 ISSN
ISSN 


-
近年来,中国城市轻轨交通系统得到了快速发展。在城市轻轨交通系统中,自动售票检票系统(auto fare collection, AFC)采集和记录了海量的乘客出行数据[1]。如何从这些数据中挖掘乘客的出行规律、出行轨迹模式等具有重要的研究价值。例如,通过对乘客出行轨迹的预测,运营商可以及时、快捷地制定针对紧急状况的应对措施、为乘客提供个性化服务、动态调整轻轨的发车频次;此外,还可以通过对乘客出行轨迹的精准预测制定轻轨广告投放策略,并可为新的交通网络设计提供决策支持。大多数研究[2-4]集中于对乘客出行目的地的预测,很少对乘客的出行轨迹进行预测。本文基于重庆市轻轨交通系统乘客的刷卡数据,提出一种基于马尔科夫链的乘客轨迹预测算法(light rail passenger trajectory prediction based on markov chain, LRPTPMC),用于预测乘客下次出行轨迹。实验表明,该算法具有较好的预测效果。
-
文献[5]基于公交IC卡数据,分别给出了由IC卡统计数据推算公交线路站点和区间出行站点的方法,并提出了基于GIS的公交IC卡数据分析处理系统框架,实现公交站点的推算;文献[6]提出了一种利用公交调度信息和智能卡刷卡信息来推断乘客上车站点的方法;文献[7]通过对北京市市民乘坐公交及地铁出行历史数据的分析,研究了乘客的个人出行模式。这些研究都是基于智能IC卡的数据,其关注点集中于公交站点及乘客个人的出行模式,未针对乘客下次出行轨迹进行预测。
在移动对象的轨迹预测方面,文献[2]基于地理和轨迹的语义特征预测移动对象下一时刻位置点信息,通过挖掘同类用户的常见行为特性来预测其未来位置;文献[3]提出基于状态的移动对象运动模型,并采用马尔科夫转移概率解释移动对象在不同状态间的转换;文献[4]采用混合马尔科夫链模型预测行人运动。然而,在这些已有的预测模型中,极大可能存在答案丢失[7]和精度依赖问题[8]。此外,这些研究均基于向量空间进行预测,无法预测具体的移动方向[9-10]。
因此,针对以上问题,本文主要针对城市轻轨交通系统中乘客的下次出行轨迹预测进行研究。
-
本节先给出相关参数定义和马尔科夫链模型,然后介绍轻轨乘客轨迹的预测算法。
-
定义1 出行轨迹。若${S_{i0}}, {S_{i1}}, \cdot \cdot \cdot , {S_{ik}}$分别是乘客第$i$次搭乘轻轨所经过的$k$个站点,其中${S_{i0}}$为进站站点,${S_{ik}}$为出站站点,则${G_i} = ({S_{i0}}, {S_{ik}})$是乘客第$i$次出行轨迹。
定义2 连续轨迹。若当前的线路轨迹${G_c}$的目的站点${S_{ck}}$与下次出行的轨迹${G_n}$的出发站点${S_{n0}}$相同,则称${G_c}$和${G_n}$是两条连续轨迹。
定义3 轨迹完整度。乘客在时间序列上的轨迹序列为${\rm{Trj}} = \{ {G_1}, {G_2}, \cdot \cdot \cdot , {G_n}\} $,则轨迹完整度表示在该序列中连续轨迹占总轨迹数的比值。
通过在真实轻轨交通数据集上的实验分析,乘客轨迹完整度取值大约为42.3%,由此可知,乘客的出行具有偏好返回特性。
定义4 轨迹线路模式。设${S_0}, {S_1}, {S_2}, {S_3}$是4个不同的轻轨站台,则相邻两次的出行状态就会呈现为:${S_0}{S_1}{S_1}{S_0}$、${S_0}{S_1}{S_0}{S_1}$、${S_0}{S_1}{S_0}{S_2}$、${S_0}{S_1}{S_1}{S_2}$、${S_0}{S_1}{S_2}{S_1}$和${S_0}{S_1}{S_2}{S_3}$等6种轨迹模式。乘客最近一个星期内最频繁的出行轨迹,即为当前轨迹模式。
定义5 乘客常住地。乘客刷卡记录中,出现次数最多的进站站点。
算法中参数说明如表 1所示。
表 1 参数列表
