 ISSN
ISSN 





-
2005年Hirsch提出了一种评价学者科研产出学术影响力的新指标——H-指数,随后引发了热烈的关注与讨论。在其后的十余年中,人们受此启发提出了几十种类似的新指标。H-指数的提出,打破了1972年提出的影响因子在学术影响力评价方面的垄断地位,而这一系列新指标的提出与研究,又极大地推动了科学计量学领域的深化和发展,甚至带来了新的产业变革,Altmetric与CiteScore等新评价体系的推出也是这种深化研究的成果之一。
学术影响力是指科研主体通过发表学术论文或论著等方式提出新的专业理论、实践方法与技术,或者对原有成果的发展、修正、革新和完善,从而对相关领域的理论和实践产生的影响[1]。实际上,这种影响力体现在科研与生产的方方面面,除了学术论文间的相互引用以外,其实还应该包括相关的教材编订、社会报道、产业技术革新、大众传播及实践运用情况等。但绝大多数学术影响力评价体系只将引证数据作为分析计算的依据,例如,影响因子、特征因子还有H-指数等都是基于引证数据的。所以,首先需要在此明确的是,所有H-系列的评价指标只是对一个学者的学术产出的影响力进行评价,而非评价该学者的学术影响力(因为它还包括学者主持科研项目的经历以及他/她在学术圈的社会影响力等)。前者更纯粹,后者更广泛也更全面。
引证分析本身存在不少缺点,这就必然导致基于引用数据的一些指标也会或多或少存在不足。本文总结了5个主要问题:1)对所有的引用关系一视同仁,无论是对非常相关的方法和内容的引用,还是不甚相关的综述性引用;无论是肯定性引用,还是批驳性引用。2)对所有引用者一视同仁,无论是学界泰斗还是学科新人。3)引用中的“马太效应”,即引用越多的文章越容易被引用。4)综述类文章的引用普遍高于原创性文章。5)引用数量在不同学科之间存在较大差异。这些问题的存在严重影响了评价的准确性和客观性。事实上,基于引证分析的指标是否非常客观,也值得思考。正如文献[2]所表达的一种观点:客观性只是引证分析这一评价体系的美丽面纱,基于主观才是它面纱之下的真容。一篇论文从创作中的参考文献遴选,到投稿期刊选择,到最后被别人引用的整个过程中的每一次评价行为都是以主观评价为基础的,而这一过程中所产生和依据的“客观”引证数据,都是对之前所有的主观评价结果所做的量化分析或总结。
尽管基于引证分析的指标存在诸多问题,但目前它们仍是被广泛使用的主流方法。我们只有对这些方法进行深入的理解和研究,才能更清楚地看到其本质和问题,从而在进一步的改进中做到有的放矢。接下来本文将以学者的引用分布曲线为统一的视角和工具,对H-指数及其23种代表性衍生指标进行介绍和分析,并指出一些指标存在的问题。
-
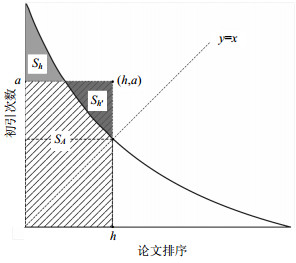
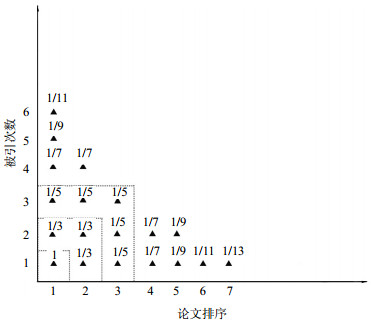
一个学者的H-指数等于h表示在其所有的Np篇论文中,有h篇论文每篇被引用至少h次,而其余的(Np-h)篇论文的被引次数均小于(h+1)[3]。H-指数因其求解简单、含义明确、同时考察了论文数量与质量,并具有较好的稳定性等优点迅速被广泛接纳。在图 1中,将一名学者的所有论文按照引用次数降序排列,然后将它们的序号对应到X轴,每篇论文的引用次数对应到Y轴,绘制出这位学者的引用分布曲线。此时,曲线与坐标轴围成的面积就等于总引用数。这个区域中以(0, 0)为一端点的最大正方形Ch(图中斜线域)的边长就是这个学者的H-指数,它也等于曲线与直线y=x的交点所对应的坐标值[2]。当然H-指数也存在一些问题,主要有4点:1) H-指数忽略了高被引论文的作用,而这些往往都是代表作。比如表 1中学者a和学者b的H-指数都是4,但学者a的影响力明显高于学者b;2) H-指数不考虑第h篇以后的论文的价值,即使他们的引用数非常接近h。比如表 1中学者c和学者d的H-指数都是4,但是学者d影响力要稍大一些;3) H-指数的值受到发表论文总数的限制,即H-指数不会超过发表论文数;4) H-指数的区分能力较弱。表 1中4人H-指数都相同,但是他们的影响力差异巨大。

图 1 H-指数[1]
表 1 H-指数的缺点示例
