 ISSN
ISSN 






-
脑胶质瘤是一种最常见的原发性脑肿瘤。根据国际卫生组织的脑肿瘤分级系统,可以将脑胶质瘤分为4级。其中,1级和2级脑胶质瘤被称为低级胶质瘤,3级和4级胶质瘤被称为高级别胶质瘤。高级别胶质瘤具有很高的死亡率,病人经治疗后平均存活时间不足两年。目前,手术是最成熟的治疗方式,并且疾病的诊断及术后恢复情况的评估主要依赖于核磁共振成像(magnetic resonance imaging, MRI)技术。常用的核磁共振图像有T1加权成像(T1-weighted MRI, T1)、钆增强对比的T1加权(T1-weighted MRI with gadolinium enhancing contrast, T1c)、T2加权成像(T2-weighted MRI, T2)和液体衰减反转恢复的T2加权成像(T2-weighted MRI with fluid-attenuated inversion recovery, FLAIR)。脑肿瘤分割就是从这4种影像中将脑组织分为5个部分,分别是正常组织、水肿、坏死、非增强肿瘤和增强肿瘤,其中坏死、非增强肿瘤和增强肿瘤称之为核心肿瘤。由于数据量很大,人工分割效率很低,因此脑肿瘤分割需要自动化或半自动化分割方法。
随着深度卷积神经网络的发展,已广泛应用于脑肿瘤分割。目前,基于深度学习的脑肿瘤分割主要基于FCN[1]网络和U-Net[2]网络。在此基础上,许多文献提出了很多的改进方法。一部分改进聚焦于提升网络的特征获取能力,包括使用ResBlock[3]来加深网络及采用多尺度特征[4-8]、多层次特征[9-10]。一部分改进则是通过增加训练数据[11-12]或改进损失函数[13-14]来提升网络的效果。虽然这些改进提升了网络的效果,但在脑肿瘤分割中,仍然存在数据不均衡问题。例如,在有些病人中,增强肿瘤在整体脑组织的占比不到1%。因此,很多工作采用了由粗到细的方法[15-17]。这些方法采用了三阶段方式,也称之为由整体到局部的方式,即先分割脑肿瘤区域,然后在脑肿瘤区域中分割出核心肿瘤区域,最后在核心肿瘤区域中分割出增强肿瘤区域。这种方法在脑肿瘤分割上取得了很好的效果,但是仍存在一些不足。首先,该方法对脑肿瘤进行了三分类,减少了很多细节信息;其次,该方法利用三阶段方式,会采用3个网络或3次训练;最后,后一阶段的结果依赖于前一阶段的结果,此外,由于缩小了输入范围,导致后面的网络缺乏更丰富的特征。因此,本文提出了一个二维的基于注意力的两阶段由粗到细的脑分割框架,该框架包含两部分,分别是粗分割部分和细分割部分。其中粗分割部分给出一个初步五分类概率图,然后细分类部分将这些概率图作为掩膜使得网络更加关注高概率区域,两阶段任务减少了网络个数或训练的次数。此外,由于细分割部分将整幅图像作为输入,因此,为了减轻数据不均衡及获取更多特征,细分割部分采用了双分支输出。一支输出五分类结果,并且采用带掩膜的交叉熵损失函数,主要用来学习肿瘤内不同组织的特征及误分割区域的特征;另一支输出二分类结果,该结果用来标注脑肿瘤区域,该分支采用了均方误差损失函数,用来学习正常组织和肿瘤组织之间的特征。该方法在BRATS 2015数据集上测试,结果表明效果良好。
HTML
-
深度卷积神经网络已广泛应用在脑肿瘤分割上,根据输入及输出方式,可以将基于深度卷积神经网络的脑肿瘤分割方法分为两类:1) 基于块的脑肿瘤分割;2) 端对端的脑肿瘤分割。在基于块的脑肿瘤分割方法中,网路输入是以滑动窗口方式从图像中选取固定大小的块,网络输出则是该块的中心像素的类别。文献[18]提出了一个单尺度的二维卷积神经网络,实现了基于块的脑肿瘤分割。但是单尺度特征并不能很好地表示不同的脑肿瘤组织,因此文献[4,19]提出了使用不同大小的块来获取中心像素点的多尺度特征。上述方法都是基于二维的块,虽然可以减少大量的显存占用,但是二维块缺乏图像之间的上下文信息,因此文献[5]提出了三维多尺度卷积神经网络来提取三维体素的多尺度特征。虽然基于块的脑肿瘤分割方法占用显存较少,但是由于滑动窗口的原因,导致大量的重复计算,耗时较高。不过基于块的方法可以通过平衡不同肿瘤组织块及正常脑组织块的数量,极大减轻数据不均衡问题。
