 ISSN
ISSN 





-
可生存系统是一种高性能的认知逻辑网络,如今已发展为各国各界信息安全领域的核心问题。它可以满足不同应用的各种需求,还可以通过感知系统的内、外部环境变化,实时动态地调整总体的网络系统配置,使其性能达到最优。在可生存系统研究中,对其生存态势的研究是最为关键的。然而,现实中的系统现状是无论如何防御入侵总会发生,无论如何检测,系统总会受到不同程度的破坏,所以系统的失效在所难免。在有限的时间里更好保证系统的良好生存态势并利用当前生存态势预测将来的生存态势,已成为亟待解决的问题。
可生存系统生存态势的研究,由参照文献[1]的定义可知,主要分为对3R(resistance, recognition, recovery)属性的研究。现有大部分文献都将研究的主要精力投入到对生存态势的可恢复性与可抵抗性方面或对可生存进行概括性的研究,如从服务生存性角度定义系统生存性[2]、通过事物与数据的实时特性定义完整性与可用性等生存性指标[3]、针对网络系统可生存性中的故障修复和网络防故障技术来描述RSCN可生存性能[4]以及将可抵抗性概念应用到优化城市中救护车定位中,最大限度地保证病人的安全,提高救护车的救援质量[5]等。但在可识别性方面国内外研究文献数量较少,大部分是基于网络安全状况和云计算环境。文献[6]对云计算中的态势识别进行研究,提出了一种监视运行中的虚拟机的数据中心层的新方法,并在实验中验证了该方法的可行性;文献[7]对云计算环境中的识别技术进行了总结,并对各种入侵检测技术在云环境下的检测能力进行了全面的分析;文献[8]在构建可生存系统认知参考模型中,提出了一种用模糊关系矩阵进行生存属性分类的方法,通过最终实验可判断在可生存系统存在异常攻击时,哪些属性是处于重要主导地位,以此为生存系统的更好设计与实现提供重要参考;文献[9]从生存性的自主识别性入手,提出自主识别单元,侧重研究可识别性检测参数定义、自主识别模式以及阈值可变方式,提出一种可识别性监测机制以此提高自主认知能力和服务承载能力。对可识别性的研究,通常应包含识别当前态势和对可生存系统生存态势在将来一段时间内发展趋势的预测。
综上,本文将事前识别与事后预测相结合,从生存态势的角度研究了可生存系统,提出了一种基于生存簇识别和预测的生存态势感知模型。
-
Ward聚类的主要思想:采取正确聚类时,同类间的数据离差平方和会尽可能的小,成功聚类后可将相似服务等级的生存簇聚集在一起。
-
在生存态势生存簇的形成中,需将每个态势数据看成一类,每减小一类,选择S增加最小的两类进行合并,直至所有样本归为所需数量的类。已知n个态势数据分成k类${G_1}, {G_2}, \cdots , {G_k}$,总的类内离差平方和计算方法为:
$$S = \sum\limits_{i = 1}^k {\sum\limits_{j = 1}^{{n_i}} {({y_{ij}} - {y_i})'({y_{ij}} - {y_i})} } $$ (1) 使用Ward聚类后,会生成不同大小的生存簇,由于数据中存在关键性数据与不合理数据,考虑到搜索成本与时间问题,成功识别不合理数据十分重要。因此,对现有Ward聚类方法进行改进,引入消错方法[13]进行决策,实现可生存系统生存态势的事前识别。
-
消错方法是从错误损失的角度看待问题,通过降低错误的损失,达到更好的数据识别效果。
在多属性决策问题中,假设m个态势数据表示为$A = \{ {a_1}, {a_2}, \cdots , {a_m}\} $,n个属性为$D = \{ {d_1}, {d_2}, \cdots , {d_n}\} $,决策矩阵为${\pmb X} = {[{x_{ij}}]_{m \times n}}$,${a_i}$在${d_i}$下的测量值为${x_{ij}}$。识别步骤如下:
1) 计算态势数据错误值t:
$${t_{i, j}} = \left\{ \begin{gathered} 1~~~~~~~~~~~~~{x_{i, j}} \geqslant {z_{\max }} \\ \frac{{{x_{i, j}} - {z_{\min }}}}{{{z_{\max }} - {z_{\min }}}}~~~~{z_{\min }} < {x_{i, j}} < {z_{\max }} \\ 1~~~~~~~~~~~~~{x_{i, j}} \leqslant {z_{\min }} \\ \end{gathered} \right.{\rm{ }}$$ (2) 式中,$i = \{ 1, 2, \cdots , m\} $;$j \in N$。根据式(2)求得备选数据${a_i}$的错误值序列为$A = \{ {t_{i, 1}}, {t_{i, 2}}, \cdots , {t_{i, n}}\} $。
