 ISSN
ISSN 


-
如何从有限的时间序列信息中挖掘节点间的邻接关系是深入了解未知网络的关键[1-2]。如:通过有限的时间序列信息识别网络用以预测分析世界贸易网络中国家之间的多边贸易关系[3],加深对生物网络的复杂调控过程的认知[4-5],了解科学家的协作行为在促进学科改革中的作用[6],从经济和金融网络中洞悉潜在的风险[7-8]。尽管各个学科领域的专家对该问题持续关注,设计了具有一定普适性的压缩感知识别模型[9]。但在不增加额外信息的条件下,该模型仍难以依靠有限的时间序列信息获得准确的网络邻接关系[10-12]。文献[13-14]发现在同一种算法下,超过300个节点的网络其稀疏性是决定网络能否准确重构的关键,稀疏的节点邻接关系比稠密关系更容易获得准确重构。文献[15-16]发现若已知等量的时间序列信息,随机网络和小世界网络的关系识别准确率相比无标度网络更高。这些有趣的发现使我们意识到网络中的部分结构属性对压缩感知识别模型存在直接的影响。文献[17]做了初步的探索,发现网络的同配系数$r$=0.2时,压缩感知识别模型识别邻接关系的准确率最高。这些结论意味着在重构网络时,网络本身的结构属性能够弥补信息的稀缺性。尽管前期工作已经取得了一定进展,然而,仍然难以确定种类繁多的结构属性中对网络重构产生直接、显著影响的是哪几项。其中部分结构属性还存在一些相关关系,如簇度相关性[18]等。因此,发展针对单一结构属性的分析方法,在该方法下围绕所有的单一网络结构属性对网络重构的效果进行定量分析是非常有必要的。
本文构建了有限信息下基于网络单一结构属性的网络结构重构分析方法。该方法基于稀疏性和同配系数对网络重构影响的研究成果,进一步深入研究了集聚系数对网络重构的独立影响。分析方法运用Holme-Kim(HK)模型[19]生成了11个稀疏性与同配系数相同,且平均集聚系数$\langle C\rangle $由0.1逐渐增加至0.6的人工网络。分析方法运用压缩感知识别模型[15, 20]进行了有限信息下的网络重构实验。实验结果表明:当仅掌握20%的有限信息时,网络的平均集聚系数$\langle C\rangle $越大,其邻接关系的平均识别准确率$\langle SR\rangle $[13, 17]和平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $[21-22]越高,且这两项指标均在平均集聚系数$\langle C\rangle $=0.6时取到最大值。此时,邻接关系的平均识别准确率$\langle {\rm{SR}}\rangle $和平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $随平均集聚系数由0.1增加到0.6而分别提高了25.33%和26.93%。进一步的实验分析说明,网络中度小于8的节点其平均识别准确率是决定网络平均识别准确率的关键。
-
本文的分析方法通过控制3项结构属性生成人工网络,并对其中的1项结构属性——集聚系数与网络重构效果做关联分析。根据文献[13, 17]的研究,稀疏性和同配系数是影响网络重构的重要因素。即使集聚系数相同的两个网络也可能拥有不同的稀疏性或同配系数。因此,在单独进行集聚系数与网络重构效果的关联分析时,为免于同时受到网络的稀疏性和同配系数的交叉影响,需要对稀疏性和同配系数加以控制。
为确保生成的人工网络具有相同的稀疏性和同配系数,预先设定网络的边数,并依次设定平均集聚系数$\langle C\rangle $为0.1、0.15、…、0.6。通过HK模型生成大量网络后,从中选取平均同配系数$\langle r\rangle $误差在10-3以内,且平均集聚系数$\langle C\rangle $不同的网络作为实验网络。
在进行重构时,实验网络的结构是未知的。网络各节点在多轮囚徒困境博弈(PDG)[23]模型下彼此交互。由于无法得到描述交互行为的所有时间序列信息,便以随机采样选取其中的部分信息作为已知的有限信息。再运用压缩感知识别模型对已知信息进行处理,识别节点间的邻接关系,进而得到网络的确切结构。
-
HK模型可以构造平均集聚系数$\langle C\rangle $可调的人工网络[19]。在生成网络时,HK模型将按要求产生固定数量的闭合三角邻接关系,以此来调节网络平均集聚系数$\langle C\rangle $的大小。HK模型生成人工网络的程序可分为4个步骤[19]:
1) 初始条件:随机生成一个由${n_{\rm{0}}}$个节点,${m_{\rm{0}}}$条边构成的连通网络。
2) 网络增长:在每个时间步增加1个新节点$i$。同时节点$i$按照择优连接或三角构成的方式选择$m$个已有节点作为邻点,且$m \leqslant {m_{\rm{0}}}$。
3) 择优连接:以网络中已有各节点$j$的度${k_j}$计算节点$j$被新节点$i$选为邻点的概率${\mathit{\Pi }_j}\;\left( {{\mathit{\Pi }_j} = {k_j}/{k_j}\sum\limits_l {({k_l})} } \right)$。新节点$i$按概率${\mathit{\Pi} _j}$选择邻点,且节点$i$的第1个邻点均按择优连接方式选取。
4) 三角构成:三角构成一般在择优连接后以1-${P_t}$的概率执行。若新节点$i$已选择了一个邻点$j$,则节点$i$的下一个邻点的选择范围即为节点$j$的所有邻点,从而构成闭合的三角邻接关系。
生成的网络最终将作为检验压缩感知识别模型重构网络准确性的对照标准。网络生成的过程中,其结构不随时间的变化而变化,发生变化的是各节点状态。节点状态的动态变化过程将由演化博弈信息生成模型刻画。
-
由于无法直接得到网络的结构信息,而节点状态随时间变化的规律是由网络本身的动力学机制以及网络结构共同决定的,本文便考虑从节点状态的动态信息来推测网络的潜在结构。在掌握节点状态的动态信息基础上,可以建立因节点邻接关系作用而改变节点状态的动态模型。若将网络中的节点视为博弈者,将节点的策略和收益视为节点状态信息,可用演化博弈模型[23-25]来刻画网络中相邻节点的交互行为。在PDG模型的第$t$轮博弈中,每个节点可选择某种策略获得收益。向量${\bf S Y}_{i}(t)=(1, 0)^{\mathrm{T}}$和${\bf S Y}_{i}(t)=(1, 0)^{\mathrm{T}}$分别表示节点$i$的协作和背叛策略。其中,${\rm{T}}$代表转置。节点的收益还由统一的收益矩阵$\boldsymbol{P}$决定,定义为:
$$\boldsymbol{P} = \left( {\begin{array}{*{20}{c}} {\rm{1}}&{\rm{0}} \\ b&{\rm{0}} \end{array}} \right)$$ (1) 式中,$b\;{\rm{(1}} < b < {\rm{2}})$为节点在选择背叛后可能获得的单位收益量,本文令$b$=1.2。节点$i$在第$t$轮与其所有邻点博弈时均使用相同的策略。节点$i$与任一邻点$j$在博弈中获得的收益为:
$$F_{i j}(t)={\bf S} {\bf Y}_{i}^{\mathrm{T}}(t) \cdot \boldsymbol{P} \cdot {\bf S} {\bf Y}_{j}(t)$$ (2) 而节点$i$在本轮的总收益${G_i}(t)$是节点$i$与各邻点博弈后获得的收益之和。
在新一轮博弈中,节点$i$将通过Fermi规则[26]调整策略以期实现收益最大化。第$t$轮博弈后,节点$i$将随机选择一个邻点$j$,并在第$t + 1$轮博弈时以概率$W$选择节点$j$的策略,概率表达为:
$$W = \frac{{\rm{1}}}{{{\rm{1}} + {\rm{exp}}[({\rm{T}}{{\rm{G}}_i}(t) - {\rm{T}}{{\rm{G}}_j}(t))/\kappa ]}}$$ (3) 式中,${\rm{T}}{{\rm{G}}_i}(t)$和${\rm{T}}{{\rm{G}}_j}(t)$分别是节点$i$和$j$自第1轮至第$t$轮博弈所获得的累计收益。参数$\kappa $反映了节点$i$的选择理性,当$\kappa $=0体现了选择的绝对理性。本文的选择理性参数$\kappa $=0.1。鉴于博弈仅限于相邻节点,博弈行为隐含了节点间邻接关系的信息。博弈期间记录下的节点的策略及收益等时间序列信息可以用来识别网络中的邻接关系[13, 27]。
-
压缩感知识别模型可基于不完整的时间序列信息对规模为$N$的网络进行重构。本文先以网络各节点为单位,将节点及其邻接关系解构为$N$个小网络[28-29]。此时,一个网络的邻接关系识别问题可以分解为$N$个节点的邻接关系识别问题。本文采用向量${\boldsymbol{A}_i} = {{\rm{(}}{a_{i{\rm{1}}}}, {a_{i{\rm{2}}}}, \cdots , {a_{i, i - {\rm{1}}}}, {a_{i, i + {\rm{1}}}}, \cdots , {a_{i, N}}{\rm{)}}^{\rm{T}}}$来描述节点$i$在网络中的邻接关系,且当节点$i$和节点$j$互为邻接关系时,${a_{ij}}$=1,否则,${a_{ij}}$=0。网络本身的稀疏性决定了节点$i$的邻接关系向量${\boldsymbol{A}_i}$为稀疏向量,表现为向量${\boldsymbol{A}_i}$中取值为0的元素占比较大,取值为1的元素占比较小。可以构建用于识别稀疏向量${\boldsymbol{A}_i}$的压缩感知识别模型。
观察收集到的非连续的第${t_{\rm{1}}}{\rm{, }}{t_{\rm{2}}}{\rm{, }} \cdots {\rm{, }}{t_M}$轮博弈中各节点的策略和收益信息,稀疏向量${\boldsymbol{A}_i}$则可以通过求解以下凸优化问题获得[30-31]:
$$\begin{array}{*{20}{l}} {\min {{\left\| {{\mathit{\boldsymbol{A}}_i}} \right\|}_1}}\\ {{\rm{ s}}{\rm{.t}}{\rm{. }}{\mathit{\boldsymbol{G}}_i} = {\mathit{\boldsymbol{ \boldsymbol{\varPhi}}}_i} \cdot {\mathit{\boldsymbol{A}}_i}} \end{array} $$ (4) 式中,${\left\| {{\boldsymbol{A}_i}} \right\|_1} = \sum\limits_{j = {\rm{1}}}^N {\left| {{a_{ij}}} \right|} $是${\boldsymbol{A}_i}$的${L_1}$范数。${\boldsymbol{G}_i} = {{\rm{(}}{G_i}{\rm{(}}{t_{\rm{1}}}{\rm{), }}{G_i}{\rm{(}}{t_{\rm{2}}}{\rm{), }} \cdots {\rm{, }}{G_i}{\rm{(}}{t_M}{\rm{))}}^T}$是已知的节点$i$的动态收益信息。${\mathit{\boldsymbol{ \boldsymbol{\varPhi}}}_i}$是一个$M \times N$的矩阵,描述了节点$i$的收益和策略之间的关系,其中$M < < N$。这里的转换矩阵${\mathit{\boldsymbol{ \boldsymbol{\varPhi}}}_i}$可以记作:
$$\left( {\begin{array}{*{20}{c}} {{F_{i{\rm{1}}}}{\rm{(}}{t_{\rm{1}}}{\rm{)}}}& \cdots &{{F_{i, i - {\rm{1}}}}{\rm{(}}{t_{\rm{1}}}{\rm{)}}}&{{F_{i, i + {\rm{1}}}}{\rm{(}}{t_{\rm{1}}}{\rm{)}}}& \cdots &{{F_{i, N}}{\rm{(}}{t_{\rm{1}}}{\rm{)}}} \\ {{F_{i{\rm{1}}}}{\rm{(}}{t_{\rm{2}}}{\rm{)}}}& \cdots &{{F_{i, i - {\rm{1}}}}{\rm{(}}{t_{\rm{2}}}{\rm{)}}}&{{F_{i, i + {\rm{1}}}}{\rm{(}}{t_{\rm{2}}}{\rm{)}}}& \cdots &{{F_{i, N}}{\rm{(}}{t_{\rm{2}}}{\rm{)}}} \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ {{F_{i{\rm{1}}}}{\rm{(}}{t_M}{\rm{)}}}& \cdots &{{F_{i, i - {\rm{1}}}}{\rm{(}}{t_M}{\rm{)}}}&{{F_{i, i + {\rm{1}}}}{\rm{(}}{t_M}{\rm{)}}}& \cdots &{{F_{i, N}}{\rm{(}}{t_M}{\rm{)}}} \end{array}} \right)$$ 由于网络中不允许有自环,所以${\mathit{\boldsymbol{ \boldsymbol{\varPhi}}}_i}$中不包含${F_{ii}}{\rm{(}}t{\rm{)}}$。转换矩阵${\mathit{\boldsymbol{ \boldsymbol{\varPhi}}}_i}$的每项元素均可通过式(2)计算得到。在对凸优化问题求解后,便可得到节点$i$的邻接关系向量${\boldsymbol{A}_i}$,再依次求解得到其他各节点的邻接关系向量。最后我们将各节点的邻接关系向量组合,便可得到整个网络的邻接关系$\boldsymbol{A}$,且$\boldsymbol{A} = {\rm{(}}{\boldsymbol{A}_{\rm{1}}}{\rm{, }}{\boldsymbol{A}_{\rm{2}}}{\rm{, }} \cdots {\rm{, }}{\boldsymbol{A}_N}{\rm{)}}$。