不同于基于块的脑肿瘤分割方法,端到端的脑肿瘤分割方法则是将整幅图片或部分图片作为输入,输出同样大小的概率图。端到端的脑肿瘤分割方法主要基于FCN网络或U-Net网路。输入图像通过多层卷积层获取不同尺度的特征,然后网络利用上采样或者双线性插值的方法获取每个像素点的特征,并利用这些特征获取像素点的类别概率。文献[6,20]给出了基于FCN网络或U-Net网络的脑肿瘤分割方法。类似于基于块的多尺度方法,文献[9,21-22]提出了多层次方法。在端到端的分割网络中,低层卷积层获取的特征是低级特征且对应的输入图像区域较小,高层卷积层获取的特征是高级特征且对应较大的输入图像区域,因此,多层次方法是将低级特征同高级特征结合起来,从而得到更丰富的特征来分割脑肿瘤。相比于基于块的分割方法,端到端的分割方法更加方便快捷,但易受数据不均衡问题的困扰。
-
由于数据不均衡问题在端到端的脑肿瘤分割算法中比较凸显。一种方法是通过改进损失函数[13-14,23]来减轻这个问题;另一种方法是通过缩小输入大小,也就是由粗到细或由整体到局部的分割方法。文献[15]采用了3个级联的网络来分割脑肿瘤。其中第1个网络分割整体肿瘤区域;第2个网络以肿瘤区域为输入来分割核心肿瘤区域;第3个网络以核心肿瘤区域为输入来分割增强肿瘤区域。在此基础上,文献[17]采用基于块的方法通过共用特征及增加卷积层来减少网络的个数,首先训练整体肿瘤区域分割网络;其次保留该网络的特征,并增加新的卷积层来训练核心肿瘤区域分割;最后保留这些特征,继续增加新的卷积层来训练增强肿瘤区域分割。然而,这些方法只是对脑肿瘤区域进行粗略了划分,缺少了很多细节信息。此外,每次训练的输入数据范围都受到了限制,尽管文献[17]保留了之前训练的特征,但由于使用了3次串联训练,易导致网络不能获取更丰富的特征。
1.1. 基于深度卷积神经网络的脑肿瘤分割
1.2. 由粗到细的脑肿瘤分割
-
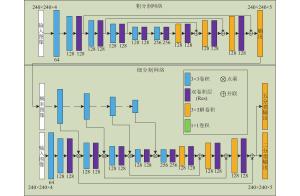
本文提出了一个二维的由粗到细的两阶段脑肿瘤分割方法,该方法分为粗分割和细分割两部分。总体的框架如图1所示,粗分割网络输入4种模态的MRI图像,输出每个像素的联合概率分布;然后该联合概率分布转化为不同肿瘤区域的概率图,作为细分割网络的注意力;最后由细分割网络得到最终结果。
-
受限于显存大小,本文采用二维图像作为输入。该方法第一阶段是粗分割网络对输入图像做分割,粗分割网络采用了编码−解码的结构,如图1所示。首先,网络使用了多个块获取输入图像的特征,其中,每个块包含一个步长为2的卷积核和一个残差块,残差块由两个步长为1的卷积构成,为自下而上的提取特征;然后,提取的特征经过一系列的解卷积及残差块,得到最终的概率图,同样可以看作是自上而下的提取特征。此外,通过水平连接,可以将自上而下的特征与自下而上的特征相结合,更有利于脑肿瘤的分割。
粗分割的输出是每个像素的类别概率,因此采用了一个简单的交叉熵损失函数:
式中,i表示训练样本数量;
${{{y}}_i}$ 表示第i个像素点的真值,为one-hot形式;${{P}}({{{x}}_i})$ 表示第i个像素点的概率向量。 -
