 ISSN
ISSN 


-
语音的自然度和表现力是人类智能的重要表现之一,因此语音信号不仅需包含表达的文本内容,还应蕴含丰富的情感信息。在情感语音合成中,给后端合成提供的语言层和语义层上的信息,都依赖于合成前端大规模的知识库和规则库。语音合成系统前端文本分析重要的任务是对输入的文本进行分析,给后端合成部分提供必要的信息[1]。
本文对输入的文本进行情感文本分类,将分类结果提供给情感韵律转换模块,从而提高情感韵律转换的准确率和情感表现力。主要研究工作包括以下4个方面:1)构建了维吾尔语文情感知识库和实验标注语料。在已有的维吾尔语韵律短语语料的基础上,考虑到维吾尔语韵律短语的节奏感及其中情感词语调的变化,选取韵律短语层(L4),对大规模情感文本进行了L4标注;2)根据维吾尔语的语言特征,统计出情感分类中能够起到作用的情感特征,也为了更好地描述和突出文本中的情感词,对一级词性标注进行力改进,将句中的情感词、副词、否定词的一级词性标签改为情感标签,从而完善了情感特征库;3)为了获取短语中隐藏的情感信息,构建了由词向量、词性向量和韵律短语向量拼接的混合向量;4)探索各种神经网络模型用不同特征向量和组合特征向量时的情感分类效果,最终搭建了基于注意力机制和BiRNN网络的适合维吾尔文的情感韵律短语模式的混合神经网络模型。此研究成果完善了情感语音合成前端知识库。在情感韵律转换之前,引入自动情感分类方法,对韵律转换模块添加了新的色彩。
-
文本情感倾向分析是对带有情感色彩文本中的主观信息进行分析,推测出对应的情感极性。文本情感是指将给定文档、句子以及主题分为积极、消极和中立3个类别。通过文本情感分类可实现多级情感分类目标。通常文本情感分析的典型方法包括基于外部知识库的方法、基于传统机器学习的方法及基于深度学习的方法等。文献[1]利用相结合获得词义的方式,将部分形容词和动词手工标记为种子词汇,之后将一些形容词和动词手工标记成为种子词,然后利用这些种子词汇对WordNet[2]中的同义和反义关系来进行了情感词的扩充,从而决定观点的情感极性[2-3]。文献[3]采用WordNet中的同义结构图来计算新出现的词与基准词的语义距离,以此得到新词的情感倾向性[4]。HowNet[5]、GI情感词典[6-7]以及SentiWordNet[8]等词典来识别了文档中的情感词,并在此基础上计算出了文档的情感倾向。文献[9]利用一系列规则抽取了文档中含有形容词和副词的短语作为情感短语,之后通过计算情感短语与种子词之间的点互信息(pointwise mutual information, PMI)定义了情感短语的情感倾向。文献[10]通过在大规模情感语料库中统计候选词汇的方式确定其情感倾向。文献[11]开创了基于机器学习方法的文本情感分类。文献[12-13]在基于半监督递归自编码器树回归模型基础上,引入单词前后的关联性特征,对词向量进行改进,之后结合softmax分类器实现了句子级的情感分类任务。文献[14]采用卷积神经网络(CNN)的方法进行了情感倾向分析与情感问题分类等工作,其结果比文献[12, 15]采用的递归模型方法有了明显的提高。文献[16]利用深层卷积神经网络(DCNN)的方法,通过调整参数、优化函数,改进了训练方式并据此实现了Twitter的情感分类。深度学习方法中效果较好的有基于卷积神经网络和基于递归神经网络模型[15-17]。
总而言之,通过上述文献综述分析得知,虽然已有的研究通过深度学习的方式提高了对中英文文本情感的分析效率,然而针对维吾尔文领域的情感的分析仍处于初步阶段。大部分工作只是运用传统的机器学习方式开展研究,并未在大量数据集上对涉及情感分类的不同深度学习技术进行综合评价。维吾尔文是形态丰富的黏着性语言,其形态结构远比中英文复杂。由于维吾尔文语言结构的复杂性,在中英文情感倾向分析领域中普遍使用的、能够获得比较理想的情感倾向性方法,在维吾尔文情感倾向性分析上的效果未必理想。
-
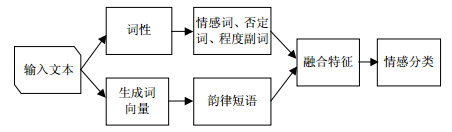
根据维吾尔语的语言特征,设计了情感多特征融合框架:1)在词向量表示基础上添加了词性特征,并将否定成分、程度副词作也加入到词性特征中,对原词性标注标准进行了改进。目的是对输入的文本进行词义消歧来使模型更加关注情感词;2)选取5种典型的情感,对句中的情感词进行标注,将5种情感词也作为新特征加入到词性特征中,进行了融合;3)根据维吾尔语的短语内部结构和韵律短语的特点,统计出最频繁出现的韵律短语包含的单词个数,设置了韵律短语单位,最终构造了维吾尔语情感多特征融合的框架,如图 1所示。

图 1 维吾尔文情感特征融合框架
维吾尔文短语中的各个词之间的组合关系是实词与实词、虚词与实词,相邻词之间存在着相互关联又各自独立的关系。这些句子片段从结构和意义上能够表达完整的意义和语义倾向性。维吾尔文短语结构由名词、形容词、动词及副词等实词组合的,且在句子中作为中心词出现[18],根据短语中心词的个数分可为两类:
1) 单个中心词:修饰词与功能词出现在中心词前后,决定中心词的倾向性。
