 ISSN
ISSN 



-
加权基因关联网络(weighted gene association network, WGAN)是表示基因间功能相关关系的复杂网络[1],其中节点代表基因,边代表基因间的相互作用,权重代表相互作用的可信度。WGAN网络的构建是为了克服目前已有的生物学实验数据与实际存在的基因功能相关关系相比严重不足、以及高通量实验的结果存在严重噪声的问题。通常采用计算方法整合与基因的功能联系相关的各种生物学特征的数据源,推断基因之间的关联关系,并对每一对关联关系赋予置信分,作为网络中边的权重,从而构建加权的基因关联网络。因此这类网络既包含了一些特定类型的基因或蛋白间的相互作用信息,如蛋白-蛋白相互作用[2](PPI)、基因共表达[3]、转录调控[4]、信号通路[5]等,又比特定类型的分子网络包含更广泛的信息。
目前,基因相关关系的数据融合方法主要分为主观打分融合方法、相似性融合方法和统计推断打分方法3种类型。通过这些方法已经构建了一些WGAN网络,就人类基因组而言,有HIPPIE[6]、HumanNet[7]、STRING[8]以及FunCoup[9]网络等。文献[6]收集了现有的蛋白-蛋白相互作用数据库BioGrid[10]、IntAct[11]、MINT[12]、DIP[13]、BIND[14]等中的数据,基于试验方法的先进性、支持基因间关联关系的文献数目以及在非人类物种中存在该连接的基因对数目3种不同的信息,自定义了一种基因对的打分方法,对每一对基因间的关联关系的可靠性进行打分,从而构建了HIPPIE网络。文献[7]基于概率似然比提出一种统一的网络边权打分方法,该方法以基因本体注释数据库GO(gene ontology)[15]为背景网络,对21个基因功能数据集中的每一条边进行重新打分,得到了HumanNet网络。文献[8]通过建立朴素贝叶斯分类器模型方法,融合多种与基因关联关系相关的生物学数据源,得到了一个加权基因关联网络STRING网络。文献[9]选取了八大真核生物体的大规模数据,通过朴素贝叶斯模型方法融合得到了FunCoup网络。
基于网络的复杂疾病病理学和药理学的研究,广泛应用人类全基因组加权基因关联网络作为背景网络,以识别疾病相关基因、探测药物对应的网络药靶,从而加深复杂疾病的医学认识、改进复杂疾病的治疗。可以想见,背景网络的质量,与相关研究结果的精确度是相关的。现有的人类全基因组基因关联网络如HumanNet、STRING和FunCoup等,各自在生物学基础研究及疾病研究中都有成功应用的案例[16-18]。然而,这些网络间却存在着巨大差异。它们虽然包含了80%以上相同的基因,但拥有的相同的关联边却很少,低于各自总边数的10%。如果在这些已有的WGAN的基础上,进一步识别其中包含的正确信息,将它们融合成一个信息更全、更准确的加权基因关联网络,对于更好地从系统水平理解细胞内部生物学过程、以及研究复杂疾病的病理, 都是很有意义的。
本文利用信息熵[19]刻画基因连边权重的不确定度,提出了基于信息熵理论的融合策略,在现有4个人类全基因组WGAN基础上,充分利用多个网络中所有连边的信息来构造包含更多节点和边的WGAN。本文将原有网络及新构建的网络分别用于肥胖症的疾病基因预测[20],以检验新网络的应用价值。
-
熵是衡量某一个体系混乱程度的变量,它在不同领域被引申为更为具体的解释。在研究随机现象的过程中,熵用来描述随机现象发生的平均不确定度,为评估随机现象发生的不确定程度提供了一个定量的指标。同样,这一指标也被广泛应用于信息理论的研究领域,被称为信息熵。
对于某一随机现象X,若X包含n种可能的结果xi,i=1, 2, …, n,且分布率为pi=P(xi), i= 1, 2, …, n,则随机现象X发生的不确定程度可以通过信息熵定义如下:
$$ H(X) =-\sum {p({x_i})} * {\log _2}p({x_i}){\rm{ }}i = 1, 2, \cdots, n $$ (1) 本文拟将此方法应用于WGAN网络的融合。对于WGAN网络,可以通过适当的归一化方法,使它的边权取之于区间(0, 1]。因此,在后面的描述中,总假设WGAN网络中的边权取之于区间(0, 1]。假设现有n个WGAN网络N1.N2, …, Nn,它们具有相同的基因,其中网络Nk中i、j基因节点的连边权重记为W(ij)。则融合这n个WGAN网络就是要将网络中任意基因对i、j的连边权重Wk(ij)=(k = 1, 2, …, m)融合成一个新的权重,作为融合后网络中基因对i、j的连边权重W(ij)。由于现有的融合算法主要限于线性融合,因此,上面的融合问题转化为寻找融合系数α1(ij), α2(ij), …, αm(ij)使:
$$ {W^{(ij)}} = {\alpha _1}^{(ij)}{W_1}^{(ij)} + {\alpha _2}^{(ij)}{W_2}^{(ij)} + \cdots + {\alpha _m}^{(ij)}{W_m}^{(ij)} $$ (2) 为了寻找合理的融合系数,需要对每一组基因对连边进行深入分析。由于WGAN网络中的边权取之于区间(0, 1],因此,W(ij)可以理解为WGAN网络中基因i、j连边的概率,由此可以定义如下随机现象Y:
$$ Y = \left\{ \begin{array}{l} 1\;\;\;i, j{\rm{基因有连边}}\\ 0\;\;\;i, j{\rm{基因无连边}} \end{array} \right. $$ 且P(Y=1)= W(ij),P(Y=0) = 1 − W(ij)。因此,Y描述了基因对i、j是否发生连边这一随机现象,根据式(1)将这一随机现象的不确定程度描述为:
$$ \begin{gathered} H({W^{(ij)}}) \triangleq H(Y) = \\ -{W^{(ij)}}{\log _2}{W^{(ij)}}-(1-{W^{(ij)}}){\log _2}(1 - {W^{(ij)}}) \\ \end{gathered} $$ (3) 因此,WGAN网络中基因i、j连边的不确定程度可以通过式(3)来刻画。显然,式(2)中融合系数α1, α2, …, αm的设计与连边自身的不确定程度密切相关,这为融合系数设计提供了有价值的途径。
-
在实际情况中,同一对基因可能在一些网络中存在连边,而在另一些网络中不存在连边,对于后者,用式(3)来刻画其连边的不确定性显然是不合适的,因为式(3)中要求连边概率W(ij)大于零。为了处理这种情况,需要对基因对的连边做适当的处理,从而使得融合更加合理。本文先求得背景网络的连边并集N,则N中的每一条连边都对应着h个权重且h ≤ m,对于那些在一些网络中存在连边,而在另一些网络中不存在连边的基因对,假设其在对应背景网络上也存在连边并将其权重设为一个非常小的数值ε。通过这种处理,N中每一条连边都存在m个权值,从而可以利用式(3)来设计融合系数。同时,如果网络的一组基因对的连边权重为1,则重新修改它的权重为1−ε。从而,通过预处理后的各WGAN网络中的基因对连边的最小权值为ε。
-
对第k个WGAN网络Nk的每一组基因对i、j的连边权重Wk(ij)(k =1, 2, …, m),利用式(3),可以定义该连边的不确定程度H(W(ij)k)。H(W(ij)k)越大,则该连边的不确定程度越大,因此,在确定融合系数时,应该赋以相应连边的融合系数一个比较小的值,反之则赋以一个比较大的融合系数。为此,对各网络的每一组基因对i、j的连边,引入如下函数:
$$ {C_k}^{(ij)} \buildrel \Delta \over = C({W_k}^{(ij)}) = 1-{{\rm{e}}^{-\frac{1}{{H{{({W_k}^{(ij)})}^\theta }}}}} $$ (4) 式中,θ>0为调整因子,主要用于调整基因对i、j连边的不确定程度对函数Ck(ij)的影响程度。在实际应用中,可以通过训练的方法来选择适当的参数θ(见1.4节)。不难分析出,函数Ck(ij)是基因对i、j连边的不确定程度H(Wk(ij))单调递减函数,因此可以利用它来定义相应的融合系数。通过对函数Ck(ij)做归一化处理,定义m个WGAN网络N1, N2, …, Nm中基因对i、j连边的融合系数为:
$$ {\alpha _k}^{(ij)} = \frac{{{C_k}^{(ij)}}}{{\sum\limits_{s = 1}^m {{C_s}^{(ij)}} }}{\rm{ }}k = 1, 2, \cdots, m $$ (5) 则对这m个WGAN网络融合后的网络中基因对i、j连边的连边权重为W(ij)=α1(ij)W1(ij)+α2(ij)W2(ij)。图 1为两个网络的融合过程简略图。

图 1 网络融合过程简略图
-
根据基因本体注释数据库GO中全体人类基因的功能信息,构建GO网络,并将它作为测试网络,确定融合模型的参数。GO数据库是基因本体联合会(Gene Onotology Consortium)所建立的数据库,该数据库对大量物种中的每个基因和蛋白质的功能用标准的生物学词汇条目(GO term)进行描述。本文构建的GO网络中节点代表人类基因,若两个基因至少有一个共同的GO term, 则它们对应的节点有连边,连边的权重为这两个基因共有的GO term的数目,并将其归一化到(0, 1]区间。因此GO网络中基因的连边代表两个基因在生物功能上有相关性,边权则代表这个相关性的强弱程度。
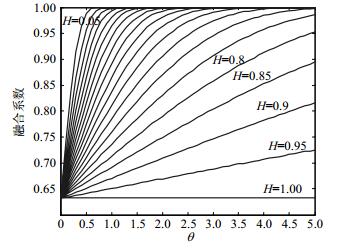
θ为调节信息熵对融合系数影响程度的调整因子。为了选择较为合适的调整区间,本文通过分析式(4)的函数模型,分别选取不同的θ(0~5,以0.1为步长)以及不同的信息熵值H(0.05~1,以0.05为步长)作为自变量,观测比较了θ和H对融合系数Ck(ij)的影响程度,如图 2所示。

图 2 θ和H对融合系数的影响
由图 2可以看出,当边权的信息熵值H比较小时,θ只有取值略小,才能使融合系数具有有效的区分度;当边权的信息熵值H比较大时,θ只有取值稍大,才能使融合系数具有有效的区分度;由于加权基因网络的边权信息熵值大小分布不均,为了使融合系数都具有有效的区分度,因此建议选择θ的调整区间为(0, 3)。
本文将把融合后网络的权值与GO网络的权值进行比较分析,计算其共同连边权值对应的差平方和,并且在这个值达到最小时选取对应的模型参数θ,从而将模型参数的确定转化为优化的求解问题:
$$ f(\theta ) = \sum {{{({W_\theta }-{W_{{\rm{GONet}}}})}^2}} $$ (6) 式中,Wθ表示参数条件下的融合后网络连边权值WGONet表示GO网络连边权值。
-
本文针对提出的网络融合模型,对4个现有的人类全基因组加权基因关联网络,即HIPPIE、HumanNet、FunCoup和STRING进行融合。将这4个原始WGAN网络分别记为N1, N2, N3, N4。4个网络的基因数和连边信息如表 1所示。
表 1 4个原始网络的基本信息
网络 节点数 连边数 共同节点所占比例/% 共同连边所占比例/% HIPPIE 16 514 235 184 73.43 11.24 FunCoup 16 626 4 044 929 72.94 0.65 HumanNet 16 243 476 399 74.66 4.05 STRING 16 213 3 180 982 74.80 0.83 因为4个网络的连边信息和节点信息各不相同,因此首先需要按照1.2节中的方法处理。先求得4个基因网络的并集网络N,再按照1.2节中的方法来补充定义某些基因对的连边权重。经过这种处理,4个网络的每一条连边都对应着4个权值,即分别为4个子网络所对应的权值。截取并集网络的一部分表 2所示。
表 2 并集网络N的部分数据
