 ISSN
ISSN 


-
在工程中,由于事物的固有随机性及各种波动的影响,需要处理各种不确定性问题,如外部载荷、加工误差等[1]。结构可靠性理论与方法是处理工程中各种不确定性的有效方法,以保障结构的高可靠性。对结构进行可靠性分析,最为关键的是确定结构失效模式及其所对应的性能函数。当性能函数为显函数时,现有的很多方法都能解决,如蒙特卡罗方法(Monte Carlo simulation, MCS)、一阶可靠性、二阶可靠性方法等[2-3]。然而,工程中绝大多数性能函数常用隐函数进行表示,对结构进行可靠性分析,需借助有限元分析等数值仿真方法。但是,大量重复的有限元分析所需计算量大,在实际工程中难以适用,比如汽车整车的有限元分析一次计算通常需要数十小时甚至数百小时,基于有限元分析及传统可靠性方法需要数月的时间。为了解决以上难点,相关学者进行了大量的研究工作。研究和工程实践表明,代理模型是减少计算资源和提高计算效率最为有效的方法之一[4]。基于代理模型方法的结构可靠性分析核心在于构建高精度高效率代理模型。其一般性原理为通过实验设计获取少量的训练样本点,然后利用代理模型(响应面、神经网络、Kriging、支持向量机等)构建输入-输出的函数关系式[5],并用现有的结构可靠性分析方法进行可靠性分析及可靠性灵敏度分析。基于代理模型的方法能有效减少计算量,其原理在于能把对有限元分析的调用转为对代理模型的调用,从而节省计算时间。在基于代理模型的结构可靠性分析中,二次响应面模型由于结构简单、易于构造,被广泛用于结构可靠性分析中[6-10]。虽然基于响应面的结构可靠性分析方法简单且便于操作,但对于非线性程度较高的性能函数,会带来较大的误差,其精度难以保证。
鉴于响应面方法对于非线性程度较高的性能函数精度较低的问题,文献[12-13]研究了基于其他代理模型(神经网络、支持向量机、Kriging等)的结构可靠性方法,取得了有效成果。近年来基于自适应Kriging代理模型方法引起了广泛关注,主要原因在于Kriging模型是一种高斯过程插值方法,容易估计未知样本点的均值和标准差,样本点的标准差可以被广泛用于下一个样本点的更新与选取。文献[14]提出AK-MCS方法,该方法能保证所选择的样本点在极限状态方程周围并具有较大的标准差,实例表明该方法能有效平衡精度和效率间的关系。基于AK-MCS的思想,文献[15]提出基于全局灵敏度分析与Kriging代理模型的结构可靠性分析方法,该方法能部分去除AK-MCS中所选取对失效概率没有贡献的样本点,因此计算效率有所提高。文献[16]在AK-MCS的基础上,考虑了样本点间的相关性,提出相关Kriging代理模型的可靠性分析方法。然而,基于Krging代理模型的自适应代理模型构建和可靠性分析方法均需估计未知样本点的标准差,对于其他代理模型(神经网络、支持向量机、响应面等),无法给出样本点的标准差,从而导致以上方法局限于Kriging代理模型而无法用于其他代理模型。鉴于此,本文提出一种新的样本点选择更新策略(学习函数),无需用到样本点的标准差信息,可使所选择的样本点分布在极限状态周围且相互之间有一定的距离(同时考虑输入变量的权重),从而避免聚集在一起。本文建立的方法由于无需用到样本点的标准差信息,类似思路也可用于现有的其他代理模型中,因此鲁棒性较好。
-
Kriging模型源于地质统计,是一种半参数化模型并具有较好的灵活性,目前已得到广泛运用[17]。由于Kriging方法具有局部估计的特点并克服了非参数方法处理高维数据的局限性,使得其对非线性程度较高的方程仍具有较好拟合效果,利用Kriging模型可表示为[4]:
$$ \tilde g(\mathit{\boldsymbol{x}}) = {\mathit{\boldsymbol{F}}^{\rm{T}}}(\mathit{\boldsymbol{x}})\mathit{\boldsymbol{\beta }} + Z(\mathit{\boldsymbol{x}}) $$ (1) 式中,${\mathit{\boldsymbol{F}}^{\rm{T}}}(\mathit{\boldsymbol{x}})\mathit{\boldsymbol{\beta }}$为高斯过程的均值;Z(x)是均值为0,方差为$\sigma _z^2$的随机过程。任意两点xi、xj的协方差可表示为:
$$ {\rm{cov}}(z({\mathit{\boldsymbol{x}}_i}), z({\mathit{\boldsymbol{x}}_j})) = \sigma _z^2{R_\theta }({\mathit{\boldsymbol{x}}_i}, {\mathit{\boldsymbol{x}}_j}) $$ (2) 式中,Rθ为相关性函数,用来刻画样本间的相关性,一般而言,可以选择高斯相关函数,表示为:
$$ {R_\theta }({\mathit{\boldsymbol{x}}_i}, {\mathit{\boldsymbol{x}}_j}) = \prod\limits_{k = 1}^{{n_s}} {{R_\theta }(\mathit{\boldsymbol{x}}_i^k - \mathit{\boldsymbol{x}}_j^k)} = \exp \left( { - \sum\limits_{k = 1}^{{n_s}} {{\theta _k}|\mathit{\boldsymbol{x}}_i^k - \mathit{\boldsymbol{x}}_j^k{|^2}} } \right) $$ (3) 式中,ns为样本量。
