 ISSN
ISSN 


-
稀疏表达(sparse representation, SR)在模式识别领域的成功应用,对字典学习(DL)起到了强大的推动作用,这种从数据中直接学习关于数据的稀疏表达方式,通常在模式分类中要优于其他预定义的表达,例如:FFT、DCT等。DL中一种流行的分支是合成字典学习,合成字典学习虽然被广泛使用,但时间消耗太大。因此,作为合成学习的对偶变换,分析字典(analysis dictionary learning, ADL)越来越受到关注。
近年来,ADL取得了一些进展。文献[1]提出了一种良态平方变换消除图像噪声;文献[2]在此基础上引入带满秩约束的分析字典;文献[3]结合分析字典与合成字典提出了用于图像分类的指定类别的字典学习方法;文献[4]提出了具有局部拓扑保留特性的分析字典学习法,同时为了增强字典的判别性与编码的连续性,还引入了监督学习的机制;文献[5]在增强字典判别性方面,提出类感知学习方法,将分析字典与支持向量机结合,使得具有相同类别的编码向量有更近的类内距,而对于不同类别的编码向量有更远的类间距。
以上方法,在增强了字典的判别特性后,对于静态图片的模式分类效果有显著提升,但对于时空特性较强的人体行为识别问题效果欠佳。主要原因在于,人体行为识别技术经常受到行为遮挡,背景杂乱,摄像机抖动等问题的影响。在真实环境中准确地识别出人体行为的关键在于,不仅需要增强行为表示的判别鲁棒性,以减少噪声的影响,更应该学习一个紧凑并且能把握全局特征的行为表达方式。因此本文在引入低秩约束获取特征之间相互关系的同时,加入Fisher判定准则,使得相同类别的特征表达更紧凑,而对于不同类别的特征,表达则更为疏远。
-
设$\boldsymbol{Y} = [{y_1}, {y_2}, \cdots , {y_n}] \in {\mathbb{R}^{m \times n}}$为样本空间的数据矩阵,DL的核心思想是学习能够表达每个样本${y_i} \in {\mathbb{R}^m}$的字典,设$\boldsymbol{X} = [{x_1}, {x_2}, \cdots , {x_n}] \in {\mathbb{R}^{p \times n}}$为通过字典得到的编码系数。
合成字典学习:大部分字典学习方法都采用这种方法,即字典$\boldsymbol{D} = [{d_1}, {d_2}, \cdots , {d_p}] \in {\mathbb{R}^{m \times p}}$,通过求解:
$$ \min\limits_{\boldsymbol{D}, \boldsymbol{X}}\|\boldsymbol{Y}-\boldsymbol{D} \boldsymbol{X}\|_{F}^{2} \quad \text { s.t. } \boldsymbol{D} \in \mathcal{D} $$ (1) 式中,$\left\| {\boldsymbol{Y - DX}} \right\|_F^2$表示对样本$\boldsymbol{Y}$的重构误差;$\mathcal{D}$是一系列约束集合,如字典结构的不连贯约束,联合字典学习与子空间聚类约束等。
分析字典学习:作为合成字典学习的对偶变换,分析字典给出了更直观的解释,它将字典直接作用于特征样本,类似于特征变换(如DWT),让编码值逼近于变换结果,可以通过求解式(2)来学习分析字典:
$$ \min\limits_{\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}, \boldsymbol{X}}\|\boldsymbol{X}-\mathit{\boldsymbol{ \boldsymbol{\varOmega}}} \boldsymbol{Y}\|_{F}^{2} \quad \text { s.t. } \mathit{\boldsymbol{ \boldsymbol{\varOmega}}} \in \mathcal{W} $$ (2) 式中,$\mathit{\boldsymbol{ \boldsymbol{\varOmega}}} \in {\mathbb{R}^{p \times n}}$;$\mathcal{W}$表示分析字典的约束集,其作用是使$\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}$有非零解。
-
给定一个观测矩阵${\boldsymbol{X}_0}$,其中包含干净的样本集合${\boldsymbol{X}_L}$和稀疏的误差矩阵$\boldsymbol{E}$,即:${\boldsymbol{X}_0} = {\boldsymbol{X}_L} + \boldsymbol{E}$。在低秩表达(low rank representation, LRR)中,往往需要通过一个低秩矩阵去挖掘观测矩阵的潜在结构,以此得出目标函数:
$$ {\min\limits_Z}||\mathit{\boldsymbol{Z}}||{_*}{\rm{ s}}{\rm{.t}}{\rm{. }}\;\mathit{\boldsymbol{X}} = \mathit{\boldsymbol{XZ}} + \mathit{\boldsymbol{E}} $$ (3) 式中,$\|\bullet\|_{*}$是核范数;$\boldsymbol{Z} \in {\mathbb{R}^{n \times m}}$即所求的表达矩阵;$\boldsymbol{X}$为$c$类训练样本,即$\boldsymbol{X} = [{x_1}, {x_2}, \cdots , {x_n}] \in {\mathbb{R}^{p \times n}}$。为了能寻求更紧凑的样本表达,本文引入分析字典$\mathit{\boldsymbol{ \boldsymbol{\varOmega}}} = [{w_1}, {w_2}, \cdots , {w_p}] \in {\mathbb{R}^{m \times p}}$将$\boldsymbol{X}$映射到低维的样本空间,令$\widetilde {\boldsymbol{X}} = {\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\rm{T}}}\boldsymbol{X} = {\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\rm{T}}}\boldsymbol{XZ}$, 同时,考虑到$n$个样本均匀分布于$c$个类别,而$n \gg c$,所以表达矩阵有低秩特性。
-
