 ISSN
ISSN 






-
自2012年AlexNet[1]在图像分类任务中取得了惊人的成果,卷积神经网络在深度学习中的地位变得不可替代。它在计算机视觉领域表现卓越,几乎替代了以前的传统机器学习方法。经众多学者进一步探索之后,基于深度学习的图片分类技术已经较为成熟,研究者们开始着重于研究更为复杂的像素级分类问题,如语义分割(semantic segmentation)。通用语义分割是目前最具挑战性的任务之一,其任务是对图片中每一个像素进行分类。
人体解析(human parsing)是语义分割的子任务。其目标是将一个人身体的各个部位或者所着衣物配饰加以识别,亦可称为服装解析(clothing parsing)。所有组成人体的像素均被标记,并且归类为对应类别。和通用语义分割不同,人体解析集中于以人为中心的分割,须识别出人体的脸部、头发、上衣、裤子等区域。人体解析在诸多领域均有应用,如人体外观转移(human appearance transfer)、行为识别(behavior recognition)、行人再识别(person re-identification)、时装合成(fashion synthesis)。因此,人体解析具有重要的研究意义和应用价值。
深度学习技术发展迅速,但目前尚缺少对于人体解析研究的总结工作。本文针对基于深度学习的人体解析研究技术进行了调研,将其归纳为以下3个方面:人体解析涉及的基础技术、人体解析的数据集和评价标准、人体解析技术现状。
-
基于深度学习的人体解析主要涉及卷积神经网络和语义分割等基础技术。卷积神经网络是人体解析的核心支撑技术;语义分割领域相关技术为人体解析提供了重要参考。本节首先介绍卷积神经网络的基本组成,然后介绍语义分割中的网络结构及3种改进技术。
-
在深度学习发展进程中,卷积神经网络占据着不可替代的位置,尤其在计算机视觉领域做出了巨大贡献。像素级分类任务不同于图片分类任务,它具有密集预测的特性。基于卷积神经网络的分割方法,通常是在图像分类网络基础上改进而来。
卷积神经网络是一种前馈神经网络,主要包括卷积层、池化层、全连接层等基础层,通过连接这些层来构建网络结构。
-
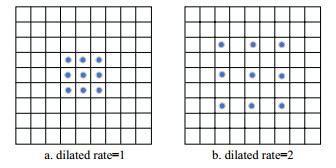
卷积层实现卷积计算。每个卷积层包含一系列卷积核,具有大小、步长等特性。卷积计算则是利用卷积核按照相应步长,在输入数据中滑动经过卷积和激活函数输出特征图。网络层初始化和训练阶段是对卷积核参数进行设置或者调整的过程。空洞卷积(dilated convolution)是一种特殊的卷积计算方式,在像素级分类任务中应用广泛,具有增大感受野的作用。与一般卷积的区别在于标准的卷积图(convolution map)中被注入了空洞。空洞卷积率(dilated rate)表示间隔数量,对于不同的空洞卷积率采样点不同,如图 1所示为3×3卷积。特殊地,当空洞卷积率为1时,与一般卷积操作一致。

图 1 空洞卷积示例
-
卷积层后紧跟池化层。和卷积层的操作类似,池化层也包含卷积核用于进行池化操作,即在扫描区域内取平均值或最大值,具有大小、步长等特性。池化操作包含平均池化(取平均值)和最大值池化(取最大值),其主要作用是进行特征选择和信息过滤,可有效防止过拟合现象。
-
在卷积网络结构的最后通常会包含全连接层。它相当于传统前馈神经网络的隐含层。全连接层的每个神经元均与前一层的所有神经元连接。
-
语义分割是指对图片内目标进行解析的过程,主要任务是识别各目标所属像素,通常不对目标物做细致分割,而人体解析则忽略背景信息,针对人体做细致分割,如图 2所示。语义分割集聚了许多前沿技术,人体解析任务中通常利用了其中一些网络构建思路。
-
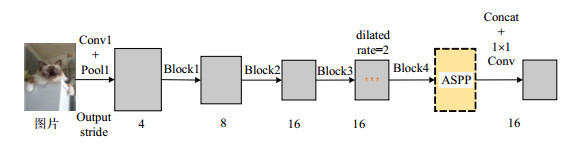
近几年,常用的图像分类网络有AlexNet[1]、VGG[5]、ResNet[6]、GoogleNet[7]等,语义分割网络结构通常以这些常用网络作为基础层,经过替换全连接层、添加卷积层或特殊结构以生成预测图。由Google提出的DeepLab系列结构较具代表性。DeepLab系列共包含4个版本,分别是:DeepLab V1[8]、DeepLab V2[9]、DeepLab V3[10]及DeepLab V3+[11]。DeepLab V3[10]网络结构如图 3所示,它以ResNet-101作为基础层,其输出的特征图Block4进一步输入到ASPP[10]模块(如图 4所示)中提取多尺度特征,最后经过1×1卷积输出最后的预测图(prediction maps)。通常,输出的预测图包含K个通道,K对应于数据集的类别数目。对于每一张预测图,每个位置对应的是该像素点被预测为某一类的可能性值。因此,对该像素点位置对应的所有类别预测图数据,取最大值即为该点最终预测类别。语义分割任务最常用的损失函数是交叉熵损失(cross entropy loss)。该损失对每个像素分别进行矢量预测评估,再求均值。

图 3 DeepLab V3[10]

图 4 ASPP结构[10](d表示dilated rate)
-
语义分割领域集聚了诸多前沿技术,本节从改进网络结构的角度总结三种关键技术。
1) 解码器(decoder):基于深度学习的方法中,解码器是语义分割网络的核心结构之一。经卷积神经网络下采样后的特征图尺寸缩小,此时须经过上采样操作得到原尺寸的预测图,而解码器则承担了这一任务。通常,卷积神经网络在卷积层之后会连接若干个全连接层,将卷积层生成的特征图映射成一个固定长度的向量。这不能应对语义分割任务中的密集分类问题。针对这一问题的开创性工作是由文献[12]提出的全卷积神经网络(fully convolutional network, FCN),该网络利用了一个卷积层替换了原来的全连接层,并采用反卷积层对最后一个卷积层的特征图进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生一个预测, 同时保留原始输入图像中的空间信息,最后在上采样的特征图上进行逐像素分类。
在FCN这一思路下,出现了许多变体解码结构来转换网络。文献[13]提出一个SegNet:它由一个编码器(encoder)和一个解码器组成,编码器交替使用卷积层和池化层,解码器交替使用反卷积层和上采样层,最后利用Softmax函数进行像素分类预测;在进行池化的过程中,保留了池化层索引,使得恢复图像大小时可根据池化层索引将数据映射到原来位置。DeepLab V3+[11]则在DeepLabV3的基础上,提出了一个解码器结构替换最后的1×1卷积,其特殊之处在于上采样操作融合了Block1和Block4的特征。进一步地,文献[14]提出了另一个改进解码器结构。在之前的方法中,通常采用双线性插值(bilinear)还原特征图的分辨率,但这种方法不能建立像素间的预测关系。针对这一问题,文献[14]提出了DUpsampling (Data-dependent Upsampling)来代替原来的双线性插值方法。实验表明,DUpsampling能够减少上采样操作对特征图分辨率的依赖,同时,还能减少30%的运算量。
2) 上下文特征提取(context knowledge extraction)。一张图片往往包含多重信息,局部特征难以反映真实信息,因此,在设计网络结构时,提取上下文特征至关重要。针对此问题,multi-scale[15]预测已被证明非常有效,但与此同时,该方法具有运算量大、内存占用大等缺点。在此背景下,3种提取多维度特征的结构被提出:金字塔池化模块(pyramid pooling module)[16]、空洞空间卷积池化金字塔(atrous spatial pyramid pooling, ASPP)[10]、密集连接的空洞空间卷积池化金字塔(densely connected atrous spatial pyramid pooling, DenseASPP)[17]。其中,pyramid pooling module是一个金字塔池化结构,通过融合4种不同金字塔尺度的特征,达到语义和细节的融合。ASPP是Google提出的利用空洞卷积提取特征的模块,如图 4,它利用了4个不同的空洞卷积率进行卷积,从而达到了多维度特征提取的目的。DenseASPP在ASPP的基础上进一步改进,采用了5个空洞卷积层,其空洞卷积率分别为3、6、12、18、24,并且每个空洞卷积层前面使用了1×1卷积,特征图以一种密集连接的方式递进输入:将每个空洞卷积的输出与原始输入特征进行连接(concatenate)操作,再输入到下一个卷积块(1×1卷积层和空洞卷积层)。这种密集连接的方式相对ASPP可以提取更大范围的多维度特征。
