 ISSN
ISSN 




-
大脑与计算机等外部设备间建立的直接交流通道称为脑机接口(brain-computer interface, BCI)。近年来脑机接口研究成为热点,其在医疗康复、智能家居、教育培训等领域皆有应用[1-3]。
大脑运动皮层的研究是BCI技术的重点,由于具有信号非线性、非平稳性,幅值微弱(一般只有5~150 μv),频率几十赫兹以下和极易受其他噪声干扰等特点,该类型研究具有很大挑战。因此,正确建立模型、有效识别脑电信号,是技术成功应用于各个领域的关键。
脑电信号识别通常包含数据预处理、特征提取和信号分类等步骤。在信号特征提取方面:文献[4]利用小波变换(wavelet transform, WT)进行滤波,虽然小波阀值常用于信号降噪,但当噪声频率接近信号频率时,常导致信号失真;文献[5]利用共同空间模式(common spatial pattern, CSP)对运动想象进行特征提取,但时域分析开销较大,需要与较多脑电导联,应用较复杂;文献[6]利用自回归模型法(autoregressive model, AR)进行预测,但AR模型一般只针对单通道分析,对于多通道脑电信号常常会忽略各通道间的相互作用。常用的分类方法有线性判别分析(latent dirichlet allocation, LDA)[7],该方法适用于线性信号,对于非线性的脑电数据效果不理想;BP神经网络[8-9]具有较高的自学习能力,但结构选择不一,当网络多层化时参数学习易收敛到局部最优;支持向量机(support vector machine, SVM)[10]可以较好地解决非线性数据分类,但它是一个有监督网络,训练样本和测试样本都需要标签,且参数设置较为复杂。
针对以上问题,本文提出无监督网络——堆叠稀疏降噪自动编码机(SSDAE)算法,通过有监督的softmax回归网络进行分类,并将其运用于运动想象脑电信号的识别,实验表明本文所提的方法能取得更好的分类结果。
-
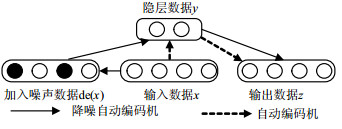
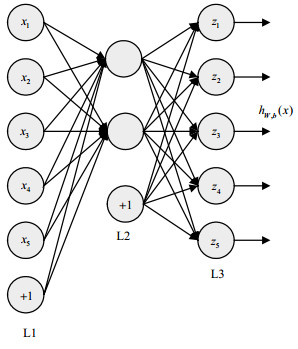
2006年,文献[11]提出利用自动编码机(auto encoder, AE)对文本和图像的特征降维,其效果优于传统的特征降维算法。自动编码机是无监督机器学习,利用神经网络学习到的低维特征来代替高维数据。其结构如图 1所示。

图 1 自动编码机
它可以看成一个三层神经网络,AE算法训练过程分为编码和解码两个阶段。其中L1、L2、L3分别为输入层、隐含层和输出层,+1为偏置项。输入向量为${\mathit{\boldsymbol{x}}} = \{ {x_1},{x_2}, \cdots ,{x_n}\} $,经过加权映射式(1)后得到隐含层特征向量${\mathit{\boldsymbol{y}}} = \{ {y_1},{y_2}, \cdots ,{y_n}\} $。
$${\mathit{\boldsymbol{y}}} = {f_\theta }({\mathit{\boldsymbol{x}}}) = s(W{\mathit{\boldsymbol{x}}} + {\mathit{\boldsymbol{b}}})$$ (1) 式中,$s(x)$为激活函数,本文取sigmoid;$W$为权值矩阵;$b$为偏移向量,此过程为编码。再对隐含层反向映射,通过式(2)得到重构的输出向量${\mathit{\boldsymbol{z}}} = \{ {z_1},{z_2}, \cdots ,{z_n}\} $,此过程为解码。隐含层到输出层的反映射函数为:
$${\mathit{\boldsymbol{z}}} = {g_\theta }({\mathit{\boldsymbol{y}}}) = s({\mathit{\boldsymbol{W'y}}} + {\mathit{\boldsymbol{b'}}})$$ (2) 式中,${\mathit{\boldsymbol{W'}}}$、${\mathit{\boldsymbol{b'}}}$和${\mathit{\boldsymbol{W}}}$、${\mathit{\boldsymbol{b}}}$,初始化都取随机数值。从输入到隐含层的权值参数记为$\theta = \{ {\mathit{\boldsymbol{W,b}}}\} $,从隐含层到输出层的权值参数记为$\theta ' = \{ {\mathit{\boldsymbol{W'}}},{\mathit{\boldsymbol{b'}}}\} $,则目标函数为:
$$\left\{ \begin{gathered} L({\mathit{\boldsymbol{x,z}}}) = - \sum\limits_{i = 1}^n {\left[ {{x_i}\lg ({z_i}) + (1 - {x_i})\lg (1 - {z_i})} \right]} \hfill \\ ({{\mathit{\boldsymbol{ { θ}} }}^{\mathit{\boldsymbol{*}}}}{\mathit{\boldsymbol{,}}}{{\mathit{\boldsymbol{ { θ}} }}^{{\mathit{\boldsymbol{*'}}}}}) = \arg \min \frac{1}{n}\sum\limits_{i = 1}^n {L({x_i},{z_i}) = } \hfill \\ \arg \min \frac{1}{n}\sum\limits_{i = 1}^n {L({x_i},{{g'}_\theta }[{f_\theta }({x_i})])} \hfill \\ \end{gathered} \right.$$ (3) 式中,$L({\mathit{\boldsymbol{x,z}}})$为损失函数;$({{\mathit{\boldsymbol{ { θ}} }}^{\mathit{\boldsymbol{*}}}}{\mathit{\boldsymbol{,}}}{{\mathit{\boldsymbol{ { θ}} }}^{{\mathit{\boldsymbol{*'}}}}})$为优化函数。
AE的本质是相似重构输入数据,实验证明它容易将输入数据直接复制输出,或只做细微改变,若测试样本和训练样本不属于同一分布,效果不佳。降噪自动编码机(denoising auto encoder, DAE)的提出弥补了以上缺陷,算法结构如图 2所示。

图 2 降噪自动编码机
它通过对原始输入向量$x$加噪处理得${\mathit{\boldsymbol{\tilde x}}}$,即按一定的比例随机选择单元强制置0,再利用擦除噪声后的数据$\tilde x$,按式(1)和式(2)进行训练。DAE的损失函数$L({\mathit{\boldsymbol{x,z}}})$不变,$({{\mathit{\boldsymbol{ { θ}} }}^{\mathit{\boldsymbol{*}}}}{\mathit{\boldsymbol{,}}}{{\mathit{\boldsymbol{ { θ}} }}^{{\mathit{\boldsymbol{*'}}}}})$优化函数变为:
$$\begin{gathered} ({{\mathit{\boldsymbol{ { θ}} }}^{\mathit{\boldsymbol{*}}}}{\mathit{\boldsymbol{,}}}{{\mathit{\boldsymbol{ { θ}} }}^{{\mathit{\boldsymbol{*'}}}}}) = \arg \min \frac{1}{n}\sum\limits_{i = 1}^n {L({x_i},{z_i})} = \\ \arg \min \frac{1}{n}\sum\limits_{i = 1}^n {L({x_i},{{g'}_\theta }[{f_\theta }({{\tilde x}_i})])} \\ \end{gathered} $$ (4) -
自编码实质上是学习${h_{w,b}}(x) \approx x$的一个函数,它尝试复现输入,若为网络结构加入一些限制,如控制隐含层神经元的数量,即可得到有效的信息。当隐藏层神经元数量较少,将其作为特征提取出来相当于对数据降维;当隐藏层神经元数目较多时,仍然可以对隐藏层的神经元加入稀疏性限制来训练网络,提取有效特征,这就是稀疏自动编码机(sparse auto-encoder, SAE)。
稀疏性[12]是指神经元输出接近于1时被激活,接近于0时被抑制,神经元大部分时间被抑制的限制称为稀疏性限制。使用$a_j^{(2)}(x)$表示自编码神经网络输入向量为${\mathit{\boldsymbol{x}}}$时,隐含层神经元$j$的激活度,则神经元$j$的平均活跃度表示为:
$${\hat \rho _j} = \frac{1}{m}\sum\limits_{i = 1}^m {[a_j^{(2)}({x^{(i)}})]} $$ (5) SAE在AE的基础上加入条件限制${\hat \rho _j} = \rho $,$\rho $为稀疏性参数(一般为接近于0的较小值)。为了实现该限制,目标函数引入了额外的惩罚因子,即相对熵(KL divergence)[13],其为测量两分布间差异的方法,原理如式(6)所示:
$${\text{KL}}(\rho \left\| {{{\hat \rho }_j}} \right.) = \rho \log \frac{\rho }{{{{\hat \rho }_j}}} + (1 - \rho )\log \frac{{1 - \rho }}{{1 - {{\hat \rho }_j}}}$$ (6) 式中,${\text{KL}}$是分别以$\rho $和${\hat \rho _j}$为均值的两个伯努利随机变量之间的相对熵,当${\hat \rho _j} = \rho $时,${\text{KL}}(\rho \left\| {{{\hat \rho }_j}} \right.) = 0$,${\text{KL}}$随着$\rho $和${\hat \rho _j}$之间的差异增加而单调递增,而当${\hat \rho _j}$靠近0或者1的时候,相对熵则变得无穷大,因此最小化该惩罚因子,可以使${\hat \rho _j}$趋近于$\rho $。SAE网络的总代价函数可表示为:
$${J_{{\text{sparse}}}}({\mathit{\boldsymbol{W,b}}}) = J({\mathit{\boldsymbol{W,b}}}) + \beta \sum\limits_{j = 1}^{{s_2}} {{\text{KL}}(\rho \left\| {{{\hat \rho }_{_j}}} \right.} )$$ (7) 式中,$J({\mathit{\boldsymbol{W,b}}})$为自编码的代价函数;$\beta $为控制稀疏性惩罚因子的权重;${\hat \rho _j}$如之前所定义为平均激活度,因为隐藏层激活度取决于${\mathit{\boldsymbol{W}}}$和${\mathit{\boldsymbol{b}}}$,所以${\hat \rho _j}$也间接取决于${\mathit{\boldsymbol{W}}}$和${\mathit{\boldsymbol{b}}}$。
-
本文结合DAE和SAE的特点,提出了堆叠稀疏降噪自动编码机(SSDAE),其在自动编码机的基础上,对输入向量加入噪声处理,隐含层引入稀疏限制,再通过贪婪逐层训练法将单层网络堆叠为深层网络,分类器选择为softmax。根据之前的推导,可知DAE的代价函数为:
$${J_{{\text{DAE}}}}({\mathit{\boldsymbol{w,b}}}) = \frac{1}{m}\sum\limits_{i = 1}^m {\left( {\frac{1}{2}{{\left\| {{h_{w,b}}{{(\tilde x)}^{(i)}} - {y^{(i)}}} \right\|}^2}} \right)} $$ (8) 式中,${h_{w,b}}(\tilde x)$为隐藏层神经元的激活值。加入稀疏限制后,SSDAE算法的代价函数变为:
$$\begin{gathered} {J_{\text{S}}}_{{\text{SDAE}}}({\mathit{\boldsymbol{w,b}}}) = \frac{1}{m}\sum\limits_{i = 1}^m {\left( {\frac{1}{2}{{\left\| {{h_{w,b}}{{(\tilde x)}^{(i)}} - {y^{(i)}}} \right\|}^2}} \right)} + \\ \beta \sum\limits_{j = 1}^{{s_l}} {{\text{KL}}} \left( {\rho \left\| {{{\tilde \rho }_j}} \right.} \right) \\ \end{gathered} $$ (9) 该分类算法具体实现过程如下:
1) 构造三层堆叠SSDAE模型,确定输入层节点数为$n$,隐藏层节点数为$m$以及数据集minibatch的分块大小。
2) 设置系数$\lambda $,对输入数据${\mathit{\boldsymbol{x}}}$按比例系数$\lambda $降噪得新的输入数据${\mathit{\boldsymbol{\tilde x}}}$,根据式(1)~式(4)得到第一层的隐含层${\mathit{\boldsymbol{y}}}$。