2) 计算${a_i}$最大错误值$t_i^ * $并判断合理性,其中$i = \{ 1, 2, \cdots , m\} $,$N = \{ 1, 2, \cdots , n\} $。当$t_i^ * = 1$时为不合理数据,表示为:
$$t_i^* = \max \{ {t_{i, j}}\} $$ (3) 3) 计算可行数据错误损失值,表示为:
$${k_{i, j}} = {a_i}{d_j}^\prime \quad \quad j = 1, 2, 3, \cdots , n$$ (4) 4) 对错误损失序列进行排序。将错误损失序列$\{ {h_{i, 1}}, {h_{i, 2}}, \cdots , {h_{i, n}}\} $看成n维空间上点${H_i}$,越接近原点,数据越好,表示为:
$${R_i} = \sqrt {\sum\limits_{j = 1}^n {{{({h_{i, j}})}^2}} } \quad \quad i \in M'$$ (5) -
对可生存系统生存态势数据只进行事前识别是不够的,还需建立模型便于对可生存系统生存态势进行预测,由此引入ARIMA模型。
-
ARIMA模型是以数学模型的方式描述预测对象根据时间的发展形成的随机序列。在可用性方面文献[14]认证了该模型的可行性。
模型构建方法如下:首先,收集可生存系统生存态势数据序列$\{ {Y_t}\} $,进行d次差分变成平稳序列$\{ {Y'_t}\} $;其次,计算$\{ {Y'_t}\} $的自相关函数(ACF)和偏自相关函数(PACF)确定p、q值;最后,通过平稳性和可逆性检验,选择合适的ARIMA(p, d, q)模型,实现事后初步预测。
-
使用模糊信息粒化与SVR模型对ARIMA模型中的残差数据进行处理。模糊信息粒化包括:窗口划分和模糊化。为计算方便本文选用三角型模糊粒子,隶属公式为:
$$F(x, \min , {\rm{avg}}, \max ) = \left\{ {\begin{array}{*{20}{c}} 0&{x \leqslant \min } \\ {\frac{{x - \min }}{{{\rm{avg}} - \min }}}&{\quad \min < x \leqslant {\rm{avg}}} \\ {\frac{{\max - x}}{{\max - {\rm{avg}}}}}&{\;\;{\rm{avg}} < x < \max } \\ 0&{x \geqslant \max } \end{array}} \right.$$ (6) 式中,x为输入的时间序列;min、avg、max分别表示相应生存态势数据变化的最小值、平均值、最大值。对于已知训练样本数集$\{ ({x_1}, {y_1}), $ $({x_2}, {y_2}), \cdots , $ $({x_n}, {y_n})\} $,在高维特征空间中构造最优决策函数:
$$\min {\mathit \Phi} ({\pmb \omega} ) = \frac{1}{2}{\left\| {\pmb \omega} \right\|^2}$$ (7) 式中,ω为权重矢量。设b为偏差值,它们满足以下约束条件:
$${y_i}({\pmb \omega} {x_i} + b) - 1 \geqslant 0\quad \quad i = 1, 2, \cdots , l$$ (8) 将该方法用于回归问题上,还需引入损失函数来保持重要属性,构建公式为:
$$\left\{ {\begin{array}{*{20}{c}} {\mathop {\min }\limits_{{\pmb \omega} , b, \xi , {\xi ^*}} \frac{1}{2}{{\pmb \omega} ^2} + C\sum\limits_{i = 1}^l {(\xi _i^* + {\xi _i})} } \\ {({\pmb \omega} \varphi ({x_i}) + b) - {y_i} \leqslant \varepsilon + {\xi _i}} \\ {{y_i} - ({\pmb \omega}\varphi ({x_i}) + b) \leqslant \varepsilon + \xi _i^*} \\ {\xi _i^*, {\xi _i} \geqslant 0} \end{array}} \right.$$ (9) 式中,${\xi _i}$和$\xi _i^*$为松弛变量;C为惩罚因子;ε为回归函数误差要求。
