 ISSN
ISSN 



-
近年来,随着刑侦技术的发展,现勘过程中的各种涉案图像资料得到全面的采集与保存,且建立共享“刑侦图像库”,但随着库中图像数量的增多,在案件侦破、串并案分析与法庭取证时,很难快速而准确地查找到相关图像。如何利用计算机按照人们理解的方式对刑侦图像进行自动分类[1],以帮助刑侦人员缩小排查范围,提高图像查找效率,是当前“科技强警”工作中一项极具挑战的前瞻性研究课题[2],在公安行业具有重要应用价值。
刑侦图像分类作为图像分类领域一个特殊分支,由于其具有较强的行业性与保密性,专门针对刑侦图像分类研究的文献较少,且通常只针对单种类型的刑侦图像,例如:文献[3]提出一种基于核心点配准模式匹配的方法,用于鞋印图像分类问题;文献[4]提出一种基于可变形细节聚类的方法,用于指纹图像识别问题;文献[5]提出一种基于Radon变换与小波变换的纹理特征提取方法,用于轮胎花纹分类问题。针对多种类型的刑侦图像分类问题,本文将利用带有空间位置信息的尺度不变特征变换(scale invariant feature transform, SIFT)描述子对刑侦图像进行多示例建模, 然后基于空间稀疏编码(spatial sparse coding, SSC)[6]技术,设计一种新的广义多示例学习(multi-instance Learning, MIL)[7]算法,用于刑侦图像分类。
自MIL概念提出之后,由于其独特性且普遍存在于现实机器学习任务之中,在图像检索、图像分类与对象识别等领域已得到广泛应用[7]。根据MIL模型定义方式的不同,MIL算法可分为二类:1)狭义(标准)MIL算法,该类算法认为每个示例都具有一个隐含的类别标号$c \in \Omega = \{ + 1, - 1\} $,如果一个包被标为正的充要条件是它至少包含有一个示例是正例。如:轴平行矩形、多样性密度(diverse density, DD)[8]、mi-SVM[9]、MI-SVM[9]与miGraph[10]等算法,其基本思想都是通过对包中每个示例标签的预测来推测包的标签,在早期MIL算法中研究的比较多,通常用于图像分类与检索问题。2)广义MIL算法,该类算法基于广义MIL模型,即认为正包的标号不是由包中的单个示例来决定,而是由包中的多个示例共同作用才能决定。其基本思想就是通过挖掘包中各示例的关系,采用一个元数据(metadata)来表征每个多示例包,从而将MIL转化成标准的单示例学习(有监督学习)问题进行求解,如:DD-SVM[11]与MILES[12]算法,其本质是先构造示例原型(instance prototype)空间,再利用非线性映射的方法来求取多示例包的元数据;文献[13]提出的miFV与miVLAD算法,其本质是利用多示例包中示例之间的相互关系而构造一个相关映射函数,从而将原始的多示例包映射成一个新的特征表示;除此之外,还有基于潜在语义分析的LSA-MIL算法[14],基于示例平均的Simple-MI算法[15]以及基于广义字典学习的GD-MIL算法[16]等。对比实验结果表明,在图像检索或分类问题中,总体上来说第二类算法比第一类算法精度更高,且成为MIL中最为有效的一类算法。
-
针对传统多示例建模没有记录示例空间位置信息的问题,且鉴于SIFT描述子在图像分类中的卓越性能[6],本文设计了一种空间稠密SIFT(space dense SIFT,SD-SIFT)采样的多示例建模方法。该方法将每幅刑侦图像当作一个包(bag),然后对图像进行均匀网格稠密采样,并提取每个采样点的SIFT描述子及其空间位置信息,作为包中的示例,将刑侦图像分类问题转化成MIL问题。设IMG为任一刑侦图像,对其SIFT采样点为n个,则IMG对应的多示例包记为:
$${\rm{Bag}} = \{ ({X_j},{S_j})|j = 1,2, \cdots ,n\} $$ (1) 式中,${X_j} \in {R^{128}}$与${S_j} \in {R^2}$分别表示第j个点的SIFT描述子及其空间位置坐标。
-
为了将MIL问题转化成标准的有监督学习问题,本文对多示例包进行空间稀疏编码,以挖掘包中示例的内在关系,用一个编码特征对每个多示例包进行表征。
-
