 ISSN
ISSN 




-
交通标志识别是无人驾驶和驾驶辅助安全系统的重要组成部分,在未来的智能交通系统(intelligent traffic system, ITS)中具有重要的战略意义[1]。但是,复杂的自然场景给交通标志的实时检测和识别带来了巨大的挑战。因此,实时高效的交通识别技术成为研究的热门。
交通标志识别一般由特征提取和分类器设计两部分组成。在特征提取方面,一般采用传统的人工设计特征描述的方法,特征描述符主要有方向梯度直方图(histogram of orientated gradient, HOG),尺度不变特征变换(scale-invariant feature transform, SIFT),局部二值模式(local binary pattern, LBP)等。文献[2]提取了大类交通标志的HOG特征,取得了较好的分类效果,但利用先验知识提取特征使其方法的泛化性能并不理想;文献[3]组合HOG、SIFT、LBP特征进行线性编码形成交通标志特征表达,其组合特征维度过高,识别的实时性难以满足。目前应用神经网络进行特征提取的方法也开始流行起来,如卷积神经网络,卷积神经网络相比于人工提取特征,它能够根据具体的分类类型自动学习到针对性更强的图像特征。文献[4]提出基于图模型和卷积神经网络的交通标志识别方法,针对限速标志获得了较好的识别效果;文献[5]利用CNN提取特征对交通标志进行检测,但在识别时仅考虑了最后一层的特征图,没有充分挖掘和利用CNN每层特征的多样性和可区分性,因而,其识别效果还有进一步改善的空间。在分类器设计方面,支持向量机(support vector machine, SVM)[6]、神经网络均具有良好的分类效果,但是SVM分类器在特征维数高的情况下因参数调整复杂识别率会变低。文献[7]使用深度网络进行交通标志识别,虽然获得了超过人类的99.46%的高识别率,但是在训练过程中使用梯度下降方法需要调整所有参数,导致训练时间过长;文献[8]提取HOG特征并使用ELM分类器进行交通标志识别,在训练和识别时间上获得了很好的效果。
针对以上问题,本文提出一种基于多层特征表达和极限学习机(MCF-ELM)的交通标志识别方法。首先利用CNN网络提取多层交通标志特征图,充分利用多层网络的识别特征;为了考虑多层特征的多尺度和上下文信息,采用多尺度池化操作将提取出的各层特征向量联合形成一个具有多尺度多属性的交通标志特征向量;构建ELM分类器模型,对输出向量进行最大值操作,实现交通标志的分类。相对于常用交通标志识别方法识别特征单一,计算量大,实时性差,本文的方法能准确快速地实现交通标志的识别。
-
CNN等深度学习方法能够挖掘出数据的多层表征,不同层级的表征分别对应识别对象不同的特征属性,如低层级表征能够反映识别对象纹理、边缘等局部细节的信息,而高层级的表征能够反映数据更抽象的语义、结构等全局信息[9]。充分利用数据的多层特征属性,可以有效地高模型的识别准确度,但是交通标志识别在考虑识别准确度的同时,还要注重模型的高效性。ELM算法在训练过程中需要调整的参数少,因此训练时间大幅减少[10]。使用CNN多层特征和ELM分类器联合模型,能够进一步提高模型的稳健性和分类效果。
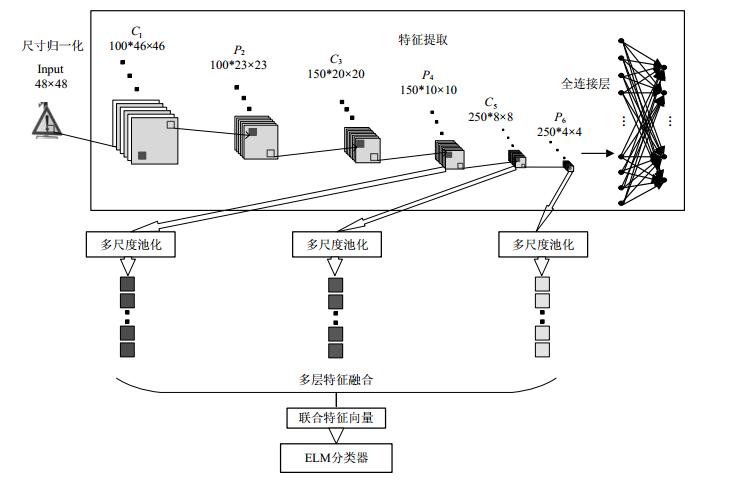
因此,为了充分利用CNN在特征提取中的优势和多层特征的全面性,以及ELM算法训练速度快等优势,本文提出多层特征表达和ELM分类器的算法结构。总体结构包括数据归一化、CNN特征提取、多层特征融合、ELM分类。总体框架如图 1所示。

图 1 MCF-ELM总体框架图
-
为了方便CNN特征提取,需要对图像进行尺寸归一化处理,固定图像大小为$w \times h$像素值。常用的尺寸归一化算法有最近邻插值,双线性插值和立方卷积插值算法等。综合考虑尺寸归一化后的图像质量和插值过程中的计算量,本文选取双线性插值算法[11]对原始交通标志图像进行尺寸归一化处理。
-
CNN属于一种具有层次结构的学习模型,它可以通过卷积和采样操作自动提取图像中的深层特征。本文所提出的网络结构包括3个卷积层、个池化层和1个全连接层。其中,C1、C3、C5表示卷积层,分别有100、150、250个不同大小的卷积核。输入的特征图通过卷积核卷积后输出,激活函数使用双曲正切函数:
$$f(x) = {\rm{tanh}}(x) = ({{\rm{e}}^x} - {{\rm{e}}^{ - x}})/({{\rm{e}}^x} + {{\rm{e}}^{ - x}})$$ (1) 卷积层之后的P2、P4、P6层为池化层,池化层的设计大大减少了训练过程中的计算量。表 1显示了络参数的设置。
