 ISSN
ISSN 



-
行人重识别(Person Re-Identification, Re-ID)是在多个摄像头中进行特定目标行人图像的检索问题。近年来,得益于大规模标注数据集和卷积神经网络的拟合能力,Re-ID取得了较大进展。然而,由于行人数据涉及隐私、标注代价等因素,高质量的行人标注图像数据的获取极为困难,目前有监督学习的Re-ID性能很大程度上受制于此。
随着生成对抗网络(Generative Adversarial Networks, GAN)[1]快速发展,基于GAN的行人数据增广[2-7]方法引起了重视。文献[8]首次提出将GAN用于Re-ID的研究,通过对DCGAN[9]生成行人图像,实现对标注数据集的扩充。文献[10-14]使用改进的CycleGAN[15]进行域之间的行人风格迁移。文献[16]提出AD-Cluster模型,根据源域与目标域图像的语义一致性,增强跨域Re-ID模型的特征表达能力。文献[17]利用FFGAN实现基于増广判别聚类的数据迁移。文献[18]使用UnityGAN学习不同摄像机之间的背景风格差异,生成基于这些差异的平均风格图像,提升Re-ID模型的泛化能力。此外,基于GAN的行人数据增广方法可解决行人姿态与外观发生变化而引起的精度降低问题。文献[19]提出一种基于姿态引导的生成对抗网络(Pose Guided Person Generation Network, PG2),根据给定的行人图像和目标姿态合成任意姿态。文献[20]将变分推理和GAN相结合,提出一种生成人物衣服的模型VariGAN。文献[21]提出ClonedPerson方法,将真实世界的人物图像中的服装克隆到虚拟的三维人物中,进而实现数据增广。
这些基于GAN的数据增广方法,在一定程度上提升了Re-ID模型的性能、降低了手工标注样本的代价。但是,它们更多关注图像风格变换,而忽略生成图像质量给Re-ID模型带来的噪声影响,生成的行人图像有时会面临局部细粒度特征表达较弱、图像整体视感质量降低的问题。虽然此类图像可以在一定程度上提升模型的鲁棒性,但过多低质量图像会在Re-ID模型提取到的特征中融入过多噪声,干扰模型训练的稳定性。
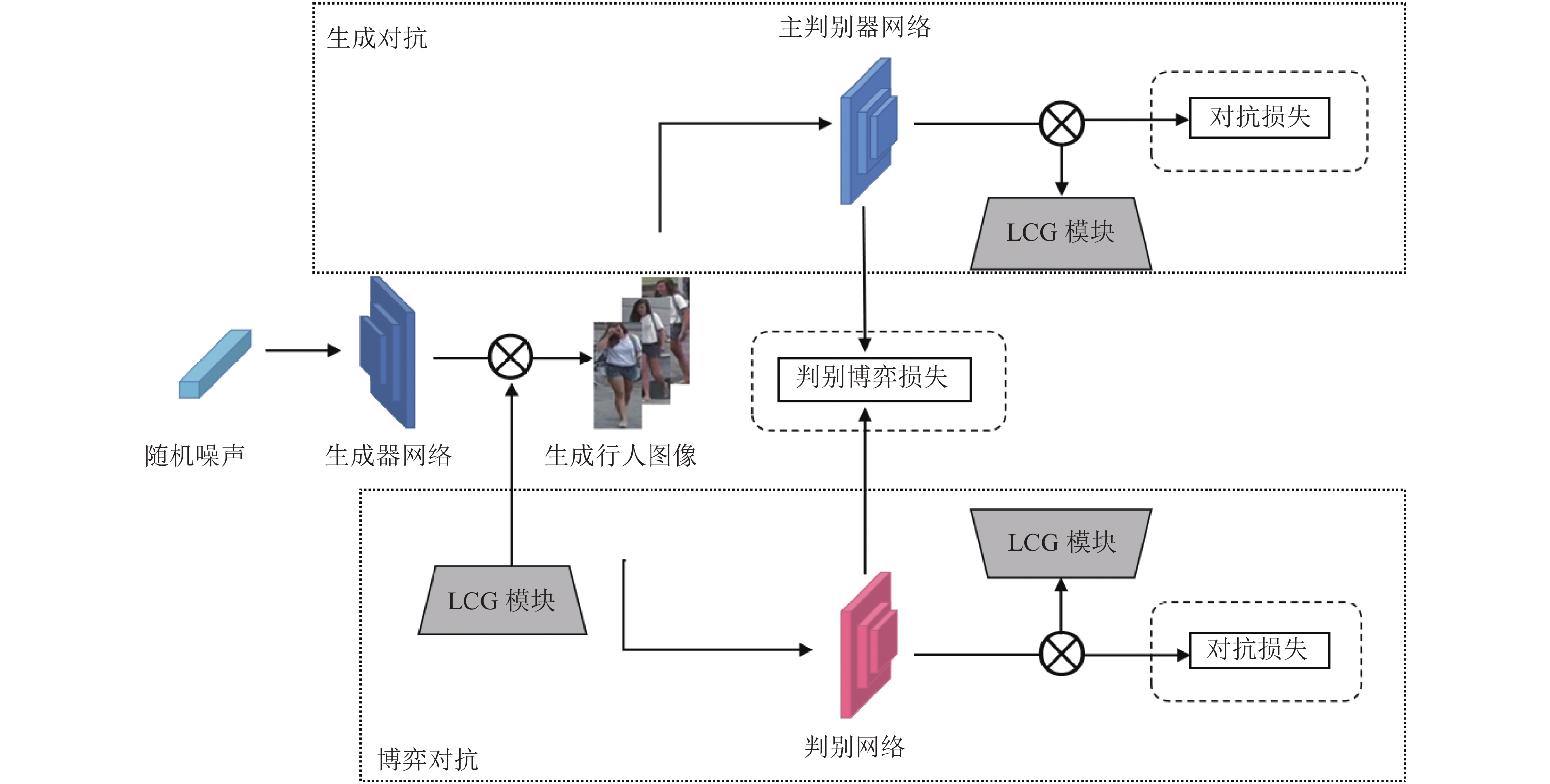
本文经过研究分析,传统GAN生成图像质量较差的原因主要包括:1)受到卷积核尺寸的影响,生成行人图像的局部信息表达、长距离相关性依赖均受到较大限制,进而导致生成图像局部伪影严重、图像整体视感质量欠佳;2)网络训练方法难以保证稳定性,直接影响生成行人的图像质量。在此基础上,本文提出一种基于多因素引导行人图像增广方法(Multi-factor Guidance Data Augmentation Method, MG-DAM)。首先,设计了一种多尺度引导机制(Local Multi-scale Guidance, LMG),通过在生成器网络中使用局部多尺度引导机制,对行人图像进行特征提取与特征融合,从而抑制生成图像的局部伪影,增强生成图像的细粒度特征表达能力;其次,提出一种长距离相关性引导机制(Long-distance Correlation Guidance, LCG),突破卷积核映射关系的限制,增加生成行人图像的长距离依赖;为提升网络训练的稳定性,设计对抗博弈判别网络(Adversarial Discrimination Network, AD),进而更改网络整体训练方式。最后,通过仿真实验证明本文所提算法的有效性。
-
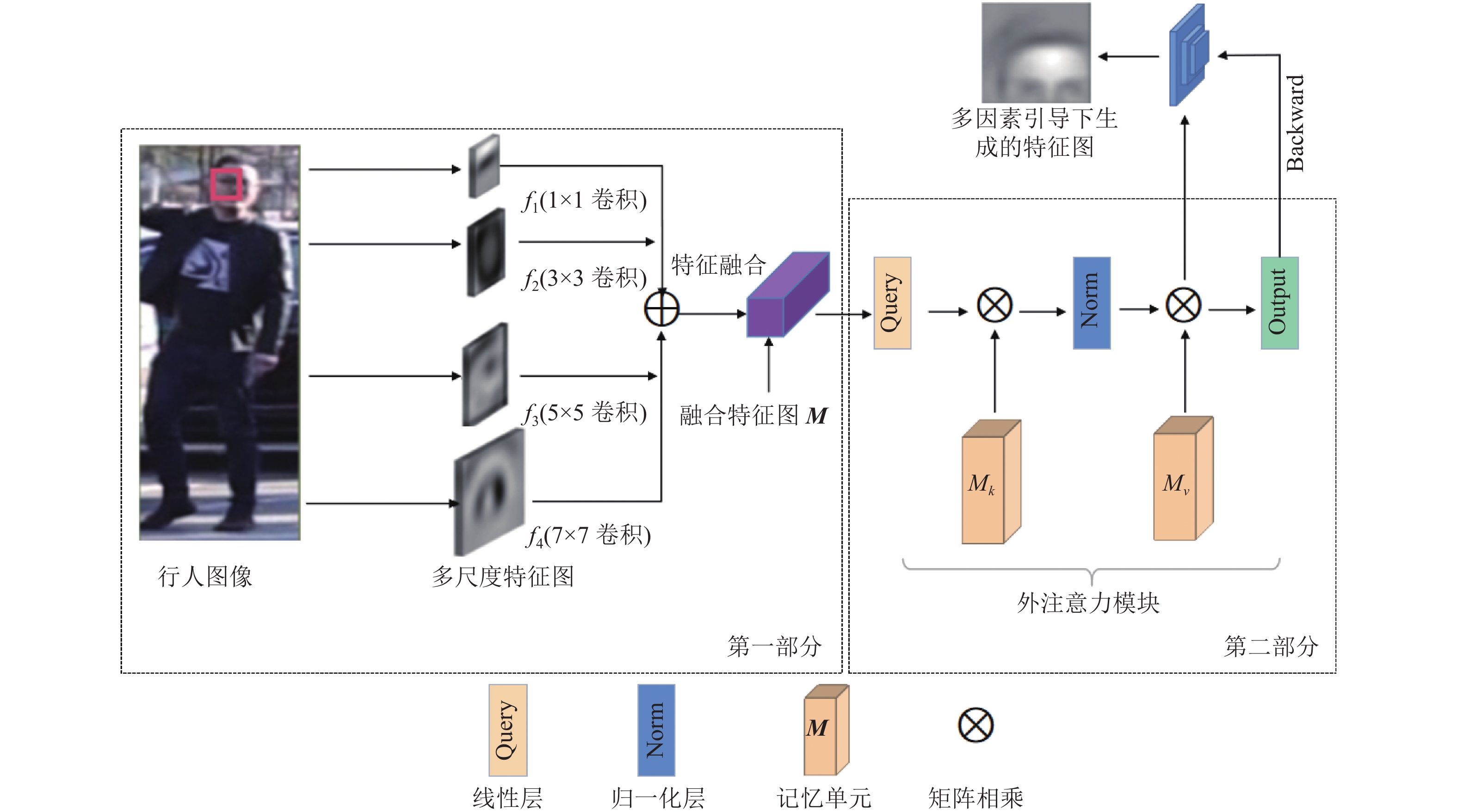
MG-DAM包括3部分:1)局部多尺度引导机制LMG:侧重解决生成图像局部信息表征能力不足而导致的局部伪影严重问题;2)长距离相关性引导机制LCG:侧重于解决生成图像整体视感质量较差的问题;3)对抗博弈判别网络AD:侧重于解决生成图像质量不稳定问题。图1为本文所提MG-DAM的结构图。

图 1 MG-DAM模型结构图
-