3) 根据稀疏性参数$\rho $,对隐含层$y$进行限制,按照最小化损失函数式(9)得到第一层网络的隐含层输出,并确定模型参数${{\mathit{\boldsymbol{ { θ}} }}_1} = \{ {\mathit{\boldsymbol{w,b}}}\} $。
4) 按照贪婪逐层训练法,将之前训练得到的参数${{\mathit{\boldsymbol{ { θ}} }}_1}$取代随机参数,隐含层输出作为第二层网络的输入,调用步骤2)和步骤3),确定参数${{\mathit{\boldsymbol{ { θ}} }}_{\mathit{\boldsymbol{2}}}}$和第二层网络隐含层输出。
5) 用步骤4)得到的参数${\theta _2}$取代随机参数,隐含层输出作为第三层网络的输入,调用步骤2)、步骤3),得到第三层堆叠网络的隐含层输出。
6) 将步骤5)的输出作为softmax的输入,输出分类结果。
其中参数$W$和$b$采用梯度下降法进行优化,流程如下:
1) 令$\Delta {W_1} = 0,\Delta {b_1} = 0$;
2) 计算${\nabla _{w(l)}}L({\mathit{\boldsymbol{x,z}}}),{\nabla _{b(l)}}L({\mathit{\boldsymbol{x,z}}})$;
3) $\Delta {W_l} = \Delta {W_l} + {\nabla _{w(l)}}L({\mathit{\boldsymbol{x,z}}})$;
4) $\Delta {b_l} = \Delta {b_l} + {\nabla _{b(l)}}L({\mathit{\boldsymbol{x,z}}})$;
5) 其中$\varepsilon $是学习率,则${{\mathit{\boldsymbol{W}}}_{\mathit{\boldsymbol{l}}}} = {{\mathit{\boldsymbol{W}}}_{\mathit{\boldsymbol{l}}}} - \varepsilon \left( {\frac{1}{m}\Delta {W_l}} \right)$,${{\mathit{\boldsymbol{b}}}_{\mathit{\boldsymbol{l}}}} = {{\mathit{\boldsymbol{b}}}_{\mathit{\boldsymbol{l}}}} - \varepsilon \left( {\frac{1}{m}\Delta {b_l}} \right)$。
-
为了测试堆叠稀疏降噪自动编码机的脑电信号识别性能,本文做了两个实验。
-
数据集1是通过Emotiv采集仪得到的左右手运动想象脑电信号。该采集设备的主要装置为电极帽,有16个电极,包括14个可拆卸用于采集脑电信号的电极和两个参考电极(CMS和DRL),电极根据国际10-20标准进行安放,如图 3所示。

图 3 Emotiv电极安放位置
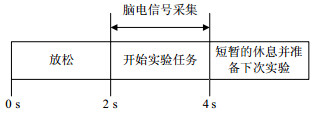
将采集到的脑电信号进行放大滤波,通过无线接收器传送到计算机,并通过自带的TestBench软件进行记录和保存。本实验共有7名受试者,大脑均正常无顽疾,实验环境安静,过程如图 4所示。

图 4 单次实验过程
t=0 s时,实验开始,受试者保持大脑放松;t=2 s时,受试者集中注意力,执行想象左右手运动的任务;t=4 s时,结束想象,做适当的休息调整,准备下次实验。本实验信号采样频率为128 Hz,采样时间为2 s,选取其中的一秒,每名受试者对各类想象任务执行125次,即每名受试者采集得到250组实验样本。
数据集2采用2005年BCI竞赛数据集IVa,由柏林医科大学(University Medical Berlin)提供[14]。该数据集包含大脑想象右手、右脚运动数据5组,每组280个样本。实验采用118个Ag/AgCl电极和100 Hz的采样频率,并进行带通滤波。5名受试者脑部健康无顽疾,分别为aa、al、av、aw、ay。其中部分数据有标签,情况如表 1所示。
表 1 数据情况
数据 aa al av aw ay 有标签/个 168 224 84 56 28 无标签/个 112 56 196 224 252 -
采集到的脑电信号通常包含多种噪声数据,如眼电、心电、肌电、工频杂波等伪迹。在BCI控制系统中,信号预处理是重要的一步,它是特征提取与分类识别的前提。本文脑电信号的预处理步骤如下。
1) 异样样本的去除。实验采集数据时可能因为人为错误操作、外界环境干扰或设备接触不良等问题,产生错误样本。本文将通道的平均电位作为基准值,与每个样本数据对比,筛除差异值较大的。在Emotiv采集过程中,总样本开始取为250个,后经过上述步骤剔除10个异样本数(为实验开始和结束阶段的多杂音信号),剩余240个样本作为数据集1;数据集2为剔除异样样本后的数据集,此步骤不作考虑。
