ,可视层和隐藏层的联合概率分布$ P\left( {v,h;\theta } \right) $ 用能量函数$ E\left( {v,h;\theta } \right) $ 定义为:$$ P\left( {v,h;\theta } \right) = \frac{1}{Z}{e^{ - E\left( {v,h;\theta } \right)}} $$ (1) 式中,
$ Z = \displaystyle\sum\nolimits_{v,h} {{e^{ - E\left( {v,h;\theta } \right)}}} $ 是归一因子,模型关于$ v $ 的边缘分布:$$ P\left( {v;\theta } \right) = \frac{1}{Z}\sum\nolimits_h {{e^{ - E\left( {v,h;\theta } \right)}}} $$ (2) 对于一个伯努利(可视层)分布-伯努利(隐藏层)分布的RBM,单元联合配置的能量函数定义为:
$$ E\left( {v,h} \right) = - \sum\limits_{i = 1}^m {\sum\limits_{j = 1}^n {{v_i}w_{ij}^R{h_j}} } - \sum\limits_{i = 1}^m {{a_i}{v_i} - \sum\limits_{j = 1}^n {{b_j}{h_j}} } $$ (3) 式中,
$ w_{ij}^R $ 是RBM的连接权重,$ {a_i} $ 和$ {b_j} $ 分别是可见层单元和隐藏层单元的偏置。$$ P\left( {{h_j} = 1/v;\theta } \right) = \sigma \left( {{b_j} + \sum\limits_{i = 1}^m {{v_i}} w_{ij}^R} \right) $$ (4) $$ P\left( {{v_i} = 1/h;\theta } \right) = \sigma \left( {{a_i} + \sum\limits_{j = 1}^n {w_{ij}^R} {h_j}} \right) $$ (5) 式中,
$ \sigma $ 为激活函数。可视层和隐藏层的概率取值标准通常是设定阈值来实现,这是因为可视层和隐藏层是伯努利二值状态。以隐藏层为例可表示为:
$$ {h_j}\left\{ {\begin{array}{*{20}{c}} 0 &if &p\left( {{h_j} = 1/v} \right) \lt \delta \\ 1 &if &p\left( {{h_j} = 1/v} \right) \gt \delta \\ \end{array}} \right. $$ (6) 式中,
$ \delta $ 为0.5$ \sim $ 1之间的常数。计算对数似然函数
$ {\text{lg}}P\left( {v;\theta } \right) $ 的梯度,可以得到RBM权值更新公式为:$$ w_{ij}^R = w_{ij}^R + \eta \Delta w_{ij}^R $$ (7) $$ \Delta w_{ij}^R = {E_{{\text{data}}}}\left( {{v_i}{h_j}} \right) - {E_{{\text{model}}}}\left( {{v_i}{h_j}} \right) $$ (8) 式中,
$ \eta $ 表示学习率;$ {E_{{\text{data}}}}\left( {{v_i}{h_j}} \right) $ 是训练集中观测的数据期望;$ {E_{{\text{model}}}}\left( {{v_i}{h_j}} \right) $ 是在模型所确定的分布上的期望,并且$ {E_{{\text{model}}}}\left( {{v_i}{h_j}} \right) $ 可由吉布斯近似得到。 -
有监督学习是对无监督学习得到的权重
$ {w^R} $ 进行精调。根据图2的输出层和最后一层隐藏层为例,设$ F $ 为模型的期望输出,定义交叉熵函数为损失函数:$$ F{{ = - }}\frac{1}{n}\sum\limits_i {\left[ {{y_i}\ln y_i' + \left( {1 - {y_i}} \right){\text{ln}}\left( {1 - y_i'} \right)} \right]} $$ (9) 式中,
$ {y_i} $ 表示目标输出经过softmax后的输出;$ y_i' $ 表示期望输出经过softmax后的输出;$ n $ 表示分类种数。权重更新公式则可表示为:
$$ {w_{out}}\left( {\tau {\text{ + }}1} \right){\text{ = }}{w_{out}}\left( \tau \right) - \eta \frac{{\partial F\left( \tau \right)}}{{\partial {w_{out}}\left( \tau \right)}} $$ (10) 利用这种方法从顶层输出层到底层输入层依次精调可以得到整个DBN网络的权重
$ w = \left( {w_{out}},{w_l}, {w_{l - 1}}, \cdots ,{w_2},w{}_{in} \right) $ 。 -
在DBN无监督学习过程中,吉布斯采样作为CD算法的核心,是一种马尔科夫链蒙特卡洛(Markov Chain Monte Carlo, MCMC)算法。在直接采样联合分布困难的情况下,用于生成某特定多参数的概率分布的一组近似观测值。吉布斯采样主要由3步组成。
1) 利用样本V初始化吉布斯链,从而得到可视层输入
$ {v^{{\text{(}}0{\text{)}}}} $ 。2) 根据式(4)~(6)分别进行采样,其中
$ {h^{{\text{(t)}}}} $ 由$ P\left( {{h^{{\text{(}}t{\text{)}}}}/{v^{\left( t \right)}};\theta } \right) $ 采样得到,$ {v^{{\text{(t + 1)}}}} $ 则由$ P\left( {{v^{{\text{(}}t + 1{\text{)}}}}/{h^{\left( t \right)}};\theta } \right) $ 采样得到,t为采样步数。3) 重复第2)步。
由于每个RBM中需要多次迭代计算,固定学习率
$ \eta $ 容易产生收敛困难等现象。因此采用自适应学习率根据参数的更新方向来确定学习率$ \eta $ 。自适应学习率的原理是连续两次迭代后的参数更新方向相同时学习率会增大;连续两次迭代后的参数更新方向相反学习率会减小。自适应学习率$ \eta $ 的更新机制如下:$$ \eta {\text{ = }}\left\{ \begin{gathered} D\eta \frac{{\left| {{{\left( {\Delta w_{ij}^R} \right)}^{\left( t \right)}}} \right| {\text{ + }}\left| {{{\left( {\Delta w_{ij}^R} \right)}^{\left( {t + 1} \right)}}} \right| }}{{{{\left( {\Delta w_{ij}^R} \right)}^{\left( t \right)}} + {{\left( {\Delta w_{ij}^R} \right)}^{\left( {t + 1} \right)}} + \varepsilon }} = 1 \\ d\eta \frac{{\left| {{{\left( {\Delta w_{ij}^R} \right)}^{\left( t \right)}}} \right| {\text{ + }}\left| {{{\left( {\Delta w_{ij}^R} \right)}^{\left( {t + 1} \right)}}} \right| }}{{{{\left( {\Delta w_{ij}^R} \right)}^{\left( t \right)}} + {{\left( {\Delta w_{ij}^R} \right)}^{\left( {t + 1} \right)}} + \varepsilon }} \ne 1 \\ \end{gathered} \right. $$ (11) $$ {\left( {\Delta w_{ij}^R} \right)^{\left( t \right)}}{\text{ = }}v_i^{\left( t \right)}h_i^{\left( t \right)} - v_i^{\left( {t + 1} \right)}h_i^{\left( {t + 1} \right)} $$ (12) $$ {\left( {\Delta w_{ij}^R} \right)^{\left( {t{\text{ + }}1} \right)}}{\text{ = }}v_i^{\left( {t{\text{ + }}1} \right)}h_i^{\left( {t{\text{ + }}1} \right)} - v_i^{\left( {t + 2} \right)}h_i^{\left( {t + 2} \right)} $$ (13) 式中,D=1.4,d=0.7,
$ \varepsilon $ 的主要目的是避免分母为0的情况产生,设置为10-6。 -
昆虫群的行为主要有以下3种[34]:
1) 分离,指个体与相邻个体之间避免静态碰撞;
2) 对齐,表示个体与相邻个体的速度匹配;
3) 凝聚,指个体倾向聚集到周围群体的中心。
改进多目标蜻蜓优化算法(Improve Multi-Objective Dragonfly Algorithm, IMODA)3个主要特征如下:1) 存档集成到蜻蜓搜索中,用来保存和检索帕累托最优解;2) 利用拥挤距离和轮盘选择有效地管理档案种群,其中包含在空间搜索探索过程中的最优非支配解;3)为缓解局部最优,在MODA中添加精英个体和基于对立的跳跃。
(1) 运动模型
昆虫群的主要行为一个是被食物吸引,另一个则是躲避天敌。所以蜻蜓个体的位置更新主要受5种因素影响,5种因素的数学模型如下:
1) 分离
静态群中,蜻蜓为了捕食蝴蝶和蚊子等其他飞行猎物会簇拥成群。为了避免在飞行过程中与其它蜻蜓产生碰撞其,分离表达式如下:
$$ {S_i} = - \sum\limits_{j = 1}^N {X - {X_j}} $$ (14) 其中,
$ X $ 表示当前个体的位置,$ {X_j} $ 表示第j个相邻个体的位置,N表示相邻个体的数量。2) 对齐
$$ {A_i} = \sum\limits_{j = 1}^N {{V_j}} /N $$ (15) 其中,
$ {V_j} $ 表示第j个相邻个体的速度.3) 凝聚
$$ {C_i} = \frac{{{{\displaystyle\sum} _{j = 1}^N{X_j}} }}{N} - X $$ (16) 其中,
$ X $ 表示当前个体的位置,$ {X_j} $ 表示第j个相邻个体的位置,N表示相邻个体的数量。4) 食物吸引
$$ {F_i} = {X^ + } - X $$ (17) 其中,
$ X $ 表示当前个体位置,$ {X^{\text{ + }}} $ 表示食物来源位置。5) 天敌驱散
$$ {E_i} = {X^ - }{\text{ + }}X $$ (18) 其中,
$ X $ 表示当前个体的位置,$ {X^ - } $ 表示敌人的位置。本文假设蜻蜓的行为是这五种纠正模式的组合.为了更新人工蜻蜓在搜索空间中的位置并模拟其运动,需要考虑两个向量: 步长(
$ \Delta X $ )和位置($ X $ ),定义如下:$$ \Delta {X_{t + 1}} = \left( {s{S_i} + a{A_i} + c{C_i} + f{F_i} + e{E_i}} \right) + \omega \Delta {X_t} $$ (19) $$ {X_{t + 1}} = {X_t}{\text{ + }}\Delta {X_{t + 1}} $$ (20) 其中,s表示分离权重,
$ {S_i} $ 表示第i个个体的分离,a表示对齐权重,$ {A_i} $ 表示第i个个体的对齐,c表示内聚权重,$ {C_i} $ 表示第i个个体的内聚,f表示食物因子,$ {F_i} $ 表示第i个个体的食物来源,e表示敌人因子,$ {E_i} $ 表示第i个个体敌人的位置,$ \omega $ 表示惯性权重,t表示迭代次数。(2) 食物选择
在MODA算法中添加一个档案,用于存储和检索优化过程中真实帕累托最优解的最佳近似值。将食物来源的选取设置在帕累托最优前沿的人口最少的区域。该区域的识别方法是:通过找到获得的帕累托最优解的最优目标和最差目标来分割搜索空间,定义一个超球面和n个覆盖所有解的网格单元,并在每次迭代中将超球划分为相等的子超球。并使用轮盘赌轮机制进行选择,利用轮盘机制可改善整个帕累托最优前沿的分布,当帕累托最优个数越多,则被选中几率越小。如下式所示:
$$ {P_i} = \frac{c}{{{N_i}}} $$ (21) 其中c=10,Ni为在第i段内获得帕累托最优解的数量。
(3) 天敌选择
在迭代过程中,食物源的存档文件每次都会更新,并且在优化过程中有可能会达到总数上限.利用管理机制对存档文件进行筛选,具体内容如下:
1) 如果存在一个解决方案可以对原存档中的帕累托最优解决方案产生主导作用,则存储该解决方案并删去原存档中被主导的解决方案;
2) 如果存在一个解决方案a与原存档的解决方案两者之间不存在主导关系,则保留原存档中的解决方案,若存档个数没有达到上限,则将解决方案a添加到存档文件中;
3) 若存档个数达到上限,则会从填充最多的阶段删除解决方案,并将解决方案a添加到存档文件中;若存在一个解决方案a可由原存档解决方案主导时,则剔除解决方案a。
将这些被删除的方案定义为天敌的位置,选择最差(个体最多)的超球体,可以有效阻止人工蜻蜓在没有前途的拥挤区域搜索。并通过轮盘赌轮机制实现,每段的概率定义为:
$$ {P_i} = \frac{{{N_i}}}{c} $$ (22) 4) Lévy flight
大多数飞行动物的行为可以用Lévy flight来描述[35]。当人工蜻蜓领域内没有解时,利用Lévy flight在搜索空间飞行,可有效改善人工蜻蜓的随机性和探索性。
$$ {\text{Lé}}{\text{vy}}\left( x \right) = 0.01 \times \frac{{{r_1} \times \sigma }}{{{{\left| {{r_2}} \right|}^{\frac{1}{\beta }}}}} $$ (23) 式中,
$ {r_1} $ 、$ {r_2} $ 为$ \left[ {0,1} \right] $ 内的随机值,$ \beta $ 设为1.5。$ \sigma $ 的计算公式如下:$$ \sigma {\text{ = }}{\left\{ {\left. {\frac{{\Gamma \left( {1{\text{ + }}\beta } \right) \times \sin \left( {\dfrac{{\pi \beta }}{2}} \right)}}{{\Gamma \left[ {\dfrac{{1{\text{ + }}\beta }}{2}} \right] \times \tau \times {2^{\left( {\beta {\text{ - }}1} \right)/2}}}}} \right\}} \right.^{\frac{1}{\beta }}} $$ (24) 式中,