标签信息对模式分类至关重要,因此本文引入基于Fisher准则的正则项$f(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}, \boldsymbol{Z})$,$f(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}, \boldsymbol{Z})=\left[\operatorname{Tr}\left(S_{B}\left(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}\right)\right) / \operatorname{Tr}\left(S_{W}\left(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}\right)\right)\right]$, 其中${\rm{Tr}}(\boldsymbol{K})$为矩阵$\boldsymbol{K}$的迹,${S_B}({\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\rm{T}}}\boldsymbol{XZ})$与${S_W}({\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\rm{T}}}\boldsymbol{XZ})$分别表示类间散度矩阵和类内散度矩阵,定义如下:
$$\boldsymbol{S}_{B}\left(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}\right)=S_{B}(\widetilde{\boldsymbol{X}})=\sum\limits_{i=1}^{c} n_{i}\left(\boldsymbol{m}_{i}-\boldsymbol{m}\right)\left(\boldsymbol{m}_{i}-\boldsymbol{m}\right)^{\mathrm{T}} $$ (4) $$S_{w}\left(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X Z}\right)=S_{w}(\widetilde{\boldsymbol{X}})=\sum\limits_{i=1}^{c} \sum\limits_{j=1}^{n_{i}}\left(\widetilde{x_{i j}}-\boldsymbol{m}_{i}\right)\left(\widetilde{x_{i j}}-\boldsymbol{m}_{i}\right)^{\mathrm{T}}$$ (5) 式中,${\boldsymbol{m}_i}$是第$i$类样本的均值向量;$\boldsymbol{m}$是所有样本的均值向量,$\widetilde {{x_{ij}}}$是第$i$类样本的第$j$个样本,根据文献[6]的证明,迹的比率问题可以转换为迹的差分问题,因此,可以重写$f(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}, \boldsymbol{Z})$得到:
$$\overline{f(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}, \boldsymbol{Z})}=\operatorname{Tr}\left(\boldsymbol{S}_{W}\left(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}\right)\right)-\operatorname{Tr}\left(\boldsymbol{S}_{B}\left(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}\right)\right)$$ (6) 通过对式(6)的观察,整理得到如下目标函数:
$$\min\limits_{Z}\|\boldsymbol{Z}\|_{*}+\lambda \overline{f(\boldsymbol{P}, \boldsymbol{Z})} \quad \text { s.t. } \quad \boldsymbol{X}=\boldsymbol{X} \boldsymbol{Z}+\boldsymbol{E}$$ (7) 式中,$\lambda $为低秩约束与判别正则项之间的平衡参数。
由于${\rm{Tr}}({\boldsymbol{S}_B})$的存在,$\overline{f(\boldsymbol{P}, \boldsymbol{Z})} $并非是关于$\boldsymbol{Z}$的凸函数,因此需要加入弹性项确保凸性,因此$\overline{f(\boldsymbol{P}, \boldsymbol{Z})} $可重写为:
$$\begin{array}{l}{\overline{f(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}, \boldsymbol{Z})}=\operatorname{Tr}\left(\boldsymbol{S}_{W}\left(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}\right)\right)-} \\ {\operatorname{Tr}\left(\boldsymbol{S}_{B}\left(\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}\right)\right)+\eta\left\|\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}\right\|_{F}^{2}}\end{array}$$ (8) 式中,$\eta $为权衡系数。将式(8)进一步转化为矩阵形式:
$$\begin{array}{*{20}{c}} {\overline {f(\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}, \mathit{\boldsymbol{Z}})} = \left\| {{\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}^{\rm{T}}}\mathit{\boldsymbol{XZ}}\left( {\mathit{\boldsymbol{I}} - {\mathit{\boldsymbol{H}}_b}} \right)} \right\|_F^2 - }\\ {\left\| {{\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}^{\rm{T}}}\mathit{\boldsymbol{XZ}}\left( {{\mathit{\boldsymbol{H}}_b} - {\mathit{\boldsymbol{H}}_t}} \right)} \right\|_F^2 + \eta \left\| {{\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}^{\rm{T}}}\mathit{\boldsymbol{XZ}}} \right\|_F^2} \end{array} $$ (9) 式中,$\boldsymbol{I} \in {\mathbb{R}^{n \times n}}$是单位矩阵;${\boldsymbol{H}_b}$,${\boldsymbol{H}_t}$为常系数矩阵,当${x_i}$,${x_j}$属于同一类别时,${\boldsymbol{H}_b}(i, j) = (1/{n_c})$,${n_c}$是一个类别中样本的个数,否则,当${x_i}$,${x_j}$不属于同一类别时,${\boldsymbol{H}_b}(i, j) = 0$,而${\boldsymbol{H}_t}(i, j) = (1/n)$。可以证明当$\eta > 1$时,式(9)仍然是关于$\boldsymbol{Z}$的凸函数。因此可以整理得到优化目标函数:
$$ \begin{array}{c} {\min\limits_{\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}, \boldsymbol{Z}, \boldsymbol{E}}\|\boldsymbol{Z}\|_{*}+\alpha\|\boldsymbol{E}\|_{1}+\lambda\left\|\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}\left(\boldsymbol{I}-\boldsymbol{H}_{b} \right)\right\|_{F}^{2}-} \\ {\left.\left\|\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}\left(\boldsymbol{H}_{b}-\boldsymbol{H}_{t}\right)\right\|_{F}^{2}+\eta\left\|\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}\right\|_{F}^{2}\right)} \\ {\text { s.t. } \boldsymbol{X}=\boldsymbol{X} \boldsymbol{Z}+\boldsymbol{E}, \quad\left\|w_{i}\right\|^{2}=1}\end{array} $$ (10) -
本文采用经典的增广拉格朗日乘子法[7]对目标函数式(10)进行优化,为此首先引入辅助变量$\boldsymbol{J}$,并将$\boldsymbol{Z} = \boldsymbol{J}$作为约束条件加入式(10),于是原问题转换为:
$$ \begin{array}{*{20}{c}} {\mathop {\min }\limits_{\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}, {\boldsymbol{z}}, {\boldsymbol{E}}} {{\left\| {\boldsymbol{Z}} \right\|}_*} + \alpha {{\left\| {\boldsymbol{E}} \right\|}_1} + \lambda \left\| {{\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}^{\rm{T}}}{\boldsymbol{XZ}}\left( {{\boldsymbol{I}} - {{\boldsymbol{H}}_b}} \right)} \right\|_F^2 - }\\ {\left\| {{\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}^{\rm{T}}}{\boldsymbol{XZ}}\left( {{{\boldsymbol{H}}_b} - {{\boldsymbol{H}}_t}} \right)} \right\|_F^2 + \eta \left\| {{\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}^{\rm{T}}}{\boldsymbol{XZ}}} \right\|_F^2) + }\\ {g({\boldsymbol{Y}}, {\boldsymbol{Z}}, {\boldsymbol{E}}, {\boldsymbol{J}})\quad {\rm{ s}}{\rm{.t}}{\rm{. }}{{\left\| {{w_i}} \right\|}^2} = 1} \end{array} $$ 式中,
$$ \begin{array}{c} {g(\boldsymbol{Y}, \boldsymbol{Z}, \boldsymbol{E}, \boldsymbol{J})= < \boldsymbol{Y}_{1}, \boldsymbol{X}-\boldsymbol{X} \boldsymbol{Z}-\boldsymbol{E}>+< \boldsymbol{Y}_{2}, \boldsymbol{Z}-\boldsymbol{J}>+} \\ {\frac{\mu}{2}\|\boldsymbol{X}-\boldsymbol{X} \boldsymbol{Z}-\boldsymbol{E}\|_{F}^{2}+\|\boldsymbol{Z}-\boldsymbol{J}\|_{F}^{2})} \end{array} $$ $\mu $为惩罚项系数,${\boldsymbol{Y}_1} \in {\mathbb{R}^{d \times n}}$,${\boldsymbol{Y}_2} \in {\mathbb{R}^{n \times m}}$,$ < A, B > $为矩阵内积。
-
$$ \begin{array}{c} {\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}_{k+1}={\mathop {\arg \min }\limits_{{\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}_k}}} \lambda(\left\|\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}_{k}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}_{k}\left(\boldsymbol{I}-\boldsymbol{H}_{b}\right)\right\|_{F}^{2}-} \\ {\left\|\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}_{k}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}_{k}\left(\boldsymbol{H}_{b}-\boldsymbol{H}_{t}\right)\right\|_{F}^{2}+\eta\left\|\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}_{k}^{\mathrm{T}} \mathrm{X} \mathrm{Z}_{k}\right\|_{F}^{2})} \\ {\text { s.t. }\left\|w_{i}\right\|^{2}=1}\end{array} $$ (11) 令:${\mathit{\boldsymbol{Z}}_{tk}} = \mathit{\boldsymbol{X}}{\mathit{\boldsymbol{Z}}_k}\left( {\mathit{\boldsymbol{I}} - {\mathit{\boldsymbol{H}}_b}} \right), {\mathit{\boldsymbol{Z}}_{bk}} = \mathit{\boldsymbol{X}}{\mathit{\boldsymbol{Z}}_k}\left( {{\mathit{\boldsymbol{H}}_b} - {\mathit{\boldsymbol{H}}_t}} \right)$, 将${\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}_k}$分解为向量形式,得到第$i$列的${\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}_k}(:, i)$,通过求关于${\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}_k}(:, i)$的梯度并令梯度为零,得到:
$$-\lambda\left(\boldsymbol{Z}_{t k} \boldsymbol{Z}_{t k}^{\mathrm{T}}-\boldsymbol{Z}_{b k} \boldsymbol{Z}_{b k}^{\mathrm{T}}+\eta \boldsymbol{X} \boldsymbol{\boldsymbol{Z}}_{k} \boldsymbol{\boldsymbol{Z}}_{k}^{\mathrm{T}} \boldsymbol{X}^{\mathrm{T}}\right)=\beta_{i} \mathit{\boldsymbol{ \boldsymbol{\varOmega}}}_{{k}}(:, i)$$ (12) 由此可以判断${\beta _i}$,${\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}_k}(:, i)$分别是$-\lambda\left(\boldsymbol{Z}_{t k} \boldsymbol{Z}_{t k}^{\mathrm{T}}-\boldsymbol{Z}_{b k} \boldsymbol{Z}_{b k}^{\mathrm{T}}+\eta \boldsymbol{X} \boldsymbol{\boldsymbol{Z}}_{k} \boldsymbol{\boldsymbol{Z}}_{k}^{\mathrm{T}} \boldsymbol{X}^{\mathrm{T}}\right)$的第$i$个特征值和特征向量。
-
$$ \begin{array}{c}{\boldsymbol{J}_{k+1}=\underset{\boldsymbol{J}_{k}}{\arg \min }\left\|J_{k}\right\|_{*}+\operatorname{tr}\left(\boldsymbol{Y}_{2 k}^{\mathrm{T}}\left(\boldsymbol{Z}_{k}-\boldsymbol{J}_{k}\right)\right)+} \\ {\frac{\mu_{k}}{2}\left\|\boldsymbol{Z}_{k}-\boldsymbol{J}_{k}\right\|_{F}^{2}=\underset{\boldsymbol{J}_{k}}{\arg \min }\left\|\boldsymbol{J}_{k}\right\|_{*}+\frac{1}{2}\left\|\boldsymbol{J}_{k}-\left(\boldsymbol{Z}_{k}+\frac{\boldsymbol{Y}_{2 k}}{\mu_{k}}\right)\right\|_{F}^{2}}\end{array} $$ (13) 使用Singular Value Thresholding(SVT)[8]求解,$\boldsymbol{J}^{*}=\boldsymbol{Z}_{k}+\frac{\boldsymbol{Y}_{2 k}}{\mu_{k}}$,对其进行SVD分解,${\rm{svd}}({\boldsymbol{J}^*}) = $ $(\mathit{\boldsymbol{U}}, \mathit{\boldsymbol{ \boldsymbol{\varSigma} }}, \mathit{\boldsymbol{V}})$,其中:$\mathit{\boldsymbol{ \boldsymbol{\varSigma} }} = {\mathop{\rm diag}\nolimits} \left( {{{\left\{ {{\sigma _i}} \right\}}_{1 \le i \le r}}} \right)$,${\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}_{1/{\mu _k}}}(\mathit{\boldsymbol{ \boldsymbol{\varSigma} }}) = {\mathop{\rm diag}\nolimits} \left( {{{\left\{ {{\sigma _i} - 1/{\mu _k}} \right\}}_ + }} \right)$,$ + $代表取$ \geqslant $0的部分,$\operatorname{diag}(\bullet)$表示提取主对角线元素;最后,得到$\boldsymbol{J}_{k+1}= $ $\mathit{\boldsymbol{U}}{\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}_{1/{u_k}}}(\mathit{\boldsymbol{ \boldsymbol{\varSigma} }}){\mathit{\boldsymbol{V}}^{\rm{T}}}$。
-
$$\begin{array}{c}{\boldsymbol{Z}_{k+1}=\mathop {\arg \min }\limits_{{Z_k}} \lambda\left\|\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}_{k}\left(\boldsymbol{I}-\boldsymbol{H}_{b}\right)\right\|_{F}^{2}-} \\ {\left.\left\|\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}_{k}\left(\boldsymbol{H}_{b}-\boldsymbol{H}_{t}\right)\right\|_{F}^{2}+\eta\left\|\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}_{k}\right\|_{F}^{2}\right)+} \\ {\operatorname{tr}\left(\boldsymbol{Y}_{1 k}^{\mathrm{T}}\left(\boldsymbol{X}-\boldsymbol{X} \boldsymbol{Z}_{k}-\boldsymbol{E}_{k}\right)\right)+\operatorname{tr}\left(\boldsymbol{Y}_{2 k}^{\mathrm{T}}\left(\boldsymbol{Z}_{k}-\boldsymbol{J}_{k+1}\right)\right)+} \\ {\frac{\mu}{2}\left(\left\|\boldsymbol{X}-\boldsymbol{X} \boldsymbol{Z}_{k}-\boldsymbol{E}_{k}\right\|_{F}^{2}+\left\|\boldsymbol{Z}_{k}-\boldsymbol{J}_{k+1}\right\|_{F}^{2}\right)}\end{array} $$ (14) 求其对应关于${\boldsymbol{Z}_k}$的梯度,令梯度为零,得到:
$$\begin{array}{c}{1 / \mu_{k} \boldsymbol{Z}_{k+1} \boldsymbol{P}+\left(\boldsymbol{X}^{\mathrm{T}} \mathit{\boldsymbol{ \boldsymbol{\varOmega}}} \mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X}\right)^{-1}\left(\boldsymbol{I}+\boldsymbol{X}^{\mathrm{T}} \boldsymbol{X}\right) \boldsymbol{Z}_{k+1}=} \\ {\left(\boldsymbol{X}^{\mathrm{T}} \mathit{\boldsymbol{ \boldsymbol{\varOmega}}} \mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X}\right)^{-1} \boldsymbol{K}_{k+1}}\end{array}$$ (15) 式中,$\boldsymbol{P}=2 \lambda\left[(1+\eta) \boldsymbol{I}-2 \boldsymbol{H}_{b}+\boldsymbol{H}_{t}\right]$;$\boldsymbol{K}_{k+1}=\boldsymbol{J}_{k+1}+\boldsymbol{X}^{\mathrm{T}}\left(\boldsymbol{X}-\boldsymbol{E}_{k}\right)+\left(\boldsymbol{X}^{\mathrm{T}} \boldsymbol{Y}_{1 k}-\boldsymbol{Y}_{2 k}\right) / \mu_{k}$,可见式(15)是关于${\boldsymbol{Z}_{k + 1}}$的标准Sylvester方程。利用现有的优化工具[9],可以方便地对${\boldsymbol{Z}_{k + 1}}$进行更新。
-
$$\boldsymbol{E}_{k+1}=\underset{E_{k}}{\arg \min } \frac{\alpha}{\mu_{k}}\left\|\boldsymbol{E}_{k}\right\|_{1}+\frac{1}{2}\left\|\boldsymbol{E}_{k}-\boldsymbol{Q}_{k}\right\|_{F}^{2}$$ (16) 式中,$\boldsymbol{Q}_{k}=\boldsymbol{X}-\boldsymbol{X} \boldsymbol{Z}_{k}+\boldsymbol{Y}_{1 k} / \mu_{k}$;$\boldsymbol{E}_{k+1}=\operatorname{sign}\left(\boldsymbol{Q}_{k}\right) \times$ $\max \left\{0, \left|\boldsymbol{Q}_{k}\right|-\alpha / \mu_{k}\right\} $
低秩约束的分析判别字典的学习过程采用循环迭代的方式,直至收敛。伪代码如算法1所示,当得到分析字典$\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}$与表达系数$\boldsymbol{Z}$的优化解后,可以得到训练样本在与测试样本在分析字典下的表达,然后利用最近邻(nearest neighbor, NN)分类器来预测测试样本的标签。运用低秩约束的分析判别字典的分类算法如伪代码算法2所示。
算法1 低秩约束的判别分析字典优化
输入:训练样本$\boldsymbol{X}$以及参数$\lambda $, $\alpha $, $\eta $, $\mu $, $\rho $, $\varepsilon $
输出:${\mathit{\boldsymbol{ \boldsymbol{\varOmega} }}_t}, {\mathit{\boldsymbol{J}}_k}, {\mathit{\boldsymbol{Z}}_k}, {\mathit{\boldsymbol{E}}_k}$
1) 初始化,令:$\mathit{\boldsymbol{Z}} = \mathit{\boldsymbol{J}} = 0, {\mathit{\boldsymbol{E}}_0} = 0, {\mathit{\boldsymbol{Y}}_{1, 0}} = 0, {\mathit{\boldsymbol{Y}}_{2, 0}} = 0$, ${Y_{2, 0}} = 0$, ${\mu _0} = 0.1$,${\mu _{\max }} = {10^{10}}$,$\rho = 1.3$,$k = 0$,$\varepsilon = {10^{ - 8}}$
2) 循环不收敛则一直进行如下操作:
3) 使用式(11)更新${\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}_{k + 1}}$
4) 使用式(13)更新${\boldsymbol{J}_{k + 1}}$
5) 使用式(14)更新${\boldsymbol{Z}_{k + 1}}$
6) 使用式(15)更新${\boldsymbol{E}_{k + 1}}$
7) 更新式拉格朗日乘子${\boldsymbol{Y}_{1, k}}$与${\boldsymbol{Y}_{2, k}}$:
$$ \begin{array}{l}{\boldsymbol{Y}_{1, k+1}=\boldsymbol{Y}_{1, k}+\mu_{k}\left(\boldsymbol{Z}_{k+1}-\boldsymbol{J}_{k+1}\right)} \\ {\boldsymbol{Y}_{2, k+1}=\boldsymbol{Y}_{2, k}+\mu_{k}\left(\boldsymbol{Z}_{k+1}-\boldsymbol{J}_{k+1}\right)}\end{array} $$ 8) 更新$ {\mu _{k + 1}} = \min (\rho {\mu _k}, {\mu _{\max }})$
9) 检查是否满足收敛条件:
$\left\|\boldsymbol{X}-\boldsymbol{X} \boldsymbol{Z}_{k+1}-\boldsymbol{E}_{k+1}\right\|_{F}^{2}<\varepsilon $
$\left\|\boldsymbol{Z}_{k+1}-\boldsymbol{J}_{k+1}\right\|_{F}^{2}<\varepsilon $
10) $k = k + 1 $
11) 循环结束
算法2 分类方法
输入:训练样本特征$\boldsymbol{X}$以及对应的标签${L_x}$,测试样本$\boldsymbol{Y}$
输出:测试样本的预测标签${L_y}$
1) 归一化每个样本特征:${x_i} = {{{x_i}} \mathord{\left/ {\vphantom {{{x_i}} {\left\| {{x_i}} \right\|}}} \right. } {\left\| {{x_i}} \right\|}}$。
2) 使用算法1得到关于字典$\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}$与表达系数$Z$的优化解。
3) 分别计算训练样本与测试样本在字典下的表达:$\widetilde{\boldsymbol{X}}=\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{X} \boldsymbol{Z}, \quad \widetilde{\boldsymbol{Y}}=\mathit{\boldsymbol{ \boldsymbol{\varOmega}}}^{\mathrm{T}} \boldsymbol{Y}$。
4) 利用最近邻法预测测试样本的标签${L_y}$。
-
本文提出的算法将在3个数据集上进行验证,这3个数据集包括:UCF Sports数据集[10]、UCF50数据集[11]以及KTH数据集[12]。
UCF Sports数据库以运动类人体动作为主体,主要来源于英国广播公司和娱乐与体育节目电视网,列举总共10类动作,每类视频数量如下:跳水(diving, 14)、打高尔夫(golf swing, 18)、踢足球(kicking, 20)、举重(lifting, 6)、骑马(riding horse, 12)、跑步(running, 13)、玩滑板(skateboarding, 12)、鞍马摇摆(swing-bench, 20)、单双杠摇摆(swing-side, 13)、散步(walking, 22)。
UCF50数据库的数据来源和UCF Sports类似,来源于YouTube上的视频剪辑,背景均为自然场景,其数据分布与KTH类似,一共包含50类,总共有6 680部剪辑视频。这50类动作中,包含25组视频,每组视频数量超过4个,同一组视频的执行者、背景和视角等相同。由于摄像机运动、物体外观和姿态多变、视点和背景杂乱无章、光照条件等方面的影响,基于该数据集的行为识别面临很大的挑战。
KTH数据库共包含6类人体行为动作:拳击(boxing)、拍手(hand clapping)、挥手(hand waving)、慢跑(jogging)、快跑(running)和散步(walking),每类动作均由25个不同的人在4个不同场景下(普通室外场景S1、拍摄尺度变化的室外场景S2、不同光照的室外场景S3和室内场景S4)完成,因此每类动作都有100个不同的视频片段,整个数据库共有600个视频。KTH数据库中的视频虽然背景较为简单,但是涉及到不同光照、不同尺度等因素,且动作之间存在一定的相似性,如步行、慢跑和快跑就较为相似,它们之间最大的不同仅为速度上的差异,类别间隔不明显。
-
在对UCFSports数据集进行评估时,采用K-fold交叉验证的方法。将数据分为5个集合,随机选取其中4个为训练集,剩余1个为测试集。
实验1:将本文设计的方法与成对字典学习算法(dictionary pair learning, DPL)[13]以及判别分析字典学习算法(discriminative analysis dictionary learning, DADL)[4]进行比较,实验中援用了对比算法的参数设置,同时采用文献[14]提供的Actionbank作为样本特征。
实验2:本文仍然采用K-fold交叉验证法对UCF50数据库进行评估。同样地,将数据分为5个集合,随机选取其中4个作为训练集,剩余1个作为测试集,并选取Actionbank作为样本特征,因考虑到样本维度与运算效率的因素,利用PCA(principal component analysis)将特征维度降到5 000维。试验中重点比较了传统的合成字典学习法与本文提出的分析字典学习法,作为对比的合成字典学习法有:Fishe判别字典学习法(Fisher discrimination dictionary learning, FDDL)[15],标签连续的K-SVD(LC- KSVD)[16],结构不连续的字典学习方法(dictionary learning with structured incoherence, DLSI)[17]。
实验3:利用KTH数据集,将目前流行的深度学习方法与本文所述方法进行了比较,验证方法采用留一交叉验证法,深度学习方法采用3D ConvNet+ linear support vector machine(C3D+ linearSVM)[18]以及sequence deep model + long short-term memory (SDM+LSTM)[19]。C3D是运用在行为任务上最成功的深度学习架构之一,由文献[18]提出并在Sports1M数据集上完成预训练。另一方面,SDM同样是基于神经网络的时间序列分类器,文献[19]将它与LSTM结合,成功运用在了人体行为课题上。
课题组借助台式电脑,在Matlab2014a上完成了实验1和实验2。电脑配置为英特尔酷睿i7-7700k处理器、4.2 GHz主频,16 GB内存。在完成实验3中有关深度学习的对比实验时,加入了GPU单元,GPU选用英伟达1 080ti,显存为11 GB。
-
应用前面所述的算法2可以成功得到分析字典的优化解,并且得到特征与测试样本在该字典下的特征表达,最后引入最近邻分类法对特征表达进行类别判断,得出测试样本的标签。所有实验随机选取测试与训练集合,平均测试10次,得出平均识别率。
从表 1中可以看出,三种字典学习方式普遍对“打高尔夫”“鞍马摇摆”和“散步”等数据量较大的行为动作的识别效果较好,均达到90%以上,而对“举重”“骑马”“跑步”和“玩滑板”等数据量较少的类别识别效果较差。这主要是由于数据量越多,使得所学习到的字典对该类行为的表达能力越强,从而使整体算法系统具有更高的识别率,而数据量的缺乏会影响字典对该动作的表达,且会造成识别率的浮动较大。从整体来看,DADL的平均识别率要高于DPL,本文提出的字典学习效果要优于DADL。原因是DADL主要从成对约束的角度引入判别准则,这种成对约束的可以看作是一种局部优化的方式,而本文引入低秩序约束,从全局角度引入特征判别,增强了判别特性,因此分类精度较好。
表 1 分析字典在UCFSports数据集上的平均识别率
