 ISSN
ISSN 




-
随着互联网和移动通讯技术的飞速发展,社交网络和电子商务平台已变成庞大的公共信息集散地,利用其中海量的数据对人们的情感和观点进行分析有着重要的科研价值和社会价值。情感分析或观点挖掘是人们对产品、服务、组织、个人、问题、事件、话题及其属性的观点、情感、情绪、评价和态度的计算研究[1]。如何利用自然语言处理(natural language processing, NLP)技术对主观意见文本进行情感分析正被越来越多的研究人员关注[2]。作为情感分析的子任务,面向目标的细粒度情感分析可以针对特定对象有效发掘上下文中的深层情感特征,已经成为该领域的热点研究问题[3]。
近年来,深度学习作为人工智能领域发展最快的研究方向,在自然言语处理领域也取得了巨大的成功,并被广泛应用于各个NLP任务中[4]。相对于传统的机器学习算法,深度学习不依赖人工构建特征,具有特征的自学习能力,非常适合语言文本的抽象、高维、复杂等特点,对机器翻译[5]、文本摘要[6]、智能问答[7]、词性标注[8]等系统性能改善显著。同时,也有许多研究人员运用卷积神经网络(CNN)和长短记忆网络(LSTM)等深度学习模型解决文本情感极性分类问题[9-11],并取得了很好的效果。
注意力机制(attention mechanism)最早由图像识别领域提出,可以让模型有效关注局部特定信息,挖掘更深的特征信息[12]。随后,在自然语言处理领域,注意力机制被验证依然有效。文献[13]首先将注意力机制与循环神经网络结合,在编码-解码模型上计算输入序列与输出序列的对齐概率矩阵,有效解决机器翻译问题。文献[14]将类似的attention方法运用于LTSM网络,提升词对关系分类精度。文献[15]提出在卷积神经网络中使用注意力机制的有效方法,以完成机器阅读理解任务。
情感分类是目标相关(aspect-level)的问题,当训练集和测试集针对不同的目标时,基于监督学习的分类方法通常会表现出较差的效果。因此,面向目标的细粒度情感分类研究显得更具有实际意义,而目标可以是上下文中具体的词汇(target),也可以是文本描述的抽象对象或所属领域。目前,很多研究人员将注意力机制应用于目标情感分类领域,取得了很好的效果。文献[16]在LSTM网络中将目标内容与序列相应中间状态进行拼接,并计算注意力加权输出,有效解决了上下文对不同目标的情感极性问题。文献[17]借鉴深度记忆网络,提出多跳注意力模型,计算基于内容和位置的注意力值,用于充分挖掘上下文针对特定目标的情感特征信息。文献[18]将注意力机制运用在区域卷积神经网络和LSTM相结合的模型中,既保留输入序列的时序依赖又提高了训练效率。文献[19]将多种注意力机制同时与卷积神经网络相结合,综合词向量、词性和位置信息对目标情感分析效果进行改善。
基于注意力机制和面向目标情感分类的最新研究成果,同时针对中文语言环境中相邻词汇语义表达的特点,本文提出一种结合多跳注意力机制和卷积神经网的深度模型。该模型不依赖句法分析、语法分析和情感词典等先验知识,并利用多维组合特征弥补一维特征注意力机制的不足。它由多个计算层组成,以获取更深层次的目标情感特征信息。每一层都包含一个基于目标内容的注意力模型,用以学习上下文中相邻词汇组合的特征权重,并在最后一层计算连续文本表示,作为情感分类的最终特征。整个模型可以进行有效的端到端训练,相对基于注意力机制的LSTM网络,该模型具有更小的训练时间开销,并能保留特征的局部词序信息。最后在一个网络公开中文数据集(包含6类领域数据)上进行实验。结果表明,该模型比普通深度网络模型、基于注意力机制的LSTM模型以及基于注意力机制的深度记忆网络模型具有更好的分类效果,并且多计算层叠加,可以有效改善分类性能。
-
卷积神经网络作为深度学习的重要模型之一,被广泛应用于计算机视觉和图像识别领域,通过多层次的特征提取和区域权值共享,使其结构对于图像的平移、缩放和倾斜等形式变化具有高度的不变性。近年来卷积神经网络的应用领域不断拓展,在语音识别、运动分析、自然语言处理等多个方向均有突破。
卷积神经网络的特征抽取器由一个卷积层和子采样层构成。在卷积层中,应用若干过滤器(卷积核)对输入数据进行处理,得到代表不同特征表示的特征图谱(feature map);同一特征图谱的神经元共享过滤器权值,这大大减少了网络中需要训练的参数,同时又降低了过拟合的风险。子采样层也叫做池化层(pooling layer),对卷积层得到的特征图谱进行重要特征信息提取,以进一步减少输入数据规模和模型参数,通常使用均值采样、最大值采样或随机采样。卷积层中特征图谱的生成方法为:
$$\mathrm{FM}=f(\boldsymbol{w} \cdot \boldsymbol{x}+b)$$ (1) 式中,w为过滤器权重矩阵;x为过滤器窗口内输入向量矩阵;b为偏置;f为过滤器激活函数。
在传统机器学习中,n元语法模型(n-gram model)被广泛运用于各种自然语言处理任务。然而卷积神经网络也可以很好地处理文本中词汇的局部相关性,并且可以避免n-gram中对于特征权重的大量概率统计计算,相对循环神经网络具有更小的训练时间开销,因此卷积神经网络也被大量用于文本处理问题[20-21]。
在典型的NLP任务预处理阶段,文本中的词汇首先使用word2vec、Glove等算法进行预训练,转换为词向量(word embedding)。然后,按照词序将词向量组成一个二维矩阵,作为CNN的输入。与图像处理不同的是,CNN在进行卷积操作时往往采用一维卷积,使用过滤器在矩阵的整个行上滑动,最后在滑动窗口内生成代表相邻n元词汇组合的特征向量。