3) 注意力机制(attention mechanism)。注意力机制起源于对人类视觉的研究。在人类观察画面时,总是只关注画面中的一部分内容,而自动忽略其他画面信息。基于这一发现,提出了注意力机制。这种机制广泛应用于计算机视觉、语音识别、自然语言处理等领域,可用于提取关键信息。
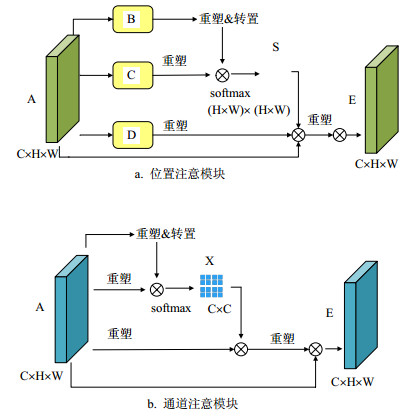
文献[18]最先引进注意力机制到语义分割任务中,随后有许多网络结构应用了这种机制。近期,文献[19]提出的DAN(dual attention network)结构较具影响力,该结构包含两个特殊的注意力模块(attention module),分别是位置注意模块(position attention module)和通道注意模块(channel attention module)。如图 5所示,位置注意模块选择性地聚合每个位置的特征,通道注意模块则选择性地着重于某个特征图,最后将两者的输出求和以得到最终的预测。该结构利用注意力机制对特征图和局部位置进行了加权处理,捕获了全局和局部的关键信息,其实验证明了该结构的有效性。

Figure 5. Dual attention[19]
-
基于深度学习展开人体解析研究,必不可少的是人体数据集。通常,每个数据集的分类方法和类别数目均有差异。数据集在很大程度上决定了训练模型的鲁棒性和有效性。
随着研究者们对人体解析关注度的提升,越来越多的数据集也随之出现。本节主要从数据集图像数量、类别数目等角度出发,详细介绍近几年人体解析领域的主流数据集,并分析其优缺点。表 1汇总了8个常用数据集的基本信息。
表 1 常用人体解析数据集汇总
数据集 类 训练 测试 验证 总数 Fashionista[20] 56 456 229 - 685 Pascal-Person[21] 7 1 716 1 817 - 3 533 ATR[22] 18 16 000 1 000 700 17 700 LIP[3] 20 30 462 10 000 10 000 50 462 CIHP[4] 20 28 280 5 000 5 000 38 280 MHP v1.0[23] 19 3 000 980 1 000 4 980 MHP v2.0[24] 59 15 403 5 000 5 000 25 403 VIP[25](video) 20 354 - 50 404 1) Fashionista[20]:该数据集于2012年公开,前几年的研究大多在此数据集上进行了验证。共包含685张图片,56个类别。但由于过多的分类和缺乏的图像资源,该数据集已逐渐被淘汰。
2) Pascal-Person-Part[21]:该数据集是PASCAL 2010的一个子集,包含3 533张图片,训练集和测试集的划分相对平均,分别为1 716和1 817。自2014年到现在,它始终是人体解析领域的标杆性数据集,具有数据量适中、人体姿态多样性等优点。
3) ATR[22]:ATR是人体解析领域第一个出现的大型数据集,共包含17 700张图片、18个类别。该数据集中的大多数图片是一些模特的图片,身体遮挡情况较少,故存在与实际场景有所差别的局限性,适用于研究理想情况下的人体分割或特殊场景应用任务下的解析工作。
4) LIP[3]:目前为止,LIP是数量最大的一个人体解析数据集,共包含50 462张图片、20个类别。该数据集中,大多数图片中只包含一个人体,这为单个人体解析提供了重要研究基础。同时,由于其数据量巨大,训练时间和计算量也相对增大。
5) CIHP[4]:CIHP是一个应对实例人体解析的数据集,每张图片均包含多个实例,相对于其他几个主流数据集,其图片更具复杂性和挑战性。关于实例人体解析的研究通常会在该数据集上加以验证。
6) MHP[23-34]:MHP是针对实例人体解析问题建立的,有两个版本。一个是MHP v1.0[23],包含4 980张图片,3 000张用于训练,1 000张用于验证,980张用于测试;每张图片包含2~16个人,共标注了7个身体部位类别和11个衣物配饰类别。另一个是MHP v2.0[24],图片数量增加到25 403张,其中,15 403张图片用于训练,验证集和测试集分别包含5 000张图片;每张图片包含2~26个人,定义了58个身体部位类别和一个背景类;其场景、视角以及人物姿态均比1.0版本更复杂化、多样化。
7) VIP[25]:目前为止,这是第一个也是唯一一个视频实例人体解析数据集。该数据集共包含20个类别,由404个视频序列组成,超过20 000帧。其中,354个序列用于训练,剩下的50个序列用于验证。这些数据来源于YouTube上的真实场景视频,富含多变性的姿态、不同视角、被遮挡目标。每个视频序列长度在10 s~120 s之间。每隔25帧,有一帧画面被标注。
除以上几个主流数据集外,还有一些近期鲜少使用的小型数据集,例如CFPD[26]、DP[27]、HPW[28]等。这些数据集所包含的图片数量大都在2 000张左右,训练时间相对较短,可以为少量训练数据的研究提供数据基础。
-
用于人体解析的评价标准有多种。其中,最常用的评价标准是均交并比(mIoU)。本节介绍4种常用的评价指标:像素精度(pixel accuracy, PA)、均像素精度(mean pixel accuracy, MPA)、均交并比(mean intersection over union, mIoU)、F1分数(F1-score)。定义参数意义如下:k+1表示数据集定义的类别总数(包括背景类“background”,通常背景类编号为“0”,故以下公式中参数i、j均从“0”开始取值);${p_{ij}}$表示类被识别为类j的像素总数,即${p_{ii}}$表示识别正确的真正例(true positive, TP)总数,而${p_{ij}}$和${p_{ji}}$则分别表示识别错误的假正例FP(false positive, FP)总数和假反例FN(false negative, FN)总数。
1) 像素精度(PA):像素精度仅计算识别正确的像素占所有像素的比例。
$${\rm{PA}} = \frac{{\sum\limits_{i = 0}^k {{p_{ii}}} }}{{\sum\limits_{i = 0}^k {\sum\limits_{j = 0}^k {{p_{ij}}} } }}$$ (1) 2) 均像素精度(MPA):均像素精度首先针对每一个类,计算其中识别正确的像素占该类所有像素的比例,接着求出所有类的平均比例。
$${\rm{MPA}} = \frac{1}{{k + 1}}\sum\limits_{i = 0}^k {\frac{{{p_{ii}}}}{{\sum\limits_{j = 0}^k {{p_{ij}}} }}} $$ (2) 3) 均交并比(mIoU):这是人体解析任务的一个标准度量。首先需要计算得出每一个类的交并比IoU,再计算所有类别的平均值mIoU。交并比IoU,是指预测像素集和真实像素集之间的比例。
$${\rm{mIoU}} = \frac{1}{{k + 1}}\sum\limits_{i = 0}^k {\frac{{{p_{ii}}}}{{\sum\limits_{j = 0}^k {{p_{ij}}} + \sum\limits_{j = 0}^k {{p_{ji}}} - {p_{ii}}}}} $$ (3) 4) F1分数(F1-score):目前,针对ATR数据集,通常以F1分数作为模型评判标准。F1分数是指查准率P(precision)和查全率R(recall)的调和平均数。