% 算法 跳水 打高尔夫 踢球 举重 骑马 跑步 滑板 鞍马摇摆 单双摇摆 散步 平均识别率 DADL 92.9 100 85.0 66.7 83.3 62.0 83.3 90.0 92.3 91.0 84.7 DPL 85.9 94.4 85.0 66.7 75.0 61.4 76.1 90.0 91.1 88.3 81.4 本文算法 100 94.4 90.0 83.3 83.3 69.2 75.0 95.0 100 97.2 88.7 在实验2中,课题组将经典的合成字典学习算法与本文提出的算法作了对比,在UCF50数据集上得出了各自的识别精度,如表 2所示。
表 2 部分合成字典学习法与分析字典学习法在UCF50数据集上的平均识别率
% FDDL LC-KSVD DLSI 本文算法 76.5 70.1 75.4 79.1 从中可以看到,本文提出的低秩序约束的判别分析字典取得了较好的效果,由于LC-KSVD与DLSI缺少判别约束,所以整体识别精度偏低,而FDDL虽然加入了判别约束,但约束项是针对的编码系数,并没有对字典本身加以约束。
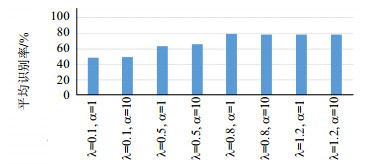
此外,课题组还利用UCF50数据库测试了算法对参数的敏感程度,本文所涉及的参数主要有$\alpha $、$\lambda $,其集合设置分别为:$\alpha = [1, 10]$,$\lambda = [0.1, 0.5, $ $0.8, 1.2]$,因此总共得到8种参数设置方式,随机抽取训练集与测试集对每一组参数设置做出评估,每一组参数评估10次然后取平均识别率,评估结果如图 1所示。

图 1 8组不同的参数设置下本文算法达到的平均识别率
从图 1中可以看出,参数$\alpha $对实验结果并不敏感,而随着判别项系数$\lambda $的增加识别率也随之增加,但当$\lambda = 1.2$时,识别率到达一个瓶颈。
实验3中,课题组首先通过深度模型提取KTH数据集的样本特征,借助3D ConvNet在Sports1M数据集上的预训练模型,将fc7层的4 096维数据作为行为特征,具体的参数选择如表 3所示。
表 3 3D ConvNet参数选择
Conv1a Pol1 Conv2a Pol2 Conv3a Conv3b Pol3 Conv4a Conv4b Pol4 Conv5a Conv5b Pol5 Fc6 Fc7 64 128 256 256 512 512 512 512 4 096 4 096 其中,Conv表示3D卷积,所有3D卷积滤波器尺寸均为3×3×3,步长为1×1×1,Pol表示3D池化,其尺寸为2×2×2,这里选择最大池化。由于3D ConvNet并非一个端到端的架构,因此需要借助SVM对输入特征进行线性分类,另一方面,延用文献[19]对SDM以及LSTM的参数设置进行实验。实验结果如表 4所示。
表 4 深度学习算法与分析字典学习法在KTH数据集上的平均识别率
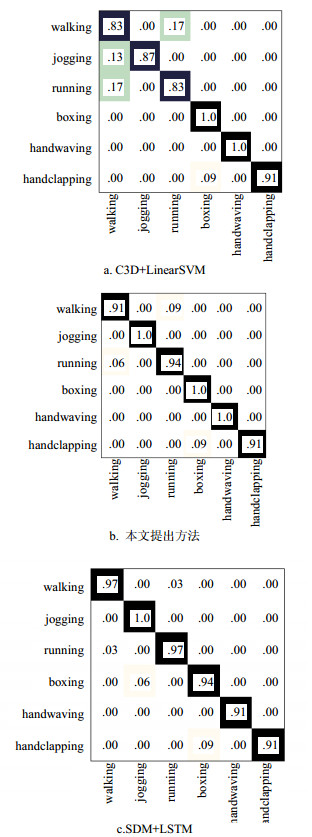
% 对比算法 平均识别率 C3D+LinearSVM 90.10 SDM+LSTM 94.39 本文算法 96.10 从表 4可以看出,本文提出的判别分析字典学习法明显优于另外两种深度学习算法,其中平均识别率比前沿的C3D+LinearSVM要高出6%,虽然C3D被证实能够很好地同步学习人体的动作和外形,但碍于数据量较小,无法对小样本行为数据做出判别性较强的表达,因此识别率较低;其次,从表 4可以看出本文算法与SDM的差距并不大,由于SDM不需要任何预训练模型,因此通过图像翻转、镜像等方法对数据集进行扩展,扩展后的KTH数据集总共达到了2 271帧图片。最后得到混淆矩阵如图 2所示。从中可以看出C3D+LinearSVM与SDM+LSTM对相似行为,例如:走路(walking)与跑步(running),慢跑(jogging)与跑步(running),会造成识别混淆,说明当深度学习受样本数量限制时,过往算法对相似的行为类别判别性较差,而本文提出的方法则保留了较强的判别性能。

图 2 深度学习方法与本文提出方法在KTH数据集上测试所得混淆矩阵图
-
本文主要研究了字典学习在行为识别任务中的应用,受合成字典学习法的启发,从对偶的角度引入分析字典学习法,利用近邻的时空描述子在同一字典下有相似的表达而具有低秩特性的特点,从全局考虑行为数据结构,增强了字典学习的鲁棒性。此外,为了提高学习字典的判别性,本文联合Fisher判定法则,减小类内散度、增大类间散度,将行为识别问题转化为低秩约束的判别分析字典优化问题。最后,通过与经典的合成字典学习算法进行比较,验证了本文算法的优势。
虽然字典学习能得出具有一定判别效果的样本表达,但字典学习法仅适合轻量级样本的学习和提炼,如何提升学习字典对大样本的表达精度将是未来工作的重点。
Research on Discriminative Analysis Dictionary Algorithm on Human Action Recognition
-
摘要: 近年来,字典学习已成功运用到模式识别领域中,但是作为字典学习里的重要分支,分析字典却极少能得到应用,主要原因是分析字典的判别力较弱。该文提出了一种新的具有鲁棒性和判别性的分析字典学习法,该字典学习法从带噪数据中寻求数据的低秩表达,并联合Fisher准则从恢复出的干净数据中学习分析字典,由于引入了监督学习的机制,因此增强了字典的判别特性。最后将该算法应用于人体行为识别任务中,通过实验验证得出,相比于其他经典的字典学习方法,该方法在行为识别数据集上取得了较好的分类精度。Abstract: Recently, dictionary learning (DL) has been applied to various pattern recognition tasks successfully, analysis dictionary learning, however as an important branch of dictionary learning, has not been fully exploited due to its poor discriminability. In this paper, a novel robust and discriminative analysis dictionary learning method is proposed, which specially seeks low rank representation from noisy data and learn a discriminative dictionary from the recovered clean data by incorporating with the Fisher criterion. The discriminability of dictionary is improved by introducing the supervised mechanism. At last, the task of human action recognition is conducted by applying the proposed method. Experiments on several human action recognition datasets show that the proposed method outperforms other classical synthesis dictionary methods.