参数 参数值 参数描述 ${W_s}(n)$ {0, 1, 2, 3, 4, 5, 6} 出发的星期 ${H_s}(n)$ {0, 1, 2, 3, 4} 出发时间的分段 ${T_{{\rm{short}}}}$ {0, 1, 2, 3$ \cdots $⋯} 与最近一次出行轨迹的距离 ${L_{{\rm{hot}}}}$ ${N^ * }$ 轨迹的热度 ${S_{{\rm{hot}}}}$ ${N^ * }$ 站台出度热度 ${S_{{\rm{in}}}}$ ${N^ * }$ 站台入度热度 $T_{{\rm{pattern}}}^n$ $\{ {S_0}, {S_1}, {S_2}, {S_3}\} $站台 当前轨迹的出行模式 $P_{{\rm{loction}}}^{}$ ID 乘客常住地 -
马尔科夫链模型认为用户下次出行的地点和之前去过的地点存在关联。MC模型中,用户的轨迹序列将构成该用户的$n$阶马尔科夫链,即用户$u$第$i$次访问的地点与该用户之前访问的$n$个地点存在关联关系,式(1)给出了其计算方法:
$$\begin{gathered} P(X_u^{i + 1} = x_{}^{i + 1}|X_u^i = x_{}^i, X_u^{i - 1} = x_{}^{i - 1}, n, X_u^1 = x_{}^1) = \\ P(X_u^{i + 1} = x_{}^{i + 1}|X_u^i = x_{}^i, X_u^{i - 1} = x_{}^{i - 1}, n, X_u^{i - n + 1} = x_{}^{i - n + 1}) \\ \end{gathered} $$ (1) 式中,$X_u^i$代表用户$u$第$i$次访问的地点。当已知用户前$n$个访问地点时,用户下次轨迹点的预测问题就转化为寻找对应马尔科夫链转移矩阵中最大可能性的地点。在LRPTPMC算法中,利用用户历史数据构建其轨迹转移矩阵。用户下次轨迹点由式(2)计算得到:
$$ P(X_u^{i + 1} = x_{}^{{\rm{pre}}}|X_u^i = x_{}^i, X_u^{i - 1} = x_{}^{i - 1}, n, X_u^{i - n + 1} = x_{}^{i - n + 1}) = \\ \max _{k = 1}^{{L_i}}\{ X_u^{i + 1} = x_{}^k|X_u^i = x_{}^i, X_u^{i - 1} = x_{}^{i - 1}, n, X_u^{i - n + 1} = x_{}^{i - n + 1}\} \\ $$ (2) -
算法预测轻轨乘客出行轨迹分两个步骤:首先,利用贝叶斯分类器对乘客下次出行是探索新的轨迹,还是选择历史出行轨迹进行分类;然后,根据乘客最近一次出行轨迹与其常住地的关系,预测下次出行轨迹。
-
根据朴素贝叶斯分类器,乘客轨迹可根据式(3)进行分类:
$$f(\mathit{\boldsymbol{x}}) = \arg \mathop {\max }\limits_{c \in Y} \frac{{P(x|c)P(c)}}{{\sum\limits_c P (x|c)P(c)}}$$ (3) 式中,$\mathit{\boldsymbol{x}}$为特征向量,$\mathit{\boldsymbol{x}}{\rm{ = (}}m, n, p, q)$,其中$m$为乘客历史轨迹的次数,$n$为历史不同轨迹的数量,$p$为历史不同轨迹的数量和历史轨迹的次数的比值,$q$为探索新线路的次数;$\mathit{\boldsymbol{Y}}$为类别标记,$\mathit{\boldsymbol{Y}}=\{0, 1\}$,0表示乘客下次出行会探索新的轨迹,1表示乘客下次出行会选择历史出行轨迹。
-
确定乘客下一次出行轨迹的分类之后,即可对乘客下一次出行轨迹进行预测。根据乘客最近一次出行轨迹与其常住地的关系,按以下4种情况预测其下次出行轨迹。
1) 进站站台为常住地
算法首先判断最近一次出行轨迹是否为新的轨迹。如果是新的轨迹,就判断该乘客的$T_{{\rm{pattern}}}^n$值,当$T_{{\rm{pattern}}}^n{\rm{ = }}2$,即出行模式为“${S_0}{S_1}{S_0}{S_1}$”时,下次出行轨迹即是最近一次出行轨迹;当$T_{{\rm{pattern}}}^n \ne 2$,结合之前的数据分析,乘客的出行具有往返的特性,下次的出行则返回常住地。如果最近一次出行轨迹不是新的轨迹,即为历史轨迹时,首先构建该乘客出行轨迹的一阶马尔科夫状态转移矩阵,从状态转移矩阵中选取值最大的轨迹作为下次出行轨迹。
2) 进出站台均不为常住地
