 ISSN
ISSN 


 下载:
下载:





-
传统图像修复技术大致可分为基于结构的图像修复算法[1]和基于纹理的图像修复算法[2]。其中,基于结构的图像修复技术通过信息扩散原理对图像进行修复,相关算法包括高阶偏微分方程模型算法[3]、快速图像修复算法[4]、全变分模型[5]等,此类算法主要适用于小尺度区域的图像修复。基于纹理的修复算法通过仿真生成局部纹理信息进行填充修复,主要有基于图像分解的修复算法[6]和基于样块的纹理合成算法[7]两大类,该方法也只适合小区域的语义缺失块修复。随着互联网数据的海量扩增和计算机计算能力的高效提升,深度学习获得了极大的关注与发展,并广泛应用于图像分类[8]、图像检测识别[9]、图像定位[10]及图像语义分割[11]等领域。
基于深度学习的图像修复算法相较于传统的修复算法能够学习更稳定、更高层的特征。如文献[12]通过训练编码-解码器模型结构并结合对抗损失函数来预测图像的缺失区域,该模型能够得到合理的图像结构并能准确评价修复指标;文献[13]提出的深度生成模型,不仅学习合成图像的背景信息,更对图像缺失区域的语义信息进行了完善。
然而,目前存在的基于深度学习的人脸图像修复算法大多都停留在监督学习或半监督学习的基础上,对人脸图像修复来说还存在许多的限制性因素。如文献[12-13]提出的修复方法中,对于鼻子、眼睛等小部件的生成效果还存在与整体的不一致性。2014年文献[14]提出的生成对抗网络为无监督学习领域提供了新的思路,取得了开创性的进展。但是,生成对抗网络也依然存在许多弊端,如数据训练过程不稳定、图像生成效果自由不可控、训练过程易崩溃等问题。为解决以上问题,本文提出了基于一种无监督学习生成对抗网络的人脸图像修复算法,主要贡献包括:
1) 网络结构:采用从粗糙到精细的级联生成式模型和局部与全局相结合的双层判别式模型。并在网络结构中加入了密集块[15],加强了特征的传递,使训练过程更加稳定,生成图像更加逼近原始图像。
2) 损失函数:使用最小化重构损失和生成对抗网络损失相结合的损失函数。使得生成图像通过对抗过程不断优化完善,最终获得与原图相似的结果。
3) 评价指标:采用主观与客观相结合的评价方式。主观上设置4种缺失类型并对这4种缺失图像的修复结果进行视觉上的分析;客观上采用峰值信噪比和结构相似性图像评价指标进行对比分析。
-
深度学习的学习方式分为监督学习、半监督学习及无监督学习。监督学习和半监督学习方式都需要带标签的样本进行训练,获取标签数据的过程不仅成本高而且相当耗时。无监督学习方式则不需要大量的带标签数据,可直接对输入的无标签数据通过聚类等方式进行建模,并且无监督学习可以从每次的错误中进行学习,以免下次犯同样的错误。但无监督学习存在难以训练,训练结果不准确等问题。
生成对抗网络(generative adversarial network, GAN)为无监督学习领域带来了里程碑式的进展。GAN的结构设计启发于博弈论中的“二人零和博弈”问题[14],模型中的博弈双方分别为生成模型(generative model, G)和判别模型(discriminator model, D)。其中,生成模型用于捕获真实数据样本的潜在分布并生成新的样本,判别模型则是一个二分类器,用于判别该样本为真实图像或者生成器生成图像的概率。博弈的结果的理想情况为,生成模型可以生成能够以假乱真的图片,判别模型难以判别图像来源于生成数据还是真实数据。
GAN的目标函数为:
$$\begin{gathered} \mathop {\min }\limits_G \mathop {\max }\limits_D f(D, G){\rm{ = }}{{\rm{E}}_{{\mathit{\pmb{x}}} \sim {P_{{\rm{data}}}}(\mathit{\pmb{x}})}}[\log D(\mathit{\pmb{{\mathit{\pmb{x}}}}})] + \\ {{\rm{E}}_{{\mathit{\pmb{z}}} \sim {P_{\mathit{\pmb{z}}}}(\mathit{\pmb{x}})}}[\log (1 - D(G({\mathit{\pmb{z}}})))] \\ \end{gathered} $$ (1) 式中,x表示从真实数据分布${P_{{\rm{data}}}}(\mathit{\pmb{x}})$中的采样值;z为随机噪声向量,从先验分布${P_z}(\mathit{\pmb{x}})$中采样;E表示期望值。首先,给定生成器G,求解最优判别器D即最小化交叉熵过程,则判别器的损失函数为:
$$\begin{gathered} {\rm{Ob}}{{\rm{j}}^D}({{\mathit{\pmb{\theta}}} _D}, {{\mathit{\pmb{\theta}}} _G}) = - \frac{1}{2}{{\rm{E}}_{{\mathit{\pmb{x}}} \sim {P_{{\rm{data}}}}({\mathit{\pmb{x}}})}}[\log D(\mathit{\pmb{x}})] - \\ \frac{1}{2}{{\rm{E}}_{{\mathit{\pmb{z}}} \sim {P_{\mathit{\pmb{z}}}}(\mathit{\pmb{x}})}}[\log (1 - D(g({\mathit{\pmb{z}}})))] \\ \end{gathered} $$ (2) 从式(2)可看出,判别器的训练数据集包含真实数据集分布${P_{{\rm{data}}}}({\mathit{\pmb{x}}})$和生成器G的数据分布Pg(x)。给定生成器G,最小化式(2),获得判别器最优解,在连续空间为:
$$ \begin{gathered} {\rm{Ob}}{{\rm{j}}^D}({{\mathit{\pmb{\theta}}} _D}, {{\mathit{\pmb{\theta}}} _G}) = - \frac{1}{2}\int\limits_{\mathit{\pmb{x}}} {{P_{{\rm{data}}}}({\mathit{\pmb{x}}})} \log (D({\mathit{\pmb{x}}})){\rm{d}}{{\mathit{\pmb{x}}}} - \\ \frac{1}{2}\int\limits_{\mathit{\pmb{z}}} {{P_z}({\mathit{\pmb{x}}})\log (1 - D(G(\mathit{\pmb{z}}))){\rm{d}}{\mathit{\pmb{z}}} - } \\ \frac{1}{2}\int\limits_{\mathit{\pmb{x}}} {[{P_{{\rm{data}}}}({\mathit{\pmb{x}}})\log (D({\mathit{\pmb{x}}})) + } {P_g}({\mathit{\pmb{x}}})\log (1 - D({\mathit{\pmb{x}}}))]{\rm{d}}{\mathit{\pmb{x}}} \\ \end{gathered} $$ (3) 上式中,${P_{{\rm{data}}}}({\mathit{\pmb{x}}})$与${P_g}({\mathit{\pmb{x}}})$为常数,分别设为$m$、$n$,$D({\mathit{\pmb{x}}})$设为y,则式(3)可表示为:
$${\rm{Ob}}{{\rm{j}}^D}({{\mathit{\pmb{\theta}}} _D}, {{\mathit{\pmb{\theta}}} _G}) = - m\log (y) - n\log (1 - y)$$ (4) 由式(4)可知,在$\frac{m}{{m + n}}$处获得最小值,则在给定生成器G的情况下,判别器的最优解为:
$$D_G^* = \frac{{{P_{{\rm{data}}}}({\mathit{\pmb{x}}})}}{{{P_{{\rm{data}}}}({\mathit{\pmb{x}}}) + {P_g}({\mathit{\pmb{x}}})}}$$ (5) 在生成对抗网络的训练过程中,首先需要训练判别器D最大化数据来源于真实数据集的概率,同时需要训练生成器模型G最小化$\log (1 - D(G(\mathit{\pmb{z}})))$。因此通过交替迭代更新的方法,即先固定生成器G,优化判别器D,使判别器D的判别准确率最大化;然后固定判别器D,优化生成器G,使得判别器D的判别准确率最小化。当且仅当${P_{\mathit{\pmb{z}}}} = {P_{{\rm{data}}}}$时,达到全局最优解。
生成对抗网络发展至今,也出现了许多优秀的衍生模型。如深度卷积生成对抗网络[16],首次将生成对抗网络GAN和卷积神经网络CNN进行了很好的结合,展示出深度卷积神经网络在无监督学习领域的巨大潜力,但随着模型训练时间的增长,也会出现训练不稳定的情况,因此本文会在该基础上进行进一步的网络结构改进;在GAN中最先引入Wasserstein距离来度量两个分布之间的距离的WGAN[17]和其改进版本WGAN-GP[18],让生成对抗网络的理论提升到了一个新的高度,有效缓解了GAN容易出现梯度消失、模型崩溃的情况。本文在后面的损失函数设计阶段将继续沿用WGAN-GP的优秀思想;加入上下文感知模块的生成对抗网络(contextual attention, GAN)[19],其网络结构中包括一个带上下文内容感知的前馈生成器网络。并将网络的训练过程分为两个阶段,第一阶段通过初步修复图像的缺失区域,得到一个比较模糊的修复结果;第二个阶段是内容感知层的训练,即使用已知图像斑块的特征作为卷积核来加工生成出来的斑块,从而精细化模糊的修复结果。本文通过使用带内容感知的模型,很好的对图像进行了修复,具有重要的研究意义,但在细节处理上还需要进行改进。
-
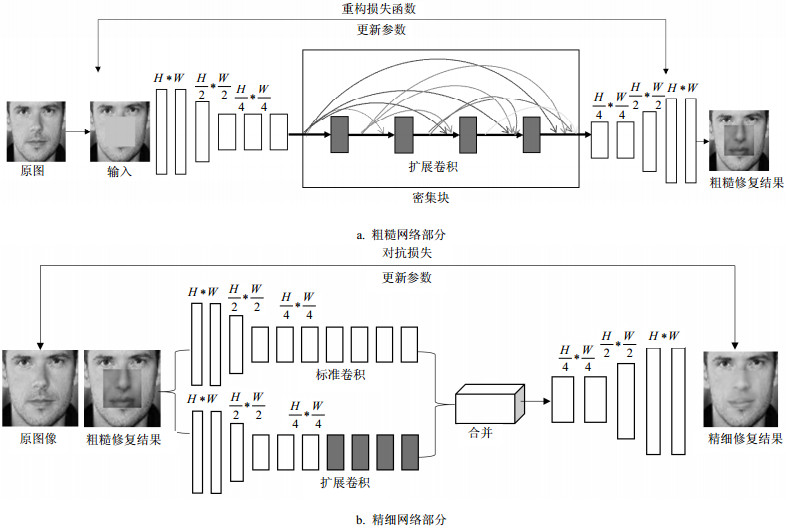
