 ISSN
ISSN 




-
目前,内部威胁已成为最具挑战性的网络安全问题之一[1]。内部用户安全行为分析技术作为内部威胁检测的重要组成部分,近年来受到了国内外专家学者的高度重视。相关调查表明,在众多安全事故当中,内部用户攻击已成为主要诱因[2-4]。内部用户因拥有企业或组织内部的特殊权限,了解公司网络及系统漏洞,一旦内部用户发起攻击,其所造成的损失相比外部攻击而言往往更为严重。
内部用户行为评估技术主要通过学习用户行为习惯来评估用户的异常操作行为,从而发出告警信息。本文既考虑用户之间操作行为的个体差异性,又考虑用户内部操作习惯的前后关联性,结合LSTM适合处理有一定时序相关问题的特性,提出一种基于LSTM的内部用户安全行为评估方法。
-
内部用户安全行为分析技术主要通过学习用户行为习惯来建立分析模型,根据模型建立时所采用的学习方法归纳,主要有隐马尔科夫(hidden Markov model, HMM)、贝叶斯分类器、支持向量机(support vector machine, SVM)等检测方法。
文献[5-6]利用隐马尔科夫模型对用户操作行为进行模型构建,并使用Baum-Welch算法对HMM模型进行训练。文献[7]将用户操作命令出现的频率结合到HMM模型当中,相比原有HMM模型,减少了状态个数与转移矩阵存储量,具备较高的检测准确率。文献[8]提出了一种基于位置信息的轮廓隐马尔可夫模型(PHMMS),实验结果表明当训练数据较少时,PHMMS模型相对于HMM模型而言具备更高的异常检测率。
文献[9]研究了基于统计理论的用户安全行为检测方法,并结合6种不同的统计学方法进行实验分析。文献[10-11]假设用户操作命令按照一定频率出现,并在文献[9]的基础上提出基于贝叶斯分类器的用户安全行为检测方法,该方法原理简单,适应性强,准确率有所提高。文献[12]提出延迟检测的概念,引入时间偏差,采用朴素贝叶斯方法对用户行为进行分析,消除了正常用户和入侵用户行为模式在时间上的不一致性产生的影响。文献[13]针对朴素贝叶斯检测器漏检率较高的问题,提出一种基于实例加权的朴素贝叶斯方法(IWNB),根据分配给每个实例的权重逐步更新用户行为,实验表明IWNB方法相比贝叶斯分类器具有更高的查准率与查全率。
文献[14]将支持向量机用于用户安全行为检测,通过两个不同的UNIX命令集合进行实验,实验表明SVM是一种有效的用户行为检测方法。文献[15]提出了一种基于共生矩阵与支持向量机的伪装检测方法,与已有SVM相比具有更好的异常检测效果。此外,也有文献采用基于生物信息[16]、决策树[17]、聚类分析[18]的方法对用户安全行为进行分析。以上文献中,大多是从用户的转移属性、频率属性的角度来对用户安全行为进行分析,较少考虑到用户之间操作行为的个体差异性及用户自身操作习惯的前后关联性。针对以上情况,本文充分考虑用户间的差异性,提出新的数据划分方案实现多用户组合;并结合用户自身操作习惯的前后相关性,利用LSTM算法对用户操作习惯进行建模。
-
文献[9]将单个用户前1/3数据划分为训练集,后2/3作为测试集,检测单用户行为异常。文献[10]在文献[9]的基础上提出1 vs 49的配置规则,选取单个用户前1/3数据作为训练集,将剩余49个用户前1/3的数据作为测试集。
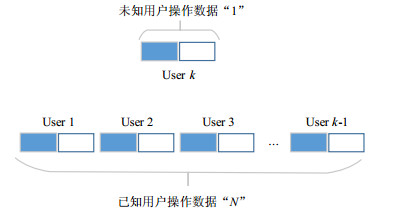
由于用户间的操作行为存在个体差异性,单独对每个用户进行建模过于繁杂。针对以上情况,本文提出N vs 1数据划分方案,该方案将多用户组合后进行统一建模。首先,将用户操作数据划分为已知用户操作数据“N”与未知用户操作数据“1”,然后利用算法对已知用户操作数据“N”进行学习建模,最终对未知用户操作数据“1”进行检测,如图 1所示。其中,已知用户数据“N”将多个用户的操作数据按顺序进行组合,未知用户操作数据“1”则只是单个用户操作数据。通过对大量用户的正常操作与异常操作进行学习建模,来检测个别用户的操作行为是否异常。

图 1 N vs 1数据划分方案
-
LSTM网络在处理二分类问题时,其输出结果${h_t}$往往被设定为0~1之间的数值,并通过一个固定的阈值来判断用户操作是否异常。阈值设定对最终结果的准确率有很大的影响,通常选择0.5作为分类阈值,当输出结果大于0.5时判定为正常操作,小于0.5时为异常操作。但在实际应用中,0.5往往不是最佳判定阈值。
双峰法也称为直方图双峰法,是一种常用的全局单阈值的图像二值化分割方法。图像二值化在图像处理中常被用来识别图像中的目标物体,分割图像的前景和背景区域,这对于正确解析出图像中所包含的信息有很大意义。
双峰阈值机制要求被处理的数据具有一定的双峰特性、数值差异较大,并选取直方图最高两峰之间的谷底对应的数值作为阈值。