-
为考察网络的集聚系数对识别节点间邻接关系的影响,本文对11个人工网络进行了网络重构的实验。这11个网络拥有如下相同的结构属性:节点数$N$=100,边数$E$=294,平均同配系数$\langle r\rangle $=-0.131,平均度$\langle k = {\rm{5}}{\rm{.880 0}}\rangle $。而11个网络的平均集聚系数$\langle C\rangle $依次为0.1, 0.15, …, 0.6。
分析方法使用等量的已知有限信息进行网络重构实验,并定义了信息充分性比例$\eta = D/N$表达已知信息的充分程度。其中,$D$为已知信息的数量。节点数$N$作为信息量充足的标准。当$\eta $=1时,信息量是充分的,当0 < $\eta $ < 1时,则不充分。
-
邻接关系识别准确率SR是衡量网络重构效果的重要指标[13, 17],定义为:
$${\rm{SR}} = \frac{1}{N}\sum\limits_{i = 1}^N {\frac{{\left| {{\mathit{\boldsymbol{ \boldsymbol{\varGamma}}}_{io}} \cap {\mathit{\boldsymbol{ \boldsymbol{\varGamma}}}_{ir}}} \right|}}{{\left| {{\mathit{\boldsymbol{ \boldsymbol{\varGamma}}}_{io}}} \right|}}} $$ (5) 式中,${\mathit{\boldsymbol{ \boldsymbol{\varGamma}}}_{io}}$和${\mathit{\boldsymbol{ \boldsymbol{\varGamma}}}_{ir}}$分别代表网络中节点$i$的实际邻点集合和由压缩感知识别模型识别出的节点$i$的邻点集合,且$\left| {\; \cdot \;} \right|$表示集合$\; \cdot \;$中元素的个数。识别准确率${\rm{SR}}\;{\rm{(0}} \leqslant {\rm{SR}} \leqslant {\rm{1)}}$越高,说明网络重构效果越好。
分析方法用真实关系召回率${R^{\rm{T}}}$[21-22]对固定数量的$L$对邻接关系作判断,考察压缩感知识别模型的识别命中率。具体形式如下:
$${R^{\rm{T}}}{\rm{(}}L{\rm{)}} = \frac{H}{{{\rm{2}}E}}$$ (6) 式中,${\rm{2}}E$是网络中描述邻接关系矩阵中非0元素的个数,在无向网络中计为边数的2倍。本文设定邻接关系数量$L$满足${\rm{2}}E < L < N{\rm{(}}N - {\rm{1)}}$,用以考察从可能存在虚假关系的关系列表中区分并识别出真实关系的情况。在不同邻接关系数量$L$的限制下,观察压缩感知识别模型得到的真实关系召回率的一致性。$H$是识别出的$L$对邻接关系中真实存在的邻接关系的数量。真实关系召回率${R^{\rm{T}}}$越大,说明邻接关系的识别命中率越高。平均识别准确率$\langle {\rm{SR}}\rangle $和平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $均是由压缩感知识别模型在50次独立运算中得到的平均后的结果。
在实验中,本文对11组网络的节点划分为4块局部网络。定义$X = \{ \langle {\rm{S}}{{\rm{R}}_{\rm{1}}}\rangle {\rm{, }}\langle {\rm{S}}{{\rm{R}}_{\rm{2}}}\rangle {\rm{, }} \cdots , \langle {\rm{S}}{{\rm{R}}_{{\rm{11}}}}\rangle \} $为11组网络的平均识别准确率的集合,$Y = \{ \langle {\rm{S}}{{\rm{R}}_{G{\rm{1}}}}\rangle , \langle {\rm{S}}{{\rm{R}}_{G{\rm{2}}}}\rangle , \cdots , \langle {\rm{S}}{{\rm{R}}_{G{\rm{11}}}}\rangle \} $为某局部网络的11组平均识别准确率的集合。由此,引入Pearson相关系数$\rho $[32],定义为:
$$\rho = \frac{{n\sum {\langle {\rm{S}}{{\rm{R}}_i}\rangle \cdot \langle {\rm{S}}{{\rm{R}}_{Gi}}\rangle } - (\sum {\langle {\rm{S}}{{\rm{R}}_i}\rangle } ) \cdot (\sum {\langle {\rm{S}}{{\rm{R}}_{Gi}}\rangle } )}}{{\sqrt {(n\sum {{{\langle {\rm{S}}{{\rm{R}}_i}\rangle }^{\rm{2}}} - {{(\sum {\langle {\rm{S}}{{\rm{R}}_i}\rangle } )}^{\rm{2}}}} ) \cdot (n\sum {{{\langle {\rm{S}}{{\rm{R}}_{Gi}}\rangle }^{\rm{2}}} - {{(\sum {\langle {\rm{S}}{{\rm{R}}_{Gi}}\rangle } )}^{\rm{2}}}} )} }}$$ (8) 式中,$n$=11,表示11组网络。Pearson相关系数$\rho $的取值介于-1~1之间,绝对值越大表明相关性越强。
-
