 ISSN
ISSN 



-
高光谱遥感是高光谱分辨率遥感的简称,是指在电磁波谱的可见光、近红外、中红外以及远红外等范围内,从感兴趣的物体中获取许多非常窄的光谱连续影像数据的技术。高光谱遥感的出现是遥感界的一场革命,它使得本来在多光谱的宽波段中不可探测的物质,在高光谱遥感中可以被探测到[1],因此,与其他技术相比,高光谱遥感技术在地表物质的识别、分类以及感兴趣目标信息的提取等方面具有更大的优势[2-3]。
鉴于高光谱数据具有图谱合一的特点,其数据处理技术已发展为国际遥感技术研究领域的热门课题[4],而地物目标分类和识别技术一直是高光谱数据处理的研究重点之一。高光谱图像分类是建立在遥感图像分类的基础上,结合高光谱图像自身特点,对图像中的像元进行区分和确认的过程。高光谱图像包含丰富的空间信息、辐射信息和光谱信息,将促进分类算法模型在图像分类中的发展与应用[5]。
近年来,基于协同表示(CR)的分类方法凭借其较快的计算速度和较低的算法复杂度已经从人脸识别领域引入到了高光谱图像的分类领域中[6-7]。协同表示分类方法的基本原理是基于系数的L2-范数最小化约束,以训练样本为字典求取编码系数,然后计算由隶属于各个地物类别的字典与其所对应的编码系数重建所得的测试样本与实际测试样本的残差,从而将测试样本归为残差最小的地物类别中去。目前的高光谱协同分类算法直接选用各类训练样本构建字典进行协同表示,字典内各基元间的相关性影响协同表示效率,进而降低协同表示分类精度。因此,本文提出基于主成分分析(PCA)与协同表示的高光谱图像分类算法,利用PCA对各类训练样本进行去相关处理以构建字典,从而减小字典内各基元之间的相关性,达到提高协同表示分类性能的目的。
-
假设有m类训练样本,记${\mathit{\boldsymbol{X}}^{(i)}}(i = 1, 2, \cdots, m)$为第i类训练样本,则所有训练样本构成的矩阵可表示为$\mathit{\boldsymbol{X}} = \left[{{\mathit{\boldsymbol{X}}^{(1)}}, {\mathit{\boldsymbol{X}}^{(2)}}, \cdots, {\mathit{\boldsymbol{X}}^{(m)}}} \right]$。传统协同表示分类算法直接选用这些训练样本构建字典,利用字典内所有基元共同表示待分类像元y,其协同表示系数α可直接使用正则化最小二乘(regularized least square,RLS)算法进行求解:
$$ \mathit{\boldsymbol{\hat \alpha }}{\rm{ = arg}}\;\mathop {{\rm{min}}}\limits_\mathit{\boldsymbol{\alpha }} \left\| {\mathit{\boldsymbol{y}} - \mathit{\boldsymbol{X\alpha }}} \right\|_2^2 + \lambda \left\| \mathit{\boldsymbol{\alpha }} \right\|_2^2 $$ (1) 式中,λ为正则化参数,用于保证最小二乘解的稳定性和最优解${\mathit{\boldsymbol{\hat \alpha }}}$具有一定的稀疏性[8]。根据式(1)可知,协同表示系数具有解析解:
$$ \mathit{\boldsymbol{\hat \alpha }} = {({\mathit{\boldsymbol{X}}^{\rm{T}}}\mathit{\boldsymbol{X}} + \lambda \mathit{\boldsymbol{I}})^{ - 1}}{\mathit{\boldsymbol{X}}^{\rm{T}}}\mathit{\boldsymbol{y}} $$ (2) 通常认为相邻的高光谱像元是由相似的地物构成,其光谱曲线具有很强的关联相似性。利用高光谱像元间的这种空间信息,可以有效提高分类的准确性[9-10]。因此本文使用联合的协同表示(simultaneous collaborative representation, SCR)分类方法求解系数矩阵。假设待分类像元y的空间邻域像元表示为$\mathit{\boldsymbol{Y}} = [\mathit{\boldsymbol{y}}, {\mathit{\boldsymbol{y}}_1}, {\mathit{\boldsymbol{y}}_2}, \cdots, {\mathit{\boldsymbol{y}}_T}]$,其中${\{ {\mathit{\boldsymbol{y}}_t}\} _{t = 1, 2, \cdots, T}}$为像元y的邻域像元,使用训练样本字典对这些空间邻域像元进行同时协同表示:
$$ \begin{array}{*{20}{c}} {\mathit{\boldsymbol{Y}} = \left[ {\begin{array}{*{20}{c}} \mathit{\boldsymbol{y}}&{{\mathit{\boldsymbol{y}}_1}}& \cdots &{{\mathit{\boldsymbol{y}}_T}} \end{array}} \right] = }\\ {\left[ {\begin{array}{*{20}{c}} {\mathit{\boldsymbol{X\alpha }}}&{\mathit{\boldsymbol{X}}{\mathit{\boldsymbol{\alpha }}_1}}& \cdots &{\mathit{\boldsymbol{X}}{\mathit{\boldsymbol{\alpha }}_T}} \end{array}} \right] = }\\ {\mathit{\boldsymbol{X}}\underbrace {\left[ {\begin{array}{*{20}{c}} \mathit{\boldsymbol{\alpha }}&{{\mathit{\boldsymbol{\alpha }}_1}}& \cdots &{{\mathit{\boldsymbol{\alpha }}_T}} \end{array}} \right]}_\mathit{\boldsymbol{A}} = \mathit{\boldsymbol{XA}}} \end{array} $$ (3) 使用正则化最小二乘算法的协同表示联合模型,可知:
$$ \mathit{\boldsymbol{\hat { A}}} = {\rm{arg}}\;\mathop {{\rm{min}}}\limits_\mathit{\boldsymbol{{ A}}} \left\| {\mathit{\boldsymbol{Y}} - \mathit{\boldsymbol{X{ A}}}} \right\|_2^2 + \lambda \left\| \mathit{\boldsymbol{{ A}}} \right\|_2^2 $$ (4) 式中,A为邻域协同表示系数矩阵。根据式(4)可知,空间邻域协同表示系数的解析解为:
$$ \mathit{\boldsymbol{\hat A}}{\rm{ = }}{({\mathit{\boldsymbol{X}}^{\rm{T}}}\mathit{\boldsymbol{X}} + \lambda \mathit{\boldsymbol{I}})^{ - 1}}{\mathit{\boldsymbol{X}}^{\rm{T}}}\mathit{\boldsymbol{Y}} $$ (5) 进行协同表示分类时,为了确定像元y的类别归属,在其空间邻域对每一类字典计算归一化残差:
$$ {\mathit{\boldsymbol{r}}^{(i)}}(\mathit{\boldsymbol{Y}}) = \frac{{||\mathit{\boldsymbol{Y}} - {\mathit{\boldsymbol{X}}^{(i)}}{{\mathit{\boldsymbol{\hat A}}}^{(i)}}|{|_2}}}{{||{{\mathit{\boldsymbol{\hat A}}}^{(i)}}|{|_2}}}\;\;\;\;\;\;i = 1, 2, \cdots , m $$ (6) 式中,${{\mathit{\boldsymbol{\hat A}}}^{(i)}}$表示第i类字典的协同表示系数。根据式(6)的分类残差,可将该像元分类到邻域像元具有联合最小残差的类别:
$$ {\rm{class}}(\mathit{\boldsymbol{y}}) = \arg \mathop {\min }\limits_{i = 1, 2, \cdots , m} {\mathit{\boldsymbol{r}}^{(i)}}(\mathit{\boldsymbol{Y}}) $$ (7) -
使用统计分析方法研究多变量问题时,变量之间的相关性表示其反映的信息有一定的重叠。如在基于协同表示的高光谱图像分类问题中,各类训练样本间的相关性表示训练样本间具有一定的信息重叠,而该种信息重叠通常会降低协同表示的效率。主成分分析可将原来众多具有一定相关性的多个指标,重新组合成一组新的互相无关的综合指标,是一种最小均方意义上的最优变换,目的是去除输入随机向量之间的相关性,突出原始数据中的隐含特性[11-12]。
PCA的目标就是使用另一组基去重新描述得到的数据空间,而新的基在相互独立的同时能尽量反映原有数据的关系。本文利用PCA分别对每一类训练样本${\mathit{\boldsymbol{X}}^{(i)}}(i = 1, 2, \cdots, m)$进行去相关处理,构建新的协同表示字典${\mathit{\boldsymbol{D}}^{(i)}}(i = 1, 2, \cdots, m)$。具体计算如下:
首先,计算原始第i类训练样本${\mathit{\boldsymbol{X}}^{(i)}} = [\mathit{\boldsymbol{x}}_1^{(i)}, \mathit{\boldsymbol{x}}_2^{(i)}, \cdots, \mathit{\boldsymbol{x}}_{{n_i}}^{(i)}]$的协方差矩阵${\bf{C}^{\left(i \right)}}$:
$$ \begin{array}{c} {\mathit{\boldsymbol{C}}^{(i)}} = \frac{1}{{{n_i}}}\sum\limits_{j = 1}^{{n_i}} {(\mathit{\boldsymbol{x}}_j^{(i)} - {{\mathit{\boldsymbol{\bar x}}}^{(i)}}){{(\mathit{\boldsymbol{x}}_j^{(i)} - {{\mathit{\boldsymbol{\bar x}}}^{(i)}})}^{\rm{T}}}} \\ i = 1, 2, \cdots , m \end{array} $$ (8) 式中,ni表示第i类的训练样本数目;x(i)为其样本集的平均向量,即:
$$ {{\mathit{\boldsymbol{\bar x}}}^{(i)}} = \frac{1}{{{n_i}}}\sum\limits_{j = 1}^{{n_i}} {\mathit{\boldsymbol{x}}_j^{(i)}} \;\;\;\;\;\;i = 1, 2, \cdots , m $$ (9) 对第i类训练样本的协方差矩阵C(i)进行主成分分析,表示为:
$$ [{\mathit{\boldsymbol{V}}^{(i)}}\;{\mathit{\boldsymbol{U}}^{(i)}}] = {\rm{PCA}}({\mathit{\boldsymbol{C}}^{(i)}}) $$ (10) 式中,PCA(·)表示PCA处理函数;V(i)和U(i)分别表示第i类训练样本矩阵的特征值和特征向量矩阵。记${\mathit{\boldsymbol{U}}^{(i)}} = (\mathit{\boldsymbol{u}}_1^{(i)}, \mathit{\boldsymbol{u}}_2^{(i)}, \cdots, \mathit{\boldsymbol{u}}_{{n_i}}^{(i)})$,第i类的训练样本可表示为:
$$ \begin{array}{c} \mathit{\boldsymbol{x}}_j^{(i)} = \mathit{\boldsymbol{\bar x}} + {\beta _1}\mathit{\boldsymbol{u}}_1^{(i)} + {\beta _2}\mathit{\boldsymbol{u}}_2^{(i)} + \cdots + {\beta _d}\mathit{\boldsymbol{u}}_{{n_i}}^{(i)}\\ j = 1, 2, \cdots , {n_i} \end{array} $$ (11) 因此,训练样本的特征向量矩阵可以看作是训练样本的一个线性变换。由于特征向量之间具有相互独立关系,本文选取每一类训练样本矩阵的特征向量构建字典,即第i类的字典构建为:
$$ {\mathit{\boldsymbol{D}}^{(i)}} = {\mathit{\boldsymbol{U}}^{(i)}} $$ (12) -
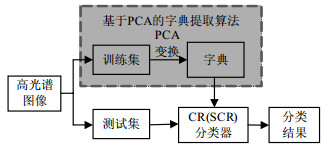
本文提出的基于PCA与协同表示的高光谱图像分类算法如图 1所示,首先根据高光谱图像中的训练集,依据本文提出的基于PCA的字典提取算法构建字典,然后依据该字典,使用协同表示分类器实现高光谱图像分类。具体算法步骤如下:

图 1 基于PCA与协同表示的高光谱图像分类算法图
输入:训练样本字典${\mathit{\boldsymbol{X}}^{(i)}}(i = 1, 2, \cdots, m)$,高光谱图像矩阵$\mathit{\boldsymbol{Y}} = [{\mathit{\boldsymbol{y}}_1}, {\mathit{\boldsymbol{y}}_2}, \cdots, {\mathit{\boldsymbol{y}}_o}]$,o为像元数目。
输出:像元y的类别class(y)。
字典变换:
对于每一类训练样本${\mathit{\boldsymbol{X}}^{(i)}}(i = 1, 2, \cdots, m)$,根据式(12)构建其对应的字典${\mathit{\boldsymbol{D}}^{(i)}}(i = 1, 2, \cdots, m)$。
分类:
For k=1, 2, ...o
1) 构建像元的空间邻域矩阵${\mathit{\boldsymbol{Y}}^{(k)}} = \left[{{\mathit{\boldsymbol{y}}_k}, \mathit{\boldsymbol{y}}_1^{(k)}, \mathit{\boldsymbol{y}}_2^{(k)}, \cdots, \mathit{\boldsymbol{y}}_T^{(k)}} \right]$;
