 ISSN
ISSN 





-
基于数据驱动的预测方法已经在各行各业得到普遍应用,虽然它们可以很好地利用时间序列上的历史变化趋势[1-6],但是却很容易忽略突发、意外情况的发生所带来的极端影响。而且,在故障诊断和预测领域,简单的数据驱动预测方法通常只能参考历史故障数据,无法加入机器当前的可靠性状态。所以,为了整合历史数据和当前状态,提高预测的精度,本文提出了一种新的综合预测数学模型。
以往很多学者都贡献了非常优秀的数据驱动的方法[7-9],如基于模糊神经系统的算法模型、基于隐马尔科夫模型(HMM)的预测器和贝叶斯网络等,这些基于历史退化趋势的预测方法,都在一定程度上取得了非常好的预测效果,因此也备受关注和赞誉。
但是这些方法的缺点也很明显,首先它们都应用于有规律的性能退化数据上,如退化趋势是平稳随机过程等。在实际的工程应用中,退化过程经常伴随着奇异点扰动,如一些间歇性的故障,或者人工操作导致数据中出现奇点信号,这些奇点扰动的情况会大大降低传统数据驱动预测方法的精确性,有的甚至会引起严重的预测偏差。这些情况会对产品的维护保证决策产生重大的负面影响,是目前可靠性预测领域中的一个棘手问题,亟需解决。
在之前的研究中[10-12],学者曾经使用小波算法检测奇点信号,并且利用小波分析的特点,对这些奇点数据进行去噪处理。根据数学定义,奇点信号可以用利普希茨指数来度量[13]。利普希茨指数可以描述一个信号的局部规律或平滑度,数学意义上,信号的奇点是信号的导数不连续或者信号本身存在的间断点。根据上述的数学定义,如何选择最合适的趋势逼近模型来表征含有奇点信号的退化趋势,是新型预测器的关键。文献[14]使用噪声辅助技术追踪和表征电路的退化趋势,但是卡尔曼滤波的方法迭代繁复,且欧氏距离的计算速度较慢,很难快速准确地描述数据趋势中的奇点扰动问题。因此,本文提出了一种基于三次非多项式样条函数模型的时间序列预测模型方法,将粒子群优化和加权隐马尔科夫模型结合,估计并且更新样条函数的相关参数,从而完成预测。根据样条函数的数学定义,本文方法不需要在预测过程中单独检测或者识别奇点数据,可以持续进行有效的后续趋势预测。
-
本文算法包含样条函数预测模块的加权隐马尔科夫模型(SWHM),应用粒子群优化(PSO)算法进行了针对性的优化。其中,预测模块的数学基础是基于二阶导数平滑的三次非多项式样条函数模型。
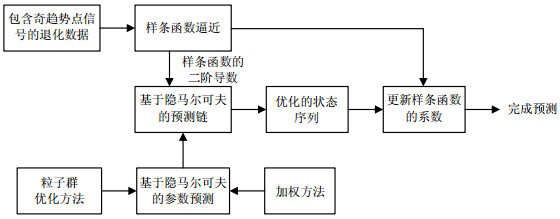
图 1为PSO-SWHM算法的预测模型及其预测过程。如图所示,奇点信号对退化数据的影响决定了趋势逼近模型的选择,基于粒子群优化的加权马尔科夫链预测器更新了样条函数的系数,从而完成预测的全部步骤。
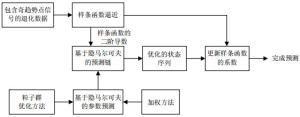
图 1 基于粒子群优化的加权马尔科夫(PSO-SWHM)预测模型
-
利普希茨指数通常描述函数的局部奇异性。如果一个函数在点${x_0}$处是不连续的或者它在点${x_0}$处的导数是不连续的,则函数在点${x_0}$处具有奇异性,此处的奇点信号用利普希茨指数进行数学定义上的描述[13]。根据这样的数学定义,如果信号在某一点处的n阶导数不连续,可能是两种情况:1)随机噪声,如高斯白噪声信号等;2)因为突发性情况或者人工操作带来的突变。这些都会突然改变信号的时域或者频域振幅,如脉冲信号或者阶跃信号等。
-
本文方法采用三角多项式样条函数,由于其无穷可微的三角函数部分可以弥补多项式有限平滑的不足,因此,与其他方法相比,可以得到更好的拟合结果。
对于$i = 0,1, \cdots ,n$间$(a,b)$离散化,使${x_i} = a + ih$,其中,${{x}_{0}}=a{{x}_{b}}=n=bh=(b-a)/n$,且$n$是正整数。然后对于每个子区间$[{{x}_{r-1}},{{x}_{r}}]r=1,2,\cdots ,n$,三次非多项式样条${s_r}(x)$为以下形式[15]:
$$\begin{array}{l} \;\;\;\;{s_r}(x) = {a_r}\cos (x - {x_{r - 1}}) + \\ {b_r}\sin (x - {x_{r - 1}}) + {c_r}(x - {x_{r - 1}}) + {d_r} \end{array}$$ (1) 式中,${a_r}$、${b_r}$、${c_r}$和${d_r}$是样条函数系数。使$w = \theta h$,可以从一系列的代数运算中得到式(1)的系数为:
$$ \left\{ {\begin{array}{*{20}{l}} {{a_r} = - {h^2}\frac{{{M_{r - 1}}}}{{{w^2}}}} \\ {{b_r} = - {h^2}\frac{{{M_r} - {M_{r - 1}}\cos w}}{{{w^2}\sin w}}} \\ {{c_r} = - h\frac{{{M_{r - 1}} - {M_r}}}{{{w^2}}} - \frac{{{y_{r - 1}} - {y_r}}}{h}} \\ {{d_r} = \frac{{{h^2}{M_{r - 1}}}}{{{w^2}}} + {y_{r - 1}}} \end{array}} \right. $$ (2) 式中,${y_r} = {s_r}({x_r})$是样条函数的一阶导数;${M_r} = s_r^{(2)}({x_r})$是函数的二阶导数,且${x_r}$是一个表示数据的正整数。因为$w = \theta h$,所以参数可以通过式(3)计算:
$$ \alpha = - \left( {\frac{1}{{{w^2}}} - \frac{1}{{w\sin w}}} \right),{\rm{ }}\beta = \frac{1}{{{w^2}}} - \frac{{\cos w}}{w},{\rm{ }}\alpha + \beta = 0.5 $$ (3) 利用一阶和二阶导数在点$({x_r},{y_r})$处的连续性,可以进一步得到以下关系[16-17]:
$$ \begin{gathered} {h^2}(\alpha {M_{r - 1}} + 2\beta {M_r} + \alpha {M_{r + 1}}) = {y_{r - 1}} - 2{y_r} + {y_{r + 1}} \\ r{\rm{ = 1,2,}} \cdots {\rm{,}}n - {\rm{1}} \\ \end{gathered} $$ (4) 由此可得:
$$ \begin{gathered} \alpha {M_{r - 1}} + 2\beta {M_r} + \alpha {M_{r + 1}} = \frac{{{y_{r - 1}} - 2{y_r} + {y_{r + 1}}}}{{{h^2}}} = \\ \frac{1}{h}\left( {\frac{{{y_{r + 1}} - {y_r}}}{h} - \frac{{{y_r} - {y_{r - 1}}}}{h}} \right) \\ \end{gathered} $$ (5) 让${d_r} = \frac{1}{h}\left( {\frac{{{y_{r + 1}} - {y_r}}}{h} - \frac{{{y_r} - {y_{r - 1}}}}{h}} \right)$,有:
$$ \alpha {M_{r - 1}} + 2\beta {M_r} + \alpha {M_{r + 1}} = {d_r}\quad \quad r{\rm{ = 1,2,}} \cdots {\rm{,}}n - {\rm{1}} $$ (6) 此外,边界条件是由下式决定:
$$ 2\beta {M_0} + \alpha {M_1} = \frac{6}{h}\left( {\frac{{{y_1} - {y_0}}}{h} - {{y'}_0}} \right) = {d_0} $$ (7) 式中,
$${y_0} = \frac{{ - {y_2} + 4{y_1} - 3{y_0}}}{{2h}}$$ 把式(6)和式(7)结合起来,可以写成矩阵形式:
$$ \left[ {\begin{array}{*{20}{c}} {2\beta }&\alpha &{}&{}&{} \\ \alpha &{2\beta }&\alpha &{}&{} \\ {}&{}& \cdots &{}&{} \\ {}&{}&\alpha &{2\beta }&\alpha \\ {}&{}&{}&\alpha &{2\beta } \end{array}} \right]\left[ {\begin{array}{*{20}{c}} {{M_0}} \\ {{M_1}} \\ \vdots \\ {{M_{n - 1}}} \\ {{M_n}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {{d_0}} \\ {{d_1}} \\ \vdots \\ {{d_{n - 1}}} \\ {{d_n}} \end{array}} \right] $$ (8) 利用式(2)解出的二阶导数向量M=(M0, M1, …, Mn)可以作为一个时间序列的向量框架,代入到PSO-SWHM整体模型中,这样就可以生成一个更新的向量$\mathit{\boldsymbol{M}}$和${s_r}(x)$。
-
针对时间序列的预测,本文提出了一种结合粒子群优化的加权马尔科夫(PSO-SWHM)模型。根据马尔科夫模型的基本描述,这个双内嵌的随机过程包含一个隐藏层和一个观测层。由马尔科夫链组成的隐藏层可以看作是一个有限状态机,其中S1是正常状态,S2是系统性能下降的中间状态,S3是故障状态。在观测层中,C1、C2和C3分别为每个状态的输出,可以作为单独的预测单元来进行时间序列预测。但是,对于超过4个状态的模型,其最大化初始值的选择变得非常敏感,难以确定最大的惩罚可能性。因此,通常的情况中,都只考虑3-状态模型。
图 2为了一个典型的3-状态的HMM模型,其中,pij表示从状态i到j的状态转换概率。
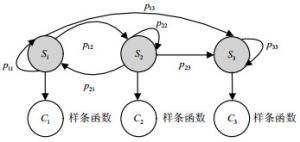
图 2 HMM模型的结构
让S={Si, i=1, 2, …, N}成为N-状态HMM的状态序列。在时间$t$处的模型状态由${q_t} \in S,0 \leqslant t \leqslant T$给出,其中,$T$是观测序列的长度,而${q_t}$则表示当前状态。
一个初始状态分布向量可以被定义为:
$${\pi _i} = \mathit{\boldsymbol{P}}({q_1} = {s_i})\quad \quad i = 1,2, \cdots ,N$$ 一种转移概率矩阵$\mathit{\boldsymbol{A}}{\rm{ = }}{\mathit{a}_{\mathit{ij}}}$,它表示在从一个$t$时刻状态${S_i}$转换到另一个$t + 1$状态${S_j}$的可能性。
${a_{ij}} = \mathit{\boldsymbol{P}}({q_{t + 1}} = {s_j}|{q_t} = {s_i})$,$(i,j = 1,2, \cdots ,N)$转移概率应该满足以下约束条件:
$$ {a_{ij}} \ge 0,\;\;1 \le i,j \le n,\sum\limits_{j = 1}^M {{a_{ij}}} = 1 $$ 而在HMM的观测状态序列中,观测状态生成的概率矩阵为$\mathit{\boldsymbol{B}} = \{ {b_j}({o_t})\} $,则有:
$$ {b_j}({o_t}) = \mathit{\boldsymbol{P}}({o_t}|{q_t} = {S_j}),1 \le j \le n,0 \le t \le T $$ (9) 式中,${b_j}({o_t})$是观测状态${o_t}$在t时刻的生成概率,通常为高斯混合模型。由此,可以通过观测状态序列来估计HMM模型参数$\lambda = (\mathit{\boldsymbol{A}},\mathit{\boldsymbol{B}},\mathit{\boldsymbol{\pi }})$,对于每一个退化的状态(k)来说,可以标记为:
$$ \lambda (k) = ({A^{(k)}},{B^{(k)}},{\pi ^{(k)}}) $$ 显然,一个包含隐藏层和观测层的完整的HMM模型能够很好地描述一个随机过程。利用矩阵A和概率分布向量B,可以很容易地得到马尔科夫链的输出序列。
另外,本文提出使用加权方法来预测马尔科夫链的状态[18],可以利用多步转移概率的加权概率分布,而不仅仅是单步的概率。这种进行加权优化的预测方法,可以使用每一阶的转移概率以及数据历史趋势的信息完成预测。
利用维特比(Viterbi)解码算法[19],状态序列可以通过一阶模型(最大阶数为K)重新建构,生成退化状态k的隐藏状态,其中退化状态k=(1, 2, 3, …, K)所对应的时间节点为时刻$t'$。然后将HMM的隐藏状态作为初始状态,利用多阶状态转移概率矩阵,可以给出在时间$t'$的状态概率分布为:
$$ \mathit{\boldsymbol{P}} = \left[ {\begin{array}{*{20}{c}} {p_1^{(1)}(t')}&{p_2^{(1)}(t')}& \cdots &{p_N^{(1)}(t')}\\ {p_1^{(2)}(t')}&{p_2^{(2)}(t')}& \cdots &{p_N^{(2)}(t')}\\ \vdots & \vdots & \ddots & \vdots \\ {p_1^{(K)}(t')}&{p_2^{(K)}(t')}& \cdots &{p_N^{(K)}(t')} \end{array}} \right] $$ (10) 结合同一个状态的加权概率分布,计算在任意的退化时刻$t'$的状态生成概率为:
$$ {p_i}(t') = \sum\limits_{k = 1}^K {{w_k}p_i^{(k)}(t')} {\rm{ }}\quad 1 \leqslant i \leqslant N $$ (11) 式中,${w_k} = \left| {{r_k}} \right|/\sum\limits_{k = 1}^K {\left| {{r_k}} \right|} $,$1 \leqslant k \leqslant K$是每一阶自相关系数的标准化权重,而k阶相关系数${r_k}$的定义为:
$$ {r_k} = \frac{{\sum\limits_{t = 1}^{T - k} {{{({\mathit{\boldsymbol{o}}_t} - \mathit{\boldsymbol{\bar o}})}^\prime }({\mathit{\boldsymbol{o}}_{t + k}} - \mathit{\boldsymbol{\bar o}})} }}{{\sqrt {\sum\limits_{t = 1}^{T - k} {[{{({\mathit{\boldsymbol{o}}_t} - \mathit{\boldsymbol{\bar o}})}^\prime }({\mathit{\boldsymbol{o}}_t} - \mathit{\boldsymbol{\bar o}})]} \sum\limits_{t = 1}^{T - k} {[{{({\mathit{\boldsymbol{o}}_{t + k}} - \mathit{\boldsymbol{\bar o}})}^\prime }({\mathit{\boldsymbol{o}}_{t + k}} - \mathit{\boldsymbol{\bar o}})]} } }} $$ (12) 可以得到一个非多项式样条函数的二阶导数的最大概率的输出,也就是在式(8)中的向量M。再利用M中二阶导数的最后两项,根据式(2),就可以利用更新的参数,重构最优的三次非多项式样条函数为:
$$ {s_p}(x) = {a_n}\cos (x - {x_n}) + {b_n}\sin (x - {x_n}) + {c_n}(x - {x_n}) + {d_n} $$ (13) 式中,${a_n}$、${b_n}$、${c_n}$和${d_n}$是重构后的三次非多项式样条函数的二阶导数的系数;${s_p}(x)$是最终的预测输出。
-
为了提高新模型的参数训练能力和模型计算精度,本文将粒子群优化(PSO)算法引入到SWHM模型中。粒子群优化是通过不断的迭代,从而改进质量度量标准来进行优化的模型[20]。它是通过模拟鸟群觅食行为而发展起来的一种基于群体协作的随机搜索算法,其基本思想是初始化一组随机粒子(随机解),不断地迭代得出最优解决方案,通过跟踪两个端点(pbest和gbest)来更新其速度,每次迭代过程为:
$$ \left\{ {\begin{array}{*{20}{l}} \begin{array}{l} {v_i} = w{v_i} + {c_1} \times {\rm{rand}}(\,)({\rm{pbes}}{{\rm{t}}_i} - {x_i}) + \\ {c_2} \times {\rm{rand}}(\,)({\rm{gbes}}{{\rm{t}}_i} - {x_i}) \end{array}\\ {{x_i} = {x_i} + {v_i}} \end{array}} \right.i = 1,2, \cdots ,D $$ (14) 式中,D是粒子群总数;w是惯性权重系数;${\rm{pbes}}{{\rm{t}}_i}$和${\rm{gbes}}{{\rm{t}}_i}$被定义为两个端点;${\rm{rand}}()$是在(0, 1)内的随机数;${v_i}$是粒子速度;${x_i}$是粒子位置;${c_1},{c_2}$是加速度常数,在(0, 2)之间随机设置。
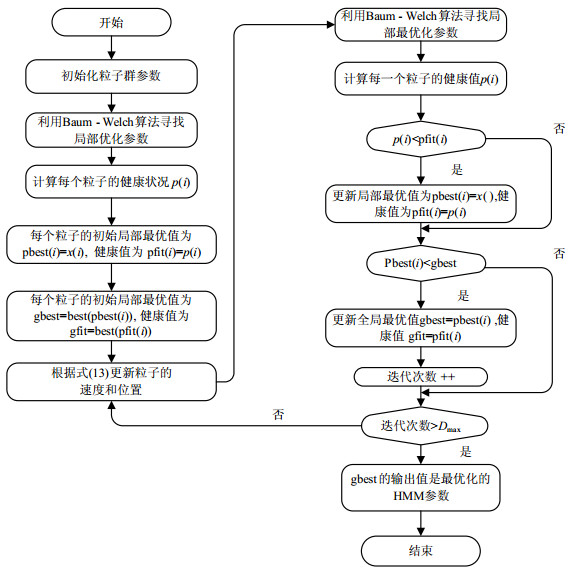
最初的Baum-Welch算法[19]很容易收敛于局部最优解的HMM参数训练,结合PSO算法的优势,以Baum-Welch算法(称为PSO-HMM算法)为极值函数寻找最优值。在PSO-HMM算法中,每个粒子都对应一个隐马尔科夫状态,而粒子在每次迭代计算后都会通过Baum-Welch算法进行局部优化。事实上,隐马尔科夫过程和整个优化的过程涉及3个参数,即初始状态分布向量$\mathit{\boldsymbol{\pi }}$,状态转换概率分布矩阵$\mathit{\boldsymbol{A}}$,以及观测状态分布概率$\mathit{\boldsymbol{B}}$。整个粒子群代表所有参与优化计算的参数集。由式(8)所得到的隐藏状态$N$和时间序列向量$\mathit{\boldsymbol{M}}$,则粒子的维数是$N \times N + $ $N \times n + N$。详细的算法描述如图 3所示。
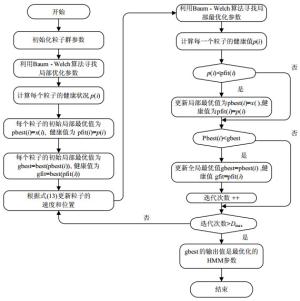
图 3 对HMM参数训练的PSO-HMM算法描述
-
通过使用Baum–Welch算法,可以得到退化状态k的HMM模型参数$\lambda (k) = ({A^{(k)}},{B^{(k)}},{\pi ^{(k)}})$。因此,预测算法的步骤可以描述如下:
1) 包含预测数据的信息被滑动窗模型划分为小的时间段,称为窗口。每个窗口的时间范围称为宽度,取决于时间序列数据系列的分布。滑动窗口方法(滑动步骤的大小相当于采样点的单位)将时间序列划分为不同的帧,然后计算每一帧中立方非多项式样条函数的二阶导数作为观测状态序列,有:
$$ \mathit{\boldsymbol{O}} = \{ {\mathit{\boldsymbol{o}}_i},i = 1,2, \cdots ,T\} ,\;{\mathit{\boldsymbol{o}}_i} = \{ {\varphi _{ir}},r = 1,2, \cdots ,R\} $$ (15) 2) 根据隐藏状态N、时间序列向量M和初始参数$\lambda (0) = ({A^{(0)}},{B^{(0)}},{\pi ^{(0)}})$,用k-均值聚类方法将一个观测状态序列分成N个部分,并以此将粒子分成n类,可以分别计算每个类的均值向量和协方差矩阵。
3) 为了执行参数估计,选择PSO-HMM训练算法,得到一个单阶预测模型${\lambda _1}$
4) 在一阶模型中重构状态序列,使用维特比解码算法,将预测时刻$t'$的第k个退化状态,标记为隐藏状态,并根据状态序列依次标记。
5) 根据上文设置的模型阶数K,可以重新组织观测状态序列O,形成每一阶的观测状态序列为:
$$ \begin{array}{*{20}{l}} {\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;{\mathit{\boldsymbol{O}}_{wk}} = \{ {\mathit{\boldsymbol{o}}_{(t - 1)k + i}}\} }\\ {1 \le k \le K,1 \le i \le k - 1,t \in \{ t|(t - 1)k + 1 \le T\} } \end{array} $$ (16) 利用一阶预测模型${\lambda _1}$,可以计算状态转移概率矩阵${\mathit{\boldsymbol{A}}^{(k)}}$,k =2, 3, …, K。
6) 计算观测状态序列的k阶相关系数${r_k}$及相应的权重${w_k}$,既可以得到时刻$t'$的预测概率矩阵${\mathit{\boldsymbol{P}}_i}^{(k)}(t')\;1 \le i \le N\;1 \le k \le K$。
7) 考虑到最大的加权概率,可以得到一个高斯混合模型,其最大概率输出值表示三次非多项式样条函数最可能的二阶导数向量。通过使用输出向量和式(1)及式(2),可以重建三次非多项式样条作为样条函数单元的最优预测器。
-
应用文献[22]开发的典型指数衰减信号模型,测试本文提出的方法。这个指数退化模型是一个随机过程,它捕获滚动轴承随时间变化的退化信号的演化过程。将退化趋势视作一个相对于时间t的连续随机过程,该模型的形式为:
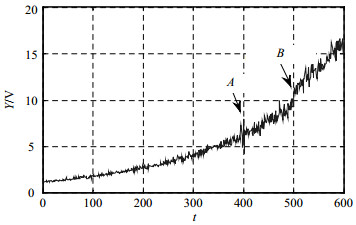
$$ Y(t) = \hat \varphi + \hat \theta \exp \left\{ {\hat \beta t + \hat \varepsilon (t) - \frac{{{\sigma ^2}}}{2}} \right\} $$ (17) 式中,$Y(t)$、$\hat \varphi $是常数确定性参数;$\hat \theta $是对数正态随机变量,其中$\ln (\hat \theta )$具有平均值${\mu _0}$和方差${\sigma _0}^2$;$\hat \beta $是正态随机变量,均值为${\mu _1}$,方差为${\sigma _1}^2$;$\hat \varepsilon (t)$是均值为0,方差为${\sigma ^2}$的正态分布随机误差项。设模型参数$\hat \varphi $=0.12,${\mu _0}$=0.05,${\sigma _0}^2$=2.5×10-7,${\mu _1}$=1.1,${\sigma _1}^2$=1×10-8,${\sigma ^2}$=1×10-6。因此,在退化模型的基础上,可以得到一组退化数据,其中前300个点作为训练数据,其余300个点作为测试数据,两个奇点设置在400点和500点,如图 4所示。在图 4中,点A是脉冲信号,通常由装置的退化过程中随机出现的一些突然故障引起,如,瞬时故障或间歇性故障;B点是一个阶跃信号,退化趋势由此发生突然变化。
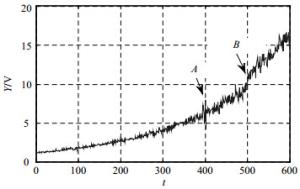
图 4 指数衰减信号模型的模拟数据
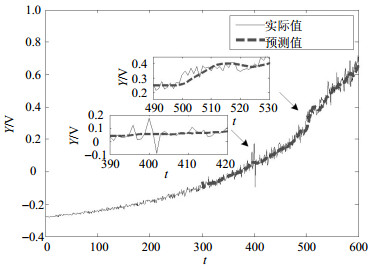
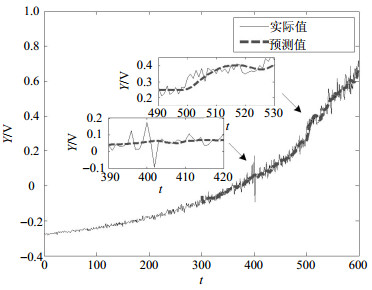
图 5~图 7分别为基于3种(本文方法、自回归(AR)、权重隐马尔科夫自回归(WHMAR))不同方法的预测结果。从这3个对比图可以清楚看到,3种方法在A点附近都有较好的预测效果,但在B点附近,本文的PSO-SWHM预测模型比其他两种方法更为有效,在奇点信号之后,可以继续有效跟踪实际曲线。为量化对比预测效果,3种方法的预测误差如表 1所示。通过对比,可以发现,PSO-SWHM模型预测的性能要优于AR和WHMAR模型。

图 5 基于AR模型的预测结果
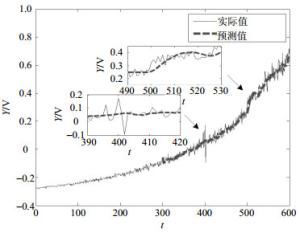
图 6 基于WHMAR模型的预测结果
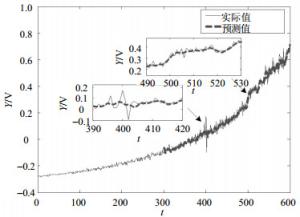
图 7 基于PSO-SWHM模型的预测结果
表 1 3种预测模型的预测精度比较
预测模型 误差 均方误差 归一化均方根误差 AR 0.992 526×10-3 1.368 742×10-1 WHMAR 1.340 769×10-3 1.590 844×10-1 PSO-SWHM 0.645 553×10-3 1.103 867×10-1 -
设计了一个实际电路对本文算法进行验证[23]。RF电路是一个典型的接收器通道模块,VPP是峰峰值电压,其范围为1 mV~10 V,带宽为DC~200 MHz,输出信号的VPP=500 mV。对于RF电路来说,信号增益是最敏感的性能参数,因此本文也采用信号增益作为电路性能退化分析的监控参数。

图 8 射频(RF)低噪声放大电路
在100 ℃的环境下,采集低噪声放大器在运行中的600个时刻,用于PSO-SWHM模型和其他预测模型的训练。实验历时2 313 h,分别在第350和第450点有两个奇点信号。
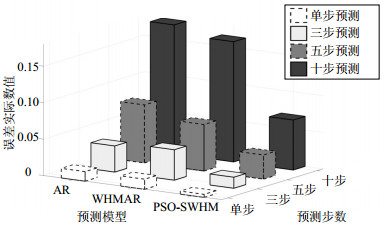
3种模型的比较结果也通过图 9的三维直方图进行了直观的展示,图 9中,Z轴表示误差的实际数值。为了量化分析3种模型的预测效果,将这些模型的预测误差进行对比,分别如表 2、表 3所示。
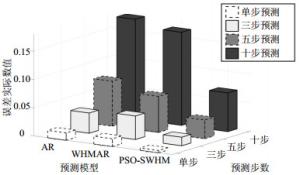
图 9 3种预测模型的三维直方图比较