本文的生成器模型整体为自动编码器的结构,将缺失图像作为生成器的输入,通过一系列卷积与反卷积[20]操作最后输出修复好的图像。其中卷积操作包括标准卷积和扩展卷积(dilated conv)。扩展卷积在不增加参数数量和模型复杂度的情况下,可以指数倍的扩大视觉野的大小,从而可以获得更大的输入域。为了更好的修复大面积缺失区域的图像,本文参考文献[19]的网络结构,将生成器网络的修复过程分为了粗糙和精细网络两个部分,粗糙网络部分生成修复的初步结果图,精细网络部分将粗糙网络的结果作为输入进行进一步的训练得到更加精细的结果。但是,随着网络层深度的加深,梯度消失的现象就愈加严重,网络难以收敛。为了解决这个问题,本文在网络结构中加入了密集块(dense block)[15],强化了特征的传播,有效解决了梯度消失的问题。如图 1所示。

图 1 生成器模型结构
图 1展示了生成器模型由粗糙网络和精细网络两部分组成。其中,粗糙网络将待修复的人脸图像作为输入,通过卷积操作,图像的大小由H*W变为H/4*W/4,中间经过含扩展卷积的密集连接块,不仅获得了更大的视觉野,更加强了特征的使用,最后经过反卷积操作得到原始H*W的大小的初步修复图。精细网络将粗糙网络的结果作为输入,精细网络有两层并行的编码器。其中上层编码器为基本的卷积网络层,学习输入图像待修复区域周围的背景信息,下层编码器通过带扩展卷积的密集连接块,学习待修复区域潜在特征。然后将两层编码器学习到的结果合并在一起输入解码器进行反卷积操作,最后得到精细网络的修复结果。通过这种双通道的编码方式,生成的图像具有更好的多样性。
-
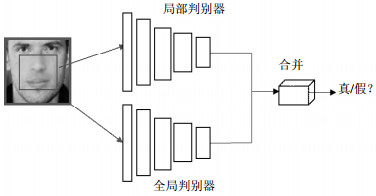
原始生成对抗网络通过最小化重建损失能够得到与原始图像相似的生成图像,并引入了一个二分类判别网路去判别图像为生成图像或真实图像,再通过对抗损失来提升生成器的效果。但是,在这种单一的判别网络的对抗优化下,生成器的生成图像仍然存在生成图像的修复区域与其他区域不协调、生成图像与原始图像语义不一致等问题。为解决这些问题,本文参考文献[21]的网络结构,采用了双重判别网络,即一个局部判别网络Local_D和全局判别网络Global_D。如图 2所示。
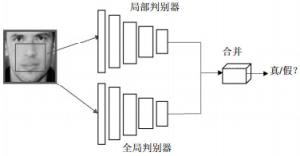
图 2 判别器网络结构
图 2展示了局部判别和全局判别网络分别用于判别局部与整体区域的图像是真实还是生成的,再综合考虑局部判别网络和全局判别网路的判别结果,最后通过对抗策略优化生成模型,从而提高生成器网络的修复效果。
-
设计好网络模型后,需要一个好的损失函数来优化整个模型。为了网络的训练更稳定和生成图像效果更好,本文的损失函数由生成网络部分的重构损失和判别网络部分的对抗损失两部分组成。其中重构损失采用L1范数:
$$ {l_{{\rm{rec}}}}({{\mathit{\pmb{x}}}_0}, {\mathit{\pmb{x}}}) = {\left\| {F({{\mathit{\pmb{x}}}_0} - {\mathit{\pmb{x}}})} \right\|_1} $$ (6) 通过L1范数让生成图像更加逼近真实图像。
对抗损失函数采用文献[18]提出的WGAN-GP损失,该损失是目前生成对网络中较好的损失函数,一定程度上缓解了原始GAN训练不稳定、梯度消失等问题。WGAN-GP损失是文献[17]提出的WGAN损失的改进版本。WGAN引入了Wasserstein距离来测量两个分布之间的距离,其定义如下:
$$ W({P_r}, {P_g}) = {\inf _{r \sim \prod {({P_r}, {P_g})} }}{{\rm{E}}_{({\mathit{\pmb{x}}}, {\mathit{\pmb{y}}}) \sim r}}\left\lfloor {||{\mathit{\pmb{x}}} - {\mathit{\pmb{y}}}||} \right\rfloor $$ (7) 式中,$\prod {({P_r}, {P_g})} $表示${P_r}$与${P_g}$的联合分布。对于其中任意一个可能的联合分布r进行采样)x, y)~r,得到真实样本x与生成样本y的距离为||x-y||。可以计算出该联合分布下样本对距离的期望值并取得下界。Wasserstein距离相比KL散度和JS散度具有优越的平滑特性。
WGAN虽然能够很好地算出两个分布之间的距离,但由于其权值剪切的操作,可能会引起梯度消失或爆炸。WGAN-GP通过加入梯度惩罚来处理这个问题,得到最终的WGAN-GP对抗损失函数:
$$ \begin{gathered} {l_{{\rm{adv}}}} = {{\rm{E}}_{x \sim {P_g}}}[D(\tilde {\mathit{\pmb{x}}})] - {{\rm{E}}_{{\mathit{\pmb{x}}} \sim {P_r}}}[D({\mathit{\pmb{x}}})] + \\ \lambda {{\rm{E}}_{\tilde {\mathit{\pmb{x}}} \sim P\tilde {\mathit{\pmb{x}}}}}[{(||{\nabla _{\tilde {\mathit{\pmb{x}}}}}D(\tilde {\mathit{\pmb{x}}})|{|^2} - 1)^2}] \\ \end{gathered} $$ (8) 式中,超参数λ控制惩罚项所占的比重,在实验中设为10。通过对抗损失函数进行对抗训练使得生成器的生成图像更加真实。将生成器的重构损失和判别器的对抗损失联合起来,得到本文的损失函数为:
$$ {l_{{\rm{loss}}}} = \alpha {l_{{\rm{rec}}}} + \beta {l_{{\rm{adv}}}} $$ (9) 式中,α, β分别表示两种损失函数所占的权重系数,通过参照文献[8, 21]等超参数配置及不断的实验调试,本文实验中设置α-0.035,β-0.965,然后通过Adam梯度优化算法不断促使网络模型更新参数,优化模型。
-
本文实验操作系统为Ubuntu16.04,64位,基于Tensorflow框架,版本为1.4.1,编程语言为Python3.5。用于人脸修复实验的数据集为公开的人脸数据集CelebA[22]及其拓展数据集CelebA-HQ[23]。为了验证本文的人脸图像修复方法较其他深度学习方法具有更好的效果,本文从3个方面进行实例验证:1)采用相同的测试数据和测试步骤,分析不同的遮挡情况下的修复效果;2)采用相同的实验数据和实验步骤,比较不同的深度学习方法的修复效果;3)使用客观的图像质量评价指标,验证本文的修复方法较其他方法的优越性。
-
为了充分展示本文的修复方法在人脸大面积损失区域的良好修复效果,本文从不同的遮挡部位展示本文的修复方法,分别如图 3、图 4所示。

图 3 眉毛、眼睛等部位被遮挡的修复图像

图 4 眉毛、眼睛、鼻子等被遮挡的修复图像
图 3显示了人脸图像眉毛及眼睛区域被遮挡后修复的效果,其中第1列为原图,第2列表示眉毛眼睛的遮挡图,第3列表示眉毛和眼睛被遮挡后的修复结果。从图中可以看出,眉毛、眼睛的整体修复效果较好,能够很好地处理眉毛和眼部细节。第4列表示眉毛眼睛鼻子遮挡图,第5列表示修复结果图,从图中可以看出,完整地修复好了眉毛、眼睛及鼻子。鼻子形状与整体脸型完美一致,图像修复得十分自然。图 4第2列显示了人脸图像眉毛、眼睛、鼻子、嘴巴被遮挡后修复的效果,从图中可以看出,整个脸部的修复效果非常好,只在嘴唇形状、牙齿等细节方面与原图存在差异。第4列显示人脸左半边被遮挡的图像,从第5列的修复结果可以看出修复的半边脸与原图十分相似,只存在细微差异。
-
为了验证本文的人脸修复方法较其他的深度学习方法具有更好的修复效果,本文重现了文献[16]、[18]及文献[19]提出的人脸修复方法。并采用相同的测试数据集,相同的遮挡区域来与本文的方法进行比较,比较结果如图 5、图 6所示。

图 5 眉毛眼睛鼻子遮挡图不同深度学习方法修复效果比较

图 6 全脸遮挡图不同深度学习方法修复效果比较
图 5展示了眉毛、眼睛、鼻子被遮挡后的修复效果比较图,图 6展示了全脸被遮挡后的修复效果比较图。其中第1列表示原图,第2列表示遮挡图,第3列表示文献[16]基于DCAGN的修复效果图,第4列表示文献[18]基于WGAN-GP的修复效果图,第5列表示文献[19]基于Contextual Attention的修复效果图,第6列表示本文方法的修复结果图。从图中可以看出,文献[16]的修复结果图的掩膜边界还比较明显,与图片周围区域信息不协调;文献[18]的修复结果图的掩膜边界基本淡化,但修复效果比较模糊、粗糙;文献[19]的修复结果整体较好,但随着遮挡区域的增大,在眼睛、鼻子、嘴等细节上修复的还不是很好,具体细节比较如图 7所示。

图 7 文献[19]与本文的修复细节对比
从图 7可以看出本文的修复结果图已经完全看不出掩膜边界,同时生成的图像比较清晰,在眉毛、眼睛、鼻子、牙齿等细节部分都处理的很好,生成图像十分逼近原图。
-
为了更加客观地展示本文人脸修复方法的有效性和优越性,本文使用了峰值信噪比(peak signal to noise ratio, PSNR)和结构相似性(structure similarity index, SSIM)两个评价指标来对修复结果进行定量评估。其中PSNR是基于对应像素点之间的误差即基于的误差敏感的评价指标,PSNR的值越大代表修复的效果越好;而SSIM是用于评估两张图片整体上的相似性,分别从亮度、对比度、结构3个方面进行度量,SSIM的值越接近1表明图像的相似性越高[24]。本文用这两个指标度量了不同深度学习方法对不同遮挡区域的修复效果,评估结果如表 1、表 2所示:
表 1 峰值信噪比
表 2 结构相似度
表 1、表 2分别展示了不同的深度学习方法对于不同的遮挡区域修复结果的PSNR和SSIM评估结果。其中,M1列表示了遮挡眉毛,M2列表示遮挡眉毛和眼睛,M3列表示遮挡眉毛、眼睛、鼻子,M4列表示遮挡眉毛、眼睛、鼻子及嘴部。从表中可以看出,本文的PSNR和SSIM结果较其他方法分别提高了1.1~7.5 dB和0.02~0.15。整体实验结果表明,本文的人脸修复方法对于大面积区域损失的人脸图像有较好的修复效果。
-