-
1) 计算初步预测值$y_{t - 1}^ * $。收集一段时间内可生存系统生存态势数据,使用差分法生成平稳时间序列,计算序列自相关函数(ACF)和偏自相关函数(PACF)确定p、q值并进行校验。2)计算残差预测值${e_{{\rm{svr}} - 1}}$。建立三角型模糊粒子;将残差时间序列分为多个子序列,进行窗口化分类,使用前一窗口处理好的模糊信息粒子数据集作为输入变量构建SVR模型,实现当前窗口模糊信息粒子和残差均值的预测。3)计算总体预测值。将初步预测值和残差预测值简单相加实现生存态势事后预测。
-
对可生存系统生存态势识别指标的选取,本文参考文献[15]建立的指标体系原则,选取了3个主要因素,即完整性、使用性和感知性。这3个因素又分为6个性能指标,分别为数据复用率、检验强度、信道利用率、信道延迟、信道吞吐率和感知率。
-
在实验中,假设网络系统服务中提供5种级别的服务A1(最高)、A2、A3、A4、A5(最低),初始数据表如表 1所示。
表 1 初始数据表
服务等级 A1 A2 A3 A4 A5 用户数量 15 25 70 70 70 完整性 数据复用率 [0.30, 0.40] [0.35, 0.50] [0.45, 0.60] [0.55, 0.75] [0.70, 0.90] 校验强度 [900, 1000] [800, 950] [700, 850] [550, 750] [500, 600] 交互性 信道延迟 [0.45, 0.55] [0.45, 0.65] [0.55, 0.60] [0.65, 0.85] [0.80, 0.90] 信道吞吐率 [800, 900] [700, 850] [550, 750] [500, 650] [500, 600] 信道利用率 [0.80, 0.90] [0.70, 0.85] [0.70, 0.80] [0.65, 0.75] [0.60, 0.70] 感知性 感知率 [0.90, 0.99] [0.75, 0.90] [0.70, 0.80] [0.60, 0.75] [0.60, 0.70] 由表 1规定当前系统内,不同服务级别的各项生存性能指标会有不同。随机抽取250位正常用户数据,其中A1级别用户15位,A2级别用户25位,A3、A4和A5级别用户各70位。
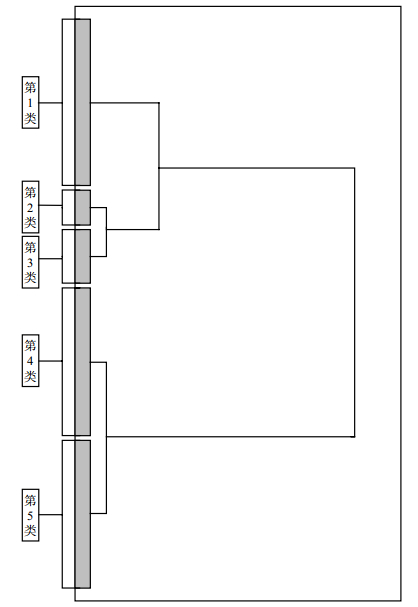
通过式(1)计算离差平方和并使用SPSS19.0软件进行聚类,将产生的Ward聚类规定簇数量为5类。经统计产生的新服务等级用户数据聚类如表 2所示,聚类方法的原理图如图 1所示。
表 2 用户聚类
服务等级 A1′ A2′ A3′ A4′ A5′ 用户数量 73 15 24 69 69 完整性 数据复用率 [0.67, 0.90] [0.30, 0.48] [0.39, 0.51] [0.58, 0.79] [0.47, 0.63] 校验强度 [500, 654] [879, 1000] [800, 926] [512, 708] [697, 820] 交互性 信道延迟 [0.79, 0.90] [0.41, 0.56] [0.53, 0.60] [0.67, 0.88] [0.56, 0.75] 信道吞吐率 [500, 580] [816, 895] [699, 846] [505, 626] [555, 698] 信道利用率 [0.60, 0.70] [0.78, 0.90] [0.68, 0.85] [0.61, 0.74] [0.66, 0.79] 感知性 感知率 [0.60, 0.72] [0.88, 0.98] [0.78, 0.90] [0.60, 0.73] [0.69, 0.82] 
图 1 Ward聚类原理图
图 1中表示的聚类种类为5类,通过SPSS19.0软件,将其数据根据特性自动聚类到这5类中。
对比表 1,发现聚类后的服务等级${A_1}^\prime $、${A_2}^\prime $、${A_3}^\prime $、${A_4}^\prime $、${A_5}^\prime $分别相当于${A_5}$、${A_1}$、${A_2}$、${A_4}$、${A_3}$级别服务,在每一级别用户数量及指标属性范围基本与初始数据分类一致。
