 ISSN
ISSN 



-
置信规则库(belief rule base, BRB)系统是由传统的IF-THEN规则库系统扩展而来,由于在IF-THEN规则中加入了置信框架,BRB系统不仅能处理定性和定量的知识,还能够在处理过程中保留信息的不确定性部分。BRB系统的核心是基于证据推理的置信规则库推理方法(RIMER)[1],该方法能对带有含糊或模糊不确定性、不完整或概率不确定性以及非线性的数据进行建模。目前BRB方法广泛应用于人工智能和复杂系统建模等领域,包括智能交通指示灯[2]、石墨成分检测[3]、输油管道检漏[4]、复杂系统的在线安全评估[5]和数控机床健康评估[6]等。
BRB系统的性能主要受BRB的参数和结构的影响,其中BRB参数包括属性权重、规则权重、候选值和置信度等;BRB结构主要取决于输入变量的个数和规则条数等。参数的选择直接影响了BRB的推理准确性,而结构的优劣影响了BRB的系统复杂度。根据现有的研究可知,提高BRB系统的推理准确性和减少BRB系统的复杂性往往是两个冲突的目标。因此需要通过合适的算法来寻找到两个目标上的平衡解。
但目前基于BRB的研究都是针对BRB参数学习或者结构约简的单目标优化。BRB系统中各个参数的取值直接影响到RIMER方法的推理准确性,因此BRB参数学习是备受关注的问题之一。最早,BRB中参数的取值是由专家依据经验给定。随后,文献[7]提出了参数优化模型。随着参数优化模型的引入,文献[8-9]提出了基于梯度下降法和基于变速PSO算法等参数优化算法。这些优化模型已能有效地解决特殊情况下BRB参数设置不合理的问题。但是,当BRB的结构不合理时,对BRB进行参数学习可能会导致RIMER方法的推理效果更差。在构造BRB时,随着前提属性数量增加,系统的规则数量会呈指数级增长,当实际问题太过复杂时,就容易引起“组合爆炸”的问题[9],所以,BRB结构的合理性对RIMER的推理准确性至关重要。现有的BRB结构优化方法已经能够有效地减少BRB的规则数量,主要的结构优化算法有:文献[10]提出的基于统计效用的结构学习方法和文献[11]提出的基于特征提取的结构学习方法等。但以上研究均未涉及BRB的多目标优化问题。因此,对提高BRB推理准确性和减少系统的复杂性这两个目标构建多目标优化模型并进行求解,具有重要的价值。
多目标优化问题涉及到多个目标的优化,这些目标之间往往是相互冲突的[12],加上每个目标单位和量纲不同,因此一个目标上性能的优化可能导致另一个目标性能在降低。研究证明多目标进化算法(multi objective evolutionary algorithms, MOEAs)[12]能有效求解多目标优化问题。多目标优化问题的解是一组均衡解,被称为非支配解(non dominated solutions, NDS)[13],这些解没有绝对的优劣之分,要根据实际的需求结合相关领域的知识,从中选择一个折中解。
为此,本文拟在BRB中结合改进型Pareto存档进化策略(M-PAES),提出基于M-PAES多目标优化的置信规则库推理方法,对BRB系统的推理精度和复杂度构建多目标优化模型,从而得到一组均衡解供决策者选择。在实验中选用标准时间序列Box-Jenkins和Mackey-glass来验证该方法的有效性。
-
BRB中置信规则是由传统IF-THEN[1]规则扩展而来,增加了分布式置信框架,加入了规则权重和前提属性权重,其中第k条规则表示为:
$$ \begin{array}{c} {R_k}:{\rm{if}}\;A_1^k \wedge A_2^k \wedge \cdots \wedge A_{{T_k}}^k\;\\ {\rm{then}}\;{\rm{ }}\{ ({D_1}, {{\bar \beta }_{1, k}}), ({D_2}, {{\bar \beta }_{2, k}}), \cdots, ({D_N}, {{\bar \beta }_{N, k}})\} \\ \;k = 1, 2, \cdots, L \end{array} $$ (1) 式中,${R_k}(k = 1, 2, \cdots, L)$表示第k条规则;第k条规则的第i个前提属性为$A_i^k(i = 1, 2, \cdots, {T_k})$;${D_j}(j = 1, 2, \cdots, N)$表示规则结果的评价等级;${\bar \beta _{j, k}}(j = 1, 2, \cdots, N;k = 1, 2, \cdots, L)$表示第k条规则的结果输出在第j个评价等级上的置信度,当$\sum\limits_{j = 1}^N {{{\bar \beta }_{j, k}} = 1} $时表示知识完整,否则知识不完整。第k条规则的规则权重表示为${\theta _k}(k = 1, 2, \cdots, L)$;第k条规则的第i个前提属性的权重表示为${\delta _{k, i}}(k = 1, 2, \cdots, L;i = 1, 2, \cdots, {T_k})$。
RIMER方法是BRB系统的核心部分,推理过程中,首先是计算出规则的激活权重,然后对评价等级的置信度进行修正,最后使用ER算法来合成规则。其中,第k条规则的激活权重为:
$$ \begin{array}{l} {\omega _k} = \frac{{{\theta _k}\prod\limits_{i = 1}^{{T_k}} {{{(\alpha _i^k)}^{{{\bar \delta }_{k, i}}}}} }}{{\sum\limits_{l = 1}^L {\left( {{\theta _l}\prod\limits_{i = 1}^{{T_k}} {{{(\alpha _i^l)}^{{{\bar \delta }_{l, i}}}}} } \right)} }}\\ {{\bar \delta }_{k, i}} = \frac{{{\delta _{k, i}}}}{{{{\max }_{i = 1, 2, \cdots, {T_k}}}\{ {\delta _{k, i}}\} }} \end{array} $$ (2) 式中,${\omega _k} \in [0, 1]$;$\alpha _i^k$表示第k条规则中第i个前提属性的候选值对应的个体匹配度;当$\alpha _i^k = 0$时,表示第k条规则未被激活。第k条规则中第i个输入xi相对于参考值$A_i^k$的个体匹配度为:
$$ \left\{ {\begin{array}{*{20}{l}} {\alpha _i^j = \frac{{A_i^{k + 1}-{x_i}}}{{A_i^{k + 1}-A_i^k}}\;\;\;\;\;\;\;\;\;\;A_i^k \le {x_i} \le A_i^{k + 1}\;\;\;\;{\rm{ and}}\begin{array}{*{20}{l}} {}&{j = k} \end{array}}\\ {\alpha _i^{j + 1} = 1-\alpha _i^k\;\;\;\;\;A_i^k \le {x_i} \le A_i^{k + 1}\;\;\;\;{\rm{ and}}\begin{array}{*{20}{c}} {}&{}&{j = k} \end{array}}\\ {\alpha _i^s = 0\;\;\;\;\begin{array}{*{20}{l}} {}&{} \end{array}s \ne \left\{ {\begin{array}{*{20}{l}} k\\ {k + 1} \end{array}\;\;\;\;\begin{array}{*{20}{l}} {}&{}&{}&{\begin{array}{*{20}{l}} {}&{}&{}&{} \end{array}} \end{array}} \right.} \end{array}} \right. $$ (3) 由于输入数据可能不完整,因此需要对激活规则结果集的置信度进行修正,其中第k条规则中第i个评价等级上的置信度修正公式如下:
$$ \left\{ \begin{array}{l} {\beta _{i, k}} = {{\bar \beta }_{i, k}}\frac{{\sum\limits_{t = 1}^{{T_k}} {\left( {\tau (t, k)\sum\limits_{j = 1}^{{J_t}} {{\alpha _{t, j}}} } \right)} }}{{\sum\limits_{t = 1}^{{T_k}} {\tau (t, k)} }}, \\ \tau (t, k) = \left\{ {\begin{array}{*{20}{c}} 1&{\;{A_t} \in {R_k}(t = 1, 2, \cdots, {T_k})}\\ 0&{其他} \end{array}} \right. \end{array} \right. $$ (4) 式中,${J_t} = |{A_t}|$表示候选值的个数,由上述公式可求得全部激活规则的激活权重及修正后的评价等级置信度。
每条被激活的规则可视为证据推理(evidential reasoning, ER)方法中的一个基本属性,用ER算法合成所有激活规则。由激活规则结果集的置信度和激活权重计算基本可信值:
$$ \left\{ \begin{array}{l} {m_{n, i}} = {\omega _i}{\beta _{n, i}}\\ {m_{H, i}} = 1-{\omega _i}\sum\limits_{n = 1}^N { = {{\bar m}_{H, i}} + {{\tilde m}_{H, i}}} \\ {{\tilde m}_{H, i}} = {\omega _i}\left( {1-\sum\limits_{n = 1}^N {{\beta _{n, i}}} } \right)\\ {{\bar m}_{H, i}} = 1-{\omega _i} \end{array} \right. $$ (5) 然后使用ER的解析公式,合成所有激活规则,一次合成公式如下:
$$ \begin{array}{c} {C_n} = k\left[ {\prod\limits_{j = 1}^L {({m_{n,j}} + {{\bar m}_{H,j}} + {{\tilde m}_{H,j}})} - \prod\limits_{j = 1}^L {({{\bar m}_{H,j}} + {{\tilde m}_{H,j}})} } \right]\\ {{\tilde C}_H} = k\left[ {\prod\limits_{j = 1}^L {({{\bar m}_{H,j}} + {{\tilde m}_{H,j}})} - \prod\limits_{j = 1}^L {{{\bar m}_{H,j}}} } \right]\\ {{\bar C}_H} = k\prod\limits_{j = 1}^L {{{\bar m}_{H,j}}} \\ {k^{ - 1}} = \sum\limits_{n = 1}^N {\prod\limits_{j = 1}^L {({m_{n,j}} + {{\bar m}_{H,j}} + {{\tilde m}_{H,j}})} - } \\ (N - 1)\prod\limits_{j = 1}^L {({{\bar m}_{H,j}} + {{\tilde m}_{H,j}})} \end{array} $$ (6) 接着,计算各个评价等级上的置信度:
$$ \left\{ \begin{array}{l} {\beta _n} = \frac{{{C_n}}}{{1 - {{\bar C}_H}}}(n = 1, 2, \cdots, N)\\ {\beta _H} = \frac{{{{\tilde C}_H}}}{{1 - {{\bar C}_H}}} \end{array} \right. $$ (7) 由ER算法合成激活规则后得到的分布式置信度是RIMER方法的常见输出类型之一,其中第i个BRB相关的分布式置信度输出可表示为:
$$ {\rm{BR}}{{\rm{B}}_i}:\{ ({D_1}, {\beta _{1, i}}), ({D_2}, {\beta _{2, i}}), \cdots, ({D_N}, {\beta _{N, i}})\} $$ (8) 当输出为数值类型时,可将置信度分布转化为平均效用值,假设等级效用值$\mu = \{ {\mu _1}, {\mu _2}, \cdots, {\mu _N}\} $,满足${\mu _1} \le {\mu _2} \le \cdots \le {\mu _N}$,平均效用计算公式为:
$$ \left\{ \begin{array}{l} {\mu _{\min }} = ({\beta _1} + {\beta _D}){\mu _1} + \sum\limits_{j = 2}^N {{\beta _j}{\mu _j}} \\ {\mu _{\max }} = ({\beta _N} + {\beta _D}){\mu _N} + \sum\limits_{j = 1}^{N - 1} {{\beta _j}{\mu _j}} \\ {\mu _{{\rm{avg}}}} = \frac{{{\mu _{\min }} + {\mu _{\max }}}}{2} \end{array} \right. $$ (9) BRB系统数值型输出为:
$$ f(x) = \sum\limits_{i = 1}^N {[\mu ({D_i}){\beta _i}(x)]} $$ (10) -
多目标优化问题(multi-objective programming, MOP)是指多个目标函数的最小化或最大化问题,它受一系列约束条件和变量的限制[14]。多目标优化问题的函数表示如下:
$$ \begin{array}{l} {\rm{Min}}/{\rm{Max}}\begin{array}{*{20}{c}} {}&{{f_m}(x)} \end{array}\begin{array}{*{20}{c}} {}&{m = 1, 2, \cdots, M} \end{array}\\ {\rm{subject to }}\left\{ \begin{array}{l} \begin{array}{*{20}{c}} {{g_j}(x) \le 0}&{j = 1, 2, \cdots, J} \end{array}\\ \begin{array}{*{20}{c}} {{h_k}(x) = 0}&{k = 1, 2, \cdots, K} \end{array}\\ x_i^{(L)} \le {x_i} \le x_i^U\;\;\;\;\;i = 1, 2, \cdots, n \end{array} \right. \end{array} $$ (11) 式中,解$x \in {R^n}$表示n维的决策空间$x = \{ {x_1}, {x_2}, \cdots, {x_n}\} $;$f(x)$表示决策空间和目标空间映射后的目标函数;${g_j}(x) \le 0$包含J个不等式约束条件;${h_k}(x) = 0$包含K个等式约束条件。
在多目标优化问题中,所有满足约束条件的解构成的集合称为可行解集Xf。假设解${x_a}, {x_b} \in {X_f}$,当${x_a}$同时满足:
1) 在所有目标函数中,${x_a}$不比${x_b}$差,即:
$$ \forall i = 1, 2, \cdots, n\;\;\;\;\;{f_i}({x_a}) \ge {f_i}({x_b}) $$ (12) 2) ${x_a}$至少在一个目标函数上比${x_b}$好,即:
$$ \exists i = 1, 2, \cdots, n\;\;\;\;\;{f_i}({x_a}) > {f_i}({x_b}) $$ (13) 则称解${x_a}$支配${x_b}$,表示为${x_a} \succ {x_b}$,符号$ \succ $表示支配关系。当解${x_a}$支配可行解${X_f}$中的所有解时,${x_a}$被称为Pareto-最优解,即:
$$ \exists x \in {X_f}\;\;x \succ {x_a} $$ (14) 所有Pareto-最优解组成的集合${P_S}$被称为Pareto-最优解集。Pareto-最优前沿指Pareto-最优解集合${P_S}$中的解对应的目标函数值组成的集合${P_F}$,定义为:
$$ {P_F} = \{ {f_1}(x), {f_2}(x), \cdots, {f_p}(x)\left| {x \in {P_s}} \right.\} $$ (15) 多目标优化问题与单目标优化问题最大的区别在于它的解不唯一,因此,求解的关键就是找到近似Pareto-最优前沿[14]。目前求解多目标优化问题的方法主要有:传统方法和多目标进化算法(MOEAs) [14]。传统方法主要将多目标问题转化成单目标问题求解,如:加权法、约束法、目标规划法和极小极大法等[14]。多目标进化算法包括:强度Pareto进化算法(SPEA)、改进型强度Pareto进化算法(SPEA2)、小生境Pareto遗传算法(NPGA)、不同类型的Pareto存档进化策略(PAES)和非劣分类遗传算法(NSGA)及改进型非劣分类遗传算法(NSGA-Ⅱ)等[15]。