本文提出的方法中,双峰阈值的确定步骤如下:
1) 读取LSTM网络输出数据,统计数据个数$n$及每个输出对应的值${h_t}$。
2) 统计0~1范围内数值出现的频率,并画出频率直方图。
3) 选取直方图中频率最高双峰之间的谷底对应的数值,并将其作为判别阈值$\omega $。
4) 遍历LSTM网络输出,用阈值对输出进行判别,不小于$\omega $的输出判定为正常操作,将${h_{{\rm{end}}}}$赋值为0,其余部分判定为异常操作,将${h_{{\rm{end}}}}$设置为1。
判定函数:
$$h_{\mathrm{end}}=\left\{\begin{array}{ll}{0} & {h_{t} \geqslant \omega} \\ {1} & {h_{t}<\omega}\end{array} \quad 0 \leqslant h_{t} \leqslant 1, \quad 1 \leqslant t \leqslant n\right.$$ (1) -
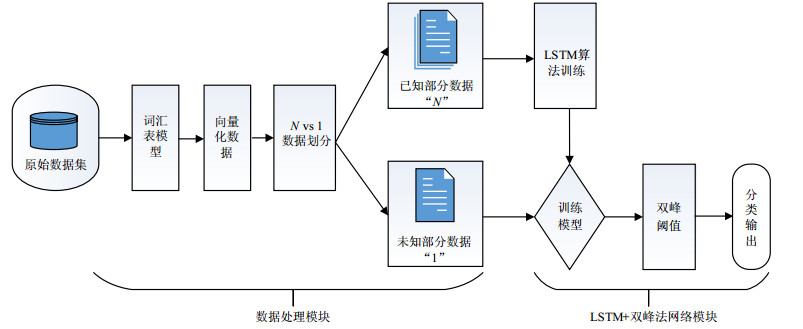
内部用户的操作行为具备一定的前后关联性,而LSTM对有时序关系的数据较为敏感,对此,本文构建了一种基于LSTM的内部用户安全行为评估模型。评估模型划分为两大模块:数据处理模块及LSTM+双峰法网络模块,如图 2所示。

图 2 内部用户安全行为评估模型
-
数据处理模块主要实现对内部用户操作数据的向量化以及数据划分。在对用户操作数据向量化时,为不影响数据的前后关系,利用词袋(bag of words,BOW)模型建立词汇表(glossary model)进行向量化处理。词袋模型是将文本看作一系列词的集合,词汇表模型基于词袋模型的思想,使用生成的词汇表对原有句子按照单词逐个进行编码。
给定单个用户的个人操作行为数据为$\boldsymbol{W}({w_1}, {w_2}, \cdots , {w_n})$,其中$n \in {N^ + }$,${w_n}$表示用户的第$n$个操作,$V{\rm{\{ }}{v_1}:1, {v_2}:2, \cdots , {v_m}:m{\rm{\} }}$是从$\boldsymbol{W}$中提取的词汇表,${v_m}:m$表示词汇表集合$V$中存在的第$m$个操作行为${v_m}$,且$m$满足条件$m \in {N^ + }$, $m \leqslant n$。对用户操作数据进行词向量处理得到:${\boldsymbol{W}^V} = (w_1^V, w_2^V, \cdots , w_n^V)$,$w_n^V \in [1, m]$,其中${\boldsymbol{W}^V}$表示数据集$W$经过词汇表$V$向量化处理后所得结果,$w_n^V$表示第$n$个操作经过词汇表映射后所对应的数值。
同理,对于多用户的个人操作行为数据集合$\boldsymbol{U}\left(\boldsymbol{W}_{1}, \boldsymbol{W}_{2}, \cdots, \boldsymbol{W}_{k}\right)$,$k \in {N^ + }$。${\boldsymbol{W}_k}({w_{{k_1}}}, {w_{{k_2}}}, \cdots , {w_{{k_n}}})$为用户$k$的操作数据,${w_{{k_n}}}$表示用户$k$的第$n$个操作,${V_{{\rm{all}}}}{\rm{\{ }}{v_1}:1, {v_2}:2, \cdots , {v_m}:m{\rm{\} }}$是从$\boldsymbol{U}$中提取的词汇表,${v_m}$对应的数值编号为$m$,且$m$满足条件$m \in {N^ + }$, $m \leqslant kn$。对用户$k$的操作数据作词向量处理得到:$\boldsymbol{W}_k^V(w_{{k_1}}^V, w_{{k_2}}^V, \cdots , w_{{k_n}}^V)$,$w_{{k_n}}^V \in [1, m]$,其中$\boldsymbol{W}_k^V$表示用户$k$的个人行为数据集$\boldsymbol{W}$经过词汇表$V$向量化处理后所得结果,$w_{{k_n}}^V$表示用户$k$的第$n$个操作经过词汇表映射后所对应的数值。
算法1 单用户操作数据向量化算法
输入:用户所有操作数据$\boldsymbol{W}({w_1}, {w_2}, \cdots , {w_n})$,$n \in {N^ + }$