当乘客最近一次出行轨迹的进站站台和出站站台均不为该乘客的常住地时,该乘客很可能处于中间状态,很难对其描述。该情形下,本文引入了轨迹状态转移矩阵,同时结合了时间、距离、线路热度等因素对其进行预测。
通过对重庆市轻轨数据的分析,发现在“中间状态”下,乘客下次出行轨迹的选择依赖于最近一次出行轨迹,同时也和出发的时间密切相关。表 1中已将连续的时间处理成离散的数据。在实际生活中,乘客下次的出行与最近几次出行具有很强的相关性,为体现这种相关性,本文定义历史轨迹中的轨迹与最近一次出行轨迹的距离${T_{{\rm{short}}}}$为:
$${T_{{\rm{short}}}} = \mathop {\min }\limits_k ({\rm{abs}}|I_{{\rm{loc}}}^{{\rm{last}}} - I_{{\rm{loc}}}^k|)$$ (4) 式中,$I_{{\rm{loc}}}^{{\rm{last}}}$表示最近一次出行轨迹在历史轨迹中的位置;$I_{{\rm{loc}}}^k$为$I_{{\rm{loc}}}^{{\rm{last}}}$在历史轨迹中上一次出现的位置。
例如,${\rm{\{ }}({S_{10}},{S_{13}}),({S_{21}},{S_{22}}),({S_{30}},{S_{34}}),({S_{41}},{S_{42}}){\rm{\} }}$为乘客的4次出行轨迹,最近一次出行轨迹$({S_{41}}, {S_{42}})$的$I_{{\rm{loc}}}^{{\rm{last}}}{\rm{ = }}4$,根据进站和出站站台可知第二次出行轨迹$({S_{21}}, {S_{22}})$与$({S_{41}}, {S_{42}})$的进站出站站台一样,即$I_{{\rm{loc}}}^{\rm{k}}{\rm{ = }}2$。所以由式(4)可得${T_{{\rm{short}}}}{\rm{ = }}2$。同时,某些轨迹会比其他轨迹更受乘客欢迎,从而选择的可能性也就更大。在模型中引入轨迹热度Lhot${L_{{\rm{hot}}}}$,表示每位乘客历史出行中各个轨迹出现的次数,当某轨迹出现的次数越多,其热度也就越高。因此,每条历史轨迹的权值$V$的计算方法为:
$$\begin{gathered} V = P(X(n + 1)|X(n), {H_s}(n), {L_{{\rm{hot}}}}, {T_{{\rm{short}}}}) = \\ \frac{{{L_{{\rm{hot}}}}P(X(n + 1)|X(n), {H_s}(n), {W_s}(n))}}{{{T_{{\rm{short}}}}}} \\ \end{gathered} $$ (5) 其中,
$$\begin{gathered} P(X(n + 1)|X(n), {H_s}(n), {W_s}(n)) = \\ P(X(n + 1)|X(n)) + P(X(n + 1)|{H_s}(n), {W_s}(n)) \\ \end{gathered} $$ (6) 式中,$P(X(n + 1)|X(n))$为出行轨迹的一阶马尔科夫转移概率;$P(X(n + 1)|{H_s}(n), {W_s}(n))$为出行时间的一阶马尔科夫转移概率,其计算表达式为:
$$\begin{gathered} F(X(n + 1)|{H_s}(n), {W_s}(n)) = \\ \sum\limits_{{H_s}} {\sum\limits_{{W_s}} {F(X(n + 1)|{H_s}(n), {W_s}(n))} } \\ \end{gathered} $$ (7) 由式(6)和式(7),式(5)可写为:
$$P(X(n + 1)|X(n), {H_s}(n), {L_{{\rm{hot}}}}, {T_{{\rm{short}}}}) = \frac{{{L_{{\rm{hot}}}} \cdot (P(X(n + 1)|X(n)) + \sum\limits_{{H_s}} {\sum\limits_W {P(X(n + 1)|{H_s}(n), {W_s}(n)} } )}}{{{T_{{\rm{short}}}}}}$$ (8) 综上所述,当进出站台均不为常住地时,预测思路为:首先构建关于时间状态转移的一阶马尔科夫矩阵以及计算历史轨迹热度值。然后判断最近一次轨迹是否为新的轨迹,如果是,则下次的出行轨迹的进站时间为时间转移矩阵中最大的时间值,根据出行时间找到该出行时间段中热度值最大的轨迹作为下次出行轨迹;如果最近一次轨迹是历史轨迹中出现过的轨迹,则构建关于轨迹状态转移的一阶马尔科夫矩阵。最后依据式(8)计算每条历史轨迹的权值$V$,并选择取值最大的轨迹作为下次出行轨迹。
