 ISSN
ISSN 



-
前景目标检测是计算机视觉领域最基础的研究课题之一,其检测效果对视频图像的后期处理质量有着极为重要的影响。目前较为主流的检测方法包括帧间差分法[1-2]、光流法[3-4]和背景减除法[5-6],其中,背景减除法最为常用。
背景减除法的核心任务是构建准确性高、适应性强的背景模型。高斯(含混合高斯)背景建模法通过对每个像素进行高斯统计建模,能够较好地刻画背景的统计特性并能对环境噪声有较强的适应能力。但其不足在于因复杂度高导致的大运算量以及多参数的求解问题[7-8],因此处理高分辨率视频流的时间消耗较大。基于模本的背景建模法通过对每个像素点在时间序列上的颜色扭曲度以及亮度信息构建码本模型,具有计算量和内存占用都较小的优势。随着码本模型的应用,近年也产生了多种改进的码本模型算法以提高其检测准确度或者算法效率。将传统的RGB空间转换为YUV空间进行码字描述[9-10],以及对码字快速排序以提高首次匹配成功率[11-12]的方法可提高算法实时性。文献[13]采用mean-shift进行码字更新提高了目标检测的准确度,通过对码字结构进行简化运算后可以减少内存消耗[14]。文献[15]通过自适应学习颜色畸变与亮度边界参数的改进也提高了前景检测准确率。上述码本模型算法虽然在提高检测速度、降低资源占用率等方面有所改进,但在处理高分辨率视频时的实时性指标方面仍有待进一步改善,特别是在计算性能与资源有限的嵌入式视频处理平台中的应用还有一定差距。
为进一步提高码本算法的检测效率,本文提出了融合超像素分割的码本模型,将传统的以像素为处理单元的方法转化为以具有相似特征的超像素为处理单元的码本构建方法,一方面可以抑制局部噪声的干扰,另一方面可以明显减小码本数量。在多组视频流数据上的实验结果表明,本文方法在保持前景检测准确率的情况下(甚至在前景检测率上略有提升),不仅显著提高了算法的运算速度,还降低了内存的占用率,特别是在基于DM6437的嵌入式视频处理平台上能显著提高检测效率,达到实时检测的效果。
-
经典码本模型是在RGB空间上对像素的颜色距离和亮度范围进行量化并以此作为码字产生的依据。由于基于RGB空间算法的时间复杂度较高,本文研究采用了更为高效的YUV空间进行颜色表示。
假设n帧视频序列中同一像素点的采样值为序列 $X = \{ {x_1},{x_2}, \cdots ,{x_N}\} $ , ${x_t}(t = 1,2, \cdots ,N)$ 表示t时刻该像素的观察值,某一个像素点的码本表示为 $C = \{ {c_1},{c_2}, \cdots ,{c_L}\} $ 。本文对每个码字结构的设计如下:包含一个二维向量 ${\mathit{\boldsymbol{v}}_i} = (\overline {{\rm{Cb}}} ,\overline {{\rm{Cr}}} )$ 和 ${\rm{au}}{{\rm{x}}_i} = < {\tilde I_i},{\hat I_i},{f_i},{\lambda _i},{p_i},{q_i} > $ ,其中各个元素的意义为:码字中的像素点的最小亮度值和最大亮度值由 ${\tilde I_i},{\hat I_i}$ 表示;码字匹配成功的次数由fi表示,fi的值通过pi和qi计算,码字第一次出现的时刻由pi表示,最后一次出现的时刻由qi表示,λi是该码字没有出现的最大消极步长阈值。
基于上述码本结构,对训练视频流码本模型的训练过程如下:
1) 对视频帧的每一个像素点建立一个空码本;
2) 对于输入的第1帧视频,给每个像素点建立码本的第一个码字;
3) 对于输入的第n帧视频,对某一个像素点xt,得到其亮度值I以后,判断该码字是否与码本中现有的码字匹配,匹配条件如下:
$${\rm{colordist}}({x_t},{v_t}) \le {\varepsilon _1}$$ (1) $${\rm{brightness}}(I, < {\tilde I_m},{\hat I_m} > ) = {\rm{true}}$$ (2) 式中, ${\rm{colordist}}({x_t},{v_t})$ 判据计算方式为:
$$I = \left\| {{x_t}} \right\| = Y$$ (3) $$\left\| {{v_t}} \right\| = \sqrt {{\rm{C}}{{\rm{b}}^2} + {\rm{C}}{{\rm{r}}^2}} $$ (4) $$ < {x_t},{v_t} > = ({\rm{Cb}}\overline {{\rm{Cb}}} + {\rm{Cr}}\overline {{\rm{Cr}}} )$$ (5) $${{p}^{2}}={{\left\| {{x}_{t}} \right\|}^{2}}{{\cos }^{2}}\theta ={<{{x}_{t}},{{v}_{t}}{{>}^{2}}}/{{{\left\| {{v}_{t}} \right\|}^{2}}}\;$$ (6) 颜色判据公式和亮度判据为:
$${\rm{colordist}}({x_t},{v_t}) = \sigma = \sqrt {{{\left\| {{x_t}} \right\|}^2} - {p^2}} $$ (7) $${\rm{brightness}}(I, < {\tilde I_m},{\hat I_m} > ) = \left\{ \begin{array}{l} {\rm{true }}\;\;\;{\rm{ }}{{\tilde I}_m} \le I \le {{\hat I}_m}\\ {\rm{false 其他}} \end{array} \right.$$ (8) 4) 如果与其对应的码本模型中没有码字或没有与之匹配的码字,则需要在此码本背景模型中新建一个码字Cl存储当前帧图像所包含的信息:
$${v_l} = ({\rm{C}}{{\rm{b}}_l},{\rm{C}}{{\rm{r}}_l})$$ (9) $${\rm{au}}{{\rm{x}}_l} = < I,I,1,t - 1,t,t > $$ (10) 5) 如检测到与像素点通道值匹配的码字Cm,则需更新Cm,Cm的YUV向量和aux分别更新为:
$${v_m} = \left[ {\frac{{{f_m}{{\overline {{\rm{Cb}}} }_m} + {\rm{C}}{{\rm{b}}_t}}}{{{f_m} + 1}},\frac{{{f_m}{{\overline {{\rm{Cr}}} }_m} + {\rm{C}}{{\rm{r}}_t}}}{{{f_m} + 1}}} \right]$$ (11) $$\begin{array}{c} {\rm{au}}{{\rm{x}}_m} = < \min (I,{{\tilde I}_m}),\max (I,{{\hat I}_m}),{f_m} + \\ 1,\max ({\lambda _{m,}},t - {q_m}),{p_m},t > \end{array}$$ (12) 6) 如果某消极码字再次被使用的最大时间间隔大于最大消极步长λi,则该码字为陈旧码字,需从码本中删除。
-
上述的码本模型是对视频帧中的每一个像素进行建模,而视频帧中物理上相邻的像素之间可能具有较为相似的颜色等特征分布,因此上述方法建立的多个码本间存在冗余关系。特别是对分辨率较高的视频流,这种冗余对存储空间以及处理时间都是一种浪费。因此,本文研究提出了融合超像素分割的思想进行码本建模。
超像素的概念最早由文献[16]提出,其核心定义是指在纹理及颜色等特征上具有局部一致性,且能够保持一定局部结构特征的图像块。在视频分析中,以这些图像块作为独立单元可降低图像的冗余信息,进而降低处理对象的规模以及后续高级处理的复杂度。