表 1 CNN网络参数
特征图大小 特征图个数 核大小 步长 input 48×48 1 —— C1 46×46 100 3×3 1 P2 23×23 100 2×2 2 C3 20×20 150 4×4 1 P4 10×10 150 2×2 2 C5 8×8 250 3×3 1 P6 4×4 250 2×2 2 F7 43个神经元 —— 因为CNN网络只是用于提取特征而不是用于分类,所以最后的全连接层相当于一个普通的前向神经网络(SLFN)分类器[5]。
-
在卷积和池化操作后,传统的CNN网络是将所有的端层特征图连接起来映射到一维向量,然后通过softmax分类器进行分类并使用反向传播(BP)来训练所有网络,但是这种网络仅考虑了最后一层特征图的信息。文献[9]详细说明了卷积神经网络的特征可视化,通过可视化角度理解网络中间每一层的特征,不同层级的表征分别对应识别对象不同的特征属性,如果能充分利用这些多属性的特征,将有效提升特征表达的能力和最终的识别效果。基于此,本文提出多特征表达的网络框架,利用多层特征图形成一个具有多属性的特征向量来表达交通标志多个方面的属性特征。
文献[12]利用CNN网络提取癌细胞的最后三层特征图,得到了较为理想的识别特征,证明了最后三层特征图包含了识别对象不同属性的特征信息。受此启发,本文在提取特征图时也选择了最后三层来表达交通标志的多种特征属性。首先,最后三层的特征图在前馈训练中被提取出来,然后利用多尺度池化操作形成特征向量。
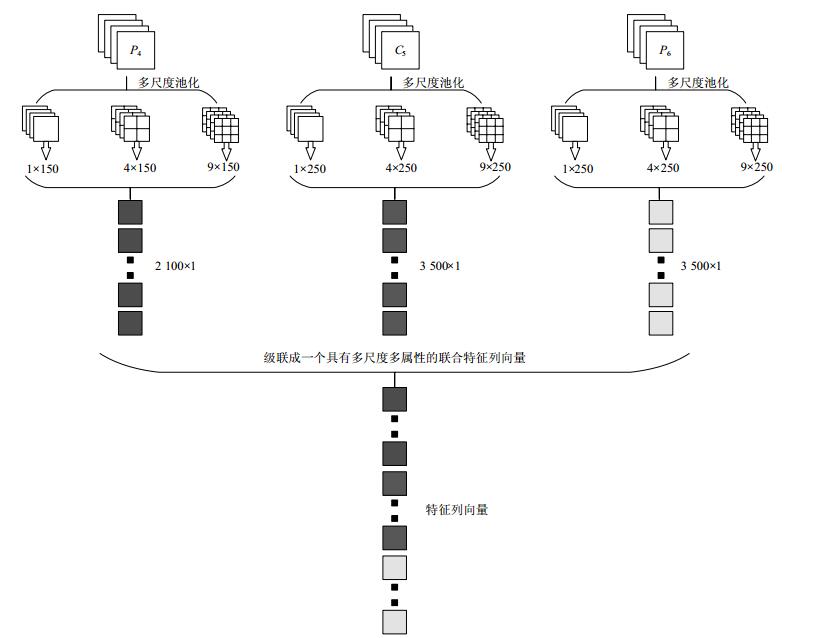
多尺度池化是基于空间金字塔池化方法的改进方法,空间金字塔的多尺度分块方法使分块呈现一种层次金字塔的结构,且局部空间块在聚合时的空间位置信息仍得到保留,从而使图像特征具有多尺度性,这些多尺度的特征恰好能适应检测目标的尺度变化,有利于目标的识别[13]。在卷积操作后对特征图进行多尺度池化操作能增强卷积神经网络提取特征的不变性,从而提高目标识别的准确性和鲁棒性[14]。多尺度池化是采用多种采样尺寸和采样步长,无论提取的特征图的尺寸是多大,每一层多尺度池化后输出的是3个不同尺度的特征矩阵,$1 \times 1 \times m$,$2 \times 2 \times m$,$3 \times 3 \times m$,其中$m$表示提取的特征图的数量。3个特征矩阵按列级联成$(14 \times m) \times 1$的列向量作为分类器的输入。P4、C5、P6层通过多尺度池化后分别得到$2{\rm{ }}100 \times 1$、$3{\rm{ }}500 \times 1$、$3{\rm{ }}500 \times 1$的特征列向量,然后将3个特征列向量按列展开并级联成具有多尺度多属性的交通标志联合特征向量。最后三层的多尺度池化操作示意图如图 2所示。

图 2 多尺度池化操作示意图
-
由于特征提取采用多层特征,特征维数相比于单层特征要大,因此必须选取一种计算量小、训练时间短、分类更高效的分类器。与传统的基于梯度下降的算法相比,ELM是一种新型的快速机器学习算法,它是一种基于单隐层前馈神经网络的监督型算法。传统的基于梯度的学习算法需要在训练过程中调整所有参数,而在ELM算法中,其输入层和隐藏层之间的权值参数以及隐藏层上的偏置参数不需要通过迭代反复调整,因而减少了算法的计算量,训练时间也相应大幅缩减。同时,ELM算法与CNN网络的联合会进一步提高模型的鲁棒性。
-
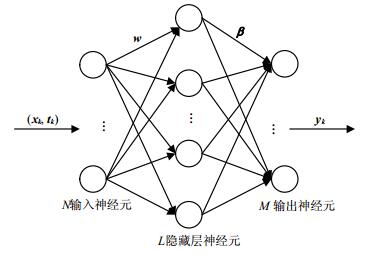
ELM分类器结构模型如图 3所示。

图 3 ELM分类器模型
输入层输入的是交通标志图片的多属性特征$\mathit{\boldsymbol{x}}$,特征维数表示为P。在隐藏层中,共有L个隐藏节点,第i个隐藏节点的输出表示为$g(\mathit{\boldsymbol{x}};{\mathit{\boldsymbol{w}}_i}, {b_i}) = g(\mathit{\boldsymbol{x}}{\mathit{\boldsymbol{w}}_i} + {b_i})$,其中g表示激活函数,${\mathit{\boldsymbol{w}}_i}$表示第i个隐藏节点与所有输入节点之间的输入权值向量,${b_i}$表示第i个隐藏节点的偏置,$i = 1, 2, \cdots , L$。在本文中,激活函数采用sigmoid函数,即:
$$g(\mathit{\boldsymbol{x}};{\mathit{\boldsymbol{w}}_i}, {b_i}) = \frac{1}{{1 + {\rm{exp}}\left[ { - (\mathit{\boldsymbol{x}}{\mathit{\boldsymbol{w}}_i} + {b_i})} \right]}}$$ (2) 输入和隐藏层之间的连接实际上是从P维空间特征映射到一个L维空间,输入一个特征向量$\mathit{\boldsymbol{x}}$,其映射特征向量表示为:
$$\mathit{\boldsymbol{h}}(\mathit{\boldsymbol{x}}) = [g(\mathit{\boldsymbol{x}};{\mathit{\boldsymbol{w}}_1}, {b_1}), g(\mathit{\boldsymbol{x}};{\mathit{\boldsymbol{w}}_2}, {b_2}), \cdots , g(\mathit{\boldsymbol{x}};{\mathit{\boldsymbol{w}}_L}, {b_L})]$$ (3) 在输出层,输出节点的个数表示为M,即交通标志的种类,每一个输出节点对应一类交通标志。第i个隐藏节点与第j个输出节点之间的输出权值表示为${\beta _{i, j}}$,其中$j = 1, 2, \cdots , M$。因此第j个输出节点的值为:
$${f_j}(\mathit{\boldsymbol{x}}) = \sum\limits_{i = 1}^L {{\beta _{i, j}} \times g(\mathit{\boldsymbol{x}};{\mathit{\boldsymbol{w}}_i}, {b_i})} $$ (4) 因此,输入样本$\mathit{\boldsymbol{x}}$,其在隐藏层的输出向量可以表示为:
$$\mathit{\boldsymbol{f}}(\mathit{\boldsymbol{x}}) = [{f_1}(\mathit{\boldsymbol{x}}), {f_2}(\mathit{\boldsymbol{x}}), \cdots , {f_M}(\mathit{\boldsymbol{x}})] = \mathit{\boldsymbol{h}}(\mathit{\boldsymbol{x}})\mathit{\boldsymbol{\beta }}$$ (5) 式中,
$$\mathit{\boldsymbol{\beta }} = \left[ \begin{array}{c} {\mathit{\boldsymbol{\beta }}_1}\\ {\mathit{\boldsymbol{\beta }}_2}\\ \vdots \\ {\mathit{\boldsymbol{\beta }}_L} \end{array} \right] = \left[ {\begin{array}{*{20}{c}} {{\beta _{1, 1}}}& \cdots &{{\beta _{1, M}}}\\ {{\beta _{2, 1}}}& \cdots &{{\beta _{2, M}}}\\ \vdots & \ddots & \vdots \\ {{\beta _{L, 1}}}& \cdots &{{\beta _{L, M}}} \end{array}} \right]$$ (6) 在检测阶段,输入测试样本$\mathit{\boldsymbol{x}}$,对应的交通标志类别表示为:
$${\rm{label}}(\mathit{\boldsymbol{x}}) = {\rm{ar}}{{\rm{g}}_{j = 1, 2, \cdots , M}}{\rm{max}}{f_j}(\mathit{\boldsymbol{x}})$$ (7) -
在ELM算法中,有两个参数需要训练:1)输入的权重和偏置$\{ {\mathit{\boldsymbol{w}}_i}, {b_i}\} $;2)输出权重$\mathit{\boldsymbol{\beta }}$。ELM可以随机初始化输入权重和偏置,因此只有输出权重$\mathit{\boldsymbol{\beta }}$需要训练。