-
本文采用染色体编码方式构建BRB多目标优化模型。由式(1),可将BRB的规则库用矩阵J表示:
$$ \mathit{\boldsymbol{J}} = \left[{\begin{array}{*{20}{c}} {{j_{1, 1}}}& \cdots &{{j_{1, {T_k}}}}&{{j_{1, {T_k} + 1}}}\\ \cdots&\cdots&\cdots&\cdots \\ {{j_{k-1, 1}}}& \cdots &{{j_{k-1, {T_k}}}}&{{j_{k-1, {T_k} + 1}}}\\ {{j_{k, 1}}}& \cdots &{{j_{k, {T_k}}}}&{{j_{k, {T_k} + 1}}} \end{array}\begin{array}{*{20}{c}} \cdots \\ \cdots \\ \cdots \\ \cdots \end{array}\begin{array}{*{20}{c}} {{j_{1, {T_k} + N}}}\\ \cdots \\ {{j_{k - 1, {T_k} + N}}}\\ {{j_{k, {T_k} + N}}} \end{array}} \right] $$ (16) 如式(1)所示,每个规则的前件部分包含了所有的输入变量。但其中有一些输入变量实际可能无关紧要,甚至会误导推理。因此,可以选取那些对BRB系统有利的输入变量来构建系统模型。为了达到这一目标,对每一个属性候选值添加一个新的划分${A_{i, 0}}$,其中$i = 1, 2, \cdots, {T_k}$。当输入值${x_i}$对应的划分区间是${A_{i, 0}}$时,表示该输入不影响激活权重的计算,可以被忽略不记。${A_{i, 0}}$的存在使得系统可以用输入变量的一个子集来生成规则,这便是一种特征选择的方式。举例说明该特征选择的方式,假设一个BRB由以下3条规则构成:
$$ \begin{array}{l} {R_1}:{\rm{if}}\;{x_1}{\rm{ is }}{A_{1, 2}} \wedge \;{x_2}{\rm{ is }}{A_{2, 1}}\\ \begin{array}{*{20}{c}} {}&\;\;{{\rm{then}}\;\{ ({D_1}, 0.1), ({D_2}, 0.7), ({D_3}, 0.2)\} } \end{array}\\ {R_2}:{\rm{if}}\;{x_1}{\rm{ is }}{A_{1, 3}} \wedge {x_2}{\rm{ is }}{A_{2, 2}}\\ \begin{array}{*{20}{c}} {}&\;\;{{\rm{then}}\;\{ ({D_1}, 0.5), ({D_2}, 0.3), ({D_3}, 0.2)\} } \end{array}\\ {R_3}:{\rm{if}}\;{x_1}{\rm{ is }}{A_{1, 1}} \wedge {x_2}{\rm{ is }}{A_{2, 0}}\\ \begin{array}{*{20}{c}} {}&\;\;{{\rm{then}}\;\{ ({D_1}, 0.1), ({D_2}, 0.4), ({D_3}, 0.5)\} } \end{array} \end{array} $$ 则,该BRB的规则J矩阵表示如下:
$$ \mathit{\boldsymbol{J}} = \left[{\begin{array}{*{20}{c}} {2.0}&{1.0}&{}\\ {3.0}&{2.0}&{}\\ {1.0}&{0.0}&{} \end{array}\begin{array}{*{20}{c}} {0.1}&{0.7}&{0.2}\\ {0.5}&{0.3}&{0.2}\\ {0.1}&{0.4}&{0.5} \end{array}} \right] $$ (17) 则相应的染色体如图 1所示:

图 1 染色体编码方式
当一个输入的变量不属于任意一条规则时,该输入变量就可以被删除,以这种方式可以对输入变量进行选择。编码时,每条染色体与一个目标向量相关联,每个值通常表达了满足该目标向量的程度。在构建BRB时,使用一个二维向量来表示。向量的第一个元素代表BRB的复杂度,用Rulesize表示。设前提属性个数为a,每个前提属性候选值划分数为K,则${\rm{Rulesize}} = ({K^a})$。向量的第2个元素代表BRB系统准确性,用均方根误差(root mean square error, RMSE)来衡量,表示了BRB系统推理输出和真实输出之间的误差。均方根误差公式如下:
$$ {\rm{RMSE}} = \sqrt {\frac{{\sum\limits_{i = 1}^n {{{({f_i}(x)-{{f'}_i}(x))}^2}} }}{n}} $$ (18) 式中,n表示查询数据的总个数;$f(x)$表示数据的真实输出值;$f'(x)$表示BRB系统的推理输出。在实际应用中,构建一个很复杂BRB推理系统其应用价并不高。因此,需设置BRB系统规则数量上限${M_{{\rm{max}}}}$和每条规则输入变量的上限${F_{\max }}$。
-