输出:映射规则$V{\rm{\{ }}{v_1}:1, {v_2}:2, \cdots , {v_m}:m{\rm{\} }}$,$m \in {N^ + }$,$m \leqslant n$;
输出数据${\boldsymbol{W}^V} = (w_1^V, w_2^V, \cdots , w_n^V)$,$w_n^V \in [1, m]$,$n \in {N^ + }$,$m \leqslant n$
While $ (\boldsymbol{W} \ne \emptyset )$
For $ (i = 0;i < n;i + + )$
If ${w_i}$首次出现
生成映射规则,$V{\rm{\{ }}{v_1}:1, {v_2}:2, \cdots , {v_m}:m{\rm{\} }}$
End if
End for
For $(j = 0;j < n;j + + ) $
If $ {w_j} = {v_m}$
生成映射结果${W^V} = (w_1^V, w_2^V, \cdots , w_n^V)$
End if
End for
Return $ V{\rm{\{ }}{v_1}:1, {v_2}:2, \cdots , {v_m}:m{\rm{\} }}$,
$ {\boldsymbol{W}^V} = (w_1^V, w_2^V, \cdots , w_n^V)$
数据划分阶段采用N vs 1划分方案,对于多用户数据集合$\mathit{\boldsymbol{U}}\left( {{\mathit{\boldsymbol{W}}_1}, {\mathit{\boldsymbol{W}}_2}, \cdots , {\mathit{\boldsymbol{W}}_k}} \right)$,按照N vs 1的方案,选取前$k - {\rm{1}}$个用户数据$\boldsymbol{W}_{1}, \boldsymbol{W}_{2}, \cdots, \boldsymbol{W}_{k-1}$作为已知部分数据用作模型训练,第$k$个用户数据${\boldsymbol{W}_k}$作为未知部分数据用作模型检验。
-
LSTM+双峰网络模块主要实现生成LSTM训练模型及LSTM模型输出与双峰法的结合。LSTM通过输入控制门、输出控制门、遗忘控制门以及一个Cell单元来实现对历史信息的遗忘和保留,能很好地分析具备长期依赖关系的数据。在经过向量化处理后的某用户操作数据为${\boldsymbol{W}^V} = (w_1^V, w_2^V, \cdots , w_n^V)$,根据LSTM算法的结构,${\boldsymbol{W}^V} = (w_1^V, w_2^V, \cdots , w_n^V)$作为算法的输入等价于$\boldsymbol{X} = ({x_1}, {x_2}, \cdots , {x_t})$,其中$n = t$。
遗忘门${\boldsymbol{f}_t}$表示为:
$$\boldsymbol{f}_{t}=\sigma\left(\boldsymbol{W}_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right)$$ (2) 式中,${\boldsymbol{W}_f}$是遗忘门的权重矩阵;$[{h_{t - 1}}, {x_t}]$表示将当前时刻的${x_t}$和上一时刻的输出${h_{t - 1}}$作为输入;${b_f}$是遗忘门的偏置项;$\sigma $是门限,选取sigmoid函数,遗忘门决定是否在${C_t}$环节中遗忘Cell单元上一时刻输入门${i_t}$表示为:
$$\boldsymbol{i}_{t}=\sigma\left(\boldsymbol{W}_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right)$$ (3) 式中,${\boldsymbol{W}_i}$是输入门的权重矩阵;$[{h_{t - 1}}, {x_t}]$表示当前时刻的输入${x_t}$和上一时刻的输出${h_{t - 1}}$作为输入;${b_i}$是输入门的偏置项;$\sigma $是门限,选取sigmoid函数,输入门决定是否将当前信息更新到${\boldsymbol{C}_t}$环节。
当前时刻的候选Cell单元状态$\tilde{\boldsymbol{C}}_{t}$表示为:
$$\tilde{\boldsymbol{C}}_{t}=\tanh \left(\boldsymbol{W}_{c} \cdot\left[h_{t-1}, x_{t}\right]+b_{c}\right)$$ (4) 式中,${\boldsymbol{W}_c}$为权重矩阵;$[{h_{t - 1}}, {x_t}]$表示以当前时刻的输入${x_t}$和上一时刻的输出${h_{t - 1}}$作为输入;${b_c}$为偏置项;tanh是门限,选取双曲正切函数。
当前时刻的Cell单元状态${\boldsymbol{C}_t}$表示为:
$$\boldsymbol{C}_{t}=\boldsymbol{f}_{t} * \boldsymbol{C}_{t-1}+\boldsymbol{i}_{t} * \tilde{\boldsymbol{C}}_{t}$$ (5) 式中,$ * $表示元素乘运算;${\boldsymbol{C}_t}$是由上一时刻的Cell单元状态${\boldsymbol{C}_{t - 1}}$与遗忘门${\boldsymbol{f}_t}$的乘积,以及前输入的候选Cell单元状态${\tilde {\boldsymbol{C}}_t}$与输入门${\boldsymbol{i}_t}$的乘积进行调节的,Cell单元状态${\boldsymbol{C}_t}$最终将输出到${\boldsymbol{o}_t}$。
输出门${\boldsymbol{o}_t}$表示为:
$$\boldsymbol{o}_{t}=\sigma\left(\boldsymbol{W}_{o} \cdot\left[h_{t-1}, x_{t}\right]+b_{o}\right)$$ (6) 式中,${\boldsymbol{W}_o}$表示输出权重矩阵;$[{h_{t - 1}}, {x_t}]$表示以当前时刻的输入${x_t}$和上时刻的输出${h_{t - 1}}$作为输入;${b_o}$表示偏置项;$\sigma $是门限,选取sigmoid函数,输出门能决定是否将当前时刻输出信息传递到${\boldsymbol{h}_t}$中。
LSTM的最终输出${\boldsymbol{h}_t}$表示为:
$$\boldsymbol{h}_{t}=\boldsymbol{o}_{t} * \tanh \left(\boldsymbol{C}_{t}\right)$$ (7) 式中,$ * $表示元素乘运算;${\boldsymbol{h}_t}$由输出门${\boldsymbol{o}_t}$和Cell单元状态${\boldsymbol{C}_t}$共同决定;tanh是门限,选取双曲正切函数。
根据输出${\boldsymbol{h}_t}$,统计0~1范围内数值的频率,画出原图像的频率直方图。根据直方图选取频率最高双峰之间的谷底对应的数值作为双峰阈值$\omega $。遍历原始输出,用阈值对输出进行判别,将不小于判别阈值$\omega $的输出划为正常操作,${h_{{\rm{end}}}}$赋值为0,其余部分划为异常操作,${h_{{\rm{end}}}}$赋值为1。
-
本文实验在Ubuntu 18.04操作系统下进行,GPU选用NVIDIA TITAN XP,编程环境采用Python 3.6,编程平台选用PyCharm Community 2017.3,LSTM神经网络利用Keras 1.2.2实现。
实验数据采用文献[19]构建的SEA实验数据集,该数据集包含50个目标用户在Unix系统下的操作命令文件和一个masquerade_summary.txt文件。每个用户文件均记录了15 000条操作命令,其中,前5 000个命令为用户的正常命令,后10 000个命令被以一定的概率注入其他20个用户的命令,并且以100个命令作为一个命令块,0表示命令块正常,1表示命令块异常。querade_summary.txt文件则保存了一个100×50的矩阵数据,行号代表测试数据中的命令块号,列号代表用户号,矩阵使用0/1来指示某用户操作数据中的某块命令是否异常。SEA数据集中给定任意一个测试命令块,其中含有恶意操作指令的概率为1%。如果一个命令块含有恶意命令,则后续命令块内有恶意命令的概率将达到80%。
实验采用本文提出的N vs 1的数据划分方案,选取SEA数据集的前10位用户数据进行实验。其中,前9位用户数据被划分为已知用户行为数据“N”用
作模型训练,将第10位用户数据划分为未知用户数据“1”用作模型评估。
-
实验采用TensorFlow自带的Web可视化展示工具TensorBoard对LSTM模型进行参数调节。基本网络参数:批尺寸大小batch_size设定为32,网络的训练迭代轮数epoch设定为200,防止过拟合参数drop_out设定为0.6。