$ \Gamma \left( x \right) = \left( {x - 1} \right){\text{!}} $ 。因此,人工蜻蜓的位置更新公式如下:
$$ {{\text{X}}_{t + 1}}{\text{ = }}{X_t} + {\text{Lé}}{\text{vy}}\left( x \right) \times {X_t} $$ (25) 5) 蜻蜓种群初始化
蜻蜓种群通常是随机初始化的。为了提高初始种群的多样性,避免算法产生早熟收敛的现象,与原本的MODA算法中随机初始化不同,本文的种群初始化利用Logistic映射代替传统的随机初始化,计算公式如下:
$$ {\text{X}}_{\text{i+1}}{\text{=ηX}}_{\text{i}}\left({\text{1-X}}_{\text{i}}\right)\text{,}0\le {\text{X}}_{0}\le 1 $$ (26) 式中,Xi为第i只蜻蜓的logistic值;X0为蜻蜓种群初生值;
$ \eta {\text{ = 4}} $ ,$ {X_{\text{0}}} \in \left( {0,1} \right) $ ,$ \text{ }{X}_{\text{0}}\notin \{0.0,0.25, 0.75,1.0\} $ 。 -
基于对立跳跃可以有效提高进化算法的性能[11, 12]。本文利用基于对立跳跃对MODA算法进行优化,防止陷入局部最优。
基于对立跳跃的
$ {X_{{\text{i}}'}}\left( {\text{t}} \right) $ 计算公式为:$$ {X_{{\text{i}}'}}\left( {\text{t}} \right){\text{ = }}\left( {{\text{L}}{{\text{b}}_{\text{i}}}{\text{ + U}}{{\text{b}}_{\text{i}}}} \right)-{X_{\text{i}}}\left( {\text{t}} \right) $$ (27) 式中,
$ {\text{L}}{{\text{b}}_{\text{i}}} $ 代表搜索空间的上界,$ {\text{U}}{{\text{b}}_{\text{i}}} $ 代表搜索空间的下界。 -
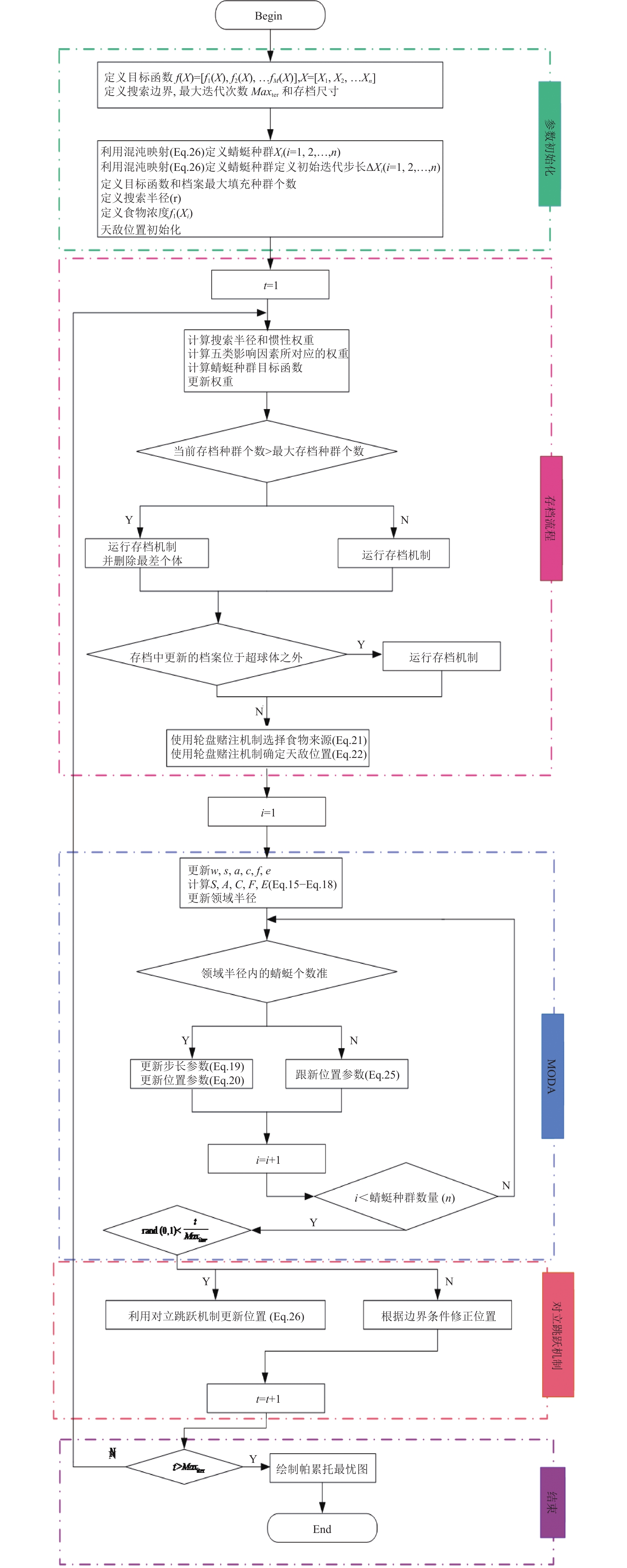
IMODA算法的流程图见图3。
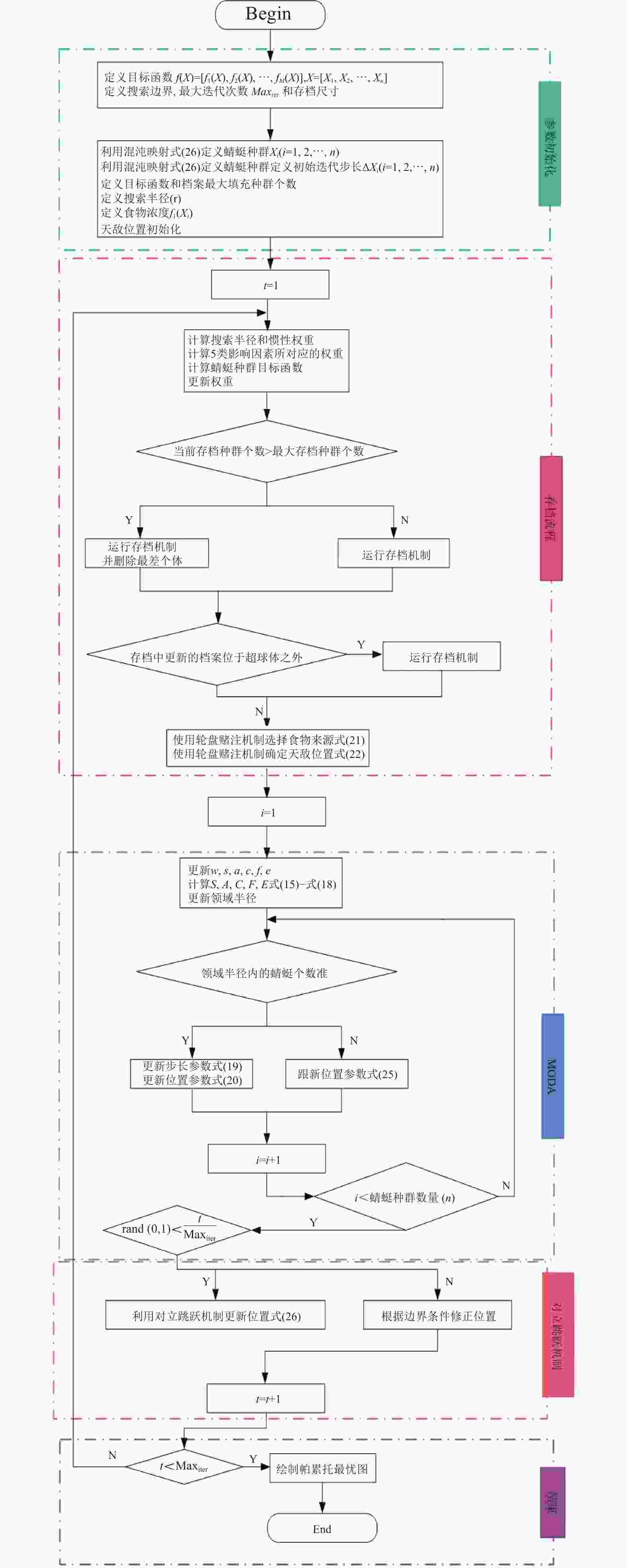
图 3 IMODA算法流程图
-
收敛速度指RBM为了达到预期的重构误差,多次利用吉布斯采样所花费的时间。 训练时间越短则表明收敛速度越快。RBM 作为一种概率模型,它的无监督学习主要是用来学习特征,这一过程称为编码。自适应学习率以变步长的方式自动调节学习因子,通过比较每两次可视层和隐含层的采样状态提高了吉布斯采样的效率,从而加速了CD算法的收敛。Hiton教授[36]指出,分层降维能够达到高维数据维数呈现指数下降的效果。同理,由于 IMODA-ADBN是由多个 RBM 进行的分层表述,当单个RBM通过自适应学习率可加速收敛的条件下,那么DBN的收敛速度则会提高。
自适应学习率实质上是以变步长的方式有规律地增大或者减小算法对数据内在关联的学习力度,在最短的时间内收敛。但BP算法作为有监督学习无其结论无法衡量RBM[37]。在无监督训练阶段中,自适应学习率算法根据参数更新方向自适应地增大或减小学习率。可以准确快速寻找最优解,避免在寻优过程中陷入局部最优的情况。
-
在DBN无监督训练阶段为了快速收敛,利用自适应学习率对RBM依次训练。为避免特殊性,在式(4)、式(5)中将Sigmoid函数上下两条渐近线用
$ {A_H} $ 和$ {A_L} $ 表示,RBM可视层的输入信息和经过t次采样得到的重构状态分别用$ f_i^0 $ 和$ f_j^t $ 表示。那么一次吉布斯采样过程中可视层和隐含层表达如下:$$ f_i^0 \in \left[ {{A_L},{A_H}} \right] $$ (28) $$ f_j^0 = {A_L} + \left( {{A_H} - {A_L}} \right)\sigma \left( {{b_j} + \sum\limits_{i = 1}^m {f_i^0{W_{ij}}} } \right) $$ (29) $$ f_i^1 = {A_L} + \left( {{A_H} - {A_L}} \right)\sigma \left( {{a_i} + \sum\limits_{j = 1}^n {{W_{ij}}f_j^0} } \right) $$ (30) $$ f_j^1 = {A_L} + \left( {{A_H} - {A_L}} \right)\sigma \left( {{b_j} + \sum\limits_{i = 1}^m {f_i^1{W_{ij}}} } \right) $$ (31) 由此可以得出,经过t次吉布斯采样后有
$$ f_i^t = {A_L} + \left( {{A_H} - {A_L}} \right)\sigma \left( {{a_i} + \sum\limits_{j = 1}^n {W_{ij}^Rf_j^{t - 1}} } \right) $$ (32) $$ f_j^t = {A_L} + \left( {{A_H} - {A_L}} \right)\sigma \left( {{b_j} + \sum\limits_{i = 1}^m {f_i^tW_{ij}^R} } \right) $$ (33) 由上式可知,网络输出与采样过程的中间状态有关。同时,算法的收敛速度和精度与自适应学习率有关,自适应学习率过大或者过小都会影响到收敛速度甚至使网络不稳定。通过上述可知,可以得到如下性能分析:
(1) 充分性证明
证明 若
$ f_j^0,f_i^1 \in \left[ {{A_L},{A_H}} \right] $ ,根据(28)到(31)可知,则$ f_j^1 \in \left[ {{A_L},{A_H}} \right] $ 。证明成立。
(2) 必要性证明
一方面若整个网络稳定,第一个RBM的输入状态满足
$ f_i^0 \in \left[ {{A_L},{A_H}} \right] $ ,则顶层RBM输出状态范围满足$ f_j^1 \in \left[ {{A_L},{A_H}} \right] $ ,必然满足$ f_j^0,f_i^1 \in \left[ {{A_L},{A_H}} \right] $ 。证明:假设网络稳定,那么每一层RBM的可视层和隐含层均满足输入输出有界。
因为Sigmoid函数单调递增,且开启的神经元个数也在不断增加,可得
$$ f_j^1 \gt f_i^1 $$ (34) $$ f_i^1 \gt f_j^0 $$ (35) 那么可以推出
$$ f_j^0,f_i^1,f_j^1 \in \left[ {{A_L},{A_H}} \right] $$ (36) 进而可以推出
$$ f_j^t \gt f_i^t $$ (37) $$ f_i^t \gt f_j^0 $$ (38) $$ f_j^0,f_i^t,f_j^t \in \left[ {{A_L},{A_H}} \right] $$ (39) 证明成立。
推广可得如下定理:
定理 1 假设
$ f_j^0,f_i^t,f_j^t $ 分别表示RBM的输入状态、中间状态及输出状态,那么网络稳定的充分必要条件则是$ f_j^0,f_i^t,f_j^t \in \left[ {{A_L},{A_H}} \right] $ 。根据式(6)可得,
$ \delta $ 越大那么神经元取1的概率就越小,导致在吉普斯采样过程中可视层和隐含层神经元的稀疏性[38]增大,那么连续两次在吉布斯采样迭代过程中权值更新方向相同的可能性会增大。$$ P\left\{ {\frac{{\left| {{{\left( {\Delta w_{ij}^R} \right)}^{\left( t \right)}}} \right| {\text{ + }}\left| {{{\left( {\Delta w_{ij}^R} \right)}^{\left( {t + 1} \right)}}} \right| }}{{{{\left( {\Delta w_{ij}^R} \right)}^{\left( t \right)}} + {{\left( {\Delta w_{ij}^R} \right)}^{\left( {t + 1} \right)}} + \varepsilon }} = 1} \right\} \propto \delta $$ (40) 根据(8)-(12)在调整权值过程中,如果误差波动不太明显时,学习率增大可以加快权网络收敛。则有
$$ D \propto P\left\{ {\frac{{\left| {{{\left( {\Delta w_{ij}^R} \right)}^{\left( t \right)}}} \right| {\text{ + }}\left| {{{\left( {\Delta w_{ij}^R} \right)}^{\left( {t + 1} \right)}}} \right| }}{{{{\left( {\Delta w_{ij}^R} \right)}^{\left( t \right)}} + {{\left( {\Delta w_{ij}^R} \right)}^{\left( {t + 1} \right)}} + \varepsilon }} = 1} \right\} $$ (41) 根据吉布斯采样可知,每当权值更新一次,中间状态伴随着两次二值化采样,主要目的是为了控制神经元的开启与关闭,并且更新的权值与状态采样成正比,因此可以得到
$ \delta $ 与学习率系数D和d的关系:$$ \left\{ \begin{gathered} D \approx 2\delta \\ d \approx \delta \\ \end{gathered} \right. $$ (42) 其中,
$ \delta $ 的目的是对二值神经元状态进行判断,一般取值为0.7[39]。 -
(1) 可归约随机矩阵的稳定性
定理 2 设P为N阶可归约随机矩阵,经过相同的行变换与列变换可以得
$ P = \left[ \begin{gathered} C \cdots 0 \\ R \cdots T \\ \end{gathered} \right] $ ,其中C为m阶本原随机矩阵,R和T为N-M阶矩阵,且R,T均不为0矩阵。 则有:$$ \begin{split} &\qquad\qquad\qquad {P^\infty }{\text{ = }}\mathop {\lim }\limits_{k \to \infty } {P^k} \\ & = \mathop {\lim }\limits_{k \to \infty }\left[ \begin{gathered} \;\;\;\;\;\;\;\;\; {C^k} \;\;\;\;\;\;\;\;\cdots \;0 \\ \sum\limits_{i = 1}^{k - 1} {{T^i}R{C^{k - i}} \cdots {T^k}} \\ \end{gathered} \right]{\text{ = }}\left[ \begin{gathered} {C^\infty } \cdots 0 \\ {R^\infty } \cdots T \\ \end{gathered} \right] \end{split} $$ (43) 其中
$ {P^\infty } $ 为稳定随机矩阵,且$ {P^\infty }{\text{ = }}{1^{'}}{P^\infty } $ 、$ {P^\infty }{\text{ = }}{P^0}{P^\infty } $ 唯一确定并且与初始分布无关,$ {P^\infty } $ 满足条件:$$ {P^\infty } = {\left[ {{P_{ij}}} \right]_{N \times N}} = \left\{ \begin{array}{*{20}{c}} {P_{ij}} \gt 0 & 1 \leqslant i \leqslant N , 1 \leqslant j \leqslant M \\ {P_{ij}} = 0& 1 \leqslant i \leqslant N , M \lt j \leqslant N \\ \end{array} \right. $$ (44) (2) IMODA算法全局收敛性证明
对于优化问题,计算式如下:
$$ \begin{split} &\qquad\qquad\qquad {\text{min}} {\text{ }}f\left( X \right) \\ &s.t.\quad {g_i}\left( X \right) \geqslant 0\;\;\;\; i = 0,1,2, \cdots M \;\;\;\;X \in Z \\ \end{split} $$ (45) 式中,
$ f\left( X \right) $ 为目标函数;$ {g_i}\left( X \right) $ 为第i个约束条件;M为约束条件总数;X为N维未知变量;Z为搜索空间。设蜻蜓总数为N,蜻蜓群用
$ {X^t} $ 表示,则$ {X^t} $ 为离散空间,但每个蜻蜓$ X_i^t $ 取值连续。那么每个蜻蜓代表优化问题(41)的一个候选解,其目标函数值为$ F\left( {X_i^t} \right) $ 。则所有蜻蜓的状态集合表示如下:
$$ F = \left\{ {F\left( {X_i^t} \right)\left| {X_i^t \in {X^t}} \right.} \right\} $$ (46) 进一步令
$ F = \left\{ {{F_1},{F_2}, \cdots ,{F_N}} \right\}, {F_1} \gt {F_2} \gt \cdots \gt {F_N} $ ,$ \forall X \in {X^t} $ 有$ {F_N} \leqslant F\left( X \right) \leqslant {F_1} $ ,可根据状态的区别将$ {X^t} $ 分为若干非空子集$ X_S^i $ 满足:$$ X_S^i{\text{ = }}\left\{ {X\left| {X \in {X^t}} \right., F\left( X \right) = {F_i}} \right\}\;\;\;\; i = 1,2, \cdots ,N $$ (47) 并且
$ X_S^i $ 满足下述条件:1)
