 ISSN
ISSN 


-
互联网的快速发展带来了生活上的便利[1-2],也带来了信息过载的困扰[3]。推荐系统[4]应运而生,通过分析用户的历史数据,帮助用户找到真正需要的信息。作为解决信息过载的有效工具[5],推荐系统成为近年来的研究热点,并已经运用于生活的方方面面[6-11]。如,最早将推荐算法应用于电子商务的Amazon,通过推荐经常被购买的图书和经常购买图书的用户所购图书[6],改善用户体验和提升销售业绩。电商巨头阿里巴巴集团也打造了自己的推荐系统[7]。Youtube根据用户在网站上的行为数据向用户推荐他可能喜欢的视频[8]。基于美食的推荐系统[9-10]通过分析用户的健康状况,生成更健康且符合用户偏好的食谱。基于地理位置的推荐系统[11]通过用户的签到行为,获取用户的时间和空间信息,从而提供个性化的基于地理位置的服务。
在推荐系统的研究中,基于扩散的推荐算法成功将统计物理学方法应用于信息推荐[12],成为了推荐算法领域的重要分支。物质扩散[13]和热传导[14]算法是这方面的先驱。在此基础上,研究人员针对基于扩散的推荐算法进行了扩展。文献[15]发现在基于网络的推荐算法中改变初始配置可以影响推荐的性能。文献[16]通过提高受欢迎产品的资源,提高了推荐算法的准确性。文献[17]结合(mass diffusion, MD)和(heat conduction, HC)算法的优势,提出了一个混合算法来解决传统推荐算法注重准确性忽略多样性的问题。文献[18]的研究表明通过优先扩散的信息过滤可以获得更好的准确性。文献[19]提出的基于节点相似性的指标提高了推荐算法的准确性。
以上提到的推荐算法都是在用户-产品组成的二部图上做推荐。用户之间的关系来自用户对产品的评分。在现实生活中,用户之间的社会关系[20-21]也会对用户的决策产生影响。因此,社会关系也被应用到推荐算法的研究中。文献[22]表明用户更愿意认可来自朋友的推荐。但是文献[23]分析了用户的朋友关系和用户的兴趣之间的相关性,发现用户之间的朋友关系并不能反映用户之间的兴趣的相似性。另外,朋友之间的信任关系会影响到用户的在线行为。为此,文献[24]将用户的偏好和信任的朋友的偏好结合在一起,并对推荐系统进行建模。结果表明信任关系可以显著提高推荐算法的性能[22, 25]。文献[26]根据用户的信任关系过滤了一些无用信息后,将信任关系和协同过滤算法结合,提出了比原协同过滤算法性能更好的推荐算法。通过对相似性和信任关系聚类,文献[25]的算法提高了推荐的覆盖率和准确性。
然而,将信任关系整合到基于扩散的推荐方法的研究仍有不足。文献[27]在物质扩散算法的基础上,结合了用户之间的隐式信任和显式信任,提高了算法的性能。但算法的关注点在大度节点上,而忽略了小度节点。这就要求我们利用多个社会信息进一步探索基于网络扩散的研究以设计更好的推荐算法。同时,二部图上的基于扩散的算法在计算用户之间的相似性时信息单一,也面临冷启动的问题。因此,本文在基于扩散算法的基础上,提出一种混合算法。具体来说,在资源扩散的过程中,用一个可调参数θ控制受信任用户所获得的资源,从而提高受信任用户所选物品的被推荐率。此算法在不增加原算法时间复杂度的情况下,充分利用用户之间的信任信息,提高对用户之间的相似性的刻画准确度。此算法结合信任关系和物质扩散算法[13]、热传导算法[14]的优势,能显著提高算法的性能,并在准确性、多样性和新颖性上优于大部分基准算法。
-
推荐系统用一个二部图网络结构G(U, O, E)表示,其中用户U={u1, u2, …, um},产品O={o1, o2, …, on}和链接E={e1, e2, …, ez}。也可用矩阵Am×n=[aij]来表示,当aij=1表示用户i选择了产品j,aij=0则表示用户i没选择产品j。
推荐系统的目的是为用户提供一个潜在需求的产品列表。标准的物质扩散算法MD[13]分为3个步骤:1)对目标用户i选择的产品赋予一个单位资源;2)资源通过均匀分配到所有选择过这些产品的用户中,假如用户j选择了产品α,而α是用户i选择过的产品,那么j从α这里得到的权重为1/kα,kα是产品α的度。用户j从i得到的资源为:
$${f_{ij}} = \sum\limits_{\alpha = 1}^n {\frac{{{a_{i\alpha }}{a_{j\alpha }}}}{{{k_\alpha }}}} $$ (1) 3) 所有用户的资源将均匀分配给他们选择的产品,产品β得到的资源为:
$${f_{i\beta }} = \sum\limits_{j = 1}^m {\frac{{{a_{j\beta }}{f_{ij}}}}{{{k_j}}}} $$ (2) 式中,kj是用户j选择的产品数目。最终得到所有产品的资源值,通过降序排列并取排名靠前的L个产品,以此给用户j建立一个推荐长度为L的推荐列表。
与物质扩散算法不同的是,热传导算法(heat conduction, HC)[14]在资源传递过程中能量不守恒。算法定义如下:
$${f_{ij}} = \sum\limits_{\alpha = 1}^n {\frac{{{a_{i\alpha }}{a_{j\alpha }}}}{{{k_j}}}} $$ (3) $${f_{i\beta }} = \sum\limits_{j = 1}^m {\frac{{{a_{j\beta }}{f_{ij}}}}{{{k_\beta }}}} $$ (4) 文献[17]在两种算法的基础上,提出了一种混合算法(hybrid algorithm, HA),在算法的准确性和多样性上取得了平衡。
$${f_{ij}} = \sum\limits_{\alpha = 1}^n {\frac{{{a_{i\alpha }}{a_{j\alpha }}}}{{k_\alpha ^\lambda k_j^{1 - \lambda }}}} $$ (5) $${f_{i\beta }} = \sum\limits_{j = 1}^m {\frac{{{a_{i\beta }}{f_{ij}}}}{{k_j^\lambda k_\beta ^{1 - \lambda }}}} $$ (6) 式中,λ是可调节参数。当λ=1时,算法表述为物质扩散算法,而当λ=0时,则为热传导算法。
事实上,fij可以用来计算用户i和j之间的相似性。而在有些真实网络上,用户之间的关系不仅存在于偏好上的相似性,还有着信任关系。本文将信任关系引入到资源扩散中,补充用户之间的相似性信息。本文在混合算法的基础上提出一种基于信任关系的新算法(trust-based hybrid algorithm, THA),采用线性组合的方式将资源扩散和信任关系结合起来,定义如下:
$${f_{ij}} = \theta {b_{ij}} + \sum\limits_{\alpha = 1}^n {\frac{{{a_{i\alpha }}{a_{j\alpha }}}}{{k_\alpha ^\lambda k_j^{1 - \lambda }}}} $$ (7) $${f_{i\beta }} = \sum\limits_{j = 1}^m {\frac{{{a_{i\beta }}{f_{ij}}}}{{k_j^\lambda k_\beta ^{1 - \lambda }}}} $$ (8) 式中,bij是用户信任矩阵中的元素,bij=1表示用户i信任用户j,否则bij=0。THA算法中有两个参数,当θ=0时,算法退化为混合算法(HA),当λ=1、θ=0时,是物质扩散算法,而λ=0、θ=0时则是热传导算法。
-
本文使用Epinions和FriendFeed两个数据集。数据分别来源于Epinions.com和FriendFeed.com。数据采用5分制评分,在实际使用数据集的时候,只考虑使用大于2的评分数据来构建二部图网络。在算法测试时,每个数据集等分为10份,轮流选取其中1份作为测试集,占比10%。其余作为训练集,占比90%。