细分割部分是在粗分割结果的基础上对图像进行再次分割,不同于其他三阶段方法不断缩小输入区域,细分割网络的输入同粗分割网络一样,是整个四模态图像。细分割网络采取注意力的机制,由于第一阶段给出了基本的分割结果,因此第二阶段要使网络更加关注第一阶段给出的高概率区域。细分割网络包含注意力流和分割流两个流,如图1所示。分割流的输入为整个四模态图像,其框架与粗分割网络相似;注意力流的输入则是粗分割的概率结果作为输入指导分割流关注高概率像素点。
由于粗分割网络的概率图为联合概率,给出的是图像中每个像素点的类别概率,本文希望网络更加分别关注单一区域的情况,因此首先将五分类的联合概率图利用阈值法(阈值选择0.5)转化为4个二分类的结果,其中
$i \in [1,4]$ ,${{{P}}_i}({{x}})$ 为第i类肿瘤区域的概率,设这4个二分类图为$\{ {{{C}}_1},{{{C}}_2},{{{C}}_3},{{{C}}_4}\} $ 。注意力流是为了给分割流提供注意力机制,因此使用卷积层提取概率图的概率特征来指导分割流。如图1所示,注意力流采用多层卷积层提取概率特征,卷积层的层数同分割流中特征提取层层数相同。设m为特征提取层层数,
$\{ {{{F}}_{i1}},{{{F}}_{i2}}, \cdots ,{{{F}}_{il}}, \cdots ,{{{F}}_{in}}\} $ 为第${{i}}({{i}} \in [1,{{m}}])$ 层特征提取层的特征,n为第i层特征提取层的特征数,$\left\{ {{{{A}}_{i1}},{{{A}}_{i2}}, \cdots ,{{{A}}_{il}}, \cdots ,{{{A}}_{in}}} \right\}$ 为注意力流第i层卷积层提取的特征图。注意力流是为了给分割流提供注意力机制,因此分割流中第i层特征层的输出为:式中,*为矩阵点乘操作。
尽管采用注意力方式,但是为了获取更多的特征,细分割网络将整个四模态图像作为输入,因此依然存在数据不均衡的问题。为了缓解这个问题,其他由粗到细的方法是缩减输入的区域,而本文则采用缩减损失函数区域,通过缩小损失函数关注的区域来缓解数据不均衡。在粗分割网络中已经给出了高概率区域,因此,可以将粗分割网络结果作为掩膜,促使细分割网络的损失函数也关注高概率区域。本文采用交叉熵损失函数,因此损失函数可以表示为:
式中,
${\rm I}[a]$ 为示性函数,即$a$ 大于0函数值为1;${{{C}}_{\rm{GT}}}$ 为整体脑肿瘤真值;${{y}}$ 为one-hot形式的标签真值;${{P}}({{x}})$ 为输出值。当使用带掩膜的交叉熵损失函数时,由于掩膜覆盖的区域绝大多数都是脑肿瘤及少量误分割区域,因此会导致网络倾向于提取脑肿瘤区域的特征,从而减少正常组织的特征。因此,本文提出了一个均方误差损失函数来标记整体脑肿瘤区域,该损失函数表示为:
式中,
${P_{\rm{wt}}}({{{x}}^i})$ 为网络像素点${{{x}}^i}$ 的整体肿瘤概率;$y_{{\rm{wt}}}^i$ 表示该像素点的真值。在上述的损失函数中,
${L_{{\rm{msc}}}}$ 主要是学习不同肿瘤区域的特征,而这些特征亦可以作为脑肿瘤特征用于标记整体脑肿瘤区域;同样${L_{{\rm{mse}}}}$ 学习的正常组织特征有助于减少带掩膜的五分类任务中的误分割。因此,在细分割网络中本文采用一个双分支输出,如图1所示,双分支输出共享同一特征空间,同一特征分别经过两个1×1卷积,然后再分别通过两个解卷积层来得到一个五分类和一个二分类结果。因此,细分割网络的总体损失函数为:式中,
${\alpha _1}$ 与${\alpha _2}$ 为细分割网络的超参数。因为两个输出分支所关注的不一样,导致两个分支结果不一致,因此本文方法最终结果是通过融合这两个分支的结果来得到。首先,选取阈值0.5对整体肿瘤输出结果进行二值化处理;然后将二值化结果作为掩膜来获取最终的五分类结果。