Gene ID Gene ID WHIPPIE WHumanNet WFunCoup WSTRING 790 1 629 0.106 ε ε 0.479 790 1 633 ε ε ε 0.413 790 1 642 1-ε ε ε ε 790 1 644 0.134 ε 0.115 0.856 3 312 3 717 0.389 0.730 0.371 0.652 表 2中,Gene ID表示某个基因的Entrez ID,W表示各背景网络中对应边的权重。本文研究中,取ε=0.001。
-
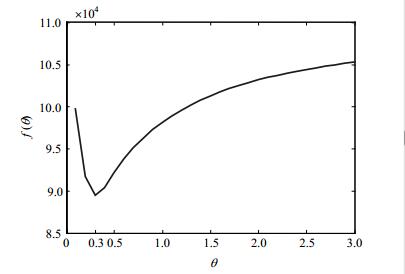
根据式(4)、式(5),需要计算各网络中每一组基因对i、j连边的Ck (ij)函数和融合系数数αk(ij)。为了选取比较合适的调整因子,本文选取了GO网络作为训练网络,分步长对融合系数函数中的θ参数进行训练。通过比较分析,实验结果得到的θ和f(θ)变化关系如图 3所示。

图 3 参数θ的训练
由图 3可以看出,f(θ)的变化先呈现递减后递增的趋势,在θ取0.3时,f(θ)达到最小。
在取θ为0.3的情况下,利用式(4)、式(5),可以将4个网络每一组基因对的i、j连边进行融合,从而得到一个新的网络FN, 其节点数为19 490,边数为7 092 510。
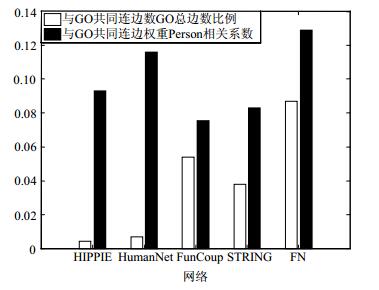
然后,比较融合前后网络与GO网络的共同连边数以及共同连边权重的Person相关系数,得到图 4。

图 4 融合前后网络与GO网络的比较
从图 4可以看出,相比原始网络,融合后的网络FN连边信息更加丰富,并且其权重经过融合后,与GO共同连边权重的Person相关系数相比原始网络有显著提高,说明FN的边权比原始网络的边权有更强的生物学相关性。
-
生物系统是由多分子和基因相互作用的结果。复杂疾病的基因不是孤立存在的,基因与基因之间有相互作用。加权基因关联网络的研究为系统生物学和疾病分子预测提供了一个崭新的平台,对预测疾病相关基因做出了较大的贡献。由于相同的疾病基因在基因关联网络中具有邻近性,因此基于网络的预测方法被广泛应用于疾病基因预测研究中。为了检验融合后网络的实用性,本文分别将融合前后的网络作为背景网络,进行肥胖症的疾病基因预测。
-
基于网络的疾病基因预测方法将已知的疾病基因作为先验信息组成种子集,根据候选基因与种子基因在网络上的拓扑关系,预测候选基因是疾病基因的可能性。本文采用直接邻居法[21],该方法是把与已知疾病致病基因直接相连的基因作为疾病的可能致病基因,基于全网络对每一个基因进行打分,得出其与已知致病基因直接相连的总得分Si,即与致病基因直接相连的边的权重总和。其模型为:
$$ {S_i} = \sum\limits_{j \in {\rm{seed}}} {{W_{ij}}} $$ (7) 式中,Wij表示基因i和致病基因j的连边权重;seed表示已知致病基因集。由此可得全网络中的每一个基因的得分值,再将所有基因依据其分值由大到小进行排序。本文截断出排名前n个基因,计算预测准确值,即测试集中的基因在这n个基因中所占的比例。
本文从人类孟德尔遗传在线数据库OMIM (online Mendelian inheritance in man, OMIM)[22]和文献中收集已知的肥胖症(obesity)的致病基因。其中从OMIM数据库获得24个肥胖症致病基因,从文献[23]中获得与肥胖症相关的373个基因。
-
本文用两种方法检验疾病基因的预测效果,一种是留一交互验证法[24], 另一种是模拟寻找疾病基因的方法[21]。
在留一交叉验证法中,将OMIM中的24个疾病基因与文献中的373个疾病基因合并,得到已知的肥胖症疾病基因集合。每次利用此集合中的一个疾病基因构成测试集,剩余的疾病基因构成种子集。用式(7)对背景网络中的每个基因打分,验证算法是否能够成功地预测测试基因为致病基因。图 5显示了按分值排名截取不同比例的网络基因组总基因数时,以不同网络为背景网络所得到的预测准确率,即在不同的比例下,合并疾病基因集中被预测到的疾病基因占集合总基因数的比值。可以看出,融合后的网络FN与网络STRING取得了最好的预测准确率。