2) 多个中心词:内部各个词对于短语语义的贡献度是相同的。
此外,短语内部词之间还会出现并列或转折连接词,或者直接组合,或者用标点符号隔开,只能根据语义和词性等方面进行分析才能判断出短语内部的结构组成,维吾尔语短语内部结构如表 1和表 2所示。根据中心词的个数、各词相互之间的的语义倾向度以及关联程度来计算倾向值[19]。
表 1 一个中心词维吾尔语短语内部结构
特征 实例 形+名 گۈزەل ۋەتەن (美丽的祖国) 名+动,名+形 ئايگۈل ئامراق (阿依古丽喜欢) 动+名,动+形 تازلاشقا خۇشتار (看起来好看) 形+动 پاكىز رەتلە (整理干净) 名+“的”+名 ۋەتەننىڭ كەلگۈسى (祖国的未来) 程度词+形/副 ئازراق ياخشى (好一点) 形/副+程度词 قىزىلراقلىرى تەملىك (红一点的好吃) 否定词+动/名/形 سەتنى تاللىما (别选难看的) 表 2 多个中心词维吾尔语短语内部结构
特征 实例 并列或转折连词 ۋە،بىلەن،لىكىن،ئەمما،ناۋادا،بىراق ،ئەگەر
(如果,但是,万一,可是,不过,和,与)形+形, 名+名, 动+动 قۇرۇپ چىقايلى (建设起来) 维吾尔语中的韵律短语是意义上彼此相近,发音时自然相连的词或者词组,结构和意义上能够表达完整意义的词组或者句子片段,也就是节奏层[1]。根据维吾尔语自然语音的发音、停顿及语音数据结构特点,维吾尔语韵律层次结构可分为5个层次:音素层(L0)、音节层(L1)、单词层(L2)、韵律词层(L3)以及韵律短语层(L4)。其中L3是意义上彼此相近,发音时自然相连的词或者词组。L4是发音时自然相连的,句子里从结构和意义上能够表达出完整意义的词组或句子片段[1]。韵律短语区别于句法上的短语,它表示韵律上的节奏感。韵律短语的节奏感将短语边界表现得很明显,其中情感词的语调表现的也很清晰。韵律短语语调的变化能够表现出说话人的态度、观点及情感倾向。因此,本文选取L4韵律短语层作为短语特征。韵律短语标注实例如下:
1)

(中国人很高贵,心胸很宽广);
2)


(这绝不是梦,这是谁都不能否定的美好现实)
在上述实例中,通过“#”来切分韵律短语,其中的一条下划线、两条下划线、波浪线分别表示情感词、程度副词和否定词。
-
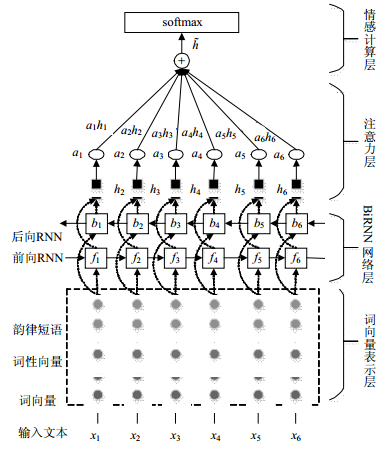
本文提出的模型整体框架由词向量表示层、BiRNN编码层、注意力机制层以及情感计算层构成,整个模型架构如图 2所示。

图 2 BiRNN-attention模型架构图
-
词向量表示层作为整个模型的输入,主要包括词向量矩阵、词性向量矩阵和韵律向量矩阵。
-
词向量(word embedding)是用于构造词和文档的向量表示最有用的深度学习算法之一[20]。本文利用word2vec的skip-gram模型作为生成词向量的方法。利用python库中Gensim实现skip-gram模型训练出了维吾尔文词向量模型。词向量可以表示为$V \to {R^D}:\boldsymbol{w} \to \boldsymbol{\theta} $,其中词$\boldsymbol{w}$从词集$V$中映射到在D维词向量空间的实数向量$\boldsymbol{\theta }$。通过统计维吾尔语语音合成语料中的韵律短语包含的单词个数,发现一条句子中由3个单词组成的韵律短语数量最多,所占的比例也大。因此,将两个单词组成韵律短语和3个单词组成的韵律短语分别作为韵律短语单位,分别设计词向量维度进行训练,词向量模型训练时,上下文窗口大小设置为5,迭代次数为5词,词向量维度分别设定为100,200,300和400维。
-
目前在维吾尔文语中词性大体上划分为实词、虚词、感叹词等。实词可分为动词和静词,静词可分为副词、数次、名词、形容词等。维吾尔语总共有42个词性,以新疆大学多语种信息技术重点实验室维吾尔语词性一级标记集加入情感词、否定词、程度副词进行手工标注,为了增强情感表现力,对一级词性标注进行力改进,将句中的情感词、副词、否定词的一级词性标签改为情感标签。比如表示高兴情感词的原词性为形容词,把形容词替换成表示高兴情感的HA来替换,如表 3所示。维吾尔语融合多特征的韵律短语词性、情感词标注方法如表 4所示。
表 3 维吾尔语韵律短语词性、情感词标注标准
序号 名称 符号 1 名词 N 2 动词 V 3 形容词 A 4 副词 D 5 代词 P 6 数词 M 7 连词 C 8 模拟词 I 9 感叹词 E 10 语气词 T 11 标点符号 Y 12 附加成分 X 13 后置词 R 14 拉丁文 L 15 量词 Q 16 高兴情感 HA 17 生气情感 AN 18 难过情感 SA 19 惊讶情感 SU 20 中性情感 NULL 21 程度副词 AD 22 否定词 NE 表 4 修改词性实例

بۇ ھەرگىز چۈش ئەمەس # بۇ ھىچكىم كۆز يۇمالمايدىغان# گۈزەل رېئاللىق.