表 2 3种预测模型的预测精度对比
效果对比(错误率) 单步预测/% 三步预测/% 五步预测/% 十步预测/% PSO-SWHM/AR 31.9 42.3 41.8 38.9 PSO-SWHM/WHMAR 29.4 36.3 51.9 41.7 从比较结果来看,虽然电路性能退化趋势中包含两个奇点,但是本文提出的方法预测依然更有效,且预测误差明显低于传统方法。
表 3 3种模型的预测精度比较
预测模型 对比标准 单步预测 三步预测 五步预测 十步预测 AR 归一化均方根误差 1.316 831×10-2 3.586 143×10-2 7.939 547×10-2 1.767 348×10-1 WHMAR 归一化均方根误差 1.391 301×10-2 4.178 134×10-2 6.390 001×10-2 1.648 012×10-1 PSO-SWHM 归一化均方根误差 4.193 574×10-3 1.512 051×10-2 3.314 618×10-2 6.866 327×10-2 -
间歇性故障或者其他操作所带来的奇异信号点扰动问题是产品可靠性领域的一个典型问题。在产品的退化趋势时间序列中,这种突发性的扰动会导致非平稳的随机退化过程,增加了预测的难度。为了解决这个问题,本文提出了新的综合预测方法。
该方法根据奇点信号的数学定义,采用三次非参数样条函数模型表征和跟踪退化趋势,并且结合加权方法与粒子群优化算法,对隐马尔科夫算法进行优化改进,这样就可以将三次非多项式样条函数向量的二阶导数作为隐马尔科夫过程中隐藏状态的观测值。然后,通过更新样条函数的最优系数,得到重构的最优化的样条函数。
本文方法的主要优点是模型无需对时间序列中的奇点信号进行提前检测或者进行去噪处理,这在无法快速或者有效识别奇点信号的情况下非常重要。在仿真和实验验证阶段,采用了滚动轴承的典型指数衰减信号模型,通过WHMAR模型和AR模型的量化对比,证明了本文方法具有更高的预测精度。同样的,在RF电路的实测实验中,本文方法也被证明是一种更有效的综合预测方法。综上所述,本文的综合预测方案对于包含奇点的性能退化趋势预测显示了很好的效果,可以广泛的适用于其他条件下的时间序列预测。
A Comprehensive Time Series Prediction Considering Singularity Perturbation Problems
-
摘要: 目前,对于各种工业产品可靠性或者剩余寿命的预测方法通常都基于历史退化数据,这些历史数据的趋势变化可以为产品最终的维修和保障决策提供理论依据。然而,退化数据中出现的奇点扰动问题经常导致预测的准确性严重下降,这是可靠性预测领域的一个巨大挑战。为解决这个问题,该文采用样条函数方法作为数据趋势逼近模型,针对退化趋势中存在的各种奇点扰动情况,三次非多项式样条模型的二阶导数可以形成观测状态序列。引入了一种改进的结合粒子群优化算法的加权隐马尔科夫方法来外推样条函数所生成的观测序列,计算所产生的参数将更新样条函数的参数,组成一套综合完整的优化预测器。仿真和实例实验均证明了该方法的有效性。Abstract: Current model for remaining useful life prognostic is usually based on the historical data, which can provide evidence for maintenance. However, singularity arising in the degradation data frequently give rise to a bad decline in prediction accuracy, this phenomenon is a great challenge for the time series prediction. To address this issue, we develop a new surrogate modeling prognostic approach based on cubic non-polynomial spline model in this paper. Meanwhile, due to the singularity perturbation in degradation tendency, the spline model's second derivative can be adopted and calculated to form a series of observation frames, and then a weighted hidden Markov model (HMM) method combined with particle swarm optimization (PSO) is used to forecast the observation sequence, then rebuild the spline function. A simulation example and a practical application involving typical singularities verified the effectiveness of the proposed method.
