 ISSN
ISSN 



-
闪存(flash memory)的技术原型最早于1967年由贝尔实验室的施敏提出,并且在过去的30年中主导了非易失存储器市场。随着微电子工艺节点的持续推进,Flash存储器历经了多个技术代的发展。由于存储单元尺寸不断微缩,但是编程、擦除操作所需的高压却不能等比例减小,器件的可靠性问题日益显著[1],并引起了国内外研究机构广泛的关注。文献[2]详细比较了源级FN擦除和沟道FN擦除的效率以及不同操作方式对Flash器件擦除一致性的影响。存储单元数据保持特性和耐受性退化的机理,以及从工艺、器件操作层面如何进行优化都得到了深入的研究[3-6]。
但是上述研究工作多数集中在单个存储器件的层面,芯片级的性能退化研究相对较少。Flash存储芯片的一个重要的可靠性问题是擦除时间退化,即完成芯片擦除所需的时间随着擦写循环增多出现显著的增加[7]。对于65 nm及以下的先进节点的NOR Flash芯片,这一现象尤为严重,可能在数千次擦写之后,擦除时间即出现成倍的增加。
本文详细讨论了NOR Flash芯片的内部擦除算法,分析了存储芯片擦除时间退化的机理;针对性地提出了阶梯脉冲电压擦写方式和抑制擦除干扰的阵列偏置方法,以改善芯片的擦除退化,并在中芯国际65 nm NOR Flash工艺平台进行了流片,验证了方案的有效性。
-
NOR Flash芯片中的存储阵列通常以Sector (4 KB)、Block(32 KB/64 KB)等区块的形式来组织。芯片进行擦除操作时,需要对整个Sector或Block中的所有存储单元统一进行操作,因此擦除一致性控制非常重要。
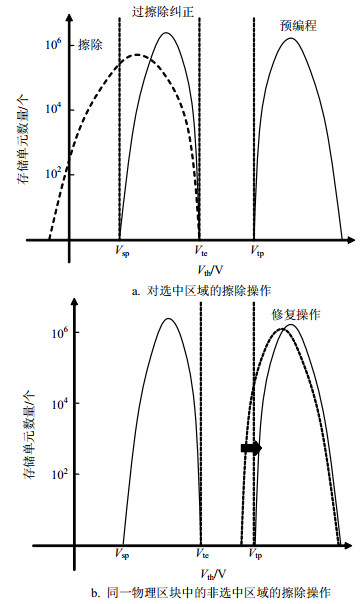
在实际的存储芯片产品中,由于制造工艺的差异,阵列中的Flash单元特性存在一定的分布,所以其擦除速度不一致。当擦除速度较慢的单元进入“擦除态”之后,部分速度较快单元的阈值电压(Vt)已经接近或者小于0 V,称为过擦除(over erase),这类器件在栅极电压为0 V时也会产生漏电。另一方面,由于NOR Flash采用无选择晶体管的1T结构,且同一条位线上的所有单元都是并联关系,因此,任何一个单元过擦除导致的漏电都将影响整条位线的读取正确性。所以在NOR Flash芯片设计中,需要对擦除过程进行精细的控制。下面以Sector擦除为例,介绍NOR Flash芯片内部的擦除算法设置:
1) 预编程操作:首先对需要擦除的区块进行预编程操作,将所有单元编程至“编程态”,即所有单元的阈值电压Vt > Vtp。这一步操作的目的是使得所有器件获得一致的擦除起点。
2) 整体擦除操作:预编程之后对选中区块进行整体擦除操作,使得阵列中所有单元的阈值电压都低于Vte,这时已经有部分擦除速度较快的单元发生过擦除。
3) 过擦除纠正操作:对阵列中所有过擦除单元进行过擦除纠正。该操作一般分为两步:首先对阵列中的位线进行检测,对产生漏电的位线进行过擦除纠正,使得阵列中所有单元的阈值电压都大于0 V;然后对阵列中单元进行软编程操作,进一步收紧阵列阈值分布,使得所有存储单元Vt > Vsp。
上述过程如图 1a所示,到此为止,对选中区域的擦除操作已经全部完成。

图 1 NOR Flash芯片中对存储阵列的擦除操作
出于减小芯片面积的考虑,NOR Flash产品设计一般将多个的Sector做在同一个P阱中,且共享位线和源线,不同的Sector由不同的WL地址区分。因此,在对选中Sector进行擦除操作时,同一物理区块中其他Sector的存储单元同样被加上了高压偏置,因此存在各种阵列干扰问题。其中对擦除过程影响最大的是漏极干扰(drain disturb)和衬底干扰(well disturb),阵列干扰的累积将导致非选中Sector中编程态器件的Vt缓慢降低,引起芯片的读取裕度减小,甚至发生读取错误。
为了解决这一问题,本文在擦除算法中加入修复(recover)操作:对非选中Sector中的所有存储单元进行读取、校验,并对受到串扰发生阈值漂移的单元进行编程操作,使其回到稳定的编程态,避免读取错误,如图 1b所示。
因此,NOR Flash芯片的整个Sector擦除操作包含以上4个过程,总的擦除时间为:
Ttotal = Tppgm +Terase + Toec + Trecover