为便于码本模型的构建,超像素分割后的图像块的数量应该尽量可控,且超像素序列的大小均匀、方差小。为此,本文研究引入了基于颜色相似度和空间距离关系的局部迭代聚类算法(simple linear iterative clustering, SLIC)[17]进行超像素的划分。SLIC算法一方面能够较好地平衡超像素边缘贴合度和紧密度两种特性,还能优化超像素生成数,实现超像素数量可控。
SLIC采用五维空间的特征向量定义原始像素,五维特征向量V = [l, a, b, x y],其中每个像素点的像素值信息由[l, a, b]表征,像素点的颜色信息有多种表示方式,本文的颜色信息采用CIELAB颜色空间表示,[x y]代表每个像素在图像中的位置坐标。
其算法流程为:
1) 设定聚类中心数K(即超像素的个数)。根据超像素的个数,得到每个超像素块预包含的原始像素个数S=N/K,N为原始像素总数。一般而言,K可以取较大值,直到聚类结果出现一定程度的饱和为止。
2) 聚类所有像素点。计算待归类的像素点与聚类中心的距离Ds,并将其聚类到距离最小的中心。更新聚类中心以后不断迭代,直到两次求得的新聚类中心的坐标不变为止。距离度量Ds的定义为:
$${D_s} = {d_{{\rm{lab}}}} + \frac{m}{S}{d_{xy}}$$ (13) 式中,dlab表示颜色距离,dxy代表空间距离,二者综合决定Ds的值;变量m控制dxy的权重,m值影响分割后各个超像素块的紧凑性。当期望聚类结果物理上更紧凑时,m取较大值;当期望聚类结果的颜色分离性更好时,m取较小值,有:
$${d_{{\rm{lab}}}} = \sqrt {{{({l_k} - {l_i})}^2} + {{({a_k} - {a_i})}^2} + {{({b_k} - {b_i})}^2}} $$ (14) $${d_{xy}} = \sqrt {{{({x_k} - {x_i})}^2} + {{({y_k} - {y_i})}^2}} $$ (15) 式中,k和i表示两个不同的像素点。基于SLIC分割算法的码本模型算法的伪代码如图 1所示。

图 1 融合超像素分割的码本模型伪代码
-
为适应光线变化导致的干扰,以及较长时间不动的前景应视为背景等多种因素的影响,需要将不再发生变化的前景更新到背景模型,实现更为准确的前景目标检测。
-
码本背景模型的更新通过缓存Cache的更新实现。在前景目标检测阶段,给每个超像素块建立一个缓存Cache来存储前景码本。码本更新的策略为:
1) 建立并初始化基于超像素的前景码本;
2) 对于超像素块M,被判断为前景后与该Cache码本进行比较,如果与现有码字匹配则更新该码字,如果与现有码字不匹配则增加该码字;
3) 如果新的码字在Cache中存放的时间大于阈值Tadd,或者旧的码字在Cache中存放的时间超过Tdel且近段时间没有被匹配,则将该码字从Cache中去除,放入该超像素背景码本中。
-
对每一帧待检测的视频流完成码本模型对比后,匹配成功的为背景,不成功的为前景。即完成前景目标的检测,得到离散的、形状大致与目标一致的前景区域,进一步对结果进行腐蚀膨胀处理后得到完整的二值图。
-
为验证本文提出的融合超像素分割的码本模型在前景目标检测中的性能,选取了CDnet数据库[18]中的室内(Office, 320*240)、室外单目标(Badweather, 540*360) 以及室外多目标(Skating, 540*360)3类场景视频进行了分析。
-
本文从前景检测的准确性、数据处理的实时性以及对存储资源占用率3个方面对前景检测算法的效果进行了分析。
前景检测的准确性是指经过算法处理后检测到的前景和背景区域在多大程度上接近真实结果。常用的反映准确性的指标包括:
1) 前景检测率FDR(foreground detection rate):