$ \displaystyle\sum\limits_{i{\text{ = }}1}^N {\left| {X_S^i} \right|} {\text{ = }}N,\forall i \in \left\{ {1,2, \cdots ,N} \right\},X_S^i \ne \phi $ ;2)
$ \forall i \ne j, $ $ \mathop \cup \limits_{i = 1}^N X_S^i = {X^t} $ $ X_S^i \cap X_S^j = \phi , $ $ \mathop \cup \limits_{i = 1}^N X_S^i = {X^t} $ 。令
$ {X^{i,j}} $ 满足$ i = 1,2, \cdots ,N,j = 1,2, \cdots ,\left| {X_S^i} \right| . $ 设$ {X^{i,j}} $ 表示在$ {X^i} $ 中第j个蜻蜓。蜻蜓在飞行过程中产生的空间位置转移记为$ {X^{i,j}} \to {X^{m,n}} $ ,发生的概率记为$ {P_{ij,mn}} $ ,$ {X^{i,j}} $ 转移到第m个区域记为$ {X^{i,j}} \to {X^m} $ ,发生的概率记为$ {P_{ij,m}} $ ,$ {X^i} $ 中任一蜻蜓空间位置转移至$ {X^m} $ 则可表示$ {X^i} \to {X^m} $ ,发生的概率用$ {P_{i,m}} $ 表示。满足:$$ {P_{ij,m}}{\text{ = }}\sum\limits_{{\text{n = }}1}^{\left| {X_S^m} \right|} {{P_{ij,mn}}} \text{,} \sum\limits_{m = 1}^N {{P_{ij,m}} = 1} \text{,} {P_{i,m}} \geqslant {P_{ij,m}} $$ 引理 1 IMODA算法
$ \forall {X^{i,j}} \in X_S^i $ $ i{\text{ = }}1,2, \cdots N, $ $ j = 1,2, \cdots ,\left| {X_S^i} \right| $ 满足:$$ \forall m \gt i,{P_{i,m}} = 0 $$ (48) $$ \exists m \lt i,{P_{i,m}} \gt 0 $$ (49) 关于引理1的证明部分如下所示:
引理1 IMODA算法
$ \forall {X^{i,j}} \in X_S^i $ $ i{\text{ = }}1,2, \cdots N, $ $ j = 1,2, \cdots ,\left| {X_S^i} \right| $ 满足:$$ \forall m \gt i,{P_{i,m}} = 0 $$ (50) $$ \exists m \lt i,{P_{i,m}} \gt 0$$ (51) (1)证明
$ \forall m \gt i,{P_{i,m}} = 0 $ 设
$ {X^{i,j}} $ 为第t次演化后蜻蜓的空间位置为$ {Y^t} $ 。设$ {Y^t} $ 空间中最优蜻蜓的空间位置为$ X_{B{\text{est}}}^t{\text{ = }}{X^{\text{*}}} $ ,则有$ F\left( {X_{B{\text{est}}}^t} \right){\text{ = }}{F_i} $ ,根据IMODA算法中存档定义及在迭代过程中最好空间位置的更新可知:$$ F\left( {{X^{t + 1}}} \right) \geqslant F\left( {{X^t}} \right) $$ 可以推出:
$$ \forall k \gt i,{P_{ij,mn}} = 0,{P_{ij,m}} = \sum\nolimits_{n = 1}^{\left| {X_S^m} \right|} {{P_{ij,mn}} = 0} ,{P_{i,m}} = 0. $$ 证明成立。
(2)证明
$ \exists m \lt i,{P_{i,m}} \gt 0 $ 。设
$ {Y^{t{\text{ + }}1}} $ 空间中最优蜻蜓的空间位置为$ X_{B{\text{est}}}^{t{\text{ + }}1} $ ,此时蜻蜓在探索邻域范围内随机选择行为,有分离行为、对齐行为、聚集行为、捕食行为、避敌行为共计5种情况。情况 1 蜻蜓选择分离行为。假设存在空间位置
$ F\left( {{X^{t + 1}}} \right) $ 优于当前蜻蜓X所处空间位置$ F\left( {{X^t}} \right) $ ,即$ F\left( {{X^{t + 1}}} \right) \geqslant F\left( {{X^t}} \right) $ ,那么蜻蜓则会更新到更优的空间位置,$ \exists m \lt i,{P_{i,m}} \gt 0 $ ,(49)得证。情况 2 蜻蜓选择对齐行为。假设存在空间位置
$ F\left( {{X^{t + 1}}} \right) $ 优于当前蜻蜓X所处空间位置$ F\left( {{X^t}} \right) $ ,即$ F\left( {{X^{t + 1}}} \right) \geqslant F\left( {{X^t}} \right) $ ,那么蜻蜓则会更新到更优的空间位置,$ \exists m \lt i,{P_{i,m}} \gt 0 $ ,(49)得证。情况 3 蜻蜓选择聚集行为。假设存在空间位置
$ F\left( {{X^{t + 1}}} \right) $ 优于当前蜻蜓X所处空间位置$ F\left( {{X^t}} \right) $ ,即$ F\left( {{X^{t + 1}}} \right) \geqslant F\left( {{X^t}} \right) $ ,那么蜻蜓则会更新到更优的空间位置,$ \exists m \lt i,{P_{i,m}} \gt 0 $ ,(49)得证。情况 4 蜻蜓选择捕食行为。假设存在空间位置
$ F\left( {{X^{t + 1}}} \right) $ 优于当前蜻蜓X所处空间位置$ F\left( {{X^t}} \right) $ ,即$ F\left( {{X^{t + 1}}} \right) \geqslant F\left( {{X^t}} \right) $ ,那么蜻蜓则会更新到更优的空间位置,$ \exists m \lt i,{P_{i,m}} \gt 0 $ ,(49)得证。情况 5 蜻蜓选择避敌行为。假设存在空间位置
$ F\left( {{X^{t + 1}}} \right) $ 优于当前蜻蜓X所处空间位置$ F\left( {{X^t}} \right) $ ,即$ F\left( {{X^{t + 1}}} \right) \geqslant F\left( {{X^t}} \right) $ ,那么蜻蜓则会更新到更优的空间位置,$ \exists m \lt i,{P_{i,m}} \gt 0 $ ,(49)得证。由IMODA算法可知,蜻蜓必选上述5种行为中任意一个,因此5种运动行为概率总和等于1。
证明成立。
定理 3 IMODA算法具有收敛性。
证明 IMODA算法具有收敛性。
$ X_S^i, i = 1,2, \cdots ,N $ 仅与当前变化有关而与历史无关,且样本空间有限,因此可视作有限马尔科夫链。 根据(2)中引理1可得马尔科夫链的转移矩阵为:$$ P = \left[ {\begin{array}{*{20}{c}} {{P_{1,1}}}&0& \cdots &0 \\ {{P_{2,1}}}&{{P_{2,2}}}& \cdots &0 \\ \vdots & \vdots & \cdots & \vdots \\ {{P_{N,1}}}&{{P_{N,2}}}& \cdots &{{P_{N,N}}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} C&0 \\ R&T \end{array}} \right] $$ (52) 根据(49)式可得:
$$ {P_{2,1}} \gt 0, R = {\left( {{P_{2,1}},{P_{3,1}}, \cdots ,{P_{N,1}}} \right)^T} $$ (53) $$ T = \left[ {\begin{array}{*{20}{c}} {{P_{2,2}}}& \cdots &0 \\ \vdots & \cdots & \vdots \\ {{P_{N,2}}}& \cdots &{{P_{N,N}}} \end{array}} \right] \ne 0, C = {P_{1,1}}{\text{ = }}1 $$ (54) P为N阶可归约随机矩阵,则满足:
$$ {P^\infty }{\text{ = }}\mathop {\lim }\limits_{k \to \infty } {P^k} = \mathop {\lim }\limits_{k \to \infty } \left[ \begin{gathered} \;\;\;\;\;\;\;\;\; {C^k} \;\;\;\;\;\;\;\;\cdots \;0 \\ \sum\limits_{i = 1}^{k - 1} {{T^i}R{C^{k - i}} \cdots {T^k}} \\ \end{gathered} \right]{\text{ = }}\left[ \begin{gathered} {C^\infty } \cdots 0 \\ {R^\infty } \cdots T \\ \end{gathered} \right] $$ 且
$ {C^\infty } {\text{ = }}1, {R^\infty }{\text{ = }}{\left[ {1,1,, \cdots ,1} \right]^T} $ 。因此
$ {P^\infty } = \left[ { \begin{array}{*{20}{c}} 1&0& \cdots &0 \\ 1&0& \cdots &0 \\ \vdots & \vdots & \vdots & \vdots \\ 1&0& \cdots &0 \end{array}} \right] $ 为稳定的随机矩阵,可得:$$ \mathop {\lim }\limits_{{\text{t}} \to \infty } P\left\{ {F\left( {X_{B{\text{est}}}^t} \right){\text{ = }}F\left( {{X^*}} \right) = {F_i}} \right\} = 1 $$ (55) 因此IMODA算法具有全局收敛性。
证明成立。
(3) IMODA算法全局稳定性证明
由(2)可知,可知IMODA算法最终收敛于全局最优点,所以
$ {X_0} $ 初始位置最终都将收敛于全局最优点$ {x_{\max }} $ 。假设 1
$ {x_{\max }} $ 为李雅普诺夫意义下的平衡点。证明
$ {x_{\max }} $ 为李雅普诺夫意义下的平衡点。设多机制水母算法的目标函数为
$ f\left( X \right) $ ,那么动态方程为:$$ \dot X{\text{ = }}f\left( {X,t} \right) $$ (56) 令x轴向上平移
$ f\left( {{x_{\max }}} \right) $ ,则动态方程更新为:$$ \dot X{\text{ = }}f\left( {X,t} \right) - f\left( {{x_{\max }}} \right) $$ (57) 根据算法收敛性可知,当
$ t \to \infty $ 时,蜻蜓的位置状态X趋近于全局最优点xmax:$$ \underset{\text{t}\to \infty }{\mathrm{lim}}\Vert X\left(t:{X}_{0},{t}_{0}\right)-{X}_{\text{e}}\Vert \text=0 $$ (58) 所以对所有的t,满足平衡状态
$$ {\dot X_{\text{e}}}{\text{ = }}f\left( {{X_{\text{e}}},t} \right) - f\left( {{x_{\max }}} \right){\text{ = }}0 $$ (59) 其中,
$ {x_{\max }} $ 为IMODA算法中的平衡点,$ {\dot X_{\text{e}}}{\text{ = }}f\left( {{x_{\max }},t} \right) $ 为平衡状态。所以IMODA算法中存在平衡点和平衡状态。
证明成立。
(4) IMODA算法在李雅普诺夫意义下的稳定
设IMODA算法的初始条件状态位于以平衡点
$ {x_{\max }} $ 为圆心、$ \varepsilon $ 为半径的超球域$ S\left( \varepsilon \right) $ 之内,则$ X \in S\left( \varepsilon \right) $ 可表示$ S\left( \varepsilon \right){\text{ = }}\left\{ {X\left| {\left\| {X - {x_{\max }}} \right\| \leqslant \varepsilon } \right.} \right\} $ 即:$$ \left\| {X - {x_{\max }}} \right\| \leqslant \varepsilon $$ (60) 如图4所示,
$ {x_{\max }} $ 为圆心半径为$ \gamma $ 的圆$ S\left( \gamma \right) $ 和半径为$ \varepsilon $ 的圆$ S\left( \varepsilon \right) $ ,边侧两边的点设为$ {x_1},{x_2} $ ,圆$ S\left( \gamma \right) $ 与$ f\left( x \right) $ 相交与$ {x_3},{x_4}, $ 假设$ f\left( x \right) $ 为目标函数函数图,$ f\left( {{x_{\max }}} \right) $ 为函数最大值,$ f\left( {{x_{\max 1}}} \right) $ 为函数次大值,$ {S_{\max }} $ 为目标函数最大值和次大值之间区域,称为最优区域。
图 4 Lyapunov意义下MODA算法的稳定性
证明 IMODA算法具有李雅普诺夫意义下的稳定性。
由(2)中IMODA全局收敛性可知,当
$ X $ 处于目标函数最大值和次大值之间的区域$ {S_{\max }} $ 时,$ X $ 会被食物吸引从而向着$ {x_{\max }} $ 运动,所以方程的初始解$ X\left(t:{X}_{0},{t}_{0}\right) $ 位于$ {S_{\max }} $ 之内,且$ {S_{\max }} $ 被包含于$ S\left( \varepsilon \right) $ 与$ f\left( x \right) $ 相交区域之内,则$ X $ 就不会逃离$ S\left( \varepsilon \right) $ . 那么$ \delta $ 满足:$$ \left\{ \begin{gathered} \delta \leqslant \min \left( {\left\| {{x_{\max }} - {x_1}} \right\|,\left\| {{x_{\max }} - {x_2}} \right\|} \right) \\ \delta \leqslant \min \left( {f\left( {{x_{\max }}} \right) - f\left( {{x_3}} \right),f\left( {{x_{\max }}} \right) - f\left( {{x_4}} \right)} \right) \\ \end{gathered} \right. $$ (61) 则有