-
随机抽取6组用户数据,每一级服务范围内抽样数量都为1,并抽取1名非法用户进行计算。判断态势数据可行性并排序,数据如表 3所示。表中,QA1、QA2、QA3、QA4、QA5、QA6分别为数据复用率、校验强度、信道吞吐率、信道延迟、信道利用率和感知率。
表 3 决策矩阵
数据 QA1 QA2 QA3 QA4 QA5 QA6 a1 0.35 990 881 0.44 0.87 0.92 a2 0.82 592 514 0.81 0.66 0.61 a3 0.56 774 703 0.59 0.75 0.71 a4 0.70 623 576 0.75 0.75 0.64 a5 0.37 936 702 0.45 0.82 0.90 a6 0.71 501 566 0.80 0.50 0.72 最小值 0.90 500 500 0.90 0.60 0.60 最大值 0.30 1000 900 0.40 0.90 0.99 根据式(2)~式(4)和环比评分(DARE)法求得各数据极限损失值为$t_1^ * = 0.18$、$t_2^ * {\rm{ = }}0.97$、$t_3^ * {\rm{ = }}0.72$、$t_4^ * {\rm{ = }}0.89$、$t_5^ * {\rm{ = }}0.49$、$t_6^ * {\rm{ = }}1$,得出数据${a_1}$、${a_2}$、${a_3}$、${a_4}$、${a_5}$为可行数据,${a_6}$为错误数据。利用式(5)和文献[16]的方法求得各属性的错误极限损失值和损失序列分别为$k_{{\rm{d}}1}^ * {\rm{ = }}0.26$、$k_{{\rm{d}}2}^ * = 0.15$、$k_{{\rm{d}}3}^ * = 0.12$、$k_{{\rm{d}}4}^ * = 0.18$、$k_{{\rm{d}}5}^ * = 0.07$、$k_{{\rm{d}}6}^ * = 0.22$,${a_1}${0.022, 0.003, 0.006, 0.014, 0.007, 0.039}、${a_2}${0.225, 0.122, 0.116, 0.148, 0.056, 0.214}、${a_3}${0.113, 0.068, 0.059, 0.068, 0.035, 0.158}、${a_4}${0.173, 0.113, 0.097, 0.126, 0.035, 0.197}、${a_5}${0.031, 0.019, 0.059, 0.018, 0.019, 0.051}。根据式(5)求得离心距为${R_1}$=0.048、${R_2}$=0.387、${R_3}$=0.227、${R_4}$=0.329、${R_5}$=0.089,可知用户数据性能排序为${a_1}$、${a_5}$、${a_3}$、${a_4}$、${a_2}$,且${a_6}$为非法用户。
为进一步说明本方法的可行性,采用两种常见的传统决策方法,即理想点法和加权平均法对这组数据进行排序,排序结果如表 4所示。
表 4 决策方法对比
方法 排序结果 消错决策方法 a1 > a5 > a4 > a3 > a2,a6为非法用户 理想点法 a1 > a5 > a6 > a4 > a3 > a2 加权平均法 a1 > a5 > a4 > a6 > a3 > a2 综上,结合了消错方法的Ward聚类法,成功将生存态势数据聚类为5种服务等级的生存簇并对不合理数据进行识别。从计算的过程、复杂性与结果看,本文提出的消错决策方法无需计算权重且计算复杂度低;从排序结果看,传统决策方法只能实现数据的排序,缺少验证合理数据的能力,本文通过计算极限损失值成功识别部分错误数据,提高了对数据的准确处理能力及响应时间,排序结果也与传统决策方法基本一致。
-
在高生存性网络服务系统中,系统响应服务次数越多,意味着系统服务生存态势越好。但由于高级别服务用户数量是有限的,其相应的服务次数也是有限的,大部分用户请求服务都集中于中间级别,想要快速、较准确地预测服务生存态势,可通过对A3与A4级别用户请求服务次数进行预测,完成对可生存系统生存态势的事后预测。
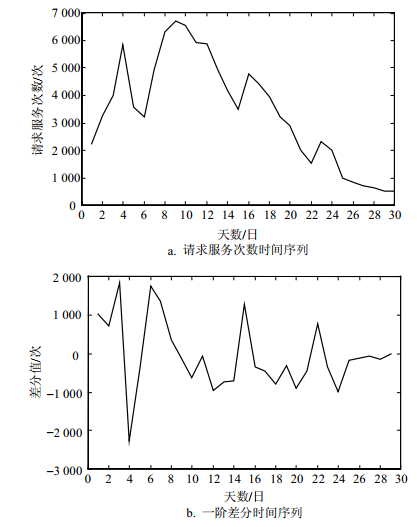
现选取用户数据进行分析与预测。计算从1月1日-1月30日这30天服务等级为A3和A4级别的用户请求服务次数,建立模型如图 2a所示,采集的数据序列图符合随机性分布,经观察为非平稳时间序列,进行一阶差分后如图 2b所示。