$${\rm{FDR}} = \frac{{{P_{{\rm{fg}}}} \cap {P_{{\rm{gt}}}}}}{{{P_{{\rm{fg}}}} \cup {P_{{\rm{gt}}}}}}$$ (16) 式中,Pfg表示算法检测得到的前景区域;Pgt表示真实的前景区域。
2) 正确率(accuracy):
$${\rm{Accuracy}} = \frac{{{\rm{TP}} + {\rm{TN}}}}{{{\rm{TP}} + {\rm{FN}} + {\rm{FP}} + {\rm{TN}}}}$$ (17) 3) F-measure:
$${\rm{F - measure}} = \frac{{2 \times \frac{{{\rm{TP}}}}{{{\rm{TP}} + {\rm{FP}}}}\frac{{{\rm{TP}}}}{{{\rm{TP}} + {\rm{FN}}}}}}{{\frac{{{\rm{TP}}}}{{{\rm{TP}} + {\rm{FP}}}} + \frac{{{\rm{TP}}}}{{{\rm{TP}} + {\rm{FN}}}}}}$$ (18) 算法的实时性主要用处理每帧图像所需要的时间t(秒/帧)来表示,存储资源占用率用算法处理过程中所占用的内存量M(兆)表示。本文基于PC系统的实验测试平台为:CPU是Intel Core i7-4770 3.4 GHz, 内存8 GB,windows7操作系统。软件环境为:Microsoft Visual Studio 6.0,编程语言为C++。算法中涉及的核心参数设置为:聚类中心数K为200,变量m的取值为20。
-
为对比验证本文算法在前景目标检测中的性能,研究对比了码本算法、自适应码本算法[15]针对同样视频流的前景检测效果。
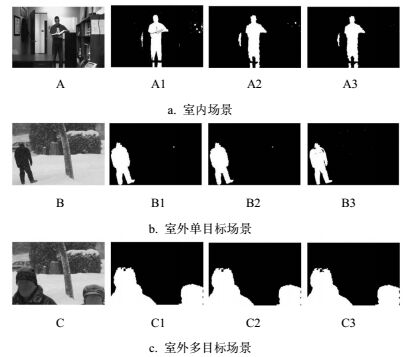
本文所选取的3种场景对应的图像帧如图 2a中的A图、图 2b中的B图与图 2c中的C图所示,码本算法、自适应码本算法以及本文提出的基于超像素的码本算法的前景检测结果分别如图 2a中的A1图、图 2b中的B1图、图 2c中的C1图,图 2a中的A2图、图 2b中的B2图、图 2c中的C2图以及图 2a中的A3图、图 2b中的B3图、图 2c中的C3图所示。由图可见,3种前景检测算法都能较为准确的检测出目标前景,得到较为满意的检测结果,而对于室内场景以及室外单目标场景中由于噪声导致的散点前景,本文算法具有相对较好的抑制作用。

图 2 3种前景检测算法在3类视频场景的代表帧图像上的前景检测结果
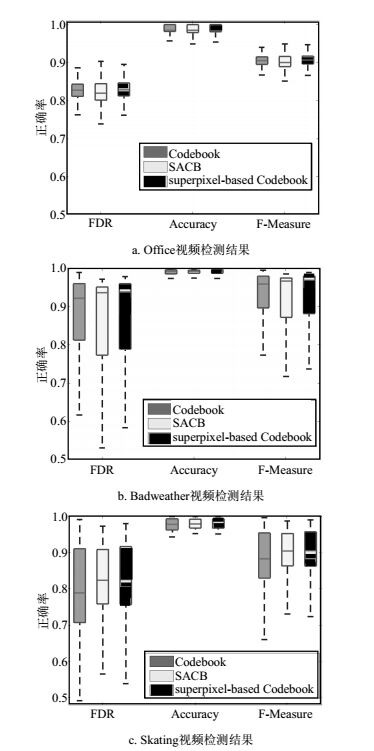
本文进一步比较了3种算法在FDR、正确性以及F-measure3个检测指标的表现情况,结果如图 3所示。由图可见,在3类场景下,3种算法的指标非常接近,本文提出的基于超像素的码本模型在室外场景中的RDR和F-measure指标上略有提高。此外,本文分析了3种算法在处理上述视频流的资源占用率与实时性指标。处理3类视频流时,3种算法的资源占用情况如表 1所示,可以看出,本文算法极大地节约了内存资源。

图 3 3种算法在3类场景中的准确性指标分析
表 1 3种算法在处理3类视频场景下的内存消耗单位:MB
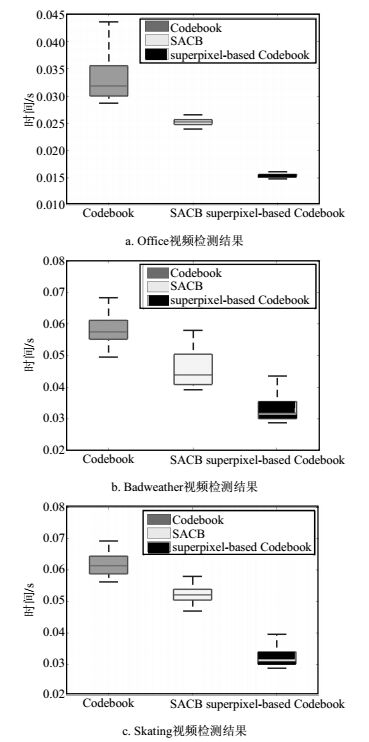
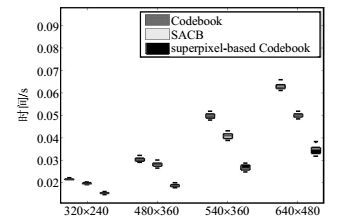
算法 Office Badweather Skating 码本 17.578 44.494 44.521 自适应码本 13.183 33.371 33.372 融合超像素的码本 2.282 3.433 3.434 图 4表征了3种算法处理3类视频流图像帧的平均时间,由图可见,本文提出的结合超像素的码本模型显著提高了每帧图像的处理速度。