-
表 1 3种预测模型的预测精度比较
预测模型 误差 均方误差 归一化均方根误差 AR 0.992 526×10-3 1.368 742×10-1 WHMAR 1.340 769×10-3 1.590 844×10-1 PSO-SWHM 0.645 553×10-3 1.103 867×10-1  下载: 导出CSV
下载: 导出CSV
表 2 3种预测模型的预测精度对比
效果对比(错误率) 单步预测/% 三步预测/% 五步预测/% 十步预测/% PSO-SWHM/AR 31.9 42.3 41.8 38.9 PSO-SWHM/WHMAR 29.4 36.3 51.9 41.7
下载: 导出CSV
表 3 3种模型的预测精度比较
预测模型 对比标准 单步预测 三步预测 五步预测 十步预测 AR 归一化均方根误差 1.316 831×10-2 3.586 143×10-2 7.939 547×10-2 1.767 348×10-1 WHMAR 归一化均方根误差 1.391 301×10-2 4.178 134×10-2 6.390 001×10-2 1.648 012×10-1 PSO-SWHM 归一化均方根误差 4.193 574×10-3 1.512 051×10-2 3.314 618×10-2 6.866 327×10-2
下载: 导出CSV
-
[1] 陈世杰, 连可, 王厚军.遗传算法优化的SVM模拟电路故障诊断方法[J].电子科技大学学报, 2009, 38(4):553-558. doi: 10.3969/j.issn.1001-0548.2009.04.019 CHEN Shi-jie, LIAN Ke, WANG Hou-jun. Method for analog circuit fault diagnosis based on GA optimized SVM[J]. Journal of University of Electronic Science and Technology of China, 2009, 38(4):553-558. doi: 10.3969/j.issn.1001-0548.2009.04.019 [2] 黄建国, 罗航, 王厚军, 等.运用GA-BP神经网络研究时间序列的预测[J].电子科技大学学报, 2009, 38(5):687-692. doi: 10.3969/j.issn.1001-0548.2009.05.028 HUANG Jian-guo, LUO Hang, WANG Hou-jun, et al. Prediction of time sequence based on GA-BP neural net[J]. Journal of University of Electronic Science and Technology of China, 2009, 38(5):687-692. doi: 10.3969/j.issn.1001-0548.2009.05.028 [3] 宋国明, 王厚军, 姜书艳, 等.最小生成树SVM的模拟电路故障诊断方法[J].电子科技大学学报, 2012, 41(3):412-417. doi: 10.3969/j.issn.1001-0548.2012.03.018 SONG Guo-ming, WANG Hou-jun, JIANG Shu-yan, et al. Fault diagnosis approach for analog circuits using minimum spanning tree SVM[J]. Journal of University of Electronic Science and Technology of China, 2012, 41(3):412-417. doi: 10.3969/j.issn.1001-0548.2012.03.018 [4] 李旻, 咸卫明, 龙兵, 等.基于特征优选模拟电路故障诊断方法[J].电子科技大学学报, 2014, 43(4):557-561. doi: 10.3969/j.issn.1001-0548.2014.04.015 LI Min, XIAN Wei-ming, LONG Bing, et al. Method for fault diagnosis of analog circuits based on feature selection[J]. Journal of University of Electronic Science and Technology of China, 2014, 43(4):557-561. doi: 10.3969/j.issn.1001-0548.2014.04.015 [5] 高昕, 王厚军, 刘震.线性模拟电路软故障建模与诊断策略[J].电子科技大学学报, 2015, 44(3):397-402. doi: 10.3969/j.issn.1001-0548.2015.03.014 GAO Xin, WANG Hou-jun, LIU Zhen. A novel soft-fault modeling and diagnosis method in linear analog circuit[J]. Journal of University of Electronic Science and Technology of China, 2015, 44(3):397-402. doi: 10.3969/j.issn.1001-0548.2015.03.014 [6] 高媛, 杨成林.基于复模型的模拟电路故障诊断[J].电子科技大学学报, 2017, 46(4):540-546. doi: 10.3969/j.issn.1001-0548.2017.04.011 GAO Yuan, YANG Cheng-lin. Complex fault modeling based analog-circuit fault diagnosis[J]. Journal of University of Electronic Science and Technology of China, 2017, 46(4):540-546. doi: 10.3969/j.issn.1001-0548.2017.04.011 [7] 覃庆努, 魏学业, 吴小进, 等.负载均担并联系统模型及可靠性分析[J].电子科技大学学报, 2013, 42(2):311-315. http://www.juestc.uestc.edu.cn/CN/abstract/abstract578.shtml QIN Qing-nu, WEI Xue-ye, WU Xiao-jin, et al. Models and reliability analysis of load-sharing parallel systems[J]. Journal of University of Electronic Science and Technology of China, 2013, 42(2):311-315. http://www.juestc.uestc.edu.cn/CN/abstract/abstract578.shtml [8] 闫涛, 赵文俊, 胡秀洁, 等.基于信息融合技术的航空电子设备故障诊断研究[J].电子科技大学学报, 2015, 44(3):392-396. doi: 10.3969/j.issn.1001-0548.2015.03.013 YAN Tao, ZHAO Wen-jun, HU Xiu-jie, et al. Fault diagnosis of avionic devices based on information fusion technology[J]. Journal of University of Electronic Science and Technology of China, 2015, 44(3):392-396. doi: 10.3969/j.issn.1001-0548.2015.03.013 [9] 张西宁, 雷威, 李兵.