详细的数据描述如表 1所示,Epinions和FriendFeed数据集分别包含用户数4 066和4 148个,包含产品7 649和5 700个。两个数据集中用户对产品的评分分别有154 122和96 942条。用户和产品构成的二部图网络的稀疏度分别是4.96×10-3和4.10×10-3。除此之外,用户与用户之间信任用有向边表示,代表用户对另一个用户的信任,连边数分别为217 071和386 804条。
表 1 详细的数据介绍
数据集 用户数 产品数 评分数 稀疏度 信任连边 Epinions 4 066 7 649 154 122 4.96×10-3 217 071 FriendFeed 4 148 5 700 96 942 4.10×10-3 386 804 -
为了测试算法,本文使用了7个评价指标。其中精确性指标包括AUC、Precision、Recall和F1;2个多样性指标为Hamming distance和Intra-similarity;1个新颖性指标Novelty。
AUC[28]从整体上衡量算法的准确性,可以理解为目标用户的测试集中产品的分数比随机选择的一个产品(用户未选择)分数高的概率。Precision定义为长度为L的推荐列表中产品被预测准确的比例,用P表示。Recall召回率R是描述测试集中被预测准确的比例。F1是一种同时考虑准确率和召回率从而比较全面地评价算法优劣的指标。Hamming distance[11]反映的是用户的推荐列表之间的差异性,用H表示。Inter-similarity[19]反映用户推荐列表中各个产品之间的差异性,用I表示。Novelty[19]衡量算法的推荐新颖产品的能力,用N表示。
-
实验过程在Epinions和FriendFeed数据集上进行,并分别与5个基准推荐算法包括全局排名算法(global ranking, GR)[17]、基于用户的协同过滤算法(user-based collaborative filter, UCF)[30]、MD[13]、HC[14]和HA[17]进行比较。
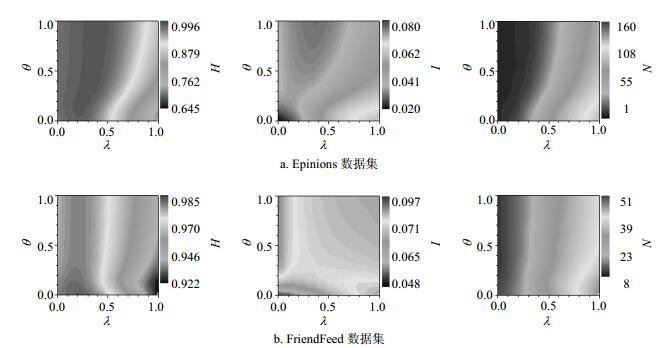
图 1展示了THA算法在Epinions和FriendFeed数据集上的3个准确性指标结果,两个参数的范围为[0, 1],推荐列表长度L=50。λ对THA算法影响很大,当λ=0.5时,THA算法在3个准确性指标AUC、P和R取得最大值,此时算法退化为HA算法。参数θ体现的是信任对推荐结果的影响。在图 1中,当θ > 0时,准确性指标AUC、P和R的值都比θ=0的时候高,并且都存在一个明显的峰值,这说明信任关系对提高推荐准确性有积极的影响。在Epinions数据集上,AUC峰值对应的参数为λ=0.5、θ=0.05,FriendFeed数据集中AUC峰值对应参数为λ=0.5、θ=0.075。对于目标用户,当θ > 0时,被信任的用户将被分配更多的资源,导致被信任的用户和目标用户之间相似性更高,从而更容易推荐已选择过的产品给目标用户,这也和现实中信任的出发点是一致的。

图 1 THA算法的准确性指标值
更详细的结果如表 2和表 3所示。加粗字体对应于评价指标的最优值。其中THA算法的参数取值为图 1中AUC取值的峰值(Epinions上参数为λ=0.5、θ=0.05,FriendFeed上为λ=0.5、θ=0.075)。表中第2、3、4、5列分别是准确性指标AUC、Precision、Recall和F1。在Epinions数据集上,HA算法在准确性上要优于MD、HC、GR和UCF算法,而THA算法在HA算法的基础上将AUC、Precision、Recall和F1值分别提高了0.98%、5.4%、10%和6.6%。这说明本文算法将信任关系作为一种辅助特征与基于扩散的算法进行结合是非常有效且合理的。而在FriendFeed数据集上,THA算法也在准确性上领先于其余5个推荐算法。图 2展示了THA算法在Epinions和FriendFeed数据集上的3个多样性和新颖性指标结果,参数与图 1一致。在多样性上,HC算法的H值最高,I值最低,多样性最好。在新颖性上,HC算法也是6个推荐算法中最优的。
表 2 不同推荐算法在Epinions数据集上的比较