2) 去均值。为了便于研究分析和降低运算复杂度,将每个样本的幅值减去平均幅值,使样本数据的均值为零。
3) 信号滤波[15]。滤波对提高脑电信号的信噪比有重要作用,本文采用了频率滤波和空间滤波两种滤波形式。在BCI系统中,运动想象的重要频带为8~30 Hz,本文对信号进行了8~30 Hz的带通滤波。空间滤波主要分为4种:耳突参考、共同平均参考法、小拉普拉斯参考和大拉普拉斯参考,本文采用大拉普拉斯参考。
-
根据本文1.3节所提新网络SSDAE,实验过程中参数设置情况如下:
实验1中各网络参数按照经典网络参数进行设置。实验2中,2通道、4通道和8通道的样本数据大小分别为240×256、240×512、240×1 024,SSDAE的网络结构为3个SDAE堆叠,网络结构分别为[256 100 50 10]、[512 200 100 20]、[1024 500 250 40],其中minibatch设置为20,迭代次数设置为300次。
SSDAE网络的学习率是网络的一个重要参数,设置网络太大容易出现超调现象,设置网络太小无法快速收敛。本文学习率按照传统的经验法,通过尝试按指数下降的学习率0.1、0.01、0.001、0.000 1,通过观察迭代次数和损失函数loss变化关系,损失函数和学习率关系图如下。

图 5 学习率与loss关系图
如图可知,当$\varepsilon $大于10-1时,loss不再收敛,当$\varepsilon $位于10-2和10-1之前时,loss下降速率最快,所以本文取$\varepsilon $=0.05。
对于SSDAE网络的降噪系数和稀疏系数选择,表 2表示了各常用系数下该网络在数据集1的6通道数据上各试者的平均分类准确率。
表 2 不同参数在数据集1下的准确率
λ取值 ρ取值 准确率/% 0.2 0.3 87.75 0.2 0.4 87.60 0.2 0.5 86.85 0.3 0.3 89.55 0.3 0.4 90.30 0.3 0.5 89.25 0.4 0.3 89.75 0.4 0.4 88.20 0.4 0.5 88.50 根据表 2所得实验结果,本文选取降噪系数$\lambda $=0.3,稀疏系数$\rho $=0.4。
-
所有算法在配置为3.10 GHz、4 GB电脑的MATLAB2010b上执行。
对于数据集1,设计了3组对比实验:
方法1:深度信念网络(deep belief nets, DBN)[16-17],训练过程可分为无监督逐层的预训练和有监督的BP微调网络两个阶段。
方法2:共同空间模式(common spatial pattern, CSP)的原理是通过两类脑电信号的估计协方差矩阵来设计每类信号的最优空间滤波器,该方法用CSP进行特征提取,再利用softmax分类。
方法3:AE按本文2.1小节所讲原理,利用自动编码机学习样本数据,提取出有效特征,再利用softmax进行分类。
实验选择6个通道(F3、F4、FC5、FC6、T7和T8)的数据样本在matlab2010b上分别进行多次实验,对结果取平均值,结果如表 3所示。
表 3 不同方法在数据集1下的准确率
受试者 方法 DBN/% CSP/% AE/% 受试者1 77.50 79.17 78.33 受试者2 84.17 89.17 86.67 受试者3 89.16 92.50 90.00 受试者4 87.50 93.33 91.66 受试者5 70.83 75.00 75.83 实验结果表明,自动编码机(AE)在数据集1上的识别准确率接近其他方法,说明该算法能够提取出脑电信号特征,证明了将自动编码机应用于脑电信号识别的可行性。
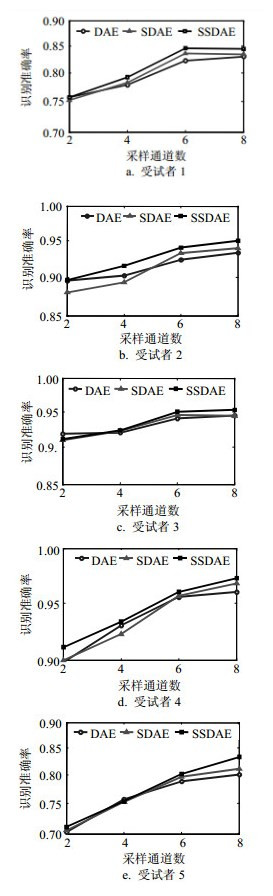
实验2同样利用数据集1,设计3组对比实验:分别用降噪自动编码机(DAE)、稀疏降噪自动编码机(SDAE)、堆叠稀疏降噪自动编码机(SSDAE)进行特征提取,分类器采用softmax。实验取2通道、4通道、8通道的数据样本,对受试者1~5各进行10次实验,结果求平均,如图 6所示。

图 6 改进算法的准确率对比
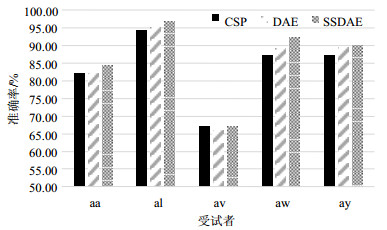
