 ISSN
ISSN 


-
随着Web服务应用领域的持续延伸,单个简单的Web服务已经无法满足实际应用需求,人们常常需要将多个Web服务组合起来以完成一个较复杂的任务。用户在关注组合服务功能的同时,往往更加注重服务的QoS (响应时间、信誉度、可靠性、价格等) 是否满足自身的需求。因此,如何为用户提供高效且满足QoS需求的Web服务组合是一个关键问题[1]。QoS感知的服务组合优化问题 (optimizing the QoS-aware service composition, O-QSC) 应运而生。
若不考虑Web语义[2-5],O-QSC的问题可以建模为一个多维多选择背包问题 (multidimensional multiple choice knapsack problem, MMKP)[6],这是众所周知的NP难问题。所以,如何为用户提供一个可信赖且可靠的服务组合是一个重大的挑战。目前,基于工作流的QSC问题已经获得了很多的研究,大体可分为三类:局部优化方法 (local optimization, LO)[6-10],全局优化方法 (global optimization, GO)[11-24]以及质量约束分解方法 (quality constriant decomposition, QCD)[25-28]。
当为工作流中的每个任务选择候选服务时,LO方法通常会对满足组合流程的一组服务的QoS指标进行加权排序,并以此作为选择各个服务实例的依据。由于每个服务都是被独立选择的[6-7],因此该方法表现出较好的性能。文献[8]提出了一种中间件平台,该平台解决了如何选择Web服务的问题,同时描述了一种基于局部选择服务的方法。文献[6]给出了一种启发式算法,它从局部视角寻找接近最优解的解决方案。虽然LO方法具有很好的时间复杂度,但不容易满足全局约束,且不容易获得最优解。
GO方法是以服务组合的整体质量满足全局QoS约束为目标的,因此在对各个服务进行选择时,需要综合考虑各服务组合后的总体质量,从而生成一个最佳组合方案。当该最佳服务组合服从全局约束时,能使聚合效用达到最大值。为了选择出最合适的候选组合,文献[11]讨论了如何确定可考虑不同QoS类别的标准,并开发出一些特定的启发式算法来解决服务组合问题。文献[12]提出了一种采用路径模板编码机制的遗传算法来解决多路径全局优化问题,在算法的收敛性与复杂度方面有所提升。在文献[13]中,O-QSC问题被建模为具有一个多项式数变量和约束的混合整数型线性规划,但它要求目标函数是线性的,且时间复杂度较高。GO方法适应性强,可以获得最优或次优解,容易满足全局约束,但时间复杂度较高。
为了综合LO方法和GO方法的优点,文献[25-26]采用了QCD方法。QCD过程旨在把全局约束分解为与组合服务任务相关联的局部约束集,但其主要思想是全局约束和用户喜好能引导着丢弃那些质量比预期的最小质量还要小的Web服务。文献[25]仅考虑了顺序模式的工作流以及和类型的QoS属性。
可见,当前O-QSC方法存在以下一个或多个不足:1) 算法效率不高或者效用不佳;2) 仅针对顺序工作流或某个具体的工作流;3) 未考虑组合服务运行异常时的自治愈能力。为此,本文提出了一种带有一定自治愈能力的基于Top-k优选的服务组合方法,主要贡献包括:1) 给出了一种正则工作流的形式定义,为自动处理工作流奠定了基础;2) 给出了一种高效的QoS感知的Web服务组合方法,可以以较小的时间复杂度获得较优的组合方案;3) 可以为所选组合方案所涉及的每个服务寻找备用服务集,具备一定的自治愈能力。
-
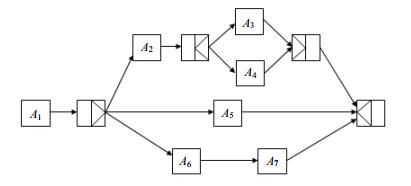
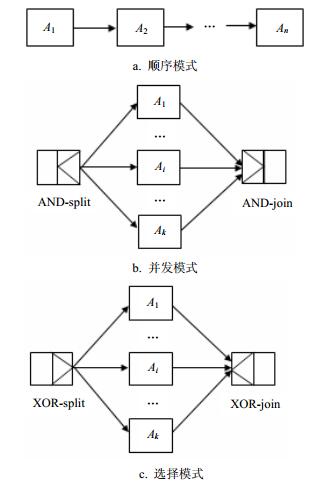