算法 AUC P R F1 H I N GR 0.697 4 0.009 4 0.031 5 0.014 4 0.133 8 0.138 9 308 HC 0.784 5 0.005 2 0.015 3 0.007 7 0.974 2 0.024 5 5 MD 0.825 6 0.018 9 0.059 0 0.028 6 0.675 3 0.114 0 235 UCF 0.814 1 0.017 0 0.053 7 0.025 9 0.574 8 0.131 7 262 HA 0.835 6 0.022 1 0.062 9 0.032 7 0.947 2 0.090 0 107 THA 0.843 8 0.023 3 0.069 2 0.034 9 0.944 7 0.091 2 107 表 3 不同推荐算法在FriendFeed数据集上的比较
算法 AUC P R F1 H I N GR 0.605 8 0.005 0 0.021 5 0.008 1 0.073 9 0.093 5 172 HC 0.883 3 0.008 8 0.037 0 0.014 2 0.990 7 0.054 2 11 MD 0.892 5 0.016 3 0.068 3 0.026 3 0.942 2 0.119 5 73 UCF 0.886 9 0.015 5 0.066 1 0.025 2 0.885 7 0.161 6 92 HA 0.897 8 0.016 7 0.063 3 0.026 5 0.989 5 0.089 0 35 THA 0.905 6 0.018 4 0.076 2 0.029 6 0.981 0 0.105 3 43 
图 2 THA算法的多样性和新颖性指标值
推荐列表的长度L也有可能影响基于L的评价指标结果,包括P、R、F1、H、I及N。以下,将探讨L如何影响推荐方法的性能。对L取值从1~100,并将THA和其他5个算法进行对比。
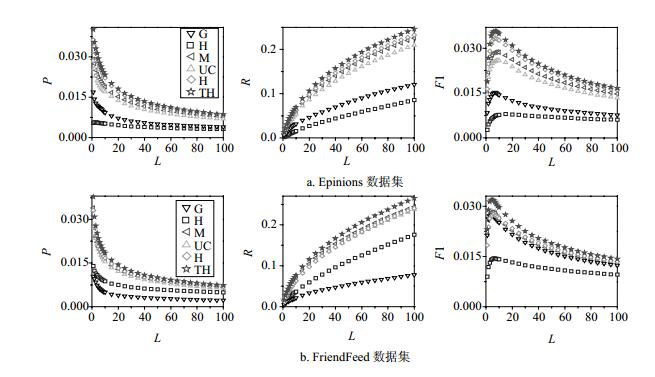
在Epinions和FriendFeed数据集上,图 3给出了3个准确性指标P、R和F1的结果。可以看出,随着推荐列表的长度L的增加,P的值将会减少,R值增加,F1值先增后减。在Epinions上L≈10时F1取得最大值,在FriendFeed是L≈5。THA算法与其他算法相比,在准确性上有明显优势,尤其是在最优L值附近,如FriendFeed上L=5。并且THA算法与原来基准算法HA相比较,也有相对改善。

图 3 不同算法的推荐结果的准确性受推荐列表长度L的影响
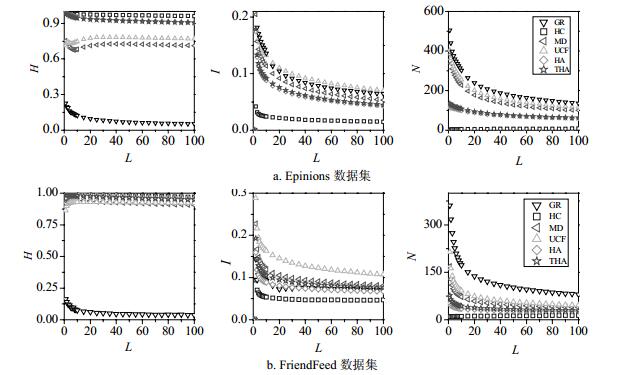
图 4展示了多样性指标和新颖性指标的结果。H值会随着L在Epinions和FriendFeed上的增加而缓慢降低。HC算法的H最高,其次是HA和THA算法。MD算法和UCF算法接近,最差的是GR算法。对于I来说,会随着L的增加而迅速增加随后缓慢下降。此指标上,UCF算法的I值最高,推荐列表丰富性最差。HC算法则在两个数据集上都有最低的I值。对于新颖性来说,N的值随列表长度L的增加而降低。总体来说,HC算法是多样性和新颖性最高的算法。

图 4 不同算法的推荐结果的多样性和新颖性受推荐列表长度的影响
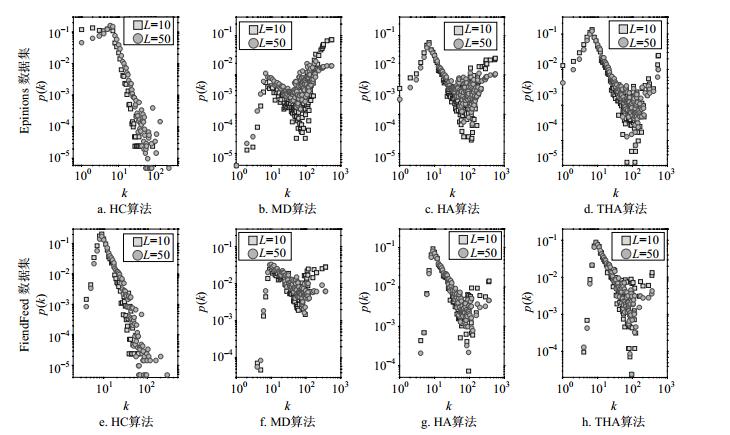
为了进一步了解算法机制,图 5展示了HC、MD、HA和THA算法的推荐列表的度分布。实验中设置了不同的推荐列表长度L=10和L=50。图 5a~5d为Epinions数据集,图 5e~5h为FirendFeed数据集。结果显示MD算法主要推荐度大的产品,而HC算法倾向于推荐度小的产品,从而导致MD的算法在准确性上要优于HC算法,而HC算法则在多样性上表现最佳。HA和THA方法通过同时推荐大度和小度物品来达到推荐的准确性和多样性之间的平衡。

图 5 不同算法的推荐列表的度分布
-
本文在MD和HC算法的基础上引入了用户的信任关系,并提出了一个基于信任关系的扩散新算法(THA)。实验结果显示THA算法比大部分基础算法在准确性、多样性和新颖性上表现更好。进一步分析算法机制后发现,物质扩散算法的高准确性来自于推荐度大的产品,而热传导算法的高多样性则是因为推荐度小的产品。THA算法在这方面结合了两个算法的优点,在产品推荐上取得了平衡。
