 ISSN
ISSN 


-
Many lower exoskeletons have been developed for strength augmentation and walking assistance scenarios over the past few decades[1-5]. For strength augmentation related applications, lower exoskeletons are designed to track the pilot's motion with little interaction force between the exoskeleton and the pilot[6-8]. The controller of these lower exoskeletons can be roughly categorized into two categories, namely, sensor-based controller and model-based controller.
For sensor-based controllers, extra sensors are always employed to measure the pilot's information and/or the interaction force between the pilot and the exoskeleton[9-11]. With the measured sensory information, many variations of control strategies can be employed to control the lower exoskeleton, i.e., impedance control strategies. For example, the Hybrid assistive limb (HAL) exoskeleton system is an impedance control strategy proposed by Y. Sankai based on measuring eletro-myo-graphical (EMG) signals of the pilot[12]. In the impedance control strategy of HAL system, EMG signals are utilized to calculate reference patterns of the pilot which aims at estimating the human-exoskeleton interaction (HEI) between the pilot and the exoskeleton[13]. Furthermore, based on measuring the pilot's motion with acceleration sensors, the active-impedance control strategy[14] and the fuzzy-based impedance control strategy[15] are proposed to adapt to the changing interaction dynamics among different pilots. However, sensor-based controllers heavily rely on complex sensory systems, which are unstable sometimes and is mostly costly. Hence, sensor-based controllers are, to some extent, limited in most strength augmentation scenarios.
On the other hand, model-based controllers are designed to simplify the sensory system of the exoskeleton, which is only based on the information from exoskeleton itself. Sensitivity amplification control (SAC) is one of the model-based controllers proposed by the berkeley lower extremity exoskeleton (BLEEX)[16]. With a sensitivity factor in the model- based controller, SAC can estimate the output joint torques based on current states (joint angle, angular velocity and angular acceleration) of the lower exoskeleton. The SAC strategy is able to reduce the interaction force between the pilot and the exoskeleton without measuring it directly, which also reduces the complexity of the exoskeleton sensory system. However, the SAC strategy requires accurate dynamic models of the lower exoskeleton (sensitive to model imperfections and different pilots) which makes the system identification process quite complicated[17].
In this paper, we propose a novel variable virtual impedance control (VVIC) strategy which inherits both advantages of sensor-based controllers and model- based controllers. On the one hand, it is a model-based control strategy, which reduces the complexity of the exoskeleton sensory system. On the other hand, we apply a reinforcement learning method based on policy improvement and path integrals (PI2) to learn parameters of the virtual impedance model, which circumvents the complicated system identification process. The main contributions of this paper can be summarized as follows:
1) A novel VVIC strategy with a model-based controller named virtual impedance controller is proposed, which reduces the exoskeleton sensory system requirement;
2) To reduce the complicated system identification process, a reinforcement learning method is utilized to learn/optimize parameters of the virtual impedance controller of VVIC strategy;
3) The proposed VVIC strategy is verified on both a single DOF platform and HUALEX system.
The proposed VVIC strategy is firstly validated on a single DOF exoskeleton platform, and then tested on a HUALEX system. Experimental results show that the proposed VVIC strategy is able to adapt different HEI to different pilots when compared with canonical model-based control strategies.
-
This section presents the proposed virtual impedance control strategy. We will firstly introduce the design details of virtual impedance controller in Subsection 1.1. Then, in Subsection 1.2, we analyze the stability of the proposed model-based controller.
-
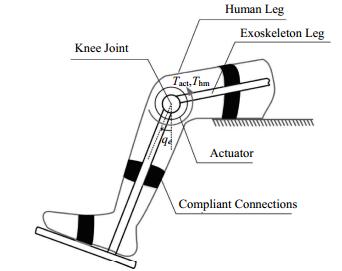
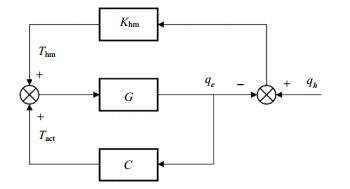
For the control of lower exoskeletons for strength augmentation related applications, the pilot always plays as a master role in the human-coupled system, which means that the exoskeleton should follow/track the pilot's motion. A general control system block diagram with the model-based controller for the single degree of freedom (DOF) case is depicted in Fig. 1, where: G represents the transfer function of the lower exoskeleton, C is the designed model-based controller of the lower exoskeleton. Khm is the impedance between the pilot and the exoskeleton. qe and qh indicate the joint angles of lower exoskeleton and the pilot, respectively. Thm is the resulting interaction torque applied by the pilot. Tact is the output torque applied by the lower exoskeleton actuator.