由图 6可知,在采样数据选择2个通道时,3种方法差别并不大,但随着采样通道数增多,数据的复杂程度和噪声增大,SDAE和SSDAE的优势变得明显,说明SSDAE对于复杂高维数据的泛化能力较强,能够自动学习有效特征,摒除噪声数据。实验证明本文提出的算法网络对多通道脑电数据的分类准确率有一定的提升效果。实验3在数据集2上进行,选择了5个通道(FC5、FC6、Cz、C3、C4)的采样数据。设计了3组对比实验,对5名受试者(aa、al、av、aw、ay)各进行10次实验,结果取平均,如图 7所示。

图 7 不同算法在数据集2下的准确率
从图 7可以看出除了受试者av,本文提出的DAE和SSDAE算法略低于CSP的准确度,其他4名受试者的准确率均有明显提升,这进一步表明了SSDAE应用于脑电信号识别的优越性。
-
将自动编码机(AE)应用于脑电信号的识别是一种新想法。本文提出了改进算法——堆叠稀疏降噪自动编码机(SSDAE),其在AE的基础上对输入层数据进行降噪,隐含层数据进行稀疏限制,再将单一结构堆叠成深层神经网络。通过在Emotiv采集仪得到的数据集和2005年BCI竞赛数据集IVa上的实验表明,本文方法对于高维复杂带有噪声的数据能够更好地进行特征提取,具有更强的鲁棒性。同时作为一种无监督网络,特征提取阶段不需要样本带有标签,可简化信号采集过程。
Recognition of EEG Based on Stacked Sparse Denoising Auto-Encoder
-
摘要: 该文以深度学习中的自动编码机为基础,对原始输入向量加入噪声处理,隐含层加入稀疏限制,再将单一的网络结构堆叠成深层神经网络,提出改进算法——堆叠稀疏降噪自动编码机。通过在两个不同数据集(实验室采集数据集和2005年BCI竞赛数据集IVa)进行对比实验,结果表明该算法在运动想象脑电信号的特征提取上具有更强的学习能力和鲁棒性。Abstract: An improved algorithm, stacked sparse denoising auto-encoder (SSDAE), is proposed in this paper. In the new algorithm, the noise of original input data is processed, the hidden layers is limited to sparse restrictions, finally, EEG features are classified with the softmax. Experiments results on two different data sets (Laboratory data sets and 2005 BCI competition data set IVa) demonstrate that SSDAE had the highest recognition accuracy than traditional algorithms, which proves that SSDAE has the stronger learning ability and robustness in motor imagery EEG feature extraction.
-
Key words:
- denoising auto-encoder /
- deep learning /
- EEG recognition /
- sparse /
- stack
-
表 2 不同参数在数据集1下的准确率
λ取值 ρ取值 准确率/% 0.2 0.3 87.75 0.2 0.4 87.60 0.2 0.5 86.85 0.3 0.3 89.55 0.3 0.4 90.30 0.3 0.5 89.25 0.4 0.3 89.75 0.4 0.4 88.20 0.4 0.5 88.50  下载: 导出CSV
下载: 导出CSV
表 3 不同方法在数据集1下的准确率
受试者 方法 DBN/% CSP/% AE/% 受试者1 77.50 79.17 78.33 受试者2 84.17 89.17 86.67 受试者3 89.16 92.50 90.00 受试者4 87.50 93.33 91.66 受试者5 70.83 75.00 75.83
下载: 导出CSV
-