根据极大似然估计,β、$\sigma _z^2$和$\tilde g(\mathit{\boldsymbol{x}})$可分别估计为[18]:
$$ \mathit{\boldsymbol{\hat \beta }} = {({\mathit{\boldsymbol{F}}^{\rm{T}}}\mathit{\boldsymbol{R}}_\theta ^{ - 1}\mathit{\boldsymbol{F}})^{ - 1}}{\mathit{\boldsymbol{F}}^{\rm{T}}}\mathit{\boldsymbol{R}}_\theta ^{ - 1}\mathit{\boldsymbol{\tilde g}} $$ (4) $$ \hat \sigma _z^2 = \frac{1}{{{n_s}}}{(\mathit{\boldsymbol{\tilde g}} - \mathit{\boldsymbol{F\hat \beta }})^{\rm{T}}}\mathit{\boldsymbol{R}}_\theta ^{ - 1}(\mathit{\boldsymbol{\tilde g}} - \mathit{\boldsymbol{F\hat \beta }}) $$ (5) $$ \widehat {\widetilde g}(\mathit{\boldsymbol{x}}) = \mathit{\boldsymbol{F}}{(\mathit{\boldsymbol{x}})^{\text{T}}}\mathit{\boldsymbol{\widehat \beta }} + {\mathit{\boldsymbol{r}}^{\text{T}}}(\mathit{\boldsymbol{x}})\mathit{\boldsymbol{R}}_\theta ^{ - 1}(\mathit{\boldsymbol{\tilde g}} - \mathit{\boldsymbol{F}}\mathit{\boldsymbol{\widehat \beta }}) $$ (6) 式(6)中,${\mathit{\boldsymbol{r}}^{\text{T}}}(\mathit{\boldsymbol{x}}) = [{R_\theta }(\mathit{\boldsymbol{x}}, {\mathit{\boldsymbol{x}}_1}), \cdots, {R_\theta }(\mathit{\boldsymbol{x}}, {\mathit{\boldsymbol{x}}_{{n_s}}})]$。
Kriging为现有的成熟技术,更多信息可以参考文献[19]。
-
构建兼顾精度和效率的高效代理模型,样本点的更新与选择是关键及核心所在。若选择的样本点过多,会浪费较多的计算资源;反之,构建的代理模型精度较低。在基于代理模型的结构可靠性分析中,为了提高精度和效率,需满足以下两种情况:1)保证所选择的样本点分布在极限状态方程周围;2)样本点之间应尽量分布均匀,避免出现相互聚集的情况,同时考虑变量在迭代过程中对失效概率贡献的权重,以下分别进行分析。
1) 记所构建的代理模型为$\tilde g(\mathit{\boldsymbol{x}})$,若样本点在极限状态方程周围,则其绝对值较小,可表示为:
$$ \left| {\tilde g(\mathit{\boldsymbol{x}})} \right| \approx 0 $$ (7) 2) 为了使样本点分布均匀并有一定的距离,n维空间任意两个点xi, xj的欧拉距离可表示为:
$$ d_E^{ij} = \sqrt {\sum\limits_{k = 1}^n {{{(x_k^i - x_k^j)}^2}} } $$ (8) 设随机产生的ns个样本点为xc,收集所得的nm个样本点为xs,由式(8)可知xc与xs之间的欧拉距离可表示为:
$$ {\mathit{\boldsymbol{d}}_E}({\mathit{\boldsymbol{x}}_c}, {\mathit{\boldsymbol{x}}_s}) = \left[ {\begin{array}{*{20}{c}} {d_E^{11}, }&{d_E^{12}, }&{ \cdots , }&{d_E^{1{n_s}}} \\ {d_E^{21}, }&{d_E^{22}, }&{ \cdots , }&{d_E^{2{n_s}}} \\ \vdots & \vdots & \ddots & \vdots \\ {d_E^{{n_m}1}, }&{d_E^{{n_m}2}, }&{ \cdots , }&{d_E^{{n_m}{n_s}}} \end{array}} \right] $$ (9) 为了使得xc与xs之间任意两点不相互聚集,应保证xc中任一点与xs所有点的最小欧拉距离大于0,最小欧拉距离可表示为:
$$ d_{E\min }^k = \min ({\mathit{\boldsymbol{d}}_E}(k, :)) $$ (10) 式中,$k = 1, 2, \cdots, {n_m}$。
式(8)中所有变量的权重是一样的,然而,在可靠性分析中,某些变量对失效概率的贡献较小,而某些变量对失效概率的贡献较大。此时,应给予失效概率贡献较大的变量较多的权重。考虑权重的欧拉距离[20]可表示为:
$$ d_{{\text{WE}}}^{ij} = \sqrt {\sum\limits_{k = 1}^n {{w_k}{{(x_k^i - x_k^j)}^2}} } $$ (11) 式中,wk为对应于第k个变量的权重。
由式(9~11)可知考虑权重的欧拉距离、欧拉最小距离可分别表示为:
$$ {\mathit{\boldsymbol{d}}_{{\text{WE}}}}({\mathit{\boldsymbol{x}}_c}, {\mathit{\boldsymbol{x}}_s}) = \left[ {\begin{array}{*{20}{c}} {d_{{\text{WE}}}^{11}, }&{d_{{\text{WE}}}^{12}, }&{ \cdots , }&{d_{{\text{WE}}}^{1{n_s}}} \\ {d_{{\text{WE}}}^{21}, }&{d_{{\text{WE}}}^{22}, }&{ \cdots , }&{d_{{\text{WE}}}^{2{n_s}}} \\ \vdots & \vdots & \ddots & \vdots \\ {d_{{\text{WE}}}^{{n_m}1}, }&{d_{{\text{WE}}}^{{n_m}2}, }&{ \cdots , }&{d_{{\text{WE}}}^{{n_m}{n_s}}} \end{array}} \right] $$ (12) $$ d_{{\text{WE}}\min }^k = \min ({\mathit{\boldsymbol{d}}_{{\text{WE}}}}(k, :)) $$ (13) 为了确定wk的值,可采用Sobol全局灵敏度分析方法,表示为:
$$ {w_k} = \frac{{{D_k}}}{D} $$ (14) 式中,Dk和D分别表示第k个方差和全部方差,其值可用蒙特卡罗仿真确定[21]:
$$ \hat D = \frac{1}{N}\sum\limits_{m = 1}^N {{{\tilde g}^2}(x_i^{(1m)}, x_{( - i)}^{(1m)})} - \widehat {\widetilde g}_0^2 $$ (15) $$ {\widehat D_k} = \frac{1}{N}\sum\limits_{m = 1}^N {\widetilde g(x_k^{(1m)}, x_{( - k)}^{(1m)})} \widetilde g(x_k^{(1m)}, x_{( - k)}^{( - k)}) - \widehat {\widetilde g}_0^2 $$ (16) 式中,${\widehat {\widetilde g}_0} = \frac{1}{N}\sum\limits_{m = 1}^N {\tilde g(x_i^{(1m)}, x_{(- i)}^{(1m)})} $;$x_i^{(1m)}$为第i个变量的第m个样本点。关于Sobol全局灵敏度分析更多信息,可参考文献[22]。
为了考虑变量权重并实现样本点不相互聚集且分布在极限状态方程周围,根据式(7)和(12~13),可得样本的更新选择策略(学习函数)表示为:
$$ \wp = \frac{{\left| {\tilde g({\mathit{\boldsymbol{x}}_c})} \right|}}{{{\mathit{\boldsymbol{d}}_{{\text{WE}}}}({\mathit{\boldsymbol{x}}_c}, {\mathit{\boldsymbol{x}}_s})}} $$ (17) 由式(17)可知,所选择的样本点应该离极限状态方程越近并且相互之间的距离越大越好。这等价于式(17)中的$\min (|\tilde g({\mathit{\boldsymbol{x}}_c})|)$和$\max ({\mathit{\boldsymbol{d}}_{{\text{WE}}}}({\mathit{\boldsymbol{x}}_c}, {\mathit{\boldsymbol{x}}_s}))$,这是一个典型的多目标优化问题。为了提高计算效率,首先用蒙特卡罗方法产生大量的候选样本点${\mathit{\boldsymbol{x}}_c} = (\mathit{\boldsymbol{x}}_c^1, \mathit{\boldsymbol{x}}_c^2, \cdots, \mathit{\boldsymbol{x}}_c^{{N_c}})$,${N_c} \geqslant 5 \times {10^5}$。基于式(17),计算每个候选样本点的值,在每一步迭代过程中则选取的样本点为:
$$ \left\{ \begin{array}{l} \mathit{\boldsymbol{x}}_c^* \in {\mathit{\boldsymbol{x}}_c}\\ {\rm{s}}{\rm{.t}}.\;\;\wp = \arg \min \left( {\frac{{|\tilde g(\mathit{\boldsymbol{x}}_c^i)|}}{{{\mathit{\boldsymbol{d}}_{{\rm{WE}}}}(\mathit{\boldsymbol{x}}_c^i, {\mathit{\boldsymbol{x}}_s})}}} \right)\;\;\;\;i = 1, 2, \cdots , {N_c} \end{array} \right. $$ (18) 由式(18)可得用于训练的样本点更新为:
$$ \left\{ \begin{gathered} {\mathit{\boldsymbol{x}}_s} = [{\mathit{\boldsymbol{x}}_s};\mathit{\boldsymbol{x}}_c^*] \hfill \\ \mathit{\boldsymbol{y}} = [\mathit{\boldsymbol{y}};g(\mathit{\boldsymbol{x}}_c^*)] \hfill \\ \end{gathered} \right. $$ (19) 为了停止所提算法的迭代过程,可参考文献[23]中的收敛准则。
-
记系统构建最后的代理模型为${{\tilde g}_s}(\mathit{\boldsymbol{x}})$,根据所产生的Nc个候选样本点${\mathit{\boldsymbol{x}}_c} = (\mathit{\boldsymbol{x}}_c^1, \mathit{\boldsymbol{x}}_c^2, \cdots, \mathit{\boldsymbol{x}}_c^{{N_c}})$,则系统失效概率可表示为:
$$ P_{f}^{\text{sys}}=\frac{1}{{{N}_{c}}}\sum\limits_{i=1}^{{{N}_{c}}}{I}[{{\tilde{g}}_{s}}(\mathit{\boldsymbol{x}}_{c}^{i})<0] $$ (20) 式中,$I\left[\centerdot \right]$为符号函数。当${{\tilde{g}}_{s}}(\mathit{\boldsymbol{x}}_{c}^{i}) < 0$时,$I\left[\centerdot \right]$=1;反之,$I\left[\centerdot \right]$=0。
当系统中存在m个失效模式时,则串联及并联系统的失效概率可分别表示为:
$$ P_{f}^{\text{sys}}=\frac{1}{{{N}_{c}}}\sum\limits_{i=1}^{{{N}_{c}}}{I}[\min (\tilde{g}_{s}^{1}(\mathit{\boldsymbol{x}}_{c}^{i}), \cdots , \tilde{g}_{s}^{1}(\mathit{\boldsymbol{x}}_{c}^{m}))<0] $$ (21) $$ P_{f}^{\text{sys}}=\frac{1}{{{N}_{c}}}\sum\limits_{i=1}^{{{N}_{c}}}{I}[\max (\tilde{g}_{s}^{1}(\mathit{\boldsymbol{x}}_{c}^{i}), \cdots , \tilde{g}_{s}^{1}(\mathit{\boldsymbol{x}}_{c}^{m}))<0] $$ (22) -
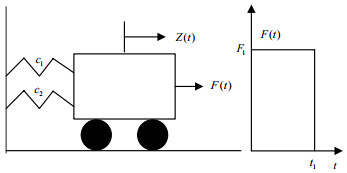
为了验证所提方法的精度和有效性,给出一个高度非线性振子系统进行说明,该系统具有6个随机变量,是一个中等规模的复杂系统。本例中,蒙特卡罗仿真产生的样本量为106个,其所得结果作为精确解用来进行对比分析。
$$ g({{c}_{1}}, {{c}_{2}}, m, r, {{t}_{1}}, {{F}_{1}})=3r-\left| \frac{2{{F}_{1}}}{m\omega _{0}^{2}}\sin \left( \frac{{{\omega }_{0}}{{t}_{1}}}{2} \right) \right| $$ (23) 
图 1 某振子系统
式中,${{\omega }_{0}}=\sqrt{\frac{{{c}_{1}}+{{c}_{2}}}{m}}$。
变量的相关分布参数信息如表 1所示。
表 1 变量的分布信息
变量 均值 方差 分布类型 m 1.0 0.05 正态 c1 1.0 0.10 正态 c2 0.1 0.01 正态 r 0.5 0.05 正态 F1 1.0 0.20 正态 t1 1.0 0.20 正态 本例中,为了与AK-MCS进行对比,产生的初始样本点取12个。为了全覆盖初始的样本空间,采用优化拉丁方采样方法或同类的方法。本文所提方法与AK-MCS、MCS方法的精度与效率对比如表 2所示。
表 2 各种方法的精度与效率对比
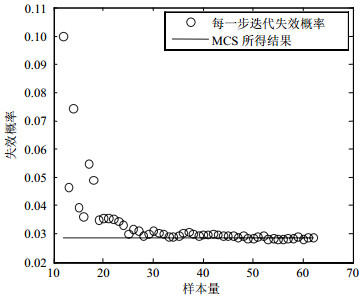
参数 方法 所提方法 AK-MCS[15] MCS 失效概率 0.028 7 0.028 4 0.028 6 可靠性指标 1.900 1 1.904 8 1.901 8 样本量 62 83 106 在每一步的迭代过程中样本量与失效概率的关系变化如图 2所示。

图 2 样本量与所对应的失效概率
本例中,用优化拉丁方试验设计方法产生12个在设计空间均匀分布的初始样本点,最终共用于训练代理模型的样本量为62个。虽然在每一步迭代过程中产生大量的随机样本,但无需用这些样本量去计算原始的极限状态方程,因此不会影响计算效率。从表 2及图 2可知,本文所提方法与MCS相比,其精度较高,但对极限状态方程的调用次数远低于MCS;与AK-MCS相比,其精度与效率基本在同一水平。但是,由于AK-MCS需要估计样本点标准差,因此其局限于Kriging代理模型,而本文所提方法无需用到样本点标准差,其鲁棒性远高于AK-MCS,因此可运用于其他现有的代理模型中。