Figure 1. A general control system diagram with the model-based controller for the single DOF case
As shown in Fig. 1, the input torque of the lower exoskeleton is combined with the actuator output torque Tact and pilot's resulting interaction torque Thm. The design goal of lower exoskeleton controller is to reduce the interaction torque, which also means that the exoskeleton can track the pilot's motion as soon as possible.
The traditional impedance controller always be designed as in Eq. (1), the pilot's angles are taken as inputs to the controller:
$$ {T_{{\rm{act}}}} = \hat G({\ddot q_e}, {\dot q_e}, {q_e}) - [k({q_h} - {q_e}) + d({\dot q_h} - {\dot q_e})] $$ (1) where $\hat G $ is the estimated dynamics of the lower exoskeleton. k and d are stiffness and damping parameters of the designed impedance model, respectively. However, for the design of model-based controllers, we do not measure sensory information from the pilot. In the exoskeleton control of strength augmentation scenarios, the exoskeleton will receive the pilot's joint states after several control cycles. Therefore, a virtual impedance model is presented for the model-based exoskeleton controller:
$${q_h} - {q_e} = {k_h}{\dot q_e}$$ (2) $${\dot q_h} - {\dot q_e} = {d_h}{\ddot q_e}$$ (3) where ${k_h}$ and ${d_h}$ are positive parameters of the virtual impedance model. Hence, the proposed virtual impedance controller can be represented as Eq. (4), which is a model-based controller only based on the states of the lower exoskeleton:
$${T_{{\rm{act}}}} = \hat G({\ddot q_e}, {\dot q_e}, {q_e}) - ({K_h}{\dot q_e} + {D_h}{\ddot q_e})$$ (4) where ${K_h} = k{k_h}$ and ${D_h} = d{d_h}$ are virtual impedance factors of the proposed virtual impedance controller.
-
Since the design goal of the lower exoskeleton controller is to reduce the interaction torque, Thm approximates to zero, and the stability of the system can be guaranteed by the stability of $ {q_e}/{q_h}$ [18].
From Fig. 1, the open loop system equation can be represented as:
$$ {{{q}}_e} = G({T_{{\rm{act}}}} + {T_{{\rm{hm}}}}) $$ (5) The proposed virtual impedance controller can be rewritten as:
$${T_{{\rm{act}}}} = (\hat G - {V_h}){q_e}$$ (6) where ${V_h} = {D_h}{s^2} + {K_h}s$. Through the model-based controller in Eq. (6) and the system equation described in Eq. (5), we have:
$${q_e} = G[(\hat G - {V_h}){q_e} + {K_{{\rm{hm}}}}({q_h} - {q_e})]$$ (7) then the equation of ${q_e}/{q_h}$ can be obtained as:
$$\frac{{{q_e}}}{{{q_h}}} = \frac{{{K_{{\rm{hm}}}}G}}{{1 - G\hat G + ({V_h} + {K_{{\rm{hm}}}})G}}$$ (8) If the dynamics of lower exoskeleton is estimated accurately ($G\hat G = 1$), then Eq. (8) can be simplified to:
$$\frac{{{q_e}}}{{{q_h}}} = \frac{{{K_{{\rm{hm}}}}}}{{{V_h} + {K_{{\rm{hm}}}}}} = \frac{{{K_{{\rm{hm}}}}}}{{{D_h}{s^2} + {K_h}s + {K_{{\rm{hm}}}}}}$$ (9) Since virtual impedance parameters ${D_h}$ and ${K_h}$ and the impedance ${K_{{\rm{hm}}}}$ all have positive values, the control system is always stable when the dynamics of lower exoskeleton can be accurately estimated.
Another situation is that we haven't gained accurate dynamic models of the lower exoskeleton. In this case, we consider a single DOF exoskeleton with the second order dynamics and ignore the gravity composition, which indicates that:
$$G = \frac{1}{{J{s^2} + Bs}}$$ (10) where J and B represent the inertial moment and viscous friction of the lower exoskeleton, respectively. The estimated exoskeleton dynamics $\hat G$ can be represented as:
$$\hat G = \hat J{s^2} + \hat Bs$$ (11) where $\hat G$ and $\hat B$ represent the estimated inertial moment and viscous friction parameters. From Eq. (10) and Eq. (11), the equation of $ {q_e}/{q_h}$ can be represented as:
$$\frac{{{q_e}}}{{{q_h}}} = \frac{{{K_{{\rm{hm}}}}}}{{({D_h} + J - \hat J){s^2} + ({K_h} + B - \hat B)s + {K_{{\rm{hm}}}}}}$$ (12) According to Eq. (12), if the virtual impedance parameters ${D_h}$ and ${K_h}$ are small enough (always positive), the system will still be stable when the dynamic model of lower exoskeleton is not over estimated ($J < \hat J, B < \hat B$). Hence, the system is always stable when the dynamic model of lower exoskeleton is not over estimated.