2.1. 粗分割部分


2.2. 细分割部分


















-
本文实验数据来源于网络公开数据集BRATS 2015,该数据集包含两个子数据集,分别是训练集和测试集。其中,训练集分为高级别肿瘤和低级别肿瘤,高级别肿瘤有220个病人影像,低级别肿瘤有57个病人影像。测试集是将高级别肿瘤和低级别肿瘤混合起来,共有110个病人影像。不论是训练集还是测试集,每个病人影像有4种模态数据,每个病人的影像大小为155×240×240。本文所有方法都是在训练集上进行训练,然后在测试集上测试,所有测试集的分割结果上传到Brats网站,并由网站评估结果。
本文方法是将脑影像分为5类,分别是正常组织或背景、水肿、坏死、非增强肿瘤和增强肿瘤。但在测试时,是进行三分类测试,其中坏死、非增强肿瘤和增强肿瘤称为核心肿瘤,核心肿瘤加上水肿区域为完整肿瘤,三分类测试就是评估完整肿瘤、核心肿瘤和增强肿瘤的分割。
本文采用Dice系数来定性描述分割结果,令A和B分别是两个二值图像,分别代表了真值和方法的分割结果,则Dice系数定义为:
-
本文方法的输入数据为四模态MRI图像,由于采集的设备不同以及不同模态MRI图像的采集参数不同,因此不同MRI图像的最大灰度值范围在300~4 000之间。为了使网络更好地工作,本文对数据进行了预处理,采用了文献[10]中的数据预处理方法:首先对MRI图像中的脑组织区域数据进行0均值标准化;其次对所有数据进行截取,将其截取到[−5.0,5.0],然后将数据缩放到[0,1.0],最后将原始MRI图像中像素值为0的像素点设为0。
-
本文的方法运行在单个NVIDIA GTX 1080显卡上,所有网络的详细结构参数已在图1中给出。该方法包含粗分割和细分割两个阶段,在粗分割网络和细分割网络的分割流中,除去第一层卷积和输出层,所有的卷积层及解卷积层后都连接一个instance norm层[24],紧随instance norm层的是lrelu激活函数。所有网络的卷积核和解卷积核都采用正态分布N(0, 0.2)来初始化,偏置初始化都为0。本文方法中,第二阶段要依赖于第一阶段,所以在训练中首先训练粗分割网络,然后在此基础上训练细分割网络。所有的网络都是在训练集上进行训练,并在测试集上进行测试。
在本文中,两个阶段的训练方法均采用Adam优化算法[25],其中momentum为0.9。所有网络在274个病例上训练,每个病例的一个模态从横断面截取可以获得155张240×240的二维图像,网络训练时的批大小选为5,训练周期设为40。训练时初始化学习率为0.000 7,采用指数衰减的方式降低,衰减基数设为0.75,衰减步数为每4个周期衰减一次。在训练细分割网络时,超参数
${\alpha _1}$ 与${\alpha _2}$ 分别设为1.0和10.0。 -
1) 二阶段分割结果
本文提出二阶段的由粗到细的分割框架,首先使用了一个基础的分割网络来获得初始结果,然后将初始结果作为下一个分割网络的注意力完成脑肿瘤分割。为此,将粗分割网络作为基准网络与本文方法进行对比,结果如表1所示。本文方法在脑肿瘤分割上的表现全部高于基准网络,也就是单一的基础分割网络。此外,为了更好地对比,还提出了使用基准网络生成一个整体肿瘤(whole tumor, WT)概率图,利用该概率图缩减图像区域,然后利用同样的基准网络分割缩减后的图像区域。从表1的结果看,单纯缩减图像区域后,增强肿瘤的分割Dice系数下降了1%,可能是因为缩减了图像区域,导致第二个网络不能学到更丰富的特征。同时,为了更好对比,本文提出了另外一个二阶段方法,该方法利用基准网络(粗分割网络)获取二分类的整体肿瘤概率图,然后利用概率图作为细分割网络的注意力。表1显示,该方法在整体肿瘤和核心肿瘤分割上的表现都有提升,但在增强肿瘤分割上效果并没有提升。对比结果显示本文方法在所有的肿瘤区域分割上效果均有提升。