$$P = \sum\limits_{i = 0}^k {\frac{{{p_{ii}}}}{{\sum\limits_{j = 0}^k {{p_{ji}}} + {p_{ii}}}}} $$ (4) $$R = \sum\limits_{i = 0}^k {\frac{{{p_{ii}}}}{{\sum\limits_{j = 0}^k {{p_{ij}}} + {p_{ii}}}}} $$ (5) $$F1 = \frac{{2 \times P \times R}}{{P + R}}$$ (6) -
现有的人体解析方法大多是从深度学习的角度出发,去尝试提高模型表现力。基于深度学习的人体解析方法中,较具代表性的4种思路有:基于特征增强、基于人体结构、基于多任务学习、基于生成对抗网络。表 2汇总了基于深度学习的人体解析方法,其中,“*”的数量与模型效果成正比;“√”表示该模型实现了实例解析或者已公布可用代码,反之用“×”表示。
表 2 基于深度学习的人体解析网络结构汇总
方法 时间 网络架构 贡献 准确率 实例 代码 M-CNN[29] 2015 CNN KNN-based * × × Co-CNN[22] 2015 CNN Contextualized convolutional neural network * × × HAZN[42] 2016 FCN Human and object parsing * √ × AOG[36] 2016 CNN+graph Pose-guided * × × LG-LSTM[53] 2016 CNN+LSTM Integrate local-global layers into CNN * × × Graph LSTM[54] 2016 CNN+graph LSTM Graph LSTM layers * × × MH-Parser[40] 2017 ResNet-101 Graph-GAN * √ × SS-JPPNet[3] 2017 DeepLab V2 Self-supervised structure-sensitive loss ** × √ RefineNet[30] 2017 ResNet-101 Multi-path refinement network *** × √ 文献[52] 2017 ResNet-101 Instance CRF ** √ × 文献[51] 2018 VGG-16 Cross-domain human parsing ** √ √ JPPNet[37] 2018 ResNet-101 Pose subnet, parsing subnet, refinement network ** × √ MMAN[50] 2018 Do-DeepLab-ASPP Achieve local and global supervision with two discriminators * × √ PGN[4] 2018 ResNet-101 A detection-free Part Grouping Network *** √ √ MuLA[55] 2018 VGG16-FCN Mutual learning to adapt for human parsing and pose estimation ** × √ NAN[49] 2018 FCN-8s Nested Adversarial Network ** √ √ 文献[39] 2018 VGG-16 Utilize pose information to weakly supervise the training ** × √ CE2P[33] 2018 ResNet-101 Identify several useful properties *** √ √ SPReID[43] 2018 Inception V3 Multi-task learning * × √ 文献[38] 2018 DeepLab Achieve human parsing using only simple object keypoints * × × Parsing R-CNN[31] 2019 ResNet-50-FPN An end-to-end pipeline, GCE *** √ √ Graphonomy[41] 2019 DeepLab V3+ Incorporate hierarchical graph transfer learning *** × √ -
增强特征信息、聚集多维度语义信息是改进人体解析网络结构的核心思路之一。真实世界的图片往往不可预期,即使预先得知图片中包含人物信息,依然面临着形变、遮掩等挑战。如何提取并增强有效特征是人体解析任务的根本问题。
文献[22, 28-29]在早期尝试了多种思路,文献[28-29]都提到了分离人体结构(分离衣服、帽子、裤子等信息),然后分别提取特征,再合并以达到增强的效果。文献[22]则尝试利用卷积神经网络来提取局部和全局特征,随后的方法均是利用卷积神经网络来实现。进一步地,文献[30]提出了多路径增强网络(multi-path refinement network),通过输入不同尺寸的图片,令其分别经过残差卷积单元(residual convolution unit, RCU)结构提取多维度特征。这种方法具有突出的效果,但是网络结构较为复杂,多尺寸图片输入也造成计算量庞大、训练时间长等问题。
文献[31]在ResNet-50-FPN[6, 32]的基础上,提出了分离抽样(proposals separation sampling, PSS)的思路,利用特征金字塔结构对FPN的每个输出块(Block)输出提取特征,以保留有效的多维度特征。从训练的角度来看,避免多尺寸输入的特征提取方法更具实用性。除以上提到的方法,在一些结构中[4, 33]利用了1.1.2节提到的金字塔池化模块、空洞空间卷积池化金字塔等结构来搭建网络,模型展现了较强的表现力。
-
从人体解析的任务来看,须识别的像素区域之间并非毫无联系。如,正常的人体应是由头部、手臂、腿部、脚等部件组成,那么,除去遮掩物等外部干扰情况,通常组成腿部和脚的像素应是相邻的。基于此特性,研究者们主要提出了两种思路:基于关键点信息、基于图结构。
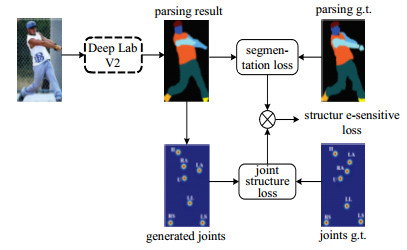
利用人体姿态(pose)或者关键点(keypoint)信息引导分割是常见的一种方法,早期有较多研究[34-35]。文献[36]提出了提取人物姿态关键点信息的结构AOG(And-Or graph),该结构的预测效果超越了之前的FCN[14]。随后,文献[3]提出了一种较为简单有效的方法,利用DeepLab V2生成解析结果(parsing result),分别计算解析结果和标注数据(ground truth)的各区域中心点作为关键连接点(joints),再利用欧式距离计算两者之间的结构损失(joint structure loss),将其与分割损失(segmentation loss)相乘作为最终的代价评估,如图 6所示。这种方法相对于前者更具有效性。针对文献[3]的工作,文献[37]在其网络结构上进行了优化并提出JPPNet(joint human parsing and pose estimation network),主要规划了姿态增强(pose refinement)和解析增强(parsing refinement)结构[12]进行优化,提升效果明显。

图 6 SS-JPPNet概览[3]
同上述方法有所不同,一些研究者提出了利用人体关键点信息进行弱监督学习的方法[38-39]。文献[39]提出了仅利用少量标注图片和关键点信息合成未标注图片的分割结果的方法,然后将合成图片作为额外的训练数据用于训练最终的解析模型。其合成数据的方法是:首先依据已标注图片和未标注图片中人物动作的相似性,进行聚类,即以人物臀部作为参照点对齐图片,根据欧式距离取前k张图作为一类;然后,计算转换关系(transformation relationship)矩阵表示个体之间的差异,进而实现分割图片的转换。