(这绝对不是梦#是个谁都无法否认的美好的现实)原词性 YN A V N P P D N D P 改进的词性 YN HA NE N P P NE N D P -
通过人工的方式,对20 000条维吾尔文情感句子进行了标注,同时对其包含的韵律短语(prosodic phrase)进行统计,本文用Fpp表示短语特征,Fpp1表示由1个单词构成的短语,Fpp2表示由2个单词构成短语,以此类推。维吾尔文情感预料韵律短语统计如表 5所示。
表 5 维吾尔文情感预料韵律短语统计表
特征 数量 比例/% 举例 Fpp1 2 880 14.40 ۋاھ (哇) Fpp2 18 281 91.40 تازا قىزىۋاتىدۇ (太热闹了) Fpp3 19 162 95.81 سەپىرىڭىز ئوڭۇشلۇق بولسۇن (祝你一路平安) Fpp4 4 720 23.60 بىز ئىسراپچىلىققا قارشى تۇرۇپ
(我们反对浪费)Fpp5 443 2.21 ئۇھەقىقەتەن بىر تالانىت ئىگىسى
(他是个真正的天才) -
递归神经网络(recurrent neural network, RNN) [21-22]是能力很强的序列学习工具。情感分类中的应用作为一个接收器,读入一个序列,最后产生一个二分类或者多分类的结果。工作原理是读入序列化后的词语,将最终的状态给予一个多层神经网络(MLP)[23],MLP的输出层是一个二输出的softmax(归一化指数函数)层。网络使用交叉熵损失函数通过带有情感标签的数据训练得到。对于更加细粒度的分类任务,需要对情感极性给予一定的取值范围。Softmax函数在多分类任务中,将多个标量映射为一个概率分布,用在神经网络的最后一层,作为输出层,完成多分类。对维吾尔文5种情感分类,对情感极性给出1~5的值,将MLP的输出神经元数量设为5,RNN模型的算法结构为:
$$p({\text{label}} = k/{w_{1:n}}) = {\hat y_{[k]}}$$ (1) $$\hat y = {\text{softmax}}({\text{MLP}}({\text{RNN}}({x_{1:n}})))$$ (2) $${x_{1:n}} = {E_{[{w_1}]}},{E_{[{w_2}]}}, \cdots ,{E_{[{w_n}]}}$$ (3) 式中,w1:n为给出的一条句子;wi是句子中的一个单词;k为分类的数量;E为词向量矩阵。用Word2Vec工具对大量无标记维吾尔文本进行深度训练,生成了维度为300的词向量。
-
BiRNN是双向循环结构,其中的一个RNN模型从文本序列起点开始前向读取,另一个RNN模型从文本序列终点读取,最后将2个前向和后向RNN模型的最终隐藏状态拼接起来送入MLP分类中。
BiRNN的结构是将式(2)扩展为两个RNN,模型算法为:
$$p({\text{lable}} = k/{w_{1:n}}) = {\hat y_{[k]}}$$ (4) $$\hat y = {\text{softmax}}({\text{MLP}}([{\text{RN}}{{\text{N}}^f}({x_{1:n}});{\text{RN}}{{\text{N}}^b}({x_{n:1}})]))$$ (5) $${x_{1:n}} = {E_{[{w_1}]}},{E_{[{w_2}]}}, \cdots ,{E_{[{w_n}]}}$$ (6) 对更长的句子,文献[24]发现BiRNN在层次化的结构上效果更好,因此本文尝试层次化的结构,对维吾尔文也用了层次化的切分方法,先将长句子以标点符号拆分成短句子,再次将短句拆分成韵律短语,每个拆分后的单位赋予式(5)描述的BiRNN中,输出向量的序列(每个句子单位为一个向量)随后被送入式(2),作为RNN的输入。比如给定的一条句子${w_{1:n}}$,将这条句子分成m个单位$w_{1:{l_1}}^1,w_{1:{l_2}}^2, \cdots ,w_{1:{l_m}}^m$,其结构表示为:
$$p({\text{label}} = k/{w_{1:n}}) = {\hat y_{[k]}}$$ (7) $$\hat y = {\text{soft}}\max ({\text{MLP}}({\text{RNN}}({z_{1:m}})))$$ (8) $${z_i} = [{\text{RN}}{{\text{N}}^f}(x_{1:{l_i}}^i);{\text{RN}}{{\text{N}}^b}(x_{{l_i}:1}^i)]$$ (9) $$x_{1:{l_i}}^i = {E_{[w_1^i]}}, \cdots ,{E_{[w_{{l_i}}^i]}}$$ (10) 通过上式可以得到m个单位获取不同的情感标签,上一层的接收器读入低一层编码器输出的信息${z_{1:m}}$,并确定最后的情感分类结果。
-
在情感倾向分析中,情感词对整个句子情感倾向起着很重要的作用。因此,对于BiRNN引入注意力机制(attention)[25-26],提出了基于BiRNN的韵律短语中的情感词注意力模型,BiRNN特点是将整个词语序列的信息压缩为一个固定长度的语义编码,一个RNN以给出的顺序读入句子的序列,另一个RNN以逆序读入句子序列,而利用注意力机制每个时刻能够学到一个表示该时刻隐藏状态所占的权重${c_i}$,最终用于分类的隐藏状态$\tilde h$通过加权和的形式计算得出,$\tilde h = \sum\limits_{i = 1}^t {{h_i}{c_i}} $,权重${c_i}$通过单层的神经网络得到的,输入为该时刻原始的隐藏状态${h_i}$,即可:
$${c_i} = {\text{exp}}({\beta _i})/\sum\limits_{k = 1}^i {{\text{exp}}({\beta _k})} $$ (11) $${\beta _i} = {V_c}{\text{tanh}}({W_c}{h_i} + {b_c})$$ (12) 式中,${W_c}$、${V_c}$是网络权重矩阵参数;${b_c}$为偏差,使用softmax函数对权重进行归一化处理,使全部权重之和为1[27]。式(11)中,权重${c_i}$反映该时刻隐藏状态对最终情感分类的重要程度,通过有监督的学习方式,模型将较大的权重赋予情感词所在时刻的隐藏状态,将$\tilde h$作为softmax分类器的输入特征进行情感分类。
-
情感计算层的任务是构建输出模型最后分类结果的分类器,通过此分类器计算每个维吾尔文句子的情感标签的得分,并将其转化为条件概率分布:
$${P_i}(\boldsymbol{{\tilde h}}) = \frac{{{\text{exp}}({{\boldsymbol{{\tilde h}}}_i})}}{{\sum\limits_{k = 1}^C {{\text{exp}}({{\boldsymbol{{\tilde h}}}_k})} }}$$ (13) 式中,$\boldsymbol{{\tilde h}}$是注意力层输出的隐藏状态向量;C表示本模型实验使用的情感分类的数目,即C=5。
本文模型使用反向传播算法来训练和更新模型,通过最小化交叉熵来优化模型,交叉熵损失函数的计算公式为:
$${\text{loss}} = - \sum\limits_{i = 1}^T {\sum\limits_{j = 1}^C {{y_i}\log } } {\hat y^j}_i + \lambda ||\theta |{|^2}$$ (14) 式中,T是训练数据集;C为情感类别数;y为文本实际情感类别;$\hat y$为模型预测的情感类别;$\lambda $为正则项,是损失函数的惩罚项;$\theta $为设置的参数。
-
1) 构建维吾尔文句子级情感语料。本文选用天山网(http://uy.ts.cn)、(http://www.nur.cn/index.shtml)等维文网站上公开发布的文章和评论信息。对收集好的语料进行分句,将它分为5种情感文本,构建了维吾尔文情感语料(UySentiData)。根据维吾尔语的韵律特征定义,对情感句进行了标注。语料标注方法如表 3所示,所使用的语料规模如表 6所示。
表 6 维吾尔文5类情感语料统计表
×1 000 特征 中性 高兴 生气 惊讶 难过 训练集/条 15 12 12 8 8 验证集/条 1.5 0.1 1 1 1 测试集/条 1 1 1 1 1 总计/条 17.5 14 14 10 10 2) 构建维吾尔文情感词库
首先,以多语种重点实验室的二分类情感词典为基础,进行多元情感分类,该词典词汇有2万多条。其次,对天山网(http://uy.ts.cn)等维文网站上收集的情感文本语料中的情感词进行多元筛选和标注,添加了的情感词汇有1.5万多条。此外,在电影文字语料库与微博语料库的基础上,筛选构建的情感词典词汇有9千多条。最后,整理和对照情感词典中的词汇,构建了新的维吾尔文情感词典(UYSentiDict),最终获得的情感词典有4.12万多条词汇。
-
采用不同的情感分类方法与本文提出的基于注意力机制的BiRNN模型进行对比,验证本文方法的有效性。
1) 多项式朴素贝叶斯(multinomial naïve bayes, MNB)是一个典型的传统机器学习方法,在许多文本分类和情感分类任务中被广泛应用。
2) CNN模型采用单通道和多通道卷积神经网络对维吾尔文句子的词向量表示进行学习,通过卷积和最大池化操作捕获维吾尔文句子的特征实现文本的分类。
3) 支持向量机(support vector machine, SVM)模型是最常用的传统机器学习情感分类方法,通常采用n-gram作为特征进行分类,本次试验使用unigram、bigram和trigram作为SVM的特征进行分类。
4) 单向循环神经网络(recurrent neural network, S-RNN)使用单个循环神经网络对维吾尔文句子进行编码表示映射到可变长的目标序列。
5) 双向循环神经网络(bidirectional neural network, BiRNN)对不带注意力机制的使用向前和向后的RNN模型对维吾尔文句子进行情感分类。
6) 基于注意力机制的BiRNN(ATT-BiRNN)模型:本文提出引入注意力机制的BiRNN模型。
-
实验中用tanh非线性激活函数涉及的权重矩阵W 和偏差向量b,使用随机均匀分布进行初始化。模型参数设计如表 7所示。
表 7 模型参数设计
参数/函数 参数 值 RNN单元数 H 200 CNN滤波器大小 F 3, 4, 5 CNN滤波器数量 fn 100 词向量维度 d 300 词性向量 dpos 30 Dropout P 0.50 学习率 lr 0.01 优化器 Adadelta 批大小 batch_size 64 激活函数 — tanh -
为了评估系统的情感分类性能,使用式(15)~式(17)计算情感分类的准确率、召回率和F1值,并作为本实验的评估方法:
$${P_i} = \frac{{{\text{T}}{{\text{P}}_i}}}{{{\text{T}}{{\text{P}}_i} + {\text{F}}{{\text{P}}_i}}}$$ (15) $${R_i} = \frac{{{\text{T}}{{\text{P}}_i}}}{{{\text{T}}{{\text{P}}_i} + {\text{F}}{{\text{N}}_i}}}$$ (16) $$F{1_i} = \frac{{2{P_i}{R_i}}}{{{P_i} + {R_i}}}$$ (17) 式中,TP将正类预测为正类数(true positive);FN将正类预测为负类数(false negative);FP将负类预测为正类;TN将负类预测为负类数