2) 利用字典$\mathit{\boldsymbol{D}} = [{\mathit{\boldsymbol{D}}^{(1)}}, {\mathit{\boldsymbol{D}}^{(2)}}, \cdots, {\mathit{\boldsymbol{D}}^{(m)}}]$对空间邻域像元Y(k)进行同时协同表示,根据式(5)获取协同表示稀疏A(k);
3) 根据式(6)计算每一类对应的表示残差;
4) 根据式(7)对像元yk进行分类。
假设高光谱图像具有b个波段,第i类的样本字典包括ni个训练样本,则协同表示的算法复杂度为O(b2ni),本文提出的基于PCA的字典去相关算法使用训练样本的主成分构建字典,有效地减小了字典规模ni,其算法复杂度远低于直接使用训练样本作为字典的协同表示分类算法。经实验验证,本文提出的基于PCA与协同表示相结合的算法可将原始的协同表示算法运行时间降低30%左右。
-
本文使用了两组网上公开的高光谱数据集来验证本文提出的基于PCA与协同表示的高光谱图像分类性能。为了方便书写,实验中把基于主成分分析与协同表示分类算法表示为CR+PCA算法,同样地,把基于主成分分析与联合协同表示分类算法简写为SCR+PCA。
-
Salina数据集是由AVIRIS传感器采集于美国加利福尼亚洲萨利纳斯山谷。该图像大小为512×217像素,空间分辨率为3.7 m,总共包含224个波段数,去掉受水吸收等影响的波段[108-112],[154-167],204,选取剩下的204个波段作为研究对象,该实验选取的样本类别、训练和测试样本数目如表 1所示。实验中,所有算法的正则化参数3×3,SCR算法分别选取3×3,5×5和7×7模板构建像元的空间邻域。
表 1 Salina数据集的选取8类地物
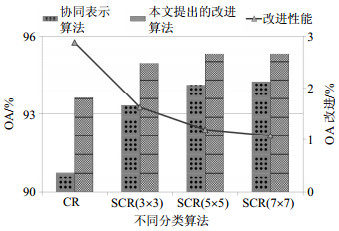
类别 类别名称 训练样本 测试样本 1 Brocoli_green_weeds_2 60 3 726 2 Fallow_smooth 60 2 678 3 Stubble 60 3 959 4 Celery 60 3 579 5 Grapes_untrained 60 11 271 6 Soil_vinyard_develop 60 6 203 7 Corn_senesced_green_weeds 60 3 278 8 Vinyard_untrained 60 7 268 表 2列出不同参数情况下基于协同表示的分类算法和本文提出的改进算法的比较结果。图 2进一步给出本文提出的基于PCA的改进算法对协同表示算法的改进结果。结合表 2和图 2的结果可以看出,本文提出的CR+PCA方法将传统CR方法的总体分类精度提高约1.85%;对于SCR算法,当邻域窗口选为3×3、5×5和7×7时,本文提出的SCR+PCA算法比传统SCR算法的总分类精度分别高出1.9%、1.92%、2.21%,且SCR+PCA方法在邻域窗口为7×7时,该数据集的第6类地物的正确率为1,即没有出现错分。实验结果表明,本文提出的CR+PCA方法和SCR+PCA方法采用PCA提取字典能够有效提高传统协同表示分类算法的精度。

图 2 Salina数据集算法比较结果
表 2 Salina数据集分类结果
类别 CR SCR 3×3邻域 5×5邻域 7×7邻域 CR+PCA CR SCR+PCA SCR SCR+PCA SCR SCR+PCA SCR 1 99.68 98.85 99.82 99.15 99.92 99.44 99.97 99.59 2 99.73 99.52 99.91 99.97 99.93 99.93 99.95 99.85 3 99.04 99.47 99.50 99.72 99.58 99.74 99.69 99.83 4 99.72 97.48 99.84 98.16 99.89 98.56 99.91 98.92 5 69.81 60.26 73.17 63.64 75.41 66.01 77.36 67.44 6 99.72 98.25 99.90 98.41 99.99 98.61 100 98.91 7 50.27 75.82 52.72 79.15 54.56 80.87 56.52 82.03 8 63.83 59.14 67.47 61.64 70.13 63.77 72.42 65.07 OA 81.55 79.70 83.37 81.47 84.61 82.69 85.70 83.49 -
Pavia Centre数据集是由德国的机载成像光谱仪ROSIS传感器在意大利北部的帕维亚中心飞行的时候拍摄。该图像大小为1 096×715像素,空间分辨率为1.3 m,总共包含115个波段数,移除13个水吸收波段和噪声干扰的波段后,剩下102个波段参与实验。Pavia Centre实验数据集共包含9类地物,各地物类别数目和名称如表 3所示。
表 3 Pavia Centre数据集的9类地物