-
For the implementation of traditional model-based controllers, i.e. SAC in BLEEX system, the system identification process is often employed to obtain system dynamics and human-related parameters of the designed controller (sensitivity factors in SAC)[19]. However, the lower exoskeleton is a kind of human- coupled system for different pilots, which requires that the controller needs to recalibrate for different pilots.
In this paper, a model-free reinforcement learning method is employed to learn the optimal virtual impedance parameters of VIC, which aims at adapting with different HEI for different pilots. Combining the learning process and the model-based controller, which is named as the VVIC strategy, we can reduce the system sensor requirement as well as the system identification process. In the reinforcement learning process, a model-free reinforcement learning method named policy improvement and path integral (PI2) algorithm[20-21] is employed to learn the parameters ${K_h}$ and ${D_h}$ of VIC.
The parameterized policy of PI2 is defined as:
$${\mathit{\boldsymbol{p}}_t} = \mathit{\boldsymbol{W}}_t^T(\mathit{\boldsymbol{ \boldsymbol{\varTheta} }} + {\epsilon }_{t})$$ (13) where $\mathit{\boldsymbol{ \boldsymbol{\varTheta} }} $ is a vector of virtual impedance parameters ${[{K_h}, {D_h}]^T}$and ${{\epsilon }_{t}}$ indicate the exploration noise. $\mathit{\boldsymbol{W}}_t^T$ is the basis function with Gaussian kernels $\omega $ :
$${[{\mathit{\boldsymbol{W}}_t}]_j} = \frac{{{\omega _j}}}{{\sum\limits_i^n {{\omega _j}} }}$$ (14) Eq. (14) calculates the jth average weight, where n is the number of parameters which is to be learned (n=2 in our case).
In the implementation of VVIC strategy, we define the immediate cost based on the measured sensory information of the pilot. For single DOF case, the immediate cost function is defined as follows:
$${r_t} = {\alpha _1}{[{q_h}(t) - {q_e}(t)]^2} + {\alpha _2}{[{\dot q_h}(t) - {\dot q_e}(t)]^2}$$ (15) where ${\alpha _1}$ and${\alpha _2}$ are positive scale factors. In order to obtain the pilot motion information during the learning process, inclinometers are utilized to measure the pilot's joint angle position ${q_h}$ and angular velocity ${\dot q_h}$.
With the defined policy and cost function, the learning process of virtual impedance parameters based on PI2 for single DOF algorithm is described in as:
1) Initialize the virtual impedance parameter vector ${\mathit{\boldsymbol{ \boldsymbol{\varTheta} }}} $.
2) Initialize basis function ${\mathit{\boldsymbol{W}}_{{t_i}}}$ according Eq. (14).
3) Repeat.
4) Run K gait cycles of the exoskeleton using stochastic parameters ${\mathit{\boldsymbol{ \boldsymbol{\varTheta} }}} +{{\epsilon }_{t}}$ at every time step.
5) For all gait cycles $k \in [1, K]$:
6) Compute the projection matrix M through Eq. (16).
7) Compute the stochastic cost S through Eq. (17).
8) Compute the probability P through Eq. (18).
9) For all time steps $i \in [1, T]$:
10) Compute $\Delta {\mathit{\boldsymbol{ \boldsymbol{\varTheta} }} _{{t_i}}}$ for each time step through Eq. (19).
11) Normalize $\Delta \mathit{\boldsymbol{ \boldsymbol{\varTheta} }} $ according Eq. (20).
12) Update $\mathit{\boldsymbol{ \boldsymbol{\varTheta} }} \leftarrow \mathit{\boldsymbol{ \boldsymbol{\varTheta} }} + \Delta \mathit{\boldsymbol{ \boldsymbol{\varTheta} }} $.
13) Run one noiseless gait cycle to compute the trajectory cost R through Eq. (21).
14) Until Trajectory cost R is converged.