在稀疏编码过程中,构造能包含图像全部特征信息的字典非常重要。本文为了利于MIL训练包的独特性质,提出一种基于多样性密度(DD)函数[8]的字典构造方法。
在MIL问题中,设训练集含有${N^ + }$个正包与${N^ - }$个负包,其中$B_i^ + $($B_i^{\rm{ - }}$)表示第i个正包(负包),$X_{i,j}^ + $($X_{i,j}^ - $)表示第i个正包(负包)中的第j个示例,$X_{i,j,k}^ + $($X_{i,j,k}^ - $)表示第i个正包(负包)中的第j个示例的第k个属性。则DD函数[8]定义为:
$${\rm{DD}}(X) = \prod\limits_i^{{N^ + }} {P(X\left| {B_i^ + } \right.)} \prod\limits_i^{{N^ - }} {P(X\left| {B_i^ - } \right.)} $$ (2) 式中,
$$\left\{ \begin{gathered} P(X\left| {B_i^ + } \right.) = 1 - \prod\limits_j {(1 - \Pr (X\left| {B_{i,j}^ + } \right.))} \hfill \\ P(X\left| {B_i^ - } \right.) = \prod\limits_j {(1 - \Pr (X\left| {B_{i,j}^ - } \right.))} \hfill \\ \Pr (X\left| {{B_{i,j}}} \right.) = \exp ( - {\left\| {{X_{i,j}} - X} \right\|_2}) \hfill \\ {\left\| {{X_{i,j}} - X} \right\|_{\rm{2}}}{\rm{ = }}\sum\limits_k {{{({B_{i,j,k}} - {x_k})}^2}} \hfill \\ \end{gathered} \right.$$ (3) 由于DD(X)是高阶非线性连续函数,存在多个局部大值点,本文则从所有正包中随机选择M个不同的搜索起点,分别采用梯度下降法可寻找DD(X)的M个局部极大值点,将它们作为字典,记为:
$$W = [{{\mathit{\boldsymbol{w}}}_1},{{\mathit{\boldsymbol{w}}}_2}, \cdots ,{{\mathit{\boldsymbol{w}}}_M}] \in {R^{128 \times M}}$$ (4) 式中,${{\mathit{\boldsymbol{w}}}_i} = {[{w_{i,1}},{w_{i,2}}, \cdots ,{w_{i,128}}]^{\rm{T}}}$为一个列向量,表示DD(X)函数的第i个局部极大值点。根据式(2)的定义,极值点反映的物理意义是每个正包至少存在一个示例离它较近,而所有负包中的所有示例都离它较远,因为这些点能体现出多示例包的独特性质,用它们作为SC字典中的码元,更具代表意义。
-
针对传统MIL算法没有考虑示例的空间位置信息的问题,本文采用图 1c所示方法将图像划分成左上、右上、左下、右下角与中心区域(虚线所示)等5个相同大小的子块,然后根据1.1节多示例建模过程记录每个SIFT点的位置坐标,对属于每个子块的所有SIFT描述子进行稀疏编码与最大池化处理,以提取多示例包的空间稀疏编码特征,即多示例包的元数据(metadata)对多示例包进行表征。

图 1 空间稀疏编码图像分块示意图
设任意刑侦图像IMG第s块所对应的所有SIFT描述子记为${\rm{Ba}}{{\rm{g}}_s} = \{ {X_j}|{X_j} \in {R^{128 \times 1}},j = 1,2, \cdots ,{n_s}\} $,也称其为IMG的一个子包,其中:${n_s}$表示子块中SIFT描述子的个数(s=1, 2, …, 5)。然后,根据稀疏编码理论,任意${X_j}$可以用字典$W \in {R^{128 \times M}}$中少量码元的线性组合来近似表示,即求解如下优化问题[6, 17]:
$${c_j} = \arg \min \left\| {{X_j} - W{c_j}} \right\| + \lambda {\left\| {{c_j}} \right\|_1}$$ (5) 式中,${c_j} \in {R^{M \times 1}}$表示${X_j}$待求的稀疏编码系数;$\lambda $表示正规参数;${\left\| {{c_j}} \right\|_1}$表示${c_j}$的L1范数。通过式(5)求得${\rm{Ba}}{{\rm{g}}_s}$中所有SIFT描述子的稀疏编码系数,记为:
$${\mathit{\boldsymbol{C}}} = [{c_1},{c_2}, \cdots ,{c_{{n_s}}}] \in {R^{M \times {n_s}}}$$ (6) 然后,选用最大池化(max pooling)函数[6]对C中的稀疏编码系数进行处理,以得到图像IMG第s个子块M维的稀疏编码特征$Z({\rm{Ba}}{{\rm{g}}_s})$,即:
$$\left\{ {\begin{array}{*{20}{c}} {Z({\rm{Ba}}{{\rm{g}}_s}) = \{ {z_p}:\;p = 1,2, \cdots ,M\} } \\ {{z_p} = \max \{ \left| {{c_{p,1}}} \right|,\left| {{c_{p,2}}} \right|, \cdots ,\left| {{c_{p,{n_s}}}} \right|\} } \end{array}} \right.$$ (7) 式中,M表示字典W中码元的个数;zp表示在${\mathit{\boldsymbol{C}}}$C中求第p行绝对值的最大项。最后,采用式(5)~式(7)的方法计算多示例包Bag(刑侦图像)所有子包的稀疏编码特征,且将它们拼接在一起,由此得到一个5M维的特征向量,即SSC特征,也称之为Bag的元数据,记为:
$${\mathit{\boldsymbol{\psi}}} ({\rm{Bag}}) = [Z({\rm{Ba}}{{\rm{g}}_1}),Z({\rm{Ba}}{{\rm{g}}_2}), \cdots ,Z({\rm{Ba}}{{\rm{g}}_5})]$$ (8) -
设${\rm{Trn}} = \{ ({\rm{Ba}}{{\rm{g}}_i},{y_i}):i = 1,2, \cdots ,N\} $为刑侦图像分类问题中的多示例训练集,${y_i} \in \{ - 1, + 1\} $表示多示例包${\rm{Ba}}{{\rm{g}}_i}$所对应的标签,$i = 1,2, \cdots ,N$, +1表示正包,1表示负包。通过1.2.2节所述方法,提取每个多示例包${\rm{Ba}}{{\rm{g}}_i}$的元数据${\mathit{\boldsymbol{\psi}}} ({\rm{Ba}}{{\rm{g}}_i})$,则训练集转化为${\rm{Trn'}} = \{ ({\mathit{\boldsymbol{\psi}}} ({\rm{Ba}}{{\rm{g}}_i}),{y_i}):i = 1,2, \cdots ,N\} $,因为${\mathit{\boldsymbol{\psi}}} ({\rm{Ba}}{{\rm{g}}_i})$是一个$5M$维的特征向量,${y_i}$是它对应的标签,由此MIL被转化成有监督学习问题,本文基于${\rm{Trn'}}$采用LIBLINEAR[18]大尺度线性SVM来训练刑侦图像分类器。最后,本文提出的SSC-MIL刑侦图像分类算法总结如下:
1) SSC-MIL训练
输入:训练图像集$D = \{ ({\rm{Im}}{{\rm{g}}_i},{y_i}):i = 1,2, \cdots ,N\} $,字典码元个数M;
输出:字典W和SVM分类器$({\alpha ^*},{b^*})$;
① 多示例建模
对$\forall {\rm{Im}}{{\rm{g}}_i} \in D$,用1.3节所述方法,将其转化成多示例包${\rm{Ba}}{{\rm{g}}_i}$,则MIL训练集记为${\rm{Trn}} = \{ ({\rm{Ba}}{{\rm{g}}_i},{y_i}):$ $i = 1,2, \cdots ,N\} $;