在LSTM模型优化阶段,分别采用4种优化算法进行实验,结果如图 3所示。相比于AdaDelta、SGD、Momentum优化函数,Adam优化函数的优化能力强,损失值${\rm{Loss}}$能降至0.05,故在LSTM模型构建时,选择Adam作为优化函数。

图 3 优化函数对比图
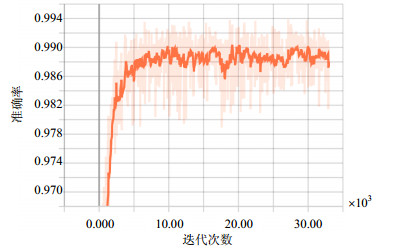
图 4展示了LSTM算法模型在确定优化函数Adam后模型准确率${\rm{Accuracy}}$变化趋势。随迭代次数的增加准确率${\rm{Accuracy}}$迅速提高并趋于稳定。

图 4 模型变化趋势
对LSTM模型输出数据做进一步分析:
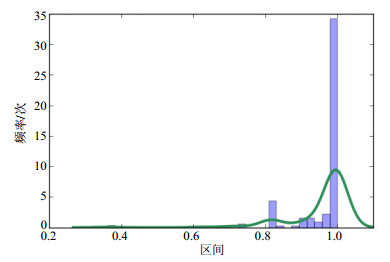
首先,统计输出数据个数$n$以及每个输出数据${Y_i}$对应的值,统计0~1范围内的数值的个数,画出对应输出数据直方图,如图 5所示。

图 5 双峰阈值直方图
然后,根据直方图确定最高双峰,选取双峰间谷底对应的数值作为判决阈值$\omega $。根据图 5可以确定$\omega {\rm{ = }}0.87$,生成阈值判决公式:
$$Y_{\mathrm{end}}=\left\{\begin{array}{ll}{1} & {Y \geqslant 0.87} \\ {0} & {Y_{i}<0.87}\end{array} \quad 0 \leqslant Y_{i} \leqslant 1, \quad 1 \leqslant i \leqslant n\right.$$ 最后,通过判决阈值公式判断用户是否存在异常操作行为。
为验证该算法的有效性,采用文献[10]的朴素贝叶斯(NB)算法和文献[5]的隐马尔科夫(HMM)算法作为对比实验算法,并根据SEA数据集的特点分别对这两种算法做了简单优化。其中,文献[10]的朴素贝叶斯(NB)算法加入词袋与TF-IDF模型,TF-IDF模型可用于评估一个词对该文件集的重要程度。文献[5]的隐马尔科夫(HMM)算法加入词袋和N-Gram模型,N-Gram模型可以评估两个字符串之间的差异,在此可以比较前后操作命令的相关度。
实验评价指标选用查准率${\rm{Precision}}$、查全率${\rm{Recall}}$和综合评价指标${\rm{F}}1$。
$${\rm{Precision = }}\frac{{{\rm{Correct }}}}{{{\rm{Output}}}} \times 100\% $$ (8) $${\rm{Recall = }}\frac{{{\rm{Correct}}}}{{{\rm{Labeled}}}} \times 100{\rm{\% }}$$ (9) $${\rm{F1 = }}\frac{{{\rm{2}} \times {\rm{Precision}} \times {\rm{Recall}}}}{{{\rm{Precision + Recall}}}}$$ (10) 式中,Correct表示模型正确分类用户行为类别的个数;Output表示模型分类用户行为类别的总数;Labeled表示测试集中实际正确类别行为的总数;查准率Precision代表能够准确识别出真实情况的能力;查全率Recall代表能够将样本中属于该类的样本全部查找出来的能力;查准率Precision与查全率Recall存在相互矛盾的问题,一般而言,查准率Prescision高时,查全率Recall往往较低,所以使用综合评价指标${\rm{F}}1$表示两者的平衡性。
实验结果如表 1所示:
表 1 算法实验结果
% 算法 Precision Recall F1 TF-IDF+NB 94.15 82.00 85.60 N-Gram+HMM 83.42 91.33 87.20 词汇表+LSTM 83.26 89.33 86.19 词汇表+LSTM+Bimodal Method 98.38 98.00 98.09 从表 1实验结果分析可知,LSTM算法与双峰阈值机制结合在用户安全行为评估中相比于朴素贝叶斯(NB)和隐马尔科夫(HMM)有明显的优势,在查准率${\rm{Precision}}$、查全率${\rm{Recall}}$和${\rm{F1}}$这3项性能指标中该方法性能均高于NB和HMM两种算法。LSTM+ Bimodal Threshold不仅能够准确判断用户操作行为是否存在异常,而且能够有效地将用户正常行为和异常行为检测出来。
为验证N vs 1数据划分方案所构建的评估模型泛化能力,从SAE数据集后40位用户中随机抽取4位未知用户作为测试对象。