图 5 用留一交叉验证比较融合前后网络的疾病基因预测效果
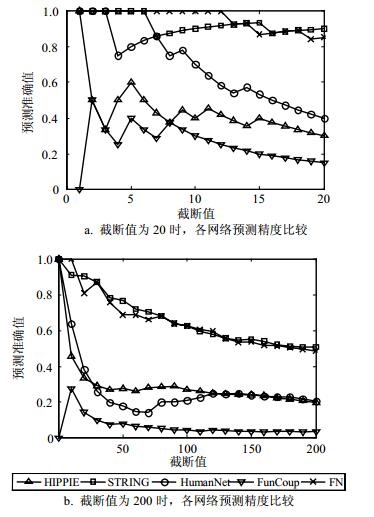
在模拟寻找疾病基因的方法中,本文以OMIM中的24个疾病基因构成种子集,文献[23]中的373个疾病相关基因作为测试集,对网络进行打分。分别选择得分最高的20和200个基因为预测的疾病基因,比较融合前后背景网络下被预测到的疾病相关基因所占比例。以排名的截断值为横坐标,以预测准确值为纵坐标将融合前的4个网络HIPPIE、HumanNet、FunCoup、STRING和融合后的网络FN做疾病基因预测效果对比分析,如图 6所示。

图 6 融合前后的网络预测效果比较
由图 6可以看出,当截断值为20时,融合后的网络FN的预测准确值比4个原始网络高;当截断值为200时,融合后的网络FN的预测准确值和STRING相当,显著高于其他3个网络的预测效果。
这些结果说明,本文融合后的网络FN可以成功地用于疾病基因预测。
-
本文研究是加权基因关联网络数据融合方面的一个新的尝试,提出了一种基于信息熵的WGAN网络数据融合方法,将现有的人类加权基因关联网络的信息进行整合。通过此方法,本文构建了一个包含现有网络所有节点和边信息的融合网络FN。通过与GO网络对比显示,FN的边权比原始网络中的边权有更强的生物学相关性。将FN与原始网络同时用于肥胖症的疾病基因预测,发现FN的预测效果高于或相当于效果最好的原始网络STRING,说明此网络可以用于疾病基因预测。此工作在生物网络数据整合以及疾病基因预测的研究方面都有重要的价值。
Integration of Weighted Gene Association Networks Based on Information Entropy
-
摘要: 针对加权基因关联网络(WGAN)的融合问题,提出了基于信息熵的加权网络数据融合方法。该方法利用信息熵来刻画基因间连边的不确定程度,并由此实现对4个现有的人类加权基因关联网络的融合,从而获得一个规模更大、生物学信息更丰富的WGAN网络。融合效果的验证结果表明,新的WGAN网络包含了更多的基因连边,其边权比原始网络中的边权有更强的生物学相关性,同时在疾病基因预测中表现出更为满意的效果。Abstract: To integrate information of several weighted genes associated networks (WGAN), this paper proposes a network data integration method based on information entropy. This method uses information entropy to depict uncertain degree of gene-gene links, and thus realizes the integration of four existing human weighted genes associated network to construct a larger WGAN network which includes richer biology information. This new WGAN network contains more edges than each of the original network, and the edge weights have higher biological relevance than in the original networks. It also exhibits more satisfactory performance in disease genes prediction.