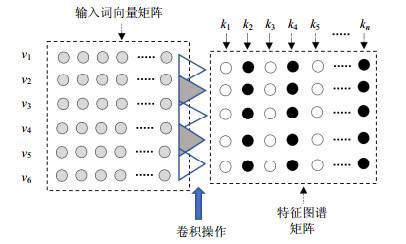
图 1展示了一个CNN卷积操作的过程。其中输入词向量矩阵中包含6个词汇(v),使用n个过滤器(k),卷积窗口为2,滑步为1。

图 1 NLP中CNN卷积操作示意
-
人类视觉系统可以通过快速扫描全局图像,获得需要重点关注的局部区域,而后对其投入更多的注意力资源,以获取更多焦点目标的细节信息,并同时忽略其他无用信息。深度学习领域中使用的注意力机制,正是研究人员借鉴人类视觉系统这种特有的大脑信号处理机制而提出,并在计算机图像识别上取得了成功。相较传统模型,注意力机制的使用极大地提高了图像信息处理系统的效率与准确性。
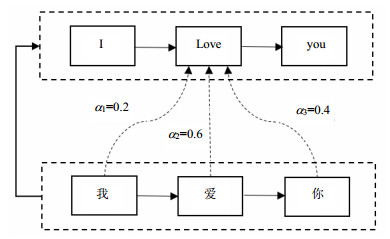
在自然语言处理领域,注意力机制首次出现在机器翻译任务中,该模型能够在翻译的同时完成对齐概率的计算[13]。如图 2所示,通过注意力机制,可以计算出每个输入对于特定输出的注意力权值(相关概率)。随后,注意力机制被广泛应用在基于RNN和CNN等神经网络模型的各种NLP任务中。

图 2 特定目标注意力权值示意
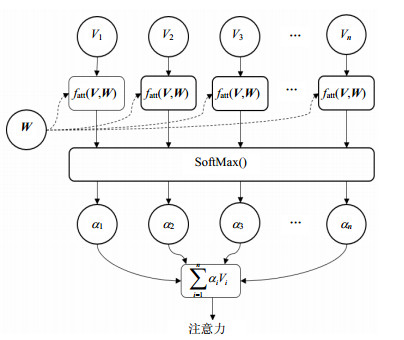
NLP任务中注意力机制的计算过程如图 3所示,首先针对具体的任务目标(W),通过相关函数fatt计算每个输入(V)的相关性;然后对原始分值进行归一化处理,得到权重系数;最后根据权重系数对输入进行加权求和,得到最终注意力值。

图 3 注意力计算过程
对于输入与目标的相关性计算可以引入不同的函数和机制,最常见的方法包括:求两者的向量点积、通过将两者向量拼接再引入额外的神经网络来求值或求两者向量的余弦相似度,如式(2)所示。本文采用拼接的方式,使得模型拥有更多的训练参数,以挖掘更多深层次特征信息。为了提取更深层次从的特征信息,使引入SoftMax函数对所有输入的相关性得分进行归一化处理,如式(3)所示,将原始计算分值转换为所有元素权重之和为1的概率分布,另外也可以使重要元素的权重更加突出。
$${\rm{ }}{f_{{\rm{att}}}}(\mathit{\boldsymbol{V}}, \mathit{\boldsymbol{W}}){\rm{ = }}\left\{ \begin{array}{c} \begin{array}{*{20}{c}} \begin{array}{c} \mathit{\boldsymbol{W}}_{}^{\rm{T}}\mathit{\boldsymbol{V}}\\ {\rm{tanh}}({U_\alpha }[\mathit{\boldsymbol{W}};\mathit{\boldsymbol{V}}] + {b_\alpha }) \end{array}\\ {\frac{{\mathit{\boldsymbol{W}}_{}^{\rm{T}}\mathit{\boldsymbol{V}}}}{{||\mathit{\boldsymbol{W}}|| \cdot ||\mathit{\boldsymbol{V}}||}}} \end{array} \end{array} \right.$$ (2) $${\alpha _i}{\rm{ = soft}}\max ({f_{att}}({\mathit{\boldsymbol{V}}_i}, \mathit{\boldsymbol{W}})){\rm{ = }}\frac{{{\rm{exp(}}{f_{{\rm{att}}}}({\mathit{\boldsymbol{V}}_i}, \mathit{\boldsymbol{W}}){\rm{)}}}}{{\sum\limits_{j = 1}^n {\exp ({f_{{\rm{att}}}}({\mathit{\boldsymbol{V}}_j}, \mathit{\boldsymbol{W}}))} }}$$ (3) 通过观察发现,与人类的视觉注意力机制节省计算资源不同,在自然语言处理任务中使用的注意力机制需要在决定输出之前遍历每个输入,并为每个输入输出组合分别计算attention权值,这将使模型结构复杂并增加额外的计算开销。但这并没有影响注意力机制在NLP领域的流行,因为其本质和人类的视觉注意力机制类似,核心目标都是从众多信息中选择出对于当前任务目标更为关键的信息。
-
为了解决面向目标的细粒度情感分类问题,本文将注意力机制与卷积神经网络进行融合,提出了一种多跳注意力深度模型。本节内容将对该模型的实现思路及细节进行描述,包括模型的概况、多维组合注意力设计和多跳注意力结构。
-
为便于处理,非结构化的文本首先被转换成结构化的数值向量。一个包含n个词的句子可以转换为S={v1, v2, …, vn},其中vi∈Rm,是第i个词的m维向量表示;S∈Rn*m代表句子的输入词向量矩阵。而句子面向目标的情感极性可以表示为式(4),其中w∈Rm,是极性针对目标的m维向量表示。
$${\rm{polarity = }}{f_{{\rm{polar}}}}{\rm{(}}\mathit{\boldsymbol{S}}, \mathit{\boldsymbol{w}}{\rm{)}}$$ (4) 图 4中3个例句都是顾客对酒店的入住体验评论,下面分别讨论这3种情况。例句1中,针对目标“服务”是积极的情感,而对于目标“房间”则是消极的情感,此时式(4)中w∈S,即极性针对目标出现在原句中;例句2中,针对“席梦思床垫”是消极情感,而此时的目标实际由两个词组成,即“席梦思”和“床垫”,此时式(4)中的w依旧可以通过原句中的词汇组合运算得到;例句3是顾客对于入住酒店非常消极的情感表达,但是很难从原句中提取内容作为积极性目标。