论文排序 论文被引数 学者a 学者b 学者c 学者d 1 100 5 21 21 2 50 5 18 18 3 7 5 7 7 4 5 5 5 5 5 3 3 0 4 6 3 3 0 4 7 1 1 0 4 8 0 0 0 4 为了解决上述问题衍生出一系列的H型指数,如R-指数[4]、e-指数[5]、m-指数[6]、K-指数[7]等,或者受H-指数启发提出的一系列相似指数,如g-指数[8]、w-指数[9]、hα-指数[10]等,下面逐一进行比较分析。
-
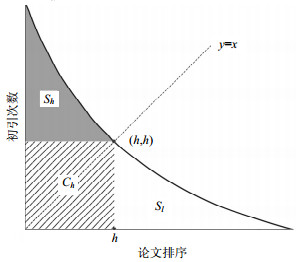
为了强调高被引论文的价值,学者提出了g-指数:一个学者发表的N篇论文中有g篇论文的引用次数之和大于等于g2,且任意(g+1)篇论文的引用次数之和都小于(g+1)2[8]。如图 2所示,我们将论文按照引用次数降序排列后绘制出其引用分布曲线,图 2中Sh与Sh'满足关系Sh≥Sh'。g-指数将前g篇论文的所有引用量用一个面积最近似的正方形Sg来表示。一般情况下有Sh≈Sh';只有当$\sum\limits_{i = 1}^g {{c_i}} = {g^2}$时,Sh=Sh'成立,其中ci为第i篇论文的引用次数。g-指数即是用正方形Sg(斜线域)的边长来表示一个学者的学术产出影响力。g-指数考虑了高被引论文的价值,同时也打破了论文总数的限制,例如表 2中的学者e的论文数为3,H-指数也为3,但是g-指数为10。另外它对于论文总数少但引用高的学者更有利,例如表 2中虽然学者f有8篇论文,H-指数为5,大于学者e,但是g-指数为6,小于学者e。尽管g-指数相比H-指数有上述优势,但它易受到高被引论文的影响,不如H-指数稳定。

图 2 g-指数
表 2 H-指数与g-指数的比较
学者e 学者f 排序r r*r 论文引用 累积引用 排序r r*r 论文引用 累积引用 1 1 100 100 1 1 10 10 2 4 9 109 2 4 9 19 3 9 7 116 3 9 7 26 4 16 0 116 4 16 5 31 5 25 0 116 5 25 5 36 … … … … 6 36 5 41 10 100 0 116 7 49 3 44 11 121 0 116 8 64 2 46 为了减少高被引论文对g-指数造成的影响,文献[11]于2010年提出了hg-指数。hg-指数是H-指数与g-指数的几何平均数,即${\rm{hg}} = \sqrt {h \cdot g} $。提出者认为hg-指数集成了两者的优点并弱化了各自的缺点,使其更稳定的同时,又具有了更高的分辨能力。
-
A-指数也是为了强调高被引论文的价值。首先介绍“H-核”的概念。H-核(Hirsch core)是指按照引用次数降序排在前h篇的论文构成的论文集合[12],其中h就是该学者的H-指数。然后用H-核中论文的平均引用次数来定义一个学者的影响力大小,即A-指数$A = \left( {\sum\limits_{i = 1}^h {{c_i}} } \right){\rm{ /}}h$,其中ci为排在第i位的论文的引用次数。A-指数相比H-指数区分能力更强,即使当H-指数不变的时候,A-指数也会随着H-核中论文的引用次数的增加而增加。如图 3所示,图中Sh=Sh',即矩形面积等于H-核中论文的总引用次数。A-指数即是用长宽分别为a(A-指数的值)和h(H-指数)的矩形SA(图 3中斜线域)的长边来表示一个学者科研产出的学术影响力。A-指数也有不合理之处,例如两个人H-核中论文的总引用次数相同时,H-指数较大的那个人的A-指数反而更低。

图 3 A-指数
R-指数为一个学者H-核中论文的总引用次数的平方根[4],即$R = \sqrt {\sum\limits_{i = 1}^h {{c_i}} } $。从图 4中可以看出,R-指数即是用边长为r(R-指数的值)的正方形(图中斜线域SR)的边长来表示一个学者科研产出的学术影响力,图中Sh=Sh',即正方形面积等于H-核中论文的总引用次数。A-指数、R-指数和H-指数三者之间满足关系$R = \sqrt {A \cdot h} $。

图 4 R-指数
-
AR-指数定义为一个学者H-核内每篇论文的年均引用次数的总和的平方根[4],即${\rm{AR}} = \sqrt {\sum\limits_{i = 1}^h {({c_i}/{a_i}} )} $。其中ai为第i篇论文的年龄——即当前年份减去该篇论文的发表年份。可以看到,H-指数只升不降,而AR-指数会随着每篇论文的引用次数和年龄升降。如果论文年引用数逐年减少,那么会使AR值降低,表示该学者科研产出的学术影响力下降。