② 构造字典W
通过式(2)构造DD函数,并采用梯度下降法求其M个局部极大值点,作为字典W;
③ 多示例包的空间稀疏编码特征提取
采用式(5)~式(8)的方法计算每个多示例包${B_i}$的空间稀疏编码特征${\mathit{\boldsymbol{\psi}}} ({B_i})$,则训练集${\rm{Trn}}$转化为${\rm{Trn'}} = \{ ({\mathit{\boldsymbol{\psi}}} ({\rm{Ba}}{{\rm{g}}_i}),{y_i}):i = 1,2, \cdots ,N\} $;
④ 采用LIBLINEAR工具箱,由${\rm{Trn'}}$训练SVM分类器$({\alpha ^*},{b^*})$。
2) SSC –MIL分类
对新图像${\rm{IMG}}$,采用上述相同方法对其进行多示例建模与SSC特征提取,再用SVM分类器$({\alpha ^*},{b^*})$进行分类识别。
-
为了验证本文SSC-MIL方法的有效性,建立一个真实刑侦图像库,该图像库共包含14类图像,即:现勘血迹、肇事车辆、现勘远景、现勘门框、现勘指纹、现勘室内图、犯罪现场图、现勘平面图、现勘鞋印、嫌犯皮肤、嫌犯纹身、现勘凶器、现勘轮胎、现勘窗户。每类刑侦图像有200幅,共2 800幅,部分样图如图 2所示。

图 2 部分刑侦图像样图
在SD-SIFT多示例建模时,稠密采样间隔为8个像素,且以每个采样点为中心将图像划分为16×16像素的子块(patch),再提取每个子块的SIFT描述子;采用DD方法训练字典时,分别以每类图像为正包,其余类的图像为负包,训练得到K个码元,最终构造字典的大小为$M = 14 \times K$;稀疏编码过程中,正规参数$\lambda $设置为0.1,且采用OMP算法[6, 17]求解式(5)SC优化问题;SVM训练时从每类图像中随机选取100幅或者120幅组成训练集,其余图像组成测试集。基于以上参数设置与实验方法,每次实验均重复20次,统计14类图像平均分类精度。
-
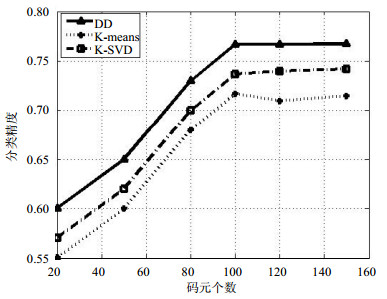
首先,为了验证本文所提基于DD函数构造字典方法的有效性,与K-Means聚类、K-SVD迭代优化等常用字典方法进行对比。当从每类图像中随机选取100幅组成训练集,且每类图像得到码元的个数由20个增加到150个时,实验结果如图 3所示。

图 3 字典构造方法对比实验结果
由图 3可见,DD字典构造方法在图像分类精度方面均优于其他两种方法。因为通过DD函数捕获的极值点反映的是每类图像的独特属性点,由它们构造字典而得到的稀疏编码特征,具有更强的图像语义表征能力,更利于将各类图像区分开来。从图 3中还可以看出,随着字典码元个数的增加,分类精度总体在提高,但当码元个数达到100时分类精度提高不再明显,则增加码元也只是增加字典冗余,所以后续对比实验中,SSC-MIL算法从每类图像中训练的码元个数为100。
为了验证本文空间稀疏编码的有效性,针对图像进行不分块(S-1方法)与分成4块(S-4方法)的情况(如图 1a、1b所示),按1.2.2节所述方法分别提取稀疏编码特征,再结合LIBLINEAR线性SVM方法, 与本文所采用的S-5分块方法进行比较,实验结果如表 1所示。
表 1 空间稀疏编码方案对比实验结果
% 方法 100幅训练 120幅训练 S-1 69.74 70.25 S-4 76.12 77.32 S-5 78.86 80.18 从表 1实验结果可以看出,S-4与S-5分块方法比不分块的S-1方法,分类精度分别提高约7%与9%,原因是分块之后利用了图像的空间信息,S-5比S-4方法提高约2%,原因是大部分刑侦图像的兴趣目标在图像中心区域,而S-5方法的第5块就是划分在图像中心区域,更能捕获图像中关键语义信息。
