 ISSN
ISSN 




-
人类行为识别有着广泛的应用前景,如视频监控和监测、对象视频摘要、智能接口、人机交互、体育视频分析、视频检索等,吸引了越来越多计算机视觉研究者的关注[1-3]。通常,行为识别涉及两个重要问题:1) 如何从原始视频数据中提取有用的运动信息;2) 如何建立运动参考模型,使训练和识别方法能有效地处理空间和时间尺度变化的类内类似行为。
行为识别可以利用各种线索,如关键姿势[4-8]、光流[9-10]、局部描述符[11-13]、运动轨迹或特征跟踪[14-19]、视觉文本信息[20-21]、人体轮廓[22-24]等,但是使用关键帧缺乏运动信息。根据光流或兴趣点的行为识别在平滑的表面、运动奇异性和低质量的视频情况下是不可靠的。由于人体外表和关节出现大的变化,特征跟踪也不容易实现。
人类行为是一种时空行为,时空模型 (如HMMs及其变种) 已被广泛用于人体动作建模[7, 12]。然而,该生成模型通常使用强烈的独立性假设,这使得它很难适应多种复杂的特征或观测中的远距离依存关系。文献[4-5, 8]提出的条件随机场模型 (CRFs) 避免了观察之间的独立性假设,同时将复杂的特征和远距离依存关系融合进模型中。本文在此基础上提出了具有联合判别学习能力的基于动作子空间与权重条件随机的行为识别方法,使用KPCA来发现关键动作空间的内在结构[25-28],并利用权重化条件随机从简单的人体轮廓观察中识别人类行为。实验结果证明了该方法的有效性和鲁棒性。
-
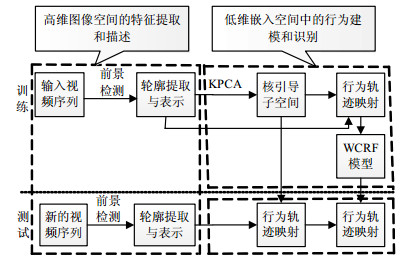
本文提出如图 1所示的行为识别综合概率框架,该框架由高维图像空间的特征提取和描述、低维嵌入空间中的行为建模和识别两个模块组成。对成功的行为识别模型而言,信息特征至关重要。本文选择人体轮廓作为基本的输入,并通过非线性降维方式来更紧凑地表示人类行为。

图 1 行为识别的框图
-
给定一个T帧的行为视频$v=\{ {I_1}, {I_2}, \cdots, {I_T}\} $,可从原始视频中获得与之相关的行为人体轮廓序列${S_s}=\{ {s_1}, {s_2}, \cdots, {s_T}\} $。前景区域的大小和位置随运动目标与相机的距离、目标的大小和已经完成的行为变化。在保持人体轮廓宽高比的基础上,对人体轮廓图像进行中心化和归一化,使产生的结果图像${\rm{RI}}=\{ {R_1}, {R_2}, \cdots, {R_T}\} $包含尽可能多的前景。在动作不发生形变的情况下,所有输入帧有相同的维数${b_i} \times {c_i}$。归一化的人体轮廓图像如图 2所示。如果以行扫描方式在${\Re ^{{r_i} \times {c_i}}}$空间用向量ri表示原始人体轮廓图像Ri,整个视频将相应表示为${\nu _r}=\left\{ {{r_1}, {r_2}, \cdots, {r_T}} \right\}$。

图 2 行走的人体轮廓序列和块特征表示图
为了提高计算效率,本文等距离划分每个人体轮廓图像为h × w个互不重叠的子块。然后用${N_i}=b (i)/{\rm{mv}}, i=1, 2, \cdots, hw$,计算每个子块的归一化值,其中,$b (i)$是第i个子块的前景像素数目,mv是所有$b (i)$的最大值。在${\Re ^{h \times w}}$空间中,第t帧的人体轮廓描述符${\boldsymbol{f}_t}={[{N_1}, {N_2}, \cdots, {N_{h \times w}}]^{\rm{T}}}$,整个视频相应表示为${\rm{vf}}=\{ {f_1}, {f_2}, \cdots, {f_T}\} $。事实上,原始人体轮廓表示vr可以被视为一种基于块特征的特例,即分块大小是1 × 1,一个像素。
-
为了获得紧凑的描述和有效的计算,本文使用KPCA算法进行非线性降维[25-28]。主要考虑两个方面:1) KPCA提供了一种有效的子空间学习方法来发现“行为空间”的非线性结构;2) KPCA能简单地应用于任何新的数据点,而ISOMAP、LLE等非线性降维方法对如何描述新的数据点仍不清楚。