As shown in Tab. 1, virtual impedance parameters of VIC will be updated every K+1 gait cycles. The updating rule is described in Tab. 1 with Eq. (16) to Eq. (20).
$${\mathit{\boldsymbol{M}}_{{t_i}, k}} = \frac{{{H^{ - 1}}{\mathit{\boldsymbol{W}}_{{t_i}, k}}\mathit{\boldsymbol{W}}_{{t_i}, k}^T}}{{\mathit{\boldsymbol{W}}_{{t_i}, k}^T{H^{ - 1}}{\mathit{\boldsymbol{W}}_{{t_i}, k}}}}$$ (16) $${\mathit{\boldsymbol{S}}_{i, k}} = \sum\limits_{j = i}^{N - 1} {{r_{{t_j}, k}}} + \frac{1}{2}\sum\limits_{j = i + 1}^{N - 1} ( \mathit{\boldsymbol{ \boldsymbol{\varTheta} }} + {\mathit{\boldsymbol{M}}_{{t_j}, k}}{\epsilon _{{t_j}, k}}{)^{\rm{T}}}H(\mathit{\boldsymbol{ \boldsymbol{\varTheta} }} + {\mathit{\boldsymbol{M}}_{{t_j}, k}}{\epsilon _{{t_j}, k}})$$ (17) $${\mathit{\boldsymbol{P}}_{i, k}} = \frac{{{{\rm{e}}^{ - \frac{1}{\lambda }{\mathit{\boldsymbol{S}}_{i, k}}}}}}{{\sum\limits_{k = 1}^K {\left[ {{{\rm{e}}^{ - \frac{1}{\lambda }{\mathit{\boldsymbol{S}}_{i, k}}}}} \right]} }} $$ (18) $$\Delta {\mathit{\boldsymbol{ \boldsymbol{\varTheta} }} _{{t_i}}} = \sum\limits_{k = 1}^K {[{\mathit{\boldsymbol{P}}_{i, k}}{\mathit{\boldsymbol{M}}_{{t_i}, k}}{\epsilon _{{t_i}, k}}]} $$ (19) $${[\Delta \mathit{\boldsymbol{ \boldsymbol{\varTheta} }} ]_j} = \frac{{\sum\limits_{i = 1}^T ( T - i){\omega _{j, {t_i}}}{{[\Delta {\mathit{\boldsymbol{ \boldsymbol{\varTheta} }} _{{t_i}}}]}_j}}}{{\sum\limits_{i = 1}^T {{\omega _{j, {t_i}}}} (T - i)}}$$ (20) Table 1. Comparison of VVIC strategy and SAC algorithm for three different simulated pilots in single DOF case
NMSE/rad Simulated pilot A Simulated pilot B Simulated pilot C VVIC 0.024 0.032 0.038 SAC 0.069 0.094 0.124 The matrix H in Eq. (16) and Eq. (17) is a positive semi-definite weight matrix. The scale factor λ in Eq. (18) is set within (0, 1]. With updated parameter vector $\mathit{\boldsymbol{ \boldsymbol{\varTheta} }} $, a noiseless gait cycle (without exploration noise ${{\epsilon }_{t}}$) is taken to determine whether the learning process should be terminated through calculating the trajectory cost R:
$$R = \rho \cdot \sum\limits_{i = 1}^T {{r_{{t_i}}}} $$ (21) where $\rho = 1/{t_d}$ (${t_d}$ indicates time duration of the gait cycle) is a normalization factor, since the duration of each gait cycle are always different in real-time applications.
In the implementation of VVIC strategy, the reinforcement learning process needs to be taken in the case of different pilots, which learns optimal virtual parameters to adapt different HEI to different pilots. Afterwards, with the learned optimal model-based controller, the lower exoskeleton is able to track the pilot's motion as soon as possible based only on joint information of lower exoskeleton.
-
In this section, the proposed VVIC strategy is validated both on a single DOF case in simulation environment and the HUALEX system. Experimental results and discussions will be introduced in next two subsections.
-
Fig. 2 illustrates the model of single DOF exoskeleton when coupling with the pilot in knee joint. As a human-coupled system, the resultant torque on exoskeleton knee joint is combined with two parts: one is Tact which is provided by the exoskeleton actuator, and another is Thm which is provided by the pilot through compliant connection between the exoskeleton and the pilot.

Figure 2. Model of single DOF exoskeleton coupling with the pilot in knee joint
The dynamics of single DOF exoskeleton including the pilot is defined as Eq. (22) in the simulation environment:
$$J{\ddot q_e} + B{\dot q_e} + mgl{\rm{sin}}{q_e} = {T_{{\rm{act}}}} + {T_{{\rm{hm}}}}$$ (22) where the last term $mgl \cdot {\rm{sin}}{q_e}$ is the gravity composition. Hence, according the control law of proposed VIC in Eq. (4), the controller of single DOF exoskeleton is designed as follows:
$${T_{{\rm{act}}}} = (\hat J - {D_h}){\ddot q_e} + (\hat B - {K_h}){\dot q_e} + mgl{\rm{sin}}{q_e}$$ (23) where $\hat J$ and $\hat B$ are estimated inertial moment and viscous friction parameters, respectively. ${K_h}$ and ${D_h}$ are the virtual impedance parameters of proposed VVIC strategy which should be learned to adapt different HEI to different pilots.