有效解决生成行人图像局部伪影的关键是增强生成图像局部特征的多层次表达能力。文献[22]提出一种单阶段可控的SSCGAN,在半监督中进行条件细粒度图像合成。文献[23]提出风格检索RIS,通过StyleGAN潜在空间的解耦特性,完成局部特征迁移。文献[24]使用图像以及图像边缘一致性,设计一种并行网络提取边缘细节特征。
与这些方法不同,本文直接通过融合多尺度特征引导图像的局部信息表征,进而建立局部多尺度引导机制LMG。所谓多尺度,就是对图像不同粒度的采样,一般来说,粒度更小、更密集的采样可得到更多的细节;粒度更大、更稀疏的采样可得到整体的趋势。如图2第一部分,LMG是对相同卷积层使用不同尺寸卷积核提取到的特征进行融合。在训练过程中,根据反馈的多尺度融合信息,生成器网络调整生成图像的局部信息表达,进而抑制局部伪影的出现。因为卷积神经网络通过逐层抽象的方式来提取目标的特征,因此卷积核尺寸的设计尤为重要。如果卷积核过小,则只能抽取到局部的特征,反之则获得更多无效的信息。同时,由于行人本身具有非刚性的特点,因此在生成行人图像时,不仅需要小卷积核获取局部细粒度特征信息,还需要大卷积核获取局部区域信息。
图 2 LMG与LCG引导机制
-
在图像生成领域,生成图像细节与全局平衡依然是一个重要问题。文献[25]提出分层自适应对角空间注意方法DAT,以分层方式分别处理样式中的空间内容;文献[26]提出了一个可微的全局流局部注意框架GLFA,用于在特征级的重组输入。这些方法均使用到了注意力机制,表明注意力可解决因卷积核尺寸受限而导致的难以获得图像长距离依赖关系的问题。考虑到计算复杂度以及样本间的联系,本文使用外注意力机制引导图像的长距离相关性生成,该方法相较基于Transformer的注意力机制,外注意力更加的轻便,训练周期缩短。如图2第二部分,外注意力模块由两个线性层、两个归一化层和两个记忆单元组成,具体为:
$$ {\boldsymbol{A}} = {(\alpha )_{i,j}} = {\rm{Norm}}({\boldsymbol{F}}{{\boldsymbol{M}}^{\rm{T}}}) $$ (1) $$ {{\boldsymbol{F}}_{{\rm{out}}}} = {\boldsymbol{AM}} $$ (2) 式中,
$ {\boldsymbol{F}} \in {{\bf{R}}^{N \times d}} $ ($ N $ 为像素个数,$ d $ 为特征维度)表示输入特征图;$ {(\alpha )_{i,j}} $ 表示第$ i $ 个元素和$ {\boldsymbol{M}} $ 的第$ j $ 行之间的相似性;记忆单元$ {\boldsymbol{M}} \in {{\bf{R}}^{S \times d}} $ 为整个训练数据集的记忆。 -
由于GAN模型存在收敛不稳定性,往往需要通过设置较多的参数去平衡判别器网络与生成器网络,进而达到纳什均衡状态。不收敛问题主要有两种原因。1)梯度消失。原始GAN使用分类误差作为真实分布与生成分布的相似度量。然而,当真实分布与生成分布的重叠区域可忽略时,生成器获得的梯度接近零,此时生成器网络得不到来自判别器网络的反馈,无法完成自我优化。2)模式崩塌。当使用梯度下降算法对GAN优化时,实际上不区分min-max和max-min,这导致生成器会过多地生成一些重复样本。
为此,本文通过在原始GAN模型的基础上添加对抗博弈判别网络AD的方式,构建一种三网络稳定博弈架构模型。与常见的三网络模型不同,AD不仅与生成器网络进行判别对抗,还会与主判别器网络进行博弈对抗,以校正最终的整体损失函数。AD详细介绍如下。
令