主分量分析和隐马尔科夫模型结合的轴承监测诊断方法[J].西安交通大学学报, 2017, 51(6):1-7, 109. http://d.old.wanfangdata.com.cn/Periodical/xajtdxxb201706001 ZHANG Xi-ning, LEI Wei, LI Bing. Bearing fault detection and diagnosis method based on principal component analysis and hidden Markov model[J]. Journal of Xi'an Jiaotong University, 2017, 51(6):1-7, 109. http://d.old.wanfangdata.com.cn/Periodical/xajtdxxb201706001 [10] ZHAO M, FAN Y, QIU N. Multi-fractal local singularity research of power load time series[C]//Conference on Automation and Logistics, 2007 IEEE International.[S.l.]: IEEE, 2007: 1689-1693. [11] FENG J, DONG L, LIU J. Singularity detection method of chaotic time series using wavelet multi-resolution analysis[C]//Conference on Industrial and Information Systems (IIS), 20102nd International.[S.l.]: IEEE, 2010, 1: 83-86. [12] LIU J, FENG J, GUAN F. Research on RBF neural network method of singularity detection in chaotic time series[C]//20102nd International Conference on Signal Processing Systems (ICSPS).[S.l.]: IEEE, 2010, 2: V2-53-V2-58. [13] MALLAT S, HWANG W L. Singularity detection and processing with wavelets[J]. IEEE Transactions on Information Theory, 1992, 38(2):617-643. doi: 10.1109/18.119727 [14] YAN L, WANG H, LIU Z, et al. A novel noise-assisted prognostic method for linear analog circuits[J]. Journal of Electronic Testing, 2017, 33(5):559-572. doi: 10.1007/s10836-017-5688-3 [15] RASHIDINIA J, MAHMOODI Z. Non-polynomial spline solution of a singularly-perturbed boundary-value problems[J]. Int J Contemp Math Sciences, 2007, 2(32):1581-1586. http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_1206.2442 [16] KHAN A, NOOR M A, AZIZ T. Parametric quintic-spline approach to the solution of a system of fourth-order boundary-value problems[J]. Journal of Optimization Theory and Applications, 2004, 122(2):309-322. doi: 10.1023/B:JOTA.0000042523.83186.4c [17] SIDDIQI S S, AKRAM G. Solution of the system of fourth-order boundary value problems using non-polynomial spline technique[J]. Applied Mathematics and Computation, 2007, 185(1):128-135. doi: 10.1016/j.amc.2006.07.014 [18] XIA L T, ZHU Y S. The Application of weighted Markov chain to the prediction of plum rains intensity of down and middle streams of Yangtze river basin[J]. Journal of Management Science and Statistical Decision, 2004, 1(1):75-84. http://www.wanfangdata.com.cn/details/detail.do?_type=conference&id=WFHYXW72319 [19] RABINER L, JUANG B. An introduction to hidden Markov models[J]. IEEE Assp Magazine, 1986, 3(1):4-16. doi: 10.1109/MASSP.1986.1165342 [20] KENNEDY J. Particle swarm optimization[M]//Encyclopedia of Machine Learning.[S.l.]: Springer, 2011: 760-766. [21] AZIZ T, KHAN A. A spline method for second-order singularly perturbed boundary-value problems[J]. Journal of Computational and Applied Mathematics, 2002, 147(2):445-452. doi: 10.1016/S0377-0427(02)00479-X [22] GEBRAEEL N Z, LAWLEY M A, LI R, et al. Residual-life distributions from component degradation signals:a Bayesian approach[J]. IIE Transactions, 2005, 37(6):543-557. doi: 10.1080/07408170590929018 [23] LIU Z, ZENG X, CHENG Y, et al. Spline cell-based hidden Markov approach for singular time series forecasting in performance degradation trend analysis[C]//Instrumentation and Measurement Technology Conference.[S.l.]: IEEE, 2016: 1-6. -

 点击查看大图
点击查看大图
图(9) / 表(3)
计量
- 文章访问数: 4469
- HTML全文浏览量: 1292
- PDF下载量: 45
- 被引次数: 0