-
In the experiments of simulated single DOF exoskeleton, different values of the impedance $ (described in Fig. 1) are used to simulate different HEIs to different pilots. Here we choose three different impedance ${K_{{\rm{hm}}}}$. The estimated dynamic parameters of model-based controller $\hat J$ and $\hat B$ are set as $\hat J $=0.9 J, $\hat B$=0.9 B with suitable values. Pilot's motion angles are set as periodic sine waves with different frequencies and amplitudes in simulation experiments.
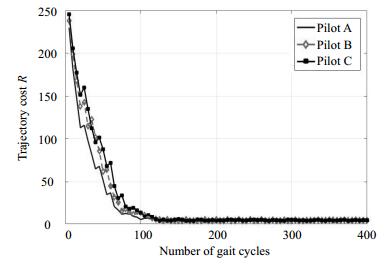
In the learning process of the proposed VVIC strategy, the exoskeleton should take several gait cycles to obtain optimal virtual impedance parameters of the controller. The exoskeleton updates parameters every 4(K=4) gait cycle and spends one gait cycle to calculate trajectory cost R (the parameters $\mathit{\boldsymbol{ \boldsymbol{\varTheta} }} $ will be updated every 5 gait cycles). Weight parameters ${\alpha _1}$ and ${\alpha _2}$ of immediate cost function (described in Eq. (15)) are both chosen as 1 500. Fig. 3 illustrates learning curves of reinforcement learning process for different simulated pilots (relationship between values of impedance parameters ${K_{{\rm{hm}}}}$ is C > B > A). As shown in Fig. 3, the learning process will take almost 120 gait cycles (24 updates) to obtain optimal virtual impedance parameters (trajectory cost R converged).

Figure 3. Learning curves of reinforcement learning process for simulated different pilots
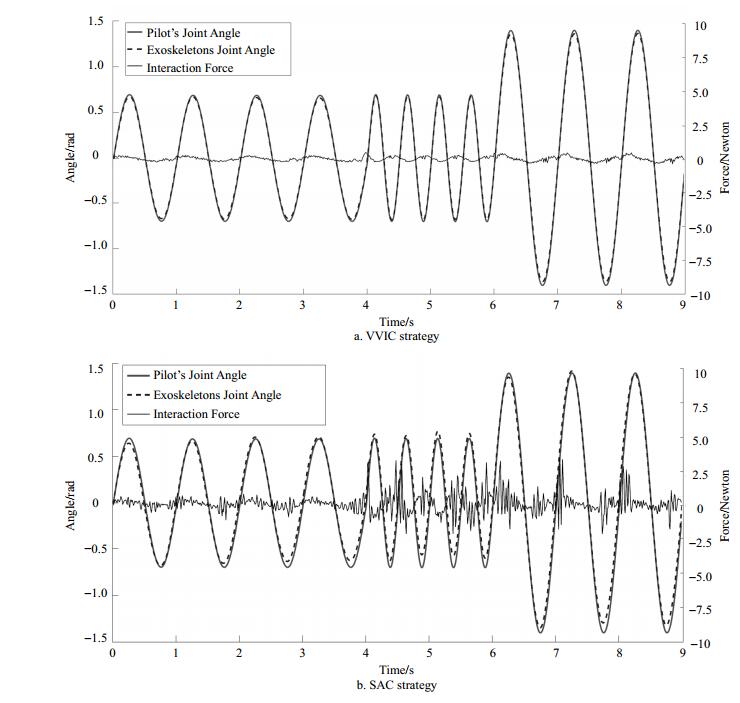
After obtaining the optimal parameters of the VVIC strategy, comparative experiments are carried out to compare the proposed VVIC and traditional SAC algorithm. Fig. 4 shows the control performances of the proposed VVIC strategy and SAC algorithm with pilot A. In the comparison experiments, we choose 11 gait cycles (total 50 gait cycles) with different motion patterns to compare control performances of VVIC strategy and SAC algorithm. Black curves in Fig. 4 represent the interaction force between the pilot and exoskeleton, which is calculated by a spring-damping model in the simulator. As shown in Fig. 4, experimental results show that the proposed VVIC strategy achieves better performance (with less interaction force) than the traditional SAC algorithm.