在${\Re ^D}$空间中,给定一个M个元素的训练样本集${T_x}=\{ {X_1}, {X_2}, \cdots, {X_M}\} $,子空间的学习目的是在低维空间${\Re ^d}$(d < D) 找到一个嵌入数据集${E_y}=\{ {Y_1}, {Y_2}, \cdots, {Y_M}\} $。对于核主成分分析方法而言,每一个矢量Xi首先通过$c$被非线性映射到希尔伯特空间H中,然后,在H上主成分分析应用到映射数据${T_\varphi }=\left\{ {\varphi ({X_1}), \varphi ({X_2}), \cdots, \varphi ({X_M})} \right\}$。本文由于使用了“内核技巧”,不需要这个映射过程。
设k是一个半正定核函数,通过式 (1) 定义两个向量xi和xj之间的非线性关系,有:
$$ k({\boldsymbol{x}_i}, {\boldsymbol{x}_j}) = \exp [-(\phi ({\boldsymbol{x}_i}) \cdot \phi ({\boldsymbol{x}_j}))] $$ (1) 在H空间寻找主成分的系数问题可以归结为内核矩阵κ的对角化:
$$ \gamma \boldsymbol{\lambda} \boldsymbol{e} = \boldsymbol{\kappa} \boldsymbol{e} $$ (2) 式中,λ是单位对角矩阵;γ为内核矩阵的秩。
${\kappa _{ij}}=k ({\boldsymbol{x}_i}, {\boldsymbol{x}_j})$, $\boldsymbol{e}={[{e_1}, {e_2}, \cdots, {e_\gamma }]^{\rm{T}}}$, 所以$Z=\sum\limits_{i=1}^\gamma {{e_i}\phi ({\boldsymbol{x}_i})} $。
将新点X映射到第j个主轴Zj可表示为:
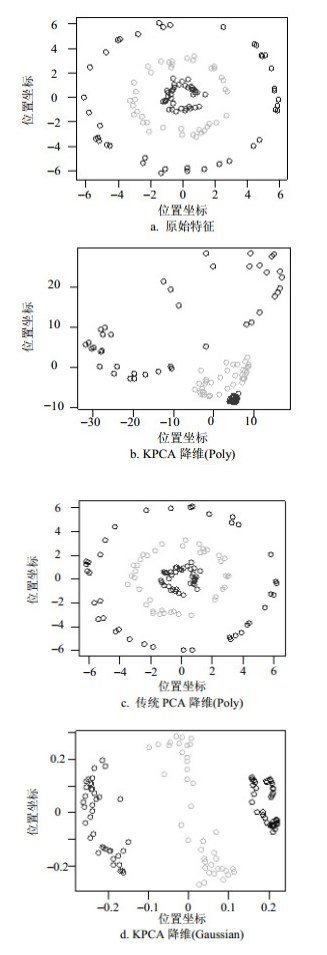
$$ ({Z^j} \cdot \varphi (\boldsymbol{x})) = \sum\limits_{i = 1}^\gamma {e_i^j(\varphi ({\boldsymbol{x}_i}) \cdot \varphi ({\boldsymbol{x}_j}))} = \sum\limits_{i = 1}^\gamma {e_i^j} k({\boldsymbol{x}_i}, {\boldsymbol{x}_j}) $$ (3) 使用KPCA可以显著地减少用于识别人类行为的特征维数,对计算机内存需求也明显减少。图 3为使用传统的PCA及使用Poly和Guassian核函数的KPCA方法来减少提取的二维特征的结果。其中,横轴和纵轴对应于各特征点从高维特征降到二维特征过程中各特征点映射到二维特征空间的位置坐标。从图 3可以看出使用Guassian核函数的KPCA方法降维效果明显优于PCA方法和使用Poly核函数的KPCA方法,因此,本文在实验中使用高斯核函数。

图 3 PCA和KPCA方法降维效果
获得包括第一个d维主成分的嵌入空间后,任何一个视频v可以被映射为d维特征空间的一个关联轨迹${T_o}=\{ {O_1}, {O_2}, \cdots, {O_T}\} $。
-
CRFs的判别性质和基本的图形结构非常适合人体行为分析。本文探讨在嵌入空间中用权重的CRFs来标签人类行为序列。
-
设G是一个建立在随机变量S和O数据集上的无向模型;设s={st},o={ot},$t=1, 2, \cdots, T$,S为观察序列O的标签序列;设$C=\{ {\boldsymbol{s}_c}, {\boldsymbol{o}_c}\} $是G中的类集,CRFs定义观察序列给定的状态 (或标签) 序列的条件概率为[22, 24]:
$$ {p_\theta }(\boldsymbol{s}|\boldsymbol{o}) = \frac{1}{{Z(o)}}\prod\limits_{c \in C} {\Phi ({s_c}}, {o_c}) $$ (4) 式中,$Z (\boldsymbol{o})=\sum\limits_s {\prod\limits_{c \in C} {\Phi ({\boldsymbol{s}_c}}, {\boldsymbol{o}_c})} $是所有状态序列的一个归一化因子;Φ是由特征集fn权重化的隐函数:
$$ \Phi ({\boldsymbol{s}_c}, {\boldsymbol{o}_c}) = \exp \left[{\sum\limits_{t = 1}^T {\sum\limits_n {{\lambda _n}{f_n}({\boldsymbol{s}_c}, {\boldsymbol{o}_c}, t)} } } \right] $$ (5) 式中,模型参数$\theta=\{ {\lambda _n}\} $是一个实权重集,每一个特征被赋予一个权重。
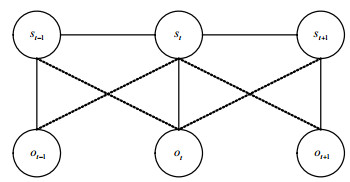
CRFs的一般框架如图 4所示[22, 24],其中一阶马尔科夫假设一般是在标签生成。因此,这种条件模型的类是节点和边,每个标签转换和每个标签的特征函数分别为${f_n}({s_{t-1}}, {s_t}, \boldsymbol{o}, t)$和${g_n}({s_t}, \boldsymbol{o}, t)$。

图 4 线性链CRF
-
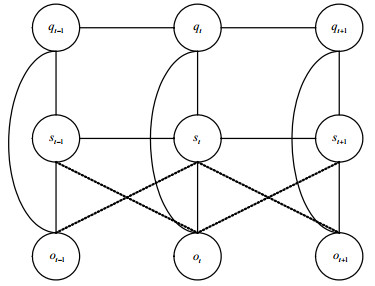
动态CRFs是线性链CRFs的一般化[28],它是状态向量序列的结构和参数的重复。允许一个标签代表分布的隐状态和链之间的复杂的相互作用。本文提出的WCRF具有标签线性链,如图 5所示。

图 5 两链之间WCRF
这种线性链中的共时标签之间有连接,从而通过信息共享提高了联合准确性。WCRF同时完成关键姿势分类和行为分类[29]。
设sl, t是L链的WCRF中链l在时间t的变量,隐状态的分布定义为:
$$ \begin{array}{l} p(\boldsymbol{s}|\boldsymbol{o}) = \frac{1}{{Z(\boldsymbol{o})}}\left[{\prod\limits_{t = 1}^{T-1} {\prod\limits_{l = 1}^\ell {{\Phi _l}({s_{l, t}}, {q_{l, t}}, {q_{l, t + 1}}, {s_{l, t + 1}}, \boldsymbol{o}, t)} } } \right] \times \\ \left[{\prod\limits_{t = 1}^T {\prod\limits_{l = 1}^{\ell-1} {{\Psi _l}({s_{l, t}}, {q_{l, t}}, {q_{l, t + 1}}, {s_{l + 1, t}}, \boldsymbol{o}, t)} } } \right] \end{array} $$ (6) 式中,Φl是内链节点的隐函数;Ψl是链轮节点的隐函数[24]。根据特征fk和G的权重λk权重化这些隐函数,有:
$$ \left\{ \begin{array}{l} {\Phi _l}( \cdot ) = \exp \left[{\sum\limits_k {{\lambda _k}{f_k}({s_{l, t}}, {q_{l, t}}, {q_{l, t + 1}}, {s_{l, t + 1}}, \boldsymbol{o}, t)} } \right]\\ {\Psi _l}( \cdot ) = \exp \left[{\sum\limits_k {{\lambda _k}{f_k}({s_{l, t}}, {q_{l, t}}, {q_{l + 1, t}}, {s_{l + 1, t}}, \boldsymbol{o}, t)} } \right] \end{array} \right. $$ (7) -
给定一个训练样本集${\rm{Tr}}=\left\{ {{\boldsymbol{o}^{(i)}}, {\boldsymbol{s}^{(i)}}} \right\}_{i=1}^N$,参数$\theta=\{ {\lambda _n}\} $可以通过优化条件对数似然函数来估计:
$$ \Omega (\theta ) = \sum\limits_i {\log {p_\theta }({\boldsymbol{s}^{(i)}}|{\boldsymbol{o}^{(i)}})} $$ (8) 式 (8) 对λk的导数与类索引C相关,有:
$$ \begin{array}{l} \frac{{\partial \Omega }}{{\partial {\lambda _k}}} = \sum\limits_i {\sum\limits_t {{f_k}(\boldsymbol{s}_{t, c}^{^{(i)}}, {\boldsymbol{o}^{(i)}}} }, t)-\\ \sum\limits_i {\sum\limits_t {\sum\limits_{c \in C} {\sum\limits_{{s_c}} {{p_\theta }(} } } } \boldsymbol{s}_c^{(i)}|\boldsymbol{o}_t^{(i)}){f_k}(\boldsymbol{s}_{t, c}^{^{(i)}}, {\boldsymbol{o}^{(i)}}, t) \end{array} $$ (9) 式中,$\boldsymbol{s}_{t, c}^{^{(i)}}$是在时间步长t、WCRF的类C中S的变量,在sc范围被分配到子类C中c。
一般来说,为了减少过度拟合,用惩罚似然函数来训练参数,即$\log p (\theta |{\rm{Tr}})=\Omega (\theta) + \log p (\theta)$,$p (\theta)$是参数的高斯先验 ($p (\theta) \propto \exp [{\left\| \theta \right\|^2}/2{\varepsilon ^2}]$),这样,梯度变为[15]:
$$ \frac{{\partial p(\theta |{\rm{Tr}})}}{{\partial {\lambda _k}}} = \frac{{\partial \Omega }}{{\partial {\lambda _k}}}-\frac{{{\lambda _k}}}{{{\varepsilon ^2}}} $$ (10) 凸面函数可以通过许多技巧来优化,如牛顿优化方法。
通常情况下需要计算所有类${\boldsymbol{s}_{t, c}}$的边缘概率$p ({\boldsymbol{s}_{t, c}}|\boldsymbol{o})$和维特比解码$\tilde s=\arg \mathop {\max }\limits_s p (\boldsymbol{s}|\boldsymbol{o})$。前者用于参数估计,后者用来标记一个新的序列。
创建关键姿势数据集的基本点是具体行为尽可能包括更多关键帧,同时,尽量使不同的行为之间的相互关键帧尽可能距离远[13]。在整个数据集中,使用MDL (最小描述长度) 规则确定关键姿势的数目K,并使用K-均值聚类算法为训练过程获取这些关键姿势${\rm{kp}}=\left\{ {{p_1}, {p_2}, \cdots, {p_k}} \right\}$。
为了处理远距离的依存关系,本文修改式 (7) 中的核函数包括一个窗口参数W,在时间t预测状态时,定义了要使用的过去和未来为式 (11),并用${f_k}({\boldsymbol{s}_{t, c}}, {\boldsymbol{q}_{t, c}}, {\boldsymbol{o}_t}, t)={\mu _k}({\boldsymbol{s}_{t, c}}, {\boldsymbol{q}_{t, c}}){\varphi _k}({\boldsymbol{o}_t}, t)$权重化成特征。其中,前者是分配的一个二元函数,而后者则是一个纯粹的输入特征函数,有:
$$ {o_t} = (t = t-\omega, \cdots, t + \omega ) \mapsto {s_t}, {q_t} $$ (11) -
使用文献[13, 22, 24]分别报道的Weizmann (WEI)、KTH (如图 6所示)、及rcv1.binary (简称rcv1) 等8个人类行为数据库进行实验。其中,文献[13]提供了一些行为的训练、测试次数及用于识别的特征个数。文献[22]中的数据集包括拾物、慢跑、推、下蹲、挥手、踢、侧弯、摔、转身、手机通话10种不同行为,用来系统地检测时间对行为识别实现的影响;文献[24]中的数据集包括弯曲、开合跳、双腿并拢向前跳、原地双腿跳、跑、横跑、走、单手挥动、双手挥动、跳过10种不同行为,用来系统地检测行为识别实现的时间和空间尺度变化的影响。实验中使用文献[22, 24]方法获得人体轮廓。先将所有人体轮廓图像中心和归一化到相同的尺寸 (即64×48像素),并将它们表示为基于块特征的不同的子块大小 (如8×8,4×4,1×1)。然后学习WCRF来建模各个角度、远距离依存关系的观测 (如ω=0或1)。在监督识别率下,凭经验调节降维维数d和核主成分分析的核宽参数。对行为数据库WEI和KTH采用留一法 (leaving-one-out) 计算识别准确性整体无偏估计,将数据集分割成10个不相交的数据集,每个数据集包含每一行为的一个实例。每次留一数据集用来测试,剩下的9个数据集为学习子空间和模型参数。因此,如果留出测试集中一个视频被正确地分类,它必须与不同人完成同样行为的视频具有很高的相似性。对比文献[13],本文方法识别人类行为使用的特征维数及训练、测试集大小如表 1所示。使用WCRF方法进行行为识别的精度如表 2所示,和其他方法比较实验结果如表 3所示。