算法的主要贡献在于:1)将信任关系作为辅助特征与传统的扩散算法结合在一起。2)算法计算过程中,仅仅通过用户的信任关系对用户资源分配进行一个线性运算,提高了原算法的准确性、多样性和新颖性,但是并没有增加时间复杂度。3)在一定程度上解决了用户评分稀少导致的推荐不准确问题,为用户提供更准确的个性化推荐服务。
传统的扩散算法在用户-产品二部图上,利用用户的评分信息计算用户之间的相似性,并将相似用户的产品进行推荐,本文算法不仅使用了二部图网络,同时也利用用户-用户的社会关系网络,使得推荐结果更加准确。同时我们也发现,社会关系对提高推荐结果的准确性影响有限,仅作为对用户关系的信息的补充。如果社会关系在推荐中权重过大,反而会降低推荐的效果。
Improved Research on Resource-Allocation Recommendation Algorithm Based on Trust Relationship
-
摘要: 近年来,一些统计物理学的方法被用于推荐算法的研究中,其中,基于扩散的推荐算法研究成为一个重要方向。然而,这些方法都只关注用户对产品的评分信息,而忽略了用户之间普遍存在的信任关系。该文将用户信任关系引入到基于扩散的推荐算法中,提出了一种基于信任关系的资源分配推荐算法。该算法在资源分配的过程中,对受信任的用户用一个可调参数分配其更多的资源,从而提高受信任用户所选物品的资源值。在Epinions和FriendFeed两个真实数据集上的实验结果显示,该算法在准确性、多样性和新颖性等方面明显优于主流的基准推荐算法。Abstract: In recent years, various recommendation methods have been proposed by referring to processes originated in statistical physics, among them the diffusion-based method is an important branch of study. However, these methods were proposed solely based on rating metrics, while the trust relations among users are always ignored. In this paper, we propose a novel information filtering algorithm by introducing users' social trust relationships into the original diffusion-based method based on the resource-allocation process. Specifically, a tunable parameter is used to scale the resources received by trusted users in the networked resource redistribution process. The objects collected by trusted users will receive more resources. Extensive experiments on the two real-world rating and trust datasets, Epinions and FriendFeed, suggest that the proposed algorithm has better performance than benchmark algorithms in terms of accuracy, diversity, and novelty in the recommendation.
