 ISSN
ISSN 



-
手姿态估计是自然人机交互领域的热点方向之一,由于其灵活、自然等特性,能够提供便捷的交互体验,使得其在虚拟现实、互动娱乐、人机交互、手语识别等领域有极大的应用价值。然而,由于手部的高自由度、遮挡严重、手部区域占比小等问题,手姿态估计仍然具有挑战性。
文献[1]比较了已发表的手姿态估计算法,发现在统一的标准下,最近临算法效果超过了大多数基于随机森林、卷积神经网络等复杂模型的算法。这些算法的效果提升需要更多、更优质的标记数据。当前获取标记数据有3种方法:人工标注、自动标注和合成数据[2]。人工标注费时费力,且标注过程带有主观判断,往往造成数据的不均一性。自动标注采用机器学习的方法辅助标注,其标注过程本身含有误差信息。合成数据能够解决一部分问题,但是和真实数据相比,仍然有差别,甚至产生一些不符合人体结构的数据。因此,文献[3]提出了基于半监督学习的方法,该方法能够充分利用模型的优势,并且降低对标记数据的依赖。
手姿态估计算法一般可以分为基于模型的方法、基于数据的方法以及综合方法。基于模型的方法需要对手的结构进行分析,定义出手部模型,通过优化模型与图像之间的误差以实现姿态估计。文献[4]采用骨架模型和级联构架,通过多次弱迭代回归得到最终姿态。文献[5]采用手三维模型库生成深度点云数据,结合粒子群优化算法(practical swarm optimization, PSO)实现模型匹配。基于数据的方法直接建立数据到姿态的映射,其优势在于不需要复杂的模型校准,且不依赖初始化的质量。文献[6]使用树形结构,采用二分的方法把手分为手掌和手指,然后逐层二分到各个关节,采用一个二分隐树模型(binary latent tree model (b-LTM))分类各层的像素点,最后投票计算每个关节的三维坐标。综合方法通过模型产生大量假设,然后进一步优化模型和图像之间的能量函数。文献[7]通过Reinitialization模块产生大量假设,采用PSO算法优化其定义的“Golden Energy”误差函数以获取最优的匹配姿态。
相比于传统的算法,文献[7]中的卷积神经网络(convolutional neural networks, CNN)在手姿态估计中展现了优势。文献[8]通过引入一种“bottleneck”层结构来融合姿态先验,以提升姿态估计的准确度。相较于直接回归坐标点,文献[9]进一步把深度图投影到3个正交面上,通过多个卷积神经网络分别预测关节点在各个正交面上的热图,最后采用后融合的方式计算各个关节点姿态。文献[7]进一步采用三维描述子(directional truncated signed distance function, D-TSDF)描述各个投影面,结合3D-CNN回归手部姿态。文献[10]则采用两个不同视角的相机数据,学习两个视角之间的隐层联系,最后回归至节点坐标。
半监督学习能够有效减少对标记数据的依赖。文献[11]利用半监督直推学习模型融合少量的标记真实数据和大量的合成数据。文献[12]学习一个双向映射网络,以连接从无标签数据中学习到的深度隐空间表征和利用标记数据学习到的手姿态隐空间表征。文献[13]直接以一个视角的数据为输入,预测另一个视角数据,通过编码-解码模型学习两个视角数据的隐层表征,其主要目的在于学习深度图的低维表征,而后通过全连接层回归到手部姿态。
虽然传统方法和基于卷积神经网络的方法在手姿态估计中均获得了较好的结果,但是存在以下问题:1)传统方法中,基于模型的方法受限于模型的复杂度和初始化策略,基于数据的方法则无法获得较好的泛化能力;2)基于2D-CNN或3D-CNN的方法需要大量的训练数据,但是手姿态的高维度链式结构使得数据的采集和标记质量难以得到保证;3)现有的半监督学习方法采用合成数据或者多个相机不同视角的数据,需求大量的计算性能,且限制了应用场景。针对这些不足,本文提出了一种基于视图的半监督学习方法。在工程界,三视图能够反映三维模型的完整信息,是一种三维模型通用的抽象表达方法。以此为启发,本文把深度图分别映射到3个正交面,进而建立3个投影视图在低维度隐空间中的关联表征,最后回归到手姿态的关节点坐标。这种方法能够有效地利用无标签数据学习高维度视图观察到低维度隐空间表征的映射,同时,端到端的结构避免了后融合等方法的复杂建模及计算。
-
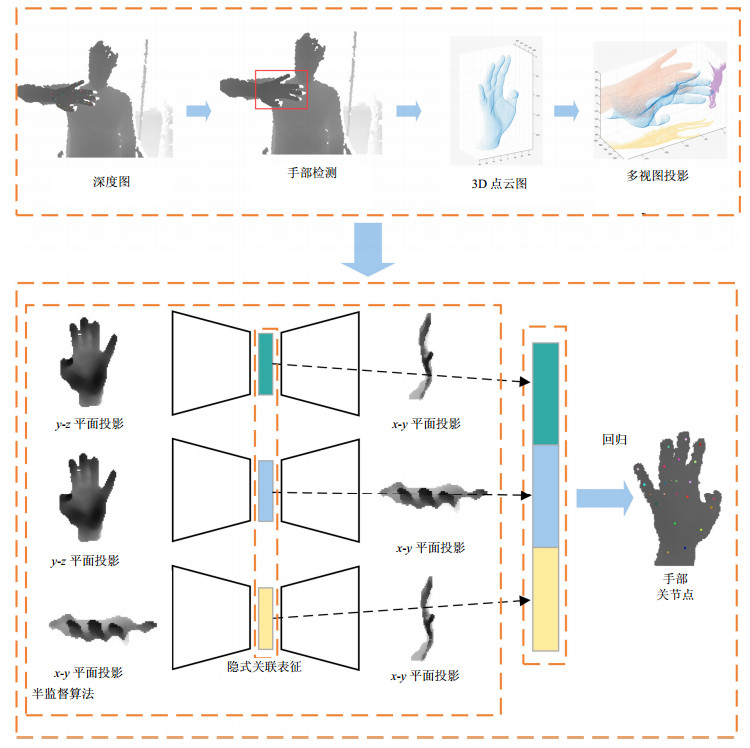