基于图结构的方法是关键点信息的转换形式,通常以节点表示类别的形式来组织像素关系。文献[40]采用图生成器(graph generator)生成了每张图片对应的图结构,将其与解析特征结合以进一步加强分割效果,并设计了一个图卷积网络(graph convolution networks)用于辨别图的准确性。文献[41]则依据各人体数据集分类情况,设计相应的图结构,然后基于图结构进行迁移学习,该结构实现的效果超越了大多数方案。
-
在早期的研究中,大多数机器学习任务属于单任务学习,即一次只学习一个任务。而随着深度学习的发展,许多研究领域存在交叉性研究内容,故而诞生了多任务学习(multi-task learning, MTL)。多任务学习是指通过共享特征,将多个具有相关性的任务融合到一个模型中,使其同时完成多个任务的预测。这种思路已经被成功应用于多个领域。
对于人体解析这一任务,有多种类型的任务与之密切相关,最具代表性的是边缘检测(edge detection)。边缘检测的目标是识别出目标界限,只需实现像素的二分类问题,如图 7所示。相比之下,人体解析是一个更复杂的像素分类任务。边缘像素须呈现在人体解析最后的分类结果中,即两个任务实际有一个递进的关系。在最近的研究成果中,文献[4, 33]都对此进行了深入探索,分别提出了PGN(part grouping network)和CE2P(context embedding with edge perceiving),均取得了显著提升。两篇论文均考虑了将边缘检测和人体解析融合到一个模型中,以端到端的形式训练,实验证明可以形成相互增强的效果。CE2P结构概览图如图 8所示,其中,基础层输出的特征进入解析分支网络和边缘检测分支网络,分别提取有效特征,再进一步合并,最后生成分割结果和边缘预测图,同时通过边缘图损失(通常也用交叉熵损失)优化模型。

图 7 边缘图示例

图 8 CE2P结构概览图[33]
除了结合边缘检测这一任务,还有一些结合目标识别(object detection)[42]、行人重识别(person re-identification)[43, 44]、姿态估计(pose estimation)[45]等任务的方法。多任务学习模型在共享特征的同时,融合了多重信息,是一种值得探究的解决思路。
-
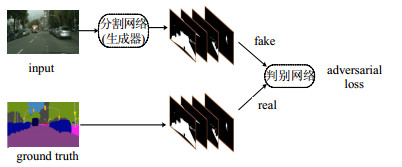
生成对抗网络(generative adversarial network, GAN)[46]至少由生成器(generator)和辨别器(discriminator)两个基本网络组成。GAN对于生成图像任务具有非常突出的效果,整个模型训练过程是生成器和辨别器相互抗衡的过程。文献[47]最先在语义分割领域引入GAN思想,将分割网络视作生成器,输入原图的同时,输入预测图或标注图(ground truth)进入辨别器,判断其真假性,产生对抗损失(adversarial loss),将其规划进代价函数中以优化模型。在此之后,大量相关工作基本遵循这种思路,在此基础上应用或加以改进[48]。语义分割领域通常使用的GAN的基本原理图如图 9所示。与文献[47]不同的是,辨别器只需输入预测图或标注图即可。

图 9 生成对抗网络基本原理图
从GAN的用途来看,它是在辨别器和生成器不断对抗的过程中生成质量越来越高的图片。人体解析的本质也是生成预测图,利用GAN来解决这一任务便成了一个重要的探索方向。文献[40]提出了一个应用GAN的网络Graph-GAN,和传统语义分割利用GAN的思路不同,Graph-GAN的生成器生成的是关系图(affinity graph),而辨别器则是辨别预测图与真实图的偏离性。进一步地,文献[49]又提出了另一种应用思路,称为嵌套式对抗网络(nested adversarial networks, NAN)。NAN是针对实例人体解析(见3.5节)的一个网络,嵌套了3个辨别器,分别实现不同的判别任务:语义显著性预测(semantic saliency prediction)、实例解析(instance-agnosticparsing)、实例人物聚类(instance-aware clustering)。3个子网络相互依赖,依次递进。这种方法是较具创新性的思路,实验也证明了其可行性。另外,在MMAN[50]中,提出了针对顶层网络造成的局部不一致性(localinconsistency)的解决思路:利用两个辨别器分别对全局和局部区域加以辨别,从而改善整体模型效果。文献[51]利用迁移学习增强预测效果的同时,也使用了GAN,用来识别标注图来自于源域(source domain)还是目标域(target domain)。
根据所调查的研究工作,可见目前利用GAN实现解析效果增强的思路各有差异,寻求最适宜、有效的思路是研究如何应用GAN的一个目标。
-
在人类面对的真实情景中,很多时候并非是单个人的画面,实例人体解析(instance-level human parsing)因此成为了必要的研究任务。实例人体解析是指在识别出人体各部位类别的同时,进一步识别这些类别属于哪一个实例。
实例人体解析比人体解析更具挑战性。在多人场景下,通常出现人与人之间的身体部位重合、单个人物所占比例较小等现象,这导致单个人体部位解析存在一定难度。近几年,有一些工作已经涉足实例人体解析的研究[4, 31, 33, 40, 49, 52],同时还有针对视频实例分析的工作[25]。现有方法通常采用两种实现方式,一种是分开进行人体解析和实例检测,最后将两者训练结果进行合并得到最终的实例解析结果[4, 33, 40, 52];另一种则是以端到端(end-to-end)的形式统一化网络结构,即人体解析和实例解析在一个网络中训练完成[31, 49]。
基于第一种实现方式,文献[52]利用了目标检测的方法,通过训练网络以获得实例目标框(box),再与人体解析得到的全局分类合并。而文献[5]的方法则不同,他们利用的是实例边缘信息,以区分多个人之间的像素界限。首先通过PGN[4]生成实例边缘图(instance-aware edge)和整体分割图(part segmentation),然后通过线性解码(line decoding)的方式将这两个任务融合得到最后的实例解析结果。
不同于前面的工作,文献[31]提出的ParsingR-CNN采用了端到端的方式,将人体解析和实例解析融合在一个网络中进行训练。他们提出的解析分支(parsingbranch)用以直接生成实例解析结果,其中嵌入了一个特殊的结构:GCE(geometric and context encoding)。该结构将ASPP和non-local[56]组合在一起,融合了两者的优点。作者在多个数据集上进行了实验,数据反映了该结构的有效性。
目前,采用第一种实现方式的工作较多,但第二种实现方式具有易训练、结构统一的优点。
-
基于深度学习的人体解析技术已经有了大幅提升,但仍然存在不足。本节就以下几个方面进行探讨:
1) 人体解析技术水平还有很大的提升空间。依据目前的研究成果,在数据集LIP、CIHP、Pascal-Person-Part上实现的最高mIoU值分别为:53.10%[33]、61.10%[31]、71.14%[41]。这个数据反映了目前的研究技术仅达到了基本水平,难以投入实际应用。因此,还有很大的提升空间等待开发。
2) 研究方案丰富,但缺乏进一步深入的工作。在调查了人体解析领域近几年基于深度学习的各种研究工作后,发现已有的研究思路各有所长,但缺乏进一步深入研究的工作。如,文献[40]于2017年提出了利用图卷积网络(graphconvolution network)的思路,但是目前依然欠缺关于这一技术的深入研究工作。图卷积网络不同于传统卷积网络结构,它可以表示图片中像素之间的拓扑关系,人体结构同时具有特殊的拓扑关系(如,“手”和“手臂”相邻,“脸部”和“头发”相邻),基于此,深入研究图卷积网络结构在人体解析中的应用是有一定意义的。
3) 实例人体解析具有重要的研究意义。在实际生活场景中,画面中包含多个人物是很常见的,因此,研究实例人体解析具有一定的应用价值。进一步地,视频实例人体解析更具有实用性。在现有的工作中,关于实例人体解析的研究较少,有待探索。