-
本文对基于高效序列代理模型的结构可靠性分析方法进行了研究,并用算例验证了该方法的合理性,具体如下:
1) 工程中性能函数常为隐函数形式,大量重复的有限元仿真分析计算量较大,在实际工程中难以运用,基于代理模型的结构可靠性分析方法可提高计算效率。
2) 本文所提的学习函数可用于选择在每一步迭代过程中的样本点,其考虑了变量在迭代过程中的权重,也能保证所选择的样本点分布在极限状态方程周围且相互之间有距离。
3) 本文所提方法的精度和鲁棒性较高,可广泛用于结构可靠性及可靠性灵敏度分析。由于无需估计样本点的标准差,因此本文所提方法不局限于Kriging代理模型,还适用于现有的其他代理模型如支持向量机、神经网络等。
Structural Reliability Analysis Using Sequential Surrogate Models
-
摘要: 工程中部件或系统的性能函数通常是隐函数形式,该文提出基于高效代理模型的结构可靠性分析方法,构造新增样本点学习函数,并用于指导在序列迭代过程中的样本点选择。所提出的学习函数考虑了变量权重并保证所选的样本点相互之间有一定的距离且分布在极限状态方程周围。算例分析表明该方法有较好的精度和鲁棒性,不仅适用于性能函数为隐函数时的结构可靠性分析,而且也适用于现有的各种代理模型(神经网络、支持向量机、响应面等),为结构可靠性分析提供新途径与新方法。Abstract: Performance functions of components and structural systems are often given using implicit functions for many practical engineering. An efficient surrogate-models-based reliability analysis method is proposed in this paper, a new sample selection learning function is constructed as a guideline to adaptively select new sample point at each iteration. The proposed learning function considers the weights of variables and ensures that the selected sample points reside not only around the limit-state functions, but also far away each other. The numerical examples show that the proposed method is accuracy and robustness, thus it can be used for structural systems with implicit performance function and various existing surrogate models (e.g., neural networks, support vector machine, response surface model). The proposed method provides a novel method for structural reliability analysis.
-
Key words:
- design of experiment /
- reliability analysis /
- structural reliability /
- surrogate models
-
表 1 变量的分布信息
变量 均值 方差 分布类型 m 1.0 0.05 正态 c1 1.0 0.10 正态 c2 0.1 0.01 正态 r 0.5 0.05 正态 F1 1.0 0.20 正态 t1 1.0 0.20 正态  下载: 导出CSV
下载: 导出CSV
-
[1] 张旭东.不确定性下的多学科设计优化研究[D].成都: 电子科技大学, 2011. http://cdmd.cnki.com.cn/Article/CDMD-10614-1011191752.htm ZHANG Xu-dong. Multidisciplinary design optimization under uncertainties[D]. Chengdu: University of Electronic Science and Technology of China, 2011. http://cdmd.cnki.com.cn/Article/CDMD-10614-1011191752.htm [2] LOW B K. FORM, SORM, and spatial modeling in geotechnical engineering[J]. Structural Safety, 2014(49):56-64. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=2a2c34b9a31960718edbfb823967e297 [3] MELCHERS R E. Structural reliability analysis and prediction[M]. 