 ISSN
ISSN 





-
唇语识别(lip reading)是近年来模式识别和人工智能领域的热门研究问题,是声学和图像图形学的交叉学科。该技术涉及嘴唇区域定位、跟踪、特征提取、音素建模和目标识别等关键技术。由于图像序列中嘴唇区域相对位置不固定,现有的技术方法尚不能同时在嘴唇区域的精确分割和实时性方面同时获得满意结果。在唇语识别系统中,最为基础和关键的步骤是实现嘴唇区域分割,即利用精确的图像分割技术界定变化的嘴唇轮廓,进而挖掘人在说话时的唇动(lip movement)特征,实现利用视觉信息实现话语内容的识别。
文献中现有的嘴唇区域分割算法可以大致分为3类:基于像素的方法、基于模型的方法和基于统计的方法。基于像素的方法利用嘴唇区域的灰度图像来获得特征向量,或将图像转换为其他颜色空间并采用PCA(principal component analysis)、LDA (linear discriminant analysis)等实现特征提取[1-4]。基于模型的方法借用一定的几何模型来确定嘴唇的内外轮廓,并借用少量参数来表征该轮廓[5-7]。基于统计的方法发掘特征空间中的数据分布特征和相邻像素之间的空间相互作用关系来进行图像分割,为嘴唇分割提供了一种新颖方法[8],如利用空间限制的马尔可夫随机场图像分割技术[9-10]。
早期嘴唇区域分割通常通过相机来直接捕获嘴部区域或手动标定唇部区域来实现[11]。然而,这并不是理想的分割方法,本文研究的最终目标是要在变化的条件下(例如变化的光照,不同的肤色或非特定人的说话者等)自动地定位和追踪嘴唇。到目前为止,已经有许多研究者从事研究相关工作。文献[12]通过使用红色排除法在一系列图像上识别嘴唇来找到嘴角,得到了较准确的结果。文献[13-14]利用基于模糊聚类的算法在有胡须的情况下分割嘴唇区域。文献[15]采用自上而下主动形状模型来发现并跟踪内外唇轮廓。然而以上的分割方法在实际的分割过程中会出现一块块的、彼此不相互连通的小区域被分割出来,在颜色对比度较低的情况下,嘴唇边缘轮廓并不十分明显,此时分割的准确率和鲁棒性有待提高。
本文提出一种新的基于局部模型校准的马尔科夫随机场的嘴唇分割方法,考虑了局部空间的约束,使得分割在各自局部模型中独立进行。采用Kullback-Leiller距离来评估相邻局部模型的一致性,提出了有助于校准其参数的模型校正标准。通过实验与现有的MCM算法比较,证明该方法拥有良好的分割准确性。
-
马尔科夫随机场理论提供了一种方便且稳健的方法来建模诸如图像像素或相关特征的环境实体。该模型的应用主要是基于马尔科夫随机场和吉布斯分布之间的等价性定理,该定理在1971年被提出并于1974年进一步发展而来。如今马尔科夫随机场已被广泛用于解决各个层面的视觉问题。
目前已有许多研究人员提出了几种估计标准来实现马尔科夫随机场模型的最佳估计。其中,最大后验估计(maximum a posterior, MAP)是最常用的最佳分割标准,并且表现出较高性能。结合标记场的先验分布和观察随机场的条件分布的知识可知,最大后验估计的本质是找到最大后验概率的解${f^ * }$,可表示为:
$$ {f^ * } = \mathop {\arg \max }\limits_f P(f|x) = \mathop {\arg \max }\limits_f P(f)P(x|f) $$ (1) 对于一幅拥有常规点阵的图像,它的坐标集由S=[1, 2, …, s]表示,邻域系统表示为N,根据Hammersley-Clifford定理,如果作用在S上的随机场X服从吉布斯分布,则它一定也是一个马尔科夫随机场。该理论将马尔科夫随机场与吉布斯分布(Gibbs distribution)结合在一起。先验概率$P(f)$被定义为:
$$ P(f) = \frac{1}{Z}{{\rm{e}}^{ - U(f)}} $$ (2) 式中,Z为归一化常数;U(f)是先验能量函数(energy function),是基团势能${V_c}(f)$之和,可表示为:
$$ U(f) = \sum\limits_{s \in S} {\sum\limits_{c \in C} {{V_c}} } ({f_s}) $$ (3) 式中,C是在S范围内的所有基团的集合。
对于给定的分割标签,观察值应是独立且随机的。类似地,本文如式(2)一样定义条件概率$P(x|f)$:
$$ P(x|f) = \prod\limits_{s \in S}^m {P({x_s}|{f_s})} = \frac{1}{Z}{{\rm{e}}^{ - U(x|f)}} $$ (4) 式中,U(x|f)是反映观察值与标签值之间相干关系的条件能量函数。在大多数情况下,假设观测数据的条件概率分布服从高斯分布是合理的,因此U(x|f)可以表示为:
$$ U(x|f) = \sum\limits_{s \in S} {U({x_s}|{f_s})} = \sum\limits_{s \in S} {(\frac{{\ln |2{\rm{ \mathsf{ π} }}\sigma _l^2|}}{2}} + \frac{{{{({x_s} - {\mu _l})}^2}}}{{2\sigma _l^2}}) $$ (5) 式中,${\mu _l}$和$\sigma _l^2$分别表示每个标记观察变量的均值和方差。
系统能量函数定义如下:
$$ U(x;f) = U(f) + U(x|f) $$ (6) 分割结果为可使能量函数最小化的标记结果${f^ * }$:
$$ {f^*} = \mathop {\arg \min }\limits_f U(x;f) $$ (7) -
根据马尔科夫随机场理论,像素之间的相互作用通常被限制在邻域系统中,并且远离轮廓线的像素是不相关的,这可能导致错误的分割。从这个观点来看,本文使用局部化的方法实现分割,有助于避免图像噪声或其他干扰因素的干扰。比如阴影下的鼻孔。因此,本文建议使用马尔科夫随机场模型来实现特定局部区域内的分割,并且沿着初始轮廓定义该局部区域的质心。
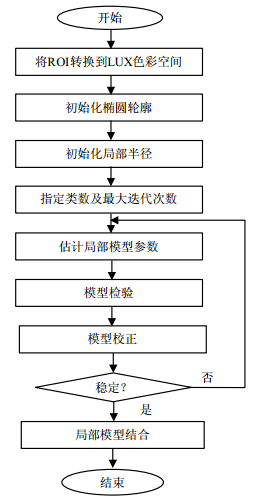
使用马尔科夫随机场模型的嘴唇轮廓分割的整个过程如图 1所示。第一步是将包含嘴的图像即感兴趣的区域变换到指定的色彩空间;然后初始化椭圆轮廓和局部半径;再指定分割总类数以及最大迭代次数。为了使局部分割结果平滑地结合在一起,后面的两步是为了进行模型检验和模型校准,此时迭代将继续,直到收敛。最后,在局部结果稳定之后,本文结合局部马尔科夫随机场模型以形成全局分割结果。

图 1 马尔科夫随机场模型流程图
-
为了验证不同光照条件下的鲁棒性,本文提出将嘴唇区域图像从RGB色彩空间转换为LUX(对数色调扩展)色彩空间。如文献[16]证明的,LUX空间中的对数化色彩分量U能够为唇部区域提供足够的对比度,区分唇部和周围皮肤之间的像素。变换方程如下:
$$ L = {(R + 1)^{0.3}}{(G + 1)^{0.6}}{(B + 1)^{0.1}} - 1 $$ $$ U = \left\{ {_{M - \frac{M}{2}\left( {\frac{{L + 1}}{{R + 1}}} \right)\quad{\rm{ 其他}}}^{\frac{M}{2}\left( {\frac{{R + 1}}{{L + 1}}} \right)\quad\quad R < L}} \right. $$ $$ X = \left\{ {_{M - \frac{M}{2}\left( {\frac{{L + 1}}{{B + 1}}} \right)\quad{\rm{ 其他}}}^{\frac{M}{2}\left( {\frac{{B + 1}}{{L + 1}}} \right)\quad\quad B < L}} \right. $$ (8) 式中,M为图像的最大灰度值,即M=256。
-
完成色彩空间转换之后,该模型需要一个围绕嘴唇轮廓初始化的封闭曲线。根据观察和研究,嘴唇是包含在一个椭圆框架内的。因此,基于嘴唇的特殊结构,本文采用椭圆轮廓模型来逼近嘴唇轮廓。
椭圆轮廓的参数的中心坐标(xc, yc)、长轴和短轴对轮廓初始化至关重要。这些参数的确定直接影响分割过程的效率。本文使用对数化颜色分量U用于定位唇部区域在上、下、左、右4个方向的端点。
假设图像像素有m行n列。每行的平均值和标准差分别为meani和stdi,每列的平均值和标准差分别为meanj和stdj,计算如下:
$$ {\rm{mea}}{{\rm{n}}_i} = \frac{1}{n}\sum\limits_{j = 1}^n {(u(i,j))\quad i = 1,2, \cdots ,m} $$ $$ {\rm{mea}}{{\rm{n}}_j} = \frac{1}{m}\sum\limits_{i = 1}^m {(u(i,j))\quad j = 1,2, \cdots ,n} $$ $$ {\rm{st}}{{\rm{d}}_i} = {\left( {\frac{1}{n}\sum\limits_{j = 1}^n {{{(u(i,j) - {\rm{mea}}{{\rm{n}}_i})}^2}} } \right)^{\frac{1}{2}}}\quad i = 1,2, \cdots ,m $$ $$ {\rm{st}}{{\rm{d}}_j} = {\left( {\frac{1}{m}\sum\limits_{i = 1}^m {{{(u(i,j) - {\rm{mea}}{{\rm{n}}_j})}^2}} } \right)^{\frac{1}{2}}}\quad j = 1,2, \cdots ,n $$ (9) 式中,U(i, j)表示图像在坐标(i, j)处的观测值。设(xc, yc)为椭圆的中心,A为椭圆的长轴值,B为短轴值,可通过如下等式计算:
$$ {x_c} = \frac{1}{2}({L_x} + {R_x})\quad {y_c} = \frac{1}{2}({U_y} + {D_y}) $$ $$ A = {x_c} - {L_x}\quad B = {y_c} - {U_y} $$ (10) 式中,${U_y}$和${D_y}$分别表示标准差${\rm{st}}{{\rm{d}}_i}$在顶部和底部变化最显著的位置;Lx和Rx分别表示标准差${\rm{st}}{{\rm{d}}_i}$在左边和右边变化最显著的位置。
椭圆可以表示为:
$$ \frac{{{{\left( {X - {x_c}} \right)}^2}}}{{{A^2}}} + \frac{{{{\left( {Y - {y_c}} \right)}^2}}}{{{B^2}}} = 1 $$ (11) -
获得椭圆轮廓后,沿着曲线定义局部区域。在局部模型中,引入窗口函数$\beta ({x_1}, {x_2})$定义马尔科夫随机场的局部区域范围。由半径参数r约束的窗口函数的表达式为:
$$ \beta ({x_1},{x_2}) = \left\{ \begin{array}{l} 1\quad \left\| {{x_1} - {x_2}} \right\| < r\\ 0\quad 其他 \end{array} \right. $$ (12) 式中,x1,x2是模型中的像素。局部马尔科夫随机场模型如图 2所示,局部区域即位于虚线以内。

图 2 局部马尔科夫随机场模型
MRF方法是基于此局部区域进行的分割。假设局部区域坐标集合为SL,CL是SL范围内的所有基团的集合,则局部区域的先验能量函数与基团势能可分别表示为:
$$ \overline {U(f)} = \sum\limits_{s \in {S_L}} {\sum\limits_{c \in {C_L}} {\overline {{V_c}({f_s})} } } $$ (13) $$ \begin{array}{c} \overline {U(x|f)} = \sum\limits_{s \in {S_L}} {\overline {U({x_s}|{f_s})} } = \\ \sum\limits_{s \in {S_L}} {\left( {\frac{{\ln |2\pi {\sigma ^2}|}}{2} + \frac{{{{({x_s} - \mu )}^2}}}{{2{\sigma ^2}}}} \right)} \end{array} $$ (14) $$ \overline {{f^ * }} = \mathop {\arg \min }\limits_f \overline {U(x;f)} $$ (15) 式中,$\overline {U(f)} $是局部区域内的先验能量函数;$\overline {{V_c}(f)} $是局部区域的基团势能;$\overline {U(x|f)} $表示条件能量函数;$\mu $和${\sigma ^2}$是局部区域内每个标记观察变量的均值和方差;$\overline {{f^ * }} $表示可以使能量函数$\overline {U(x; f)} $最小化的最终分割结果,这里$\overline {U(x; f)} = \overline {U(f)} + \overline {u(x|f)} $。
-
为了使局部MRF模型与其邻域的分割结果相协调,本文提出了一种可实现模型检验和模型校准的算法。首先需要为局部MRF定义邻域系统,将此邻域系统表示为NS(M),M是局部MRF模型,通过下式计算出相对应k的平均值及方差:
$$ \forall k = 1,2, \cdots ,t\left\{ \begin{array}{l} {{\bar \mu }_k} = {D^{ - 1}}\sum\limits_{c' \in {\rm{NS}}(M)} {\mu _k^cd(c,c')} \\ {{\bar \sigma }_k} = {D^{ - 1}}\sum\limits_{c' \in {\rm{NS}}(M)} {\sigma _k^{c'}d(c,c')} \end{array} \right. $$ (16) 式中,$D = \sum {d(c, c')} $;t表示类数;c和c'是局部模型与其邻区的中心;$d(c, c')$表示c和c'之间的欧氏距离;$\mu _k^{c'}$和$\sigma _k^{c'}$对应相应的均值和方差。
其次,KL距离Dk用来衡量第k类分割的两个局部MRF模型之间的差异,有:
$$ \begin{array}{l} {D_k} = {\rm{KL}}({\mu _k},{\sigma _k},\overline {{\mu _k}} ,\overline {{\sigma _k}} ) = \\ \frac{{(\sigma _k^2 - \overline {\sigma _k^2} ) + ({\mu _k} - \overline {{\mu _k}} )(\sigma _k^2 + \overline {\sigma _k^2} )}}{{4\sigma _k^2\overline {\sigma _k^2} }} \end{array} $$ (17) 经校准后的平均值标记为$\overline{\overline {{\mu _k}}} $和$\overline{\overline {{\sigma _k}}} $,根据下式计算:
$$ \left\{ \begin{array}{l} \overline{\overline {{\mu _k}}} = (1 - \kappa ){\mu _k} + \kappa \overline {{\mu _k}} \\ \overline{\overline {{\sigma _k}}} = (1 - \kappa ){\sigma _k} + \kappa \overline {{\sigma _k}} \end{array} \right. $$ (18) 式中,$\kappa \in [0, 1]$。定义两个阈值Tk与Tr(Tk < Tr)用于模型校准,如下所示:
如果Dk≤Tk,局部模型的参数不需要调整,因此$\kappa = 0$。
如果Dk > Tk,局部模型需要调整,使参数$\kappa = 1$。
如果Tk < Dk < Tr,$\kappa = ({D_k} - {T_k})/({T_r} - {T_k})$。
-
为了验证该方法的有效性,本文使用了的公开可用的CUAVE数据库[17],该数据库由克莱姆森大学提供使用。人脸区域的位置可由OpenCV技术检测。
OpenCV是一种基于开源协议BSD((Berkeley software distribution)许可发行的跨平台计算机视觉库。它提供了很多分类、聚类的算法,在人脸检测的问题中主要是利用它的机器学习模块(ml)中关于Boosting算法中的一个应用,即Haar分类器进行人脸特征的检测。
人脸区域的检测和定位的具体步骤如下:
1) 选取OpenCV中“haarcsacade-frontface-alt. xml”,将检测目标的分类信息用该文件保存,之后使用cvLoad函数将该文件加载,再对图片格式的类型进行转换;
2) 选取OpenCV中专门用来检测图像中是否包含目标的cvHaarDetectObjects函数,调用该函数,可将人脸区域位置由矩形标定出;
3) 选取cvHect变量,将步骤2)中标定的人脸区域返回并保存至cvHect变量中,完成人脸检测。
包含嘴唇的区域可由人脸比例计算出来,实验中,本文认定嘴唇区域位于$\frac{1}{4}{W_{{\rm{face}}}} < {W_{{\rm{mouth}}}} < \frac{3}{4}{W_{{\rm{face}}}}$和$\frac{2}{3}{H_{{\rm{face}}}} < {H_{{\rm{mouth}}}} < \frac{9}{{10}}{H_{{\rm{face}}}}$的人脸区域内,其中${W_{{\rm{face}}}}$代表人脸的宽度,${H_{{\rm{face}}}}$代表人脸的高度,这两个参数可由OpenCV技术直接检测得到。从图 3中可看出,只要在人脸能够准确定位的前提下,该方法在定位嘴唇方面切实可行。

图 3 嘴唇区域
在此基础上,选取了同一个人说话时的4种不同口型,运用本文提出的方法进行嘴唇分割,得到的结果如图 4所示。

图 4 分割结果
从图 4中可以观察到,局部MRF模型分割结果明显优于传统的MRF模型,特别是最后一种情况,传统MRF模型几乎不能对唇部形成有效的分割,而本文提出的模型则表现出了优良性能。
-
为了定量研究本文算法的分割性能,本文采用广泛使用的重叠(overlap, OL)率和分割误差(segmentation error, SE)率[18]来评测分割效果,OL和SE分别为:
$$ {\rm{OL}} = \frac{{2({A_1} \cap {A_2})}}{{{A_1} + {A_2}}} \times 100\% $$ (19) $$ {\rm{SE}} = \frac{{{\rm{OLE}} + {\rm{ILE}}}}{{2{\rm{TL}}}} \times 100\% $$ (20) 式中,OL为测算本文算法所得嘴唇区域A1与真实的嘴唇区域A2之间的重叠率;SE为测算误分割百分比;OLE表示唇外分割错误;ILE表示唇内分割错误。真实的嘴唇区域则由人工手工分割所得,可认为是理想的嘴唇区域。