图 6 行为数据集实例图像
表 1 人类行为识别使用的特征维数及训练、测试集大小比较
行为库 本文行为识别 文献[13]中的行为识别 使用特征维数 训练集大小 测试集大小 使用特征维数 训练集大小 测试集大小 WEI 226 1 023 113 506 4 092 2 156 KTH 128 8 762 975 480 10 742 9 868 a2a 59 1 023 9 085 123 2265 30 296 epsilon 287 56 960 78 632 2 000 400 000 100 000 madelon 175 831 226 500 2 000 600 rcv1 7 632 10 278 333 594 47 236 20 242 677 399 w7a 106 8 659 7 963 300 24 692 25 057 segment 203 17 490 9 687 429 43 500 14 500 表 2 使用WCRF方法行为正确分类的精度
表 3 使用不同方法的行为分类
方法 识别正确率/% 模板匹配 81.86 HMM模型 89.23 CRFs模型 (w=0) 91.75 CRFs模型 (w=1) 95.08 WCRF模型 (w=0) 99.84 WCRF模型 (w=1) 99.97 从表 1中可以看出,识别同样的人类行为,本文方法使用的特征维数及训练、测试集大小都明显地变小,从而可以减少计算机的处理工作量,满足实时行为识别的要求。
从表 2中可以得出以下结论:
1) 动态人体轮廓变化对人类行为分析是有益的。
2) 本文的框架可以有效地识别由不同人,以不同的身体部位构建和不同运动方式及速度完成的行为;
3) 当子块大小增加时,识别正确率普遍下降,特别是子块大小为8×8时,下降幅度最大。
4) 尽管计算过于密集,原始人体轮廓表示识别效果最好。这是因为它保留了充分的信息,而其他较大尺寸的基于块特征的方法丢失相当多的人体轮廓信息。引入一些离散误差是基于块的特征在实际应用中如何选择计算精度和计算开销之间较好的折中方法。
5) 在WCRF模型中引入远距离观测普遍提高了识别的准确率 (表中粗体例外,可能是由于训练参数的过度拟合)。
从表 3中可以看出:
1) 模板匹配方法性能最差。这可能是由于其对噪声特征的敏感性和无法获取时空转换。
2) 虽然计算开销大,但状态空间方法一般优于模板匹配方法。
3) CRFs和WCRF都具有比HMMs更好的性能,这表明判别模型一般优于产生式模型。
4) 即使不考虑远距离的相关性,WCRF比CRFs性能更好,这表明通过不同标签的序列之间的信息交流学习的共同判别的优势。
5) CRFs及WCRF性能随窗口大小的增加而得到改进,这表明结合远距离的依存关系是有益的。
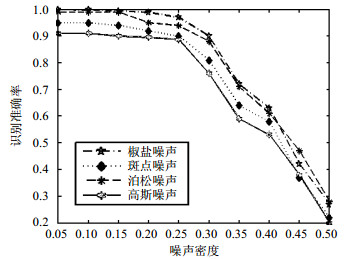
为了测试本文方法的鲁棒性,人体轮廓图像中加入各种人工合成噪声,模拟损坏的人体轮廓。实验使用原始 (未受噪声污染的) 人体轮廓序列进行训练,用噪声污染的人体轮廓序列进行测试。行为识别结果如图 7所示。从图 7中可以看出本文的方法能够容忍相当程度的噪声 (25%)。这可能是因为WCRF的统计特性补偿了表示与识别的整体鲁棒性。服装、遮挡和运动风格等因素对本文方法鲁棒性的影响实验结果如表 4所示。表 4总结包括最匹配的测试结果,从中可以看出,除了4个序列,其他所有测试序列是“走”动作的正确分类。这表明,在尺寸变化相当大、服装部分遮挡、步行形式不规则的情况下该方法的识别准确率相对较低。

图 7 不同噪声和不同噪声密度下的行为识别精度
表 4 其他因素影响下的鲁棒性评价
测试序列 变化条件 实验结果 识别是否正确 对角走 尺度和视点 跳 不正确 原地跳步 非刚性变形 跑 不正确 摆动着包步行 刚性变形 跳 不正确 横向步行 行走风格 侧跳 不正确 跛行 行走风格 走 正确 走路时膝盖抬起 行走风格 走 正确 穿着裙子走 服装 走 正确 走路时腿部分遮挡 部分遮挡 走 正确 步行/携带公文包 携带物体 走 正确 正常走 背景 走 正确 -