2nd ed. New York:Wiley, 1999. [4] KAYMAZ I. Application of kriging method to structural reliability problems[J]. Structural Safety, 2005(27):133-151. https://www.sciencedirect.com/science/article/pii/S0167473004000463 [5] EASON J, CREMASCHI S. Adaptive sequential sampling for surrogate model generation with artificial neural networks[J]. Computers and Chemical Engineering, 2014, 68:220-232. doi: 10.1016/j.compchemeng.2014.05.021 [6] GOSWAMI S, GHOSH S, CHAKRABORTY S. Reliability analysis of structures by iterative improved response surface method[J]. Structural Safety, 2016(60):56-66. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=8327835b002a45e2dd6e9aab32fa7ef3 [7] BUCHER C G, BOURGUND U. A fast and efficient response surface approach for structural reliability problems[J]. Structural Safety, 1990, 7(1):57-66. doi: 10.1016/0167-4730(90)90012-E [8] KAYMAZ I, MCMAHON C A. A response surface method based on weighted regression for structural reliability analysis[J]. Probabilistic Engineering Mechanics, 2005, 20:11-17. doi: 10.1016/j.probengmech.2004.05.005 [9] NGUYEN X S, SELLIER A, DUPRAT F, et al. Adaptive response surface method based on a double weighted regression technique[J]. Probabilistic Engineering Mechanics, 2009, 24:135-143. doi: 10.1016/j.probengmech.2008.04.001 [10] GOSWAMI S, GHOSH S, CHAKRABORTY S. Reliability analysis of structures by iterative improved response surface method[J]. Structural Safety, 2016(60):56-66. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=8327835b002a45e2dd6e9aab32fa7ef3 [11] SUNDAR V S, SHIELDS M D. Surrogate-enhanced stochastic search algorithms to identify implicitly defined functions for reliability analysis[J]. Structural Safety, 2016(62):1-11. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=26eed8934e8971b7f4902ab0e8e397b8 [12] BOURINET J M. Rare-event probability estimation with adaptive support vector regression surrogates[J]. Reliability Engineering and System Safety, 2016, 150:210-221. doi: 10.1016/j.ress.2016.01.023 [13] PAPADOPOULOS V, GIOVANIS D G, LAGAROS N D, et al. Accelerated subset simulation with neural networks for reliability analysis[J]. Computer Methods in Applied Mechanics and Engineering, 2012, 223-224:70-80. doi: 10.1016/j.cma.2012.02.013 [14] ECHARD B, GAYTON N, LEMAIRE M. AK-MCS:an active learning reliability method combining Kriging and Monte Carlo