式中,Tppgm、Terase、Toec分别为对选中Sector进行预编程、阵列整体擦除、过擦除纠正操作的时间;Trecover为对非选中Sector进行修复操作所需要的时间。
-
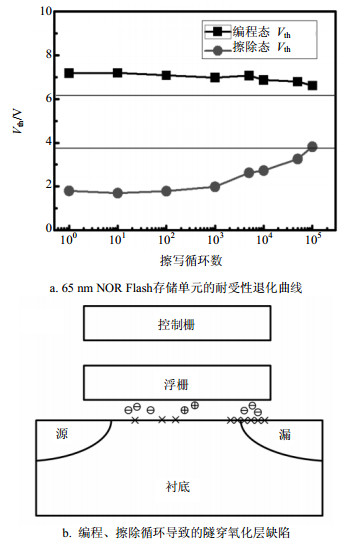
为了更深入地讨论芯片擦除时间的退化原因,本文首先对65 nm NOR Flash存储单元的擦写退化特性进行分析。图 2a给出了65 nm NOR Flash器件单元透射电镜(transmission electron microscope, TEM)照片,器件采用经典的ETOX结构,栅长128 nm,沟道宽度80 nm,隧穿氧化层厚度约为9 nm。对单元器件进行了10万次循环擦写操作:器件编程操作采用沟道热电子(channel hot electron injection, CHE)注入方式,栅极电压Vg=9.5 V,漏极电压Vd=4.2 V,编程时间1 us;擦除采用FN隧穿方式,栅极电压Vg= -9 V,衬底电压Vb=8 V,擦除时间1 ms。图 2b给出了不同擦写循环次数后器件的Id-Vg曲线,可以看到随着擦写循环增加,器件的阈值电压及亚阈值摆幅都出现了明显的退化。

图 2 65 nm NOR Flash器件的基本特性
随着擦写次数的增加,器件编程态和擦除态阈值均出现明显的漂移,如图 3a所示,10万次擦写循环后,存储窗口从初始的5.3 V退化到2.9 V。器件的编程态Vt随着擦写循环增加缓慢下降。这是因为在CHE编程过程中,由于热载流子效应,在靠近漏结附近的氧化层中产生了电荷陷阱,形成热电子注入的阻挡势垒,降低编程效率,因此导致了编程态的退化。

图 3 65 nm NOR Flash器件的耐受性退化机理
对于擦除态情形,初始阶段的擦除态Vt降低是由于空穴被隧穿氧化层中的陷阱所俘获。而后期随着擦写循环(cycle)增加擦除态Vt抬升,则是由于氧化层陷阱俘获电子以及界面态持续产生导致沟道电流减小所致。图 3b给出了编程、擦除循环导致的隧穿氧化层缺陷示意图。
由上述分析可知,反复的高压擦写导致器件氧化层缺陷增多,存储单元性能出现退化,如擦写效率降低、阈值漂移、漏电增加等,进而对整体的芯片擦除时间也产生重要影响:
1) 漏结附近隧穿氧化层中累积的电荷陷阱形成阻挡势垒,降低了编程时热电子注入的效率,导致完成预编程的时间Tppgm增大;对于擦除操作,沟道区的负电荷陷阱累积同样会导致FN擦除的速度降低[7],因此带来Terase的增加。
2) 氧化层界面态显著增加,导致器件的开态电流降低。为了使器件具有足够大的读电流以通过擦除态校验,需要将器件擦除至更低的Vt,这本身导致器件擦除时间增加;而另一方面,擦写过程中部分器件隧穿氧化层中的陷阱俘获空穴,导致局部势垒降低,形成擦除增强的不稳定擦除现象:即这部分存储器件具有更快的擦除速度,更容易发生过擦除。
这两方面因素叠加起来,当把Sector中较慢的器件擦除至擦除态时,相当多的不稳定单元(erratic cell)已经被过擦除。随着擦写循环的增加,的数量也会显著增多,因此需要很多的过擦除纠正操作,导致Toec增加。
3) 氧化层陷阱的增加也使得应力致漏电(SILC)效应更加严重,这将加剧存储阵列中的擦除干扰现象。主要表现为非选中Sector中有更多的编程态器件发生阈值衰减,需要通过修复操作再次编程进行纠正。修复操作每次对8/16个器件进行修复,如果需要纠正的器件太多,同样会导致Trecover和整体擦除时间的增加。
-
经过上述讨论,得出NOR Flash芯片擦除时间退化的主因是:高压反复操作使得存储单元的隧穿氧化层出现退化,器件更容易发生数据丢失和干扰问题;同时随着擦写循环增加,阵列中的不稳定单元增多,阵列分布变差。为了纠正过擦除问题并进一步收紧Vt分布,Flash控制电路采取大量的“修补”操作,从而导致擦除时间的增加。本文从两方面对这一问题进行优化:改善擦写条件降低存储单元的退化;优化阵列偏置条件抑制阵列干扰。
-
CHE编程过程导致的退化主要是由于热载流子效应所致,根据理论分析,热载流子效应与沟道电场的峰值成正相关的关系[8],为了降低热载流子效应对隧穿氧化层造成的损伤,有效的办法是降低漏结编程电压。