图 4 3种算法在3类场景中的耗时对比(PC系统)
以上分析表明,与常用的码本算法以及自适应码本算法相比,本文提出的融合超像素的码本模型的目标检测算法在保持前景检测准确性(甚至略有改善)的前提下,可以显著减少内存占用量,提高每帧图像的处理速度,具有良好的性能优势。
-
为进一步提高码本模型在前景检测中的速度以及降低资源的占用率,本文提出了融合超像素分割的码本模型构建算法。通过对物理空间上具有相似特征的像素点的提取与划分,该方法在一定程度上抑制了局部噪声的干扰,减少了待处理视频帧的处理单元,即减少码本数量,达到显著提高处理速度的目的。基于3类标准数据集的实验结果表明,本文方法不仅在一定程度上提高了检测准确度,还显著提高了算法检测的快速性、降低了内存的使用率,具有良好的应用前景,特别是在嵌入式视频处理平台上具有明显的优势。
超像素分割中的两个关键参数K和m对目标检测的性能具有一定的影响,K的取值一般是几百的量级,而m的取值一般为几十的量级。其具体值的选择与待检测图像的目标形状以及颜色分布组成都有密切联系,实际中需要根据少量代表帧的分割结果进行确定。
当然,本文方法仍然存在一定局限性,如其二值化前景图的边缘不够清晰,对于局部特征变化较大(局部特征相似度不高)的场景效果并不理想。因此,使算法适应局部场景变化以及改善检测结果边缘效果,以进一步提高检测结果准确度是下一步的研究方向。
Object Detection Algorithm Based on the Combination of the Superpixel Segmentation and Codebook Model
-
摘要: 针对码本模型在前景目标检测中的效率有待进一步提高的现状,提出了融合超像素分割的码本构建算法。为减小处理对象的规模,设计了按照颜色及空间相似度聚类原始像素点的思路。以超像素作为码本构建单元,有利于抑制局部噪声并降低码本的冗余度。实验结果表明,融合超像素分割的码本模型算法在保持前景目标检测准确性的情况下,能显著减少视频处理过程中的内存消耗以及提高视频帧处理效率,在基于DM6437的嵌入式处理平台上达到了实时处理的性能。Abstract: A novel codebook model combined with the superpixel segmentation method is proposed in this paper to improve the efficiency of object detection. The original pixels are clustered based on the similarities of both color and location information to reduce the processing cost. Our revised codebook model based on the superpixel could not only suppress the effect of local noise, but also reduce the redundancy of codebook. Simulation results indicate that, our proposed algorithm could reduce the memory consumption and improve the processing speed significantly without sacrificing the detection precision. Our algorithm could implement the object detection in real time in the embedded video processing system based on the DM6437 processor.