最后,为了进一步验证SSC-MIL算法的有效性,基于上述刑侦图像库与实验方法,与MI-SVM[9]、mi-SVM[9]、miGraph[10]、DD-SVM[11]、MILES[12]、miFV[13]、miVLAD[13]、LSA-MIL[14]、Simple-MI [15]与GD-MIL[16]等MIL方法进行对比实验。实验中分别使用100、120幅图像做训练集,分别统计每种MIL方法的平均分类精度和方差,实验结果如表 2所示,从中看出本文所提SSC-MIL算法均优于其他算法。这是因为:SD-SIFT多示例建模能提取到丰富的图像局部信息,然后通过对多示例包进行空间稀疏编码特征提取,更能表征图像的内在语义信息及上下文关系,具有更强的图像表征能力,而其他MIL算法均没考虑包中示例的位置信息,一定程度上影响了相关MIL算法挖掘图像语义上下文关系的能力,最终导致分类精度受限。
表 2 空间稀疏编码方案对比实验结果
% 方法 100幅训练 120幅训练 SSC-MIL 78.7±2.0 80.4±2.5 miFV 73.9±7.0 76.6±7.1 miVLAD 73.5±8.1 75.2±7.9 GD-MIL 59.3±2.4 61.0±2.2 LSA-MIL 58.1±2.1 59.8±1.9 miGraph 76.3±7.0 78.0±7.2 MILES 55.4±2.3 57.1±2.8 DD-SVM 54.2±6.0 55.9±2.8 mi-SVM 71.6±1.5 73.3±1.4 MI-SVM 41.3±1.2 43.0±3.0 Simple-MI 68.5±9.0 70.2±9.9 在上述实验过程中,每类图像利用120幅图像构造训练集,基于SSC-MIL算法20次重复实验的混淆矩阵如表 3所示(C1到C14分别代表:现勘室内图、现勘血迹、肇事车辆、现勘远景图、现勘门框、现勘指纹、犯罪现场图、现勘平面图、现勘鞋印、嫌犯皮肤、嫌犯纹身、现勘凶器、现勘轮胎、现勘窗户),其中对角线处表示每类刑侦图像被正确分类的百分比,非对角线处显示的是错误分类的百分比。实验结果表明,分类精度较低的是C7(犯罪现场图)与C14(现勘窗户)这二类图像。这是因为犯罪现场是一类综合性的图像,其在拍摄取景时经常要将案发现场的车辆、血迹、鞋印与凶器等目标一起拍摄进来,如其中11.0%被错分到C3(肇事车辆)中,其原因是犯罪现场包含有车祸现场这类图像,这里面也存在车辆目标,导致该二类图像之间存在错分现象;再则,C14(现勘窗户)的18.0%被错分到C5(现勘门框),这是因为这两类图像在拍摄取景时,经常将门框与窗户拍摄在一起,相应的C5(现勘门框)在分类时,其中12%被错分到了C14(现勘窗户)中,导致C5和C14相互错分。
表 3 SSC-MIL算法图像分类混淆矩阵
% C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 C1 67.0 7.0 0.0 2.0 11.0 0.0 0.0 0.0 0.0 0.0 2.0 0.0 0.0 11.0 C2 8.0 62.0 4.0 4.0 1.0 1.0 5.0 0.0 5.0 0.0 4.0 5.0 0.0 1.0 C3 5.0 1.0 74.0 15.0 0.0 0.0 5.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 C4 3.0 1.0 3.0 87.0 0.0 0.0 3.0 0.0 1.0 0.0 1.0 1.0 0.0 0.0 C5 6.0 0.0 0.0 5.0 71.0 0.0 3.0 1.0 0.0 0.0 2.0 0.0 0.0 12.0 C6 0.0 0.0 0.0 0.0 0.0 96.0 2.0 0.0 2.0 0.0 0.0 0.0 0.0 0.0 C7 1.0 8.0 11.0 2.0 4.0 0.0 52.0 0.0 8.0 0.0 3.0 8.0 0.0 3.0 C8 0.0 0.0 2.0 1.0 0.0 0.0 0.0 97.0 0.0 0.0 0.0 0.0 0.0 0.0 C9 0.0 8.0 2.0 0.0 0.0 0.0 7.0 3.0 75.0 0.0 2.0 1.0 1.0 1.0 C10 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 100 0.0 0.0 0.0 0.0 C11 1.0 1.0 0.0 0.0 0.0 0.0 4.0 0.0 3.0 0.0 87.0 4.0 0.0 0.0 C12 2.0 6.0 2.0 2.0 2.0 0.0 6.0 0.0 3.0 0.0 4.0 71.0 0.0 2.0 C13 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 99.0 0.0 C14 5.0 1.0 3.0 4.0 18.0 1.0 1.0 1.0 0.0 0.0 2.0 1.0 0.0 63.0 -