常规MRF分割方法应用于嘴唇分割的效果不佳,如图 4d所示。将本文分割方法与近年提出且性能较佳的混合轮廓模型分割方法(mixed contour model,MCM)进行比较[19],得到如表 1所示的结果,其中MCM算法得到的OL平均值为87.8%,SE平均值为10.9%,本文算法得到的OL平均值为91.0%,SE平均值为7.9%。可见本文提出的算法在OL和SE性能指标上均优于MCM算法。
表 1 性能比较
MCM算法/% 本文算法/% OL SE OL SE 87.3 10.0 90.7 8.2 88.9 11.3 91.2 7.9 90.1 9.4 91.7 7.7 87.9 10.2 91.1 7.9 86.5 11.7 90.5 8.9 85.9 13.5 89.3 9.2 87.2 10.6 91.4 7.4 88.8 9.1 91.6 7.3 85.6 12.7 90.4 7.6 89.7 10.3 92.0 7.1 本文实验均在MATLAB上进行,系统环境为英特尔酷睿i5-4200H 2.8Ghz,4GB RAM。
-
本文提出了一种基于局部MRF模型LUX颜色空间中的嘴唇分割方法。通过在一个椭圆轮廓的基础之上,结合初始化窗口函数来指定MRF模型的局部范围,实现嘴唇区域的分割。最后,提出了MRF模型的参数模型检查和校准方法。实验表明该方法可对唇部进行有效的分割。
A Local MRF Model Based Lip Segmentation Method with Model Calibration
-
摘要: 为了有效挖掘人说话时的唇动特征,提出了一种综合局部区域马尔科夫随机场(Markov random field,MRF)特性和模型校准的嘴唇分割方法。将嘴唇区域图像从RGB转换到LUX色彩空间,并利用对数化色彩分量U实现初始化轮廓的确定。沿轮廓选取固定半径的圆形窗口函数界定局部区域,再利用马尔科夫随机场进行嘴唇分割,并使用基于Kullback-Leiller(KL)距离的模型校准方法使局部区域之间的分割结果相互协调。实验证明,该方法可以在皮肤中分离出嘴唇,分割准确率高,鲁棒性好,具有较高的实用价值。Abstract: In order to effectively exploit the lip feature of human speech, a lip segmentation method based on Markov random field (MRF) and model calibration is proposed. In this paper, we conduct the color space transformation from RGB to LUX color space for the lip region image, and we make use of the logarithmic chroma U to determine the initial contour. A mask with fixed radius is selected along the contour to define the local region, the Markov random field is used to segment the lips, and the Kullback-Leiller (KL) distance based model calibration method is used to coordinate the segmentation results between the local regions. Experiments show that the method can separate the lips in the skin with high accuracy and robustness and is of high practical value.
-
Key words:
- image segmentation /
- lip reading /
- lip segmentation /
- local model calibration /
- Markov random field
-
表 1 性能比较
MCM算法/% 本文算法/% OL SE OL SE 87.3 10.0 90.7 8.2 88.9 11.3 91.2 7.9 90.1 9.4 91.7 7.7 87.9 10.2 91.1 7.9 86.5 11.7 90.5 8.9 85.9 13.5 89.3 9.2 87.2 10.6 91.4 7.4 88.8 9.1 91.6 7.3 85.6 12.7 90.4 7.6 89.7 10.3 92.0 7.1  下载: 导出CSV
下载: 导出CSV
-