图 4 酒店评论文本示例
目前大部分目标情感分析研究都基于例句1和例句2的情况开展,假定目标可由原始文本加工获得,并结合位置信息特征的使用,使其模型在各项评测中都取得很好的结果。但不得不指出,网络文本不规范、内容随意发散、新词汇层出不穷,让目标抽取难度大大增加。另外,例句3的情况普遍存在,并且网络文本数量呈级数增加,也使得对所有训练和测试数据进行情感目标抽取变得不太实际。因此本文提出的模型中,情感目标将由文本内容所属领域的抽象实体代替,例如图 4中3个例句都将赋予情感目标“酒店”。在对粒度粗细进行适当调整以后,面向目标的情感分析具体为面向领域数据的情感分析,使得模型的实用性大大增强。
-
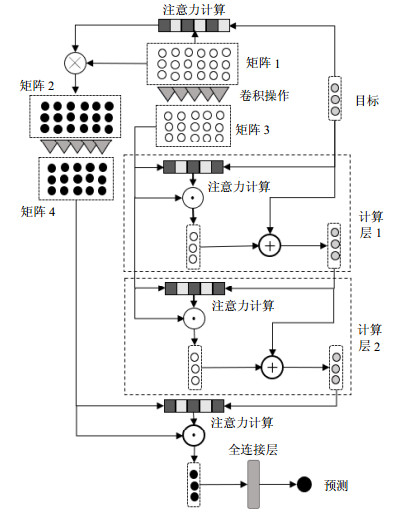
本文提出的多跳注意力深度模型(MHA-CNN)其结构如图 5所示。模型中包含了多个卷积操作模块和多个注意力计算层次,以便针对不同目标从输入文本序列中更好地学习深层特征信息。首先对模型中涉及的3个计算操作进行说明,然后自上而下对模型就行描述。假设V= {V1, V2, …, Vn},表示词向量矩阵;α={α1, α2, …, αn},表示注意力权值向量,则3种计算操作定义如下:

图 5 多跳注意力模型结构
$$\left\{ \begin{array}{l} \mathit{\boldsymbol{V}} \odot \mathit{\boldsymbol{\alpha }}{\rm{ = }}\mathit{\boldsymbol{V}} \cdot \mathit{\boldsymbol{\alpha }}{\rm{ = }}\sum\limits_{{\rm{i = 1}}}^{\rm{n}} {{\alpha _{\rm{i}}} \cdot {\mathit{\boldsymbol{V}}_n}} \\ \mathit{\boldsymbol{V}} \otimes \mathit{\boldsymbol{\alpha }}{\rm{ = \{ }}{\alpha _1} \cdot {\mathit{\boldsymbol{V}}_1}, {\alpha _{\rm{2}}} \cdot {\mathit{\boldsymbol{V}}_2}, \cdots , {\alpha _{\rm{n}}} \cdot {\mathit{\boldsymbol{V}}_n}{\rm{\} }}\\ \mathit{\boldsymbol{\alpha }} \oplus \mathit{\boldsymbol{\beta }}{\rm{ = }}\mathit{\boldsymbol{\alpha }}{\rm{ + }}\mathit{\boldsymbol{\beta }} \end{array} \right.$$ (5) 模型的输入包括词向量矩阵1和目标词向量。在最顶层,对输入词向量矩阵进行预处理,包括两个卷积操作模块。一方面直接对matrix1进行一维卷积操作,生成相邻词汇组合特征向量矩阵3;另一方面,计算矩阵1针对目标的注意力计算权值向量,并将矩阵1与得到的权值向量进行$ \otimes $操作,得到注意力加权词向量矩阵2,再对其进行一维卷积操作,生成加权相邻词汇组合特征向量矩阵4。
模型往下,在第一个注意力计算层,计算矩阵3针对目标向量的注意力权值向量,并将矩阵3与得到的权值向量进行⊙操作,得到一个注意力加权和向量,随后将其与目标进行$ \oplus $操作,生成的新目标向量。注意力计算层可以不断堆叠,重复上述计算步骤,但用于注意力权值计算的目标向量不再是原始目标词向量,而是由上一个计算层提供。
在最后一个计算层,计算矩阵4针对目标向量(由上一层提供)的注意力权值向量,并将矩阵4与得到的权值向量进行⊙操作,得到一个注意力加权和向量,将其作为输入文本的最终向量表示,在通过一个全连接层后,得到最后的情感分类预测结果。
-
特征的设计和使用在机器学习中起着非常重要的作用,但是简单依靠增加特征的数目,并不能有效突破模型的极限预测性能。在自然语言处理任务中,通常使用由语料产生的词库作为模型输入,然而这种浅层的直观特征对于隐含关系的表达并不充分。适当的引入词组,将模型输入从浅层特征转换为深层特征,便拥有了更多的语义信息,以挖掘上下文更多的深层交互特性。
中文语境中,单个词汇往往具有一定的歧义,例如形容词在修饰不同的名词时往往体现不同的情感倾向,此时将相邻词汇组合形成的语义特征,才能表达明确的情感极性。而卷积神经网络可以使用卷积核对文本中的多个相邻的词汇进行卷积操作,产生词组语义特征,并且保留了原始输入词汇之间的局部词序信息。
注意力机制的目的是让模型在训练过程中学习输入数据的重要性,并高度关注那些更重要的信息。在本文提出的多跳注意力深度模型中,前面各跳注意力计算模块中使用由卷积操作产生的二维词汇组合特征,并将其注意力权值信息不断向下层传递。而在最后一跳计算之前,模型使用注意力对输入的一维词汇进行加权处理,再进行卷积操作,生成参与最后注意力计算的加权二维词汇组合特征。通过上述操作,模型同时拥有了一维和二维词汇特征的注意力权值信息,使其能够充分利用注意力机制在多维特征空间中提取和学习关于目标更多的隐藏信息,以更好地预测基于不同目标的情感极性。
-
自然语言处理任务中涉及很多复杂的语义计算,普遍认为浅层模型并不能很好解决如否定、歧义和长距离依赖等问题。而由多个计算层叠加形成的深度模型具有学习更高级别数据抽象表示的能力,同时结合注意力机制,可以更有效的应对实际应用[22-23]。
