 ISSN
ISSN 




-
静脉溶栓可以一定程度上开通闭塞血管,恢复血流灌注,是治疗急性缺血性脑卒中(Acute Ischemic Stroke, AIS)的有效方式。对静脉溶栓治疗效果的评估常常需要借助X射线数字减影血管造影(Digital Subtraction Angiography, DSA)成像,DSA成像是诊断脑血管疾病的重要方法,它的基本原理是将造影前后拍摄的X射线图像进行减影,以消除血管造影影像上的骨骼和软组织结构,从而获得清晰的血管影像。在获得DSA图像后,医生可以基于图像对AIS治疗后的再灌注程度进行mTICI评分。mTICI评分根据血管再通程度分为5级,分别为0级、1级、2a级、2b级和3级。为了分级更准确,经常采用正面和侧面的DSA显影图像对以获取更充分的信息。然而,对DSA图像的识别、诊断和分级工作通常是由专业的医生来完成。近年来,随着人工智能、深度学习的快速发展,使用计算机辅助诊断可以显著提高诊断效率[1]。其中,基于深度学习的图像分类是计算机辅助诊断的常用方法,将医疗图像作为输入,通过训练好的模型对其进行预测,输出病患病情进行智能辅助诊断。
在脑卒中辅助智能诊断模型研究中,文献[2]提出了一种基于视频的卒中损伤评估系统,使用Mask R-CNN[3]、级联金字塔网络和时域卷积网络模型实现了自动评分。文献[4]基于血管造影参数成像(Angiographic Parametric Imaging, API)图,设计了一个能够自动评估机械血栓切除术(Mechanical Thrombectomy, MT)过程中神经血管的再灌注情况的卷积神经网络,对血管是否再通成功的预测准确率达81%。文献[5]基于卒中患者核磁共振图像(Magnetic Resonance Imaging, MRI)研究了一种基于深度学习和机器学习的混合方法,用于预测患者的语言障碍严重程度,使用CNN的高级特征和主成分分析(PCA)的图像特征作为岭回归的输入,实现了比仅使用深度学习或机器学习模型更好的性能。文献[6]基于医疗服务使用和健康行为数据,利用深度神经网络和PCA预测患者卒中的概率,AUC值达83.48%,对于具有较高卒中风险患者的早期发现具有重要意义。文献[7]使用卷积神经网络进行了急性缺血性卒中患者组织病变体积的预测,以便于医生根据患者病变体积制定科学的治疗方案,表明了使用深度卷积神经网络对卒中患者组织形态和治疗效果预测的有效性。文献[8]使用集成网络结合多个平面的API图来评估再灌注水平,使用CNN将API图分类为充分/不充分的再灌注;对于模型的输出,采用网格搜索算法对每个网络输出进行加权,结果表明使用来自多个视图的模型评估再灌注水平比使用单一视图更有效。文献[9]提出了一种基于CNN的全自动的定量TICI评分算法autoTICI,首先,利用多路径卷积神经网络将每个DSA图像序列划分为4个时期,分别为非对比度期、动脉期、实质造影期以及静脉期;其次,使用运动校正的动脉期和实质造影期的图像序列计算最小强度图,在最小强度图上,分割血管、灌注和背景;最后将autoTICI评分量化为治疗后的再灌注像素比率,实现对再灌注水平的定量分析。
以上研究表明:当前深度学习模型应用于AIS辅助影像智能诊断的研究工作主要基于CNN,且处理的大多是单面影像;文献[9]提出的模型可以同时处理正面和侧面影像,但两个视频流输入模型不仅导致数据处理量大,而且无法适应不同成像设备导致的视频流规格不一致问题,此外,提出的autoTICI的定量分析方法具有4个阶段,无法实现端到端训练。且CNN模型感受野较小,难以捕获图像全局特征。为了获得图像全局信息,并结合临床需要的正、侧面图像结合诊断,本文设计了一种基于Transformer的双路径图像分类模型Dual-Path Vision Transformer(DPVF)用于AIS辅助诊断,模型的两个路径分别用于提取患者正面和侧面DSA图像的信息特征。
-
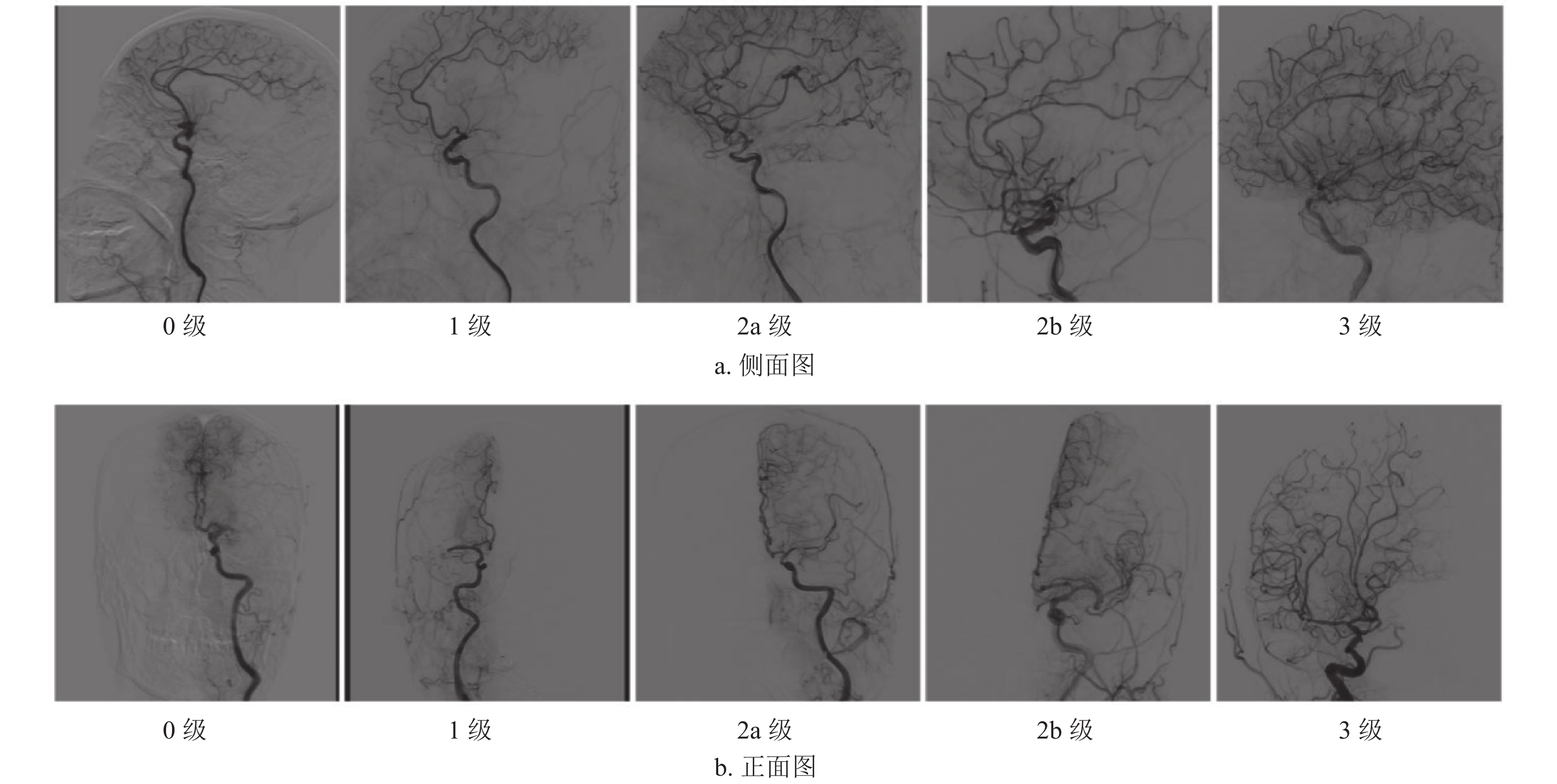
本研究采用mTICI评分的正面和侧面DSA图像,如图1所示,0级表示无灌注,血管闭塞远端无顺向血流;1级表示渗透性灌注,远端分支灌注有限;2a级表示前向血流部分灌注小于一半下游缺血区;2b级表示前向血流部分灌注大于一半下游缺血区;3级表示前向血流完全灌注下游缺血区。当mTICI评分为2b级或3级时,表示患者血管再通成功。
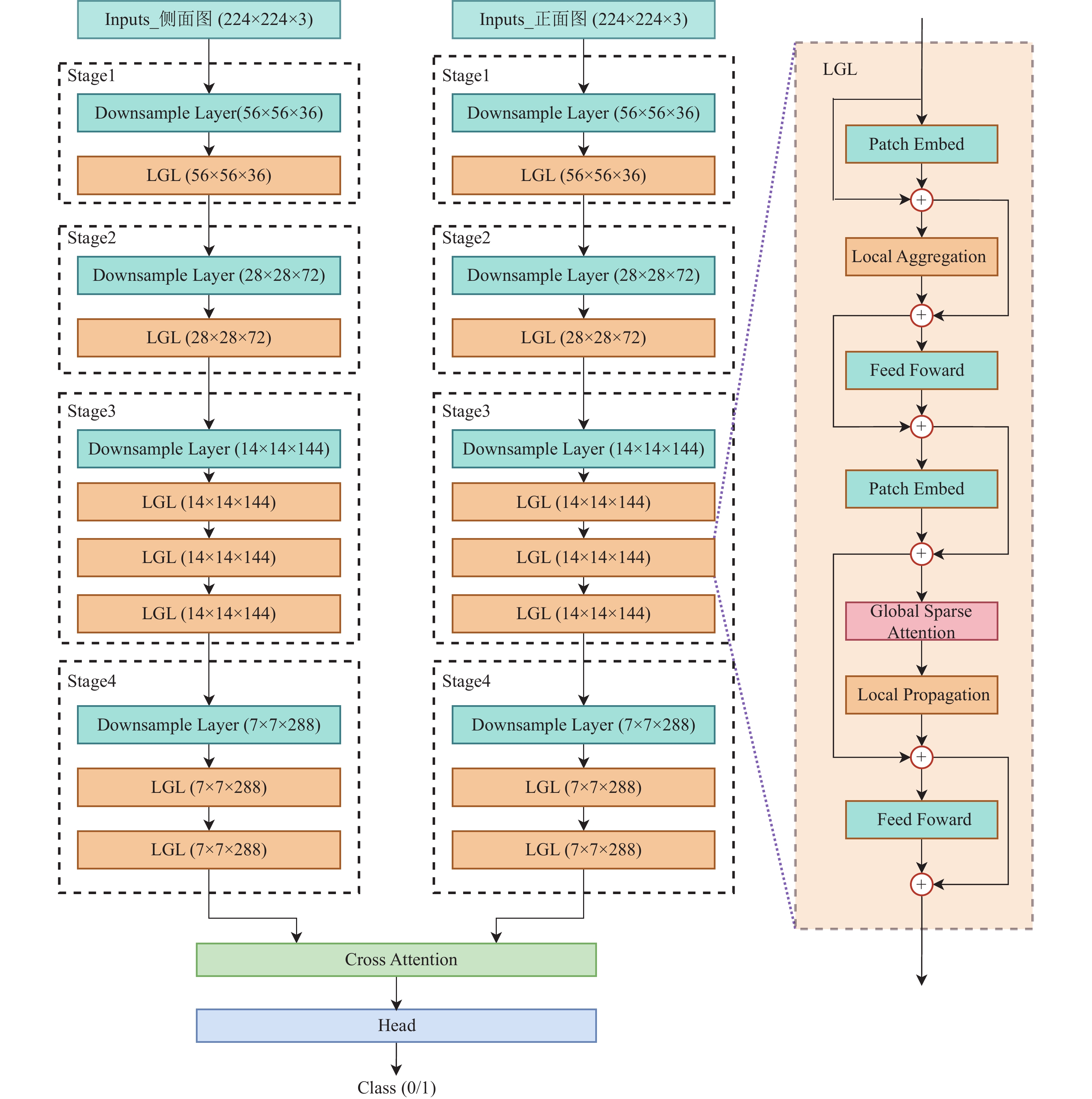