类别 类别名称 训练样本 测试样本 1 Water 60 65 971 2 Trees 60 7 598 3 Meadows 60 3 090 4 Self_Blocking Bricks 60 2 685 5 Bare soil 60 6 584 6 Asphalt 60 9 248 7 Bitumen 60 7 287 8 Tiles 60 42 826 9 Shadows 60 2 863 该实验的参数选择与实验1完全一致。表 4和图 3给出几种算法在该数据集上的比较实验结果。结合表 4和图 3可以看出,基于本文提出的基于PCA的字典提取算法,CR算法的总体分类精度提高约2.88%;对于SCR算法,当邻域窗口选为3×3、5×5和7×7时,本文提出的SCR+PCA方法比传统SCR方法的总分类精度分别高出1.63%、1.2%和1.08%。该实验结果也表明Pavia Centre数据集使用PCA算法从训练样本集中提取字典,可有效提高传统协同表示算法的分类性能。

图 3 Pavia Centre数据集算法比较结果
表 4 Pavia Centre数据集分类结果
类别 CR SCR 3×3邻域 5×5邻域 7×7邻域 CR+PCA CR SCR+PCA SCR SCR+PCA SCR SCR+PCA SCR 1 99.77 98.58 99.79 98.90 99.80 98.96 99.82 99.00 2 76.37 76.40 78.48 78.63 79.44 79.32 80.21 79.64 3 77.96 59.03 79.37 62.57 80.16 64.96 79.76 65.98 4 77.23 82.54 89.14 97.16 95.04 99.58 95.33 99.77 5 80.19 74.02 83.27 78.72 84.53 81.75 85.44 82.95 6 98.38 77.53 99.33 85.11 99.64 85.65 99.78 83.45 7 79.71 79.85 81.97 82.61 82.08 82.96 81.68 82.80 8 92.35 91.91 94.67 95.55 95.01 97.01 94.82 97.75 9 99.75 81.38 99.97 87.79 99.96 89.26 99.86 86.36 OA 93.62 90.74 94.96 93.33 95.32 94.12 95.33 94.25 -
本文提出了基于PCA与协同表示的高光谱图像分类算法,利用PCA算法构建字典进行协同表示,消除了传统直接采用训练样本做字典时基元间的相关性,提高协同表示分类的性能。同时也在分类时利用了地物分布的空间平滑特性,弥补了传统分类方法只考虑单像元而忽略空间信息的不足,进一步提高了算法性能。
Hyperspectral Image Classification Algorithm Based on PCA and Collaborative Representation
-
摘要: 在基于协同表示(CR)的高光谱图像分类问题中,通常直接选用训练样本构建各类字典,但各类字典内训练样本基元间的相关性往往会降低协同表示分类性能。为此,该文提出采用主成分分析(PCA)对各类训练样本进行去相关处理以构建字典,降低了训练样本间的相关性对分类结果的影响,可有效提高协同表示分类的有效性。高光谱真实数据分类实验结果表明,该算法可有效提高传统协同表示分类的正确率。Abstract: In traditional collaborative representation (CR) based hyperspectral image classification, the training samples are directly used to construct a dictionary for representation. However, the correlation among the training samples within a class tends to degrade the performance of collaborative representation based classification. In the paper, the principal component analysis (PCA) is used to de-correlate the training samples within a class. As a result, the influence of correlation among training samples on subsequent collaborative representation-based classification can be alleviated. Experimental results on two benchmark datasets show that the proposed algorithm can effectively improve the performance of traditional collaborative representation-based classification.