基于上述11个人工网络数据,依据压缩感知识别模型对网络进行重构,计算得到平均识别准确率$\langle {\rm{SR}}\rangle $和平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $。为了体现压缩感知识别模型的可靠性和有效性,本文将文献[33-34]中基于自变量和其增量相关性的网络重构模型中自变量的增量替换为网络节点收益的增量,即应变量增量后,以新模型——基于自变量和应变量增量相关性的网络重构模型做了相同的重构实验。该模型通过构造逆矩阵,由可观测到的节点在每一轮博弈获得的收益增长量倒推出节点之间的邻接关系。
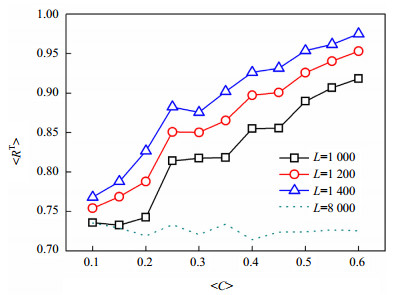
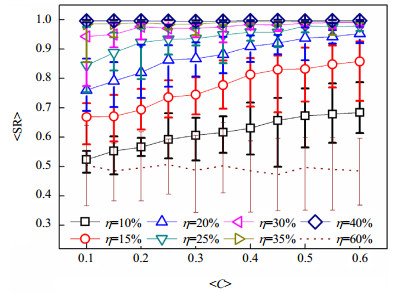
图 1给出了有限信息下节点邻接关系的平均识别准确率$\langle {\rm{SR}}\rangle $随网络的平均集聚系数$\langle C\rangle $变化的趋势。图中带符号的实线描述的是压缩感知识别模型的实验结果,当信息充分性比例$\eta $≤30%时,平均识别准确率$\langle {\rm{SR}}\rangle $随平均集聚系数$\langle C\rangle $的增加而单调提高,且在平均集聚系数$\langle C\rangle $=0.6时取到最大值。如$\eta $=20%时,平均识别准确率$\langle {\rm{SR}}\rangle $在平均集聚系数$\langle C\rangle $由0.1增加到0.6后提高了25.33%。当30% < $\eta $ < 100%时,压缩感知识别模型得到更多信息,识别准确率显著提高。此时,无论平均集聚系数$\langle C\rangle $在0.1和0.6之间如何变化,平均识别准确率$\langle {\rm{SR}}\rangle $均十分贴近数值1。

图 1 网络邻接关系的平均识别准确率$\langle {\rm{SR}}\rangle $随不同集聚系数的网络的变化曲线
图中的虚线则刻画了基于自变量和应变量增量相关性的网络重构模型在获得了信息充分性比例$\eta $达到60%时的重构结果。当平均集聚系数$\langle C\rangle $由0.1增加到0.6时,平均识别准确率$\langle {\rm{SR}}\rangle $曲线在0.472 7和0.506 7之间轻微波动,相对压缩感知识别模型的$\langle {\rm{SR}}\rangle $曲线而言,基于自变量和应变量增量相关性的网络重构模型得到的重构准确率较低。重构准确率较低的原因在于该模型因信息量不足,难以构造刻画节点策略与节点收益间关联关系的确切逆矩阵。同样地,在平均识别准确率$\langle {\rm{SR}}\rangle $较低的情况下,基于自变量和应变量增量相关性的网络重构模型也难以描述平均识别准确率$\langle {\rm{SR}}\rangle $随网络平均集聚系数$\langle C\rangle $变化的规律。
当信息充分性比例$\eta $=20%时,深入考察由压缩感知识别模型在不同的邻接关系数量$L$下得到的邻接关系召回率。图 2展示了平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $随平均集聚系数$\langle C\rangle $增加的变化曲线。图中带符号的实线描述的是压缩感知识别模型的实验结果,当邻接关系数量$L$=1 000时,如图 2所示,平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $的曲线随平均集聚系数$\langle C\rangle $的增加而呈现阶梯状提升,且在平均集聚系数$\langle C\rangle $=0.6时升到最大值。在图中,对应相邻平均集聚系数$\langle C\rangle $的平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $出现了取值较接近的现象。其原因在于平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $仅体现了$L$对可能存在的邻接关系的判定结果,并未反映$N{\rm{(}}N - {\rm{1)}}$对可能存在的邻接关系的总体判定结果。随着邻接关系数量$L$逐渐增加,平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $中包含了更多邻接关系的判定信息。当邻接关系数量$L$=1 400时,平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $随平均集聚系数$\langle C\rangle $的增大而单调提升的特征更加显著。此时,压缩感知识别模型得到的真实关召回率$\langle {R^{\rm{T}}}\rangle $随平均集聚系数$\langle C\rangle $由0.1增加到0.6而提高了26.93%。

图 2 网络平均真实邻接关系召回率$\langle {R^{\rm{T}}}\rangle $随不同集聚系数的网络的变化曲线
图中的虚线则刻画了当信息充分性比例$\eta $达到60%,且邻接关系数量$L$=8 000时,基于自变量和应变量增量相关性的网络重构模型所得到的平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $。当平均集聚系数$\langle C\rangle $由0.1增加到0.6时,平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $曲线在0.714 4和0.735 4之间轻微波动。相对压缩感知识别模型的$\langle {R^{\rm{T}}}\rangle $曲线而言,基于自变量和应变量增量相关性的网络重构模型得到的平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $也因信息量不足而取值较小,且没有呈现随平均集聚系数$\langle C\rangle $的增大而逐渐增大的变化规律。
-
为探究集聚系数变化对网络重构产生影响的本质原因,本文将11个人工网络进行划分,并结合2.3节中压缩感知识别模型的实验数据做深入分析。具体的做法是将网络节点按度由小到大排列,依次按节点总数的1/2、1/4、1/8和1/8提取节点,形成4组局部网络。其中,列表中排序为88的节点同时属于第3和4组,将该节点的各项指标的一半用于各组统计计算。
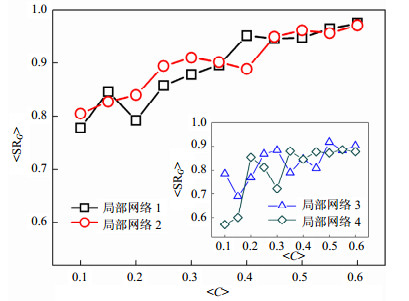