-
为了验证本文方法的有效性,本实验做了5组实验,在UySentiData数据集上进行了情感分类,将准确率、召回率和F1作为实验的评测方法。
-
为了对比传统词典方法、机器学习计模型与深度学习模型在维吾尔文情感分类任务上的性能,本实验在实验室提供的UySentiData数据集上分别用词典方法、MNB、SVM、RNN、CNN、BiRNN进行维吾尔文情感分类任务,实验结果如8表所示。
表 8 与深度学习模型对比结果
模型 准确率/% 召回率/% F1 词典方法 55.34 60.56 57.83 MNB 61.24 59.87 60.55 SVM-unigram 77.40 76.10 76.74 SVM-bigram 79.68 78.82 79.24 SVM-trigram 76.24 75.67 79.95 RNN 71.50 70.44 70.96 CNN 83.48 82.64 83.05 BiRNN 85.18 83.56 84.36 本次实验中针对SVM模型,采用了LIBSVM工具(https://www.csie.ntu.edu.tw/~cjlin/libsvm),用unigram、bigram和trigram作为特征进行了维吾尔文情感分类任务,从表 8可以看出,SVM-bigram的准确率较高,BiRNN模型的准确率最高。
-
本组实验中为了验证词向量维度对维吾尔文情感分类任务的影响,使用gensim工具的skim-gram生成了纬度为100、200、300、400的词向量。在同等条件下将这些词向量作为BiRNN模型的输入进行情感分类任务,在测试集上考察了不同向量维度对BiRNN模型维吾尔文情感分类的准确率、召回率和F1的影响。
由表 9可看出,当向量维度设为300时,BiRNN模型取得了最高的准确率。这是因为词向量维度代表了词语的特征,当维度过低时模型的词区分能力较弱,特征越多能够更准确的将词与词区分。但在实际应用中维度太多训练出来的模型会越大,虽然维度越多能够更好区分,但词与词之间的关系也会被淡化[27]。因此,本文在后续实验中将向量维度固定为300。
表 9 向量维度对BiRNN模型情感分类的影响
向量维度 准确率/% 召回率/% F1 100 83.43 82.38 82.90 200 84.25 83.60 83.92 300 85.18 84.56 84.86 400 83.85 84.25 84.04 -
为了验证词性向量特征对维吾尔文情感分类的有效性,在词向量的基础上加词性特征进行训练,用不同神经网络框架做了对比实验。从表 10可以看出,添加词性特征后RNN、CNN和BiRNN的F1分别提高了1.23%,0.95%,1.99%。本组实验中,词向量维度为300,词性向量维度为30。
表 10 词性特征对情感分类的影响
模型 准确率/% 召回率/% F1 RNN (word2vec+Fpos) 72.87 71.54 72.19 CNN (word2vec+Fpos) 84.23 83.78 84.00 BiRNN(word2vec+Fpos) 86.74 85.98 86.35 -
本次实验中,分别将由2个和3个单词构成的韵律短语作为CNN、RNN和BiRNN模型的输入进行训练,实验结果如表 11所示。如果表明,由2个单词构成的韵律短语作为特征时,系统情感分类准确率最高。在实验中由3个单词组成的韵律短语作为短语单位,对于那些由1个或2个单词构成的短语进行了补0处理,保证输入向量具有统一的维度。
表 11 韵律短语特征对情感分类的影响
模型 准确率/% 召回率/% F1 RNN (word2vec+Fpp2) 74.34 73.68 74.00 RNN (word2vec+Fpp3) 76.38 75.29 75.83 CNN (word2vec+ Fpp2) 85.58 84.51 85.04 CNN (word2vec+ Fpp3) 85.36 84.89 85.12 BiRNN (word2vec+Fpp2) 87.24 86.76 86.99 BiRNN (word2vec+Fpp3) 86.56 85.87 86.21 -
为了提高维吾尔文情感分类的准确率,本文在RNN和BiRNN模型的基础上增加了注意力机制,并将词向量单独作为RNN与BiRNN的输入进行训练。
从表 12可以看出,引入注意力机制后RNN模型和BiRNN模型的情感分类准确率、F1均得到了提高。ATT-RNN模型的F1值比RNN模型提高了4.14%,ATT-BiRNN模型比BiRNN模型提高了2.94%。
表 12 注意力机制对情感分类的影响
模型 准确率/% 召回率/% F1 ATT-RNN (word2vec) 75.35 74.86 75.10 ATT-BiRNN (word2vec) 87.78 86.83 87.30 -
在最后的一个实验中,将韵律短语、词性特征拼接后的混合向量作为基于注意力机制的BiRNN模型的输入进行训练。本次试验分别将由2个或3个单词构成韵律短语和对应的词性作为特征进行实验。实验结果表明,本文提出的模型在混合特征下达到了情感分类最好的准确率。
从表 13可以看出,本文提出的ATT-BiRNN模型使用Fpp2+ Fpos2拼接向量为特征进行训练的分类准确率比使用Fpp3+Fpos3的高,其F1提高了0.71%。
表 13 混合特征对情感分类的影响
模型 准确率/% 召回率/% F1 ATT-RNN (word2vec+ Fpp2+ Fpos2) 76.89 76.24 76.56 ATT-RNN (word2vec+ Fpp3+ Fpos3) 75.68 74.65 75.16 ATT-BiRNN (word2vec+ Fpp2+ Fpos2) 89.69 87.47 88.56 ATT-BiRNN (word2vec+ Fpp3+ Fpos3) 88.34 87.38 87.85 -