输入N个不同的训练样本$({\mathit{\boldsymbol{x}}_k}, {\mathit{\boldsymbol{t}}_k})$,其中${\mathit{\boldsymbol{t}}_k}$为交通标志多属性特征向量${\mathit{\boldsymbol{x}}_k}$对应的二进制交通标志类别,${\mathit{\boldsymbol{t}}_k} = [{t_{k, 1}}, {t_{k, 2}}, \cdots , {t_{k, M}}]$,$k = 1, 2, \cdots , N$。训练样本由公式(4)可以得到一个线性表达式:
$$\mathit{\boldsymbol{H\beta }} = \mathit{\boldsymbol{Y}}$$ (8) 式中,$\mathit{\boldsymbol{Y}}$表示训练样本实际输出向量,有:
$$ \mathit{\boldsymbol{Y}} = \left[ \begin{array}{c} {\mathit{\boldsymbol{y}}_1}\\ {\mathit{\boldsymbol{y}}_2}\\ \vdots \\ {\mathit{\boldsymbol{y}}_N} \end{array} \right] = \left[ {\begin{array}{*{20}{c}} {{y_{1, 1}}}& \cdots &{{y_{1, M}}}\\ {{y_{2, 1}}}& \cdots &{{y_{2, M}}}\\ \vdots & \ddots & \vdots \\ {{y_{N, 1}}}& \cdots &{{y_{N, M}}} \end{array}} \right] $$ (9) H表示隐藏层输出向量,有:
$$\mathit{\boldsymbol{H}} = \left[ \begin{array}{c} \mathit{\boldsymbol{h}}({\mathit{\boldsymbol{x}}_1})\\ \mathit{\boldsymbol{h}}({\mathit{\boldsymbol{x}}_2})\\ \vdots \\ \mathit{\boldsymbol{h}}({\mathit{\boldsymbol{x}}_N}) \end{array} \right] = \left[ {\begin{array}{*{20}{c}} {g({\mathit{\boldsymbol{x}}_1};{\mathit{\boldsymbol{w}}_1}, {b_1})}& \cdots &{g({\mathit{\boldsymbol{x}}_1};{\mathit{\boldsymbol{w}}_L}, {b_L})}\\ {g({\mathit{\boldsymbol{x}}_2};{\mathit{\boldsymbol{w}}_2}, {b_2}}& \cdots &{g({\mathit{\boldsymbol{x}}_2};{\mathit{\boldsymbol{w}}_L}, {b_L})}\\ \vdots & \ddots & \vdots \\ {g({\mathit{\boldsymbol{x}}_N};{\mathit{\boldsymbol{w}}_1}, {b_1})}& \cdots &{g({\mathit{\boldsymbol{x}}_N};{\mathit{\boldsymbol{w}}_L}, {b_L})} \end{array}} \right]$$ (10) 训练的过程即是最小化训练误差${\left\| {\mathit{\boldsymbol{T}} - \mathit{\boldsymbol{H\beta }}} \right\|^2}$和输出权重的范数$\left\| \mathit{\boldsymbol{\beta }} \right\|$,因此训练过程可以表示为约束优化问题:
$$\begin{array}{c} {\rm{min}}:\psi (\mathit{\boldsymbol{\beta }}, \mathit{\boldsymbol{\xi }}) = \frac{1}{2}{\left\| \mathit{\boldsymbol{\beta }} \right\|^2} + \frac{C}{2}{\left\| \mathit{\boldsymbol{\xi }} \right\|^2}\\ {\rm{st}}:\mathit{\boldsymbol{ H\beta }} = \mathit{\boldsymbol{T}} - \mathit{\boldsymbol{\xi }} \end{array}$$ (11) 式中,常数C表示正则化因子。$\mathit{\boldsymbol{\xi }}$表示引入的误差容忍参数,增强模型的泛化能力。
