 ISSN
ISSN 


-
随着信息化时代的到来,通信、传感器和计算机等技术发展迅猛,使得各类测量数据急剧膨胀,催生出一个发展广阔且军事意义重大的应用研究领域——数据流分析。作为一个连续到达的数据序列,与传统时间序列相比,数据流具有无界性、高速性等显著特点[1]。携带有不完整、不精确信息的数据流被称为不确定数据流,它在无线传感器网络、互联网、战场态势等领域有极大的应用需求[2-3]。目前,有关不确定数据流的研究主要包括聚类、查询和分类等方面,而关于不确定数据流内隐含的关系、规则及模式等知识挖掘方面则很少提及[4-6]。
本文借鉴生物信息学中序列模式发现思想,研究不确定数据流中功能或行为相似的流段(模体),用于分析或预测产生数据流的实体行为。为了发现不确定数据流在不同时刻滑动窗口下的模体,实现对不确定数据流的预测、规则挖掘、分类和异常检测,设计了基于MEME的不确定数据流模体发现算法,在传统时间序列模体发现的基础上,增加了处理不确定性和动态性的功能。
-
在生物信息学中,模体发现的近似算法主要分为两类:一类是基于启发式或贪心技术的算法,主要有WEEDER、VINE、Pattern Branching算法等;另一类是基于统计技术的算法,主要有EM、MEME、吉布斯采样以及HMM算法等。
MEME算法[7-9]是目前最流行的符号序列集合模体发现算法,它可将模体从由背景成分和模体成分组成的混合符号序列中辨识出来。对于由符号序列${{S}_{i}}={{s}_{i1}}{{s}_{i2}}\cdots {{s}_{iL}}$$(i=1,2,\cdots ,t)$组成的符号序列集合$S=\{{{S}_{1}},{{S}_{2}},\cdots ,{{S}_{t}}\}$而言,用$l-\text{mer}$表示一个长度为l的碱基片段,即$l-\text{mer}={{s}_{i,j+1}}{{s}_{i,j+2}}\cdots {{s}_{i,j+l}}$。MEME算法就是从符号序列集合中识别出重复出现的$l-\text{mer}$。
MEME算法的核心是定义了一个二元随机变量${{Z}_{ij}}(j=1,\ 2,\cdots ,{{L}_{i}})$,通过计算每一个$l-\text{mer}$的似然值来寻找模体,具体见文献[5]和文献[7]。其中,${{Z}_{ij}}$表示每一个$l-\text{mer}$对应的背景成分或模体成分,即当字符${{s}_{ij}}$表示为一个结合位点时,${{Z}_{ij}}=1$,否则${{Z}_{ij}}=0$。该算法将整个序列集合的似然值表示为:
$$\log (p(X,Z|{{\theta }_{0}},\Theta ))=\sum\limits_{i=1}^{t}{\sum\limits_{j=1}^{{{L}_{i}}-l+1}{{{Z}_{ij}}}}\times \log p({{X}_{ij}}|{{Z}_{ij}},{{\theta }_{0}},\Theta )$$ (1) 式中,${{X}_{ij}}$表示第i行第j个$l-\text{mer}$;${{\theta }_{0}}$表示背景分布(此处采用零阶马尔科夫模型,即假设字符各自独立的分布);$\Theta =({{\theta }_{1k}},\cdots ,{{\theta }_{wk}},\cdots ,{{\theta }_{lk}})\text{ }(k\in \Omega )$表示模体分布;${{\theta }_{wk}}$表示字符k在模体第w个位置出现的概率。期望最大化算法正是通过更新潜在的隐变量Z使得似然值最大化,主要过程分为E步和M步。
E步可以表示为:
$$Z_{ij}^{(T)}=\frac{p(X\left| {{Z}_{ij}},{{\Theta }^{(T)}} \right.)}{\sum\limits_{{{L}_{i}}-l+1}{p(X\left| {{Z}_{ij}},{{\Theta }^{(T)}} \right.)}}$$ (2) M步可以表示为:
$${{\Theta }^{(T+1)}}=\arg \max \text{E}[\log p(X,Z\left| {{\Theta }^{(T)}} \right.)]$$ (3) E步和M步重复执行多次直至收敛。此外,通过描述位点如何分布,MEME又将概率模型细分为OOPS、ZOOPS和TCM这3类。OOPS模型表示每条序列中有且只有一个模体出现,这是模体发现问题最基本的假设;ZOOPS模型表示每条序列中含有一个或零个模体;TCM模型允许一条序列中有零或多个模体出现。
-
基于MEME的不确定数据流模体发现算法的核心是如何将具有时序性、海量性、无界性、实时性、高速性和连续性等特点的数据序列合理地转换为符号序列集合。它的难点是如何对有效时间内的不确定数据流进行合理划分以及对具有不确定性的数据序列进行符号化。因此,在对不确定滑动窗口技术和SAX符号化策略进行改进和扩展的基础上,本文综合利用这两种思想的优点,提出了一种适用于不确定数据流的符号化方法。利用MEME算法对符号化的不确定数据流进行模体发现,进而解决不确定数据流模体发现问题。
根据可能世界模型[10],利用一组不确定数据流U
,假设各元组可以在离散域B中取多个规范化值[4],则该数据流可以被描述为: $$(\left\langle {{t}_{1}},{{i}_{1}},{{p}_{1}} \right\rangle ,\left\langle {{t}_{2}},{{i}_{2}},{{p}_{2}} \right\rangle ,\cdots ,\left\langle {{t}_{j}},{{i}_{j}},{{p}_{j}} \right\rangle ,\cdots )$$ (4) 式中,tj是元组到达的时刻;pj表示元组的存在概率;${{i}_{j}}\in B$。由式(4)可知,在对不确定数据流进行建模与规范化的基础上,文中首先采用滑动窗口对有效时间内的不确定数据流进行划分,然后对满足一定条件的数据进行符号化,最后执行MEME算法,进行模体发现。
-
考虑到不确定数据流具有无限性,要处理从数据出现到当前时刻的所有数据是不可能的。基于此,文献[11]提出了不确定滑动窗口的概念,其核心思想是根据一定的置信概率a使滑动窗口中存在的元组数目为w,但该方法在应用中需要进行大量的复杂概率计算。因此,本文提出了不确定滑动窗口的简化计算方法,该方法可以大幅度减少更新滑动窗口时的计算量,提高处理速度。
-
为了便于观察,不确定滑动窗口的符号说明及定义如表 1所示。
表 1 符号说明
符号名称 含义 w 某不确定数据流 w´ 滑动窗口的期望长度 a 滑动窗口的实际长度 m 置信概率 m U中最新元组的索引值 $W(U,w)$ 针对U的长度为w的滑动窗口 $\hat{W}(U,w)$ $W(U,w)$的子窗口 $|\hat{W}(U,w)|$ $\hat{W}(U,w)$中存在的元组数目 定义 1 不确定滑动窗口:滑动窗口的实际长度w´具有不确定性。因此,该窗口被定义为不确定滑动窗口,且满足:
$$\left\{ \begin{array}{*{35}{l}} \min \text{ }{w}' \\ \text{s}\text{.t}\text{.}\begin{matrix} {} & P(|\hat{W}(U,{w}')|\ge w)\ge \alpha \\ \end{matrix} \\ \end{array} \right.$$ (5) 当新元组到来时,更新滑动窗口的计算流程如下。
输入:$U,w,\alpha $
输出:$W(U,{w}',\alpha )$
$W(U,{w}',\alpha )$被赋予空集
Loop
If (U中的新元组u到达) then
$W(U,{w}',\alpha )$←$W(U,{w}',\alpha )$∪$\{u\}$
While $P(|\hat{W}(U,{w}'-1)|\ge w)\ge \alpha $do
$W(U,{w}',\alpha )$←$W(U,{w}',\alpha )$\$\{{u}'\}$
${u}'$是窗口$W(U,{w}',\alpha )$中最早的元素
End while
End if
End loop
-
从前面可以看出,不确定滑动窗口更新过程的核心是$P(|\hat{W}(U,{w}')|\ge w)\ge \alpha $的计算。基于此,根据不确定数据流中元组的存在概率,本文提出了一种不等式简化计算方法,其具体实现方法如下。
对于任意元组${{u}_{i}}$,设定当随机变量${{X}_{i}}=0$时,表示${{u}_{i}}$存在,存在概率为$1-p({{u}_{i}})$;当${{X}_{i}}=1$时,表示${{u}_{i}}$不存在,不存在概率为$p({{u}_{i}})$,即${{X}_{i}}$服从以$p({{u}_{i}})$为参数的$[0,1]$分布,因而有:
$$P(|\hat{W}(U,{w}')|\ge w)\ge \alpha \Leftrightarrow P\left( \sum\limits_{i=1}^{{{w}'}}{{{X}_{i}}}\ge w \right)\ge \alpha $$ (6) 若$Y=\sum\limits_{i=1}^{{{w}'}}{{{X}_{i}}}$,则有:
$$P\left( \sum\limits_{i=1}^{{{w}'}}{{{X}_{i}}}\ge w \right)\ge \alpha =P(Y\ge w)\ge \alpha $$ (7) 由于$P(Y=w)=\sum\limits_{A\in {{F}_{w}}}{\prod\limits_{{{u}_{i}}\in A}{p({{u}_{i}})}}\prod\limits_{{{u}_{i}}\notin A}{(1-p({{u}_{i}}))}$,因此有:
$$P(Y\ge w)=1-\sum\limits_{i=0}^{w-1}{P(Y=i)}$$ (8) 式中,${{F}_{w}}$表示在长度为${w}'$的滑动窗口中出现w个有效元组的所有可能组合;A是${{F}_{w}}$中的一种组合方式。为了简化计算,文中采用均值为$\mu =\text{E}[Y]=$ $\sum\limits_{i=1}^{{{w}'}}{p({{u}_{i}})}$,标准差$\sigma =\sqrt{\text{Var}(Y)}=\sum\limits_{i=1}^{{{w}'}}{p({{u}_{i}})}\times $$(1-p({{u}_{i}}))$的高斯近似[12]来计算该概率,即满足:
$$P\left( Y\ge w \right)\approx 1-\Phi \left( \frac{w+0.5-\mu }{\sigma } \right)$$ (9) -
SAX[13-14]是一种针对一元时间序列符号化的方法,可以用于聚类、分类、索引和异常检测等。为了将该方法拓展到不确定数据流,确保每个滑动窗口中存在元组的数目差别不大,本文将SAX的符号化策略改进为以下3个步骤。
1) 根据2.1节的分析,在长度为${w}'$的滑动窗口中,以置信概率a抽取该窗口中存在的w个元组,用向量$\mathbf{D}={{d}_{1}},{{d}_{2}},\cdots ,{{d}_{w}}$进行表示;
2) PAA过程,即用一小段序列的平均值代表该序列;
3) 符号化,即用不同的符号表示每小段的平均值。
上述步骤中,步骤1)的目的是为了确保每个滑动窗口中存在元组的数目近似为w。步骤2)是将原本的w维时间序列降为m维,即用一组向量$\mathbf{\bar{D}}={{\bar{d}}_{1}},{{\bar{d}}_{2}},\cdots ,{{\bar{d}}_{m}}$表示原来的时间序列。其中,第i个元素的计算公式为:
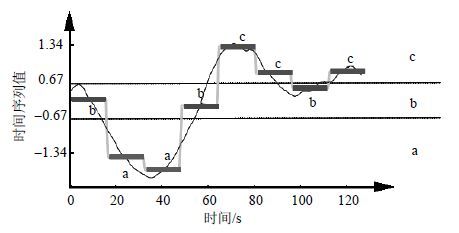
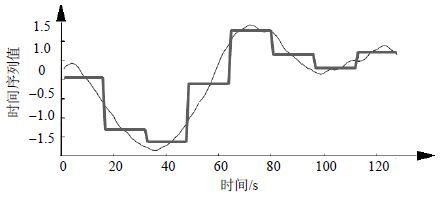
$${{\bar{d}}_{i}}=\frac{m}{w}\sum\limits_{j=\frac{w}{m}(i-1)+1}^{\frac{w}{m}i}{{{d}_{j}}}$$ (10) 如图 1所示,采用PAA过程后,一个128维的时间序列(浅线条)可以用的8维时间序列(粗线条)进行表示。

图 1 PAA过程示例
步骤3)的目的是为了选取合适的字符集进行符号化,其关键是分界点的选取,文献[14]中给出了常用的分界点值及所需字符集的数目,如表 2所示。
表 2 常用的分界点值及所需字符集的数目
$\beta _{i}^{\alpha }$ 3 4 5 6 7 8 9 10 ${{\beta }_{1}}$ -0.43 -0.67 -0.84 -0.97 -1.07 -1.15 -1.22 -1.28 ${{\beta }_{2}}$ 0.43 0 -0.25 -0.43 -0.57 -0.67 -0.76 -0.84 ${{\beta }_{3}}$ 0.67 0.25 0 -0.18 -0.32 -0.43 -0.52 ${{\beta }_{4}}$ 0.84 0.43 0.18 0 -0.14 -0.25 ${{\beta }_{5}}$ 0.97 0.57 0.32 0.14 0 ${{\beta }_{6}}$ 1.07 0.67 0.43 0.25 ${{\beta }_{7}}$ 1.15 0.76 0.52 ${{\beta }_{8}}$ 1.22 0.84 ${{\beta }_{0}}$ 1.28 对于图 1中所示的时间序列,当用3个字符进行表示时,该序列的符号化情况如图 2所示,符号化结果为baabccbc。

图 2 时间序列的符号化表示
-
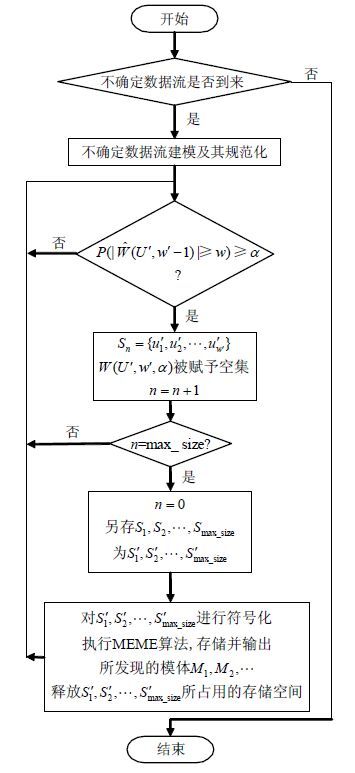
综合2.1节的方法和2.2节的改进策略,本节设计了基于MEME算法的不确定数据流模体发现算法,该算法可以对任意一组不确定数据流进行模体发现,流程图如图 3所示。

图 3 算法流程图
具体算法描述如下。
输入:$U,w,\alpha ,\max \_\text{size}$
输出:$M=\{{{M}_{1}},{{M}_{2}},\cdots \}$//发现的模体集合
1) 初始化参数$w,\alpha ,\max \_\text{size}$,设置$n=0$;
2) 判断不确定数据流是否到来,是转步骤3),
否则算法结束;
3) 对U进行建模及规范化,得到:
${U}'=\{{{{u}'}_{1}},{{{u}'}_{2}},\cdots \}=\{\left\langle {{t}_{1}},{{i}_{1}},{{p}_{1}} \right\rangle ,\left\langle {{t}_{2}},{{i}_{2}},{{p}_{2}} \right\rangle ,\cdots \}$;
4) 不确定滑动窗口的更新及数据缓存:
LOOP
If (${U}'$中的新元组${u}'$到达) then
$W({U}',{w}',\alpha )$←$W({U}',{w}',\alpha )$∪$\{{u}'\}$;
If $P(|\hat{W}\left( {U}',{w}'-1 \right)|\ge w)\ge \alpha $then
${{S}_{n}}=\{{{{u}'}_{1}},{{{u}'}_{2}},\cdots ,{{{u}'}_{{{w}'}}}\}$;
$W({U}',{w}',\alpha )$被赋予空集;
$n=n+1$;
If $n=\max \_\text{size}$then
$n=0$;
另存${{S}_{1}},{{S}_{2}},\cdots ,{{S}_{\text{max }\!\!\_\!\!\text{ size}}}$为
${{{S}'}_{1}},{{{S}'}_{2}},\cdots ,{{{S}'}_{\max \_\text{size}}}$,
转步骤5;
Else
continue;
End if
Else
continue;
End if
End if
5) 对序列集${{{S}'}_{1}},{{{S}'}_{2}},\cdots ,{{{S}'}_{\text{max }\!\!\_\!\!\text{ size}}}$进行符号化;
6) 执行MEME算法,存储并输出所发现的模体
${{M}_{1}},{{M}_{2}},\cdots $;
7) 释放${{{S}'}_{1}},{{{S}'}_{2}},\cdots ,{{{S}'}_{\text{max }\!\!\_\!\!\text{ size}}}$所占用的存储空间;
End loop
综上所述,由于采用了并行计算和不确定滑动窗口简化计算方法,文中算法计算时间较短,运算效率高。
-
防空反导情报传感器网络是军事中产生不确定数据流的典型应用,本文对该网络中产生的一组距离不确定数据流进行模体发现。
1) 设置窗口中有效元组数目w=100,置信概率a=0.95,n=0,$\max \_size=3$。
2) 用可能世界模型对距离不确定数据流进行建模,再通过$(x-\mu )/\sigma $对其规范化后,其部分数据如表 3所示。
表 3 部分规范化不确定数据流示例
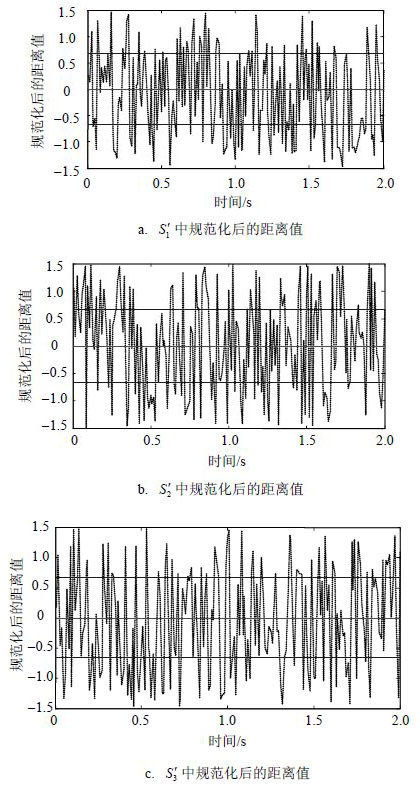
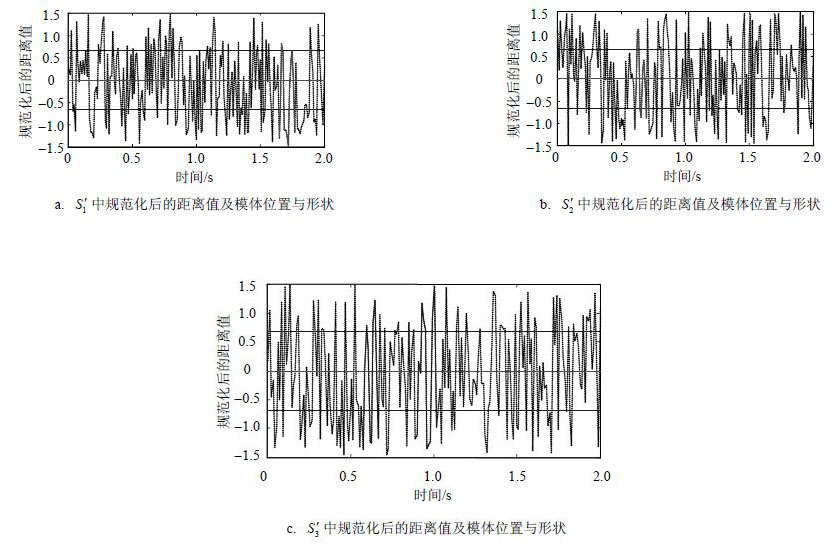
时间 规范化后的距离值 存在概率 t1 0.24675 0.5 t2 0.12222 0.9 t3 1.10982 0 t4 -0.7056 0.6 $\vdots $ $\vdots $ $\vdots $ 3) 继续采集诸如表 3中的数据,根据存在概率判断是否满足不等式$P(|\hat{W}({U}',{w}'-1)|\ge w)\ge \alpha $,直到$n=\max \_\text{size}$,得到${{{S}'}_{1}},{{{S}'}_{2}},\cdots ,{{{S}'}_{\text{max }\!\!\_\!\!\text{ size}}}$(具体如图 4所示,黑点表示元组存在,白点表示元组不存在),返回初始状态。

图 4 ${{{S}'}_{1}},{{{S}'}_{2}},{{{S}'}_{3}}$的图形表示
4) 对${{{S}'}_{1}},{{{S}'}_{2}},\cdots ,$${{{S}'}_{\max \text{ }\!\!\_\!\!\text{ size}}}$进行符号化,字符集采用 $\{A,G,C,T\}$,具体见2.2节的分析。根据图 2中分界点值的划设规范,确立3个分界点:-0.67、0和0.67,设置$m=2$,得到符号序列集合如表 4所示。
表 4 ${{{S}'}_{1}},{{{S}'}_{2}},{{{S}'}_{3}}$符号化结果
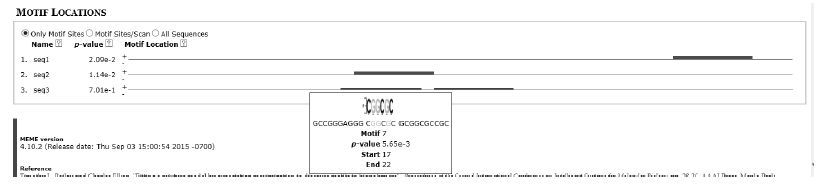
编号 上述三条综合指标序列所对应的字符串 seq1 CCCCAGTGCCGGCGGCCCCCCCGGAGGCCCGGGGGGCCGGCGACAAACGG seq2 TTCCCCCTGCGAAGCCGGACCTAGGCGGCCGGGTCGCGCTACTCGCGTCG seq3 CGCCCGGCCGGGAGGGCGGCGCGCGGCGCCGCACCCGGCCCGGCCGCCCC 5) 根据MEME算法,采用DNA序列分析工具,对表 4中的符号序列集合进行模体发现,其结果如图 6所示。
由图 5可知,在表 3所示规范化后的距离值中,共发现了两种模体,分别由两种粗细的线条进行表示。进而根据所发现模体的排序及位置(如图 5中方框内所示),可以反推出原数据中模体的位置及形状,如图 6所示。

图 5 模体发现结果

图 6 模体在原数据中的位置及形状
从图 6可发现,所发现模体在形状上具有一定的相似性,满足“模体”在时间序列中的定义,也验证了文中算法的可行性。
6) MEME算法执行完毕后,释放出${{{S}'}_{1}},{{{S}'}_{2}},{{{S}'}_{3}}$所占用的存储空间,并存储所发现的模体。
-
通过3.1节的案例分析,文中算法的可行性得到验证。为进一步分析文中算法的有效性,本节设计了两个实验来进行验证。
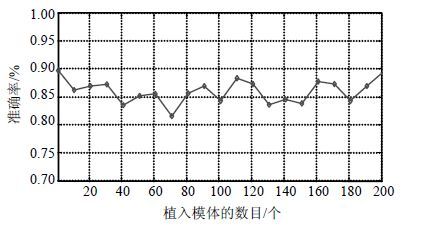
实验1:若对不确定数据流进行模体植入,当植入模体的数目依次为$x=1,10,20,\cdots ,200$时,本文算法所发现模体的准确率如图 7所示。

图 7 本文算法所发现模体的准确率
从图 7可知,在不同的模体植入情况下,文中算法的模体发现准确率在0.8~0.9之间,稳定性强,验证了该算法的有效性。
实验2:考虑到目前还没有关于不确定数据流模体发现的相关算法,文中设定不确定数据流中元组的存在概率都为1,设置滑动窗口长度为w=200。此时假设滑动窗口不更新,将不确定数据流转换为确定的时间序列。在相同的3个白噪声数据集上依次植入随机数目的模体,得到3组实验数据集,将文中算法与文献[15-16]提出的MK和MOEN算法进行比较,其模体发现准确率结果如表 5所示。
表 5 算法准确率比较
算法 数据集 数据集1 数据集2 数据集3 MK 0.87 0.85 0.82 MOEN 0.90 0.86 0.85 本文算法 0.91 0.89 0.88 从表 5可知,文中算法的模体发现准确率高于MK和MOEN算法,进一步验证了该算法的有效性。
-
本文在传统时间序列模体发现的基础上加入了不确定性和动态性,建立起了序列数据挖掘和不确定数据流挖掘之间的桥梁,并采用生物信息学算法完成了对不确定数据流的模体发现。
1) 提出了基于MEME的不确定数据流模体发现算法,根据防空反导传感器网络对距离的实时测量数据进行模体发现,验证了其可行性;
2) 通过多次模体植入实验和算法性能对比实验,验证了本文算法的有效性。仿真分析表明,在同等仿真条件下,本文算法优于MK和MOEN算法;
3) 该文部分内容属于探索性的研究,相关理论和研究可以对不确定数据流的模体发现提供理论和应用支撑;
4) 本文所建立的不确定数据流是基于离散属性值,对具有连续属性的不确定数据流进行模体发现是本文下一步的研究内容。
New Motif Discovery Algorithm for Uncertain Data Stream
-
摘要: 借鉴生物信息学中序列模式发现思想,提出了基于MEME(multiple expectation-maximization for motif elicitation)的不确定数据流模体发现算法。该算法根据不确定数据流的特点,设计了不确定滑动窗口的简化计算方法,改进了SAX(symbolic aggregate approximation)的符号化策略,用防空反导情报传感器网络中的一组不确定数据流验证了其可行性,通过植入不同数目模体的方法测试了其准确性,并在元组存在概率为1的条件下与已有算法进行比较,验证其有效性。Abstract: A new MEME-based motif discovery algorithm for uncertain data stream is proposed by using the idea of sequential pattern discovery in bioinformatics. According to features of uncertain data stream, the new algorithm designs a simplified calculation method for uncertain sliding window and modifies the SAX symbolic strategy. The feasibility of the proposed algorithm is verified by one uncertain test data stream from air and missile defense sensors. And its accuracy is measured through planting different number motifs. Furthermore, the proposed algorithm is validated by comparing with existing algorithms in the condition that the existence probability of tuples is set to 1.
-
Key words:
- MEME algorithm /
- motif discovery /
- SAX /
- uncertain data stream /
- uncertain sliding window
-
表 1 符号说明
符号名称 含义 w 某不确定数据流 w´ 滑动窗口的期望长度 a 滑动窗口的实际长度 m 置信概率 m U中最新元组的索引值 $W(U,w)$ 针对U的长度为w的滑动窗口 $\hat{W}(U,w)$ $W(U,w)$的子窗口 $|\hat{W}(U,w)|$ $\hat{W}(U,w)$中存在的元组数目  下载: 导出CSV
下载: 导出CSV
表 2 常用的分界点值及所需字符集的数目
$\beta _{i}^{\alpha }$ 3 4 5 6 7 8 9 10 ${{\beta }_{1}}$ -0.43 -0.67 -0.84 -0.97 -1.07 -1.15 -1.22 -1.28 ${{\beta }_{2}}$ 0.43 0 -0.25 -0.43 -0.57 -0.67 -0.76 -0.84 ${{\beta }_{3}}$ 0.67 0.25 0 -0.18 -0.32 -0.43 -0.52 ${{\beta }_{4}}$ 0.84 0.43 0.18 0 -0.14 -0.25 ${{\beta }_{5}}$ 0.97 0.57 0.32 0.14 0 ${{\beta }_{6}}$ 1.07 0.67 0.43 0.25 ${{\beta }_{7}}$ 1.15 0.76 0.52 ${{\beta }_{8}}$ 1.22 0.84 ${{\beta }_{0}}$ 1.28
下载: 导出CSV
表 3 部分规范化不确定数据流示例
时间 规范化后的距离值 存在概率 t1 0.24675 0.5 t2 0.12222 0.9 t3 1.10982 0 t4 -0.7056 0.6 $\vdots $ $\vdots $ $\vdots $
下载: 导出CSV
表 4 ${{{S}'}_{1}},{{{S}'}_{2}},{{{S}'}_{3}}$符号化结果
编号 上述三条综合指标序列所对应的字符串 seq1 CCCCAGTGCCGGCGGCCCCCCCGGAGGCCCGGGGGGCCGGCGACAAACGG seq2 TTCCCCCTGCGAAGCCGGACCTAGGCGGCCGGGTCGCGCTACTCGCGTCG seq3 CGCCCGGCCGGGAGGGCGGCGCGCGGCGCCGCACCCGGCCCGGCCGCCCC
下载: 导出CSV
表 5 算法准确率比较
算法 数据集 数据集1 数据集2 数据集3 MK 0.87 0.85 0.82 MOEN 0.90 0.86 0.85 本文算法 0.91 0.89 0.88
下载: 导出CSV
-
[1] 梁春泉. 不确定数据流分类算法研究[D]. 西安:西北农林科技大学, 2014. http://cn.bing.com/academic/profile?id=abdfdb48dde46c8057972be9be946bd0&encoded=0&v=paper_preview&mkt=zh-cn LIANG Chun-quan. Classification algorithm based on uncertain data stream[D]. Xi'an:Northwest Agriculture and Forestry University, 2014. http://cn.bing.com/academic/profile?id=abdfdb48dde46c8057972be9be946bd0&encoded=0&v=paper_preview&mkt=zh-cn [2] THANH T L T, PENG L P, DIAO Y L, et al. CLARO:Modeling and processing uncertain data streams[J]. VLDB Journal, 2012, 21:651-676. doi: 10.1007/s00778-011-0261-7 [3] JIN C Q, JEFFREY X Y, ZHOU A Y, et al. Efficient clustering of uncertain data streams[J]. Knowl Inf Syst, 2014, 40:509-539. doi: 10.1007/s10115-013-0657-3 [4] 朱跃龙, 彭力, 李士进, 等. 水文时间序列模体挖掘[J]. 水利学报, 2012, 43(12):1422-1430. http://www.cnki.com.cn/Article/CJFDTOTAL-SLXB201212007.htm ZHU Yue-long, PENG Li, LI Shi-jin, et al. Research on hydrological time series mining[J]. Hydraulic Engineering, 2012, 43(12):1422-1430. http://www.cnki.com.cn/Article/CJFDTOTAL-SLXB201212007.htm [5] PUNEET A, GAUTAM S, SARMIMALA S, et al. Efficiently discovering frequent motifs in large-scale sensor data[EB/OL].[2015-06-30]. https://www.researchgate.net/publication/270454309_Efficiently_Discovering_Frequent_Motifs_in_Large-scale_Sensor_Data. [6] 邹力鹍, 张其善. 基于多最小支持度的加权关联规则挖掘算法[J]. 北京航空航天大学学报, 2007, 33(5):590-593. http://www.cnki.com.cn/Article/CJFDTOTAL-BJHK200705020.htm ZOU Li-pu, ZHANG Qi-shan. Algorithm of weighted association rules mining with multiple minimum supports[J]. Beijing University of Aeronautics and Astronautics Technology, 2007, 33(5):590-593. http://www.cnki.com.cn/Article/CJFDTOTAL-BJHK200705020.htm [7] 张懿璞, 霍红卫, 于强, 等. 用于转录因子结合位点识别的定位投影求精算法[J]. 计算机学报, 2013, 36(12):2545-2559. http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201312015.htm ZHANG Yi-pu, HUO Hong-wei, YU Qiang, et al. A novel fixed-position projection refinement algorithm for TFBS Identification[J]. Journal of Computers, 2013, 36(12):2545-2559. http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201312015.htm [8] TIMOTHY L B. Dreme:Motif discovery in transcription factor ChIP-seq data[J]. Original Paper, 2011, 17(12):1653-1659. http://cn.bing.com/academic/profile?id=1711bf89a73a2521ce6940c978692280&encoded=0&v=paper_preview&mkt=zh-cn [9] DANIEL Q, XIE X H. Extreme:an online EM algorithm for motif discovery[J]. Original Paper, 2014, 30(12):1667-1673. http://cn.bing.com/academic/profile?id=e398b43a11bd9a86c4418d3ef756b20b&encoded=0&v=paper_preview&mkt=zh-cn [10] 李明, 张维明. 不确定数据流多维建模方法[J]. 国防科技大学学报, 2014, 36(5):174-179. http://www.cnki.com.cn/Article/CJFDTOTAL-GFKJ201405029.htm LI Ming, ZHANG Wei-ming. Multi-dimensional modeling method of uncertain data stream[J]. Journal of the National Defense University, 2014, 36(5):174-179. http://www.cnki.com.cn/Article/CJFDTOTAL-GFKJ201405029.htm [11] MICHELE D. Modeling and querying data series and data streams with uncertainty[D]. The Autonomous Province of Trento:Universita` degli Studi di Trento, 2014, [12] HONG Y. On computing the distribution function for the sum of independent and non-identical random indicators[EB/OL].[2015-10-10]. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.220.8708. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.220.8708&rep=rep1&type=pdf [13] 曲文龙, 张克君, 杨炳儒, 等. 基于奇异事件特征聚类的时间序列符号化方法[J]. 系统工程与电子技术, 2006, 28(8):1131-1134. http://www.cnki.com.cn/Article/CJFDTOTAL-XTYD200608004.htm QU Wen-long, ZHANG Ke-jun, YANG Bing-ru, et al. Time series symbolization based on singular event feature clustering[J]. Systems Engineering and Electronics, 2006, 28(8):1131-1134. http://www.cnki.com.cn/Article/CJFDTOTAL-XTYD200608004.htm [14] LIN J, KENOGH E J, WEI D L, et al. Experiencing SAX:a novel symbolic representation of time series[J]. Data Min Knowl Disc, 2007, 15:107-144. doi: 10.1007/s10618-007-0064-z [15] MUEEN A, KEOGH E J, ZHU Q, et al. Exact discovery of time series motif[C]//Society for Industrial and Applied Mathematics Conf. on Data Mining.[S.l.]:Springer, 2009. [16] ABDULLAH M, NIKAN C. Enumeration of time series motifs of all lengths[J]. Knowl Inf Syst, 2015, 45:105-132. doi: 10.1007/s10115-014-0793-4 -

 点击查看大图
点击查看大图
图(7) / 表(5)
计量
- 文章访问数: 4142
- HTML全文浏览量: 1265
- PDF下载量: 68
- 被引次数: 0