本文提出的双路径视觉Transformer用于急性缺血性脑卒中辅助诊断模型DPVF的整体结构如图2所示。DPVF每一路径均基于轻量化模型EdgeViT[10]进行设计,为了提升轻量化模型的分类精度,重新设计EdgeViT的多头自注意力模块为稀疏空间−通道自注意力模块(Sparse Dual Attention);为了融合两路径提取的正面和侧面图像信息,构建了交叉注意力模块(Cross Attention)以实现两路径特征的交叉融合,从而使模型提取到更丰富的信息,提高模型的可信度。本文设计的DPVF模型主要包含3个模块:LGL(Local-Global-Local)模块、Cross Attention模块以及Head模块。LGL模块用于提取输入图像特征,Cross Attention模块用于DPVF模型两分支的特征融合,Head模块用于将融合后的特征输出为卒中DSA图像的mTICI评分类别。

图 1 正面和侧面DSA图像实例图
-
Transformer[11]最初是在自然语言处理(NLP)领域中提出的,通过引入自注意力机制来捕捉输入序列中的全局关系,取得了比传统循环神经网络更好的效果和性能。随着深度学习的发展,Transformer也被引入计算机视觉领域,典型代表模型是ViT[12],它将输入图像分成若干个图块(patches),将这些patches转化为一个序列(tokens),再利用多头自注意力机制学习图像的全局语义信息。然而,由于图像具有较高的空间冗余性,在每个空间位置都执行自注意力的计算是低效的。EdgeViT的LGL模块只使用输入tokens的一部分子集计算自注意力,但可以实现完全的空间交互,在保证性能的前提下减少了特征的计算量和参数量。
-
如图2最右侧虚线框所示,LGL模块主要包含3部分,分别为Local Aggregation、Global Sparse Attention、Local Propagation。Local Aggregation模块的主要功能是对于每个token,利用深度可分离卷积在大小为k×k的局部窗口中聚合信息,如图3a所示。Global Sparse Attention模块的主要功能是对均匀分布在整个空间中的一组稀疏代表性token进行采样,每个r×r(r表示下采样率)窗口对应一个代表性token,然后对这些选定的token应用自注意力进行全局建模,如图3b所示。Local Propagation模块的主要功能是通过转置卷积将代表性tokens中编码的全局上下文信息传播到其相邻的tokens,如图3c所示。
-
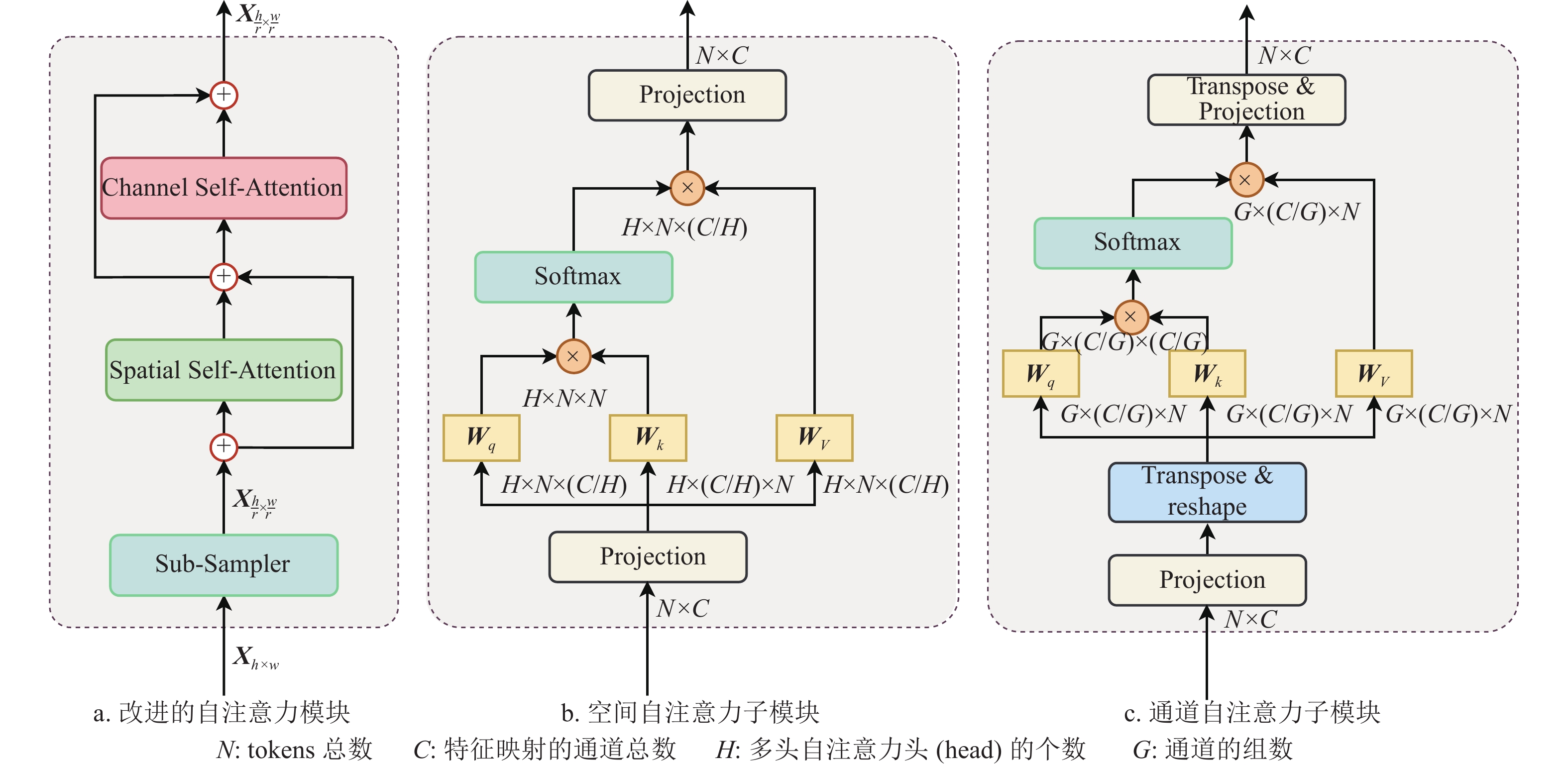
LGL模块使用稀疏空间自注意力机制来建模输入序列(tokens)中每个位置之间的空间关系,通过计算输入序列中每个位置之间的相关性得分来决定哪些位置对当前位置的表示具有更大的贡献,以使模型能够更好地关注于目标相关的信息。为提升LGL模块的建模能力,本文对LGL模块的Global Sparse Attention子模块进行了如下改进:构建空间−通道稀疏自注意力模块来高效地实现全局建模,使用通道自注意力建立输入序列中不同通道之间的关系,通过计算不同通道之间的相关性得分来决定哪些通道对当前位置的表示具有更大的贡献,从而能够更好地学习到输入序列中的特征。将空间自注意力和通道自注意力进行结合,从两个正交的角度进行自注意力的计算,可以帮助模型更好地捕捉输入序列中的空间和通道特征,从而提高模型的分类性能。
改进的Global Sparse Attention模块结构图如图4a所示,这里使用空间−通道双注意力机制来对输入图像进行特征建模,并采取残差结构以避免模型退化。空间自注意力子模块如图4b所示,计算公式为:
$$ {\text{Attention(}}{\boldsymbol{Q,K,V}}{\text{) = Concat(}}{h_1},{h_2},\cdots,{h_H}) $$ (1) $$ {h_i} = {\text{Attention}}({{\boldsymbol{Q}}_i}{\boldsymbol{,}}{{\boldsymbol{K}}_i}{\boldsymbol{,}}{{\boldsymbol{V}}_i}) $$ (2) $$ {\text{Attention}}({{\boldsymbol{Q}}_i}{\boldsymbol{,}}{{\boldsymbol{K}}_i}{\boldsymbol{,}}{{\boldsymbol{V}}_i}) = {\text{softmax}}\left[\frac{{{{\boldsymbol{Q}}_i}{{{{\boldsymbol{K}}_i}}^{\text{T}}}}}{{\sqrt {C/H} }}\right]{{\boldsymbol{V}}_i} $$ (3) 式中,