4) 前沿深度学习技术在人体解析任务中的应用尚未发掘。深度学习的发展非常迅速,研究者们提出了许多实现人工智能的思路。目前,人体解析的研究工作涉及了其中一些前沿技术,例如生成对抗网络、多任务学习等。事实上,还有一些深度学习技术尚未被应用在人体解析任务中,如知识蒸馏(knowledge distillation)、元学习(meta learning)等技术。而这些技术是否适用于该任务,仍处于未知状态。
-
本文从人体解析的应用价值出发,对该任务的研究意义进行了探讨。在技术层面,本文从3个方面总结了基于深度学习的人体解析研究工作:
1) 人体解析涉及的基础技术:卷积神经网络是该任务的技术支撑;作为语义分割的一个子任务,人体解析技术汲取了语义分割的许多研究技术。
2) 人体解析的数据集和评价标准:现有的数据集具有数据量大、场景复杂等特点;衡量模型的常用标准是均交并比(mIoU)。
3) 人体解析技术现状:现有的基于深度学习的人体解析方法中,具有代表性的4种思路:基于特征增强、基于人体结构、基于多任务学习、基于生成对抗网络。
最后,针对目前研究工作的现状,提出了一些不足和尚待发掘的研究思路。
本文主要针对人体解析现有技术进行概括和梳理,旨在提供技术概览和参考性研究思路,各方法细节仍须参考原文献。
A Review on Deep Learning Techniques Applied to Human Parsing
-
摘要: 人体解析的任务是对图片中人物进行像素级识别,将人体各部位和衣物配饰进行归类。该文从基础技术、数据集和评价标准、技术现状3个方面概述了基于深度学习的人体解析技术。首先,介绍了人体解析涉及的基础技术:卷积神经网络、语义分割。其次,从图像数量、类别数目、优缺点等角度,对比了人体解析领域的8种主流数据集;并介绍了4种常用的评价指标。最后,介绍了4种具有代表性的基于深度学习的人体解析方法:基于特征增强、基于人体结构、基于多任务学习、基于生成对抗网络,并归纳了实例人体解析的解决方案,提出了一些尚待发掘的研究思路。Abstract: Human parsing aims at identifying the body parts and clothing items from human images at pixel level. This paper investigates and analyzes the approaches of human parsing based on deep learning, which mainly includes three aspects:the basic technologies involved in human parsing, the main datasets and evaluation standard, and the existing methods. Firstly, the basic technologies involved in human parsing based on deep learning, including convolutional neural network and semantic segmentation are reviewed. Secondly, this paper introduces 8 datasets for human parsing in detail according to the number of images, the number of categories, advantages and disadvantages. In addition, four commonly used evaluation metrics are summarized. Finally, existing representative schemes for human paring based on deep learning are concerned, including feature enhancement, structure of human body, multi-task learning, and generative adversarial networks. This paper summarizes the approaches of instance-level human parsing, and presents some ideas worth studying.
-
Key words:
- deep learning /
- human parsing /
- instance-level human parsing /
- semantic segmentation
-
表 1 常用人体解析数据集汇总
数据集 类 训练 测试 验证 总数 Fashionista[20] 56 456 229 - 685 Pascal-Person[21] 7 1 716 1 817 - 3 533 ATR[22] 18 16 000 1 000 700 17 700 LIP[3] 20 30 462 10 000 10 000 50 462 CIHP[4] 20 28 280 5 000 5 000 38 280 MHP v1.0[23] 19 3 000 980 1 000 4 980 MHP v2.0[24] 59 15 403 5 000 5 000 25 403 VIP[25](video) 20 354 - 50 404  下载: 导出CSV
下载: 导出CSV
表 2 基于深度学习的人体解析网络结构汇总
方法 时间 网络架构 贡献 准确率 实例 代码 M-CNN[29] 2015 CNN KNN-based * × × Co-CNN[22] 2015 CNN Contextualized convolutional neural network * × × HAZN[42] 2016 FCN Human and object parsing * √ × AOG[36] 2016 CNN+graph Pose-guided * × × LG-LSTM[53] 2016 CNN+LSTM Integrate local-global layers into CNN * × × Graph LSTM[54] 2016 CNN+graph LSTM Graph LSTM layers * × × MH-Parser[40] 2017 ResNet-101 Graph-GAN * √ × SS-JPPNet[3] 2017 DeepLab V2 Self-supervised structure-sensitive loss ** × √ RefineNet[30] 2017 ResNet-101 Multi-path refinement network *** × √ 文献[52] 2017 ResNet-101 Instance CRF ** √ × 文献[51] 2018 VGG-16 Cross-domain human parsing ** √ √ JPPNet[37] 2018 ResNet-101 Pose subnet, parsing subnet, refinement network ** × √ MMAN[50] 2018 Do-DeepLab-ASPP Achieve local and global supervision with two discriminators * × √ PGN[4] 2018 ResNet-101 A detection-free Part Grouping Network *** √ √ MuLA[55] 2018 VGG16-FCN Mutual learning to adapt for human parsing and pose estimation ** × √ NAN[49] 2018 FCN-8s Nested Adversarial Network ** √ √ 文献[39] 2018 VGG-16 Utilize pose information to weakly supervise the training ** × √ CE2P[33] 2018 ResNet-101 Identify several useful properties *** √ √ SPReID[43] 2018 Inception V3 Multi-task learning * × √ 文献[38] 2018 DeepLab Achieve human parsing using only simple object keypoints * × × Parsing R-CNN[31] 2019 ResNet-50-FPN An end-to-end pipeline, GCE *** √ √ Graphonomy[41] 2019 DeepLab V3+ Incorporate hierarchical graph transfer learning *** × √