e-指数的提出是为了解决H-指数区分能力不足的问题。e-指数是H-核中论文总引用次数减去表征H-指数的正方形之后剩余部分的平方根,即图 1中Sh区域面积的平方根,其定义式为$e = \sqrt {\sum\limits_{i = 1}^h {({c_i} - h)} } = \sqrt {\sum\limits_{i = 1}^h {{c_i} - {h^2}} } $[5]。e-指数与H-指数的结合使用,可以有效提高H-指数的分辨能力,即使在两个人的H-指数相同的情况下也很可能对其做出有效区分。R-指数,H-指数和e-指数三者满足关系${R^2} = {h^2} + {e^2}$。
-
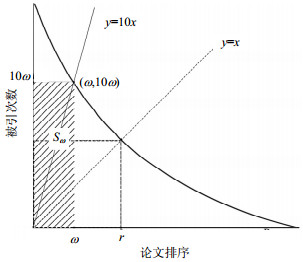
w-指数同样是为了强调高被引论文对科研产出的影响力的价值。一个学者的w-指数等于w表示这个学者有w篇论文的引用次数大于等于10w,且其余论文的引用次数均小于10(w+1)[13]。如图 5所示,w-指数即是用长宽分别为整数10w和w的矩形Sw(斜线域)的短边w来表示一个学者的科研产出影响力。相比于H-指数是求引用分布曲线与直线y=x的交点,w-指数实际上是求引用分布曲线与直线y=10x的交点。w-指数更偏爱高被引论文的学术价值,但同时也使得w-指数计算过程中满足考察条件的论文数急剧减少,忽略了更多论文的贡献。

图 5 w-指数
文献[10]将w-指数扩展到更一般的形式,提出了hα-指数。一个学者的hα-指数等于hα是指他/她有hα篇论文的引用次数大于等于αh,而其余论文的引用次数均小于α(h+1)。若α=1,hα-指数就变成了H-指数;若α=10,hα-指数就变成了w-指数。通过调整参数α可以解决不同领域引文量之间存在差异的问题。与图 5类似,hα-指数实际上为引用分布曲线与$y = \alpha x(a \ge 1)$交点的横坐标,且α越大,越关注高被引论文的价值。
-
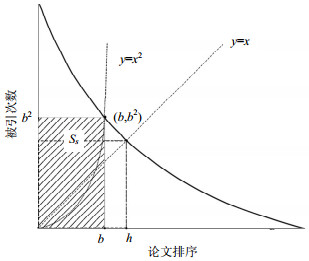
在H-指数计算中,有时会因为学者同名而使得计算结果被张冠李戴。更多地考察高被引论文,能够在一定程度上解决这个问题。一个学者的h(2)-指数等于s是指他/她最多有b篇论文的引用次数均大于等于b2,而其余论文的引用次数均小于(b+1)2[14]。从图 6可以看出,h(2)-指数的计算过程实际上就是求解引用分布曲线与曲线y=x2的交点,即用长宽分别为整数b2与b的矩形Ss(斜线域)的短边b来表示一个学者的科研产出的学术影响力。

图 6 h(2)-指数
h(n)-指数是h(2)-指数更一般的形式。一个学者的h(n)-指数等于p是指他/她最多有p篇论文的引用次数均大于等于pn,而其余论文的引用次数均小于(p+1)n[14]。给定不同的n值,就可以解决不同学科引用差异问题。和h(2)-指数类似,其实质即求解引用分布曲线与曲线y=xn的交点问题。当指数n=1时该模型退化为H-指数,当指数n=2时该模型退化为h(2)-指数。h(2)-指数和h(n)-指数的区分能力会随着n的增加变的越来越低。n越大考察的论文范围越小,越偏重高被引论文。
-
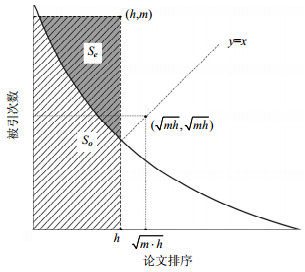
考虑到单篇最高被引论文的影响,文献[15]提出了o-指数,其定义为一个学者的H-指数h与单篇最高被引次数m的几何平均数,即$o = \sqrt {m \cdot h} $。从图 7可以看出,o-指数即是用与矩形So(斜线域)面积相等的正方形的边长来表示一个学者的科研产出的学术影响力,但是o-指数凭空增加了Se部分,而且m越大,Se也越大,过分夸大了单篇最高引用论文的影响,使得引证数据失实。

图 7 o-指数
A+-指标同样考虑了单篇最高被引论文的贡献,其定义为$A + = \left( {m + \sum\limits_{i = 1}^h {{c_i}} } \right)/h$[16]。A+-指数其实就是在A-指数的基础上增加了m/h部分,来强调最高论文的价值。从图 8可以看出它和A-指数相似,a'便是其A+-指数的值。唯一不同的是,它重复计算了单篇最高被引次数,即图中紧贴Y轴的深色阴影区,且有${S_h} + m = {S_m}$。一个学者的最高被引次数m越大,他/她的影响力就被A+-指数放大越多。