BRB系统的推理准确性提高的同时复杂度也在增加,因此,需要寻找到系统准确性和复杂性之间的一组均衡解。针对BRB系统的多目标优化问题,本文选用改进的Pareto存档进化策略法(M-PAES)构建BRB的多目标优化模型。M-PAES的算法思想简单、复杂度低、进化性能佳和收敛速度快。
-
Pareto存档进化策略(PAES)是Knoweles和Cone提出的[14]。经典(1+1)PAES算法是通过变异一个父解来产生子解,然后赋给子解个体适应度,比较父解和子解的支配关系,再由精英保留策略获取较好的解[14]。在这过程建立一个非支配解档案(NDS)用于保存得到的解。混合PAES算法(M-PAES)是由原始(1+1)PAES算法改进得到的。M-PAES在产生新解时施加了重组与变异的混合操作[14]。档案集合的更新方式与原始PAES算法相类似,通过对当前个体采用二进制锦标赛选择。与(1+1)PAES算法的主要区别在于:M-PAES使用了两个档案集合,档案集合G用于存储全局最优解;档案集合H用于存档局部最优解。集合H在每次局部搜索开始时为空,然后从集合G中不断选出比当前个体差的解放到集合H中。M-PAES算法主要通过自适应网格算法保证解集的多样性。
-
自适应网格算法的基本思想是:把目标空间划分成多个网格,并为每个个体分配一个网格[13]。这样可以择优保留父解和子解,同时可根据候选解的情况更新档案集NDS。其主要过程如算法1所示。
算法1 自适应网格法
输入:当前解x, 候选解$x'$。输出:Pareto最优前沿。
1) 判断候选解是否被NDS中的任意解支配。
If $\exists {a_{x'}} \in {\rm{NDS}}:{a_{x'}} \succ x'$($ax'$支配$x'$)
Then 删除${a_d}$
Else 执行下一步
2) 判断候选解是否支配NDS中的解。
If $\exists {a_d} \in {\rm{NDS}}:x' \succ {a_d}$(${a_d}$是所有被$x'$支配的解)
Then删除${a_d}$,并将$x'$加入档案NDS中
Else执行下一步
3) 判断档案是否已满。
If Maxsize
Then执行步骤5)
Else 执行下一步
4) 把$x'$加入档案中,并执行步骤6)。
5) 判断候选解是否增加了档案NDS的密度。
If $x'$增加NDS密度
Then删除NDS中密度最大的网格中的任意一个解,加入$x'$,并执行下一步
Else执行下一步
6) 和当前解x比较,判断候选解$x'$是否在较稀疏的一边,其中稀疏性由拥挤系数进行判断。
If $x'$在较稀疏的一边
Then去掉当前解x,接收候选解$x'$
Else丢弃候选解$x'$
档案集NDS的大小会在迭代过程中不断增加或者减少,并通过自适应算法自动调整网格的大小,对NDS中解在网格中的位置重新进行划分。NDS进行网格更新时分两种情况[14]:1)当NDS档案已满时,就随机删除NDS中网格拥挤系数大的点,再将新的解加入NDS中。2) NDS档案未满时,首先对网格重新划分,然后将新解加入档案集NDS。
-
改进型M-PAES算法是通过变异和重组的混合操作来生成新的解,算法包括候选解的产生、候选解的选择和构建非支配个体的档案集[14]。算法在产生新个体时,利用参数pc来决定重组与变异操作所占的比重。变异的方式与原始PAES算法的变异过程相同,重组与传统的混合PAES算法不同。重组过程中:对于m个长度为n的解,M-PAES算法首先选择m-1个分割点,然后将每个解分成m段,第一个解提供分割的第一段,第二个提供第二段,……,从而重组出一个新的解,重复上述过程,生成m个新解。M-PAES算法生成新解的方法如算法2所示。
算法2 加入重组优化的多目标变异算法
P ←档案中所有候选集
Loop
PS←从P中随机选取m个候选解
r←随机选取[0, 1]的一个值
if $r < pc$
Then ${P_o} \leftarrow $重组操作(${P_S}$)
Else
${P_o} \leftarrow $对每一个解$x \in {P_S}$,随机选一位进行取反
End if
For每一个解$x' \in {P_o}$
If $z \in P$ 满足$z \ge x'$
Then $P \leftarrow (P-\{ z \in P\left| {x' \succ z} \right.\} ) \cup \{ x'\} $
End if
End for
End loop
改进型M-PAES局部搜索机制与原始PAES类似,不过终止准则有所变化。当搜索次数达到最大局部搜索次数,或者达到最大局部搜索失败次数时,终止搜索[15]。算法设置一个fail参数,初始值为0,只要变异后的个体被当前个体支配,fail加1;否则fail=0。算法终止条件有两个:迭代结束或迭代未结束但已没有新的解加入档案。候选解接受策略生成一个只包含非劣解的档案,初始档案为空,随机生成第一个父解。算法终止时,档案中包含了一组近似Pareto-最优前沿的解。具体实现详见算法3。
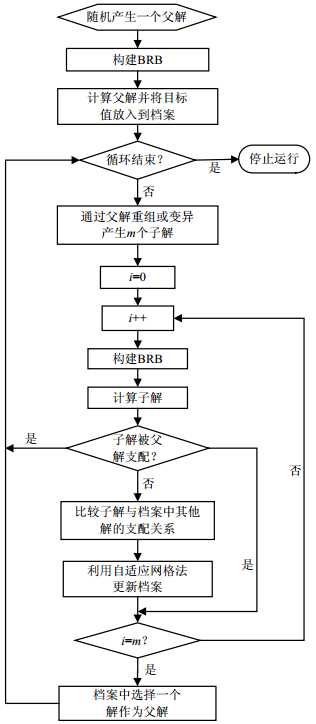
算法3 多目标优化算法M-PAES
1) 随机产生一个父解x。
2) 计算父解并将目标值放入档案。
3) 如果循环结束End,否则进行下一步。
4) 通过父解x变异或重组产生子解s(调用算法2)。
$$ s \leftarrow x $$ 5) 计算子解的适应值$f(s)$,本文中算法的适应值由规则数Rulesize和均方根误差RMSE组成。
6) 比较子解与父解的支配关系。
$$ {\rm{If}}\;f(s) \prec f(x) $$ 对比子解与NDS档案中其他解的支配关系,利用自适应网格法更新NDS (调用算法1)。
7) 从NDS中选择一个新的父解,返回步骤3)。