-
表 1 详细的数据介绍
数据集 用户数 产品数 评分数 稀疏度 信任连边 Epinions 4 066 7 649 154 122 4.96×10-3 217 071 FriendFeed 4 148 5 700 96 942 4.10×10-3 386 804  下载: 导出CSV
下载: 导出CSV
表 2 不同推荐算法在Epinions数据集上的比较
算法 AUC P R F1 H I N GR 0.697 4 0.009 4 0.031 5 0.014 4 0.133 8 0.138 9 308 HC 0.784 5 0.005 2 0.015 3 0.007 7 0.974 2 0.024 5 5 MD 0.825 6 0.018 9 0.059 0 0.028 6 0.675 3 0.114 0 235 UCF 0.814 1 0.017 0 0.053 7 0.025 9 0.574 8 0.131 7 262 HA 0.835 6 0.022 1 0.062 9 0.032 7 0.947 2 0.090 0 107 THA 0.843 8 0.023 3 0.069 2 0.034 9 0.944 7 0.091 2 107
下载: 导出CSV
表 3 不同推荐算法在FriendFeed数据集上的比较
算法 AUC P R F1 H I N GR 0.605 8 0.005 0 0.021 5 0.008 1 0.073 9 0.093 5 172 HC 0.883 3 0.008 8 0.037 0 0.014 2 0.990 7 0.054 2 11 MD 0.892 5 0.016 3 0.068 3 0.026 3 0.942 2 0.119 5 73 UCF 0.886 9 0.015 5 0.066 1 0.025 2 0.885 7 0.161 6 92 HA 0.897 8 0.016 7 0.063 3 0.026 5 0.989 5 0.089 0 35 THA 0.905 6 0.018 4 0.076 2 0.029 6 0.981 0 0.105 3 43
下载: 导出CSV
-
[1] 高见, 周涛.大数据揭示经济发展状况[J].电子科技大学学报, 2016, 45(4):625-633. doi: 10.3969/j.issn.1001-0548.2016.04.015 GAO Jian, ZHOU Tao. Big data reveal the status of economic development[J]. Journal of University of Electronic Science and Technology of China, 2016, 45(4):625-633. doi: 10.3969/j.issn.1001-0548.2016.04.015 [2] GAO Jian, ZHOU Tao. Quantifying China's regional economic complexity[J]. Physica A, 2018, 492:1591-1603. doi: 10.1016/j.physa.2017.11.084 [3] EDMUNDS A, MORRIS A. The problem of information overload in business organizations:A review of the literature[J]. International Journal of Information Management, 2000, 20(1):17-28. doi: 10.1016/S0268-4012(99)00051-1 [4] PORCEL C, HERRERA-VIEDMA E. Dealing with incomplete information in a fuzzy linguistic recommender system to disseminate information in university digital libraries[J]. Knowledge-Based Systems, 2010, 23(1):32-39. doi: 10.1016/j.knosys.2009.07.007 [5] ZHANG Z K, LIU C, ZHANG Y C, et al. Solving the cold-start problem in recommender systems with social tags[J]. Europhysics Letters, 2010, 92(2):28002. doi: 10.1209/0295-5075/92/28002 [6] SCHAFER J B, KONSTAN J, RIEDL J. Recommender systems in e-commerce[C]//The 1st ACM Conference on Electronic Commerce. Denver: ACM, 1999: 158-166. [7] ZHAO X, ZHANG L, DING Z, et al. Recommendations with negative feedback via pairwise deep reinforcement learning[C]//The 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. London: ACM, 2018: 1040-1048. [8] DAVIDSON J, LIEBALD B, LIU J, et al. The youtube video recommendation system[C]//The 4th ACM Conference on Recommender Systems. New York: ACM, 2010: 293-296. [9] GE M, RICCI F, MASSIMO D. Health-aware food recommender system[C]//The 9th ACM Conference on Recommender Systems. Vienna: ACM, 2015: 333-334. [10] BIANCHINI D, ANTONELLIS V D, FRANCESCHI N, et al. PREFer:A prescription-based food recommender system[J]. Computer Standards & Interfaces, 2017, 54(2):64-75. http://d.old.wanfangdata.com.cn/Periodical/bjgydxxb201412013 [11] GAO H, TANG J, HU X, et al. Exploring temporal effects for location recommendation on location-based social networks[C]//The 7th ACM Conference on Recommender Systems. Hong Kong, China: ACM, 2013: 93-100. [12] ZHANG Z K, LIU C, ZHAN X X, et al. Dynamics of information diffusion and its applications on complex networks[J]. Physics Reports, 2016, 651:1-34. doi: 10.1016/j.physrep.2016.07.002 [13] ZHOU T, REN J, MEDO M, et al. Bipartite network projection and personal recommendation[J]. Physical Review E, 