本文的研究内容基于单帧深度图的手姿态估计, 其主要任务可定义为学习单帧深度图到各个关节三维坐标的映射,输入为单帧深度图,输出为$K$个关节的坐标值。本文提出了基于视图投影的半监督手姿态估计算法,如图 1所示,该算法主要包括手部分割、多视图投影、手姿态估计3个部分,其中手姿态估计分为隐空间表征学习和姿态回归两个步骤。手部分割目的在于从单张深度图中截取出手掌区域,去除无用信息。和文献[8-10, 12]类似,本文假定手部区域位于深度图的最前端,采用三维深度阈值分割手掌区域。多视图投影对点云数据进行主成分分析,以3个特征值最大对应的特征向量分量为坐标轴方向,将点云投影至各个坐标平面。隐空间学习采用无监督编解码框架,以单视图数据为输入,另一视图为重建目标,低维空间编码即为两个视图的关联隐空间表征。最后,姿态回归融合各个视图的关联表征为输入,直接回归到关节点坐标值。相较于其他算法,本文提出的算法在NYU数据库的实验中,在不需要额外的合成数据或者多相机视角数据等附加数据的情况下,取得了更好的结果。

图 1 算法框架图
-
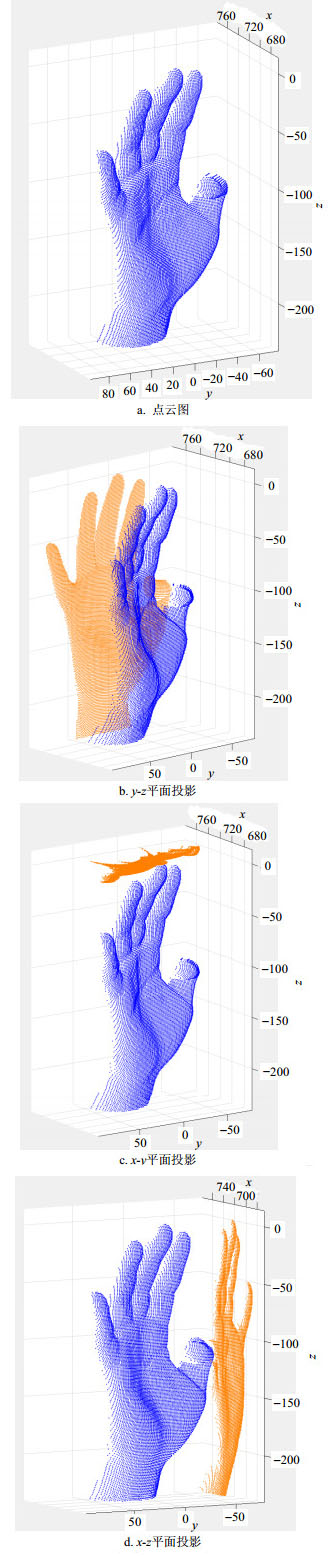
在人机交互过程中,通过深度相机采集到的是整个场景的深度图像${I_d}$,需要分割出手部区间${I_h}$。结合相机参数,深度图被转换为以相机为中心的世界坐标系的点云数据,如图 2b,而后通过对最前端目标的检测分割获得手部点云数据,如图 2c。

图 2 手部分割过程
-
手部是一个高自由度链式结构,其姿态变化空间极大,对姿态估计造成很多困难。本文将手部姿态估计分解为全局姿态估计及手指姿态估计两个步骤,以降低手姿态的搜索空间,提高姿态识别的准确度。全局姿态指的是手掌的姿态,本文利用基于点云的主成分分析算法(principal components analysis,PCA)计算手的全局方向。采用3个最大的特征值对应的特征向量方向作为手掌姿态方向,以此为坐标系,将所有点投影至此坐标系下得到转换后的点云图,如图 2d所示。
视图投影的目的在于获取手部点云数据在3个视图平面$x{\rm{ - }}y{\rm{, }}y{\rm{ - }}z{\rm{, }}x{\rm{ - }}z$上的投影,各个投影的值为投影平面到点的距离,所有的投影值被归一化到[-1, 1],其中最近的点为-1,最远的点为1。当有多个点投影到同一位置时,取最小的值为投影值。由于点云本身的稀疏性,最后会通过中值滤波填充投影图中的空缺点。投影结果示意如图 3所示。

图 3 各个视图平面投影图
-
本文的主要出发点在于三视图包含了三维目标的所有信息,通过3个视图之间的关联分析,能够隐式地得到三维目标的各项参数。基于这种认知,在手姿态估计问题中,通过分析两两视图之间的关联表征,可以获得三视图在隐空间中的关联信息,这可以认为是手姿态在这个低维空间的特定表征。${I_{{\rm{xy}}}}, {I_{{\rm{yz}}}}, {I_{{\rm{xz}}}}$分别表示在3个视图面的投影图,${\phi _{{\rm{yz - xy}}}}, {\phi _{{\rm{xy - xz}}}}, {\phi _{{\rm{yz - xz}}}}$分别表示两两视图之间的关联表征。以${I_{{\rm{xy}}}}, {I_{{\rm{yz}}}}$两个视图为例,可以假设存在一个特定的映射${f^{{\rm{en}}}}$使得:
$${\phi _{{\rm{yz - xy}}}} = {f^{{\rm{en}}}}({I_{{\rm{yz}}}})$$ (1) 式中,${\phi _{{\rm{yz - xy}}}}$表征了视图投影${I_{{\rm{xy}}}}$和${I_{{\rm{yz}}}}$隐层关联信息,其包含了手姿态在这两个视图中蕴含的信息。另一方面,隐层关联表征${\phi _{{\rm{yz - xy}}}}$中包含了手姿态在两视图面的信息,可以被认为在当前手姿态下,投影视图${I_{{\rm{yz}}}}$是可以根据这个低维表征重建得到,因此存在映射${f^{{\rm{de}}}}$使得:
$${I_{{\rm{xy}}}} = {f^{{\rm{de}}}}({\phi _{{\rm{yz - xy}}}})$$ (2) 基于以上假设,可以发现,两个视图可以通过隐层关联表征相互映射,因而当一个投影视图已知时,另一个视图的投影观测能够通过两次映射重建得到:
$${I_{{\rm{xy}}}} = {f^{{\rm{de}}}}({f^{{\rm{en}}}}({I_{{\rm{yz}}}}))$$ (3) 同理,其他的视图面均可获得相应的映射关系。3个投影视图根据不同的输入和输出,可以组成6种映射组合,这里选取组合中视图信息量相对较多的视图作为输入,因此,可以获得3组映射对:${\rm{\{ }}f_{{\rm{yz - xy}}}^{{\rm{en}}}, f_{{\rm{yz - xy}}}^{{\rm{de}}}{\rm{ \} }}$,${\rm{\{ }}f_{{\rm{xy - xz}}}^{{\rm{en}}}, f_{{\rm{xy - xz}}}^{{\rm{de}}}{\rm{ \} }}$,${\rm{\{ }}f_{{\rm{yz - xz}}}^{{\rm{en}}}, f_{{\rm{yz - xz}}}^{{\rm{de}}}{\rm{\} }}$。
视图之间的隐层关联表征包含了特定手姿态在两个视图下的投影信息,是手姿态的在隐空间中的特定表达。因此,手姿态可以通过这些表征重建获得,即存在映射${f^r}$使得:
$$\hat y = {f^r}({\phi _{{\rm{yz - xy}}}}, {\phi _{{\rm{xy - xz}}}}, {\phi _{{\rm{yz - xz}}}})$$ (4) 式中,$\hat y$为手姿态三维坐标。
-
本文采用编解码(Encoder-Decoder)框架实现两个视图之间的映射学习,利用大量的无标签数据,进行端到端的无监督学习。以${I_{p1}}, {I_{p2}}$表示两个投影视图,其中${I_{p1}}$为输入投影视图,${I_{p2}}$为目标投影视图。编解码模型包含两个卷积神经网络过程,其中编码网络(encoder network)${f^{{\rm{en}}}}$以投影视图${I_{p1}}$为输入,低维表征(code)${\phi _{p1 - p2}}$为输出,低维表征${\phi _{p1 - p2}}$即为视图在隐空间中的表征,再经过解码网络(decoder network)从编码重建另一个视图${\hat I_{p2}}$。以${\hat I_{p2}}$和${I_{p2}}$误差为优化目标,进行迭代训练。通过控制表征${\phi _{p1 - p2}}$的维数,相当于迫使编解码网络以低维参数学习两个高维度视图的关联表征。
本文将手姿态回归定义为半监督学习问题,编解码网络的参数学习利用无标签数据学习,而从隐空间关联表征到手部姿态的回归网络参数则由有标签数据训练优化。编解码网络的各层参数如表 1所示,编码网络使用了批归一化,以处理初始化不良导致的训练问题,输出层使用Tanh激活函数,以保证重建数据和视图数据的幅度一致,处于[-1, 1]之内,而在其他层使用ReLU激活函数,在解码网络上则使用leaky ReLU激活函数。
表 1 各层网络参数表
层 滤波器 激活函数 编码网络 输入 $96 \times 96$ - 卷积层1 $64 \times 4 \times 4(2, 1)$ ReLU 卷积层2 $128 \times 4 \times 4(2, 1)$ ReLU 卷积层3 $256 \times 4 \times 4(2, 1)$ ReLU 卷积层4 $512 \times 4 \times 4(2, 1)$ ReLU 卷积层5 $30 \times 6 \times 6(1, 0)$ ReLU 输出 $30 \times 1$ - 解码网络 输入 $30 \times 1$ - 反卷积层1 $512 \times 6 \times 6(2, 1)$ Leaky ReLU 反卷积层2 $256 \times 4 \times 4(2, 1)$ Leaky ReLU 反卷积层3 $128 \times 4 \times 4(2, 1)$ Leaky ReLU 反卷积层4 $64 \times 4 \times 4(2, 1)$ Leaky ReLU 反卷积层5 $1 \times 4 \times 4(2, 1)$ Tanh 输出 $96 \times 96$ - 回归网络 输入 $30 \times 3$ - 全连接层 3 780 Tanh 输出 $14 \times 3$ - 半监督学习包含无标签数据训练和有标签数据训练。对于视图间的关联表征学习,使用无标记数据,其目的在于使得生成的重建视图${\hat I_{p2}}$和目标视图${I_{p2}}$的误差最小,隐空间表征学习部分训练的误差定义为:
$${\ell _p} = {\rm{dist}}({\hat I_{p2}}, {I_{p2}})$$ (5) 式中,${\rm{dist}}()$表示相似距离;${\hat I_{p2}}$为重建视图,${\hat I_{p2}} = {f^{{\rm{de}}}}({f^{{\rm{en}}}}({I_{p1}}))$。对于姿态回归网络训练,则采用有标签数据,其误差为$k$个关节节点的预测坐标和标签坐标之间的误差和:
$${\ell _r} = \sum\limits_k^{} {{\ell _{{\rm{Huber}}}}} (||{y_k} - {\hat y_k}|{|_2}){\rm{ }}k = 1, 2, \cdots , K$$ (6) 式中,${\hat y_k}$为第$k$节点的三维坐标预测值,$K$为关节点个数,坐标误差采用$L2$范数。Huber损失函数是一种常用于回归问题的带参数损失函数,针对这里的关节点坐标回归问题,Huber损失函数的引入可以增强系统的稳定性。因此,半监督学习的最终损失函数定义为:
$$\ell = {\ell _p} + \gamma {\ell _r}$$ (7) 式中,$\gamma $为权重参数,平衡视图重建误差和关键点预测误差的比重。本文采用3组投影视图映射以获取完整的隐空间关联特征,因此,损失函数包含3组视图的预测误差:
$${\ell _p} = \ell _p^{{\rm{yz - xy}}} + \ell _p^{{\rm{xy - xz}}} + \ell _p^{{\rm{yz - xz}}}$$ (8) 式7中关节点误差${\ell _r}$由3组投影视图隐空间特征回归得到:
$${\ell _r} = \sum\limits_k^{} {{\ell _{{\rm{Huber}}}}} (||{y_k} - {f^r}({\phi _{{\rm{yz - xy}}}}, {\phi _{{\rm{xy - xz}}}}, {\phi _{{\rm{yz - xz}}}})|{|_2})$$ (9) -
近年来,有大量的手姿态估计相关数据库发布,NYU手势数据库[13]是其中具有代表性的数据库。数据库采用RGBD相机连续采集彩色及深度数据,而后分割为单帧样本。数据库提供3个不同相机视角的数据以及人工合成数据,训练集包含72 757帧样本,测试集包含8 252帧样本。为了公平比较,本文采用和文献[10]一致的样本集,因其需要用到多个相机视角的数据,而相机位置在数据库中有移动,从而在训练时采用了筛选后的训练数据,共包含43 641个样本,验证集和测试集不变。
虽然数据库提供36个关节节点数据,但是和大部分研究一致,本文关注其中关键的14个关节点,即$k = 14$。量化评判标准采用常用的3个关键参数关节点平均误差(mean error, ME),关节点预测成功率(joint-based success, JS)和帧预测成功率(frame-based success, FS)。节点平均误差为14个关节节点三维坐标的平均误差,单位为mm,关节点及帧成功率均采用80 mm为阈值判定,即JS80和FS80。
对于网络训练,输入数据维度为$128 \times 1 \times 96 \times 96$,其中128为批尺寸,1为数据维度,图片分辨率为$96 \times 96$。优化算法采用Adam算法,学习率为${10^{ - 1}}$,最后选取100次迭代中的最优结果为最终结果。
-
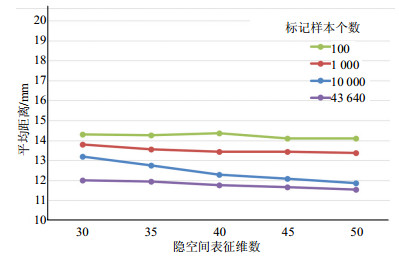
隐空间表征的维度是本算法的一个关键参数。隐空间表征的维度直接关系到对姿态的表达完整性,文献[8]认为对于$3 \times K$个关节点数据,只需要8维度数据即可表征,但当维度为30时获得了最优结果,文献[12]获得了类似的结果,但当维度超过50时提升效果不大。因此本文在验证集上比较了多个细分维度${d_\phi } \in {\rm{\{ 3}}0, 35, 40, 45, 50{\rm{\} }}$下的结果,如图 4所示,当维度为50时,节点平均误差距离最小。