图 8 A+-指数
-
考虑到所有论文的引用对于学术影响力都是有贡献的,文献[17]提出了hT-指数。图 9用Ferrers图的方式给出了hT-指数的计算方法。先将所有论文按照引用次数降序排列并绘入坐标系中,每一个小三角形代表一个引用,被小三角形围出的最大正方形称为Durfee方块,Durfee方块的边长3即为该学者的H-指数。我们为每一个引用赋值:如果Durfee方块的边长a=1,则Durfee方块内只有一个引用,那么该引用被赋值为1,以后Durfee方块的边长每增加1时,那些被新包含进去的引用就被赋值为1/(2a-1),以此类推,直到为所有引用完成赋值。hT-指数就等于所有引用分值的和。在实际计算中,也可以使用公式hT=h+△h,其中h为该学者的H-指数,△h为Durfee方块之外的所有引用的分值之和。图 9中的学者的hT-指数为${h_T} = 3 + 4 \times 1/7 + 3 \times 1/9 + 2 \times 1/11 + 1/13 \approx 4.16$。可以看出,hT-指数的分辨能力强于H-指数,但计算过程也更繁琐。

图 9 Ferrers图
同年,文献[18]提出了一个相似但更加简单的指标,有理数H-指数,即hrat-指数[18]。它定义为${h_{rat}} = \left( {h + 1} \right) - {n_c}/\left( {2h + 1} \right)$,其中nc是指当H-指数增长1时还需要获得的引用次数。以图 9为例,该学者的hrat-指数为${h_{rat}} = (3 + 1) - 3{\rm{ /}}(2 \times 3 + 1) = 25{\rm{ /}}7$。hrat-指数可以在一定程度上预测H-指数的增长,也比hT-指数更加简单,但也不再考虑所有引用对学术影响力的价值。
-
除了以上这些强调高被引论文学术价值的方法外,还有很多的其他指标。例如,文献[6]提出的m-指数定义为H-核中论文引用次数的中位数。他们认为引用次数的分布是不对称的,所以用中位数来代替A-指数中的算术平均数更为合理。这样既准确度量了H-核中论文引用次数的中心趋势,又减轻了超高被引次数的过度影响。
文献[19]提出了一种对H-核内论文的引用次数变化比较敏感的指数,即连续引文权变指数(the continuous citation-weighted H-index),记为hw-指数。hw-指数的定义式为${h_w} = \sqrt {\sum\limits_{j = 1}^{{r_0}} {{c_j}} } $,其中cj为第j篇被引用最多的论文的引用次数,r0是满足${r_w}(i) \le {c_i}$且${r_w}(i) = \sum\limits_{j = 1}^i {{c_j}} /h$的最大行的行序号[19]。以表 3为例,其H-指数h=4,${r_w}(3) = 7.25 \le 8$而${r_w}(4) = 9.25 > 7$,所以r0=3,该学者的hw-指数为$\sqrt {30} $。
表 3 hw-指数计算示例
论文降序r 引用数y ${r_w} = \sum {/h} {\rm{ }}$ 1 12 12/4=3 2 10 (12+10)/4=5.5 3 8 (12+10+8)/4=7.5 4 7 (12+10+8+7)/4=9.25 5 4 (12+10+8+7+4)/4=10.2 也有一些人认为将发表论文数不同的学者放在一起比较是不公平的,为此文献[20]提出了一种归一化的H-指数, 记为hn-指数,其定义为${h^n} = h/{N_p}$,其中Np为该学者发表的总论文数[20]。显然hn-指数对高产的学者具有惩罚效应,对低产的学者反而有所奖励,这种机制本身又是另一种不公平。
为消除科研资历对学术影响力评价的影响,文献[3]提出了m熵-指数(m-quotient), 其定义式为m=h/y,其中y为该学者的学术年龄。m熵-指数和H-指数一样忽略了高被引论文的学术价值。除了这种考虑学者学术年龄的指标外,也有考虑论文“年龄”的指标,例如文献[18]提出的hc-指数(contemporary H-index)更注重新论文的引用贡献。hc-指数需要先按照公式${S^c}(i) = \gamma * {(Y({\rm{now}}) - Y(i) + 1)^{ - \delta }} * \left| {C(i)} \right|$对引用数据进行处理,然后在Sc的基础上按照原来的H-指数定义来计算学者的hc-指数。其中Y(i)和C(i)分别是论文i的发表年份和被引次数,Y(now)是当下的统计年份,γ和δ是两个参数。当γ和δ均为1时Sc表示论文i的年平均被引次数。实证发现通常γ和δ取值分别为4和1。这样一来更早发表的论文对影响力的贡献就会随着时间而衰减,从而强调了新论文的引用贡献。