本文使用拉格朗日乘子法[15]解决上述约束优化问题,如果矩阵$((\mathit{\boldsymbol{I}}/C) + {\mathit{\boldsymbol{H}}^{\rm{T}}}\mathit{\boldsymbol{H}})$是非奇异矩阵,则:
$$\mathit{\boldsymbol{\beta }} = {\left( {\frac{\mathit{\boldsymbol{I}}}{C} + {\mathit{\boldsymbol{H}}^{\rm{T}}}\mathit{\boldsymbol{H}}} \right)^{ - 1}}{\mathit{\boldsymbol{H}}^{\rm{T}}}\mathit{\boldsymbol{H}}$$ (12) 如果矩阵$((\mathit{\boldsymbol{I}}/C) + \mathit{\boldsymbol{H}}{\mathit{\boldsymbol{H}}^{\rm{T}}})$是非奇异矩阵,则:
$$\mathit{\boldsymbol{\beta }} = {\mathit{\boldsymbol{H}}^{\rm{T}}}{\left( {\frac{\mathit{\boldsymbol{I}}}{C} + \mathit{\boldsymbol{H}}{\mathit{\boldsymbol{H}}^{\rm{T}}}} \right)^{ - 1}}\mathit{\boldsymbol{T}}$$ (13) 因为矩阵$((\mathit{\boldsymbol{I}}/C) + {\mathit{\boldsymbol{H}}^{\rm{T}}}\mathit{\boldsymbol{H}}) $的维数是$L \times L$,矩阵$((\mathit{\boldsymbol{I}}/C) + \mathit{\boldsymbol{H}}{\mathit{\boldsymbol{H}}^{\rm{T}}}) $的维数是$N \times N$,所以当训练样本的数量足够大时,选用式(12)计算$\mathit{\boldsymbol{\beta }}$,保证减少计算量;否则选用式(13)计算$\mathit{\boldsymbol{\beta }}$。
最后根据式(8)计算出输出节点的输出向量${\mathit{\boldsymbol{y}}_k}$。
综上所述,本文ELM分类器训练过程为:
Input:训练样本$({\mathit{\boldsymbol{x}}_k}, {\mathit{\boldsymbol{t}}_k})$,$k = 1, 2, \cdots , N$;激活函数g;隐藏层节点数目L。
1) 随机生成隐藏层节点的参数,即输入权值${\mathit{\boldsymbol{w}}_i}$和偏置${b_i}$,$i = 1, 2, \cdots , L$;
2) 计算隐藏层输出矩阵H;
3) 根据约束条件计算隐藏层输出权重$\mathit{\boldsymbol{\beta }} $,$\mathit{\boldsymbol{\beta }} = {\left( {\frac{\mathit{\boldsymbol{I}}}{C} + {\mathit{\boldsymbol{H}}^{\rm{T}}}\mathit{\boldsymbol{H}}} \right)^{ - 1}}{\mathit{\boldsymbol{H}}^{\rm{T}}}\mathit{\boldsymbol{H}}$或$\mathit{\boldsymbol{\beta }} = {\mathit{\boldsymbol{H}}^{\rm{T}}}{\left( {\frac{\mathit{\boldsymbol{I}}}{C} + \mathit{\boldsymbol{H}}{\mathit{\boldsymbol{H}}^{\rm{T}}}} \right)^{ - 1}}\mathit{\boldsymbol{T}}$。