[1] BODDA S, CHANDRANPILLAI H, VISWAM P, et al. Categorizing imagined right and left motor imagery BCI tasks for low-cost robotic neuroprosthesis[C]//International Conference on Electronics, and Optimization Techniques. Chennai: [s.n.], 2016: 3670-3673. [2] 孙会文, 伏云发, 熊馨.基于HHT运动想象脑电模式识别究[J].自动化学报, 2015, 41(9):1686-1692. http://www.cqvip.com/QK/90250X/201509/665978491.html SUN Hui-wen, FU Yun-fa, XIONG Xin. Identification of EEG induced by motor imagery based on Hilbert-Huang Transform[J]. Acta Automatica Sinica, 2015, 41(9):1686-1692. http://www.cqvip.com/QK/90250X/201509/665978491.html [3] DAS A K, SURESH S, SUNDARARAJAN N. A discriminative subject-specific spatio-spectral filter selection approach for EEG based motor-imagery task classification[J]. Expert Systems with Applications, 2016, 64:375-384. doi: 10.1016/j.eswa.2016.08.007 [4] 赵林, 孙施浩, 贾英民, 等.基于小波变换的分布式信息一致滤波算法[J].控制与决策, 2016, 1:45-60. http://d.old.wanfangdata.com.cn/Periodical/kzyjc201601005 ZHAO Lin, SUN Shi-hao, JIA Ying-min, et al. Wavelet transform based distributed information consensus filter[J]. Control and Decision, 2016(1):45-60. http://d.old.wanfangdata.com.cn/Periodical/kzyjc201601005 [5] AGHAEI S, MAHANTA M S, PLATANIOTIS K N. Separable common spatio-spectral patterns for motor imagery BCI systems[J]. IEEE Trans on Biomedical Engineering, 2016(1):15-29. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=7195222fe6536ccd55e986b5fb1c45cb [6] 陈茹雯, 黄仁.非线性自回归时序模型研究及其预测应用[J].系统工程理论与实践, 2015, 35(9):2370-2379. http://d.old.wanfangdata.com.cn/Periodical/xtgcllysj201509022 CHENG Ru-wen, HUANG Ren. Research of general expressin for nonlinear auto regressive model and its forecast application[J]. System Engineering Theory and Practice, 2015, 35(9):2370-2379. http://d.old.wanfangdata.com.cn/Periodical/xtgcllysj201509022 [7] HENDRYLI J, FANANY M I. Classifying abnormal activities in exam using multi-class Markov chain LDA based on MODEC features[C]//International Conference on Information and Communication Technology. Bandung, Indonesia: IEEE, 2016. [8] ZHENG W L, LU B L. Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks[C]//International IEEE/EMBS Conference.