对于多个作者合作发表的论文,如何分配这种学术影响力也是一个重要问题。文献[21]针对此问题提出了hI-指数,定义为${h_I} = h/\langle {N_a}\rangle = {h^2}/N_a^{\left(T \right)}$,其中$N_a^{\left(T \right)}$是H-核中的作者数。hI-指数等于hI表示该学者单独发表论文的话,至少有hI篇论文的引用次数大于等于hI。hI-指数的不合理之处在于,那些H-核中偶有合作的合作者会分配掉该学者单独发表的论文的引用价值。为此,文献[22]又提出了hm-指数。他的思路是N个人合著的一篇论文相当于每个人只发表了1/N篇论文。然后按照论文被引次数降序排列,累加论文篇数得到Sa,按照H-指数的计算过程,找出Sa的最大值,这个Sa即是他/她的hm-指数。还有一种着重考察引用者的aH指数[23]。在一个学者的所有Nc个引用者中,如果有a个引用者每人都至少引用了a次,其余的(Nc-a)个引用者对他/她的文章的引用量都小于a次,那么这位学者的aH指数就是a。
除了以上列举的指标以外,还有很多基于H-指数的改进方法[24]。H-指数相比其他方法被更广泛的应用,其主要原因在于H-指数开创了一种评估学者学术影响力的新框架。尽管它提出时并不完美,但在这一框架下,所有后来提出的新指标虽有或多或少的改进,但并不能超越H-指数多少。要么含义简单明了但更加的有失偏颇,要么考虑了更多的信息但计算更加繁琐。如何在准确和效率这两者之间取得平衡,如何更大程度地保证公平,依然是有待深入思考的问题。
-
如何评价这些指标的性能和合理性是一个重要的问题。常见的评价方法主要有以下4类:
1) 基于实证数据进行对比分析。选取真实的引证数据,计算经典指标,如期刊影响因子、H-指数,以及其他相关指标,然后对它们的值或排名进行比较分析。一种方式是对某一个具体的排名对象(如某个学者)的排名变化进行分析。另一种方式是计算新指标与原有指标之间的相关性,并对比这种相关性在不同数据集和不同领域上的稳定性,从而说明新指标的准确性与稳定性。例如文献[25]计算了美国31位著名的信息学家的H-指数与总被引次数之间的相关性,发现两者之间的正相关性非常高,并最终认为H-指数更适合于学者产出的学术影响力评估。
2) 利用数学关系与模型进行评价。探索新指标与原有指标或者文献计量学的著名定律之间的数学关系,是评价学术影响力指标的另一类主要方法。例如,推导H-指数与被引次数[3]、论文数量[26]、影响因子[27]等指标之间的数学关系,分析它的有效性与合理性,计算动态H-指数的数学模型并对比实证数据,分析它的预测性[28]等。
3) 与同行评议结果进行对比分析。将指标的排名结果与权威性的同行评议结果进行对比,说明指标的价值所在。例如文献[29]研究了147个科研团队的H-指数与同行评议结果之间的相关性,并发现他们之间的相关性显著。因此,可以利用这些指标进行成本更低、规模更大的学术产出影响力测评。
4) 与单个知名奖项或综合多个奖项的获奖者进行对比分析。文献[3]选取了20年中的诺贝尔物理学奖获得者,计算他们的H-指数并与其他未获奖的人进行比较分析。另外又对姓氏以A或者B为首的美国物理学院士的H-指数进行计算,并通过进一步的比较说明了H-指数对学术产出影响力的评价是准确的、稳定的,且符合实际情况的。
-
本文总结了数十种常见的H-系列指标,并基于学者的引用分布曲线,用统一的视角探讨了这些指标的本质,并指出其存在的不足。H-系列的大多数指标,都可以理解为从引用分布曲线下方区域截取最能代表一个人的学术产出影响力的部分来刻画他/她的学术成就。如何截取最有效的部分就成为了核心问题。一些指标会存在重复计算引用的问题使得评价失真。