图 2 ARIMA模型校验
自相关系数和偏自相关系数如表 5所示,规定标签数最大为12。选取ARIMA(0, 1, 0)为最优预测模型,模型预测结果如图 3所示。
表 5 自相关系数和偏自相关系数
滞后 AC PAC 1 0.093 0.093 2 -0.205 -0.216 3 -0.159 -0.123 4 0.140 0.133 5 0.092 0.011 6 0.061 0.088 7 0.044 0.096 8 0.148 0.173 9 0.004 0.011 10 -0.089 -0.038 11 0.274 -0.280 12 0.017 -0.036 
图 3 ARIMA(0, 1, 0)模型预测结果
图 3中,实线表示实际A3与A4级别用户请求服务次数,虚线表示ARIMA(0, 1, 0)模型预测的用户请求的服务次数,总体上来说模型的预测结果与实际情形实现初步拟合,但存在一定的延迟且精准度有待提升。
-
由于ARIMA模型预测数据存在误差,现将1月1日-1月30日30天内产生的30个数据与实际数据之间的误差值作为训练集,以1月31-2月2日作为预测集,每3天为一个信息粒化窗口,数据模糊粒化为Low、Medium、High3个参数,如图 4所示。其中Low、Medium和High分别描述的是服务等级为A3和A4级别的用户请求服务次数的最小、平均和最大变化数。

图 4 粒化结果
将模糊信息粒子数据集作为输入变量构建SVR模型。对模糊信息粒子及窗口化残差进行预测,数据进行归一化处理,利用GS算法进行参数寻优,分别在Low、Medium、High下获取规范化参数与核参数为Low:c=38.1,g=38.1;Medium:c=32,g=16;High:c=32,g=1,测试集输出结果如图 5所示。

图 5 Low、Medium和High参数预测结果、误差和Low、Medium和High参数的网格寻优结果
由图 5可知,SVR模型总体残差预测准确率较高,对于Low参数预测结果较为准确,High参数的预测结果较差。但对于窗口化残差值相差很大时如2、3窗口时,模型中Low、Medium两个参数预测值存在很大误差,主要是因为SVR模型中通过前一个窗口的模糊信息粒子完成对后一窗口数据的预测,所以当用户请求服务次数波动很大时预测准确度会下降。因此,SVR模型对事后残差数据的预测是可行的,但也存在不足。
-
将ARIMA模型预测值和SVR残差预测值合并,预测未来3天的用户请求服务次数,如表 6所示。
表 6 组合模型预测结果
时间 1月31日-2月2日 用户请求服务次数 1 726 ARIMA预测值($y_{t - 1}^ * $) 1 230 ARIMA准确率/% 71.3 SVR残差预测值(${e_{{\rm{svr}} - 1}}$) 234 组合模型预测值(${y_p}$) 1 464 组合模型准确率/% 84.8 由实验结果可知,ARIMA模型预测1月31日-2月2日服务等级为A3和A4级别的用户请求服务次数分别为469、410、351与实际用户请求服务次数665、574、487有差距,但增减趋势一致,SVR模型对事后预测的残差数据进行修正,残差修正后总体预测准确度提升13.5%,但组合模型的准确率达到84.8%。
综上,ARIMA模型与SVR模型结合可对服务等级为A3和A4级的用户请求服务次数进行预测,通过图 2可发现随着时间的推移,在相同时间段内,用户每天的请求服务次数总体呈下降趋势,表明系统的总体服务生存态势在下降,通过该方法,完成对可生存系统生存态势的事后预测。
-
本文提出一种基于生存簇识别和预测的生存态势感知模型,侧重研究了生存态势数据合法性判断和系统服务生存性的预测等。在仿真实验中对网络系统中服务数据与请求服务次数进行性能仿真,实验结果显示模型可以实现对可生存系统生存态势的事前识别和预测生存态势。但该模型存在相应的不足,首先,事前识别中缺乏对外部攻击的识别,识别真实场景准确率有待提高;其次,事前识别中只识别出合理性数据,但对合理性数据所属级别并不能较好的识别;最后,预测模型的精确度有待提高并存在一定的延迟,尤其是在面对数据波动较大的数据源时,局部精准度表现较差。在后续可生存系统生存态势的自感知的研究中,将会考虑构建一种更好的识别模型和更准确的预测模型。
本文的研究工作得到了哈尔滨市科技创新人才研究专项资金(2016RAQXJ036)的资助,在此表示感谢!