Figure 4. Control performances of the proposed VVIC strategy and SAC algorithm
Tab. 1 shows the normalized mean square error (nMSE) of VVIC strategy and SAC algorithm in total 50 gait cycles with three different simulated pilots. Results show that the proposed VVIC strategy achieves better performance when dealing with different HEI to different pilots, e.g. with simulated pilot C, nMSE of the SAC algorithm is almost three times comparing with the proposed VVIC strategy (0.124 rad compare to 0.038 rad).
-
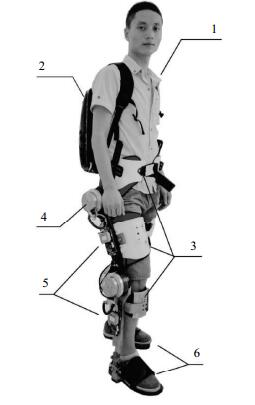
HUALEX system is designed for the strength augmentation applications. Fig. 5 shows the total HUALEX system with a pilot. In Fig. 5, 1— The pilot; 2— The load backpack with the power unit and main controller (rigid connection with the HUALEX spline); 3— Semi-rigidly connecting HUALEX to the pilot (waist, thighs, shanks and feet); 4— Active joints with DC servo motors (hip joints and knee joints); 5— Node controllers for active joints; 6— Smart shoes with plantar sensors.

Figure 5. HUALEX with the pilot
As shown in Fig. 5, four active joints (hips and knees) are designed to provide active torques for strength augmentation. Ankle joints of HUALEX system are energy-storage mechanisms which can store energy in the stance phase and release it in the swing phase. Between the pilot and HUALEX system, many compliant connections are utilized to connect the pilot and HUALEX system in a semi-rigid way.
The control system of HUALEX is combined with one main controller and four node controllers for each active joints. The control algorithm is running on the main controller, and node controllers are aiming to collect sensory information and execute control commands. In the HUALEX system, three kinds of sensors are utilized in the sensory system: 1) Encoders are embedded in each active joint to measure motion information of HUALEX. 2) IMU sensors are utilized to measure motion information of the pilot if necessary. 3) Plantar sensors in smart shoes are aiming to judge the walking phases of HUALEX.
-
In experiments of the HULEX system, three different pilots (A: 172 cm/76 kg, B: 176 cm/80 kg, C: 180 cm/96 kg) are chosen to operate the HUALEX system in sequence, which indicates that during learning process of VVIC strategy, the learned optimal parameters of VVIC with pilot A will be regarded as initial values of VVIC with pilot B (note that the VVIC parameters of each joint of HUALEX system are learned independently). During the learning process, IMU sensors are utilized to measure the pilot's motion information for obtaining optimal virtual impedance parameters. Besides the virtual impedance parameters of VVIC, parameters of HUALEX dynamics are identified through Solidworks software. After obtaining optimal parameters of VVIC, IMU sensors are remained to capture the pilot's motion information (not use for control) which are aiming to validate the control performance of the proposed VVIC strategy.
-
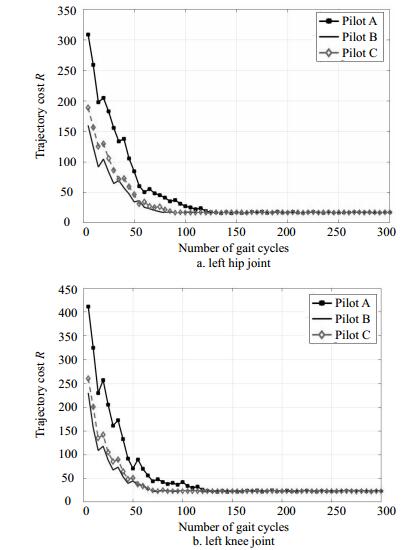
Fig. 6 shows the learning curves of VVICs in the HUALEX system with different pilots (in left hip and knee joints). As discussed in experimental setup section, pilot A operates the HUALEX system at first so that the learning process of VVIC strategy needs to spend more training gait cycles (almost 140 gait cycles). With better initial values from pilot A, the learning process of pilot B and C can be reduced to almost 80 gait cycles.

Figure 6. Learning curves of VVICs in the HUALEX system with different pilots at joint
After obtaining optimal virtual impedance parameters of the VVIC strategy through the reinforcement learning process, we validate the control performance of proposed VVIC strategy with comparison to the traditional SAC algorithm. The results show that the proposed VVIC strategy achieves good control performances. Moreover, Tab. 2 gives the comparison of the VVIC strategy and SAC algorithm with different pilots (100 gait cycles for each pilot). As shown in Tab. 2, the proposed VVIC strategy achieves better performances in experiments of the HUALEX system with different pilots, e.g. in the right knee joint of pilot C, the nMSE of SAC algorithm is almost three times than that of the VVIC strategy (0.094/rad compare to 0.032/rad).