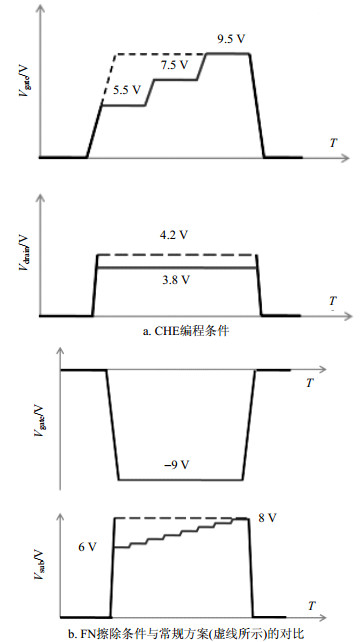
优化的编程条件如图 4a所示,漏级电压Vd的数值从4.2 V降低到3.8 V,以降低编程中的热载流子效应,进而改善隧穿氧化层退化;同时Vd的减小,也可以有效降低对非选中单元的漏极干扰。栅极电压Vg分为5.5、7.5、9.5 V这3个台阶阶跃上升,每个台阶脉冲宽度为500 ns,此编程设置将器件Vt分步骤抬升,有助于获得更好的阈值分布,同时也有效降低了每一步编程操作的电流(功耗),可以降低外围高压电路的负载和面积。

图 4 采用阶梯脉冲的编程、擦除操作方式
常规的FN擦除一般在栅极和衬底施加固定偏置:栅极电压Vg= -9 V,衬底电压Vb=8 V;擦除过程中,随着浮栅层中的电子隧穿回沟道,浮栅和衬底之间的电压差迅速降低。因此擦除初始阶段,隧穿氧化层电场峰值很大,而随着擦除进行,隧穿电场逐步降低。
基于文献[9]的研究,采用高擦除电场会导致隧穿氧化层退化更显著,过擦除现象也更严重。因此在本文的工作中,对擦除电压也采用了阶梯脉冲的方式,Vb从6 V阶跃增加至8 V,每个阶梯增加0.25 V,如图 4b所示。此种操作方式降低了擦除初始阶段的电场,而且整个擦除过程中的电场更为平均,使得擦除分布更均匀[10]。
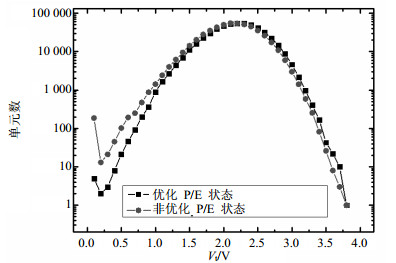
为了验证该操作方式的有效性,本文设计了对比试验。采用本文提出的阶梯脉冲方式和常规条件分别对存储阵列进行5 000次擦写循环,并统计擦除后的阵列阈值电压分布,如图 5所示,可以看到采用优化操作条件的存储阵列,其发生过擦除的单元明显较少,因此节省了过擦除纠正和软编程的操作次数,有效减少了Sector擦除的时间。

图 5 经过5 000次擦写循环后的阵列擦除态阈值分布(未经过擦除纠正)
-
在常规的存储阵列操作表设置中,对于同一物理区块中不选中的Sector,擦除时一般将其字线电压设置为0 V或者VCC(衬底为+8 V偏置)。这样非选中单元的浮栅和衬底之间仍然存在一定的电压应力,将导致衬底干扰现象的产生,尤其对于经过反复擦写后隧穿氧化层严重退化的存储单元,阈值损失的现象尤其明显。
为此,本文提出了优化的阵列偏置方案,对于同一物理区块中的非选中Sector,将其字线全部浮空,如表 1所示。在擦除操作过程中,其栅极电压被抬升至与衬底电压Vb相等,衬底和浮栅之间没有任何电压差,也就避免了衬底干扰的影响,从而节省了修复操作所需的时间。
表 1 擦除操作的阵列偏置条件
区块 操作 Vg/V Vd Vs/V Vb/V 同一物理区块 选中Sector -9 浮空 6~8 6~8 非选中Sector 浮空 浮空 6~8 6~8 不同物理区块 0 V 浮空 0 0 -
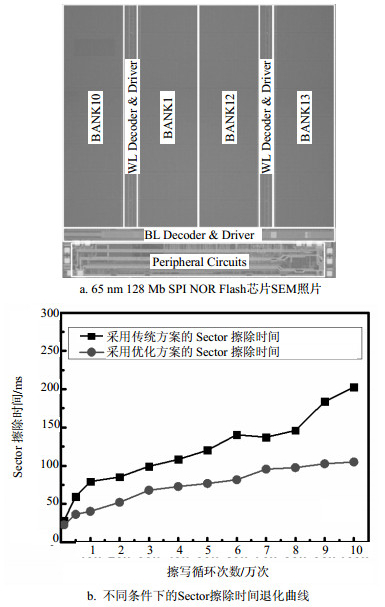
为了验证上述方案的有效性,本文基于65 nm ETOX工艺设计开发了全功能的128 Mb SPI NOR Flash芯片,并在中芯国际完成了流片和测试工作,芯片的扫描电子显微镜(scanning electron microscopy, SEM)照片如图 6a所示。

图 6 65 nm 128 Mb SPI NOR Flash芯片测试结果
通过测试模式中的方案设计,将芯片设置为常规操作方式以及本文提出的优化模式进行对比验证。并对两种模式下芯片擦除特性的退化情况进行了测试和比较。芯片Sector擦除时间随着擦写次数的退化曲线如图 6b所示。可以看到,两种模式下,芯片的初始擦除速度都较快,30 ms之内即可完成Sector擦除。随着擦写循环的进行,擦除时间均有所增加,但是采用优化条件的芯片明显退化更慢:当完成10万次擦写循环后,4 KB Sector擦除时间增加为104.9 ms。而对于未优化的芯片,其擦除时间在3万次之后即达到100 ms以上,10万次擦写后,擦除时间超过200 ms。上述测试结果表明,本文提出的优化方案,可以有效改善NOR Flash芯片擦除性能退化的问题。
-
对于65 nm及以下节点的NOR Flash产品,芯片擦除速度随着擦写循环的增加而出现退化已经成为影响芯片性能和使用寿命的重要问题。