表 1为4组局部网络的结构属性。其中,${N_G}$、$\langle {E_G}\rangle $和$\langle {k_G}\rangle $分别是局部网络的节点数、平均总边数和平均度。依据2.3节中信息充分性比例$\eta $=20%时得到的各节点平均邻接关系识别准确率,计算4个局部网络的平均邻接关系识别准确率$\langle {\rm{S}}{{\rm{R}}_G}\rangle $并加以分析。图 3展示了4个局部网络的平均识别准确率$\langle {\rm{S}}{{\rm{R}}_G}\rangle $随平均集聚系数$\langle C\rangle $增大而变化的趋势。其中,局部网络1和2的平均识别准确率$\langle {\rm{S}}{{\rm{R}}_G}\rangle $呈现出随平均集聚系数$\langle C\rangle $的增加近似单调提高的趋势,几乎与图 1的平均识别准确率$\langle {\rm{SR}}\rangle $的总体趋势相一致。经计算,局部网络1、局部网络2与网络在平均识别准确率上的Pearson相关系数$\rho $的取值接近于1,分别为0.949 0和0.963 6。这说明这2个局部网络与网络本身的平均识别准确率的相关性较高。在图 3的子图中,局部网络3和4的平均识别准确率$\langle {\rm{S}}{{\rm{R}}_G}\rangle $虽然也有随平均集聚系数$\langle C\rangle $的增加而渐趋提高的趋势,但同时伴有显著的波动。此时,局部网络3、局部网络4则与网络在平均识别准确率上的Pearson相关系数$\rho $分别为0.749 8和0.839 9,相关性相对较低。平均识别准确率$\langle {\rm{S}}{{\rm{R}}_G}\rangle $的曲线随平均集聚系数$\langle C\rangle $的增大而波动的原因在于局部网络3和4中的节点度$k$≥8,其邻接关系变得稠密,而压缩感知识别模型的识别能力恰与节点的稠密度成反比。在此条件下,压缩感知识别模型的识别能力则变得不稳定,故在识别准确率的曲线上难以体现单调性。
表 1 局部网络的结构属性
网络 ${N_G}$ $\langle {E_G}\rangle $ $\langle {k_G}\rangle $ 局部网络1 50 162 6.48 局部网络2 25 123.6 9.90 局部网络3 12.5 97.8 15.65 局部网络4 12.5 204.6 32.74 
图 3 4个局部网络邻接关系的平均识别准确率$\langle {\rm{S}}{{\rm{R}}_G}\rangle $随不同集聚系数网络的变化曲线
同时,注意到表 1中局部网络1和2的节点总数占全部节点的75%,这些节点均为度小于8的节点。这意味着,局部网络1和2的节点邻接关系识别准确率是影响网络重构的关键因素,并在很大程度上决定了网络邻接关系的识别准确率。
-
本文构建了有限信息下基于网络单一结构属性的网络结构重构分析方法,并由网络的局部结构属性入手,分析了集聚系数对网络重构的独立影响。分析方法通过HK模型生成了平均集聚系数由0.1至0.6变化的11个人工网络。同时,HK模型将人工网络的稀疏性和同配系数加以固定。基于分析方法,本文设计了压缩感知识别模型,并运用模型对人工网络进行了有限信息下的重构实验。实验结果表明,若采集到的时间序列信息的充分性比例$\eta $≤30%,网络的平均识别准确率$\langle {\rm{SR}}\rangle $随平均集聚系数$\langle C\rangle $的增加而单调提高。同时,在平均集聚系数$\langle C\rangle $取0.6时,平均识别准确率$\langle {\rm{SR}}\rangle $取得最大值。当仅能掌握20%的网络节点间交互的时间序列信息时,网络的邻接关系平均识别准确率随网络平均集聚系数由0.1增至0.6后提高了25.33%。若信息充分性比例$\eta $ > 30%时,平均识别准确率$\langle {\rm{SR}}\rangle $接近于1,此时节点间邻接关系能得到准确识别。若分析方法将识别结果限制在$L$对邻接关系中,其得到的真实关系召回率$\langle {R^{\rm{T}}}\rangle $也随平均集聚系数$\langle C\rangle $的增加而提高。同时,在平均集聚系数$\langle C\rangle $取0.6时,平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $取得最大值。若掌握了20%的网络节点间交互的时间序列信息,分析方法根据识别出的1400对关系计算召回率,发现真实关系召回率$\langle {R^{\rm{T}}}\rangle $随网络平均集聚系数$\langle C\rangle $由0.1增至0.6后提高了26.93%。本文用基于自变量和应变量增量相关性的网络重构模型做了相同的实验,发现尽管获得更多信息量,基于自变量和应变量增量相关性的网络重构模型反而得到了质量较低的平均识别准确率$\langle {\rm{SR}}\rangle $和平均真实关系召回率$\langle {R^{\rm{T}}}\rangle $。对压缩感知识别模型得到的实验结果做了进一步分析,发现网络中度小于8的节点(节点数占全部节点的75%)其邻接关系识别准确率随集聚系数的变化规律与网络本身的识别准确率较为一致,密切相关。
尽管本文发现了不同集聚性的网络对网络关系识别存在影响,但对完全掌握和了解其中客观存在的规律仍有不足。1)在基于网络单一结构属性的网络结构重构分析方法中,虽然本文同时考察了网络的稀疏性、平均同配系数$\langle r\rangle $和平均集聚系数$\langle C\rangle $的相互影响,但还有其他的结构属性未能同时考察。本文未能构造一个普适的多项结构属性的分析方法。2)在运用压缩感知识别模型时,本文对网络中的稀疏关系的准确、高效的识别模型难以推广到对稠密关系的识别上。稠密关系和稠密关系网络的识别仍是一个挑战。3)本文因在生成网络时,受到稀疏性和平均同配系数等结构属性的限制,未能运用压缩感知识别模型对平均集聚系数$\langle C\rangle $ > 0.6的网络做进一步的重构分析。根据初步推测,若网络的节点数、稀疏性和平均同配系数保持不变时,平均集聚系数$\langle C\rangle $由0.6开始持续增加,网络中三角形的数量随之增加。在网络总边数不变的情况下,三角形个数的增加应会使大部分稠密节点的边转移到其他非稠密节点的邻接关系中,压缩感知识别模型应能随平均集聚系数的增加而获得更加准确的重构结果。网络的平均识别准确率和平均真实关系召回率均在网络平均集聚系数取最大值时达到最佳的重构效果。但目前缺乏实验数据的支撑,有待进一步研究分析。尽管如此,本文由网络的集聚系数入手,分析了有限信息下集聚系数对网络邻接关系识别的影响,丰富了我们对网络结构属性对网络关系识别效果影响的认识。