Output:输出节点的输出向量${\mathit{\boldsymbol{y}}_k}$。
-
为验证算法有效性,本文以德国交通标志数据库(GTSRB)[16]作为实验数据。GTSRB数据集共有43类交通标志,采集于真实场景下的德国交通标志,包含51 839张交通标志图片,其中训练集39 209张,测试集12 630张。数据集中的图片大小不等,在$15{\rm{ pixles}} \times 15{\rm{ pixles}}$到$250{\rm{ pixles}} \times 250{\rm{ pixles}}$之间,由于CNN要求所有输入的图像大小一致,所以预先把所有图像转化为${\rm{48pixles}} \times 48{\rm{pixles}}$大小。本文所有实验均在配置为Intel Core i7 CPU、主频3.4 GHz、内存16 GB的计算机上进行,有GPU加速,GPU型号为NVIDIA GTX1060,6 GB GDDR5显存,核心频率1 506 MHz。
本文随机选取一张交通标志的图片输入到训练好的网络中,网络各层的特征图如图 4所示。通过可视化发现CNN学习到的特征呈现分层特性,这一特性正与人类视觉系统类似。

图 4 特征图可视化
-
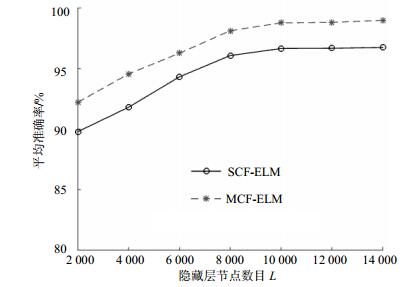
为验证多层特征对交通标志识别具有很好的分类效果,通过实验得到单层特征(SCF)和多层特征(MCF)在ELM分类下的识别准确率,单层特征为CNN网络提取的端层特征。从图 5可以看出,利用多层特征的识别准确率明显高于单层特征的识别准确率,平均高达两个百分点。该实验中隐藏层节点的个数L是影响准确率的一个重要参数,如图 5所示,不同隐藏层节点个数对应的分类准确率。随着隐藏层节点数目的增加,识别准确率显著增加,当$L > 8{\rm{ }}000$时,准确率增加缓慢。隐藏层节点数目的设置不仅要考虑准确率,同时还要兼顾训练时间,设置过多的隐藏层节点会大量增加计算成本,所以本实验选取隐藏层节点数量L为8 000。从图中的实验数据可以看出,利用单层特征的平均准确率为96.08%,利用多层特征的平均准确率为98.13%。由于单层特征并不能充分展现特征的全面性和多属性特点,所以准确率并不理想;多层特征充分利用了特征的多样性,显著提高分类准确率。

图 5 不同隐藏层节点数目对应的准确率
为进一步验证本文算法的鲁棒性,对复杂环境下的交通标志进行测试。图 6a~图 6c分别是光照不足、受到遮挡、图像模糊情况下的交通标志图像。每种情况下的交通标志图像采用30幅图像作为测试集,训练集仍采用正常的数据集。将本文算法MCF-ELM和SCF-ELM算法在识别准确率方面进行对比,实验结果如表 2所示。相比于图 5中的识别准确率,复杂环境下的准确率有所下降,尤其在遮挡情况下,准确率下降最为明显。SCF-ELM算法只考虑了端层特征,在复杂环境下识别准确率偏低;而本文提出的方法即使在交通标志信息不全的情况下依然能提取出有效的信息,虽然准确率有所下降,但仍高于单层特征的准确率,平均准确率超过了96%。因此,通过实验表明本文算法在复杂环境下仍具有较强鲁棒性。

图 6 复杂环境下的交通标志图像
表 2 复杂环境下的平均准确率
实验方法 复杂环境 光照不足/% 受到遮挡/% 图像模糊/% SCF-ELM 95.01 93.72 94.63 MCF-ELM 97.15 96.01 96.68 -
为验证本文所用ELM分类器的优势,在分类识别阶段将ELM分类器与softmax分类器、SVM分类器从平均准确率、训练时间和识别时间3个方面进行比较,实验结果如表 3所示。
表 3 不同分类器的性能比较
分类器 准确率/% 训练时间/ min 识别时间/ms·帧-1 softmax 96.51 45.8 15.5 SVM 96.90 32.5 38.2 ELM 98.13 3.7 5.46 从表 3可以看出,ELM分类器的平均准确率高于softmax和SVM分类器的平均准确率,准确率高达98.13%。由于ELM算法在训练迭代过程中调整的参数少,计算量小,因此ELM算法在训练时间上要远远小于其他算法。且ELM分类器在识别时间上也具有优势,每幅图片的平均识别时间缩短到5.46 ms,可以到达实时识别的应用要求。
-