工作流描述了服务功能的结合方式以满足用户需求[29]。在工作流中,一个任务代表功能相同的一系列Web服务,一种模式代表不同任务之间的依赖关系[13]。与文献[13]一样,本文将考虑顺序模式 (SEQ)、并发模式 (AND) 以及选择模式 (XOR) 等3种常见模式 (如图 1),其中Ai代表某个任务,AND-split、AND-join分别表示并发模式的起点与终点,XOR-split、XOR-join分别表示选择模式的起点与终点。

图 1 工作流基本模式
-
常见的复杂工作流由以上3种模式 (顺序、并发、选择) 经过有限次的连接嵌套而成。如果分别用⊙,⊕和⊗来表示SEQ、AND和XOR模式,那么常见的复杂工作流可递归定义为:
1) 当A和B是任务时,(A⊙B)、(A⊕B) 和 (A⊗B) 是工作流;
2) 当P和Q是工作流时,(P⊙Q)、(P⊕Q) 和 (P⊗Q) 也是工作流;
3) 当A是一个任务,P是一个工作流时,(A⊙P)、(A⊕P) 和 (A⊗P) 是工作流。
由此,一个复杂工作流可以表示为一个符号串。以图 2所描述的旅行规划工作流[13]为例,它可以表示为 (A1⊙((A2⊙(A3⊕A4))⊗A5⊗(A6⊙A7)))。

图 2 复杂工作流的例子
-
为了描述方便,将一个任务看作一个二元组A < ID, SG > ,ID是一个用来唯一确定A的标识符,SG是执行任务A的所有Web服务的集合。当用一个符号串来表示一个工作流时,串中任何一对小括号可描述该工作流的一个子工作流,可将其看成一个虚拟任务,并描述为一个三元组VA < ID, SG, UA > ,ID是用来唯一确定VA的标识符,SG表示其所有实例的集合,UA表示其所涉及的任务的集合。
用Q(s)= (q1(s), q2(s), …, qr(s)) 表示服务s的QoS属性,其中qi(s) 决定了s的第i个属性的值。设A1、A2为两个任务,@表示某种模式,则 (A1@A2) 可合并成一个虚拟任务VA < ID, SG, UA > ,其中VA.ID=A1.ID +A2.ID;VA.SG={cs1@cs2|cs1∈A1.SG and cs2∈A2.SG},qi(cs1@cs2) = fk(qi(cs1), qi(cs2)),fk(x, y) 是一个聚合函数 (见表 1);VA.UA={A, B}。该合并过程也可以用于两个虚拟任务或一个虚拟任务与一个任务之间。
表 1 聚合函数的定义
QoS属性 顺序 并发 选择 响应时间 q(x)+q(y) max{q(x), q(y)} (q(x)+q(y))/2 吞吐量 min{q(x), q(y)} max{q(x), q(y)} (q(x)+q(y))/2 可靠性 q(x)q(y) q(x)q(y) (q(x)+q(y))/2 VA.UA中的每个元素代表了可完成VA的一个虚拟任务vs,其效用函数可用式 (1) 定义:
$$ U(\text{vs})=\sum\limits_{i=1}^{r}{{{w}_{i}}\times \text{s}{{\text{q}}_{i}}(\text{vs})} $$ (1) 式中,wi≥0且$ \sum\limits_{i=1}^{r}{{{w}_{i}}=1}$,sqi(vs) 为vs的第i个QoS属性的归一化值,由式 (2) 定义:
$$ \begin{align} &\ \ \ \ \ \ \ \ \ \ \ \ \text{s}{{\text{q}}_{i}}(\text{vs})= \\ &\left\{ \begin{matrix} \frac{q\max (\text{VA}, i)-{{q}_{i}}(\text{vs})}{q\max (\text{VA}, i)-q\min (\text{VA}, i)}\text{ }{{q}_{i}}为消极属性 \\ \frac{{{q}_{i}}(\text{vs})-q\min (\text{VA}, i)}{q\max (\text{VA}, i)-q\min (\text{VA}, i)}\text{ }{{q}_{i}}为积极属性 \\ \end{matrix} \right. \\ \end{align} $$ (2) 式中,qmax (VA, i)、qmin (VA, i) 分别为VA.UA中第i个QoS属性的最大值与最小值。当qmax (VA, i) = qmin (VA, i) 时,sqi(vs) 取值为1。