[1] LEE K D, LEE K, LEE S Y. Extraction of frame-difference features based on PCA and ICA for lip-reading[C]//IEEE International Joint Conference on Neural Networks. [S. l. ]: [s. n. ], 2005. [2] NATH R, RAHMAN F S, NATH S, et al. Lip contour extraction scheme using morphological reconstruction based segmentation[C]//International Conference on Electrical Engineering and Information and Communication Technology. [S. l. ]: IEEE, 2014: 1-4. [3] YAN Li, YE Hang, WANG Yi-kai, et al. A lip localization method based on HSV transformation in smart phone environment[C]//International Conference on Signal Processing. [S. l. ]: IEEE, 2014: 1285-1290. [4] GRITZMAN A D, RUBIN D M, PANTANOWITZ A. Comparison of colour transforms used in lip segmentation algorithms[J]. Signal, Image and Video Processing, 2015, 9(4):1-11. doi: 10.1007%2Fs11760-014-0615-x [5] KASS M, WITKIN A, TERZOPOULOS D. Snakes:Active contour models[J]. International Journal of Computer Vision, 1988, 1(4):321-331. doi: 10.1007/BF00133570 [6] NASUHA A, SARDJONO T A, PURNOMO M H. Lip Segmentation and tracking based on Chan-Vese model[C]//International Conference on Information Technology and Electrical Engineering: "Intelligent and Green Technologies for Sustainable Development". [S. l. ]: ICITEE, 2013: 155-158. [7] SUN Chen-yang, LU Hong, ZHANG Wen-qiang, et al. Lip segmentation based on facial complexion template[C]//Advances in Multimedia Information Processing. [S. l. ]: Springer International Publishing, 2014. [8] FU Jian-wen, WANG Shi-lin, LIN Xiang. Robust lip region segmentation based on competitive FCM clustering[C]//International Conference on Digital Image Computing: Techniques and Applications. [S. l. ]: IEEE, 2016. [9] YANG F, JIANG T. Pixon-based image segmentation with Markov random fields[J]. IEEE Transactions on Image Processing, 2003, 12(12):1552-1559. doi: 10.1109/TIP.2003.817242 [10] CHEUNG Y M, LI M, CAO X. Lip segmentation and tracking under MAP-MRF framework with unknown segment number[J]. Neurocomputing, 2013, 104:155-169. doi: 10.1016/j.neucom.2012.10.009 [11] 荣传振, 岳振军, 贾永兴, 等.模糊语言模型在唇读系统中的应用[J].