本文针对人脸图像缺失区域的修复问题,提出一种新的基于级联无监督生成对抗网络的人脸图像修复方法。其中生成网络采用了从粗糙网络到精细网络两个部分,判别网络采用了局部判别与全局判别的双重判别方式,损失函数采用重构损失和对抗损失相结合的方式。从而使得本文的生成对抗网络对图像的结构性预测更加准确,对图像的细节化处理也更加完美。通过与各种基于GAN的深度学习算法在相同的人脸数据测试集上实验结果进行对比,本文的修复结果在主观视觉上的效果更好,在客观的峰值信噪比和结构相似性指标上也得到了提升,因此本文人脸修复模型算法较现有方法具有更好的修复效果。
本文基于无监督学习生成对抗网络的人脸修复算法在人脸图像上取得了一定的效果,但是修复对象较为单一,修复模型不具有通用型。因此,在未来的模型训练中,将尝试加入多种类、多样式的训练数据,提高模型的泛化性能。同时,在实验过程中加入随机生成的不规则遮挡区域,提高模型的实际应用能力。
Face Image Inpainting Using Cascaded Generative Adversarial Networks
-
摘要: 人脸图像修复技术为近年来图像处理领域的研究热点。该文提出一种基于级联生成对抗网络的人脸图像修复方法,从生成器、判别器、损失函数三个方面进行改良。生成器采用由粗到精的级联式模型,并结合密集连接模块使所修复区域更加精细;判别器采用局部与全局特征相融合的双重判别式模型以提升判别准确性;损失函数采用最小化重构损失和对抗网络损失相结合以获得更好训练效果。基于CelebA数据集的实验显示,该方法可实现面部区域丢失50%以上的人脸图像修复,在客观评价指标PSNR和SSIM上,较现有方法分别提高了1.1~7.5 dB和0.02~0.15。从主观效果来看,该方法修复的人脸图像拥有更丰富的细节、更显自然。Abstract: Face image inpainting is a hot topic of image processing research in recent years. This paper proposes a face image restoration method based on cascade generative adversarial network. In this method, the generator employs a cascading structure consisting of a coarse network and a refinement network and adopts dense connections to recover more details of the missing face area; the discriminator uses a dual discriminant model combining local and global features to improve the discriminant accuracy; the loss function consists of reconstruction loss and generative adversarial loss for better training performance. Experiments on CelebA dataset show that the proposed method can restore facial image with more than 50% missing area. The objective evaluation index PSNR and SSIM are 1.1 dB to 7.5 dB and 0.02 to 0.15 higher respectively compared with state of the arts. For subjective evaluation, the restored face images look more detailed and natural.
-
[1] 何雨亭, 唐向宏, 张越, 等.结构张量的改进Criminisi修复[J].中国图象图形学报, 2018(10):64-79. http://d.old.wanfangdata.com.cn/Periodical/zgtxtxxb-a201810005 HE Yu-ting, TANG Xiang-hong, ZHANG Yue, et al. Improved Criminisi algorithm based on structure tensor[J]. Journal of Image and Graphics, 2018(10):64-79. http://d.old.wanfangdata.com.cn/Periodical/zgtxtxxb-a201810005 [2] 兰小丽, 刘洪星, 姚寒冰.基于纹理块与梯度特征的图像修复改进算法[J].