针对刑侦图像分类问题,提出一种新的MIL算法,即SSC-MIL算法,其创新性体现如下:1)在多示例建模与计算多示例包的元数据时,均考虑了示例在图像中的空间位置信息,更利于挖掘图像关键区域的空间上下文关系,以提高图像分类精度;2)将MIL的DD函数引入到SC的字典学习之中,即通过构造DD函数与搜索极值点作为字典码元,以捕获每类图像的独特属性点,从而提高稀疏编码特征的语义鉴别能力。实验结果表明,本文方法优于其他MIL方法,是一种有效的刑侦图像分类方法。
Spatial Sparse Coding Based MIL Algorithm for Criminal Investigation Image Classification
-
摘要: 针对刑侦图像分类问题,提出一种基于空间稀疏编码(SSC)的多示例学习(MIL)算法。首先,利用稠密尺度不变特征转换(SIFT)原理设计一种带有示例位置信息的多示例建模方案,将刑侦图像分类问题转化为MIL问题;然后,基于多样性密度(DD)函数及稀疏编码(SC)理论,设计了一种针对MIL的字典构造方法及空间稀疏编码方案,用于计算多示例包的元数据(metadata);最后,结合大尺度线性支持向量机方法,提出了一种SSC-MIL的MIL新算法。14类真实刑侦图像的对比实验表明,该算法是有效的,且分类精度高于其他方法。Abstract: Focusing on the classification problem of the criminal investigation, a multi-instance learning (MIL) algorithm based on spatial sparse coding (SSC) is proposed. By using the dense scale invariant feature transform (SIFT) principle, a multi-instance modeling scheme with instance position information is constructed to transform the problem of criminal investigation image classification into a multi-instance learning (MIL) problem. Based on the diversity density (DD) function and the sparse coding theory, a new dictionary construct method and spatially sparse coding (SSC) technique are designed for MIL, to extract the metadata for each multi-instance bag. At last, a new MIL algorithm called SSC-MIL is proposed by combining the large-scale linear support vector machine method. Experimental results on the 14 cases of real criminal investigation image show that the proposed method is effective, and the classification accuracy is higher than other methods.