下载: 导出CSV
-
[1] KRIZHEVSKYA, SUTSKEVERI, HINTON G E. ImageNet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems 25: 26th AnnualConference on Neural Information Processing Systems 2012. Lake Tahoe, USA: IEEE, 2012: 1106-1114. [2] CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding[C]//Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 3213-3223. [3] GONG Ke, LIANG Xiao-dan, ZHANG Dong-yu, et al. Lookinto person: Self-supervised structure-sensitive learning anda new benchmark for human parsing[C]//Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 6757-6765. [4] GONG Ke, LIANG Xiao-dan, LI Yi-cheng, et al. Instance-level human parsing via part grouping network[C]//European Conference on Computer Vision. Munich, Germany: IEEE, 2018: 805-822. [5] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]//3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [6] HE Kai-ming, ZHANG Xiang-yu, REN Shao-qing, et al. Deep residual learning for image recognition[C]//Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 770-778. [7] SZEGEDY C, LIU Wei, JIA Yang-qing, et al. Going deeper with convolutions[C]//Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015: 1-9. [8] CHEN L C, PAPANDREOU C, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[C]//3rd International Conference on Learning Representations. San Diego, USA: ICLR, 2015. [9] CHEN L C, PAPANDREOU C, KOKKINOS I, et al. DeepLab:Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4):834-848. doi: 10.1109/TPAMI.2017.2699184 [10] CHEN L C, PAPANDREOU C, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL].[2017-12-05]. https: //arxiv.org/pdf/1-706.05587. [11] CHEN L C, ZHU Y, PAPANDREOU C, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//European Conference on Computer Vision. Munich, Germany: ECCV, 2018: 833-851. [12] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//Con-ference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015: 3431-3440. [13] BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation[EB/OL].[2015-11-10]. http://arxi-v.org/abs/1511.00561. [14] TIAN Zhi, HE Tong, SHEN Chun-hua, et al. Decoders matter for semantic segmentation: Data-dependent decoding enables flexible feature aggregation[EB/OL].[2019-03-10]. http://ar-xiv.org/abs/1903.02120. [15] EIGEN D, FERGUS R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]//International Conference on Computer Visi-on. Santiago, Chile: IEEE, 2015: 2650-2658. [16] ZHAO Heng-shuang, SHI Jian-ping, QI Xiao-juan, et al. Pyramid scene parsing network[C]//Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 6230-6239. [17] YANG Mao-ke, YU Kun, ZHANG Chi, et al. DenseASPP for semantic segmentation in street scenes[C]//Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018: 3684-3692. [18] CHEN LC, YANG Yi, WANG Jiang, et al. Attention to scale: Scale-aware semantic image segmentation[C]//Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 3640-3649. [19] FU Jun, LIU Jing, TIAN Hai-jie, et al. Dual attention network for scene segmentation[EB/OL].[2018-09-21]. htt-p://arxiv.org/abs/1809.02983. [20] YAMAGUCHI K, KIAPOUR M H, ORTIZ M E, et al. Parsing clothing in fashion photographs[C]//Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE, 2012: 3570-3577. [21] CHEN Xian-jie, MOTTAGHI R, LIU Xiao-bai, et al. Detect what you can: Detecting and representing objects using holistic models and body parts[C]//Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014: 1979-1986. [22] LIANG Xiao-dan, XU Chun-yan, SHEN Xiao-hui, et al. Human parsing with contextualized convolutional neural network[C]//International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 1386-1394. [23] LI Jian-shu, ZHAO Jian, WEI Yun-chao, et al. Multiple-human parsing in the wild[EB/OL].[2017-05-15]. https://ar-xiv.org/pdf/1705.07206. [24] ZHAO Jian, LI Jian-shu, CHENG Yu, et al. Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing[C]//Mul-timedia Conference on Multimedia Conference. Seoul, Republic of Korea: ACM, 2018: 792-800. [25] ZHOU Qi-xian, LIANG Xiao-dan, GONG Ke, et al. Adaptive temporal encoding network for video instance-level human parsing[C]//Multimedia Conference on Multimedia Conference. Seoul, Republic of Korea: ACM, 2018: 1527-1535. [26] LIU Si, FENG Jia-shi, DOMOKOS C, et al. Fashion parsing with weak color-category labels[J]. IEEE Transactions on Multimedia, 2014, 16(1):253-265. doi: 10.1109/TMM.2013.2285526 [27] DONG Jian, CHEN Qiang, XIA Wei, et al. A deformable mixture parsing model with parselets[C]//International Conference on Computer Vision. Sydney, Australia: IEEE, 2013: 3408-3415. [28] LIANG Xiao-dan, LIU Si, SHEN Xiao-hui, et al. Deep human parsing with active template regression[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(12):2402-2414. doi: 10.1109/TPAMI.2015.2408360 [29] LIU Si, LIANG Xiao-dan, LIU Luo-qi, et al. Matching-CNN meets KNN: Quasi-parametric human parsing[C]//Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE, 2015: 1419-1427. [30] LIN Guo-sheng, MILAN A, SHEN Chun-hua, et al. RefineNet: Multi-path refinement networks for high-resolution semantic segmentation[C]//Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 5168-5177. [31] YANG Lu, SONG Qing, WANG Zhi-hui, et al. Parsing R-CNN for instance-level human analysis[EB/OL].[2018-11-30]. http://arxiv.org/abs/1811.12596. [32] LIN T Y, DOLLAR P, GIRSHICK R B, et al. Feature pyramid networks for object detection[C]//Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 936-944. [33] LIU Ting, RUAN Tao, HUANG Zi-long, et al. Devil in the details: towards accurate single and multiple human parsing[EB/OL].[2018-09-29]. http://arxiv.org/abs/1809.05-996. [34] LADICKY L, TORR P H S, ZISSERMAN A. Human pose estimation using a joint pixel-wise and part-wise formulation[C]//Conference on Computer Vision and Pattern Recognition. Portland, USA: IEEE, 2013: 3578-3585. [35] DONG Jian, CHEN Qiang, SHEN Xiao-hui, et al. Towards unified human parsing and pose estimation[C]//Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE, 2014: 843-850. [36] XIA Fang-ting, ZHU Jun, WANG Peng, et al. Pose-guided human parsing by an and/or graph using pose-context features[C]//Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence. Phoenix, USA: AAAI, 2016: 3632-3640. [37] LIANG Xiao-dan, GONG Ke, SHEN Xiao-hui, et al. Look into person:joint body parsing & pose estimation network and a new benchmark[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(4):871-885. doi: 10.1109/TPAMI.2018.2820063 [38] WU Zhong-hua, LIN Guo-sheng, CAI Jian-fei. Keypoint based weakly supervised human parsing[EB/OL].[2018-09-14]. http://arxiv.org/abs/1809.05285. [39] FANG Hao-shu, LU Guan-song, FANG Xiao-lin, et al. Weakly and semi supervised human body part parsing via pose-guided knowledge transfer[C]//Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018: 70-78. [40] LI Jian-shu, ZHAO Jian, WEI Yun-chao, et al. Multi-human parsing in the wild[EB/OL].[2017-05-15]. https://arxiv.or-g/abs/1705.07206. [41] GONG Ke, GAO Yi-ming, LIANG Xiao-dan, et al. Graphonomy: Universal human parsing via graph transfer learning[EB/OL].[2019-04-09]. http://arxiv.org/abs/1904.0-4536. [42] XIA Fang-ting, WANG Peng, CHEN L C, et al. Zoom better to see clearer: Human and object parsing with hierarchical auto-zoom net[C]//European Conference on Computer Vision. Amsterdam, Netherlands: ECCV, 2016: 648-663. [43] KALAYEH M M, BASARAN E, GOKMEN M, et al. Human semantic parsing for person re-identifica-tion[C]//Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018: 1062-1071. [44] BASARAN E, TESFAYE Y T, SHAH M. EgoReID: Person re-identification in egocentric videos acquired by mobile devices with first-person point-of-view[EB/OL].[2019-05-16]. http://arxiv.org/abs/1812.09570. [45] NIE Xue-cheng, FENG Jia-shi, ZUO Yi-ming, et al. Human pose estimation with parsing induced learner[C]//Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018: 2100-2108. [46] GOODFELLOW I J, ABADIE J P, MIRZA M, et al. Generative adversarial nets[C]//Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014. Montreal, Canada: NIPS, 2014: 2672-2680. [47] LUC P, COUPRIE C, CHINTALA S, et al. Semantic segmentation using adversarial networks[EB/OL].[2016-11-25]. https://arxiv.org/pdf/1611.08408. [48] HUNG W C, TSAI Y H, LIOU Y T, et al. Adversarial learning for semi-supervised semantic segmentation[C]//Bri-tish Machine Vision Conference. Northumbria University, UK: BMVC, 2018: 65. [49] ZHAO Jian, LI Jian-shu, CHENG Yu, et al. Understanding humans in crowded scenes: Deep nested adversarial learning and a new benchmark for multi-human parsing[C]//2018 ACM Multimedia Conference on Multimedia Conference. Seoul, Republic of Korea: ACM, 2018: 792-800. [50] LUO Ya-wei, ZHENG Zhe-dong, ZHENG Liang, et al. Macro-micro adversarial network for human parsing[C]//Eu-ropean Conference on Computer Vision. Munich, Germany: ECCV, 2018: 424-440. [51] LIU Si, SUN Yao, ZHU De-fa, et al. Cross-domain human parsing via adversarial feature and label adaptation[C]//Pro-ceedings of the Thirty-Second AAAI Conference on Artificial Intelligence. New Orleans, USA: AAAI, 2018: 7146-7153. [52] LI Qi-zhu, ARNAB A, HOLISTIC P H S T. Holistic, instance-level human parsing[C]//British Machine Vision Conference. London, UK: BMVC, 2017. [53] LIANG Xiao-dan, SHEN Xiao-hui, XIANG Dong-lai, et al. Semantic object parsing with local-global long short-term memory[C]//Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 3185-3193. [54] LIANG Xiao-dan, SHEN Xiao-hui, FENG Jia-shi, et al. Semantic object parsing with graph LSTM[C]//European Conference on Computer Vision. Amsterdam, The Netherlands: ECCV, 2016: 125-143. [55] NIE Xue-cheng, FENG Jia-shi, YAN Shui-cheng. Mutual learning to adapt for joint human parsing and pose estimateon[C]//European Conference on Computer Vision. Munich, Germany: ECCV, 2018: 519-534. [56] WANG Xiao-long, GIRSHICK R B, GUPTA A, et al. Non-local neural networks[C]//Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE, 2018: 7794-7803. -

 点击查看大图
点击查看大图
图(9) / 表(2)
计量
- 文章访问数: 5840
- HTML全文浏览量: 1759
- PDF下载量: 328
- 被引次数: 0