-
Key words:
- codebook model /
- detection efficiency /
- embedded platform /
- object detection /
- superpixel segmentation
-
表 1 3种算法在处理3类视频场景下的内存消耗单位:MB
算法 Office Badweather Skating 码本 17.578 44.494 44.521 自适应码本 13.183 33.371 33.372 融合超像素的码本 2.282 3.433 3.434  下载: 导出CSV
下载: 导出CSV
-
[1] HARWOOD I D, DAVIS L W. Real-time surveillance of people and their activities[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(8):809-830. doi: 10.1109/34.868683 [2] 屈晶晶, 辛云宏.连续帧间差分与背景差分相融合的运动目标检测方法[J].光子学报, 2014, 43(7):213-220. http://www.cnki.com.cn/Article/CJFDTOTAL-GZXB201407040.htm QU Jing-jing, XIN Yun-hong. Combined continuous frame difference with background difference method for moving object detection[J]. Acta Photonica Sinica, 2014, 43(7):213-220. http://www.cnki.com.cn/Article/CJFDTOTAL-GZXB201407040.htm [3] ADIV G. Determining three-dimensional motion and structure from optical flow generated by several moving objects[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 1985, PAMI-7(4):384-401. https://www.ncbi.nlm.nih.gov/pubmed/21869277 [4] 魏志强, 纪筱鹏, 冯业伟.基于自适应背景图像更新的运动目标检测方法[J].电子学报, 2005, 33(12):2261-2264. doi: 10.3321/j.issn:0372-2112.2005.12.038 WEI Zhi-qiang, JI Xiao-peng, FENG Ye-wei. A moving object detection method based on self-adaptive updating of background[J]. Acta Electronica Sinica, 2005, 33(12):2261-2264. doi: 10.3321/j.issn:0372-2112.2005.12.038 [5] WREN C R, AZARBAYEJANI A, DARRELL T, et al. Real-time tracking of the human body[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(7):780-785. doi: 10.1109/34.598236 [6] 陈磊, 邹北骥.基于动态阈值对称差分和背景差法的运动对象检测算法[J].计算机应用研究, 2008, 25(2):488-490. http://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ200802053.htm CHEN Lei, ZOU Bei-ji. New algorithm for detecting moving object based on adaptive background subtraction and symmetrical differencing[J]. Application Research of Computers, 2008, 25(2):488-490. http://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ200802053.htm [7] SUHR J K, JUNG H G, LI G, et al. Mixture of Gaussians-based background subtraction for Bayer-pattern image sequences[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2011, 21(3):365-370. https://www.researchgate.net/profile/Gen_Li16/publication/220597834_Mixture_of_Gaussians-Based_Background_Subtraction_for_Bayer-Pattern_Image_Sequences/links/5693772f08aec14fa55e88fa.pdf?origin=publication_detail [8] NGUYEN T M, WU Q M J. Fast and robust spatially constrained Gaussian mixture model for image segmentation[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2013, 23(4):621-635. https://www.researchgate.net/publication/260665267_Fast_and_Robust_Spatially_Constrained_Gaussian_Mixture_Model_for_Image_Segmentation [9] 王雯, 陈丽, 李晨, 等. YUV空间下基于码本模型的视频运动目标检测方法[J].武汉大学学报:工学版, 2015(3):412-416. http://www.cnki.com.cn/Article/CJFDTOTAL-WSDD201503024.htm WANG Wen, CHEN Li, LI Chen, et al. Moving target detection method based on codebook model under YUV space[J]. Engineering Journal of Wuhan University, 2015(3):412-416. http://www.cnki.com.cn/Article/CJFDTOTAL-WSDD201503024.htm [10] 徐成, 田峥, 李仁发.