在本文的深度模型中,单个计算层的注意力机制本质上是一个加权合成函数,用以对有用的上下文信息进行计算,然后将函数输出往下一层传递,并在下一跳注意力计算时参考上层注意历史,即考虑之前哪些词汇被注意。通过多跳注意力计算使得深度网络能够学习多个抽象层次的文本表示,其中每层检索上下文中的重要词汇,并将前一层的表示输出向更高、更抽象的级别转换。针对特定目标,通过足够跳数的注意力堆叠转换,可以使模型学习得到的句子表示蕴含更加复杂、抽象的非线性特征。
对长距离词汇之间的转移关系进行建模,并描述它们的依赖,一直是影响系统性能的关键。目前,采用递归神经网络模型是解决长距离依赖的有效手段。本文的多跳注意力模型是一种采用递归架构的深度记忆神经网络[24],不同于LSTM和GRU网络,其存储单元已经从标量存储扩展为向量存储。模型在每一跳注意力计算时都要对外部存储单元进行访问,输出前外部存储器将被多次读取,这样在模型的多个计算层中,所有的输入元素借由注意力的递归计算过程充分交互。与链式结构递归网络相比,结合外部存储单元的多跳注意力模型可以采用端到端训练,在更短路径上捕获远程依赖。
-
目前,用于情感分析的中文标注语料并不丰富,且大多存在样本数量不足、涵盖领域有限等问题。本文提出的模型主要用于解决针对领域的中文文本情感计算,因此为了能够有效完成模型的训练和测试,本文采用一个包含6类领域数据的公开中文数据集进行实验。该语料文本涉及的6个领域分别是书籍、酒店、电脑、牛奶、手机和热水器,每类领域数据均由用户评论组成,数据样本按照情感极性分为正面和负面两大类。实验数据统计如表 1所示。最后,每类领域数据按照情感极性,被随机分成数量相同的两部分,一半作为训练数据对模型进行训练,另一半作为测试数据用于模型性能评测。
表 1 实验数据统计
极性 类别 书籍 酒店 电脑 牛奶 手机 热水器 合计 正面 4 000 2 000 2 000 1 005 1 160 512 10 677 负面 4 000 2 000 2 000 1 170 1 158 100 10 428 数据总计 21 105 -
本文采用结巴分词工具对中文数据集进行分词处理,利用Keras深度学习框架完成MHA-CNN模型开发,并以TensorFlow作为运行后端。卷积层选择ReLU函数作为激活函数,设置滑动步长为1。其他超参数设置如表 2所示。
表 2 模型超参设置
参数名称 参数值 词嵌入维度 350 卷积核窗口大小 1, 2, 3, 4 卷积核数量 250 正则项限制(L2) 0.01 mini batch 32 dropout 0.25 -
为验证本文提出模型的有效性,引入6种典型模型与MHA-CNN进行对比,包括一些性能基线方法和最新的研究成果。将7种模型在选定的多领域公开数据集上进行实验,并根据数据集的实际情况对各模型参数进行全面优化,以获得最优分类精度,最终的实验结果如表 3所示。
表 3 各模型在数据集上的分类精度
模型名称 分类精度 CNN 0.913 6 LSTM 0.908 3 SVM 0.914 7 ABCNN 0.916 2 ATAE-LSTM 0.917 3 MemNet 0.916 8 MHA-CNN 0.922 2 1) CNN:最基础的卷积神经网络模型,使用分词后得到的特征作为网络模型的输入,没有注意力机制,无法针对特定目标对模型进行优化。
2) LSTM:最基础的LSTM网络模型,该模型可以保留输入特征的词序关系,并能一定程度上解决语句长依赖关系问题,被广泛用于NLP任务。没有注意力机制,无法针对特定目标对模型进行优化。
3) SVM:传统的机器学习方法,对人工特征工程依赖较强,在很多任务中展现比一般深度学习方法更好的性能,常被用于性能评价基线。
4) ABCNN[25]:针对句子对建模任务,将注意力机制与卷积神经网络相结合,并取得了比以往研究更好的性能。该模型将注意力机制作用在卷积层,可以使模型在训练过程中关注特定目标的权重信息,分析细粒度情感极性。
5) ATAE-LSTM[16]:该模型将注意力机制与LSTM网络相结合,首先用目标向量与输入特征进行拼接,然后计算隐层状态序列的注意力权重信息,加权合成后输出,能够很好的提升传统LSTM网络的细粒度情感分类性能。
6) MemNet[17]:该模型将注意力机制与深度记忆网络相结合,并且通过多计算层叠加的方式,稳定提高模型的分类精度,在评测中比LSTM架构的注意力模型性能更优,且训练时间开销大大减少。
从表 3中实验结果可以看出,CNN模型的分类精度为0.913 6,LSTM模型的分类精度为0.908 3,SVM模型的分类精度为0.914 7,3种传统方法取得最低分值,其中基于特征的SVM模型分类结果好于普通深度模型。而加入注意力机制以后,ABCNN模型的分类精度为0.916 2,ATAE-LSTM模型的分类精度为0.917 3,都比传统模型有了明显提升。可见注意力机制的引入,的确可以使得模型在训练过程中针对特定的目标领域信息进行优化,高度关注目标并挖掘更多的隐藏情感特征信息,这也说明了注意力机制在针对目标的细粒度情感分类任务中的有效作用。
MemNet模型只是在每个计算层将简单的神经网络与注意力机制结合,而分类精度为0.916 8,与ABCNN和ATAE-LSTM性能相当,验证了多层叠加的深度结构对于挖掘隐藏特征和优化分类性能的有效性。最后本文提出的MHA-CNN模型性能最优,分类精度为0.922 2,与MemNet模型一样采用了多跳注意力计算结构,但是模型利用卷积层获得多维组合特征信息输入,使得模型性能得到优化。相对于ABCNN和ATAE-LSTM模型,MHA-CNN模型取得更好的分类效果,证明多跳记忆网络结合注意力机制能够更好的针对任务目标挖掘更深的隐藏情感信息,并能有效处理长距离依赖问题。