$ \{ {x_i}\} _{i = 0}^n \subseteq X $ 表示从未知的行人数据分布${P_{{\rm{data}}}}$ 中提取的训练数据集,$ \{ {z_i}\} _{i = 0}^n \subseteq Z $ 表示从先验分布噪声${P_z}$ 中采样得到的样本。在传统GAN网络模型中,将随机采样的噪声输入到生成器网络中,通过判别器网络与生成器网络进行最大最小博弈产生新的行人图像$ \{ \widetilde x\} _{i = 0}^n = G(z) $ ,其服从新的生成分布${P_G}$ ,博弈过程如下:$$ \begin{split} &\qquad\qquad\mathop {\min }\limits_{\text{G}} \mathop {\max }\limits_D V(D,G) = \\ &{E_{x\sim{P_{{\rm{data}}}}}}[\log D(x)] + {E_{z\sim{P_z}}}[\log (1 - D(G(z)))] \end{split}$$ (3) 针对传统GAN网络训练困难的问题,本文在上述GAN模型结构的基础上融入了新的对抗再判别网络,同时使用了新的数据分布形式:
$$ {P}_{{\rm{Game}}}(\forall x\subseteq {P}_{{\rm{data}}},{P}_{G}:{P}_{{\rm{Game}}}=\left[\text{ }{P}_{{\rm{data}}}+\text{ }{P}_{G}\right]/2\text{ }) $$ 新的判别网络与生成网络间的最大最小博弈过程为:
$$ \begin{split} &\qquad\qquad\mathop {\min }\limits_{\text{G}} \mathop {\max }\limits_{{{\text{D}}_{\text{1}}},{D_2}} V({D_1},{D_2},G) = \\ & {E_{x\sim P{\rm{data}}}}[\log {D_1}(x)] + {E_{z\sim Pz}}[\log (1 - {D_1}(G(z)))] + \\ & {E_{x\sim P{\rm{data}}}}[\log {D_2}(x)] + {E_{z\sim Pz}}[\log (1 - {D_2}(G(z)))] + \\ &\qquad\qquad\qquad\qquad \lambda {{\text{D}}_{s\_{\rm{Game}}}} \end{split} $$ (4) 其中,判别器网络之间的相互博弈过程如下:
$$ \begin{split} &{\text{D}}_{s\_{\rm{Game}}}={E}_{x \sim {P}_{{\rm{game}}}}[\underset{(a)}{f({D}_{1}(x),l({D}_{2}(x) > \frac{1}{2}))}-\\ &\quad \underset{(b)}{\mu f({D}_{1}({x}_{{x}_{P\_g1}}),l({D}_{2}({x}_{P\_g2}) > \frac{1}{2}))}]+\\ &\quad {E}_{x \sim {P}_{{\rm{game}}}}[\underset{(c)}{f({D}_{2}(x),l({D}_{1}(x) > \frac{1}{2}))}-\\ &\quad \underset{(d)}{\mu f({D}_{2}({x}_{{x}_{P\_g1}}),l({D}_{1}({x}_{P\_g2}) > \frac{1}{2}))}] \end{split}$$ (5) 式中,x、xp_g1、xp_g2相互独立,且xp_g1、xp_g2随机取样于PGame;
$ l( \cdot ) $ 为指示函数;$ \mu 、\lambda \in \left[0,\text{ }1\right] $ 为调节权重的超参;$ f $ 为评估函数,具体如下:$$ f({D_i}(x),y) = \left\{ \begin{gathered} \log ({D_i}(x)) \to {\rm{if}}(y = 1) \\ \log (1 - {D_i}(x)) \to {\rm{if}}(y = 0) \\ \end{gathered} \right. $$ (6) 式(4)中,