-
根据工作流及虚拟任务的描述,O-QSC问题可以看成是从里到外的一系列虚拟任务的合并过程。以串 ((A⊙B)⊕(C⊗D)) 为例,可将 (A⊙B) 合并为V1,(C⊗D) 合并为V2,再将 (V1⊕V2) 合并为V3,最后从V3.SG中优选一个组合实例。若某工作流涉及n个任务,每个任务有m个候选服务,则最后生成的虚拟任务将有mn个候选服务,仍为指数形式的时空复杂度。本文采用的Top-k方法则是在每次合并虚拟任务时,仅为其保留k个最优的实例。该过程可由算法1描述。
若用合并虚拟任务的次数来度量算法1的时间复杂度,显然为O(n)。考虑到每次合成虚拟任务时,需要从m2或mxk或k2个组合实例中优选k个,若采用先排序后选择的策略,且k < m,则算法1的时间复杂度可达到O(nmlog2m)。合并过程中,算法1将产生的所有虚拟任务依次保存于虚拟任务列表 (VAL) 中,它将作为算法2的输入之一。
算法1:Top-k服务组合
输入:描述工作流的串OL及k值
输出:组合实例cs及虚拟任务列表VAL
Initial an object stack OS;
for each object in OL
{
if (object!= “)”)
OS.push (object);
else
{
A1=OS.pop ();
Pattern = OS.pop ();
A2=OS.pop ();
OS.pop ();
VA←Combine (A1, Pattern, A2);
OS.push (VA);
VAL.add (VA);
}
}
VA←OS.pop ();
from CS (VA), search the cs with best utility;
return cs
-
基于案例推理 (case-based reasoning, CBR) 策略,文献[30]提出了一种自治愈框架,其中一个关键问题就是当组合方案中的某个服务运行出现异常时,如何高效地为其寻找到一个合适的替代服务。尽管算法1实际上可以给出k组组合方案,但这些组合方案往往都涉及某些服务,当这些服务中的某个出现异常时,就不能相互替换了。因此,本文通过算法2为组合方案中涉及的每个服务寻找一个替代服务,其中cs (A) 表示任务A的候选服务集,UCS (cs) 表示组合实例cs涉及的原子服务的集合。该算法基于如下的假设:对于一个虚拟任务的两个优选候选服务,如果它们所涉及的原子服务中仅有一对是不相同的,则这对原子服务是可以相互替换的。例如,对于工作流 (P⊙A),若存在优选的组合实例 (P11, A11) 与 (P11, A12),则A11与A12是可替换的。
设一个虚拟任务的优选候选服务个数为k,它们可以形成k(k-1)/2对服务组合,故算法2的时间复杂度为O (nk2),n为工作流中涉及的任务个数。该算法并不能总为每个服务寻找到至少一个可替代服务,但当k稍大时,能够成功找到的概率是很大的,后面的测试将证明这一点。
算法2:寻找替换服务
输入:组合实例cs,虚拟任务列表VAL
输出:替换服务列表AS
For each WSi appeared in cs
{
Look for At where cs (At)∋WSi;
From VAL, search the first VAj which
combined by At in turn;
For each pair of cs1 and cs2 in CS (VAj)
If ((UCS (cs1)–UCS (cs2)) == {WSi} then
add UCS (cs2) – UCS (cs1) to ASi.