[S.l.]: IEEE, 2015: 154-157. [9] GUO Y, TAO D, YU J, et al. Deep neural networks with relativity learning for facial expression recognition[C]//IEEE International Conference on Multimedia & Expo workshops.[S.l.]: IEEE, 2016: 1-6 [10] 郭明玮, 赵宇宙, 项俊平, 等.基于支持向量机的目标检测算法综述[J].控制与决策, 2014(2):193-200. http://d.old.wanfangdata.com.cn/Periodical/kzyjc201402001 GUO Ming-wei, ZHAO Yu-zhou, XIANG Jun-ping, et al. Review of object detection methods based on SVM[J]. Control and Decision, 2014(2):193-200. http://d.old.wanfangdata.com.cn/Periodical/kzyjc201402001 [11] HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786):504-507. doi: 10.1126/science.1127647 [12] 史彩娟, 阮秋琦.基于增强稀疏性特征选择的网络图像标注[J].软件学报, 2015, 7:1800-1811. http://d.old.wanfangdata.com.cn/Periodical/rjxb201507019 [13] 张梅, 王俊.基于改进的符号相对熵的脑电信号时间不可逆性研究[J].物理学报, 2013, 62(3):038701. http://d.old.wanfangdata.com.cn/Periodical/wlxb201303071 ZHANG Mei, WANG jun. Modified symbolic relative entropy based electroencephalogram time irreversibility analysis[J]. Acta Physica Sinica, 2013, 62(3):038701. http://d.old.wanfangdata.com.cn/Periodical/wlxb201303071 [14] DORNHEGE G, BLANKERTZ B, GABRIEL C, et al. Boosting bit rates in non-invasive EEG single-trial classifications by feature combination and multi-class paradigms[J]. IEEE Tran on Biomed Eng, 2004, 51(6):993-1002. doi: 10.1109/TBME.2004.827088 [15] CHU H, JIN C, CHEN J X, et al. A 3-D millimeter-wave filtering antenna with high selectivity and low cross-polarization[J]. IEEE Trans On Antennas and Propagation, 2015, 5:2375-2380. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=0ef48729a3a6a83d9acb9eb11402c21b [16] HINTON G, SALAKHUTDINOV R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(504):504-507. doi: 10.1126-science.1127647/ [17] ZHENG W L, GUO H T, LU B L. Revealing critical channels and frequency bands for emotion recognition from EEG with deep belief network[C]//International Ieee/embs Conference on Neural.[S.l.]: IEEE, 2015: 154-157. -

 点击查看大图
点击查看大图
图(7) / 表(3)
计量
- 文章访问数: 4188
- HTML全文浏览量: 1350
- PDF下载量: 97
- 被引次数: 0