$ {D_1} $ 与$ {D_2} $ 拥有相同的网络结构与优化方式,并与生成器网络G进行对抗训练。式(5)表示判别器网络之间的对抗训练过程,针对梯度弥散问题,式(5)的$ (a) $ 与$ (c) $ 约束$ {D_1} $ 与$ {D_2} $ 具有相同的判别结果,最终使两个判别器达到彼此收敛;针对模式崩塌问题,本文在目标函数中引入$ (b) $ 与$ (d) $ 来惩罚$ {D_1} $ 与$ {D_2} $ 的判别结果。在对$ (b) $ 与$ (d) $ 的采样过程中,xp_g1、xp_g2是相互独立样本,由于独立性的作用,使得判别器网络之间的判别结果不会过度的一致,从而避免两个判别器网络的判别结果过度一致而导致梯度消失。 -
为验证本文方法的有效性,仿真实验数据集为VIPeR[27]、Market-1501[28]以及DukeMTMC-reID。这3个数据集规模与风格差异较大,可较好地验证本方法的有效性。实验环境: Intel Xeon(R) E5-2640,32 GB,GTX2070super。模型性能评估采用标准的评价指标Rank-1和平均准确率(mean average precision, mAP),mAP反映模型的总体性能。
-
将MG-DAM与多种主流GAN模型在3个不同规模的数据集上进行数据增广,并使用相同的Re-ID方法,结果如表1。
1)在使用本文所提方法增广过的数据集上进行Re-ID,实验效果一般优于所比较的方法。其中,在小规模数据集VIPeR上,本文方法明显优于其他方法,Rank-1为67.8%,mAP为51.6%。
2)在Market-1501数据集上,本文方法略低于DGNet方法0.3%,DGNet是关注行人换装的网络,一定程度上提升了Re-ID抗干扰能力,本文方法更加关注生成行人图像的质量;在DukeMTMC-reID数据集上,本文方法识别精度超过DGNet,原因是DGNet的跨域能力与实际换装能力有限,降低了生成图像的质量和模型的识别精度。
表 1 与其他主流方法对比实验数据表
% 方法 VIPeR Market-1501 DukeMTMC-reID Rank-1 mAP Rank-1 mAP Rank-1 mAP DeformGAN[29] — — 80.6 61.3 — — PTGAN[30] 62.1 49.5 87.7 75.9 71.6 46.6 AD-Cluster[16] — — 90.3 80.9 75.6 48.9 FFGAN[17] — — 89.4 77.6 76.2 52.0 UnityGAN[18] 65.3 48.6 91.3 78.3 74.3 49.7 PG2[19] 64.3 45.2 89.4 75.7 72.2 50.6 VariGAN[20] 66.2 47.7 89.3 78.8 72.2 51.3 DGNet[31] — — 91.7 84.0 77.2 52.3 ClonedPerson[32] — — 84.5 59.9 — — 本文 67.8 51.6 91.4 83.2 78.6 52.7 -
为验证局部多尺度引导机制LMG对提高生成图像的局部信息表达能力的有效性,设计以下3组实验:第一组使用ResNet作为判别器网络的主干网络结构;第二组实验在第一组实验的基础上增加LMG,不同组实验所使用的Re-ID方法完全一致。从表2可以看出:在第一组实验的基础上,加入了LMG的第二组实验在各个数据集上的表现都超越了原始模型,在小规模数据集VIPeR上尤为明显,最高的Rank-1达到了53.8%,mAP达到了36.2%。因此,局部多尺度引导机制LMG可以增强生成图像的局部特征表达能力,抑制生成图像出现局部伪影,同时有效提升了Re-ID方法的识别精度。
表 2 局部多尺度特征引导机制LMG验证数据表
% 实验