从以上分析中可以看到,H-系列的指标主要分成以下几类:1)强调高被引论文价值的指标,如g-指数、w-指数等;2)考虑所有论文价值的指标,如hT-指数等;3)考虑考察主体年龄的指标,具体又分为三类:考虑学者学术年龄的m熵-指数等,考虑论文年龄的R-指数和hc-指数等;4)考虑论文数量的指标,如hn-指数等;5)考虑学者数量的指标,又可分为考虑作者数量的hI-指数和考虑引用作者数量的aH-指数等。其中以第1类最多。除此之外,还有一些考虑其他更复杂因素的指标,不再一一列举。
最后,基于以往的研究,本文总结了以下6个问题,希望能够引起学者们的重视和思考,在今后的研究中得到完美解决[2]:
1) 引用质量存在差异的问题。所有基于引用数据的评价方法要想获得好的效果就必须保证引用数据是真实可靠且有价值的。对引用的质量及来源进行区分是非常必要的,同时,对于引用缺失的问题也要引起关注[30]。
2) 不同学术年龄比较的问题。越早发表的论文越可能有更多的引用,越资深的学者越可能获得更高的评价。因此,在对不同学术年龄的主体进行比较的时候需要考虑时间因素的影响[31]。
3) 跨学科领域难以比较的问题。基于引用的评价方法都存在跨领域的比较问题,比如物理论文的引用一般大于数学论文。因此,评价指标的设计需要考虑不同学科领域的特点。例如,将评分值用同一领域论文的平均分数重新标度[32]。
4) 指标缺乏预测能力的问题。静态的刻画指标缺乏对影响力增长的预测能力。论文引用的增长不仅受到“富者越富”机制的影响,还与论文的适应性(也称内在质量)和时间衰减效应相关[33]。基于这三个因素就可以构建引用增长的预测模型。
5) 合作论文学术贡献的分配问题。大多分配方法都注重第一作者和通讯作者的贡献,而其他作者按序递减。这一方法仅从单篇论文出发,虽然简单易算,但并不一定合理。一种新的思路是在考察作者对一篇学术论文的贡献时,还需要考虑这些作者发表的其他相关的论文,这种方法对诺贝尔奖具有更高的预测能力[34]。
6) 社交媒体学术影响力的刻画问题。如今,学者不仅可以在期刊发表论文,还可以通过社交媒体在第一时间发表最新的学术成果和观点。未来,我们在继续完善现有学术评价体系的同时,还需思考和探索将社交媒体上发表的研究成果纳入学术考评体系的方式。这些问题无疑将为学术影响力的评价提出新的挑战。
正如《旧金山宣言》[35]中呼吁的那样,学术影响力评估要基于研究本身的价值而不是发表该研究的期刊。让评价主体回归到研究本身,让评价范围扩大到引证数据之外,才能更加全面和尽可能客观地进行评价。
The Study on the Essence of H-index and Its Derivative Indices
-
摘要: 如何更加客观公正地进行学术影响力评价一直以来都是一个重要且备受关注的问题。H-指数的提出,打破了原来以影响因子为单一评价指标的现状,引发了广泛的关注和讨论,并在随后数年产生了几十种衍生指标,这些工作极大地推动了科学计量学领域的深入研究和发展。该文详细介绍了H-指数及其具有代表性的23种衍生指标,以学者或单位的引用分布曲线为统一的视角,探讨了这些指标的本质,并讨论了各自的优缺点。最后对学术产出的影响力评价研究进行了展望。Abstract: How to impartially quantify the scientific impact has always been a significant issue and attracted much attentions. To solve this problem, the H-index and its dozens of derivative indicators have been proposed. In this paper, we review H-index and many of its representative variants. We apply the Citation Distribution Curve of scholars or organizations as a unified perspective to discuss the essences of these representative indices and compare their advantages and disadvantages. Finally, we give an outlook for the future research directions.