simulation[J]. Structural Safety, 2011(33):145-154. http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0232275207/ [15] HU Z, MAHADEVAN S. Global sensitivity analysis-enhanced surrogate (GSAS) modeling for reliability analysis[J]. Structural and Multidisciplinary Optimization, 2016, 53(3):501-521. doi: 10.1007/s00158-015-1347-4 [16] ZHU Z F, DU X. Reliability analysis with Monte Carlo simulation and dependent Kriging predictions[J]. ASME Journal of Mechanical Design, 2016, 138:1214031-12140311. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=b89796cf967292fb888086e69371f5da [17] 苏永华, 罗正东, 张盼凤, 等.基于Kriging的边坡稳定可靠度主动搜索法[J].岩土工程学报, 2013, 35(10):1863-1869. http://www.cnki.com.cn/Article/CJFDTotal-YTGC201310015.htm SU Yong-hua, LUO Zheng-dong, ZHANG Pan-feng, et al. Active searching algorithm for slope stability reliability based on kriging model[J]. Chinese Journal of Geotechnical Engineering, 2013, 35(10):1863-1869. http://www.cnki.com.cn/Article/CJFDTotal-YTGC201310015.htm [18] GASPAR B, TEIXEIRA A P, GUEDES SOARES C. Assessment of the efficiency of kriging surrogate models for structural reliability analysis[J]. Probabilistic Engineering Mechanics, 2014, 37:24-34. doi: 10.1016/j.probengmech.2014.03.011 [19] DUBOURG V, SUDRET B. Meta-model-based importance sampling for reliability sensitivity analysis[J]. Structural Safety, 2014(49):27-36. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=5caf1b857065ccc3873b72ed32a19555 [20] JIN R C, SUDJIANTO A, CHEN W. On sequential sampling for global metamodeling in engineering design[C]//Proceedings of DETC 2002. Canada: [s.n.], 2002. [21] DUAN L, XIAO N C, HU Z, et al. An efficient lightweight design strategy for body-in-white based on implicit parameterization technique[J]. Structural and Multidisciplinary Optimization, 2017, 55(5):1927-1943. doi: 10.1007/s00158-016-1621-0 [22] CANNAVO F. Sensitivity analysis for volcanic source modeling quality assessment and model selection[J]. Computers and Geosciences, 2012, 44:52-59. doi: 10.1016/j.cageo.2012.03.008 [23] XIAO N C, ZUO M J, ZHOU C. A new adaptive sequential sampling method to construct surrogate models for efficient reliability analysis[J]. Reliability Engineering and System Safety, 2018, 169:330-338. doi: 10.1016/j.ress.2017.09.008 -

 点击查看大图
点击查看大图
图(2) / 表(2)
计量
- 文章访问数: 3873
- HTML全文浏览量: 1468
- PDF下载量: 100
- 被引次数: 0