$ {h_i} $ 表示自注意力计算的第i个head,H表示多头自注意力头(head)的个数,第i个head的$ {{\boldsymbol{Q}}_i}{\boldsymbol{,}}{{\boldsymbol{K}}_i}{\boldsymbol{,}}{{\boldsymbol{V}}_i} $ 通过如下线性映射得到:$$ {{\boldsymbol{Q}}_i} = {{\boldsymbol{X}}_i}{\boldsymbol{W}}_i^{\boldsymbol{Q}} $$ (4) $$ {{\boldsymbol{K}}_i} = {{\boldsymbol{X}}_i}{\boldsymbol{W}}_i^{\boldsymbol{K}} $$ (5) $$ {{\boldsymbol{V}}_i} = {{\boldsymbol{X}}_i}{\boldsymbol{W}}_i^{\boldsymbol{V}} $$ (6) 通道自注意力子模块如图4c所示,计算过程可以用如下公式表示:
$$ {\text{Attention}}({\boldsymbol{Q,K,V}}) = {\text{Concat}}({h_1},{h_2},\cdots,{h_G}) $$ (7) $$ {h_i} = {\text{Attention}}({{\boldsymbol{Q}}_i}{\boldsymbol{,}}{{\boldsymbol{K}}_i}{\boldsymbol{,}}{{\boldsymbol{V}}_i}) $$ (8) $$ {\text{Attention}}({{\boldsymbol{Q}}_i}{\boldsymbol{,}}{{\boldsymbol{K}}_i}{\boldsymbol{,}}{{\boldsymbol{V}}_i}) = {\text{softmax}}\left[\frac{{{{\boldsymbol{Q}}_i}^{\text{T}}{{\boldsymbol{K}}_i}}}{{\sqrt {C/G} }}\right]{{\boldsymbol{V}}_i}^{\text{T}} $$ (9) 式中,G表示通道的组数,
$ {{\boldsymbol{Q}}_i}{\boldsymbol{,}}{{\boldsymbol{K}}_i}{\boldsymbol{,}}{{\boldsymbol{V}}_i} $ 的线性投射方式与空间自注意力一致,而在通道自注意力计算时,将$ {{\boldsymbol{Q}}_i}{\boldsymbol{,}}{{\boldsymbol{K}}_i}{\boldsymbol{,}}{{\boldsymbol{V}}_i} $ 的维度进行反转,便可实现在通道维度上的自注意力的计算。因此,改进的LGL模块可以表示为:
$$ {\boldsymbol{X}} = {\text{LocalAgg}}({\text{Norm}}({{\boldsymbol{X}}_{{\text{in}}}})) + {{\boldsymbol{X}}_{{\text{in}}}} $$ (10) $$ {\boldsymbol{Y}} = {\text{FFN(Norm}}({\boldsymbol{X}})) + {\boldsymbol{X}} $$ (11) $$ {{\boldsymbol{Y}}'} = {\text{GlobalSparseAttn(Norm}}({\boldsymbol{Y}})) + {\boldsymbol{Y}} $$ (12) $$ {\boldsymbol{Z}} = {\text{LocalProp(Norm}}({{\boldsymbol{Y}}'})) + {{\boldsymbol{Y}}'} $$ (13) $$ {{\boldsymbol{X}}_{{\text{out}}}} = {\text{FFN(Norm}}({\boldsymbol{Z}})) + {\boldsymbol{Z}} $$ (14) 式中,
$ {{\boldsymbol{X}}_{{\text{in}}}} $ 表示LGL模块的输入;$ {{\boldsymbol{X}}_{{\text{out}}}} $ 表示LGL模块的输出;Norm表示层归一化[13](Layer Normalization);LocalAgg表示LGL模块的Local Aggregation子模块;GlobalSparseAttn表示空间−通道稀疏自注意模块;LocalProp表示LGL模块的Local Propagation子模块。
图 2 DPVF网络结构图
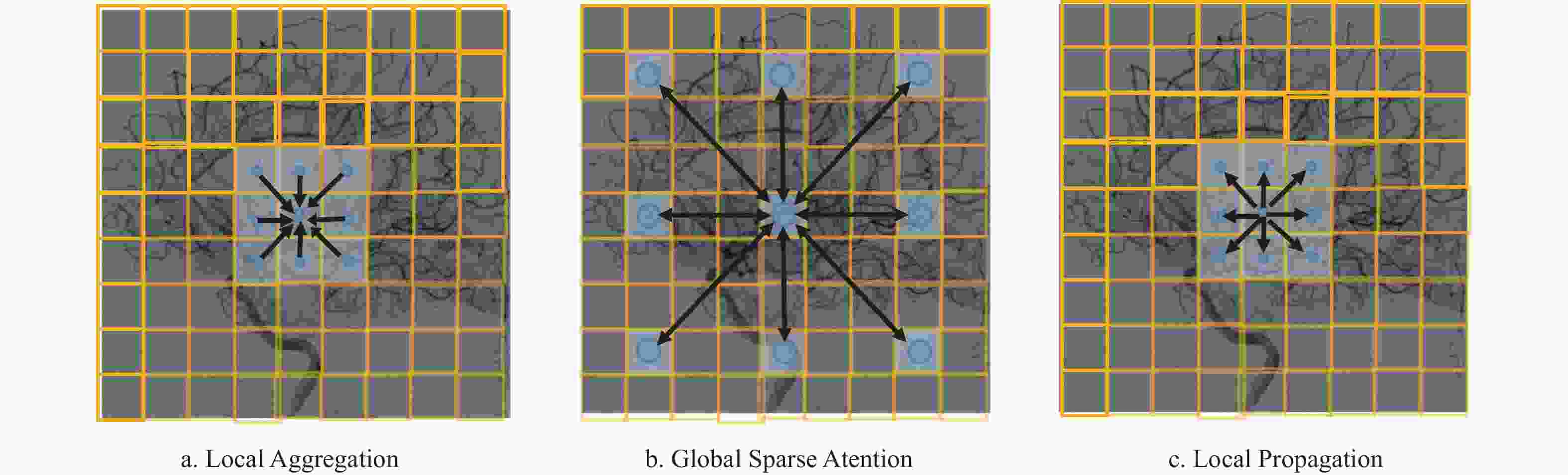
图 3 LGL模块的3个子模块操作示意图
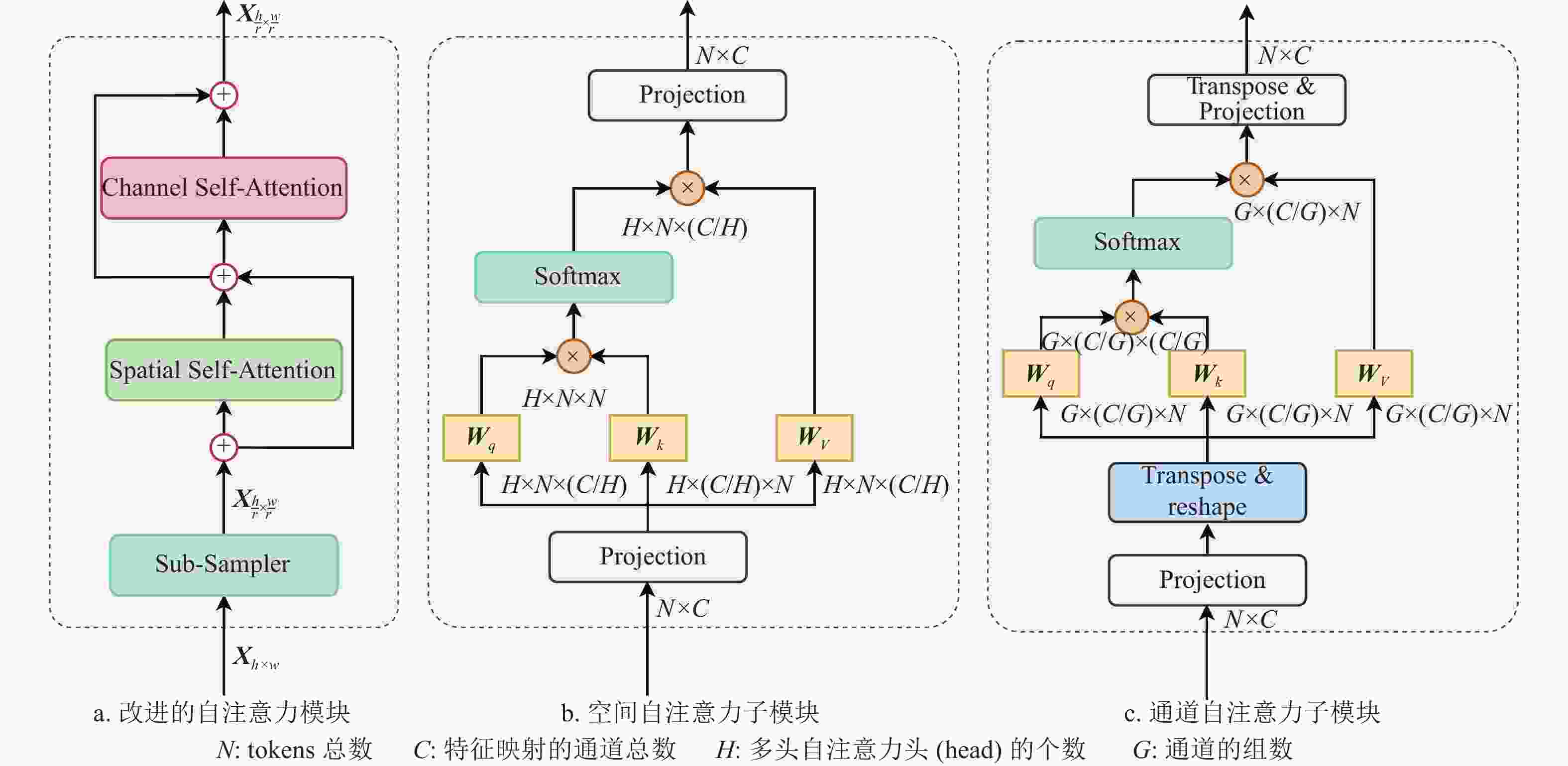
图 4 空间−通道稀疏自注意力模块
-
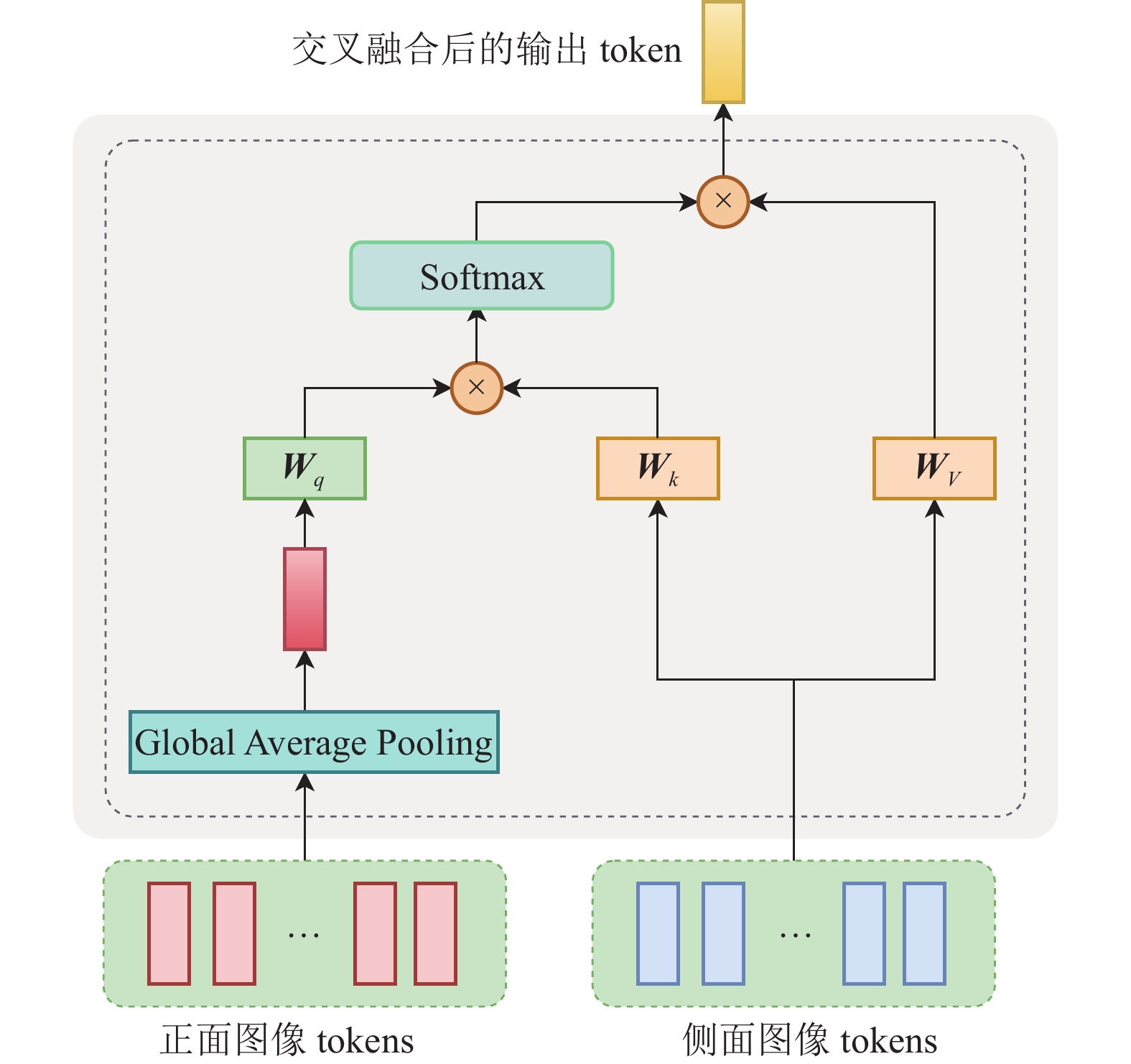
为了充分融合AIS患者的正面和侧面DSA图像信息,构建交叉注意力模块实现双分支网络的特征融合。如图5所示,将经过改进的LGL模块训练的正面图像tokens和侧面图像tokens进行交叉融合,为降低自注意计算的运算量,将正面图像tokens进行全局平均池化,得到一个包含正面图像全局信息的token,将此token与侧面图像的tokens进行多头自注意的计算,输出包含正侧面图像信息的token。侧面图像tokens与正面图像tokens之间的交叉融合与此过程一致。经过Cross Attention模块的最终输出是正面和侧面DSA图像tokens交叉融合后的两个token。
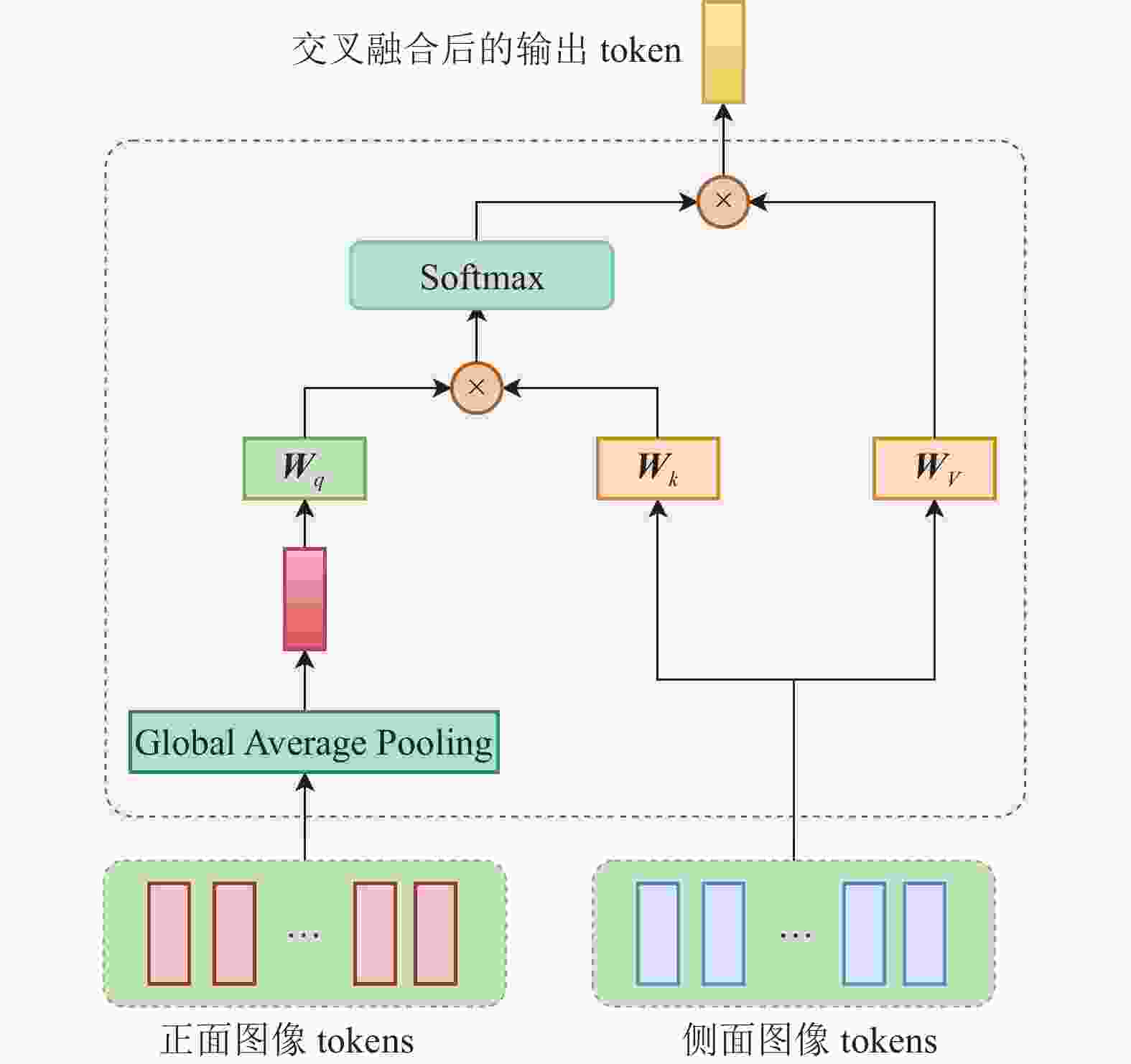
图 5 Cross Attention模块
-
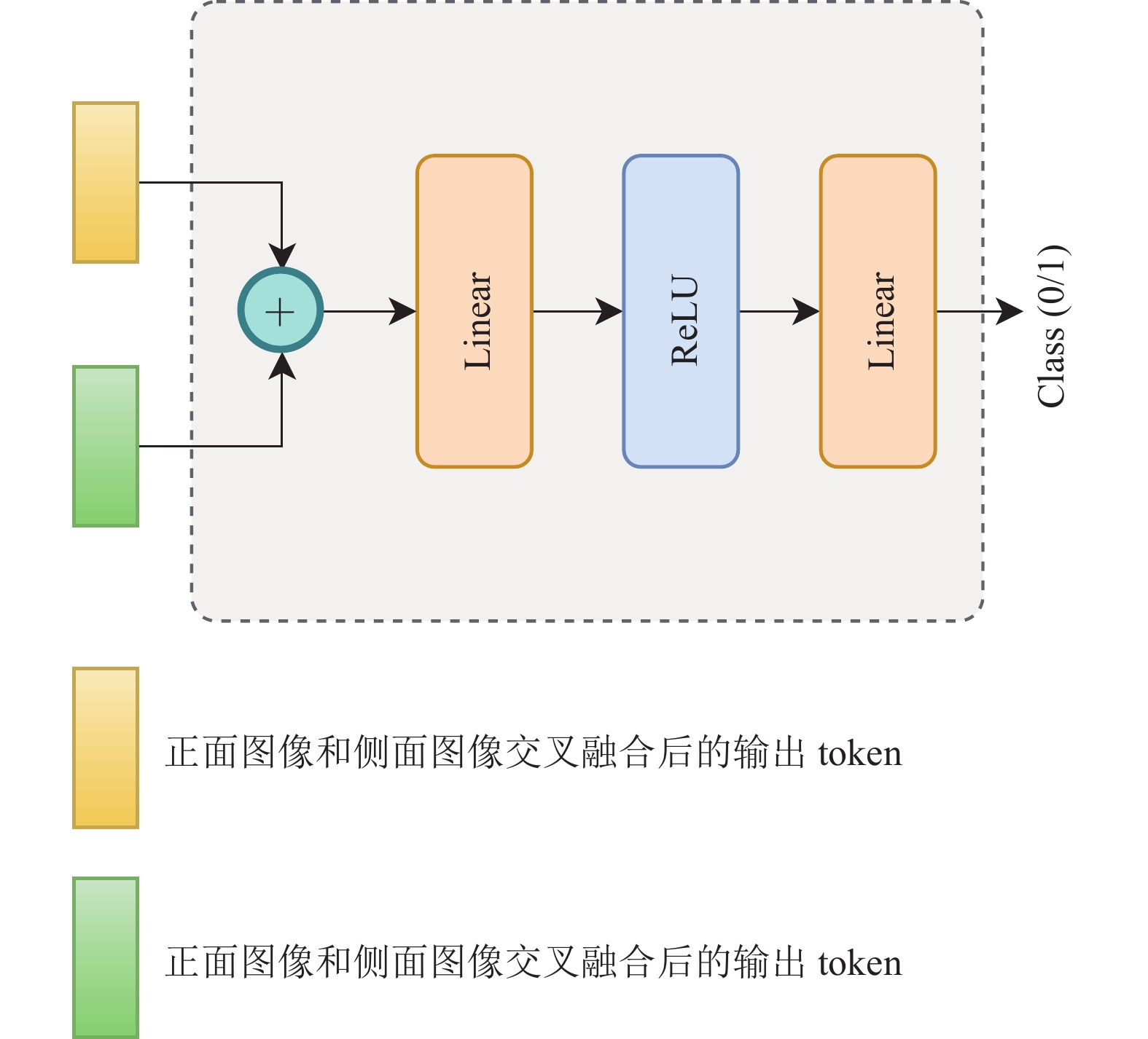
对于Head模块,它的主要作用是根据Cross Attention模块最终输出的tokens实现卒中DSA图像的mTICI评级分类。如图6所示,Head模块将经过Cross Attention模块融合后的两分支的输出进行拼接,对拼接结果应用两个线性层,以输出模型最终的分类结果。
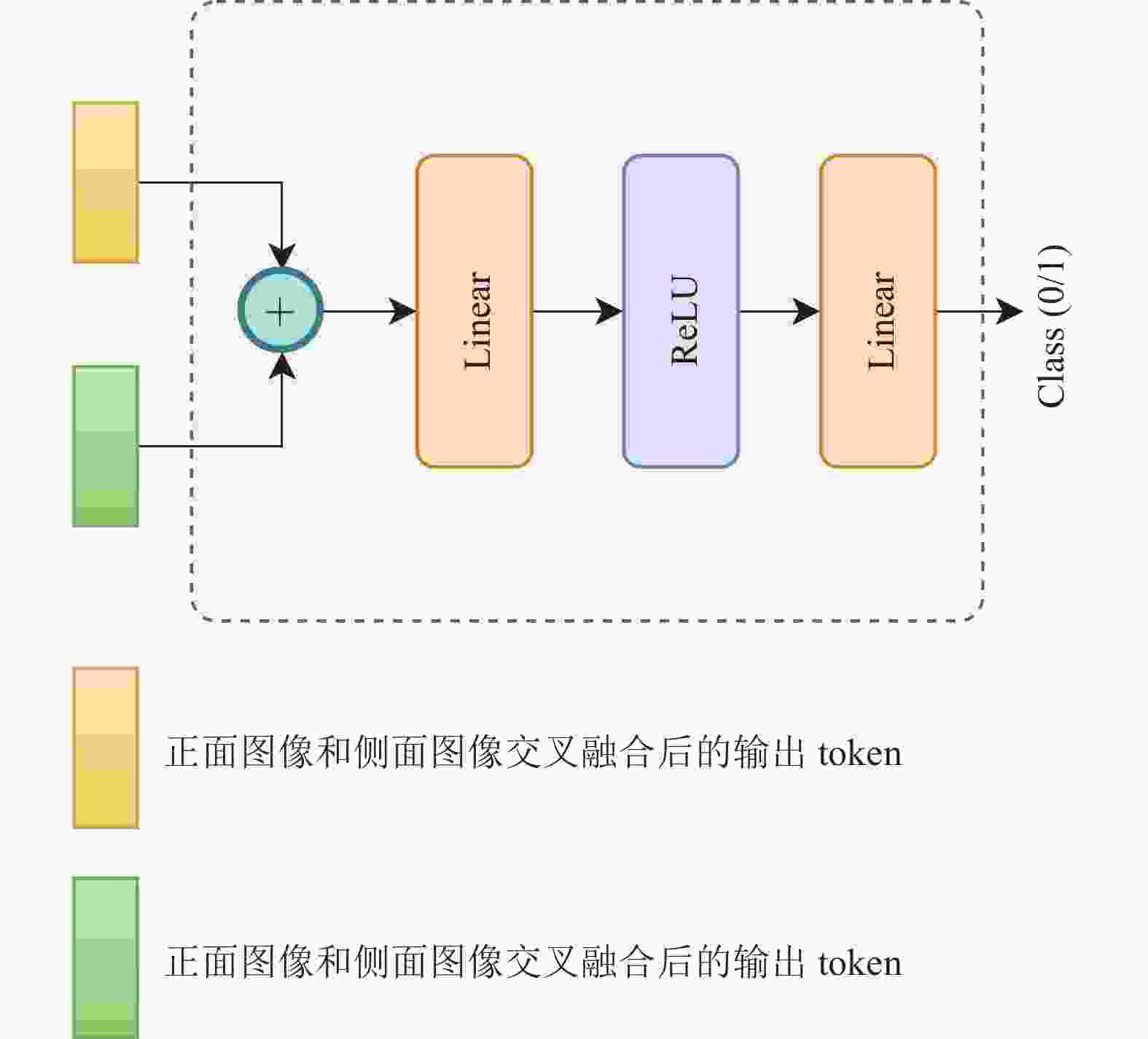
图 6 Head模块结构图
-
本实验使用的数据集涉及194名AIS患者,使用DSA设备采集减影血管图像序列,每个序列包含15~30帧不等,对这些患者在治疗过程中拍摄得到的DSA图像进行筛选分级,得到1019对质量良好的正侧面图像。根据脑血管再通是否成功作为分类依据,将mTICI评级为2b或3标为类别1,血管未再通成功(mTICI评级为0、1或2a)标注为类别0。再通成功数据共计537对,未再通成功共计482对,具体如表1所示。训练集和测试集按照8:2的比例随机划分。
表 1 数据集详情表
mTICI级别 数量/对 所属分类 0 368 0 1 40 0 2a 74 0 2b 170 1 3 367 1 -
对于医学图像分类模型,常用的评价指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1得分(F1 score),分别表示为:
$$ {\text{Accuracy = }}\frac{{{\text{TP + TN}}}}{{{\text{TP + TN + FP + FN}}}} $$ (15) $$ {\text{Precision}} = \frac{{{\text{TP}}}}{{{\text{TP + FP}}}} $$ (16) $$ {\text{Recall}} = \frac{{{\text{TP}}}}{{{\text{TP + FN}}}} $$ (17) $$ {\text{F1 score = }}\frac{{2 \times {\text{TP}}}}{{2 \times {\text{TP + FP + FN}}}} $$ (18) 式中,TP、TN、FP、FN分别代表真阳性、真阴性、假阳性、假阴性,也即分别代表“预测为正样本,且预测正确”“预测为负样本,且预测正确”“预测为正样本,但预测错误”“预测为负样本,但预测错误”。
-
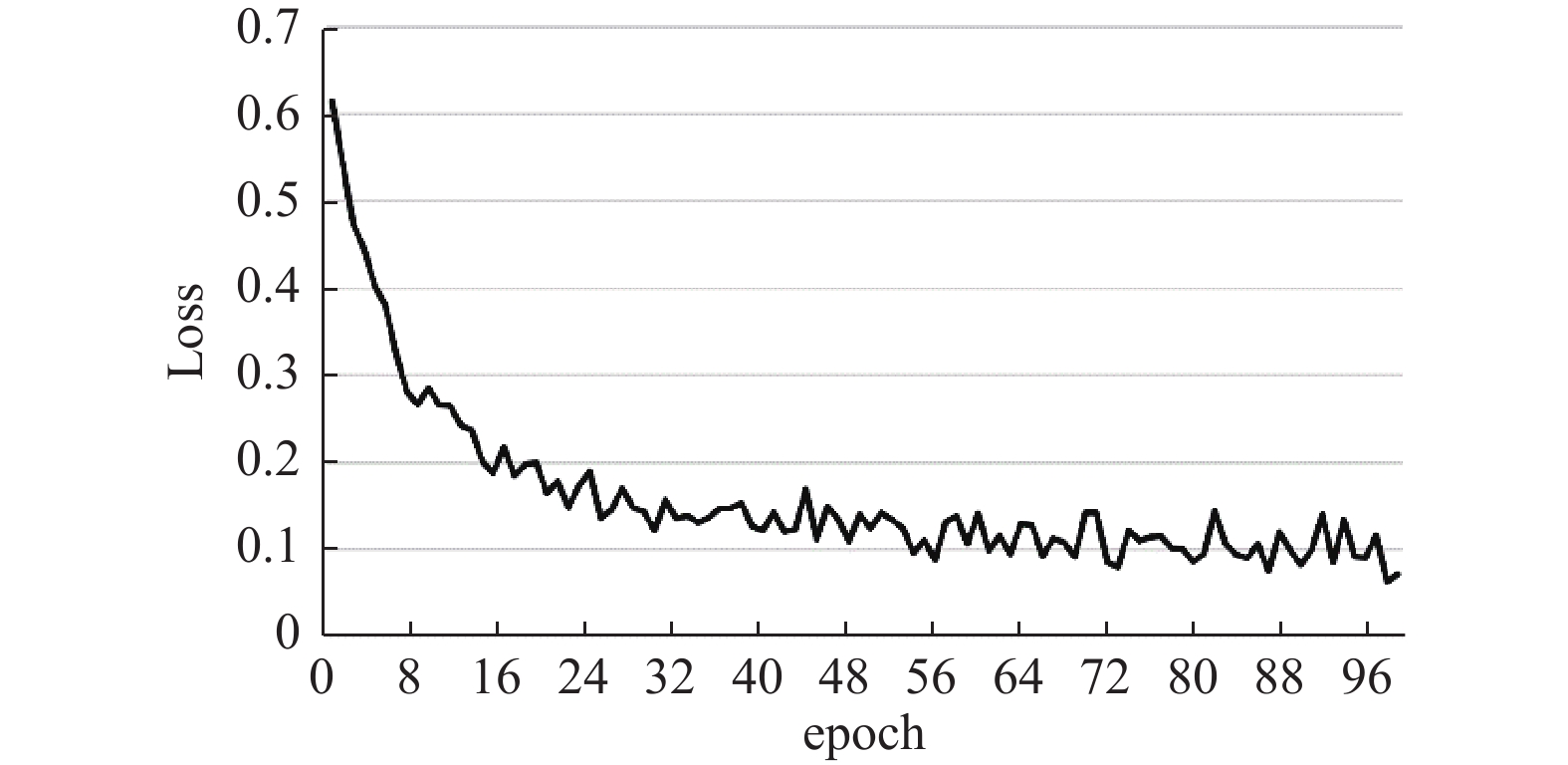
在RTX 2080Ti上基于深度学习框架Pytorch进行模型的训练,迭代次数为100,batch size设置为8,初始学习率为0.0001,使用Adam优化器[14]。DPVF模型的训练过程如图7和图8所示,可以看出,DPVF的准确率随epoch增加而增加,损失值随epoch增加而减小,约迭代20次后,准确率和损失都收敛到一个较小的区间范围,说明DPVF经过了充分的训练后能够快速收敛。

图 7 DPVF模型训练准确率随epoch变化曲线
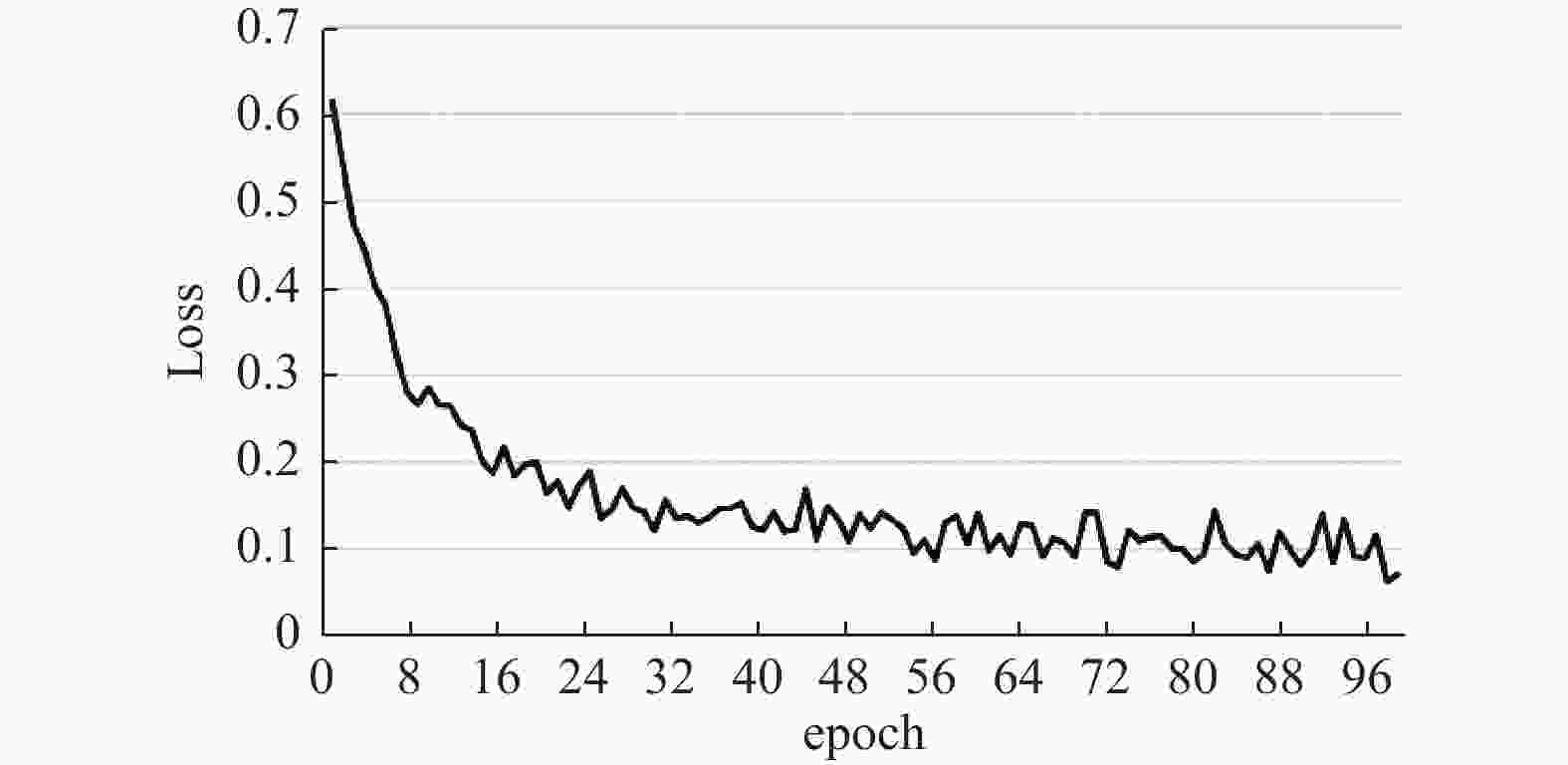
图 8 DPVF模型训练损失随epoch变化曲线
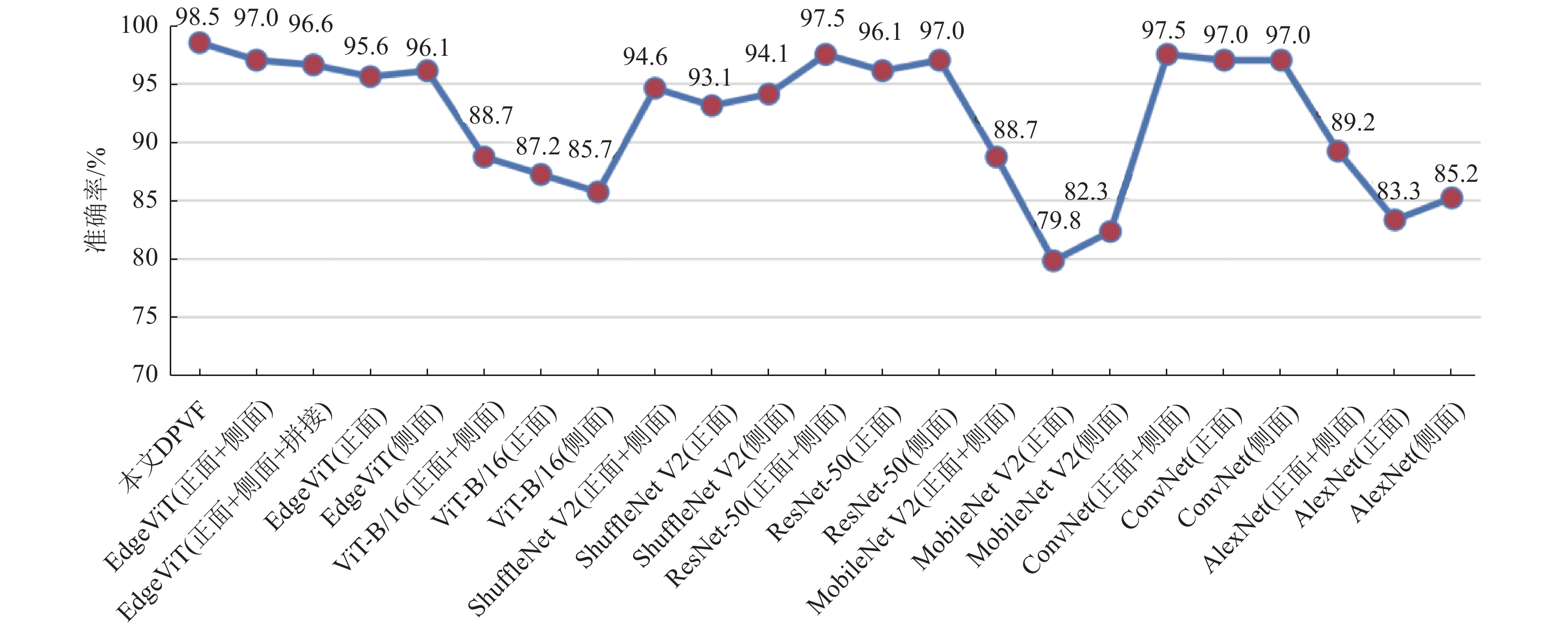
对经过训练的DPVF模型与现有主流模型在测试集上测试,其中,每个经典模型的测试包括3方面,分别为输入单张正面图像的单分支模型、输入单张侧面图像的单分支模型,以及同时输入正面和侧面两张图像的采用Concat融合方式的双分支模型,分别计算每个模型的混淆矩阵、准确率、精准率、召回率和F1得分,对比实验结果如表2所示。
表 2 DPVF与其他分类模型在测试集上的实验结果对比
模型 TP FP FN TN Accuracy/% Precision/% Recall/% F1 score/% 本文DPVF 94 2 1 106 98.5 97.9 98.9 98.4 EdgeViT(正+侧) 95 1 5 102 97.0 99.0 95.0 97.0 EdgeViT(正+侧)拼接 93 3 4 103 96.6 96.9 95.9 96.4 EdgeViT(正) 91 5 4 103 95.6 94.8 95.8 95.3 EdgeViT(侧) 90 6 2 105 96.1 93.8 97.8 95.8 ViT-B/16(正+侧) 83 13 10 97 88.7 86.5 89.2 87.8 ViT-B/16(正) 96 0 26 81 87.2 100 78.7 88.1 ViT-B/16(侧) 83 13 16 91 85.7 86.5 83.8 85.1 ShuffleNet V2(正+侧) 88 8 3 104 94.6 91.7 96.7 94.1 ShuffleNet V2(正) 92 4 10 97 93.1 95.8 90.2 92.9 ShuffleNet V2(侧) 93 3 9 98 94.1 96.9 91.2 94.0 ResNet-50(正+侧) 95 1 4 103 97.5 99.0 96.0 97.5 ResNet-50(正) 90 6 2 105 96.1 93.8 97.8 95.8 ResNet-50(侧) 95 1 5 102 97.0 99.0 95.0 97.0 MobileNet V2(正+侧) 76 20 3 104 88.7 79.2 96.2 86.9 MobileNet V2(正) 73 23 18 89 79.8 76.0 80.2 78.0 MobileNet V2(侧) 75 21 15 92 82.3 78.1 83.3 80.6 ConvNeXt(正+侧) 95 1 4 103 97.5 99.0 96.0 97.5 ConvNeXt(正) 92 4 2 105 97.0 95.8 97.9 96.8 ConvNeXt(侧) 94 2 4 103 97.0 97.9 95.9 96.9 AlexNet(正+侧) 94 2 20 87 89.2 97.9 82.5 89.5 AlexNet(正) 83 13 21 86 83.3 86.5 79.8 83.0 AlexNet(侧) 78 18 12 95 85.2 81.3 86.7 83.9 使用折线图对每个模型在测试集上的准确率进行可视化,如图9所示,可以看出,本文提出的DPVF模型在测试集上的准确率达到了最高的98.5%,优于基于EdgeViT的正面加侧面图像输入的双分支模型,说明了本文改进的LGL模块的有效性;此外,可以看出,EdgeViT的双分支采用交叉注意力的融合方式的准确率达97.0%,而采用拼接融合方式的准确率为96.6%,说明本文构建的交叉注意力模块可以达到比拼接方式更好的特征融合效果,证明了本文构建的交叉注意力模块的有效性;此外,输入正面和侧面两幅图像的双分支模型的准确率均高于输入单幅图像对应的单分支模型,说明同时输入正面和侧面两幅图像有助于模型提取到更丰富的特征,可以有效提升图像分类的准确率和精度。结合表2可以看出,DPVF在准确率、精准率、召回率和F1得分上均取得了较好的表现,其中准确率达98.5%,F1得分、精准率和召回率分别达到了98.4%、97.9%、98.9%。与单分支ViT模型及其他模型相比,DPVF在各个指标上均具有一定的优势,说明本文构建的正面和侧面图像交叉融合有效地提取了正面和侧面图像多角度的特征,优于两幅图像的简单拼接融合,从而提升了模型的mTICI自动分级准确率。
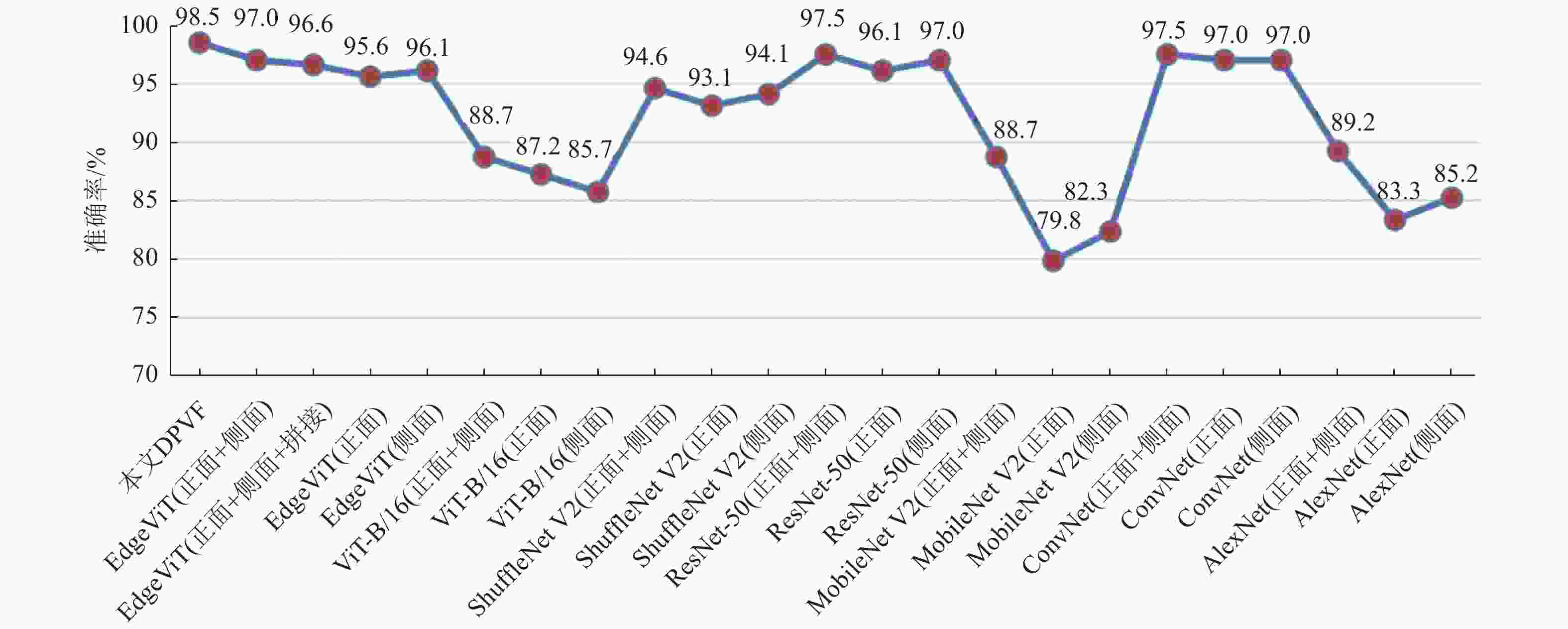
图 9 DPVF模型与其他模型在测试集上的准确率比较
-
本文构建了一个基于Vision Transformer的轻量级双路径图像分类模型DPVF用于急性缺血性脑卒中患者DSA图像的自动分级。基于EdgeViT的轻量化设计思想进行了模型的构建,并提出空间−通道自注意力模块对原有自注意力模块进行改进,以使模型保持轻量化的同时捕获更全面的特征信息,提高模型表达能力;此外,构建交叉注意力模块对DPVF模型的两分支进行交叉融合,促使模型提取更丰富的特征,从而提高模型表现。实验结果表明,本文构建的DPVF比其他图像分类模型要好,证明了本文方法的可行性和有效性。
Dual-Path Vision Transformer for Auxiliary Diagnosis of Acute Ischemic Stroke
-
摘要: 急性缺血性脑卒中是由于脑组织血液供应障碍导致的脑功能障碍,数字减影脑血管造影(DSA)是诊断脑血管疾病的金标准。基于患者的正面和侧面DSA图像,对急性缺血性脑卒中的治疗效果进行分级评估,构建基于Vision Transformer的双路径图像分类智能模型DPVF。为了提高辅助诊断速度,基于EdgeViT的轻量化设计思想进行了模型的构建;为了使模型保持轻量化的同时具有较高的精度,提出空间−通道自注意力模块,促进Transformer模型捕获更全面的特征信息,提高模型的表达能力;此外,对于DPVF的两分支的特征融合,构建交叉注意力模块对两分支输出进行交叉融合,促使模型提取更丰富的特征,从而提高模型表现。实验结果显示DPVF在测试集上的准确率达98.5%,满足实际需求。
-
关键词:
- 急性缺血性脑卒中 /
- 视觉Transformer /
- 双分支网络 /
- 特征融合
Abstract: Acute ischemic stroke is one of the fatal brain dysfunction diseases caused by the interruption of blood supply to the brain tissue. Digital Subtract Angiography (DSA) is the gold standard for diagnosing such cerebrovascular diseases. Based on the frontal and lateral DSA images of the patients, a dual-path image classification intelligent model, Dual-Path Vision Transformer (DPVF), is constructed in this paper to evaluate the treatment effectiveness of acute ischemic stroke in a graded manner. In order to improve the speed of auxiliary diagnosis, the model is constructed based on the lightweight design idea of EdgeViT. And in order to make the model have high accuracy, the spatial-channel self-attention module is proposed to promote the transformer model to capture more comprehensive feature information and improve the model representation. In addition, for the feature fusion of two branches of DPVF, a cross-attention module is constructed to cross-fuse the outputs of the two branches, which promotes the model to extract richer features and thus improves the model performance. The experimental results show that the accuracy of DPVF on the test set reaches 98.5%, which can effectively meet the practical requirements.-
Key words:
- acute ischemic stroke /
- vision Transformer /
- dual-path /
- feature fusion
-
表 2 DPVF与其他分类模型在测试集上的实验结果对比
模型 TP FP FN TN Accuracy/% Precision/% Recall/% F1 score/% 本文DPVF 94 2 1 106 98.5 97.9 98.9 98.4 EdgeViT(正+侧) 95 1 5 102 97.0 99.0 95.0 97.0 EdgeViT(正+侧)拼接 93 3 4 103 96.6 96.9 95.9 96.4 EdgeViT(正) 91 5 4 103 95.6 94.8 95.8 95.3 EdgeViT(侧) 90 6 2 105 96.1 93.8 97.8 95.8 ViT-B/16(正+侧) 83 13 10 97 88.7 86.5 89.2 87.8 ViT-B/16(正) 96 0 26 81 87.2 100 78.7 88.1 ViT-B/16(侧) 83 13 16 91 85.7 86.5 83.8 85.1 ShuffleNet V2(正+侧) 88 8 3 104 94.6 91.7 96.7 94.1 ShuffleNet V2(正) 92 4 10 97 93.1 95.8 90.2 92.9 ShuffleNet V2(侧) 93 3 9 98 94.1 96.9 91.2 94.0 ResNet-50(正+侧) 95 1 4 103 97.5 99.0 96.0 97.5 ResNet-50(正) 90 6 2 105 96.1 93.8 97.8 95.8 ResNet-50(侧) 95 1 5 102 97.0 99.0 95.0 97.0 MobileNet V2(正+侧) 76 20 3 104 88.7 79.2 96.2 86.9 MobileNet V2(正) 73 23 18 89 79.8 76.0 80.2 78.0 MobileNet V2(侧) 75 21 15 92 82.3 78.1 83.3 80.6 ConvNeXt(正+侧) 95 1 4 103 97.5 99.0 96.0 97.5 ConvNeXt(正) 92 4 2 105 97.0 95.8 97.9 96.8 ConvNeXt(侧) 94 2 4 103 97.0 97.9 95.9 96.9 AlexNet(正+侧) 94 2 20 87 89.2 97.9 82.5 89.5 AlexNet(正) 83 13 21 86 83.3 86.5 79.8 83.0 AlexNet(侧) 78 18 12 95 85.2 81.3 86.7 83.9  下载: 导出CSV
下载: 导出CSV
-
[1] 邱甲军, 吴跃, 惠孛, 等. 肝细胞癌MR图像的纹理分类研究[J]. 电子科技大学学报, 2019, 48(4): 619-626. doi: 10.3969/j.issn.1001-0548.2019.04.021 QIU J J, WU Y, HUI B, et al. Texture classification study of mr images for hepatocellular carcinoma[J]. Journal of University of Electronic Science and Technology of China, 2019, 48(4): 619-626. doi: 10.3969/j.issn.1001-0548.2019.04.021 [2] 沈子祺, 谢文军, 刘晓平. 基于视频的自动Fugl-Meyer评估方法研究[J]. 电子测量与仪器学报, 2022, 36(2): 1-11. SHEN Z Q, XIE W J, LIU X P. Automatic Fugl-Meyer assessment based on videos[J]. Journal of Electronic Measurement and Instrument, 2022, 36(2): 1-11. [3] HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision. [S.l.]: IEEE, 2017: 2961-2969. [4] SHIRAZ B M M, SNYDER K V, WAQAS M, et al. Use of quantitative angiographic methods with a data-driven model to evaluate reperfusion status (mTICI) during thrombectomy[J]. Neuroradiology, 2021, 63(9): 1429-1439. doi: 10.1007/s00234-020-02598-3 [5] CHAUHAN S, VIG L, DE F D G M, et al. A comparison of shallow and deep learning methods for predicting cognitive performance of stroke patients from MRI lesion images[J]. Frontiers in Neuroinformatics, 2019, 13: 53. doi: 10.3389/fninf.2019.00053 [6] CHEON S, KIM J, LIM J. The use of deep learning to predict stroke patient mortality[J]. International Journal of Environmental Research and Public Health, 2019, 16(11): 1876. doi: 10.3390/ijerph16111876 [7] NIELSEN A, HANSEN M B, TIETZE A, et al. Prediction of tissue outcome and assessment of treatment effect in acute ischemic stroke using deep learning[J]. Stroke, 2018, 49(6): 1394-1401. doi: 10.1161/STROKEAHA.117.019740 [8] BHURWANI M M S, SNYDER K V, WAQAS M, et al. Use of biplane quantitative angiographic imaging with ensemble neural networks to assess reperfusion status during mechanical thrombectomy[C]//Medical Imaging 2021: Computer-Aided Diagnosis. [S.l.]: Springer, 2021, 11597: 328-336. [9] SU R, CORNELISSEN S A P, VAN D S M, et al. AutoTICI: Automatic brain tissue reperfusion scoring on 2D DSA images of acute ischemic stroke patients[J]. IEEE Transactions on Medical Imaging, 2021, 40(9): 2380-2391. doi: 10.1109/TMI.2021.3077113 [10] PAN J, BULAT A, TAN F, et al. Edgevits: Competing light-weight CNNS on mobile devices with vision transformers[C]//Computer Vision-ECCV 2022: 17th European Conference. [S.l.]: Springer, 2022: 294-311. [11] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EB/OL]. [2022-10-22]. https://arxiv.org/pdf/1706.03762.pdf. [12] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[EB/OL]. [2022-06-15]. https://arxiv.org/abs/2010.11929v1. [13] BA J L, KIROS J R, HINTON G E. Layer normalization[EB/OL]. [2022-06-25]. https://arxiv.org/pdf/1607.06450.pdf. [14] KINGMA D P, BA J. Adam: A method for stochastic optimization[EB/OL]. [2022-07-10]. http://www.arxiv.org/pdf/1412.6980.pdf. -

 点击查看大图
点击查看大图
图(9) / 表(2)
计量
- 文章访问数: 2324
- HTML全文浏览量: 688
- PDF下载量: 6
- 被引次数: 0
