基于对65 nm NOR Flash存储单元的擦写耐受性分析,本文得出器件性能退化的主因是隧穿氧化层在反复擦写的高压应力下出现各类缺陷,因而导致了器件擦写效率降低,存储单元更容易受到应力串扰和发生电荷损失。另一方面,反复擦写之后存储阵列阈值分布会进一步变差,过擦除单元数量显著增加。而为了修正上述问题,芯片控制电路需要增加额外的操作步骤,调节阵列的阈值分布,导致擦除时间增加。
本文通过阶梯式脉冲编程的方式减缓了器件退化;通过对非选中Sector进行字线浮空设置消除了衬底擦除干扰问题,有效减少了芯片内部调整擦除态阈值分布的操作步骤,从而实现对擦除速度退化的改善。该优化方案通过65 nm 128 Mb NOR Flash芯片进行了验证,与常规操作方式的测试对比,10万次擦写后,采用优化方案的芯片Sector擦除速度得到50%的提升,表明本文提出的改进方案可以有效改善NOR Flash芯片擦除退化。
Optimization of Erase Time Degradation in 65nm NOR Flash Memory Chips
-
摘要: 随着制造工艺进入65 nm节点,闪存的可靠性问题也越来越突出,其中闪存芯片擦除速度随着擦写循环的增加出现明显退化。该文从单个存储器件的擦写退化特性入手,详细讨论了隧穿氧化层缺陷的产生原因、对器件性能的影响及其导致整个芯片擦除时间退化的内在机理,并提出针对性的优化方案:采用阶梯脉冲电压擦写方式减缓存储单元退化;对非选中区块进行字线浮空偏置以抑制擦除时的阵列干扰。该文基于65 nm NOR Flash工艺平台开发了128 Mb闪存芯片,并对该方案进行了验证,测试结果表明,采用优化设计方案的芯片经过10万次擦写后的Sector擦除时间为104.9 ms,较采用常规方案的芯片(大于200 ms)具有明显的提升。Abstract: With the rapid development of microelectronics manufacture process, the reliability of flash memory has become more and more significant especially beyond 65 nm technology node. One of the most critical reliability issues is that the erase speed of flash memory chip degrades obviously with the increase of erase cycle. In this paper, the erasure degradation characteristics of flash cell were carefully reviewed. The generation mechanism of the tunneling oxide defect and its effects on device performance degradation are also well discussed. The optimization schemes are then proposed in this paper, including low stress program/erase scheme with staircase pulse and disturb-immune array bias condition for the unselected Sectors. A 128 Mb flash memory chip is developed based on SMIC 65 nm NOR flash technology to verify the optimization schemes. The testing results show that the Sector erase time of the optimized chip after 105 program/erase cycles is 104.9 ms, which is obviously improved compared with that of the conventional flash chip (more than 200 ms).