-
Key words:
- citation distribution curve /
- H-family indices /
- H-index /
- ranking scientists /
- scientific impacts
-
表 1 H-指数的缺点示例
论文排序 论文被引数 学者a 学者b 学者c 学者d 1 100 5 21 21 2 50 5 18 18 3 7 5 7 7 4 5 5 5 5 5 3 3 0 4 6 3 3 0 4 7 1 1 0 4 8 0 0 0 4  下载: 导出CSV
下载: 导出CSV
表 2 H-指数与g-指数的比较
学者e 学者f 排序r r*r 论文引用 累积引用 排序r r*r 论文引用 累积引用 1 1 100 100 1 1 10 10 2 4 9 109 2 4 9 19 3 9 7 116 3 9 7 26 4 16 0 116 4 16 5 31 5 25 0 116 5 25 5 36 … … … … 6 36 5 41 10 100 0 116 7 49 3 44 11 121 0 116 8 64 2 46
下载: 导出CSV
表 3 hw-指数计算示例
论文降序r 引用数y ${r_w} = \sum {/h} {\rm{ }}$ 1 12 12/4=3 2 10 (12+10)/4=5.5 3 8 (12+10+8)/4=7.5 4 7 (12+10+8+7)/4=9.25 5 4 (12+10+8+7+4)/4=10.2
下载: 导出CSV
-
[1] 邱均平.信息计量学(九):第九讲文献信息引证规律和引文分析法[J].情报理论与实践, 2001, 24(3):236-40. doi: 10.3969/j.issn.1000-7490.2001.03.028 QIU Jun-ping. Lecture 9 literature information citation rules and citation analysis[J]. Information studies:Theory & Application, 2001, 24(3):236-40. doi: 10.3969/j.issn.1000-7490.2001.03.028 [2] 范天龙, 吕琳媛.学术影响力评价方法:回顾与展望[J].中国计算机学会通讯, 2017, 13(11):52-6. http://d.old.wanfangdata.com.cn/Periodical/kjglyj200811031 FAN Tian-long, LÜ Lin-yuan. Evaluation of scientific impacts:Reviews and prospects[J]. Communications of the CCF, 2017, 13(11):52-6. http://d.old.wanfangdata.com.cn/Periodical/kjglyj200811031 [3] HIRSCH J E. An index to quantify an individual's scientific research output[J]. Proceedings of the National Academy of Sciences of the United States of America, 2005, 102(46):16569-16572. doi: 10.1073/pnas.0507655102 [4] 金碧辉, RONALD R. R指数、AR指数:h指数功能扩展的补充指标[J].科学观察, 2007(3):1-8. http://www.cnki.com.cn/Article/CJFDTEMP-KCGC200703000.htm JIN Bi-hui, RONALD R. R-index and AR-index:Complementing indicators to h-index[J]. Science Focus, 2007(3):1-8. http://www.cnki.com.cn/Article/CJFDTEMP-KCGC200703000.htm [5] ZHANG Chun-ting. The e-index, complementing the h-index for excess citations[J]. Plos One, 2009, 4(5):e5429. doi: 10.1371/journal.pone.0005429 [6] BORNMANN L, MUTZ R, DANIEL H D. Are there better indices for evaluation purposes than the, h, index? A comparison of nine different variants of the, h, index using data from biomedicine[J]. Journal of the Association for Information Science & Technology, 2008, 59(5):830-837. https://www.researchgate.net/publication/227606297_Are_there_better_indices_for_evaluation_purposes_than_the_h_Index_A_comparison_of_nine_different_variants_of_the_h_Index_using_data_from_biomedicine [7] 安静, 夏旭, 李海燕, 等.类h指数:K指数的修正机理及实证分析[J].科技管理研究, 2009(6):382-384. doi: 10.3969/j.issn.1000-7695.2009.06.036 AN Jing, XIA Xu, LI Hai-yan, et al. Hirsch-type index:Correction mechanism and empirical analysis of K-index[J]. Science and Technology Management Research, 2009(6):382-384. doi: 10.3969/j.issn.1000-7695.2009.06.036 [8] EGGHE L. Theory and practice of the g-index[J]. Scientometrics, 2006, 69(1):131-52. doi: 10.1007/s11192-006-0144-7 [9] WU Q. The w-index:a significant improvement of the h-index[J]. Journal of the American Society for Information Science and Technology, 2010, 61(3):609-614. http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_0805.4650 [10] ECK N J V, WALTMAN L. Generalizing the h-and g -indices[J]. Journal of Informetrics, 2008, 2(4):263-71. doi: 10.1016/j.joi.2008.09.004 [11] ALONSO S, CABRERIZO F J, HERRERA-VIEDMA E, et al. Hg-index:a new index to characterize the scientific output of researchers based on the h-and g-indices[J]. Scientometrics, 2010, 82(2):391-400. doi: 10.1007/s11192-009-0047-5 [12] RONALD R. New developments related to the Hirsch index[J]. Science Focus, 2006, 1(4):23-25. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=QK200602032123 [13] WU Qiang. The w-index:a measure to assess scientific impact by focusing on widely cited papers[J]. Journal of the American Society for Information Science & Technology, 2014, 61(3):609-614. [14] KOSMULSKI M. A new Hirsch-type index saves time and works equally well as the original h-index[J]. ISSI Newsletter, 2006, 2(3):4-6. [15] DOROGOVTSEV S N, MENDES J F F. Ranking scientists[J]. Nature Physics, 2015, 11(11):882. doi: 10.1038/nphys3533 [16] 王凌峰.