图 4 不同参数下的实验结果
为了验证本算法的有效性,将其与Prior++[8]、Crossing Nets[10]和PreView[12]算法进行比较。Prior++算法隐式地添加一种基于PCA的先验到网络中,形成类似瓶颈的结构,其本质可以认为是另一种低维隐空间表征方法,在NYU等数据库上均取得了较好的效果。Crossing Nets算法提出设计一个共享隐空间将两个深度产生式模型联系起来[12],和本文不同,其无监督学习部分采用自编码的方法。PreView算法采用两个视角的相机数据,以已知视角数据预测另一视角数据,在NYU数据库上和半监督学习算法中,结果为当前最优[10]。4种算法的对比结果如表 2所示。
表 2 本文算法与相关算法结果比较
标记样本个数 100 1 000 10 000 43 640 评价标准 ME/mm FS80 JS80 ME/mm FS80 JS80 ME/mm FS80 JS80 ME/mm FS80 JS80 DeepPrior++ 38.07 0.14 0.53 31.01 0.23 0.61 24.14 0.37 0.69 20.87 0.44 0.73 Crossing Nets 67.65 0.00 0.25 36.25 0.16 0.55 28.97 0.29 0.64 25.57 0.34 0.68 PreView 29.35 0.31 0.63 22.83 0.43 0.71 19.81 0.50 0.75 19.60 0.51 0.75 本文算法 21.58 0.46 0.70 19.07 0.47 0.75 17.68 0.55 0.77 17.04 0.56 0.78 本文对比了标记数${\rm{nu}}{{\rm{m}}_{{\rm{label}}}}$在取不同值时的算法结果,如图 4所示,${\rm{nu}}{{\rm{m}}_{{\rm{label}}}} \in {\rm{\{ 10}}0, 1\;000, 10\;000, $ $43\;640{\rm{\} }}$。从结果可以看出,本文算法获得了最好的结果。当数据量少时,本文相较于Prior++和Crossing Nets有较好的提升。Crossing Nets同样是基于半监督学习,但是其复杂的网络结构使得其对数据量的需求较高,当数据量不足时结果较差。在训练时间上,同样设置训练100次全样本迭代(epoches),使用Nvidia TITAN X显卡,DeepPrior++及Crossing Nets需要训练约10 h,Preview和本文算法则需要约7 h,其主要速度受限于数据的预存取,在投影数据预缓存的情况下,训练时间可以缩短至约2 h。在运行速度方面,在仅使用I5 CPU的情况下,4个算法均能够达到30 fps以上的运行速度,差距不大。
-
本文提出了基于多视角投影的半监督学习算法解决手姿态估计因高维度、高相关的链式结构而造成标签数据的获取困难问题。通过对单个深度图的3视图投影,利用编解码模型学习各个视图之间的隐空间关联表征,从而回归得到手部的三维姿态。实验验证了本文提出的方法在NYU数据库上的有效性,但是当手部姿态有缺失或遮挡时,其效果仍然较差。因此,如何融入手部结构的先验知识,提升算法鲁棒性是未来研究的关键问题之一。针对实际应用场景,双手交互及手与其他物体交互会进一步加剧遮挡问题,造成观测信息的缺失,如何在信息不完备的情况下估计手部姿态对未来手姿态估计的实际应用有重要意义。
Hand Pose Estimation through Semi-Supervised Learning with Multi-View Projection
-
摘要: 为解决手姿态估计中标签数据的获取困难问题,该文提出了一种基于多视图投影的半监督学习方法,减少对标记数据的需求。首先,从单张深度图中分割出手部区域,将其投影至3个正交平面;而后,采用编解码模型学习两个投影视图在低维度隐空间中的关联表征;最终,结合标记数据,学习低维度隐空间表征到手姿态三维坐标的回归映射。实验表明,该方法减少了对标记数据的依赖,在NYU手姿态估计数据库上获得了较好的结果。