从图 6实验结果分析可知,当未知用户中异常操作数较多时(User24、User42),本文方法的评估结果较为准确;当异常操作数值较少时(User12、User15),评估的准确度受检测值影响变化较大,但异常检测的查全率得到了保证,即能将所有异常操作检测出来。

图 6 未知用户异常检测
-
本文提出一种基于LSTM的内部用户安全行为评估方法。该方法在数据划分阶段考虑用户之间操作存在差异性,提出将多用户进行组合来构建训练模型,使模型充分学习各类用户的操作行为习惯。另外,考虑到用户内部操作存在前后关联性,选用LSTM算法对用户操作行为习惯进行学习,并利用双峰阈值机制生成判决阈值来评估用户安全行为。实验结果表明,本文提出的评估方法能够在学习已知用户操作行为的基础上,对未知用户操作行为进行准确评估,模型具备检测未知用户异常行为的能力。
Internal User Security Behavior Evaluation Method Based on LSTM
-
摘要: 内部用户安全行为评估方法由于较少考虑用户操作行为的前后关联性,导致用户操作行为评估的准确率受到影响。针对该情况,结合长短期记忆网络(LSTM)适合处理时间序列问题的特性,提出了一种基于LSTM的内部用户安全行为评估方法。该方法首先对数据作向量化处理;然后按照N vs 1方案进行数据划分,利用LSTM算法对已知用户操作行为习惯进行统一建模;最后使用双峰阈值(bimodal threshold)机制来确定判决阈值,并对用户操作行为进行评估。实验结果表明,该方法的数据划分方案提升了其检测未知用户操作异常的能力,而且通过引入双峰阈值机制,提高了其检测未知用户异常操作的查准率与查全率。
-
关键词:
- 双峰阈值 /
- 数据划分 /
- 内部用户安全行为评估 /
- LSTM
Abstract: The internal user security behavior assessment method affects the accuracy of the user's operational behavior assessment due to less considers the contextual relevance of the user's operational behaviors. In view of this situation, and considering the characteristics of long-short term memory (LSTM) is suitable for dealing with time series problems, an internal user security behavior evaluation method based on LSTM is proposed. In this method, the data are vectorized firstly and then divided according to the N vs. 1 scheme. The LSTM algorithm is used to uniformly model the known user's behavior habits. Finally, the decision threshold is determined by the bimodal threshold mechanism and user behaviors are evaluated. Experimental results show that the data partitioning scheme of this method improves the ability to detect abnormal operation of unknown users, and by introducing a bimodal threshold mechanism, the accuracy and recall of the algorithm for detecting abnormal operations of unknown users are improved.-
Key words:
- bimodal threshold /
- data partitioning /
- internal user security behavior evaluation /
- LSTM
-
表 1 算法实验结果
% 算法 Precision Recall F1 TF-IDF+NB 94.15 82.00 85.60 N-Gram+HMM 83.42 91.33 87.20 词汇表+LSTM 83.26 89.33 86.19 词汇表+LSTM+Bimodal Method 98.38 98.00 98.09  下载: 导出CSV