数据采集与处理, 2012, 27(s2):277-283. http://www.cqvip.com/QK/92416X/201510/666524320.html RONG Chuan-zhen, YUE Zhen-jun, JIA Yong-xing, et al. Research advances in key technology of lip-reading[J]. Joumal of Data Acquisition & Processing, 2012, 27(s2):277-283. http://www.cqvip.com/QK/92416X/201510/666524320.html [12] LEWIS T, POWERS D. Lip feature extraction using red exclusion[C]//Selected Papers from Pan-Sydney Workshop on Visualization. [S. l. ]: [s. n. ], 2002. [13] WANG S L, LAU W H, LEUNG S H, et al. Lip segmentation with the presence of beards[C]//International Conference on Acoustics, Speech, & Signal Processing. [S. l. ]: IEEE, 2004. [14] LEUNG S, WANG S, LAU W. Lip image segmentation using fuzzy clustering incorporating an elliptic shape function[J]. IEEE Transactions on Image Processing, 2004, 13(1):51-62. doi: 10.1109/TIP.2003.818116 [15] MATTHEWS I, COOTES T F, BANGHAM J A. Extraction of visual features for lipreading[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(2):198-213. doi: 10.1109/34.982900 [16] LIÉVIN M, LUTHON F. Nonlinear color space and spatiotemporal MRF for hierarchical segmentation of face features in video[J]. IEEE Transactions on Image Processing, 2004, 13(1):63-71. doi: 10.1109/TIP.2003.818013 [17] PATTERSON E K, GURBUZ S, TUFEKCI Z, et al. CUAVE: a new audio-visual database for multimodal human-computer interface research[C]//IEEE International Conference on Acoustics, Speech & Signal Processing. [S. l. ]: IEEE, 2002. [18] LIEW W C, LEUNG S H, LAU W H. Segmentation of color lip images by spatial fuzzy clustering[J]. IEEE Transactions on Fuzzy Systems, 2003, 11(4):542-549. doi: 10.1109/TFUZZ.2003.814843 [19] STILLITTANO S, GIRONDEL V, CAPLIER A. Lip contour segmentation and tracking compliant with lip-reading application constraints[J]. Machine Vision & Applications, 2013, 24(24):1-18. https://www.researchgate.net/publication/257334063_Lip_contour_segmentation_and_tracking_compliant_with_lip-reading_application_constraints -

 点击查看大图
点击查看大图
图(4) / 表(1)
计量
- 文章访问数: 4034
- HTML全文浏览量: 1260
- PDF下载量: 110
- 被引次数: 0