组号方法 VIPeR Market-1501 DukeMTMC-reID Rank-1 mAP Rank-1 mAP Rank-1 mAP 第一组 GAN[1] 41.6 — 57.6 49.5 53.6 34.2 WGAN[30] 45.5 30.3 68.5 49.9 61.3 37.2 CycleGAN[15] 48.3 31.2 70.6 52.1 62.1 38.1 DualGAN[33] 44.6 30.0 72.3 51.2 60.0 37.1 第二组 GAN + LMG 47.6 — 57.6 57.6 61.5 36.1 WGAN + LMG 53.1 35.4 72.7 58.6 64.3 40.3 CycleGAN + LMG 53.8 36.2 74.5 59.0 65.8 40.6 DualGAN + LMG 50.2 34.8 71.3 58.6 62.7 40.0 -
为验证全局相关性依赖机制LCG对提高生成行人图像整体视感质量的有效性,设计以下3组实验:第一组实验选用自注意力(Self-Attention, SA)作为长距离依赖机制与相应的GAN模型结合;第二组实验选用其他较先进的基于长距离依赖的GAN方法进行数据增广;第三组实验在第一组实验的基础上,选用LCG替代自注意力。实验结果如表3。对比第一、三组实验,由于LCG可以考虑到样本间的差异,其在各个数据集上的表现均优于自注意力机制,最高的Rank-1达到了83.9%、mAP达到了73.9%;相较于第二组实验中目前较为先进的方法,虽然本文所提方法并未达到与其相同的实验效果,但是Rank-1与mAP之差基本浮动在3%左右,最小的Rank-1精度仅差2.7%,mAP精度仅差1.7%。
结合本模块的实验效果图(图3②)可以看到,生成行人图像的整体视感质量正在逐步提升。因此,不难看出,LCG可以解决因为卷积核尺寸受限导致的生成图像整体质感质量的问题,切实提升ReID方法的识别精度。
表 3 长距离相关性引导机制LCG验证数据表
% 实验
组号方法 VIPeR Market-1501 DukeMTMC-Re-ID Rank-1 mAP Rank-1 mAP Rank-1 mAP 第一组 GAN[1] + SA 44.6 — — — 59.3 36.3 WGAN[30]+ SA 49.6 31.6 78.6 63.7 63.1 39.0 CycleGAN[15] + SA 50.1 32.3 79.3 68.5 63.5 40.0 DualGAN[33] + SA 48.7 30.2 79.6 69.3 61.0 39.6 第二组 DAT[25] — — 85.7 74.6 73.2 73.6 GLFA[26] — — 86.6 75.8 74.2 74.6 第三组 GAN + LCG 50.3 — 72.6 59.4 62.7 38.3 WGAN + LCG 56.2 38.2 80.6 70.8 66.3 41.7 CycleGAN[15] + LCG 56.6 39.5 83.9 73.9 67.3 43.8 DualGAN + LCG 53.7 37.0 82.4 73.3 65.8 42.5 
图 3 模型实验效果对比图
-
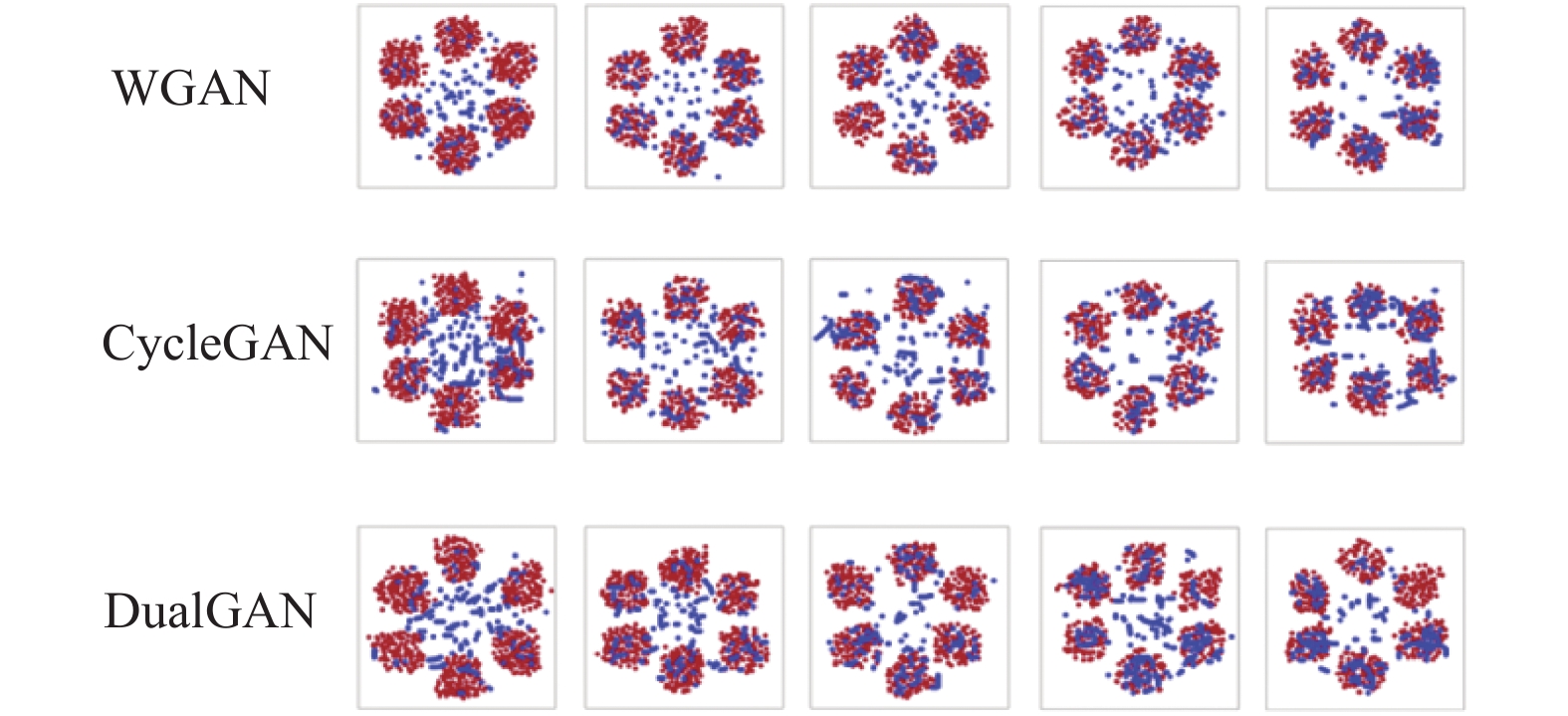
为验证对抗博弈判别网络AD能够提升网络训练的稳定性,设计了基于自拟数据集进行聚类的对比仿真实验,验证各类模型生成样本种类的多样性。模型训练稳定性的验证结果如图4所示,生成样本种类已经涵盖所有类别,而其他方法达到同样效果至少需要20000个epoch。且在训练过程中并无出现因梯度弥散而导致聚类失败的状况。因此,AD可以更加快速的推进网络生产多样性样本,增加了Re-ID模型的鲁棒性。虽然该方法在GAN的基础上添加了新的判别网络模型,但仅仅引入了很少的计算量。相对于当前的GPU计算效率,引入计算量可忽略不计。同时,相较于较为主流的GAN模型,本文使用的判别网络模型均为无标签学习,这进一步提升了网络的计算效率。
图 4 模型多样性样本匹配图
-