-
表 1 Salina数据集的选取8类地物
类别 类别名称 训练样本 测试样本 1 Brocoli_green_weeds_2 60 3 726 2 Fallow_smooth 60 2 678 3 Stubble 60 3 959 4 Celery 60 3 579 5 Grapes_untrained 60 11 271 6 Soil_vinyard_develop 60 6 203 7 Corn_senesced_green_weeds 60 3 278 8 Vinyard_untrained 60 7 268  下载: 导出CSV
下载: 导出CSV
表 2 Salina数据集分类结果
类别 CR SCR 3×3邻域 5×5邻域 7×7邻域 CR+PCA CR SCR+PCA SCR SCR+PCA SCR SCR+PCA SCR 1 99.68 98.85 99.82 99.15 99.92 99.44 99.97 99.59 2 99.73 99.52 99.91 99.97 99.93 99.93 99.95 99.85 3 99.04 99.47 99.50 99.72 99.58 99.74 99.69 99.83 4 99.72 97.48 99.84 98.16 99.89 98.56 99.91 98.92 5 69.81 60.26 73.17 63.64 75.41 66.01 77.36 67.44 6 99.72 98.25 99.90 98.41 99.99 98.61 100 98.91 7 50.27 75.82 52.72 79.15 54.56 80.87 56.52 82.03 8 63.83 59.14 67.47 61.64 70.13 63.77 72.42 65.07 OA 81.55 79.70 83.37 81.47 84.61 82.69 85.70 83.49
下载: 导出CSV
表 3 Pavia Centre数据集的9类地物
类别 类别名称 训练样本 测试样本 1 Water 60 65 971 2 Trees 60 7 598 3 Meadows 60 3 090 4 Self_Blocking Bricks 60 2 685 5 Bare soil 60 6 584 6 Asphalt 60 9 248 7 Bitumen 60 7 287 8 Tiles 60 42 826 9 Shadows 60 2 863
下载: 导出CSV
表 4 Pavia Centre数据集分类结果
类别 CR SCR 3×3邻域 5×5邻域 7×7邻域 CR+PCA CR SCR+PCA SCR SCR+PCA SCR SCR+PCA SCR 1 99.77 98.58 99.79 98.90 99.80 98.96 99.82 99.00 2 76.37 76.40 78.48 78.63 79.44 79.32 80.21 79.64 3 77.96 59.03 79.37 62.57 80.16 64.96 79.76 65.98 4 77.23 82.54 89.14 97.16 95.04 99.58 95.33 99.77 5 80.19 74.02 83.27 78.72 84.53 81.75 85.44 82.95 6 98.38 77.53 99.33 85.11 99.64 85.65 99.78 83.45 7 79.71 79.85 81.97 82.61 82.08 82.96 81.68 82.80 8 92.35 91.91 94.67 95.55 95.01 97.01 94.82 97.75 9 99.75 81.38 99.97 87.79 99.96 89.26 99.86 86.36 OA 93.62 90.74 94.96 93.33 95.32 94.12 95.33 94.25
下载: 导出CSV
-
[1] 韩震, 陈西庆, 恽才兴.海洋高光谱遥感研究进展[J].海洋科学, 2003, 27(1):22-25. doi: 10.3969/j.issn.1000-3096.2003.01.007 HAN Zhen, CHEN Xi-qing, YUN Cai-xing. Research progress of marine hyperspectral remote sensing[J]. Marine Sciences, 2003, 27(1):22-25. doi: 10.3969/j.issn.1000-3096.2003.01.007 [2] 辛勤, 粘永健, 万建伟, 等.基于FastICA的高光谱图像压缩技术[J].电子科技大学学报, 2010, 39(5):711-715. doi: 10.3969/j.issn.1001-0548.2010.05.014 XIN Qin, NIAN Yong-jian, WAN Jian-wei, et al. Compression technique for hyperspectral imagery based on FastICA[J]. Journal of University of Electronic Science and Technology of China, 2010, 39(5):711-715. doi: 10.3969/j.issn.1001-0548.2010.05.014 [3] MEI S, HE M, WANG Z, et al. Spatial purity based endmember extraction for spectral mixture analysis[J]. IEEE Transaction on Geoscience and Remote Sensing, 2010, 48(9):3434-3445. doi: 10.1109/TGRS.2010.2046671 [4] 张良培, 张立福.