下载: 导出CSV
-
[1] NURSE J R C, BUCKLEY O, LEGG P A, et al. Understanding insider threat: A framework for characterising attacks[C]//IEEE Security and Privacy Workshops. San Jose, USA: IEEE Computer Society, 2014: 214-228. https://ieeexplore.ieee.org/document/6957307 [2] TRZECIAK R F. SEI Cyber minute: Insider threats[EB/OL].[2018-12-18]. http://resources.sei.cmu.edu/library/asset-view.cfm?assetid=496626. [3] COLLINS L M, THEIS C M, TRZECIAK R F, et al. Common sense guide to prevention and detection of insider threats 5th edition[R].[S.l.]: Carnegie Mellon University, 2016. [4] MATHEW S, PETROPOULOS M, NGO H Q, et al. A data-centric approach to insider attack detection in database systems[C]//Recent Advances in Intrusion Detection. Ottawa, Canada: Springer, 2010: 382-401. doi: 10.1007%2F978-3-642-15512-3_20 [5] LANE T D. Machine learning techniques for the computer security domain of anomaly detection[D]. West Lafayette: Purdue University, 2000. [6] LANE T D, BRODLEY C E. An empirical study of two approaches to sequence learning for anomaly detection[J]. Machine Learning, 2003, 51(1):73-107. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=c7565060f0f37fd79bf5676dfc6df206 [7] 肖喜, 田新广, 翟起滨, 等.基于shell命令和Markov链模型的用户伪装攻击检测[J].通信学报, 2011, 32(3):98-105. doi: 10.3969/j.issn.1000-436X.2011.03.013 XIAO Xi, TIAN Xin-guang, ZHAI Qi-bin, et al. Masquerade detection based on shell commands and Markov chain models[J]. Journal on Communications, 2011, 32(3):98-105. doi: 10.3969/j.issn.1000-436X.2011.03.013 [8] HUANG L, STAMP M. Masquerade detection using profile hidden Markov models[J]. Computers & Security, 2011, 30(8):732-747. http://d.old.