}
Return AS
-
为了验证该方法的有效性,本文分别从k值对效用值的影响、算法的求解质量、时间开销以及可替代性能4个方面进行分析。
-
该实验是在一台拥有Intel (R) Core (TM) i5-2 430 M、2.4 GHz Intel Xeon双核处理器、4 GB RAM、Win7操作系统的Lenovo PC机上实现的,实验代码用Java 7编写。测试时,包含顺序、选择和并发模式的复杂工作流是随机产生的,其中并发、选择模式的数量各占1/4。分配给每个候选Web服务的QoS值来源于QWS数据集[31-32],它包含了2 508个真实Web服务,每个服务拥有10个质量属性,测试时选用了具有代表性的响应时间、吞吐量、可靠性等3个属性。每种规模测试20次后取平均值。
-
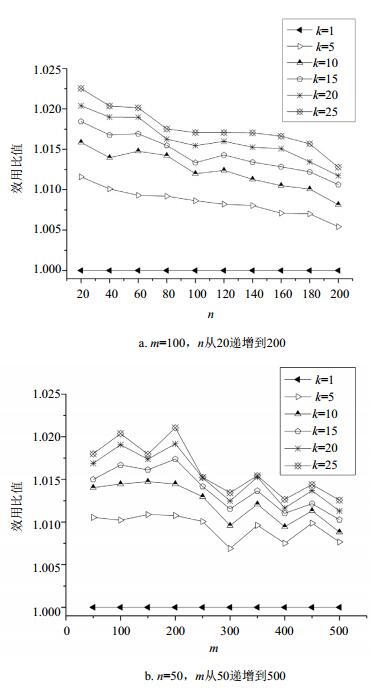
图 3为不同规模、不同k值时的效用,为了使不同情况下效用值的对比效果更明显,突出k值对效用的影响,这里以k=1时的效用值为参考标准 (即设k=1时的效用比值为1),其它k值时的效用比值为其实际效用值与k=1时的实际效用值之比。从图中可以看出:1) 相同问题规模下,效用比值随k值的增大而缓慢增大;2) 当k=10时,已经可以得到较为理想的优化效果;3) 同样的k值时,效用随问题规模的增大而略有降低。

图 3 不同k值下的效用比值
-
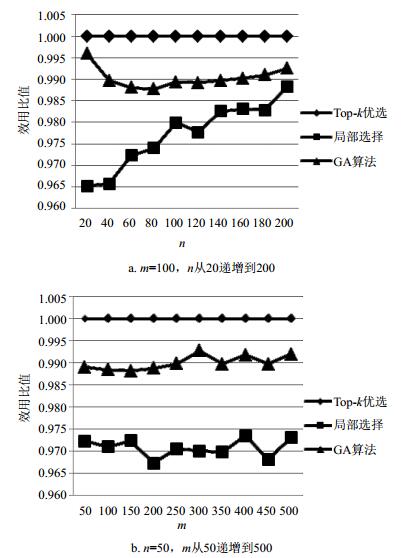
图 4对不同问题规模下Top-k优选 (k=10)、局部选择、遗传算法 (genetic algorithm, GA) 等3种方法的效用值进行了比较。该图的纵坐标是以Top-10方法得到的效用值为参考标准的,即设Top-k方法的效用比值为1,而其它情况为其效用值与Top-10方法效用值之比。从图中可以看出,Top-k优选的效用值明显高于局部选择算法和GA算法。

图 4 算法求解质量的比较
-
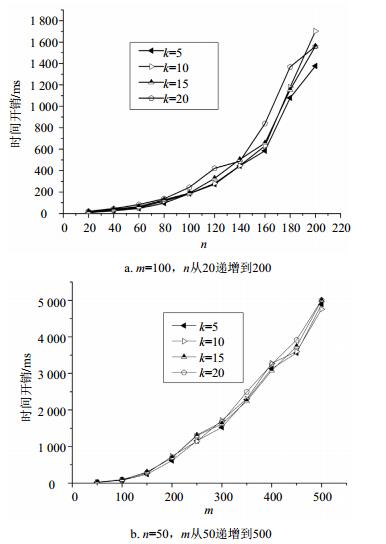
图 5给出了不同k值、不同规模下,Top-k方法的时间开销情况。从中可以发现,该方法的时间开销大致与n2、m2成正比,与k值关联不大。测试代码仍有一定优化空间,整体时间开销较为理想。

图 5 不同k值下的时间开销
-
本文从能够寻找到替代方案的概率r/t(r表示方案中所提到的Web服务个数,t表示至少寻找到一个可替代服务的Web服务个数) 及替代方案的质量两个方面评价算法的可替代性能。
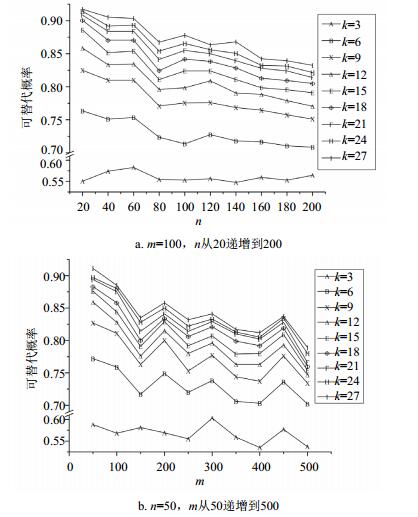
从图 6可以看出,可替代概率随k值的增大而增大;当k=12时,该概率可达80%。

图 6 不同k值下的可替代概率
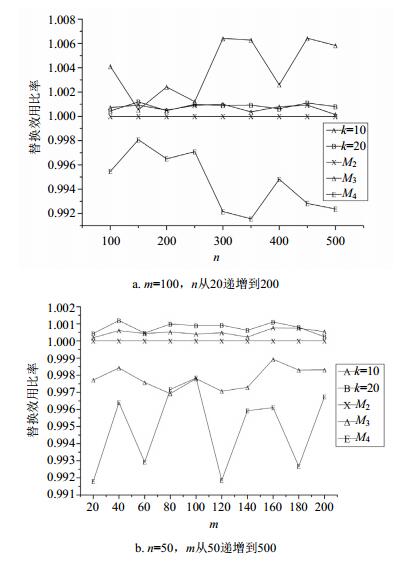