本文针对维吾尔语语音合成输入文本进行了情感分类任务,提出了基于注意力机制的BiRNN情感分类模型。该模型使用韵律短语特征向量及词性向量拼接的向量作为输入进行训练。通过计算注意力概率分布,突出由情感词或情感短语构成的韵律短语对于情感分类的影响作用,从而提高了情感分类的准确率。在实验室提供的5分类情感语料库上进行了对比试验,实验结果表明,本文提出的方法情感分类F1值比SVM-bigram方法提升了9.32%。下一步将针对维吾尔文中的一些复杂语法结构进行研究,扩充语料库的规模,从而进一步提高维吾尔情感分类的准确性。
Uyghur Sentiment Rhythm Phrase Attention Model Based on BiRNN
-
摘要: 当前维吾尔语情感语音合成采用韵律边界预测方法来实现情感语音转换。通过该方法合成出来的语音,虽然可表现出相应的情感,然而其情感表现力不够理想。针对此问题,该文提出一种基于BiRNN的维吾尔语情感韵律短语注意力模型。在情感韵律转换前使用该模型进行情感分类,并将其分类结果作为韵律边界预测的输入,改进了情感韵律转换方法。使用改进的词性特征向量和韵律短语向量作为词向量的补充,从而有效提升维吾尔文文本情感分类的准确率。实验结果表明,该模型由两个单词构成的韵律短语作为特征时,准确率在维吾尔五分类情感数据集上达到了很好的分类效果。Abstract: At present, Uyghur sentimental speech synthesis uses prosodic boundary prediction method to realize emotional speech conversion. The speech synthesized by this method can express the corresponding emotions, but its emotional expression is not ideal. To solve this problem, this paper proposes an attention model of Uygur emotional prosodic phrases based on BiRNN. The model is used to classify emotion before prosodic conversion, and the classification results are used as input for prosodic boundary prediction to improve the method of prosodic conversion. The improved part-of-speech feature vector and prosodic phrase vectors are used to supplement the word vector, which effectively improve the accuracy of Uyghur text sentiment classification. The experimental results show that when the prosodic phrase composed of two words is used as a feature, the accuracy of the model achieves the best classification effect on the Uyghur five-category sentiment data set.
-
Key words:
- neural network /
- part of speech tagging /
- prosodic phrase /
- sentiment analysis /
- speech synthesis /
- Uyghur
-
表 1 一个中心词维吾尔语短语内部结构
特征 实例 形+名 گۈزەل ۋەتەن (美丽的祖国) 名+动,名+形 ئايگۈل ئامراق (阿依古丽喜欢) 动+名,动+形 تازلاشقا خۇشتار (看起来好看) 形+动 پاكىز رەتلە (整理干净) 名+“的”+名 ۋەتەننىڭ كەلگۈسى (祖国的未来) 程度词+形/副 ئازراق ياخشى (好一点) 形/副+程度词 قىزىلراقلىرى تەملىك (红一点的好吃) 否定词+动/名/形 سەتنى تاللىما (别选难看的)  下载: 导出CSV
下载: 导出CSV
表 2 多个中心词维吾尔语短语内部结构
特征 实例 并列或转折连词 ۋە،بىلەن،لىكىن،ئەمما،ناۋادا،بىراق ،ئەگەر
(如果,但是,万一,可是,不过,和,与)形+形, 名+名, 动+动 قۇرۇپ چىقايلى (建设起来)
下载: 导出CSV
表 3 维吾尔语韵律短语词性、情感词标注标准
序号 名称 符号 1 名词 N 2 动词 V 3 形容词 A 4 副词 D 5 代词 P 6 数词 M 7 连词 C 8 模拟词 I 9 感叹词 E 10 语气词 T 11 标点符号 Y 12 附加成分 X 13 后置词 R 14 拉丁文 L 15 量词 Q 16 高兴情感 HA 17 生气情感 AN 18 难过情感 SA 19 惊讶情感 SU 20 中性情感 NULL 21 程度副词 AD 22 否定词 NE
下载: 导出CSV
表 4 修改词性实例
بۇ ھەرگىز چۈش ئەمەس # بۇ ھىچكىم كۆز يۇمالمايدىغان# گۈزەل رېئاللىق.