机器学习中最重要的特点之一就是具有较强的泛化能力,为验证本文用GTSRB数据集训练出的算法能否适用于其他新的数据集,本文将提出的算法用于新的数据集。新的数据集选用LISA (laboratory for intelligent & safe automobiles)[17]和BTSCB (belgium traffic sign classification benchmark)[18]交通标志数据集,由于LISA数据集包含47类交通标志,BTSCB包含62类交通标志,而本文提出的算法有43个输出节点,所以只选取LISA和BTSCB数据中的对应的43类各100张共200张交通标志作为新的测试数据集。实验结果显示平均准确率达到96.93%,每张图片的平均识别时间为8.21 ms,仍然具有较高的识别率,表明MCF-ELM算法具有很好的泛化性和实时性。
-
为了充分利用卷积神经网络多层特征的全面性和差异性,及大幅减少计算量和训练时间,本文提出并实现了一种基于多层特征表达和极限学习机的交通标志识别方法。利用CNN网络提取多层交通标志特征图,解决了传统网络仅利用端层特征进行分类导致特征不全面的问题;然后采用多尺度池化操作将提取出的各层特征向量联合形成一个具有多尺度多属性的交通标志特征向量,进一步丰富了图像的特征表达;使用ELM分类器实现交通标志的识别,ELM分类器可以在保证分类性能的前提下显著减少算法计算量,解决了其他算法运算量大导致训练和识别时间过长的问题。实验结果表明,本文提出的方法能够有效地提高交通标志的识别准确率,大幅缩短训练和识别时间,能够达到实时识别的现实需求;算法在多个数据集上的实验结果表明,该算法具有良好的泛化能力,满足实际运用的要求。
Traffic Sign Recognition Method Based on Multi-layer Feature CNN and Extreme Learning Machine
-
摘要: 针对传统神经网络仅利用端层特征进行分类导致特征不全面,以及交通标志识别中计算量大、时间长等问题,提出基于多层特征表达和极限学习机的交通标志识别方法。利用CNN网络提取多层交通标志特征图;采用多尺度池化操作,将提取出的各层特征向量联合形成一个具有多尺度多属性特征的交通标志特征向量;使用极限学习机分类器准确快速地实现交通标志的识别。实验结果表明,该方法能有效地提高交通标志识别的准确率,且具有较好的泛化能力和实时性。Abstract: The traditional neural network only uses the end-layer feature and needs massive and time-consuming computation in the traffic sign recognition, thereby resulting in an inaccurate and non-real-time classification. To solve the problem, a traffic sign recognition (TSR) method based on multi-layer feature expression and extreme learning machine (ELM) is proposed. Firstly, the multi-layer features of traffic signs are extracted using the convolutional neural network (CNN). Then, the multi-scale pooling operation is used to combine the extracted feature vectors of each layer to form a multi-scale multi-attribute traffic sign feature vector. Finally, the extreme learning machine (ELM) classifier is used to realize the classification of traffic signs. Experimental results show that the proposed method can effectively improve the accuracy and it has strong generalization ability and real-time performance in TSR.