3) 出站站台为常住地
当乘客最近一次出行轨迹中出站站台为常住地时,本文根据人类出行具有的最近相关性,引入了乘客的最近出行模式;同时,根据乘客出行的群集效应,引入了站台出度热度${S_{{\rm{in}}}}$,入度热度${S_{{\rm{out}}}}$以及轨迹热度${L_{{\rm{hot}}}}$。出度热度${S_{{\rm{in}}}}$和入度热度${S_{{\rm{out}}}}$的计算方法分别如下:
$$S_{{\rm{in}}}^k = \sum\limits_{i = 1}^n {(S_{{\rm{TRAN}}{{\rm{S}}_{{\rm{CODE}}}}}^k = 21)} $$ (9) $$S_{{\rm{out}}}^k = \sum\limits_{i = 1}^n {(S_{{\rm{TRAN}}{{\rm{S}}_{{\rm{CODE}}}}}^k = 22)} $$ (10) 式中,$S_{{\rm{TRAN}}{{\rm{S}}_{{\rm{CODE}}}}}^k{\rm{ = }}21$表示有乘客进入第$k$个站台,为乘客进站刷卡标识;$S_{{\rm{TRAN}}{{\rm{S}}_{{\rm{CODE}}}}}^k{\rm{ = }}22$表示有乘客离开第$k$个站台,为乘客出站刷卡标识。算法伪代码如下。
LRPTPMC Prediction when arr station is $P_{{\rm{loction}}}^{}$
compute the ${L_{{\rm{hot}}}}$ of each unique route
if The current line us a new line then
if $T_{{\rm{pattern}}}^n$=${S_0}{S_1}{S_1}{S_0}$ then
The next line is to go back
else if $T_{{\rm{pattern}}}^n$=${S_0}{S_1}{S_1}{S_2}$ then
The next line is from $P_{{\rm{loction}}}^{}$ to $S_{{\rm{out}}}^{{\rm{max}}}$ with not equal $P_{{\rm{loction}}}^{}$
else if $T_{{\rm{pattern}}}^n$=${S_0}{S_1}{S_0}{S_1}$ then
The next line is the current line
else if $T_{{\rm{pattern}}}^n$=${S_0}{S_1}{S_0}{S_2}$ then
The next line is from dpt station to $S_{{\rm{in}}}^{\max }$ with not equal $P_{{\rm{loction}}}^{}$
else if $T_{{\rm{pattern}}}^n$=${S_0}{S_1}{S_2}{S_1}$ then
The next line is from $S_{{\rm{out}}}^{{\rm{max}}}$ with not equal $P_{{\rm{loction}}}^{}$ to arr station
else
The next line is the line with the biggest value Lhot${L_{{\rm{hot}}}}$ except the current line
end if
else
Construct trip line transition matrix M of 1-MC
choose the row r in M corresponding to the current line
find the column with the most times from the M for the row r
This line is the next line
end if
4) 探索新轨迹