-
表 1 4个原始网络的基本信息
网络 节点数 连边数 共同节点所占比例/% 共同连边所占比例/% HIPPIE 16 514 235 184 73.43 11.24 FunCoup 16 626 4 044 929 72.94 0.65 HumanNet 16 243 476 399 74.66 4.05 STRING 16 213 3 180 982 74.80 0.83  下载: 导出CSV
下载: 导出CSV
表 2 并集网络N的部分数据
Gene ID Gene ID WHIPPIE WHumanNet WFunCoup WSTRING 790 1 629 0.106 ε ε 0.479 790 1 633 ε ε ε 0.413 790 1 642 1-ε ε ε ε 790 1 644 0.134 ε 0.115 0.856 3 312 3 717 0.389 0.730 0.371 0.652
下载: 导出CSV
-
[1] 周涛, 张子柯, 陈关荣, 等.复杂网络研究的机遇与挑战[J].电子科技大学学报, 2014, 43(1):1-5. http://manu50.magtech.com.cn/dzkjdx/CN/abstract/abstract354.shtml ZHOU Tao, ZHANG Zi-ke, CHEN Guan-rong, et al. The opportunities and challenges of complex network research[J]. Journal of University of Electronic Science and Technology of China, 2014, 43(1):1-5. http://manu50.magtech.com.cn/dzkjdx/CN/abstract/abstract354.shtml [2] WILLIAMSON M P, SUTCLIFFE M J. Protein-protein interactions[J]. Biochemical Society Transactions, 2010, 38(4):875-878. doi: 10.1042/BST0380875 [3] ZHANG B, HORVATH S. A general framework for weighted gene co-expression network analysis[J]. Statistical Applications in Genetics and Molecular Biology, 2005, 4(1):1128. http://www.bepress.com/sagmb/vol4/iss1/art17/ [4] CILIBERTO G, COLANTUONI V, DE FRANCESCO R, et al. Transcriptional control of gene expression in hepatic cells[M]//KARIN M. Gene Eexpression: General and Cell-Type-Specific. [S. l. ]: Birkhäuser, 1993. [5] MARTINI P, SALES G, MASSA M S, et al. Along signal paths:an empirical gene set approach exploiting pathway topology[J]. Nucleic Acids Research, 2013, 41(1):e19. doi: 10.1093/nar/gks866 [6] SCHAEFER M H, FONTAINE J F, VINAYAGAM A, et al. HIPPIE:Integrating protein interaction networks with experiment based quality scores[J]. PloS One, 2012, 7(2):e31826. doi: 10.1371/journal.pone.0031826 [7] LEE I, BLOM U M, WANG P I, et al. Prioritizing candidate disease genes by network-based boosting of genome-wide association data[J]. Genome Research, 2011, 21(7):1109-1121. doi: 10.1101/gr.118992.110 [8] FRANCESCHINI A, SZKLARCZYK D, FRANKILD S, et al. STRING v9. 1:Protein-protein interaction networks, with increased coverage and integration[J]. Nucleic Acids Research, 2013, 41(D1):D808-D815. http://nar.oxfordjournals.org/content/early/2012/11/29/nar.gks1094.abstract?cited-by=yeslgks1094v1rgks1094v1 [9] ALEXEYENKO A, SONNHAMMER E L. Global networks of functional coupling in eukaryotes from comprehensive data integration[J]. Genome Research, 2009, 19(6):1107-1116. doi: 10.1101/gr.087528.108 [10] CHATR-ARYAMONTRI A, BREITKREUTZ B J, OUGHTRED R, et al. The BioGRID interaction database:2015 update[J]. Nucleic Acids Research, 2015, 43(D1):D470-D478. doi: 10.1093/nar/gku1204 [11] HERMJAKOB H, MONTECCHI-PALAZZI L, LEWINGTON C, et al. IntAct:an open source molecular interaction database[J]. Nucleic Acids Research, 2004, 32(suppl 