本文提出了一种基于多因素引导的行人数据增广方法,通过局部多尺度引导机制LMG增强生成行人图像的局部特征表达能力,抑制生成图像局部伪影的产生;通过长距离相关性引导机制LCG突破了卷积核映射关系的限制,提升生成行人图像的整体视感质量;通过对抗博弈判别网络AD的使用,改变了GAN模型的对抗机制,提升了网络训练的稳定性。在数据集VIPeR、Market-1501和DukeMTMC-reID上的实验结果表明,本文所提方法可以提升Re-ID模型的性能,并且在一定程度上优于多数较为流行的GAN模型,为有效提升高质量的行人图像生成与数据增广提供了研究思路。
Research on Pedestrian Re-Identification Data Augmentation Method Based on Multi-Factor Guidance
-
摘要: 为解决行人重识别研究领域中行人标注图像获取困难的问题,提出一种多因素引导的行人数据增广方法。首先,在生成器网络中设计了一种局部多尺度引导机制,通过特征融合抑制生成图像的局部伪影;其次,提出了长距离相关性引导机制,通过外注意力引导生成图像的长距离依赖,提高生成行人图像的整体视感质量;最后,提出一种抗博弈判别网络,通过嵌入到生成对抗网络,从而构建一种三网络稳定博弈架构模型,增加生成对抗网络训练的稳定性。通过VIPeR、Market-1501、DukeMTMC-reID这3种不同规模数据集的仿真实验,结果表明该方法与目前主流方法相比,mAP与Rank-1精度上均有不同程度的提升,在小规模数据集上的提升较为显著。Abstract: To solve the difficulty in obtaining annotated pedestrian images in the field of pedestrian re-identification research, a novel data augmentation method guided by multi-factor is proposed in this paper. Firstly, a local multi-scale guidance mechanism is designed in the generator network. It can suppress the local artifacts in generated images through feature fusion. Secondly, a long-distance correlation guidance mechanism is proposed to improve the overall visual quality of the generated pedestrian image by guiding the long-distance dependence of the generated image with external attention. Lastly, an adversarial discrimination network is designed and embed into original generative adversarial networks. The three network stability architecture model increases the stability of generative adversarial network training. The experiment are validated on the VIPeR, Market-1501 and DukeMTMC-reID benchmark datasets. The results demonstrate our method outperforms the state-of-the-art with the mAP and rank-1 scores, especially in small-scale datasets.