在替代方案的质量测试中,本文将k=10、k=20时的替代效果与M2(局部最优)、M3(QoS效用差距最小[30])、M4(随机选择)3种情况进行了比较 (见图 7,以M2的效用值作为参考)。M2是选择候选服务中综合效用最高的 (局部最优),M3是选择候选服务中与需要替换的服务的QoS差距最小的,M4是从候选服务中随机选择。该算法的效果略优于其他算法。

图 7 替代效果的比较
-
通过将工作流描述为一个符号串,本文提出了一种由里及外逐步合并虚拟任务的Web服务组合方法;为了降低时空复杂度,在每次合并虚拟任务时采用了Top-k优选策略。这种方法兼顾了局部优选与全局优选的特点,可以以较小的时间复杂度获得较优的组合方案。同时,本文给出了一种新的寻找可替换服务的算法,支持一定的自治愈能力。
A Self-Healing QoS-Aware Web Service Composition Method
-
摘要: 基于工作流的服务质量(QoS)感知的Web服务组合是Web服务领域的一个研究热点,其目标是选择一个满足QoS约束且QoS效用最大的组合服务。该文给出了常见工作流的一种形式化定义方法及虚拟任务的合成规则,从而提出了一种基于top-k优选策略的Web服务组合方法,其核心思想是递归运用虚拟任务的合成规则将原工作流转换成一个虚拟任务,并在每次合成虚拟任务时,仅为其保留k个优选的服务或组合服务实例。该文还提出了一种新的寻找替换服务的方法以支持自治愈性。仿真实验分析了k值对效用的影响、算法的效用与时间开销以及可替代性能。Abstract: The quality of service (QoS)-aware web service composition problem is a research hotspot. Its objective is to select a composite service which can maximizes the QoS utility while preserving QoS constraints. By giving the definition of usual workflow and the combination rule of virtual tasks, a top-k based web service composition approach is proposed. Its core idea is to transform the original workflow into a virtual task by recursively calling the combination rule of virtual tasks. Moreover, a new scheme is presented to select suitable replaceable services to support the self-healing property. The effectiveness of the k value and the performances of algorithms are analyzed through simulation experiments.