高光谱遥感[M].武汉:武汉大学出版社, 2005. ZHANG Liang-pei, ZHANG Li-fu. Hyperspectral remote sensing[M]. Wuhan:WuHan University Publishing Press, 2005. [5] WANG M, ZHANG L, CHEN S, et al. The analysis about factors influencing the supervised classification accuracy for vegetation hyperspectral remote sensing imagery[C]//The 4th International Congress on Image and Signal Processing (CISP).[S.l.]: IEEE, 2011, 3: 1685-1689. [6] ZHANG L, YANG M, FENG X. Sparse representation or collaborative representation: Which helps face recognition?[C]//International Conference on Computer Vision.[S.l.]: IEEE Computer Society, 2011: 471-478. [7] LI W, TRAMEL E W, PRASAD S, et al. Nearest regularized subspace for hyperspectral classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2013, 52(1):477-489. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=bd5b35fd42796b19f76b5e447be5fa02 [8] 李占利, 崔磊磊, 刘金瑄.基于协同表示的步态识别[J].计算机应用研究, 2016, 33(9):2878-2880. doi: 10.3969/j.issn.1001-3695.2016.09.073 LI Zhan-li, CUI Lei-lei, LIU Jin-xuan. Gait recognition based on collaborative representation[J]. Journal of Computer Applications, 2016, 33(9):2878-2880. doi: 10.3969/j.issn.1001-3695.2016.09.073 [9] TARABALKA Y, BENEDIKTSSON J A, CHANUSSOT J. Spectral-spatial classification of hyperspectral imagery based on partitional clustering techniques[J]. IEEE Transactions on Geoscience & Remote Sensing, 2009, 47(8):2973-2987. [10] PLAZA A, BENEDIKTSSON J A, BOARDMAN J W, et al. Recent advances in techniques for hyperspectral image processing[J]. Remote Sensing of Environment, 2009, 113(1):S110-S122. http://cn.bing.com/academic/profile?id=91b43753c028a435784b9e7a51455051&encoded=0&v=paper_preview&mkt=zh-cn [11] 赵蔷.主成分分析方法综述[J].软件工程, 2016, 19(6):1-3. doi: 10.3969/j.issn.1008-0775.2016.06.001 ZHAO Qiang. A review of principal component analysis[J]. Software Engineering, 2016, 19(6):1-3. doi: 10.3969/j.issn.1008-0775.2016.06.001 [12] 姜斌, 潘景昌, 郭强, 等. PCA和相融性度量在聚类算法中的应用[J].电子科技大学学报, 2007, 36(6):1292-1295. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=SciencePaper201303040000020333 JIANG Bin, PAN Jing-chang, GUO Qiang, et al. Application of PCA and coherence measure in clustering algorithm[J]. Journal of University of Electronic Science and Technology of China, 2007, 36(6):1292-1295. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=SciencePaper201303040000020333 -

 点击查看大图
点击查看大图
图(3) / 表(4)
计量
- 文章访问数: 4157
- HTML全文浏览量: 1316
- PDF下载量: 109
- 被引次数: 0