-
表 1 CNN网络参数
特征图大小 特征图个数 核大小 步长 input 48×48 1 —— C1 46×46 100 3×3 1 P2 23×23 100 2×2 2 C3 20×20 150 4×4 1 P4 10×10 150 2×2 2 C5 8×8 250 3×3 1 P6 4×4 250 2×2 2 F7 43个神经元 ——  下载: 导出CSV
下载: 导出CSV
表 2 复杂环境下的平均准确率
实验方法 复杂环境 光照不足/% 受到遮挡/% 图像模糊/% SCF-ELM 95.01 93.72 94.63 MCF-ELM 97.15 96.01 96.68
下载: 导出CSV
表 3 不同分类器的性能比较
分类器 准确率/% 训练时间/ min 识别时间/ms·帧-1 softmax 96.51 45.8 15.5 SVM 96.90 32.5 38.2 ELM 98.13 3.7 5.46
下载: 导出CSV
-
[1] GUDIGAR A, CHOKKADI S, RAGHAVENDRA U. A review on automatic detection and recognition of traffic sign[J]. Multimedia Tools and Applications, 2016, 75(1):333-364. doi: 10.1007/s11042-014-2293-7 [2] WANG G, REN G, WU Z, et al. A hierarchical method for traffic sign classification with support vector machines[C]//The 2013 International Joint Conference on Neural Networks. Dallas, USA: IEEE, 2013: 1-6. [3] ZHU Y, WANG X, YAO C, et al. Traffic sign classification using two-layer image representation[C]//2013 IEEE International Conference on Image Processing. Melbourne: IEEE, 2013: 3755-3759. [4] 刘占文, 赵祥模, 李强, 等.基于图模型与卷积神经网络的交通标志识别方法[J].交通运输工程学报, 2016, 5:122-131. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jtysgcxb201605014 LIU Zhan-wen, ZHAO Xiang-mo, LI Qiang, et al. Traffic sign recognition method based on graphical model and convolutional neural network[J]. Journal of Traffic and Transportation Engineering, 2016, 5:122-131. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jtysgcxb201605014 [5] ZENG Y, XU X, FANG Y, et al. Traffic sign recognition using deep convolutional networks and extreme learning machine[C]//5th International Conference on Intelligent Science and Big Data Engineering. Suzhou: Springer, 2015: 272-280. [6] MALDONADO-BASCON S, LAFUENTE-ARROYO S, GIL-JIMENEZ P, et al. Road-sign detection and recognition based on support vector machines[J]. IEEE Transactions on Intelligent Transportation Systems, 2007, 8(2):264-278. doi: 10.1109/TITS.2007.895311 [7] CIREŞAN D, MEIER U, MASCI J, et al. Multi-column deep neural network for traffic sign classification[J]. Neural Networks, 2012, 32:333-338. doi: 10.1016/j.neunet.2012.02.023 [8] HUANG Z, YU Y, GU J, et al. An efficient method for traffic sign recognition based on extreme learning machine[J]. IEEE Transactions on Cybernetics, 2017, 47(4):920-933. doi: 10.1109/TCYB.2016.2533424 [9] ZEILER M, FERGUS R. Visualizing and understanding convolutional networks[C]//13th European Conference on Computer Vision. Zurich: Springer, 2014: 818-833. [10] HUANG G, ZHU Q, SIEW C. Extreme learning machine:Theory and applications[J]. Neurocomputing, 2006, 70(1):489-501. [11] XIE Y, LIU L, LI C, et al. Unifying visual saliency with HOG feature learning for traffic sign detection[C]//2009 IEEE Intelligent Vehicles Symposium. Xi'an: IEEE, 2009: 24-29. [12] LI S, JIANG H, PANG W. Joint multiple fully connected convolutional neural network with extreme learning machine for hepatocellular carcinoma nuclei grading[J]. Computers in Biology and Medicine, 2017, 84:156-167. doi: 10.1016/j.compbiomed.2017.03.017 [13] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[C]//13th European Conference on Computer Vision. Zurich: Springer, 2014: 346-361. [14] GONG Y, WANG L, GUO R, et al. Multi-scale orderless pooling of deep convolutional activation features[C]//13th European Conference on Computer Vision. Zurich: Springer, 2014: 392-407. [15] HUANG G, ZHOU X, DING X, et al. Extreme learning machine for regression and multiclass classification[J]. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2012, 42(2):513-529. doi: 10.1109/TSMCB.2011.2168604 [16] STALLKAMP J, SCHLIPSING M, SALMEN J, et al. The German traffic sign recognition benchmark: a multi-class classification competition[C]//The 2011 International Joint Conference on Neural Networks. San Jose, USA: IEEE, 2011: 1453-1460. [17] MOGELMOSE A, TRIVEDI M M, MOESLUND T B. Vision-based traffic sign detection and analysis for intelligent driver assistance systems:Perspectives and survey[J]. IEEE Transactions on Intelligent Transportation Systems, 2012, 13(4):1484-1497. doi: 10.1109/TITS.2012.2209421 [18] MATHIAS M, TIMOFTE R, BENENSON R, et al. Traffic sign recognition-How far are we from the solution?[C]//The 2013 International Joint Conference on Neural Networks. Dallas, USA: IEEE, 2013: 1-8. -

 点击查看大图
点击查看大图
图(6) / 表(3)
计量
- 文章访问数: 4466
- HTML全文浏览量: 1361
- PDF下载量: 310
- 被引次数: 0