-
Key words:
- QoS-aware /
- self-healing /
- service composition /
- top-k optimization
-
表 1 聚合函数的定义
QoS属性 顺序 并发 选择 响应时间 q(x)+q(y) max{q(x), q(y)} (q(x)+q(y))/2 吞吐量 min{q(x), q(y)} max{q(x), q(y)} (q(x)+q(y))/2 可靠性 q(x)q(y) q(x)q(y) (q(x)+q(y))/2  下载: 导出CSV
下载: 导出CSV
-
[1] LIU Xuan-zhe, HUANG Gang, HONG Mei. Discovering homogeneous web service community in the user-centric web environment[J]. IEEE Transaction on Services Computing, 2009, 2(2): 167-181. doi: 10.1109/TSC.2009.11 [2] 张佩云, 黄波, 孙亚民.面向服务组合的服务语义匹配机制[J].电子科技大学学报, 2008, 37(6): 917-921. http://www.cnki.com.cn/Article/CJFDTOTAL-DKDX200806033.htm ZHANG Pei-yun, HUANG Bo, SUN Ya-min. Service semantic matching mechanism for web services composition[J]. Journal of University of Electronic Science and Technology of China, 2008, 37(6): 917-921. http://www.cnki.com.cn/Article/CJFDTOTAL-DKDX200806033.htm [3] ZOU Guo-bing, LU Qiang, CHEN Yi-xin, et al. QoS-Aware dynamic composition of web services using numerical temporal planning[J]. IEEE Transactions on Services Computing, 2014, 7(1): 18-31. doi: 10.1109/TSC.2012.27 [4] WANG Peng-wei, DING Zhi-jun, JIANG Chang-jun, et al. Constraint-aware approach to web service composition[J]. IEEE Transactions on Systems Man & Cybernetics Systems, 2014, 44(6): 770-784. http://ieeexplore.ieee.org/document/6637082/ [5] 陈文宇, 张忠全, 向涛, 等.基于相似度的语义Web服务发现技术研究[J].电子科技大学学报, 2010, 39(6): 896-899. http://www.juestc.uestc.edu.cn/CN/abstract/abstract1217.shtml CHEN Wen-yu, ZHANG Zhong-quan, XIANG Tao, et al. Research on similarity-based semantic web services discovery[J]. Journal of University of Electronic Science and Technology of China, 2010, 39(6): 896-899. http://www.juestc.uestc.edu.cn/CN/abstract/abstract1217.shtml [6] YU Tao, ZHANG Yue, LIN Kwei-jay. Efficient algorithms for web services selection with end-to-end QoS constraints[J]. ACM Transactions on the Web Service, 2007, 1(1): 1-26. doi: 10.1145/1232722 [7] ARDAGNA D, PERNICI B. Adaptive service composition in flexible processes[J]. IEEE Transactions on Software Engineering, 2007, 33(6): 369-384. doi: 10.1109/TSE.2007.1011 [8] ZENG Liang-zhao, BENATALLAH B, DUMAS M, et al. QoS-aware middleware for web services composition[J]. IEEE Transactions Software Engineering, 2004, 30(5): 311-327. doi: 10.1109/TSE.2004.11 [9] ALRIFAI M, RISSE T. Combining global optimization with local selection for efficient QoS-aware service composition[C]//Proceedings of the 18th International Conference on World Wide Web. New York: ACM, 2009: 881-890. [10] LUO Yuan-sheng, QI Yong, HOU Di, et al. A novel heuristic algorithm for QoS-aware end-to-end service composition[J]. Computer Communications, 2011, 34(9): 1137-1144. doi: 10.1016/j.comcom.2010.02.028 [11] JAEGER M C, MUHL G, GOLZE S. QoS-aware composition of web services: an evaluation of selection algorithms[C]//OTM Confederated International Conference. Berlin Heidelberg: Springer, 2005: 646-661. [12] 冯建周, 孔立富.基于QoS的Web服务组合中多路径全局优化方法的研究[J].