计算机工程与应用, 2018(20):177-182. http://d.old.wanfangdata.com.cn/Periodical/jsjgcyyy201820028 LAN Xiao-li, LIU Hong-xing, YAO Han-bing. Improved image inpainting algorithm based on texture blocks and gradient feature[J]. Computer Engineering and Applications, 2018(20):177-182. http://d.old.wanfangdata.com.cn/Periodical/jsjgcyyy201820028 [3] 胡彬, 邱淑芳, 杨志辉, 等.一种新的4阶偏微分方程图像处理方法[J].江西师范大学学报(自然科学版), 2016(6):603-607. http://d.old.wanfangdata.com.cn/Periodical/jxsfdxxb201606013 HU Bin, QIU Shu-fang, YANG Zhi-hui, et al. The image denoising by fourth-order partial differential equations[J]. Journal of Jiangxi Normal University (Natural Science Edition), 2016(6):603-607. http://d.old.wanfangdata.com.cn/Periodical/jxsfdxxb201606013 [4] 杜闪闪, 韩超.基于腐蚀处理和多参数因子的CDD修复算法[J].激光与光电子学进展, 2019(16):106-114. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jgygdzxjz201916013 DU Shan-shan, HAN Chao. CDD repair algorithm based on corrosion treatment and multi-parameter factors[J]. Laser & Optoelectronics Progress, 2019(16):106-114. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jgygdzxjz201916013 [5] 张弘, 周晓莉.基于小波阈值和全变分模型的图像去噪[J].计算机应用研究, 2018(10):182-185. ZHANG Hong, ZHOU Xiao-li. Method for image denoising based on wavelet transform and total variatioal model[J]. Application Research of Computers, 2018(10):182-185. [6] 谢斌, 丁成军, 刘壮.基于图像分解的图像修复算法[J].激光与红外, 2018(5):117-124. http://d.old.wanfangdata.com.cn/Periodical/jgyhw201805021 XIE Bin, DING Cheng-jun, LIU Zhuang. Image restoration algorithm based on image decomposition[J]. Laser & Infrared, 2018(5):117-124. http://d.old.wanfangdata.com.cn/Periodical/jgyhw201805021 [7] 孙利君.基于样本的纹理合成方法研究[D].济南: 山东大学, 2012. SUN Li-jun. Research on texture synthesis method based on samples[D]. Jinan: Shandong University, 2012. [8] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[EB/OL]. (2015-03-14). https://arxiv.org/abs/1512.03385. [9] ZITNICK C, DOLLAR P. Edge boxes: Locating object proposals from edges[C]//Computer Vision-ECCV 2014.[S.l.]: Springer, 2014: 86-93. [10] OUYANG W, LUO P, ZENG X, et al. Deep ID-Net: Multi-stage and deformable deep convolutional neural networks for object detection[EB/OL]. (2014-05-18). https://arxiv.org/abs/1409.3505v1. [11] QUOC V Le. Building high-level features using large scale unsupervised learning[C]//Acoustics, Speech and Signal Processing (ICASSP). Vancouver, Canada: IEEE, 2013: 8595-8598. [12] PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context encoders: Feature learning by inpainting[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE, 2016: 2536-2544. [13] LI Y, LIU S, YANG J, et al. Generative face completion[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE, 2017: 3911-3919. [14] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[J]. Advances in Neural Information Processing Systems, 2014(4): 2672-2680. [15] HUANG Gao, LIU Zhuang, LAUREN S. Densely connected convolutional networks[EB/OL]. (2018-08-24). https://arxiv.org/abs/1608.06993. [16] RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[EB/OL]. (2015-10-14). https://arxiv.org/abs/1511.06434. [17] ARJOVSKY M, CHINTALA S, BOTTOU L. Wasserstein gan[EB/OL]. (2017-10-24). https://arxiv.org/abs/1701.07875. [18] GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of wasserstein gans[EB/OL]. (2017-12-24). https://arxiv.org/abs/1704.00028v3. [19] JIAHUI Y, ZHE L, JIMEI Y, et al. Generative image inpainting with contextual attention[C]//IEEE Conference Computer Vision and Pattern Recognition.[S.l.]: IEEE, 2018: 5505-5514. [20] DUMOULIN V, VISIN F. A guide to convolution arithmetic for deep learning[EB/OL]. (2016-08-24). https://arxiv.org/abs/1603.07285. [21] IIZUKA S, SIMO-SERRA E, ISHIKAWA H. Globally and locally consistent image completion[J]. ACM Transactions on Graphics (TOG), 2017, 36(4):1-14. [22] LIU Z, LUO P, WANG X, et al. Deep learning face attributes in the wild[EB/OL]. (2014-11-28). https://arxiv.org/abs/1411.7766. [23] KARRAS T, AILA T, LAINE S, et al. Progressive growing of gans for improved quality, stability, and variation[EB/OL]. (2017-07-05). https://arxiv.org/abs/1710.10196. [24] 赵文哲, 秦世引.图像质量评价的研究进展和若干问题的解决途径[J].激光与光电子学进展, 2010, 47(4):46-54. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jgygdzxjz201004009 ZHAO Wen-zhe, QIN Shi-yin. Image quality assessment and some solve approaches to current issues[J]. Laser & Optoelectronics Progress, 2010, 47(4):46-54. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jgygdzxjz201004009 -

 点击查看大图
点击查看大图
图(7) / 表(2)
计量
- 文章访问数: 5088
- HTML全文浏览量: 1591
- PDF下载量: 72
- 被引次数: 0