-
表 2 空间稀疏编码方案对比实验结果
% 方法 100幅训练 120幅训练 SSC-MIL 78.7±2.0 80.4±2.5 miFV 73.9±7.0 76.6±7.1 miVLAD 73.5±8.1 75.2±7.9 GD-MIL 59.3±2.4 61.0±2.2 LSA-MIL 58.1±2.1 59.8±1.9 miGraph 76.3±7.0 78.0±7.2 MILES 55.4±2.3 57.1±2.8 DD-SVM 54.2±6.0 55.9±2.8 mi-SVM 71.6±1.5 73.3±1.4 MI-SVM 41.3±1.2 43.0±3.0 Simple-MI 68.5±9.0 70.2±9.9  下载: 导出CSV
下载: 导出CSV
表 3 SSC-MIL算法图像分类混淆矩阵
% C1 C2 C3 C4 C5 C6 C7 C8 C9 C10 C11 C12 C13 C14 C1 67.0 7.0 0.0 2.0 11.0 0.0 0.0 0.0 0.0 0.0 2.0 0.0 0.0 11.0 C2 8.0 62.0 4.0 4.0 1.0 1.0 5.0 0.0 5.0 0.0 4.0 5.0 0.0 1.0 C3 5.0 1.0 74.0 15.0 0.0 0.0 5.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 C4 3.0 1.0 3.0 87.0 0.0 0.0 3.0 0.0 1.0 0.0 1.0 1.0 0.0 0.0 C5 6.0 0.0 0.0 5.0 71.0 0.0 3.0 1.0 0.0 0.0 2.0 0.0 0.0 12.0 C6 0.0 0.0 0.0 0.0 0.0 96.0 2.0 0.0 2.0 0.0 0.0 0.0 0.0 0.0 C7 1.0 8.0 11.0 2.0 4.0 0.0 52.0 0.0 8.0 0.0 3.0 8.0 0.0 3.0 C8 0.0 0.0 2.0 1.0 0.0 0.0 0.0 97.0 0.0 0.0 0.0 0.0 0.0 0.0 C9 0.0 8.0 2.0 0.0 0.0 0.0 7.0 3.0 75.0 0.0 2.0 1.0 1.0 1.0 C10 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 100 0.0 0.0 0.0 0.0 C11 1.0 1.0 0.0 0.0 0.0 0.0 4.0 0.0 3.0 0.0 87.0 4.0 0.0 0.0 C12 2.0 6.0 2.0 2.0 2.0 0.0 6.0 0.0 3.0 0.0 4.0 71.0 0.0 2.0 C13 0.0 0.0 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 99.0 0.0 C14 5.0 1.0 3.0 4.0 18.0 1.0 1.0 1.0 0.0 0.0 2.0 1.0 0.0 63.0
下载: 导出CSV
-
[1] 曹健, 魏星, 李海生, 等.基于局部调整的图像分类方法[J].电子科技大学学报, 2017, 46(1):69-74. doi: 10.3969/j.issn.1001-0548.2017.01.011 CAO Jian, WEI Xing, LI Hai-sheng, et al. Image classification methods based on local feature[J]. Journal of University of Electronic Science and Technology of China, 2017, 46(1):69-74. doi: 10.3969/j.issn.1001-0548.2017.01.011 [2] 韩德明.信息化背景下侦查权范式的要素系谱[J].中国人民公安大学学报(社会科学版), 2016, 182(4):66-72. http://d.old.wanfangdata.com.cn/Periodical/zgrmjgdxxb-zxshkxb201604011 HAN De-ming. Essential genealogy of the right of investigation in the context of information[J]. Journal of People's Public Security University of China (Social Science Edition), 2016, 182(4):66-72. http://d.old.wanfangdata.com.cn/Periodical/zgrmjgdxxb-zxshkxb201604011 [3] GWO C Y, WEI C H. Shoeprint retrieval:Core point alignment for pattern comparison[J]. Science & Justice, 2016, 56(5):341-350. https://www.sciencedirect.com/science/article/pii/S1355030616300521 [4] MEDINA M A, MORENO A M, BALLESTER M A F, et al. Latent fingerprint identification using deformable minutiae clustering[J]. Neurocomputing, 2016, 175(1):851-865. https://www.sciencedirect.com/science/article/pii/S0925231215015982 [5] LIU Y, YAN H, LIM K P. Study on rotation-invariant texture feature extraction for tire pattern retrieval[J]. Multidimensional Systems & Signal Processing, 2015, 21(2):1-14. doi: 10.1007/s11045-015-0373-0 [6] YANG J, YU K, GONG Y, et al. Linear spatial pyramid matching using sparse coding for image classification[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.