(这绝对不是梦#是个谁都无法否认的美好的现实)原词性 YN A V N P P D N D P 改进的词性 YN HA NE N P P NE N D P
下载: 导出CSV
表 5 维吾尔文情感预料韵律短语统计表
特征 数量 比例/% 举例 Fpp1 2 880 14.40 ۋاھ (哇) Fpp2 18 281 91.40 تازا قىزىۋاتىدۇ (太热闹了) Fpp3 19 162 95.81 سەپىرىڭىز ئوڭۇشلۇق بولسۇن (祝你一路平安) Fpp4 4 720 23.60 بىز ئىسراپچىلىققا قارشى تۇرۇپ
(我们反对浪费)Fpp5 443 2.21 ئۇھەقىقەتەن بىر تالانىت ئىگىسى
(他是个真正的天才)
下载: 导出CSV
表 6 维吾尔文5类情感语料统计表
×1 000 特征 中性 高兴 生气 惊讶 难过 训练集/条 15 12 12 8 8 验证集/条 1.5 0.1 1 1 1 测试集/条 1 1 1 1 1 总计/条 17.5 14 14 10 10
下载: 导出CSV
表 7 模型参数设计
参数/函数 参数 值 RNN单元数 H 200 CNN滤波器大小 F 3, 4, 5 CNN滤波器数量 fn 100 词向量维度 d 300 词性向量 dpos 30 Dropout P 0.50 学习率 lr 0.01 优化器 Adadelta 批大小 batch_size 64 激活函数 — tanh
下载: 导出CSV
表 8 与深度学习模型对比结果
模型 准确率/% 召回率/% F1 词典方法 55.34 60.56 57.83 MNB 61.24 59.87 60.55 SVM-unigram 77.40 76.10 76.74 SVM-bigram 79.68 78.82 79.24 SVM-trigram 76.24 75.67 79.95 RNN 71.50 70.44 70.96 CNN 83.48 82.64 83.05 BiRNN 85.18 83.56 84.36
下载: 导出CSV
表 9 向量维度对BiRNN模型情感分类的影响
向量维度 准确率/% 召回率/% F1 100 83.43 82.38 82.90 200 84.25 83.60 83.92 300 85.18 84.56 84.86 400 83.85 84.25 84.04
下载: 导出CSV
表 10 词性特征对情感分类的影响
模型 准确率/% 召回率/% F1 RNN (word2vec+Fpos) 72.87 71.54 72.19 CNN (word2vec+Fpos) 84.23 83.78 84.00 BiRNN(word2vec+Fpos) 86.74 85.98 86.35
下载: 导出CSV
表 11 韵律短语特征对情感分类的影响
模型 准确率/% 召回率/% F1 RNN (word2vec+Fpp2) 74.34 73.68 74.00 RNN (word2vec+Fpp3) 76.38 75.29 75.83 CNN (word2vec+ Fpp2) 85.58 84.51 85.04 CNN (word2vec+ Fpp3) 85.36 84.89 85.12 BiRNN (word2vec+Fpp2) 87.24 86.76 86.99 BiRNN (word2vec+Fpp3) 86.56 85.87 86.21
下载: 导出CSV
表 12 注意力机制对情感分类的影响
模型 准确率/% 召回率/% F1 ATT-RNN (word2vec) 75.35 74.86 75.10 ATT-BiRNN (word2vec) 87.78 86.83 87.30
下载: 导出CSV
表 13 混合特征对情感分类的影响
模型 准确率/% 召回率/% F1 ATT-RNN (word2vec+ Fpp2+ Fpos2) 76.89 76.24 76.56 ATT-RNN (word2vec+ Fpp3+ Fpos3) 75.68 74.65 75.16 ATT-BiRNN (word2vec+ Fpp2+ Fpos2) 89.69 87.47 88.56 ATT-BiRNN (word2vec+ Fpp3+ Fpos3) 88.34 87.38 87.85
下载: 导出CSV
-
[1] 帕丽旦·木合塔尔, 吾守尔·斯拉木.基于HMM的维吾尔语可训练语音合成文本分析关键技术研究[D].乌鲁木齐: 新疆大学, 2012. http://cdmd.cnki.com.cn/Article/CDMD-10755-1012433625.htm PALIDAN Muhetaer, WUSHOUER Silamu. Research the text analysis key technologies of Uyghur trainable synthetic system based on HMM[D]. Urumqi: Xinjiang University, 2012. http://cdmd.cnki.com.cn/Article/CDMD-10755-1012433625.htm [2] HU M, LIU B. Mining and summarizing customer reviews[C]//Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Seattle: ACM, 2004: 168-177. [3] KIM S M, HOVY E. Determining the sentiment of opinions[C]//International Conference on Computational Linguistics.[S.l.]: Association for Computational Linguistics, 2004: 1367. [4] KAMPS J. Using wordnet to measure semantic orientation of adjectives[C]//International Conference on Language Resources and Evaluation. Centro Cultural De Belem, Lisbon, Portugal: [s.n.], 2004: 1115-1118. [5] 朱嫣岚, 闵锦, 周雅倩, 等.基于HowNet的词汇语义倾向计算[J].中文信息学报, 2006, 20(1):14-20. doi: 10.3969/j.issn.1003-0077.2006.01.003 ZHU Yan-lan, MIN Jin, ZHOU Ya-qian, et al. Semantic orientation computing based on hownet[J]. Journal of Chinese Information Processing, 2006, 20(1):14-20. doi: 10.3969/j.issn.1003-0077.2006.01.003 [6] KENNEDY A, INKPEN D. Sentiment classification of movie reviews using contextual valence shifters[J]. Computational Intelligence, 2006, 22(2):110-125. doi: 10.1111/coin.2006.22.issue-2 [7] KEVIN C, VIDYASAGAR P, THARAMS D. General inquirer categories[EB/OL].[2017-05-15]. http://www.wjh.harvard.edu/~inquirer/homecat.htm. [8] OHANA B, TIERNEY B. Sentiment classification of reviews using sentiment word net[C]//IT & T Conference.[S.l.]: Springer, 2009: 10.21427/D77S56. [9] TURNEY P D. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews[C]//Meeting on Association for Computational Linguistics.[S.l.]: Association for Computational Linguistics, 2002: 417. [10] READ J, CARROLL J. Weakly supervised techniques for domain-independent sentiment classification[C]//International CIKM Workshop on Topic-Sentiment Analysis for MASS Opinion.[S.l.]: ACM, 2009: 45-52. [11] PANG B, LEE L, VAITHYANATHAN S. Thumbs up? Sentiment classification using machine learning techniques[C]//In ACL-02 Conference on Empirical Methods in Natural Language Processing.