-
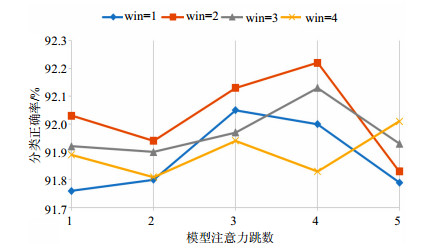
为验证之前对于相邻词汇语义表达重要性的假设,同时考察多跳注意力结构对模型性能的影响,本文在选定的公开数据集上选取多种卷积窗口和不同注意力计算跳数进行实验,结果如图 6所示。

图 6 不同卷积窗口下的分类正确率
从图 6中可以发现,无论选取何种卷积窗口,随着注意力计算跳数的增加,模型在选定数据集上的分类精度也在不断提高。其中当卷积窗口设置为1时,3跳注意力计算层使模型性能最优;当卷积窗口设置为2和3时,4跳注意力计算层使模型性能最优;当卷积窗口设置为4时,5跳注意力计算层使模型性能最优。由此可见,多跳结构对于模型的性能有至关重要的影响。由于各跳中注意力计算模块完全相同,也使模型可以很容易通过叠加注意力计算层进行扩展,通过可伸缩的方式集成到端到端神经网络模型中。除此之外,随着跳数的不断增加,模型的参数规模会呈爆炸式增长,也会给模型带来过拟合风险,导致性能下降。
特征表达语义的能力直接影响任务模型的性能,本文通过设置不同的卷积滑动窗口来构造多维组合特,并结合注意力机制进行实验。图 6结果表明,当设置滑动窗口为1时,其最高分类准确率为0.920 5;当设置滑动窗口为2时,取得最好的分类准确率0.922 2;当设置滑动窗口为3时,最高分类准确率为0.921 3。可见实验中由相邻的2个或3个词汇卷积而成的词组特征比单个词汇具有更好的语义表达能力。最后当设置滑动窗口为4时,模型分类精度下降为0.920 1,证明中文语境中将过多的相邻词汇组合会带来语义模糊的风险。另外,卷积滑动窗口大小的最优选取应当根据具体的应用场景灵活处理。
-
本文在相同的软硬件环境下,对各个深度网络模型进行时间开销评测。在GPU(NVIDIA GeForce GTX 960M)上,利用所选的公开数据集对模型进行训练,并分别统计完成一次迭代的训练时间,对比结果如图 7所示。其中MemNet和MHA-CNN取性能最优架构,跳数分别为7和4。

图 7 各模型单次迭代训练时间
从图 7结果可以看出,在相同的环境下,CNN网络的训练时间最短,一次迭代时间为32 s,而ABCNN模型由于加入了注意力机制,训练开销略有上升,完成一次迭代的时间为46 s。相比之下LSTM网络训练需要更大的时间开销,其完成一次迭代的训练时间为252 s,约为CNN模型的8倍,而ATAE-LSTM模型在加入注意力机制后完成一次训练迭代所用的时间最多,为520 s。不难发现CNN网络的训练时间要远低于LSTM网络,因为LSTM网络模型接收序列化输入,GPU很难实现对其运算的并行加速。
MemNet作为多跳深度记忆网络模型,当注意力计算层数为7时,在数据集上性能表现最优,完成一次训练迭代所需时间为53 s。本文提出的MHA-CNN模型将CNN网络和多跳深度记忆网络结合,完成一次训练迭代所需时间为89 s,相比ATT-CNN网络和MemNet网络,提升性能的同时,训练时间开销增加到可接受范围内,但是相比LSTM架构的深度模型,其训练性能拥有绝对优势。
-
本文针对面向领域的细粒度情感分类问题,提出一种结合卷积神经网络和记忆网络的多跳注意力深度模型。该模型能够利用中文语境中相邻词汇语义表达的特点,并通过多维组合特征对一维特征注意力机制进行补充。同时,多计算层叠加的架构也使得模型能够获取更深层次的目标情感特征信息,并有效处理长距离依赖问题。最后在一个包含6类领域数据的网络公开中文数据集上进行对比实验,结果验证了本文提出模型的有效性。该模型不仅比普通深度网络模型和基于注意力机制的深度模型具有更好的分类性能,相较于LSTM架构的深度网络模型在训练时间开销上优势明显。
从实验结果可以看出,不同滑动窗口下的多维组合特征都能充分作用于分类结果,因此在将来的研究工作中,考虑同时使用这些多维特征来对模型性能进行提升,同时尝试结合不同的注意力机制以及组合多种深度架构来对模型进行优化。
A Multi-Hop Attention Deep Model for Aspect-Level Sentiment Classification
-
摘要: 文本情感分类是近年来自然语言处理领域的研究热点,旨在对文本蕴含的主观倾向进行分析,其中,基于特定目标的细粒度情感分类问题正受到越来越多的关注。在传统的深度模型中加入注意力机制,可以使分类性能显著提升。针对中文的语言特点,提出一种结合多跳注意力机制和卷积神经网络的深度模型(MHA-CNN)。该模型利用多维组合特征弥补一维特征注意力机制的不足,可以在没有任何先验知识的情况下,获取更深层次的目标情感特征信息。相对基于注意力机制的LSTM网络,该模型训练时间开销更小,并能保留特征的局部词序信息。最后在一个网络公开中文数据集(包含6类领域数据)上进行实验,取得了比普通深度网络模型、基于注意力机制的LSTM模型以及基于注意力机制的深度记忆网络模型更好的分类效果。