1):D452-D455. https://www.ncbi.nlm.nih.gov/pubmed/14681455 [12] CHATR-ARYAMONTRI A, CEOL A, PALAZZI L M, et al. MINT:the molecular INTeraction database[J]. Nucleic Acids Research, 2007, 35(suppl 1):D572-D574. doi: 10.1093/nar/gkl950 [13] XENARIOS I, SALWINSKI L, DUAN X J, et al. DIP, the database of interacting proteins:a research tool for studying cellular networks of protein interactions[J]. Nucleic Acids Research, 2002, 30(1):303-305. doi: 10.1093/nar/30.1.303 [14] BADER G D, BETEL D, HOGUE C W V. BIND:the biomolecular interaction network database[J]. Nucleic Acids Research, 2003, 31(1):248-250. doi: 10.1093/nar/gkg056 [15] Gene Ontology Consortium. The gene ontology (GO) database and informatics resource[J]. Nucleic Acids Research, 2004, 32(suppl 1):D258-D261. https://www.scienceopen.com/document/vid/ff8e67ed-27b9-43c2-9fe5-0060e046222f [16] RE M, VALENTINI G. Random walking on functional interaction networks to rank genes involved in cancer[C]//IFIP International Conference on Artificial Intelligence Applications and Innovations. Berlin, Heidelberg: Springer, 2012: 66-75. [17] TABOADA B, VERDE C, MERINO E. High accuracy operon prediction method based on STRING database scores[J]. Nucleic Acids Research, 2010, 38(12):e130. doi: 10.1093/nar/gkq254 [18] ZHAO J, WANG C L, YANG T H, et al. A comparison of three weighted human gene functional association networks[C]//2012 IEEE 6th International Conference on Systems Biology (ISB). [S. l. ]: IEEE, 2012: 26-31. [19] COVER T M, THOMAS J A. Elements of information theory[M].[S.l.]:John Wiley & Sons, 2012. [20] 吕琳媛.复杂网络链路预测[J].电子科技大学学报, 2010, 39(5):651-661. http://manu50.magtech.com.cn/dzkjdx/CN/abstract/abstract1170.shtml LÜ Lin-yuan. Link prediction on complex network[J]. Journal of University of Electronic Science and Technology of China, 2010, 39(5):651-661. http://manu50.magtech.com.cn/dzkjdx/CN/abstract/abstract1170.shtml [21] LINGHU B, SNITKIN E S, HU Z, et al. Genome-wide prioritization of disease genes and identification of disease-disease associations from an integrated human functional linkage network[J]. Genome Biology, 2009, 10(9):1-17. http://www.genomebiology.com/2009/10/9/R91/citation [22] HAMOSH A, SCOTT A F, AMBERGER J S, et al. Online mendelian inheritance in man (OMIM), a knowledgebase of human genes and genetic disorders[J]. Nucleic Acids Research, 2005, 33(suppl 1):D514-D517. doi: 10.1093/nar/gki033 [23] HANCOCK A M, WITONSKY DB, GORDON A S, et al. Adaptations to climate in candidate genes for common metabolic disorders[J]. PLoS Genetics, 2008, 4(2):e32. doi: 10.1371/journal.pgen.0040032 [24] REFAEILZADEH P, TANG L, LIU H. Cross-validation[M]//Encyclopedia of Database Systems. [S. l. ]: Springer US, 2009: 532-538. -

 点击查看大图
点击查看大图

图(6) / 表(2)
计量
- 文章访问数: 4057
- HTML全文浏览量: 1275
- PDF下载量: 123
- 被引次数: 0