Abstract: For hand pose estimation, one immediate problem is to reduce the need for labeled data which is difficult to provide in desired quantity, realism and accuracy. To meet this need, a novel multi-view projection based semi-supervised learning algorithm is proposed. Firstly, 3D hand points are extracted from a single depth image without label and projected onto three orthogonal planes. Secondly, an encoder-decoder model is applied to learn the latent representation of two projections. Finally, small amount of labeled data is used to learn a mapping from latent representation to hand joint coordinates. The propose algorithm is evaluated on NYU hand pose estimation dataset, and the experimental results demonstrate the effectiveness and advantages of our proposed algorithm.
-
Key words:
- depth image /
- hand pose estimation /
- multi-view /
- semi-supervise learning
-
表 1 各层网络参数表
层 滤波器 激活函数 编码网络 输入 $96 \times 96$ - 卷积层1 $64 \times 4 \times 4(2, 1)$ ReLU 卷积层2 $128 \times 4 \times 4(2, 1)$ ReLU 卷积层3 $256 \times 4 \times 4(2, 1)$ ReLU 卷积层4 $512 \times 4 \times 4(2, 1)$ ReLU 卷积层5 $30 \times 6 \times 6(1, 0)$ ReLU 输出 $30 \times 1$ - 解码网络 输入 $30 \times 1$ - 反卷积层1 $512 \times 6 \times 6(2, 1)$ Leaky ReLU 反卷积层2 $256 \times 4 \times 4(2, 1)$ Leaky ReLU 反卷积层3 $128 \times 4 \times 4(2, 1)$ Leaky ReLU 反卷积层4 $64 \times 4 \times 4(2, 1)$ Leaky ReLU 反卷积层5 $1 \times 4 \times 4(2, 1)$ Tanh 输出 $96 \times 96$ - 回归网络 输入 $30 \times 3$ - 全连接层 3 780 Tanh 输出 $14 \times 3$ -  下载: 导出CSV
下载: 导出CSV
表 2 本文算法与相关算法结果比较
标记样本个数 100 1 000 10 000 43 640 评价标准 ME/mm FS80 JS80 ME/mm FS80 JS80 ME/mm FS80 JS80 ME/mm FS80 JS80 DeepPrior++ 38.07 0.14 0.53 31.01 0.23 0.61 24.14 0.37 0.69 20.87 0.44 0.73 Crossing Nets 67.65 0.00 0.25 36.25 0.16 0.55 28.97 0.29 0.64 25.57 0.34 0.68 PreView 29.35 0.31 0.63 22.83 0.43 0.71 19.81 0.50 0.75 19.60 0.51 0.75 本文算法 21.58 0.46 0.70 19.07 0.47 0.75 17.68 0.55 0.77 17.04 0.56 0.78
下载: 导出CSV
-