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ0224896980/ [9] SCHONLAU M, DUMOUCHEL W, JU W H, et al. Computer intrusion:Detecting masquerades[J]. Statistical Science, 2001, 16(1):58-74. doi: 10.1214/ss/998929476 [10] MAXION R A, TOWNSEND T N. Masquerade detection using truncated command lines[C]//International Conference on Dependable Systems and Networks. Washington, USA: IEEE Computer Society, 2002: 219-228. [11] MAXION R A, TOWNSEND T N. Masquerade detection using enriched command lines[C]//International Conference on Dependable Systems and Networks. San Francisco, USA: IEEE Computer Society, 2003: 5-14. [12] DASH S K, REDDY K S, PUJARI A K. Adaptive Naive Bayes method for masquerade detection[J]. Security and Communication Networks, 2011, 4(4):410-417. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=10.1002/sec.168 [13] SEN S. Using instance-weighted naive Bayes for adapting concept drift in masquerade detection[J]. International Journal of Information Security, 2014, 13(6):583-590. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=38cbf5df87005925edf5f145243f2f1d [14] KIM H S, CHA S D. Empirical evaluation of SVM-based masquerade detection using UNIX commands[J]. Computers & Security, 2005, 24(2):160-168. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=7599729d2db9f29830cef770c597f52b [15] SALEM M B, STOLFO S J. Modeling user search behavior for masquerade detection[C]//Recent Advances in Intrusion Detection. Menlo Park, USA: Springer, 2011: 181-200. [16] COULL S, BRANCH J, SZYMANSKI B, et al. Intrusion detection: A bioinformatics approach[C]//Computer Security Applications Conference. Las Vegas, USA: IEEE Computer Society, 2003: 24-33. [17] JIAN Z, SHIRAI H, TAKAHASHI I, et al. Masquerade detection by boosting decision stumps using UNIX commands[J]. Computers and Security, 2007, 26(4):311-318. doi: 10.1016/j.cose.2006.11.008 [18] RAVEENDRAN R, DHANYA K A. Applicability of clustering techniques on masquerade detection[C]//International Conference on Advances in Computing, Communications and Informatics. Delhi, India: IEEE, 2014: 2343-2348. [19] SCHONLAU M. Masquerading user data[EB/OL].[2018-12-18]. http://www.schonlau.net/intrusion.html. -

 点击查看大图
点击查看大图
图(6) / 表(1)
计量
- 文章访问数: 4530
- HTML全文浏览量: 1408
- PDF下载量: 127
- 被引次数: 0