小型微型计算机系统, 2013, 34(7): 1493-1497. http://www.cnki.com.cn/Article/CJFDTOTAL-XXWX201307008.htm FENG Jian-zhou, KONG Li-fu. Research on the method of multi-path global optimization in QoS-based Web service composition[J]. Journal of Chinese Computer Systems, 2013, 34(7): 1493-1497. http://www.cnki.com.cn/Article/CJFDTOTAL-XXWX201307008.htm [13] GABREL V, MANOUVRIER M, MURAT C. Web services composition: Complexity and models[J]. Discrete Applied Mathematics, 2014, 196(2): 67-82. https://www.researchgate.net/publication/268694169_Web_services_composition_Complexity_and_models [14] KLEIN A, ISHIKAWA F, HONIDEN S. Efficient heuristic approach with improved time complexity for QoS-aware service composition[C]//IEEE International Conference on Web Services. Washington, USA: IEEE Computer Society, 2011: 436-443. [15] DING Zhi-jun, LIU Jun-jun, SUN You-qing, et al. A transaction and QoS-aware service selection approach based on genetic algorithm[J]. IEEE Transactions on Systems Man & Cybernetics Systems, 2015, 45(7): 1035-1046. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7047222&punumber%3D6221021 [16] YU Yang, MA Hui, ZHANG Meng-jie. An adaptive genetic programming approach to QoS-aware web services composition[C]//IEEE Congress on Evolutionary Computation. Cancun: IEEE Computer Society, 2013: 1740-1747. [17] 温涛, 盛国军, 郭权, 等.基于改进粒子群算法的Web服务组合[J].计算机学报, 2013, 36(5): 1031-1046. http://cdmd.cnki.com.cn/Article/CDMD-10357-1016128003.htm WEN Tao, SHENG Guo-jun, GUO Quan, et al. Web service composition based on modified particle swarm optimization[J]. Chinese Journal of Computers, 2013, 36(5): 1031-1046. http://cdmd.cnki.com.cn/Article/CDMD-10357-1016128003.htm [18] YU Qing, CHEN Ling, LI Bin. Ant colony optimization applied to web service compositions in cloud computing[J]. Computer and Electrical Engineering, 2015, 41(1): 18-27. https://www.researchgate.net/publication/270398167_Ant_colony_optimization_applied_to_web_service_compositions_in_cloud_computing [19] YILMAZ A E, KARAGOZ P. Improved genetic algorithm based approach for QoS aware web service composition[C]//IEEE International Conference on Web Services. Anchorage: IEEE Computer Society, 2014: 463-470. [20] 张燕平, 荆紫慧, 张以文, 等.基于离散粒子群算法的动态Web服务组合[J].计算机科学, 2015, 42(6): 71-75. doi: 10.11896/j.issn.1002-137X.2015.06.016 ZHANG Yan-ping, JING Zi-hui, ZHANG Yi-wen, et al. Dynamic web service composition based on discrete particle swarm optimization[J]. Computer Science, 2015, 42(6): 71-75. doi: 10.11896/j.issn.1002-137X.2015.06.016 [21] YIN Hao, ZHANG Chang-sheng, GUO Ying, et al. An improved evolutionary multiobjective service composition algorithm[C]//The International Symposium on Computational Intelligence and Design. Hangzhou, China: IEEE, 2013, 1: 269-272. [22] 苏凯, 马良荔, 郭晓明, 等.一种QoS感知的服务全局优化选择算法[J].