一种基于改进码本模型的快速运动检测算法[J].计算机研究与发展, 2010, 47(12):2149-2156. http://www.cnki.com.cn/Article/CJFDTOTAL-JFYZ201012023.htm XU Cheng, TIAN Zheng, LI Ren-fa. A fast motion detection method based on improved codebook model[J]. Journal of Computer Research and Development, 2010, 47(12):2149-2156. http://www.cnki.com.cn/Article/CJFDTOTAL-JFYZ201012023.htm [11] 姜柯, 李艾华, 苏延召.基于改进码本模型的视频运动目标检测算法[J].电子科技大学学报, 2012, 41(6):932-936. http://www.juestc.uestc.edu.cn/CN/abstract/abstract1465.shtml JIANG Ke, LI Ai-hua, SU Yan-zhao. Moving targets detecting algorithm in video based on improved codebook model[J]. Journal of University of Electronic Science and Technology of China, 2012, 41(6):932-936. http://www.juestc.uestc.edu.cn/CN/abstract/abstract1465.shtml [12] 姜柯, 李艾华, 苏延召.双重自适应码本模型在运动目标检测中的应用[J].计算机辅助设计与图形学学报, 2013, 25(1):67-73. http://www.cnki.com.cn/Article/CJFDTOTAL-JSJF201301009.htm JIANG Ke, LI Ai-hua, SU Yan-zhao. Moving objects detection with double adaptive codebook model[J]. Journal of Computer-Aided Design & Computer Graphics, 2013, 25(1):67-73. http://www.cnki.com.cn/Article/CJFDTOTAL-JSJF201301009.htm [13] 郭春生, 王盼.一种基于码本模型的运动目标检测算法[J].中国图象图形学报, 2010, 15(7):1079-1083. doi: 10.11834/jig.080502 GUO Chun-sheng, WANG Pan. An algorithm based on codebook model to moving objects detection[J]. Journal of Image and Graphics, 2010, 15(7):1079-1083. doi: 10.11834/jig.080502 [14] 李文辉, 李慧春, 王莹, 等.对码本模型中码字结构的改进[J].吉林大学学报:理学版, 2012, 50(3):517-522. http://www.cnki.com.cn/Article/CJFDTOTAL-JLDX201203030.htm LI Wen-hui, LI Hui-chun, WANG Ying, et al. Improvement on codeword structure in codebook model[J]. Journal of Jilin University(Science Edition), 2012, 50(3):517-522. http://www.cnki.com.cn/Article/CJFDTOTAL-JLDX201203030.htm [15] SHAH M, DENG J D, WOODFORD B J. A self-adaptive codebook (SACB) model for real-time background subtraction[J]. Image & Vision Computing, 2015, 38:52-64. https://www.researchgate.net/profile/Jeremiah_Deng/publication/275058799_A_Self-Adaptive_CodeBook_SACB_Model_for_Real-time_Background_Subtraction/links/55b0b41f08aeb0ab4669a5c7.pdf?inViewer=0&pdfJsDownload=0&origin=publication_detail [16] REN X, MALIK J. Learning a classification model for segmentation[C]//2003 IEEE International Conference on Computer Vision.[S.l.]:IEEE, 2003, 1:10-17. [17] ACHANTA R, SHAJI A, SMITH K A, et al. SLIC superpixels compared to state-of-the-art superpixel methods[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(11):2274-2282. doi: 10.1109/TPAMI.2012.120 [18] GOYETTE N, JODOIN P M, PORIKLI F, et al. Change detection net:a new change detection benchmark dataset[C]//IEEE Computer Society Conference on Computer Vision & Pattern Recognition Workshops.[S.l.]:IEEE, 2012:1-8. -

 点击查看大图
点击查看大图

图(6) / 表(1)
计量
- 文章访问数: 4000
- HTML全文浏览量: 1253
- PDF下载量: 199
- 被引次数: 0