由于马尔科夫模型是基于历史轨迹对下次出行轨迹进行预测,不能有效解决乘客探索新轨迹的问题。因此,当预测到乘客下次的出行为探索新轨迹时,本文根据其他乘客的出行选择解决乘客探索新轨迹的问题。首先构建该乘客出行时间的状态转移矩阵,根据该矩阵来预测其下次出行的时间。然后根据这个出行时间,计算该时间段内所有乘客历史轨迹的${L_{{\rm{hot}}}}$值(不包括该乘客的历史轨迹),预测的下次出行的轨迹即为${L_{{\rm{hot}}}}$值最大的轨迹。
-
本文的实验基于Spark集群(1台master,4台slave主机)。实验所用到的数据集是重庆市轻轨轨道交通系统中2014年12月1日—2015年5月31日的轻轨刷卡数据,表 2给出了具体的数据描述。
表 2 数据集描述
数据集 值 时间范围 2014.12.01~2015.05.31 记录数/条 137 911 846 乘客数量/人 404 879 每位乘客平均的出行天数/天 95.97 每位乘客每天平均的出行次数/次 1.77 原始数据集中包含444 743 582条刷卡记录,7 473 709位轻轨乘客。本节数据只保留了在这6个月内出行次数不少于100次的乘客的出行数据。
-
本文所分析的数据是2014年12月—2015年5月共6个月的重庆市轨道交通的刷卡数据。该数据集包含了7 473 709个智能IC卡的共计444 743 582条的轨道交通刷卡记录,每条记录包含一次轻轨出行中乘客所搭乘轻轨的时间以及站台信息。主要包含的字段有:卡ID(TICKET_ID)、刷卡日期(TXN_DATE)、刷卡时间(TXN_TIME)、刷卡站台ID(TXN_ STATION_ID)、卡类型(TICKET_TYPE)、进出站标志(TRANS_CODE)和换乘标识(TXN_AMT)等。
-
刷卡记录是按照刷卡时间来记录的,数据可能存在记录错误和数据缺失问题。本文利用Spark框架对海量的数据进行了轨迹提取,过程如下:
1) 创建一个CardID标识,初始值设为0,并将数据集按照日期和时间升序的原则进行排序。
2) 访问最开始的记录,将CardID设为该记录的TICKET_ID的值,并检查TRANS_CODE字段的值;如果值为21,则进行步骤3),如果值为22,则视此条记录为“脏记录”,并访问下一条TICKET_ID字段的值等于CardID的记录,重复步骤2)的工作。
3) 存储记录中的TICKET_ID、TXN_DATE、TXN_TIME、TXN_STATION_ID字段的值后删除此条记录,并访问下一条TICKET_ID字段的值等于CardID的记录。
4) 检查该记录中TRANS_CODE字段的值。如果值为22,则存储记录中的TICKET_ID,TXN_DATE,TXN_TIME,TXN_STATION_ID字段的值;如果值为21,则视此条记录为“脏记录”。最后删除此条记录,并访问下一条TICKET_ID字段的值等于CardId的记录,并重复步骤4)。
5) 上述步骤中两次存储的记录就是卡ID为CardId值的乘客一次出行的完整轨迹,从步骤2)开始重复,直到访问到最后一条TICKET_ID字段的值等于CardId的记录,则可以得到卡ID为CardId值的乘客所有出行的完整轨迹。再将CardId的值设为0,重复步骤2)直到处理完全部记录。
-
1) 准确率和召回率
在本文中,准确率可以被视为预测精度,用于评价预测算法。公式如下:
$${\rm{Accuracy}} = {P_{{\rm{correct}}}}/{P_{{\rm{total}}}}$$ (11) 式中,${P_{{\rm{total}}}}$表示预测的总次数;${P_{{\rm{correct}}}}$表示预测正确的次数。
召回率计算公式如下:
$${\rm{Recall}} = {P_{{\rm{correct}}}}/{T_{{\rm{total}}}}$$ (12) 2) F1分数
引入F1分数可以评价模型的综合性能,其计算公式如下:
$$F1 = 2 \times \frac{{{\rm{Accuracy}} \times {\rm{Recall}}}}{{{\rm{Accuracy}} + {\rm{Recall}}}}$$ (13) -
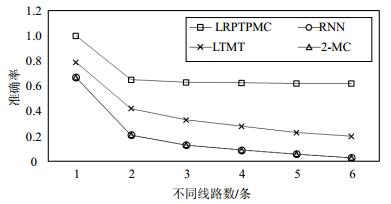