一个新的h-type指标——A+指数[J].情报杂志, 2013(1):55-58. doi: 10.3969/j.issn.1002-1965.2013.01.013 WANG Ling-feng. A new h-type index-A+ index[J]. Journal of Intelligence, 2013(1):55-58. doi: 10.3969/j.issn.1002-1965.2013.01.013 [17] ANDERSON T, HANKIN R, KILLWORTH P. Beyond the Durfee square:Enhancing the h-index to score total publication output[J]. Scientometrics, 2008, 76(3):577-588. doi: 10.1007/s11192-007-2071-2 [18] RUANE F, TOL R. Rational (successive) h-indices:an application to economics in the Republic of Ireland[J]. Scientometrics, 2008, 75(2):395-405. doi: 10.1007/s11192-007-1869-7 [19] EGGHE L, ROUSSEAU R. An h-index weighted by citation impact[J]. Information Processing & Management, 2008, 44(2):770-780. https://www.researchgate.net/publication/220229608_An_h-index_weighted_by_citation_impact [20] SIDIROPOULOS A, KATSAROS D, MANOLOPOULOS Y. Generalized Hirsch h-index for disclosing latent facts in citation networks[J]. Scientometrics, 2007, 72(2):253-80. doi: 10.1007/s11192-007-1722-z [21] BATISTA P D, CAMPITELI M G, LINOUCHI O. Is it possible to compare researchers with different scientific interests?[J]. Scientometrics, 2006, 68(1):179-89. doi: 10.1007/s11192-006-0090-4 [22] SCHREIBER M. To share the fame in a fair way, hm modifies h for multi-authored manuscripts[J]. New Journal of Physics, 2008, 10(4):1131-1137. doi: 10.1088-1367-2630-10-4-040201/ [23] KUDELKA M, PLATO J, LR MER P. Author evaluation based on H-index and citation response[C]//International Conference on Intelligent Networking and Collaborative Systems.[S.l.]: IEEE, 2016: 375-379. [24] OBERESCH E, GROPPE S. The mf-index:a citation-based multiple factor index to evaluate and compare the output of scientists[J]. Open Journal of Web Technologies, 2017, 4(1):1-32. [25] CRONIN B, MEHO L. Using the h-index to rank influential information scientistss:Brief communication[J]. Journal of the Association for Information Science & Technology, 2006, 57(9):1275-1278. [26] EGGHE L R R. An informetric model for the Hirsch-index[J]. Scientometrics, 2006, 69(1):121-129. doi: 10.1007/s11192-006-0143-8 [27] GLANZEL W. On the h-index-A mathematical approach to a new measure of publication activity and citation impact[J]. Scientometrics, 2006, 67(2):315-321. doi: 10.1007/s11192-006-0102-4 [28] EGGHE L. Dynamic h-index:the Hirsch index in function of time:Brief communication[J]. Journal of the American Society for Information Science & Technology, 2007, 58(3):452-454. https://www.researchgate.net/publication/227600413_Dynamic_h-index_The_Hirsch_index_in_function_of_time_Brief_Communication [29] VAN RAAN A F J. Comparison of the Hirsch-index with standard bibliometric indicators and with peer judgment for 147 chemistry research groups[J]. Scientometrics, 2006, 67(3):491-502. doi: 10.1556/Scient.67.2006.3.10 [30] SU Cheng, PAN Yun-tao, ZHEN Yan-ning, et al. PrestigeRank:a new evaluation method for papers and journals[J]. Journal of Informetrics, 2011, 5(1):1-13. doi: 10.1016/j.joi.2010.03.011 [31] RADICCHI F, FORTUNATO S, CASTELLANO C. Universality of citation distributions:Toward an objective measure of scientific impact[J]. Proceedings of the National Academy of Sciences, 2008, 105(45):17268-17272. doi: 10.1073/pnas.0806977105 [32] MARIANI M S, MEDO M, ZHANG Yi-cheng. Identification of milestone papers through time-balanced network centrality[J]. Journal of Informetrics, 2016, 10(4):1207-1223. doi: 10.1016/j.joi.2016.10.005 [33] WANG Da-shun, SONG Chao-ming, BARABASI A L. Quantifying long-term scientific impact[J]. Science, 2013, 342(6154):127-32. doi: 10.1126/science.1237825 [34] SHEN Hua-wei, BARABASI A L. Collective credit allocation in science[J]. Proceedings of the National Academy of Sciences of the United States of America, 2014, 111(34):12325. doi: 10.1073/pnas.1401992111 [35] BUTLER-ADAM J. DORA:The San Francisco declaration on research assessment[J]. Biology Open, 2013, 2(6):533-534. doi: 10.1242/bio.20135330 -

 点击查看大图
点击查看大图
图(9) / 表(3)
计量
- 文章访问数: 4748
- HTML全文浏览量: 1339
- PDF下载量: 148
- 被引次数: 0