华中科技大学学报 (自然科学版), 2014, 42(4): 72-76. http://www.cnki.com.cn/Article/CJFDTOTAL-HZLG201404016.htm SU Kai, MA Liang-li, GUO Xiao-ming, et al. QoS-aware service selection global optimization algorithm[J]. Journal of Huazhong University of Science and Technology. (Natural Science Edition), 2014, 42(4): 72-76. http://www.cnki.com.cn/Article/CJFDTOTAL-HZLG201404016.htm [23] ZHANG Wei, CHANG C K, FENG Tai-ming, et al. QoS-based dynamic web service composition with ant colony optimization[C]//37th Annual IEEE International Computer Software and Applications Conference. Seoul: IEEE Computer Society, 2010: 493-502. [24] 夏亚梅, 程渤, 陈俊亮, 等.基于改进蚁群算法的服务组合优化[J].计算机学报, 2012, 35(2): 270-281. http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201202009.htm XIA Ya-mei, CHENG Bo, CHEN Jun-liang, et al. Optimizing services composition based on improved ant colony algorithm[J]. Chinese Journal of Computers, 2012, 35(2): 270-281. http://www.cnki.com.cn/Article/CJFDTOTAL-JSJX201202009.htm [25] 王尚广, 孙其博, 杨放春.基于全局QoS约束分解的Web服务动态选择[J].软件学报, 2011, 22(7): 1426-1439. http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201107001.htm WANG Shang-guang, SUN Qi-bo, YANG Fang-chun. Web service dynamic selection by the decomposition of global QoS constraints[J]. Journal of Software, 2011, 22(7): 1426-1439. http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201107001.htm [26] MARDUKHI F, NEMATBAKHSH N, ZAMANIFAR K, et al. QoS decomposition for service composition using genetic algorithm[J]. Applied Soft Computing, 2013, 6(5): 3409-3421. https://www.researchgate.net/publication/257636146_QoS_decomposition_for_service_composition_using_genetic_algorithm [27] SUN S X, ZHAO Jing. A decomposition-based approach for service composition with global QoS guarantees[J]. Information Sciences, 2012, 199(15): 138-153. https://www.researchgate.net/publication/256721040_A_Decomposition-based_Approach_for_Service_Composition_with_Global_QoS_Guarantees [28] LIU Zhi-zhong, XUE Xiao, SHEN Ji-quan, et al. Web service dynamic composition based on decomposition of global QoS constraints[J]. Int J Adv Manuf Technol, 2013, 69(9): 2247-2260. https://www.researchgate.net/publication/257337913_Web_service_dynamic_composition_based_on_decomposition_of_global_QoS_constraints [29] TAN Wei, ZHOU Meng-chu. Business and scientific workflow: a web service-oriented approach[M]. IEEE Press Series on Systems Science and Engineering. Wiley: IEEE, 2013. [30] LI Guo-qiang, LIAO Le-jian, SONG Dan-dan, et al. A fault-tolerant framework for QoS-aware web service composition via case-based reasoning[J]. International Journal of Web and Grid Services, 2014, 10(1): 88-99. http://www.inderscience.com/link.php?id=58764 [31] AL-MASRIE E, MAHMOUD Q H. Discovering the best web service[C]//Proceedings of the 16th International Conference on World Wide Web. New York: ACM, 2007: 1257-1258. [32] AL-MASRI E, MAHMOUD Q H. QoS-based discovery and ranking of web services[C]//Proceedings of the 16th International Conference on Computer Communications and Networks. Honolulu: IEEE, 2007: 529-534. -

 点击查看大图
点击查看大图
图(7) / 表(1)
计量
- 文章访问数: 3866
- HTML全文浏览量: 1261
- PDF下载量: 100
- 被引次数: 0