本文所用到的3个对比算法分别为LTMT、RNN及2-MC,其中LTMT为乘客历史轨迹中出现次数最多的线路(line of travel most times);RNN为循环神经网络[11];2-MC为二阶马尔科夫链,常用于目的地预测[12]。图 1给出了预测精度测试对比结果。

图 1 预测精度对比图
由图 1可知,本文的预测算法的预测精度明显优于其他3种算法,而随着乘客历史轨迹不同线路的增加,其预测精度也随之下降。其中RNN和2-MC的预测精度很相近,图中的离散点大致重合。
所有评价指标的对比如表 3所示。根据图 1和ttt_aaa_bbb2的结果可知,本文提出的LRPTPMC预测算法在精度、召回率和F1值等方面均优于其他3种常见算法。对于单一的二阶马尔科夫模型来说,其预测精度不及LRPTPMC算法的一半,说明本文的预测算法在马尔科夫模型基础上的改进有效。
表 3 算法对比
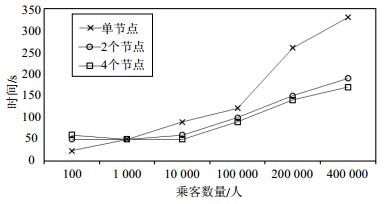
算法 预测精度/% 召回率 F1/% LTMT 36 1 52.94 RNN 22 1 36.06 2-MC 22 1 36.06 LRPTPMC 58 67.68% 62.47 本文的实验基于分布式处理框架Spark,对预测算法进行了并行化处理。图 2对比了单机环境下的算法和并行化算法进行运行时间。采用了6组数据,根据预测乘客的数量不同来体现运行时间的差异。如图 2所示,当乘客数量规模大于1 000时,集群能有效利用其计算资源,能有效减少算法运算时间。

图 2 运行时间对比
-
城市轻轨交通系统中采集和积累了海量的乘客出行数据。本文基于对重庆市轻轨交通数据的研究,提出了一种基于马尔科夫链的乘客轨迹预测(LRPTPMC)算法。实验结果表明,相比既有的预测算法,本文的LRPTPMC算法优于其他3个对比算法。同时利用分布式处理平台Spark来进行实验,极大地减少了实验运行时间。利用本文算法,可帮助轻轨运营管理者预测站台和轻轨流量,合理安排轻轨班次,改善轻轨交通服务。事实上,天气、影响力传播等因素也会对乘客出行产生影响,将这些因素融入轻轨乘客出行轨迹预测是本文下一步研究方向。
Novel Algorithm of Light Rail Passenger Trajectory Prediction Based on Markov Chain
-
摘要: 利用重庆轻轨的乘客刷卡数据,分析了乘客出行特征,并提出了一种基于马尔科夫链的乘客轨迹预测算法。该算法首先利用贝叶斯分类器对乘客下次出行轨迹进行分类;然后,根据乘客最近一次出行轨迹与其常住地的关系,预测其下次出行轨迹。在真实轻轨交通数据集上的实验结果表明,该算法对乘客出行轨迹的预测效果优于LTMT、RNN和2-MC;同时,该算法基于大数据处理框架Spark进行编码,减少了运行时间。Abstract: By utilizing the smart card data from Chongqing light rail system, the travel characteristics of light rail passengers are analyzed and a trajectory prediction algorithm based on Markov chain is proposed. In the algorithm, the next travel trajectory of a passenger is classified by Bayesian classification and then predicted according to the relationship between the passenger's last travel trajectory and her/his residence. Experimental results based on real datasets show that the algorithm outperforms LTMT, RNN and 2-MC on predicting passenger's next travel trajectory. Meanwhile, the algorithm is coded on Spark, a big data processing framework, which reduces its runtime.