2007, 76:046115. doi: 10.1103/PhysRevE.76.046115 [14] ZHANG Y C, BLATTNER M, YU Y K. Heat conduction process on community networks as a recommendation model[J]. Physical Review Letters, 2007, 99(15):154301. doi: 10.1103/PhysRevLett.99.154301 [15] ZHOU T, JIANG L L, SU R Q, et al. Effect of initial configuration on network-based recommendation[J]. Europhysics Letters, 2008, 81(5):58004. doi: 10.1209/0295-5075/81/58004 [16] JIA C X, LIU R R, SUN D, et al. A new weighting method in network-based recommendation[J]. Physica A, 2008, 387(23):5887-5891. doi: 10.1016/j.physa.2008.06.046 [17] ZHOU T, KUSCSIK Z, LIU J G, et al. Solving the apparent diversity-accuracy dilemma of recommender systems[J]. Proceedings of the National Academy of Science, 2010, 107(10):4511. doi: 10.1073/pnas.1000488107 [18] LÜ L, LIU W. Information filtering via preferential diffusion[J]. Physical Review E, 2011, 83(6):066119. doi: 10.1103/PhysRevE.83.066119 [19] CHEN L J, ZHANG Z K, LIU J H, et al. A vertex similarity index for better personalized recommendation[J]. Physica A, 2017, 466:607-615. doi: 10.1016/j.physa.2016.09.057 [20] LIU N N, HE L, ZHAO M. Social temporal collaborative ranking for context aware movie recommendation[J]. ACM Transactions on Intelligent Systems & Technology, 2013, 4(1):15. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=00b0a52cd51bb5f4ea7d245bdffaee4c [21] YUAN J, ZHANG Q M, GAO J, et al. Promotion and resignation in employee networks[J]. Physica A, 2016, 444:442-447. doi: 10.1016/j.physa.2015.10.039 [22] LI Y M, WU C T, LAI C Y. A social recommender mechanism for e-commerce:Combining similarity, trust, and relationship[J]. Decision Support Systems, 2013, 55(3):740-752. doi: 10.1016/j.dss.2013.02.009 [23] MA H. On measuring social friend interest similarities in recommender systems[C]//The 37th International ACM SIGIR Conference on Research & Development in Information Retrieval. New York: ACM, 2014: 465-474. [24] MA H, KING I, LYU M R. Learning to recommend with social trust ensemble[C]//The 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2009: 203-210. [25] GUO G, ZHANG J, YORKE-SMITH N. Leveraging multiviews of trust and similarity to enhance clustering-based recommender systems[J]. Knowledge-Based Systems, 2015, 74:14-27. doi: 10.1016/j.knosys.2014.10.016 [26] SHEN X, LONG H, MA C. Incorporating trust relationships in collaborative filtering recommender system, Software engineering[C]//The 16th International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD). Takamatsu: IEEE, 2015: 1-8. [27] WANG X, LIU Y, ZHANG G, et al. Diffusion-based recommendation with trust relations on tripartite graphs[J]. Journal of Statistical Mechanics:Theory and Experiment, 2017(8):083405. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=IOP_9359654 [28] HANLEY J A, MCNEIL B J. The meaning and use of the area under a receiver operating characteristic (ROC) curve[J]. Radiology, 1982, 143(1):29-36. doi: 10.1148/radiology.143.1.7063747 [29] ZHOU T, LÜ L, ZHANG Y C. Predicting missing links via local information[J]. European Physical Journal B, 2009, 71(4):623-630. doi: 10.1140/epjb/e2009-00335-8 [30] HERLOCKER J L, KONSTAN J A, TERVEEN L G, et al. Evaluating collaborative filtering recommender systems[J]. ACM Transactions on Information Systems (TOIS), 2004, 22(1):5-53. doi: 10.1145/963770 -

 点击查看大图
点击查看大图

图(5) / 表(3)
计量
- 文章访问数: 4715
- HTML全文浏览量: 1511
- PDF下载量: 192
- 被引次数: 0