[S.l.]: Association for Computational Linguistics, 2002: 79-86. [12] SOCHER R, PENNINGTON J, HUANG E H, et al. Semi-supervised recursive autoencoders for predicting sentiment distributions[C]//Conference on Empirical Methods in Natural Language Processing. Edinburgh, UK: [s.n.], 2011: 151-161. [13] 朱少杰.基于深度学习的文本情感分类研究[D].哈尔滨: 哈尔滨工业大学, 2014. ZHU Shao-jie. Research on text sentiment classification based on deep learning[D]. Harbin: Harbin University of Technology, 2014. [14] KIM Y. Convolutional neural networks for sentence classification[EB/OL].[2017-09-20]. https: //arxiv.org/abs/1408.5882. [15] NARENDRA B, SAI K U, RAJESH G, et al. Sentiment analysis on movie reviews:a comparative study of machine learning algorithms and open source technologies[J]. International Journal of Intelligent Systems Technologies and Applications, 2016, 8(8):66-70. doi: 10.5815/ijisa [16] SEVERYN A, MOSCHITTI A. Twitter sentiment analysis with deep convolutional neural networks[C]//International ACM SIGIR Conference.[S.l.]: ACM, 2015: 10.1145/2766462.2767830. [17] SANTOS C N D, GATTIT M. Deep convolutional neural networks for sentiment analysis of short texts[C]//International Conference on Computational Linguistics. Dublin, Ireland: [s.n.], 2014: 69-78. [18] SOCHER R, HUVAL B, MANNING D, et al. Semantic compositionality through recursive matrix-vector spaces[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Jeju Island, Korea: [s.n.], 2012: 1201-1211. [19] 王树恒, 吐尔根·依布拉音, 卡哈尔江·阿比的热西提, 等.基于BLSTM的维吾尔语文本情感分析[J].计算机工程与设计, 2017(10):2879-2886. http://d.old.wanfangdata.com.cn/Periodical/jsjgcysj201710051 WANG Shu-heng, TURGUN Ibrahim, Kahaerjiang Abiderexiti, et al. Sentiment classification of Uyghur text based on BLSTM[J]. Computer Engineering and Design, 2017(10):2879-2886. http://d.old.wanfangdata.com.cn/Periodical/jsjgcysj201710051 [20] 王荣波, 谌志群, 周建政, 等.基于Wikipedia的短文本语义相关度计算方法[J].计算机应用与软件, 2015, 32:82-86. http://d.old.wanfangdata.com.cn/Periodical/jsjyyyrj201501021 WANG Rong-bo, CHEN Zhi-qun, ZHOU Jian-zheng, et al. Short texts semantic relevance computation method based on wikipedia[J]. Computer Applications and Software, 2015, 32:82-86. http://d.old.wanfangdata.com.cn/Periodical/jsjyyyrj201501021 [21] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9:1735-1780. doi: 10.1162/neco.1997.9.8.1735 [22] ALEX G, GREG W, DANIHELKA I, et al. Neural turing machines[EB/OL].[2017-10-17]. https://arxiv.org/abs/1410.5401v2. [23] OUARDA W, TRICHILI H, ALIMI A M, et al. MLP neural network for face recognition based on gabor features and dimensionality reduction techniques[C]//Multimedia computing and systems(ICMCS). Marrakech, Morocco: [s.n.], 2014: 10.1109/ICMCS.2014.6911265. [24] LI Dong, WEI Fu-ru, MING Zhou, et al. Question answering over freebase with multicolumn convolutional neural networks[C]//Proc of the 53rd Annual Meeting of the Association for computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing: [s.n.], 2015: 10.3115/v1/p15-1026. [25] 何炎祥, 孙松涛, 牛菲菲, 等.用于微博情感分析的一种情感语义增强的深度学习模型[J].计算机学报, 2017, 40(4):773-790. http://d.old.wanfangdata.com.cn/Periodical/jsjxb201704001 HE Yan-xiang, SUN Song-tao, NIU Fei-fei, et al. A deep learning model enhanced with emotion semantic microblog sentiment analysis[J]. Chinese Journal of Computers, 2017, 40(4):773-790. http://d.old.wanfangdata.com.cn/Periodical/jsjxb201704001 [26] 李松如, 陈锻生.采用循环神经网络的情感分析注意力模型[J].华侨大学学报(自然科学版), 2018(2):252-255. http://d.old.wanfangdata.com.cn/Periodical/hqdxxb201802016 LI Song-ru, CHENG Duan-sheng, Recurrent neural network using attention model for sentiment analysis[J]. Journal of Huaqiao University(Natural Science), 2018(2):252-255. http://d.old.wanfangdata.com.cn/Periodical/hqdxxb201802016 [27] 艾力·海如拉, 吾守尔·斯拉木.基于神经网络的维吾尔文词向量表示方法及其应用研究[D].乌鲁木齐: 新疆大学, 2018. AILI Hairula, WUSHOUER Silamu. Research on neural networks based Uyghur word vectors representation and its application[D]. Urumqi: Xinjiang University, 2018. -

 点击查看大图
点击查看大图
计量
- 文章访问数: 4348
- HTML全文浏览量: 1408
- PDF下载量: 84
- 被引次数: 0