-
采用改进型M-PAES构建的BRB多目标优化系统可以寻找到一组具有不同准确率和复杂度的Pareto最优解集,让决策者根据实际需要进行选择最佳的折中解。具体的算法流程如图 2所示。

图 2 M-PAES-BRB算法流程图
-
实验部分将对M-PAES-BRB多目标优化方法的有效性进行分析,并将该算法与现有模糊规则库FRBSs多目标优化方法进行对比。
-
本文选用两组标准时间序列数据集BJGF(the Box-Jenkins gas furnace)和MG (the Mackey-Glass chaotic time series)进行实验分析[16]。把每组数据都分成训练数据和测试数据。实验中每个前提属性候选值的划分数均设为4。用均方根误差RMSE来衡量BRB系统的推理准确性,用规则库大小Rulesize来衡量BRB系统的复杂度。实验环境为:Intel Core i5-4570 3.20 GHz处理器,内存6.00 GB,Windows 8.1操作系统,算法用C++实现,Matlab生成实验图表。
-
Box-Jenkins煤气炉中空气和甲烷形成一种含有CO2的气体混合物。气炉中空气的输入速率是一个常量,而甲烷进给速率随时都在变化。由此产生的CO2浓度是由气炉排放的废气测量得到的。Box- Jenkins煤气炉的时间序列包含296对输入和输出数据,表示成$\{ u(t), y(t)\} $。甲烷的供给速度是$u(t)$,输出数据$y(t)$表示了煤气炉中CO2的浓度值。实验用$\{ y(t - 1), y(t - 2), y(t - 3), u(t - 1), u(t - 2), u(t - 3), u(t - 4), u(t - 5), u(t - 6)\} $来推测CO2的浓度,数据对表示如下:
$$ [u(t-6), \cdots, u(t-1), y(t-4), \cdots, y(t - 1);y(t)] $$ (19) 本实验迭代次数设为3 000,实验中将数据集随机分成50%的数据作为训练数据,另外50%为测试数据,分别从规则条数和决策准确性两方面进行分析。
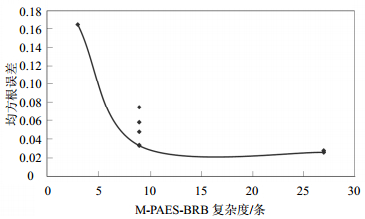
采用M-PAES-BRB方法求解BJGF数据集,获得的Pareto最优解集如图 3所示。由图 3可知,在保证推理准确性的同时,采用M-PAES-BRB方法建模,系统的规则数可以由原来的262 144条约简到81条以内,极大降低了BRB的系统复杂度。

图 3 BJGF数据集的Pareto最优前沿
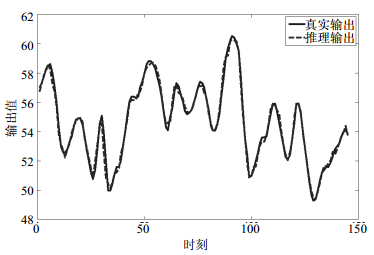
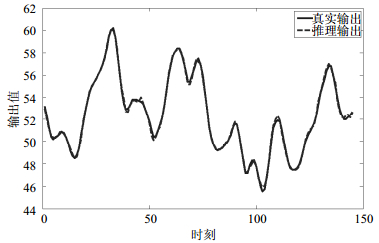
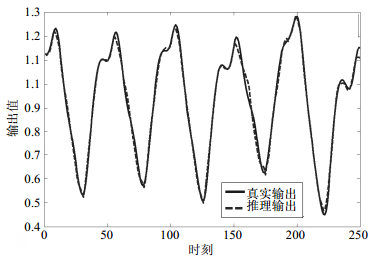
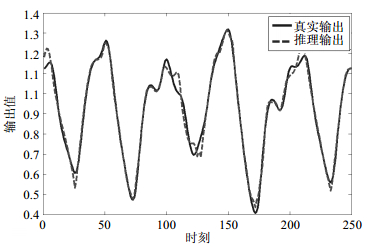
M-PAES-BRB方法对BJGF训练数据集和测试数据集的预测结果的拟合曲线如图 4和图 5所示。从图 4和图 5可知,本文方法推理得到的CO2浓度和气炉真实的CO2浓度非常接近,同时BRB系统复杂度被大幅降低。可见,采用算法不仅提升了推理准确性还极大约简了BRB系统的规则数。

图 4 BJGF训练数据集拟合结果

图 5 BJGF测试数据集拟合结果
为了进一步说明M-PAES-BRB方法的有效性,表 1详细列出了M-PAES-BRB方法与现有其他模糊规则库的多目标优化方法(FRBSs)[16]用于推理BJGF数据集CO2浓度时的均方根误差RMSE。
表 1 BJGF数据集推理准确性(RMSE)对比
方法 推理精度 训练数据 测试数据 M-PAES-BRB 0.26 0.39 (2+2)M-PAES-FRBSs(10, 20) 0.56 0.79 NSGA-Ⅱ-FRBSs 0.60 0.90 MOGA--FRBSs 1.91 2.02 PAES--FRBSs 0.62 0.80 (2+2) PAES--FRBSs 0.58 0.75 SOGA--FRBSs 0.62 1.18 由表 1可知,针对BJGF的训练数据和测试数据,M-PAES-BRB方法的推理得到的均方根误差都是最小的,推理准确度高于现有FRBSs方法。
-
麦克-格拉斯(Mackey-Glass)时间序列是一种经典的混沌时间序列,由Mackey等人在1977年所提出的一个模型,经常被用于验证模型的有效性。其可由时滞微分方程得到:
$$ \frac{{{\rm{d}}x(t)}}{{{\rm{d}}t}} = \frac{{ax(t-\tau )}}{{1 + {x^{10}}(1-\tau )}}-bx(t) $$ (20) 实验中设$a = 0.2$,$b = 0.1$,$\tau = 17$,用4阶Runge-Kutta方法来生成数据,$x(0) = 1.2$,步长设为0.1。随机选取某区间的500个如下形式的数据对:
$$ [x(t-18), x(t-12), x(t-6), x(t);x(t + 6)] $$ (21) 从数据集中选出250个对数据作为训练集,250个数据对作为测试数据集。算法的迭代次数为3 000。实验从规则条数和决策准确性两方面进行分析,求解得到的Pareto最优解集如图 6所示。

图 6 Mackey-glass数据集的Pareto最优前沿
从图 6分析可知,M-PAES-BRB方法能很好地拟合Mackey-glass时间序列,同时用于构建BRB系统的规则数也由原来的256条约简到27条以内,大大降低了系统复杂度。对Mackey-glass训练集和测试集的拟合结果分别如图 7和图 8所示。分析可知,对于Mackey-glass时间序列的训练数据集和测试数据集,M-PAES-BRB方法均能很好地进行推理预测。