Abstract: Text sentiment classification is a hot topic in the field of natural language processing in recent years. It aims to analyze the subjective sentiment polarity of text. More and more attention has been paid to the problem of fine grained sentiment classification based on specific aspects. In traditional deep models, the attention mechanism can significantly improve the classification performance. Based on the characteristics of Chinese language, a deep model combining multi-hop attention mechanism and convolutional neural network (MHA-CNN) is proposed. The model makes use of the multidimensional combination features to remedy the deficiency of one dimensional feature attention mechanism, and can get deeper aspect sentiment feature information without any prior knowledge. Relative to the attention mechanism based long short-term memory (LSTM) network, the model has smaller time overhead and can retain word order information of the characteristic part. Finally, we conduct experiments on a network open Chinese data set (including 6 kinds of field data), and get better classification results than the ordinary deep network model, the attention-based LSTM model and the attention-based deep memory network model.
-
表 1 实验数据统计
极性 类别 书籍 酒店 电脑 牛奶 手机 热水器 合计 正面 4 000 2 000 2 000 1 005 1 160 512 10 677 负面 4 000 2 000 2 000 1 170 1 158 100 10 428 数据总计 21 105  下载: 导出CSV
下载: 导出CSV
表 2 模型超参设置
参数名称 参数值 词嵌入维度 350 卷积核窗口大小 1, 2, 3, 4 卷积核数量 250 正则项限制(L2) 0.01 mini batch 32 dropout 0.25
下载: 导出CSV
表 3 各模型在数据集上的分类精度
模型名称 分类精度 CNN 0.913 6 LSTM 0.908 3 SVM 0.914 7 ABCNN 0.916 2 ATAE-LSTM 0.917 3 MemNet 0.916 8 MHA-CNN 0.922 2
下载: 导出CSV
-
[1] LIU Bing, ZHANG Lei. Sentiment analysis and opinion mining[M].[S.l.]:Morgan & Claypool Publishers, 2012. [2] YIOU Lin, HANG Lei, WU Jia, et al. An empirical study on sentiment classification of Chinese review using word embedding[C]//29th Pacific Asia Conference on Language, Information and Computation. Shanghai, China: [s.n.], 2015: 258-266. [3] PONTIKI M, GALANIS D, PAVLOPOULOS J, et al. Semeval-2014 task 4: Aspect based sentiment analysis[C]//Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval2014).[S.l.]: [s.n.], 2014: 27-35. https://pure.york.ac.uk/portal/en/publications/semeval2015-task-12(d7554532-f5ee-4a20-b535-15715bd78a28)/export.html [4] 林奕欧, 雷航, 李晓瑜, 等.自然语言处理中的深度学习:方法及应用[J].电子科技大学学报, 2017, 46(6):913-919. doi: 10.3969/j.issn.1001-0548.2017.06.021 LIN Yi-ou, LEI Hang, LI Xiao-yu, et al. Deep learning in NLP:Methods and applications[J]. Journal of University of Electronic Science and Technology of China. 