-
表 1 分析字典在UCFSports数据集上的平均识别率
% 算法 跳水 打高尔夫 踢球 举重 骑马 跑步 滑板 鞍马摇摆 单双摇摆 散步 平均识别率 DADL 92.9 100 85.0 66.7 83.3 62.0 83.3 90.0 92.3 91.0 84.7 DPL 85.9 94.4 85.0 66.7 75.0 61.4 76.1 90.0 91.1 88.3 81.4 本文算法 100 94.4 90.0 83.3 83.3 69.2 75.0 95.0 100 97.2 88.7  下载: 导出CSV
下载: 导出CSV
表 3 3D ConvNet参数选择
Conv1a Pol1 Conv2a Pol2 Conv3a Conv3b Pol3 Conv4a Conv4b Pol4 Conv5a Conv5b Pol5 Fc6 Fc7 64 128 256 256 512 512 512 512 4 096 4 096
下载: 导出CSV
表 4 深度学习算法与分析字典学习法在KTH数据集上的平均识别率
% 对比算法 平均识别率 C3D+LinearSVM 90.10 SDM+LSTM 94.39 本文算法 96.10
下载: 导出CSV
-
[1] RAVISHANKAR S, BRESLER Y. Learning sparsifying transforms[J]. IEEE Transactions on Signal Processing, 2013, 61(5):1072-1086. doi: 10.1109/TSP.2012.2226449 [2] SHEKHAR S, PATEL V M, CHELLAPPA R. Analysis sparse coding models for image-based classification[C]//IEEE International Conference on Image Processing.[S.l.]: IEEE, 2015: 5207-5211. https://ieeexplore.ieee.org/document/7026054 [3] GU S, ZHANG L, ZUO W, et al. Projective dictionary pair learning for pattern classification[C]//International Conference on Neural Information Processing Systems.[S.l.]: MIT Press, 2014: 793-801. [4] GUO J, GUO Y, KONG X, et al. Discriminative analysis dictionary learning[C]//Conference on Artificial Interlligence (AAAI).[S.l.]: MIT Press, 2016: 1617-1623. [5] WANG J, GUO Y, GUO J, et al. Class-aware analysis dictionary learning for pattern classification[J]. IEEE Signal Processing Letters, 2017, 24(12):1822-1826. doi: 10.1109/LSP.2017.2734860 [6] GUO Y F, LI S J, YANG J Y, et al. A generalized Foley-Sammon transform based on generalized Fisher discriminant criterion and its application to face recognition[J]. Pattern Recognition Letters, 2003, 24(1):147-158. doi: 10.1016-S0167-8655(02)00207-6/ [7] LIN Z, LIU R, SU Z. Linearized alternating direction method with adaptive penalty for low-rank representation[J]. Advances in Neural Information Processing Systems, 2011:612-620. http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_1109.0367 [8] CAI J F, CANDES E J, SHEN Z. A singular value thresholding algorithm for matrix completion[J]. Siam Journal on Optimization, 2008, 20(4):1956-1982. doi: 10.1137-080738970/ [9] BARTELS R H, STEWART G W. Solution of the matrix equation AX+XB=C[F4] [J]. Communications of the ACM, 1972, 15(9):820-826. doi: 10.1145/361573.361582 [10] SOOMRO K, ZAMIR A R. Action recognition in realistic sports videos[M]//Computer Vision in Sports.[S.l.]: Springer, 2014: 181-208. [11] REDDY K K, SHAH M. Recognizing 50 human action categories of web videos[J]. Machine Vision and Applications, 2013, 24(5):971-981. doi: 10.1007/s00138-012-0450-4 [12] SCHULDT C, LAPTEV I, CAPUTO B. Recognizing human actions: a local SVM approach[C]//Proceedings of the 17th International Conference on Pattern Recognition.[S.l.]: IEEE, 2004, 3: 32-36. https://ieeexplore.ieee.org/document/1334462 [13] GU S, ZHANG L, ZUO W, et al. Projective dictionary pair learning for pattern classification[C]//Advances in neural information processing systems.[S.l.]: [s.n.], 2014: 793-801. [14] SADANAND S, CORSO J J. Action bank: A high-level representation of activity in video[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]: IEEE, 2012: 1234-1241. https://ieeexplore.ieee.org/document/6247806 [15] YANG M, ZHANG L, FENG X, et al. Fisher discrimination dictionary learning for sparse representation[C]//2011 IEEE International Conference on Computer Vision (ICCV).[S.l.]: IEEE, 2011: 543-550. https://ieeexplore.ieee.org/document/6126286 [16] JIANG Z, LIN Z, DAVIS L S. Learning a discriminative dictionary for sparse coding via label consistent K-SVD[C]//2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).[S.l.]: IEEE, 2011: 1697-1704. https://ieeexplore.ieee.org/document/5995354 [17] RAMIREZ I, SPRECHMANN P, SAPIRO G. Classification and clustering via dictionary learning with structured incoherence and shared features[C]//2010 IEEE Computer Society Conference on Computer Vision and Pattern Recongnition.[S.l.]: IEEE, 2010: 3501-3508. [18] TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks[C]//Proceedings of the IEEE International Conference on Computer Vision.[S.l.]: IEEE, 2015: 4489-4497. http://www.oalib.com/paper/4067376 [19] BACCOUCHE M, MAMALET F, WOLF C, et al. Sequential deep learning for human action recognition[C]//International Workshop on Human Behavior Understanding. Berlin, Heidelberg: Springer, 2011: 29-39. -

 点击查看大图
点击查看大图
图(2) / 表(4)
计量
- 文章访问数: 4024
- HTML全文浏览量: 1344
- PDF下载量: 117
- 被引次数: 0