图 7 Mackey-glass训练数据集拟合结果

图 8 Mackey-glass测试数据拟合结果
同时,为了进一步说明M-PAES-BRB方法对Mackey-Glass推理的有效性,在表 2中详细对比了M-PAES-BRB方法和现有其他模糊规则库多目标优化方法(FRBSs)[16]的均方根误差。根据表 2分析可知,针对训练数据和测试数据,M-PAES-BRB的RMSE均最低,即推理准确性最高。
表 2 Mackey-glass数据集推理准确性对比
方法 推理精度 训练数据 测试数据 M-PAES-BRB 0.02 0.03 (2+2)M-PAES-FRBS(4, 40) 0.07 0.08 NSGA-Ⅱ-FRBS 0.08 0.10 MOGA--FRBS 0.16 0.18 PAES--FRBS 0.08 0.09 (2+2) PAES--FRBS 0.09 0.11 SOGA--FRBS 0.05 0.08 综上实验分析表明,算法M-PAES-BRB能够较好地适应不同应用场景,能进行自适应优化,从而寻找到一组最优解集供决策者选择。因此,本文所提出的M-PAES-BRB方法是有效可行的。
-
本文针对BRB系统中提升推理准确率和降低系统复杂度的多目标优化问题进行建模。采用特殊的编码方法来生成具有最少规则数和最少输入变量的BRB系统,从而降低系统的复杂度。此外,在原始混合PAES算法中增加了重组操作,提出基于混合Pareto存档进化策略的置信规则库推理算法M-PAES-BRB。实验采用基于真实数据集的仿真实验来验证M-PAES-BRB算法的有效性和可行性。实验表明算法能寻找到一组具有不同准确率和复杂度的Pareto最优解集,供决策者根据实际需要选择。
Belief Rule Base Inference Algorithm Based on Mixed Pareto Archived Evolutionary Strategy
-
摘要: 目前对置信规则库(BRB)的研究主要是关于BRB系统的参数或结构的单目标优化。然而,BRB系统中提高推理准确性和减少系统复杂度往往是两个相互冲突的目标。因此,设计合适算法来寻找到两个目标上的最优解具有重要意义。鉴于此,该文提出基于混合Pareto存档进化策略(M-PAES)的置信规则库推理方法(M-PAES-BRB),通过最小化系统的均方根误差和系统复杂性来寻找到近似的Pareto最优前沿。该算法采用了改进型M-PAES算法来构建多目标优化模型,通过重组和变异操作生成候选解。该文选取两个标准时间序列,Mackey-Glass和Box-Jenkins作为实验数据,对M-PAES-BRB的可行性及有效性进行分析。实验结果表明,相比于模糊规则库的多目标优化方法(FRBSs),该文方法的推理准确性更高,同时系统复杂度更低。Abstract: Most of the existing methods for belief rule based (BRB) focus on single objective optimization for parameter or structure. However, according to the existing research, improving reasoning accuracy and reducing the complexity of BRB system usually conflict each other. Thus, designing a suitable algorithm to find right trade-off for the two goals is necessary. For this purpose, an algorithm named M-PAES-BRB (belief rule base inference method based on multi-objective optimization) is proposed to determine an approximation of the optimal Pareto front by concurrently minimizing the root mean squared error and the complexity. The algorithm adopts an improved mixed pareto archived evolutionary strategy (M-PAES) to build a multi-objective optimization model, M-PAES use recombination operator and mutation operator to generate candidate solutions. In the experiment, we select two standard time series, Mackey-Glass and Box-Jenkins as the experimental datasets, to test the feasibility and effectiveness of M-PAES-BRB. Compared to fuzzy rule base multi-objective evolutionary algorithms (FRBSs), the experiment results show that M-PAES-BRB's reasoning accuracy is higher and the complexity is lower.