Survival Situation Awareness Model Based on Survival Cluster Recognition and Prediction
-
摘要: 可生存系统安全态势的形势日趋严峻,增强生存性的前提是识别出目标系统的生存态势,该文构建了一种基于生存簇识别和预测的生存态势感知模型。首先,对生存态势数据采用Ward增强聚类法实现不同服务等级生存簇的分类和识别;其次,使用自回归积分滑动平均(ARIMA)模型预测目标系统生存态势的未来趋势,并对预测结果进行了残差修正;最后,结合事前识别和事后预测实现了对可生存系统生存态势的感知。仿真实验表明,该模型具有良好识别效果和较高的预测准确度。
-
关键词:
- 自回归积分滑动平均模型 /
- 残差修正 /
- 生存簇 /
- 生存态势 /
- Ward聚类
Abstract: The security situation of survivable system is becoming more and more serious. The premise of enhancing survivability is to recognize the survival situation of the target system. A survival situation awareness model is constructed based on survival cluster recognition and prediction. Firstly, the improved Ward clustering method is used to realize the classification and recognition of different service levels. Secondly, the autoregressive integrated moving average (ARIMA) model is used to predict the future trend of the target system's survival situation and the residuals of the prediction results are corrected. Finally, the survival situation of survivable system is realized by the combination of pre-recognition and post-prediction. Simulation results show that the proposed model has better recognition effect and higher prediction accuracy.-
Key words:
- ARIMA model /
- residual modification /
- survival cluster /
- survival situation /
- Ward cluster
-
表 1 初始数据表
服务等级 A1 A2 A3 A4 A5 用户数量 15 25 70 70 70 完整性 数据复用率 [0.30, 0.40] [0.35, 0.50] [0.45, 0.60] [0.55, 0.75] [0.70, 0.90] 校验强度 [900, 1000] [800, 950] [700, 850] [550, 750] [500, 600] 交互性 信道延迟 [0.45, 0.55] [0.45, 0.65] [0.55, 0.60] [0.65, 0.85] [0.80, 0.90] 信道吞吐率 [800, 900] [700, 850] [550, 750] [500, 650] [500, 600] 信道利用率 [0.80, 0.90] [0.70, 0.85] [0.70, 0.80] [0.65, 0.75] [0.60, 0.70] 感知性 感知率 [0.90, 0.99] [0.75, 0.90] [0.70, 0.80] [0.60, 0.75] [0.60, 0.70]  下载: 导出CSV
下载: 导出CSV
表 2 用户聚类
服务等级 A1′ A2′ A3′ A4′ A5′ 用户数量 73 15 24 69 69 完整性 数据复用率 [0.67, 0.90] [0.30, 0.48] [0.39, 0.51] [0.58, 0.79] [0.47, 0.63] 校验强度 [500, 654] [879, 1000] [800, 926] [512, 708] [697, 820] 交互性 信道延迟 [0.79, 0.90] [0.41, 0.56] [0.53, 0.60] [0.67, 0.88] [0.56, 0.75] 信道吞吐率 [500, 580] [816, 895] [699, 846] [505, 626] [555, 698] 信道利用率 [0.60, 0.70] [0.78, 0.90] [0.68, 0.85] [0.61, 0.74] [0.66, 0.79] 感知性 感知率 [0.60, 0.72] [0.88, 0.98] [0.78, 0.90] [0.60, 0.73] [0.69, 0.82]
下载: 导出CSV
表 3 决策矩阵
数据 QA1 QA2 QA3 QA4 QA5 QA6 a1 0.35 990 881 0.44 0.87 0.92 a2 0.82 592 514 0.81 0.66 0.61 a3 0.56 774 703 0.59 0.75 0.71 a4 0.70 623 576 0.75 0.75 0.64 a5 0.37 936 702 0.45 0.82 0.90 a6 0.71 501 566 0.80 0.50 0.72 最小值 0.90 500 500 0.90 0.60 0.60 最大值 0.30 1000 900 0.40 0.90 0.99
下载: 导出CSV
表 4 决策方法对比
方法 排序结果 消错决策方法 a1 > a5 > a4 > a3 > a2,a6为非法用户 理想点法 a1 > a5 > a6 > a4 > a3 > a2 加权平均法 a1 > a5 > a4 > a6 > a3 > a2
下载: 导出CSV