The Identification of Networks' Adjacent Connective Relationships Based on Limited Information
-
摘要: 如何根据有限的网络交互信息确定网络结构是当前网络科学研究的重要问题之一。该文提出了基于网络单一结构属性的网络结构重构分析方法。首先,该方法通过Holme-Kim模型生成一系列集聚系数可调的人工网络。然后,该方法通过压缩感知识别模型对有限信息下的网络结构进行重构。实验结果表明,当仅能掌握20%的网络节点间交互的时间序列信息时,网络邻接关系的平均识别准确率和平均真实关系召回率均随网络平均集聚系数的增大而提高。当网络的平均集聚系数在0.1~0.6变化时,平均集聚系数为0.6的网络将获得最高的平均识别准确率和平均真实关系召回率。进一步的实验分析说明,网络中度小于8的节点其平均识别准确率是决定网络平均识别准确率的关键。
-
关键词:
- 集聚系数 /
- Holme-Kim模型 /
- 有限信息 /
- 网络重构
Abstract: To uncover the networks' structure according to limited interactional information is one of the significant problems in the field of network science. We develop a method for reconstructing and analyzing the networks' structure based on single structure attribute of network. First, a series of synthetic networks with tunable clustering coefficient are generated under Holme-Kim model. Then, the networks' structure is reconstructed by virtue of a compressive-sensing identification model with limited information. Experimental results demonstrate that when we have 20% time-series information of interactions between nodes in the networks, both the average identification accuracy and the average recall of existent links of the whole networks would be increased with the increment of the average clustering coefficient. In this paper, the average clustering coefficient of the target networks is varying from 0.1 to 0.6. The average identification accuracy and the average recall of existent links would reach the optimum value when the network's average clustering coefficient is 0.6. Further, we make a deeper investigation into the experimental data. We find that the average identification accuracy of the networks largely depends on that of the corresponding nodes, whose degree is less than 8 in networks.-
Key words:
- clustering coefficient /
- Holme-Kim model /
- limited information /
- networks reconstruction
-
表 1 局部网络的结构属性
网络 ${N_G}$ $\langle {E_G}\rangle $ $\langle {k_G}\rangle $ 局部网络1 50 162 6.48 局部网络2 25 123.6 9.90 局部网络3 12.5 97.8 15.65 局部网络4 12.5 204.6 32.74  下载: 导出CSV
下载: 导出CSV
-
[1] GARDNER T S, DI BERNARDO D, LORENZ D, et al. Inferring genetic networks and identifying compound mode of action via expression profiling[J]. Science, 2003, 301(5629):102-105. doi: 10.1126/science.1081900 [2] HU Z L, HAN X, LAI Y C, et al. Optimal localization of diffusion sources in complex networks[J]. Royal Society Open Science, 2017, 4(4):170091. doi: 10.1098/rsos.170091 [3] DING C, LI K. Estimating multilateral trade behaviors on the world trade web with limited information[J]. Neurocomputing, 2016, 210:66-80. doi: 10.1016/j.neucom.2015.11.127 [4] LEE W P, TZOU W S. Computational methods for discovering gene networks from expression data[J]. Briefings in Bioinformatics, 2009, 10(4):408-423. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=HighWire000001861793 [5] HECKER M, LAMBECK S, TOEPFER S, et al. Gene regulatory network inference:Data integration in dynamic models:A review[J]. Biosystems, 2009, 96(1):86-103. doi: 10.1016/j.biosystems.2008.12.004 [6] KE Q, AHN Y Y. Tie Strength distribution in scientific collaboration networks[J]. Physical Review E, 2014, 90(3):032804. doi: 10.1103/PhysRevE.90.032804 [7] CIMINI G, SQUARTINI T, GARLASCHELLI D, et al. Systemic risk analysis on reconstructed economic and financial networks[J]. Scientific Reports, 2015, 5:15758. doi: 10.1038/srep15758 [8] MUSMECI N, BATTISTON S, CALDARELLI G, et al. Bootstrapping topological properties and systemic risk of complex networks using the fitness model[J]. Journal of Statistical Physics, 2013, 151(3-4):720-734. doi: 10.1007/s10955-013-0720-1 [9] WANG W X, LAI Y C, GREBOGI C. Data based identification and prediction of nonlinear and complex dynamical systems[J]. Physics Reports, 2016, 644:1-76. doi: 10.1016/j.physrep.2016.06.004 [10] XU M, XU C Y, WANG H, et al. Global and partitioned reconstructions of undirected complex networks[J]. The European Physical Journal B, 2016, 89(3):55. doi: 10.1140/epjb/e2016-60956-2 [11] CHING E S C, TAM H C. Reconstructing links in directed networks from noisy dynamics[J]. Physical Review E, 2017, 95(1):010301. doi: 10.1103/PhysRevE.95.010301 [12] NAPOLETANI D, SAUER T D. Reconstructing the topology of sparsely connected dynamical networks[J]. Physical Review E, 2008, 77(2):026103. http://cn.bing.com/academic/profile?id=31637e57d26d72e2a672bbf9f0a71d52&encoded=0&v=paper_preview&mkt=zh-cn [13] WANG W X, LAI Y C, GREBOGI C, et al. Network reconstruction based on evolutionary-game data via compressive sensing[J]. Physical Review X, 2011, 1(2):021021. doi: 10.1103/PhysRevX.1.021021 [14] SHEN Z, WANG W X, FAN Y, et al. Reconstructing propagation networks with natural diversity and identifying hidden sources[J]. Nature Communications, 2014, 5:4323. doi: 10.1038/ncomms5323 [15] HAN X, SHEN Z, WANG W X, et al. Reconstructing direct and indirect interactions in networked public goods game[J]. Scientific Reports, 2016, 6:30241. doi: 10.1038/srep30241 [16] MA L, HAN X, SHEN Z, et al. Efficient reconstruction of heterogeneous networks from time series via compressed sensing[J]. PLoS ONE, 2015, 10(11):e0142837. doi: 10.1371/journal.pone.0142837 [17] GUO Q, LIANG G, FU J Q, et al. Roles of mixing patterns in the network reconstruction[J]. Physical Review E, 2016, 94(5):052303. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=bfe62ddf4ea8fc434e10a6859c327d45 [18] RAVASZ E, BARABÁSI A L. Hierarchical organization in complex networks[J]. Physical Review E, 2003, 67(2):026112. doi: 10.1103/PhysRevE.67.026112 [19] HOLME P, KIM B J. Growing scale-free networks with tunable clustering[J]. Physical Review E, 2002, 65(2):026107. doi: 10.1103/PhysRevE.65.026107 [20] BARRANCA V J, ZHOU D, CAI D. Compressive sensing reconstruction of feed-forward connectivity in pulse-coupled nonlinear networks[J]. Physical Review E, 2016, 93(6):060201. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=5f957df601dffed1d725941ff80f2aa5 [21] ZHOU T, REN J, MEDO M, et al. Bipartite network projection and personal recommendation[J]. Physical Review E, 2007, 76(4):046115. doi: 10.1103/PhysRevE.76.046115 [22] LIU J G, SHI K, GUO Q. Solving the accuracy-diversity dilemma via directed random walks[J]. Physical Review E, 2012, 85(1):016118. doi: 10.1103/PhysRevE.85.016118 [23] NOWAK M A, MAY R M. Evolutionary games and spatial chaos[J]. Nature, 1992, 359(6398):826-829. doi: 10.1038/359826a0 [24] RONG Z, YANG H X, WANG W X. Feedback reciprocity mechanism promotes the cooperation of highly clustered scale-free networks[J]. Physical Review E, 2010, 82(4):047101. doi: 10.1103/PhysRevE.82.047101 [25] LI X, WU Y, RONG Z, et al. The prisoner's dilemma in structured scale-free networks[J]. Journal of Physics A:Mathematical and Theoretical, 2009, 42(24):245002. doi: 10.1088/1751-8113/42/24/245002 [26] SZABÓ G, TŐKE C. Evolutionary prisoner's dilemma game on a square lattice[J]. Physical Review E, 1998, 58(1):69-73. doi: 10.1103/PhysRevE.58.69 [27] WU K, LIU J, WANG S. Reconstructing networks from profit sequences in evolutionary games via a multiobjective optimization approach with Lasso initialization[J]. Scientific Reports, 2016, 6:37771. doi: 10.1038/srep37771 [28] WANG W X, YANG R, LAI Y C, et al. Time-series-based prediction of complex oscillator networks via compressive sensing[J]. Europhysics Letters, 2011, 94(4):48006. doi: 10.1209/0295-5075/94/48006 [29] HAN X, SHEN Z, WANG W X, et al. Robust reconstruction of complex networks from sparse data[J]. Physical Review Letters, 2015, 114(2):028701. doi: 10.1103/PhysRevLett.114.028701 [30] CANDÈS E J, ROMBERG J, TAO T. Robust Uncertainty principles:Exact signal reconstruction from highly incomplete frequency information[J]. IEEE Transactions on Information Theory, 2006, 52(2):489-509. doi: 10.1109/TIT.2005.862083 [31] CANDÈS E J, WAKIN M B. An introduction to compressive sampling[J]. IEEE Signal Processing Magazine, 2008, 25(2):21-30. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=f038caf0ee508db10a5b5fd193679bc2 [32] PEARSON K. Notes on regression and inheritance in the case of two parents[J]. Proceedings of the Royal Society of London, 1895, 58:240-242. doi: 10.1098/rspl.1895.0041 [33] LEVNAJIĆ Z. Derivative-variable correlation reveals the structure of dynamical networks[J]. The European Physical Journal B, 2013, 86(7):298. doi: 10.1140/epjb/e2013-30986-5 [34] LEVNAJIĆ Z, PIKOVSKY A. Untangling complex dynamical systems via derivative-variable correlations[J]. Scientific Reports, 2014, 4:5030. http://cn.bing.com/academic/profile?id=2fe7006eede10f74b6fa2dddfa83cf52&encoded=0&v=paper_preview&mkt=zh-cn -

 点击查看大图
点击查看大图
图(3) / 表(1)
计量
- 文章访问数: 4062
- HTML全文浏览量: 1247
- PDF下载量: 138
- 被引次数: 0