-
Key words:
- belief rule base /
- multi-objective optimization /
- Pareto /
- RIMER
-
表 1 BJGF数据集推理准确性(RMSE)对比
方法 推理精度 训练数据 测试数据 M-PAES-BRB 0.26 0.39 (2+2)M-PAES-FRBSs(10, 20) 0.56 0.79 NSGA-Ⅱ-FRBSs 0.60 0.90 MOGA--FRBSs 1.91 2.02 PAES--FRBSs 0.62 0.80 (2+2) PAES--FRBSs 0.58 0.75 SOGA--FRBSs 0.62 1.18  下载: 导出CSV
下载: 导出CSV
表 2 Mackey-glass数据集推理准确性对比
方法 推理精度 训练数据 测试数据 M-PAES-BRB 0.02 0.03 (2+2)M-PAES-FRBS(4, 40) 0.07 0.08 NSGA-Ⅱ-FRBS 0.08 0.10 MOGA--FRBS 0.16 0.18 PAES--FRBS 0.08 0.09 (2+2) PAES--FRBS 0.09 0.11 SOGA--FRBS 0.05 0.08
下载: 导出CSV
-
[1] YANG J B, LIU J, WANG J, et al. Belief rule-base inference methodology using the evidential reasoning approachRIMER[J]. IEEE Transactions on Systems Man & Cybernetics Part A Systems & Humans, 2006, 36(2):266-285. https://ieeexplore.ieee.org/document/1597400/ [2] LIN Y Q, LI M, CHEN X C, et al. A belief rule base approach for smart traffic lights[C]//International Symposium on Computational Intelligence and Design. Hangzhou: IEEE, 2017: 460-463. [3] YANG J B, LIU J, XU D L, et al. Optimal learning method for training belief rule based systems[J]. IEEE Transactions on Systems, Man, and Cybernetics-Part A:Systems and Humans, 2007, 37(4):569-585. doi: 10.1109/TSMCA.2007.897606 [4] ZHOU Z J, HU C H, YANG J B, et al. Online updating belief rule based system for pipeline leak detection under expert intervention[J]. Expert Systems with Applications, 2009, 36(4):7700-7709. doi: 10.1016/j.eswa.2008.09.032 [5] ZHAO F J, ZHOU Z J, HU C H, et al. A new evidential reasoning-based method for online safety assessment of complex systems[J]. IEEE Transactions on Systems Man & Cybernetics Systems, 2018, 48(6):954-966. http://cn.bing.com/academic/profile?id=4c4c95ba3d5a7c428830f3aa30bdb52e&encoded=0&v=paper_preview&mkt=zh-cn [6] YIN X, ZHANG B, ZHOU Z, et al. A new health estimation model for CNC machine tool based on infinite irrelevance and belief rule base[J]. Microelectronics Reliability, 2018, 84:187-196. doi: 10.1016/j.microrel.2018.03.031 [7] ZHOU Z J, HU C H, YANG J B, et al. Online updating belief-rule-base using the RIMER approach[J]. IEEE Transactions on Systems Man & Cybernetics Part A Systems & Humans, 2011, 41(6):1225-1243. http://cn.bing.com/academic/profile?id=e57ae0fdd1810538e78ea40a6e581d43&encoded=0&v=paper_preview&mkt=zh-cn [8] 吴伟昆, 杨隆浩, 傅仰耿, 等.基于加速梯度求法的置信规则库参数训练方法[J].计算机科学与探索, 2014, 8(8):989-1001. http://d.old.wanfangdata.com.cn/Periodical/pre_2475811e-0fb4-4a56-ac2a-d8b72990e074 WU Wei-kun, YANG Long-hao, FU Yang-geng, et al. Parameter training approach for belief rule base using the accelerating of gradient algorithm[J]. Journal of Frontiers of Computer Science and Technology, 2014, 8(8):989-1001. http://d.old.wanfangdata.com.cn/Periodical/pre_2475811e-0fb4-4a56-ac2a-d8b72990e074 [9] 苏群, 杨隆浩, 傅仰耿, 等.基于变速粒子群优化的置信规则库参数训练方法[J].计算机应用, 2014, 34(8):2161-2165. http://d.old.wanfangdata.com.cn/Periodical/jsjyy201408004 SU Qun, YANG Long-hao, FU Yang-geng, et al. Parameter training approach based on variable particle swarm optimization for belief rule base[J]. Journal of Computer Applications, 2014, 34(8):2161-2165. http://d.old.wanfangdata.com.cn/Periodical/jsjyy201408004 [10] 周志杰, 杨剑波, 胡昌华, 等.置信规则库专家系统与复杂系统建模[M].北京:科学出版社, 2011:1-119. ZHOU Zhi-jie, YANG Jian-bo, HU Chang-hua, et al. Belief rule base expert system and complex system[M]. Beijing:Science Press, 2011:1-119. [11] CHANG L, ZHOU Y, JIANG J, et al. Structure learning for belief rule base expert system:a comparative study[J]. Knowledge-Based Systems, 2013, 39:159-172. doi: 10.1016/j.knosys.2012.10.016 [12] DEY A, CHOUDHURY A B. A comparative study between scalarization approach and pareto approach for multiobjective optimization problem using genetic algorithm (MOGA) formulated based on superconducting fault current limiter[C]//IEEE International Conference on Power Electronics, Intelligent Control and Energy Systems. Delhi: IEEE, 2017: 1-4. [13] 童晶.多目标优化的Pareto解的表达与求取[D].武汉: 武汉科技大学, 2009. TONG Jing. Expressing and obtaining pareto solutions in multi-objective optimization problem[D]. Wuhan: Wuhan University of Science and Technology, 2009. [14] 张自如. PAES多目标优化算法及其应用研究[D].兰州: 兰州理工学院, 2012. ZHANG Zi-ru. PAES-The algorithm of multi-objective optimization and its applied research[D]. Lanzhou: Lanzhou University of Technology, 2012. [15] HUANG Ren-fang, LUO Xian-wu, JI Bin, et al. Multiobjective optimization of a mixed-flow pump impeller using modified NSGA-Ⅱ algorithm[J]. Science China (Technological Sciences), 2015, 58(12):2122-2130. doi: 10.1007/s11431-015-5865-5 [16] MARCO C, PIETRO D, BEATRICE L, et al. A paretobased multi-objective evolutionary approach to the identification of mamdani fuzzy systems[J]. Soft Computing, 2007, 11(11):1013-1031. doi: 10.1007/s00500-007-0150-6 -

 点击查看大图
点击查看大图

图(8) / 表(2)
计量
- 文章访问数: 4345
- HTML全文浏览量: 1204
- PDF下载量: 113
- 被引次数: 0