表 5 自相关系数和偏自相关系数
滞后 AC PAC 1 0.093 0.093 2 -0.205 -0.216 3 -0.159 -0.123 4 0.140 0.133 5 0.092 0.011 6 0.061 0.088 7 0.044 0.096 8 0.148 0.173 9 0.004 0.011 10 -0.089 -0.038 11 0.274 -0.280 12 0.017 -0.036
下载: 导出CSV
表 6 组合模型预测结果
时间 1月31日-2月2日 用户请求服务次数 1 726 ARIMA预测值($y_{t - 1}^ * $) 1 230 ARIMA准确率/% 71.3 SVR残差预测值(${e_{{\rm{svr}} - 1}}$) 234 组合模型预测值(${y_p}$) 1 464 组合模型准确率/% 84.8
下载: 导出CSV
-
[1] WESTMARK V R. A definition for information system survivability[C]//Proceedings of the 37th Hawaii International Conference on System Sciences. Washington: [s.n.], 2004: 2086-2096. http://dl.acm.org/citation.cfm?id=963306 [2] 耿技, 宋旭, 陈伟, 等.基于系统结构和运行环境的系统生存性模型[J].电子科技大学学报, 2014, 43(1):101-106. 于系统结构和运行环境的系统生存性模 GENG Ji, SONG Xu, CHEN Wei, et al. Based on system structure and runtime environment[J]. Journal of University of Electronic Science and Technology of China, 2014, 43(1):101-106. 于系统结构和运行环境的系统生存性模 [3] 陈长清, 裴小兵, 周恒, 等.入侵容忍实时数据库的半马尔可夫生存能力评价模型[J].计算机学报, 2011, 34(10):1907-1916. http://www.cqvip.com/QK/90818X/201110/39746138.html CHEN Chang-qing, PEI Xiao-bing, ZHOU Heng, et al. A semi Markov evaluation model for the survivability of real time database with intrusion tolerance[J]. Chinese Journal of Computers, 2011, 34(10):1907-1916. http://www.cqvip.com/QK/90818X/201110/39746138.html [4] 赵靓, 邹宏, 张校辉.基于随机Petri网的虚拟网可生存性模型研究[J].通信学报, 2016, 37(3):71-78. doi: 10.11959/j.issn.1000-436x.2016054 ZHAO Liang, ZOU Hong, ZHANG Xiao-hui. Survivability model for reconfigurable service carrying network based on the stochastic Petri net[J]. Journal on Communications, 2016, 37(3):71-78. doi: 10.11959/j.issn.1000-436x.2016054 [5] ZAFFAR M A, RAJAGOPALAN H K, SAYDAM C, et al. Coverage, survivability or response time:a comparative study of performance statistics used in ambulance location models via simulation optimization[J]. Operations Research for Health Care, 2016, 11:1-12. doi: 10.1016/j.orhc.2016.08.001 [6] PATRASCU A, VELCIU M A, PATRICIU V V. Cloud computing digital forensics framework for automated anomalies detection[C]//IEEE International Symposium on Applied Computational Intelligence and Informatics. [S.l.]: IEEE, 2015: 505-510. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=7208257 [7] MISHRA P, PILLI E S, VARADHARAJAN V, et al. Intrusion detection techniques in cloud environment:A survey[J]. Journal of Network & Computer Applications, 2017, 77(C):18-47. http://www.sciencedirect.com/science/article/pii/S1084804516302417 [8] 王健, 赵国生, 张楠.基于模糊关系矩阵的可生存系统认知参考模型分析[J].武汉大学学报(理学版), 2015, 61(1):60-66. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=whdxxb-zr200705006 WANG Jian, ZHAO Guo-sheng, ZHANG Nan. Analysis of cognitive reference model for survivable system based on fuzzy relation matrix[J]. Journal of Wuhan University (Natural Science Edition), 2015, 61(1):60-66. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=whdxxb-zr200705006 [9] 赵国生, 刘海龙, 王健.可生存系统的自主可识别性机制研究[J].高技术通讯, 2014, 24(10):999-1006. http://www.cqvip.com/QK/92817X/201404/49314736.html ZHAO Guo-sheng, LIU Hai-long, WANG Jian. Study on the autonomous recognition mechanism for survivable systems[J]. Chinese High Technology Letters, 2014, 24(10):999-1006. http://www.cqvip.com/QK/92817X/201404/49314736.html [10] BENJAMIN G, IRIS P, INGE H, et al. A comparison of heuristic and model-based clustering methods for dietary pattern analysis[J]. Public Health Nutrition, 2015, 19(2):1-10. http://europepmc.org/abstract/med/25600126 [11] ELIETE N P, CASSIUS T S, LUIZ A T. Time series forecasting by using a neural ARIMA, model based on wavelet decomposition[J]. Independent Journal of Management & Production, 2016, 7(1):252-270. http://www.researchgate.net/publication/296618975_TIME_SERIES_FORECASTING_BY_USING_A_NEURAL_ARIMA_MODEL_BASED_ON_WAVELET_DECOMPOSITION [12] HUANG W, ZHAO Y, HUANGPENG Q. SOC prediction of Lithium battery based on fuzzy information granulation and support vector regression[C]//International Conference on Electrical and Electronic Engineering. [S.l.]: IEEE, 2017: 177-180. http://www.researchgate.net/publication/317390910_SOC_prediction_of_Lithium_battery_based_on_fuzzy_information_granulation_and_support_vector_regression?ev=prf_high [13] 黄灏然, 江尚乐, 蔡肯.关键重要型多属性消错决策方法[J].数学的实践与认识, 2015, 45(11):15-20. http://www.cqvip.com/QK/85032X/201501/664160200.html HUANG Hao-ran, JIANG Shang-le, CAI Ken. Key important multiple attribute error-eliminating decision-making method[J]. Mathematics in Practice and Theory, 2015, 45(11):15-20. http://www.cqvip.com/QK/85032X/201501/664160200.html [14] ABDOLLAH K F, FARZANEH K F. A new hybrid correction method for short-term load forecasting based on ARIMA, SVR and CSA[J]. Journal of Experimental & Theoretical Artificial Intelligence, 2013, 25(4):559-574. [15] 赵国生, 王慧强, 王健.基于灰色关联分析的网络可生存性态势评估研究[J].小型微型计算机系统, 2006, 27(10):1861-1864. doi: 10.3969/j.issn.1000-1220.2006.10.015 ZHAO Guo-sheng, WANG Hui-qiang, WANG Jian. Study on situation evaluation for network survivability based on grey relation in analysis[J]. Mini-Micro Systems, 2006, 27(10):1861-1864. doi: 10.3969/j.issn.1000-1220.2006.10.015 [16] 黄灏然. 多属性消错决策方法研究[D]. 广州: 广东工业大学, 2014. http://cdmd.cnki.com.cn/Article/CDMD-11911-1014294009.htm HUANG Hao-ran. The research of multiple attribute error-Eliminating decision-Making method[D]. Guangzhou: Guangdong University of Technology, 2014. http://cdmd.cnki.com.cn/Article/CDMD-11911-1014294009.htm -

 点击查看大图
点击查看大图
图(5) / 表(6)
计量
- 文章访问数: 3606
- HTML全文浏览量: 1191
- PDF下载量: 95
- 被引次数: 0