方法 整体肿瘤 核心肿瘤 增强肿瘤 基准 0.84 0.69 0.59 基准(WT)+基准 0.84 0.69 0.58 基准(WT)+细分割 0.85 0.70 0.59 本文方法 0.85 0.70 0.61 2) 双分支输出结果
在细分割网络中,为了缓解数据不均衡问题,本文提出了双分支输出,一支输出五分类结果并使用带掩膜的交叉熵损失函数,另一支输出二分类结果使用均方误差损失函数。此外,Dice损失函数[21]与Focal损失函数[23]也同样能够减缓数据不均衡问题。
如表2所示,Dice损失函数表现较差,甚至不如常规的交叉熵损失函数,尤其是在增强肿瘤分割上,一个可能的原因是由于增强肿瘤区域的大小在不同病人上变化非常大,导致了Dice损失函数在增强肿瘤分割的训练不稳定。相较于常规的交叉熵损失函数,Focal损失函数在核心肿瘤分割上带来了一定的提升。本文提出的双分支输出及带掩膜的交叉熵损失函数在核心肿瘤和增强肿瘤上都有提升,此外本文方法几乎不需要增加额外的计算,且易于训练。
3) 同其他方法对比
受限于显存限制,本文的方法运行在二维图像上,因此,本节同其他常用的最新的二维分割算法进行了对比,结果如表3所示。在这些方法中,前两个是基于块的分割方法,文献[18]采用了传统的卷积神经网络来分割脑肿瘤,文献[4]在此基础上采用了多尺度的方法来分割脑肿瘤。不同于上面两个基于块的分割方法,U-Net和FCNN则是常用的端到端的分割方法。除了这些基于卷积神经网络的分割方法,最后两个是基于对抗生成网络的分割方法[27]。CB-GAN使用了GAN网络来生成更多虚拟训练数据,从而变相地实现训练数据增强[11]。而SegAN则直接采用GAN网络作为生成模型来分割脑肿瘤,在SegAN中使用1个生成网络和3个判别网络来实现脑肿瘤三分类,生成网络生成3个脑肿瘤区域,分别是整体肿瘤区域、核心肿瘤区域和增强肿瘤区域。
方法 整体肿瘤 核心肿瘤 增强肿瘤 常规的交叉熵损失函数 0.85 0.69 0.60 Dice损失函数 0.85 0.68 0.51 Focal损失函数 0.85 0.70 0.60 本文方法 0.85 0.70 0.61 从结果可以看出,本文的方法在整体肿瘤区域和核心肿瘤区域分割效果上超过其他方法,但在增强肿瘤分割上,Pereira方法效果最好。同时,证明了基于块的方法在缓解数据不均衡问题上要优于端到端的方式。此外,本文方法在基准方法上有很大的提升,而且可以选择不同的基准网络。
3.1. 实验数据及评价指标
3.2. 数据预处理
3.3. 实验设置


3.4. 实验结果及分析
-
本文提出了一个二维的两阶段由粗到细的脑肿瘤分割方法,不同于别的三阶段由粗到细分割方法将脑肿瘤分为3类,本文的方法只需要2个阶段,且将脑肿瘤分为4类,具有更多的细节信息。此外,部分由粗到细的分割方法不断缩减输入区域,导致网络不能获得更丰富的特征,本文方法则是采用了注意力机制,将粗分割的结果作为注意力来指导细分割网络,从而不用缩减输入的图像区域。同时,为了减缓数据不均衡问题,本文提出了双分支输出,一支输出图像五分类结果并采用带掩模的交叉熵损失函数,另一支输出图像二分类结果用来标记整体脑肿瘤区域并采用均方误差损失函数,最终结果则是通过融合这两个结果得到。由于受显存大小的影响,本文方法运行在二维图像上,但可以扩展到三维图像上。此外,本文方法可以使用不同的基准网络模型。经过BRATS 2015数据集验证,证明了本文方法在整体肿瘤分割和核心肿瘤分割上具有很好的效果。

 DownLoad:
DownLoad: