 ISSN
ISSN 


-
随着社交平台的快速发展,微博凭借其短文本、低门槛、实时性和传播迅速等特性吸引了大量忠实用户。信息在微博上快速传播与分享,但谣言也大量蔓延[1-2]。微博网络的复杂性,使谣言信息在不同群体中通过多级节点大面积扩散,频繁汇聚转发增加了其表面上的可信度。微博平台每天发表大量微博,如何提高判定其可信度的准确性成为亟待解决的问题。微博可信度研究在信息过滤、舆情监控和信息传播引导过程中发挥着积极的作用,且有助于微博社会化推荐、微博搜索引擎等方面的应用研究[3]。
目前针对微博信息的可信研究,主要根据用户行为特点进行特征分析从而设计分类算法。基于特征分类方法对微博信任评估具有较好效果,文献[1]通过2010年智利地震研究了Twitter用户发布博文的特征和信息传播的特点,发现谣言与新闻的传播方式不同,谣言在Twitter社区的讨论会逐渐被怀疑。文献[2]基于推文和转发微博行为特征 (内容、用户、话题和传播特征) 提出了自动评估可信性的方法。文献[4]通过大量调查发现,用户认为可信的与确切可信的信息存在不同的特征,并对不同特征 (用户特征、话题信息、博文内容) 进行比较实验。文献[5]为解决谣言探测问题提出了3种特征:基于内容、基于网络和正确定义谣言的微博具体模型。文献[6]通过半监督的推文可信度排序模型 (TweetCred) 来实时评估其信任值。
辩论是智能主体间为了消除信念不一致的一种基于言语的交互行为。辩论模型是对辩论推演过程的形式化描述,其研究内容包括辩论空间构造以及辩论结果生成算法[7]。辩论模型中影响力较大的有抽象辩论框架[8],Toulmin模型[9]IBIS (issue-based information system) 模型[10]和基于以上扩展的模型[11-12]。文献[7]基于相关辩论模型的应用方面对辩论建模时考虑了不确定信息处理因素,并提出一种基于可信度的辩论模型。
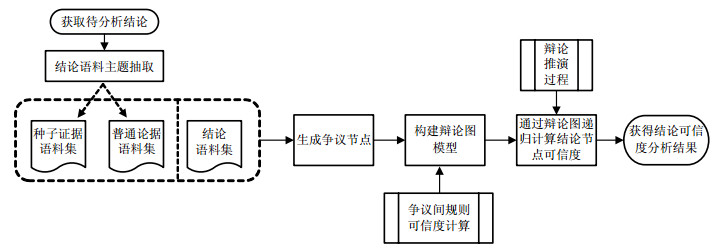
针对微博信息量大、不确定和混杂特性,特征提取方法需大量人工标注,且都是静态数据的特征统计[13],缺乏理论依据的推断与支持,故本文提出基于辩论图的微博信任评估模型,以辩论为基本思想,以争议间的支持或攻击强度为权值来构建有向带权图,且递归辩论推演得到信息可信度。该模型更直观地体现出判别可信的过程及辩论间的推演关系。
-
辩论图框架主要描述辩论结构间的关系。本文从争议节点、争议间的关系和最终结论出发构建辩论图模型。争议节点和结论为辩论图中的节点,争议间的主题情感和潜在逻辑关系为规则可信度,并将规则可信度设置为图中边上的权值。最后递归进行辩论推演,直观展示出可信度的判别过程。
-
辩论框架定义主要延用文献[7]的表示。争议为一个二元组$A=(H, h)$,分为前提和结论两个部分。其中,$H={h_1}, {h_2} \cdots, {h_n}\} $为陈述子集,代表争议的规则前提。h是一个陈述,为争议结论。由争议前提得到结论,记为$H \Rightarrow h$。前提H通过争议得到结论h的规则可信度表示为${\rm{CF}}(H, h)$。若一个争议A的结论是另一个争议B的前提,则称为争议A对争议B的对话,记为$\left\langle {A, B} \right\rangle $。本模型通过争议间的对话来实现图的构建。
证据表示为E,其可信度记为CF (E),取值范围为[-1, 1]。若可信度大于0,表明此证据可信,反之则不可信。证据分为种子证据Seed和过渡证据Tran,种子证据为人工选取,由专家在微博平台选取权威信息,并赋予可信度。通过种子证据的推导和合成来获得结论的确定性,并把相关的结论作为过渡证据,递归进行判别,最后得到信息的可信度。
辩论图是由对话、证据可信度CF (E) 和规则可信度${\rm{CF}}(H, h)$构成。对话形成有向带权图,图中顶点代表争议中的前提证据和结论,图中边上权值为前提与结论间的规则可信度。辩论图中的每一个子图为某些争议过程,形象具体地表现出争议间的内部结构和辩论推演过程,用户可直观感受可信判别过程。
-
辩论图模型中节点分为3种:种子证据节点SNode、过渡证据节点TNode和结论节点CNode。种子证据集Seeds由领域专家分析结论节点CNode的主题,并从微博上选取该话题权威度高的信息,赋予对应的可信度值。
过渡证据节点TNode的产生借鉴随机游走模型思想。先计算结论节点CNode与种子证据的规则可信度${\rm{CF}}({\rm{SNode}}, {\rm{CNode}})$,由于规则可信度值有正负之分,故选取法则:由${\rm{CF}}({\rm{SNode}}, {\rm{CNode}})$的绝对值是否大于阈值${\rm{CF}}({\rm{SNode}}, {\rm{CNode}})$来决定结论节点${\rm{CNode}}$与种子证据是否有关联。如果$|{\rm{CF}}({\rm{SNode}}, {\rm{CNode}})| > \omega $,根据文献[7]中可信度的计算公式${\rm{CF}}({\rm{CNode}})={\rm{CF}}({\rm{SNode}})$${\rm{CF}}({\rm{SNode}}, {\rm{CNode}})$直接得到结论的可信度。否则,就构造对应话题语料论据库${\rm{ArgL}}$,赋予一个空的争议节点C,从论据库中选择一个陈述s作为争议C的结论,并由该结论去选取种子证据集${\rm{Seeds}}$中的陈述集Set作为前提,并判断$\left| {{\rm{CF}}(Set, s)} \right|$是否大于阈值$\omega $。若争议C存在,计算出结论的可信度值,并作为过渡证据。依此产生争议节点,并再次判别结论与证据间的规则可信度值是否大于$\omega $,依此递归进行。需判别可信度的信息作为结论节点,从种子证据和过渡证据推演出结论节点的可信度值。因此,争议节点产生算法如下:
算法1:判别结论与证据间的联系
输入:结论${\rm{CNode}}$、证据集Evidences
输出:争议集
ComRelation_Judge (Evidences, CNode){
产生新争议节点$C=(H, {\rm{CNode}})$
FOR EACH证据E在证据集${\rm{Evidences}}$中{
IF (|RuleCentainty_Calulate ()| > $\omega $){
//判别证据与结论的规则可信度是否大于$\omega $
把证据E作为争议前提H中的一个子集}}
IF (H!=NULL){
形成争议$C=(H, {\rm{CNode}})$
RETURN H}
ELSE RETURN NULL}
算法2:争议节点产生
输入:结论节点${\rm{CNode}}$
输出:争议节点集
获得结论节点${\rm{CNode}}$的主题T
专家选取种子证据集Seeds且赋可信度值
获得话题T语料论据库ArgL
ArgumentNodes_Creat (Seeds, ArgL){
IF (ComRelate_Judge (Seeds, CNode)=NULL){
//种子节点和结论节点不存在关联
FOR EACH在ArgL中的陈述s{
//论据库ArgL中选取陈述s为争议C的结论
产生新空争议节点$C=(H, s)$
FOR EACH在Seeds中的陈述e{
//种子证据集中选取e作为前提
IF (|RuleCentainty_Calulate ()| > $\omega $){
e为前提H的子集,s为过渡证据${\rm{TNode}}$
语料库${\rm{ArgL}}$中去除陈述s
IF (ComRelation_Judge (s, ${\rm{ArgL}}$)=NULL){
//判别证据S与结论${\rm{CNode}}$是否存在关联
Continue
}ELSE{
Return ${\rm{CF}}(e, s), {\rm{CF}}(s, {\rm{CNode}})$}}}}
形成争议$C=(H, s)$
过渡证据H和${\rm{Seeds}}$作为证据集${\rm{Evidences}}$
ArgumentNodes_Creat (${\rm{Evidences}}$, ${\rm{ArgL}}$)
} ELSE {
Return ${\rm{CF}}(H, {\rm{CNode}})$}}
-
争议前提对结论存在着支持或攻击关系,此关系由规则可信度进行强度量化。规则可信度计算分为:争议间的主题情感相关度${\rm{Rel}}$与潜在逻辑关系${\rm{Pot}}$。主题情感相关度验证争议存在是否合理,前提与结论是否存在主题和情感相关。潜在逻辑关系包含蕴涵关系与矛盾关系,进一步考核争议内部是否真实相关,并体现出争议间支持或攻击关系强度。
-
争议间主题情感相关度${\rm{Rel}}$,主要用于判断争议存在的合理性,争议间的主题相关表示为${\rm{Theme}}$,情感记为${\rm{Sen}}$。此分析过程为验证主题是否相关,和整体情感状况,情感是否一致或相反。若它们的主题情感度值相差在可控范围内,则说明争议存在的合理性,否则该争议不能对本辩论框架提供论据,无存在的必要性。
微博的短文本性,故陈述也为短文本。本文模型采用潜在的狄利克雷分布 (latent Dirichlet allocation, LDA)[14]和JS散度 (Jensen-Shannon divergence) 来计算争议中主题是否相关。根据LDA模型获得对应的争议主题概率分布$PH=\{ P ({h_1}), \cdots, $$P ({h_i}), \cdots, P ({h_n})\} $和$P (h)$,其中$P ({h_i})=\{ {h_i}(1), \cdots, {h_i}(j), $$\cdots, {h_i}(N)\} $,$P (h)=\{ h (1), \cdots, $$h (j), \cdots, h (N)\} $,N为LDA模型中的主题数,${h_i}(j)$和$h (j)$分别为第i前提和结论的第j个主题概率。则第i个前提$h (j)$与结论$h$的主题相似度计算为:
$$ J({h_i}, h) = \frac{1}{2}(D({h_i}||h) + D(h||{h_i})) $$ (1) $$ D({h_i}||h) = \sum\limits_{j \in N} {{h_i}(j)\log \frac{{{h_i}(j)}}{{h(j)}}} $$ (2) $$ D(h||{h_i}) = \sum\limits_{j \in N} {h(j)\log \frac{{h(j)}}{{{h_i}(j)}}} $$ (3) 式中,$J ({h_i}, h)$值在[0, 1]间,该值越小,说明前提${h_i}$与结论$h$的主题越相关,若$J ({h_i}, h)$在一定主题相关度误差$\lambda $内,即$J ({h_i}, h) < \lambda $,则保留该前提,不然放弃此前提。而$\lambda $由实验效果对比进行设定。主题相关度越高,规则可信度也越高,初始规则可信度${\rm{CF}}({h_i}, h)$计算为:
$$ {\rm{CF}}({h_i}, h) = \left\{ {\begin{array}{*{20}{c}} {1 - J({h_i}, h)}&{{\rm{ }}J({h_i}, h) < \lambda }\\ 0&{{\rm{ }}J({h_i}, h) \ge \lambda } \end{array}} \right. $$ (4) 争议间的情感分为两种,正极情感${\rm{Pos}}$和负极情感${\rm{Neg}}$。若规则前提$H$和结论$h$的主题情感一致,则为正极情感,说明前提对结论的支持作用,若主题情感相反,则为负极情感,体现前提对结论的攻击性。可信度判别信息为短文本语料,根据文献[15]提出结合TF-IDF与方差统计的多分类特征抽取的计算方法,对争议进行情感分析。
情感极性分析可以验证规则前提对结论是支持或攻击。此时,规则可信度随着情感分析而改变,若争议间情感为正极,规则可信度${\rm{CF}}({h_i}, h)$为正值,体现支持作用。若为负极,则${\rm{CF}}({h_i}, h)$为负值,表明攻击作用。争议前提${h_i}$的情感分析表示为${\rm{Sen}}({h_i})$。其变化如式 (5) 所示:
$$ {\rm{CF}}({h_i}, h) = \left\{ {\begin{array}{*{20}{c}} {{\rm{CF}}({h_i}, h)}&{{\rm{Sen}}({h_i}){\rm{ is Pos}}}\\ { - {\rm{CF}}({h_i}, h)}&{{\rm{ Sen}}({h_i}){\rm{ is Neg}}} \end{array}} \right. $$ (5) -
争议的潜在逻辑关系${\rm{Pot}}$分析是必要的,通过主题情感分析得到的关联情况不一定可靠,可能存在虚假相关的情况。由于争议具有支持和攻击功能,故潜在逻辑关系分为蕴涵关系${\rm{Entail}}$和矛盾关系${\rm{Contra}}$。若该争议间的潜在逻辑关系为蕴涵关系,则说明规则前提对结论是推断的,若潜在逻辑关系为矛盾关系,则说明规则前提对结论是反驳的。潜在逻辑关系的分析进一步体现出争议间的本质,对于辩论效果会更加准确高效。
前提${h_i}$和结论h的潜在逻辑关系分析为两步:蕴涵关系和矛盾关系判别。对争议间的蕴涵关系根据文献[16]提出的推理模型,推断争议间是否存在蕴涵关系,并得到蕴涵关系存在于争议间的概率,即为前提对结论的防卫强度${\rm{Des}}$。依据文献[17]的基于语义规则识别争议间的矛盾关系,把优化分类结果的概率值作为争议间的攻击强度${\rm{Ats}}$。经过主题情感相关度判别后,规则可信度更新为${\rm{CF}}({h_i}, h)$,逻辑潜在关系分析后,争议间的规则可信度再次进行更新,更新过程如下:
$$ {\rm{CF}}({h_i}, h) = \left\{ {\begin{array}{*{20}{c}} {{\rm{CF}}({h_i}, h) \times {\rm{Ats}}}&{{\rm{Pot(}}{h_i}{\rm{) is Entail}}}\\ {{\rm{CF}}({h_i}, h) \times {\rm{Des}}}&{{\rm{ Pot(}}{h_i}{\rm{) is Contra}}} \end{array}} \right. $$ (6) 主题情感和潜在逻辑关系的综合值作为辩论图的权值,展示出争议间的防卫和攻击强度。规则可信度计算描述如下:
算法3:规则可信度算法
输入:争议间各节点的主题概率值
输出:争议间的规则可信度
RuleCentainty_Calulate (){
h的主题概率分布$P (h)=\{ h (1), h (2), \cdots, h (N)\} $
//h为争议结论,N为LDA模型中主题数
FOR EACH ${h_i}$in H {
//H为争议前提,${h_i}$为第i个前提
${h_i}$的主题概率分布$P ({h_i})=\{ {h_i}(1), {h_i}(2), \cdots, $
${h_i}(N)\} $
获得$J ({h_i}, h)$
IF$J ({h_i}, h) < \lambda ${
情感值${\rm{Sen}}({h_i}, h)$和潜在逻辑关系${\rm{Pot}}({h_i}, h)$
通过式 (4)~(6) 更新${\rm{CF}}({h_i}, h)$
RETURN ${\rm{CF}}({h_i}, h)$}}}
-
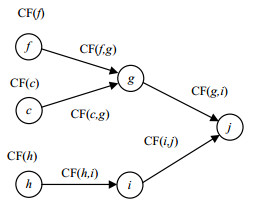
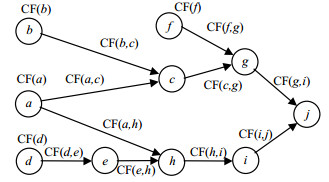
辩论图中,争议的规则前提和结论作为节点,规则可信度为它们间的联系边,通过以上的准备工作,对辩论图进行举例构建。假设有如下争议$A=\{ \{ a, b\}, c\}, $$B=\{ \{ d\}, e\}, $$C=\{ \{ c, f\}, g\}, $$D=\{ \{ a, e\}, h\} $, $E=\{ \{ h\}, i\}, $$F=\{ \{ g, i\}, j\} $,辩论框架由6个争议组合,对话集有$ < A, C >, < B, D >, $$ < C, F >, $$ < D, E > $$ < E, F > $。辩论图的初始构造如图 1所示。

图 1 辩论图初始示例
种子证据$a, b, d, f$且赋可信度${\rm{CF}}(a), {\rm{CF}}(b), $${\rm{CF}}(d), {\rm{CF}}(f)$,争议间规则可信度分别作为辩论图中对应边上的权值,并对图进行递归简化且获得结果。其算法如下:
算法4:辩论图推演算法
输入:争议集
输出:递归推演的争议集和相关节点的可信度
ArgumentGraph_Deduce (Args){
FOR EACH node in Args{
//node为争议节点前提,Args为争议
IF node没有前提且可信度${\rm{CF}}({\rm{node}})${
RuleCentainty_Calulate ()
//计算争议间的规则可信度
根据文献[1]中争议结论可信度计算公式获得前提${h_i}$推理结论h的规则可信度${\rm{CF}}({h_i} \Rightarrow h)={\rm{CF}}({h_i}){\rm{CF}}({h_i}, h)$
结论h的可信度${\rm{CF}}(h)=\frac{{\sum\limits_{i=1}^k {{\rm{CF}}({h_i} \Rightarrow h)} }}{k}$
移除前提${h_i}$与结论h的边
F node is conclusion{
Return ${\rm{CF}}({\rm{node}})$}
ArgumentGraph_Deduce (h为前提的争议)
}ELSE {
ArgumentGraph_Deduce (node为结论的争议)}}}
对于不同争议的评价算法,分别根据文献[7]中对争议结论可信度计算、可信度合成、可信度传递情况来计算。辩论图 1经争议A、B、D演化后得到结论$c, e, h$的可信度度值${\rm{CF}}(c), {\rm{CF}}(e), {\rm{CF}}(h)$,又因结论$c, h$为下一个争议的前提,故辩论推演过程如图 2所示。

图 2 简化后的辩论图
-
为体现辩论图模型对微博可信度评估的影响,实验总体设计分为以下3个部分:1) 实验数据准备及预处理工作;2) 辩论图模型中阈值λ、ω、主题数和不同潜在逻辑关系组合的设定实验;3) 对比分析以验证辩论图模型在可信度判别中具有较好的效果。
-
本实验数据主要从微博开放API获得,通过2015年6月~2015年8月中旬间隔地采集微博数据,选取热点话题和相关信息如表 1所示。对抓取到的微博语料进行清洗、去噪、分词等预处理工作,并由3名工作人员进行种子节点选取和人工标注赋值,种子节点选取和可信度赋值流程如下。
表 1 实验语料信息表
所属话题 采集时间 语料规模 平均长度/词 种子规模 高官落马 2015.6.29~2015.7.5 1 849 44.2 20 国产电影票房 2015.7.25~2015.7.30 1 266 31.8 15 天津爆炸 2015.8.13~2015.8.18 1 650 34.3 18 1) 专家判定需要进行可信度分析的信息主题。
2) 从微博平台上获取用户权威度高且与该主题相关的博文。权威度判别条件为其是否被新浪微博认证,如人民网、环球时报或华尔街日报等新浪微博认证公众号。
3) 通过政府网站、媒介等渠道对所选取的微博信息进行多方面求证,判断其可信度。
4) 可信度区域依据文献[18]分为非常可信、一般可信、不可信和不能决定,且依据克朗巴哈系数 (Cronbach Alpha) 给微博信息赋可信度值。若该微博非常可信,则可信度值为[0.8, 1],一般可信为[0.7, 0.8),不可信则小于0.7。
5) 对于每1条与主题相关的微博语料,若有2名工作人员给出相近且在同一区域的分值则取其平均值为其可信度值,若3名工作人员给出差异较大的分值则舍弃该条微博。
6) 本实验选取非常可信的语料作为种子证据。
根据以上步骤选取非常可信的微博作为种子证据并依次赋可信度值。
实验选用的第三方工具:中文分词工具ICTCLAS、SVM算法工具包LibSVM、LDA主题建模工具Mallet。以上工具中,LibSVM设置使用径向基核函数 (radial basis function, RBF),其余采用缺省值。由于准确率 (P)、召回率 (R)、F值普遍作为分类实验评价的标准[5],所以本文也采用其作为试验标准。
-
该实验主要分为3个部分:1) 阈值$\lambda, \omega $设定对综合指标影响;2) 主题数设置对评价指标影响;3) 潜在逻辑关系对评价指标的影响。
主题相似度小于$\lambda $的前提在规则可信度计算中被保留。争议节点产生算法中,若规则可信度绝对值大于$\omega $就形成新争议,故调整$\lambda, \omega $值可影响辩论图模型对微博可信度判别的性能。本实验把综合指标$F$作为衡量阈值调整实验结果的标准。
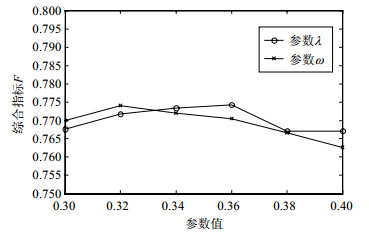
$\lambda $越大,主题相关性越小,被误判成可信的微博数逐渐增加,使得准确率降低,但也由于过滤掉一些不可信的微博,导致召回率增加。同理,争议节点产生算法中的阈值$\omega $对实验结果也有很大影响。由于阈值$\omega $是主题相关度与潜在逻辑关系积的绝对值,随着阈值$\omega $的增大,误判为可信的微博数减少,以致准确率下降,同时会因过滤掉一些可信的微博使得召回率降低。由图 4可知,主题相关度参数$\lambda $和规则可信度$\omega $分别在值0.36和0.32时准确率和召回率能取得较好的平衡,因此在本模型中对这两个阈值的取值为0.36和0.32。

图 4 参数$\lambda ,\omega $调整实验结果
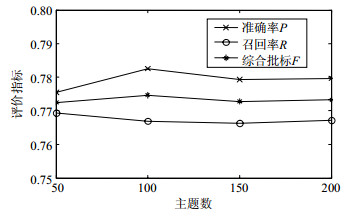
由于微博的短文本性,信息量少,所以设置不同主题数会对综合指标产生不同影响。实验在主题情感和潜在逻辑关系基础上 (TSEC模型) 进行不同主题数实验结果比较,主题数分别选取50、100、150和200,图 5显示了准确率、召回率和综合指标随主题数的变化情况。

图 5 不同主题数实验结果图
当主题数不一样时,准确率、召回率和综合指标也不相同,但能稳定在一定的区域间。通过实验对比结果看出,主题数为100时整体性能最好,因此,本模型实验采用主题数为100。
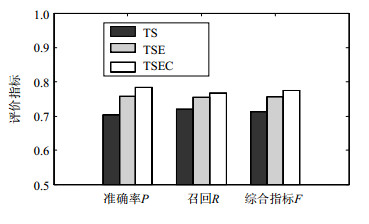
潜在逻辑关系分为主题Theme、情感Sen、蕴涵关系Entail和矛盾关系Contra这4个方面,主要考察潜在逻辑关系对辩论图模型的影响。本节设计Theme+Sen (TS模型)、Theme+Sen+Entail (TSE模型) 和Theme+Sen+Entail+Contra (TSEC模型)3个比较实验,话题数设定为100,实验结果如图 6所示。

图 6 不同模型实验结果图
图 6展示出不同模型时得到的结果,可以看出辩论图模型只考虑主题情感比既考虑了主题情感又包含潜在逻辑关系获得的准确率、召回率和综合指标实验结果都较低。从实验对比结果可知,辩论模型中争议间的支持和攻击强度对实验结果存在着较大的影响,争议间的防卫和攻击强度不同,结论的可信度也不相同。
-
为了验证辩论图模型的有效性,本文将TSEC模型分别与基于SVM的特征分类方法 (SVM),基于用户特征、话题信息、博文内容分类方法 (MCP)[4]及谣言探测模型 (RDM)[5]进行实验对比,结果如表 2所示。
表 2 不同方法实验对比结果表
方法 准确率P 召回率R F SVM 0.689 7 0.714 3 0.701 8 MCP 0.761 0.76 0.7605 RDM 0.778 0.755 0.7663 TSEC 0.782 5 0.767 0 0.774 6 从表中可以看出,传统SVM分类方法的准确率、召回率和综合指标值约为0.70,而基于不同特征、谣言探测模型和辩论图模型均能有效地判别微博内容是否可信。由于文献[4-5]采用英文语料进行实验,本实验采用的为中文语料,故实验结果在一定程度上与原文有所偏差。相比其他方法,辩论图模型的3个指标均有所提升,体现出此方法能更准确地判别微博平台信息的可信度,对于微博可信度判别有很好的应用。
-
为了解决微博可信度评估问题,提出一种面向微博可信度评估的辩论图模型。该模型基于辩论思想,且以图来描述辩论推演过程。实验结果表明,本模型在准确率、召回率和综合指标上都取得较好的结果,证明了此辩论图模型的有效性。模型争议前提中可能存在相互包含关系,故下一步将考虑前提间是否存在合取和析取关系,防止争议间支持和攻击的重复化。
Argumentation Graphical Model for Microblog Credibility Assessment
-
摘要: 微博内容具有信息混杂和不确定性等特点,传统可信度判别方法存在一定局限性。因此,该文提出一种面向微博可信度评估的辩论有向图模型,从辩论的角度出发,以图模型直观、形象化地描述了辩论推演过程。通过话题语料构成争议节点,利用争议间的主题情感和潜在逻辑关系定义规则可信度,并设置图中边的权值来代表争议间的防卫和攻击强度。根据相关算法得出结论的可信度,递归进行辩论图演化,得到需判别信息的可信度。实验结果表明该模型比传统方法综合指标值平均提升6%。Abstract: Due to the mix and uncertainty of the microblog information data, the credibility assessment has difficulty to distinguish. An argumentation directedgraphical model for microblog credibility assessment is presented. From the point of view of argumentation, the model, the argument deduction process is described intuitively by graphical model. In the credibility assessment process, we create the argument node based on the relevant topic corpus, define the rule credibility by the thematic sentiment and potential logical relationship, set the weights on the edges, and represent the defense and attack strength between arguments for this reason. The conclusion credibility is achieved and the argumentation graphical with recursion is evolved according to the relevant algorithm. At last the distinguish information could get the credibility. Experimental results show that this model obtains an accuracy up to 6% in comprehensive indexmeasure compared to the traditional methods.
-
Key words:
- argumentation /
- argument node /
- directed graphs /
- reliability
-
表 1 实验语料信息表
所属话题 采集时间 语料规模 平均长度/词 种子规模 高官落马 2015.6.29~2015.7.5 1 849 44.2 20 国产电影票房 2015.7.25~2015.7.30 1 266 31.8 15 天津爆炸 2015.8.13~2015.8.18 1 650 34.3 18  下载: 导出CSV
下载: 导出CSV
表 2 不同方法实验对比结果表
方法 准确率P 召回率R F SVM 0.689 7 0.714 3 0.701 8 MCP 0.761 0.76 0.7605 RDM 0.778 0.755 0.7663 TSEC 0.782 5 0.767 0 0.774 6
下载: 导出CSV
-
[1] MENDOZA M, POBLETE B, CASTILLO C. Twitter under crisis:Can we trust what we RT?[C]//Proceedings of the First Workshop on Social Media Analytics. New York:ACM, 2010:71-79. [2] CASTILLO C, MENDOZA M, POBLETE B. Information credibility on Twitter[C]//Proceedings of the 20th International Conference on World Wide Web. New York:ACM, 2011:675-684. [3] 蒋盛益, 陈东沂, 庞观松, 等.微博信息可信度分析研究综[J].图书情报工作, 2013, 57(12):136-142. http://www.cnki.com.cn/Article/CJFDTOTAL-TSQB201312029.htm JIANG Sheng-yi, CHEN Dong-yi, PANG Guan-song, et al. Research review of information credibility analysis on Microblog[J]. Library and Information Service, 2013, 57(12):136-142. http://www.cnki.com.cn/Article/CJFDTOTAL-TSQB201312029.htm [4] MORRIS M R, COUNTS S, ROSEWAY A, et al. Tweeting is believing? understanding micoroblog credibility perceptions[C]//Proc of the 15th ACM Conf on Computer Supported Cooperative Work (CSCW12). New York:ACM, 2012:441-450. [5] QAZVINIAN V, ROSENGREN E, RADEV D R, et al. Rumor has it:Indentifying misinformation in Microblogs[C]//Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. Edinburgh:ACL, 2011:1589-1599. [6] GUPTA A, KUMARAGURU P, CASTILLO C, et al. Tweetcred:a real-time web-based system for assessing credibility of content on twitter[EB/OL].[2015-07-25]. http://arxiv.org/abs/1405.5490. [7] 熊才权, 欧阳勇, 梅清.基于可信度的辩论模型及争议评价算法[J].软件学报, 2014, 25(6):1225-1238. http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201406008.htm XIONG Cai-quan, OUYANG Yong, MEI Qing. Argumentation model based on certainty-factor and algorithms of argumentevaluation[J]. Journal of Software, 2014, 25(6):1225-1238. http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201406008.htm [8] DANG P M. On the acceptability of arguments and its fundamental role in nonmonotonic reasoning logic programming and n-person games[J]. Artificial Intelligence, 1995, 77(2):321-357. doi: 10.1016/0004-3702(94)00041-X [9] TOULMIN S E. The uses of argument[J]. Ethics, 1959, 10(1):251-252. [10] KUNZ W, RITTEL H W J. Issues as elements of information systems[D]. Berkeley:University of California, 1970. [11] 熊才权, 李德华.一种研讨模型[J].软件学报, 2009, 20(8):2181-2190. doi: 10.3724/SP.J.1001.2009.03465 XIONG Cai-quan, LI De-hua. Model of argumentation[J]. Journal of Software, 2009, 20(8):2181-2190. doi: 10.3724/SP.J.1001.2009.03465 [12] 陈俊良, 王长春, 陈超.一种扩展双极辩论模型[J].软件学报, 2012, 23(6):1444-1457. doi: 10.3724/SP.J.1001.2012.04067 CHEN Jun-liang, WANG Chang-chun, CHEN Chao. Extended bipolar argumentation model[J]. Journal of Software, 2012, 23(6):1444-1457. doi: 10.3724/SP.J.1001.2012.04067 [13] 苑卫国, 刘云, 程军军, 等.微博网络中用户特征量和增长率分布的研究[J].计算机学报, 2014, (4):767-778. http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201404004.htm YUAN Wei-guo, LIU Yun, CHENG Jun-jun, et al. Research on the user characteristics and growth rates distribution in microblog[J]. Chinese Journal of Computers. 2014, 37(4):767-778. http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201404004.htm [14] BLEI D M, NG A Y, JORDAN M I. Latent dirichlet allocation[J]. Journal of Machine Research, 2003, 3(3):993-1022. [15] 贺飞艳, 何炎祥, 刘楠, 等.面向微博短文本的细粒度情感特征抽取方法[J].北京大学学报 (自然科学版), 2014, 50(1):48-54. http://www.cnki.com.cn/Article/CJFDTOTAL-BJDZ201401007.htm HE Fei-yan, HE Yan-xiang, LIU Nan, et al. A microblog short text oriented multi-class feature extraction method of fine-grained sentiment analysis[J]. Acta Scientiarum Naturalium Universitaits Pekinensis, 2014, 50(1):48-54. http://www.cnki.com.cn/Article/CJFDTOTAL-BJDZ201401007.htm [16] DAGAN I, GLICKMAN O. Probabilistic textual entailment:Generic applied modeling of language variability[C]//PASAL Workshop on Learning Methods for Text Understanding and Mining. Grenoble France:[s.n.], 2004. [17] 刘茂福, 王月, 顾进广.基于语义规则的中文矛盾关系识别方法[J].计算机工程与科学, 2015, 37(4):806-812. http://www.cnki.com.cn/Article/CJFDTOTAL-JSJK201504030.htm LIU Mao-fu, WANG Yue, GU Jin-guang. Chinese textual contradiction recognition based on semantic rules[J]. Computer Engineering & Science, 2015, 37(4):806-812. http://www.cnki.com.cn/Article/CJFDTOTAL-JSJK201504030.htm [18] GUPTA A, KUMARAGURU P. Credibility ranking of tweets duringhigh impact events[EB/OL].[2015-07-25]. http://precog.iiitd.edu.in/Publicationsfiles/a2-gupta.pdf.2012. -

 点击查看大图
点击查看大图
图(6) / 表(2)
计量
- 文章访问数: 4493
- HTML全文浏览量: 1214
- PDF下载量: 89
- 被引次数: 0