-
Key words:
- Bayesian classification /
- Markov chain /
- trajectory prediction /
- travel trajectory
-
表 1 参数列表
参数 参数值 参数描述 ${W_s}(n)$ {0, 1, 2, 3, 4, 5, 6} 出发的星期 ${H_s}(n)$ {0, 1, 2, 3, 4} 出发时间的分段 ${T_{{\rm{short}}}}$ {0, 1, 2, 3$ \cdots $⋯} 与最近一次出行轨迹的距离 ${L_{{\rm{hot}}}}$ ${N^ * }$ 轨迹的热度 ${S_{{\rm{hot}}}}$ ${N^ * }$ 站台出度热度 ${S_{{\rm{in}}}}$ ${N^ * }$ 站台入度热度 $T_{{\rm{pattern}}}^n$ $\{ {S_0}, {S_1}, {S_2}, {S_3}\} $站台 当前轨迹的出行模式 $P_{{\rm{loction}}}^{}$ ID 乘客常住地  下载: 导出CSV
下载: 导出CSV
表 2 数据集描述
数据集 值 时间范围 2014.12.01~2015.05.31 记录数/条 137 911 846 乘客数量/人 404 879 每位乘客平均的出行天数/天 95.97 每位乘客每天平均的出行次数/次 1.77
下载: 导出CSV
表 3 算法对比
算法 预测精度/% 召回率 F1/% LTMT 36 1 52.94 RNN 22 1 36.06 2-MC 22 1 36.06 LRPTPMC 58 67.68% 62.47
下载: 导出CSV
-
[1] 李淑庆.重庆主城区公共交通发展规划目标研究[J].重庆交通大学学报(自然科学版), 2007, 26(1):83-86. doi: 10.3969/j.issn.1674-0696.2007.01.020 LI Shu-qing. Research on the goal of public transportation development planning in the main city of Chongqing[J]. Journal of Chongqing Jiaotong University, 2007, 26(1):83-86. doi: 10.3969/j.issn.1674-0696.2007.01.020 [2] JIANG B, YIN J, ZHAO S. Characterizing the human mobility pattern in a large street network[J]. Physical Review E Statistical Nonlinear & Soft Matter Physics, 2009, 80(1):1711-1715. doi: 10.1103-PhysRevE.80.021136/ [3] SONG L, KOTZ D, JAIN R, et al. Evaluating next-cell predictors with extensive wi-fi mobility data[J]. IEEE Transactions on Mobile Computing, 2006, 5(12):1633-1649. doi: 10.1109/TMC.2006.185 [4] ASAHARA A, MARUYAMA K, SATO A, et al. Pedestrian-movement prediction based on mixed Markov-chain model[C]//ACM Sigspatial International Symposium on Advances in Geographic Information Systems, Acm-Gis. Chicago, USA: IEEE, 2011: 25-33. http://dl.acm.org/citation.cfm?id=2093979 [5] TAO Z, ZHAI C, GAO Z. Approaching bus OD matrices based on data reduced from bus IC cards[J]. Urban Transport of China, 2007, 5(3):48-52. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=csjt200703011 [6] GAO L X, WU Jian-ping. An algorithm for mining passenger flow information from smart card data[J]. Journal of Beijing University of Posts & Telecommunications, 2011, 34(3):94-97. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=bjyddx201103021 [7] MA X, WU Y J, WANG Y, et al. Mining smart card data for transit riders' travel patterns[J]. Transportation Research Part C Emerging Technologies, 2013, 36:1-12. doi: 10.1016/j.trc.2013.07.010 [8] ZHONG C, BATTY M, MANLEY E, et al. Variability in regularity:Mining temporal mobility patterns in london, singapore and beijing using smart-card data[J]. Plos One, 2016, 11(2):e0149222. doi: 10.1371/journal.pone.0149222 [9] ZHONG C, MANLEY E, ARISONA S M, et al. Measuring variability of mobility patterns from multiday smart-card data[J]. Journal of Computational Science, 2015, 9:125-130. doi: 10.1016/j.jocs.2015.04.021 [10] BARABÁSI A L. The origin of bursts and heavy tails in human dynamics[J]. Nature, 2005, 435(7039):207-211. doi: 10.1038/nature03459 [11] MIKOLOV T, KARAFIÁT M, BURGET L, et al. Recurrent neural network based language model[C]//INTERSPEECH 2010, Conference of the International Speech Communication Association. Makuhari, Chiba, Japan: [s.n.], 2010: 1045-1048. [12] KILLIJIAN M O. Next place prediction using mobility Markov chains[C]//Proceedings of the 1st Workshop on Measurement, Privacy, and Mobility.[S.l.]: ACM, 2012. http://dl.acm.org/citation.cfm?id=2181199&preflayout=flat -

 点击查看大图
点击查看大图
图(2) / 表(3)
计量
- 文章访问数: 4351
- HTML全文浏览量: 1404
- PDF下载量: 118
- 被引次数: 0