-
Key words:
- erase time degradation /
- NOR flash memory /
- oxide traps /
- reliability /
- staircase pulse
-
表 1 擦除操作的阵列偏置条件
区块 操作 Vg/V Vd Vs/V Vb/V 同一物理区块 选中Sector -9 浮空 6~8 6~8 非选中Sector 浮空 浮空 6~8 6~8 不同物理区块 0 V 浮空 0 0  下载: 导出CSV
下载: 导出CSV
-
[1] HONG S. Memory technology trend and future challenges[C]//International Electron Devices Meeting.[S.l.]: IEEE, 2010: 10.1109/IEDM.2010.5703348. https://www.researchgate.net/publication/224215649_Memory_Technology_Trend_and_Future_Challenges [2] YOSHIKAWA K, YAMADA S, MIYAMOTO J, et al. Comparison of current flash EEPROM erasing methods: Stability and how to control[C]//International Electron Devices Meeting.[S.l.]: IEEE, 1992, 93(74): 595-598. https://www.researchgate.net/publication/3565466_Comparison_of_current_flash_EEPROM_erasing_methods_stability_and_how_to_control?ev=prf_high [3] WEI Dai-long, CAO Zi-gui, TANG Zhi-lin. An effective approach to improve split-gate flash product data retention[J]. Journal of Semiconductor, 2017, 38(10):107-110. http://d.old.wanfangdata.com.cn/Periodical/bdtxb201710019 [4] HEINRICH-BARNA S, DUNN C, VERRET D. Low temperature endurance failures on flash memory[C]//International Symposium on Quality Electronic Design.[S.l.]: IEEE, 2017: 87-92. https://www.researchgate.net/publication/316721809_Low_temperature_endurance_failures_on_flash_memory [5] SUN Zhong, ZHANG Man-hong, HUO Zong-liang. et al. Effect of damage in source and drain on the endurance of a 65-nm-Node NOR flash memory[J]. IEEE Transactions on Electron Devices, 2013, 12(60):3989-3995. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=800de62a992d96464910b51fea6edd5e [6] TORRENTE G, COIGNUS J, VERNHET A, et al. Microscopic analysis of erase-induced degradation in 40 nm NOR flash technology[J]. IEEE Transactions on Device and Materials Reliability, 2016, 4(16):597-603. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=980e1d1ff12ed5fbfccfc513ab617304 [7] SIKORA A, PESL F P, UNGER W. Technologies and reliability of modern embedded flash cells[J]. Microelectronics Reliability, 2006, 46(12):1980-2005. doi: 10.1016/j.microrel.2006.01.003 [8] ZAMBELLI C, VINCENZI T, OLIVO P. A compact model for erratic event simulation in flash memory arrays[J]. IEEE Transactions on Electron Devices, 2014, 11(61):3716-3722. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=a4919de303c2caf23e5fac1c7a6608e3 [9] CHIMENTON A, OLIVO P. Impact of high tunneling electric fields on erasing instabilities in NOR flash memories[J]. IEEE Transactions on Electron Devices, 2006, 1(53):97-102. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=ca8bbdb39a017c4b36e05331d44b0609 [10] BEZ R, CANTARELLI D, MOIOLI L, et al. A new erasing method for a single-voltage long-endurance flash memory[J]. IEEE Electron Device Letters, 2002, 2(19):37-39. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=0c60d11b81d12d45b714aae740e4e8d8 -

 点击查看大图
点击查看大图
图(6) / 表(1)
计量
- 文章访问数: 4703
- HTML全文浏览量: 1353
- PDF下载量: 98
- 被引次数: 0