[1] YUAN S, GARCIA H G, STENGER B, et al. Depth-based 3d hand pose estimation: From current achievements to future goals[C]//The IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 2636-2645. https://arxiv.org/pdf/1712.03917.pdf [2] SUPANCIC J S, ROGEZ G, YANG Y, et al. Depth-based hand pose estimation: data, methods, and challenges[C]//2015 IEEE International Conference on Computer Vision(ICCV). Santiago, Chile: IEEE, 2015: 1868-1876. https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Supancic_Depth-Based_Hand_Pose_ICCV_2015_paper.pdf [3] NEVEROVA N, WOLF C, NOBOUT F, et al. Hand pose estimation through semi-supervised and weakly-supervised learning[J]. Computer Vision and Image Understanding, 2017, 164:56-67. doi: 10.1016/j.cviu.2017.10.006 [4] SUN X, WEI Yi, LIANG S, et al. Cascaded hand pose regression[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Boston, MA, USA: IEEE, 2015: 824-832. https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Sun_Cascaded_Hand_Pose_2015_CVPR_paper.pdf [5] SHARP T, KESKIN C, ROBERTSON D, et al. Accurate, robust, and flexible real-time hand tracking[C]//Proceedings of the 33th Annual ACM Conference on Human Factors in Computing Systems. Seoul, Republic of Korea: ACM, 2015: 3633-3642. http://www.cs.toronto.edu/~jtaylor/papers/CHI2015-HandTracking.pdf [6] TANG D, JIN C, TEJANI A, et al. Latent regression forest: Structured estimation of 3D articulated hand posture[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH, USA: IEEE, 2014: 3786-3793. https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Tang_Latent_Regression_Forest_2014_CVPR_paper.pdf [7] GE L, LIANG H, YUAN J, et al. 3d convolutional neural networks for efficient and robust hand pose estimation from single depth images[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 1-5. http://openaccess.thecvf.com/content_cvpr_2017/papers/Ge_3D_Convolutional_Neural_CVPR_2017_paper.pdf [8] OBERWEGER M, LEPETIT V. Deepprior++: Improving fast and accurate 3d hand pose estimation[C]//2017 IEEE International Conference on Computer Vision Workshop (ICCVW). Venice, Italy: IEEE, 2017: 585-594. http://openaccess.thecvf.com/content_ICCV_2017_workshops/papers/w11/Oberweger_DeepPrior_Improving_Fast_ICCV_2017_paper.pdf [9] GE L, LIANG H, YUAN J, et al. Robust 3D hand pose estimation in single depth images: from single-view cnn to multi-view cnns[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, NV, USA: IEEE, 2016: 3593-3601. http://openaccess.thecvf.com/content_cvpr_2016/papers/Ge_Robust_3D_Hand_CVPR_2016_paper.pdf [10] POIER G, SCHINAGL D, BISCHOF H. Learning pose specific representations by predicting different views[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA: IEEE, 2018: 60-69. http://openaccess.thecvf.com/content_cvpr_2018/papers/Poier_Learning_Pose_Specific_CVPR_2018_paper.pdf [11] TANG D, YU T H, KIM T K. Real-time articulated hand pose estimation using semi-supervised transductive regression forests[C]//2013 IEEE International Conference on Computer Vision. Sydney, NSW, Australia: IEEE, 2013: 3224-3231. https://labicvl.github.io/docs/pubs/Danny_ICCV_2013.pdf [12] WAN C, PROBST T, VAN G L, et al. Crossing nets: combining gans and vaes with a shared latent space for hand pose estimation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA: IEEE, 2017: 1196-1205. http://openaccess.thecvf.com/content_cvpr_2017/papers/Wan_Crossing_Nets_Combining_CVPR_2017_paper.pdf [13] TOMPSON J, STEIN M, LECUN Y, et al. Real-time continuous pose recovery of human hands using convolutional networks[J]. ACM Transactions on Graphics, 2014, 33(5):169. http://yann.lecun.com/exdb/publis/pdf/tompson-siggraph-14.pdf -

 点击查看大图
点击查看大图
图(4) / 表(2)
计量
- 文章访问数: 5692
- HTML全文浏览量: 2191
- PDF下载量: 170
- 被引次数: 0