2017, 46(6):913-919. doi: 10.3969/j.issn.1001-0548.2017.06.021 [5] CHO K, VAN MERRIËNBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]//Proceedings of EMNLP Processing. Doha, Qatar: ACL Press, 2014: 1724-1734. http://www.oalib.com/paper/4082023 [6] ALEXANDER M, CHOPRA S, WESTON J. A neural attention model for sentence summarization[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon, Portugal: [s.n.], 2015: 379-389. http://www.oalib.com/paper/4051215 [7] SAGARA T, HAGIEARA M. Natural language neural network and its application to question-answering system[J]. Neurocomputing, 2014, 142:201-208. doi: 10.1016/j.neucom.2014.04.048 [8] MA X, HOVY E. End-to-end sequence labeling via bi-directional lstm-cnns-crf[C]//Proceedings of ACL. Berlin, Germany: ACL Press, 2016: 1064-1074. https://arxiv.org/abs/1603.01354 [9] TANG D, QIN B, LIU T. Document modeling with gated recurrent neural network for sentiment classification[C]//Proceedings of EMNLP. Lisbon, Portugal: ACL Press, 2015: 1422-1432. [10] TANG Du-yu, QIN Bing, FENG Xiaoc-heng, et al. Effective LSTMs for target-dependent sentiment classification[C]//Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics. Osaka, Japan: [s.n.], 2016: 3298-3307, https://arxiv.org/abs/1512.01100 [11] 刘龙飞, 杨亮, 张绍武, 等.基于卷积神经网络的微博情感倾向性分析[J].中文信息学报, 2015, 29(6):159-169. doi: 10.3969/j.issn.1003-0077.2015.06.021 LIU Long-fei, YANG Liang, ZHANG Shao-wu, et al. Convolutional neural networks for Chinese micro-blog sentiment analysis[J]. Journal of Chinese Information Processing, 2015, 29(6):159-169. doi: 10.3969/j.issn.1003-0077.2015.06.021 [12] MNIH V, HEESS N, GRAVES A. Recurrent models of visual attention[C]//Proceedings of Advances in Neural Information Processing Systems 27(NIPS 2014). Cambridge, MA: MIT Press, 2014: 2204-2212. http://www.oalib.com/paper/4082117 [13] BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate[EB/OL].[2018-09-21]. http://arxiv.org/pdf/1409.04732v2.pdf. [14] ZHOU P, SHI W, TIAN J, et al. Attention-based bidirectional long short-term memory networks for relation classification[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: [s.n.], 2016: 207-212 [15] YIN Wen-peng, EBERT S, SCHUTZE H. Attention-based convolutional neural network for machine comprehension[C]//Proceedings of 2016 NAACL Human-compllter Question Answering Workshop. San Diego, Califormia: Association for Computational Linguistics, 2016: 15-21. https://arxiv.org/abs/1602.04341v1 [16] WANG Ye-quan, HUANG Min-lie, ZHAO Li, et al. Attention-based LSTM for Aspect-level Sentiment Classification[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas: [s.n.], 2016: 606-615. [17] TANG Du-yu, QIN Bing, LIU Ting. Aspect level sentiment classification with deep memory network[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas: [s.n.], 2016: 214-224. https://arxiv.org/abs/1605.08900 [18] 刘全, 梁斌, 徐进, 等.一种用于基于方面情感分析的深度分层网络模型[J].计算机学报, 2018, 12:2637-2652. doi: 10.11897/SP.J.1016.2018.02637 LIU Quan, LIANG Bin, XU Jin, et al. A deep hierarchical neural network model for aspect-based sentiment analysis[J]. Chinese Journal of Computers, 2018, 12:2637-2652. doi: 10.11897/SP.J.1016.2018.02637 [19] 梁斌, 刘全, 徐进, 等.基于多注意力卷积神经网络的特定目标情感分析[J].计算机研究与发展, 2017, 54(8):1724-1735. http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz201708010 LIANG Bin, LIU Quan, XU Jin, et al. Aspect-Based sentiment analysis based on multi-attention CNN[J]. Journal of Computer Research and Development. 2017, 54(8):1724-1735. http://d.old.wanfangdata.com.cn/Periodical/jsjyjyfz201708010 [20] KIM Y. Convolutional neural networks for sentence classification[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: [s.n.], 2014: 1746-1751. http://www.oalib.com/paper/4046794 [21] KALCHBRENNER N, GREFENSTETTE E, BLUNSOM P. A convolutional neural network for modelling sentences[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Baltimore, Maryland, USA: [s.n.], 2014: 655-665. [22] GEHRING J, AULI M, GRANGIER D, et al. Convolutional sequence to sequence learning[C]//Proceedings of the 34th International Conference on Machine Learning. Sydney, Australia: PMLR, 2017: 1243-1252. https://arxiv.org/abs/1705.03122 [23] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//31st Conference on Neural Information Processing Systems (NIPS 2017). Long Beach, CA, USA: [s.n.]. 2017. [24] SUKHBAATAR S, SZLAM A, WESTON J, et al. End-to-end memory networks[C]//Advances in Neural Information Processing Systems 28(NIPS 2015). Montreal, Canada: MIT press, 2015: 2431-2439. [25] YIN Wen-peng, SCHUTZE H, XIANG Bing, et al. ABCNN:Attention-based convolutional neural network for modeling sentence pairs[J]. Transactions of the Association for Computational Linguistics, 2016, 4:259-272. doi: 10.1162/tacl_a_00097 -

 点击查看大图
点击查看大图
图(7) / 表(3)
计量
- 文章访问数: 5169
- HTML全文浏览量: 1380
- PDF下载量: 125
- 被引次数: 0