-
表 1 与其他主流方法对比实验数据表
% 方法 VIPeR Market-1501 DukeMTMC-reID Rank-1 mAP Rank-1 mAP Rank-1 mAP DeformGAN[29] — — 80.6 61.3 — — PTGAN[30] 62.1 49.5 87.7 75.9 71.6 46.6 AD-Cluster[16] — — 90.3 80.9 75.6 48.9 FFGAN[17] — — 89.4 77.6 76.2 52.0 UnityGAN[18] 65.3 48.6 91.3 78.3 74.3 49.7 PG2[19] 64.3 45.2 89.4 75.7 72.2 50.6 VariGAN[20] 66.2 47.7 89.3 78.8 72.2 51.3 DGNet[31] — — 91.7 84.0 77.2 52.3 ClonedPerson[32] — — 84.5 59.9 — — 本文 67.8 51.6 91.4 83.2 78.6 52.7  下载: 导出CSV
下载: 导出CSV
表 2 局部多尺度特征引导机制LMG验证数据表
% 实验
组号方法 VIPeR Market-1501 DukeMTMC-reID Rank-1 mAP Rank-1 mAP Rank-1 mAP 第一组 GAN[1] 41.6 — 57.6 49.5 53.6 34.2 WGAN[30] 45.5 30.3 68.5 49.9 61.3 37.2 CycleGAN[15] 48.3 31.2 70.6 52.1 62.1 38.1 DualGAN[33] 44.6 30.0 72.3 51.2 60.0 37.1 第二组 GAN + LMG 47.6 — 57.6 57.6 61.5 36.1 WGAN + LMG 53.1 35.4 72.7 58.6 64.3 40.3 CycleGAN + LMG 53.8 36.2 74.5 59.0 65.8 40.6 DualGAN + LMG 50.2 34.8 71.3 58.6 62.7 40.0
下载: 导出CSV
表 3 长距离相关性引导机制LCG验证数据表
% 实验
组号方法 VIPeR Market-1501 DukeMTMC-Re-ID Rank-1 mAP Rank-1 mAP Rank-1 mAP 第一组 GAN[1] + SA 44.6 — — — 59.3 36.3 WGAN[30]+ SA 49.6 31.6 78.6 63.7 63.1 39.0 CycleGAN[15] + SA 50.1 32.3 79.3 68.5 63.5 40.0 DualGAN[33] + SA 48.7 30.2 79.6 69.3 61.0 39.6 第二组 DAT[25] — — 85.7 74.6 73.2 73.6 GLFA[26] — — 86.6 75.8 74.2 74.6 第三组 GAN + LCG 50.3 — 72.6 59.4 62.7 38.3 WGAN + LCG 56.2 38.2 80.6 70.8 66.3 41.7 CycleGAN[15] + LCG 56.6 39.5 83.9 73.9 67.3 43.8 DualGAN + LCG 53.7 37.0 82.4 73.3 65.8 42.5
下载: 导出CSV
-
[1] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[J]. Advances in Neural Information Processing Systems, 2014(2): 2672-2680. [2] LI Y J, CHEN Y C, LIN Y Y, et al. , Recover and identify: A generative dual model for cross-resolution person re-identification[C]//Proceedings of the IEEE International Conference on Computer Vision (ICCV). Seoul: IEEE, 2019: 8089-8098. [3] CHEN Y B, ZHU X T, GONG S G. Instance-guided context rendering for cross-domain person re-identification[C]//Proceedings of the IEEE International Conference on Computer Vision (ICCV). Seoul: IEEE, 2019: 232-242. [4] LIANG W Q, WANG G C, LAI J H. Asymmetric cross-domain transfer learning of person re-identification based on the many-to-many generative adversarial network[J]. Acta Automatica Sinica, 2022, 48(1): 103-120. [5] WANG Z X, WANG Z, ZHENG Y Q, et al. Learning to reduce dual-level discrepancy for infrared-visible person re-identification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach: IEEE, 2019: 618-626. [6] ZHENG Z D, YANG X D, YU Z D, et al. Joint discriminative and generative learning for person re-identification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach: IEEE, 2019: 2133-2142. [7] ZHA Z J, LIU J W, CHEN D, et al. Adversarial attribute-text embedding for person search with natural language query[J]. IEEE Transactions on Multimedia, 2020, 22(7): 1836-1846. doi: 10.1109/TMM.2020.2972168 [8] ZHENG Z D, ZHENG L, YANG Y. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro[C]//Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice: IEEE, 2017: 3774-3782. [9] RADFORD A, METZ L, CHINTALA S, et al. Unsupervised representation learning with deep convolutional generative adversarial networks[EB/OL]. [2020-12-22]. https://arxiv.org/pdf/1511.06434.pdf. [10] WEI L H, ZHANG S L, GAO W, et al. Person transfer GAN to bridge domain gap for person re-identifification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City: IEEE, 2018: 79-88. [11] DENG W J, ZHENG L, YE Q X, et al. Image-image domain adaptation with preserved self-similarity and domain-dissimilarity for person re-identifification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City: IEEE, 2018: 994-1003. [12] HUANG Y, XU J, WU Q, et al. Multi-pseudo regularized label for generated data in person re-identification[J]. IEEE Transactions on Image Processing, 2018, 28(3): 1391-1403. [13] QIAN X L, FU Y W, XIANG T, et al. Pose-normalized image