Table 2. Comparison of SAC and VVIC strategy in HUALEX with different pilots in total 100 gait cycles
NMSE/rad VVIC|SAC Pilot A Pilot B Pilot C Left hip 0.026 0.078 0.028 0.085 0.025 0.086 Left knee 0.036 0.086 0.038 0.092 0.032 0.09 Right hip 0.024 0.065 0.023 0.068 0.026 0.075 Right knee 0.028 0.087 0.031 0.079 0.032 0.094 -
This paper has proposed a novel VVIC strategy to control of a HUALEX system, which aims at adapting different HEI to different pilots. The proposed VVIC strategy is based on a novel VIC, which is a model-based controller with a virtual impedance model. In order to adapt different HEI to different pilots, the PI2 reinforcement learning algorithm is employed to obtain optimal parameters in virtual impedance of VIC. Control performances of the proposed VVIC strategy are validated on a single DOF exoskeleton simulation environment as well as the HUALEX system. Experimental results indicate that the proposed VVIC has better performances compared with the traditional SAC algorithm, and can deal with variation HEI from different pilots.
In the future, we will investigate the methods which can learn/update the parameters of VVIC online. In this case, the HUALEX will be able to 'get used to' the pilot during the operation process. Moreover, the estimation to the accurate dynamic models of HUALEX is also important, the accurate dynamic models always achieve better performances for model-based controller in strength augmentation lower exoskeletons.
-
摘要: 提出了一种基于增强学习的变虚阻抗控制算法,其控制器设计为一个结合人机交互模型的虚阻抗控制器。为了适应不同穿戴者所产生的交互力,采用了PI2增强学习算法对控制器中的参数进行在线学习。该控制策略在一自由度外骨骼平台和HUALEX下肢助力外骨骼上进行了实验验证,证明了所提出控制算法的有效性。Abstract: This paper presents a novel variable virtual impedance control (VVIC) strategy which can adapt HEI to different pilots with a virtual impedance controller. The controller is model-based with a virtual impedance which models HEI between the pilot and the exoskeleton. To adapt different pilots with different HEI, a reinforcement learning method based on policy improvement and path integrals (PI2) is employed to adjust and optimize parameters of virtual impedance. We demonstrate the efficiency of the proposed VVIC strategy on a single degree-of-freedom (DOF) exoskeleton platform as well as a human-powered augmentation lower exoskeleton (HUALEX) system. Experimental results indicate that the proposed VVIC strategy is able to adapt HEI to different pilots and outperforms traditional model-based control strategies in terms of interaction forces.
-
Figure 1. A general control system diagram with the model-based controller for the single DOF case
Figure 3. Learning curves of reinforcement learning process for simulated different pilots
Figure 6. Learning curves of VVICs in the HUALEX system with different pilots at joint
Table 1. Comparison of VVIC strategy and SAC algorithm for three different simulated pilots in single DOF case
NMSE/rad Simulated pilot A Simulated pilot B Simulated pilot C VVIC 0.024 0.032 0.038 SAC 0.069 0.094 0.124  下载: 导出CSV
下载: 导出CSV
Table 2. Comparison of SAC and VVIC strategy in HUALEX with different pilots in total 100 gait cycles
NMSE/rad VVIC|SAC Pilot A Pilot B Pilot C Left hip 0.026 0.078 0.028 0.085 0.025 0.086 Left knee 0.036 0.086 0.038 0.092 0.032 0.09 Right hip 0.024 0.065 0.023 0.068 0.026 0.075 Right knee 0.028 0.087 0.031 0.079 0.032 0.094
下载: 导出CSV
-