$$ \Vert X\left(t:{X}_{0},{t}_{0}\right)-{X}_{\text{e}}\Vert \le \gamma ,t\ge {t}_{0} $$ (62) 其中,
$ {S_{\max }} $ 为目标函数最大值和次大值之间的区域;其中x1 ,x2 ,x3 ,x4.所以,当
$ t \to \infty $ 时,$ \forall t $ 使得$ X\left(t:{X}_{0},{t}_{0}\right)\in S\left(\gamma \right) $ 因此,满足李雅普诺夫意义下的稳定。因此
$ \forall \gamma \gt 0, \exists \varepsilon $ 且$ \varepsilon $ 满足公式(59),初始状态$ {x_0} $ 满足$ \left\| {{x_0} - {x_{\max }}} \right\| \leqslant \varepsilon $ ,那么$ {x_0} $ 均满足$ \Vert X\left(t:{X}_{0},{t}_{0}\right)- {X}_{\text{e}}\Vert \le \varepsilon $ . 因此,可得$ \varepsilon $ 与$ {t_0} $ 无关,IMODA算法的平衡状态$ {x_{\max }} $ 是一致稳定。证明成立。
-
本文提出的IMODA-ADBN故障诊断模型,主要为以下5个流程:
(1) 被测电路两端施加脉冲信号,采集故障数据;
(2) 对数据进行故障编码;
(3) 将数据集划分为训练集、测试集;
(4) 在无监督学习过程中保留权重,并利用自适应学习率加速训练过程;在有监督学习过程中,使用IMODA优化算法精调权重;
(5) 模型测试:测试集的真实编码与模型的预测编码进行对比,若预测编码与真实编码一致,则分类正确;若预测编码与真实编码不一致,则分类错误。
-
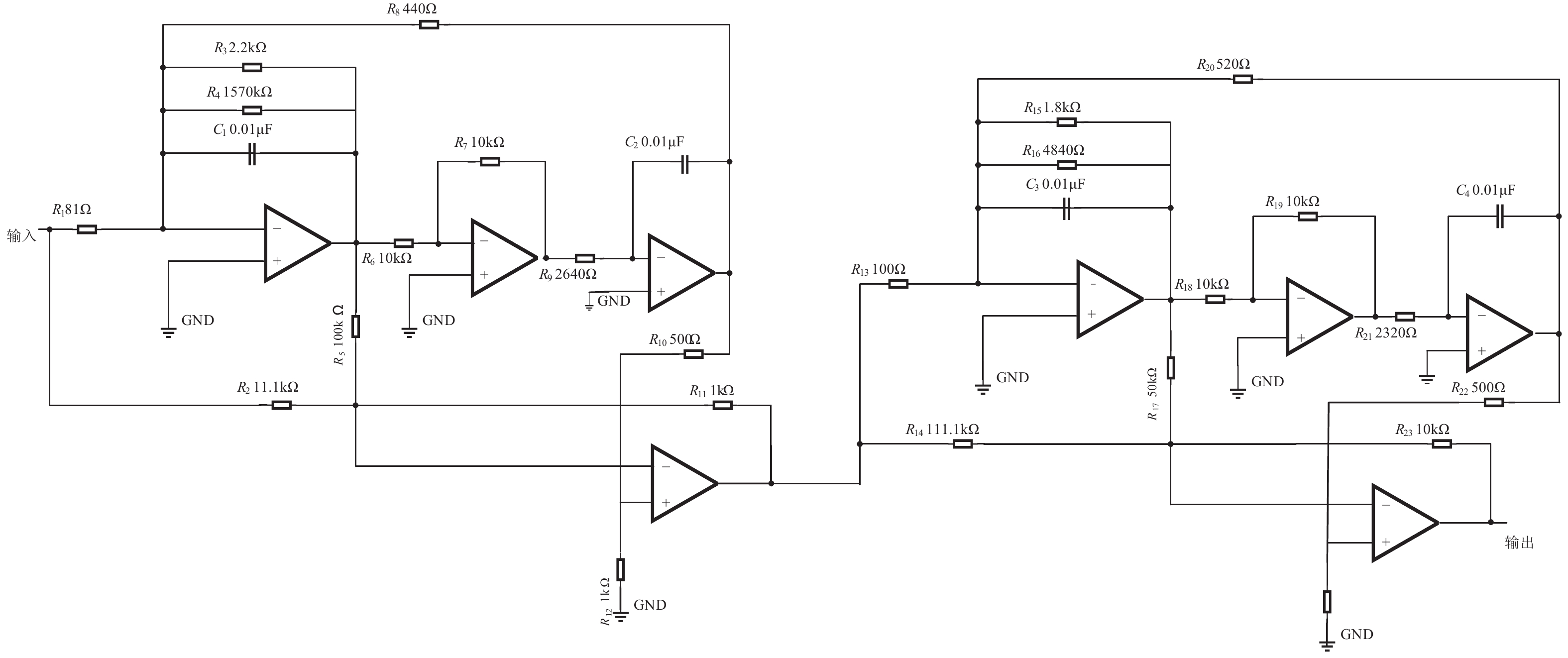
本文用输入为幅值为 5 V,频率为10 kHz 的正弦波信号激励的二级四运放双二阶低通滤波器(图5)[40]。验证本文所提出的IMODA-ADBN模型,将电路中电阻及电容的容差分别均设置为5%。根据一般元件的参数性故障定义:当元件参数值偏离标称值50%时,即可判定该元件发生故障[3]。本次实验设定滤波器中单一的电阻或电容出现故障时,而其它的电阻或电容在容差范围内随意变化,即处于正常状态。并且根据灵敏度测试结果,选择电阻 R3,R19 和电容C1,C4 四种元器件作为研究对象进行实验分析,由表1所示。
深度学习网络多采用三层隐藏层叠加,可使重构误差达到最小。利用均方误差(MSE)、绝对百分比误差(APE)及运行时间为参考标准,用实验法选出最佳神经元个数。图6是模型误差与隐含层神经元个数关系图,由图可知当隐含层的神经元个数为20时性能效果最佳。此时APE、MSE分别是0.0507和0.0542。
$$ {\text{APE}} = \frac{1}{{{N_t}}}\sum\limits_{i = 1}^{{N_t}} {\left| {\frac{{{{\hat y}_i} - {y_i}}}{{{y_i}}}} \right|} \times 100\% $$ (63) $$ {\text{MSE}} = \frac{1}{{{N_t}}}\sum\limits_{i = 1}^{{N_t}} {{{\left( {{{\hat y}_i} - {y_i}} \right)}^2}} $$ (64) 其中,
$ {y_i} $ 和$ {\hat y_i} $ 分别表示真实值和预测分类值,$ {N_t} $ 表示测试样本个数。为客观证明IMODA-ADBN最佳的模型结构是10-20-20-20-9,将双二阶四运放低通滤波器单次采样时间设为0.05s,将同种故障模式下20种不同时域的数据样本设置为一组,每种故障采集20组,9种故障共计,构成 9×400原始数据集。随机选取280组作为训练样本,剩余的120组作为测试样本。
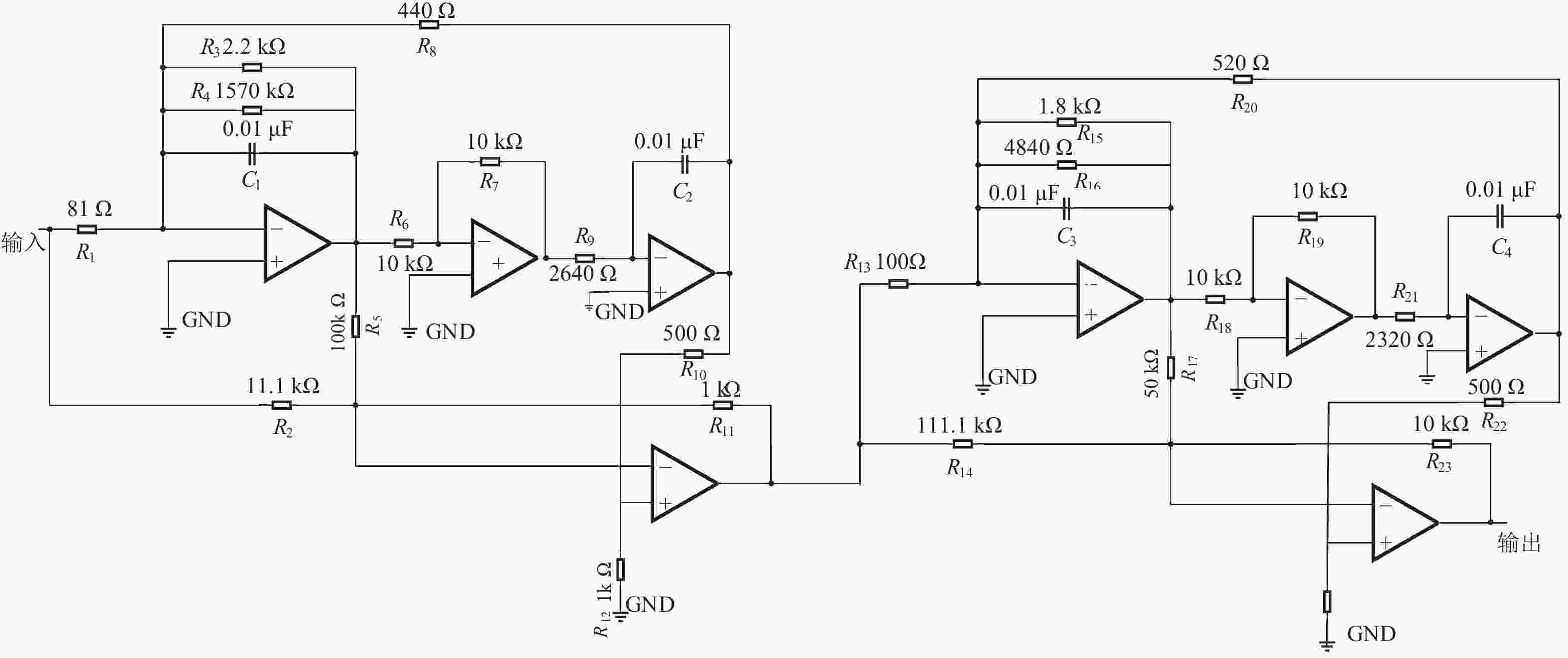
图 5 二级四运放双二阶低通滤波器
表 1 二级四运放双二阶低通滤波器电路故障模式
故障代码 故障类型 容差/% 标称值 故障值 f1 无故障 — — — f2 R9增大 5 2640 Ω 3960 Ω f3 R9减小 5 2640 Ω 1320 Ω f4 R19增大 5 10 kΩ 15 kΩ f5 R19减小 5 10 kΩ 5 kΩ f6 C1增大 5 0.01 nF 0.005 nF f7 C1减小 5 0.01 nF 0.015 nF f8 C4增大 5 0.01 nF 0.005 nF f9 C4减小 5 0.01 nF 0.015 nF 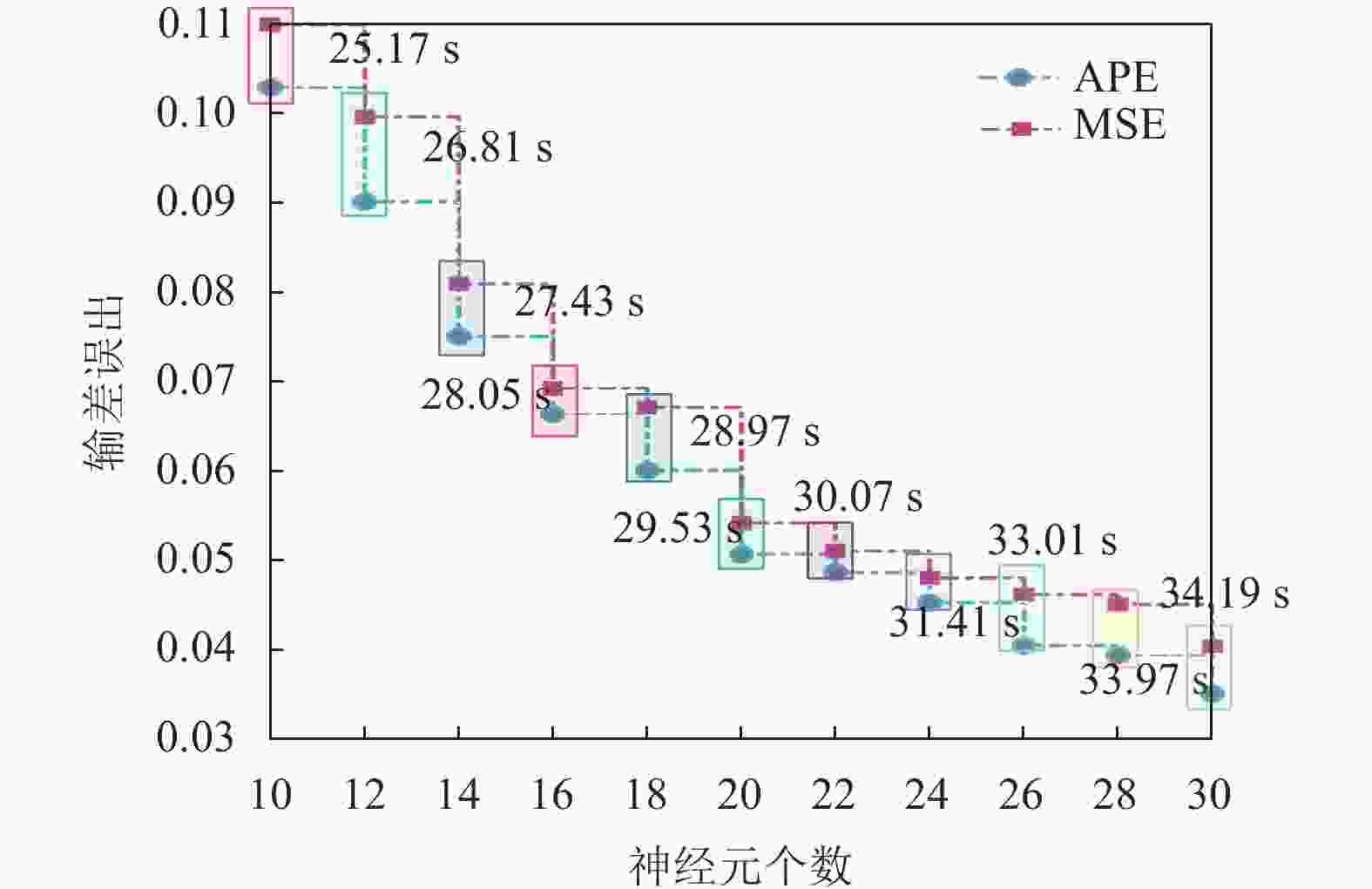
图 6 不同神经元个数模型误差图
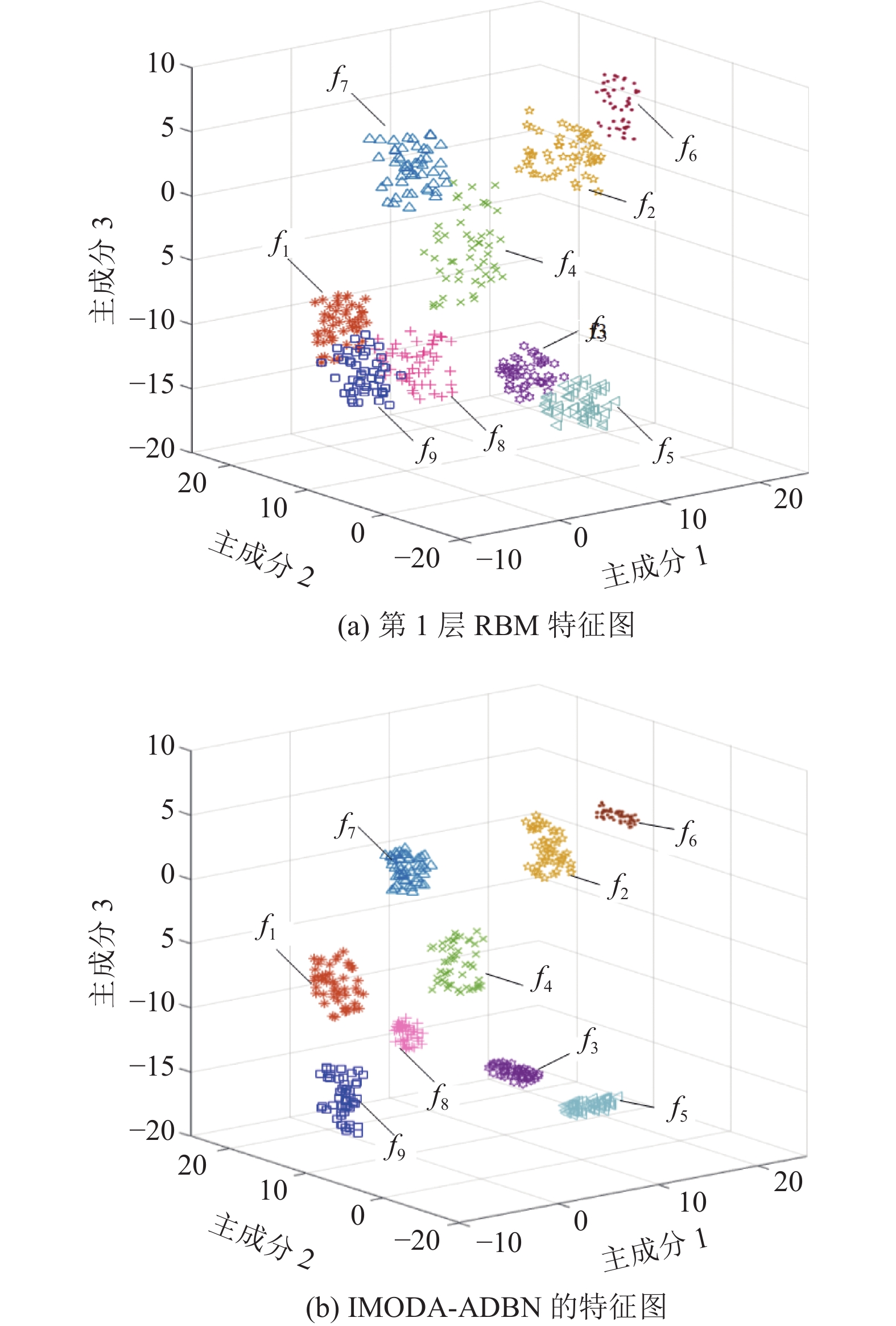
在无监督训练阶段中每个RBM设置迭代90次,学习率系数分别设置为D=1.4,d=0.7。利用KPCA(kernel principal component analysis)提取第一个RBM输出特征的三个主成分和DBN最终输出特征的三个主成分,分别由图7a和图7b表示。
从图7a中可以看出f7、f8和f9有重叠现象产生;f4、f7有轻微重叠现象;f3、f5故障相聚较近;剩余故障虽然没有重叠现象产生但同类故障之间的特征点分布较为分散。输入数据经过IMODA-ADBN模型会进行4次非线性映射并重构数据,从图7b中可以看出9种故障经本文提出的方法可以被精准区分。并且相较图7a而言,经IMODA-ADBN模型处理后的同类故障的主成分分布相对于图7a更加紧凑,因此,可以得出IMODA-ADBN模型可以通过增加RBM的个数提高模型的特征表达能力,从而能够更加精确抽象表达输入数据。
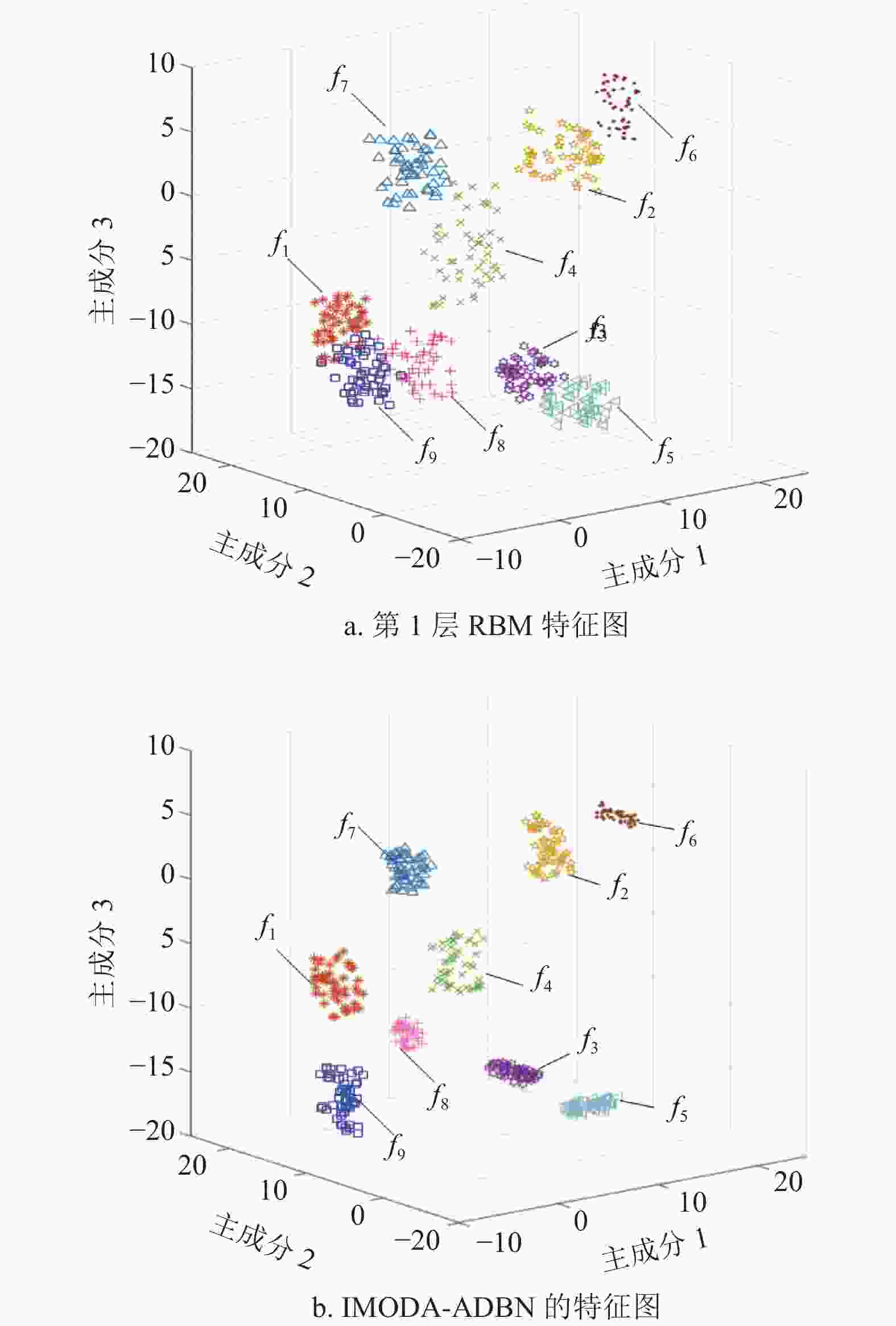
图 7 特征主成分分布图
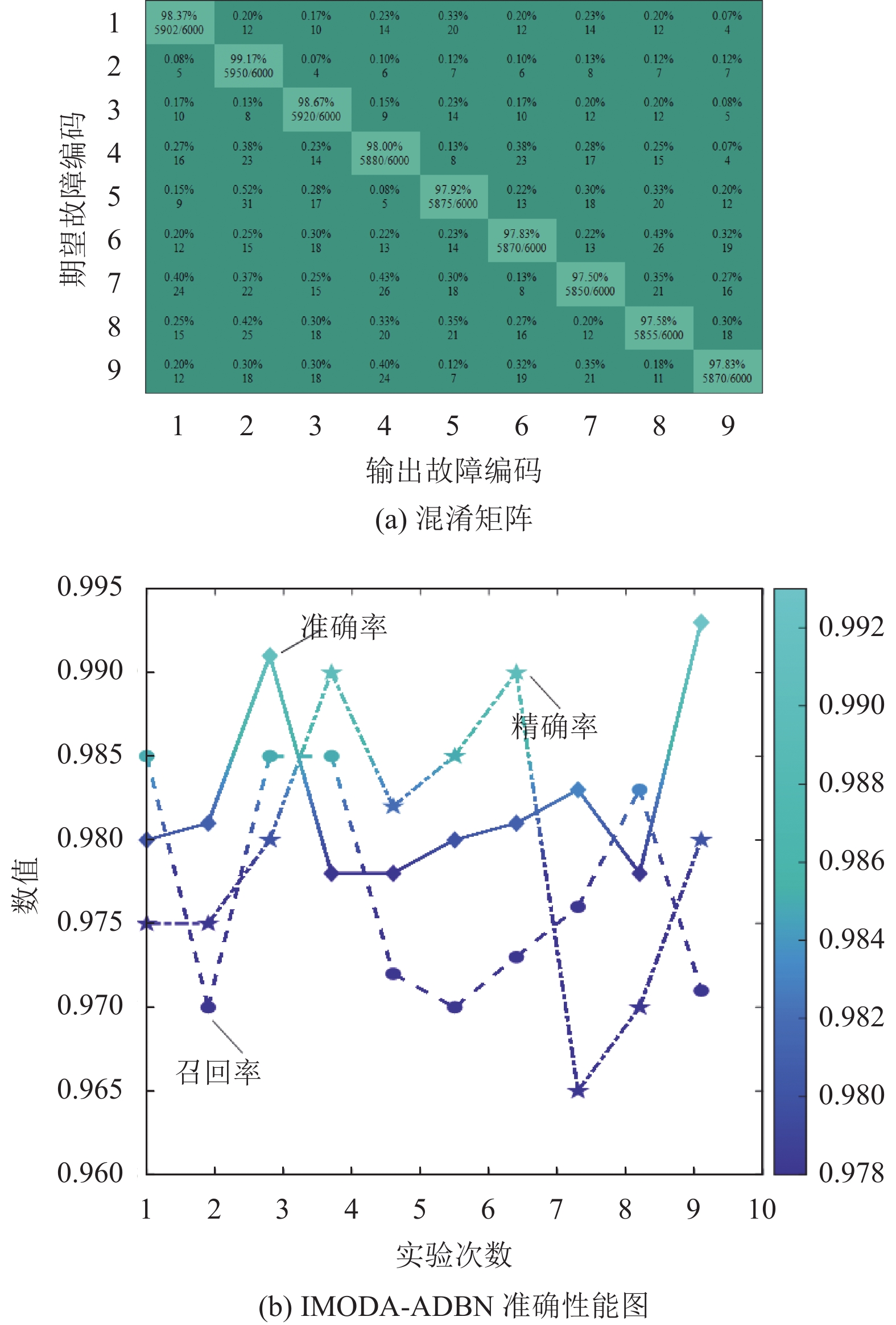
为降低实验随机性对模型诊断性能的评判影响,对二级四运放双二阶低通滤波器电路进行10次独立诊断实验。其中,图8a为IMODA-ADBN模型的10次诊断故障混淆矩阵图,其中每类故障的准确率计算10次均值,而错分个数则进行10次实验累计统计。从图8a中可以看出,将故障错分为其它故障类型的累计错分率均不超过1%,并且每类故障诊断准确率均在98%以上。表明本文提出的IMODA-ADBN模型对9种故障可以精准识别;图8b表示IMODA-ADBN模型在10次诊断实验中的准确率、精确率及召回率三种指标的性能曲线图。从图中可以看出,在10次实验过程中,IMODA-ADBN模型在每一次实验过程中的精确率、准确率、召回率均在96%以上。因此,可以证明本文提出的IMODA-ADBN模型具有较强的鲁棒性。
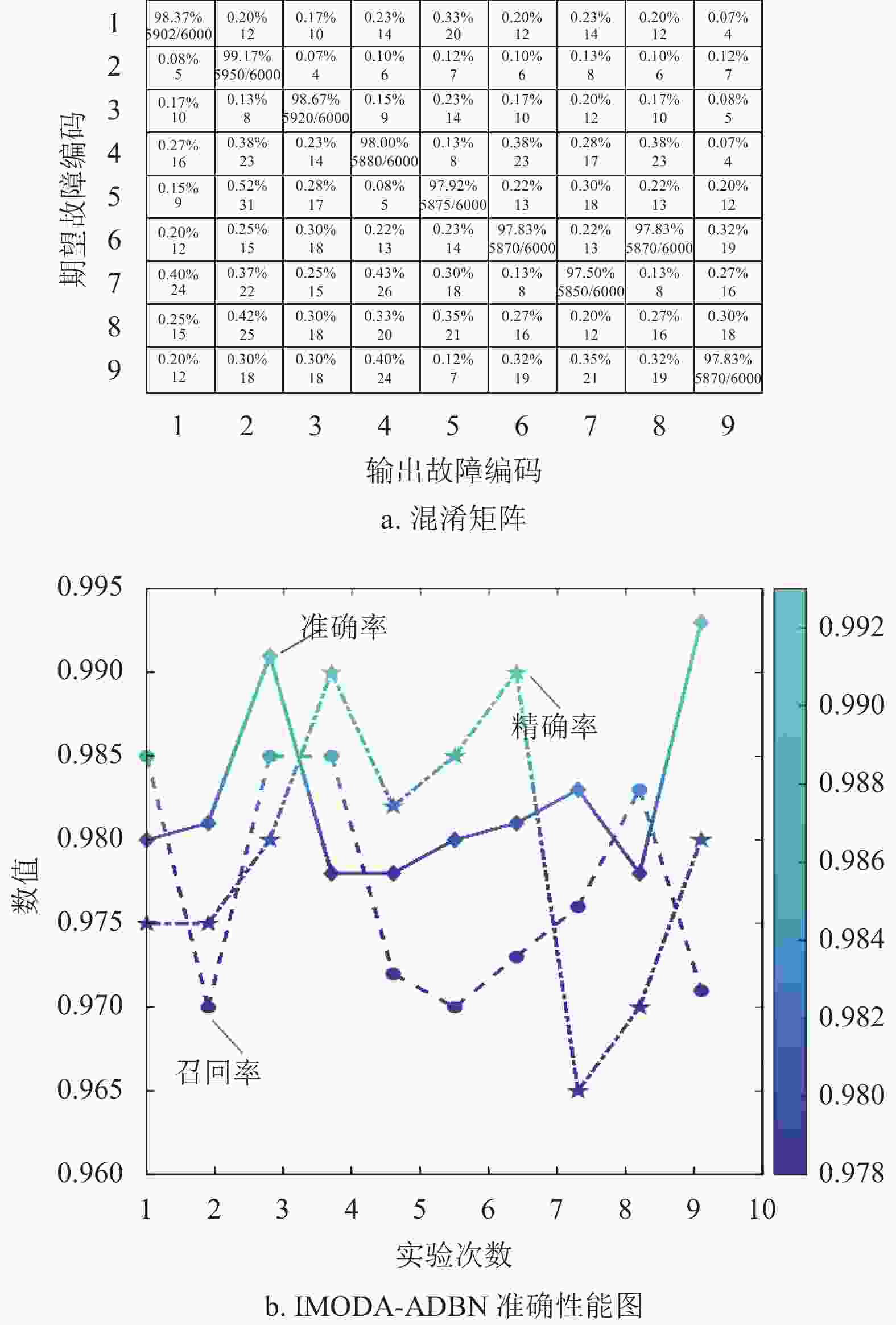
图 8 IMODA-ADBN诊断结果图
-
(1) 自适应学习实验验证
RBM作为概率模型,因此,RBM极易受到权重对其的影响。为了保证RBM准确提取特征,我们需要保证合理的权重。由公式(7)-(10)可以看出,DBN在学习过程中,权重的大小由学习率决定。然而,以往DBN在学习过程中学习率都依靠人工经验设定,缺乏合理性。因此,为进一步地证明自适应学习率的合理性与有效性,本文选取固定学习率与自适应学习率作为实验对象,采用误差作为实验目标进行对比试验。其中,固定学习率设置为0.01、0.05、0.1、0.5和1,并固定有监督学习部分并进行10次对比实验。将4.1小节获得的仿真数据划分训练数据和测试数据进行实验验证。
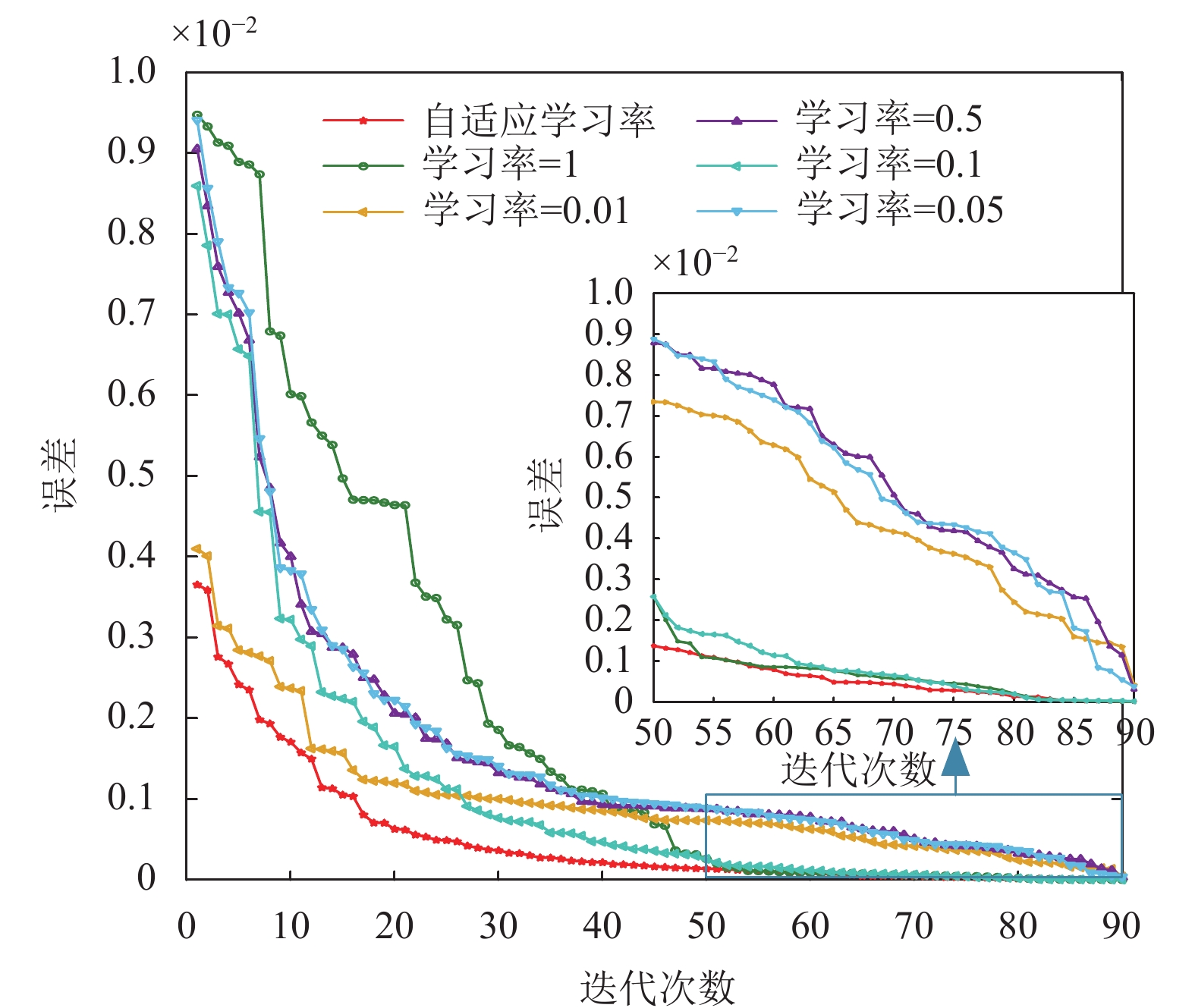
图9为迭代次数和误差关系图。从图9可以看出,模型误差会随迭代次数的增加而逐渐降低。表2代表不同学习率情况下模型在10次实验过程中的平均诊断准确率。结合图9和表2可以得出以下结果:

图 9 迭代次数和误差关系图
表 2 不同学习率对应的平均准确率
学习率 平均准确率/% 0.01 94.26 0.05 93.73 0.1 96.21 0.5 94.57 1 93.75 自适应学习率 98.02 (1) 以固定学习率为研究目标,以IMODA-ADBN模型的10次诊断实验平均准确率作为衡量指标,可以得出:将学习率设置为0.1时模型的诊断性能最好(96.21%)。而将学习率设置为1和0.05时模型的诊断性能均不太理想(93.75%和93.73%)。学习率设置为0.5时,平均诊断率为94.57%,虽在迭代前期时模型误差下降幅度较大,但与最优固定学习率0.1相比,诊断准确率却下降了1.64%;而将学习率设置为0.01时,虽在迭代前期时模型误差较小,准确率下降了1.95%。
(2) 以学习率为0.1作为参考线,其中学习率高(学习率为0.5和1)造成的准确率下降可能是因为参数更新过大,使模型无法收敛;学习率低(学习率为0.01和0.05)造成的准确率下降的原因可能是在学习率过低的情况下,模型可能在训练初期就停滞在一个较差的局部最小值,而没有足够的能量去跳出这个局部最小值并继续学习。
(3) 自适应学习率的设计使模型大约在75次左右迭代时已经趋于稳定,在55次左右迭代时误差已经小于0.01,保证模型收敛速度的同时有效降低模型的误差,从而在对比实验中获得了最高的平均诊断率(98.02%)。与固定学习率最优值0.1相比,准确率提高了1.84%。可以证明:所提出的基于参数更新方向设置的自适应学习率与传统经验学习率相比更具有先进性与合理性。
(2) IMODA优化算法性能验证
为了增加MODA优化过程中的多样性,以及改善陷入局部最优的情况,我们在传统MODA优化算法中增加了Logstic映射和对立跳跃。 二者可以提高初始种群的多样性,并降低“早熟”的概率[41];选用ZTD函数[42]、Schaffer[43]和DTLZ函数[44]共计7种测试函数验证IMODA算法的性能,并与3种著名的多目标优化算法(MODA、MOPSO[45]和NSGA-II[46])进行了比较,其中算法的参数设置见表3,测试函数的表达式及限定范围见表4,并根据对应的帕累托最优前沿特征进行归纳。表5则对不同算法的性能进行了实验验证。
表 3 不同算法的参数设置
算法 参数 IMODA 种群数量:$ N{\text{ = }}150 $ 档案大小:$ {N_{{\text{rep}}}}{\text{ = }}150 $$ 网格分量: $ {n_{grid}}{\text{ = }}20 $ 最大迭代次数: $ M{\text{a}}{{\text{x}}_{{\text{iter}}}}{\text{ = }}2500 $ MODA 种群数量:$ N{\text{ = }}150 $ 档案大小:$ {N_{{\text{rep}}}}{\text{ = }}150 $$ 最大迭代次数: $ M{\text{a}}{{\text{x}}_{{\text{iter}}}}{\text{ = }}2500 $ MOPSO 种群数量:$ N{\text{ = }}150 $ 档案大小:$ {N_{{\text{rep}}}}{\text{ = }}150 $$ 网格分量:$ {n_{grid}}{\text{ = }}20 $ 最大迭代次数: $ M{\text{a}}{{\text{x}}_{{\text{iter}}}}{\text{ = }}2500 $ 惯性权重 (初始): $ w{\text{ = 0}}{\text{.5}} $
惯性权重 (最终): $ w{\text{ = 0}}{\text{.001}} $变异概率: $ {P_M}{\text{ = }}0.1 $ NSGA-II 种群数量:$ N{\text{ = }}150 $ 网格分量:$ {n_{grid}}{\text{ = }}20 $ 最大迭代次数: $ M{\text{a}}{{\text{x}}_{{\text{iter}}}}{\text{ = }}2500 $ 变异概率: $ {P_M}{\text{ = }}0.5 $ 表 4 多目标测试函数的特性
测试函数 变量个数 目标函个数 变量范围 表达式 特征 ZTD1 30 2 $ \left[ {0,1} \right] $ $ g\left( x \right) = 1 + \dfrac{9}{{N - 1}}\displaystyle\sum\limits_{i = 2}^N {{x_i}} $
$ h\left( {{f_1}\left( x \right),g\left( x \right)} \right) = 1 - \sqrt {\dfrac{{{f_1}\left( x \right)}}{{g\left( x \right)}}} $
$ {f_1}\left( x \right) = {x_1} $
$ {f_2}\left( x \right) = g\left( x \right) \times h\left( {{f_1}\left( x \right),g\left( x \right)} \right) $帕累托最优前沿有一个凸前沿 ZTD2 30 2 $ \left[ {0,1} \right] $ $ g\left( x \right) = 1 + \dfrac{9}{{N - 1}}\displaystyle\sum\limits_{i = 2}^N {{x_i}} $
$ h\left( {{f_1}\left( x \right),g\left( x \right)} \right) = 1 - {\left( {\dfrac{{{f_1}\left( x \right)}}{{g\left( x \right)}}} \right)^2} $
$ {f_1}\left( x \right) = {x_1} $
$ {f_2}\left( x \right) = g\left( x \right) \times h\left( {{f_1}\left( x \right),g\left( x \right)} \right) $帕累托最优前沿有一个非转换前沿 ZTD3 30 2 $ \left[ {0,1} \right] $ $ g\left( x \right) = 1 + \dfrac{9}{{29}}\displaystyle\sum\limits_{i = 2}^N {{x_i}} $