[S.l.]: IEEE, 2009: 1794-1801. [7] 李大湘, 赵小强, 李娜.图像语义分析的MIL算法综[J].控制与决策, 2013, 28(4):481-488. http://d.old.wanfangdata.com.cn/Periodical/kzyjc201304003 LI Da-xiang, ZHAO Xiao-qiang, LI Na. A survey of MIL algorithm for image semantic analysis[J]. Control and Decision Making, 2013, 28(4):481-488. http://d.old.wanfangdata.com.cn/Periodical/kzyjc201304003 [8] MARON O, RATAN A L. Multiple-instance learning for natural scene classification[C]//Proceedings of the 15th International Conference on Machine Learning. Sab Frabcuscim, CA, USA: Morgan Kaufmann Publishers Inc, 1998: 341-349. [9] ANDREWS S, TSOCHANTARIDIS I, HOFMANN T. Support vector machines for multiple-instance learning[C]//Proceedings of the 15th Neural Information Processing Systems. Cambridge, MA, USA: MIT, 2003: 561-568. [10] ZHOU Z H, SUN Y Y, LI Y F. Multi-Instance learning by treating instances as non-I.I.D. samples[C]//Proceedings of the 26th International Conference on Machine Learning. Montreal, Canada: [s.n.], 2009: 1249-1256. [11] CHEN Y, WANG J Z. Image categorization by learning and reasoning with regions[J]. Journal of Machine Learning Research, 2004, 5(8):913-939. [12] CHEN Y, BI J, WANG J Z. MILES:Multiple-Instance learning via embedded instance selection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(12):1931-1947. doi: 10.1109/TPAMI.2006.248 [13] WEI X S, WU J, ZHOU Z H. Scalable algorithms for multi-instance learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(4):975-987. doi: 10.1109/TNNLS.2016.2519102 [14] LI D X, PENG J Y, LI Z, et al. LSA based multi-instance learning algorithm for image retrieval[J]. Signal Processing, 2011, 91(8):1993-2000. doi: 10.1016/j.sigpro.2011.03.004 [15] AMORES J. Multiple instance classification:Review, taxonomy and comparative study[J]. Artificial Intelligence, 2013, 201(4):81-105. http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0231226816/ [16] SHRIVASTAVA A, PATEL V M, PILLAI J K, et al. Generalized dictionaries for multiple instance learning[J]. International Journal of Computer Vision, 2015, 114(2-3):288-305. doi: 10.1007/s11263-015-0831-z [17] 李宗民, 蒋迪, 刘玉杰, 等.结合空间上下文的局部约束线性特征编码[J].计算机辅助设计与图形学学报, 2017, 29(2):254-261. doi: 10.3969/j.issn.1003-9775.2017.02.006 LI Zong-min, JIANG Di, LIU Yu-jie, et al. Local constrained linear feature coding based on spatial context[J]. Journal of Computer Aided Design & Computer Graphics, 2017, 29(2):254-261. doi: 10.3969/j.issn.1003-9775.2017.02.006 [18] FAN R E, CHANG K W, HSIEH C J, et al. LIBLINEAR: a library for large linear classification[EB/OL].[2017-02-21]. http://www.csie.ntu.edu.tw/~cjlin/liblinear/. -

 点击查看大图
点击查看大图

图(3) / 表(3)
计量
- 文章访问数: 4404
- HTML全文浏览量: 1226
- PDF下载量: 80
- 被引次数: 0