[1] KAZEROONI H, CHU A, STEGER R. That which does not stabilize, will only make us stronger[J]. International Journal of Robotics Research, 2007, 26(1):5-89. doi: 10.1177/0278364907073779 [2] SANKAI Y. HAL:Hybrid assistive limb based on cybernics[J]. Robotics Research, 2010:25-34. doi: 10.1007/978-3-642-14743-2_3 [3] WALSH C J, PALUSKA D, PASCH K, et al. Development of a lightweight, under-actuated exoskeleton for load- carrying augmentation[C]//IEEE International Conference on Robotics and Automation (ICRA). Florida, USA: IEEE, 2006: 3485-3491. [4] STAUSSE K A, KAZEROONI H. The development and testing of a human machine interface for a mobile medical exoskeleton[C]//IEEE International Conference on Intelligent Robots and Systems (IROS). California, USA: IEEE, 2011: 4911-4916. [5] ESQUENAZI A, TALATY M, PACKEL A, et al. The rewalk powered exoskeleton to restore ambulatory function to individuals with theracic-level motor-complete spinal cord injury[J]. American Journal of Physical Medicine and Rehabilitation, 2012, 91(11):911-921. doi: 10.1097/PHM.0b013e318269d9a3 [6] HUANG R, CHENG H, CHEN Q, et al. Interative learning for sensitivity factors of a human-powered augmentation lower exoskeleton[C]//IEEE International Conference on Intelligent Robots and Systems (IROS). Hamburg, Germany: IEEE, 2015: 6409-6415. [7] WALSH C J, PASCH K, HERR H. An autonomous, under-actuated exoskeleton for load-carrying augmentation[C]//IEEE International Conference on Intelligent Robots and Systems (IROS). Hamburg, Germany: IEEE, 2006: 1410-1415. [8] ZOSS A, KAZEROONI H, CHU A. On the mechanical design of the berkeley lower extremity exoskeleton (BLEEX)[C]//IEEE International Conference on Intelligent Robots and Systems (IROS). Edmonton, Canada: IEEE, 2005: 3132-3139. [9] TRAN H T, CHENG H, LIN X, et al. The relationship between physical human-exoskeleton interaction and dynamic factors:using a learning approach for control applications[J]. Science China Information Science, 2014, 57(12):1-13. [10] KAZEROONI H, STEGER R, HUANG L, et al. Hybrid control of the berkeley lower extremity exoskeleton (BLEEX)[J]. International Journal of Robotics Research, 2006, 25(6):561-573. [11] KAWAMOTO H, SANKAI Y. Power assist method based on phase sequence and muscle force condition for HAL[J]. Advance Robotics, 2005, 19(7):717-734. doi: 10.1163/1568553054455103 [12] LEE S, SANKAI Y. Power Assist control for walking aid with hal-3 based on EMG and impedance adjustment around knee joint[C]//International Conference on Intelligent Robots and Systems (IROS). Lausanne, Switzerland: [s. n. ], 2002: 1499-1504. [13] HAYASHI T, KAWAMOTO H, SANKAI Y. Control method of robot suit HAL working as operator's muscle using biologic and dynamical information[C]//IEEE International Conference on Intelligent Robots and Systems (IROS). Edmonton, Canada: IEEE, 2005: 3063-3068. [14] GABRIEL A O, COLGATE J E, PESHKIN M A, et al. Active-impedance control of a lower-limb assistive exoskeleton[C]//IEEE International Conference on Rehabilitation Robotics. Noordwijk, Netherlands: IEEE, 2007: 188-195. [15] TRAN H T, CHENG H, DUONG M K, et al. Fuuzy-based impedance regulation for control of the coupled human-exoskeleton system[C]//IEEE International Conference on Robotics and Biomimetics. Bali, Indonesia: IEEE, 2014: 986-992. [16] KAZEROONI H, RACINE J L, HUANG L, et al. On the control of the berkeley lower extremity exoskeleton (BLEEX)[C]//International Conference of Robotics and Automation (ICRA). Barcelona, Spain: [s. n. ], 2005: 4353-4360. [17] GHAN J, STEGER R, KAZEROONI H. Control and system identification for the berkeley lower extremity exoskeleton[J]. Advanced Robotics, 2006, 20(9):989-1014. doi: 10.1163/156855306778394012 [18] RACINE J L. Control of a lower extremity exoskeleton for human performance amplification[D]. California, USA: University of California, Berkeley, 2003. [19] GHAN J, KAZEROONI H. System identification for the berkeley lower extremity exoskeleton (BLEEX)[C]//International Conference of Robotics and Automation (ICRA). Florida, USA: [s. n. ], 2006: 3477-3484. [20] THEODOROU E A, BUCHILI J, SCHAAL S. A generalized path integral control aproach to reinforcement learning[J]. Journal of Machine Learning Research, 2010, 11:3137-3181. [21] BUCHLI J, STULP F, THEODOROU E A, et al. Learning variable impedance control[J]. International Journal of Robotics Research, 2011, 30(7):820-833. doi: 10.1177/0278364911402527 -

 点击查看大图
点击查看大图
计量
- 文章访问数: 4327
- HTML全文浏览量: 1316
- PDF下载量: 213
- 被引次数: 0