$ h\left( {{f_1}\left( x \right),g\left( x \right)} \right) = 1 - \sqrt {\dfrac{{{f_1}\left( x \right)}}{{g\left( x \right)}}} - \left( {\dfrac{{{f_1}\left( x \right)}}{{g\left( x \right)}}} \right)\sin \left( {10\pi {f_1}\left( x \right)} \right) $
$ {f_1}\left( x \right) = {x_1} $
$ {f_2}\left( x \right) = g\left( x \right) \times h\left( {{f_1}\left( x \right),g\left( x \right)} \right) $帕累托最优前沿具有不连续前沿 Schaffer 1 2 $ \left[ { - 5,5} \right] $ $ {f_1}\left( x \right) = x_i^2 $
$ {f_2}\left( x \right) = {\left( {x - 2} \right)^2} $帕累托最优前沿有一个凸前沿 DTLZ1 7 3 $ \left[ {0,1} \right] $ $ g\left( {{x_M}} \right) = 100\left[ {\left| {{x_M}} \right| + \displaystyle\sum\limits_{{x_i} \in {x_M}} {{{\left( {{x_i} - 0.5} \right)}^2} - \cos \left( {20\pi \left( {{x_i} - 0.5} \right)} \right)} } \right] $
$ {f_1}\left( x \right) = \dfrac{1}{2}{x_1}{x_2} \cdots {x_{M - 1}}\left( {1 + g\left( {{x_M}} \right)} \right) $
$ {f_2}\left( x \right) = \dfrac{1}{2}{x_1}{x_2} \cdots \left( {1 - {x_{M - 1}}} \right)\left( {1 + g\left( {{x_M}} \right)} \right) $
$ {f_3}\left( x \right) = \dfrac{1}{2}{x_1}{x_2} \cdots \left( {1 - {x_{M - 2}}} \right){x_{M - 1}}\left( {1 + g\left( {{x_M}} \right)} \right) $帕累托最优前沿有一个线性前沿 DTLZ2 12 3 $ \left[ {0,1} \right] $ $ g\left( {{x_M}} \right) = \displaystyle\sum\limits_{{x_i} \in {x_M}} {{{\left( {{x_i} - 0.5} \right)}^2}} $
$ {f_1}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \cos \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right)\cos \left( {\dfrac{{{x_{M - 1}}\pi }}{2}} \right) $
$ {f_2}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \cos \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right){\text{sin}}\left( {\dfrac{{{x_{M - 1}}\pi }}{2}} \right) $
$ {f_3}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \sin \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right) $帕累托最优前沿为球面前沿 DTLZ3 12 3 $ \left[ {0,1} \right] $ $ g\left( {{x_M}} \right) = 100\left[ {\left| {{x_M}} \right| + \displaystyle\sum\limits_{{x_i} \in {x_M}} {{{\left( {{x_i} - 0.5} \right)}^2} - {\text{cos}}} \left( {20\pi \left( {{x_i} - 0.5} \right)} \right)} \right] $
$ {f_1}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \cos \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right)\cos \left( {\dfrac{{{x_{M - 1}}\pi }}{2}} \right) $
$ {f_2}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \cos \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right){\text{sin}}\left( {\dfrac{{{x_{M - 1}}\pi }}{2}} \right) $
$ {f_3}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \sin \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right) $帕累托最优前沿具有多前沿 表 5 不同算法测试函数性能对比
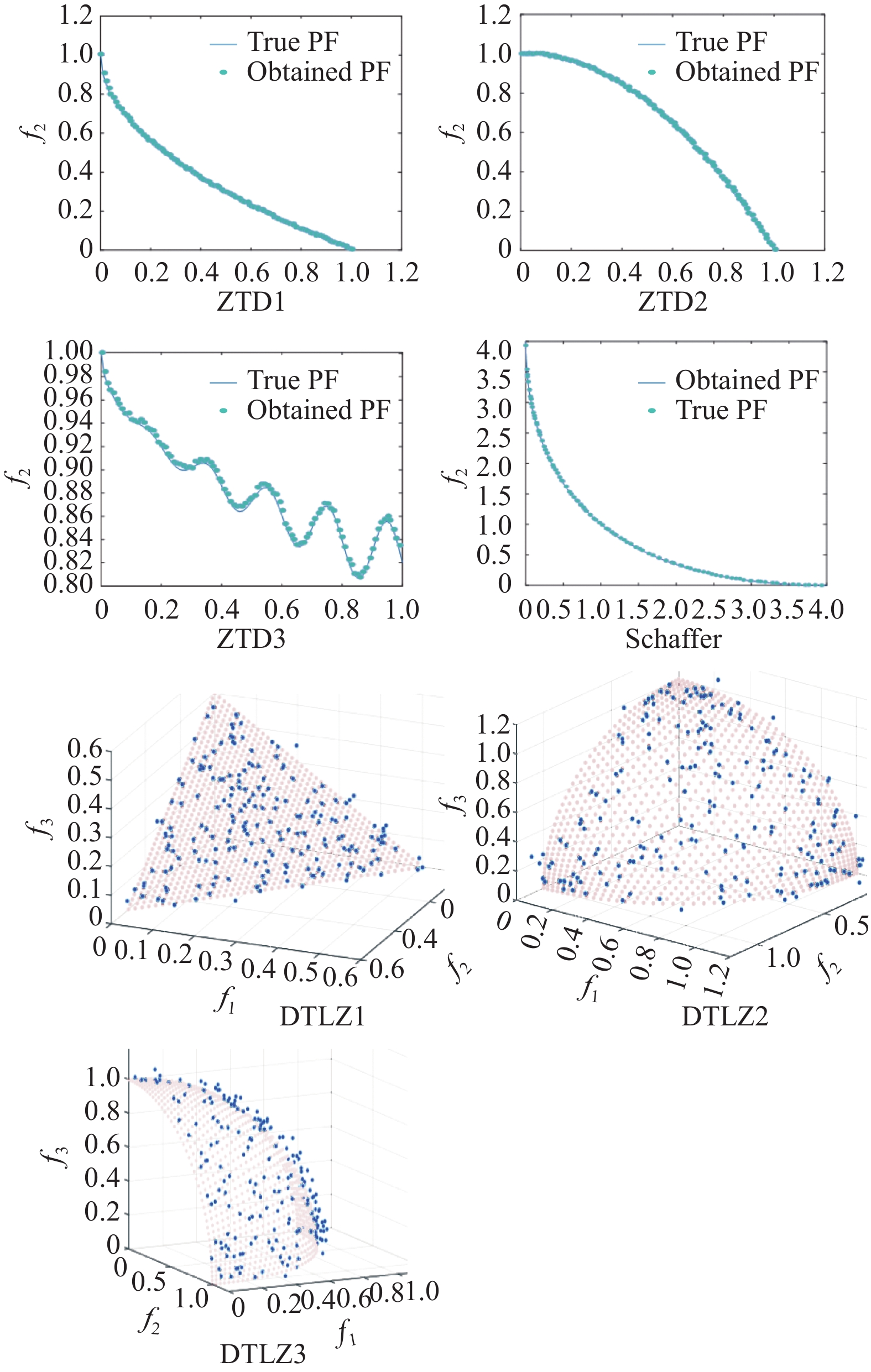
测试函数 IGD 算法 IMODA MODA MOPSO NSGA-II ZDT1 平均值 0.00547 0.00587 0.00472 0.04217 标准差 0.00231 0.00301 0.00418 0.00671 中值 0.00642 0.00770 0.00406 0.04133 最优值 0.00214 0.00253 0.00172 0.02071 最差值 0.00713 0.00827 0.01224 0.05922 ZDT2 平均值 0.00337 0.00426 0.00672 0.04017 标准差 0.00185 0.00271 0.00395 0.00332 中值 0.00257 0.00307 0.00799 0.03373 最优值 0.0022 0.00242 0.00443 0.02510 最差值 0.00593 0.00611 0.00724 0.04521 ZDT3 平均值 0.00921 0.03017 0.03674 0.04833 标准差 0.00907 0.00416 0.00608 0.00972 中值 0.00951 0.03372 0.03941 0.04157 最优值 0.00830 0.02151 0.02097 0.03270 最差值 0.00954 0.03849 0.04172 0.05122 Schaffer 平均值 0.00284 0.00372 0.00507 0.00693 标准差 0.00301 0.00399 0.00500 0.00710 中值 0.00240 0.00357 0.00416 0.00593 最优值 0.00126 0.00242 0.00212 0.00392 最差值 0.00337 0.00475 0.00501 0.00714 DTLZ1 平均值 0.00551 0.00608 0.05922 0.09150 标准差 0.00208 0.00409 0.03061 0.06003 中值 0.00471 0.00407 0.05030 0.07701 最优值 0.00210 0.00192 0.00188 0.04710 最差值 0.00902 0.00971 0.01027 0.12205 DTLZ2 平均值 0.00894 0.01098 0.05140 0.08511 标准差 0.00067 0.00901 0.01525 0.05720 中值 0.01022 0.00870 0.02081 0.06587 最优值 0.00901 0.00611 0.01429 0.04930 最差值 0.01078 0.01207 0.06814 0.10221 DTLZ3 平均值 0.00309 0.00661 0.03879 0.04102 标准差 0.00255 0.00520 0.00819 0.00907 中值 0.00261 0.00587 0.04066 0.04099 最优值 0.00223 0.00317 0.02109 0.03022 最差值 0.00372 0.00911 0.04307 0.05088 通过10次独立实验得出的最佳帕累托最优前沿(图10所示),并用Inverse generational distance(IGD)作为衡量指标。公式如下:
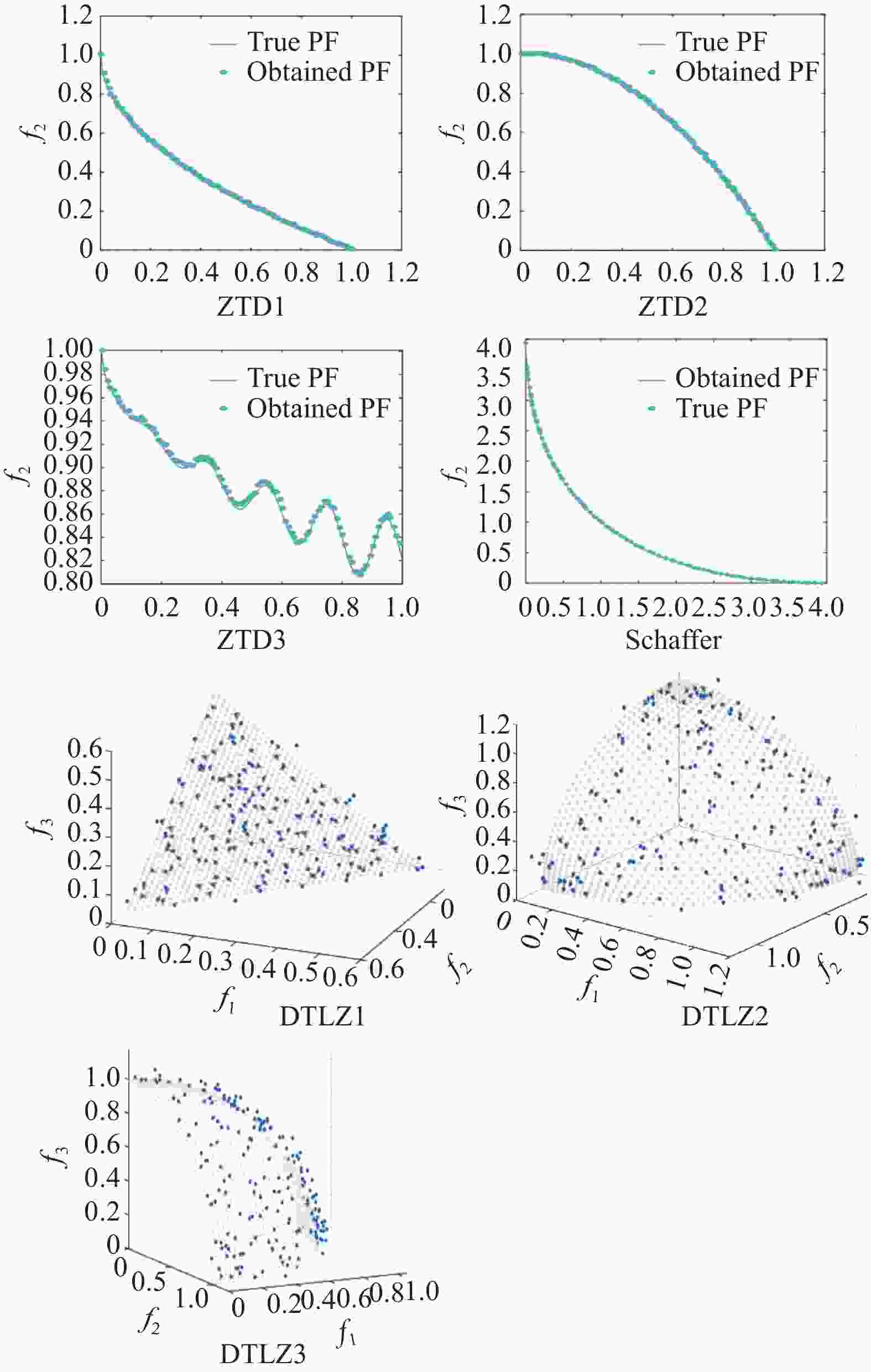
图 10 IMODA测试函数性能图
$$ IGD = \frac{{\sqrt {\displaystyle\sum\nolimits_{i = 1}^n {d_i^2} } }}{n} $$ (65) 其中,n是帕累托最优解的数目,
$ {d_i} $ 表示第i个帕累托最优解与参考集中最接近的帕累托最优解之间的欧氏距离。从表5可以看出,IMODA算法与MODA算法、MOPSO算法和NSGA-II算法相比,IMODA算法在7种测试函数中平均值、标准差、中值、最优值和最差值共计5种评价指标均达到了最佳性能;图10为IMODA在上述7种测试函数上的上的 Pareto解,可以看出IMODA算法得出的解可以全覆盖 Pareto 前沿,并且解的分布较为均匀,表明引入Logstic映射和对立跳跃策略能有效改善 MODA 算法的性能。
(3) IMODA-ADBN模型验证
将本文方法与一些常用模拟电路故障诊断与分类的方法进行对比实验来证明IMODA-ADBN模型对复杂电路故障诊断分类的有效性和优越性。 在浅层方面,用BP、ELM、SVM、LSSVM[16]进行分类诊断,在深层方面,采用传统DBN、 CDBN[47];另外利用重叠采样扩充数据集后用ECA-CNN[49]及CBAM-CNN进行对比[48],因为选取的对比模型中部分模型并不只针对模拟电路的故障进行诊断, 所以做出以下两点约束:(1)ECA-CNN、CBAM-CNN的输入均按照6∶2∶2划分训练集、验证集和测试集;(2) DBN、CDBN的模型结构与IMODA-ADBN模型结构相同。
将上述模型与本文提出的IMODA-ADBN进行10次独立诊断实验进行对比,如表6所示,其中对比指标包括平均时间、F1-Measure和平均准确率。
表 6 不同模型性能对比
(1) 仅从平均正确率角度出发,采用的浅层机器学习方法BP、ELM、SVM以及LSSVM作为诊断模型的平均正确率均低于深层机器学习模型。在深层机器学习模型中,以CNN为基础模型框架,采用注意力机制改进的ECA-CNN以及CBAM-CNN模型的诊断准确率分别为95.43%和97.91%;以DBN为诊断模型的平均诊断准确率最低(91.08%),而DBN的改进模型CDBN和IMODA-ADBN模型的平均诊断准确率分别为92.72%和98.14%,并且IMODA-ADBN诊断模型取得了最优表现。
(2) 仅从平均运行时间角度出发,浅层机器学习模型相对于深层机器学习模型均较为耗时。在深层机器学习模型中,ECA-CNN以及CBAM-CNN模型测试较快(6.51 s和6.72 s),但前期采用的重叠采样增强数据集操作增大了数据制作成本。DBN及CDBN模型的测试时间为43.91s和40.77s,IMODA-ADBN相较于DBN和CDBN分别降低了12.97 s和24.22 s。
仅从诊断准确率或运行时间单一角度出发并不能对模型性能做出最公平的判断。结合平均正确率及运行时间两种角度出发分析各类模型,本文提出的IMODA-ADBN主要优势如下: (1)与浅层相比,可以有效提取数据的本质特征;(2)对DBN合理优化可以使准确和性能都有不同程度的提升;(3)与SENet-CNN和CBAM-CNN相比,对数据集的需求量较小;因此IMODA-ADBN在故障的精准识别方面具有一定的优势。
(4) IMODA-ADBN模型噪声验证
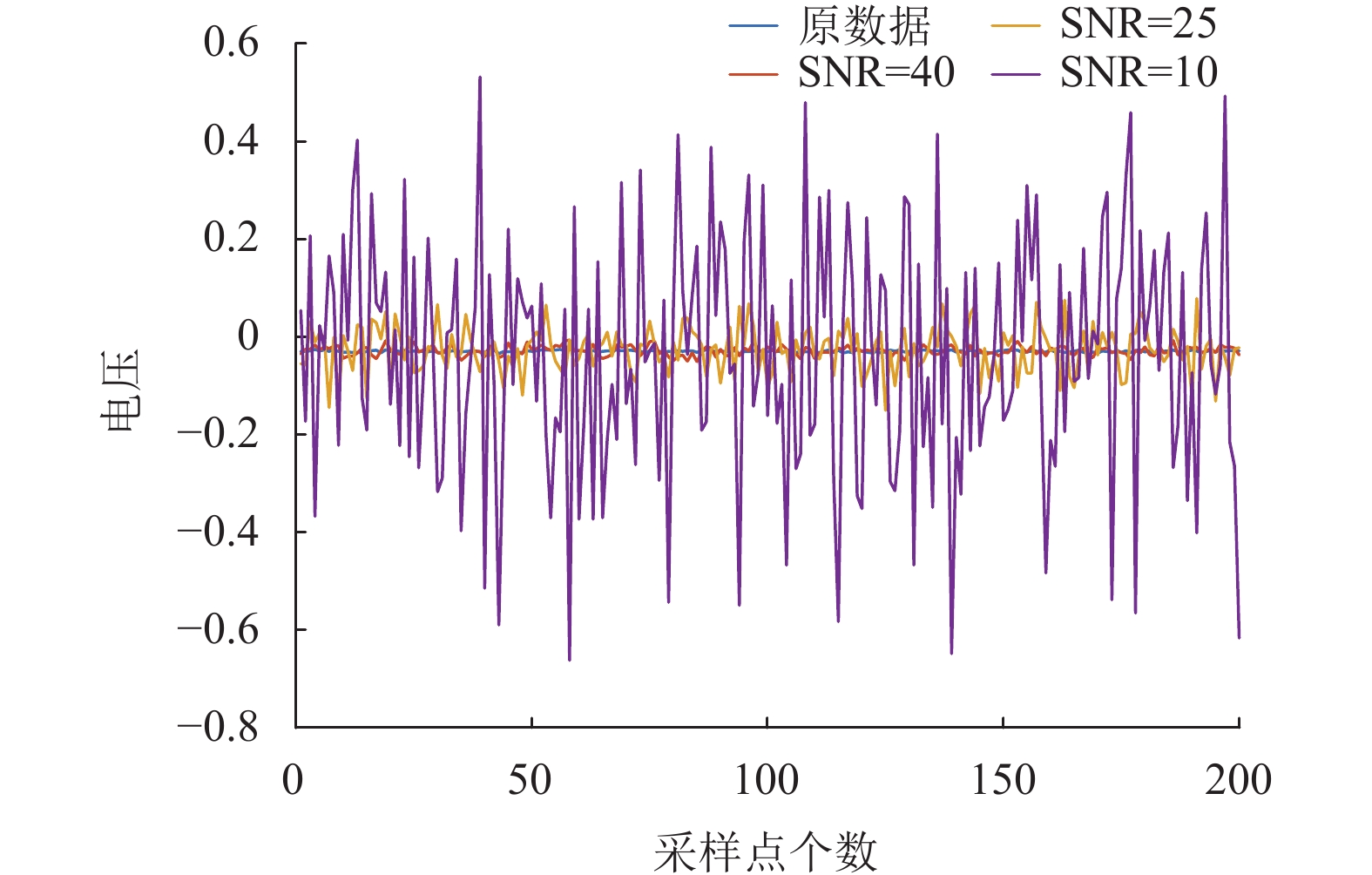
考虑到模拟电路中通常有白噪声的干扰,同时,为进一步评估IMODA-ADBN模型的鲁棒性,我们在4.1小节中所获取的仿真数据基础上,分别添加信噪比为40 dB、25 dB和10 dB的白噪声进行噪声实验验证。以正常输出部分波形为例,如图11展示了正常输出情况下的部分电压曲线及添加了三种不同噪声的电压曲线。
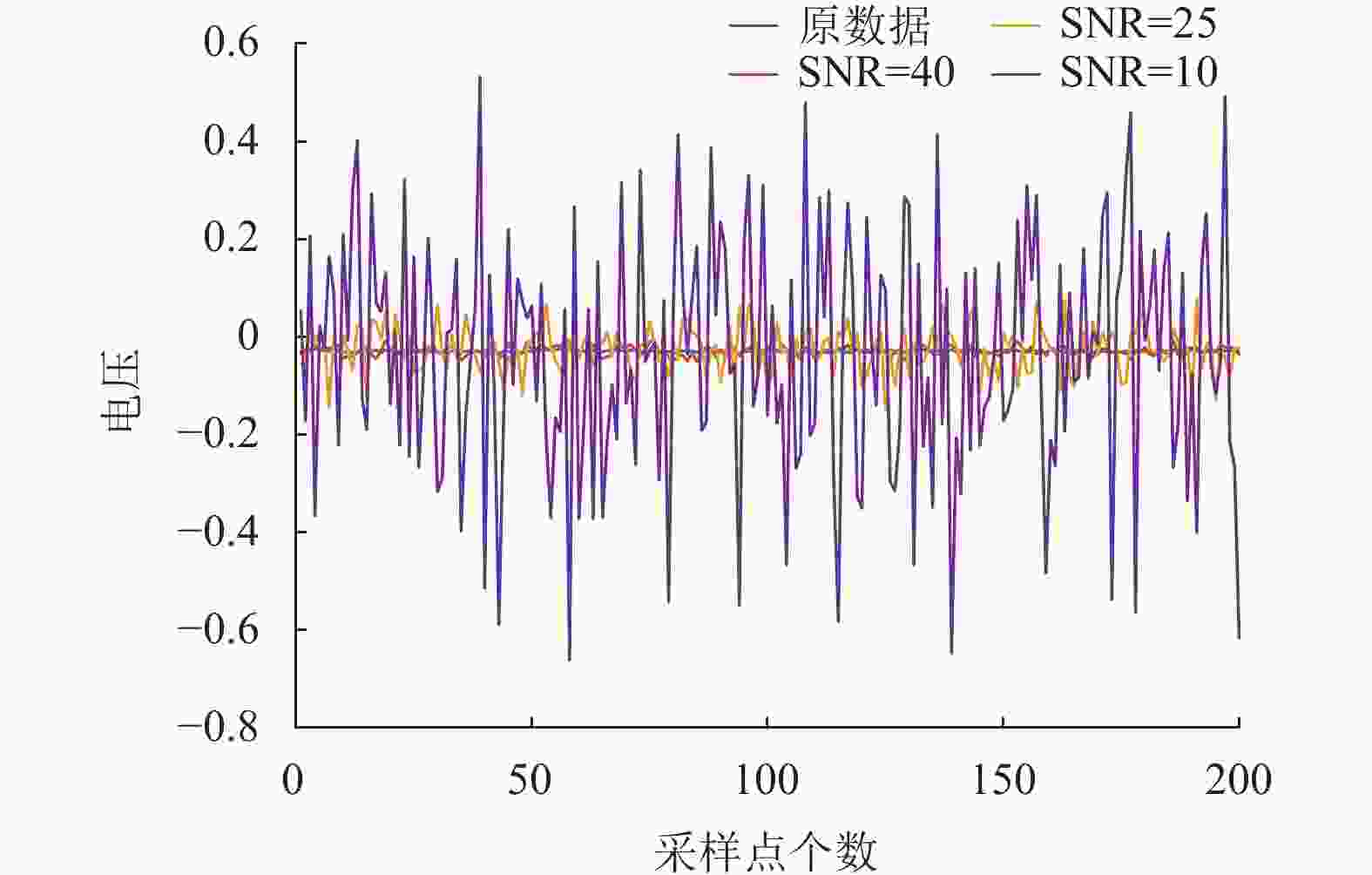
图 11 添加不同白噪声的电压曲线图
通过表6分析可知,浅层机器学习与深度机器学习相比,浅层机器学习的特征提取能力还是存有一定不足。鉴于此,在噪声实验中,选择DBN、CDBN、ECA-CNN以及IMODA-CNN作为对比模型来衡量IMODA-ADBN模型的性能优劣。为避免随机性对模型性能的影响,进行5次独立诊断实验并取平均值作为最后的衡量指标,评价指标包含正确率和F1 Measure,实验结果如表6所示。
从表7可以看出,其中IMODA-ADBM模型在40 dB、25 dB以及10 dB三种白噪声情况下,均取得了最佳性能,而传统DBN模型却仍有一定的改进空间。以CNN为基础模型采用ECA模块和CBAM模块改进后的ECA-CNN模型以及CBAM-CNN模型虽然在三种噪声扰动下也表现出不错的故障诊断性能,但因其CNN模型对数据量的要求导致这两类模型对数据成本要求过大,经济成本也较高,并且与IMODA-ADBN模型相比还是存在一定差距;结合CNN与DBN的CDBN模型的性能与DBN模型相比虽然有了一定的提高,但由于引入了CNN模型,除了对数据量的要求较高以外,CDBN模型也更加依赖参数的设置。
表 7 不同噪声下的模型性能对比
方法 SNR/dB 平均正确率/% F1 Measure DBN 40 89.93 0.895 25 85.24 0.833 10 79.27 0.790 CDBN 40 91.53 0.904 25 85.69 0.849 10 80.93 0.801 ECA-CNN 40 93.21 0.922 25 89.59 0.890 10 86.24 0.859 CBAM-CNN 40 93.85 0.934 25 89.27 0.889 10 87.01 0.868 IMODA-ADBN 40 95.21 0.951 25 92.26 0.917 10 89.14 0.884 -
DBN作为深度学习中最典型的模型已经在不同领域中得到了研究与应用。DBN在面对大量数据时,无监督预训练耗时也会急剧增加,利用Graphic processing unit (GPU) 硬件加速收敛已成为近几年的主要手段,然而该方法需要较大的经济成本;另外在反向精调过程中,BP算法由于本身性质易陷入局部最优。针对上述问题,本文提出了一种基于IMODA-ADBN的模拟电路故障诊断方法,以应对DBN在大数据背景下的训练耗时和反向精调中的挑战。研究创新点如下:
1) 对MODA算法进行优化,加入Logstic混沌映射和对立跳跃增加多样性,并对改进的IMODA算法与传统MODA算法、MOPSO算法和NSGA-II算法比较,利用测试函数进行实验验证,实验表明IMODA算法产生的Pareto解的分布更加均匀。
2) 引入自适应学习率以加速无监督预训练阶段的网络收敛,并证明优化后的无监督部分具有稳定性。
3) 利用IMODA算法对有监督部分进行精细调整,证明其具有全局收敛性,并验证优化系统在李雅普诺夫意义下的稳定性。
最终将IMODA-ADBN利用双二阶四运放低通滤波器进行模拟实验验证。仿真实验和噪声实验结果表明, IMODA-ADBN模型能够实现对故障高效分类与定位,在模拟电路故障诊断等领域中,可以作为一种新的解决方案。
A Fault Diagnosis Method for Complex Analog Circuits Based on IMODA Adaptive Deep Belief Network
-
摘要: 针对传统DBN在无监督训练过程中预训练耗时久、诊断精度差等问题,提出了一种基于改进多目标蜻蜓优化自适应深度信念网络(IMODA-ADBN)的模拟电路故障诊断方法。首先根据参数更新方向的异同提出了自适应学习率,提高网络收敛速度;其次,传统DBN在有监督调优过程利用BP算法,然而BP算法存在易陷入局部最优的问题,为了改善该问题,利用改进的MODA算法取代BP算法提高网络分类精度。在IMODA算法中, 添加Logistic混沌印射和基于对立跳跃以获得帕累托最优解,增加算法的多样性,提高算法的性能。 该算法在7个多目标数学基准问题上进行了测试,并与3种著名的元启发式优化算法(MODA、MOPSO和NSGA-II)进行了比较,同时证明了IMODA-ADBN网络模型具有稳定性。最后将IMODA-ADBN运用到二级四运放双二阶低通滤波器的诊断实验中,实验结果表明所提出的IMODA-ADBN在收敛速度快的基础上保证了分类精度,IMODA-ADBN比本文提到的其他方法都具有更高的诊断率,能够实现高难故障的分类与定位。Abstract: Aiming at the problems of time-consuming pre-training and poor diagnostic accuracy in the process of unsupervised training of traditional DBN, In this paper, an Improved Multi-Objective Dragonfly Optimization Adaptive Deep Belief Network (IMODA-ADBN) is proposed. IMODA-ADBN for analog circuit fault diagnosis. Firstly, an adaptive learning rate is proposed according to the similarities and differences of parameter update directions to improve the convergence speed of the network. Secondly, traditional DBN uses BP algorithm in the supervised tuning process. However, BP algorithm has the problem that it is easy to fall into local optimum. In order to improve the problem, IMODA algorithm is used to replace BP algorithm to improve the accuracy of network classification. In the improved MODA algorithm, Logistic chaotic imprinting and oppositional jumping are added to obtain the Pareto optimal solution, which increases the diversity of the algorithm and improves its performance of the algorithm. The proposed algorithm is tested on eight multi-objective mathematical benchmark problems and compared with three well-known meta-heuristic optimization algorithms (MODA, MOPSO, and NSGA-II), and the stability of IMODA-ADBN network model is proved. Finally, IMODA-ADBN is applied to the diagnosis experiment of a two-stage four-op-amplifier double-second-order low-pass filter. The experimental results show that the proposed IMODA-ADBN can ensure classification accuracy on the basis of fast convergence, and IMODA-ADBN has higher diagnosis rate than other methods mentioned in this paper, which can realize the classification and location of high-difficulty faults.
-
Key words:
- analog circuit /
- MODA algorithm /
- adaptive learning rate /
- deep belief network /
- fault diagnosis
-
表 1 二级四运放双二阶低通滤波器电路故障模式
故障代码 故障类型 容差/% 标称值 故障值 f1 无故障 — — — f2 R9增大 5 2640 Ω 3960 Ω f3 R9减小 5 2640 Ω 1320 Ω f4 R19增大 5 10 kΩ 15 kΩ f5 R19减小 5 10 kΩ 5 kΩ f6 C1增大 5 0.01 nF 0.005 nF f7 C1减小 5 0.01 nF 0.015 nF f8 C4增大 5 0.01 nF 0.005 nF f9 C4减小 5 0.01 nF 0.015 nF  下载: 导出CSV
下载: 导出CSV
表 3 不同算法的参数设置
算法 参数 IMODA 种群数量: $ N{\text{ = }}150 $ 档案大小: $ {N_{{\text{rep}}}}{\text{ = }}150 $ $ 网格分量: $ {n_{grid}}{\text{ = }}20 $ 最大迭代次数: $ M{\text{a}}{{\text{x}}_{{\text{iter}}}}{\text{ = }}2500 $ MODA 种群数量: $ N{\text{ = }}150 $ 档案大小: $ {N_{{\text{rep}}}}{\text{ = }}150 $ $ 最大迭代次数: $ M{\text{a}}{{\text{x}}_{{\text{iter}}}}{\text{ = }}2500 $ MOPSO 种群数量: $ N{\text{ = }}150 $ 档案大小: $ {N_{{\text{rep}}}}{\text{ = }}150 $ $ 网格分量: $ {n_{grid}}{\text{ = }}20 $ 最大迭代次数: $ M{\text{a}}{{\text{x}}_{{\text{iter}}}}{\text{ = }}2500 $ 惯性权重 (初始): $ w{\text{ = 0}}{\text{.5}} $
惯性权重 (最终):$ w{\text{ = 0}}{\text{.001}} $ 变异概率: $ {P_M}{\text{ = }}0.1 $ NSGA-II 种群数量: $ N{\text{ = }}150 $ 网格分量: $ {n_{grid}}{\text{ = }}20 $ 最大迭代次数: $ M{\text{a}}{{\text{x}}_{{\text{iter}}}}{\text{ = }}2500 $ 变异概率: $ {P_M}{\text{ = }}0.5 $
下载: 导出CSV
表 4 多目标测试函数的特性
测试函数 变量个数 目标函个数 变量范围 表达式 特征 ZTD1 30 2 $ \left[ {0,1} \right] $ $ g\left( x \right) = 1 + \dfrac{9}{{N - 1}}\displaystyle\sum\limits_{i = 2}^N {{x_i}} $ $ h\left( {{f_1}\left( x \right),g\left( x \right)} \right) = 1 - \sqrt {\dfrac{{{f_1}\left( x \right)}}{{g\left( x \right)}}} $ $ {f_1}\left( x \right) = {x_1} $ $ {f_2}\left( x \right) = g\left( x \right) \times h\left( {{f_1}\left( x \right),g\left( x \right)} \right) $ 帕累托最优前沿有一个凸前沿 ZTD2 30 2 $ \left[ {0,1} \right] $ $ g\left( x \right) = 1 + \dfrac{9}{{N - 1}}\displaystyle\sum\limits_{i = 2}^N {{x_i}} $ $ h\left( {{f_1}\left( x \right),g\left( x \right)} \right) = 1 - {\left( {\dfrac{{{f_1}\left( x \right)}}{{g\left( x \right)}}} \right)^2} $ $ {f_1}\left( x \right) = {x_1} $ $ {f_2}\left( x \right) = g\left( x \right) \times h\left( {{f_1}\left( x \right),g\left( x \right)} \right) $ 帕累托最优前沿有一个非转换前沿 ZTD3 30 2 $ \left[ {0,1} \right] $ $ g\left( x \right) = 1 + \dfrac{9}{{29}}\displaystyle\sum\limits_{i = 2}^N {{x_i}} $ $ h\left( {{f_1}\left( x \right),g\left( x \right)} \right) = 1 - \sqrt {\dfrac{{{f_1}\left( x \right)}}{{g\left( x \right)}}} - \left( {\dfrac{{{f_1}\left( x \right)}}{{g\left( x \right)}}} \right)\sin \left( {10\pi {f_1}\left( x \right)} \right) $ $ {f_1}\left( x \right) = {x_1} $ $ {f_2}\left( x \right) = g\left( x \right) \times h\left( {{f_1}\left( x \right),g\left( x \right)} \right) $ 帕累托最优前沿具有不连续前沿 Schaffer 1 2 $ \left[ { - 5,5} \right] $ $ {f_1}\left( x \right) = x_i^2 $ $ {f_2}\left( x \right) = {\left( {x - 2} \right)^2} $ 帕累托最优前沿有一个凸前沿 DTLZ1 7 3 $ \left[ {0,1} \right] $ $ g\left( {{x_M}} \right) = 100\left[ {\left| {{x_M}} \right| + \displaystyle\sum\limits_{{x_i} \in {x_M}} {{{\left( {{x_i} - 0.5} \right)}^2} - \cos \left( {20\pi \left( {{x_i} - 0.5} \right)} \right)} } \right] $ $ {f_1}\left( x \right) = \dfrac{1}{2}{x_1}{x_2} \cdots {x_{M - 1}}\left( {1 + g\left( {{x_M}} \right)} \right) $ $ {f_2}\left( x \right) = \dfrac{1}{2}{x_1}{x_2} \cdots \left( {1 - {x_{M - 1}}} \right)\left( {1 + g\left( {{x_M}} \right)} \right) $ $ {f_3}\left( x \right) = \dfrac{1}{2}{x_1}{x_2} \cdots \left( {1 - {x_{M - 2}}} \right){x_{M - 1}}\left( {1 + g\left( {{x_M}} \right)} \right) $ 帕累托最优前沿有一个线性前沿 DTLZ2 12 3 $ \left[ {0,1} \right] $ $ g\left( {{x_M}} \right) = \displaystyle\sum\limits_{{x_i} \in {x_M}} {{{\left( {{x_i} - 0.5} \right)}^2}} $ $ {f_1}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \cos \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right)\cos \left( {\dfrac{{{x_{M - 1}}\pi }}{2}} \right) $ $ {f_2}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \cos \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right){\text{sin}}\left( {\dfrac{{{x_{M - 1}}\pi }}{2}} \right) $ $ {f_3}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \sin \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right) $ 帕累托最优前沿为球面前沿 DTLZ3 12 3 $ \left[ {0,1} \right] $ $ g\left( {{x_M}} \right) = 100\left[ {\left| {{x_M}} \right| + \displaystyle\sum\limits_{{x_i} \in {x_M}} {{{\left( {{x_i} - 0.5} \right)}^2} - {\text{cos}}} \left( {20\pi \left( {{x_i} - 0.5} \right)} \right)} \right] $ $ {f_1}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \cos \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right)\cos \left( {\dfrac{{{x_{M - 1}}\pi }}{2}} \right) $ $ {f_2}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \cos \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right){\text{sin}}\left( {\dfrac{{{x_{M - 1}}\pi }}{2}} \right) $ $ {f_3}\left( x \right) = \left( {1 + g\left( {{x_M}} \right)} \right)\cos \left( {\dfrac{{{x_1}\pi }}{2}} \right) \cdots \sin \left( {\dfrac{{{x_{M - 2}}\pi }}{2}} \right) $ 帕累托最优前沿具有多前沿