本文介绍了基于动作子空间与权重条件随机场的行为识别的有效概率框架。该方法的创新之处在于两方面:
1) 特征提取和表示方面,本文选择简单而易于提取的时空人体轮廓作为输入,并将它们嵌入到一个低维的内核空间。
2) 行为建模和识别方面,本文提出在视觉领域使用WCRF,与HMMs和一般CRFs比较表现出优势。本文提出的框架不依赖于使用的特征,可以很容易地扩展到其他类型的视频行为分析。本文方法使用的特征维数及训练、测试集大小都明显地变小,从而可以减少计算机的处理工作量,满足实时行为识别的要求。
本文的研究工作得到了柳州市科学研究与技术开发计划 (2016C050205)、广西信息科学实验中心开放基金 (KF1403)、广西科技大学博士基金 (院科博12Z14)、广西科技大学创新团队“图像处理与智能认知及应用”的资助,在此表示感谢!
Behavior Recognition Based on Action Subspace and Weight Condition Random Field
-
摘要: 针对单目视频中的人类行为识别,提出了基于动作子空间与权重条件随机场的行为识别方法。该方法结合了基于特征提取的核主分量分析 (KPCA) 与基于运动建模的权重条件随机场 (WCRF) 模型。探讨了通过非线性降维行为空间的基本结构,并在运动轨迹投影过程中保留清晰的时间顺序,使人体轮廓数据表示更紧凑。WCRF通过多种交互途径对时间序列建模,从而提高了信息共享的联合精确度,具有超越生成模型的优势 (如放宽观察之间独立性的假设,有效地将重叠的特征和远距离依存关系合并起来的能力)。实验结果表明,该行为识别方法不仅能够准确地识别随时间、区域内外人员变化的人类行为,而且对噪声和其他因素鲁棒性强。Abstract: For human behavior recognition in monocular video, a method for recognizing human behavior based on action subspace and weighted condition random field is presented in this paper. This method combines kernel principal component analysis (KPCA) based on feature extraction and weighted conditional random field (WCRF) based on activity modeling. Silhouette data of human is represented more compactly by nonlinear dimensionality reduction that explores the basic structure of action space and preserves explicit temporal orders in the course of projection trajectories of motions. Temporal sequences are modeled in WCRF by using multiple interacting ways, thus increasing joint accuracy by information sharing, and this model has superiority over generative ones (e.g., relaxing independence assumption between observations and the ability to effectively incorporate both overlapping features and long-range dependencies). The experimental results show that the proposed behavior recognition method can not only accurately recognize human activities with temporal, external and internal person variations, but also considerably robust to noise and other factors.
-
表 1 人类行为识别使用的特征维数及训练、测试集大小比较
行为库 本文行为识别 文献[13]中的行为识别 使用特征维数 训练集大小 测试集大小 使用特征维数 训练集大小 测试集大小 WEI 226 1 023 113 506 4 092 2 156 KTH 128 8 762 975 480 10 742 9 868 a2a 59 1 023 9 085 123 2265 30 296 epsilon 287 56 960 78 632 2 000 400 000 100 000 madelon 175 831 226 500 2 000 600 rcv1 7 632 10 278 333 594 47 236 20 242 677 399 w7a 106 8 659 7 963 300 24 692 25 057 segment 203 17 490 9 687 429 43 500 14 500  下载: 导出CSV
下载: 导出CSV
表 3 使用不同方法的行为分类
方法 识别正确率/% 模板匹配 81.86 HMM模型 89.23 CRFs模型 (w=0) 91.75 CRFs模型 (w=1) 95.08 WCRF模型 (w=0) 99.84 WCRF模型 (w=1) 99.97
下载: 导出CSV
表 4 其他因素影响下的鲁棒性评价
测试序列 变化条件 实验结果 识别是否正确 对角走 尺度和视点 跳 不正确 原地跳步 非刚性变形 跑 不正确 摆动着包步行 刚性变形 跳 不正确 横向步行 行走风格 侧跳 不正确 跛行 行走风格 走 正确 走路时膝盖抬起 行走风格 走 正确 穿着裙子走 服装 走 正确 走路时腿部分遮挡 部分遮挡 走 正确 步行/携带公文包 携带物体 走 正确 正常走 背景 走 正确
下载: 导出CSV
-
[1] MARYAM Z, ROBERT B. Semantic human activity recognition:a literature review[J]. Pattern Recognition, 2015, 48(8):2329-2345. doi: 10.1016/j.patcog.2015.03.006 [2] MATTHEW F, DAVID S, PAN Z X, et al. Recognizing human motions through mixture modeling of inertial data[J]. Pattern Recognition, 2015, 48(8):2394-2406. doi: 10.1016/j.patcog.2015.03.004 [3] POPOOLA O P, WANG K J. Video-based abnormal human behavior recognition-a review[J]. IEEE Transactions on Systems, Man and Cybernetics Part C:Applications and Reviews, 2012, 42(6):1-14. http://www.oalib.com/references/9307043 [4] NIEBLES J C, WANG H C, LI F F. Unsupervised learning of human action categories using spatial-temporal words[J]. International Journal of Computer Vision, 2008, 79(3):299-318. doi: 10.1007/s11263-007-0122-4 [5] GORELICK L, BLANK M, SHECHTMAN E, et al. Action as space-time shapes[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(12):2247-2253. doi: 10.1109/TPAMI.2007.70711 [6] BOBICK A, DAVIS J. The recognition of human movement using temporal templates[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2001, 23(3):257-267. doi: 10.1109/34.910878 [7] WANG S, ARIADNA Q, MORENCY L P, et al. Hidden conditional random fields for gesture recognition[C]//CVPR. New York:IEEE, 2006, 2:1521-1527. [8] PEHLIVAN S, DUYGULU P. A new pose-based representation for recognizing actions from multiple cameras[J]. Computer Vision & Image Understanding, 2011, 115(2):140-151. [9] WEINLAND D, RONFARD R, BOYER E. A survey of vision-based methods for action representation, segmentation and recognition[J]. Computer Vision & Image Understanding, 2011, 115(2):224-241. https://www.researchgate.net/publication/256979980_A_Survey_of_Vision-Based_Methods_for_Action_Representation_Segmentation_and_Recognition [10] MORRIS B T, TRIVEDI M M. Trajectory learning for activity understanding:Unsupervised, multilevel, and long-term adaptive approach[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2011, 33(11):2287-2301. [11] HOLZER S, ILIC S, NAVAB N. Multi-layer adaptive linear predictors for real-time tracking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 35(1):105-117. https://www.researchgate.net/publication/223969594_Multi-Layer_Adaptive_Linear_Predictors_for_Real-Time_Tracking [12] SCHULDT C, LAPTEV I, CAPUTO B. Recognizing human actions:a local SVM approach[C]//17th International Conference on Pattern Recognition. Cambridge:IEEE, 2004:3:32-36. [13] SELEN P, DAVID A F. Recognizing activities in multiple views with fusion of frame judgments[J]. Image and Vision Computing, 2014, 32(4):237-249. doi: 10.1016/j.imavis.2014.01.006 [14] SHAO Z P, LI Y F. Integral invariants for space motion trajectory matching and recognition[J]. Pattern Recognition, 2015, 48(8):2418-2432. doi: 10.1016/j.patcog.2015.02.029 [15] KEREM A, KARON E M. Recognizing affect in human touch of a robot[J]. Pattern Recognition Letters, 2015, 66(15):31-40. [16] STIKIC M, LARLUS D, EBERT S, et al. Weakly supervised recognition of daily life activities with wearable sensors[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2011, 33(12):2521-2537. http://www.academia.edu/16023877/Weakly_Supervised_Recognition_of_Daily_Life_Activities_with_Wearable_Sensors [17] WANG Zu-chao, LU Min, YUAN Xiao-ru, et al. Visual traffic jam analysis based on trajectory data[J]. IEEE Transactions on Visualization and Computer Graphics, 2013, 19(12):2159-2168. doi: 10.1109/TVCG.2013.228 [18] WANG Heng, KLÄSER A, SCHMID C, et al. Dense trajectories and motion boundary descriptors for action recognition[J]. International Journal of Computer Vision, 2013, 103(1):60-79. doi: 10.1007/s11263-012-0594-8 [19] BASHIR F I, KHOKHAR A A, DAN S. View-invariant motion trajectory-based activity classification and recognition[J]. Multimedia Systems, 2006, 12(1):45-54. doi: 10.1007/s00530-006-0024-2 [20] CHO S Y, SOOY K, HYE B. Recognizing human-human interaction activities using visual and textual information[J]. Pattern Recognition Letters, 2013, 34(15):1840-1848. doi: 10.1016/j.patrec.2012.10.022 [21] LIU Hao-wei, MATTHAI P, MARTIN P, et al. Recognizing object manipulation activities using depth and visual cues[J]. Journal of Visual Communication and Image Representation, 2014, 25(4):719-726. doi: 10.1016/j.jvcir.2013.03.015 [22] WANG Liang, SUTER D. Recognizing human activities from silhouettes:Motion subspace and factorial discriminative graphical model[C]//CVPR. Minneapolis:IEEE, 2007:1-8. [23] VERES G V, GORDON L, CARTER J N, et al. What image information is important in silhouette-based gait recognition?[C]//CVPR. Washington:IEEE, 2004, 2:776-782. [24] REDDY K, SHAH M. Recognizing 50 human action categories of web videos[J]. Machine Vision and Applications, 2013, 24(5):971-981. doi: 10.1007/s00138-012-0450-4 [25] 王晓, 刘小芳.基于NSVM的核空间训练数据减少方法[J].电子科技大学学报, 2013, 42(4):592-596. http://www.xb.uestc.edu.cn/nature/index.php?p=item&item_id=1330 WANG Xiao, LIU Xiao-fang. Nonlinear support vector machine for training data reduction in kernel space[J]. Journal of University of Electronic Science and Technology of China, 2013, 42(4):592-596. http://www.xb.uestc.edu.cn/nature/index.php?p=item&item_id=1330 [26] WU Jian-ning, WANG Jue, LIU Li. Feature extraction via KPCA for classification of gait patterns[J]. Human Movement Science, 2007, 26(3):393-411. doi: 10.1016/j.humov.2007.01.015 [27] SCHOLKOPF B, SMOLA A, MULLER K. Nonlinear component analysis as a kernel eigenvalue problem[J]. Neural Computation, 1998, 10(5):1299-1319. doi: 10.1162/089976698300017467 [28] VEERARAGHAVAN A, CHELLAPPA R, ROY A K. The function space of an activity[C]//CVPR. New York:IEEE, 2006, 1:959-966. [29] 李旭, 何明一, 张雷. WorldView-2遥感图像融合新方法[J].电子科技大学学报, 2015, 44(1):28-32. http://www.xb.uestc.edu.cn/nature/index.php?p=item&item_id=1624 LI Xu, HE Ming-yi, ZHANG Lei. New pansharpening method for WorldView-2 satellite images[J]. Journal of University of Electronic Science and Technology of China, 2015, 44(1):28-32. http://www.xb.uestc.edu.cn/nature/index.php?p=item&item_id=1624 -

 点击查看大图
点击查看大图
图(7) / 表(4)
计量
- 文章访问数: 4707
- HTML全文浏览量: 1449
- PDF下载量: 120
- 被引次数: 0