generation for person re-identifification[EB/OL]. [2021-06-22]. https://arxiv.org/pdf/1712.02225.pdf. [14] ZHONG Z, ZHENG L, ZHENG Z D, et al. Camera style adaptation for person re-identifification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City: IEEE, 2018: 5157-5166. [15] ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision (ICCV). Venice: IEEE, 2017: 2242-2251. [16] ZHAI Y P, LU S J, YE Q X, et al. AD-Cluster: Augmented discriminative clustering for domain adaptive person re-identification[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle: IEEE, 2020: 9018-9027. [17] ZHANG X W, LYU M Q, LI H. Cross-domain person re-identification based on partial semantic feature invariance[J]. Journal of Beijing University of Aeronautics and Astronautics, 2020, 46(9): 1682-1690. [18] LIU C, CHANG X J, SHEN Y D. Unity style transfer for person re-identification[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle: IEEE, 2020: 6886-6895. [19] MA L, JIA X, SUN Q, et al. Pose guided person image generation[C]//Proceedings of the Conference on Neural Information Processing Systems (NIPS). Long Beach: NIPS, 2017: 405-415. [20] ZHAO B, WU X, CHENG Z Q, et al. Multi-view image generation from a single-view[EB/OL]. [2022-07-15]. https://arxiv.org/pdf/1704.04886.pdf. [21] WANG Y, LIANG X, LIAO S. Cloning outfits from real-world images to 3D characters for generalizable person re-identification[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 4900-4909. [22] CHEN T, LIU Y, ZHANG Y, et al. Semi-supervised single-stage controllable GANs for conditional fine-grained image generation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Montreal: IEEE, 2021: 9244-9253. [23] CHONG M J, CHU W S, KUMAR A. Retrieve in style: Unsupervised facial feature transfer and retrieval[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Montreal: IEEE, 2021: 3867-3876. [24] 卢涛, 陈冲, 许若波, 等. 基于边缘增强生成对抗网络的人脸超分辨率重建[J]. 华中科技大学学报:自然科学版, 2020, 48(1): 87-92. LU T, CHEN C, XU R B, et al. Face hallucination based on edge enhanced generative adversarial network[J]. Journal of Huazhong University of Science and Technology, 2020, 48(1): 87-92. [25] KWON G, YE J C. Diagonal attention and style-based gan for content-style disentanglement in image generation and translation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Montreal: IEEE, 2021: 13960-13969. [26] REN Y, YU X, CHEN J, et al. Deep image spatial transformation for person image generation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle: IEEE, 2020: 7687-7696. [27] GRAY D, HAI T. Viewpoint invariant pedestrian recognition with an ensemble of localized features[C]//Proceedings of European Conference on Computer Vision (ECCV). [S.l.]: IEEE, 2008: 3408-3416. [28] ZHENG L, SHEN L, LU T, et al. Scalable person re-identification: A benchmark[C]//Proceedings of the IEEE International Conference on Computer Vision (ICCV). Santiago: IEEE, 2015: 1116-1124. [29] ALIAKSANDR S, ENVER S, STEPHANE L, et al. Deformable GANs for pose-based human image generation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Salt Lake City: IEEE, 2018: 3408-3416. [30] GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of wasserstein gans[EB/OL]. [2022-09-15]. https://arxiv.org/pdf/1704.00028.pdf. [31] ZHENG Z, YANG X, YU Z, et al. Joint discriminative and generative learning for person re-identification[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach: IEEE, 2020: 2133-2142. [32] WEI L H, ZHANG S L, GAO W, et al. Person transfer GAN to bridge domain gap for person re-identification[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 79-88. [33] YI Z, ZHANG H, TAN P, et al. DualGAN: Unsupervised dual learning for image-to-image translation[J]. IEEE Computer Society, 2017: 2849-2857. -

 点击查看大图
点击查看大图
图(4) / 表(3)
计量
- 文章访问数: 2056
- HTML全文浏览量: 498
- PDF下载量: 10
- 被引次数: 0




