下载: 导出CSV
表 5 不同算法测试函数性能对比
测试函数 IGD 算法 IMODA MODA MOPSO NSGA-II ZDT1 平均值 0.00547 0.00587 0.00472 0.04217 标准差 0.00231 0.00301 0.00418 0.00671 中值 0.00642 0.00770 0.00406 0.04133 最优值 0.00214 0.00253 0.00172 0.02071 最差值 0.00713 0.00827 0.01224 0.05922 ZDT2 平均值 0.00337 0.00426 0.00672 0.04017 标准差 0.00185 0.00271 0.00395 0.00332 中值 0.00257 0.00307 0.00799 0.03373 最优值 0.0022 0.00242 0.00443 0.02510 最差值 0.00593 0.00611 0.00724 0.04521 ZDT3 平均值 0.00921 0.03017 0.03674 0.04833 标准差 0.00907 0.00416 0.00608 0.00972 中值 0.00951 0.03372 0.03941 0.04157 最优值 0.00830 0.02151 0.02097 0.03270 最差值 0.00954 0.03849 0.04172 0.05122 Schaffer 平均值 0.00284 0.00372 0.00507 0.00693 标准差 0.00301 0.00399 0.00500 0.00710 中值 0.00240 0.00357 0.00416 0.00593 最优值 0.00126 0.00242 0.00212 0.00392 最差值 0.00337 0.00475 0.00501 0.00714 DTLZ1 平均值 0.00551 0.00608 0.05922 0.09150 标准差 0.00208 0.00409 0.03061 0.06003 中值 0.00471 0.00407 0.05030 0.07701 最优值 0.00210 0.00192 0.00188 0.04710 最差值 0.00902 0.00971 0.01027 0.12205 DTLZ2 平均值 0.00894 0.01098 0.05140 0.08511 标准差 0.00067 0.00901 0.01525 0.05720 中值 0.01022 0.00870 0.02081 0.06587 最优值 0.00901 0.00611 0.01429 0.04930 最差值 0.01078 0.01207 0.06814 0.10221 DTLZ3 平均值 0.00309 0.00661 0.03879 0.04102 标准差 0.00255 0.00520 0.00819 0.00907 中值 0.00261 0.00587 0.04066 0.04099 最优值 0.00223 0.00317 0.02109 0.03022 最差值 0.00372 0.00911 0.04307 0.05088
下载: 导出CSV
表 7 不同噪声下的模型性能对比
方法 SNR/dB 平均正确率/% F1 Measure DBN 40 89.93 0.895 25 85.24 0.833 10 79.27 0.790 CDBN 40 91.53 0.904 25 85.69 0.849 10 80.93 0.801 ECA-CNN 40 93.21 0.922 25 89.59 0.890 10 86.24 0.859 CBAM-CNN 40 93.85 0.934 25 89.27 0.889 10 87.01 0.868 IMODA-ADBN 40 95.21 0.951 25 92.26 0.917 10 89.14 0.884
下载: 导出CSV
-
[1] SAI S V A, LONG B, PECHT M. Diagnostics and prognostics method for analog electronic circuits[J]. IEEE Transactions on Industrial Electronics, 2013, 60(11): 5277-5291. doi: 10.1109/TIE.2012.2224074 [2] AO Y, SHI Y, WEI Z, et al. An approximate calculation of ratio of normal variables and its application in analog circuit fault diagnosis[J]. Journal of Electronic Testing Theory & Applications, 2013, 29(4): 555-565. [3] YANG C L. Parallel-series multi objective genetic algorithm for optimal tests selection with multiple constraints[J]. IEEE Transactions on Instrumentation and Measurement, 2018, 67(8): 1-18. doi: 10.1109/TIM.2018.2851760 [4] TANG X, XU A. Practical analog circuit diagnosis based on fault features with minimum ambiguities[J]. Journal of Electronic Testing, 2016, 32(1): 1-13. doi: 10.1007/s10836-016-5569-1 [5] TADEUSIEWICZ M, HALGAS S. A method for local parametric fault diagnosis of a broad class of analog integrated circuits[J]. IEEE Transactions on Instrumentation and Measurement, 2018, 67(2): 328-337. doi: 10.1109/TIM.2017.2775438 [6] AMINIAN M, AMINIAN F. A modular fault-diagnostic system for analog electronic circuits using neural networks with wavelet transform as a preprocessor[J]. IEEE Transactions on Instrumentation and Measurement, 2007, 56(5): 1546-1554. doi: 10.1109/TIM.2007.904549 [7] LAURAIN V, TÓTH R, PIGA D, et al. An instrumental least squares support vector machine for nonlinear system identification[J]. Automatica, 2015, 54: 340-347. doi: 10.1016/j.automatica.2015.02.017 [8] HU Q L, XIAO B. Adaptive fault tolerant control using integral sliding mode strategy with application to flexible spacecraft[J]. International Journal of Systems Science, 2013, 44(12): 2273-2286. doi: 10.1080/00207721.2012.702236 [9] 段晨东, 何正嘉, 姜洪开. 非线性小波变换在故障特征提取中的应用[J]. 振动工程学报, 2005(1): 129-132. doi: 10.3969/j.issn.1004-4523.2005.01.025 DUAN C D, HE Z J, JIANG H K. Fault feature extraction using nonlinear wavelet transform[J]. Journal of Vibration Engineering, 2005(1): 129-132. doi: 10.3969/j.issn.1004-4523.2005.01.025 [10] COHEN A, TIPLICA T, KOBI A. Design of experiments and statistical process control using wavelets analysis[J]. Control Engineering Practice, 2016, 49(4): 129-138. [11] TADEUSIEWICZ M, HALGAS S. A new approach to multiple soft fault diagnosis of analog BJT and CMOS circuits[J]. IEEE Transactions on Instrumentation and Measurement, 2015, 64(10): 2688-2695. doi: 10.1109/TIM.2015.2421712 [12] SPYRONASIOS A D, DIMOPOULOS M G, HATZOPOULOS A A. Wavelet analysis for the detection of parametric and catastrophic faults in mixed-signal circuits[J]. IEEE Transactions on Instrumentation and Measurement, 2011, 60(6): 2025-2038. doi: 10.1109/TIM.2011.2115550 [13] GAN X S, GUO W M, DAI Z, et al. Research on WNN soft fault diagnosis for analog circuit based on adaptive UKF algorithm[J]. Applied Soft Computing, 2017, 50: 252-259. doi: 10.1016/j.asoc.2016.11.012 [14] XIAO Y Q, FENG L G. A novel linear ridgelet network approach for analog fault diagnosis using wavelet-based fractal analysis and kernel PCA as preprocessors[J]. Measurement, 2012, 45(3): 297-310. doi: 10.1016/j.measurement.2011.11.018 [15] LONG B, LI M, WANG H J, et al. Diagnostics of analog circuits based on LS-SVM using time-domain features[J]. Circuits Systems & Signal Processing, 2013, 32(6): 2683-2706. [16] LONG B, XIAN W M, LI M, et al. Improved diagnostics for the incipient faults in analog circuits using LSSVM based on PSO algorithm with mahalanobis distance[J]. Neurocomputing, 2014, 133: 237-248. doi: 10.1016/j.neucom.2013.11.012 [17] PENG C, YUAN L F, HE Y G, et al. An improved SVM classifier based on double chains quantum genetic algorithm and its application in analogue circuit diagnosis[J]. Neurocomputing, 2016, 211: 202-211. doi: 10.1016/j.neucom.2015.12.131 [18] RAJAGOPAL M. Multiple parametric fault diagnosis using computational intelligence techniques in linear filter circuit[J]. Journal of Ambient Intelligence and Humanized Computing, 2020, 11(2): 5533-5545. [19] GUO S, WU B, ZHOU J, et al. An analog circuit fault diagnosis method based on circle model and extreme learning machine[J]. Applied Sciences, 2020, 10(7): 2386-2400. doi: 10.3390/app10072386 [20] HUANG G B, DING X, ZHOU H. Optimization method based extreme learning machine for classification[J]. Neurocomputing, 2010, 74(1-3): 155-163. doi: 10.1016/j.neucom.2010.02.019 [21] GUO X J, CHEN L, SHEN C Q. Hierarchical adaptive deep convolution neural network and its application to bearing fault diagnosis[J]. Measurement, 2016, 93: 490-502. doi: 10.1016/j.measurement.2016.07.054 [22] JIA F, LEI Y G, LIN J, et al. Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data[J]. Mechanical Systems & Signal Processing, 2016, 72-73: 303-315. [23] SHAO H D, JIANG H K, WANG F, et al. Rolling bearing fault diagnosis using adaptive deep belief network with dual-tree complex wavelet packet[J]. ISA Transactions, 2017, 69: 187-201. doi: 10.1016/j.isatra.2017.03.017 [24] FANG F, LI L Y, GU Y, et al. A novel hybrid approach for crack detection[J]. Pattern Recognition, 2020, 107: 107474. doi: 10.1016/j.patcog.2020.107474 [25] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 39(4): 640-651. [26] LIU C, CHENG G, CHEN X, et al. Planetary gears feature extraction and fault diagnosis method based on VMD and CNN[J]. Sensors, 2018, 18(5): 1523-1542. doi: 10.3390/s18051523 [27] LIU R, MENG G, YANG B, et al. Dislocated time series convolutional neural architecture: an intelligent fault diagnosis approach for electric machine[J]. IEEE Transactions on Industrial Informatics, 2017, 13(3): 1310-1320. doi: 10.1109/TII.2016.2645238 [28] ZHAO G Q, LIU X Y, ZHANG B, et al. A novel approach for analog circuit fault diagnosis based on deep belief network[J]. Measurement, 2018, 121: 170-178. doi: 10.1016/j.measurement.2018.02.044 [29] LIU Z, JIA Z, VONG C M, et al. Capturing high-discriminative fault features for electronics-rich analog system via deep learning[J]. IEEE Transactions on Industrial Informatics, 2017, 1(3): 1213-1226. [30] ZHONG T, QU J F, FANG X Y, et al. The intermittent fault diagnosis of analog circuits based on EEMD-DBN[J]. Neurocomputing, 2021, 436: 74-91. doi: 10.1016/j.neucom.2021.01.001 [31] MENG G, CONG W, ZHU C A. Construction of hierarchical diagnosis network based on deep learning and its application in the fault pattern recognition of rolling element bearings[J]. Mechanical Systems & Signal Processing, 2016, 72-73: 92-104. [32] 张朝龙, 何怡刚, 杜博伦. 基于DBN特征提取的模拟电路早期故障诊断方法[J]. 仪器仪表学报, 2019, 40(10): 112-119. ZHANG C L, HE Y G, DU B L. Analog circuit incipient fault diagnosis method based on DBN feature extraction[J]. Chinese Journal of Scientific Instrument, 2019, 40(10): 112-119. [33] CHEN Z Y, LI W H. Multisensor feature fusion for bearing fault diagnosis using sparse autoencoder and deep belief network[J]. IEEE Transactions on Instrumentation and Measurement, 2017, 66(7): 1693-1702. doi: 10.1109/TIM.2017.2669947 [34] MIRJALILI S. Dragonfly algorithm: a new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems[J]. Neural Computing and Applications, 2016, 27(4): 1053-1073. doi: 10.1007/s00521-015-1920-1 [35] PAVLYUKEVICH I. Lévy flights, non-local search and simulated annealing[J]. Journal of Computational Physics, 2007, 226: 1830-1844. doi: 10.1016/j.jcp.2007.06.008 [36] HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507. doi: 10.1126/science.1127647 [37] 乔俊飞, 王功明, 李晓理, 等. 基于自适应学习率的深度信念网设计与应用[J]. 自动化学报, 2017, 43(8): 1339-1349. QIAO J F, WANG G M, LI X L, et al. Design and application of deep belief network with adaptive learning rate[J]. Acta Automatica Sinica, 2017, 43(8): 1339-1349. [38] JIA N N, ZHANG J S, ZHANG C X. A sparse-response deep belief network based on rate distortion theory[J]. Pattern Recognition, 2014, 47(9): 3179-3191. doi: 10.1016/j.patcog.2014.03.025 [39] 王功明, 李文静, 乔俊飞. 基于PLSR自适应深度信念网络的出水总磷预测[J]. 化工学报, 2017, 68(5): 1987-1997. WANG G M, LI W J, QIAO J F. Prediction of Effluent Total Phosphorus Using PLSR-based Adaptive Deep Belief Network[J]. CIESC Journal, 2017, 68(5): 1987-1997. [40] GONG B, DU X J. Fault diagnosis of analog circuit based on multi-input convolution[J]. Journal of Electronics and Information Science, 2022, 7(1): 89-93. [41] CHOU J S, NGO N T. Modified firefly algorithm for multidimensional optimization in structural design problems[J]. Structural and Multidisciplinary Optimization, 2017, 55(6): 2013-2038. doi: 10.1007/s00158-016-1624-x [42] ZITZLER E, DEB K, THIELE L. Comparison of multiobjective evolutionary algorithms: empirical results[J]. Evolutionary Computation, 2000, 8(2): 173-195. doi: 10.1162/106365600568202 [43] CHOU J S, TRUONG D N. Multiobjective optimization inspired by behavior of jellyfish for solving structural design problems[J]. Chaos, Solitons & Fractals, 2020, 135: 109738. [44] 张屹, 万兴余, 郑小东, 等. 基于正交设计的元胞多目标遗传算法[J]. 电子学报, 2016, 44(1): 87-94. doi: 10.3969/j.issn.0372-2112.2016.01.013 ZHANG Y, WAN X Y, ZHENG X D, et al. Cellular genetic algorithm for multiobjective optimization based on orthogonal design[J]. Acta Electronica Sinica, 2016, 44(1): 87-94. doi: 10.3969/j.issn.0372-2112.2016.01.013 [45] COELLO C, PULIDO G T, LECHUGA M S. Handling multiple objectives with particle swarm optimization[J]. IEEE Trans Evolutionary Computation. 2004, 8(3): 256-279. [46] DEB K, MOHAN M, MISHRA S. Evaluating the ε-Domination based multiobjective evolutionary algorithm for a quick computation of pareto-optimal solutions[J]. Evolutionary Computation, 2005, 13(4): 501-525. doi: 10.1162/106365605774666895 [47] SHAO H D, JIANG H K, ZHANG H Z, et al. Electric locomotive bearing fault diagnosis using a novel convolutional deep belief network[J]. IEEE Transactions on Industrial Electronics, 2017, 2727-2736. [48] 杜先君, 巩彬, 余萍, 等. 基于CBAM-CNN的模拟电路故障诊断[J]. 控制与决策, 2022, 37(10): 2609-2618. DU X J, GONG B, YU P, et al. Research on CBAM-CNN based analog circuit fault diagnosis[J]. Control and Decision, 2022, 37(10): 2609-2618. [49] SHI Y K, WANG Z W, DU X J, et al. Research on the membrane fouling diagnosis of MBR membrane module based on ECA-CNN[J]. Journal of Environmental Chemical Engineering, 2022, 10(3): 107649. doi: 10.1016/j.jece.2022.107649 -

 点击查看大图
点击查看大图
图(11) / 表(7)
计量
- 文章访问数: 397
- HTML全文浏览量: 91
- PDF下载量: 5
- 被引次数: 0

















































































































































































































































































